| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌБОЮФжївЊНщЩмСЫpostgresqlСЌНгВщбЏЗНЪНЁЂгХЛЏЫМТЗЁЂгХЛЏЗНАИЕШЯрЙижЊЪЖЁЃ |
|
вЛИігХЛЏЕФSQLЃК
SELECT order_date,
order_source,
SUM(commodity_num) num,
SUM(actual_charge) charge
FROM (
SELECT to_char(oc.create_date, 'yyyyMMdd') AS
order_date,
(CASE
WHEN oo.event_type = 'ONLINE_COMMODITY_ORDER'
THEN
'ЯпЩЯ'
ELSE
'ЯпЯТ'
END) order_source,
oc.commodity_num,
oc.actual_charge actual_charge
FROM ord.ord_commodity_hb_2017 AS oc, ord.ord_order_hb_2017
AS oo
WHERE oc.order_id = oo.order_id
AND oc.op_type = 3 -- 3ИіжЕ ЃЌ3->5000 ДѓИХ1/20ЕФЪ§Он
AND oc.create_date BETWEEN '2017-02-05' AND '2017-12-07'
-- ЮогУ
AND oc.corp_org_id = 106 -- ЮогУ
AND oo.trade_state = 11 -- 3ИіжЕ 11 --> 71ЭђааЃЌвЛАыЪ§Он
AND oo.event_type IN (values('ONLINE_COMMODITY_ORDER'),
('USER_CANCEL'),
('USER_COMMODITY_UPDATE')) -- ДѓИХ1/10 Ъ§Он
ORDER BY oc.create_date -- ШчЙћвЕЮёВЛЧПжЦЃЌзюКУШЅЕєХХађЃЌШчЙћВЛФмШЅЕєЃЌзюКУЕШЙ§ТЫЪ§ОнСПЕНОЁСПаЁЪБдйХХађ
) T
GROUP BY order_date, order_source; |
ЯТУцФЌШЯвдpostgresqlЮЊР§ЃК
вЛЁЂХХађ:
1. ОЁСПБмУт
2. ХХађЕФЪ§ОнСПОЁСПЩйЃЌВЂБЃжЄдкФкДцРяЭъГЩХХађЁЃ
ЃЈжСгкОпЬхЪВУДЪ§ОнСПФмдкФкДцжаЭъГЩХХађЃЌВЛЭЌЪ§ОнПтгаВЛЭЌЕФХфжУЃК
oracleЪЧsort_area_sizeЃЛ
postgresqlЪЧwork_mem (integer)ЃЌЕЅЮЛЪЧKBЃЌФЌШЯжЕЪЧ4MBЁЃ
mysqlЪЧsort_buffer_size зЂвтЃКИУВЮЪ§ЖдгІЕФЗжХфФкДцЪЧУПСЌНгЖРеМЃЁ
ЃЉ
ЖўЁЂЫїв§ЃК
1. Й§ТЫЕФЪ§ОнСПБШНЯЩйЃЌвЛАуРДЫЕ<20%,гІИУзпЫїв§ЁЃ20%-40% ПЩФмзпЫїв§вВПЩФмВЛзпЫїв§ЁЃ>
40% ЃЌЛљБОВЛзпЫїв§(ЛсШЋБэЩЈУш)
2. БЃжЄжЕЕФЪ§ОнРраЭКЭзжЖЮЪ§ОнРраЭвЊвЛжБЁЃ
3. ЖдЫїв§ЕФзжЖЮНјааМЦЫуЪБЃЌБиаыдкдЫЫуЗћгвВрНјааМЦЫуЁЃвВОЭЪЧ to_char(oc.create_date,
'yyyyMMdd')ЪЧУЛгУЕФ
4. БэзжЖЮжЎМфЙиСЊЃЌОЁСПИјЯрЙизжЖЮЩЯЬэМгЫїв§ЁЃ
5. ИДКЯЫїв§ЃЌзёДгзюзѓЧАзКЕФддђ,МДзюзѓгХЯШЁЃЃЈЕЅЖРгвВрзжЖЮВщбЏУЛгаЫїв§ЕФЃЉ
Ш§ЁЂСЌНгВщбЏЗНЪНЃК
1ЁЂhash join
ЗХФкДцРяНјааЙиСЊЁЃ
ЪЪгУгкНсЙћМЏБШНЯДѓЕФЧщПіЁЃ
БШШчЖМЪЧ200000Ъ§Он
2ЁЂnest loop
ДгНсЙћ1 ж№ааШЁГіЃЌШЛКѓгыНсЙћМЏ2НјааЦЅХфЁЃ
ЪЪгУгкСНИіНсЙћМЏЃЌЦфжавЛИіЪ§ОнСПдЖДѓгкСэЭтвЛИіЪБЁЃ
НсЙћМЏвЛЃК1000
НсЙћМЏЖўЃК1000000
ЫФЁЂЖрБэСЊВщЪБЃК
дкЖрБэСЊВщЪБЃЌашвЊПМТЧСЌНгЫГађЮЪЬтЁЃ
1ЁЂЕБpostgresqlжаНјааВщбЏЪБЃЌШчЙћЖрБэЪЧЭЈЙ§ЖККХЃЌЖјВЛЪЧjoinСЌНгЃЌФЧУДСЌНгЫГађЪЧЖрБэЕФЕбПЈЖћЛ§жаШЁзюгХЕФЁЃШчЙћгаЬЋЖрЪфШыЕФБэЃЌ
PostgreSQLЙцЛЎЦїНЋДгЧюОйЫбЫїЧаЛЛЮЊЛљвђИХТЪЫбЫїЃЌвдМѕЩйПЩФмадЪ§ФП(бљБОПеМф)ЁЃЛљвђЫбЫїЛЈЕФЪБМфЩйЃЌ
ЕЋЪЧВЂВЛвЛЖЈФмевЕНзюКУЕФЙцЛЎЁЃ
2ЁЂЖдгкJOINЃЌ
LEFT JOIN / RIGHT JOIN ЛсвЛЖЈГЬЖШЩЯжИЖЈСЌНгЫГађЃЌЕЋЪЧЛЙЪЧЛсдкФГжжГЬЖШЩЯжиаТХХСаЃК
FULL JOIN ЭъШЋЧПжЦСЌНгЫГађЁЃ
ШчЙћвЊЧПжЦЙцЛЎЦїзёбзМШЗЕФJOINСЌНгЫГађЃЌЮвУЧПЩвдАбдЫааЪБВЮЪ§join_collapse_limitЩшжУЮЊ
1
ЮхЁЂPostgreSQLЬсЙЉСЫвЛаЉадФмЕїгХЕФЙІФмЃК
гХЛЏЫМТЗЃК
0ЁЂЮЊУПИіБэжДаа ANALYZE <table>ЁЃШЛКѓЗжЮі EXPLAIN (ANALYZEЃЌBUFFERS)
sqlЁЃ
1ЁЂЖдгкЖрБэВщбЏЃЌВщПДУПеХБэЪ§ОнЃЌШЛКѓИФНјСЌНгЫГађЁЃ
2ЁЂЯШВщевФЧВПЗжЪЧжиЕугяОфЃЌБШШчЩЯУцSQLЃЌЭтУцЕФЧЖЬзВуЖдгкгХЛЏРДЫЕУЛгавтвхЃЌПЩвдШЅЕєЁЃ
3ЁЂВщПДгяОфжаЃЌwhereЕШЬѕМўзгОфЃЌУПИізжЖЮФмЙ§ТЫЕФаЇТЪЁЃевГіПЩгХЛЏДІЁЃ
БШШчoc.order_id = oo.order_idЪЧЙиСЊЬѕМўЃЌашвЊМгЫїв§
oc.op_type = 3 ФмЙ§ТЫГі1/20ЕФЪ§ОнЃЌ
oo.event_type IN (...) ФмЙ§ТЫГі1/10ЕФЪ§ОнЃЌ
етСНИіЪЧгХЛЏЕФжиЕуЃЌвВОЭЪЧЪЕЯжШЗБЃop_typeгыevent_typeвбОМгСЫЫїв§ЃЌЦфДЮШЗБЃЫїв§гУЕНСЫЁЃ
гХЛЏЗНАИЃК
a) ећЬхгХЛЏЃК
1ЁЂЪЙгУEXPLAIN
EXPLAINУќСюПЩвдВщПДжДааМЦЛЎЃЌетИіЗНЗЈЪЧЮвУЧзюжївЊЕФЕїЪдЙЄОпЁЃ
2ЁЂМАЪБИќаТжДааМЦЛЎжаЪЙгУЕФЭГМЦаХЯЂ
гЩгкЭГМЦаХЯЂВЛЪЧУПДЮВйзїЪ§ОнПтЖМНјааИќаТЕФЃЌвЛАуЪЧдк VACUUM ЁЂ ANALYZE ЁЂ CREATE
INDEXЕШDDLжДааЕФЪБКђЛсИќаТЭГМЦаХЯЂЃЌ
вђДЫжДааМЦЛЎЫљгУЕФЭГМЦаХЯЂКмгаПЩФмБШНЯОЩЁЃ етбљжДааМЦЛЎЕФЗжЮіНсЙћПЩФмЮѓВюЛсБфДѓЁЃ
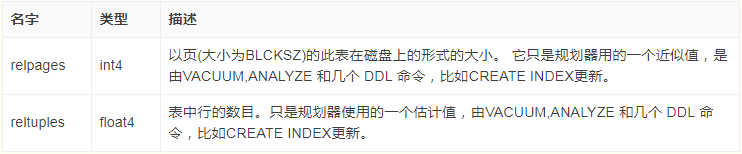
вдЯТЪЧБэtenk1ЕФЯрЙиЕФвЛВПЗжЭГМЦаХЯЂЁЃ
SELECT relname,
relkind, reltuples, relpages
FROM pg_class
WHERE relname LIKE 'tenk1%';
relname | relkind | reltuples | relpages
----------------------+---------+-----------+----------
tenk1 | r | 10000 | 358
tenk1_hundred | i | 10000 | 30
tenk1_thous_tenthous | i | 10000 | 30
tenk1_unique1 | i | 10000 | 30
tenk1_unique2 | i | 10000 | 30
(5 rows) |
Цфжа relkindЪЧРраЭЃЌrЪЧздЩэБэЃЌiЪЧЫїв§indexЃЛreltuplesЪЧЯюФПЪ§ЃЛrelpagesЪЧЫљеМгВХЬЕФПщЪ§ЁЃ
ЙРМЦГЩБОЭЈЙ§ ЃЈДХХЬвГУцЖСШЁЁОrelpagesЁП*seq_page_costЃЉ+ЃЈааЩЈУшЁОreltuplesЁП*cpu_tuple_costЃЉМЦЫуЁЃ
ФЌШЯЧщПіЯТЃЌ seq_page_costЪЧ1.0ЃЌcpu_tuple_costЪЧ0.01ЁЃ
3ЁЂЪЙгУСйЪББэЃЈwithЃЉ
ЖдгкЪ§ОнСПДѓЃЌЧвЮоЗЈгааЇгХЛЏЪБЃЌПЩвдЪЙгУСйЪББэРДЙ§ТЫЪ§ОнЃЌНЕЕЭЪ§ОнЪ§СПМЖЁЃ
4ЁЂЖдгкЛсгАЯьНсЙћЕФЗжЮіЃЌПЩвдЪЙгУ begin;...rollback;РДЛиЙіЁЃ

b) ВщбЏгХЛЏЃК
1ЁЂУїШЗгУjoinРДЙиСЊБэЃЌШЗБЃСЌНгЫГађ
вЛАуаДЗЈЃКSELECT * FROM a, b, c WHERE a.id = b.id AND b.ref
= c.id;
ШчЙћУїШЗгУjoinЕФЛАЃЌжДааЪБКђжДааМЦЛЎЯрЖдШнвзПижЦвЛаЉЁЃ
Р§згЃК
SELECT * FROM a CROSS JOIN b CROSS JOIN c WHERE a.id
= b.id AND b.ref = c.id;
SELECT * FROM a JOIN (b JOIN c ON (b.ref = c.id))
ON (a.id = b.id);
c) ВхШыИќаТгХЛЏ
1ЁЂЙиБездЖЏЬсНЛЃЈautocommit=falseЃЉ
ШчЙћгаЖрЬѕЪ§ОнПтВхШыЛђИќаТЕШЃЌзюКУЙиБездЖЏЬсНЛЃЌетбљФмЬсИпаЇТЪ
2ЁЂЖрДЮВхШыЪ§ОнгУcopyУќСюИќИпаЇ
ЮвУЧгаЕФДІРэжавЊЖдЭЌвЛеХБэжДааКмЖрДЮinsertВйзїЁЃетИіЪБКђЮвУЧгУcopyУќСюИќгааЇТЪЁЃвђЮЊinsertвЛДЮЃЌЦфЯрЙиЕФindexЖМвЊзівЛДЮЃЌБШНЯЛЈЗбЪБМфЁЃ
3ЁЂСйЪБЩОГ§indexЁООпЬхПЩвдВщПДNavicatБэЪ§ОнЩњГЩsqlЕФгяОфЃЌОЭЪЧЯШЩОдйНЈЕФЁП
гаЪБКђЮвУЧдкБИЗнКЭжиаТЕМШыЪ§ОнЕФЪБКђЃЌШчЙћЪ§ОнСПКмДѓЕФЛАЃЌвЊКУМИИіаЁЪБВХФмЭъГЩЁЃетИіЪБКђПЩвдЯШАбindexЩОГ§ЕєЁЃЕМШыКѓдйНЈindexЁЃ
4ЁЂЭтМќЙиСЊЕФЩОГ§
ШчЙћБэЕФгаЭтМќЕФЛАЃЌУПДЮВйзїЖМУЛШЅcheckЭтМќећКЯадЁЃвђДЫБШНЯТ§ЁЃЪ§ОнЕМШыКѓдйНЈСЂЭтМќвВЪЧвЛжжбЁдёЁЃ
d) аоИФВЮЪ§ЃК
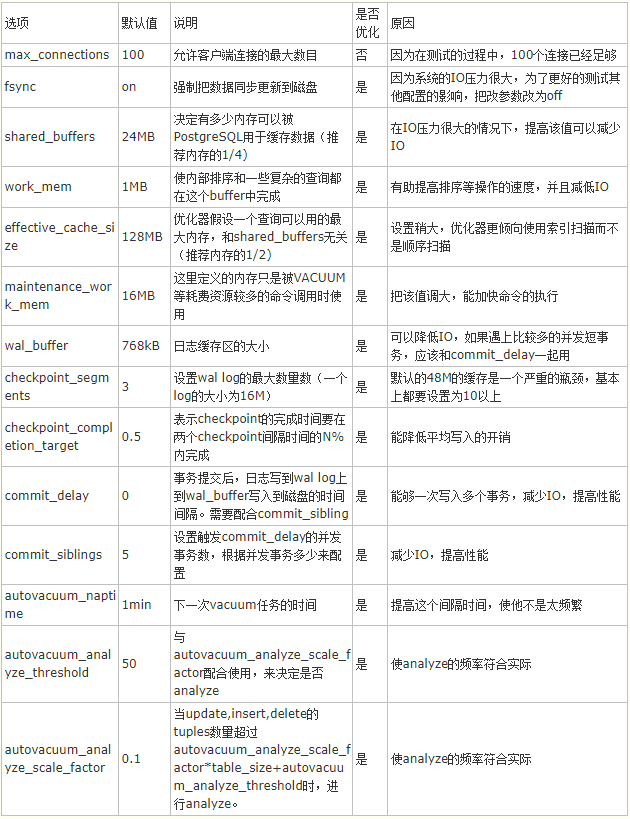
ЯТУцНщЩмМИИіЮвШЯЮЊживЊЕФЃК
1ЁЂдіМгmaintenance_work_memВЮЪ§ДѓаЁ
діМгетИіВЮЪ§ПЩвдЬсЩ§CREATE INDEXКЭALTER TABLE ADD FOREIGN KEYЕФжДаааЇТЪЁЃ
2ЁЂдіМгcheckpoint_segmentsВЮЪ§ЕФДѓаЁ
діМгетИіВЮЪ§ПЩвдЬсЩ§ДѓСПЪ§ОнЕМШыЪБКђЕФЫйЖШЁЃ
3ЁЂЩшжУarchive_modeЮоаЇ
етИіВЮЪ§ЩшжУЮЊЮоаЇЕФЪБКђЃЌФмЙЛЬсЩ§вдЯТЕФВйзїЕФЫйЖШ
?CREATE TABLE AS SELECT
?CREATE INDEX
?ALTER TABLE SET TABLESPACE
?CLUSTERЕШЁЃ
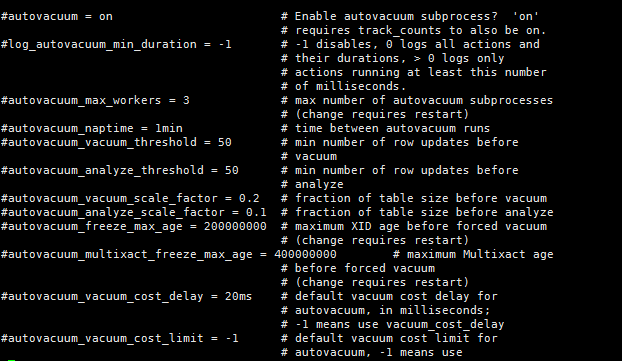
4ЁЂautovacuumЯрЙиВЮЪ§
autovacuumЃКФЌШЯЮЊonЃЌБэЪОЪЧЗёПЊЦ№autovacuumЁЃФЌШЯПЊЦ№ЁЃЬиБ№ЕФЃЌЕБашвЊЖГНсxidЪБЃЌОЁЙмДЫжЕЮЊoffЃЌPGвВЛсНјааvacuumЁЃ
autovacuum_naptimeЃКЯТвЛДЮvacuumЕФЪБМфЃЌФЌШЯ1minЁЃ етИіnaptimeЛсБЛvacuum
launcherЗжХфЕНУПИіDBЩЯЁЃautovacuum_naptime/num of dbЁЃ
log_autovacuum_min_durationЃКМЧТМautovacuumЖЏзїЕНШежОЮФМўЃЌЕБvacuumЖЏзїГЌЙ§ДЫжЕЪБЁЃ
ЁА-1ЁББэЪОВЛМЧТМЁЃЁА0ЁББэЪОУПДЮЖММЧТМЁЃ
autovacuum_max_workersЃКзюДѓЭЌЪБдЫааЕФworkerЪ§СПЃЌВЛАќКЌlauncherБОЩэЁЃ
autovacuum_work_mem ЃКУПИіworkerПЩЪЙгУЕФзюДѓФкДцЪ§ЁЃ
autovacuum_vacuum_threshold ЃКФЌШЯ50ЁЃгыautovacuum_vacuum_scale_factorХфКЯЪЙгУЃЌ
autovacuum_vacuum_scale_factorФЌШЯжЕЮЊ20%ЁЃЕБupdate,deleteЕФtuplesЪ§СПГЌЙ§autovacuum_vacuum_scale_factor
*table_size+autovacuum_vacuum_thresholdЪБЃЌНјааvacuumЁЃШчЙћвЊЪЙvacuumЙЄзїЧкЗмЕуЃЌдђНЋДЫжЕИФаЁЁЃ
autovacuum_analyze_threshold ЃКФЌШЯ50ЁЃгыautovacuum_analyze_scale_factorХфКЯЪЙгУЁЃ
autovacuum_analyze_scale_factor ЃКФЌШЯ10%ЁЃЕБupdate,insert,deleteЕФtuplesЪ§СПГЌЙ§autovacuum_analyze_scale_factor
*table_size+autovacuum_analyze_thresholdЪБЃЌНјааanalyzeЁЃ
autovacuum_freeze_max_ageЃК200 millionЁЃРыЯТвЛДЮНјааxidЖГНсЕФзюДѓЪТЮёЪ§ЁЃ
autovacuum_multixact_freeze_max_ageЃК400 millionЁЃРыЯТвЛДЮНјааxidЖГНсЕФзюДѓЪТЮёЪ§ЁЃ
autovacuum_vacuum_cost_delay ЃКШчЙћЮЊ-1ЃЌШЁvacuum_cost_delayжЕЁЃ
autovacuum_vacuum_cost_limit ЃКШчЙћЮЊ-1ЃЌЕНvacuum_cost_limitЕФжЕЃЌетИіжЕЪЧЫљгаworkerЕФРлМгжЕЁЃ

| 








