| БрМЭЦМі: |
| БОЮФРДздгкjianshuЃЌБОЮФжївЊНщЩмСЫЮЊЪВУДMySQLЕШжїСїЪ§ОнПтбЁдёB+ЪїЕФЫїв§НсЙЙКЭГЃМћЕФMySQLЫїв§гХЛЏЫМТЗЕШЯрЙижЊЪЖЁЃ |
|
MySQLЕФMyISAMЁЂInnoDBв§ЧцФЌШЯОљЪЙгУB+ЪїЫїв§ЃЈВщбЏЪБЖМЯдЪОЮЊЁАBTREEЁБЃЉЃЌБОЮФЬжТлСНИіЮЪЬтЃК
ЮЊЪВУДMySQLЕШжїСїЪ§ОнПтбЁдёB+ЪїЕФЫїв§НсЙЙЃП
ШчКЮЛљгкЫїв§НсЙЙЃЌРэНтГЃМћЕФMySQLЫїв§гХЛЏЫМТЗЃП
ЮЊЪВУДЫїв§ЮоЗЈШЋВПзАШыФкДц
Ыїв§НсЙЙЕФбЁдёЛљгкетбљвЛИіаджЪЃКДѓЪ§ОнСПЪБЃЌЫїв§ЮоЗЈШЋВПзАШыФкДцЁЃ
ЮЊЪВУДЫїв§ЮоЗЈШЋВПзАШыФкДцЃПМйЩшЪЙгУЪїНсЙЙзщжЏЫїв§ЃЌМђЕЅЙРЫувЛЯТЃК
МйЩшЕЅИіЫїв§НкЕу12BЃЌ1000wИіЪ§ОнааЃЌuniqueЫїв§ЃЌдђвЖзгНкЕуЙВеМдМ100MBЃЌећПУЪїзюЖр200MBЁЃ
МйЩшвЛааЪ§ОнеМгУ200BЃЌдђЪ§ОнЙВеМдМ2GЁЃ
МйЩшЫїв§ДцДЂдкФкДцжаЁЃвВОЭЪЧЫЕЃЌУПдкЮяРэХЬЩЯБЃДц2GЕФЪ§ОнЃЌОЭвЊеМгУ200MBЕФФкДцЃЌЫїв§:Ъ§ОнЕФеМгУБШдМЮЊ1/10ЁЃ1/10ЕФеМгУБШЫуВЛЫуДѓФиЃПЮяРэХЬБШФкДцСЎМлЕФЖрЃЌвдвЛЬЈФкДц16GгВХЬ1TЕФЗўЮёЦїЮЊР§ЃЌШчЙћвЊДцТњ1TЕФгВХЬЃЌжСЩйашвЊ100GЕФФкДцЃЌдЖДѓгк16GЁЃ
ПМТЧЕНвЛИіБэЩЯПЩФмгаЖрИіЫїв§ЁЂСЊКЯЫїв§ЁЂЪ§ОнааеМгУИќаЁЕШЧщПіЃЌЪЕМЪЕФеМгУБШЭЈГЃДѓгк1/10ЃЌФГаЉЪБКђФмДяЕН1/3ЁЃдкЛљгкЫїв§ЕФДцДЂМмЙЙжаЃЌЫїв§:Ъ§ОнЕФеМгУБШЙ§ИпЃЌвђДЫЃЌЫїв§ЮоЗЈШЋВПзАШыФкДцЁЃ
ЦфЫћНсЙЙЕФЮЪЬт
гЩгкЮоЗЈзАШыФкДцЃЌдђБиШЛвРРЕДХХЬЃЈЛђSSDЃЉДцДЂЁЃЖјФкДцЕФЖСаДЫйЖШЪЧДХХЬЕФГЩЧЇЩЯЭђБЖЃЈгыОпЬхЪЕЯжгаЙиЃЉЃЌвђДЫЃЌКЫаФЮЪЬтЪЧЁАШчКЮМѕЩйДХХЬЖСаДДЮЪ§ЁБЁЃ
ЪзЯШВЛПМТЧвГБэЛњжЦЃЌМйЩшУПДЮЖСЁЂаДЖМжБНгДЉЭИЕНДХХЬЃЌФЧУДЃК
ЯпадНсЙЙЃКЖС/аДЦНОљO(n)ДЮ
ЖўВцЫбЫїЪїЃЈBSTЃЉЃКЖС/аДЦНОљO(log2(n))ДЮЃЛШчЙћЪїВЛЦНКтЃЌдђзюВюЖС/аДO(n)ДЮ
здЦНКтЖўВцЫбЫїЪїЃЈAVLЃЉЃКдкBSTЕФЛљДЁЩЯМгШыСЫздЦНКтЫуЗЈЃЌЖС/аДзюДѓO(log2(n))ДЮ
КьКкЪїЃЈRBTЃЉЃКСэвЛжжздЦНКтЕФВщевЪїЃЌЖС/аДзюДѓO(log2(n))ДЮ
BSTЁЂAVLЁЂRBTКмКУЕФНЋЖСаДДЮЪ§ДгO(n)гХЛЏЕНO(log2(n))ЃЛЦфжаЃЌAVLКЭRBTЖМБШBSTЖрСЫздЦНКтЕФЙІФмЃЌНЋЖСаДДЮЪ§НЕЕНзюДѓO(log2(n))ЁЃ
МйЩшЪЙгУзддіжїМќЃЌдђжїМќБОЩэЪЧгаађЕФЃЌЪїНсЙЙЕФЖСаДДЮЪ§ФмЙЛгХЛЏЕНЪїИпЃЌЪїИпдНЕЭЖСаДДЮЪ§дНЩйЃЛздЦНКтБЃжЄСЫЪїНсЙЙЕФЮШЖЈЁЃШчЙћЯыНјвЛВНгХЛЏЃЌПЩвдв§ШыBЪїКЭB+ЪїЁЃ
BЪїНтОіСЫЪВУДЮЪЬт
КмЖрЮФеТНЋBЪїЮѓГЦЮЊB-ЃЈМѕЃЉЪїЃЌетПЩФмЪЧЖдЦфгЂЮФУћЁАB-TreeЁБЕФЮѓНтЃЈИќгаЩѕепЃЌНЋBЪїГЦЮЊЖўВцЪїЛђЖўВцЫбЫїЪїЃЉЁЃЬиБ№ЪЧгыB+ЪївЛЦ№НВЕФЪБКђЁЃЯыЕБШЛЕФШЯЮЊгаB+ЃЈМгЃЉЪїОЭгаB-ЃЈМѕЃЉЪїЃЌЪЕМЪЩЯB+ЪїЕФгЂЮФУћЪЧЁАB+-TreeЁБЁЃ
ШчЙћХзПЊЮЌЛЄВйзїЃЌФЧУДBЪїОЭЯёвЛПУЁАmВцЫбЫїЪїЁБЃЈmЪЧзгЪїЕФзюДѓИіЪ§ЃЉЃЌЪБМфИДдгЖШЮЊO(logm(n))ЁЃШЛЖјЃЌBЪїЩшМЦСЫвЛжжИпаЇМђЕЅЕФЮЌЛЄВйзїЃЌЪЙBЪїЕФЩюЖШЮЌГждкдМlog(ceil(m/2))(n)~logm(n)жЎМфЃЌДѓДѓНЕЕЭЪїИпЁЃ
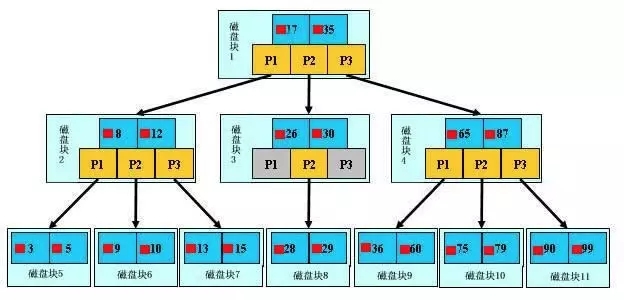
дйДЮЧПЕїЃК
ВЛвЊОРНсгкЪБМфИДдгЖШЃЌгыЕЅДПЕФЫуЗЈВЛЭЌЃЌДХХЬIOДЮЪ§ВХЪЧИќДѓЕФгАЯьвђЫиЁЃЖСепПЩвдЭЦЕМПДПДЃЌBЪїгыAVLЕФЪБМфИДдгЖШЪЧЯрЭЌЕФЃЌЕЋгЩгкBЪїЕФВуЪ§ЩйЃЌДХХЬIOДЮЪ§ЩйЃЌЪЕМљжаBЪїЕФадФмвЊгХгкAVLЕШЖўВцЪїЁЃ
ЭЌЖўВцЫбЫїЪїРрЫЦЃЌУПИіНкЕуДцДЂСЫЖрИіkeyКЭзгЪїЃЌзгЪїгыkeyАДЫГађХХСаЁЃ
вГБэЕФФПЕФЪЧРЉеЙФкДц+МгЫйДХХЬЖСаДЁЃвЛИівГЃЈPageЃЉЭЈГЃ4KЃЈЕШгкДХХЬЪ§ОнПщblockЕФДѓаЁЃЌМћinodeгыblockЕФЗжЮіЃЉЃЌДгДХХЬЖСаДЕФНЧЖШГіЗЂЃЌВйзїЯЕЭГУПДЮвдвГЮЊЕЅЮЛНЋФкШнДгДХХЬМгдиЕНФкДцЃЈвдЬЏЗжбАЕРГЩБОЃЉЃЌаоИФвГКѓЃЌдйдёЦкНЋИУвГаДЛиДХХЬЁЃПМТЧЕНвГБэЕФСМКУаджЪЃЌПЩвдЪЙУПИіНкЕуЕФДѓаЁдМЕШгквЛИівГЃЈЪЙmЗЧГЃДѓЃЉЃЌетУПДЮМгдиЕФвЛИівГОЭФмЭъећИВИЧвЛИіНкЕуЃЌвдБубЁдёЯТвЛВузгЪїЃЛЖдзгЪїЭЌРэЁЃЖдгквГБэРДЫЕЃЌAVLЃЈЛђRBTЃЉЯрЕБгк1Иіkey+2ИізгЪїЕФBЪїЃЌгЩгкТпМЩЯЯрСкЕФНкЕуЃЌЮяРэЩЯЭЈГЃВЛЯрСкЃЌвђДЫЃЌЖСШывЛИі4kвГЃЌвГУцФкОјДѓВПЗжПеМфЖМНЋЪЧЮоаЇЪ§ОнЁЃ
МйЩшkeyЁЂзгЪїНкЕужИеыОљеМгУ4BЃЌдђBЪїНкЕузюДѓm * (4 + 4) = 8m BЃЛвГУцДѓаЁ4KBЁЃдђm
= 4 * 1024 / 8 = 512ЃЌвЛИі512ВцЕФBЪїЃЌ1000wЕФЪ§ОнЃЌЩюЖШзюДѓ log(512/2)(10^7)
= 3.02 ~= 4ЁЃЖдБШЖўВцЪїШчAVLЕФЩюЖШЮЊlog(2)(10^7) = 23.25 ~= 24ЃЌЯрВюСЫ5БЖвдЩЯЁЃе№ОЊЃЁBЪїЫїв§ЩюЖШОЙШЛШчДЫЃЁ
СэЭтЃЌBЪїЖдОжВПаддРэЗЧГЃгбКУЁЃШчЙћkeyБШНЯаЁЃЈБШШчЩЯУц4BЕФзддіkeyЃЉЃЌдђГ§СЫвГБэЕФМгГЩЃЌЛКДцЛЙФмНјвЛВНдЄЖСМгЫйЁЃУРзЬзЬ~
B+ЪїНтОіСЫЪВУДЮЪЬт
BЪїЕФЪЃгрЮЪЬт
ШЛЖјЃЌШчЙћвЊЪЕМЪгІгУЕНЪ§ОнПтЕФЫїв§жаЃЌBЪїЛЙгавЛаЉЮЪЬтЃК
ЮДЖЈЮЛЪ§Онаа
ЮоЗЈДІРэЗЖЮЇВщбЏ
ЮЪЬт1
Ъ§ОнБэЕФМЧТМгаЖрИізжЖЮЃЌНіНіЖЈЮЛЕНжїМќЪЧВЛЙЛЕФЃЌЛЙашвЊЖЈЮЛЕНЪ§ОнааЁЃга3ИіЗНАИНтОіЃК
жБНгНЋkeyЖдгІЕФЪ§ОнааЃЈПЩФмЖдгІЖрааЃЉДцДЂдкНкЕужаЁЃ
Ъ§ОнааЕЅЖРДцДЂЃЛНкЕужадіМгвЛИізжЖЮЃЌЖЈЮЛkeyЖдгІЪ§ОнааЕФЮЛжУЁЃ
аоИФkeyгызгЪїЕФХаЖЯТпМЃЌЪЙзгЪїДѓгкЕШгкЩЯвЛkeyаЁгкЯТвЛkeyЃЌзюжеЫљгаЗУЮЪЖМНЋТфгквЖзгНкЕуЃЛвЖзгНкЕужажБНгДцДЂЪ§ОнааЛђЪ§ОнааЕФЮЛжУЁЃ
ЗНАИ1жаЃЌЪ§ОнааЭЈГЃЗЧГЃДѓЃЌДцДЂЪ§ОнааНЋМѕЩйвГУцжаЕФзгЪїИіЪ§ЃЌmМѕаЁЪїИпдіДѓЁЃМйЩшЪ§ОнааеМгУ200BЃЌПЩКіТдзщжЏBЪїЕФжИеыЃЌдђаТЕФm
= 4 * 1024 / 200 = 20.48 ~= 21ЃЌЩюЖШзюДѓ log(21/2)(10^7)
~= 7ЁЃдіМгСЫвЛБЖвдЩЯЕФIOЃЌВЛПМТЧЁЃ
ЗНАИ2жаЃЌНкЕудіМгСЫвЛИізжЖЮЁЃМйЩшЪЧ4BЕФжИеыЃЌдђаТЕФm = 4 * 1024 / 12 = 341.33
~= 341ЃЌЩюЖШзюДѓ log(341/2)(10^7) = 3.14 ~= 4ЁЃгы3ВюБ№ВЛДѓЃЌПЩвдПМТЧЁЃ
ЗНАИ3ЕФНкЕуmгыЩюЖШВЛБфЃЌЕЋЪБМфИДдгЖШБфЮЊЮШЖЈЕФO(logm(n))ЁЃПМТЧЁЃ
ЮЪЬт2
ЪЕМЪвЕЮёжаЃЌЗЖЮЇВщбЏЕФЦЕТЪЗЧГЃИпЃЌBЪїжЛФмЖЈЮЛЕНвЛИіЫїв§ЮЛжУЃЈПЩФмЖдгІЖрааЃЉЃЌКмФбДІРэЗЖЮЇВщбЏЁЃИјГі2жжЗНАИЃК
ВЛИФЖЏЃКВщбЏЕФЪБКђЯШВщЕНзѓНчЃЌдйВщЕНгвНчЃЌШЛКѓDFSЃЈЛђBFSЃЉБщРњзѓНчЁЂгвНчжЎМфЕФНкЕуЁЃ
дкЁАЮЪЬт1-ЗНАИ3ЁБЕФЛљДЁЩЯЃЌгЩгкЫљгаЪ§ОнааЖМДцДЂдквЖзгНкЕуЃЌBЪїЕФвЖзгНкЕуБОЩэвВЪЧгаађЕФЃЌПЩвддіМгвЛИіжИеыЃЌжИЯђЕБЧАвЖзгНкЕуАДжїМќЫГађЕФЯТвЛвЖзгНкЕуЃЛВщбЏЪБЯШВщЕНзѓНчЃЌдйВщЕНгвНчЃЌШЛКѓДгзѓНчЕНгаНчЯпадБщРњЁЃ
еЇвЛПДИаОѕЗНАИ1БШЗНАИ2КУЁЊЁЊЪБМфИДдгЖШКЭГЃЪ§ЯюЖМвЛбљЃЌЗНАИ1ЛЙВЛашвЊИФЖЏЁЃЕЋЪЧБ№ЭќСЫОжВПаддРэЃЌВЛЙмНкЕужаДцДЂЕФЪЧЪ§ОнааЛЙЪЧЪ§ОнааЮЛжУЃЌЗНАИ2ЕФКУДІдкгкЃЌвЖзгНкЕуСЌајДцДЂЃЌЖдвГБэКЭЛКДцгбКУЁЃЖјЗНАИ1дђУцСйНкЕуТпМЯрСкЁЂЮяРэЗжРыЕФШБЕуЁЃ
в§ГіB+Ъї
злЩЯЃЌЮЪЬт1ЕФЗНАИ2гыЮЪЬт2ЕФЗНАИ1ПЩећКЯЮЊвЛжжЗНАИЃЈЛљгкBЪїЕФЫїв§ЃЉЃЌЮЪЬт1ЕФЗНАИ3гыЮЪЬт2ЕФЗНАИ2ПЩећКЯЮЊвЛжжЃЈЛљгкB+ЪїЕФЫїв§ЃЉЁЃЪЕМЪЩЯЃЌЪ§ОнПтЁЂЮФМўЯЕЭГгааЉВЩгУСЫBЪїЃЌгааЉВЩгУB+ЪїЁЃ
гЩгкФГаЉКязгднЮДУїАзЕФдвђЃЌАќРЈMySQLдкФкЕФжїСїЪ§ОнПтЖрбЁдёСЫB+ЪїЁЃМДЃК
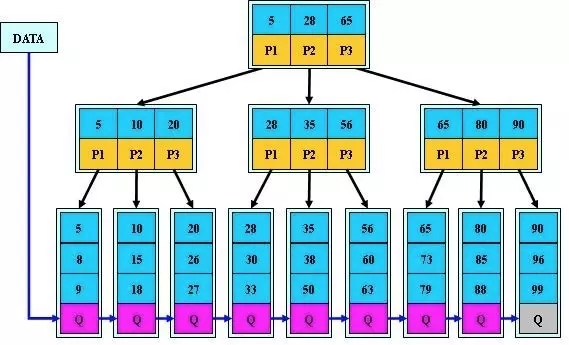
жївЊБфЖЏШчЩЯЫљЪіЃК
аоИФkeyгызгЪїЕФзщжЏТпМЃЌНЋЫїв§ЗУЮЪЖМТфЕНвЖзгНкЕу
АДЫГађНЋвЖзгНкЕуДЎЦ№РДЃЈЗНБуЗЖЮЇВщбЏЃЉ
BЪїКЭB+ЪїЕФдіЁЂЩОЁЂВщЙ§ГЬ
BЪїЕФдіЩОЙ§ГЬднЪБПЩВЮПМДгBЪїЁЂB+ЪїЁЂB*ЪїЬИЕНR ЪїЕФЁА6ЁЂBЪїЕФВхШыЁЂЩОГ§ВйзїЁБаЁНкЃЌB+ЪїЕФдіЩОЭЌРэЁЃДЫДІднВЛзИЪіЁЃ
MysqlЫїв§гХЛЏ
ИљОнB+ЪїЕФаджЪЃЌКмШнвзРэНтИїжжГЃМћЕФMySQLЫїв§гХЛЏЫМТЗЁЃ
днВЛПМТЧВЛЭЌв§ЧцжЎМфЕФЧјБ№ЁЃ
гХЯШЪЙгУзддіkeyзїЮЊжїМќ
ЧАУцЕФЗжЮіжаЃЌМйЩшгУ4BЕФзддіkeyзїЮЊЫїв§ЃЌдђmПЩДяЕН512ЃЌВуИпНіга3ЁЃЪЙгУзддіЕФkeyгаСНИіКУДІЃК
зддіkeyвЛАуЮЊintЕШећЪ§аЭЃЌkeyБШНЯНєДеЃЌетбљmПЩвдЗЧГЃДѓЃЌЖјЧвЫїв§еМгУПеМфаЁЁЃзюМЋЖЫЕФР§згЃЌШчЙћЪЙгУ50BЕФvarcharЃЈАќРЈГЄЖШЃЉЃЌФЧУДm
= 4 * 1024 / 54m = 75.85 ~= 76ЃЌЩюЖШзюДѓ log(76/2)(10^7)
= 4.43 ~= 5ЃЌдйМгЩЯcacheШБЪЇЁЂзжЗћДЎБШНЯЕФГЩБОЃЌЪБМфГЩБОдіМгНЯДѓЁЃЭЌЪБЃЌkeyгЩ4BдіГЄЕН50BЃЌећПУЫїв§ЪїЕФПеМфеМгУдіГЄвВЪЧМЋЮЊПжВРЕФЃЈШчЙћЖўМЖЫїв§ЪЙгУжїМќЖЈЮЛЪ§ОнааЃЌдђПеМфдіГЄИќМгбЯжиЃЉЁЃ
зддіЕФаджЪЪЙЕУаТЪ§ОнааЕФВхШыЧыЧѓБиШЛТфЕНЫїв§ЪїЕФзюгвВрЃЌЗЂЩњНкЕуЗжСбЕФЦЕТЪНЯЕЭЃЌРэЯыЧщПіЯТЃЌЫїв§ЪїПЩвдДяЕНЁАТњЁБЕФзДЬЌЁЃЫїв§ЪїТњЃЌвЛЗНУцВуИпИќЕЭЃЌвЛЗНУцЩОГ§НкЕуЪБЗЂЩњНкЕуКЯВЂЕФЦЕТЪвВНЯЕЭЁЃгХЛЏОРњЃК
КязгдјЪЙгУvarchar(100)ЕФСазіЙ§жїМќЃЌДцДЂcontainerIdЃЌЙ§СЫ3ЁЂ4Ьь100GЕФЪ§ОнПтОЭТњСЫЃЌDBAаЁНуНугЪМўРяЮЏЭёБэЪОСЫЖдЮвЕФБЩЪгЁЃЁЃЁЃжЎКѓдіМгСЫзддіСазїЮЊжїМќЃЌcontainerIdзїЮЊuniqueЕФЖўМЖЫїв§ЃЌЪБМфЁЂПеМфгХЛЏаЇЙћЯрЕБЯджјЁЃ
зюзѓЧАзКЦЅХф
Ыїв§ПЩвдМђЕЅШчвЛИіСа(a)ЃЌвВПЩвдИДдгШчЖрИіСа(a, b, c, d)ЃЌМДСЊКЯЫїв§ЁЃШчЙћЪЧСЊКЯЫїв§ЃЌФЧУДkeyвВгЩЖрИіСазщГЩЃЌЭЌЪБЃЌЫїв§жЛФмгУгкВщевkeyЪЧЗёДцдкЃЈЯрЕШЃЉЃЌгіЕНЗЖЮЇВщбЏ(>ЁЂ<ЁЂbetweenЁЂlikeзѓЦЅХф)ЕШОЭВЛФмНјвЛВНЦЅХфСЫЃЌКѓајЭЫЛЏЮЊЯпадВщевЁЃвђДЫЃЌСаЕФХХСаЫГађОіЖЈСЫПЩУќжаЫїв§ЕФСаЪ§ЁЃ
ШчгаЫїв§(a, b, c, d)ЃЌВщбЏЬѕМўa = 1 and b = 2 and c > 3
and d = 4ЃЌдђЛсдкУПИіНкЕувРДЮУќжаaЁЂbЁЂcЃЌЮоЗЈУќжаdЁЃвВОЭЪЧзюзѓЧАзКЦЅХфддђЁЃ
=ЁЂinздЖЏгХЛЏЫГађ
ВЛашвЊПМТЧ=ЁЂinЕШЕФЫГађЃЌmysqlЛсздЖЏгХЛЏетаЉЬѕМўЕФЫГађЃЌвдЦЅХфОЁПЩФмЖрЕФЫїв§СаЁЃ
ШчгаЫїв§(a, b, c, d)ЃЌВщбЏЬѕМўc > 3 and b = 2 and a = 1
and d < 4гыa = 1 and c > 3 and b = 2 and d <
4ЕШЫГађЖМЪЧПЩвдЕФЃЌMySQLЛсздЖЏгХЛЏЮЊa = 1 and b = 2 and c > 3
and d < 4ЃЌвРДЮУќжаaЁЂbЁЂcЁЃ
Ыїв§СаВЛФмВЮгыМЦЫу
гаЫїв§СаВЮгыМЦЫуЕФВщбЏЬѕМўЖдЫїв§ВЛгбКУЃЈЩѕжСЮоЗЈЪЙгУЫїв§ЃЉЃЌШчfrom_unixtime(create_time)
= '2014-05-29'ЁЃ
двђКмМђЕЅЃЌШчКЮдкНкЕужаВщевЕНЖдгІkeyЃПШчЙћЯпадЩЈУшЃЌдђУПДЮЖМашвЊжиаТМЦЫуЃЌГЩБОЬЋИпЃЛШчЙћЖўЗжВщевЃЌдђашвЊеыЖдfrom_unixtimeЗНЗЈШЗЖЈДѓаЁЙиЯЕЁЃ
вђДЫЃЌЫїв§СаВЛФмВЮгыМЦЫуЁЃЩЯЪіfrom_unixtime(create_time) = '2014-05-29'гяОфгІИУаДГЩcreate_time
= unix_timestamp('2014-05-29')ЁЃ
ФмРЉеЙОЭВЛвЊаТНЈЫїв§
ШчЙћвбгаЫїв§(a)ЃЌЯыНЈСЂЫїв§(a, b)ЃЌОЁСПбЁдёаоИФЫїв§(a)ЮЊЫїв§(a, b)ЁЃ
аТНЈЫїв§ЕФГЩБОКмШнвзРэНтЁЃЖјЛљгкЫїв§(a)аоИФЮЊЫїв§(a, b)ЕФЛАЃЌMySQLПЩвджБНгдкЫїв§aЕФB+ЪїЩЯЃЌОЙ§ЗжСбЁЂКЯВЂЕШаоИФЮЊЫїв§(a,
b)ЁЃ
ВЛашвЊНЈСЂЧАзКгаАќКЌЙиЯЕЕФЫїв§
ШчЙћвбгаЫїв§(a, b)ЃЌдђВЛашвЊдйНЈСЂЫїв§(a)ЃЌЕЋЪЧШчЙћгаБивЊЃЌдђШдШЛашПМТЧНЈСЂЫїв§(b)ЁЃ
бЁдёЧјЗжЖШИпЕФСазїЫїв§
КмШнвзРэНтЁЃШчЃЌгУадБ№зїЫїв§ЃЌФЧУДЫїв§НіФмНЋ1000wааЪ§ОнЛЎЗжЮЊСНВПЗжЃЈШч500wФаЃЌ500wХЎЃЉЃЌЫїв§МИКѕЮоаЇЁЃ
ЧјЗжЖШЕФЙЋЪНЪЧcount(distinct <col>) / count(*)ЃЌБэЪОзжЖЮВЛжиИДЕФБШР§ЃЌБШР§дНДѓЧјЗжЖШдНКУЁЃЮЈвЛМќЕФЧјЗжЖШЪЧ1ЃЌЖјвЛаЉзДЬЌЁЂадБ№зжЖЮПЩФмдкДѓЪ§ОнУцЧАЕФЧјЗжЖШЧїНќгк0ЁЃ
етИіжЕКмФбШЗЖЈЃЌвЛАуашвЊjoinЕФзжЖЮвЊЧѓЪЧ0.1вдЩЯЃЌМДЦНОљ1ЬѕЩЈУш10ЬѕМЧТМЁЃ
| 








