| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌБОЮФжївЊНщЩмСЫsqlгяОфжаЕФЃЌinsertВхШыЃЌаоИФЩОГ§гяОфЃЌunionЙиМќзжЕШЯрЙигХЛЏЕФжЊЪЖЁЃ |
|
ПЊУХМћЩНЃЌЮЪЬтЫљдк
sqlгяОфадФмДяВЛЕНФуЕФвЊЧѓЃЌжДаааЇТЪШУФуШЬЮоПЩШЬЃЌвЛАуЛсЪБЯТУцМИжжЧщПіЁЃ
ЭјЫйВЛИјСІЃЌВЛЮШЖЈЁЃ
ЗўЮёЦїФкДцВЛЙЛЃЌЛђепSQL БЛЗжХфЕФФкДцВЛЙЛЁЃ
sqlгяОфЩшМЦВЛКЯРэ
УЛгаЯргІЕФЫїв§ЃЌЫїв§ВЛКЯРэ
УЛгагааЇЕФЫїв§ЪгЭМ
БэЪ§ОнЙ§ДѓУЛгагааЇЕФЗжЧјЩшМЦ
Ъ§ОнПтЩшМЦЬЋ2ЃЌДцдкДѓСПЕФЪ§ОнШпгр
Ыїв§СаЩЯШБЩйЯргІЕФЭГМЦаХЯЂЃЌЛђепЭГМЦаХЯЂЙ§Цк
....
ФЧУДЮвУЧШчКЮИјевГіРДЕМжТадФмТ§ЕФЕФдвђФиЃП
ЪзЯШФувЊжЊЕРЪЧЗёИњsqlгяОфгаЙиЃЌШЗБЃВЛЪЧЛњЦїПЊВЛПЊЛњЃЌЗўЮёЦїгВМўХфжУЬЋВюЃЌУЛЭјФуЫЕpАЁ
НгзХФуЪЙгУЮвЩЯвЛЦЊЮФеТжаЬсЕНЕФ2ПТФЯsqlадФмМьВтЙЄОп--sql server profilerЃЌЗжЮіГіsqlТ§ЕФЯрЙигяОфЃЌОЭЪЧжДааЪБМфЙ§ГЄЃЌеМгУЯЕЭГзЪдДЃЌcpuЙ§ЖрЕФ
ШЛКѓЪЧетЦЊЮФеТвЊЫЕЕФЃЌsqlгХЛЏЗНЗЈИњММЧЩЃЌБмУтвЛаЉВЛКЯРэЕФsqlгяОфЃЌШЁднгХsql
дйШЛКѓХаЖЯЪЧЗёЪЙгУРВЃЌКЯРэЕФЭГМЦаХЯЂЁЃsql serverжаПЩвдздЖЏЭГМЦБэжаЕФЪ§ОнЗжВМаХЯЂЃЌЖЈЪБИљОнЪ§ОнЧщПіЃЌИќаТЭГМЦаХЯЂЃЌЪЧКмгаБивЊЕФ
ШЗШЯБэжаЪЙгУРВКЯРэЕФЫїв§ЃЌетИіЫїв§ЮвЧАУцВЉПЭжавВгаЬсЙ§ЃЌВЛЙ§ФЧЦЊВЉПЭжЎКѓЃЌЛЙвЊНјвЛВНЖдЫїв§аДЦЊЮФеТ
Ъ§ОнЬЋЖрЕФБэЃЌвЊЗжЧјЃЌЫѕаЁВщевЗЖЮЇ
ЗжЮіБШНЯжДааЪБМфМЦЛЎЖСШЁЧщПі
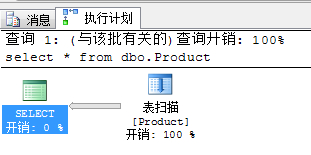
| select * from
dbo.Product |
жДааЩЯУцгяОфвЛАуЧщПіЯТжЛИјФуЗЕЛиНсЙћКЭжДааааЪ§ЃЌФЧУДФудѕУДЗжЮіФиЃЌдѕУДжЊЕРФугХЛЏжЎКѓИњУЛгагХЛЏЕФЧјБ№ФиЁЃ
ЯТУцИјФуЫЕМИжжЗНЗЈЁЃ
1.ВщПДжДааЪБМфКЭcpuеМгУЪБМф
set statistics
time on
select * from dbo.Product
set statistics time off |
ДђПЊФуВщбЏжЎКѓЕФЯћЯЂРяУцОЭФмПДЕНРВЁЃ
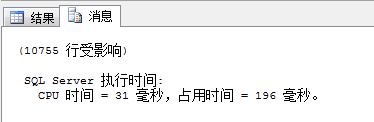
2.ВщПДВщбЏЖдI/0ЕФВйзїЧщПі
set statistics
io on
select * from dbo.Product
set statistics io off |
жДаажЎКѓ

ЩЈУшМЦЪ§ЃКЫїв§ЛђБэЩЈУшДЮЪ§
ТпМЖСШЁЃКЪ§ОнЛКДцжаЖСШЁЕФвГЪ§
ЮяРэЖСШЁЃКДгДХХЬжаЖСШЁЕФвГЪ§
дЄЖСЃКВщбЏЙ§ГЬжаЃЌДгДХХЬЗХШыЛКДцЕФвГЪ§
lobТпМЖСШЁЃКДгЪ§ОнЛКДцжаЖСШЁЃЌimageЃЌtextЃЌntextЛђДѓаЭЪ§ОнЕФвГЪ§
lobЮяРэЖСШЁЃКДгДХХЬжаЖСШЁЃЌimageЃЌtextЃЌntextЛђДѓаЭЪ§ОнЕФвГЪ§
lobдЄЖСЃКВщбЏЙ§ГЬжаЃЌДгДХХЬЗХШыЛКДцЕФimageЃЌtextЃЌntextЛђДѓаЭЪ§ОнЕФвГЪ§
ШчЙћЮяРэЖСШЁДЮЪ§КЭдЄЖСДЮЫЕБШНЯЖрЃЌПЩвдЪЙгУЫїв§НјаагХЛЏЁЃ
ШчЙћФуВЛЯыЪЙгУsqlгяОфУќСюРДВщПДетаЉФкШнЃЌЗНЗЈвВЪЧгаЕФЃЌИчНЬФуИќМђЕЅЕФЁЃ
ВщбЏ--->>ВщбЏбЁЯю--->>ИпМЖ
БЛКьШІЬзЩЯЕФ2ИібЁЩЯЃЌШЅЕєsqlгяОфжаЕФset statistics io/time on/off
ЪдЪдаЇЙћЁЃХЖвВЃЌФуГЩЙІРВЁЃЁЃ
3.ВщПДжДааМЦЛЎЃЌжДааМЦЛЎЯъНт
бЁжаВщбЏгяОфЃЌЕуЛї ШЛКѓПДЯћЯЂРяУцЃЌЛсГіЯжЯТУцЕФЭМР§ ШЛКѓПДЯћЯЂРяУцЃЌЛсГіЯжЯТУцЕФЭМР§
ЪзЯШЮветИіР§згЕФгяОфЬЋЙ§МђЕЅЃЌФуећИіИДдгЕФЃЌАќКАЁЁЃ
ЗжЮіЃКЪѓБъЗХдкЭМБъЩЯЛсЯдЪОДЫВНжшжДааЕФЯъЯИФкШнЃЌУПИіБэЯТУцЖМЯдЪОвЛИіПЊЯњАйЗжБШЃЌЗжЮіеОАйЗжБШЖрЕФЕФвЛПщЃЌПЩвдИљОнжиаТЩшМЦЪ§ОнНсЙЙЃЌЛђетжиаДsqlгяОфЃЌРДЖдДЫНјаагХЛЏЁЃШчЙћДцдкЩЈУшБэЃЌЛђепЩЈУшОлМЏЫїв§ЃЌетБэЪОдкЕБЧАВщбЏжаФуЕФЫїв§ЪЧВЛКЯЪЪЕФЃЌЪЧУЛгаЦ№ЕНзїгУЕФЃЌФЧУДФуОЭвЊаоИФЭъЩЦгХЛЏФуЕФЫїв§ЁЃ
selectВщбЏвеЪѕ
1.БЃжЄВЛВщбЏЖргрЕФСагыааЁЃ
ОЁСПБмУтselect * ЕФДцдкЃЌЪЙгУОпЬхЕФСаДњЬц*ЃЌБмУтЖргрЕФСа
ЪЙгУwhereЯоЖЈОпЬхвЊВщбЏЕФЪ§ОнЃЌБмУтЖргрЕФаа
ЪЙгУtopЃЌdistinctЙиМќзжМѕЩйЖргржиИДЕФаа
2.ЩїгУdistinctЙиМќзж
distinctдкВщбЏвЛИізжЖЮЛђепКмЩйзжЖЮЕФЧщПіЯТЪЙгУЃЌЛсБмУтжиИДЪ§ОнЕФГіЯжЃЌИјВщбЏДјРДгХЛЏаЇЙћЁЃ
ЕЋЪЧВщбЏзжЖЮКмЖрЕФЧщПіЯТЪЙгУЃЌдђЛсДѓДѓНЕЕЭВщбЏаЇТЪЁЃ
гЩетИіЭМЃЌЗжЮіЯТ:
КмУїЯдДјdistinctЕФгяОфcpuЪБМфКЭеМгУЪБМфЖМИпгкВЛДјdistinctЕФгяОфЁЃдвђЪЧЕБВщбЏКмЖрзжЖЮЪБЃЌШчЙћЪЙгУdistinctЃЌЪ§ОнПтв§ЧцОЭЛсЖдЪ§ОнНјааБШНЯЃЌЙ§ТЫЕєжиИДЪ§ОнЃЌШЛЖјетИіБШНЯЃЌЙ§ТЫЕФЙ§ГЬдђЛсКСВЛПЭЦјЕФеМгУЯЕЭГзЪдДЃЌcpuЪБМфЁЃ
3.ЩїгУunionЙиМќзж
ДЫЙиМќзжжївЊЙІФмЪЧАбИїИіВщбЏгяОфЕФНсЙћМЏКЯВЂЕНвЛИіНсЙћМЏжаЗЕЛиИјФуЁЃгУЗЈ
<select гяОф1>
union
<select гяОф2>
union
<select гяОф3>
... |
ТњзуunionЕФгяОфБиаыТњзуЃК1.СаЪ§ЯрЭЌЁЃ 2.ЖдгІСаЪ§ЕФЪ§ОнРраЭвЊБЃГжМцШнЁЃ
жДааЙ§ГЬЃК
вРДЮжДааselectгяОф-->>КЯВЂНсЙћМЏ--->>ЖдНсЙћМЏНјааХХађЃЌЙ§ТЫжиИДМЧТМЁЃ
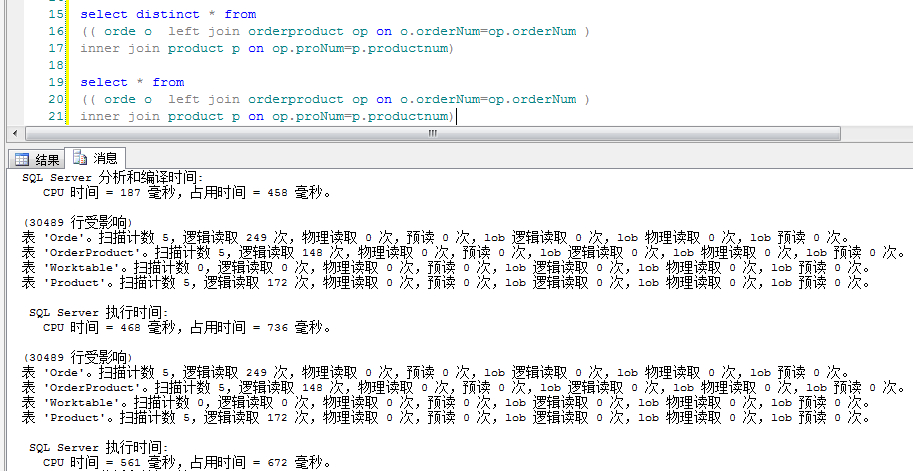
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum
)
inner join product p on op.proNum=p.productnum)
where p.id<10000
union
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum
)
inner join product p on op.proNum=p.productnum)
where p.id<20000 and p.id>=10000
union
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum
)
inner join product p on op.proNum=p.productnum)
where p.id>20000 ---етРяПЩвдаДp.id>100 НсЙћвЛбљЃЌвђЮЊЫћЩИбЁЙ§РВ
-------ЖдБШЩЯЯТСНИігяОф--------
select * from
(( orde o left join orderproduct op on o.orderNum=op.orderNum
)
inner join product p on op.proNum=p.productnum) |

гЩДЫПЩМћаЇТЪШЗЪЕЕЭЃЌЫљвдВЛЪЧдкБивЊЧщПіЯТБмУтЪЙгУЁЃЦфЪЕгаЫћжДааЕФЕкШ§ВПЃКЖдНсЙћМЏНјааХХађЃЌЙ§ТЫжиИДМЧТМЁЃОЭФмПДГіВЛЪЧЪВУДКУФёЁЃШЛЖјВЛЖдНсЙћМЏХХађЙ§ТЫЃЌЯдШЛаЇТЪЪЧБШunionИпЕФЃЌФЧУДВЛХХађЙ§ТЫЕФЙиМќзжгаТ№ЃПД№ЃЌгаЃЌЫћЪЧunion
allЃЌЪЙгУunion allФмЖдunionНјаавЛЖЈЕФгХЛЏЁЃЁЃ
4.ХаЖЯБэжаЪЧЗёДцдкЪ§Он
select count(*)
from product
select top(1) id from product |
КмЯдШЛЯТУцЭъЪЄ
5.СЌНгВщбЏЕФгХЛЏ
ЪзЯШФувЊХЊУїАзФуЯывЊЕФЪ§ОнЪЧЪВУДбљзгЕФЃЌШЛКѓдйзіГіОіЖЈЪЙгУФФвЛжжСЌНгЃЌетКмживЊЁЃ
ИїжжСЌНгЕФШЁжЕДѓаЁЮЊЃК
ФкСЌНгНсЙћМЏДѓаЁШЁОігкзѓгвБэТњзуЬѕМўЕФЪ§СП
зѓСЌНгШЁОігызѓБэДѓаЁЃЌгвЯрЗДЁЃ
ЭъШЋСЌНгКЭНЛВцСЌНгШЁОігызѓгвСНИіБэЕФЪ§ОнзмЪ§СП
select * from
( (select * from orde where OrderId>10000)
o left join orderproduct op on o.orderNum=op.orderNum
)
select * from
( orde o left join orderproduct op on o.orderNum=op.orderNum
)
where o.OrderId>10000 |

гЩДЫПЩМћМѕЩйСЌНгБэЕФЪ§ОнЪ§СППЩвдЬсИпаЇТЪЁЃ
insertВхШыгХЛЏ
--ДДНЈСйЪББэ
create table #tb1
(
id int,
name nvarchar(30),
createTime datetime
)
declare @i int
declare @sql varchar(1000)
set @i=0
while (@i<100000) --бЛЗВхШы10wЬѕЪ§Он
begin
set @i=@i+1
set @sql=' insert into #tb1 values
('+convert(varchar(10),@i)+',''erzi'+
convert(nvarchar(30),@i)+''','''+
convert(nvarchar(30),getdate())+''')'
exec(@sql)
end
|
ЮветРядЫааЪБМфЪЧ51Уы
--ДДНЈСйЪББэ
create table #tb2
(
id int,
name nvarchar(30),
createTime datetime
)
declare @i int
declare @sql varchar(8000)
declare @j int
set @i=0
while (@i<10000) --бЛЗВхШы10wЬѕЪ§Он
begin
set @j=0
set @sql=' insert into #tb2 select '+
convert(varchar(10),@i*100+@j)+','
'erzi'+convert(nvarchar(30),@i*100+@j)+''','
''+convert(varchar(50),getdate())+''''
set @i=@i+1
while(@j<10)
begin
set @sql=@sql+' union all select '+
convert(varchar(10),@i*100+@j)+',''
erzi'+convert(nvarchar(30),@i*100+@j)+''',
'''+convert(varchar(50),getdate())+''''
set @j=@j+1
end
exec(@sql)
end
drop table #tb2
select count(1) from #tb2 |
ЮветРядЫааЪБМфДѓИХЪЧ20Уы
ЗжЮіЫЕУїЃКinsert into selectХњСПВхШыЃЌУїЯдЬсЩ§аЇТЪЁЃЫљвдвдКѓОЁСПБмУтвЛИіИібЛЗВхШыЁЃ
гХЛЏаоИФЩОГ§гяОф
ШчЙћФуЭЌЪБаоИФЛђЩОГ§Й§ЖрЪ§ОнЃЌЛсдьГЩcpuРћгУТЪЙ§ИпДгЖјгАЯьБ№ШЫЖдЪ§ОнПтЕФЗУЮЪЁЃ
ШчЙћФуЩОГ§ЛђаоИФЙ§ЖрЪ§ОнЃЌВЩгУЕЅвЛбЛЗВйзїЃЌФЧУДЛсЪЧаЇТЪКмЕЭЃЌвВОЭЪЧВйзїЪБМфЙ§ГЬЛсКмТўГЄЁЃ
етбљФуИУдѕУДзіФиЃП
елжаЕФАьЗЈОЭЪЧЃЌЗжХњВйзїЪ§ОнЁЃ
delete product
where id<1000
delete product where id>=1000 and id<2000
delete product where id>=2000 and id<3000
..... |
ЕБШЛетбљЕФгХЛЏЗНЪНВЛвЛЖЈЪЧзюгХЕФбЁдёЃЌЦфЪЕетШ§жжЗНЪНЖМЪЧПЩвдЕФЃЌетвЊИљОнФуЯЕЭГЕФЗУЮЪШШЖШРДЖЈЖсЃЌЙиМќФувЊУїАзЪВУДбљЕФгяОфЪЧЪВУДбљЕФаЇЙћЁЃ
змНсЃКгХЛЏЃЌзюживЊЕФЪЧдкгкФуЦНЪБЩшМЦгяОфЃЌЪ§ОнПтЕФЯАЙпЃЌЗНЪНЁЃШчЙћФуЦНЪБВЛдквтЃЌЛузмЕНвЛПщдйзігХЛЏЃЌФуОЭашвЊФЭаФЕФЗжЮіЃЌШЛЖјЗжЮіЕФЙ§ГЬОЭПДФуЕФЮђадЃЌашЧѓЃЌжЊЪЖЫЎЦНРВЁЃ | 








