| БрМЭЦМі: |
| БОЮФРДздгкcsdn,жївЊНВНтMySQLТпММмЙЙКЭMySQLВщбЏЙ§ГЬ
ЯЕЭГХфжУгыЮЌЛЄгХЛЏЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ |
|
MySQLТпММмЙЙ
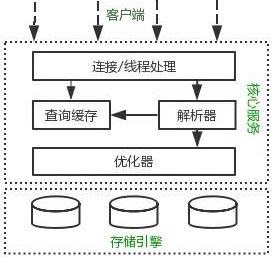
MySQLТпММмЙЙећЬхЗжЮЊШ§Ву :
1>ПЭЛЇЖЫ : ВЂЗЧMySQLЫљЖРгаЃЌжюШч : СЌНгДІРэЁЂЪкШЈШЯжЄЁЂАВШЋЕШЙІФмОљдкетвЛВуДІРэ
2>КЫаФЗўЮё :АќРЈВщбЏНтЮіЁЂЗжЮіЁЂгХЛЏЁЂЛКДцЁЂФкжУКЏЪ§(БШШч : ЪБМфЁЂЪ§бЇЁЂМгУмЕШКЏЪ§)ЃЌЫљгаЕФПчДцДЂв§ЧцЕФЙІФмвВдкетвЛВуЪЕЯж
: ДцДЂЙ§ГЬЁЂДЅЗЂЦїЁЂЪгЭМЕШ
3>ДцДЂв§Чц :ИКд№ MySQL жаЕФЪ§ОнДцДЂКЭЬсШЁЃЌКЭ Linux ЯТЕФЮФМўЯЕЭГРрЫЦЃЌУПжжДцДЂв§ЧцЖМгаЦфгХЪЦКЭСгЪЦЃЌжаМфЕФЗўЮёВуЭЈЙ§
API гыДцДЂв§ЧцЭЈаХЃЌетаЉ APIНгПк ЦСБЮВЛЭЌДцДЂв§ЧцМфЕФВювь
MySQLВщбЏЙ§ГЬ
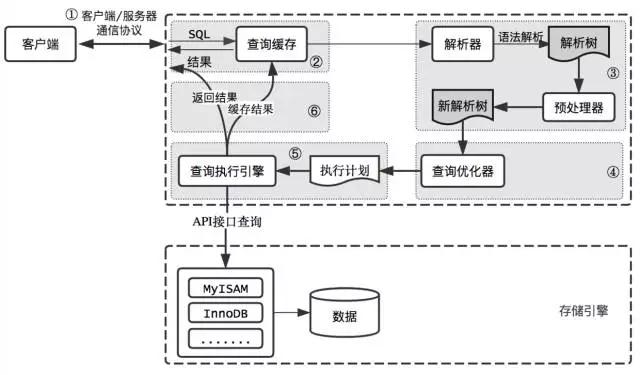
MySQL ећИіВщбЏжДааЙ§ГЬЃЌзмЕФРДЫЕЗжЮЊ 5 ИіВНжш :
1> ПЭЛЇЖЫЯђ MySQL ЗўЮёЦїЗЂЫЭвЛЬѕВщбЏЧыЧѓ
2> ЗўЮёЦїЪзЯШМьВщВщбЏЛКДцЃЌШчЙћУќжаЛКДцЃЌдђСЂПЬЗЕЛиДцДЂдкЛКДцжаЕФНсЙћЃЌЗёдђНјШыЯТвЛНзЖЮ
3> ЗўЮёЦїНјаа SQLНтЮіЁЂдЄДІРэЁЂдйгЩгХЛЏЦїЩњГЩЖдгІЕФжДааМЦЛЎ
4> MySQL ИљОнжДааМЦЛЎЃЌЕїгУДцДЂв§ЧцЕФ APIРДжДааВщбЏ
5> НЋНсЙћЗЕЛиИјПЭЛЇЖЫЃЌЭЌЪБЛКДцВщбЏНсЙћ
ПЭЛЇЖЫ/ЗўЮёЖЫЭЈаХавщ
MySQLПЭЛЇЖЫ/ЗўЮёЖЫЭЈаХавщ ЪЧ ЁААыЫЋЙЄЁБ ЕФЃЌдкШЮвЛЪБПЬЃЌвЊУДЪЧЗўЮёЦїЯђПЭЛЇЖЫЗЂЫЭЪ§ОнЃЌвЊУДЪЧПЭЛЇЖЫЯђЗўЮёЦїЗЂЫЭЪ§ОнЃЌетСНИіЖЏзїВЛФмЭЌЪБЗЂЩњЁЃвЛЕЉвЛЖЫПЊЪМЗЂЫЭЯћЯЂЃЌСэвЛЖЫвЊНгЪеЭъећИіЯћЯЂВХФмЯьгІЫќЃЌЫљвдЮоЗЈвВЮоаыНЋвЛИіЯћЯЂЧаГЩаЁПщЖРСЂЗЂЫЭЃЌвВУЛгаАьЗЈНјааСїСППижЦЁЃПЭЛЇЖЫгУвЛИіЕЅЖРЕФЪ§ОнАќНЋВщбЏЧыЧѓЗЂЫЭИјЗўЮёЦїЃЌЫљвдЕБВщбЏгяОфКмГЄЕФЪБКђЃЌашвЊЩшжУ
max_allowed_packetВЮЪ§ЃЌШчЙћВщбЏЪЕдкЪЧЬЋДѓЃЌЗўЮёЖЫЛсОмОјНгЪеИќЖрЪ§ОнВЂХзГівьГЃЁЃгыжЎЯрЗДЕФЪЧЃЌЗўЮёЦїЯьгІИјгУЛЇЕФЪ§ОнЭЈГЃЛсКмЖрЃЌгЩЖрИіЪ§ОнАќзщГЩЁЃЕЋЪЧЕБЗўЮёЦїЯьгІПЭЛЇЖЫЧыЧѓЪБЃЌПЭЛЇЖЫБиаыЭъећЕФНгЪеећИіЗЕЛиНсЙћЃЌЖјВЛФмМђЕЅЕФжЛШЁЧАУцМИЬѕНсЙћЃЌШЛКѓШУЗўЮёЦїЭЃжЙЗЂЫЭЁЃвђЖјдкЪЕМЪПЊЗЂжаЃЌОЁСПБЃГжВщбЏМђЕЅЧвжЛЗЕЛиБиашЕФЪ§ОнЃЌМѕаЁЭЈаХМфЪ§ОнАќЕФДѓаЁКЭЪ§СПЪЧвЛИіЗЧГЃКУЕФЯАЙпЃЌетвВЪЧВщбЏжаОЁСПБмУтЪЙгУ
SELECT * вдМАМгЩЯ LIMIT ЯожЦЕФдвђжЎвЛ
ВщбЏЛКДц
дкНтЮівЛИіВщбЏгяОфЧАЃЌШчЙћВщбЏЛКДцЪЧДђПЊЕФЃЌФЧУД MySQL ЛсМьВщетИіВщбЏгяОфЪЧЗёУќжаВщбЏЛКДцжаЕФЪ§ОнЁЃШчЙћЕБЧАВщбЏЧЁКУУќжаВщбЏЛКДцЃЌдкМьВщвЛДЮгУЛЇШЈЯоКѓжБНгЗЕЛиЛКДцжаЕФНсЙћЁЃетжжЧщПіЯТЃЌВщбЏВЛЛсБЛНтЮіЃЌвВВЛЛсЩњГЩжДааМЦЛЎЃЌИќВЛЛсжДааЁЃMySQLНЋЛКДцДцЗХдквЛИів§гУБэ
(ВЛвЊРэНтГЩtableЃЌПЩвдШЯЮЊЪЧРрЫЦгк HashMap ЕФЪ§ОнНсЙЙ)ЃЌЭЈЙ§вЛИіЙўЯЃжЕЫїв§ЃЌетИіЙўЯЃжЕЭЈЙ§ВщбЏБОЩэЁЂЕБЧАвЊВщбЏЕФЪ§ОнПтЁЂПЭЛЇЖЫавщАцБОКХЕШвЛаЉПЩФмгАЯьНсЙћЕФаХЯЂМЦЫуЕУРДЁЃЫљвдСНИіВщбЏдкШЮКЮзжЗћЩЯЕФВЛЭЌ
(Р§Шч : ПеИёЁЂзЂЪЭ)ЃЌЖМЛсЕМжТЛКДцВЛЛсУќжа
ШчЙћВщбЏжаАќКЌШЮКЮгУЛЇздЖЈвхКЏЪ§ЁЂДцДЂКЏЪ§ЁЂгУЛЇБфСПЁЂСйЪББэЁЂMySQLПтжаЕФЯЕЭГБэЃЌЦфВщбЏНсЙћЖМВЛЛсБЛЛКДцЁЃБШШчКЏЪ§
NOW() Лђеп CURRENT_DATE() ЛсвђЮЊВЛЭЌЕФВщбЏЪБМфЃЌЗЕЛиВЛЭЌЕФВщбЏНсЙћЃЌдйБШШчАќКЌ
CURRENT_USER Лђеп CONNECION_ID() ЕФВщбЏгяОфЛсвђЮЊВЛЭЌЕФгУЛЇЖјЗЕЛиВЛЭЌЕФНсЙћЃЌНЋетбљЕФВщбЏНсЙћЛКДцЦ№РДУЛгаШЮКЮЕФвтвх
MySQL ВщбЏЛКДцЯЕЭГЛсИњзйВщбЏжаЩцМАЕФУПИіБэЃЌШчЙћетаЉБэ (Ъ§ОнЛђНсЙЙ) ЗЂЩњБфЛЏЃЌФЧУДКЭетеХБэЯрЙиЕФЫљгаЛКДцЪ§ОнЖМНЋЪЇаЇЁЃе§вђЮЊШчДЫЃЌдкШЮКЮЕФаДВйзїЪБЃЌMySQLБиаыНЋЖдгІБэЕФЫљгаЛКДцЖМЩшжУЮЊЪЇаЇЁЃШчЙћВщбЏЛКДцЗЧГЃДѓЛђепЫщЦЌКмЖрЃЌетИіВйзїОЭПЩФмДјРДКмДѓЕФЯЕЭГЯћКФЃЌЩѕжСЕМжТЯЕЭГНЉЫРвЛЛсЖљЃЌЖјЧвВщбЏЛКДцЖдЯЕЭГЕФЖюЭтЯћКФвВВЛНіНідкаДВйзїЃЌЖСВйзївВВЛР§Эт
:
1>ШЮКЮЕФВщбЏгяОфдкПЊЪМжЎЧАЖМБиаыОЙ§МьВщЃЌМДЪЙетЬѕ SQLгяОф гРдЖВЛЛсУќжаЛКДц
2>ШчЙћВщбЏНсЙћПЩвдБЛЛКДцЃЌФЧУДжДааЭъГЩКѓЃЌЛсНЋНсЙћДцШыЛКДцЃЌвВЛсДјРДЖюЭтЕФЯЕЭГЯћКФ
ЛљгкДЫЃЌВЂВЛЪЧЪВУДЧщПіЯТВщбЏЛКДцЖМЛсЬсИпЯЕЭГадФмЃЌЛКДцКЭЪЇаЇЖМЛсДјРДЖюЭтЯћКФЃЌЬиБ№ЪЧаДУмМЏаЭгІгУЃЌжЛгаЕБЛКДцДјРДЕФзЪдДНкдМДѓгкЦфБОЩэЯћКФЕФзЪдДЪБЃЌВХЛсИјЯЕЭГДјРДадФмЬсЩ§ЁЃПЩвдГЂЪдДђПЊВщбЏЛКДцЃЌВЂдкЪ§ОнПтЩшМЦЩЯзівЛаЉгХЛЏ
:
1> гУЖрИіаЁБэДњЬцвЛИіДѓБэЃЌзЂвтВЛвЊЙ§ЖШЩшМЦ
2> ХњСПВхШыДњЬцбЛЗЕЅЬѕВхШы
3> КЯРэПижЦЛКДцПеМфДѓаЁЃЌвЛАуРДЫЕЦфДѓаЁЩшжУЮЊМИЪЎезБШНЯКЯЪЪ
4> ПЩвдЭЈЙ§ SQL_CACHE КЭ SQL_NO_CACHE РДПижЦФГИіВщбЏгяОфЪЧЗёашвЊНјааЛКДц
зЂ :SQL_NO_CACHE ЪЧНћжЙЛКДцВщбЏНсЙћЃЌЕЋВЂВЛвтЮЖзХ cache ВЛзїЮЊНсЙћЗЕЛиИј queryЃЌжЎЧАЕФЛКДцНсЙћжЎКѓвВПЩвдВщбЏЕН
mysql> SELECT
SQL_CACHE COUNT(*) FROM a;
+----------+
| COUNT(*) |
+----------+
|98304 |
+----------+
1 row in set, 1 warning (0.01 sec)
mysql> SELECT SQL_NO_CACHE COUNT(*) FROMa;
+----------+
| COUNT(*) |
+----------+
|98304 |
+----------+
1 row in set, 1 warning (0.02 sec)
|
ПЩвддк SELECT гяОфжажИЖЈВщбЏЛКДцЕФбЁЯюЃЌЖдгкФЧаЉПЯЖЈвЊЪЕЪБЕФДгБэжаЛёШЁЪ§ОнЕФВщбЏЃЌЛђепЖдгкФЧаЉвЛЬьжЛжДаавЛДЮЕФВщбЏЃЌЖМПЩвджИЖЈВЛНјааВщбЏЛКДцЃЌЪЙгУ
SQL_NO_CACHE бЁЯюЁЃЖдгкФЧаЉБфЛЏВЛЦЕЗБЕФБэЃЌВщбЏВйзїКмЙЬЖЈЃЌПЩвдНЋИУВщбЏВйзїЛКДцЦ№РДЃЌетбљУПДЮжДааЕФЪБКђВЛЪЕМЪЗУЮЪБэКЭжДааВщбЏЃЌжЛЪЧДгЛКДцЛёЕУНсЙћЃЌПЩвдгааЇЕиИФЩЦВщбЏЕФадФмЃЌЪЙгУ
SQL_CACHE бЁЯю
ВщПДПЊЦєЛКДцЕФЧщПі
mysql> SHOW
VARIABLES LIKE '%query_cache%';
+------------------------------+---------+
| Variable_name| Value|
+------------------------------+---------+
| have_query_cache| YES|
| query_cache_limit| 1048576 |
| query_cache_min_res_unit| 4096|
| query_cache_size| 1048576 | #ИјЛКДцЗжХфЕФзюДѓФкДцПеМф
| query_cache_type| OFF| #ЪЧЗёПЊЦєВщбЏЛКДцЃЌ0
БэЪОВЛПЊЦєВщбЏЛКДцЃЌ1 БэЪОЪМжеПЊЦєВщбЏЛКДц (ВЛвЊЛКДцЪЙгУ sql_no_cache)ЃЌ
2 БэЪОАДашПЊЦєВщбЏЛКДц (ашвЊЛКДцЪЙгУ sql_cache)
| query_cache_wlock_invalidate | OFF|
+------------------------------+---------+
6 rows in set (0.00 sec)
|
ЖдгкВщбЏЛКДцЕФвЛаЉВйзї
FLUSH QUERY CACHE : ЧхРэВщбЏЛКДцФкДцЫщЦЌ
RESET QUERY CACHE : ДгВщбЏЛКДцжавЦГіЫљгаВщбЏ
FLUSH TABLES : ЙиБеЫљгаДђПЊЕФБэЃЌЭЌЪБИУВйзїНЋЛсЧхПеВщбЏЛКДцжаЕФФкШнВщбЏгХЛЏ
ОЙ§ЧАУцЕФВНжшЩњГЩЕФгяЗЈЪїБЛШЯЮЊЪЧКЯЗЈЕФСЫЃЌВЂЧвгЩгХЛЏЦїНЋЦфзЊЛЏГЩВщбЏМЦЛЎЁЃЖрЪ§ЧщПіЯТЃЌвЛЬѕВщбЏПЩвдгаКмЖржжжДааЗНЪНЃЌзюКѓЖМЗЕЛиЯргІЕФНсЙћЁЃгХЛЏЦїЕФзїгУОЭЪЧевЕНетЦфжазюКУЕФжДааМЦЛЎЁЃMySQLЪЙгУЛљгкГЩБОЕФгХЛЏЦїЃЌЫќГЂЪддЄВтвЛИіВщбЏЪЙгУФГжжжДааМЦЛЎЪБЕФГЩБОЃЌВЂбЁдёЦфжаГЩБОзюаЁЕФвЛИіЁЃдк
MySQL ПЩвдЭЈЙ§ВщбЏЕБЧАЛсЛАЕФ last_query_cost ЕФжЕРДЕУЕНЦфМЦЫуЕБЧАВщбЏЕФГЩБО
mysql> SELECT
* FROM p_product_fee WHERE total_price BETWEEN
580000 AND 680000;
mysql>SHOW STATUS LIKE 'last_query_cost';
# ЯдЪОвЊзіЖрЩйвГЕФЫцЛњВщбЏВХФмЕУЕНзюКѓвЛВщбЏНсЙћЃЌетИіНсЙћЪЧИљОнвЛаЉСаЕФЭГМЦаХЯЂМЦЫуЕУРДЕФЃЌетаЉЭГМЦаХЯЂАќРЈ
: УПеХБэЛђепЫїв§ЕФвГУцИіЪ§ЁЂЫїв§ЕФЛљЪ§ЁЂЫїв§КЭЪ§ОнааЕФГЄЖШЁЂЫїв§ЕФЗжВМЧщПіЕШЕШ
|
гаЗЧГЃЖрЕФдвђЛсЕМжТ MySQL бЁдёДэЮѓЕФжДааМЦЛЎЃЌБШШчЭГМЦаХЯЂВЛзМШЗЁЂВЛЛсПМТЧВЛЪмЦфПижЦЕФВйзїГЩБО(гУЛЇздЖЈвхКЏЪ§ЁЂДцДЂЙ§ГЬ)ЁЂMySQLШЯЮЊЕФзюгХИњЮвУЧЯыЕФВЛвЛбљ
(ЮвУЧЯЃЭћжДааЪБМфОЁПЩФмЖЬЃЌЕЋ MySQL жЕбЁдёЫќШЯЮЊГЩБОаЁЕФЃЌЕЋГЩБОаЁВЂВЛвтЮЖзХжДааЪБМфЖЬ) ЕШЕШ
MySQLЕФВщбЏгХЛЏЦїЪЧвЛИіЗЧГЃИДдгЕФВПМўЃЌЫќЪЙгУСЫЗЧГЃЖрЕФгХЛЏВпТдРДЩњГЩвЛИізюгХЕФжДааМЦЛЎ :
1> жиаТЖЈвхБэЕФЙиСЊЫГађ (ЖреХБэЙиСЊВщбЏЪБЃЌВЂВЛвЛЖЈАДее SQL жажИЖЈЕФЫГађНјааЃЌЕЋгавЛаЉММЧЩПЩвджИЖЈЙиСЊЫГађ)
2> гХЛЏ MIN() КЭ MAX()КЏЪ§ (евФГСаЕФзюаЁжЕЃЌШчЙћИУСагаЫїв§ЃЌжЛашвЊВщев B+TreeЫїв§
зюзѓЖЫЃЌЗДжЎдђПЩвдевЕНзюДѓжЕ)
3> ЬсЧАжежЙВщбЏ (БШШч : ЪЙгУ Limit ЪБЃЌВщевЕНТњзуЪ§СПЕФНсЙћМЏКѓЛсСЂМДжежЙВщбЏ)
4> гХЛЏХХађ (дкРЯАцБО MySQL ЛсЪЙгУСНДЮДЋЪфХХађЃЌМДЯШЖСШЁаажИеыКЭашвЊХХађЕФзжЖЮдкФкДцжаЖдЦфХХађЃЌШЛКѓдйИљОнХХађНсЙћШЅЖСШЁЪ§ОнааЃЌЖјаТАцБОВЩгУЕФЪЧЕЅДЮДЋЪфХХађЃЌвВОЭЪЧвЛДЮЖСШЁЫљгаЕФЪ§ОнааЃЌШЛКѓИљОнИјЖЈЕФСаХХађЁЃЖдгкI/OУмМЏаЭгІгУЃЌаЇТЪЛсИпКмЖр)
ВщбЏжДаав§Чц
дкЭъГЩНтЮіКЭгХЛЏНзЖЮвдКѓЃЌMySQLЛсЩњГЩЖдгІЕФжДааМЦЛЎЃЌВщбЏжДаав§ЧцИљОнжДааМЦЛЎИјГіЕФжИСюж№ВНжДааЕУГіНсЙћЁЃећИіжДааЙ§ГЬЕФДѓВПЗжВйзїОљЪЧЭЈЙ§ЕїгУДцДЂв§ЧцЪЕЯжЕФНгПкРДЭъГЩЃЌетаЉНгПкБЛГЦЮЊ
handler APIЁЃВщбЏЙ§ГЬжаЕФУПвЛеХБэгЩвЛИі handler ЪЕР§БэЪОЁЃЪЕМЪЩЯЃЌMySQLдкВщбЏгХЛЏНзЖЮОЭЮЊУПвЛеХБэДДНЈСЫвЛИі
handlerЪЕР§ЃЌгХЛЏЦїПЩвдИљОнетаЉЪЕР§ЕФНгПкРДЛёШЁБэЕФЯрЙиаХЯЂЃЌАќРЈБэЕФЫљгаСаУћЁЂЫїв§ЭГМЦаХЯЂЕШЁЃДцДЂв§ЧцНгПкЬсЙЉСЫЗЧГЃЗсИЛЕФЙІФмЃЌЕЋЦфЕзВуНігаМИЪЎИіНгПкЃЌетаЉНгПкЯёДюЛ§ФОвЛбљЭъГЩСЫвЛДЮВщбЏЕФДѓВПЗжВйзї
ЗЕЛиНсЙћИјПЭЛЇЖЫ
ВщбЏжДааЕФзюКѓвЛИіНзЖЮОЭЪЧНЋНсЙћЗЕЛиИјПЭЛЇЖЫЁЃМДЪЙВщбЏВЛЕНЪ§ОнЃЌMySQL ШдШЛЛсЗЕЛиетИіВщбЏЕФЯрЙиаХЯЂЃЌБШШчИУВщбЏгАЯьЕНЕФааЪ§вдМАжДааЪБМфЕШЁЃШчЙћВщбЏЛКДцБЛДђПЊЧветИіВщбЏПЩвдБЛЛКДцЃЌMySQLвВЛсНЋНсЙћДцЗХЕНЛКДцжаЁЃНсЙћМЏЗЕЛиПЭЛЇЖЫЪЧвЛИідіСПЧвж№ВНЗЕЛиЕФЙ§ГЬЁЃгаПЩФм
MySQL дкЩњГЩЕквЛЬѕНсЙћЪБЃЌОЭПЊЪМЯђПЭЛЇЖЫж№ВНЗЕЛиНсЙћМЏЁЃетбљЗўЮёЖЫОЭЮоаыДцДЂЬЋЖрНсЙћЖјЯћКФЙ§ЖрФкДцЃЌвВПЩвдШУПЭЛЇЖЫЕквЛЪБМфЛёЕУЗЕЛиНсЙћЁЃашвЊзЂвтЕФЪЧЃЌНсЙћМЏжаЕФУПвЛааЖМЛсвдвЛИіТњзуПЭЛЇЖЫ/ЗўЮёЦїЭЈаХавщЕФЪ§ОнАќЗЂЫЭЃЌдйЭЈЙ§
TCPавщ НјааДЋЪфЃЌдкДЋЪфЙ§ГЬжаЃЌПЩФмЖд MySQL ЕФЪ§ОнАќНјааЛКДцШЛКѓХњСПЗЂЫЭВщбЏЯЕЭГадФм
SHOW STATUS LIKE 'value';
valueВЮЪ§ЕФМИИіЭГМЦВЮЪ§ШчЯТ :
Connections : СЌНг MySQL ЗўЮёЦїЕФДЮЪ§
Uptime : MySQL ЗўЮёЦїЕФЩЯЯпЪБМф
Slow_queries : Т§ВщбЏДЮЪ§
Com_Select : ВщбЏВйзїЕФДЮЪ§
Com_insert : ВхШыВйзїЕФДЮЪ§
Com_update : ИќаТВйзїЕФДЮЪ§
Com_delete : ЩОГ§ВйзїЕФДЮЪ§
1> ЗжЮіВщбЏгяОф
EXPLAINЃЌDESCRIBEгУгкЗжЮіSELECTгяОфЕФжДааЧщПі
EXPLAIN SELECT гяОф;
DESCRIBE SELECT гяОф;
ЗЕЛиЕФВщбЏНсЙћаХЯЂ :
id : БэЪО SELECT гяОфЕФБрКХ
select_type : БэЪО SELECT гяОфРраЭЁЃИУВЮЪ§гаМИИіГЃгУЕФШЁжЕЃЌМД SIMPLE
БэМђЕЅВщбЏЃЌЦфжаВЛАќРЈСЌНгВщбЏКЭзгВщбЏЃЛPRIMARY БэЪОжїВщбЏЃЌЛђепЪЧзюЭтВуЕФВщбЏгяОфЃЛUNION
БэЪОСЌНгВщбЏЕФЕкЖўИіЛђКѓУцЕФВщбЏгяОф
table : БэЪОВщбЏЕФБэ
type : БэЪОБэЕФСЌНгРраЭЁЃИУВЮЪ§гаМИИіГЃгУЕФШЁжЕЃЌМД system БэЪОБэжажЛгавЛЬѕМЧТМЃЛconst
БэЪОБэжагаЖрЬѕМЧТМЃЌЕЋжЕДгБэжаВщбЏвЛЬѕМЧТМЃЛALL БэЪОЖдБэНјааЭъећЕФЩЈУшЃЛeq_ref БэЪОЖрБэСЌНгЪБЃЌКѓУцЕФБэЪОгУ
UNIQUE Лђеп PRIMARY KEYЃЛref БэЪОЖрБэВщбЏЪБЃЌКѓУцЕФБэЪОгУЦеЭЈЫїв§ЃЛunique_subquery
БэЪОзгВщбЏжаЪЙгУ UNIQUE Лђеп PRIMARY KEYЃЛindex_subquery БэЪОзгВщбЏжаЪЙгУЦеЭЈЫїв§ЃЛrange
БэЪОВщбЏгяОфжаИјГіВщбЏЗЖЮЇЃЛindex БэЪОЖдБэжаЕФЫїв§НјааЭъећЕФЩЈУш
possible_keys : БэЪОВщбЏжаПЩФмЪЙгУЕФЫїв§
key : БэЪОВщбЏЪЙгУЕНЕФЫїв§
key_len : БэЪОЫїв§зжЖЮЕФГЄЖШ
ref : БэЪОЪЙгУФФИіСаЛђГЃЪ§гыЫїв§вЛЦ№РДВщбЏМЧТМ
rows : БэЪОВщбЏЕФааЪ§
Extra : БэЪОВщбЏЙ§ГЬЕФИНМгаХЯЂ
2> Ыїв§ВщбЏ
<1> ЪЙгУ LIKE ЙиМќзжВщбЏЪБЃЌШєЦЅХфзжЗћДЎЕФЕквЛИізжЗћЮЊ % ЪБЃЌЫїв§ВЛЛсБЛЪЙгУЃЌШчЙћВЛдкЕквЛИіЮЛжУЃЌЫїв§ОЭЛсБЛЪЙгУ
<2> ЖрСаЫїв§ЪЧдкБэЕФЖрИізжЖЮЩЯДДНЈвЛИіЫїв§ЃЌжЛгаВщбЏЬѕМўжаЪЙгУетаЉзжЖЮжаЕквЛИізжЖЮЪБЃЌЫїв§ВХЛсБЛЪЙгУ
<3> ВщбЏгяОфжЛга OR ЙиМќзжЪБЃЌШє OR ЧАКѓСНИіЬѕМўЕФСаЖМЪЧЫїв§ЪБВщбЏжаНЋЪЙгУЫїв§ЃЌШє
OR ЧАКѓгавЛИіЬѕМўЕФСаВЛЪЧЫїв§ЃЌФЧУДВщбЏжаНЋВЛЛсЪЙгУЫїв§
<4>гІОЁСПБмУтдкWHEREзгОфжаЖдзжЖЮНјааNULLжЕХаЖЯЃЌЗёдђНЋЕМжТв§ЧцЗХЦњЪЙгУЫїв§ЖјНјааШЋБэЩЈУш
<5>ЪЙгУЖрСаЫїв§ЪБжївтЫГађКЭВщбЏЬѕМўБЃГжвЛжТЃЌЭЌЪБЩОГ§ВЛБивЊЕФЕЅСаЫїв§
<6>ОЁСПБмУтдкWHEREзгОфжаЪЙгУ != Лђ <>ВйзїЗћЃЌЗёдђНЋв§ЧцЗХЦњЪЙгУЫїв§ЖјНјааШЋБэЩЈУш
3> гХЛЏзгВщбЏ : згВщбЏЪБЃЌЯЕЭГФкВуВщбЏгяОфЕФВщбЏНсЙћНЈСЂвЛИіСйЪББэЃЌШЛКѓЭтВуВщбЏгяОфдйдкСйЪББэжаВщбЏМЧТМЃЌВщбЏЭъГЩКѓГЗЯњЕєетаЉСйЪББэЃЌвђДЫЪЙгУСЌНгВщбЏРДДњЬцзгВщбЏЃЌетЪЧгЩгкСЌНгВщбЏВЛашвЊНЈСЂСйЪББэЃЌЦфЫйЖШБШзгВщбЏвЊПь
<1> НЋзжЖЮКмЖрЕФБэЗжНтГЩЖрИіБэ : гааЉБэдкЩшМЦСЫКмЖрзжЖЮЃЌЦфжагааЉзжЖЮЪЙгУЦЕТЪЕЭЃЌЕБИУБэЪ§ОнСПДѓЪБЃЌВщбЏЪ§ОнЕФЫйЖШОЭЛсБЛЭЯТ§ЃЌвђДЫНЋФЧаЉЪЙгУЦЕТЪКмЕЭЕФзжЖЮЗХжУдкСэЭтвЛИіБэжа(СНЭтвЛИіБэПЩвдЪЧ
*_extra)
<2> діМгжаМфБэ : дкВщбЏСНИіБэжаЕФМИИізжЖЮЃЌОГЃСЌБэВщбЏЛсНЕЕЭЪ§ОнПтВщбЏЫйЖШЃЌПЩНЋетаЉзжЖЮНЈСЂвЛИіжаМфБэВЂНЋдРДФЧМИИіБэЕФЪ§ОнВхШыЕНжаМфБэжаЃЌжЎКѓЪЙгУжаМфБэРДНјааВщбЏКЭЭГМЦЃЌвдДЫЬсИпВщбЏЫйЖШ
<3> діМгШпгрзжЖЮЃКБэЕФЙцЗЖЛЏГЬЖШдНИпЃЌБэгыБэжЎМфЕФЙиЯЕОЭдНЖрЃЌШєОГЃНјааЖрБэСЌНгВщбЏЛсРЫЗбКмЖрЪБМфЃЌПЩдіМгШпгрзжЖЮЕФЗНЪНРДЬсИпВщбЏЫйЖШ
4> гХЛЏвЛааЪ§ОнЕФВщбЏЃЌШєвбжЊВщбЏЁЂИќаТЛђЩОГ§НсЙћжЛгавЛЬѕЃЌдкВщбЏЁЂИќаТЛђЩОГ§гяОфжЎКѓЬэМг
LIMIT 1 ПЩвддкЪ§ОнПтв§ЧцЛсдкевЕНвЛЬѕЪ§ОнКѓЭЃжЙЫбЫїЃЌЖјВЛЪЧМЬајЭљКѓВщевЯТвЛЬѕЗћКЯМЧТМЕФЪ§Он
5> ЪЙгУ JOIN МЖСЊВщбЏЪБЃЌгІИУБЃжЄСНБэжа JOIN ЕФзжЖЮвбНќНЈСЂЙ§Ыїв§ЧвРраЭЯрЭЌЃЌетбљMySQL
ФкВПЛсЦєЖЏгХЛЏ JOIN ЕФ SQLгяОфЕФЛњжЦЃЌШч : ШчЙћвЊАб DECIMAL зжЖЮКЭвЛИі INT
зжЖЮJOINдквЛЦ№ЃЌMySQL ОЭЮоЗЈЪЙгУЫќУЧЕФЫїв§ЁЃЖдгкФЧаЉ STRINGРраЭЃЌЛЙашвЊгаЯрЭЌЕФзжЗћМЏВХаа
6>БмУт SELECT * ВщбЏЪ§ОнЃЌДгЪ§ОнПтРяЖСГідНЖрЕФЪ§ОнЃЌФЧУДВщбЏОЭЛсБфЕУдНТ§ВЂЧвЃЌШчЙћЪ§ОнПтЗўЮёЦїКЭWEBЗўЮёЦїЪЧСНЬЈЖРСЂЕФЗўЮёЦїЕФЛАЃЌетЛЙЛсдіМгЭјТчДЋЪфЕФИКдиЁЃЫљвдЃЌгІИУбјГЩвЛИіашвЊЪВУДОЭШЁЪВУДЕФКУЕФЯАЙп
7> ФмЪЙгУ ENUM ЖјОЭВЛвЊЪЙгУ VARCHARЃЌENUMРраЭЪЧЗЧГЃПьКЭНєДеЕФЃЌЪЕМЪЩЯ
ENUM БЃДцЕФЪЧ TINYINTЃЌЕЋЦфЭтБэЩЯЯдЪОЮЊзжЗћДЎЁЃетбљгУетИізжЖЮРДзівЛаЉбЁЯюСаБэБфЕУЯрЕБЕФЭъУРЁЃШчЙћгавЛИізжЖЮЃЌБШШчЁАадБ№ЁБЃЌЁАЙњМвЁБЃЌЁАУёзхЁБЃЌЁАзДЬЌЁБЛђЁАВПУХЁБЃЌетаЉзжЖЮЕФШЁжЕЪЧгаЯоЖјЧвЙЬЖЈЕФЃЌФЧУДЃЌФугІИУЪЙгУ
ENUM ЖјВЛЪЧ VARCHAR
8> Дг PROCEDURE ANALYSE() ШЁЕУНЈвщ ЃКPROCEDURE ANALYSE()
ЛсШУ MySQL АяФуШЅЗжЮіФуЕФзжЖЮКЭЦфЪЕМЪЕФЪ§ОнЃЌВЂЛсИјФувЛаЉгагУЕФНЈвщЁЃжЛгаБэжагаЪЕМЪЕФЪ§ОнЃЌетаЉНЈвщВХЛсБфЕУгагУЃЌвђЮЊвЊзівЛаЉДѓЕФОіЖЈЪЧашвЊгаЪ§ОнзїЮЊЛљДЁ
PROCEDURE ANALYSE() гяЗЈШчЯТ :
SELECT ... FROM
... WHERE ... PROCEDURE ANALYSE([max_elements,[max_memory]])
max_elements : (ФЌШЯжЕ256) analyze ВщевУПвЛСаВЛЭЌжЕЪБЫљашЙизЂЕФзюДѓВЛЭЌжЕЕФЪ§СПЃЌanalyze
ЛЙгУетИіжЕРДМьВщгХЛЏЕФЪ§ОнРраЭЪЧЗёИУЪЧ ENUMЃЌШчЙћИУСаЕФВЛЭЌжЕЕФЪ§СПГЌЙ§max_elementsжЕ
ENUM ОЭВЛзіЮЊНЈвщгХЛЏЕФЪ§ОнРраЭ
max_memory : (ФЌШЯжЕ8192) analyze ВщевУПвЛСаЫљгаВЛЭЌжЕЪБПЩФмЗжХфЕФзюДѓЕФФкДцЪ§СП
|
mysql> DESC
user_account;
+-----------+------------------+------+-----+---------+----------------+
| Field| Type| Null | Key |
Default | Extra|
+-----------+------------------+------+-----+---------+----------------+
| USERID| int(10) unsigned | NO| PRI |
NULL| auto_increment |
| USERNAME| varchar(10)| NO||
NULL||
| PASSSWORD | varchar(30)| NO||
NULL||
| GROUPNAME | varchar(10)| YES||
NULL||
+-----------+------------------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
mysql> select * from user_account PROCEDURE
ANALYSE(1)\G
*************************** 1. row ***************************
Field_name: ibatis.user_account.USERID
Min_value: 1
Max_value: 103
Min_length: 1
Max_length: 3
Empties_or_zeros: 0
Nulls: 0
Avg_value_or_avg_length: 51.7500
Std: 50.2562
Optimal_fieldtype: TINYINT(3) UNSIGNED NOT
NULL
*************************** 2. row ***************************
Field_name: ibatis.user_account.USERNAME
Min_value: dfsa
Max_value: LMEADORS
#analyze ЗжЮі ibatis.user_account.USERID СазюаЁжЕ1ЃЌзюДѓжЕ103ЃЌзюаЁГЄЖШ1ЃЌзюДѓГЄЖШ3ЕШаХЯЂЃЌВЂИјГіаоИФзжЖЮЕФгХЛЏНЈвщ
: НЈвщНЋИУзжЖЮЕФЪ§ОнРраЭИФГЩ TINYINT(3) UNSIGNED NOT NULL
|
9> ОЁПЩФмЕФЪЙгУ NOT NULLЃКNULLЛсеМгУЖюЭтЕФПеМфРДМЧТМЦфжЕЪЧЗёЮЊПеЃЌЖдгк MyISAMБэ
УПИіПеСаЖМашвЊЖюЭтЕФвЛИізжНкВЂНЋЦфЫФЩсЮхШыЕНзюНќЕФзжНкЁЃMySQLФбвдгХЛЏв§гУПЩПеСаВщбЏЃЌЫќЛсЪЙЫїв§ЁЂЫїв§ЭГМЦКЭжЕИќМгИДдг
ПЩПеСаБЛЫїв§КѓЃЌУПЬѕМЧТМЖМашвЊвЛИіЖюЭтЕФзжНкЃЌЛЙФмЕМжТ MyISAM жаЙЬЖЈДѓаЁЕФЫїв§БфГЩПЩБфДѓаЁЕФЫїв§ЁЃдкНјааБШНЯЕФЪБКђЛсЪЧГЬађИќИДдгЃЌЦфЫљДњБэЕФвтвхдкВЛЭЌЕФЪ§ОнПтжаЛсгаЫљВЛЭЌПгЪЧзжЗћДЎ
"Empty"ЁЂ"NULL"ЛђЪЧNULLЃЌвђДЫОЁСПЪЙгУ NOT
NULL
<1>ЫљгаЪЙгУ NULLжЕЕФЧщПіЃЌЖМПЩвдЭЈЙ§вЛИігавтвхЕФжЕРДДњЬцЃЌетбљгаРћгкДњТыЕФПЩЖСадКЭПЩЮЌЛЄадЃЌВЂФмДгдМЪјЩЯдіЧПвЕЮёЪ§ОнЕФЙцЗЖад
<2> NULLжЕ ЕН ЗЧNULL ЕФИќаТЮоЗЈзіЕНдЕиИќаТЃЌИќШнвзЗЂЩњЫїв§ЗжСбЃЌДгЖјгАЯьадФм
зЂ :Аб NULLСа ИФЮЊ NOT NULL ДјРДЕФадФмЬсЩ§КмаЁЃЌГ§ЗЧШЗЖЈЫќДјРДСЫЮЪЬтЃЌЗёдђВЛвЊАбЫќЕБГЩгХЯШЕФгХЛЏДыЪЉЃЌзюживЊЕФЪЧЪЙгУЕФСаЕФРраЭЕФЪЪЕБад
<3>NULLжЕ дк timestampРраЭ ЯТШнвзГіЮЪЬтЃЌЬиБ№ЪЧУЛгаЦєгУВЮЪ§ explicit_defaults_for_timestamp
<4>NOT INЁЂ!= ЕШИКЯђЬѕМўВщбЏдкга NULL жЕЕФЧщПіЯТЗЕЛигРдЖЮЊПеНсЙћЃЌВщбЏШнвзГіДэ
mysql>CREATE
TABLE table_2(id INT(11) NOT NULL,user_name
VARCHAR(20) NOT NULL);
mysql>CREATE TABLE table_3(id INT(11) NOT
NULL,user_name VARCHAR(20));
mysql>INSERT INTO table_2 VALUES(4,'zhaoliu_2_1'),(2,'lisi_2_1'),
(3,'wangmazi_2_1'),(1,'zhangsan_2'),
(2,'lisi_2_2'),(4,'zhaoliu_2_2'),(3,'wangmazi_2_2');
mysql>INSERTINTO table_3 VALUES(1,"zhaoliu_2_1"),(2,
null);
#NOT INзгВщбЏдкгаNULLжЕЕФЧщПіЯТЗЕЛигРдЖЮЊПеНсЙћЃЌВщбЏШнвзГіДэ
mysql> SELECT user_name FROM table_2 WHERE
user_name NOT IN
(SELECT user_name FROMtable_3 WHEREid!=1);
Empty set (0.00 sec)
# ЕЅСаЫїв§ВЛДц NULLжЕЃЌИДКЯЫїв§ВЛДцШЋЮЊ NULLжЕЃЌШчЙћСадЪаэЮЊ NULLЃЌ
ПЩФмЛсЕУЕНЁАВЛЗћКЯдЄЦкЁБЕФНсЙћМЏ
# ШчЙћnameдЪаэЮЊNULLЃЌЫїв§ВЛДцДЂ NULLжЕЃЌНсЙћМЏжаВЛЛсАќКЌетаЉМЧТМЁЃ
ЫљвдЃЌЧыЪЙгУ NOT NULLдМЪјвдМАФЌШЯжЕ
mysql> SELECT* FROMtable_3 WHEREuser_name!='zhaoliu_2_1';
Empty set (0.00 sec)
#ШчЙћдкСНИізжЖЮНјааЦДНг : БШШчЬтКХ+ЗжЪ§ЃЌЪзЯШвЊИїзжЖЮНјааЗЧnullХаЖЯЃЌ
ЗёдђжЛвЊШЮвтвЛИізжЖЮЮЊПеЖМЛсдьГЩЦДНгЕФНсЙћЮЊnull
mysql> SELECTCONCAT("1",null);
+------------------+
| CONCAT("1",null) |
+------------------+
| NULL|
+------------------+
1 row in set (0.00 sec)
# ШчЙћга NULL column ДцдкЕФЧщПіЯТЃЌcount(NULL column)ашвЊИёЭтзЂвтЃЌ
NULL жЕВЛЛсВЮгыЭГМЦ
mysql> SELECT* FROM table_3;
+----+-------------+
| id | user_name|
+----+-------------+
|1 | zhaoliu_2_1 |
|2 | NULL|
+----+-------------+
2 rows in set (0.00 sec)
mysql> SELECTCOUNT(user_name) FROM table_3;
+------------------+
| count(user_name) |
+------------------+
|1 |
+------------------+
1 row in set (0.00 sec)
#зЂвт NULLзжЖЮЕФХаЖЯЗНЪНЃЌ= NULLНЋЛсЕУЕНДэЮѓЕФНсЙћ
mysql> CREATE INDEX idx_test ON table_3(user_name);
mysql> SELECT * FROM table_3 WHERE user_name
IS NULL;
+----+-----------+
| id | user_name |
+----+-----------+
|2 | NULL|
+----+-----------+
1 row in set (0.00 sec)
mysql> DESC SELECT * FROM table_3 WHERE user_name='zhaoliu_2_1';
+----+-------------+---------+------------+------+---------------
+----------+---------+-------+------+----------+-------+
| id | select_type | table| partitions |
type | possible_keys
| key| key_len | ref| rows | filtered
| Extra |
+----+-------------+---------+------------+------+---------------
+----------+---------+-------+------+----------+-------+
|1 | SIMPLE| table_3 | NULL|
ref| idx_test
| idx_test | 23| const |1 |100.00
| NULL|
+----+-------------+---------+------------+------+---------------
+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> DESC SELECT * FROM table_3 WHERE user_name=null;
+----+-------------+-------+------------+------+---------------
+------+---------+------+------+----------+--------------------------------+
| id | select_type | table | partitions | type
| possible_keys
| key| key_len | ref| rows | filtered |
Extra|
+----+-------------+-------+------------+------+---------------
+------+---------+------+------+----------+--------------------------------+
|1 | SIMPLE| NULL| NULL| NULL
| NULL| NULL | NULL| NULL | NULL
|NULL | no matching row in const table
|
+----+-------------+-------+------------+------+---------------
+------+---------+------+------+----------+--------------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> DESC SELECT * FROM table_3 WHERE user_name
IS NULL;
+----+-------------+---------+------------+------+---------------
+----------+---------+-------+------+----------+-----------------------+
| id | select_type | table| partitions |
type | possible_keys | key| key_len |
ref| rows | filtered | Extra|
+----+-------------+---------+------------+------+---------------
+----------+---------+-------+------+----------+-----------------------+
|1 | SIMPLE| table_3 | NULL|
ref| idx_test| idx_test | 23|
const |1 |100.00 | Using index condition
|
+----+-------------+---------+------------+------+---------------
+----------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
<5>Null СаашвЊИќЖрЕФДцДЂПеМф : ашвЊвЛИіЖюЭтзжНкзїЮЊХаЖЯЪЧЗёЮЊ
NULL ЕФБъжОЮЛ
mysql> ALTER TABLE table_3 ADD INDEX idx_user_name(user_name);
mysql> ALTERTABLE table_2 ADD INDEXidx_user_name(user_name);
mysql> EXPLAIN SELECT * FROM table_2 WHERE
user_name='zhaoliu_2_1';
+----+-------------+---------+------------+------+---------------
+---------------+---------+-------+------+----------+-------+
| id | select_type | table| partitions |
type | possible_keys | key| key_len
| ref| rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------
+---------------+---------+-------+------+----------+-------+
|1 | SIMPLE| table_2 | NULL|
ref| idx_user_name | idx_user_name
| 22| const |1 |100.00 | NULL|
+----+-------------+---------+------------+------+---------------
+---------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> EXPLAIN SELECT * FROM table_3 WHERE
user_name='zhaoliu_2_1';
+----+-------------+---------+------------+------+------------------------
+----------+---------+-------+------+----------+-------+
| id | select_type | table| partitions |
type | possible_keys
| key| key_len | ref| rows | filtered
| Extra |
+----+-------------+---------+------------+------+------------------------
+----------+---------+-------+------+----------+-------+
|1 | SIMPLE| table_3 | NULL|
ref| idx_test,idx_user_name
| idx_test | 23| const |1 |100.00
| NULL|
+----+-------------+---------+------------+------+------------------------
+----------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
|
ПЩвдПДЕНЭЌбљЕФ varchar(20) ГЄЖШЃЌtable_2 вЊБШ table_3 Ыїв§ГЄЖШДѓЃЌетЪЧвђЮЊ
: СНеХБэЕФзжЗћМЏВЛвЛбљЃЌЧвзжЖЮвЛИіЮЊ NULL вЛИіЗЧ NULL
key_len ЕФМЦЫуЙцдђКЭШ§ИівђЫигаЙи : Ъ§ОнРраЭЁЂзжЗћБрТыЁЂЪЧЗёЮЊ NULL
table_3 НЈСЂЕФЫїв§дкПеМфЯћКФЩЯУцашвЊдіМгЖюЭтвЛИізжНкДцДЂЪ§ОнЪЧЗёЮЊ NULLЃЌЫљвдЫЕЫїв§зжЖЮзюКУВЛвЊЮЊ
NULLЃЌвђЮЊ NULLЛсЪЙЫїв§ЁЂЫїв§ЭГМЦКЭжЕИќМгИДдгЃЌВЂЧвашвЊЖюЭтвЛИізжНкЕФДцДЂПеМфЁЃЛљгквдЩЯетаЉРэгЩКЭдвђЃЌЫљвдВЛНЈвщЪЙгУ
NULL
10> Аб IPЕижЗ ДцГЩ INTUNSIGNEDЃЛШчЙћгУећаЮРДДцЗХЃЌжЛашвЊ4ИізжНкЃЌВЂЧвФуПЩвдгаЖЈГЄЕФзжЖЮЁЃЖјЧвЃЌетЛсЮЊФуДјРДВщбЏЩЯЕФгХЪЦЃЌгШЦфЪЧЕБашвЊЪЙгУетбљЕФ
WHEREЬѕМў : IP between ip1 and ip2
ХфКЯЪЙгУКѓУцСНИіКЏЪ§РДзЊЛЛipаХЯЂ : INET_ATONЃКНЋ IPЕижЗ зЊЛЛГЩЪ§зжаЭ
INET_NTOAЃКНЋЪ§зжаЭзЊЛЛГЩIPЕижЗ
11> В№ЗжДѓЕФ DELETE Лђ INSERT гяОфЃКгЩгкDELETEКЭ
INSERTВйзїЪБЛсЫјБэЕФЃЌБэвЛЫјзЁБ№ЕФВйзїЖМЮоЗЈНјааЃЌЖдгкЗУЮЪСПДѓЕФЭјеОЫљЛ§Рл НјГЬ/ЯпГЬ ЕФбгГйЛсШУWebЗўЮёCrashЃЌЛЙЛсЪЙетИіЗўЮёЦїЙвЕєЃЌвђДЫЯожЦвЛДЮЖдЪ§ОнПтЪ§ОнаоИФЕФДЮЪ§ЃЌЖдDELETEВЩгУLIMT
12> дНаЁЕФСаЛсдНПьЃКШчЙћвЛИіБэжЛЛсгаМИСаАеСЫ (БШШчЫЕзжЕфБэЃЌХфжУБэ)ЃЌФЧУДЃЌОЭУЛгаРэгЩЪЙгУ
INT РДзіжїМќЃЌЪЙгУ MEDIUMINT, SMALLINT ЛђЪЧИќаЁЕФ TINYINT ЛсИќОМУвЛаЉЁЃШчЙћВЛашвЊМЧТМЪБМфЃЌЪЙгУ
DATE вЊБШ DATETIME КУЕУЖр
зЂ : ашвЊСєЙЛзуЙЛЕФРЉеЙПеМфЃЌЗёдђШеКѓаоИФБэЪБЛсКмРЇФб
13> ЖдБэбЁдёе§ШЗЕФДцДЂв§ЧцЃК
MyISAM : ЪЪКЯгквЛаЉашвЊДѓСПВщбЏЕФгІгУЃЌЕЋЦфЖдгкгаДѓСПаДВйзїВЂВЛЪЧКмКУЃЌЩѕжСжЛЪЧашвЊ
update вЛИізжЖЮЃЌећИіБэЖМЛсБЛЫјЦ№РДЃЌЖјБ№ЕФНјГЬЃЌОЭЫуЪЧЖСНјГЬЖМЮоЗЈВйзїжБЕНЖСВйзїЭъГЩЁЃСэЭтЃЌMyISAM
Ждгк SELECT COUNT(*) етРрЕФМЦЫуЪЧГЌПьЮоБШЕФ
InnoDB : ЪЧвЛИіЗЧГЃИДдгЕФДцДЂв§ЧцЃЌЖдгквЛаЉаЁЕФгІгУЃЌЫќЛсБШ MyISAM ЛЙТ§ЁЃЫћЪЧЫќжЇГжЁАааЫјЁБ
ЃЌгкЪЧдкаДВйзїБШНЯЖрЕФЪБКђЃЌЛсИќгХауЁЃВЂЧвЃЌЫћЛЙжЇГжИќЖрЕФИпМЖгІгУЃЌБШШчЃКЪТЮё
14> гХЛЏВхШыМЧТМЕФЫйЖШ
<1> НћгУЫїв§ : ВхШыМЧТМЪБЫїв§ЛсЖдВхШыЕФМЧТМНјааХХађЃЌШєВхШыДѓСПЪ§ОнЪБЃЌетаЉХХађЛсНЕЕЭВхШыЪ§ОнЕФЫйЖШЃЌвђДЫдкВхШыДѓСПЪ§ОнЪБЃЌЯШНћгУЫїв§ЃЌД§ВхШыЪ§ОнЭъБЯдйПЊЦєЫїв§
НћгУЫїв§ЕФгяОф : ALTER TABLE БэУћ DISABLE KEYS;
жиаТПЊЦєЫїв§ЕФгяОф : ALTER TABLE БэУћ ENABLE KEYS;
<2> НћгУЮЈвЛадМьВщ : ВхШыМЧТМЪБЯЕЭГЛсНјааЮЈвЛадаЃбщЃЌаЃбщЛсНЕЕЭВхШыМЧТМЕФЫйЖШЃЌПЩвддкВхШыМЧТМжЎЧАНћгУЮЈвЛадМьВщЃЌД§ВхШыЪ§ОнЭъБЯдйПЊЦє
НћгУЮЈвЛадМьВщЕФгяОф :SET UNIQUE_CHECKS=0;
жиаТПЊЦєЮЈвЛадМьВщЕФгяОф :SET UNIQUE_CHECKS=1;
<3> гХЛЏINSERTгяОф : ЕБВхШыЖрЬѕЪ§ОнЪБЃЌЭЈЙ§вЛЬѕВхШыгяОфБШЗжЖрЬѕВхШыгяОфжДаааЇТЪЫйЖШПьКмЖрЃЌетЪЧгЩгкМѕЩйгыЪ§ОнПтжЎМфЕФСЌНгЕШВйзїЃЌвђДЫФмЪЙгУ
LOAD DATA INFILEгяОфБШ INSERTгяОфЫйЖШПь
<4>дкЪТЮёжаНјааВхШыДІРэЃЌНјаавЛИі INSERT ВйзїЪБЃЌMySQLФкВПЛсНЈСЂвЛИіЪТЮёЃЌдкЪТЮёФкВХНјааеце§ВхШыДІРэВйзїЁЃЭЈЙ§ЪЙгУЪТЮёПЩвдМѕЩйДДНЈЪТЮёЕФЯћКФЃЌЫљгаВхШыЖМдкжДааКѓВХНјааЬсНЛВйзїЃЌвђДЫВЩгУЪТЮёВйзїПЩЬсИпВхШыЪ§ОнЕФЫйЖШ
<5> ВхШыЪ§ОнЪЧгаађЕФЃЌетбљПЩМѕЩйЫїв§ЕФЮЌЛЄГЩБО
зЂ :КЯВЂЪ§Он+ЪТЮё+гаађЪ§ОнЕФЗНЪНдкЪ§ОнСПДяЕНЧЇЭђМЖвдЩЯБэЯжвРОЩЪЧСМКУЃЌдкЪ§ОнСПНЯДѓЪБЃЌгаађЪ§ОнЫїв§ЖЈЮЛНЯЮЊЗНБуЃЌВЛашвЊЦЕЗБЖдДХХЬНјааЖСаДВйзїЃЌЫљвдПЩвдЮЌГжНЯИпЕФадФм
15> ЗжЮіБэЁЂМьВщБэКЭгХЛЏБэ
<1>ЗжЮіБэЃЌгяЗЈИёЪН : ANALYZE TABLE БэУћ1[,БэУћ2,...];
ЗЕЛиЕФНсЙћ
Table : БэЪОБэЕФУћГЦ
Op : БэЪОжДааЕФВйзїЃЛanalyze БэЪОНјааЗжЮіВйзїЃЛcheck БэЪОНјааМьВщВщевЃЛoptimize
БэЪОНјаагХЛЏВйзї
Msg_type : БэЪОаХЯЂРраЭЃЌЦфЯдЪОЕФжЕЭЈГЃЪЧзДЬЌЁЂОЏИцЁЂДэЮѓКЭаХЯЂетЫФепжЎвЛ
Msg_text : ЯдЪОаХЯЂ
<2>МьВщБэЃЌгяЗЈИёЪН : CHECK TABLE БэУћ1[,БэУћ2...][option];
optionВЮЪ§га5ИіВЮЪ§ЗжБ№ЪЧ QUICKЁЂFASTЁЂCHANGEDЁЂMEDIUMКЭEXTENDEDЃЌет5ИіВЮЪ§ЕФжДаааЇТЪвРДЮНЕЕЭ
зЂ : optionбЁЯюжЛЖд MyISAM РраЭЕФБэгааЇЃЌЖд InnoDBРраЭЕФБэЮоаЇЃЌCHECK
TABLEгяОфдкжДааЙ§ГЬжаЛсИјБэМгЩЯжЛЖСЫј
<3> гХЛЏБэЃЌЪЙгУOPTIMIZE TABLEгяОфРДгХЛЏБэЃЌИУгяОфжЛЖд InnoDB
КЭ MyISAMРраЭЕФБэгааЇЃЌЧвИУгяОфжЛФмгХЛЏVARCHARЁЂBLOBЛђTEXTРраЭЕФзжЖЮЃЌИУгяОфПЩвдЯћГ§ЩОГ§КЭИќаТдьГЩЕФДХХЬЫщЦЌДгЖјМѕЩйПеМфЕФРЫЗбЃЌгяЗЈИёЪН
: OPTIMIZE TABLE БэУћ1[,БэУћ2...];
16>ОЁСПЪЙгУ TIMESTAMP Жј ЗЧDATETIME
17> ВЛгУЭтМќЃЌгЩГЬађБЃжЄдМЪјЃЛОЁСПВЛгУUNIQUEЃЌгЩГЬађБЃжЄдМЪј
18>ORИФаДГЩIN : ORЕФаЇТЪЪЧnМЖБ№ЃЌINЕФаЇТЪЪЧ log(n)МЖБ№ЃЌinЕФИіЪ§НЈвщПижЦдк200вдФк
19>ЖдгкСЌајЪ§жЕЃЌЪЙгУ BETWEEN ВЛгУ IN : SELECT id FROM t
WHERE num BETWEEN 1 AND 5
20> гХЛЏ MySQLЗўЮёЦїЃЌВЩгУЪ§ОнПтжїДгЕФаЮЪННЋЪ§ОнПтНјааЖСаДЗжРы
21>ОЋШЗЖШгыПеМфЕФзЊЛЛЁЃдкДцДЂЯрЭЌЪ§жЕЗЖЮЇЕФЪ§ОнЪБЃЌИЁЕуЪ§РраЭЭЈГЃЖМЛсБШ DECIMALРраЭЪЙгУИќЩйЕФПеМфЁЃFLOATзжЖЮЪЙгУ4зжНкДцДЂЪ§ОнЁЃDOUBLEРраЭашвЊ8ИізжНкВЂгЕгаИќИпЕФОЋШЗЖШКЭИќДѓЕФЪ§жЕЗЖЮЇЃЌDECIMALРраЭЕФЪ§ОнНЋЛсзЊЛЛГЩDOUBLEРраЭ
22>ЯЕЭГХфжУгыЮЌЛЄгХЛЏ
<1> живЊЕФвЛаЉБфСП
key_buffer_size Ыїв§ПщЛКДцЧјДѓаЁЃЌеыЖд MyISAMДцДЂв§ЧцЃЌИУжЕдНДѓЃЌадФмдНКУЃЌЕЋЪЧГЌЙ§ВйзїЯЕЭГФмГаЪмЕФзюДѓжЕЃЌЗДЖјЛсЪЙ
mysql БфЕУВЛЮШЖЈ
sort_buffer_size етЪЧЫїв§дкХХађЛКГхЧјДѓаЁЃЌШєХХађЪ§ОнДѓаЁГЌЙ§ИУжЕЃЌдђДДНЈСйЪБЮФМўЃЌзЂвтКЭ
myisam_sort_buffer_sizeЕФЧјБ№
read_rnd_buffer_size ЕБХХађКѓАДХХађКѓЕФЫГађЖСШЁааЪБЃЌдђЭЈЙ§ИУЛКГхЧјЖСШЁааЃЌБмУтЫбЫїгВХЬЁЃНЋИУБфСПЩшжУЮЊНЯДѓЕФжЕПЩвдДѓДѓИФНј
ORDER BY ЕФадФмЁЃЕЋЪЧЃЌетЪЧЮЊУПИіПЭЛЇЖЫЗжХфЕФЛКГхЧјЃЌвђДЫФуВЛгІНЋШЋОжБфСПЩшжУЮЊНЯДѓЕФжЕЁЃЯрЗДЃЌжЛЮЊашвЊдЫааДѓВщбЏЕФПЭЛЇЖЫИќИФЛсЛАБфСП
join_buffer_size гУгкБэМфЙиСЊ(join)ЕФЛКДцДѓаЁ
tmp_table_size ЛКДцБэЕФДѓаЁ
table_cache дЪаэ MySQL ДђПЊЕФБэЕФзюДѓИіЪ§ЃЌВЂЧветаЉЖМ cache дкФкДцжа
delay_key_write еыЖд MyISAMДцДЂв§ЧцЃЌбгГйИќаТЫїв§ЃЌвтЫМЪЧЫЕЃЌupdateМЧТМЪБЃЌЯШНЋЪ§ОнupЕНДХХЬЃЌЕЋВЛupЫїв§ЃЌНЋЫїв§ДцдкФкДцРяЃЌЕББэЙиБеЪБЃЌНЋФкДцЫїв§ЃЌаДЕНДХХЬ
22> ЦфЫћММЧЩ
<1> ОЁСПЪЙгУcount(*) МЦЫуЪ§СП :СаЕФЦЋвЦСПОіЖЈадФмЃЌСадНППКѓЃЌЗУЮЪЕФПЊЯњдНДѓЁЃгЩгкcount(*)
ЕФЫуЗЈгыСаЦЋвЦСПЮоЙиЃЌЫљвд count(*) зюПьЃЌcount(зюКѓСа)зюТ§
<2>ЕЅЪЕР§ЛђепЕЅНкЕузщ :зддіIDЯрЖдUUIDРДЫЕЃЌзддіIDжїМќадФмИпгкUUIDЃЌДХХЬДцДЂЗбгУБШUUIDНкЪЁвЛАыЕФЧЎЃЌЫљвддкЕЅЪЕР§ЩЯЛђепЕЅНкЕузщЩЯЃЌЪЙгУздді
ID зїЮЊЪзбЁжїМќ
ЗжВМЪНМмЙЙГЁОА : 20ИіНкЕузщЯТЕФаЁаЭЙцФЃЕФЗжВМЪНГЁОАЃЌЮЊСЫПьЫйЪЕЯжВПЪ№ЃЌПЩвдВЩгУЖрЛЈДцДЂЗбгУЁЂЮўЩќВПЗжадФмЖјЪЙгУ
UUID жїМќПьЫйВПЪ№ЃЛ20ЕН200ИіНкЕузщЕФжаЕШЙцФЃЕФЗжВМЪНГЁОАЃЌПЩвдВЩгУ зддіID+ВНГЄЕФНЯПьЫйЗНАИЃЛ200вдЩЯНкЕузщЕФДѓЪ§ОнЯТЕФЗжВМЪНГЁОАЃЌПЩвдНшМјРрЫЦ
twitterбЉЛЈЫуЗЈЙЙдьЕФШЋОж зддіID зїЮЊжїМќ
| 








