| БрМЭЦМі: |
| БОЮФРДздгкcsdn,ЖдгкmysqlКмЖрШЫЖрВЛФАЩњЃЌФЧУДmysqlдРэЪЧЪВУДбљЕФФиЃЌдѕУДгХЛЏЃПдѕУДЪЙгУЃППЩФмгааЉШЫжЊЪЖВЛГЩЬхЯЕЃЌФЧУДЯТЮФЮЊДѓМвНВНтЁЃ |
|
ЫЕЕНЫїв§ЃЌКмЖрШЫЖМжЊЕРЁАЫїв§ЪЧвЛИіХХађЕФСаБэЃЌдкетИіСаБэжаДцДЂзХЫїв§ЕФжЕКЭАќКЌетИіжЕЕФЪ§ОнЫљдкааЕФЮяРэЕижЗЃЌдкЪ§ОнЪЎЗжХгДѓЕФЪБКђЃЌЫїв§ПЩвдДѓДѓМгПьВщбЏЕФЫйЖШЃЌетЪЧвђЮЊЪЙгУЫїв§КѓПЩвдВЛгУЩЈУшШЋБэРДЖЈЮЛФГааЕФЪ§ОнЃЌЖјЪЧЯШЭЈЙ§Ыїв§БэевЕНИУааЪ§ОнЖдгІЕФЮяРэЕижЗШЛКѓЗУЮЪЯргІЕФЪ§ОнЁЃЁБ
ЕЋЪЧЫїв§ЪЧдѕУДЪЕЯжЕФФиЃПвђЮЊЫїв§ВЂВЛЪЧЙиЯЕФЃаЭЕФзщГЩВПЗжЃЌвђДЫВЛЭЌЕФDBMSгаВЛЭЌЕФЪЕЯжЃЌЮвУЧеыЖдMySQLЪ§ОнПтЕФЪЕЯжНјааЫЕУїЁЃБОЮФФкШнЩцМАMySQLжаЫїв§ЕФгяЗЈЁЂЫїв§ЕФгХШБЕуЁЂЫїв§ЕФЗжРрЁЂЫїв§ЕФЪЕЯждРэЁЂЫїв§ЕФЪЙгУВпТдЁЂЫїв§ЕФгХЛЏМИВПЗжЁЃ
вЛЁЂMySQLжаЫїв§ЕФгяЗЈ
ДДНЈЫїв§
дкДДНЈБэЕФЪБКђЬэМгЫїв§
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
); |
дкДДНЈБэвдКѓЬэМгЫїв§
ALTER TABLE my_table
ADD [UNIQUE] INDEX index_name(column_name);
Лђеп
CREATE INDEX index_name ON my_table(column_name); |
зЂвтЃК
1ЁЂЫїв§ашвЊеМгУДХХЬПеМфЃЌвђДЫдкДДНЈЫїв§ЪБвЊПМТЧЕНДХХЬПеМфЪЧЗёзуЙЛ
2ЁЂДДНЈЫїв§ЪБашвЊЖдБэМгЫјЃЌвђДЫЪЕМЪВйзїжаашвЊдквЕЮёПеЯаЦкМфНјаа
ИљОнЫїв§ВщбЏ
ОпЬхВщбЏЃК
SELECT * FROM table_name WHERE column_1=column_2;(ЮЊcolumn_1НЈСЂСЫЫїв§)
ЛђепФЃК§ВщбЏ
SELECT * FROM table_name WHERE column_1 LIKE '%Ш§'
SELECT * FROM table_name WHERE column_1 LIKE 'Ш§%'
SELECT * FROM table_name WHERE column_1 LIKE '%Ш§%'
SELECT * FROM table_name WHERE column_1 LIKE '_КУ_'
ШчЙћвЊБэЪОдкзжЗћДЎжаМШгаAгжгаBЃЌФЧУДВщбЏгяОфЮЊЃК
SELECT * FROM table_name WHERE column_1 LIKE '%A%'
AND column_1 LIKE '%B%';
SELECT * FROM table_name WHERE column_1 LIKE '[еХРюЭѕ]Ш§';
//БэЪОcolumn_1жагаЦЅХфеХШ§ЁЂРюШ§ЁЂЭѕШ§ЕФЖМПЩвд
SELECT * FROM table_name WHERE column_1 LIKE '[^еХРюЭѕ]Ш§';
//БэЪОcolumn_1жагаЦЅХфГ§СЫеХШ§ЁЂРюШ§ЁЂЭѕШ§ЕФЦфЫћШ§ЖМПЩвд
//дкФЃК§ВщбЏжаЃЌ%БэЪОШЮвт0ИіЛђЖрИізжЗћЃЛ_БэЪОШЮвтЕЅИізжЗћЃЈгаЧвНігаЃЉЃЌЭЈГЃгУРДЯожЦзжЗћДЎГЄЖШ;[]БэЪОЦфжаЕФФГвЛИізжЗћЃЛ[^]БэЪОГ§СЫЦфжаЕФзжЗћЕФЫљгазжЗћ
ЛђепдкШЋЮФЫїв§жаФЃК§ВщбЏ
SELECT * FROM table_name WHERE MATCH(content)
AGAINST('word1','word2',...);
- |
ЩОГ§Ыїв§
DROP INDEX my_index
ON tablenameЃЛ
Лђеп
ALTER TABLE table_name DROP INDEX index_name; |
ВщПДБэжаЕФЫїв§
| SHOW INDEX FROM
tablename |
ВщПДВщбЏгяОфЪЙгУЫїв§ЕФЧщПі
//explain МгВщбЏгяОф
explain SELECT * FROM table_name WHERE column_1='123'; |
ЖўЁЂЫїв§ЕФгХШБЕу
гХЪЦЃКПЩвдПьЫйМьЫїЃЌМѕЩйI/OДЮЪ§ЃЌМгПьМьЫїЫйЖШЃЛИљОнЫїв§ЗжзщКЭХХађЃЌПЩвдМгПьЗжзщКЭХХађЃЛ
СгЪЦЃКЫїв§БОЩэвВЪЧБэЃЌвђДЫЛсеМгУДцДЂПеМфЃЌвЛАуРДЫЕЃЌЫїв§БэеМгУЕФПеМфЕФЪ§ОнБэЕФ1.5БЖЃЛЫїв§БэЕФЮЌЛЄКЭДДНЈашвЊЪБМфГЩБОЃЌетИіГЩБОЫцзХЪ§ОнСПдіДѓЖјдіДѓЃЛЙЙНЈЫїв§ЛсНЕЕЭЪ§ОнБэЕФаоИФВйзїЃЈЩОГ§ЃЌЬэМгЃЌаоИФЃЉЕФаЇТЪЃЌвђЮЊдкаоИФЪ§ОнБэЕФЭЌЪБЛЙашвЊаоИФЫїв§БэЃЛ
Ш§ЁЂЫїв§ЕФЗжРр
ГЃМћЕФЫїв§РраЭгаЃКжїМќЫїв§ЁЂЮЈвЛЫїв§ЁЂЦеЭЈЫїв§ЁЂШЋЮФЫїв§ЁЂзщКЯЫїв§
1ЁЂжїМќЫїв§ЃКМДжїЫїв§ЃЌИљОнжїМќpk_clolumЃЈlengthЃЉНЈСЂЫїв§ЃЌВЛдЪаэжиИДЃЌВЛдЪаэПежЕЃЛ
| ALTER TABLE 'table_name'
ADD PRIMARY KEY pk_index('col')ЃЛ |
2ЁЂЮЈвЛЫїв§ЃКгУРДНЈСЂЫїв§ЕФСаЕФжЕБиаыЪЧЮЈвЛЕФЃЌдЪаэПежЕ
| ALTER TABLE
'table_name' ADD UNIQUE index_name('col')ЃЛ |
3ЁЂЦеЭЈЫїв§ЃКгУБэжаЕФЦеЭЈСаЙЙНЈЕФЫїв§ЃЌУЛгаШЮКЮЯожЦ
| ALTER TABLE
'table_name' ADD INDEX index_name('col')ЃЛ |
4ЁЂШЋЮФЫїв§ЃКгУДѓЮФБОЖдЯѓЕФСаЙЙНЈЕФЫїв§ЃЈЯТвЛВПЗжЛсНВНтЃЉ
| ALTER TABLE
'table_name' ADD FULLTEXT INDEX ft_index('col')ЃЛ |
5ЁЂзщКЯЫїв§ЃКгУЖрИіСазщКЯЙЙНЈЕФЫїв§ЃЌетЖрИіСажаЕФжЕВЛдЪаэгаПежЕ
| ALTER TABLE
'table_name' ADD INDEX index_name ('col1', 'col2', 'col3')ЃЛ |
*зёбЁАзюзѓЧАзКЁБддђЃЌАбзюГЃгУзїЮЊМьЫїЛђХХађЕФСаЗХдкзюзѓЃЌвРДЮЕнМѕЃЌзщКЯЫїв§ЯрЕБгкНЈСЂСЫcol1,col1col2,
col1col2col3Ш§ИіЫїв§ЃЌЖјcol2Лђепcol3ЪЧВЛФмЪЙгУЫїв§ЕФЁЃ
*дкЪЙгУзщКЯЫїв§ЕФЪБКђПЩФмвђЮЊСаУћГЄЖШЙ§ГЄЖјЕМжТЫїв§ЕФkeyЬЋДѓЃЌЕМжТаЇТЪНЕЕЭЃЌдкдЪаэЕФЧщПіЯТЃЌПЩвджЛШЁcol1КЭcol2ЕФЧАМИИізжЗћзїЮЊЫїв§
| ALTER TABLE
'table_name' ADD INDEX index_name(col1(4),col2ЃЈ3))ЃЛ |
БэЪОЪЙгУcol1ЕФЧА4ИізжЗћКЭcol2ЕФЧА3ИізжЗћзїЮЊЫїв§
ЫФЁЂЫїв§ЕФЪЕЯждРэ
MySQLжЇГжжюЖрДцДЂв§ЧцЃЌЖјИїжжДцДЂв§ЧцЖдЫїв§ЕФжЇГжвВИїВЛЯрЭЌЃЌвђДЫMySQLЪ§ОнПтжЇГжЖржжЫїв§РраЭЃЌШчBTreeЫїв§ЃЌB+TreeЫїв§ЃЌЙўЯЃЫїв§ЃЌШЋЮФЫїв§ЕШЕШЃЌ
1ЁЂЙўЯЃЫїв§ЃК
жЛгаmemoryЃЈФкДцЃЉДцДЂв§ЧцжЇГжЙўЯЃЫїв§ЃЌЙўЯЃЫїв§гУЫїв§СаЕФжЕМЦЫуИУжЕЕФhashCodeЃЌШЛКѓдкhashCodeЯргІЕФЮЛжУДцжДИУжЕЫљдкааЪ§ОнЕФЮяРэЮЛжУЃЌвђЮЊЪЙгУЩЂСаЫуЗЈЃЌвђДЫЗУЮЪЫйЖШЗЧГЃПьЃЌЕЋЪЧвЛИіжЕжЛФмЖдгІвЛИіhashCodeЃЌЖјЧвЪЧЩЂСаЕФЗжВМЗНЪНЃЌвђДЫЙўЯЃЫїв§ВЛжЇГжЗЖЮЇВщевКЭХХађЕФЙІФмЁЃ
2ЁЂШЋЮФЫїв§ЃК
FULLTEXTЃЈШЋЮФЃЉЫїв§ЃЌНіПЩгУгкMyISAMКЭInnoDBЃЌеыЖдНЯДѓЕФЪ§ОнЃЌЩњГЩШЋЮФЫїв§ЗЧГЃЕФЯћКФЪБМфКЭПеМфЁЃЖдгкЮФБОЕФДѓЖдЯѓЃЌЛђепНЯДѓЕФCHARРраЭЕФЪ§ОнЃЌШчЙћЪЙгУЦеЭЈЫїв§ЃЌФЧУДЦЅХфЮФБОЧАМИИізжЗћЛЙЪЧПЩааЕФЃЌЕЋЪЧЯывЊЦЅХфЮФБОжаМфЕФМИИіЕЅДЪЃЌФЧУДОЭвЊЪЙгУLIKE
%word%РДЦЅХфЃЌетбљашвЊКмГЄЕФЪБМфРДДІРэЃЌЯьгІЪБМфЛсДѓДѓдіМгЃЌетжжЧщПіЃЌОЭПЩЪЙгУЪБFULLTEXTЫїв§СЫЃЌдкЩњГЩFULLTEXTЫїв§ЪБЃЌЛсЮЊЮФБОЩњГЩвЛЗнЕЅДЪЕФЧхЕЅЃЌдкЫїв§ЪБМАИљОнетИіЕЅДЪЕФЧхЕЅРДЫїв§ЁЃFULLTEXTПЩвддкДДНЈБэЕФЪБКђДДНЈЃЌвВПЩвддкашвЊЕФЪБКђгУALTERЛђепCREATE
INDEXРДЬэМгЃК
//ДДНЈБэЕФЪБКђЬэМгFULLTEXTЫїв§
CTREATE TABLE my_table(
id INT(10) PRIMARY KEY,
name VARCHAR(10) NOT NULL,
my_text TEXT,
FULLTEXT(my_text)
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
|
//ДДНЈБэвдКѓЃЌдкашвЊЕФЪБКђЬэМгFULLTEXTЫїв§
ALTER TABLE my_table ADD FULLTEXT INDEX ft_index(column_name);
|
ШЋЮФЫїв§ЕФВщбЏвВгаздМКЬиЪтЕФгяЗЈЃЌЖјВЛФмЪЙгУLIKE %ВщбЏзжЗћДЎ%ЕФФЃК§ВщбЏгяЗЈ
| SELECT * FROM
table_name MATCH(ft_index) AGAINST('ВщбЏзжЗћДЎ'); |
зЂвтЃК
*ЖдгкНЯДѓЕФЪ§ОнМЏЃЌАбЪ§ОнЬэМгЕНвЛИіУЛгаFULLTEXTЫїв§ЕФБэЃЌШЛКѓЬэМгFULLTEXTЫїв§ЕФЫйЖШБШАбЪ§ОнЬэМгЕНвЛИівбОгаFULLTEXTЫїв§ЕФБэПьЁЃ
*5.6АцБОЧАЕФMySQLздДјЕФШЋЮФЫїв§жЛФмгУгкMyISAMДцДЂв§ЧцЃЌШчЙћЪЧЦфЫќЪ§Онв§ЧцЃЌФЧУДШЋЮФЫїв§ВЛЛсЩњаЇЁЃ5.6АцБОжЎКѓInnoDBДцДЂв§ЧцПЊЪМжЇГжШЋЮФЫїв§
*дкMySQLжаЃЌШЋЮФЫїв§жЇЖггЂЮФгагУЃЌФПЧАЖджаЮФЛЙВЛжЇГжЁЃ5.7АцБОжЎКѓЭЈЙ§ЪЙгУngramВхМўПЊЪМжЇГжжаЮФЁЃ
*дкMySQLжаЃЌШчЙћМьЫїЕФзжЗћДЎЬЋЖЬдђЮоЗЈМьЫїЕУЕНдЄЦкЕФНсЙћЃЌМьЫїЕФзжЗћДЎГЄЖШжСЩйЮЊ4зжНкЃЌДЫЭтЃЌШчЙћМьЫїЕФзжЗћАќРЈЭЃжЙДЪЃЌФЧУДЭЃжЙДЪЛсБЛКіТдЁЃ
* ИќЩюШыЕФРэНтВЮПМЮФеТЃКШЋЮФЫїв§ЕФЩюШыРэНт
3ЁЂBTreeЫїв§КЭB+TreeЫїв§
BTreeЫїв§
BTreeЪЧЦНКтЫбЫїЖрВцЪїЃЌЩшЪїЕФЖШЮЊ2dЃЈd>1ЃЉЃЌИпЖШЮЊhЃЌФЧУДBTreeвЊТњзувдвЛЯТЬѕМўЃК
УПИівЖзгНсЕуЕФИпЖШвЛбљЃЌЕШгкhЃЛ
УПИіЗЧвЖзгНсЕугЩn-1ИіkeyКЭnИіжИеыpointзщГЩЃЌЦфжаd<=n<=2d,
keyКЭpointЯрЛЅМфИєЃЌНсЕуСНЖЫвЛЖЈЪЧkeyЃЛ
вЖзгНсЕужИеыЖМЮЊnullЃЛ
ЗЧвЖзгНсЕуЕФkeyЖМЪЧ[key,data]ЖўдЊзщЃЌЦфжаkeyБэЪОзїЮЊЫїв§ЕФМќЃЌdataЮЊМќжЕЫљдкааЕФЪ§ОнЃЛ
BTreeЕФНсЙЙШчЯТЃК
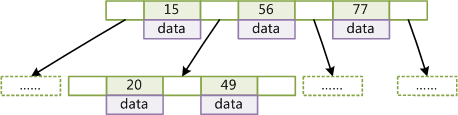
дкBTreeЕФЛњЙЙЯТЃЌОЭПЩвдЪЙгУЖўЗжВщевЕФВщевЗНЪНЃЌВщевИДдгЖШЮЊh*log(n)ЃЌвЛАуРДЫЕЪїЕФИпЖШЪЧКмаЁЕФЃЌвЛАуЮЊ3зѓгвЃЌвђДЫBTreeЪЧвЛИіЗЧГЃИпаЇЕФВщевНсЙЙЁЃ
B+TreeЫїв§
B+TreeЪЧBTreeЕФвЛИіБфжжЃЌЩшdЮЊЪїЕФЖШЪ§ЃЌhЮЊЪїЕФИпЖШЃЌB+TreeКЭBTreeЕФВЛЭЌжївЊдкгкЃК
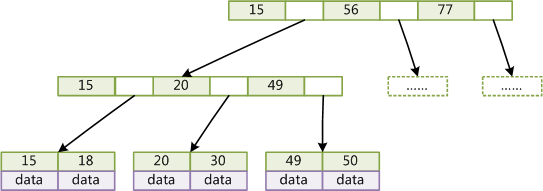
B+TreeжаЕФЗЧвЖзгНсЕуВЛДцДЂЪ§ОнЃЌжЛДцДЂМќжЕЃЛ
B+TreeЕФвЖзгНсЕуУЛгажИеыЃЌЫљгаМќжЕЖМЛсГіЯждквЖзгНсЕуЩЯЃЌЧвkeyДцДЂЕФМќжЕЖдгІdataЪ§ОнЕФЮяРэЕижЗЃЛ
B+TreeЕФУПИіЗЧвЖзгНкЕугЩnИіМќжЕkeyКЭnИіжИеыpointзщГЩЃЛ
B+TreeЕФНсЙЙШчЯТЃК
B+TreeЖдБШBTreeЕФгХЕуЃК
1ЁЂДХХЬЖСаДДњМлИќЕЭ
вЛАуРДЫЕB+TreeБШBTreeИќЪЪКЯЪЕЯжЭтДцЕФЫїв§НсЙЙЃЌвђЮЊДцДЂв§ЧцЕФЩшМЦзЈМвЧЩУюЕФРћгУСЫЭтДцЃЈДХХЬЃЉЕФДцДЂНсЙЙЃЌМДДХХЬЕФзюаЁДцДЂЕЅЮЛЪЧЩШЧјЃЈsectorЃЉЃЌЖјВйзїЯЕЭГЕФПщЃЈblockЃЉЭЈГЃЪЧећЪ§БЖЕФsectorЃЌВйзїЯЕЭГвдвГЃЈpageЃЉЮЊЕЅЮЛЙмРэФкДцЃЌвЛвГЃЈpageЃЉЭЈГЃФЌШЯЮЊ4KЃЌЪ§ОнПтЕФвГЭЈГЃЩшжУЮЊВйзїЯЕЭГвГЕФећЪ§БЖЃЌвђДЫЫїв§НсЙЙЕФНкЕуБЛЩшМЦЮЊвЛИівГЕФДѓаЁЃЌШЛКѓРћгУЭтДцЕФЁАдЄЖСШЁЁБддђЃЌУПДЮЖСШЁЕФЪБКђЃЌАбећИіНкЕуЕФЪ§ОнЖСШЁЕНФкДцжаЃЌШЛКѓдкФкДцжаВщевЃЌвбжЊФкДцЕФЖСШЁЫйЖШЪЧЭтДцЖСШЁI/OЫйЖШЕФМИАйБЖЃЌФЧУДЬсЩ§ВщевЫйЖШЕФЙиМќОЭдкгкОЁПЩФмЩйЕФДХХЬI/OЃЌФЧУДПЩвджЊЕРЃЌУПИіНкЕужаЕФkeyИіЪ§дНЖрЃЌФЧУДЪїЕФИпЖШдНаЁЃЌашвЊI/OЕФДЮЪ§дНЩйЃЌвђДЫвЛАуРДЫЕB+TreeБШBTreeИќПьЃЌвђЮЊB+TreeЕФЗЧвЖНкЕужаВЛДцДЂdataЃЌОЭПЩвдДцДЂИќЖрЕФkeyЁЃ
2ЁЂВщбЏЫйЖШИќЮШЖЈ
гЩгкB+TreeЗЧвЖзгНкЕуВЛДцДЂЪ§ОнЃЈdataЃЉЃЌвђДЫЫљгаЕФЪ§ОнЖМвЊВщбЏжСвЖзгНкЕуЃЌЖјвЖзгНкЕуЕФИпЖШЖМЪЧЯрЭЌЕФЃЌвђДЫЫљгаЪ§ОнЕФВщбЏЫйЖШЖМЪЧвЛбљЕФЁЃ
ИќЖрВйзїЯЕЭГФкШнВЮПМЃК
гВХЬНсЙЙ
ЩШЧјЁЂПщЁЂДиЁЂвГЕФЧјБ№
ВйзїЯЕЭГВугХЛЏЃЈНјНзЃЌГѕбЇВЛгУПДЃЉ
ДјЫГађЫїв§ЕФB+TREE
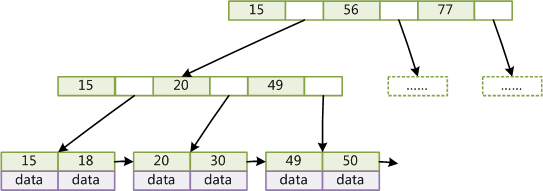
КмЖрДцДЂв§ЧцдкB+TreeЕФЛљДЁЩЯНјааСЫгХЛЏЃЌЬэМгСЫжИЯђЯрСквЖНкЕуЕФжИеыЃЌаЮГЩСЫДјгаЫГађЗУЮЪжИеыЕФB+TreeЃЌетбљзіЪЧЮЊСЫЬсИпЧјМфВщевЕФаЇТЪЃЌжЛвЊевЕНЕквЛИіжЕФЧУДОЭПЩвдЫГађЕФВщевКѓУцЕФжЕЁЃ
B+TreeЕФНсЙЙШчЯТЃК
ОлДиЫїв§КЭЗЧОлДиЫїв§
ЗжЮіСЫMySQLЕФЫїв§НсЙЙЕФЪЕЯждРэЃЌШЛКѓЮвУЧРДПДПДОпЬхЕФДцДЂв§ЧцдѕУДЪЕЯжЫїв§НсЙЙЕФЃЌMySQLжазюГЃМћЕФСНжжДцДЂв§ЧцЗжБ№ЪЧMyISAMКЭInnoDBЃЌЗжБ№ЪЕЯжСЫЗЧОлДиЫїв§КЭОлДиЫїв§ЁЃ
ОлДиЫїв§ЕФНтЪЭЪЧ:ОлДиЫїв§ЕФЫГађОЭЪЧЪ§ОнЕФЮяРэДцДЂЫГађ
ЗЧОлДиЫїв§ЕФНтЪЭЪЧ:Ыїв§ЫГађгыЪ§ОнЮяРэХХСаЫГађЮоЙи
ЃЈетбљЫЕЦ№РДВЂВЛКУРэНтЃЌШУШЫУўВЛзХЭЗФдЃЌЧхМЬајПДЯТЮФЃЌВЂдкВхЭМЯТЗНЖдЩЯЪіСНОфЛАгаНтЪЭЃЉ
ЪзЯШвЊНщЩмМИИіИХФюЃЌдкЫїв§ЕФЗжРржаЃЌЮвУЧПЩвдАДееЫїв§ЕФМќЪЧЗёЮЊжїМќРДЗжЮЊЁАжїЫїв§ЁБКЭЁАИЈжњЫїв§ЁБЃЌЪЙгУжїМќМќжЕНЈСЂЕФЫїв§ГЦЮЊЁАжїЫїв§ЁБЃЌЦфЫќЕФГЦЮЊЁАИЈжњЫїв§ЁБЁЃвђДЫжїЫїв§жЛФмгавЛИіЃЌИЈжњЫїв§ПЩвдгаКмЖрИіЁЃ
MyISAMЁЊЁЊЗЧОлДиЫїв§
MyISAMДцДЂв§ЧцВЩгУЕФЪЧЗЧОлДиЫїв§ЃЌЗЧОлДиЫїв§ЕФжїЫїв§КЭИЈжњЫїв§МИКѕЪЧвЛбљЕФЃЌжЛЪЧжїЫїв§ВЛдЪаэжиИДЃЌВЛдЪаэПежЕЃЌЫћУЧЕФвЖзгНсЕуЕФkeyЖМДцДЂжИЯђМќжЕЖдгІЕФЪ§ОнЕФЮяРэЕижЗЁЃ
ЗЧОлДиЫїв§ЕФЪ§ОнБэКЭЫїв§БэЪЧЗжПЊДцДЂЕФЁЃ
ЗЧОлДиЫїв§жаЕФЪ§ОнЪЧИљОнЪ§ОнЕФВхШыЫГађБЃДцЁЃвђДЫЗЧОлДиЫїв§ИќЪЪКЯЕЅИіЪ§ОнЕФВщбЏЁЃВхШыЫГађВЛЪмМќжЕгАЯьЁЃ
жЛгадкMyISAMжаВХФмЪЙгУFULLTEXTЫїв§ЁЃ(mysql5.6вдКѓinnoDBвВжЇГжШЋЮФЫїв§)
*зюПЊЪМЮввЛжБВЛЖЎМШШЛЗЧОлДиЫїв§ЕФжїЫїв§КЭИЈжњЫїв§жИЯђЯрЭЌЕФФкШнЃЌЮЊЪВУДЛЙвЊИЈжњЫїв§етИіЖЋЮїФиЃЌКѓРДВХУїАзЫїв§ВЛОЭЪЧгУРДВщбЏЕФТ№ЃЌгУдкФЧаЉЕиЗНФиЃЌВЛОЭЪЧWHEREКЭORDER
BY гяОфКѓУцТ№ЃЌФЧУДШчЙћВщбЏЕФЬѕМўВЛЪЧжїМќдѕУДАьФиЃЌетИіЪБКђОЭашвЊИЈжњЫїв§СЫЁЃ
InnoDBЁЊЁЊОлДиЫїв§
ОлДиЫїв§ЕФжїЫїв§ЕФвЖзгНсЕуДцДЂЕФЪЧМќжЕЖдгІЕФЪ§ОнБОЩэЃЌИЈжњЫїв§ЕФвЖзгНсЕуДцДЂЕФЪЧМќжЕЖдгІЕФЪ§ОнЕФжїМќМќжЕЁЃвђДЫжїМќЕФжЕГЄЖШдНаЁдНКУЃЌРраЭдНМђЕЅдНКУЁЃ
ОлДиЫїв§ЕФЪ§ОнКЭжїМќЫїв§ДцДЂдквЛЦ№ЁЃ
ОлДиЫїв§ЕФЪ§ОнЪЧИљОнжїМќЕФЫГађБЃДцЁЃвђДЫЪЪКЯАДжїМќЫїв§ЕФЧјМфВщевЃЌПЩвдгаИќЩйЕФДХХЬI/OЃЌМгПьВщбЏЫйЖШЁЃЕЋЪЧвВЪЧвђЮЊетИідвђЃЌОлДиЫїв§ЕФВхШыЫГађзюКУАДеежїМќЕЅЕїЕФЫГађВхШыЃЌЗёдђЛсЦЕЗБЕФв§Ц№вГЗжСбЃЌбЯжигАЯьадФмЁЃ
дкInnoDBжаЃЌШчЙћжЛашвЊВщевЫїв§ЕФСаЃЌОЭОЁСПВЛвЊМгШыЦфЫќЕФСаЃЌетбљЛсЬсИпВщбЏаЇТЪЁЃ
*ЪЙгУжїЫїв§ЕФЪБКђЃЌИќЪЪКЯЪЙгУОлДиЫїв§ЃЌвђЮЊОлДиЫїв§жЛашвЊВщеввЛДЮЃЌЖјЗЧОлДиЫїв§дкВщЕНЪ§ОнЕФЕижЗКѓЃЌЛЙвЊНјаавЛДЮI/OВщевЪ§ОнЁЃ
*вђЮЊОлДиИЈжњЫїв§ДцДЂЕФЪЧжїМќЕФМќжЕЃЌвђДЫПЩвддкЪ§ОнаавЦЖЏЛђепвГЗжСбЕФЪБКђНЕЕЭГЩБОЃЌвђЮЊетЪБВЛгУЮЌЛЄИЈжњЫїв§ЁЃЕЋЪЧгЩгкжїЫїв§ДцДЂЕФЪЧЪ§ОнБОЩэЃЌвђДЫОлДиЫїв§ЛсеМгУИќЖрЕФПеМфЁЃ
*ОлДиЫїв§дкВхШыаТЪ§ОнЕФЪБКђБШЗЧОлДиЫїв§Т§КмЖрЃЌвђЮЊВхШыаТЪ§ОнЪБашвЊМьВтжїМќЪЧЗёжиИДЃЌеташвЊБщРњжїЫїв§ЕФЫљгавЖНкЕуЃЌЖјЗЧОлДиЫїв§ЕФвЖНкЕуБЃДцЕФЪЧЪ§ОнЕижЗЃЌеМгУПеМфЩйЃЌвђДЫЗжВММЏжаЃЌВщбЏЕФЪБКђI/OИќЩйЃЌЕЋОлДиЫїв§ЕФжїЫїв§жаДцДЂЕФЪЧЪ§ОнБОЩэЃЌЪ§ОнеМгУПеМфДѓЃЌЗжВМЗЖЮЇИќДѓЃЌПЩФмеМгУКУЖрЕФЩШЧјЃЌвђДЫашвЊИќЖрДЮI/OВХФмБщРњЭъБЯЁЃ
ЯТЭМПЩвдаЮЯѓЕФЫЕУїОлДиЫїв§КЭЗЧОлДиЫїв§ЕФЧјБ№
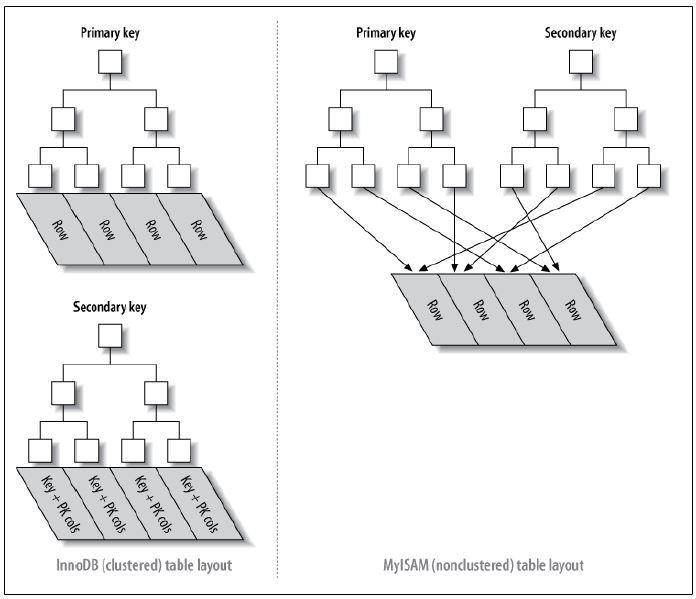
ДгЩЯЭМжаПЩвдПДЕНОлДиЫїв§ЕФИЈжњЫїв§ЕФвЖзгНкЕуЕФdataДцДЂЕФЪЧжїМќЕФжЕЃЌжїЫїв§ЕФвЖзгНкЕуЕФdataДцДЂЕФЪЧЪ§ОнБОЩэЃЌвВОЭЪЧЫЕЪ§ОнКЭЫїв§ДцДЂдквЛЦ№ЃЌВЂЧвЫїв§ВщбЏЕНЕФЕиЗНОЭЪЧЪ§ОнЃЈdataЃЉБОЩэЃЌФЧУДЫїв§ЕФЫГађКЭЪ§ОнБОЩэЕФЫГађОЭЪЧЯрЭЌЕФЃЛ
ЖјЗЧОлДиЫїв§ЕФжїЫїв§КЭИЈжњЫїв§ЕФвЖзгНкЕуЕФdataЖМЪЧДцДЂЕФЪ§ОнЕФЮяРэЕижЗЃЌвВОЭЪЧЫЕЫїв§КЭЪ§ОнВЂВЛЪЧДцДЂдквЛЦ№ЕФЃЌЪ§ОнЕФЫГађКЭЫїв§ЕФЫГађВЂУЛгаШЮКЮЙиЯЕЃЌвВОЭЪЧЫїв§ЫГађгыЪ§ОнЮяРэХХСаЫГађЮоЙиЁЃ
ДЫЭтMyISAMКЭinnoDBЕФЧјБ№змНсШчЯТЃК
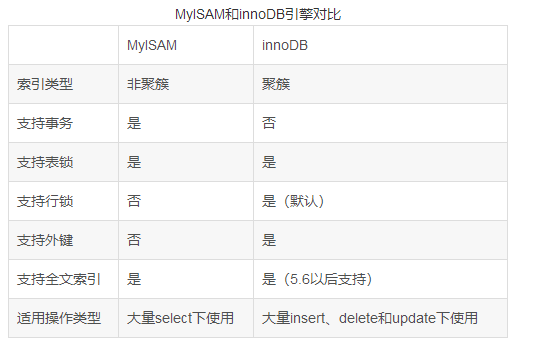
змНсШчЯТЃК
InnoDB жЇГжЪТЮёЃЌжЇГжааМЖБ№ЫјЖЈЃЌжЇГж B-treeЁЂFull-text ЕШЫїв§ЃЌВЛжЇГж Hash
Ыїв§ЃЛ
MyISAM ВЛжЇГжЪТЮёЃЌжЇГжБэМЖБ№ЫјЖЈЃЌжЇГж B-treeЁЂFull-text ЕШЫїв§ЃЌВЛжЇГж Hash
Ыїв§ЃЛ
ДЫЭтЃЌMemory ВЛжЇГжЪТЮёЃЌжЇГжБэМЖБ№ЫјЖЈЃЌжЇГж B-treeЁЂHash ЕШЫїв§ЃЌВЛжЇГж Full-text
Ыїв§ЃЛ
ИќЖрMyISAMКЭinnoDBЕФЧјБ№ОпЬхФкШнВЮПМЃКMyISAMheinnoDBЕФЧјБ№ЃЌАќРЈааМЖЫјЫРЫјЕФОпЬхЗжЮі
ЮхЁЂЫїв§ЕФЪЙгУВпТд
ЪВУДЪБКђвЊЪЙгУЫїв§ЃП
жїМќздЖЏНЈСЂЮЈвЛЫїв§ЃЛ
ОГЃзїЮЊВщбЏЬѕМўдкWHEREЛђепORDER BY гяОфжаГіЯжЕФСавЊНЈСЂЫїв§ЃЛ
зїЮЊХХађЕФСавЊНЈСЂЫїв§ЃЛ
ВщбЏжагыЦфЫћБэЙиСЊЕФзжЖЮЃЌЭтМќЙиЯЕНЈСЂЫїв§
ИпВЂЗЂЬѕМўЯТЧуЯђзщКЯЫїв§ЃЛ
гУгкОлКЯКЏЪ§ЕФСаПЩвдНЈСЂЫїв§ЃЌР§ШчЪЙгУСЫmax(column_1)Лђепcount(column_1)ЪБЕФcolumn_1ОЭашвЊНЈСЂЫїв§
ЪВУДЪБКђВЛвЊЪЙгУЫїв§ЃП
ОГЃдіЩОИФЕФСаВЛвЊНЈСЂЫїв§ЃЛ
гаДѓСПжиИДЕФСаВЛНЈСЂЫїв§ЃЛ
БэМЧТМЬЋЩйВЛвЊНЈСЂЫїв§ЁЃжЛгаЕБЪ§ОнПтРявбОгаСЫзуЙЛЖрЕФВтЪдЪ§ОнЪБЃЌЫќЕФадФмВтЪдНсЙћВХгаЪЕМЪВЮПММлжЕЁЃШчЙћдкВтЪдЪ§ОнПтРяжЛгаМИАйЬѕЪ§ОнМЧТМЃЌЫќУЧЭљЭљдкжДааЭъЕквЛЬѕВщбЏУќСюжЎКѓОЭБЛШЋВПМгдиЕНФкДцРяЃЌетНЋЪЙКѓајЕФВщбЏУќСюЖМжДааЕУЗЧГЃПь--ВЛЙмгаУЛгаЪЙгУЫїв§ЁЃжЛгаЕБЪ§ОнПтРяЕФМЧТМГЌЙ§СЫ1000ЬѕЁЂЪ§ОнзмСПвВГЌЙ§СЫMySQLЗўЮёЦїЩЯЕФФкДцзмСПЪБЃЌЪ§ОнПтЕФадФмВтЪдНсЙћВХгавтвхЁЃ
Ыїв§ЪЇаЇЕФЧщПіЃК
дкзщКЯЫїв§жаВЛФмгаСаЕФжЕЮЊNULLЃЌШчЙћгаЃЌФЧУДетвЛСаЖдзщКЯЫїв§ОЭЪЧЮоаЇЕФЁЃ
дквЛИіSELECTгяОфжаЃЌЫїв§жЛФмЪЙгУвЛДЮЃЌШчЙћдкWHEREжаЪЙгУСЫЃЌФЧУДдкORDER BYжаОЭВЛвЊгУСЫЁЃ
LIKEВйзїжаЃЌ'%aaa%'ВЛЛсЪЙгУЫїв§ЃЌвВОЭЪЧЫїв§ЛсЪЇаЇЃЌЕЋЪЧЁЎaaa%ЁЏПЩвдЪЙгУЫїв§ЁЃ
дкЫїв§ЕФСаЩЯЪЙгУБэДяЪНЛђепКЏЪ§ЛсЪЙЫїв§ЪЇаЇЃЌР§ШчЃКselect * from users where
YEAR(adddate)<2007ЃЌНЋдкУПИіааЩЯНјаадЫЫуЃЌетНЋЕМжТЫїв§ЪЇаЇЖјНјааШЋБэЩЈУшЃЌвђДЫЮвУЧПЩвдИФГЩЃКselect
* from users where adddate<ЁЏ2007-01-01ЁфЁЃЦфЫќЭЈХфЗћЭЌбљЃЌвВОЭЪЧЫЕЃЌдкВщбЏЬѕМўжаЪЙгУе§дђБэДяЪНЪБЃЌжЛгадкЫбЫїФЃАхЕФЕквЛИізжЗћВЛЪЧЭЈХфЗћЕФЧщПіЯТВХФмЪЙгУЫїв§ЁЃ
дкВщбЏЬѕМўжаЪЙгУВЛЕШгкЃЌАќРЈ<ЗћКХЁЂ>ЗћКХКЭЃЁ=ЛсЕМжТЫїв§ЪЇаЇЁЃЬиБ№ЕФЪЧШчЙћЖджїМќЫїв§ЪЙгУЃЁ=дђВЛЛсЪЙЫїв§ЪЇаЇЃЌШчЙћЖджїМќЫїв§ЛђепећЪ§РраЭЕФЫїв§ЪЙгУ<ЗћКХЛђеп>ЗћКХВЛЛсЪЙЫїв§ЪЇаЇЁЃЃЈОerwkjrfhjwkdbЭЌбЇЬсабЃЌВЛЕШгкЃЌАќРЈ<ЗћКХЁЂ>ЗћКХКЭЃЁЃЌШчЙћеМзмМЧТМЕФБШР§КмаЁЕФЛАЃЌвВВЛЛсЪЇаЇЃЉ
дкВщбЏЬѕМўжаЪЙгУIS NULLЛђепIS NOT NULLЛсЕМжТЫїв§ЪЇаЇЁЃ
зжЗћДЎВЛМгЕЅв§КХЛсЕМжТЫїв§ЪЇаЇЁЃИќзМШЗЕФЫЕЪЧРраЭВЛвЛжТЛсЕМжТЪЇаЇЃЌБШШчзжЖЮemailЪЧзжЗћДЎРраЭЕФЃЌЪЙгУWHERE
email=99999 дђЛсЕМжТЪЇАмЃЌгІИУИФЮЊWHERE email='99999'ЁЃ
дкВщбЏЬѕМўжаЪЙгУORСЌНгЖрИіЬѕМўЛсЕМжТЫїв§ЪЇаЇЃЌГ§ЗЧORСДНгЕФУПИіЬѕМўЖММгЩЯЫїв§ЃЌетЪБгІИУИФЮЊСНДЮВщбЏЃЌШЛКѓгУUNION
ALLСЌНгЦ№РДЁЃ
ШчЙћХХађЕФзжЖЮЪЙгУСЫЫїв§ЃЌФЧУДselectЕФзжЖЮвВвЊЪЧЫїв§зжЖЮЃЌЗёдђЫїв§ЪЇаЇЁЃЬиБ№ЕФЪЧШчЙћХХађЕФЪЧжїМќЫїв§дђselect
* вВВЛЛсЕМжТЫїв§ЪЇаЇЁЃ
ОЁСПВЛвЊАќРЈЖрСаХХађЃЌШчЙћвЛЖЈвЊЃЌзюКУЮЊетЖгСаЙЙНЈзщКЯЫїв§ЃЛ
СљЁЂЫїв§ЕФгХЛЏ
1ЁЂзюзѓЧАзК
Ыїв§ЕФзюзѓЧАзККЭКЭB+TreeжаЕФЁАзюзѓЧАзКдРэЁБгаЙиЃЌОйР§РДЫЕОЭЪЧШчЙћЩшжУСЫзщКЯЫїв§<col1,col2,col3>ФЧУДвдЯТ3жаЧщПіПЩвдЪЙгУЫїв§ЃКcol1ЃЌ<col1,col2>ЃЌ<col1,col2,col3>ЃЌЦфЫќЕФСаЃЌБШШч<col2,col3>ЃЌ<col1,col3>ЃЌcol2ЃЌcol3ЕШЕШЖМЪЧВЛФмЪЙгУЫїв§ЕФЁЃ
ИљОнзюзѓЧАзКддђЃЌЮвУЧвЛАуАбХХађЗжзщЦЕТЪзюИпЕФСаЗХдкзюзѓБпЃЌвдДЫРрЭЦЁЃ
2ЁЂДјЫїв§ЕФФЃК§ВщбЏгХЛЏ
дкЩЯУцвбОЬсЕНЃЌЪЙгУLIKEНјааФЃК§ВщбЏЕФЪБКђЃЌ'%aaa%'ВЛЛсЪЙгУЫїв§ЃЌвВОЭЪЧЫїв§ЛсЪЇаЇЁЃШчЙћЪЧетжжЧщПіЃЌжЛФмЪЙгУШЋЮФЫїв§РДНјаагХЛЏЃЈЩЯЮФгаНВЕНЃЉЁЃ
3ЁЂЮЊМьЫїЕФЬѕМўЙЙНЈШЋЮФЫїв§ЃЌШЛКѓЪЙгУ
| SELECT * FROM
tablename MATCH(index_colum) ANGAINST(ЁЎwordЁЏ); |
4ЁЂЪЙгУЖЬЫїв§
ЖдДЎСаНјааЫїв§ЃЌШчЙћПЩФмгІИУжИЖЈвЛИіЧАзКГЄЖШЁЃР§ШчЃЌШчЙћгавЛИіCHAR(255)ЕФ СаЃЌШчЙћдкЧА10
ИіЛђ20 ИізжЗћФкЃЌЖрЪ§жЕЪЧЮЉвЛЕФЃЌФЧУДОЭВЛвЊЖдећИіСаНјааЫїв§ЁЃЖЬЫїв§ВЛНіПЩвдЬсИпВщбЏЫйЖШЖјЧвПЩвдНкЪЁДХХЬПеМфКЭI/OВйзїЁЃ
| 








