| БрМЭЦМі: |
| БОЮФРДздгкwww.cnblogs.com,СЫНтMySQLЫїв§ЕзВуЪЕЯждРэТ№ЃПжївЊНщЩмСЫЫїв§ЕФБОжЪЃЌЯрЙиЕФжїДцШЁдРэЃЌДХХЬдРэЃЌОжВПаддРэЃЌДјДѓМвСЫНтНјааЯъЯИЕФЪЕЯжЁЃ |
|
Ыїв§ЕФБОжЪ
MySQLЙйЗНЖдЫїв§ЕФЖЈвхЮЊЃКЫїв§ЃЈIndexЃЉЪЧАяжњMySQLИпаЇЛёШЁЪ§ОнЕФЪ§ОнНсЙЙЁЃЬсШЁОфзгжїИЩЃЌОЭПЩвдЕУЕНЫїв§ЕФБОжЪЃКЫїв§ЪЧЪ§ОнНсЙЙЁЃ
ЮвУЧжЊЕРЃЌЪ§ОнПтВщбЏЪЧЪ§ОнПтЕФзюжївЊЙІФмжЎвЛЁЃЮвУЧЖМЯЃЭћВщбЏЪ§ОнЕФЫйЖШФмОЁПЩФмЕФПьЃЌвђДЫЪ§ОнПтЯЕЭГЕФЩшМЦепЛсДгВщбЏЫуЗЈЕФНЧЖШНјаагХЛЏЁЃзюЛљБОЕФВщбЏЫуЗЈЕБШЛЪЧЫГађВщевЃЈlinear
searchЃЉЃЌетжжИДдгЖШЮЊO(n)ЕФЫуЗЈдкЪ§ОнСПКмДѓЪБЯдШЛЪЧдуИтЕФЃЌКУдкМЦЫуЛњПЦбЇЕФЗЂеЙЬсЙЉСЫКмЖрИќгХауЕФВщевЫуЗЈЃЌР§ШчЖўЗжВщевЃЈbinary
searchЃЉЁЂЖўВцЪїВщевЃЈbinary tree searchЃЉЕШЁЃШчЙћЩдЮЂЗжЮівЛЯТЛсЗЂЯжЃЌУПжжВщевЫуЗЈЖМжЛФмгІгУгкЬиЖЈЕФЪ§ОнНсЙЙжЎЩЯЃЌР§ШчЖўЗжВщеввЊЧѓБЛМьЫїЪ§ОнгаађЃЌЖјЖўВцЪїВщевжЛФмгІгУгкЖўВцВщевЪїЩЯЃЌЕЋЪЧЪ§ОнБОЩэЕФзщжЏНсЙЙВЛПЩФмЭъШЋТњзуИїжжЪ§ОнНсЙЙЃЈР§ШчЃЌРэТлЩЯВЛПЩФмЭЌЪБНЋСНСаЖМАДЫГађНјаазщжЏЃЉЃЌЫљвдЃЌдкЪ§ОнжЎЭтЃЌЪ§ОнПтЯЕЭГЛЙЮЌЛЄзХТњзуЬиЖЈВщевЫуЗЈЕФЪ§ОнНсЙЙЃЌетаЉЪ§ОнНсЙЙвдФГжжЗНЪНв§гУЃЈжИЯђЃЉЪ§ОнЃЌетбљОЭПЩвддкетаЉЪ§ОнНсЙЙЩЯЪЕЯжИпМЖВщевЫуЗЈЁЃетжжЪ§ОнНсЙЙЃЌОЭЪЧЫїв§ЁЃ
ПДвЛИіР§згЃК
ЩЯЭМеЙЪОСЫвЛжжПЩФмЕФЫїв§ЗНЪНЁЃзѓБпЪЧЪ§ОнБэЃЌвЛЙВгаСНСаЦпЬѕМЧТМЃЌзюзѓБпЕФЪЧЪ§ОнМЧТМЕФЮяРэЕижЗЃЈзЂвтТпМЩЯЯрСкЕФМЧТМдкДХХЬЩЯвВВЂВЛЪЧвЛЖЈЮяРэЯрСкЕФЃЉЁЃЮЊСЫМгПьCol2ЕФВщевЃЌПЩвдЮЌЛЄвЛИігвБпЫљЪОЕФЖўВцВщевЪїЃЌУПИіНкЕуЗжБ№АќКЌЫїв§МќжЕКЭвЛИіжИЯђЖдгІЪ§ОнМЧТМЮяРэЕижЗЕФжИеыЃЌетбљОЭПЩвддЫгУЖўВцВщевдкO(logn2)O(log2n)ЕФИДдгЖШФкЛёШЁЕНЯргІЪ§ОнЁЃ
ЫфШЛетЪЧвЛИіЛѕецМлЪЕЕФЫїв§ЃЌЕЋЪЧЪЕМЪЕФЪ§ОнПтЯЕЭГМИКѕУЛгаЪЙгУЖўВцВщевЪїЛђЦфНјЛЏЦЗжжКьКкЪїЃЈred-black
treeЃЉЪЕЯжЕФЃЌдвђЛсдкЯТЮФНщЩмЁЃ
ЖўВцХХађЪї
дкНщЩмBЪїжЎЧАЃЌЯШРДПДСэвЛПУЩёЦцЕФЪїЁЊЁЊЖўВцХХађЪїЃЈBinary Sort TreeЃЉЃЌЪзЯШЫќЪЧвЛПУЪїЃЌЁАЖўВцЁБетИіУшЪівбОКмУїЯдСЫЃЌОЭЪЧЪїЩЯЕФвЛИљЪїжІПЊСНИіВцЃЌгкЪЧЕнЙщЯТРДОЭЪЧЖўВцЪїСЫЃЈЯТЭМЫљЪОЃЉЃЌЖјетПУЪїЩЯЕФНкЕуЪЧвбОХХКУађЕФЃЌОпЬхЕФХХађЙцдђШчЯТЃК
ШєзѓзгЪїВЛПеЃЌдђзѓзгЪїЩЯЫљгаНкЕуЕФжЕОљаЁгкЫќЕФИљНкЕуЕФжЕ
ШєгвзгЪїВЛПеЃЌдђгвзжЪ§ЩЯЫљгаНкЕуЕФжЕОљДѓгкЫќЕФИљНкЕуЕФжЕ
ЫќЕФзѓЁЂгвзгЪївВЗжБ№ЮЊЖўВцХХађЪ§ЃЈЕнЙщЖЈвхЃЉ
ДгЭМжаПЩвдПДГіЃЌЖўВцХХађЪїзщжЏЪ§ОнЪБЃЌгУгкВщевЪЧБШНЯЗНБуЕФЃЌвђЮЊУПДЮОЙ§вЛДЮНкЕуЪБЃЌзюЖрПЩвдМѕЩйвЛАыЕФПЩФмЃЌВЛЙ§МЋЖЫЧщПіЛсГіЯжЫљгаНкЕуЖМЮЛгкЭЌвЛВрЃЌжБЙлЩЯПДОЭЪЧвЛЬѕжБЯпЃЌФЧУДетжжВщбЏЕФаЇТЪОЭБШНЯЕЭСЫЃЌвђДЫашвЊЖдЖўВцЪїзѓгвзгЪїЕФИпЖШНјааЦНКтЛЏДІРэЃЌгкЪЧОЭгаСЫЦНКтЖўВцЪїЃЈBalenced
Binary TreeЃЉЁЃ
ЫљЮНЁАЦНКтЁБЃЌЫЕЕФЪЧетПУЪїЕФИїИіЗжжЇЕФИпЖШЪЧОљдШЕФЃЌЫќЕФзѓзгЪїКЭгвзгЪїЕФИпЖШжЎВюОјЖджЕаЁгк1ЃЌетбљОЭВЛЛсГіЯжвЛЬѕжЇТЗЬиБ№ГЄЕФЧщПіЁЃгкЪЧЃЌдкетбљЕФЦНКтЪїжаНјааВщевЪБЃЌзмЙВБШНЯНкЕуЕФДЮЪ§ВЛГЌЙ§ЪїЕФИпЖШЃЌетОЭШЗБЃСЫВщбЏЕФаЇТЪЃЈЪБМфИДдгЖШЮЊO(logn)ЃЉ
BЪї
ЛЙЪЧжБНгПДЭМБШНЯЧхГўЃЌЭМжаЫљЪОЃЌBЪїЪТЪЕЩЯЪЧвЛжжЦНКтЕФЖрВцВщевЪїЃЌвВОЭЪЧЫЕзюЖрПЩвдПЊmИіВцЃЈm>=2ЃЉЃЌЮвУЧГЦжЎЮЊmНзbЪїЃЌЮЊСЫЬхЯжБОВЉПЭЕФСМаФжЎДІЃЌВЛЭЌгкЦфЫћЕиЗНЖМФмПДЕН2НзBЪїЃЌетРяЬивтЛСЫвЛПУ5НзBЪї
ЁЃ
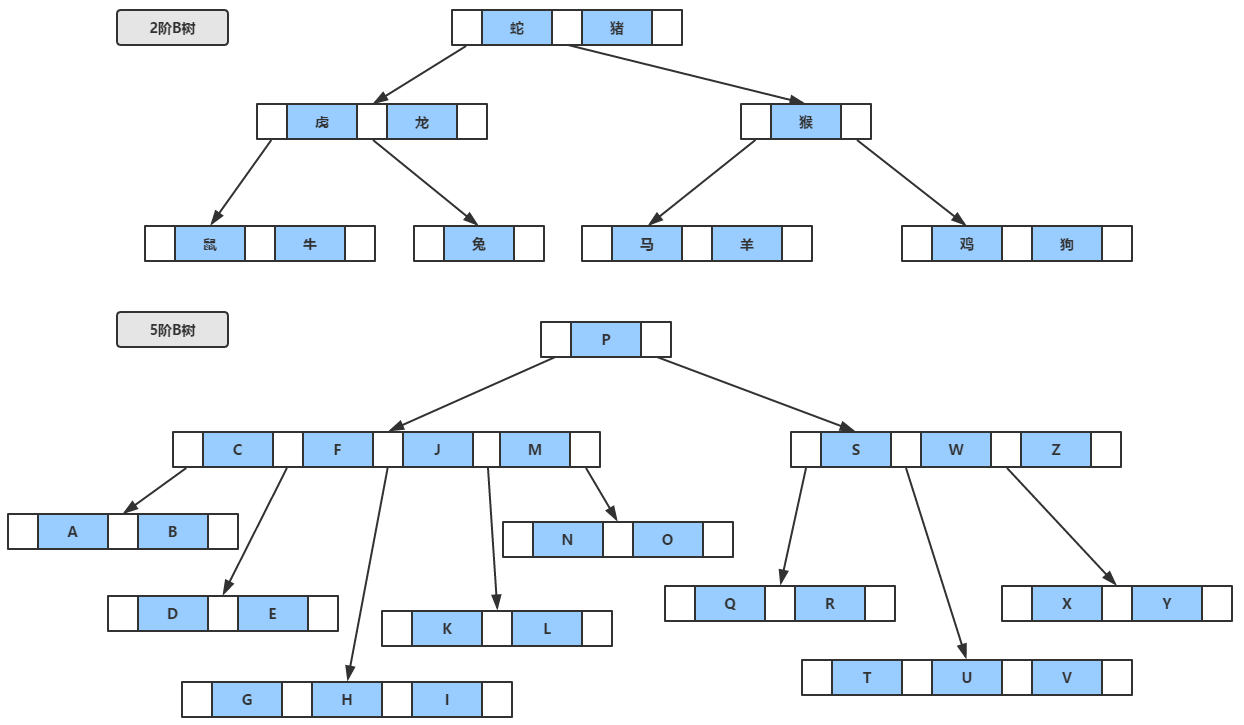
змЕФРДЫЕЃЌmНзBЪїТњзувдЯТЬѕМўЃК
УПИіНкЕужСЖрПЩвдгЕгаmПУзгЪїЁЃ
ИљНкЕуЃЌжЛгажСЩйга2ИіНкЕуЃЈвЊУДМЋЖЫЧщПіЃЌОЭЪЧвЛПУЪїОЭвЛИіИљНкЕуЃЌЕЅЯИАћЩњЮяЃЌМДЪЧИљЃЌвВЪЧвЖЃЌвВЪЧЪї)ЁЃ
ЗЧИљЗЧвЖЕФНкЕужСЩйгаЕФCeil(m/2)ИізгЪї(CeilБэЪОЯђЩЯШЁећЃЌЭМжа5НзBЪїЃЌУПИіНкЕужСЩйга3ИізгЪїЃЌвВОЭЪЧжСЩйга3ИіВц)ЁЃ
ЗЧвЖНкЕужаЕФаХЯЂАќРЈ[n,A0,K1,A1,K2,A2,Ё,Kn,An]ЃЌЃЌЦфжаnБэЪОИУНкЕужаБЃДцЕФЙиМќзжИіЪ§ЃЌKЮЊЙиМќзжЧвKi<Ki+1ЃЌAЮЊжИЯђзгЪїИљНкЕуЕФжИеыЁЃ
ДгИљЕНвЖзгЕФУПвЛЬѕТЗОЖЖМгаЯрЭЌЕФГЄЖШЃЌвВОЭЪЧЫЕЃЌвЖзгНкдкЯрЭЌЕФВуЃЌВЂЧветаЉНкЕуВЛДјаХЯЂЃЌЪЕМЪЩЯетаЉНкЕуОЭБэЪОевВЛЕНжИЖЈЕФжЕЃЌвВОЭЪЧжИЯђетаЉНкЕуЕФжИеыЮЊПеЁЃ
BЪїЕФВщбЏЙ§ГЬКЭЖўВцХХађЪїБШНЯРрЫЦЃЌДгИљНкЕувРДЮБШНЯУПИіНсЕуЃЌвђЮЊУПИіНкЕужаЕФЙиМќзжКЭзѓгвзгЪїЖМЪЧгаађЕФЃЌЫљвджЛвЊБШНЯНкЕужаЕФЙиМќзжЃЌЛђепбизХжИеыОЭФмКмПьЕиевЕНжИЖЈЕФЙиМќзжЃЌШчЙћВщевЪЇАмЃЌдђЛсЗЕЛивЖзгНкЕуЃЌМДПежИеыЁЃ
Р§ШчВщбЏЭМжазжФИБэжаЕФKЃК
ДгИљНкЕуPПЊЪМЃЌKЕФЮЛжУдкPжЎЧАЃЌНјШызѓВржИеыЁЃ
зѓзгЪїжаЃЌвРДЮБШНЯCЁЂFЁЂJЁЂMЃЌЗЂЯжKдкJКЭMжЎМфЁЃ
бизХJКЭMжЎМфЕФжИеыЃЌМЬајЗУЮЪзгЪїЃЌВЂвРДЮНјааБШНЯЃЌЗЂЯжЕквЛИіЙиМќзжKМДЮЊжИЖЈВщевЕФжЕЁЃ
BЪїЫбЫїЕФМђЕЅЮБЫуЗЈШчЯТЃК
BTree_Search(node,
key) {
if(node == null) return null;
foreach(node.key)
{
if(node.key[i] == key) return node.data[i];
if(node.key[i] > key) return BTree_Search(point[i]->node);
}
return BTree_Search(point[i+1]->node);
}
data = BTree_Search(root, my_key); |
BЪїЕФЬиЕуПЩвдзмНсЮЊШчЯТЃК
ЙиМќзжМЏКЯЗжВМдкећПХЪїжаЁЃ
ШЮКЮвЛИіЙиМќзжГіЯжЧвжЛГіЯждквЛИіНкЕужаЁЃ
ЫбЫїгаПЩФмдкЗЧвЖзгНкЕуНсЪјЁЃ
ЦфЫбЫїадФмЕШМлгкдкЙиМќзжМЏКЯФкзівЛДЮЖўЗжВщевЁЃ
BЪїдкВхШыЩОГ§аТЕФЪ§ОнМЧТМЛсЦЦЛЕB-TreeЕФаджЪЃЌвђЮЊдкВхШыЩОГ§ЪБЃЌашвЊЖдЪїНјаавЛИіЗжСбЁЂКЯВЂЁЂзЊвЦЕШВйзївдБЃГжB-TreeаджЪЁЃ
PlusАц ЁЊ B+Ъї
зїЮЊBЪїЕФМгЧПАцЃЌB+ЪїгыBЪїЕФВювьдкгк
гаnПУзгЪїЕФНкЕуКЌгаnИіЙиМќзжЃЈвВгаШЯЮЊЪЧn-1ИіЙиМќзжЃЉЁЃ
ЫљгаЕФЙиМќзжШЋВПДцДЂдквЖзгНкЕуЩЯЃЌЧввЖзгНкЕуБОЩэИљОнЙиМќзжздаЁЖјДѓЫГађСЌНгЁЃ
ЗЧвЖзгНкЕуПЩвдПДГЩЫїв§ВПЗжЃЌНкЕужаНіКЌгаЦфзгЪїЃЈИљНкЕуЃЉжаЕФзюДѓЃЈЛђзюаЁЃЉЙиМќзжЁЃ
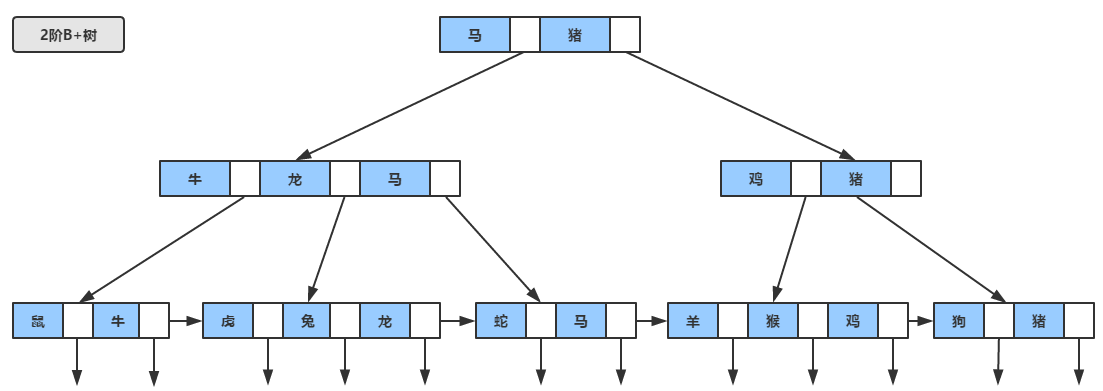
B+ЪїЕФВщевЙ§ГЬЃЌгыBЪїРрЫЦЃЌжЛВЛЙ§ВщевЪБЃЌШчЙћдкЗЧвЖзгНкЕуЩЯЕФЙиМќзжЕШгкИјЖЈжЕЃЌВЂВЛжежЙЃЌЖјЪЧМЬајбизХжИеыжБЕНвЖзгНкЕуЮЛжУЁЃвђДЫдкB+ЪїЃЌВЛЙмВщевГЩЙІгыЗёЃЌУПДЮВщевЖМЪЧзпСЫвЛЬѕДгИљЕНвЖзгНкЕуЕФТЗОЖЁЃ
B+ЪїЕФЬиадШчЯТЃК
ЫљгаЙиМќзжЖМДцДЂдквЖзгНкЩЯЃЌЧвСДБэжаЕФЙиМќзжЧЁКУЪЧгаађЕФЁЃ
ВЛПЩФмЗЧвЖзгНкЕуУќжаЗЕЛиЁЃ
ЗЧвЖзгНкЕуЯрЕБгквЖзгНкЕуЕФЫїв§ЃЌвЖзгНкЕуЯрЕБгкЪЧДцДЂЃЈЙиМќзжЃЉЪ§ОнЕФЪ§ОнВуЁЃ
ИќЪЪКЯЮФМўЫїв§ЯЕЭГЁЃ
ДјгаЫГађЗУЮЪжИеыЕФB+Tree
вЛАудкЪ§ОнПтЯЕЭГЛђЮФМўЯЕЭГжаЪЙгУЕФB+TreeНсЙЙЖМдкОЕфB+TreeЕФЛљДЁЩЯНјааСЫгХЛЏЃЌдіМгСЫЫГађЗУЮЪжИеыЁЃ
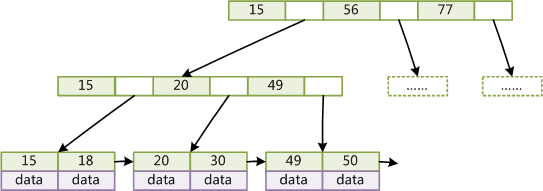
ШчЩЯЭМЫљЪОЃЌдкB+TreeЕФУПИівЖзгНкЕудіМгвЛИіжИЯђЯрСквЖзгНкЕуЕФжИеыЃЌОЭаЮГЩСЫДјгаЫГађЗУЮЪжИеыЕФB+TreeЁЃзіетИігХЛЏЕФФПЕФЪЧЮЊСЫЬсИпЧјМфЗУЮЪЕФадФмЃЌР§ШчЭМ4жаШчЙћвЊВщбЏkeyЮЊДг18ЕН49ЕФЫљгаЪ§ОнМЧТМЃЌЕБевЕН18КѓЃЌжЛашЫГзХНкЕуКЭжИеыЫГађБщРњОЭПЩвдвЛДЮадЗУЮЪЕНЫљгаЪ§ОнНкЕуЃЌМЋДѓЬсЕНСЫЧјМфВщбЏаЇТЪЁЃ
MySQLЮЊЪВУДЪЙгУBЪїЃЈB+ЪїЃЉ
КьКкЪїЕШЪ§ОнНсЙЙвВПЩвдгУРДЪЕЯжЫїв§ЃЌЕЋЪЧЮФМўЯЕЭГвдМАЪ§ОнПтЯЕЭГЦеБщВЩгУBЪїЛђепB+ЪїЃЌетвЛНкНЋНсКЯМЦЫуЛњзщГЩдРэЯрЙижЊЪЖЬжТлB-/+TreeзїЮЊЫїв§ЕФРэТлЛљДЁЁЃ
вЛАуРДЫЕЃЌЫїв§БОЩэвВКмДѓЃЌВЛПЩФмШЋВПДцДЂдкФкДцжаЃЌвђДЫЫїв§ЭљЭљвдЫїв§ЮФМўЕФаЮЪНДцДЂдкДХХЬЩЯЁЃетбљЕФЛАЃЌЫїв§ВщевЙ§ГЬжаОЭвЊВњЩњДХХЬI/OЯћКФЃЌЯрЖдгкФкДцДцШЁЃЌI/OДцШЁЕФЯћКФвЊИпМИИіЪ§СПМЖЃЌЫљвдЦРМлвЛИіЪ§ОнНсЙЙзїЮЊЫїв§ЕФгХСгзюживЊЕФжИБъОЭЪЧдкВщевЙ§ГЬжаДХХЬI/OВйзїДЮЪ§ЕФНЅНјИДдгЖШЁЃЛЛОфЛАЫЕЃЌЫїв§ЕФНсЙЙзщжЏвЊОЁСПМѕЩйВщевЙ§ГЬжаДХХЬI/OЕФДцШЁДЮЪ§ЁЃЯТУцЯШНщЩмФкДцКЭДХХЬДцШЁдРэЃЌШЛКѓдйНсКЯетаЉдРэЗжЮіB-/+TreeзїЮЊЫїв§ЕФаЇТЪЁЃ
жїДцДцШЁдРэ
ФПЧАМЦЫуЛњЪЙгУЕФжїДцЛљБОЖМЪЧЫцЛњЖСаДДцДЂЦїЃЈRAMЃЉЃЌЯжДњRAMЕФНсЙЙКЭДцШЁдРэБШНЯИДдгЃЌетРяБОЮФХзШДОпЬхВюБ№ЃЌГщЯѓГівЛИіЪЎЗжМђЕЅЕФДцШЁФЃаЭРДЫЕУїRAMЕФЙЄзїдРэЁЃ
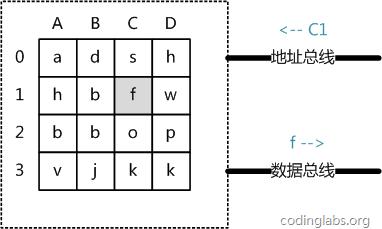
ДгГщЯѓНЧЖШПДЃЌжїДцЪЧвЛЯЕСаЕФДцДЂЕЅдЊзщГЩЕФОиеѓЃЌУПИіДцДЂЕЅдЊДцДЂЙЬЖЈДѓаЁЕФЪ§ОнЁЃУПИіДцДЂЕЅдЊгаЮЈвЛЕФЕижЗЃЌЯжДњжїДцЕФБржЗЙцдђБШНЯИДдгЃЌетРяНЋЦфМђЛЏГЩвЛИіЖўЮЌЕижЗЃКЭЈЙ§вЛИіааЕижЗКЭвЛИіСаЕижЗПЩвдЮЈвЛЖЈЮЛЕНвЛИіДцДЂЕЅдЊЁЃЩЯЭМеЙЪОСЫвЛИі4
x 4ЕФжїДцФЃаЭЁЃ
жїДцЕФДцШЁЙ§ГЬШчЯТЃК
ЕБЯЕЭГашвЊЖСШЁжїДцЪБЃЌдђНЋЕижЗаХКХЗХЕНЕижЗзмЯпЩЯДЋИјжїДцЃЌжїДцЖСЕНЕижЗаХКХКѓЃЌНтЮіаХКХВЂЖЈЮЛЕНжИЖЈДцДЂЕЅдЊЃЌШЛКѓНЋДЫДцДЂЕЅдЊЪ§ОнЗХЕНЪ§ОнзмЯпЩЯЃЌЙЉЦфЫќВПМўЖСШЁЁЃ
аДжїДцЕФЙ§ГЬРрЫЦЃЌЯЕЭГНЋвЊаДШыЕЅдЊЕижЗКЭЪ§ОнЗжБ№ЗХдкЕижЗзмЯпКЭЪ§ОнзмЯпЩЯЃЌжїДцЖСШЁСНИізмЯпЕФФкШнЃЌзіЯргІЕФаДВйзїЁЃ
етРяПЩвдПДГіЃЌжїДцДцШЁЕФЪБМфНігыДцШЁДЮЪ§ГЪЯпадЙиЯЕЃЌвђЮЊВЛДцдкЛњаЕВйзїЃЌСНДЮДцШЁЕФЪ§ОнЕФЁАОрРыЁБВЛЛсЖдЪБМфгаШЮКЮгАЯьЃЌР§ШчЃЌЯШШЁA0дйШЁA1КЭЯШШЁA0дйШЁD3ЕФЪБМфЯћКФЪЧвЛбљЕФЁЃ
ДХХЬДцШЁдРэ
ЩЯЮФЫЕЙ§ЃЌЫїв§вЛАувдЮФМўаЮЪНДцДЂдкДХХЬЩЯЃЌЫїв§МьЫїашвЊДХХЬI/OВйзїЁЃгыжїДцВЛЭЌЃЌДХХЬI/OДцдкЛњаЕдЫЖЏКФЗбЃЌвђДЫДХХЬI/OЕФЪБМфЯћКФЪЧОоДѓЕФЁЃ
ЯТЭМЪЧДХХЬЕФећЬхНсЙЙЪОвтЭМЃК
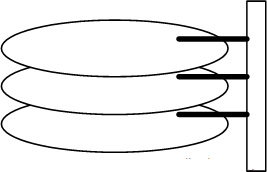
вЛИіДХХЬгЩДѓаЁЯрЭЌЧвЭЌжсЕФдВаЮХЬЦЌзщГЩЃЌДХХЬПЩвдзЊЖЏЃЈИїИіДХХЬБиаыЭЌВНзЊЖЏЃЉЁЃдкДХХЬЕФвЛВргаДХЭЗжЇМмЃЌДХЭЗжЇМмЙЬЖЈСЫвЛзщДХЭЗЃЌУПИіДХЭЗИКд№ДцШЁвЛИіДХХЬЕФФкШнЁЃДХЭЗВЛФмзЊЖЏЃЌЕЋЪЧПЩвдбиДХХЬАыОЖЗНЯђдЫЖЏЃЈЪЕМЪЪЧаБЧаЯђдЫЖЏЃЉЃЌУПИіДХЭЗЭЌвЛЪБПЬвВБиаыЪЧЭЌжсЕФЃЌМДДге§ЩЯЗНЯђЯТПДЃЌЫљгаДХЭЗШЮКЮЪБКђЖМЪЧжиЕўЕФЃЈВЛЙ§ФПЧАвбОгаЖрДХЭЗЖРСЂММЪѕЃЌПЩВЛЪмДЫЯожЦЃЉЁЃ
ЯТЭМЪЧДХХЬНсЙЙЕФЪОвтЭМЃК
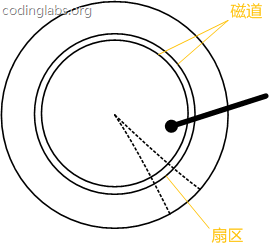
ХЬЦЌБЛЛЎЗжГЩвЛЯЕСаЭЌаФЛЗЃЌдВаФЪЧХЬЦЌжааФЃЌУПИіЭЌаФЛЗНазівЛИіДХЕРЃЌЫљгаАыОЖЯрЭЌЕФДХЕРзщГЩвЛИіжљУцЁЃДХЕРБЛбиАыОЖЯпЛЎЗжГЩвЛИіИіаЁЕФЖЮЃЌУПИіЖЮНазівЛИіЩШЧјЃЌУПИіЩШЧјЪЧДХХЬЕФзюаЁДцДЂЕЅдЊЁЃЮЊСЫМђЕЅЦ№МћЃЌЮвУЧЯТУцМйЩшДХХЬжЛгавЛИіХЬЦЌКЭвЛИіДХЭЗЁЃ
ЕБашвЊДгДХХЬЖСШЁЪ§ОнЪБЃЌЯЕЭГЛсНЋЪ§ОнТпМЕижЗДЋИјДХХЬЃЌДХХЬЕФПижЦЕчТЗАДеебАжЗТпМНЋТпМЕижЗЗвыГЩЮяРэЕижЗЃЌМДШЗЖЈвЊЖСЕФЪ§ОндкФФИіДХЕРЃЌФФИіЩШЧјЁЃЮЊСЫЖСШЁетИіЩШЧјЕФЪ§ОнЃЌашвЊНЋДХЭЗЗХЕНетИіЩШЧјЩЯЗНЃЌЮЊСЫЪЕЯжетвЛЕуЃЌДХЭЗашвЊвЦЖЏЖдзМЯргІДХЕРЃЌетИіЙ§ГЬНазібАЕРЃЌЫљКФЗбЪБМфНазібАЕРЪБМфЃЌШЛКѓДХХЬа§зЊНЋФПБъЩШЧја§зЊЕНДХЭЗЯТЃЌетИіЙ§ГЬКФЗбЕФЪБМфНазіа§зЊЪБМфЁЃ

ОжВПаддРэгыДХХЬдЄЖС
гЩгкДцДЂНщжЪЕФЬиадЃЌДХХЬБОЩэДцШЁОЭБШжїДцТ§КмЖрЃЌдйМгЩЯЛњаЕдЫЖЏКФЗбЃЌДХХЬЕФДцШЁЫйЖШЭљЭљЪЧжїДцЕФМИАйЗжЗжжЎвЛЃЌвђДЫЮЊСЫЬсИпаЇТЪЃЌвЊОЁСПМѕЩйДХХЬI/OЁЃЮЊСЫДяЕНетИіФПЕФЃЌДХХЬЭљЭљВЛЪЧбЯИёАДашЖСШЁЃЌЖјЪЧУПДЮЖМЛсдЄЖСЃЌМДЪЙжЛашвЊвЛИізжНкЃЌДХХЬвВЛсДгетИіЮЛжУПЊЪМЃЌЫГађЯђКѓЖСШЁвЛЖЈГЄЖШЕФЪ§ОнЗХШыФкДцЁЃетбљзіЕФРэТлвРОнЪЧМЦЫуЛњПЦбЇжажјУћЕФОжВПаддРэЃК
ЕБвЛИіЪ§ОнБЛгУЕНЪБЃЌЦфИННќЕФЪ§ОнвВЭЈГЃЛсТэЩЯБЛЪЙгУЁЃ
ЫљвдЃЌГЬађдЫааЦкМфЫљашвЊЕФЪ§ОнЭЈГЃгІЕББШНЯМЏжаЁЃ
гЩгкДХХЬЫГађЖСШЁЕФаЇТЪКмИпЃЈВЛашвЊбАЕРЪБМфЃЌжЛашКмЩйЕФа§зЊЪБМфЃЉЃЌвђДЫЖдгкОпгаОжВПадЕФГЬађРДЫЕЃЌдЄЖСПЩвдЬсИпI/OаЇТЪЁЃ
дЄЖСЕФГЄЖШвЛАуЮЊвГЃЈpageЃЉЕФећБЖЪ§ЁЃвГЪЧМЦЫуЛњЙмРэДцДЂЦїЕФТпМПщЃЌгВМўМАВйзїЯЕЭГЭљЭљНЋжїДцКЭДХХЬДцДЂЧјЗжИюЮЊСЌајЕФДѓаЁЯрЕШЕФПщЃЌУПИіДцДЂПщГЦЮЊвЛвГЃЈдкаэЖрВйзїЯЕЭГжаЃЌвГЕУДѓаЁЭЈГЃЮЊ4kЃЉЃЌжїДцКЭДХХЬвдвГЮЊЕЅЮЛНЛЛЛЪ§ОнЁЃЕБГЬађвЊЖСШЁЕФЪ§ОнВЛдкжїДцжаЪБЃЌЛсДЅЗЂвЛИіШБвГвьГЃЃЌДЫЪБЯЕЭГЛсЯђДХХЬЗЂГіЖСХЬаХКХЃЌДХХЬЛсевЕНЪ§ОнЕФЦ№ЪМЮЛжУВЂЯђКѓСЌајЖСШЁвЛвГЛђМИвГдиШыФкДцжаЃЌШЛКѓвьГЃЗЕЛиЃЌГЬађМЬајдЫааЁЃ
B-/+TreeЫїв§ЕФадФмЗжЮі
ЕНетРяжегкПЩвдЗжЮіB-/+TreeЫїв§ЕФадФмСЫЁЃ
ЩЯЮФЫЕЙ§вЛАуЪЙгУДХХЬI/OДЮЪ§ЦРМлЫїв§НсЙЙЕФгХСгЁЃЯШДгB-TreeЗжЮіЃЌИљОнB-TreeЕФЖЈвхЃЌПЩжЊМьЫївЛДЮзюЖрашвЊЗУЮЪhИіНкЕуЁЃЪ§ОнПтЯЕЭГЕФЩшМЦепЧЩУюРћгУСЫДХХЬдЄЖСдРэЃЌНЋвЛИіНкЕуЕФДѓаЁЩшЮЊЕШгквЛИівГЃЌетбљУПИіНкЕужЛашвЊвЛДЮI/OОЭПЩвдЭъШЋдиШыЁЃЮЊСЫДяЕНетИіФПЕФЃЌдкЪЕМЪЪЕЯжB-TreeЛЙашвЊЪЙгУШчЯТММЧЩЃК
УПДЮаТНЈНкЕуЪБЃЌжБНгЩъЧывЛИівГЕФПеМфЃЌетбљОЭБЃжЄвЛИіНкЕуЮяРэЩЯвВДцДЂдквЛИівГРяЃЌМгжЎМЦЫуЛњДцДЂЗжХфЖМЪЧАДвГЖдЦыЕФЃЌОЭЪЕЯжСЫвЛИіnodeжЛашвЛДЮI/OЁЃ
B-TreeжавЛДЮМьЫїзюЖрашвЊh-1ДЮI/OЃЈИљНкЕуГЃзЄФкДцЃЉЃЌНЅНјИДдгЖШЮЊO(h)=O(logdN)O(h)=O(logdN)ЁЃвЛАуЪЕМЪгІгУжаЃЌГіЖШdЪЧЗЧГЃДѓЕФЪ§зжЃЌЭЈГЃГЌЙ§100ЃЌвђДЫhЗЧГЃаЁЃЈЭЈГЃВЛГЌЙ§3ЃЉЁЃЃЈhБэЪОЪїЕФИпЖШ
& ГіЖШdБэЪОЕФЪЧЪїЕФЖШЃЌМДЪїжаИїИіНкЕуЕФЖШЕФзюДѓжЕЃЉ
злЩЯЫљЪіЃЌгУB-TreeзїЮЊЫїв§НсЙЙаЇТЪЪЧЗЧГЃИпЕФЁЃ
ЖјКьКкЪїетжжНсЙЙЃЌhУїЯдвЊЩюЕФЖрЁЃгЩгкТпМЩЯКмНќЕФНкЕуЃЈИИзгЃЉЮяРэЩЯПЩФмКмдЖЃЌЮоЗЈРћгУОжВПадЃЌЫљвдКьКкЪїЕФI/OНЅНјИДдгЖШвВЮЊO(h)ЃЌаЇТЪУїЯдБШB-TreeВюКмЖрЁЃ
ЩЯЮФЛЙЫЕЙ§ЃЌB+TreeИќЪЪКЯЭтДцЫїв§ЃЌдвђКЭФкНкЕуГіЖШdгаЙиЁЃДгЩЯУцЗжЮіПЩвдПДЕНЃЌdдНДѓЫїв§ЕФадФмдНКУЃЌЖјГіЖШЕФЩЯЯоШЁОігкНкЕуФкkeyКЭdataЕФДѓаЁЃК
dmax=floor(pagesize/(keysize+datasize+pointsize))
floorБэЪОЯђЯТШЁећЁЃгЩгкB+TreeФкНкЕуШЅЕєСЫdataгђЃЌвђДЫПЩвдгЕгаИќДѓЕФГіЖШЃЌгЕгаИќКУЕФадФмЁЃ
MySQLЫїв§ЪЕЯж
дкMySQLжаЃЌЫїв§ЪєгкДцДЂв§ЧцМЖБ№ЕФИХФюЃЌВЛЭЌДцДЂв§ЧцЖдЫїв§ЕФЪЕЯжЗНЪНЪЧВЛЭЌЕФЃЌБОЮФжївЊЬжТлMyISAMКЭInnoDBСНИіДцДЂв§ЧцЕФЫїв§ЪЕЯжЗНЪНЁЃ
MyISAMЫїв§ЪЕЯж
MyISAMв§ЧцЪЙгУB+TreeзїЮЊЫїв§НсЙЙЃЌвЖНкЕуЕФdataгђДцЗХЕФЪЧЪ§ОнМЧТМЕФЕижЗЁЃЯТЭМЪЧMyISAMЫїв§ЕФдРэЭМЃК
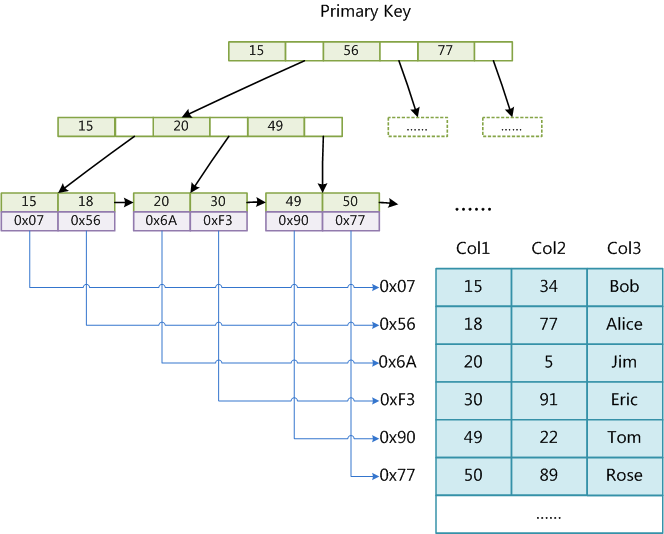
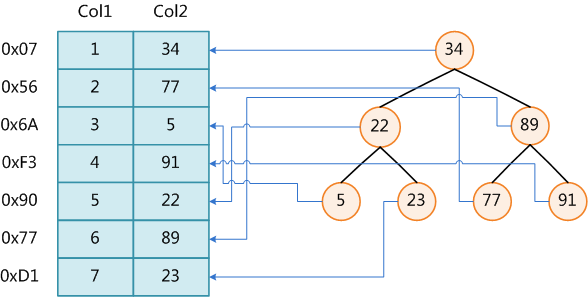
етРяЩшБэвЛЙВгаШ§СаЃЌМйЩшЮвУЧвдCol1ЮЊжїМќЃЌдђЩЯЭМЪЧвЛИіMyISAMБэЕФжїЫїв§ЃЈPrimary
keyЃЉЪОвтЁЃПЩвдПДГіMyISAMЕФЫїв§ЮФМўНіНіБЃДцЪ§ОнМЧТМЕФЕижЗЁЃдкMyISAMжаЃЌжїЫїв§КЭИЈжњЫїв§ЃЈSecondary
keyЃЉдкНсЙЙЩЯУЛгаШЮКЮЧјБ№ЃЌжЛЪЧжїЫїв§вЊЧѓkeyЪЧЮЈвЛЕФЃЌЖјИЈжњЫїв§ЕФkeyПЩвджиИДЁЃШчЙћЮвУЧдкCol2ЩЯНЈСЂвЛИіИЈжњЫїв§ЃЌдђДЫЫїв§ЕФНсЙЙШчЯТЭМЫљЪОЃК
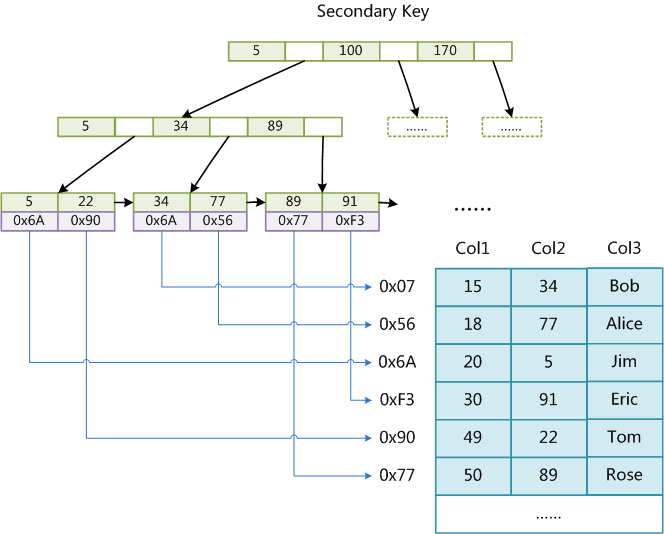
ЭЌбљвВЪЧвЛПУB+ЪїЃЌdataгђБЃДцЪ§ОнМЧТМЕФЕижЗЁЃвђДЫЃЌMyISAMжаЫїв§МьЫїЕФЫуЗЈЮЊЪзЯШАДееB+TreeЫбЫїЫуЗЈЫбЫїЫїв§ЃЌШчЙћжИЖЈЕФKeyДцдкЃЌдђШЁГіЦфdataгђЕФжЕЃЌШЛКѓвдdataгђЕФ жЕЮЊЕижЗЃЌЖСШЁЯргІЪ§ОнМЧТМЁЃ
MyISAMЕФЫїв§ЗНЪНвВНазіЁАЗЧОлМЏЁБЕФЃЌжЎЫљвдетУДГЦКєЪЧЮЊСЫгыInnoDBЕФОлМЏЫїв§ЧјЗжЁЃ
InnoDBЫїв§ЪЕЯж
ЫфШЛInnoDBвВЪЙгУB+TreeзїЮЊЫїв§НсЙЙЃЌЕЋОпЬхЪЕЯжЗНЪНШДгыMyISAMНиШЛВЛЭЌЁЃ
ЕквЛИіжиДѓЧјБ№ЪЧInnoDBЕФЪ§ОнЮФМўБОЩэОЭЪЧЫїв§ЮФМўЁЃДгЩЯЮФжЊЕРЃЌMyISAMЫїв§ЮФМўКЭЪ§ОнЮФМўЪЧЗжРыЕФЃЌЫїв§ЮФМўНіБЃДцЪ§ОнМЧТМЕФЕижЗЁЃЖјдкInnoDBжаЃЌБэЪ§ОнЮФМўБОЩэОЭЪЧАДB+TreeзщжЏЕФвЛИіЫїв§НсЙЙЃЌетПУЪїЕФвЖНкЕуdataгђБЃДцСЫЭъећЕФЪ§ОнМЧТМЁЃетИіЫїв§ЕФkeyЪЧЪ§ОнБэЕФжїМќЃЌвђДЫInnoDBБэЪ§ОнЮФМўБОЩэОЭЪЧжїЫїв§ЁЃ
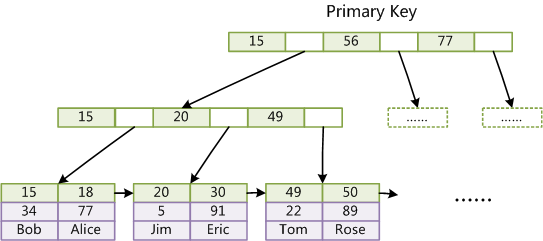
ЩЯЭМЪЧInnoDBжїЫїв§ЃЈЭЌЪБвВЪЧЪ§ОнЮФМўЃЉЕФЪОвтЭМЃЌПЩвдПДЕНвЖНкЕуАќКЌСЫЭъећЕФЪ§ОнМЧТМЁЃетжжЫїв§НазіОлМЏЫїв§ЁЃвђЮЊInnoDBЕФЪ§ОнЮФМўБОЩэвЊАДжїМќОлМЏЃЌЫљвдInnoDBвЊЧѓБэБиаыгажїМќЃЈMyISAMПЩвдУЛгаЃЉЃЌШчЙћУЛгаЯдЪНжИЖЈЃЌдђMySQLЯЕЭГЛсздЖЏбЁдёвЛИіПЩвдЮЈвЛБъЪЖЪ§ОнМЧТМЕФСазїЮЊжїМќЃЌШчЙћВЛДцдкетжжСаЃЌдђMySQLздЖЏЮЊInnoDBБэЩњГЩвЛИівўКЌзжЖЮзїЮЊжїМќЃЌетИізжЖЮГЄЖШЮЊ6ИізжНкЃЌРраЭЮЊГЄећаЭЁЃ
ЕкЖўИігыMyISAMЫїв§ЕФВЛЭЌЪЧInnoDBЕФИЈжњЫїв§dataгђДцДЂЯргІМЧТМжїМќЕФжЕЖјВЛЪЧЕижЗЁЃЛЛОфЛАЫЕЃЌInnoDBЕФЫљгаИЈжњЫїв§ЖМв§гУжїМќзїЮЊdataгђЁЃР§ШчЃЌЩЯЭМЮЊЖЈвхдкCol3ЩЯЕФвЛИіИЈжњЫїв§ЃК
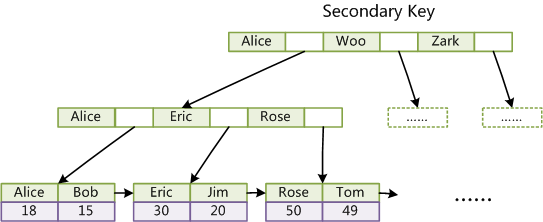
етРявдгЂЮФзжЗћЕФASCIIТызїЮЊБШНЯзМдђЁЃОлМЏЫїв§етжжЪЕЯжЗНЪНЪЙЕУАДжїМќЕФЫбЫїЪЎЗжИпаЇЃЌЕЋЪЧИЈжњЫїв§ЫбЫїашвЊМьЫїСНБщЫїв§ЃКЪзЯШМьЫїИЈжњЫїв§ЛёЕУжїМќЃЌШЛКѓгУжїМќЕНжїЫїв§жаМьЫїЛёЕУМЧТМЁЃ
СЫНтВЛЭЌДцДЂв§ЧцЕФЫїв§ЪЕЯжЗНЪНЖдгке§ШЗЪЙгУКЭгХЛЏЫїв§ЖМЗЧГЃгаАяжњЃЌР§ШчжЊЕРСЫInnoDBЕФЫїв§ЪЕЯжКѓЃЌОЭКмШнвзУїАзЮЊЪВУДВЛНЈвщЪЙгУЙ§ГЄЕФзжЖЮзїЮЊжїМќЃЌвђЮЊЫљгаИЈжњЫїв§ЖМв§гУжїЫїв§ЃЌЙ§ГЄЕФжїЫїв§ЛсСюИЈжњЫїв§БфЕУЙ§ДѓЁЃдйР§ШчЃЌгУЗЧЕЅЕїЕФзжЖЮзїЮЊжїМќдкInnoDBжаВЛЪЧИіКУжївтЃЌвђЮЊInnoDBЪ§ОнЮФМўБОЩэЪЧвЛПУB+TreeЃЌЗЧЕЅЕїЕФжїМќЛсдьГЩдкВхШыаТМЧТМЪБЪ§ОнЮФМўЮЊСЫЮЌГжB+TreeЕФЬиадЖјЦЕЗБЕФЗжСбЕїећЃЌЪЎЗжЕЭаЇЃЌЖјЪЙгУзддізжЖЮзїЮЊжїМќдђЪЧвЛИіКмКУЕФбЁдёЁЃ
| 








