| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмСЫMySQL
InnoDBФкДцКЭЛКГхГиЗНУцЕФжЊЪЖЃЌЯЃЭћЖдФњФмгаЫљАяжњЁЃ |
|
ЮвУЧЖМжЊЕРЃЌInnoDBв§ЧцЪЧЛљгкДХХЬДцДЂЕФЃЌЕЋгЩгкЮяРэгВХЬЗУЮЪЫйЖШгыФкДцЗУЮЪЫйЖШДцдкзХОоДѓЕФКшЙЕЃЌInnoDBГЃгУЛКГхГиММЪѕРДЬсИпЪ§ОнПтЕФадФмЁЃ
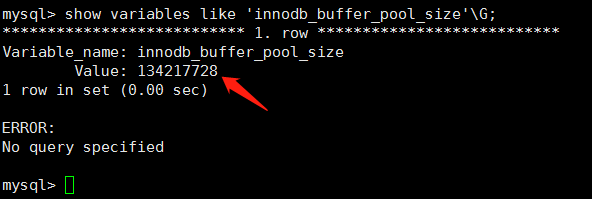
гыГЃгУЕФЛКДцЫМЯыРрЫЦЃЌдкЪ§ОнПтжаЖСШЁвГЕФВйзїЃЌЪзЯШНЋДХХЬЖСЕНЕФвГЗХдкЛКГхГиЕБжаЃЌЯТвЛДЮдйЖСЯрЭЌвГЪБЃЌЯШМьВщИУвГЪЧЗёдкЛКГхГиЕБжаЁЃШєдкЛКГхГижаЃЌдђИУвГдкЛКГхГижаБЛУќжаЃЌжБНгЖСШЁИУвГЃЌЗёдђЖСШЁДХХЬжаЕФвГЁЃПЩМћЃЌЛКГхГиЕФДѓаЁЗЧГЃгАЯьMySQLЕФадФмЁЃЛКГхГидкMySQLгУinnodb_buffer_pool_sizeБфСПБэЪОЃЌПЩвддкmy.cnfЮФМўжаЩшжУЃЌВщПДЗНЪНШчЯТЭМЃЌПЩМћЃЌЛКГхГиЕФДѓаЁЪЧ134217728/1024/1024=128M(ЕБШЛдкЩњВњЛЗОГЯТ128MЬЋаЁ)ЁЃ
| show variables
like 'innodb_buffer_pool_size'\G; |
дкЪ§ОнПтжааоИФвГЕФВйзїЃЌЪзЯШаоИФЛКГхГижавГЕФЪ§ОнЃЌШЛКѓвдвЛЖЈЦЕТЪвьВНЕиНЋЛКГхГивГЫЂаТЕНДХХЬЩЯЃЌетжжММЪѕНаCheckpointЛњжЦЃЌетбљЕФФПЕФвВЪЧЮЊСЫЬсИпMySQLећЬхадФмЁЃ
ЛКГхГиЪЧвЛПщКмДѓЕФФкДцЧјгђЃЌЦфжаДцЗХИїжжРраЭЕФвГЃЌФЌШЯУПвГЕФДѓаЁЪЧ16KЃЌШУЮвУЧРДПДвЛЯТЛКГхГижаЪ§ОнвГЕФРраЭЃКЫїв§вГЃЌЪ§ОнвГЃЌredoвГЃЌВхШыЛКГхЃЌздЪЪгІЙўЯЃЫїв§ЃЌЫјаХЯЂЃЌЪ§ОнзжЕфЕШЃЌФЧУДInnoDBЪЧШчКЮЙмРэФкДцЕФФиЃП
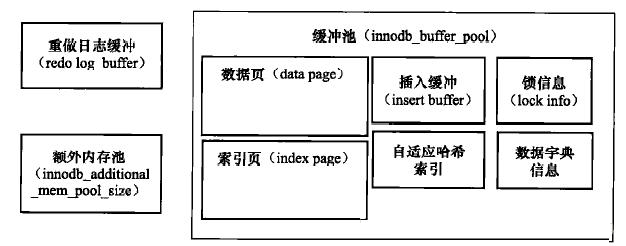
вЛЁЂвГЕФЙмРэ
1ЁЂLRU List
LRUЃЌLatest Recent UsedЃЌзюНќзюЩйЪЙгУЫуЗЈЁЃЛКДцГиПЩвдБЛШЯЮЊвЛЬѕГЄLRUСДБэЃЌИУСДБэгжЗжЮЊ2ИізгСДБэЃЌвЛИізгСДБэДцЗХold
pages(РяУцДцЗХЕФЪЧГЄЪБМфЮДБЛЗУЮЪЕФЪ§ОнвГ)ЃЌСэвЛИізгСДНгДцЗХnew pagesЃЈРяУцДцЗХЕФЪЧзюНќБЛЗУЮЪЕФЪ§ОнвГУцЃЉЁЃ
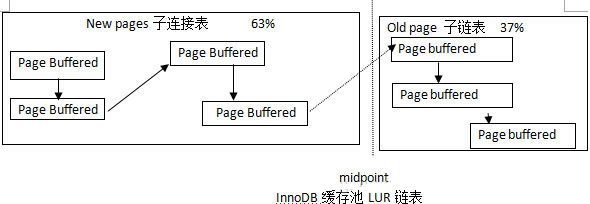
гыДЋЭГЕФLRUЫуЗЈВЛЭЌЃЌinnoDBЖдLRUЫуЗЈНјаагХЛЏЃЌВхШыЕФЪ§ОнВЛдкLRU ListЕФЪзВПЃЌдкinnoDBжав§ШыСЫвЛИіmidpointЕФИХФюЃЌНЋаТЕФЪ§ОнВхШыЕНLRU
ListЕФmidpointЮЛжУДІЁЃЮвУЧПЩвдЭЈЙ§УќСюВщПДmidpointЕФжЕ
| show variables
like 'innodb_old_blocks_pct'\G; |
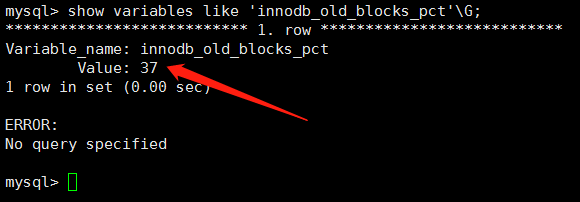
ПЩвдПДЕНmidpointФЌШЯжЕЪЧ37ЃЌmidpointжЎЧАЪЧnewPageеМ37%ЃЌmidpointжЎКѓЪЧoldPageЃЌПЩвдЭЈЙ§УќСюЕїећmidpoint'ЕФжЕ
| set global innodb_old_blocks_pct=38 |
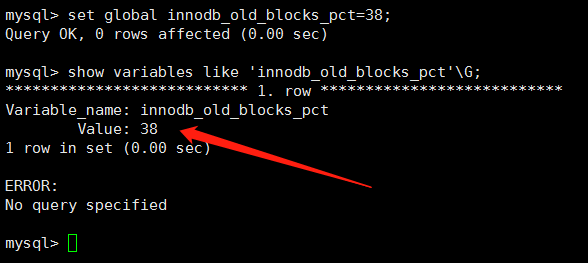
ЫМПМЃКinnodbЮЊЪВУДвЊЩшжУmidpointЖјВЛгУДЋЭГЕФLRUЫуЗЈФиЃП
Д№ЃКетЪЧвђЮЊШєжБНгНЋЖСШЁЕФвГЗХдкLRUСаБэЕФЪзВПЃЌФЧУДФГаЉSQLВйзїПЩФмЛсЪЙЛКГхГижаЕФвГБЛЫЂаТГіЃЌДгЖјгАЯьЛКГхЕФУќжаТЪЁЃГЃМћЕФВйзїШчашвЊЗУЮЪБэжаЕФКмЖрвГЃЌвВаэетаЉвГВЂВЛЪЧШШЕуЪ§ОнЃЌШчЙћЗХдкLRUСаБэЪзВПЃЌЕЋетаЉвГгаПЩФмЛсНЋШШЕуЪ§ОнЫЂГіЛКГхГиЁЃв§ШыmidpointЃЌНЋаТВщЕФЪ§ОнДцДЂдкmidpontЮЛжУжаЃЌmidpointжЎЧАЕФШдЮЊзюШШЪ§ОнЁЃ
2ЁЂFree List
ЕБMySQLИеЦєЖЏЪБЃЌLRU ListЪЧПеЕФЃЌетЪБЕФвГЖМДцЗХдкFree
ListжаЁЃЕБашвЊДгЛКГхГижаЗжвГЪБЃЌЪзЯШДгFree ListжаВщевЪЧЗёгаПеЯавГЃЌШчЙћгадђДгFreeListжавЦГ§ЃЌЗХдкLRU
ListжаЁЃЮвУЧПЩвдИљОнвдЯТУќСюВщПДLRU ListКЭFree ListЕФЪ§Он
| show engine
innodb status\G; |
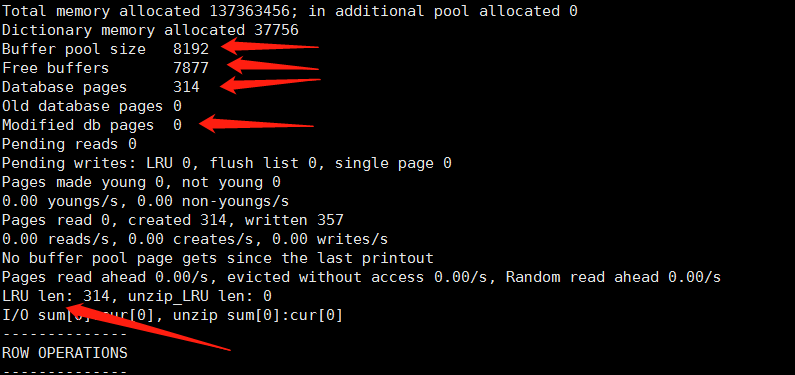
ЦфжагаМИИіживЊЕФВЮЪ§ЃЌЮввбОБъКьЃЌдкЯТУцвЛвЛНтЪЭЃК
Buffer pool sizeЃКЛКГхГижавГЕФИіЪ§ЃЌУПвГФЌШЯДѓаЁ16kЃЌдђЛКГхГиЕФДѓаЁЪЧ8192*16/1024=128MЁЃ
Free buffersЃКFree ListвГЕФИіЪ§
Database pagesЃКLRU ListвГЕФИіЪ§
Modified db pagesЃКдрвГЕФИіЪ§ЃЌгЩгкдкНјааupdateВйзїЪБЪзЯШЛсаоИФЛКГхГижаЕФЪ§ОнЃЌдкЖЈЪБвьВНЕФНЋЛКГхГиЕФЪ§ОнЫЂаТЕНДХХЬжаЃЈcheckpointММЪѕЃЉЃЌЫљвдЛКГхГиЕФЪ§ОнгыДХХЬЕФЪ§ОнЛсВњЩњВЛвЛжТЃЌГЦЮЊдрвГЁЃ
LRU lenЃКLRU ListЕФГЄЖШЁЃ
3ЁЂFlush List
дкLRUжаЕФвГБЛаоИФКѓЃЌИУвГГЦЮЊдрвГЃЌМДЛКГхГижаЕФвГКЭДХХЬЩЯЕФвГВњЩњСЫВЛвЛжТЃЌЖјFlush
ListжаЕФвГМДЮЊдрвГСаБэЁЃзЂвтЃКдрвГМШДцдкгкLRU ListжаЃЌвВДцдкFlush ListжаЃЌLRU
ListгУРДЙмРэЛКГхГижаПЩгУЕФвГЃЌFlush ListгУРДЙмРэНЋдрвГЫЂаТЕНДХХЬЩЯЃЌЖўепЛЅВЛгАЯьЁЃЯТУцЮвгУвЛИіР§згРДИјДѓМвбщжЄFlush
ListКЭModified db pages;
гавЛеХuserБэДцгаШчЯТЪ§ОнЃК
етЪБЮвУЧВщПДModified db pagesЕФжЕЮЊ0ЃК
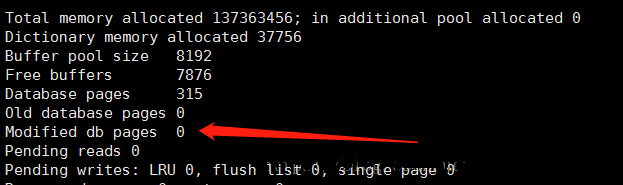
ЕБЮвУЧupdateЕФЪБКђЃЌЮвжДааШчЯТУќСюЃЌаоИФЪ§ОнВЂВщПДдрвГЕФжЕЃЌжЎЫљвдСНЬѕУќСювЛЦ№жДааЃЌЪЧЮЊСЫПЩвдПДЕНдрвГЕФжЕЕФБфЛЏЃЌШчЙћЗжГЩСНДЮжДааЃЌгаПЩФмcheckpointЛњжЦвбНЋаоИФЕФЪ§ОнЫЂаТЕНДХХЬжаЖјЙлВтВЛЕНдрвГЕФжЕЁЃ
| update user
set id=5 where id=4;show engine innodb status\G; |
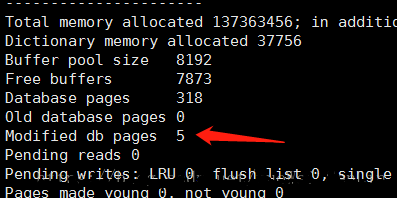
ЮвУЧПЩвдПДЕНModified db pagesЕФжЕШЗЪЕБфЛЏСЫЃЌБэУїгждрвГВњЩњЁЃ
ЖўЁЂВхШыЛКГхЃЈInsert BufferЃЉ
Ь§ЕНетИіУћзжЃЌПЩФмЛсШУШЫШЯЮЊinsert? bufferЪЧЛКГхГижаЕФвЛВПЗжЃЌЦфЪЕВЛЪЧЃЌinsert
bufferКЭЪ§ОнвГвЛбљЃЌвВЪЧЮяРэвГжаЕФвЛИізщГЩВПЗжЁЃ
дкInnoDBжаЃЌжїМќЪЧааЕФЮЈвЛБъЪЖЃЌШчЙћЮвУЧЕФжїМќЪЧauto_incrementЕФЛАЃЌВхШыЫГађЪЧгаађЕФЃЌвЛАуЧщПіЯТВЛашвЊЖСШЁСэвЛвГЕФЪ§ОнЃЌЫљвдВхШыЫйЖШЗЧГЃПьЃЌШчЯТБэЃК
ЕЋВЛПЩФмУПеХБэЖМжЛгавЛИіОлМЏЫїв§ЃЌДѓЖрЧщПіЯТЃЌУПеХБэЛсгаЗЧОлМЏЫїв§ЁЃБШШчгУЛЇАДееbзжЖЮВщбЏЃЌЖјЧвbзжЖЮВЛЪЧЮЈвЛЕФЃЌдкinsertЪБЃЌжїМќaЛЙЪЧАДеегаађДцЗХЃЌЕЋЗЧОлМЏЫїв§bЕФвЖзгНкЕуВхШыЕФВЛвЛЖЈЪЧгаађСЫЁЃШчЯТБэЃК
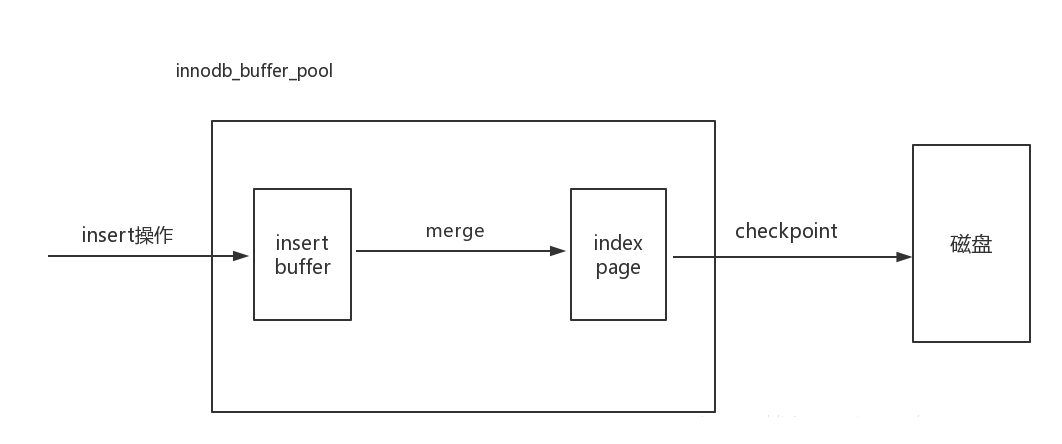
InnoDBЩшМЦЕФInsert BufferЃЌЖдЗЧОлМЏЫїв§ЕФВхШыКЭИќаТВйзїЃЌВЛЪЧУПДЮвЛЖМжБНгВхШыЫїв§вГЃЈindex
pageЃЉжаЃЌЖјЪЧЯШХаЖЯВхШыЕФЗЧОлМЏЫїв§вГЪЧЗёдкЛКГхГижаДцдкЃЌШєдкдђжБНгВхШыЃЌШєВЛдкЃЌдђЯШЗХШыЕНвЛИіInsert
BufferЖдЯѓжаЁЃШЛКѓдйвдвЛЖЈЦЕТЪжДааInsert BufferКЭindex pageЕФКЯВЂВйзїЃЌетЪБКђФмНЋЖрИіinsertКЯВЂЕНвЛИіВйзїжаЃЌДѓДѓЬсИпСЫЗЧОлМЏЫїв§ВхШыЕФадФмЁЃЮвРэНтЕФInsert
BufferЕФВйзїШчЯТЭМЫљЪОЃКЖдгкinsertВйзїЃЌЪзЯШНјШыinsert bufferжаЃЌШЛКѓвдвЛЖЈЦЕТЪНЋЫїв§mergeЕНindex
pageжаЃЌcheckpointЖЈЪБНЋЪ§ОнЫЂаТЕНДХХЬжаЁЃ
ШЛЖјЃЌInnoDBЪЙгУInsert BufferашвЊЭЌЪБТњзувЛЯТСНИіЬѕМўЃК
Ыїв§ЪЧЗЧОлМЏЫїв§
Ыїв§ВЛЪЧЮЈвЛЕФ
ШчЙћЫїв§ЪЧЮЈвЛЕФЃЌдкУПДЮВхШыЕФЪБКђЯШЛсХаЖЯЫїв§жЕЪЧЗёвбОДцдкЃЌетбљЛсЫцЛњЖСШЁindex pageЃЌДгЖјЕМжТInsert
BufferЪЇШЅСЫвтвхЁЃ
ЭЈЙ§УќСюПЩвдВщПДЕНinsert bufferЕФаХЯЂЃК
| show engine
innodb status\G; |
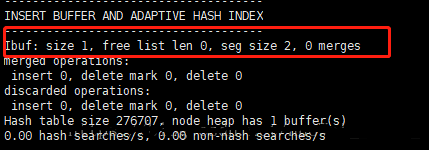
size:вбОКЭindex pageКЯВЂВЂМЧТМвГЕФЪ§СПЃЛ
free list:ПеЯаСаБэЕФГЄЖШЃЛ
seg size:ЕБЧАinsert bufferЕФДѓаЁЃЌ2*16k=32kЁЃ
Ждinsert bufferЕФаЮЯѓРэНт(еЊздЭјТч)ЃК
ЮвУЧШЅЭМЪщЙнЛЙЪщЃЌЖдгІЭМЪщЙнРДЫЕЃЌЫћЪЧзіСЫinsert(діМг)ВйзїЃЌЙмРэдБдк1аЁЪБФкНгЪмСЫ100БОЪщЃЌетЪБКђЫћга2жжзіЗЈАбЛЙЛиРДЕФЪщЙщЮЛЕНЪщМмЩЯ
1ЃЉУПЛЙЛиРДвЛБОЪщЃЌИљОнетБОЪщЕФБрТыЃЈЪщЙёЧј-ХХ-КХЃЉАбЪщЫЭЛиМмЩЯ
2ЃЉднЪБВЛзіЙщЮЛВйзїЃЌЯШЗХЕНЙёУцЩЯЃЌЕШВЛУІЕФЪБКђЃЌдйАбетаЉЪщАДееЪщЙёЧј-ХХ-КХЯШХХКУЃЌШЛКѓвЛДЮадЙщЮЛ
гУЗНЗЈ1ЃЌЙмРэдБашвЊНјГіЃЈIOЃЉВиЪщЧј100ДЮЃЌВЛЭЃЕФЕЧИпХРЕЭЭъГЩЭМЪщЙщЮЛВйзїЃЌРлЫРРлЛюЃЌаЇТЪКмВюЁЃ
гУЗНЗЈ2ЃЌЙмРэдБжЛашвЊНјГіЃЈIOЃЉВиЪщЧј1ДЮЃЌЖдЭЌвЛИіЮЛжУЕФЪщЃЌВЛЙмЖрЩйЃЌЖМжЛвЊХРвЛДЮТЅЬнЃЌДѓДѓМѕЧсСЫЙмРэдБЕФЙЄзїСПЁЃ
ЮЊЪВУДЖдгкЗЧОлМЏЫїв§ЃЈЗЧЮЈвЛЃЉЕФВхШыКЭИќаТгааЇ?
ЛЙЪЧгУЛЙЪщЕФР§згРДЫЕЃЌЛЙвЛБОЪщAЕНЭМЪщЙнЃЌЙмРэдБвЊХаЖЯвЛЯТетБОЪщЪЧВЛЪЧЮЈвЛЕФЃЌЫћдкЙёЬЈЩЯЪЧПДВЛЕНЕФЃЌБиаыХРЕНжИЖЈЮЛжУШЅШЗШЯЃЌетИіЙ§ГЬЦфЪЕвбОВњЩњСЫвЛДЮIOВйзїЃЌЯрЕБгкУЛгаНкЪЁШЮКЮВйзїЁЃ
ЫљвдетИіbufferжЛФмДІРэЗЧЮЈвЛЕФВхШыЃЌВЛвЊЧѓХаЖЯЪЧЗёЮЈвЛЁЃ
Ш§ЁЂздЪЪгІЙўЯЃЫїв§ЃЈAdaptive Hash IndexЃЉ
ДЫЫїв§ЗЧБЫЫїв§ЁЃInnodbДцДЂв§ЧцЛсМрПиЖдБэЩЯЦеЭЈЫїв§ЕФВщевЃЌШчЙћЗЂЯжФГЫїв§БЛЦЕЗБЗУЮЪЃЌдђИУЫїв§ГЩЮЊШШЪ§ОнЃЌНЈСЂЙўЯЃЫїв§ПЩвдДјРДЫйЖШЕФЬсЩ§ЁЃПДЯТЭМЃЌAHIЕФЮЛжУдкЦеЭЈЫїв§жЎЧАЃЌВщбЏЪБЯШВщAHIЃЌКѓВщЦеЭЈЫїв§ЁЃ
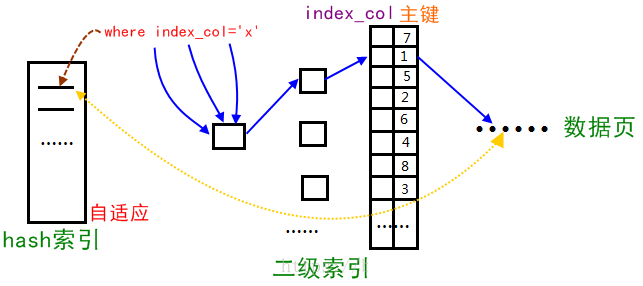
ВњЩњAHIЕФЬѕМўЃК
ЭЈЙ§жїМќВщбЏЃЌЛђепЭЈЙ§СЊКЯЫїв§(a,b)ВщбЏЃЌБШШчselect * from t where a=xxxЛђselect
* from t where a=xxx and b=yyy;
вдИУФЃЪНВщбЏжСЩй100ДЮЁЃ
вГЭЈЙ§ИУФЃЪНЗУЮЪжСЩйNДЮЃЌN=вГжаЕФМЧТМЪ§*1/16;
AHIжЛЖдЕШжЕВщбЏгааЇЃЌЖдЗЖЮЇВщбЏЮоаЇЁЃ
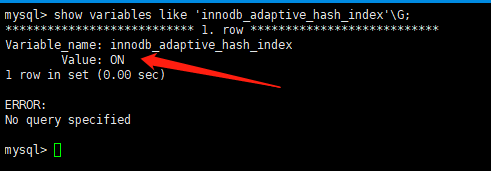
СэЭтЃЌЮвУЧвЊжЊЕРЃЌAHIЪЧInnoDBПижЦЕФЃЌвђДЫЮвУЧВЛФмЖдAHIНјааИЩдЄЁЃЮвУЧПЩвдВщПДAHIЕФЪЧЗёПЊЦєЃЌФЌШЯЪЧПЊЦєONзДЬЌЁЃ
| show variables
like 'innodb_adaptive_hash_index'\G; |
ЭЈЙ§УќСюЮвУЧПЩвдВщЕНAHIЕФЪЙгУзДПіЁЃ
| show engine
innodb status\G; |
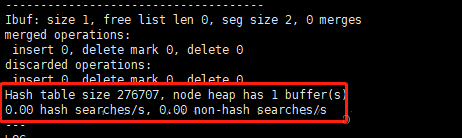
hashБэЪОЯЕЭГЪЙгУAHIВщбЏЕФЫйЖШЃЌnon-hashЪЧУЛгаЪЙгУAHIЕФВщбЏЫйЖШЁЃШчЙћЖСепЯывЊПДЕНЪ§жЕЃЌПЩвдСЌајВщбЏФГЪ§Он100ДЮвдЩЯЃЌдђПЩвдПДЕНhashЕФжЕЁЃ
select * from
t where id=1;show engine innodb status\G;
Лђ
select * from t where id>1;show engine innodb
status\G; |
| 








