| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФНщЩмСЫInnoDBБэПеМфЮФМўжаЕФжївЊзщжЏНсЙЙЖЮЃЌЧј/ДиЃЌвГЕШЯрЙиИХФюЃЌвдМАinnodbЕФЮФМўЙмРэЗНЪНЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ |
|
вЛ ађЃК
дкећРэInnoDBДцДЂв§ЧцЕФЫїв§ЕФЪБКђЃЌЗЂЯжB+ЪїЪЧРыВЛПЊвГУцpageЕФЁЃЫљвдЯШећРэInnoDBЕФЪ§ОнДцДЂНсЙЙЁЃ
ЙиМќДЪЃКPages, Extents, Segments, and Tablespaces
ШчКЮДцДЂБэ
MySQL ЪЙгУ InnoDB ДцДЂБэЪБЃЌЛсНЋБэЕФЖЈвхКЭЪ§ОнЫїв§ЕШаХЯЂЗжПЊДцДЂЃЌЦфжаЧАепДцДЂдк .frm
ЮФМўжаЃЌКѓепДцДЂдк .ibd ЮФМўжаЃЌетвЛНкОЭЛсЖдетСНжжВЛЭЌЕФЮФМўЗжБ№НјааНщЩмЁЃ
.frm
ЮоТлдк MySQL жабЁдёСЫФФИіДцДЂв§ЧцЃЌЫљгаЕФ MySQL БэЖМЛсдкгВХЬЩЯДДНЈвЛИі .frm ЮФМўгУРДУшЪіБэЕФИёЪНЛђепЫЕЖЈвхЃЛ
.frm ЮФМўЕФИёЪНдкВЛЭЌЕФЦНЬЈЩЯЖМЪЧЯрЭЌЕФЁЃ
.ibd ЮФМў
InnoDB жагУгкДцДЂЪ§ОнЕФЮФМўзмЙВгаСНИіВПЗжЃЌвЛЪЧЯЕЭГБэПеМфЮФМўЃЌАќРЈ ibdata1ЁЂ ibdata2
ЕШЮФМўЃЌЦфжаДцДЂСЫ InnoDB ЯЕЭГаХЯЂКЭгУЛЇЪ§ОнПтБэЪ§ОнКЭЫїв§ЃЌЪЧЫљгаБэЙЋгУЕФЁЃ
ЕБДђПЊ innodb_file_per_table бЁЯюЪБЃЌ .ibd ЮФМўОЭЪЧУПвЛИіБэЖРгаЕФБэПеМфЃЌЮФМўДцДЂСЫЕБЧАБэЕФЪ§ОнКЭЯрЙиЕФЫїв§Ъ§ОнЁЃ
БэПеМф
innodbДцДЂв§ЧцдкДцДЂЩшМЦЩЯФЃЗТСЫOracleЕФДцДЂНсЙЙЃЌЦфЪ§ОнЪЧАДееБэПеМфНјааЙмРэЕФЁЃаТНЈвЛИіЪ§ОнПтЪБЃЌinnodbДцДЂв§ЧцЛсГѕЪМЛЏвЛИіУћЮЊibdata1
ЕФБэПеМфЮФМўЃЌФЌШЯЧщПіЯТЃЌетИіЮФМўЛсДцДЂЫљгаБэЕФЪ§ОнЃЌвдМАЮвУЧЫљЪьжЊЕЋПДВЛЕНЕФЯЕЭГБэsys_tablesЁЂsys_columnsЁЂsys_indexes
ЁЂsys_fieldsЕШЁЃДЫЭтЃЌЛЙЛсДцДЂгУРДБЃжЄЪ§ОнЭъећадЕФЛиЙіЖЮЪ§ОнЃЌЕБШЛетВПЗжЪ§ОндкаТАцБОЕФMySQLжаЃЌвбОПЩвдЭЈЙ§ВЮЪ§РДЩшжУЛиЙіЖЮЕФДцДЂЮЛжУСЫЃЛ
ПДЯТЙйЭјЕФНщЩмЃК
A data file that can hold data for one or more InnoDB
tables and associated indexes.
The system tablespace contains the InnoDB data dictionary,
and prior to MySQL 5.6 holds all other InnoDB tables
by default.
The innodb_file_per_table option, enabled by default
in MySQL 5.6 and higher, allows tables to be created
in their own tablespaces. File-per-table tablespaces
support features such as efficient storage of off-page
columns, table compression, and transportable tablespaces.
See Section 14.7.4, ЁАInnoDB File-Per-Table TablespacesЁБ
for details.
innodbДцДЂв§ЧцЕФЩшМЦКмСщЛюЃЌПЩвдЭЈЙ§ВЮЪ§innodb_file_per_tableРДЩшжУЃЌЪЙЕУУПвЛИіБэЖМЖдгІвЛИіздМКЕФЖРСЂБэПеМфЮФМўЃЌЖјВЛЪЧДцДЂЕНЙЋЙВЕФibdata1ЮФМўжаЁЃЖРСЂЕФБэПеМфЮФМўжЎДцДЂЖдгІБэЕФB+ЪїЪ§ОнЁЂЫїв§КЭВхШыЛКГхЕШаХЯЂЃЌЦфграХЯЂЛЙЪЧДцДЂдкФЌШЯБэПеМфжаЁЃ
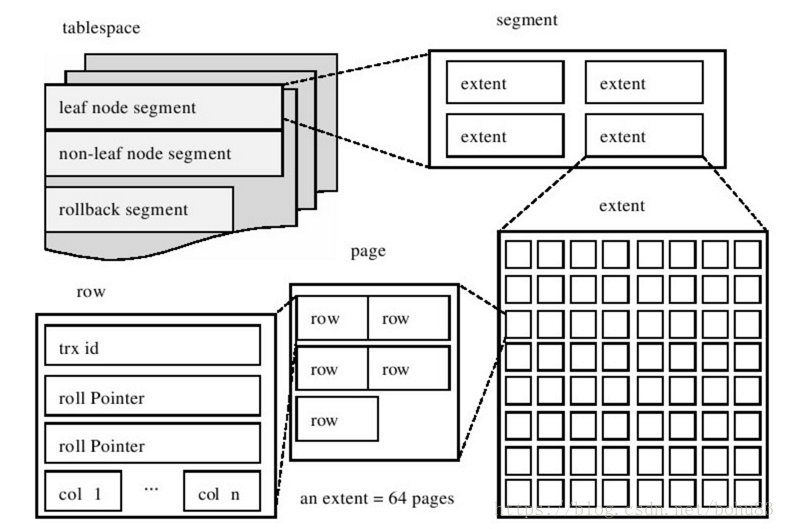
етИіЮФМўЫљДцДЂЕФФкШнжївЊОЭЪЧB+ЪїЃЈЫїв§ЃЉЃЌвЛИіБэПЩвдгаЖрИіЫїв§ЃЌвВОЭЪЧдквЛИіЮФМўжаЃЌПЩвдДцДЂЖрИіЫїв§ЃЌЖјШчЙћвЛИіБэУЛгаЫїв§ЕФЛАЃЌгУРДДцДЂЪ§ОнЕФБЛГЦЮЊОлДиЫїв§ЃЌвВОЭЪЧЫЕетвВЪЧвЛИіЫїв§ЁЃзюжеЕФНсТлЪЧЃЌibdЮФМўДцДЂЕФОЭЪЧвЛИіБэЕФЫљгаЫїв§Ъ§ОнЁЃ
Ыїв§ЮФМўгаЖЮЃЈsegmentЃЉ,ДиЃЈextendsЃЉЃЈгаЕФЮФеТЗвыЮЊЧјЃЉЃЌвГУцЃЈpageЃЉзщГЩЁЃ
ЙигкааМЧТМИёЪНЃЌЕЅЖРећРэвЛЦЊЁЃ
Жў ЖЮЃЈsegmentЃЉ
ЖЮЪЧБэПеМфЮФМўжаЕФжївЊзщжЏНсЙЙЃЌЫќЪЧвЛИіТпМИХФюЃЌгУРДЙмРэЮяРэЮФМўЃЌЪЧЙЙГЩЫїв§ЁЂБэЁЂЛиЙіЖЮЕФЛљБОдЊЫиЁЃ
ЩЯЭМжаЯдЪОСЫБэПеМфЪЧгЩИїИіЖЮзщГЩЕФЃЌГЃМћЕФЖЮгаЪ§ОнЖЮЁЂЫїв§ЖЮЁЂЛиЙіЖЮЕШЁЃInnoDBДцДЂв§ЧцБэЪЧЫїв§зщжЏЕФЃЈindex
organizedЃЉЃЌвђДЫЪ§ОнМДЫїв§ЃЌЫїв§МДЪ§ОнЁЃФЧУДЪ§ОнЖЮМДЮЊB+ЪїЕФвГНкЕуЃЈЩЯЭМЕФleaf node
segmentЃЉЃЌЫїв§ЖЮМДЮЊB+ЪїЕФЗЧЫїв§НкЕуЃЈЩЯЭМЕФnon-leaf node segmentЃЉЁЃ
ДДНЈвЛИіЫїв§ЃЈB+ЪїЃЉЪБЛсЭЌЪБДДНЈСНИіЖЮЃЌЗжБ№ЪЧФкНкЕуЖЮКЭвЖзгЖЮЃЌФкНкЕуЖЮгУРДЙмРэЃЈДцДЂЃЉB+ЪїЗЧвЖзгЃЈвГУцЃЉЕФЪ§ОнЃЌвЖзгЖЮгУРДЙмРэЃЈДцДЂЃЉB+ЪївЖзгНкЕуЕФЪ§ОнЃЛвВОЭЪЧЫЕЃЌдкЫїв§Ъ§ОнСПвЛжБдіГЄЕФЙ§ГЬжаЃЌЫљгааТЕФДцДЂПеМфЕФЩъЧыЃЌЖМЪЧДгЁАЖЮЁБетИіИХФюжаЩъЧыЕФЁЃ
ЮЊСЫНщЩмЫїв§ЮЊФПЕФЃЌЫљвдВЛеЙПЊНщЩмЛиЙіЖЮЕШФкШнЁЃ
Ш§ Чј/ДиЃЈextentsЃЉ
ЖЮЪЧИіТпМИХФюЃЌinnodbв§ШыСЫДиЕФИХФюЃЌдкДњТыжаБЛГЦЮЊextentЃЛ
ДиЪЧгЩ64ИіСЌајЕФвГзщГЩЕФЃЌУПИівГДѓаЁЮЊ16KBЃЌМДУПИіДиЕФДѓаЁЮЊ1MBЁЃДиЪЧЙЙГЩЖЮЕФЛљБОдЊЫиЃЌвЛИіЖЮгЩШєИЩИіДиЙЙГЩЁЃвЛИіДиЪЧЮяРэЩЯСЌајЗжХфЕФвЛИіЖЮПеМфЃЌУПвЛИіЖЮжСЩйЛсгавЛИіДиЃЌдкДДНЈвЛИіЖЮЪБЛсДДНЈвЛИіФЌШЯЕФДиЁЃШчЙћДцДЂЪ§ОнЪБЃЌвЛИіДивбОВЛзувдЗХЯТИќЖрЕФЪ§ОнЃЌДЫЪБашвЊДгетИіЖЮжаЗжХфвЛИіаТЕФДиРДДцЗХаТЕФЪ§ОнЁЃвЛИіЖЮЫљЙмРэЕФПеМфДѓаЁЪЧЮоЯоЕФЃЌПЩвдвЛжБРЉеЙЯТШЅЃЌЕЋЪЧРЉеЙЕФзюаЁЕЅЮЛОЭЪЧДиЁЃ
ЫФ вГЃЈpageЃЉ
InnoDBгавГЃЈpageЃЉЕФИХФюЃЌПЩвдРэНтЮЊДиЕФЯИЛЏЁЃвГЪЧInnoDBДХХЬЙмРэЕФзюаЁЕЅЮЛЁЃ
ГЃМћЕФвГРраЭгаЃК
Ъ§ОнвГЃЈB-tree NodeЃЉЁЃ
UndoвГЃЈUndo Log PageЃЉЁЃ
ЯЕЭГвГЃЈSystem PageЃЉЁЃ
ЪТЮёЪ§ОнвГЃЈTransaction system PageЃЉЁЃ
ВхШыЛКГхЮЛЭМвГЃЈInsert Buffer BitmapЃЉЁЃ
ВхШыЛКГхПеЯаСаБэвГЃЈInsert Buffer Free ListЃЉЁЃ
ЮДбЙЫѕЕФЖўНјжЦДѓЖдЯѓвГЃЈUncompressed BLOB PageЃЉЁЃ
бЙЫѕЕФЖўНјжЦДѓЖдЯѓвГЃЈCompressed BLOB PageЃЉЁЃ
дкТпМЩЯЃЈвГУцКХЖМЪЧДгаЁЕНДѓСЌајЕФЃЉМАЮяРэЩЯЖМЪЧСЌајЕФЁЃдкЯђБэжаВхШыЪ§ОнЪБЃЌШчЙћвЛИівГУцвбОБЛаДЭъЃЌЯЕЭГЛсДгЕБЧАДижаЗжХфвЛИіаТЕФПеЯавГУцДІРэЪЙгУЃЌШчЙћЕБЧАДижаЕФ64ИівГУцЖМБЛЗжХфЭъЃЌЯЕЭГЛсДгЕБЧАвГУцЫљдкЖЮжаЗжХфвЛИіаТЕФДиЃЌШЛКѓдйДгетИіДижаЗжХфвЛИіаТЕФвГУцРДЪЙгУЃЛ
ПДЯТЙйЭјЕФНщЩмЃК
Pages, Extents, Segments, and Tablespaces
Each tablespace consists of database?pages. Every
tablespace in a MySQL instance has the same?page size.
By default, all tablespaces have a page size of 16KB;
you can reduce the page size to 8KB or 4KB by specifying
the?innodb_page_size?option when you create the MySQL
instance. You can also increase the page size to 32KB
or 64KB. For more information, refer to the?innodb_page_sizedocumentation.
The pages are grouped into?extents?of size 1MB for
pages up to 16KB in size (64 consecutive 16KB pages,
or 128 8KB pages, or 256 4KB pages). For a page size
of 32KB, extent size is 2MB. For page size of 64KB,
extent size is 4MB. The?ЁАfilesЁБ?inside a tablespace
are called?segments?in?InnoDB. (These segments are
different from the?rollback segment, which actually
contains many tablespace segments.)
When a segment grows inside the tablespace,?InnoDB?allocates
the first 32 pages to it one at a time. After that,?InnoDB?starts
to allocate whole extents to the segment.?InnoDB?can
add up to 4 extents at a time to a large segment to
ensure good sequentiality of data.
Two segments are allocated for each index in?InnoDB.
One is for nonleaf nodes of the?B-tree, the other
is for the leaf nodes. Keeping the leaf nodes contiguous
on disk enables better sequential I/O operations,
because these leaf nodes contain the actual table
data.
Some pages in the tablespace contain bitmaps of other
pages, and therefore a few extents in an?InnoDB?tablespace
cannot be allocated to segments as a whole, but only
as individual pages.
Юх зщжЏНсЙЙ
етРядкЁЖMySQLдЫЮЌФкВЮЁЗЫЕЕФВЛЪЧЬиБ№ЯИЃКвЛИіБэПеМфПЩвдгаЖрИіЮФМўЃЌУПИіЮФМўЖМгаИїздЕФБрКХЃЌДДНЈвЛИіБэПеМфЪБЃЌжСЩйгавЛИіЮФМўЃЌетИіЮФМўБЛГЦЮЊЁА0КХЮФМўЁБЁЃвЛИіЮФМўЪЧБЛЧаИюЮЊЕШГЄЁАФЌШЯ16KBЁБЕФПщЃЌетИіПщЭЈГЃБЛГЦЮЊвГУцЃЌФЧУДдкЁА0КХЮФМўЁБЕФЕквЛИівГУцЃЈpage_noЮЊ0ЃЉжаЃЌДцДЂСЫетИіБэПеМфжаЫљгаЖЮДивВЙмРэЕФШыПкЃЌФЧУДдкетИівГУцДцДЂЕФЪ§ОнОЭЪЧ16KBЃЌЕЋЭЈГЃЛсгавГУцЭЗаХЯЂЛсеМгУвЛаЉПеМфЃЌеце§ЕФЙмРэаХЯЂЪ§ОнЪЧДгвГУцЦЋвЦЮЊfil_page_data(38)ЕФЮЛжУПЊЪМЕФЃЌетИіЮЛжУДцДЂСЫБэПеМфЕФУшЪіаХЯЂЃЛ
ЬдБІЕФmysqlИјГіСЫИќЯъЯИЃКЯШПДетИіЭМЃЌгаИіДѓИХИХФюЃЌдйЭљЯТПДЁЃ
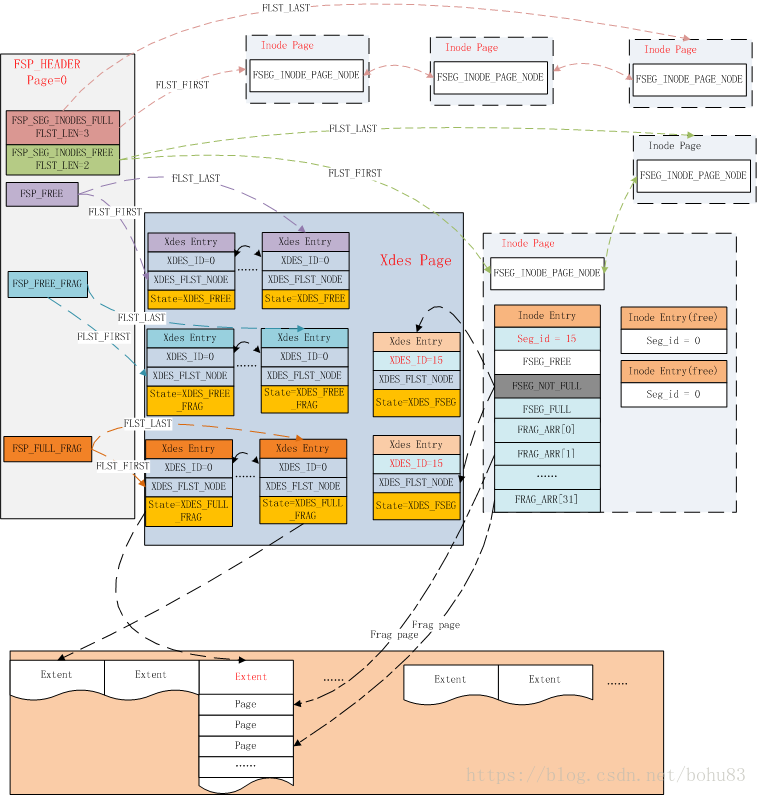
5.1 FSP_HDR PAGE
Ъ§ОнЮФМўЕФЕквЛИіPageРраЭЮЊFIL_PAGE_TYPE_FSP_HDRЃЌдкДДНЈвЛИіаТЕФБэПеМфЪБНјааГѕЪМЛЏ(fsp_header_init)ЃЌИУpageЭЌЪБгУгкИњзйЫцКѓЕФ256ИіExtent(дМ256MBЮФМўДѓаЁ)ЕФПеМфЙмРэЃЌЫљвдУПИє256MBОЭвЊДДНЈвЛИіРрЫЦЕФЪ§ОнвГЃЌРраЭЮЊFIL_PAGE_TYPE_XDES?ЃЌXDES
PageГ§СЫЮФМўЭЗВПЭтЃЌЦфЫћЖМКЭFSP_HDRвГОпгаЯрЭЌЕФЪ§ОнНсЙЙЃЌПЩвдГЦжЎЮЊExtentУшЪівГЃЌУПИіExtentеМгУ40ИізжНкЃЌвЛИіXDES
PageзюЖрУшЪі256ИіExtentЁЃ
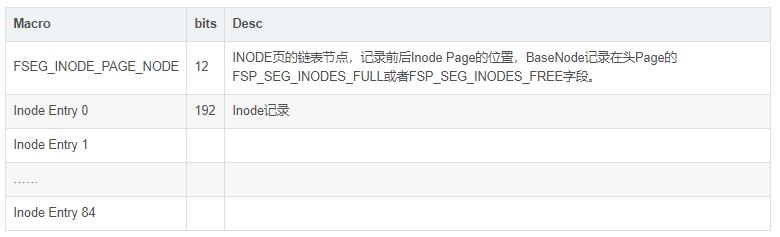
FSP_HDRвГЕФЭЗВПЪЙгУFSP_HEADER_SIZEИізжНкРДМЧТМЮФМўЕФЯрЙиаХЯЂЃЌОпЬхЕФАќРЈЃК
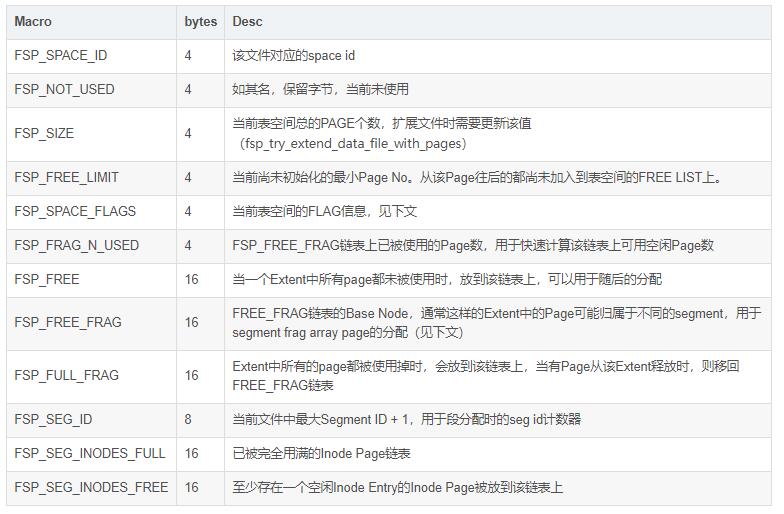
ДиЛђепЗжЧјЃЈextentЃЉЪЧЖЮЕФзщГЩдЊЫиЃЌдкЮФМўЭЗЪЙгУFLAGУшЪіСЫДДНЈБэаХЯЂЃЌГ§ДЫжЎЭтЦфЫћВПЗжЕФЪ§ОнНсЙЙКЭXDES
PAGEЖМЪЧЯрЭЌЕФЃЌЪЙгУСЌајЪ§зщЕФЗНЪНЃЌУПИіXDES PAGEзюЖрДцДЂ256ИіXDES EntryЃЌУПИіEntryеМгУ40ИізжНкЃЌУшЪі64ИіPageЃЈМДвЛИіExtentЃЉЁЃИёЪНШчЯТЃК

XDES_STATEБэЪОИУExtentЕФЫФжжВЛЭЌзДЬЌЃК

ЭЈЙ§XDES_STATEаХЯЂЃЌЮвУЧжЛашвЊвЛИіFLIST_NODEНкЕуОЭПЩвдЮЌЛЄУПИіExtentЕФаХЯЂЃЌЪЧДІгкШЋОжБэПеМфЕФСДБэЩЯЃЌЛЙЪЧФГИіbtree
segmentЕФСДБэЩЯЁЃ
IBUF BITMAP PAGE вВОЭЪЧpageРраЭЮЊFIL_PAGE_IBUF_BITMAPВЛеЙПЊЃЌД§ЕЅЖРећРэЁЃдйПДЖЮЕФЁЃ
5.2 INODE PAGE
Ъ§ОнЮФМўЕФЕк3ИіpageЕФРраЭЮЊFIL_PAGE_INODEЃЌгУгкЙмРэЪ§ОнЮФМўжаЕФsegementЃЌУПИіЫїв§еМгУ2ИіsegmentЃЌЗжБ№гУгкЙмРэвЖзгНкЕуКЭЗЧвЖзгНкЕуЁЃУПИіinodeвГПЩвдДцДЂFSP_SEG_INODES_PER_PAGEЃЈФЌШЯЮЊ85ЃЉИіМЧТМЁЃ
УПИіInode EntryЕФНсЙЙШчЯТБэЫљЪОЃК
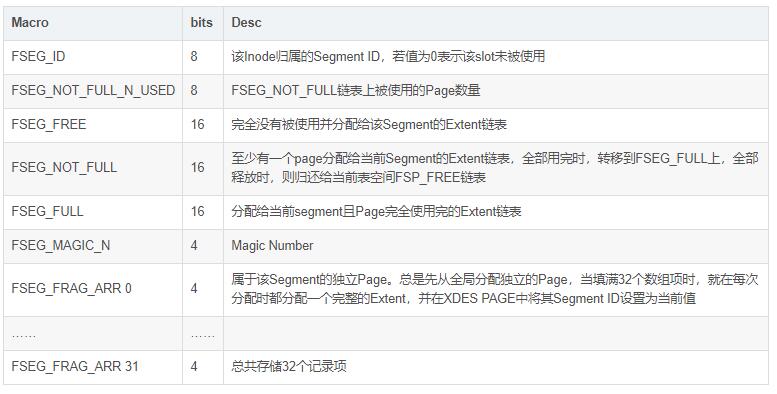
ПДЕНетРяЃЌЩЯУцЕФЭМгІИУЪЧРэНтСЫЃЌЕБШЛЪщЩЯЛЙЪЧИјСЫвЛИіМђЛЏЕФЭМЃК
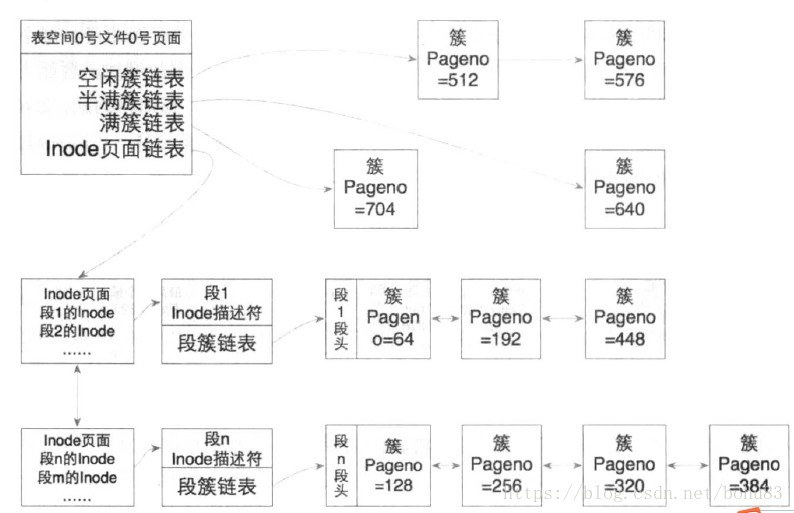
5.3 ЮФМўЮЌЛЄ
ДгЩЯЮФЮвУЧПЩвдПДЕНЃЌInnoDBЭЈЙ§Inode EntryРДЙмРэУПИіSegmentеМгУЕФЪ§ОнвГЃЌУПИіsegmentПЩвдПДзівЛИіЮФМўвГЮЌЛЄЕЅдЊЁЃInode
EntryЫљдкЕФinode pageгаПЩФмДцЗХТњЃЌвђДЫгжЭЈЙ§ЭЗPageЮЌЛЄСЫInode PageСДБэЁЃ
дкibdЕФЕквЛИіPageжаЛЙЮЌЛЄСЫБэПеМфФкExtentЕФFREEЁЂFREE_FRAGЁЂFULL_FRAGШ§ИіExtentСДБэЃЛЖјУПИіInode
EntryвВЮЌЛЄСЫЖдгІЕФFREEЁЂNOT_FULLЁЂFULLШ§ИіExtentСДБэЁЃетаЉСДБэжЎМфДцдкзХзЊЛЛЙиЯЕЃЌвдИпаЇЕФРћгУЪ§ОнЮФМўПеМфЁЃзЂвтЧјБ№ЃКБэПеМфжаЕФСДБэЙмРэЕФЪЧећИіБэПеМфжаЫљгаЕФДиЃЌАќРЈТњДиЁЂАыТњДиМАПеЯаДиЃЌЖјЖЮЕФiNodeаХЯЂжаЙмРэЕФЪЧЪєгкздМКЖЮжаЕФТњДиЁЂАыТњДиМАПеЯаДиЁЃ
ЕБДДНЈвЛИіаТЕФЫїв§ЪБЃЌЪЕМЪЩЯЙЙНЈвЛИіаТЕФbtree(btr_create)ЃЌЯШЮЊЗЧвЖзгНкЕуSegmentЗжХфвЛИіinode
entryЃЌдйДДНЈroot pageЃЌВЂНЋИУsegmentЕФЮЛжУМЧТМЕНroot pageжаЃЌШЛКѓдйЗжХфleaf
segmentЕФInode entryЃЌВЂМЧТМЕНroot pageжаЁЃЕБЩОГ§ФГИіЫїв§КѓЃЌИУЫїв§еМгУЕФПеМфашвЊФмБЛжиаТРћгУЦ№РДЁЃ
ДДНЈвЛИіsegmentЃК
КЏЪ§ШыПкЃКfseg_create_generalЃЌКѓУцЬљвЛЯТДњТыЃЌжївЊЪЧЪщЩЯЕФНтЪЭЁЃ
1.ИљОнПеМфidЕУЕНБэПеМфЭЗаХЯЂЁЃ
2. ДгЕУЕНЕФБэПеМфЭЗаХЯЂЗжХфInode:ОпЬхЪЕЯжЮЊЖСШЁЮФМўЭЗPageВЂМгЫјЃЈfsp_get_space_headerЃЉЃЌШЛКѓПЊЪМЮЊЦфЗжХфInode
Entry(fsp_alloc_seg_inode)ЁЃ
ЮЊСЫЙмРэInode PageЃЌдкЮФМўЭЗДцДЂСЫСНИіInode PageСДБэЃЌвЛИіСДНгвбОгУТњЕФinode
pageЃЌвЛИіСДНгЩаЮДгУТњЕФinode pageЁЃШчЙћЕБЧАInode PageЕФПеМфЪЙгУЭъСЫЃЌОЭашвЊдйЗжХфвЛИіinode
pageЃЌВЂМгШыЕНFSP_SEG_INODES_FREEСДБэЩЯ(fsp_alloc_seg_inode_page)ЁЃЖдгкЖРСЂБэПеМфЃЌЭЈГЃвЛИіinode
pageОЭзуЙЛСЫЁЃ
ЯТУцПДОпЬхВщевinode PageЙ§ГЬЃКЪзЯШХаЖЯFSP_SEG_INODES_FREEСДБэЪЧЗёЛЙгаПеЯавГУцЃЌШчЙћгаЃЌдђДгвГУцЕФЪ§ОнДцДЂЮЛжУПЊЪМЩЈУшЃЌУЛеввЛИіInodeЃЌЯШХаЖЯЪЧЗёПеЯаЃЈПеЯаБэЪОЦфВЛЙщЪєШЮКЮsegmentЃЌМДFSEG_IDжУЮЊ0ЃЉЁЃевЕНдђЗЕЛиЁЃевЕНетИіЧветИіInodeЮЊетИівГзюКѓвЛИіInode.дђИУinode
pageжаЕФМЧТМгУТњСЫЃЌОЭДгFSP_SEG_INODES_FREEСДБэЩЯзЊвЦЕНFSP_SEG_INODES_FULLСДБэЁЃШчЙћFSP_SEG_INODES_FREEУЛгаПеЯаЕФInodeвГУцЃЌдђжиаТЗжХфвЛИіinodeвГУцЃЌЗжХфКѓАбЫљгаУшЪіЗћРяУцЕФFSEG_IDжУЮЊ0ЃЌжиИДЩЯУцЙ§ГЬЁЃ
3.ИјаТЗжХфЕФInodeЩшжУSEG_ID. етИіIDКХвЊДгБэПеМфЭЗаХЯЂЕФFSP_SEG_IDзїЮЊЕБЧАsegmentЕФseg
idаДШыЕНinode entryжаЁЃЭЌЪБИќаТFSP_SEG_IDЕФжЕЮЊID+1ЃЌзїЮЊЯТвЛИіЖЮЕФIDКХЁЃ
4.дкЭъГЩinode entryЕФЬсШЁКѓЃЌГѕЪМЛЏетИіInodeаХЯЂЁЃАбFSEG_NOT_FULL_N_USEDжУЮЊ0ЃЌГѕЪМЛЏFSEG_FREEЁЂFSEG_NOT_FULLЃЌFSEG_FULLЁЃ
5. ДгетИіЖЮЗжХфГівЛИівГУцЁЃЃЈетПщТпМВЛЬЋЖЎЃЉ
6.ЗжХфКУвГУцКѓЃЌЭЈЙ§ЛКДцевЕНЖЮЕФЪзвГУцЃЈвГУцКХЮЊpage+indexЃЉЁЃОЭНЋИУinode entryЫљдкinode
pageЕФЮЛжУМАвГФкЦЋвЦСПДцДЂЕНЖЮЪзвГЃЌ10ИізжНкЕФinodeаХЯЂАќРЈЃК

жСДЫЖЮОЭЗжХфЭъГЩСЫЃЌвдКѓШчЙћашвЊдкетИіЖЮжаЗжХфПеМфЃЌжЛашвЊевЕНЦфЪзвГЃЌШЛКѓИљОнЖдгІЕФInodeЗжХфПеМфЁЃ
Creates a new
segment.
@return the block where the segment header is
placed, x-latched, NULL
if could not create segment because of lack of
space */
UNIV_INTERN
buf_block_t*
fseg_create_general(
/*================*/
ulint space, /*!< in: space id */
ulint page, /*!< in: page where the segment
header is placed: if
this is != 0, the page must belong to another
segment,
if this is 0, a new page will be allocated and
it
will belong to the created segment */
ulint byte_offset, /*!< in: byte offset of
the created segment header
on the page */
ibool has_done_reservation, /*!< in: TRUE if
the caller has already
done the reservation for the pages with
fsp_reserve_free_extents (at least 2 extents:
one for
the inode and the other for the segment) then
there is
no need to do the check for this individual
operation */
mtr_t* mtr) /*!< in: mtr */
{
ulint flags;
ulint zip_size;
fsp_header_t* space_header;
fseg_inode_t* inode; //typedef byte fseg_inode_t;
ib_id_t seg_id;
buf_block_t* block = 0; /* remove warning */
fseg_header_t* header = 0; /* remove warning */
rw_lock_t* latch;
ibool success;
ulint n_reserved;
ulint i;
ut_ad(mtr);
ut_ad(byte_offset + FSEG_HEADER_SIZE
<=
UNIV_PAGE_SIZE - FIL_PAGE_DATA_END);
latch = fil_space_get_latch(space, &flags);
zip_size = dict_table_flags_to_zip_size(flags);
if (page != 0) {
block = buf_page_get(space, zip_size, page, RW_X_LATCH,
mtr);
header = byte_offset + buf_block_get_frame(block);
}
ut_ad(!mutex_own(&kernel_mutex)
|| mtr_memo_contains(mtr, latch, MTR_MEMO_X_LOCK));
mtr_x_lock(latch, mtr);
if (rw_lock_get_x_lock_count(latch) == 1) {
/* This thread did not own the latch before this
call: free
excess pages from the insert buffer free list
*/
if (space == IBUF_SPACE_ID) {
ibuf_free_excess_pages();
}
}
if (!has_done_reservation) {
success = fsp_reserve_free_extents(&n_reserved,
space, 2,
FSP_NORMAL, mtr);
if (!success) {
return(NULL);
}
}
space_header = fsp_get_space_header (space, zip_size,
mtr);//ЯъМћ
inode = fsp_alloc_seg_inode(space_header, mtr);
//ЩъЧыinode entry ЯъМћ if (inode == NULL) {
goto funct_exit;
}
/* Read the next segment id from space header
and increment the
value in space header */
seg_id = mach_read_from_8(space_header + FSP_SEG_ID);
//ЩшжУЯТвЛЯТseg id
mlog_write_ull(space_header + FSP_SEG_ID, seg_id
+ 1, mtr);
/**
*#define FSEG_ID 0
*#define FSEG_NOT_FULL_N_USED 8
*#define FSEG_FREE 12
*#define FSEG_NOT_FULL (12 + FLST_BASE_NODE_SIZE)
*#define FLST_BASE_NODE_SIZE (4 + 2 * FIL_ADDR_SIZE)
*#define FIL_ADDR_SIZE 6
*
*#define FSEG_FULL (12 + 2 * FLST_BASE_NODE_SIZE)
*
*/
mlog_write_ull(inode + FSEG_ID, seg_id, mtr);
mlog_write_ulint(inode + FSEG_NOT_FULL_N_USED,
0, MLOG_4BYTES, mtr);
flst_init(inode + FSEG_FREE, mtr); //ГѕЪМЛЏinodeжаЕФseg
list ЯъМћ
flst_init(inode + FSEG_NOT_FULL, mtr);
flst_init(inode + FSEG_FULL, mtr);
mlog_write_ulint(inode + FSEG_MAGIC_N, FSEG_MAGIC_N_VALUE,
MLOG_4BYTES, mtr);
//#define FSEG_FRAG_ARR_N_SLOTS (FSP_EXTENT_SIZE
/ 2) 64/2=32 for (i = 0; i < FSEG_FRAG_ARR_N_SLOTS;
i++) {
fseg_set_nth_frag_page_no(inode, i, FIL_NULL,
mtr); //ЩшжУfrag ЫщЦЌ ЯъМћ
}
if (page == 0) {
block = fseg_alloc_free_page_low(space, zip_size,
inode, 0, FSP_UP, mtr, mtr);
if (block == NULL) {
fsp_free_seg_inode(space, zip_size, inode, mtr);
goto funct_exit;
}
ut_ad(rw_lock_get_x_lock_count(&block->lock)
== 1);
header = byte_offset + buf_block_get_frame(block);
mlog_write_ulint(buf_block_get_frame(block) +
FIL_PAGE_TYPE,
FIL_PAGE_TYPE_SYS, MLOG_2BYTES, mtr);
}
//ЩшжУfset_headerаХЯЂ
mlog_write_ulint(header + FSEG_HDR_OFFSET ,page_offset(inode),
MLOG_2BYTES, mtr);
mlog_write_ulint(header + FSEG_HDR_PAGE_NO,page_get_page_no(page_align(inode)),
MLOG_4BYTES, mtr);
mlog_write_ulint(header + FSEG_HDR_SPACE, space,
MLOG_4BYTES, mtr);
funct_exit:
if (!has_done_reservation) {
fil_space_release_free_extents(space, n_reserved);
}
return(block);
} |
ЗжХфЪ§ОнвГКЏЪ§ fsp_alloc_free_page
БэПеМфExtentЕФЗжХфКЏЪ§fsp_alloc_free_extent ЃЌВЛдкДЫеЙПЊЁЃ
ЖдгІЕФЛЙгаЪЭЗХSegment ЕБЮвУЧЩОГ§Ыїв§ЛђепБэЪБЃЌашвЊЩОГ§btreeЃЈbtr_free_if_existsЃЉЃЌЯШЩОççСЫrootНкЕуЭтЕФЦфЫћВПЗж(btr_free_but_not_root)ЃЌдйЩОГ§rootНкЕу(btr_free_root)
гЩгкЪ§ОнВйзїЖМашвЊМЧТМredoЃЌЮЊСЫБмУтВњЩњЗЧГЃДѓЕФredo logЃЌleaf segmentЭЈЙ§ЗДИДЕїгУКЏЪ§fseg_free_stepРДЪЭЗХЦфеМгУЕФЪ§ОнвГЁЃ
Сљ ДДНЈB+Ыїв§
ЩЯУцЮвУЧвбОДѓИХСЫНтСЫinnodbЕФЮФМўЙмРэЗНЪНЃЌКЫаФФПЕФЪЧЮЊСЫЙмРэКУB+Ыїв§ЁЃ
ibdЮФМўжаеце§ЙЙНЈЦ№гУЛЇЪ§ОнЕФНсЙЙЪЧBTREEЃЌдкФуДДНЈвЛИіБэЪБЃЌвбОЛљгкЯдЪНЛђвўЪНЖЈвхЕФжїМќЙЙНЈСЫвЛИіbtreeЃЌЦфвЖзгНкЕуЩЯМЧТМСЫааЕФШЋВПСаЪ§ОнЃЈМгЩЯЪТЮёidСаМАЛиЙіЖЮжИеыСаЃЉЃЛШчЙћФудкБэЩЯДДНЈСЫЖўМЖЫїв§ЃЌЦфвЖзгНкЕуДцДЂСЫМќжЕМгЩЯОлМЏЫїв§МќжЕЁЃЫљвдЪщЩЯЬљвЛЖЮДДНЈB+Ыїв§ЕФДњТыЁЃЭјЩЯевСЫ5.6.15АцБОЕФЁЃетИіКЏЪ§ОЭЪЧДДНЈвЛИіB+ЪїЃЌжЛЪЧИХФюЩЯЕФЃЌЛЙУЛгаеце§ЕФЪ§ОнаДШыЁЃ
ЯрЙижЊЪЖЕуЃКB+ЪїЃЌЫїв§ЃЌЖЮЃЌЧј/ДиЃЈextentЃЉ,вГ вбОДЎЦ№РДСЫЁЃ
Creates the root
node for a new index tree.
@return page number of the created root, FIL_NULL
if did not succeed */
UNIV_INTERN
ulint
btr_create(
/*=======*/
ulint type, /*!< in: type of the index */
ulint space, /*!< in: space where created */
ulint zip_size,/*!< in: compressed page size
in bytes
or 0 for uncompressed pages */
index_id_t index_id,/*!< in: index id */
dict_index_t* index, /*!< in: index */
mtr_t* mtr) /*!< in: mini-transaction handle
*/
{
ulint page_no;
buf_block_t* block;
buf_frame_t* frame;
page_t* page;
page_zip_des_t* page_zip;
/* Create the two new segments (one, in the case
of an ibuf tree) for
the index tree; the segment headers are put on
the allocated root page
(for an ibuf tree, not in the root, but on a separate
ibuf header
page) */
if (type & DICT_IBUF) {
/* Allocate first the ibuf header page */
buf_block_t* ibuf_hdr_block = fseg_create(
space, 0,
IBUF_HEADER + IBUF_TREE_SEG_HEADER, mtr);
buf_block_dbg_add_level(
ibuf_hdr_block, SYNC_IBUF_TREE_NODE_NEW);
ut_ad(buf_block_get_page_no(ibuf_hdr_block)
== IBUF_HEADER_PAGE_NO);
/* Allocate then the next page to the segment:
it will be the
tree root page */
block = fseg_alloc_free_page(
buf_block_get_frame(ibuf_hdr_block)
+ IBUF_HEADER + IBUF_TREE_SEG_HEADER,
IBUF_TREE_ROOT_PAGE_NO,
FSP_UP, mtr);
ut_ad(buf_block_get_page_no(block) == IBUF_TREE_ROOT_PAGE_NO);
} else {
#ifdef UNIV_BLOB_DEBUG
if ((type & DICT_CLUSTERED) && !index->blobs)
{
mutex_create(PFS_NOT_INSTRUMENTED,
&index->blobs_mutex,
SYNC_ANY_LATCH);
index->blobs = rbt_create(sizeof(btr_blob_dbg_t),
btr_blob_dbg_cmp);
}
#endif /* UNIV_BLOB_DEBUG */
block = fseg_create(space, 0,
PAGE_HEADER + PAGE_BTR_SEG_TOP, mtr);
}
if (block == NULL) {
return(FIL_NULL);
}
page_no = buf_block_get_page_no(block);
frame = buf_block_get_frame(block);
if (type & DICT_IBUF) {
/* It is an insert buffer tree: initialize the
free list */
buf_block_dbg_add_level(block, SYNC_IBUF_TREE_NODE_NEW);
ut_ad(page_no == IBUF_TREE_ROOT_PAGE_NO);
flst_init(frame + PAGE_HEADER + PAGE_BTR_IBUF_FREE_LIST,
mtr);
} else {
/* It is a non-ibuf tree: create a file segment
for leaf
pages */
buf_block_dbg_add_level(block, SYNC_TREE_NODE_NEW);
if (!fseg_create(space, page_no,
PAGE_HEADER + PAGE_BTR_SEG_LEAF, mtr)) {
/* Not enough space for new segment, free root
segment before return. */
btr_free_root(space, zip_size, page_no, mtr);
return(FIL_NULL);
}
/* The fseg create acquires a second latch on
the page,
therefore we must declare it: */
buf_block_dbg_add_level(block, SYNC_TREE_NODE_NEW);
}
/* Create a new index page on the allocated segment
page */
page_zip = buf_block_get_page_zip(block);
if (page_zip) {
page = page_create_zip(block, index, 0, 0, mtr);
} else {
page = page_create(block, mtr,
dict_table_is_comp(index->table));
/* Set the level of the new index page */
btr_page_set_level(page, NULL, 0, mtr);
}
block->check_index_page_at_flush = TRUE;
/* Set the index id of the page */
btr_page_set_index_id(page, page_zip, index_id,
mtr);
/* Set the next node and previous node fields
*/
btr_page_set_next(page, page_zip, FIL_NULL, mtr);
btr_page_set_prev(page, page_zip, FIL_NULL, mtr);
/* We reset the free bits for the page to allow
creation of several
trees in the same mtr, otherwise the latch on
a bitmap page would
prevent it because of the latching order */
if (!(type & DICT_CLUSTERED)) {
ibuf_reset_free_bits(block);
}
/* In the following assertion we test that two
records of maximum
allowed size fit on the root page: this fact is
needed to ensure
correctness of split algorithms */
ut_ad(page_get_max_insert_size(page, 2) > 2
* BTR_PAGE_MAX_REC_SIZE);
return(page_no);
} |
|









