| БрМЭЦМі: |
| БОЮФРДздгкcsdn,жївЊНВНтЪ§ОнПтЗУЮЪадФмгХЛЏЕФЗНЗЈЃЌИДдгдЫЫудкПЭЛЇЖЫДІРэНЈвщЕШЯрЙиЁЃ |
|
ЫљгаЪ§ОнПтАќРЈOracleЕФsqlгХЛЏЖМЪЧеыЖдГЬађдБЕФЃЌЖјВЛЪЧеыЖдdbaЕФЃЌЕквЛЃЌОЁСПЗРжЙФЃК§ЃЌУїШЗжИГіЃЌМДгУСаУћДњЬц*ЃЌЕкЖўЃЌдкwhereгяОфЩЯЯТЙЄЗђЁЃЕкШ§ЖрБэВщбЏКЭзгВщбЏЃЌЕкЫФОЁСПЪЙгУАѓЖЈЁЃ

ИљОнМЦЫуЛњгВМўЕФЛљБОадФмжИБъМАЦфдкЪ§ОнПтжажївЊВйзїФкШнЃЌПЩвдећРэГіШчЯТЭМЫљЪОЕФадФмЛљБОгХЛЏЗЈдђЃК
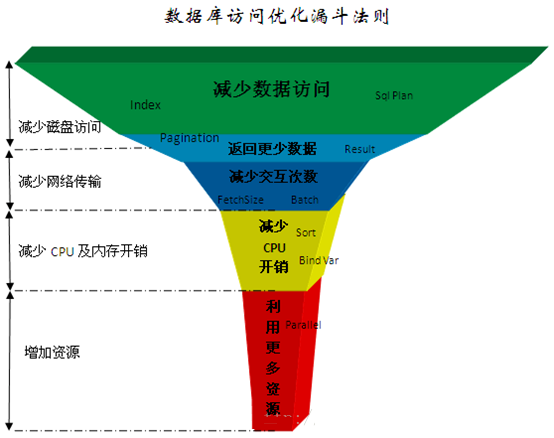
етИігХЛЏЗЈдђЙщФЩЮЊ5ИіВуДЮЃК
1ЁЂМѕЩйЪ§ОнЗУЮЪЃЈМѕЩйДХХЬЗУЮЪЃЉ
2ЁЂЗЕЛиИќЩйЪ§ОнЃЈМѕЩйЭјТчДЋЪфЛђДХХЬЗУЮЪЃЉ
3ЁЂМѕЩйНЛЛЅДЮЪ§ЃЈМѕЩйЭјТчДЋЪфЃЉ
4ЁЂМѕЩйЗўЮёЦїCPUПЊЯњЃЈМѕЩйCPUМАФкДцПЊЯњЃЉ
5ЁЂРћгУИќЖрзЪдДЃЈдіМгзЪдДЃЉ
гЩгкУПвЛВугХЛЏЗЈдђЖМЪЧНтОіЦфЖдгІгВМўЕФадФмЮЪЬтЃЌЫљвдДјРДЕФадФмЬсЩ§БШР§вВВЛвЛбљЁЃДЋЭГЪ§ОнПтЯЕЭГЩшМЦЪЧвВЪЧОЁПЩФмЖдЕЭЫйЩшБИЬсЙЉгХЛЏЗНЗЈЃЌвђДЫеыЖдЕЭЫйЩшБИЮЪЬтЕФПЩгХЛЏЪжЖЮвВИќЖрЃЌгХЛЏГЩБОвВИќЕЭЁЃЮвУЧШЮКЮвЛИіSQLЕФадФмгХЛЏЖМгІИУАДетИіЙцдђгЩЩЯЕНЯТРДеяЖЯЮЪЬтВЂЬсГіНтОіЗНАИЃЌЖјВЛгІИУЪзЯШЯыЕНЕФЪЧдіМгзЪдДНтОіЮЪЬтЁЃ
вдЯТЪЧУПИігХЛЏЗЈдђВуМЖЖдгІгХЛЏаЇЙћМАГЩБООбщВЮПМЃК
| гХЛЏЗЈдђ |
адФмЬсЩ§аЇЙћ |
гХЛЏГЩБО |
| МѕЩйЪ§ОнЗУЮЪ |
1~1000 |
ЕЭ |
| ЗЕЛиИќЩйЪ§Он |
1~100 |
ЕЭ |
| МѕЩйНЛЛЅДЮЪ§ |
1~20 |
ЕЭ |
| МѕЩйЗўЮёЦїCPUПЊЯњ |
1~5 |
ЕЭ |
| РћгУИќЖрзЪдД |
@~10 |
Ип |
1 МѕЩйЪ§ОнЗУЮЪ
1.1 ДДНЈВЂЪЙгУе§ШЗЕФЫїв§
Ъ§ОнПтЫїв§ЕФдРэЗЧГЃМђЕЅЃЌЕЋдкИДдгЕФБэжаеце§Фме§ШЗЪЙгУЫїв§ЕФШЫКмЩйЃЌМДЪЙЪЧзЈвЕЕФDBAвВВЛвЛЖЈФмЭъШЋзіЕНзюгХЁЃ
Ыїв§ЛсДѓДѓдіМгБэМЧТМЕФDML(INSERT,UPDATE,DELETE)ПЊЯњЃЌе§ШЗЕФЫїв§ПЩвдШУадФмЬсЩ§100ЃЌ1000БЖвдЩЯЃЌВЛКЯРэЕФЫїв§вВПЩФмЛсШУадФмЯТНЕ100БЖЃЌвђДЫдквЛИіБэжаДДНЈЪВУДбљЕФЫїв§ашвЊЦНКтИїжжвЕЮёашЧѓЁЃ
вЛЁЂSQLЪВУДЬѕМўЛсЪЙгУЫїв§ЃП
ЕБзжЖЮЩЯНЈгаЫїв§ЪБЃЌЭЈГЃвдЯТЧщПіЛсЪЙгУЫїв§ЃК
INDEX_COLUMN = ?
INDEX_COLUMN > ?
INDEX_COLUMN >= ?
INDEX_COLUMN < ?
INDEX_COLUMN <= ?
INDEX_COLUMN between ? and ?
INDEX_COLUMN in (?,?,...,?)
INDEX_COLUMN like ?||'%'ЃЈКѓЕМФЃК§ВщбЏЃЉ
T1. INDEX_COLUMN=T2. COLUMN1ЃЈСНИіБэЭЈЙ§Ыїв§зжЖЮЙиСЊЃЉ
ЖўЁЂSQLЪВУДЬѕМўВЛЛсЪЙгУЫїв§ЃП
|
ВщбЏЬѕМў |
ВЛФмЪЙгУЫїв§двђ |
INDEX_COLUMN
<> ?
INDEX_COLUMN not in (?,?,...,?) |
ВЛЕШгкВйзїВЛФмЪЙгУЫїв§ |
function(INDEX_COLUMN)
= ?
INDEX_COLUMN + 1 = ?
INDEX_COLUMN || 'a' = ? |
ОЙ§ЦеЭЈдЫЫуЛђКЏЪ§дЫЫуКѓЕФЫїв§зжЖЮВЛФмЪЙгУЫїв§ |
INDEX_COLUMN
like '%'||?
INDEX_COLUMN like '%'||?||'%' |
КЌЧАЕМФЃК§ВщбЏЕФLikeгяЗЈВЛФмЪЙгУЫїв§ |
| INDEX_COLUMN
is null |
B-TREEЫїв§РяВЛБЃДцзжЖЮЮЊNULLжЕМЧТМЃЌвђДЫIS
NULLВЛФмЪЙгУЫїв§ |
NUMBER_INDEX_COLUMN='12345'
CHAR_INDEX_COLUMN=12345 |
OracleдкзіЪ§жЕБШНЯЪБашвЊНЋСНБпЕФЪ§ОнзЊЛЛГЩЭЌвЛжжЪ§ОнРраЭЃЌШчЙћСНБпЪ§ОнРраЭВЛЭЌЪБЛсЖдзжЖЮ
жЕвўЪНзЊЛЛЃЌЯрЕБгкМгСЫвЛВуКЏЪ§ДІРэЃЌЫљвдВЛФмЪЙгУЫїв§ЁЃ |
| a.INDEX_COLUMN=a.COLUMN_1 |
ИјЫїв§ВщбЏЕФжЕгІЪЧвбжЊЪ§ОнЃЌВЛФмЪЧЮДжЊзжЖЮжЕЁЃ |
зЂЃКОЙ§КЏЪ§дЫЫузжЖЮЕФзжЖЮвЊЪЙгУПЩвдЪЙгУКЏЪ§Ыїв§ЃЌетжжашЧѓНЈвщгыDBAЙЕЭЈЁЃ
гаЪБКђЮвУЧЛсЪЙгУЖрИізжЖЮЕФзщКЯЫїв§ЃЌШчЙћВщбЏЬѕМўжаЕквЛИізжЖЮВЛФмЪЙгУЫїв§ЃЌФЧећИіВщбЏвВВЛФмЪЙгУЫїв§ЁЃ
ШчЃКЮвУЧcompanyБэНЈСЫвЛИіid+nameЕФзщКЯЫїв§ЃЌвдЯТSQLЪЧВЛФмЪЙгУЫїв§ЕФ
Select * from company where name=?
Oracle9iКѓв§ШыСЫвЛжжindex skip scanЕФЫїв§ЗНЪНРДНтОіРрЫЦЕФЮЪЬтЃЌЕЋЪЧЭЈЙ§index
skip scanЬсИпадФмЕФЬѕМўБШНЯЬиЪтЃЌЪЙгУВЛКУЗДЖјадФмЛсИќВюЁЃ |
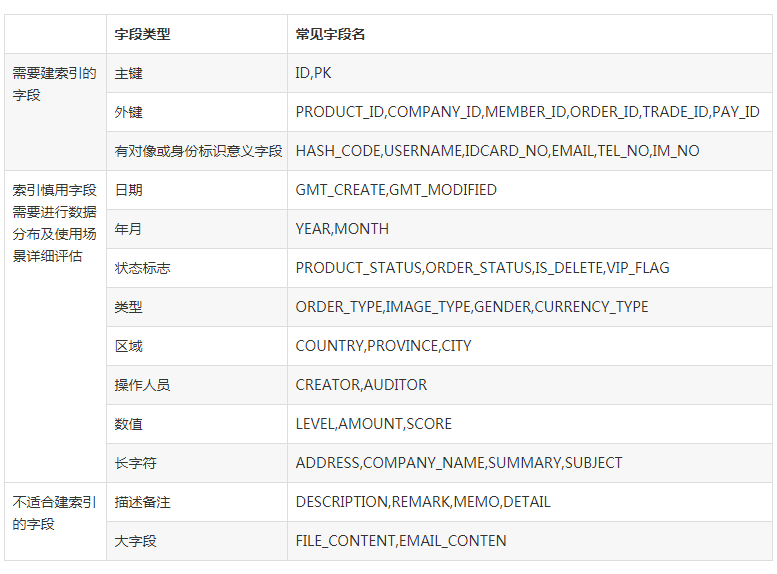
Ш§ЁЂЮвУЧвЛАудкЪВУДзжЖЮЩЯНЈЫїв§ЃП
етЪЧвЛИіЗЧГЃИДдгЕФЛАЬтЃЌашвЊЖдвЕЮёМАЪ§ОнГфЗжЗжЮіКѓдйФмЕУГіНсЙћЁЃжїМќМАЭтМќЭЈГЃЖМвЊгаЫїв§ЃЌЦфЫќашвЊНЈЫїв§ЕФзжЖЮгІТњзувдЯТЬѕМўЃК
1ЁЂзжЖЮГіЯждкВщбЏЬѕМўжаЃЌВЂЧвВщбЏЬѕМўПЩвдЪЙгУЫїв§ЃЛ
2ЁЂгяОфжДааЦЕТЪИпЃЌвЛЬьЛсгаМИЧЇДЮвдЩЯЃЈВЂЗЂВтЪдБиаыгаЫїв§ЃЉЃЛ
3ЁЂЭЈЙ§зжЖЮЬѕМўПЩЩИбЁЕФМЧТММЏКмаЁЃЌФЧЪ§ОнЩИбЁБШР§ЪЧЖрЩйВХЪЪКЯЃП
етИіУЛгаЙЬЖЈжЕЃЌашвЊИљОнБэЪ§ОнСПРДЦРЙРЃЌвдЯТЪЧОбщЙЋЪНЃЌПЩгУгкПьЫйЦРЙРЃК
аЁБэ(МЧТМЪ§аЁгк10000ааЕФБэ)ЃКЩИбЁБШР§<10%ЃЛ
ДѓБэЃК(ЩИбЁЗЕЛиМЧТМЪ§)<(БэзмМЧТМЪ§*ЕЅЬѕМЧТМГЄЖШ)/10000/16
ЕЅЬѕМЧТМГЄЖШЁжзжЖЮЦНОљФкШнГЄЖШжЎКЭ+зжЖЮЪ§*2
вдЯТЪЧвЛаЉзжЖЮЪЧЗёашвЊНЈB-TREEЫїв§ЕФОбщЗжРрЃК
ЫФЁЂШчКЮжЊЕРSQLЪЧЗёЪЙгУСЫе§ШЗЕФЫїв§ЃП
МђЕЅSQLПЩвдИљОнЫїв§ЪЙгУгяЗЈЙцдђХаЖЯЃЌИДдгЕФSQLВЛКУАьЃЌХаЖЯSQLЕФЯьгІЪБМфЪЧвЛжжВпТдЃЌЕЋЪЧетЛсЪмЕНЪ§ОнСПЁЂжїЛњИКдиМАЛКДцЕШвђЫиЕФгАЯьЃЌгаЪБЪ§ОнШЋдкЛКДцРяЃЌПЩФмШЋБэЗУЮЪЕФЪБМфБШЫїв§ЗУЮЪЪБМфЛЙЩйЁЃвЊзМШЗжЊЕРЫїв§ЪЧЗёе§ШЗЪЙгУЃЌашвЊЕНЪ§ОнПтжаВщПДSQLецЪЕЕФжДааМЦЛЎЃЌетИіЛАЬтБШНЯИДдгЃЌЯъМћSQLжДааМЦЛЎзЈЬтНщЩмЁЃ
вдЯТЪЧжДааМЦЛЎЛёШЁЗНЪНЃК
select SQL_TEXT,SQL_ID,OPTIMIZER_MODE,parsing_schema_name,LAST_ACTIVE_TIME
from V$SQLAREA;
select*fromtable(dbms_xplan.display_cursor('gsyvkdr40w01r'));----gsyvkdr40w01rЮЊSQL_ID
ЮхЁЂЫїв§ЖдDML(INSERT,UPDATE,DELETE)ИНМгЕФПЊЯњгаЖрЩйЃП
етИіУЛгаЙЬЖЈЕФБШР§ЃЌгыУПИіБэМЧТМЕФДѓаЁМАЫїв§зжЖЮДѓаЁУмЧаЯрЙиЃЌвдЯТЪЧвЛИіЦеЭЈБэВтЪдЪ§ОнЃЌНіЙЉВЮПМЃК
Ыїв§ЖдгкInsertадФмНЕЕЭ56%
Ыїв§ЖдгкUpdateадФмНЕЕЭ47%
Ыїв§ЖдгкDeleteадФмНЕЕЭ29%
вђДЫЖдгкаДIOбЙСІБШНЯДѓЕФЯЕЭГЃЌБэЕФЫїв§ашвЊзаЯИЦРЙРБивЊадЃЌСэЭтЫїв§вВЛсеМгУвЛЖЈЕФДцДЂПеМфЁЃ
1.2 жЛЭЈЙ§Ыїв§ЗУЮЪЪ§Он
гааЉЪБКђЃЌЮвУЧжЛЪЧЗУЮЪБэжаЕФМИИізжЖЮЃЌВЂЧвзжЖЮФкШнНЯЩйЃЌЮвУЧПЩвдЮЊетМИИізжЖЮЕЅЖРНЈСЂвЛИізщКЯЫїв§ЃЌетбљОЭПЩвджБНгжЛЭЈЙ§ЗУЮЪЫїв§ОЭФмЕУЕНЪ§ОнЃЌвЛАуЫїв§еМгУЕФДХХЬПеМфБШБэаЁКмЖрЃЌЫљвдетжжЗНЪНПЩвдДѓДѓМѕЩйДХХЬIOПЊЯњЁЃ
ШчЃКselect id,name from company where type='2';
ШчЙћетИіSQLОГЃЪЙгУЃЌЮвУЧПЩвддкtype,id,nameЩЯДДНЈзщКЯЫїв§
create index my_comb_index on company(type,id,name);
гаСЫетИізщКЯЫїв§КѓЃЌSQLОЭПЩвджБНгЭЈЙ§my_comb_indexЫїв§ЗЕЛиЪ§ОнЃЌВЛашвЊЗУЮЪcompanyБэЁЃ
ЛЙЪЧФУзжЕфОйР§ЃКгавЛИіашЧѓЃЌашвЊВщбЏвЛБОККгязжЕфжаЫљгаККзжЕФИіЪ§ЃЌШчЙћЮвУЧЕФзжЕфУЛгаФПТМЫїв§ЃЌФЧЮвУЧжЛФмДгзжЕфФкШнРявЛИівЛИізжМЦЪ§ЃЌзюКѓЗЕЛиНсЙћЁЃШчЙћЮвУЧгавЛИіЦДвєФПТМЃЌФЧОЭПЩвджЛЗУЮЪЦДвєФПТМЕФККзжНјааМЦЪ§ЁЃШчЙћвЛБОзжЕфга1000вГЃЌЦДвєФПТМга20вГЃЌФЧЮвУЧЕФЪ§ОнЗУЮЪГЩБОЯрЕБгкШЋБэЗУЮЪЕФ50ЗжжЎвЛЁЃ
ЧаМЧЃЌадФмгХЛЏЪЧЮожЙОГЕФЃЌЕБадФмПЩвдТњзуашЧѓЪБМДПЩЃЌВЛвЊЙ§ЖШгХЛЏЁЃдкЪЕМЪЪ§ОнПтжаЮвУЧВЛПЩФмАбУПИіSQLЧыЧѓЕФзжЖЮЖМНЈдкЫїв§РяЃЌЫљвдетжжжЛЭЈЙ§Ыїв§ЗУЮЪЪ§ОнЕФЗНЗЈвЛАужЛгУгкКЫаФгІгУЃЌвВОЭЪЧФЧжжЖдКЫаФБэЗУЮЪСПзюИпЧвВщбЏзжЖЮЪ§ОнСПКмЩйЕФВщбЏЁЃ
1.3 гХЛЏSQLжДааМЦЛЎ
SQLжДааМЦЛЎЪЧЙиЯЕаЭЪ§ОнПтзюКЫаФЕФММЪѕжЎвЛЃЌЫќБэЪОSQLжДааЪБЕФЪ§ОнЗУЮЪЫуЗЈЁЃгЩгквЕЮёашЧѓдНРДдНИДдгЃЌБэЪ§ОнСПвВдНРДдНДѓЃЌГЬађдБдНРДдНРСЖшЃЌSQLвВашвЊжЇГжЗЧГЃИДдгЕФвЕЮёТпМЃЌЕЋSQLЕФадФмЛЙашвЊЬсИпЃЌвђДЫЃЌгХауЕФЙиЯЕаЭЪ§ОнПтГ§СЫашвЊжЇГжИДдгЕФSQLгяЗЈМАИќЖрКЏЪ§ЭтЃЌЛЙашвЊгавЛЬзгХауЕФЫуЗЈПтРДЬсИпSQLадФмЁЃ
ФПЧАORACLEгаSQLжДааМЦЛЎЕФЫуЗЈдМ300жжЃЌЖјЧввЛжБдкдіМгЃЌЫљвдSQLжДааМЦЛЎЪЧвЛИіЗЧГЃИДдгЕФПЮЬтЃЌвЛИіЦеЭЈDBAФмеЦЮе50жжОЭКмВЛДэСЫЃЌОЭЫуЪЧзЪЩюDBAвВВЛПЩФмАбУПИіжДааМЦЛЎЕФЫуЗЈУшЪіЧхГўЁЃЫфШЛгаетУДЖржжЫуЗЈЃЌЕЋВЂВЛБэЪОЮвУЧЮоЗЈгХЛЏжДааМЦЛЎЃЌвђЮЊЮвУЧГЃгУЕФSQLжДааМЦЛЎЫуЗЈвВОЭЪЎМИИіЃЌШчЙћвЛИіГЬађдБФмАбетЪЎМИИіЫуЗЈИуЧхГўЃЌФЧОЭеЦЮеСЫ80%ЕФSQLжДааМЦЛЎЕїгХжЊЪЖЁЃ
ЭЦМіЪЙгУЕФSQLжДааМЦЛЎгХЛЏЙЄОпЃКDell SQL Optimizer for Oracle
2 ЗЕЛиИќЩйЕФЪ§Он
2.1 Ъ§ОнЗжвГДІРэ
вЛАуЪ§ОнЗжвГЗНЪНгаЃК
1ЁЂПЭЛЇЖЫ(гІгУГЬађЛђфЏРРЦї)ЗжвГ
НЋЪ§ОнДггІгУЗўЮёЦїШЋВПЯТдиЕНБОЕигІгУГЬађЛђфЏРРЦїЃЌдкгІгУГЬађЛђфЏРРЦїФкВПЭЈЙ§БОЕиДњТыНјааЗжвГДІРэ
гХЕуЃКБрТыМђЕЅЃЌМѕЩйПЭЛЇЖЫгыгІгУЗўЮёЦїЭјТчНЛЛЅДЮЪ§
ШБЕуЃКЪзДЮНЛЛЅЪБМфГЄЃЌеМгУПЭЛЇЖЫФкДц
ЪЪгІГЁОАЃКПЭЛЇЖЫгыгІгУЗўЮёЦїЭјТчбгЪБНЯДѓЃЌЕЋвЊЧѓКѓајВйзїСїГЉЃЌШчЪжЛњGPRSЃЌГЌдЖГЬЗУЮЪЃЈПчЙњЃЉЕШЕШЁЃ
2ЁЂгІгУЗўЮёЦїЗжвГ
НЋЪ§ОнДгЪ§ОнПтЗўЮёЦїШЋВПЯТдиЕНгІгУЗўЮёЦїЃЌдкгІгУЗўЮёЦїФкВПдйНјааЪ§ОнЩИбЁЁЃвдЯТЪЧвЛИігІгУЗўЮёЦїЖЫJavaГЬађЗжвГЕФЪОР§ЃК
List list=executeQuery(ЁАselect * from employee order
by idЁБ);
Int count= list.size();
List subList= list.subList(10, 20);
гХЕуЃКБрТыМђЕЅЃЌжЛашвЊвЛДЮSQLНЛЛЅЃЌзмЪ§ОнгыЗжвГЪ§ОнВюВЛЖрЪБадФмНЯКУЁЃ
ШБЕуЃКзмЪ§ОнСПНЯЖрЪБадФмНЯВюЁЃ
ЪЪгІГЁОАЃКЪ§ОнПтЯЕЭГВЛжЇГжЗжвГДІРэЃЌЪ§ОнСПНЯаЁВЂЧвПЩПиЁЃ
3ЁЂЪ§ОнПтSQLЗжвГ
ВЩгУЪ§ОнПтSQLЗжвГашвЊСНДЮSQLЭъГЩ
вЛИіSQLМЦЫузмЪ§СП
вЛИіSQLЗЕЛиЗжвГКѓЕФЪ§Он
гХЕуЃКадФмКУ
ШБЕуЃКБрТыИДдгЃЌИїжжЪ§ОнПтгяЗЈВЛЭЌЃЌашвЊСНДЮSQLНЛЛЅЁЃ
oracleЪ§ОнПтвЛАуВЩгУrownumРДНјааЗжвГЃЌГЃгУЗжвГгяЗЈгаШчЯТСНжжЃК
ЃЈ1ЃЉжБНгЭЈЙ§rownumЗжвГЃК
select*from(
select a.*,rownum rn from
(select*from product a where company_id=?
orderby status) a
whererownum<=20)
where rn>10; |
Ъ§ОнЗУЮЪПЊЯњ=Ыїв§IO+Ыїв§ШЋВПМЧТМНсЙћЖдгІЕФБэЪ§ОнIO
ЃЈ2ЃЉВЩгУrowidЗжвГгяЗЈ
гХЛЏдРэЪЧЭЈЙ§ДПЫїв§евГіЗжвГМЧТМЕФROWIDЃЌдйЭЈЙ§ROWIDЛиБэЗЕЛиЪ§ОнЃЌвЊЧѓФкВуВщбЏКЭХХађзжЖЮШЋдкЫїв§РяЁЃ
createindex
myindex on product(company_id,status);
select b.*from(
select*from(
select a.*,rownum rn from
(selectrowid rid,status from product a where
company_id=? orderby status) a
whererownum<=20)
where rn>10) a, product b
wherea.rid=b.rowid; |
Ъ§ОнЗУЮЪПЊЯњ=Ыїв§IO+Ыїв§ЗжвГНсЙћЖдгІЕФБэЪ§ОнIO
ЪЕР§ЃК
вЛИіЙЋЫОВњЦЗга1000ЬѕМЧТМЃЌвЊЗжвГШЁЦфжа20ИіВњЦЗЃЌМйЩшЗУЮЪЙЋЫОЫїв§ашвЊ50ИіIOЃЌ2ЬѕМЧТМашвЊ1ИіБэЪ§ОнIOЁЃ
ФЧУДАДЕквЛжжROWNUMЗжвГаДЗЈЃЌашвЊ550(50+1000/2)ИіIOЃЌАДЕкЖўжжROWIDЗжвГаДЗЈЃЌжЛашвЊ60ИіIO(50+20/2);
2.2 жЛЗЕЛиашвЊЕФзжЖЮ
ЭЈЙ§ШЅГ§ВЛБивЊЕФЗЕЛизжЖЮПЩвдЬсИпадФмЃЌР§ЃК
ЕїећЧАЃКselect * from product where company_id=?;
ЕїећКѓЃКselect id,name from product where company_id=?;
гХЕуЃК
1ЁЂМѕЩйЪ§ОндкЭјТчЩЯДЋЪфПЊЯњ
2ЁЂМѕЩйЗўЮёЦїЪ§ОнДІРэПЊЯњ
3ЁЂМѕЩйПЭЛЇЖЫФкДцеМгУ
4ЁЂзжЖЮБфИќЪБЬсЧАЗЂЯжЮЪЬтЃЌМѕЩйГЬађBUG
5ЁЂШчЙћЗУЮЪЕФЫљгазжЖЮИеКУдквЛИіЫїв§РяУцЃЌдђПЩвдЪЙгУДПЫїв§ЗУЮЪЬсИпадФмЁЃ
ШБЕуЃКдіМгБрТыЙЄзїСП
гЩгкЛсдіМгвЛаЉБрТыЙЄзїСПЃЌЫљвдвЛАуашЧѓЭЈЙ§ПЊЗЂЙцЗЖРДвЊЧѓГЬађдБетУДзіЃЌЗёдђЕШЯюФПЩЯЯпКѓдйећИФЙЄзїСПИќДѓЁЃ
ШчЙћФуЕФВщбЏБэжагаДѓзжЖЮЛђФкШнНЯЖрЕФзжЖЮЃЌШчБИзЂаХЯЂЁЂЮФМўФкШнЕШЕШЃЌФЧдкВщбЏБэЪБвЛЖЈвЊзЂвтетЗНУцЕФЮЪЬтЃЌЗёдђПЩФмЛсДјРДбЯжиЕФадФмЮЪЬтЁЃШчЙћБэОГЃвЊВщбЏВЂЧвЧыЧѓДѓФкШнзжЖЮЕФИХТЪКмЕЭЃЌЮвУЧПЩвдВЩгУЗжБэДІРэЃЌНЋвЛИіДѓБэЗжВ№ГЩСНИівЛЖдвЛЕФЙиЯЕБэЃЌНЋВЛГЃгУЕФДѓФкШнзжЖЮЗХдквЛеХЕЅЖРЕФБэжаЁЃШчвЛеХДцДЂЩЯДЋЮФМўЕФБэЃК
T_FILEЃЈID,FILE_NAME,FILE_SIZE,FILE_TYPE,FILE_CONTENTЃЉ
ЮвУЧПЩвдЗжВ№ГЩСНеХвЛЖдвЛЕФЙиЯЕБэЃК
T_FILEЃЈID,FILE_NAME,FILE_SIZE,FILE_TYPEЃЉ
T_FILECONTENTЃЈID, FILE_CONTENTЃЉ
ЭЈЙ§етжжЗжВ№ЃЌПЩвдДѓДѓЬсЩйT_FILEБэЕФЕЅЬѕМЧТММАзмДѓаЁЃЌетбљдкВщбЏT_FILEЪБадФмЛсИќКУЃЌЕБашвЊВщбЏFILE_CONTENTзжЖЮФкШнЪБдйЗУЮЪT_FILECONTENTБэЁЃ
3 МѕЩйНЛЛЅДЮЪ§
3.1 batch DML
Ъ§ОнПтЗУЮЪПђМмвЛАуЖМЬсЙЉСЫХњСПЬсНЛЕФНгПкЃЌjdbcжЇГжbatchЕФЬсНЛДІРэЗНЗЈЃЌЕБФувЛДЮадвЊЭљвЛИіБэжаВхШы1000ЭђЬѕЪ§ОнЪБЃЌШчЙћВЩгУЦеЭЈЕФexecuteUpdateДІРэЃЌФЧУДКЭЗўЮёЦїНЛЛЅДЮЪ§ЮЊ1000ЭђДЮЃЌАДУПУыжгПЩвдЯђЪ§ОнПтЗўЮёЦїЬсНЛ10000ДЮЙРЫуЃЌвЊЭъГЩЫљгаЙЄзїашвЊ1000УыЁЃШчЙћВЩгУХњСПЬсНЛФЃЪНЃЌ1000ЬѕЬсНЛвЛДЮЃЌФЧУДКЭЗўЮёЦїНЛЛЅДЮЪ§ЮЊ1ЭђДЮЃЌНЛЛЅДЮЪ§ДѓДѓМѕЩйЁЃВЩгУbatchВйзївЛАуВЛЛсМѕЩйКмЖрЪ§ОнПтЗўЮёЦїЕФЮяРэIOЃЌЕЋЪЧЛсДѓДѓМѕЩйПЭЛЇЖЫгыЗўЮёЖЫЕФНЛЛЅДЮЪ§ЃЌДгЖјМѕЩйСЫЖрДЮЗЂЦ№ЕФЭјТчбгЪБПЊЯњЃЌЭЌЪБвВЛсНЕЕЭЪ§ОнПтЕФCPUПЊЯњЁЃ
МйЩшвЊЯђвЛИіЦеЭЈБэВхШы1000ЭђЪ§ОнЃЌУПЬѕМЧТМДѓаЁЮЊ1KзжНкЃЌБэЩЯУЛгаШЮКЮЫїв§ЃЌПЭЛЇЖЫгыЪ§ОнПтЗўЮёЦїЭјТчЪЧ100MbpsЃЌвдЯТЪЧИљОнЯждквЛАуМЦЫуЛњФмСІЙРЫуЕФИїжжbatchДѓаЁадФмЖдБШжЕЃК
| ЁЁЕЅЮЛЃКms |
No batch |
Batch=10 |
Batch=100 |
Batch=1000 |
Batch=10000 |
| ЗўЮёЦїЪТЮёДІРэЪБМф |
0.1 |
0.1 |
0.1 |
0.1 |
0.1 |
| ЗўЮёЦїIOДІРэЪБМф |
0.02 |
0.2 |
2 |
20 |
200 |
| ЭјТчНЛЛЅЗЂЦ№ЪБМф |
0.1 |
0.1 |
0.1 |
He0.1 |
0.1 |
| ЭјТчЪ§ОнДЋЪфЪБМф |
0.01 |
0.1 |
1 |
10 |
100 |
| аЁМЦ |
0.23 |
0.5 |
3.2 |
30.2 |
300.2 |
| ЦНОљУПЬѕМЧТМДІРэЪБМф |
0.23 |
0.05 |
0.032 |
0.0302 |
0.03002 |
ЁЁ
ДгЩЯПЩвдПДГіЃЌInsertВйзїМгДѓBatchПЩвдЖдадФмЬсИпНќ8БЖадФмЃЌвЛАуИљОнжїМќЕФUpdateЛђDeleteВйзївВПЩФмЬсИп2-3БЖадФмЃЌЕЋВЛШчInsertУїЯдЃЌвђЮЊUpdateМАDeleteВйзїПЩФмгаБШНЯДѓЕФПЊЯњдкЮяРэIOЗУЮЪЁЃвдЩЯНіЪЧРэТлМЦЫужЕЃЌЪЕМЪЧщПіашвЊИљОнОпЬхЛЗОГВтСПЁЃСэЭтДгВтЪдНЧЖШРДЫЕЃЌЪЙгУBatchвВНЕЕЭСЫВЂЗЂадЃЈБЯОЙBatchЪєгкЪТЮёВйзїЃЉЁЃ
3.2 In List
КмЖрЪБКђЮвУЧашвЊАДвЛаЉIDВщбЏЪ§ОнПтМЧТМЃЌЮвУЧПЩвдВЩгУвЛИіIDвЛИіЧыЧѓЗЂИјЪ§ОнПтЃЌШчЯТЫљЪОЃК
for:varin ids[] do begin
select*from mytable whereid=:var;
end;
ЮвУЧвВПЩвдзівЛИіаЁЕФгХЛЏЃЌ ШчЯТЫљЪОЃЌгУID INLISTЕФетжжЗНЪНаДSQLЃК
select*frommytable whereidin(:id1,id2,...,idn);
ЭЈЙ§етбљДІРэПЩвдДѓДѓМѕЩйSQLЧыЧѓЕФЪ§СПЃЌДгЖјЬсИпадФмЁЃФЧШчЙћга10000ИіIDЃЌФЧЪЧВЛЪЧШЋВПЗХдквЛЬѕSQLРяДІРэФиЃПД№АИПЯЖЈЪЧЗёЖЈЕФЁЃЪзЯШДѓВПЗнЪ§ОнПтЖМЛсгаSQLГЄЖШКЭINРяИіЪ§ЕФЯожЦЃЌШчORACLEЕФINРяОЭВЛдЪаэГЌЙ§1000ИіжЕЁЃ
СэЭтЕБЧАЪ§ОнПтвЛАуЖМЪЧВЩгУЛљгкГЩБОЕФгХЛЏЙцдђЃЌЕБINЪ§СПДяЕНвЛЖЈжЕЪБгаПЩФмИФБфSQLжДааМЦЛЎЃЌДгЫїв§ЗУЮЪБфГЩШЋБэЗУЮЪЃЌетНЋЪЙадФмМБОчБфЛЏЁЃЫцзХSQLжаINЕФРяУцЕФжЕИіЪ§діМгЃЌSQLЕФжДааМЦЛЎЛсИќИДдгЃЌеМгУЕФФкДцНЋЛсБфДѓЃЌетНЋЛсдіМгЗўЮёЦїCPUМАФкДцГЩБОЁЃ
ЦРЙРдкINРяУцвЛДЮЗХЖрЩйИіжЕЛЙашвЊПМТЧгІгУЗўЮёЦїБОЕиФкДцЕФПЊЯњЃЌгаВЂЗЂЗУЮЪЪБвЊМЦЫуБОЕиЪ§ОнЪЙгУжмЦкФкЕФВЂЗЂЩЯЯоЃЌЗёдђПЩФмЛсЕМжТФкДцвчГіЁЃ
злКЯПМТЧЃЌвЛАуINРяУцЕФжЕИіЪ§ГЌЙ§20ИівдКѓадФмЛљБОУЛЪВУДЬЋДѓБфЛЏЃЌвВЬиБ№ЫЕУїВЛвЊГЌЙ§100ЃЌГЌЙ§КѓПЩФмЛсв§Ц№жДааМЦЛЎЕФВЛЮШЖЈадМАдіМгЪ§ОнПтCPUМАФкДцГЩБОЃЌетИіашвЊзЈвЕDBAЦРЙРЁЃ
3.3 ЩшжУFetch Size
ЕБЮвУЧВЩгУselectДгЪ§ОнПтВщбЏЪ§ОнЪБЃЌЪ§ОнФЌШЯВЂВЛЪЧвЛЬѕвЛЬѕЗЕЛиИјПЭЛЇЖЫЕФЃЌвВВЛЪЧвЛДЮШЋВПЗЕЛиПЭЛЇЖЫЕФЃЌЖјЪЧИљОнПЭЛЇЖЫfetch_sizeВЮЪ§ДІРэЃЌУПДЮжЛЗЕЛиfetch_sizeЬѕМЧТМЃЌЕБПЭЛЇЖЫгЮБъБщРњЕНЮВВПЪБдйДгЗўЮёЖЫШЁЪ§ОнЃЌжБЕНзюКѓШЋВПДЋЫЭЭъГЩЁЃЫљвдШчЙћЮвУЧвЊДгЗўЮёЖЫвЛДЮШЁДѓСПЪ§ОнЪБЃЌПЩвдМгДѓfetch_sizeЃЌетбљПЩвдМѕЩйНсЙћЪ§ОнДЋЪфЕФНЛЛЅДЮЪ§МАЗўЮёЦїЪ§ОнзМБИЪБМфЃЌЬсИпадФмЁЃ
вдЯТЪЧjdbcВтЪдЕФДњТыЃЌВЩгУБОЕиЪ§ОнПтЃЌБэЛКДцдкЪ§ОнПтCACHEжаЃЌвђДЫУЛгаЭјТчСЌНгМАДХХЬIOПЊЯњЃЌПЭЛЇЖЫжЛБщРњгЮБъЃЌВЛзіШЮКЮДІРэЃЌетбљИќФмЬхЯжfetchВЮЪ§ЕФгАЯьЃК
String vsql ="select
* from t_employee";
PreparedStatementpstmt =conn.prepareStatement(vsql,ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(1000);
ResultSetrs = pstmt.executeQuery(vsql);
int cnt = rs.getMetaData().getColumnCount();
Object o;
while(rs.next()) {
for(int i =1; i <= cnt; i++) {
o = rs.getObject(i);
}
} |
ВтЪдЪОР§жаЕФemployeeБэга100000ЬѕМЧТМЃЌУПЬѕМЧТМЦНОљГЄЖШ135зжНк
вдЯТЪЧВтЪдНсЙћЃЌЖдУПжжfetchsizeВтЪд5ДЮдйШЁЦНОљжЕЃК
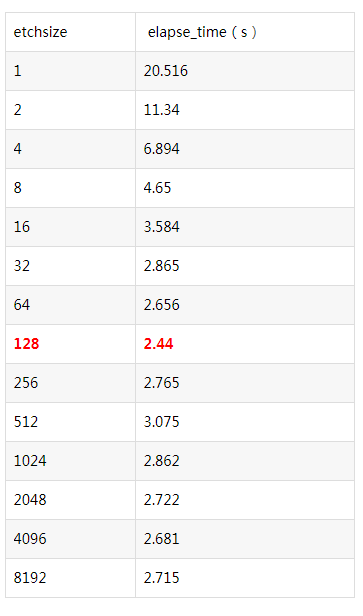
Oracle jdbc fetchsizeФЌШЯжЕЮЊ10ЃЌгЩЩЯВтЪдПЩвдПДГіfetchsizeЖдадФмгАЯьЛЙЪЧБШНЯДѓЕФЃЌЕЋЪЧЕБfetchsizeДѓгк100ЪБОЭЛљБОЩЯУЛгагАЯьСЫЁЃfetchsizeВЂВЛЛсДцдквЛИізюгХЕФЙЬЖЈжЕЃЌвђЮЊећЬхадФмгыМЧТММЏДѓаЁМАгВМўЦНЬЈгаЙиЁЃИљОнВтЪдНсЙћНЈвщЕБвЛДЮадвЊШЁДѓСПЪ§ОнЪБетИіжЕЩшжУЮЊ100зѓгвЃЌВЛвЊаЁгк40ЁЃзЂвтЃЌfetchsizeВЛФмЩшжУЬЋДѓЃЌШчЙћвЛДЮШЁГіЕФЪ§ОнДѓгкJVMЕФФкДцЛсЕМжТФкДцвчГіЃЌЫљвдНЈвщВЛвЊГЌЙ§1000ЃЌЬЋДѓСЫвВУЛЪВУДадФмЬсИпЃЌЗДЖјПЩФмЛсдіМгФкДцвчГіЕФЮЃЯеЁЃ
зЂЃКЭМжаfetchsizeдк128вдКѓЛсгавЛаЉаЁЕФВЈЖЏЃЌетВЂВЛЪЧВтЪдЮѓВюЃЌЖјЪЧгЩгкresultsetЬюГфЕНОпЬхЖдЯёЪБМфВЛЭЌЕФдвђЃЌгЩгкresultsetвбОЕНБОЕиФкДцРяСЫЃЌЫљвдЙРМЦЪЧгЩгкCPUЕФL1,L2
CacheУќжаТЪБфЛЏдьГЩЃЌгЩгкБфЛЏВЛДѓЃЌЫљвдБЪепвВЮДЩюШыЗжЮідвђЁЃ
3.4 ЪЙгУДцДЂЙ§ГЬ
ДѓаЭЪ§ОнПтвЛАуЖМжЇГжДцДЂЙ§ГЬЃЌКЯРэЕФРћгУДцДЂЙ§ГЬвВПЩвдЬсИпЯЕЭГадФмЁЃШчФугавЛИівЕЮёашвЊНЋAБэЕФЪ§ОнзівЛаЉМгЙЄШЛКѓИќаТЕНBБэжаЃЌЕЋЪЧгжВЛПЩФмвЛЬѕSQLЭъГЩЃЌетЪБФуашвЊШчЯТ3ВНВйзїЃК
aЃКНЋAБэЪ§ОнШЋВПШЁГіЕНПЭЛЇЖЫЃЛ
bЃКМЦЫуГівЊИќаТЕФЪ§ОнЃЛ
cЃКНЋМЦЫуНсЙћИќаТЕНBБэЁЃ
ШчЙћВЩгУДцДЂЙ§ГЬФуПЩвдНЋећИівЕЮёТпМЗтзАдкДцДЂЙ§ГЬРяЃЌШЛКѓдкПЭЛЇЖЫжБНгЕїгУДцДЂЙ§ГЬДІРэЃЌетбљПЩвдМѕЩйЭјТчНЛЛЅЕФГЩБОЁЃ
ЕБШЛЃЌДцДЂЙ§ГЬвВВЂВЛЪЧЪЎШЋЪЎУРЃЌДцДЂЙ§ГЬгавдЯТШБЕуЃК
aЁЂВЛПЩвЦжВадЃЌУПжжЪ§ОнПтЕФФкВПБрГЬгяЗЈЖМВЛЬЋЯрЭЌЃЌЕБФуЕФЯЕЭГашвЊМцШнЖржжЪ§ОнПтЪБзюКУВЛвЊгУДцДЂЙ§ГЬЁЃ
bЁЂбЇЯАГЩБОИпЃЌDBAвЛАуЖМЩУГЄаДДцДЂЙ§ГЬЃЌЕЋВЂВЛЪЧУПИіГЬађдБЖМФмаДКУДцДЂЙ§ГЬЃЌГ§ЗЧФуЕФЭХЖггаНЯЖрЕФПЊЗЂШЫдБЪьЯЄаДДцДЂЙ§ГЬЃЌЗёдђКѓЦкЯЕЭГЮЌЛЄЛсВњЩњЮЪЬтЁЃ
cЁЂвЕЮёТпМЖрДІДцдкЃЌВЩгУДцДЂЙ§ГЬКѓвВОЭвтЮЖзХФуЕФЯЕЭГгавЛаЉвЕЮёТпМВЛЪЧдкгІгУГЬађРяДІРэЃЌетжжМмЙЙЛсдіМгвЛаЉЯЕЭГЮЌЛЄКЭЕїЪдГЩБОЁЃ
dЁЂДцДЂЙ§ГЬКЭГЃгУгІгУГЬађгябдВЛвЛбљЃЌЫќжЇГжЕФКЏЪ§МАгяЗЈгаПЩФмВЛФмТњзуашЧѓЃЌгааЉТпМОЭжЛФмЭЈЙ§гІгУГЬађДІРэЁЃ
eЁЂШчЙћДцДЂЙ§ГЬжагаИДдгдЫЫуЕФЛАЃЌЛсдіМгвЛаЉЪ§ОнПтЗўЮёЖЫЕФДІРэГЩБОЃЌЖдгкМЏжаЪНЪ§ОнПтПЩФмЛсЕМжТЯЕЭГПЩРЉеЙадЮЪЬтЁЃ
fЁЂЮЊСЫЬсИпадФмЃЌЪ§ОнПтЛсАбДцДЂЙ§ГЬДњТыБрвыГЩжаМфдЫааДњТы(РрЫЦгкjavaЕФclassЮФМў)ЃЌЫљвдИќЯёОВЬЌгябдЁЃЕБДцДЂЙ§ГЬв§гУЕФЖдЯё(БэЁЂЪгЭМЕШЕШ)НсЙЙИФБфКѓЃЌДцДЂЙ§ГЬашвЊжиаТБрвыВХФмЩњаЇЃЌдк24*7ИпВЂЗЂгІгУГЁОАЃЌвЛАуЖМЪЧдкЯпБфИќНсЙЙЕФЃЌЫљвддкБфИќЕФЫВМфвЊЭЌЪББрвыДцДЂЙ§ГЬЃЌетПЩФмЛсЕМжТЪ§ОнПтЫВМфбЙСІЩЯЩ§в§Ц№ЙЪеЯ(OracleЪ§ОнПтОЭДцдкетбљЕФЮЪЬт)ЁЃ
ИіШЫЙлЕуЃКЦеЭЈвЕЮёТпМОЁСПВЛвЊЪЙгУДцДЂЙ§ГЬЃЌЖЈЪБадЕФETLШЮЮёЛђБЈБэЭГМЦКЏЪ§ПЩвдИљОнЭХЖгзЪдДЧщПіВЩгУДцДЂЙ§ГЬДІРэЁЃ
3.5 гХЛЏвЕЮёТпМ
вЊЭЈЙ§гХЛЏвЕЮёТпМРДЬсИпадФмЪЧБШНЯРЇФбЕФЃЌеташвЊГЬађдБЖдЫљЗУЮЪЕФЪ§ОнМАвЕЮёСїГЬЗЧГЃЧхГўЁЃ
ОйИіР§згЃК12306ЭјеОЕФДКдЫЙКЦБбЙСІКмДѓЃЌПЩвдЭЈЙ§вЕЮёгХЛЏРДНтОіВПЗжЮЪЬтЃЌБШШчАДПЭСїСПЗжЩЂЃЌвЛЗНУцДгЪБМфЩЯЗжЩЂЃЈдЪаэЬсЧАСНИідТЖЉЦБЃЌНЋЙКТђбЙСІЗжЩЂЕНВЛЭЌЪБМфЖЮЃЉЃЌСэвЛЗНУцАДПЭдЫЖЮЗжВМЃЈАДЪЁЪаЁЂПЭЛЇЖЮЗжВМЪлЦБЃЌБмУтЦБдДМЏжаЗЂЪлЃЉЃЌЛЙПЩвдАДашЧѓВювьЗжРрДІРэЃЈБШШчАДTЁЂKЁЂGЁЂDГЕаЭЗжРрЃЌвЛЕШзљЁЂЖўЕШзљЁЂгВзљЁЂЮдЦЬЗжРрЕШЃЉЁЃ
3.6 ЪЙгУResultSetгЮБъДІРэМЧТМ
ЯждкДѓВПЗжJavaПђМмЖМЪЧЭЈЙ§jdbcДгЪ§ОнПтШЁГіЪ§ОнЃЌШЛКѓзАдиЕНвЛИіlistРядйДІРэЃЌlistРяПЩФмЪЧвЕЮёObjectЃЌвВПЩФмЪЧhashmapЁЃ
гЩгкJVMФкДцвЛАуЖМаЁгк4GЃЌЫљвдВЛПЩФмвЛДЮЭЈЙ§sqlАбДѓСПЪ§ОнзАдиЕНlistРяЁЃЮЊСЫЭъГЩЙІФмЃЌКмЖрГЬађдБЯВЛЖВЩгУЗжвГЕФЗНЗЈДІРэЃЌШчвЛДЮДгЪ§ОнПтШЁ1000ЬѕМЧТМЃЌЭЈЙ§ЖрДЮбЛЗИуЖЈЃЌБЃжЄВЛЛсв§Ц№JVM
Out of memoryЮЪЬтЁЃ
КмЖрГжОУВуПђМмЃЈШчiBatisЃЉЮЊСЫОЁСПШУГЬађдБЪЙгУЗНБуЃЌЗтзАСЫjdbcЭЈЙ§statementжДааЪ§ОнЗЕЛиЕНresultsetЕФЯИНкЃЌЕМжТГЬађдБЛсЯыВЩгУЗжвГЕФЗНЪНДІРэЮЪЬтЁЃЪЕМЪЩЯШчЙћЮвУЧВЩгУjdbcдЪМЕФresultsetгЮБъДІРэМЧТМЃЌдкresultsetбЛЗЖСШЁЕФЙ§ГЬжаДІРэМЧТМЃЌетбљОЭПЩвдвЛДЮДгЪ§ОнПтШЁГіЫљгаМЧТМЁЃЯджјЬсИпадФмЁЃ
етРяашвЊзЂвтЕФЪЧЃЌВЩгУresultsetгЮБъДІРэМЧТМЪБЃЌгІИУНЋгЮБъЕФДђПЊЗНЪНЩшжУЮЊFORWARD_READONLYФЃЪН(ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY)ЃЌЗёдђЛсАбНсЙћЛКДцдкJVMРяЃЌдьГЩJVM
Out of memoryЮЪЬтЁЃвдЯТДњТыЪОР§ЃК
String vsql ="select
* from t_employee";
PreparedStatementpstmt =conn.prepareStatement(vsql,ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);
pstmt.setFetchSize(100);
ResultSetrs = pstmt.executeQuery(vsql);
int col_cnt = rs.getMetaData().getColumnCount();
Object o;
while(rs.next()) {
for(int j =1; j <= col_cnt; j++) {
o = rs.getObject(j);
}
} |
вдЩЯДњТыЪЕМЪжДааЪБМфЮЊ3.156УыЃЌЖјВЩгУЗжвГЕФЗНЗЈДІРэЪЕМЪашвЊ6.516УыЁЃадФмЬсИпСЫ1БЖЖрЃЌШчЙћВЩгУЗжвГФЃЪНЪ§ОнПтУПДЮЛЙашЗЂЩњДХХЬIOЕФЛАФЧадФмПЩвдЬсИпИќЖрЁЃ
4 МѕЩйЪ§ОнПтЗўЮёЦїCPUдЫЫу
4.1 ЪЙгУАѓЖЈБфСП
АѓЖЈБфСПЪЧжИSQLжаЖдБфЛЏЕФжЕВЩгУБфСПВЮЪ§ЕФаЮЪНЬсНЛЃЌЖјВЛЪЧдкSQLжажБНгЦДаДЖдгІЕФжЕЁЃ
ЗЧАѓЖЈБфСПаДЗЈЃКSelect * from employee where id=1234567
АѓЖЈБфСПаДЗЈЃК
Select * from employee where id=?
Preparestatement.setInt(1,1234567)
JavaжаPreparestatementОЭЪЧЮЊДІРэАѓЖЈБфСПЬсЙЉЕФЖдЯёЃЌАѓЖЈБфСПгавдЯТгХЕуЃК
1ЁЂЗРжЙSQLзЂШы
2ЁЂЬсИпSQLПЩЖСад
3ЁЂЬсИпSQLНтЮіадФмЃЌВЛЪЙгУАѓЖЈБфИќЮвУЧвЛАуГЦЮЊгВНтЮіЃЌЪЙгУАѓЖЈБфСПЮвУЧГЦЮЊШэНтЮіЁЃ
Ек1КЭЕк2ЕуКмКУРэНтЃЌзіБрТыЕФШЫгІИУЖМЧхГўЃЌетРяВЛЯъЯИЫЕУїЁЃЙигкЕк3ЕуЃЌЕНЕзФмЬсИпЖрЩйадФмФиЃЌЯТУцОйвЛИіР§згЫЕУїЃК
МйЩшгаетИіетбљЕФвЛИіЪ§ОнПтжїЛњЃК
2Иі4КЫCPU
100ПщДХХЬЃЌУПИіДХХЬжЇГжIOPSЮЊ160
вЕЮёгІгУЕФSQLШчЯТЃК
select * from table where pk=?
етИіSQLЦНОљ4ИіIOЃЈ3ИіЫїв§IO+1ИіЪ§ОнIOЃЉ
IOЛКДцУќжаТЪ75%ЃЈЫїв§ШЋдкФкДцжаЃЌЪ§ОнашвЊЗУЮЪДХХЬЃЉ
SQLгВНтЮіCPUЯћКФЃК1ms ЃЈГЃгУОбщжЕЃЉ
SQLШэНтЮіCPUЯћКФЃК0.02msЃЈГЃгУОбщжЕЃЉ
МйЩшCPUУПКЫадФмЪЧЯпаддіГЄЃЌЗУЮЪФкДцCacheжаЕФIOЪБМфКіТдЃЌвЊЧѓМЦЫуЯЕЭГЖдШчЩЯгІгУВЩгУгВНтЮігыВЩгУШэНтЮіжЇГжЕФУПУызюДѓВЂЗЂЪ§ЃК
| ЪЧЗёЪЙгУАѓЖЈБфСП |
CPUжЇГжзюДѓВЂЗЂЪ§ |
ДХХЬIOжЇГжзюДѓВЂЗЂЪ§ |
| ВЛЪЙгУ |
2*4*1000=8000 |
100*160=16000 |
| ЪЙгУ |
2*4*1000/0.02=400000 |
100*160=16000 |
ДгвдЩЯМЦЫуПЩвдПДГіЃЌВЛЪЙгУАѓЖЈБфСПЕФЯЕЭГЕБВЂЗЂДяЕН8000ЪБЛсдкCPUЩЯВњЩњЦПОБЃЌЕБЪЙгУАѓЖЈБфСПЕФЯЕЭГЕБВЂааДяЕН16000ЪБЛсдкДХХЬIOЩЯВњЩњЦПОБЁЃЫљвдШчЙћФуЕФЯЕЭГCPUгаЦПОБЪБЧыЯШМьВщЪЧЗёДцдкДѓСПЕФгВНтЮіВйзїЁЃ
ЪЙгУАѓЖЈБфСПЮЊКЮЛсЬсИпSQLНтЮіадФмЃЌетИіашвЊДгЪ§ОнПтSQLжДаадРэЫЕУїЃЌвЛЬѕSQLдкOracleЪ§ОнПтжаЕФжДааЙ§ГЬШчЯТЭМЫљЪОЃК
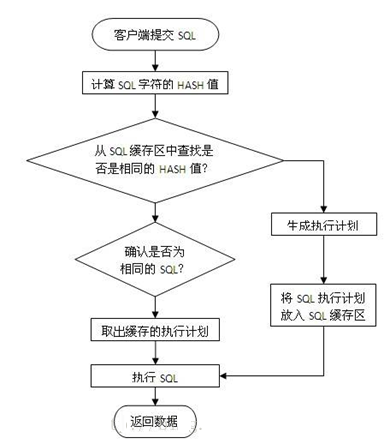
ЕБвЛЬѕSQLЗЂЫЭИјЪ§ОнПтЗўЮёЦїКѓЃЌЯЕЭГЪзЯШЛсНЋSQLзжЗћДЎНјааhashдЫЫуЃЌЕУЕНhashжЕКѓдйДгЗўЮёЦїФкДцРяЕФSQLЛКДцЧјжаНјааМьЫїЃЌШчЙћгаЯрЭЌЕФSQLзжЗћЃЌВЂЧвШЗШЯЪЧЭЌвЛТпМЕФSQLгяОфЃЌдђДгЙВЯэГиЛКДцжаШЁГіSQLЖдгІЕФжДааМЦЛЎЃЌИљОнжДааМЦЛЎЖСШЁЪ§ОнВЂЗЕЛиНсЙћИјПЭЛЇЖЫЁЃ
ШчЙћдкЙВЯэГижаЮДЗЂЯжЯрЭЌЕФSQLдђИљОнSQLТпМЩњГЩвЛЬѕаТЕФжДааМЦЛЎВЂБЃДцдкSQLЛКДцЧјжаЃЌШЛКѓИљОнжДааМЦЛЎЖСШЁЪ§ОнВЂЗЕЛиНсЙћИјПЭЛЇЖЫЁЃ
ЮЊСЫИќПьЕФМьЫїSQLЪЧЗёдкЛКДцЧјжаЃЌЪзЯШНјааЕФЪЧSQLзжЗћДЎhashжЕЖдБШЃЌШчЙћЮДевЕНдђШЯЮЊУЛгаЛКДцЃЌШчЙћДцдкдйНјааЯТвЛВНЕФзМШЗЖдБШЃЌЫљвдвЊУќжаSQLЛКДцЧјгІБЃжЄSQLзжЗћЪЧЭъШЋвЛжТЃЌжаМфгаДѓаЁаДЛђПеИёЖМЛсШЯЮЊЪЧВЛЭЌЕФSQLЁЃ
ШчЙћЮвУЧВЛВЩгУАѓЖЈБфСПЃЌВЩгУзжЗћДЎЦДНгЕФФЃЪНЩњГЩSQL,ФЧУДУПЬѕSQLЖМЛсВњЩњжДааМЦЛЎЃЌетбљЛсЕМжТЙВЯэГиКФОЁЃЌЛКДцУќжаТЪвВКмЕЭЁЃ
вЛаЉЮоашЪЙгУАѓЖЈБфСПЕФГЁОАЃК
aЁЂЪ§ОнВжПтгІгУЃЌетжжгІгУвЛАуВЂЗЂВЛИпЃЌЕЋЪЧУПИіSQLжДааЪБМфКмГЄЃЌSQLНтЮіЕФЪБМфЯрБШSQLжДааЪБМфБШНЯаЁЃЌАѓЖЈБфСПЖдадФмЬсИпВЛУїЯдЁЃЪ§ОнВжПтвЛАуЖМЪЧФкВПЗжЮігІгУЃЌЫљвдвВВЛЬЋЛсЗЂЩњSQLзЂШыЕФАВШЋЮЪЬтЁЃ
bЁЂЪ§ОнЗжВМВЛОљдШЕФЬиЪтТпМЃЌШчВњЦЗБэЃЌМЧТМга1вкЃЌгавЛВњЦЗзДЬЌзжЖЮЃЌЩЯУцНЈгаЫїв§ЃЌгаЩѓКЫжаЃЌЩѓКЫЭЈЙ§ЃЌЩѓКЫЮДЭЈЙ§3жжзДЬЌЃЌЦфжаЩѓКЫЭЈЙ§9500ЭђЃЌЩѓКЫжа1ЭђЃЌЩѓКЫВЛЭЈЙ§499ЭђЁЃ
вЊзіетбљвЛИіВщбЏЃК
select count(*) from product where status=?
ВЩгУАѓЖЈБфСПЕФЛАЃЌФЧУДжЛЛсгавЛИіжДааМЦЛЎЃЌШчЙћзпЫїв§ЗУЮЪЃЌФЧУДЖдгкЩѓКЫжаВщбЏКмПьЃЌЖдЩѓКЫЭЈЙ§КЭЩѓКЫВЛЭЈЙ§ЛсКмТ§ЃЛШчЙћВЛзпЫїв§ЃЌФЧУДЖдгкЩѓКЫжагыЩѓКЫЭЈЙ§КЭЩѓКЫВЛЭЈЙ§ЪБМфЛљБОвЛбљЃЛ
ЖдгкетжжЧщПігІИУВЛЪЙгУАѓЖЈБфСПЃЌЖјжБНгВЩгУзжЗћЦДНгЕФЗНЪНЩњГЩSQLЃЌетбљПЩвдЮЊУПИіSQLЩњГЩВЛЭЌЕФжДааМЦЛЎЃЌШчЯТЫљЪОЁЃ
select count(*) from product where status='approved';
//ВЛЪЙгУЫїв§(ЩѓКЫЭЈЙ§)
select count(*) from product where status='tbd'; //ВЛЪЙгУЫїв§(ЩѓКЫЮДЭЈЙ§)
select count(*) from product where status='auditing';//ЪЙгУЫїв§(ЩѓКЫжа)
4.2 КЯРэЪЙгУХХађ
OracleЕФХХађЫуЗЈвЛжБдкгХЛЏЃЌЕЋЪЧзмЬхЪБМфИДдгЖШдМЕШгкnLog(n)ЁЃЦеЭЈOLTPЯЕЭГХХађВйзївЛАуЖМЪЧдкФкДцРяНјааЕФЃЌЖдгкЪ§ОнПтРДЫЕЪЧвЛжжCPUЕФЯћКФЃЌдјдкPCЛњзіЙ§ВтЪдЃЌЕЅКЫЦеЭЈCPUдк1УыжгПЩвдЭъГЩ100ЭђЬѕМЧТМЕФШЋФкДцХХађВйзїЃЌЫљвдЫЕгЩгкЯждкCPUЕФадФмдіЧПЃЌЖдгкЦеЭЈЕФМИЪЎЬѕЛђЩЯАйЬѕМЧТМХХађЖдЯЕЭГЕФгАЯьвВВЛЛсКмДѓЁЃЕЋЪЧЕБФуЕФМЧТММЏдіМгЕНЩЯЭђЬѕвдЩЯЪБЃЌФуашвЊзЂвтЪЧЗёвЛЖЈвЊетУДзіСЫЃЌДѓМЧТММЏХХађВЛНідіМгСЫCPUПЊЯњЃЌЖјЧвПЩФмЛсгЩгкФкДцВЛзуЗЂЩњгВХЬХХађЕФЯжЯѓЃЌЕБЗЂЩњгВХЬХХађЪБадФмЛсМБОчЯТНЕЃЌетжжашЧѓашвЊгыDBAЙЕЭЈдйОіЖЈЃЌШЁОігкФуЕФашЧѓКЭЪ§ОнЃЌЫљвджЛгаФуздМКзюЧхГўЃЌЖјВЛвЊБЛБ№ШЫЫЕХХађКмТ§ОЭЯХЕЙЁЃ
вдЯТСаГіСЫПЩФмЛсЗЂЩњХХађВйзїЕФSQLгяЗЈЃК
Order by
Group by
Distinct
ExistsзгВщбЏ
Not ExistsзгВщбЏ
InзгВщбЏ
Not InзгВщбЏ
UnionЃЈВЂМЏЃЉЃЌUnion AllвВЪЧвЛжжВЂМЏВйзїЃЌЕЋЪЧВЛЛсЗЂЩњХХађЃЌШчЙћФуШЗШЯСНИіЪ§ОнМЏВЛашвЊжДааШЅГ§жиИДЪ§ОнВйзїЃЌФЧЧыЪЙгУUnion
All ДњЬцUnionЁЃ
MinusЃЈВюМЏЃЉ
IntersectЃЈНЛМЏЃЉ
Create Index
Merge JoinЃЌетЪЧвЛжжСНИіБэСЌНгЕФФкВПЫуЗЈЃЌжДааЪБЛсАбСНИіБэЯШХХађКУдйСЌНгЃЌгІгУгкСНИіДѓБэСЌНгЕФВйзїЁЃШчЙћФуЕФСНИіБэСЌНгЕФЬѕМўЖМЪЧЕШжЕдЫЫуЃЌФЧПЩвдВЩгУHash
JoinРДЬсИпадФмЃЌвђЮЊHash JoinЪЙгУHash дЫЫуРДДњЬцХХађЕФВйзїЁЃОпЬхдРэМАЩшжУВЮПМSQLжДааМЦЛЎгХЛЏзЈЬтЁЃ
4.3 МѕЩйБШНЯВйзї
ЮвУЧSQLЕФвЕЮёТпМОГЃЛсАќКЌвЛаЉБШНЯВйзїЃЌШчa=bЃЌa<bжЎРрЕФВйзїЃЌЖдгкетаЉБШНЯВйзїЪ§ОнПтЖМЬхЯжЕУКмКУЃЌЕЋЪЧШчЙћгавдЯТВйзїЃЌЮвУЧашвЊБЃГжОЏЬшЃК
LikeФЃК§ВщбЏЃЌШчЯТЫљЪОЃК
a like ЁЎ%abc%ЁЏ
LikeФЃК§ВщбЏЖдгкЪ§ОнПтРДЫЕВЛЪЧКмЩУГЄЃЌЬиБ№ЪЧФуашвЊФЃК§МьВщЕФМЧТМгаЩЯЭђЬѕвдЩЯЪБЃЌадФмБШНЯдуИтЃЌетжжЧщПівЛАуПЩвдВЩгУзЈгУSearchЛђепВЩгУШЋЮФЫїв§ЗНАИРДЬсИпадФмЁЃ
ВЛФмЪЙгУЫїв§ЖЈЮЛЕФДѓСПIn ListЃЌШчЯТЫљЪОЃК
a in (:1,:2,:3,Ё,:n) ----n>20
ШчЙћетРяЕФaзжЖЮВЛФмЭЈЙ§Ыїв§БШНЯЃЌФЧЪ§ОнПтЛсНЋзжЖЮгыinРяУцЕФУПИіжЕЖМНјааБШНЯдЫЫуЃЌШчЙћМЧТМЪ§гаЩЯЭђвдЩЯЃЌЛсУїЯдИаОѕЕНSQLЕФCPUПЊЯњМгДѓЃЌетИіЧщПігаСНжжНтОіЗНЪНЃК
aЁЂНЋinСаБэРяУцЕФЪ§ОнЗХШывЛеХжаМфаЁБэЃЌВЩгУСНИіБэHash JoinЙиСЊЕФЗНЪНДІРэЃЛ
bЁЂВЩгУstr2varListЗНЗЈНЋзжЖЮДЎСаБэзЊЛЛвЛИіСйЪББэДІРэЃЌЙигкstr2varListЗНЗЈПЩвддкЭјЩЯжБНгВщбЏЃЌетРяВЛЯъЯИНщЩмЁЃ
вдЩЯСНжжНтОіЗНАИЖМашвЊгыжаМфБэHash JoinЕФЗНЪНВХФмЬсИпадФмЃЌШчЙћВЩгУСЫNested LoopЕФСЌНгЗНЪНадФмЛсИќВюЁЃ
ШчЙћЗЂЯжЮвУЧЕФЯЕЭГIOУЛЮЪЬтЕЋЪЧCPUИКдиКмИпЃЌОЭгаПЩФмЪЧЩЯУцЕФдвђЃЌетжжЧщПіВЛЬЋГЃМћЃЌШчЙћгіЕНСЫзюКУФмКЭDBAЙЕЭЈВЂШЗШЯзМШЗЕФдвђЁЃ
4.4 ДѓСПИДдгдЫЫудкПЭЛЇЖЫДІРэ
ЪВУДЪЧИДдгдЫЫуЃЌвЛАуЮвШЯЮЊЪЧвЛУыжгCPUжЛФмзі10ЭђДЮвдФкЕФдЫЫуЁЃШчКЌаЁЪ§ЕФЖдЪ§МАжИЪ§дЫЫуЁЂШ§НЧКЏЪ§ЁЂ3DESМАBASE64Ъ§ОнМгУмЫуЗЈЕШЕШЁЃ
ШчЙћгаДѓСПетРрКЏЪ§дЫЫуЃЌОЁСПЗХдкПЭЛЇЖЫДІРэЃЌвЛАуCPUУПУыжавВжЛФмДІРэ1Эђ-10ЭђДЮетбљЕФКЏЪ§дЫЫуЃЌЗХдкЪ§ОнПтФкВЛРћгкИпВЂЗЂДІРэЁЃ
5 РћгУИќЖрЕФзЪдД
5.1 ПЭЛЇЖЫЖрНјГЬВЂааЗУЮЪ
ЖрНјГЬВЂааЗУЮЪЪЧжИдкПЭЛЇЖЫДДНЈЖрИіНјГЬ(ЯпГЬ)ЃЌУПИіНјГЬНЈСЂвЛИігыЪ§ОнПтЕФСЌНгЃЌШЛКѓЭЌЪБЯђЪ§ОнПтЬсНЛЗУЮЪЧыЧѓЁЃЕБЪ§ОнПтжїЛњзЪдДгаПеЯаЪБЃЌЮвУЧПЩвдВЩгУПЭЛЇЖЫЖрНјГЬВЂааЗУЮЪЕФЗНЗЈРДЬсИпадФмЁЃШчЙћЪ§ОнПтжїЛњвбОКмУІЪБЃЌВЩгУЖрНјГЬВЂааЗУЮЪадФмВЛЛсЬсИпЃЌЗДЖјПЩФмЛсИќТ§ЁЃЫљвдЪЙгУетжжЗНЪНзюКУгыDBAЛђЯЕЭГЙмРэдБНјааЙЕЭЈКѓдйОіЖЈЪЧЗёВЩгУЁЃ
Р§ШчЃК
ЮвУЧга10000ИіВњЦЗIDЃЌЯждкашвЊИљОнIDШЁГіВњЦЗЕФЯъЯИаХЯЂЃЌШчЙћЕЅЯпГЬЗУЮЪЃЌАДУПИіIOвЊ5msМЦЫуЃЌКіТджїЛњCPUдЫЫуМАЭјТчДЋЪфЪБМфЃЌЮвУЧашвЊ50sВХФмЭъГЩШЮЮёЁЃШчЙћВЩгУ5ИіВЂааЗУЮЪЃЌУПИіНјГЬЗУЮЪ2000ИіIDЃЌФЧУД10sОЭгаПЩФмЭъГЩШЮЮёЁЃ
ФЧЪЧВЛЪЧВЂааЪ§дНЖрдНКУФиЃЌПЊ1000ИіВЂааЪЧЗёжЛвЊ50msОЭИуЖЈЃЌД№АИПЯЖЈЪЧЗёЖЈЕФЃЌЕБВЂааЪ§ГЌЙ§ЗўЮёЦїжїЛњзЪдДЕФЩЯЯоЪБадФмОЭВЛЛсдйЬсИпЃЌШчЙћдйдіМгЗДЖјЛсдіМгжїЛњЕФНјГЬМфЕїЖШГЩБОКЭНјГЬГхЭЛЛњТЪЁЃ
вдЯТЪЧвЛаЉШчКЮЩшжУВЂааЪ§ЕФЛљБОНЈвщЃК
ШчЙћЦПОБдкЗўЮёЦїжїЛњЃЌЕЋЪЧжїЛњЛЙгаПеЯазЪдДЃЌФЧУДзюДѓВЂааЪ§ШЁжїЛњCPUКЫЪ§КЭжїЛњЬсЙЉЪ§ОнЗўЮёЕФДХХЬЪ§СНИіВЮЪ§жаЕФзюаЁжЕЃЌЭЌЪБвЊБЃжЄжїЛњгазЪдДзіЦфЫќШЮЮёЁЃ
ШчЙћЦПОБдкПЭЛЇЖЫДІРэЃЌЕЋЪЧПЭЛЇЖЫЛЙгаПеЯазЪдДЃЌФЧНЈвщВЛвЊдіМгSQLЕФВЂааЃЌЖјЪЧгУвЛИіНјГЬШЁЛиЪ§ОнКѓдкПЭЛЇЖЫЦ№ЖрИіНјГЬДІРэМДПЩЃЌНјГЬЪ§ИљОнПЭЛЇЖЫCPUКЫЪ§МЦЫуЁЃ
ШчЙћЦПОБдкПЭЛЇЖЫЭјТчЃЌФЧНЈвщзіЪ§ОнбЙЫѕЛђепдіМгЖрИіПЭЛЇЖЫЃЌВЩгУmap reduceЕФМмЙЙДІРэЁЃ
ШчЙћЦПОБдкЗўЮёЦїЭјТчЃЌФЧашвЊдіМгЗўЮёЦїЕФЭјТчДјПэЛђепдкЗўЮёЖЫНЋЪ§ОнбЙЫѕКѓдйДІРэСЫЁЃ
5.2 Ъ§ОнПтВЂааДІРэ
Ъ§ОнПтВЂааДІРэЪЧжИПЭЛЇЖЫвЛЬѕSQLЕФЧыЧѓЃЌЪ§ОнПтФкВПздЖЏЗжНтГЩЖрИіНјГЬВЂааДІРэЃЌШчЯТЭМЫљЪОЃК
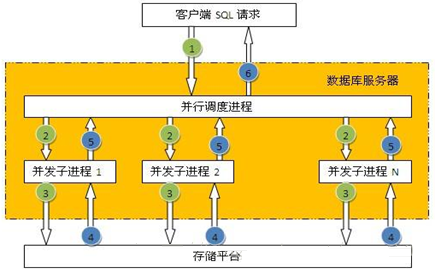
ВЂВЛЪЧЫљгаЕФSQLЖМПЩвдЪЙгУВЂааДІРэЃЌвЛАужЛгаЖдБэЛђЫїв§НјааШЋВПЗУЮЪЪБВХПЩвдЪЙгУВЂааЁЃЪ§ОнПтБэФЌШЯЪЧВЛДђПЊВЂааЗУЮЪЃЌЫљвдашвЊжИЖЈSQLВЂааЕФЬсЪОЃЌШчЯТЫљЪОЃК
select /*+parallel(a,4)*/ * from employee;
ВЂааЕФгХЕуЃК
ЪЙгУЖрНјГЬДІРэЃЌГфЗжРћгУЪ§ОнПтжїЛњзЪдДЃЈCPU,IOЃЉЃЌЬсИпадФмЁЃ
ВЂааЕФШБЕуЃК
1ЁЂЕЅИіЛсЛАеМгУДѓСПзЪдДЃЌгАЯьЦфЫќЛсЛАЃЌЫљвджЛЪЪКЯдкжїЛњИКдиЕЭЪБЦкЪЙгУЃЛ
2ЁЂжЛФмВЩгУжБНгIOЗУЮЪЃЌВЛФмРћгУЛКДцЪ§ОнЃЌЫљвджДааЧАЛсДЅЗЂНЋдрЛКДцЪ§ОнаДШыДХХЬВйзїЁЃ
зЂЃК
1ЁЂВЂааДІРэдкOLTPРрЯЕЭГжаЩїгУЃЌЪЙгУВЛЕБЛсЕМжТвЛИіЛсЛААбжїЛњзЪдДШЋВПеМгУЃЌЖје§ГЃЪТЮёЕУВЛЕНМАЪБЯьгІЃЌЫљвдвЛАужЛЪЧгУгкЪ§ОнВжПтЦНЬЈЛђДѓЪ§ОнДІРэЦНЬЈЁЃ
2ЁЂвЛАуЖдгкАйЭђМЖМЧТМвдЯТЕФаЁБэВЩгУВЂааЗУЮЪадФмВЂВЛФмЬсИпЃЌЗДЖјПЩФмЛсШУадФмИќВюЁЃ | 








