| БрМЭЦМі: |
| БОЮФРДздгкВЉПЭдАЃЌБОЮФжївЊЭЈЙ§ОйР§ЫЕУїmysqlШЋЮФЫїв§ЪЧвЛжжЬиЪтРраЭЕФЫїв§ЃЌЫќВщевЕФЪЧЮФБОжаЕФЙиМќДЪЃЌЖјВЛЪЧжБНгБШНЯЫїв§жаЕФжЕЁЃ |
|
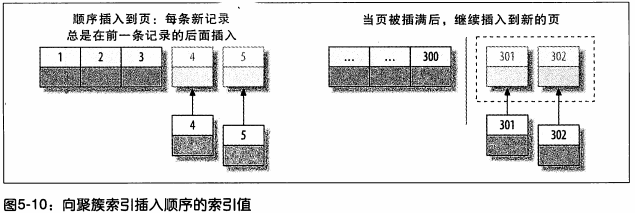
Ыїв§ЕФРраЭ
Ыїв§гХЛЏгІИУЪЧЖдВщбЏадФмгХЛЏзюгааЇЕФЪжЖЮСЫЁЃ
mysqlжЛФмИпаЇЕиЪЙгУЫїв§ЕФзюзѓЧАзКСаЁЃ
mysqlжаЫїв§ЪЧдкДцДЂв§ЧцВуЖјВЛЪЧЗўЮёЦїВуЪЕЯжЕФ
B-TreeЫїв§
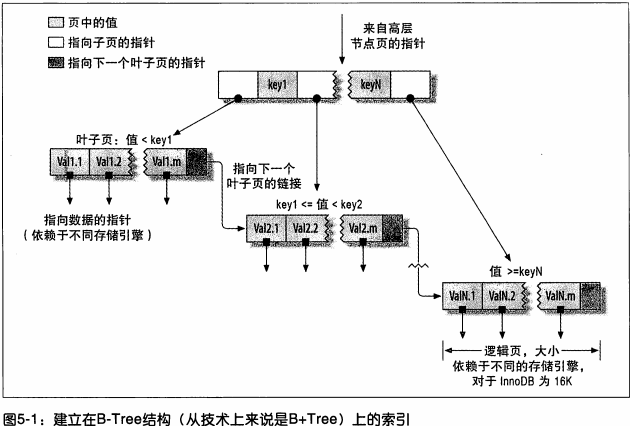
B-TreeЭЈГЃвтЮЖзХЫљгаЕФжЕЖМЪЧАДЫГађДцДЂЕФЃЌВЂЧвУПвЛИівЖзгвГЕНИљЕФОрРыЯрЭЌЁЃ
ЭМжаИљНкЕуУЛгаЛГіРДЁЃ
B-TreeЖдЫїв§СаЪЧЫГађзщжЏДцДЂЕФЃЌЫїв§КмЪЪКЯВщевЗЖЮЇЪ§ОнЁЃ
B-TreeЫїв§ЕФЯожЦ
ШчЙћВЛЪЧАДееЫїв§ЕФзюзѓСаПЊЪМВщевЃЌдђЮоЗЈЪЙгУЫїв§ЁЃ
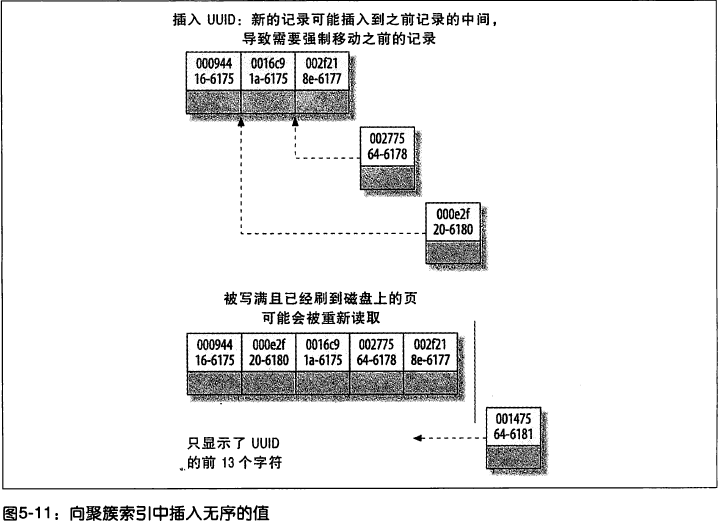
ВЛФмЬјЙ§Ыїв§жаЕФСа
ШчЙћВщбЏжагаФГСаЕФЗЖЮЇВщбЏЃЌдђЦфгвБпЫљгаСаЖМЮоЗЈЪЙгУЫїв§гХЛЏВщбЏЁЃ
етаЉЯожЦЖМКЭЫїв§СаЕФЫГађДцДЂгаЙиЯЕЁЃЛђепЫЕЪЧЫїв§ЫГађДцДЂЕМжТСЫетаЉЯожЦЁЃ
ЙўЯЃЫїв§ЃЈhash indexЃЉ
ЙўЯЃЫїв§ЛљгкЙўЯЃБэЪЕЯжЕФЃЌжЛгаОЋШЗЦЅХфЫїв§ЫљгаСаЕФВщбЏВХгааЇЁЃ
ЖдгкУПвЛааЪ§ОнЃЌДцДЂв§ЧцЖМЛсЖдЫљгаЕФЫїв§СаМЦЫувЛИіЙўЯЃжЕЃЈhash
codeЃЉЃЌЙўЯЃжЕЪЧвЛИіНЯаЁЕФжЕЃЌВЂЧвВЛЭЌМќжЕЕФааМЦЫуГіРДЕФЙўЯЃжЕВЛвЛбљЁЃЙўЯЃЫїв§НЋЫљгаЕФЙўЯЃжЕДцДЂдкЫїв§жаЃЌЭЌЪББЃДцжИЯђУПИіЪ§ОнааЕФжИеыЃЌетбљОЭПЩвдИљОнЃЌЫїв§жабАевЖдгкЙўЯЃжЕЃЌШЛКѓдкИљОнЖдгІжИеыЃЌЗЕЛиЕНЪ§ОнааЁЃ
mysqlжажЛгаmemoryв§ЧцЯдЪНжЇГжЙўЯЃЫїв§ЃЌinnodbЪЧвўЪНжЇГжЙўЯЃЫїв§ЕФЁЃ
ЙўЯЃЫїв§ЯожЦЃК
ЙўЯЃЫїв§жЛАќКЌЙўЯЃжЕКЭаажИеыЃЌВЛДцДЂзжЖЮжЕЃЌЫљвдВЛФмЪЙгУ"ИВИЧЫїв§"ЕФгХЛЏЗНЪНЃЌШЅБмУтЖСШЁЪ§ОнБэЁЃ
ЙўЯЃЫїв§Ъ§ОнВЂВЛЪЧАДееЫїв§жЕЫГађДцДЂЕФЃЌЫїв§вВОЭЮоЗЈгУгкХХађ
ЙўЯЃЫїв§вГВЛжЇГжВПЗжЫїв§СаЦЅХфВщевЃЌвђЮЊЙўЯЃЫїв§ЪМжеЪЧЪЙгУЫїв§СаЕФШЋВПФкШнМЦЫуЙўЯЃжЕЕФЁЃ
ЙўЯЃЫїв§жЛжЇГжЕШжЕБШНЯВщбЏЃЌАќРЈ=ЃЌin(),<=>ЃЌВЛжЇГжШЮКЮЗЖЮЇВщбЏЁЃСаШыwhere
price>100
ЗУЮЪЙўЯЃЫїв§ЕФЪ§ОнЗЧГЃПьЃЌГ§ЗЧгаКмЖрЙўЯЃГхЭЛЃЈВЛЭЌЕФЫїв§СажЕШДгаЯрЭЌЕФЙўЯЃжЕЃЉ
ШчЙћЙўЯЃГхЭЛКмЖрЕФЛАЃЌвЛаЉЫїв§ЮЌЛЄВйзїЕФДњМлвВЛсКмИпЁЃ
вђЮЊетаЉЯожЦЃЌЙўЯЃЫїв§жЛЪЪгУгкФГаЉЬиЖЈЕФГЁКЯЁЃЖјвЛЕЉЪЪКЯЙўЯЃЫїв§ЃЌдђЫќДјРДЕФадФмЬсЩ§НЋЗЧГЃЯджјЁЃ
innodbв§ЧцгавЛИіЬиЪтЕФЙІФмЁАздЪЪгІЙўЯЃЫїв§ЁБЃЌЕБinnodbзЂвтЕНвЛаЉЫїв§жЕБЛЪЙгУЕФЗЧГЃЦЕЗБЪБЃЌЧвЗћКЯЙўЯЃЬиЕуЃЈШчУПДЮВщбЏЕФСаЖМвЛбљЃЉЃЌЫќЛсдкФкДцжаЛљгкB-TreeЫїв§жЎЩЯдйДДНЈвЛИіЙўЯЃЫїв§ЁЃетЪЧвЛИіЭъШЋздЖЏЕФЃЌФкВПааЮЊЁЃ
ДДНЈздЖЈвхЙўЯЃЫїв§ЃЌЯёФЃФтinnodbвЛбљДДНЈЙўЯЃЫїв§ЁЃ
Р§ШчжЛашвЊКмаЁЕФЫїв§ОЭПЩвдЮЊГЌГЄЕФМќДДНЈЫїв§ЁЃ
ЫМТЗЃКдкB-TreeЛљДЁЩЯДДНЈвЛИіЮБЙўЯЃЫїв§ЁЃетКЭеце§ЕФЙўЯЃЫїв§ВЛЪЧвЛЛиЪТЃЌвђЮЊЛЙЪЧЪЙгУB-TreeНјааВщевЃЌЕЋЪЧЫќЪЙгУЙўЯЃжЕЖјВЛЪЧМќБОЩэНјааЫїв§ВщевЁЃашвЊзіЕФОЭЪЧдкВщбЏЕФwhere
згОфжаЪжЖЏжИЖЈЪЙгУЙўЯЃКЏЪ§ЁЃ
Р§згЃК
ШчЙћашвЊДцДЂДѓСПЕФurlЃЌВЂашвЊИљОнurlНјааЫбЫїВщевЁЃШчЙћЪЙгУB-TreeРДДцДЂURLЃЌДцДЂЕФФкШнОЭЛсКмДѓЃЌвђЮЊURLБОЩэЖМКмГЄЁЃе§ГЃЧщПіЯТЛсгаШчЯТВщбЏЃК
| mysql> select
id from url where url='http://www.mysql.com';
|
ШєЩОГ§дРДurlСаЩЯЕФЫїв§ЃЌЖјаТдівЛИіБЛЫїв§ЕФurl_crcСаЃЌЪЙгУcrc32зіЙўЯЃЁЃОЭПЩвдЪЕЯжвЛИіЮБЙўЯЃЫїв§ЃЛВщбЏОЭБфГЩЯТУцЕФЗНЪНЃК
mysql> select
id from url where url='http://www.mysql.com'
-> and url_crc=crc32("http://www.mysql.com");
|
етбљадФмЛсЬсИпКмЖрЁЃ
ЕБШЛетбљЪЕЯжЕФШБЯнЪЧашвЊЮЌЛЄЙўЯЃжЕЃЌОЭЪЧurlИФБфЖдгІЙўЯЃжЕвВгІИУИФБфЁЃПЩвдЪжЖЏЮЌЛЄЃЌЕБШЛзюКУЪЧЪЙгУДЅЗЂЦїЪЕЯжЁЃ
ДДНЈURLБэ
create table
URL ЃЈ
id int unsigned NOT NULL auto_increment,
url varchar(255) NOT NULL,
url_crc int unsigned NOT NULL DEFAULT 0,
PRIMARY KEY (id),
KEY (url_crc)
ЃЉ; |
ДДНЈДЅЗЂЦїЃК
delimiter //
create trigger url_hash_crc_ins before insert
on URL FOR EACH ROW BEGIN
SET NEW.url_crc=crc32(NEW.url);
END;
//
CREATE TRIGGER url_hash_crc_upd BEFORE UPDATE
ON URL FOR EACH ROW BEGIN
SET NEW.url_crc=crc32(NEW.url);
END;
//
delimiter ;
mysql> select * from URL;
+----+-----------------------+------------+
| id | url | url_crc |
+----+-----------------------+------------+
| 1 | htttp://www.mysql.com | 1727608869 |
+----+-----------------------+------------+
1 row in set (0.00 sec)
mysql> insert into URL(url) values('htttp://www.');
Query OK, 1 row affected (0.00 sec)
mysql> select * from URL;
+----+-----------------------+------------+
| id | url | url_crc |
+----+-----------------------+------------+
| 1 | htttp://www.mysql.com | 1727608869 |
| 2 | htttp://www. | 1196108391 |
+----+-----------------------+------------+
2 rows in set (0.00 sec)
mysql> UPDATE URL SET url='http://www.baidu.com'
where id=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from URL;
+----+-----------------------+------------+
| id | url | url_crc |
+----+-----------------------+------------+
| 1 | htttp://www.mysql.com | 1727608869 |
| 2 | http://www.baidu.com | 3500265894 |
+----+-----------------------+------------+
2 rows in set (0.00 sec) |
ШчЙћВЩгУетжжЗНЪНЃЌВЛвЊЪЙгУSHA1()КЭMD5()зїЮЊЙўЯЃКЏЪ§ЃЌгІИУетИіКЏЪ§МЦЫуГіРДЕФЙўЯЃжЕЪЧЗЧГЃГЄЕФзжЗћДЎЃЌЛсРЫЗбДѓСППеМфЃЌБШНЯЪБвГЛиИќТ§ЁЃ
ЖјШчЙћЪ§ОнБэЗЧГЃДѓЃЌcrc32()ЛсГіЯжДѓСПЕФЙўЯЃГхЭЛЃЌЖјНтОіЙўЯЃГхЭЛЃЌПЩвддкВщбЏжадіМгurlБОЩэЃЌНјааНјвЛВНХХГ§ЃЛ
ШчЯТУцВщбЏОЭПЩвдНтОіЙўЯЃГхЭЛЕФЮЪЬтЃК
mysql> select
id from url where url='http://www.mysql.com'
-> and url_crc=crc32("http://www.mysql.com");
|
ПеМфЪ§ОнЫїв§ЃЈR-TreeЃЉ
myisam БэжЇГжПеМфЫїв§ЃЌПЩвдгУзїЕиРэЪ§ОнДцДЂЁЃ
ШЋЮФЫїв§
ШЋЮФЫїв§ЪЧвЛжжЬиЪтРраЭЕФЫїв§ЃЌЫќВщевЕФЪЧЮФБОжаЕФЙиМќДЪЃЌЖјВЛЪЧжБНгБШНЯЫїв§жаЕФжЕЁЃЕк7еТжаЛсЯъЯИНщЩм
Ыїв§ЕФгХЕу
Ыїв§ДѓДѓМѕЩйСЫЗўЮёЦїашвЊЩЈУшЕФЪ§ОнСП
Ыїв§ПЩвдАяжњЗўЮёЦїБмУтХХађКЭСйЪББэ
Ыїв§ПЩвдНЋЫцЛњI/OБфГЩЫГађI/O
Ыїв§жЛвЊАяжњДцДЂв§ЧцПьЫйВщевЕНМЧТМЃЌДјРДЕФКУДІДѓгкЦфДјРДЕФЖюЭтЙЄзїЪБЃЌЫїв§ВХЪЧгааЇЕФЁЃЖдгкЗЧГЃаЁЕФБэЃЌОЭВЛЪЪКЯЫїв§ЁЃвђЮЊШЋБэЩЈУшРДЕФИќжБНгЃЌЫїв§ЛЙашвЊЮЌЛЄЃЌПЊЯњвВВЛаЁЁЃ
ЖјЖдгкЬиДѓаЭЕФБэЃЌНЈСЂКЭЪЙгУЫїв§ЕФДњМлЫцжЎдіГЄЁЃетжжЧщПіЯТЃЌдђашвЊвЛжжММЪѕПЩвджБНгЧјЗжГіВщбЏашвЊЕФвЛзщЪ§ОнЃЌЖјВЛЪЧвЛЬѕМЧТМЁЃР§ШчПЩвдЪЙгУЗжЧјЃЌЛђепПЩвдНЈСЂдЊЪ§ОнаХЯЂБэЕШЁЃЖдгкTPМЖБ№ЕФЪ§ОнЃЌЖЈЮЛЕЅЬѕМЧТМЕФвтвхВЛДѓЃЌЫїв§ОГЃЛсЪЙгУПщМЖБ№дЊЪ§ОнММЪѕРДЬцДњЫїв§ЁЃ
ИпадФмЕФЫїв§ВпТд
е§ШЗЕиДДНЈКЭЪЙгУЫїв§ЪЧЪЕЯжИпадФмВщбЏЕФЛљДЁЁЃ
1 ЖРСЂЕФСа
ЁАЖРСЂЕФСаЁБЪЧжИЫїв§СаВЛФмЪЧБэДяЪНЕФвЛВПЗжЃЌвВВЛФмЪЧКЏЪ§ЕФВЮЪ§ЁЃ
Р§ШчЃКЯТУцдђЮоЗЈЪЙгУactor_idСаЕФЫїв§ЃК
| mysql> select
actor_id from sakila.actor where actor_id + 1
= 5 |
ЖјЯТУцЕФactor_id СаЕФЫїв§дђЛсБЛЪЙгУ
| mysql> select
actor_id from sakila.actor where actor_id = 5
- 1 |
2 ЧАзКЫїв§КЭЫїв§бЁдёад
ЧАзКЕФбЁдёадМЦЫуЃК
mysql> select
count(DISTINCT city)/count(*) from table_name
ЧАзКШЅжиЪ§ Г§ змЪ§ЁЃ
mysql> select
count(DISTINCT LEFT(city,3)) / count(*) AS sel3,
count(DISTINCT LEFT(city,4)) / count(*) AS sel4,
count(DISTINCT LEFT(city,5)) / count(*) AS sel5,
count(DISTINCT LEFT(city,6)) / count(*) AS sel6,
count(DISTINCT LEFT(city,7)) / count(*) AS sel7
from city;
+--------+--------+--------+--------+--------+
| sel3 | sel4 | sel5 | sel6 | sel7 |
+--------+--------+--------+--------+--------+
| 0.7633 | 0.9383 | 0.9750 | 0.9900 | 0.9933 |
+--------+--------+--------+--------+--------+
|
ПЩвдПДЕНЕБЧАзКГЄЖШДяЕН6жЎКѓЃЌбЁдёадЬсЩ§ЕФЗљЖШвбОКмаЁСЫЁЃ
вђДЫбЁдёЧАзКГЄЖШЮЊ6ЃЛ
ЧАзКЫїв§ЪЧвЛжжФмЪЙЫїв§ИќаЁЃЌИќПьЕФгааЇАьЗЈЃЌЕЋвВЪЧгаШБЕуЕФЃК
mysqlЮоЗЈЪЙгУЧАзКЫїв§зіorder by КЭgroup byЃЌвВЮоЗЈЪЙгУЧАзКЫїв§зіИВИЧЩЈУшЁЃ
3 ЖрСаЫїв§
дкЖрИіСаЩЯНЈСЂЕФЕЅСаЫїв§ДѓВПЗжЧщПіЯТВЂВЛФмЬсИпmysqlЕФВщбЏадФмЁЃmysql5.0вдКѓв§ШыСЫвЛжжНа"Ыїв§КЯВЂ(index
merge)"ЕФВпТдЃЌвЛЖЈГЬЖШЩЯПЩвдЪЙгУБэЩЯЕФЖрИіЕЅСаЫїв§РДЖЈЮЛжИЖЈЕФааЁЃ
Р§згЃКБэfilm_actorдкзжЖЮfilm_id КЭ actor_idЩЯИїгавЛИіЕЅСаЫїв§ЁЃ
mysql> show
create table film_actor;
| film_actor | CREATE TABLE `film_actor` (
`actor_id` smallint(5) unsigned NOT NULL,
`film_id` smallint(5) unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_fk_film_id` (`film_id`),
CONSTRAINT `fk_film_actor_actor` FOREIGN KEY (`actor_id`)
REFERENCES `actor` (`actor_id`) ON UPDATE CASCADE,
CONSTRAINT `fk_film_actor_film` FOREIGN KEY (`film_id`)
REFERENCES `film` (`film_id`) ON UPDATE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
mysql> explain select film_id,actor_id from
film_actor where actor_id=1 or film_id =1\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
type: index_merge
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY,idx_fk_film_id
key_len: 2,2
ref: NULL
rows: 29
Extra: Using union(PRIMARY,idx_fk_film_id); Using
where |
ПЩвдПДЕНЪЙгУКЯВЂЫїв§ЃЈindex_mergeЃЉММЪѕЃЌгХЛЏСЫДЫДЮВщбЏЃЛ
ЪЕМЪЩЯвВЫЕУїСЫБэЩЯЕФЫїв§НЈЕУКмдуИтЃЌВЛШЛОЭВЛгУЯЕЭГгХЛЏСЫЃЛ
КЯВЂЫїв§гаШ§ИіБфжжЃКORЬѕМўЕФСЊКЯ(union),andЬѕМўЕФЯрНЛ(intersection),зщКЯЧАСНжжЧщПіЕФСЊКЯвдМАЯрНЛЁЃ
ЕБГіЯжЗўЮёЦїЖдЖрИіЫїв§зіЯрНЛВйзїЪБЃЈЭЈГЃгаЖрИіANDЬѕМўЃЉЃЌЭЈГЃвтЮЖзХашвЊвЛИіАќКЌЫљгаЯрЙиСаЕФЖрСаЫїв§ЃЌЖјВЛЪЧЖрИіЖРСЂЕФЕЅСаЫїв§ЁЃ
ЕБЗўЮёЦїашвЊЖдЖрИіЫїв§зіСЊКЯВйзїЪБЃЈЭЈГЃгаЖрИіORЬѕМўЃЉЃЌЭЈГЃашвЊКФЗбДѓСПCPUКЭФкДцзЪдДдкЫуЗЈЕФЛКДцЃЌХХађЃЌКЭКЯВЂВйзїЩЯЁЃЬиБ№ЪЧЕБЦфжагааЉЫїв§ЕФбЁдёадВЛИпЃЌашвЊКЯВЂЩЈУшЗЕЛиДѓСПЪ§ОнЕФЪБКђЁЃ
ИќживЊЕФЪЧЃЌгХЛЏЦїВЛЛсАбетаЉМЦЫуЕН"ВщбЏГЩБО(cost)"жаЃЌгХЛЏЦїжЛЙиаФЫцЛњвГУцЖСШЁЁЃ
змжЎШчЙћдкexplainжаПДЕНЫїв§КЯВЂЃЌгІИУКУКУМьВщвЛЯТВщбЏКЭБэЕФНсЙЙЃЌПДЪЧВЛЪЧвбОЪЧзюгХЕФЁЃвВПЩвдЭЈЙ§optimizaer_switchРДЙиБеЫїв§КЯВЂЙІФмЁЃвВПЩвдЪЙгУINGORE
INDEXЬсЪО ШУгХЛЏЦїКіТдЕєФГаЉЫїв§ЁЃ
4 бЁдёКЯЪЪЕФЫїв§СаЫГађ
е§ШЗЕФЫГађвРРЕгкЪЙгУИУЫїв§ЕФВщбЏЃЌВЂЧвЭЌЪБашвЊПМТЧШчКЮИќКУЕиТњзуХХађКЭЗжзщЕФашвЊЁЃ
дквЛИіЖрСаBTreeЫїв§жаЃЌЫїв§СаЕФЫГађвтЮЖзХЫїв§ЪзЯШАДеезюзѓСаНјааХХађЃЌЦфДЮЪЧЕкЖўСаЕШД§ЁЃЫљвдЃЌЫїв§ПЩвдАДееЩ§ађЛђепНЕађНјааЩЈУшЃЌвдТњзуОЋШЗЗћКЯСаЫГађЕФORDER
BY ,GROUP BY,DISTINCTЕШзгОфЕФВщбЏашЧѓЁЃ
ЕБВЛашвЊПМТЧХХађКЭЗжзщЪБЃЌНЋбЁдёадзюИпЕФСаЗХдкЧАУцЭЈГЃЪЧКмКУЕФЁЃетЪБКђЫїв§ЕФзїгУжЛЪЧгУгкгХЛЏwhereЬѕМўЕФВщбЏЁЃ
вдЯТУцЕФВщбЏЮЊР§ЃК
| mysql> select
* from payment where staff_id =2 and customer_id=584;
|
ЪЧгІИУДДНЈвЛИі(staff_id,customer_id)Ыїв§ЛЙЪЧгІИУЕпЕЙвЛЯТЃППЩвдХмвЛаЉВщбЏРДШЗЖЈдкетИіБэжажЕЕФЗжВМЧщПіЃЌВЂШЗЖЈФФИіСаЕФбЁдёадИќИпЁЃ
mysql> select
sum(staff_id=2),sum(customer_id=584) from payment
\G;
*************************** 1. row ***************************
sum(staff_id=2): 7992
sum(customer_id=584): 30
1 row in set (0.04 sec) |
гІИУНВcustomer_idЗХдкЧАУцЃЌвђЮЊЖдгкЬѕМўжЕЕФcustomer_idЪ§СПИќаЁЁЃ
mysql> select
sum(staff_id=2) from payment where customer_id=584
\G;
*************************** 1. row ***************************
sum(staff_id=2): 17
1 row in set (0.00 sec) |
ПЩвдПДЕНcustmoer_id=584ЪБstaff_id=2 жЛга17ИіЃЛ
ашвЊзЂвтЃЌВщбЏНсЙћЗЧГЃвРРЕгкбЁЖЈЕФОпЬхжИЖЈжЕЃЛ
ЕБШЛЛЙПЩвдЪЙгУМЦЫуСНВЮЪ§ЕФбЁдёадЃЌРДШЗЖЈФФИіВЮЪ§ЗХдкЧАУцЃК
mysql> select
count(DISTINCT staff_id) / count(*) AS staff_id_first,
count(DISTINCT customer_id) / count(*) AS customer_id_first
from payment\G
*************************** 1. row ***************************
staff_id_first: 0.0001
customer_id_first: 0.0373 |
ЯдШЛcustomer_idЕФбЁдёадЃЈСаШЅжиЪ§ Г§ ЫљгаСазмЪ§ЃЉ ИќКУЃЌ
Ыїв§СаЕФЛљЪ§ЃЈМДЬиЖЈЬѕМўЯТЕФЪ§СПЃЉЃЌЛсгАЯьЫїв§адФмЃЛ
ОЁЙмЙигкбЁдёадКЭЛљЪ§ЕФОбщЗЈдђжЕЕУШЅбаОПКЭЗжЮіЃЌЕЋвЛЖЈвЊМЧзЁwhere
згОфжаЕФХХађЃЌЗжзщКЭЗЖЮЇЬѕМўЕШЦфЫћвђЫиЃЌетаЉвђЫиПЩФмЖдВщбЏЕФадФмдьГЩЗЧГЃДѓЕФгАЯьЁЃ
5 ОлДиЫїв§
ОлДиЫїв§ВЂВЛЪЧвЛжжЕЅЖРЕФЫїв§РраЭЃЌЖјЪЧвЛжжЪ§ОнДцДЂЗНЪНЁЃ
innodbЕФОлДиЫїв§ЪЕМЪЩЯдкЭЌвЛНсЙЙжаБЃДцСЫBTreeЫїв§КЭЪ§ОнааЁЃЃЈжїМќЪЧBTreeЫїв§+МЧТМЪЧЪ§ОнааЃЉ
ЕББэгаОлДиЫїв§ЪБЃЌЫќЕФЪ§ОнааЪЕМЪЩЯДцЗХдкЫїв§ЕФвЖзгвГжаЁЃЪѕгя"ОлДи"БэЪОЪ§ОнааКЭЯрСкЕФМќжЕНєДеЕиДцДЂдквЛЦ№ЁЃ
ЯТЭМеЙЪОСЫОлДиЫїв§жаЕФМЧТМЪЧШчКЮДцЗХЕФЁЃзЂвтЕНЃЌвЖзгвГАќКЌСЫааЕФШЋВПЪ§ОнЃЌЕЋНкЕувГжЛАќКЌСЫЫїв§СаЁЃдкетИіАИР§жаЃЌЫїв§СаАќКЌЕФЪЧећЪ§жЕЁЃ
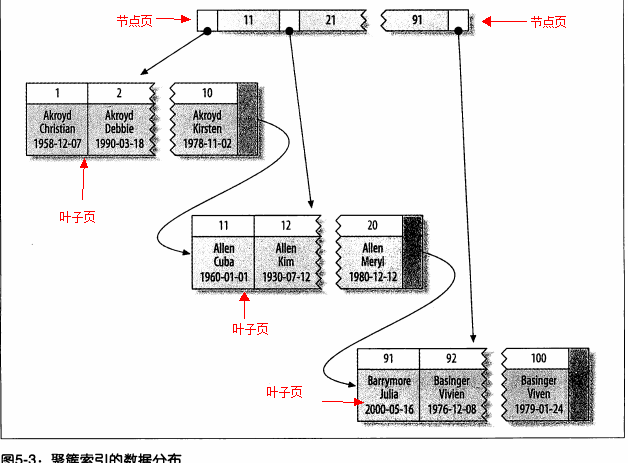
innodbЭЈЙ§жїМќОлМЏЪ§ОнЃЌЩЯЭМжаЕФ"БЛЫїв§ЕФСа"ОЭЪЧжїМќСаЁЃ
ОлМЏЕФгХЕуЃК
ПЩвдАбЯрЙиЪ§ОнБЃДцдквЛЦ№ЁЃМѕЩйДХХЬI/O
Ъ§ОнЗУЮЪИќПь
ЪЙгУИВИЧЫїв§ЩЈУшЕФВщбЏПЩвджБНгЪЙгУвГНкЕужаЕФжїМќжЕ
ОлМЏЕФШБЕуЃК
ОлДиЪ§ОнзюДѓЯоЖШЕиЬсИпСЫI/OУмМЏаЭгІгУЕФадФмЃЌЕЋШчЙћЪ§ОнШЋВПЖМЗХдкФкДцжаЃЌдђЗУЮЪЕФЫГађОЭУЛгаФЧУДживЊСЫЃЌОлДиЫїв§вВОЭУЛЪВУДгХЪЦСЫЁЃ
ВхШыЫйЫйбЯживРРЕгкВхШыЫГађЁЃ
ИќаТОлДиЫїв§СаЕФДњМлКмИпЁЃ
ГіШыаТааЛђепжїМќИќаТашвЊвЦЖЏЪБЃЌПЩФмУцСй"вГЗжСб(page split)"ЮЪЬтЁЃЕБааЕФжїМќжЕвЊЧѓБиаыВхШыЕНФГИівбТњЕФвГжаЪБЃЌДцДЂв§ЧцЛсНЋИУвГЗжСбГЩСНИівГУцРДШнФЩИУааЃЌетОЭЪЧвЛДЮвГЗжСбВйзїЁЃвГЗжСбЛсЕМжТБэеМгУИќЖрЕФДХХЬПеМфЁЃ
ЖўМЖЫїв§ЃЈЗЧОлДиЫїв§ЃЉМДЦеЭЈЫїв§ЃЌдкЦфвЖзгНкЕуАќКЌСЫв§гУааЕФжїМќСаЁЃ
innodbКЭmyisamЕФЪ§ОнЗжВМЖдБШЃК
crate table layout_test(
col1 int NOT NULL,
col2 int NOT NULL,
PRIMARY KEY(col1),
KEY(col2)
); |
МйЩшcol1 ШЁжЕ1--10000ЃЌАДееЫцЛњЫГађВхШыЁЃcol2ШЁжЕДг1--100жЎМфЫцЛњИГжЕЃЌЫљвдгаКмЖржиИДЕФжЕЁЃ
myisamЕФЪ§ОнЗжВМЗЧГЃМђЕЅЃЌАДееЪ§ОнВхШыЕФЫГађДцДЂдкДХХЬЩЯЁЃШчЯТЭМЃК
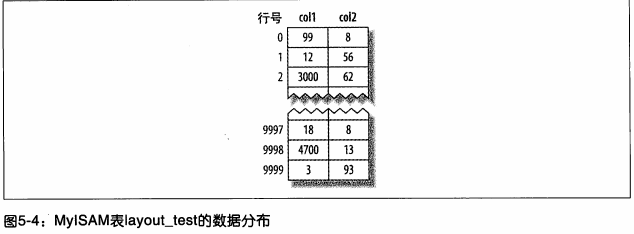
етжжЗжВМЗНЪНКмШнвзДДНЈЫїв§ЃЌЯТЭМЃЌвўВиСЫвГЕФЮяРэЯИНкЃЌжЛЯдЪОЫїв§жаЕФ"НкЕу"
Ыїв§жаЕФУПИівЖзгНкЕуАќКЌ"ааКХЁЃБэЕФжїМќКЭааКХдквЖзгНкЕужаЃЌЧввЖзгНкЕуИљОнжїМќЫГађХХСаЁЃ
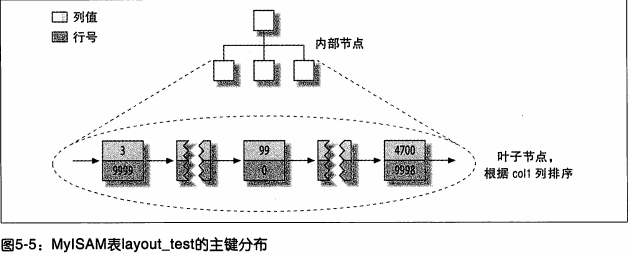
ФЧcol2СаЩЯЕФЫїв§гжЛсдѕУДбљФиЃПгаЪВУДЬиЪтТ№ЃПД№АИЪЧЗёЖЈЕФЃЌЫћКЭЦфЫћШЮКЮЫїв§вЛбљЁЃ
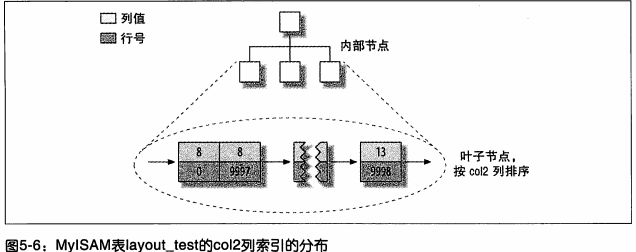
ЪТЪЕЩЯЃЌmyisamжажїМќЫїв§КЭЦфЫћЫїв§дкНсЙЙЩЯУЛгаЪВУДВЛЭЌЁЃжїМќЫїв§ОЭЪЧвЛИіУћЮЊPRIMARYЕФЮЈвЛЗЧПеЫїв§ЁЃ
innodbЕФЪ§ОнЗжВМЁЃвђЮЊinnodbжЇГжОлДиЫїв§ЃЌЫїв§ЪЙгУЗЧГЃВЛЭЌЕФЗЖЪНДцДЂЭЌбљЕФЪ§ОнЁЃПДЯТЭМЃК
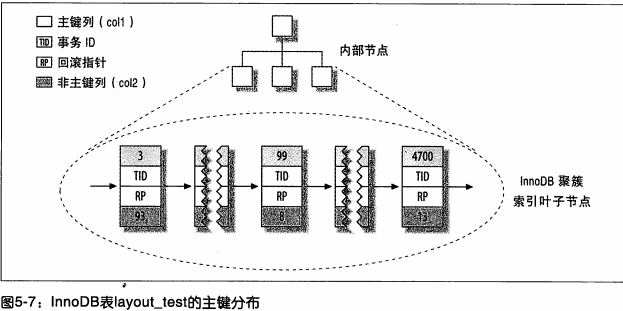
ЕквЛблПДЩЯШЅЃЌИаОѕКЭЧАУцЕФЭМ5-5УЛгаЪВУДВЛЭЌЃЌЦфЪЕИУЭМЃЌЯдЪОСЫећИіБэЃЌЖјВЛЪЧжЛгаЫїв§ЁЃвђЮЊдкinnodbжаЃЌОлДиЫїв§"ОЭЪЧ"БэЃЌЫљвдВЛгУЯыmyisamФЧбљашвЊЖРСЂЕФааДцДЂЁЃ
innodbЖўМЖЫїв§ЕФвЖзгНкЕужаДцДЂЕФВЛЪЧ"аажИеы"ЃЈМДВЛЪЧФЧИіааКХЃЉЃЌЖјЪЧжїМќжЕЃЌВЂвдДЫзїЮЊжИЯђааЕФ"жИеы"ЁЃетбљЕФВпТдМѕЩйСЫЕБГіЯжаавЦЖЏЛђепЪ§ОнвГЗжСбЪБЖўМЖЫїв§ЕФЮЌЛЄЙЄзїЁЃЕБШЛЪЧгУжїМќжЕЕБзі
жИеыЛсШУЖўМЖЫїв§еМгУИќЖрЕФПеМфЃЌЭЌЪББмУтСЫааГіЯжвЦЖЏЛђепЪ§ОнЗжвГЪБЖўМЖЫїв§ЕФЮЌЛЄЁЃ
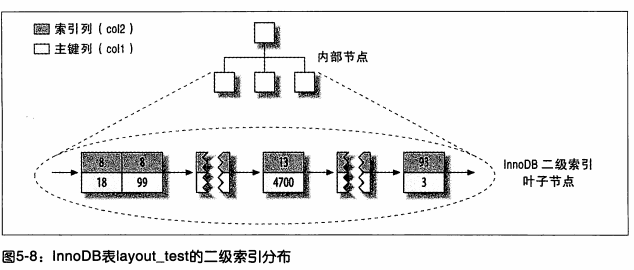
ОлДиКЭЗЧОлДиБэЕФЖдБШЭМ
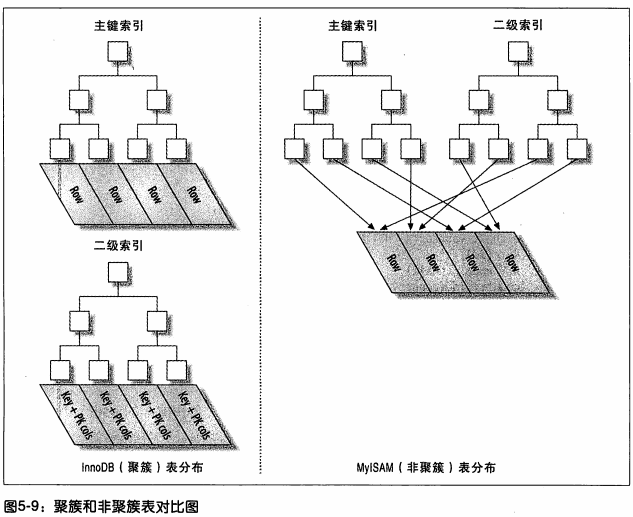
innodb зюКУжїМќЩшжУЮЊзддіРраЭ ећЪ§ЃЛ
ЯђОлДиЫїв§ВхШыЫГађЕФЫїв§жЕ
ЯђОлДиЫїв§жаВхШыЮоађЕФжЕЃК
етбљЕФШБЕу:
аДШыЕФФПБъвГПЩФмвбОЫЂаТЕНДХХЬЩЯВЂДгЛКДцжавЦГ§ЃЌЛђепЛЙУЛгаМгдиЕНЛКДцжаЃЌетбљinnodbдкВхШыЧАВЛЕУВЛЯШевЕНВЂДгДХХЬЖСШЁФПБъвГЕНФкДцжаЁЃЕМжТСЫДѓСПЕФЫцЛњI/OЁЃ
вђЮЊаДШыЪЧТвађЕФЃЌinnodbВЛЕУВЛЦЕЗБЕизівГЗжСбВйзїЃЌвдБуЮЊаТЕФааЗжХфПеМфЁЃвГЗжСбЛсЕМжТвЦЖЏДѓСПЪ§ОнЃЌвЛДЮВхШызюЩйашвЊаоИФШ§ИівГЖјВЛЪЧвЛИівГЁЃ
гЩгкЦЕЗБЕФвГЗжСбЃЌвГЛсБфЕУЯЁЪшБЛВЛЙцдђЕиЬюГфЃЌЫљвдзюжеЪ§ОнЛсгаЫщЦЌЁЃ
6 ИВИЧЫїв§
ИВИЧЫїв§ЃЌвЛИіЫїв§АќКЌЫљгаашвЊВщбЏЕФзжЖЮЕФжЕЁЃ
гХЕуЃК
Ыїв§ЬѕФПЭЈГЃдЖаЁгкЪ§ОнааДѓаЁЃЌЫљвдШчЙћжЛашвЊЖСШЁЫїв§ЃЌФЧУДmysqlОЭЛсМЋДѓЕиМѕЩйЪ§ОнЗУЮЪСПЁЃ
вђЮЊЫїв§ЪЧАДееСажЕЫГађДцДЂЕФЃЈжСЩйдкЕЅИівГФкЪЧШчДЫЃЉЃЌЫљвдЖдгкI/OУмМЏаЭЕФЗЖЮЇВщбЏЛсБШЫцЛњДгДХХЬЖСШЁУПвЛааЪ§ОнЕФI/OвЊЩйЕУЖрЁЃ
вЛаЉДцДЂв§ЧцШчMyisamдкФкДцжажЛЛКДцЫїв§ЃЌЪ§ОндђвРРЕгкВйзїЯЕЭГРДЛКДцЃЌвђДЫвЊЗУЮЪЪ§ОнашвЊвЛДЮЯЕЭГЕїгУЁЃ
гЩгкinnodbЕФОлДиЫїв§ЃЌИВИЧЫїв§ЖдinnodbБэЬиБ№гагУЁЃ
ЪЙгУИВИЧЫїв§ЕФЧщПіЃК
mysql> explain
select store_id,film_id from inventory \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: inventory
type: index
possible_keys: NULL
key: idx_store_id_film_id
key_len: 3
ref: NULL
rows: 3496
Extra: Using index
1 row in set (0.00 sec) |
ДЫЪБЃЌгаВщЕФзжЖЮselect store_id,film_idЃЌгавЛИіЖрСаЫїв§idx_store_id_film_idЃЌДЫЪББуЪЙгУЕНСЫИВИЧЫїв§ЃЌВЛЛсдйЗЕЛиЪ§ОнБэШЅевЪ§ОнааЃЌвђЮЊЫїв§жавбОАќКЌСЫЃЛ
МйЩшЫїв§ИВИЧСЫwhereЬѕМўжаЕФзжЖЮЃЌЕЋЪЧећИіВщбЏЩцМАЕФзжЖЮЃЌРДПДПДЛсЗЂЪВУДЧщПіЃЌвдМАШчКЮжиаДВщбЏвдНтОіИУЮЪЬтЁЃ

зЂвтЃКextraСаЕФ"using index"
КЭtypeСаЕФ"index"ВЛЭЌЃЌtypeСаКЭИВИЧЫїв§КСЮоЙиЯЕЃЌЫќжЛЪЧБэЪОетИіВщбЏЗУЮЪЪ§ОнЕФЗНЪНЃЌЛђепЫЕmysqlВщевааЕФЗНЪНЁЃЖјextraСаЕФ"using
index"дђЫЕУїЁЃЪ§ОнЪЙгУСЫ ИВИЧЫїв§ЃЛ
ЩЯУцР§згжаЃЌЪЙгУСЫACTORЫїв§ЃЌЕЋЪЧУЛгаЪЙгУИВИЧЫїв§жБНгЕУЕНЪ§ОндвђЃК
УЛгаШЮКЮЫїв§ФмЙЛИВИЧетИіВщбЏЁЃ
mysqlФмдкЫїв§жазюзѓЧАзКЦЅХфЕФlikeБШНЯШч"Apoll%",ЖјЮоЗЈзіЭЈХфЗћПЊЭЗЕФlike
Шч"%Apoll%"
вВгаАьЗЈПЩвдНтОіЩЯУцЫЕЕФЮЪЬтЃЌЪЙЦфЪЙгУИВИЧЫїв§ЁЃашвЊжиаДВщбЏВЂЧЩУюЕиЩшМЦЫїв§ЁЃЯШаТНЈвЛИіШ§ИіСаЫїв§(actor,title,prod_id)ЃЛШЛКѓжиаДВщбЏЃК

ЮвУЧАбетжжЗНЪННазібгГйЙиСЊ(defferred join),вђЮЊбгГйСЫЖдСаЕФЗУЮЪЁЃ
ВщбЏдкзгВщбЏжаЪЙгУСЫИВИЧЫїв§ЃЌВЂевЕНСЫprod_id,ШЛКѓзіСЫФкСЌНгЃЌЭЈЙ§prod_idдйШЅВщЦфЫћСа
ЛсПьКмЖрЁЃ
ЕБШЛетвЛЧаЖМвЊЛљгк Ъ§ОнМЏЃЌМйЩшетИіproductsБэжага100ЭђааЃЌЮвУЧРДПДвЛЯТЩЯУцСНИіВщбЏдкШ§ИіВЛЭЌЕФЪ§ОнМЏЩЯЕФБэЯжЃЌУПИіЪ§ОнМЏЖМАќКЌ100ЭђааЃК
ЕквЛИіЪ§ОнМЏЃЌSean Carrey ГібнСЫ30000ВПзїЦЗЃЌЦфжага20000ВПБъЬтАќКЌСЫApollo
ЕквЛИіЪ§ОнМЏЃЌSean Carrey ГібнСЫ30000ВПзїЦЗЃЌЦфжага40ВПБъЬтАќКЌСЫApollo
ЕквЛИіЪ§ОнМЏЃЌSean Carrey ГібнСЫ50ВПзїЦЗЃЌЦфжага10ВПБъЬтАќКЌСЫApollo
ВтЪдНсЙћЃК

НсЙћЗжЮіЃК
дкЕквЛИіЪ§ОнМЏжаЃК
дВщбЏЃКДгЫїв§actorжаЖСЕН30000ЬѕЪ§ОнЃЌдйИљОнЕУЕНЕФжїМќIDЛиЪ§ОнБэжадйЖС30000ЬѕЪ§ОнЃЛзмЙВЖСШЁ60000ЬѕЃЛ
гХЛЏКѓЕФВщбЏЃКЯШДгЫїв§actor2жаЖСЕН30000Ьѕsena carreyЃЌжЎКѓдкЫљгаSean Carrey
жазіlike БШНЯ ЃЌевЕН20000Ьѕprod_idЃЛжЎКѓЛЙЪЧвЊЛиЕНЪ§ОнБэжаЃЌИљОнprod_idдйЖСШЁ20000ЬѕМЧТМЃЛзмЙВЖСШЁ50000ЬѕЃЛ
ЗжЮіЃКзмЪ§ЫфШЛЩйСЫ17%ЃЌЕЋЪЧзгВщбЏжаЕФlikeБШНЯПЊЯњЛсБШНЯДѓЃЌЯрЕжжЎКѓаЇТЪВЂУЛгаЪВУДЬсЩ§ЁЃ
дкЕкЖўИіЪ§ОнМЏжаЃК
дВщбЏЃКДгЫїв§actorжаЖСЕН30000ЬѕЪ§ОнЃЌдйИљОнЕУЕНЕФжїМќIDЛиЪ§ОнБэжадйЖС30000ЬѕЪ§ОнЃЛзмЙВЖСШЁ60000ЬѕЃЛ
гХЛЏКѓЕФВщбЏЃКЯШДгЫїв§actor2жаЖСЕН30000Ьѕsena carreyЃЌжЎКѓдкЫљгаSean Carrey
жазіlike БШНЯ ЃЌевЕН40Ьѕprod_idЃЛжЎКѓЛЙЪЧвЊЛиЕНЪ§ОнБэжаЃЌИљОнprod_idдйЖСШЁ40ЬѕМЧТМЃЛзмЙВЖСШЁ30040ЬѕЃЛ
ЗжЮіЃКЖСШЁзмЪ§НЕЕЭСЫ50%, ЯрБШзгВщбЏжаЕФПЊЯњ ЛЙЪЧжЕЕУЃЛ
ЕкШ§ИіЪ§ОнМЏЃКЯдЪОСЫзгВщбЏаЇТЪЗДЖјЯТНЕЕФЧщПіЁЃвђЮЊЫїв§Й§ТЫЪБЗћКЯЕквЛИіЬѕМўЕФНсЙћМЏвбОКмаЁЃЌЫїв§згВщбЏДјРДЕФГЩБОЗДЖјБШДгБэжажБНгЬсШЁЭъећааИќИпЁЃ
7 ЪЙгУЫїв§ЩЈУшРДзіХХађ
ЃЈМДorder by ЃЌgroup by ЪЙгУЕНСЫЫїв§ЃЉ
mysqlЩшМЦЫїв§ЪБгІИУОЁСПЭЌЪБТњзуХХађЃЌгагжгыВщевааЁЃ
жЛгаЕБЫїв§ЕФСаЫГађКЭorder byзгОфЕФЫГађЭъШЋвЛжТЃЌВЂЧвЫљгаСаЕФХХађЗНЯђ(ЕЙађЛђе§ађ)ЖМЪЧвЛбљЪБЃЌmysqlВХФмЪЙгУЫїв§РДЖдНсЙћзіХХађЁЃ
ШчЙћВщбЏашвЊЙиСЊЖреХБэЃЌдђжЛгаЕБorder by згОфв§гУЕФзжЖЮШЋВПЮЊвЛИіБэЪБЃЌВХФмЪЙгУЫїв§зіХХађЁЃ
order by згОфТњзузюзѓЧАзКЕФвЊЧѓЃЌЛђепзюзѓЧАзКЮЊГЃЪ§ЃЌХХађЗНЯђвВвЊвЛжТЃЛ
idx_a_b (a,b)
ФмЙЛЪЙгУЫїв§АяжњХХађЕФВщбЏЃК
order by a
ТњзузюзѓЧАзКвЊЧѓ
a = 3 order by b
ТњзузюзѓЧАзКЮЊГЃЪ§
order by a,b
ТњзузюзѓЧАзКвЊЧѓ
order by a desc,b desc
ТњзузюзѓЧАзКвЊЧѓ
a>5 order by aЃЌb
ТњзузюзѓЧАзКвЊЧѓ
ВЛФмЪЙгУЫїв§АяжњХХађЕФВщбЏ
order by b
ВЛТњзузюзѓЧАзКвЊЧѓ
a >5 order by b
ВЛТњзузюзѓЧАзКЃЌЧвЃЌзюзѓЧАзКВЛЪЧГЃЪ§
a in (1,3) order by b
ВЛТњзузюзѓЧАзКЃЌЧвЃЌзюзѓЧАзКВЛЪЧГЃЪ§
oder by a asc ,b desc
ХХађЗНЯђВЛвЛжТ
idx_a_b_c(a,b,c)
where a = 5 order by c
ВЛФмЪЙгУЫїв§НјааХХађЃЌВЛФмПчдНЫїв§ЯюНјааХХађЃЛвВЪЧвЛжжВЛТњзузюзѓЧАзКЕФЧщПіЃЛ
8 бЙЫѕЃЈЧАзКбЙЫѕЃЉЫїв§
myisamЪЙгУЧАзКбЙЫѕРДМѕЩйЫїв§ЕФДѓаЁЃЌДгЖјШУИќЖрЕФЫїв§ПЩвдЗХШыФкДцЃЌетдкФГаЉЧщПіЯТФмМЋДѓЕиЬсЩ§адФмЁЃФЌШЯжЛбЙЫѕзжЗћДЎЃЌЕЋЭЈЙ§ВЮЪ§ЩшжУвВПЩвдЖдећЪ§бЙЫѕЁЃ
9 ШпгрКЭжиИДЫїв§
mysqlдЪаэдкЯрЭЌСаЩЯДДНЈЖрИіЫїв§ЃЌЕЋашвЊЕЅЖРЮЌЛЄжиИДЕФЫїв§ЃЌВЂЧвгХЛЏЦїдкгХЛЏВщбЏЕФЪБКђвВашвЊж№ИіПМТЧЃЌетЛсгАЯьадФмЁЃ
жиИДЫїв§ЃК
ЪЕМЪЩЯдкIDЩЯНЈСЫШ§ИіЫїв§ЃЌетОЭЪЧжиИДЫїв§ЁЃ
ШпгрЫїв§ЃК
вбгаЫїв§(A,B),дйжиНЈЫїв§(A)ОЭЪЧШпгрЫїв§ЃЛ
ЖјДЫЪБ(B,A)ЃЌдђВЛЪЧШпгрЫїв§ЁЃЫїв§(B)вВВЛЪЧЫїв§(A,B)ЕФШпгрЫїв§ЃЛ
вбгаЫїв§(A),дйНЈЫїв§(A,ID),ЦфжаIDЪЧжїМќЃЌЖдinnodbРДЫЕжїМќСавбОАќКЌдкЖўМЖЫїв§жаСЫЃЌЫљвдетвВЪЧШпгрЫїв§ЃЛ
ДѓЖрЪ§ЧщПіЖМВЛашШпгрЫїв§ЃЌгІИУОЁСПРЉеЙвбгаЕФЫїв§ЖјВЛЪЧДДНЈаТЫїв§ЁЃ
ЕБШЛгаЪБКђвВЪЧашвЊШпгрЫїв§ЕФЃЌвђЮЊРЉеЙвбгаЕФЫїв§ЛсЕМжТЦфБфЕУЬЋДѓЃЌДгЖјгАЯьЦфЫћЪЙгУИУЫїв§ЕФВщбЏЕФадФмЁЃ
ДДНЈЫїв§
ЕЅСаЫїв§
| create index
idx_test1 on tb_student(name); |
СЊКЯЫїв§
| create index
idx_test2 on tb_student(name,age) |
Ыїв§жаЯШИљОнnameХХађЃЌnameЯрЭЌЕФЧщПіЯТЃЌИљОнageХХађ
ЩшМЦЫїв§ддђЃК
ЫбЫїЕФЫїв§СаЁЃ
ВЛвЛЖЈЪЧЫљвЊбЁдёЕФСаЃЛМДwhere КѓУцЕФВщбЏЬѕМўМгЫїв§ЃЌЖјВЛЪЧselect КѓУцЕФбЁдёСа
ЪЙгУЮЈвЛЫїв§ЁЃ
ЪЙгУЖЬЫїв§ЁЃ
ШчЙћЖдзжЗћДЎСаНјааЫїв§ЃЌгІИУжИЖЈвЛИіЧАзКГЄЖШЃЌжЛвЊгаПЩФмОЭгІИУетбљзіЁЃ
РћгУзюзѓЧАзКЁЃ
ВЛвЊЙ§ЖШЫїв§
innodbБэЃЌжИЖЈжїМќЃЌВЂЧвЪЧзддіЕФзюКУЃЛ
BTREEЫїв§КЭHASHЫїв§ЃК
ЖМПЩвдгУдкЃЌwhere col=1 or col in (15,18,20),етбљЕФЖЈжЕВщбЏжаЃЛ
ЖјдкЗЖЮЇВщбЏжаЃЌwhere col>1 and col<10
Лђеп col like 'ab%' or col between 'lisa' and 'simon';ДЫЪБжЛгаBTREEЫїв§ФмЪЙгУЃЛHASHЫїв§дкетжжЧщПіжаЃЌВЛЛсБЛЪЙгУЕНЃЌЛсЖдШЋБэНјааЩЈУшЃЛ
ЮЌЛЄЫїв§гыБэ
ЮЌЛЄЫїв§КЭБэ
ЮЌЛЄБэгаШ§ИіжївЊФПЕФЃК
евЕНВЂаоИДЫ№ЛЕЕФБэ
ЮЌЛЄзМШЗЕФЫїв§ЭГМЦаХЯЂ
МѕЩйЫщЦЌ
евЕНВЂаоИДЫ№ЛЕЕФБэ
check table tb_name:МьВщЪЧЗёЗЂЩњСЫБэЫ№ЛЕ
repair table tb_name:
ИќаТЫїв§ЭГМЦаХЯЂ
mysqlгХЛЏЦїЭЈЙ§СНИіAPIРДСЫНтДцДЂв§ЧцЕФЫїв§жЕЕФЗжВМаХЯЂЃЌвдОіЖЈШчКЮЪЙгУЫїв§ЁЃ
records_in_range():ЭЈЙ§ЯђДцДЂв§ЧцДЋШыСНИіБпНчжЕЛёШЁдкетИіЗЖЮЇДѓИХгаЖрЩйЬѕМЧТМЁЃ
info()ЃКИУНгПкЗЕЛиИїжжРраЭЕФЪ§ОнЃЌАќРЈЫїв§ЕФЛљЪ§ЃЈУПИіМќжЕгаЖрЩйЬѕМЧТМЃЉ
mysqlгХЛЏЦїЪЙгУЕФЪЧЛљгкГЩБОЕФФЃаЭЃЌЖјКтСПГЩБОЕФжївЊжИБъОЭЪЧвЛИіВщбЏашвЊЩЈУшЖрЩйааЁЃШчЙћБэУЛгаЭГМЦаХЯЂЃЌЛђепЭГМЦаХЯЂВЛзМШЗЃЌгХЛЏЦїОЭКмПЩФмзіГіДэЮѓЕФОіЖЈЁЃ
analyze table ЃКжиаТЩњГЩЭГМЦаХЯЂЃЛ
mysql> show
index from actor\G;
*************************** 1. row ***************************
Table: actor
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: actor_id
Collation: A
Cardinality: 200
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: actor
Non_unique: 1
Key_name: idx_actor_last_name
Seq_in_index: 1
Column_name: last_name
Collation: A
Cardinality: 200
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
2 rows in set (0.00 sec)
CardinalityЃЌЯдЪОСЫДцДЂв§ЧцЙРЫуЫїв§СагаЖрЩйИіВЛЭЌЕФШЁжЕЁЃ
mysql5.6 вдКѓПЩвдЭЈЙ§ВЮЪ§innodb_analyze_is_persistentЃЌРДПижЦanalyze
ЪЧЗёЦєЖЏЃЛ
МѕЩйЫїв§КЭЪ§ОнЕФЫщЦЌ
Ъ§ОнЫщЦЌШ§жжРраЭЃК
ааЫщЦЌ(row fragmentation)
Ъ§ОнааБЛДцДЂЮЊЖрИіЕиЗНЕФЖрИіЦЌЖЮжаЁЃ
ааМфЫщЦЌ(Intra-row fragmentation)
ТпМЩЯЫГађЕФвГЃЌдкДХХЬЩЯВЛЪЧЫГађДцДЂЕФЁЃ
ЪЃгрПеМфЫщЦЌ(Free space fragmentation)
Ъ§ОнвГжагаДѓСПЕФПегрПеМфЁЃ
ЪЙгУУќСюЃК
optimize table tb_nameЃЌЧхРэЫщЦЌЁЃ
mysql> OPTIMIZE TABLE actor;
+--------------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+--------------+----------+----------+-------------------------------------------------------------------+
| sakila.actor | optimize | note | Table does
not support optimize, doing recreate + analyze
instead |
| sakila.actor | optimize | status | OK |
+--------------+----------+----------+-------------------------------------------------------------------+
2 rows in set (0.02 sec) |
ЖдгкВЛжЇГжИУУќСюЕФв§ЧцПЩвдЭЈЙ§вЛИіВЛзіШЮКЮВйзїЃЈno-opЃЉЕФalter table ВйзїРДжиНЈБэЁЃ
mysql> alter
table actor engine=innodb;
Query OK, 200 rows affected (0.02 sec)
Records: 200 Duplicates: 0 Warnings: 0 |
Ыїв§ЯюЕФжЕЗЂЩњИФБфЃЌДЫЪБЫїв§ЯюдкЫїв§БэжаЕФЮЛжУЃЌОЭашвЊЗЂЩњИФБфЃЌетбљвЛИіааЮЊГЦЮЊЫїв§ЮЌЛЄЃЛ
вђЮЊШчЙћВЛНјааЫїв§ЮЌЛЄЕФЛАЃЌОЭЪЧЫЕЫїв§ЯюЕФжЕИФБфКѓЃЌВЂУЛгажиаТХХађЃЌетбљИФБфЯюЖрСЫжЎКѓЃЌОЭВЛЪЧвЛИіЫГађХХађСЫЃЌОЭЦ№ВЛЕНЫїв§ЕФаЇЙћСЫЃЛ
Ыїв§ЮЌЛЄгЩЪ§ОнПтздЖЏЭъГЩ
ВхШы/аоИФ/ЩОГ§УПвЛИіЫїв§ааЖМБфГЩвЛИіФкВПЗтзАЕФЪТЮё
Ыїв§дНЖрЃЌЪТЮёдНГЄЃЌДњМлдНИп
Ыїв§дНЖрЖдБэЕФВхШыКЭЫїв§зжЖЮаоИФОЭдНТ§
МйЩшвЛИіБэДјСЫСНИіЫїв§ЃЛ
ФЧУДЯЕЭГЛсзмЙВДДНЈ3еХБэЃЌвЛИіЪ§ОнБэЃЌСНИіЫїв§БэЃЛ
дкаоИФвЛИіЫїв§ЯюЪ§ОнЕФЪБКђЃЌЛсФкВПЗтзАГЩвЛИіЪТЮёЃЌЭЌЪБетШ§еХБэНјаааоИФЃЛ
ЪЙгУЫїв§
1.ЪЙгУWHEREВщбЏЬѕМўНЈСЂЫїв§
select a,b from tab where c=?;
idx_c (c)
select a,b from tab where c=? and d=?
idx_cd(c,d) 
2.ХХађORDER BY,GROUP BY,DISTINCT зжЖЮЬэМгЫїв§
3.СЊКЯЫїв§гыЧАзКВщбЏ
СЊКЯЫїв§ФмЮЊЧАзКЕЅСаЃЌИДСаВщбЏЬсЙЉАяжњ 
дкmysql5.6ЧАЃЌwhere a? and c? жЛФмВПЗж
КЯРэДДНЈСЊКЯЫїв§ЃЌБмУтШпгр
(a),(a,b),(a,b,c)
ЦфЪЕжЛашвЊЖд(a,b,c)НЈСЂЫїв§МДПЩЃЛ
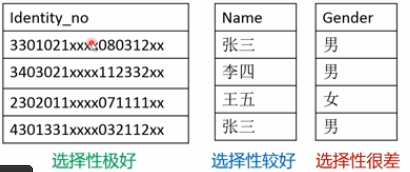
Ыїв§гызжЖЮбЁдёад
ФГИізжЖЮЦфжЕЕФжиИДГЬЖШЃЌГЦЮЊИУзжЖЮЕФбЁдёадЃЛ
бЁдёадКмВюЕФзжЖЮЭЈГЃВЛЪЪКЯДДНЈЕЅСаЫїв§
ФаХЎБШР§ЯрЗТЕФБэжаадБ№ВЛЪЪКЯДДНЈЕЅСаЫїв§
ШчЙћФаХЎБШР§МЋВЛЦНКтЃЌвЊВщбЏЕФгжЪЧЩйЪ§ЗНЃЈРэЙЄдКаЃВщХЎЩњЃЉПЩвдПМТЧЪЙгУЫїв§
СЊКЯЫїв§жабЁдёадКУЕФзжЖЮгІИУХХдкЧАУц
ГЄзжЖЮЕФЫїв§
дкЗЧГЃГЄЕФзжЖЮЩЯНЈСЂЫїв§гАЯьадФм
innodbЫїв§ЕЅзжЖЮЃЈutf8ЃЉжЛФмШЁЧА767bytes
ЖдГЄзжЖЮДІРэЕФЗНЗЈ
email РрЃЌНЈСЂЧАзКЫїв§
Mail_addr varchar(2048)
idx_mailadd (Mail_addr(30))----жЛБЃДцЧА30ИізжЗћЮЊЫїв§
mysqlдЪаэЖдзжЖЮНјааЧАзКЫїв§
ЖдГЄзжЖЮЮвУЧвВПЩвджїЖЏжЛШЁзжЖЮЕФЧААыВПЗжЃЛ
зЁжЗРрЃЌЗжВ№зжЖЮ
Home_address varchar(2048)
idx_Homeadd (Home_addr(30)) ????
-зіЧАзКЫїв§КмПЩФмааВЛЭЈЕФЃЌвђЮЊКмПЩФмЧААыЖЮЖМЪЧЯрЭЌЕФЪЁЪаЧјНжЕРУћГЦ
ЗНЗЈЃКЗжВ№зжЖЮ
Province varchar(1024), City varchar(1024),District
varcharЃЈ1024ЃЉЃЌLocal _ address varchar (1024)
ШЛКѓНЈСЂСЊКЯЫїв§ЛђЕЅСаЫїв§ЃЛ
Ыїв§ИВИЧЩЈУш(жБНгЪЙгУЫїв§жаЕФЪ§ОнЃЌВЛашвЊДгЪ§ОнБэжаЗЕЛиЪ§Он)
зюКЫаФSQLПМТЧЫїв§ИВИЧ
select name from tb_user where UserId=?
Key idx_uid_name(userid,name)
ВЛашвЊЛиБэЛёШЁnameзжЖЮЃЌIOзюЩйЃЌаЇТЪзюИпЃЛ
ЮоЗЈЪЙгУЫїв§
Ыїв§СаНјааЪ§бЇдЫЫуЛђКЏЪ§дЫЫу
where id+1 = 10 ЁС
where id = (10-1) ЁЬ
year(col) < 2007 ЁС
col < '2007-01-01'ЁЬ
ЮДКЌИДКЯЫїв§ЕФЧАзКзжЖЮ
idx_abc (a,b,c):
where b=? and c=? ЁС
idx_bc(b,c) ЁЬ
зЂвтЃКidx_adb ЃЈa,b,cЃЉАќКЌ idx_a (a),АќКЌidx_ab(a,b),дк5.6жЎКѓЛЙАќКЌidx_acЃЈa,cЃЉ
ЧАзКЭЈХфЁЎ_ЁЏ КЭЁЎ%ЁЏЭЈХфЗћ
LIKE '%XXX%' ЁС
LIKE 'XXX%' ЁЬ
ЕБЪЙгУЕН like'%xx%'ЪБЃЌЮоЗЈЪЙгУЫїв§ЃЌНтОіАьЗЈЪЧЃЌЪЙгУШЋЮФЫїв§дк5.6жЎКѓЁЃЛђепЃЌЪЙгУСЌНг
ФкВуЩЈУш ШЋЫїв§БэЃЌжЎКѓевЕНЗћКЯЬѕМўЕФЃЌдйЛиЕНБэжа Вщев МЧТМЃЌетбљПЩвдНЕЕЭIOЯћКФЃЌвђЮЊ вЛАуРДНВ
Ыїв§Бэ БШНЯаЁЃЌШЋЩЈЫїв§БэЕФЛАЯрЖдПЊЯњ БШ ШЋЩЈЪ§ОнБэЃЌвЊаЁКмЖрЃЛ
гУORЗжИюПЊЕФЬѕМўЃЌШчЙћorЧАЕФЬѕМўжаЕФСагаЫїв§ЃЌЖјКѓУцЕФСажаУЛгаЫїв§ЃЌФЧУДЫљЩцМАЕФЫїв§ЖМВЛЛсБЛгУЕНЁЃвђЮЊКѓУцЕФВщбЏПЯЖЈвЊзпШЋБэЩЈУшЃЌдкДцдкШЋБэЩЈУшЕФЧщПіЯТЃЌОЭУЛгаБивЊЖрвЛДЮЫїв§ЩЈУшдіМгI/OЗУЮЪЃЌвЛДЮШЋБэЩЈУшЙ§ТЫЬѕМўОЭзуЙЛСЫЁЃ
whereЬѕМўЪЙгУNOT,<>,!=
зжЖЮРраЭЦЅХф
ВЂВЛОјЖдЃЌЕЋЪЧЮоЗЈдЄВтЕиЛсдьГЩЮЪЬтЃЌВЛвЊЪЙгУЃЛ
Р§згЃКa int(11) , idx_a (a)ЃЛ
where a = '123' ЁС
where a = 123 ЁЬ
гЩгкРраЭВЛЭЌЃЌmysqlашвЊзівўЪНРраЭзЊЛЛВХФмНјааБШНЯЁЃ
зЂвтзжЖЮЕФРраЭЃЌгШЦфЪЧintаЭЪБШчЙћЪЙгУзжЗћаЭШЅЦЅХфЃЌФмЕУЕНе§ШЗНсЙћЃЌЖјВЛЛсЪЙгУЫїв§ЃЛЭЌбљШчЙћзжЖЮЪЧЃЌvarcharаЭЃЌФЧУДwhere
КѓУцШчЙћЪЧвЛИі INTЃЌвВЪЧВЛФмЪЙгУЫїв§ЃЛ
mysqlБШНЯзЊЛЛЙцдђЃК
СНИіВЮЪ§жСЩйвЛИіЪЧnullЪЧВЛашвЊзЊЛЛЃЛ
СНИіВЮЪ§РраЭвЛбљЪБВЛашвЊзЊЛЛЃЛ
TIMESTAMP/DATATIME КЭ ГЃСП БШНЯ-->ГЃСПзЊЛЛЮЊtimestamp/datetime
decimalКЭећЪ§БШНЯ---------------------->ећЪ§зЊЛЛЮЊdecimal
decimalКЭИЁЕуЪ§------------------------->decimalзЊЛЛЮЊИЁЕуЪ§
СНИіВЮЪ§ЖМЛсБЛзЊЛЛЮЊИЁЕуЪ§дйНјааБШНЯЃК
ШчЙћзжЗћДЎаЭЃЌБШНЯЃЌ=ЃЌ+ЃЌ-ЃЌЕШЃЛ
вЛИізжЗћДЎКЭвЛИіећаЮ-------------------->ОљзЊЛЛГЩИЁЕуаЭ
mysql> select
'18015376320243459'=18015376320243459;
+---------------------------------------+
| '18015376320243459'=18015376320243459 |
+---------------------------------------+
| 1 |
mysql> select '1801'+0;
+----------+
| '1801'+0 |
+----------+
| 1801 |
+----------+ |
ШчЙћ age int(10), index_age(age);
mysql> explain
select name from indextest where age='30'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: indextest
type: ref
possible_keys: idx_age
key: idx_age
key_len: 1
ref: const
rows: 1
Extra:
1 row in set (0.00 sec) |
Ыїв§ЪЧЪ§жЕЃЛВщбЏЬѕМўЪЧзжЗћДЎ'30',зЊЛЛГЩШЗЖЈЪ§жЕ30ЃЌзЊЛЛЪЙгУЫїв§ЃЛ
Ыїв§ЪБзжЗћДЎЃЌВщбЏЪЧЪ§жЕЪБЃЌЮоЗЈЪЙгУЫїв§ЃЛ
ЪЙгУcastКЏЪ§ЖдageзіЯдЪОЕФРраЭзЊЛЛЃЌЛсЪЙЫїв§ЯћЪЇЃЛ
МДЖдЫїв§ЯюзіШЮКЮЕФКЏЪ§ИФБфЃЌЖМЛсЪЙЫїв§ЪЇаЇЃЛ
змНс
BTREE
ДцДЂЫїв§ЯюгыжїМќ
BTREEЫїв§ПЩгУдкЖЈжЕВщбЏЃЌЗЖЮЇВщбЏЃЌ
HASH
ДцДЂЙўЯЃжЕгыаажИеы
НігУгкЖЈжЕВщбЏЃЌДДНЈЮБЙўЯЃЫїв§ЃЛ
ЧАзКЕФбЁдёадМЦЫуЃЈШЅжиЧАзКЪ§Г§змЪ§ЃЉ
mysql> select count(DISTINCT city)/count(*) from
table_name
Ыїв§КЯВЂЃЈindex mergeЃЉЃКЫЕУїДЫЪББэЩЯЫїв§ЃЌБэНсЙЙЕШашвЊгХЛЏСЫЃЛ
бЁдёКЯЪЪЕФЫїв§СаЫГађЃКашвЊИљОнБэжаЪЕМЪЪ§ОнНјаабЁдёЃЌбЁдёадИпЕФЗХдкЧАЃЛ
ОлДиЫїв§ЃКinnodbЕФОлДиЫїв§ЪЕМЪЩЯдкЭЌвЛНсЙЙжаБЃДцСЫBTreeЫїв§КЭЪ§Онаа
myisamЕФЪ§ОнЗжВМ
myisamАДееЪ§ОнВхШыЕФЫГађДцДЂдкДХХЬЩЯ
жїМќЫїв§ЪБЃЌздЖЏдіМгааКХЃЌБэЕФжїМќКЭааКХдквЖзгНкЕужаЃЌЧввЖзгНкЕуИљОнжїМќЫГађХХСаЃЛ
ЦфЫћСаЫїв§КЭжїМќЫїв§ЮоЧјБ№ЃЛ
innodbЪ§ОнЗжВМ:
ЪЙгУОлДиЫїв§ЃЛ
ЖўМЖЫїв§АќКЌЫїв§ЯюКЭжїМќжЕ
ИВИЧЫїв§ЃК
extraжаusing indexЃЛ
бгГйЙиСЊ(defferred join)ЃЛ
ЕБШЛИВИЧЫїв§ВЂВЛЪЧЖМФмЬсЩ§адФмЃЌашвЊИљОнМЏЬхЪ§ОнМЏЃЛ
ЪЙгУЫїв§НјааХХађЃЌВЛФмПчдНЫїв§ЯюНјааХХађЃЛ
Ыїв§ЮЌЛЄЃКгЩЪ§ОнПтздЖЏЭъГЩЃЌНЋDMLЗтзАГЩФкВПЪТЮёЃЌЫїв§дНЖрДњМлдНИпЃЌ
ИќаТЫїв§ЭГМЦаХЯЂЃК
records_in_range()ЛёШЁЗЖЮЇжагаЖрЩйМќжЕЃЌ
info()ЛёШЁЫїв§ЛљЪ§
ЧхРэЫщЦЌЃК
optimize table tbl,
alter table tbl engine=innodb;
ЪЙгУЫїв§
where
order by ЁЂgroup byЁЂdistinct,
СЊКЯЫїв§ЃКзЂвтШпгрЃЌбЁдёадКУЕФЗХдкСЊКЯЫїв§зѓВрЃЛ
ГЄзжЖЮЕФЫїв§ЃК
НЈСЂЧАзКЫїв§
ЗжВ№зжЖЮНЈСЂСЊКЯЫїв§ЃЌ
ЮоЗЈЪЙгУЫїв§ЃК
Ыїв§СаНјааЪ§бЇдЫЫуЛђКЏЪ§дЫЫу
ЮДзёЪизюзѓЧАзКддђ
orЬѕМўКѓвЛСаУЛгаЫїв§
whereЬѕМўЪЙгУnot <> !=
зжЖЮРраЭВЛЦЅХфЃЛ
| 








