| БрМЭЦМі: |
| БОЮФРДздгкИіШЫЭМЪщЙн,БОЮФжївЊТлЪіМйЩшвбОДцдквЛИіЩшМЦКУЕФРрФЃаЭЃЌШчКЮдкЭъШЋЙиЯЕЪ§ОнПтЩЯВуУцЯђЖдЯѓЕФРрФЃаЭНјааЗжВуЁЃ |
|
НщЩм
ЕБашвЊЮЊШэМўЯЕЭГЯЕЭГЬсЙЉвЛжжПЩППЃЌСщЛюЖјгжИпаЇЕФЖдЯѓГжОУЛЏЗНЗЈЪБЃЌЕБНёЕФЩшМЦЪІКЭМмЙЙЪІУЧУцСйзХжкЖрЕФбЁдёЁЃДгММЪѕЕФВуУцЩЯЃЌетИібЁдёЭљЭљНщгкЭъШЋУц
ЯђЖдЯѓЃЌЖдЯѓЙиЯЕЛьКЯЃЌЭъШЋЙиЯЕЛЏКЭНЈСЂдкЙЋПЊЛђзЈгаЮФМўИёЪНЩЯЕФГЃЙцНтОіЗНАИжЎМфЃЈШчЃКXMLЃЌOLEЕФНсЙЙЛЏДцДЂЃЉЁЃДгЬсЙЉепЕФВуУц
ЩЯЃЌOracleЃЌ IBMЃЌ MicrosoftЃЌ POET КЭЦфЫќЕФЙЋЫОЬсЙЉСЫЯрЫЦЃЌЕЋЪЧБЫДЫМфЭљЭљВЛЯрШнЕФНтОіЗНАИЁЃ
етВЂВЛБэУїЫќЪЧЮЈвЛЁЂзюКУЖјгжМђЕЅЕФНтОіЗНАИЃЌЕЋЪЧДгЪЕгУЕФНЧЖШПДЃЌЫќЪЧзюГЃгУЕФвЛжжРраЭЃЌШДвВЪЧзюШнвзБЛгУДэЕФвЛжжЁЃ
ЮвУЧЯШПьЫйфЏРРСНИіЩшМЦСьгђЕФФЃаЭЃЌВЂЪдЭМАбЫќУЧСЌНгЦ№РДЃКЕквЛЃЌНщЩмгУUMLБэДяУцЯђЖдЯѓЕФРрФЃаЭЃЛЕкЖўЃЌЙиЯЕЪ§ОнПтФЃаЭЁЃ
ЖдУПвЛИіСьгђЮвУЧжЛЩцМАгАЯьЕНЮвУЧШЮЮёЕФжївЊЙІФмЁЃШЛКѓЮвУЧНЋЙизЂДгРрФЃаЭЕНЪ§ОнПтФЃаЭгГЩфЕФММЪѕКЭЮЪЬтЃЌАќРЈЖдЯѓГжОУадЃЌЖдЯѓааЮЊЃЌЖдЯѓКЭЖдЯѓБъЪЖжЎМф
ЕФЙиЯЕЁЃЮвУЧНЋзмНсЖдUMLЪ§ОнprofileЕФЛиЙЫЃЈRational Software ЭЦМіЃЉЁЃвЛаЉУцЯђЖдЯѓЩшМЦЃЌUMLКЭЙиЯЕЪ§ОнПтНЈФЃЕФЯрЫЦадвВЛсБЛЬсМАЁЃ
РрФЃаЭЪЧUMLгУРДБэДяШэМўЯЕЭГТпМНсЙЙЕФжївЊЙЄМўЁЃ ЫќгУРДМЧТМЪ§ОнашЧѓКЭФЃаЭСьгђФкЖдЯѓЕФааЮЊЁЃБОЮФВЛЬжТлДДНЈКЭЯъЯИУшЪіИУФЃаЭЕФММЪѕЃЌЮвУЧНЋМйЩшвбОДцдквЛИіЩшМЦКУЕФРрФЃаЭЃЌЫќашвЊгГЩфЕНЙиЯЕЪ§ОнПтЩЯЁЃ
РрФЃаЭ
РрдкUMLжаЪЧвЛИіЛљБОЕФТпМЪЕЬхЁЃЫќЖЈвхСЫвЛИіНсЙЙЕЅдЊЕФЪ§ОнКЭааЮЊЁЃвЛИіРрЪЧвЛИіФЃАхЛђдЫааЪБДДНЈЪЕР§КЭЖдЯѓЕФФЃаЭЁЃЕБПЊЗЂвЛИіТпМФЃаЭЃЌШчUMLжа
ЕФНсЙЙВуДЮЃЌЮвУЧНЋУїШЗЕиАбЫќУЧЕБзїРрРДДІРэЁЃЕБУцЖдЖЏЬЌЭМЪБЃЌШчЫГађЭМКЭазїЭМЃЌЮвУЧвВвЊДІРэРрЕФЪЕР§КЭЖдЯѓЃЌвдМАЫќУЧдЫааЪБЕФФкВПЖЏзїЁЃЪ§ОнвўВиКЭЗт
зАддђЪЧЛљгкзїгУгђаЇЙћЁЃРргаЫќЕФФкВПЪ§ОндЊЫиЁЃЗУЮЪетаЉЪ§ОндЊЫиашвЊЭЈЙ§РрЖдЭтЕФааЮЊЛђНгПкЁЃзёбетИіддђЛсЩњГЩИќвзгкЮЌЛЄЕФДњТыЁЃ
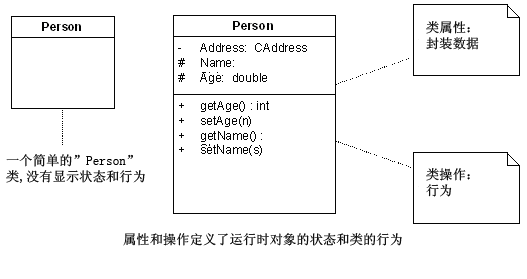
ааЮЊ
ааЮЊЪЙгУСЫРрЖЈвхЕФВйзїЃЌдкРрФЃаЭжаБЛМЧТМЁЃВйзїЪЧПЩвдЭтВППЩМћЕФЃЈpublicЃЉЃЌЖдзгРрПЩМћЕФЃЈprotectedЃЉКЭвўВиЕФЃЈprivateЃЉЁЃЭЈ
Й§НсКЯвўВиЪ§ОнКЭЙЋЙВЗУЮЪНгПкЃЌвўВиЛђБЃЛЄЪ§ОнЕФВйзїЃЌРрЕФЩшМЦШЫдБПЩвдНЈСЂМЋвзЮЌЛЄЕФНсЙЙЕЅдЊЃЌетаЉНсЙЙЕЅдЊЪЧжЇГжЖјВЛЪЧзшАБфЛЏЕФЁЃ
ЙиЯЕКЭЬиад
ЙиСЊЪЧСНИіРржЎМфЕФвЛжжЙиЯЕЁЃЙиЯЕвЛВрЕФРржЊЕРКЭдкФГжжГЬЖШЩЯЪЙгУЛђВйПиСэвЛВрЕФРрЁЃетжжЙиСЊПЩвдЪЧЙІФмЩЯЕФЃЈЮЊЮвзіФГЪТЃЉвВПЩвдЪЧНсЙЙЩЯЕФЃЈЪЧЪВУДЃЉЁЃ
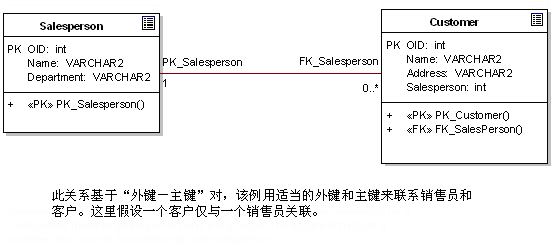
дкБОЮФжаИќЖрЕФЪЧВржиНсЙЙЩЯЕФЙиЯЕЁЃШчЃКвЛИіЁАAddressЁБРрПЩвдЙиСЊвЛИіЁАPersonЁБРрЃЌНЋетжжЙиЯЕгГЩфЕНЪ§ОнПеМфашвЊЖрМгзЂвтЁЃ
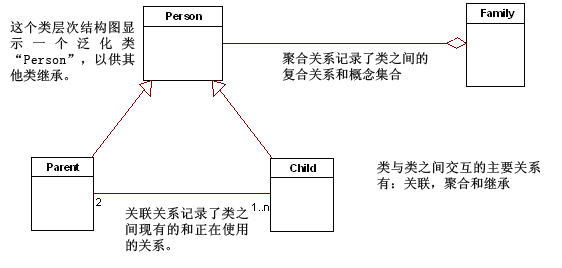
ОлКЯЪЧЙиСЊЕФвЛжжаЮЪНЃЌБэЪОвЛИіРрЖрИіЖдЯѓЕФМЏКЯдкСэвЛИіРржаЁЃИДКЯЪЧвЛжжИќЧПЕФОлКЯаЮЪНЃЌЫЕУївЛИіЖдЯѓЪЕМЪЩЯгЩЦфЫќЖдЯѓЙЙГЩЁЃЖдгкЙиСЊЙиЯЕРДЫЕЃЌЫќвтЮЖ
зХвЛИіИДдгЕФРрЪєадЃЌНЋИУЪєадгГЩфЕНЙиЯЕФЃаЭЪБашвЊИќЯъЯИЕФПМТЧЁЃЕБвЛИіРрБэЪОЮЊЩњГЩаэЖрЖдЯѓЪЕР§ЕФФЃАхЛђФЃаЭЪБЃЌЖдЯѓашвЊдкдЫааЪБгаЪЖБ№здМКЕФЗНЪНЃЌет
бљБЛЙиСЊЖдЯѓПЩвдЖде§ШЗЕФЖдЯѓЪЕР§ЪЉМгзїгУЁЃдкБрГЬгябджаЃЌШчCЃЋЃЋЃЌЖдЯѓжИеыПЩФмЛсДЋЕнЃЌВЂЪЙЫљжИЖдЯѓПЩвдЗУЮЪвЛИіЖРвЛЮоЖўЕФЖдЯѓЪЕР§ЁЃЭЈГЃОЁЙмвЛИіЖд
ЯѓЛсБЛЯњЛйЃЌЕЋЪЧдкашвЊЪБЃЌгжЯѓЩЯвЛДЮгааЇЪЕР§ЦкМфФЧбљБЛжиНЈЁЃЫљвдЃЌетаЉЖдЯѓашвЊвЛИіДцДЂЛњжЦРДБЃСєЫќУЧЕФФкВПзДЬЌКЭЙиСЊЃЌВЂдкашвЊЪБЛжИДЫљашзДЬЌЁЃ
МЬГаИјРрФЃаЭЬсЙЉвЛжжЗНЪНЃЌИУЗНЪНЬсШЁЭЈгУааЮЊЕНЗКЛЏЕФРржаЃЌЪЙетИіЗКЛЏРрЩдКѓПЩвдзіЮЊдквЛАужїЬтЩЯжюЖрБфвьЕФдаЮЁЃМЬГаЪЧвЛжжЙмРэжигУКЭИДдгадГЬЖШЕФЗН
ЪНЁЃШчЮвУЧНЋПДЕНЕФЃЌЙиЯЕФЃаЭВЂУЛгагыМЬГаЙиЯЕЕФжБНгЖдгІЯюЃЌетИјЪ§ОнФЃаЭНЈСЂепНЈСЂвЛИіДгЖдЯѓФЃаЭЕНЙиЯЕПђМмдьГЩСЫРЇФбЁЃДгвЛИідЫааЪБЕФЖдЯѓЕНСэЭтвЛИі
ЖдЯѓЕФЕМКНЪЧНЈСЂдкЭъШЋв§гУЕФЛљДЁжЎЩЯЁЃвЛИіЖдЯѓгаЖржжаЮЪНЕФСЌНгЃЈжИеыЛђЮЈвЛЕФЖдЯѓБъЪЖЃЉЃЌгУетаЉСЌНгПЩвдЖЈЮЛКЭжиНЈЫљашЕФЖдЯѓЁЃ
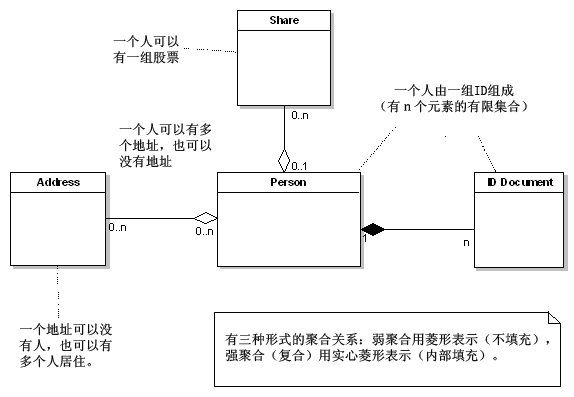
ЙиЯЕФЃаЭ
ЙиЯЕЪ§ОнФЃаЭвбОЪЙгУЖрФъЃЌЬсЙЉЕФадФмКЭСщЛюадвЛжБаажЎгааЇЁЃЫќБОжЪЩЯЪЧЛљгкМЏКЯЕФЃЈsetЃbasedЃЉЃЌВЂЧвгУЁЎБэЁЏзіЮЊЫќЕФЛљБОЕЅдЊЃЌБэгЩвЛИіЛђЖрИіЁЎСаЁЏзщГЩЃЌУПвЛИіСаАќКЌвЛИіЪ§ОндЊЫиЁЃ
БэКЭСаЃКвЛИіЙиЯЕБэЪЧвЛИіЛђЖрИіСаЕФМЏКЯЃЌУПИіСадкБэНсЙЙжагавЛИіЮЈвЛУћГЦЃЌВЂЧвБЛЖЈвхГЩвЛИіЬиЖЈЛљБОЪ§ОнРраЭЃЌШчЃКЪ§зжЁЂЮФБОЁЂЖўдЊЪ§ОнЁЃБэЖЈвхЪЧвЛИі
ФЃАхЃЌБэЕФЁАааЁБДгетИіФЃАхжаБЛДДНЈЃЌааПЩФмзіЮЊвЛИіБэЪЕР§ЕФЪЕР§ЁЃЙиЯЕФЃаЭНіНіЬсЙЉвЛИіЙЋЙВЪ§ОнЗУЮЪЕФФЃаЭЁЃЫљгаЪ§ОнЯђЭтЖдШЮКЮвЛИіЙ§ГЬПЊЗХЃЌвдБугкБЛ
ИќаТЃЌВщбЏКЭВйПиЁЃаХЯЂвўБЮЃЈinformation hidingЃЉЪЧЮДжЊЕФЁЃ
ааЮЊ
гыБэЯрЙиСЊЕФааЮЊЭЈГЃЪЧЛљгкЫљгІгУЪЕЬхЕФвЕЮёЛђТпМЙцдђЁЃдМЪјвдЖрИіаЮЪНгІгУЕНЁАСаЁБЃЌШчЃКЖРЬиадашЧѓЁЂЖдгІЦфЫќБэКЭСаЕФЙиЯЕЭъећаддМЪјЃЌдЪаэЕФжЕКЭЪ§ОнРраЭЁЃ
ДЅЗЂЦїЬсЙЉСЫЙиСЊЕНвЛИіЪЕЬхЕФаэЖрИНМгааЮЊЁЃЭЈГЃдкЪ§ОнБЛВхШыЁЂЩОГ§КЭИќаТЧАКѓЃЌЧПжЦжДааЪ§ОнЕФЭъећадМьВщЁЃЪ§ОнПтДцДЂЙ§ГЬЬсЙЉСЫвЛжжЭЈЙ§зЈгагябдРЉеЙРД
бгЩьЪ§ОнПтЙІФмЕФЗНЪНЃЌетаЉРЉеЙЭЈГЃгУРДЙЙдьЙІФмадЕЅдЊЃЈНХБОЃЉЁЃетаЉЙІФмВЛЛсжБНггГЩфЕНетаЉЪЕЬхЃЌвВВЛЛсгыЫќУЧгаТпМЙиЯЕЁЃЭЈЙ§ЙиЯЕЪ§ОнМЏЕФЕМКНЪЧЛљгк
ЁАааЁББщРњКЭБэСЌНгЪЕЯжЁЃSQLЪЧгУРДДгБэМЏбЁдёЁАааЁБКЭЗХжУЪЕР§ЕФвЛжжжївЊЕФгябдЁЃ
ЙиЯЕКЭЪЖБ№
БэЕФжїМќЮЊЪЖБ№ааЬсЙЉвЛИіЬиЖЈжЕЁЃетРягаСНжжЮвУЧЙизЂЕФжїМќЃКЪзЯШЪЧвтвхМќЃЈmeaning keyЃЉЃЌЫќгЩЪ§ОнСаЙЙГЩЃЌетаЉЪ§ОнСадквЕЮёСьгђгавтвхЁЃЦфДЮЪЧвЛИіГщЯѓЕФЮЈвЛБъЪЖЗћЃЌШчМЦЪ§ЦїжЕЃЌЫќУЛгаЩЬвЕвтвхЃЌЕЋЪЧПЩвдЮЈвЛЕиБъЪЖвЛИіааЁЃЮвУЧНЋЯШ
ЬжТлГщЯѓЮЈвЛБъЪЖЗћЃЌШЛКѓдйВћЪівтвхМќЁЃвЛИіБэПЩвдАќКЌгГЩфЕНСэвЛИіБэжїМќЕФЁАСаЁБЁЃБэМфЕФЙиЯЕЖЈвхСЫвЛИіЭтМќЃЌЫЕУїСЫдкетСНИіБэжЎМфЕФНсЙЙЙиЯЕЛђЙиСЊЁЃ
аЁНк
ДгвдЩЯЕФИХЪіЃЌЮвУЧПЩвдПДГіЖдЯѓФЃаЭЪЧНЈСЂдкРыЩЂЪЕЬхЛљДЁЩЯЃЌетаЉЪЕЬхМШгазДЬЌЃЈЪєадКЭЪ§ОнЃЉЃЌвВгаааЮЊЃЌвЛАуНіЭЈЙ§РрЕФЙЋЙВНгПкРДЗУЮЪЗтзАЪ§ОнЁЃЙиЯЕФЃ
аЭЭЌЕШЕиЯдТЖЫљгаЪ§ОнЃЌгаЯожЇГжРћгУДЅЗЂЦїДгааЮЊЕНЪ§ОндЊЫиЕФЙиСЊЁЃвРППЪЙгУЮЈвЛЖдЯѓБъЪЖЗћЃЌПЩвдДгвЛИіЖдЯѓвЦЖЏЕНСэвЛИіЖдЯѓЃЌетЪЙЕУЮвУЧПЩвддкЖдЯѓФЃаЭ
жаЕМКНЃЌВЂНЈСЂЖдЯѓЙиЯЕЃЈРрЫЦгкЭјТчЪ§ОнФЃаЭЃЉЁЃдкЙиЯЕФЃаЭжаЃЌЭЈЙ§ЪЙгУМьЫїБъзМЃЌSQLКЯВЂКЭЙ§ТЫНсЙћМЏЃЌФуПЩвдВщевевЫљашЕФааЁЃБъЪЖЗћдкЖдЯѓФЃаЭжаМШ
ПЩвдЪЧЪЕЪБв§гУЃЌвВПЩвдЪЧГжОУЕФЮЈвЛБъЪЖЗћЃЈГЦзїOIDЃЉЁЃдкЙиЯЕСьгђРяЃЌжїМќЖЈвхСЫЪ§ОнМЏдкећИіЪ§ОнПеМфжаЕФЮЈвЛадЁЃ
ЖдЯѓФЃаЭжагаЗсИЛЕФЙиЯЕМЏКЯЃКМЬГаЃЌОлКЯЃЌЙиСЊЃЌИДКЯЃЌвРРЕЃЌвдМАЦфЫќЁЃдкЙиЯЕФЃаЭжаЃЌПЩвдНіЪЙгУЭтМќРДжИУївЛжжЙиЯЕЁЃЮвУЧвбОЖдИааЫШЄЕФСНИіСьгђНјааСЫНщЩмВЂБШНЯСЫУПвЛИіСьгђЕФМИИіживЊЙІФмЃЌШЛКѓНЋМђЕЅСЫНтUMLжаЙиЯЕЪ§ОнФЃаЭЕФБъзЂЁЃ
UMLЪ§ОнФЃаЭProfileЃЈЬиадУшЪіЃЉ
Ъ§ОнФЃаЭProfileЪЧEnterprise ArchitectЕФUMLРЉеЙРДжЇГжЙиЯЕЪ§ОнПтНЈФЃЁЃЫќАќРЈвЛаЉЖЈжЦРЉеЙЃЌШчЃКБэЃЌЪ§ОнПтЭМБэЃЌБэМќЃЌДЅЗЂЦїКЭдМЪјЁЃЫќЪЧвЛжждкUMLжаЖдЙиЯЕЪ§ОнПтНЈФЃЕФММЪѕЁЃ
БэКЭСа БэдкUMLЪ§ОнProfileжаЪЧДјЁЖTableЁЗЙЙдьаЭЕФРрЃЌЫќдкгвЩЯНЧЯдЪОвЛИіБэЕФЗћКХЁЃЪ§ОнПтжаЕФСагУЁЖTableЁЗРрЕФЪєадРДНЈФЃЁЃ
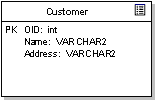
Р§ШчЃКЩЯУцЭМаЭЯдЪОгыПЭЛЇБэЙиСЊЕФЪєадЁЃдкДЫЪОР§жаЃЌЖдЯѓIDБЛЖЈвхЮЊБэЕФжїМќЃЌЛЙгаСНИіСаЃКЁАNameЁБКЭЁАAddressЁБЁЃзЂвтЩЯЭМР§згжаСаЕФЪ§ОнРраЭЪЧАДеедDBMSЕФЪ§ОнРраЭЖЈвхЕФЁЃ
ааЮЊ ЕНФПЧАЮЊжЙЃЌЮвУЧНіЖЈвхСЫБэЕФТпМЃЈОВЬЌЃЉНсЙЙЁЃДЫЭтЃЌЮвУЧНЋУшЪігыСаЙиСЊЕФааЮЊЃЌАќРЈЃКЫїв§ЃЌМќЃЌДЅЗЂЦїЃЌЙ§ГЬЕШЕШЁЃааЮЊБэЪОЮЊДјЙЙдьаЭЕФВйзїЁЃ
ЯТЭМЯдЪОЮвУЧЬжТлЕФБэЃЌЫќгавЛИіжїМќдМЪјКЭЫїв§ЃЌОљБЛЖЈвхЮЊДјЙЙдьаЭЕФВйзїЁЃ
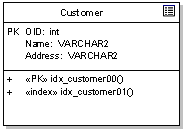
зЂвтЃКЁАOIDЁБСаЩЯЕФPKБъЧЉЖЈвхСЫТпМжїМќЃЌЖјЙЙдьаЭВйзїЁА?PK?
idx_customer00ЁБЖЈвхСЫгыжїМќЪЕЯжЯрЙиСЊЕФдМЪјКЭааЮЊЃЈМДжїМќЕФааЮЊЃЉЁЃ
ЖдЩЯР§НјаадіМгЃЌЮвУЧЯждкПЩвдЖЈвхИНМгааЮЊЃЌШчЃКДЅЗЂЦїЃЌдМЪјЃЌДцДЂЙ§ГЬЁЃМћЯТЭМЃК
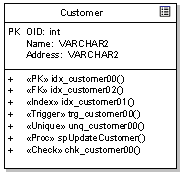
етИіР§згУшЪіСЫЯТСаааЮЊ:
вЛИіжїМќдМЪјЃЈPKЃЉ;
вЛИіЭтМќдМЪјЃЈFKЃЉ;
вЛИіЫїв§дМЪјЃЈIndexЃЉ;
вЛИіДЅЗЂЦїЃЈTriggerЃЉ;
вЛИіЮЈвЛаддМЪјЃЈUniqueЃЉ;
вЛИіДцДЂЙ§ГЬЃЈProcЃЉ
вЛИігааЇадМьВщЃЈCheckЃЉ.
ЪЙгУЩЯУцЬсЙЉЕФБъзЂЃЌЮвУЧПЩвддкDBMSВуДЮЩЯЃЌЖдИДдгЕФЪ§ОнНсЙЙКЭааЮЊНЈФЃЁЃСэЭтЃЌUMLЛЙЬсЙЉБэДяТпМЪЕЬхМфЙиЯЕЕФБъзЂЁЃ
ЙиЯЕ
UMLЪ§ОнНЈФЃprofileЖЈвхСЫСНИіБэМфШЮвтвЛжжвРРЕЙиЯЕЁЃЫќБэЪОЮЊвЛЙЙдьаЭЕФЙиСЊВЂАќРЈвЛзщжїМќКЭЭтМќЁЃЪ§ОнprofileШдШЛашвЊвЛжжЙиЯЕвЛжБВЮ
гыЕНИИРрКЭзгРржЎМфЃЌИИРрЖЈвхвЛИіжїМќЃЌзгРрЪЕЯжвЛИіНЈСЂгкШЋВПЛђВПЗжИИРржїМќЛљДЁЩЯЕФЭтМќЁЃетжжЙиЯЕНЋБЛЧјЗжЮЊЃКЁАЖЈвхЕФЁБЃЈШчЙћИУзгРрЭтМќАќКЌЫљгаИИ
РржїМќдЊЫиЃЉКЭЁАЗЧЖЈвхЕФЁБЃЈШчЙћжЛАќРЈВПЗжжїМќдЊЫиЃЉЁЃетИіЙиЯЕПЩвдАќРЈЛљЪ§аддМЪјЃЌвдМАВЩгУГЩЖдЕФЯрЙижїМќгыЭтМќРДНЈФЃЃЌВЂУќУћЮЊЙиСЊНЧЩЋЁЃЯТЭМУшЪі
СЫЪЙгУUMLЖдетжжЙиЯЕЕФНЈФЃЁЃ

ЮяРэФЃаЭ
UMLвВЬсЙЉвЛаЉЛњжЦРДБэЪОЪ§ОнПтЕФећЬхЮяРэНсЙЙЃЌЫќЕФФкШнКЭВПЪ№ЮЛжУЁЃЮвУЧгУЙЙдьаЭзщМўРДБэЪОвЛИіЮяРэЪ§ОнПтЁЃМћЯТЭМЃК

вЛИізщМўБэЪОСЫвЛИіРыЩЂЃЌПЩВПЪ№ЕФЪЕЬхЁЃдкЮяРэФЃаЭжаЃЌзщМўПЩвдгГЩфЕНвЛИіЮяРэгВМўЃЈUMLЕФНкЕуЃЉЁЃЖдгкЪ§ОнПтФкЕФЙиЯЕФЃЪНЃЌЮвУЧгУДјЁЖSchemaЁЗ
ЙЙдьаЭЕФАќРДБэЪОЁЃвЛИіБэПЩвдЗХжУЕНЁЖSchemaЁЗжаРДНЈСЂЫќдкЪ§ОнПтжаЕФЗЖЮЇКЭЮЛжУЁЃ
ДгРрФЃаЭЕНЙиЯЕФЃаЭЕФгГЩф
ЮвУЧвбОУшЪіСЫЫљЙизЂЕФСНИіСьгђКЭЫќУЧЪЙгУЕФБъзЂЃЌЯждкНЋЮвУЧЕФзЂвтСІзЊвЦЕНШчКЮгГЩфЃЌМАШчКЮДгвЛИіСьгђзЊЛЛЕНСэвЛИіСьгђЁЃвдЯТВЩгУЕФВпТдКЭБэДяЫГађЪЧНЈвщадЕФЃЌЖјВЛЪЧБиаыЕФЁЃВЩгУКЮжжВНжшКЭЙ§ГЬвЊИљОнИіШЫЕФашвЊКЭЛЗОГЖјЖЈЁЃ
1. РрЕФНЈФЃ
ЪзЯШЮвУЧМйЩшДгвЛИівбОДДНЈЕФРрФЃаЭЙЙНЈвЛИіаТЕФЙиЯЕЪ§ОнПтФЃЪНЁЃЯдШЛетЪЧвЛИізюШнвзЕФЗНЯђЃЌетЪЧвђЮЊФЃаЭвЛжБдкЮвУЧЕФПижЦжЎЯТЃЌВЂЧвЮвУЧФмИљОнРрФЃаЭРД
гХЛЏетЙиЯЕФЃаЭЁЃдкЯжЪЕЛЗОГЯТЃЌФуПЩФмашвЊдкдгаЪ§ОнФЃаЭжЎЩЯЖдРрФЃаЭЗжВуЃЌетЪЧИќФбЕФвЛжжЧщПіЃЌОпгаЬєеНадЁЃдкетРяЃЌЮвУЧжЛЙизЂЕквЛжжЧщПіЁЃжСЩйРрФЃаЭ
ЛсМЧТМдЊЫиЕФЙиСЊЃЌМЬГаКЭОлКЯЙиЯЕЁЃ
2. БъЪЖГжОУЖдЯѓ
НЈСЂРрФЃаЭКѓЃЌЮвУЧашвЊНЋРрФЃаЭЕФдЊЫиЗжГЩашвЊГжОУадКЭВЛашвЊГжОУадСНРрЁЃР§ШчЃЌШчЙћЮвУЧВЩгУЁАФЃаЭЃЪгЭМЃПижЦЁБЕФЩшМЦФЃЪНРДЩшМЦЮвУЧЕФгІгУГЬађЃЌФЧУДжЛдкФЃаЭВПЗжЕФРрНЋашвЊГжОУзДЬЌЁЃ
3. МйЩшУПвЛИіГжОУРргГЩфЕНвЛИіЙиЯЕБэ
етЪЧвЛИіДѓЕФМйЩшЃЌЕЋЪЧЫќЖдДѓЖрЪ§ЧщПігагУЃЈЯждкЯШАбМЬГаЕФЮЪЬтЗХвЛБпЃЉЁЃдквЛИізюМђЕЅФЃаЭжаЃЌвЛИіРДздТпМФЃаЭЕФРргГЩфЕНЙиЯЕБэЕФШЋВПЛђвЛВПЗжЁЃетИігГЩфЕФТпМРЉеЙЪЧвЛИіЕЅЖРЕФЖдЯѓЃЈЛђРрЕФЪЕР§ЃЉгГЩфЕНБэжаЕЅЖРЕФЁАааЁБЁЃ
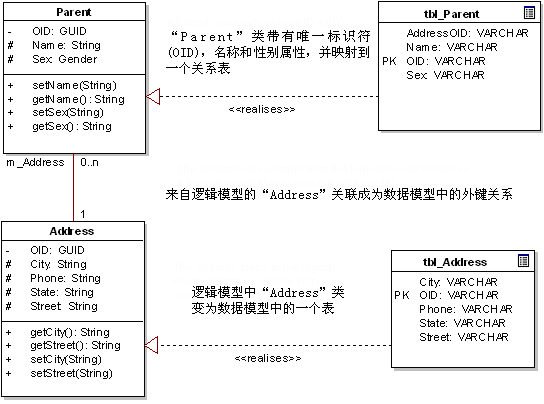
4. бЁдёвЛИіМЬГаВпТд.
МЬГаПЩФмЪЧДгУцЯђЖдЯѓФЃаЭзЊЛЛЕНЙиЯЕФЃаЭЙ§ГЬжазюШнвзГіЯжЮЪЬтЕФЙиЯЕКЭТпМНсЙЙЁЃЙиЯЕСьгђБОжЪЩЯЪЧЦНУцЕФЃЌУПвЛИіЪЕЬхздЩэЭъГЩЃЌЖјЖдЯѓФЃаЭГЃГЃЪЧвЛИіОпга
ЩюЖШЕФЃЌЩшМЦЭъЩЦЕФРрВуДЮНсЙЙЁЃетбљЩюЖШЕФРрФЃаЭПЩвдгаЖрВуЕФМЬГаЪєадКЭааЮЊЃЌдЫааЪБЩњГЩзюКѓШЋЙІФмЕФЖдЯѓ:
УПвЛИіРрВуДЮНсЙЙгавЛИіЕЅЖРЖдгІЕФБэЃЌетИіБэАќКЌЫљгадЊЫиЕФМЬГаЪєадЃвђДЫЃЌетИіБэЪЧИУВуДЮНсЙЙжаУПИіРрЕФСЊКЯЁЃР§ШчЃЌШЫЃЌИИФИЃЌКЂзгКЭЫязгПЩФмаЮГЩвЛИіЕЅЖРЕФРрВуДЮНсЙЙЃЌВЂЧвУПИіРржаЕФдЊЫиЖМЛсГіЯждкЯрЭЌЕФЙиЯЕБэжа;
РрВуДЮНсЙЙжаЕФУПвЛИіРргавЛИіЖдгІЕФБэЃЌИУБэгаНіФмБЛИУРрЗУЮЪЕФЪєадЃЈАќРЈМЬГаЪєадЃЉЁЃР§ШчЃЌШчЙћЁАКЂзгЁБНіНіДгЁАШЫЁБМЬГаЖјРДЃЌБэНЋНіАќКЌЁАШЫЁБКЭЁАКЂзгЁБЕФдЊЫи;
РрВуДЮНсЙЙжаЕФУПИіРрЕФздгаЪєадЖдгІвЛИіБэЁЃР§ШчЃЌЁАКЂзгЁБНЋгГЩфЕНвЛИіНіДјКЂзгЪєадЕФЕЅИіБэ
ЖдУПвЛжжЗНЗЈЃЌЮвУЧгаЖдгІЕФАИР§ЁЃЕЋЪЧЮвУЧЭЦМіЕкШ§жжЗНЗЈЃЌвђЮЊЫќзюМђЕЅЃЌзюШнвзЮЌЛЄКЭзюВЛШнвзГіДэЁЃЕквЛжжЗНЗЈЬсЙЉСЫдЫааЪБзюМбЕФадФмЁЃЕкЖўжжЗНЗЈЪЧЕк
вЛжжгыЕкШ§жжЕФелждЁЃЕквЛжжЗНЗЈеЙПЊВуДЮНсЙЙЃЌдквЛИіБэРяЗХжУЫљгаЕФЪєадЃЌетбљЗНБуРрВуДЮНсЙЙжаЖдРрЕФИќаТКЭЬсШЁЃЌЕЋЪЧВЛвзгкбщжЄКЭЮЌЛЄЁЃгыЁАааЁБЙиСЊЕФ
вЕЮёЙцдђЪЧФбвдЪЕЯжЕФЃЌвђЮЊБэжаЕФУПвЛааЖМПЩФмБЛЪЕР§ЛЏЮЊВуДЮНсЙЙжаЕФЖдЯѓЁЃЁАСаЁБжЎМфЕФвРРЕЙиЯЕПЩФмБфЕУЯрЕБИДдгЁЃДЫЭтЃЌЖдВуДЮНсЙЙжаШЮКЮвЛИіРрЕФИќаТ
НЋПЩФмгАЯьВуДЮНсЙЙжаЦфЫќУПИіРрЃЌШчБэжаЕФСаБЛЬэМгЃЌЩОГ§КЭаоИФЁЃ
ЕкЖўжжЗНЗЈЪЧвЛжжелждЗНАИЃЌЬсЙЉСЫИќКУЕФЗтзАКЭЯћГ§ПеСаЁЃПЩЪЧЃЌЖдИИРрЕФаоИФПЩФмашвЊдкЫљгазгРрЕФБэжаНјааИДжЦЃЌИќдуЕФЪЧЃЌгаСНИіЛђЖрИізгРрЕФИИРрЪ§ОнПЩ
ФмБЛШпгрЕиДцДЂдкаэЖрБэжаЃЛШчЙћИИРрЕФЪєадБЛаоИФЃЌФЧУДвЊЛЈЯрЕБЕФЪБМфШЅВщевЯрЙиЕФзгБэЃЌВЂИќаТЪмгАЯьЕФааЁЃ
ЕкШ§жжЗНЗЈОЋШЗЕиЗДгГСЫЖдЯѓФЃаЭЃЌЫќНЋВуДЮНсЙЙжаЕФУПвЛИіРргГЩфГЩвЛИіЖРСЂЕФБэЁЃИИРрЛђзгРрЕФИќаТЪЧдке§ШЗПеМфЕФОжВПЗЖЮЇФкНјааЕФЁЃЖдЪЕЬхЕФШЮКЮаоИФБЛбЯ
ИёЯоЖЈгкЕЅИіБэФкЃЌвђДЫБэЕФЮЌЛЄвВОЭЯрЖдМђЕЅЁЃШБЕуЪЧашвЊдкдЫааЪБжиЙЙНсЙЙВуДЮЃЌРДОЋШЗВњЩњвЛИізгРрЕФзДЬЌЁЃвЛИіЁАChildЁБЕФЖдЯѓПЩФмашвЊвЛИі
ЁАPersonЁБЕФГЩдББфСПгУгкБэЪОЫќЕФИИБВЁЃгЩгкетСНепЖМашвЊМгдиЃЌСНДЮЕїгУЪ§ОнПтРДГѕЪМЛЏвЛИіЖдЯѓЁЃЫцзХРрНсЙЙВуДЮМгЩюЃЌГѕЪМЛЏЛђИќаТвЛИіЕЅЖРЖдЯѓЕФ
Ъ§ОнПтЕїгУДЮЪ§вВЫцжЎдіМгЁЃ
ЕБФугГЩфМЬГаЙиЯЕЕНЙиЯЕФЃаЭЪБЃЌРэНтЩЯЪівЊЕуЪЧКмживЊЕФЃЌетбљФуОЭбЁдёзюЪЪКЯФуЕФЗНАИЁЃ
5. ЮЊУПвЛИіРрЬэМгвЛИіЮЈвЛЕФЖдЯѓБъЪЖЗћ
дкЙиЯЕКЭЖдЯѓЕФСьгђРяЃЌашвЊЮЈвЛБъЪЖвЛИіЖдЯѓЛђЪЕЬхЁЃдкЖдЯѓФЃаЭжаЃЌЗЧГжОУЖдЯѓдкдЫааЪБЭЈГЃБЛжБНгв§гУЛђЖдЯѓжИеыРДБъЪЖЁЃвЛЕЉЖдЯѓБЛДДНЈЃЌЮвУЧПЩвдгУЫќдЫ
ааЪБЕФБъЪЖЗћРДв§гУЫќЁЃЕЋЪЧЃЌШчЙћЮвУЧНЋЖдЯѓаДШыДцДЂПеМфЃЌФЧУДШчКЮАДашвЊЕУЕНЭъШЋЯрЭЌЕФЪЕР§ЪЧвЛИіЮЪЬтЁЃзюБуНнЕФЗНЪНЪЧЖЈвхвЛИіOIDЃЈЖдЯѓБъЪЖЗћЃЉЃЌ
ЫќдкЙизЂЕФУќУћПеМфЪЧБЛШЗБЃЮЈвЛЕФЁЃИљОнашвЊЃЌетПЩФмЗЂЩњдкРрЃЌАќЛђЯЕЭГЕФВуМЖЩЯЁЃ
ЯЕЭГМЖБ№OIDЕФвЛИіР§згПЩвдЪЧвЛИіЪЙгУЮЂШэЁАguidgenЁБЙЄОпДДНЈЕФGUIDЃЈШЋОжЮЈвЛБъЪЖЗћЃЉЃЌШч{A1A68E8E-CD92-420b-
BDA7-118F847B71EB}ЁЃРрМЖБ№ЕФOIDПЩвдгУМђЕЅЕУЪ§зжЪЕЯжЃЈШчЃКЃГЃВЮЛМЦЪ§ЦїЃЉЁЃШчЙћвЛИіЖдЯѓОпгаЖдЦфЫќЖдЯѓЕФв§гУЃЌЫќПЩвдВЩгУЪЙгУЫќ
УЧЕФOIDЕФЗНЗЈЁЃФЧУДЃЌдкдЫааЪБгааЇЕиНЋв§гУЕФЖдЯѓДгДцДЂЧјМгдиЕНФЃаЭжаЁЃЙигкЩЯЪіOIDжЕЕФжиЕуЪЧЫќУЛгаГЌГіЖЈвхЫќЮЊБъЪЖЗћЕФМђЕЅКЌвхЁЃЫќУЧНіЪЧТпМ
жИеыЖјУЛгаЦфЫќвтвхЁЃдкЙиЯЕФЃаЭжаЃЌЧщПіЭљЭљЪЧВЛЭЌЕФЁЃ
ЙиЯЕФЃаЭжаБъЪЖе§ГЃЕигУвЛИіжїМќЪЕЯжЁЃжїМќЪЧвЛИіБэжаЕФвЛзщЁАСаЁБЃЌЫќУЧКЯЦ№РДПЩвдЮЈвЛЕиБъЪЖвЛИіааЁЃР§ШчЃКУћГЦКЭЕижЗПЩвдЮЈвЛЕиБъЪЖвЛИіЁАПЭЛЇЁБЁЃЦфЫќ
ЪЕЬхЃЌШчЃКЁАЯњЪлдБЁБв§гУЁАПЭЛЇЁБЃЌЫќУЧвЊЪЕЯжЛљгкЁАПЭЛЇЁБжїМќЕФЭтМќЁЃетИіЗНЗЈДцдкЕФЮЪЬтЪЧЃКНЋвЕЮёаХЯЂЃЈШчПЭЛЇУћКЭЕижЗЃЉЧЖШыБъЪЖЗћжаЖдЮвУЧФПБъЕФгА
ЯьЁЃЩшЯыШ§ИіЛђЫФИіБэШЋВПОпгаЛљгкЁАПЭЛЇЁБжїМќЕФЭтМќЃЌЖдгквЛИіашвЊаоИФПЭЛЇжїМќЃЈШчЃКдіМгвЛИігУЛЇРраЭЃЉЕФЯЕЭГаоИФЃЌФЧУДМШвЊаоИФПЭЛЇБэЃЌвВвЊаоИФгыЭт
МќЯрЙиЕФЪЕЬхЃЌетИіЙЄзїЪЧЪЎЗжОоДѓЕФЁЃ
СэвЛЗНУцЃЌШчЙћвЛИіOIDБЛЕБзїжїМќЪЕЯжЃЌВЂЮЊЦфЫќБэНЈСЂЭтМќЃЌФЧУДаоИФЗЖЮЇНіЯогкжїБэЃЌВЂЧваоИФЕФгАЯьвВвђДЫДѓДѓМѕаЁЁЃЪЕМЪЩЯЃЌвЛИіЛљгквЕЮёЪ§ОнЕФжїМќ
вВаэЛсБЛаоИФЁЃШчЃКвЛИіПЭЛЇПЩвдаоИФЕижЗКЭУћзжЃЌМШШЛетбљЃЌетИіБфЛЏашвЊБЛе§ШЗЕФДЋЕнЕНЫљгаЦфЫќЯрЙиЕФЪЕЬхЃЌИќВЛгУЬсИФБфВПЗжжїМќаХЯЂЕФРЇФбЁЃ
вЛИіOIDзмЪЧв§гУЭЌвЛИіЪЕЬхЃЌЖјВЛЙмЦфЫќаХЯЂдѕУДИФБфЁЃдкЩЯУцЕФР§згжаЃЌПЭЛЇПЩвдаоИФУћГЦКЭЕижЗЃЌгыЫќЯрЙиСЊЕФБэВЛашвЊБЛаоИФЁЃЕБАбЖдЯѓФЃаЭгГЩфЕНЙиЯЕ
БэЪБЃЌЪЕЯжЭъШЋOIDЕФБъЪЖЗћБШВЩгУвЕЮёСЊЯЕЕФжїМќИќМгБуНнЁЃгУOIDзіЮЊжїМќКЭЭтМќЕФЗНЗЈНЋЮЊЖдЯѓЬсЙЉИќКУЕФМгдиКЭИќаТаЇТЪЃЌНЋЮЌЛЄЗўЮёМѕЕНзюЩйЁЃЪЕМЪ
ЩЯЃЌвЛИігывЕЮёЯрСЊЯЕЕФжїМќПЩвдЬцЛЛЮЊЃК
вЛИіЮЈвЛаддМЪјЛђЯрЙиСаЕФЫїв§;
ЧЖШыРрааЮЊЕФвЕЮёЙцдђ;
ЛђНЋЩЯЪіСНжжНсКЯЦ№РД.
дйДЮжиЩъЃЌЪЧЪЙгУгавтвхЕФМќЛЙЪЧЪЙгУOIDШЁОігкБЛПЊЗЂЯЕЭГЕФЪЕМЪашвЊЁЃ
6. гГЩфЪєадЕНЁАСаЁБ
ЭЈГЃЃЌЮвУЧНЋМђЕЅЕФРрЪ§ОнЪєадгГЩфЕНЙиЯЕБэЕФСаЁЃР§ШчЃЌвЛИіЮФБОЛђЪ§зжзжЖЮПЩвдЗжБ№БэЪОвЛИіШЫЕФУћзжКЭФъСфЃЌетжжжБНггГЩфВЛЛсв§Ц№ЪВУДЮЪЬтЃЌжЛЪЧМђЕЅЕидкЪ§ОнПтЗўЮёЩЬЕФЙиЯЕФЃаЭжабЁдёЪЪЕБЕФЃЌгыРрЪєадЯрЖдгІЕФЪ§ОнРраЭЁЃ
ЖдИДдгЪєадЃЈМДЪєадЮЊЦфЫќЖдЯѓЃЉЪЙгУЯТУцЯъЯИЕФВНжшРДДІРэЙиСЊКЭОлКЯЙиЯЕЁЃ
7. гГЩфЙиСЊЕНЭтМќ
ИќИДдгЕФРрЪєадЃЈМДЫќУЧДњБэЦфЫќРрЃЉЭЈГЃНЈФЃЮЊЙиСЊЙиЯЕЁЃвЛИіЙиСЊЪЧЖдЯѓМфЕФНсЙЙЙиЯЕЁЃР§ШчЃЌвЛИіШЫПЩвдОгзЁдквЛИіЕижЗЃЌЕБетИіШЫБЛНЈФЃЃЌЫћЛсгаГЧЪаЃЌНж
ЕРЃЌгЪБрЕФЪєадЁЃдкЖдЯѓКЭЙиЯЕСьгђРяЃЌЮвУЧЧуЯђгкАбетИіаХЯЂЕБзїЕЅЖРЕФЪЕЬхРДЙЙдь:ЁАЕижЗЁБЁЃдкЖдЯѓСьгђРяЃЌЕижЗДњБэвЛИіЖРвЛЮоЖўЕФЮяРэЖдЯѓЃЌВЂПЩФмДјга
вЛИіЮЈвЛOIDЁЃдкЙиЯЕСьгђЃЌвЛИіЕижЗПЩвдЪЧЕижЗБэжаЕФвЛааЃЌИУБэЕФжїМќБЛгУзїЮЊЦфЫќЪЕЬхЕФЭтМќЁЃ
дкетСНжжФЃаЭжаЃЌЧїЯђгквЦЖЏЕижЗаХЯЂЕНЖРСЂЪЕЬхЃЌетгажњгкБмУтШпгрЪ§ОнКЭЬсИпПЩЮЌЛЄадЁЃЫљвдЖдгкУПвЛИіРрФЃаЭжаЕФЙиСЊЃЌвЊПМТЧДДНЈвЛИіДгзгРрЕНИИРрБэЕФЭтМќЁЃ
8. гГЩфОлКЯКЭИДКЯ
ОлКЯКЭИДКЯЙиЯЕРрЫЦгкЙиСЊЙиЯЕЃЌВЂЭЈЙ§ЁАжїМќЃЭтМќЁБЖдРДгГЩфГЩБэЁЃЕЋЪЧЃЌашвЊЬсабЕФЪЧЃКЦеЭЈОлКЯЃЈШѕОлКЯЃЉЖдЙиЯЕНЈФЃЃЌШчЃКвЛИіШЫзЁдквЛИіЛђЖрИіЕижЗЃЌ
дкДЫР§жаЃЌГЌЙ§вЛИівдЩЯЕФШЫПЩФмзЁдкЯрЭЌЕижЗЃЌШчЙћетИіШЫВЛдкетРязЁСЫЃЌгыЫћЯрСЌЕФЕижЗШдШЛДцдкЁЃетИіР§згР§ОйСЫЙиЯЕЪѕгяжаГЦжЎЮЊЁАЖрЖдЖрЕФЙиЯЕЁБЃЌВЂЧв
ЭЈГЃЪЕЯжЮЊвЛИіЖРСЂЕФБэЃЌИУБэАќКЌСЫДгвЛИіБэИёЕФжїМќЕНСэвЛИіБэИёжїМќЕФгГЩфЁЃ
ШѕОлКЯЕФЕкЖўИіР§згЪЧЃКвЛИіЪЕЬхдкФЧРяЪЙгУЛђХХГ§СЫСэвЛИіЪЕЬхЕФЫљгаШЈЁЃР§ШчЃКвЛИіЁАШЫЁБЕФЪЕЬхгЕгавЛзщЙЩЦБЃЌетБъУїетИіШЫПЩФмгывЛИіЁАЙЩЦБЁББэжаЕФФГаЉ
ЙЩЦБгаЙиСЊЃЌвВПЩФмУЛгаЙиЯЕЁЃЕЋЪЧУПИіЙЩЦБПЩвдСЊЯЕвЛИіШЫЃЌЛђВЛгыШЮКЮШЫЗЂЩњЙиЯЕЁЃШчЙћетИіШЫВЛдкСЫЃЌетИіЙЩЦБНЋБфЮЊЁАЮожїЁБЕФЃЌЛђепБЛДЋЕнИјЯТвЛИіШЫЁЃ
дкетИіЙиЯЕФЃаЭжаЃЌПЩвдЭЈЙ§УПИіЙЩЦБгавЛИіЁАЫљгаепЁБСаРДЪЕЯжЃЌетИіЁАЫљгаепЁБСаНЋДцДЂвЛИіШЫЕФБъЪЖЗћЃЈOIDЃЉЁЃ
ЧПОлКЯаЮЪНдђгагыжЎЙиСЊЕФЭъећдМЪјЁЃИДКЯБэУївЛИіЪЕЬхгЩВПМўзщГЩЃЌВЂЧветаЉВПМўЖдећЬхгавРРЕЙиЯЕЁЃР§ШчЃКвЛИіШЫПЩвдгаКмЖржЄУїЮФМўЃЌШчЛЄееЃЌГіЩњжЄУїЃЌМн
ееЕШЁЃетИіШЫЕФЪЕЬхПЩвдгЩетбљЕФвЛзщЮФМўзщГЩЁЃШчЙћетИіШЫДгЯЕЭГРяБЛЩОГ§ЃЌФЧУДжЄУїЮФМўвВвЊБЛЩОГ§ЃЌвђЮЊетаЉЮФМўБЛгГЩфЕНвЛИіЮЈвЛИіЬхЁЃ
ШчЙћЮвУЧднЪБКіТдOIDЃЌШѕОлКЯПЩФмЪЙгУжаМфБэРДЪЕЯжЃЈЖдЖрЖдЖрЕФЧщПіЃЉЛђепдквЛИіОлКЯЕФРрЛђБэВЩгУвЛИіЭтМќРДЪЕЯжЃЈвЛЖдЖрЕФЧщПіЃЉЁЃдкЖрЖдЖрЙиЯЕЕФЧщПі
ЯТЃЌШчЙћИИРрБЛЩОГ§ЃЌжаМфБэжаЕФЪЕЬхвВвЊБЛЩОГ§ЁЃдквЛЖдЖрЕФЧщПіЯТЃЌШчЙћИИРрБЛЩОГ§ЃЌЭтМќЪфШыЃЈШчЁАЫљгаепЁБЃЉБиаыБЛЧхГ§ЁЃ
дкИДКЯЕФЧщПіЯТЃЌЭтМќЕФЪЙгУЪЧЧПжЦЕФЃЌдМЪјЬѕМўЪЧИИРрЩОГ§КѓЃЌВПМўвВБиаыБЛЩОГ§ЁЃТпМЩЯЃЌИДКЯЪЧгавЛжжКЌвхЃЌВПМўжїМќаЮГЩСЫШЋВПжїМќЕФвЛВПЗжЁЃР§ШчЃКвЛИіШЫЕФжїМќгЩЫћжЄУїЮФМўзщГЩЁЃОЁЙмЪЕМЪЩЯЪЧЯрЕБШпГЄЕФЃЌЕЋТпМЙиЯЕЩЯЮЊецЁЃ
9. ЖЈвхЙиЯЕзїгУ
ЖдгкУПвЛИіЙиСЊЙиЯЕЃЌПЩФмЛсНјвЛВНжИУїЙиЯЕУПвЛИіЖЫЕуЕФНЧЩЋаХЯЂЁЃЭЈГЃАќКЌжїМќдМЪјУћКЭЭтМќдМЪјУћЁЃЭМЃЖР§ЪОСЫетИіИХФюЃЌетдкТпМЩЯЖЈвхСНИіРржЎМфЕФЙи
ЯЕЁЃСэЭтЃЌПЩФмЛсдкзїгУУћЩЯБъУїИНМгдМЪјЃЈМД{ЗЧПе}ЃЉКЭЛљЪ§аддМЪјЃЈМДЃА..ЃюЃЉЁЃ
10. ФЃаЭааЮЊ
ЮвУЧЯждкРДЬжТлСэвЛИіФбЬтЃКЪЧгГЩфВПЗжЛЙЪЧЫљгаЕФРрааЮЊЕНЪ§ОнПтЩЬЬсЙЉЕФЙІФмЩЯЃЌетаЉЙІФмвдДЅЗЂЦїЃЌДцДЂЙ§ГЬЃЌЮЈвЛадЃЌЪ§ОндМЪјКЭЙиЯЕЭъећадЕФаЮЪНГіЯжЁЃ
вЛИіЗЧГжОУЖдЯѓФЃаЭЭЈГЃПЩвдЪЕЯжвЛжжЛђЖржжгябдЃЈШчJavaКЭЃУ++ЃЉашвЊЕФЫљгаааЮЊЁЃУПвЛИіРрНЋгУЙЋЙВЕФЃЌБЃЛЄЕФКЭЫНгаЕФЗНЪНУшЪіЫќБЛИГгшЕФааЮЊКЭжА
д№ЁЃ
ВЛЭЌЪ§ОнПтЩЬЕФЙиЯЕЪ§ОнПтЭЈГЃАќКЌВЛЭЌаЮЪНЕФЃЌЛљгкSQLЕФПЩБрГЬНХБОгябдЃЌгУРДЪЕЯжЖдЪ§ОнЕФВйзїЁЃзюГЃгУЕФР§зг
ЪЧДЅЗЂЦїКЭДцДЂЙ§ГЬЁЃЕБЮвУЧЛьКЯЖдЯѓКЭЙиЯЕФЃаЭЃЌвЊзіЕФОіЖЈЭљЭљЪЧЃКЪЧЪЕЯжРрФЃаЭжаЫљгаЕФвЕЮёТпМЃЌЛЙЪЧНЋВПЗжЕФвЕЮёТпМЗХдкЙиЯЕDBMSжаИќГЃгУЖјгааЇ
ТЪЕФДЅЗЂЦїКЭДцДЂЙ§ГЬжаЁЃДгЭъШЋУцЯђЖдЯѓЕФНЧЖШПДЃЌД№АИЪЧБмУтЪЙгУДЅЗЂЦїКЭДцДЂЙ§ГЬЃЌВЂЧвНЋЫљгаааЮЊЗХЕНРржаЁЃетбљЛсЪЙааЮЊОжВПЛЏЃЌДгЖјЬсЙЉСЫвЛИіИќЧхЮњ
ЕФЩшМЦЃЌМђЛЏСЫЮЌЛЄЃЌВЂЧвЬсЙЉСЫдкВЛЭЌDBMSЬсЙЉЩЬжЎМфИќКУЕФвЦжВадЁЃ
дкЯжЪЕЪРНчЃЌДцДЂЙ§ГЬКЭДЅЗЂЦїЕФЩшМЦФПБъЕзЯпПЩвдЪЧУПУыжСЩйжДааМИАйДЮЛђМИЧЇДЮжЎЖрЁЃШчЙћЮЊСЫзЗЧѓФЃаЭЕФЧхЮњЃЌвЦжВадЃЌПЩЮЌЛЄадКЭСщЛюадЃЌФЧУДОЭНЋЫљгаЕФааЮЊЗХдкЖдЯѓЗНЗЈжаЁЃ
ШчЙћадФмЪЧЙизЂЕФНЙЕуЃЌПЩвдПМТЧНЋВПЗжааЮЊНЛИјИќгааЇЕФDBMSБрГЬгябдЁЃзЂвтЕННЋЖдЯѓФЃаЭгыДцДЂЙ§ГЬвдАВШЋЗНЪНМЏГЩЫљЛЈЕФЖюЭтЪБМфЃЌАќРЈдЖГЬгАЯьКЭЕїЪдЕФЮЪЬтЃЌПЩФмвЊБШМђЕЅВПЪ№ИќИпадФмЕФгВМўИќЖрЁЃ
ШчЧАУцЫљЪіЃЌUMLЪ§ОнprofileЬсЙЉЯТСаРЉеЙЃЈЙЙдьаЭВйзїЃЉЃЌПЩгУРДЖдDBMSааЮЊНЈФЃ:
жїМќдМЪјЃЈPKЃЉ;
ЭтМќдМЪјЃЈFKЃЉ;
Ыїв§дМЪјЃЈIndexЃЉ;
ДЅЗЂЦїЃЈTriggerЃЉ;
ЮЈвЛаддМЪјЃЈUniqueЃЉ;
гааЇадМьВщЃЈCheckЃЉ.
11. ВњЩњЮяРэФЃаЭ
дкЃеЃЭЃЬжаЃЌЮяРэФЃаЭУшЪіСЫЮяЬхШчКЮдкЯжЪЕЪРНчРяВПЪ№ЃКгВМўЦНЬЈЃЌЭјТчСЌНгЃЌШэМўЃЌВйзїЯЕЭГЃЌЖЏЬЌСЌНгПтКЭЦфЫќзщМўЁЃФуашвЊЩњГЩвЛИіЮяРэФЃаЭРДЭъГЩетИіжм
ЦкЃКДгвЛИіГѕЪМЕФгУР§ЛђСьгђФЃаЭЃЌЕНРрФЃаЭКЭЪ§ОнФЃаЭЃЌзюКѓЕНВПЪ№ФЃаЭЁЃЭЈГЃЖдетИіФЃаЭЃЌФувЊДДНЈвЛИіЛђЖрИіНкЕуЃЌетаЉНкЕуПЩвдДцЗХЪ§ОнПтЃЌВЂАВзА
DBMSзщМўЁЃШчЙћЪ§ОнПтБЛЗжГЩЖргквЛИіЕФDBMSЪЕР§ЃЌФуПЩвдЗжХфБэЕФАќЁЖSchemaЁЗИјЕЅИіDBMSзщМўРДжИУїЪ§ОнЮЛжУЁЃ
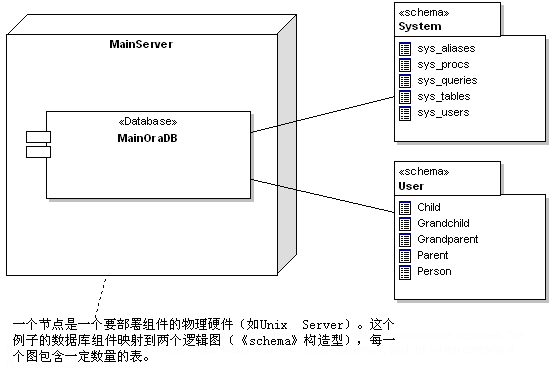
змНс
ЪЙгУUMLНјааЪ§ОнПтНЈФЃЃЌОЭЯѓФуПДЕНЕФЃЌЕБДгЖдЯѓСьгђгГЩфЕНЙиЯЕСьгђЪБЃЌгаКмЖрвЊзЂвтЕФЮЪЬтЁЃUMLЬсЙЉСЫетСНИіСьгђжЎМфЕФЧХСКЁЃUMLЪ§ОнprofileвВЪЧвЛжжГЩЙІЕиАбСНИіСьгђМЏГЩЦ№РДЕФгХауЕФРЉеЙгябдЁЃ
| 








