| БрМЭЦМі: |
| БОЮФРДздгкwww.v2ex.com,TiDB
ЪЧвЛПюЖЈЮЛгкдкЯпЪТЮёДІРэ/дкЯпЗжЮіДІРэЕФШкКЯаЭЪ§ОнПтВњЦЗЃЌЪЕЯжСЫвЛМќЫЎЦНЩьЫѕЃЌЧПвЛжТадЕФЖрИББОЪ§ОнАВШЋЃЌЗжВМЪНЪТЮёЃЌЪЕЪБ
OLAP ЕШживЊЬиадЁЃЭЌЪБМцШн MySQL авщКЭЩњЬЌЃЌЧЈвЦБуНнЃЌдЫЮЌГЩБОМЋЕЭЁЃ |
|
ПЊЦЊ
ЪРНчМЖЕФПЊдДЗжВМЪНЪ§ОнПт TiDB зд 2016 Фъ 12 дТе§ЪНЗЂВМЕквЛИіАцБОвдРДЃЌвЕФкжюЖрЙЋЫОж№ВНв§ШыЪЙгУЃЌВЂШЁЕУЙуЗКШЯПЩЁЃ
ЖдгкЛЅСЊЭјЙЋЫОЃЌЪ§ОнДцДЂЕФживЊадВЛбдЖјгїЁЃдк NewSQL Ъ§ОнПтГіЯжжЎЧАЃЌвЛАуВЩгУЕЅЛњЪ§ОнПтЃЈБШШч
MySQL ЃЉзїЮЊДцДЂЃЌЫцзХЪ§ОнСПЕФдіМгЃЌЁАЗжПтЗжБэЁБЪЧдчЭэУцСйЕФЮЪЬтЃЌМДЪЙгажюШч MyCatЁЂShardingJDBC
ЕШгХауЕФжаМфМўЃЌЁАЗжПтЗжБэЁБЛЙЪЧИј RD КЭ DBA ДјРДНЯИпЕФГЩБОЃЛ NewSQL Ъ§ОнПтГіЯжКѓЃЌгЩгкЫќВЛНіга
NoSQL ЖдКЃСПЪ§ОнЕФЙмРэДцДЂФмСІЁЂЛЙжЇГжДЋЭГЙиЯЕЪ§ОнПтЕФ ACID КЭ SQLЃЌЫљвдЖдвЕЮёПЊЗЂРДЫЕЃЌДцДЂЮЪЬтвбОБфЕУИќМгМђЕЅгбКУЃЌНјЖјПЩвдИќзЈзЂгквЕЮёБОЩэЁЃЖј
TiDBЃЌе§ЪЧ NewSQL ЕФвЛИіНмГіДњБэЃЁ
еОдквЕЮёПЊЗЂЕФЪгНЧЃЌTiDB зюЮќв§ШЫЕФМИДѓЬиадЪЧЃК
жЇГж MySQL авщЃЈПЊЗЂНгШыГЩБОЕЭЃЉЃЛ
100% жЇГжЪТЮёЃЈЪ§ОнвЛжТадЪЕЯжМђЕЅЁЂПЩППЃЉЃЛ
ЮоЯоЫЎЦНЭиеЙЃЈВЛБиПМТЧЗжПтЗжБэЃЉЁЃ
ЛљгкетМИДѓЬиадЃЌTiDB дквЕЮёПЊЗЂжаЪЧжЕЕУЭЦЙуКЭЪЕМљЕФЃЌЕЋЪЧЃЌЫќБЯОЙВЛЪЧДЋЭГЕФЙиЯЕаЭЪ§ОнПтЃЌвджТЮвУЧЖдЙиЯЕаЭЪ§ОнПтЕФвЛаЉЪЙгУОбщКЭЛ§РлЃЌдк
TiDB жаЪЧДцдкВювьЕФЃЌЯжжївЊВћЪіЁАЪТЮёЁБКЭЁАВщбЏЁБСНЗНУцЕФВювьЁЃ
TiDB ЪТЮёКЭ MySQL ЪТЮёЕФВювь
MySQL ЪТЮёКЭ TiDB ЪТЮёЖдБШ

дк TiDB жажДааЕФЪТЮё bЃЌЗЕЛигАЯьЬѕЪ§ЪЧ 1 ЃЈШЯЮЊвбОаоИФГЩЙІЃЉЃЌЕЋЪЧЬсНЛКѓВщбЏЃЌstatus
ШДВЛЪЧЪТЮё b аоИФЕФжЕЃЌЖјЪЧЪТЮё a аоИФЕФжЕЁЃ
ПЩМћЃЌMySQL ЪТЮёКЭ TiDB ЪТЮёДцдкетбљЕФВювьЃК
MySQL ЪТЮёжаЃЌПЩвдЭЈЙ§гАЯьЬѕЪ§ЃЌзїЮЊаДШыЃЈЛђаоИФЃЉЪЧЗёГЩЙІЕФвРОнЃЛЖјдк
TiDB жаЃЌетШДЪЧВЛПЩааЕФЃЁ
зїЮЊПЊЗЂепЮвУЧашвЊПМТЧЯТУцЕФЮЪЬтЃК
ЭЌВН RPC ЕїгУжаЃЌШчЙћашвЊбЯИёвРРЕгАЯьЬѕЪ§вдШЗШЯЗЕЛижЕЃЌФЧНЋШчКЮЪЧКУЃП
ЖрБэВйзїжаЃЌШчЙћашвЊбЯИёвРРЕФГИіжїБэЪ§ОнИќаТНсЙћЃЌзїЮЊЪЧЗёИќаТЃЈЛђаДШыЃЉЦфЫћБэЕФХаЖЯвРОнЃЌФЧгжНЋШчКЮЪЧКУЃП
двђЗжЮіМАНтОіЗНАИ
Ждгк MySQLЃЌЕБИќаТФГЬѕМЧТМЪБЃЌЛсЯШЛёШЁИУМЧТМЖдгІЕФааМЖЫјЃЈХХЫћЫјЃЉЃЌЛёШЁГЩЙІдђНјааКѓајЕФЪТЮёВйзїЃЌЛёШЁЪЇАмдђзшШћЕШД§ЁЃ
Ждгк TiDBЃЌЪЙгУ Percolator ЪТЮёФЃаЭЃКПЩвдРэНтЮЊРжЙлЫјЪЕЯжЃЌЪТЮёПЊЦєЁЂЪТЮёжаЖМВЛЛсМгЫјЃЌЖјЪЧдкЬсНЛЪБВХМгЫјЁЃВЮМћ
етЦЊЮФеТЃЈ TiDB ЪТЮёЫуЗЈЃЉЁЃ
ЦфМђвЊСїГЬШчЯТЃК
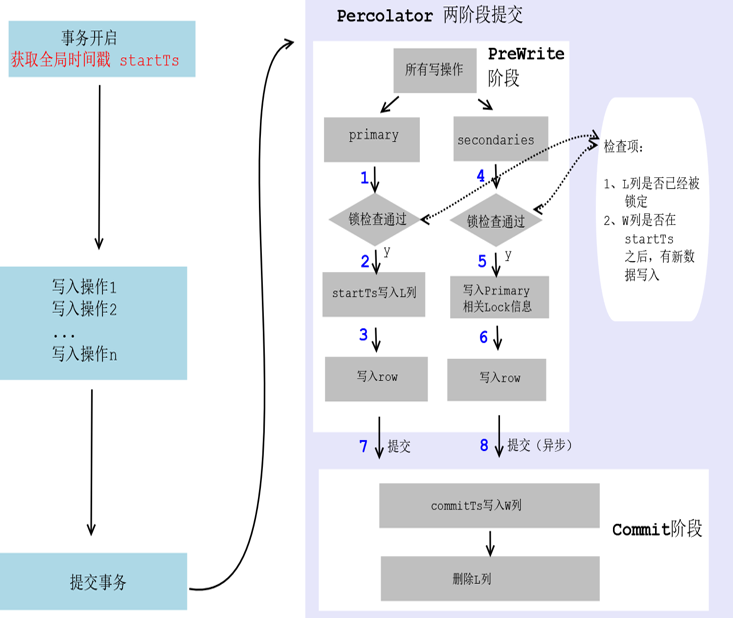
дкЪТЮёЬсНЛЕФ PreWrite НзЖЮЃЌЕБЁАЫјМьВщЁБЪЇАмЪБЃКШчЙћПЊЦєГхЭЛжиЪдЃЌЪТЮёЬсНЛНЋЛсНјаажиЪдЃЛШчЙћЮДПЊЦєГхЭЛжиЪдЃЌНЋЛсХзГіаДШыГхЭЛвьГЃЁЃ
ПЩМћЃЌЖдгк MySQLЃЌгЩгкдкаДШыВйзїЪБМгЩЯСЫХХЫћЫјЃЌБфЯрНЋВЂааЪТЮёДгТпМЩЯДЎааЛЏЃЛЖјЖдгк
TiDBЃЌЪєгкРжЙлЫјФЃаЭЃЌдкЪТЮёЬсНЛЪБВХМгЫјЃЌВЂЪЙгУЪТЮёПЊЦєЪБЛёШЁЕФЁАШЋОжЪБМфДСЁБзїЮЊЁАЫјМьВщЁБЕФвРОнЁЃ
ЫљвдЃЌдквЕЮёВуУцБмУт TiDB ЪТЮёВювьЕФБОжЪдкгкБмУтЫјГхЭЛЃЌМДЃЌЕБЧАЪТЮёжДааЪБЃЌВЛВњЩњБ№ЕФЪТЮёЪБМфДСЃЈЮоЦфЫћЪТЮёВЂааЃЉЁЃДІРэЗНЪНЮЊЪТЮёДЎааЛЏЁЃ
TiDB ЪТЮёДЎааЛЏ
дквЕЮёВуЃЌПЩвдНшжњЗжВМЪНЫјЃЌЪЕЯжДЎааЛЏДІРэЃЌШчЯТЃК
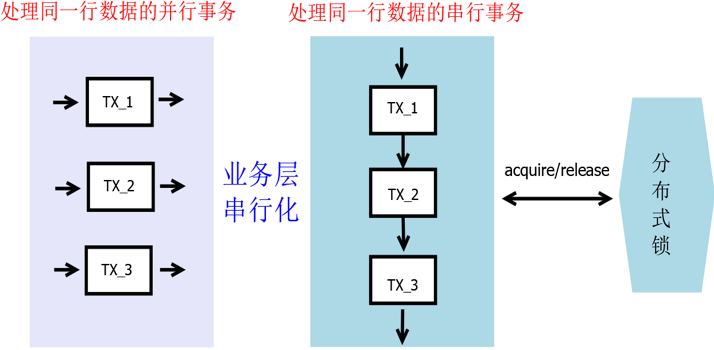
Лљгк Spring КЭЗжВМЪНЫјЕФЪТЮёЙмРэЦїЭиеЙ
дк Spring ЩњЬЌЯТЃЌspring-tx жаЖЈвхСЫЭГвЛЕФЪТЮёЙмРэЦїНгПкЃКPlatformTransactionManagerЃЌЦфжагаЛёШЁЪТЮёЃЈ
getTransaction ЃЉЁЂЬсНЛЃЈ commit ЃЉЁЂЛиЙіЃЈ rollback ЃЉШ§ИіЛљБОЗНЗЈЃЛЪЙгУзАЪЮЦїФЃЪНЃЌЪТЮёДЎааЛЏзщМўПЩзіШчЯТЩшМЦЃК
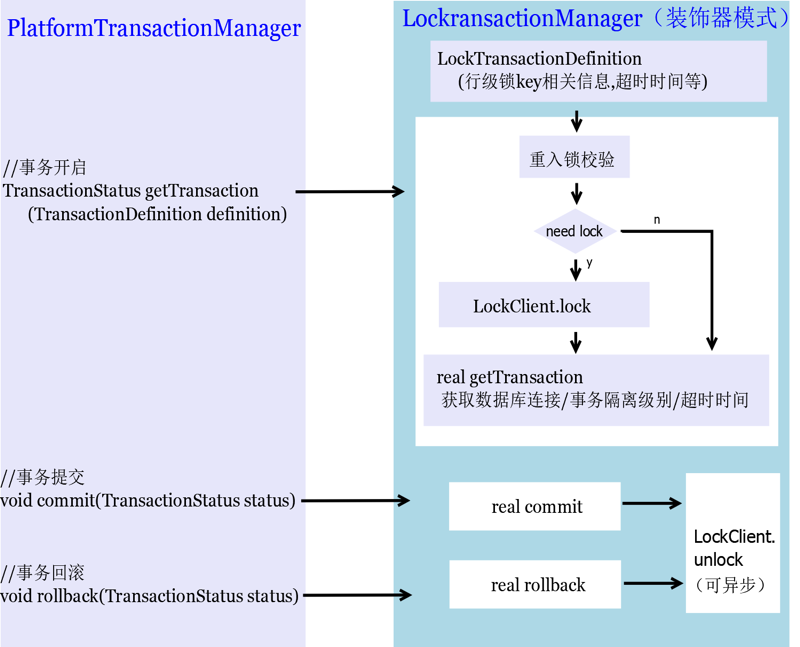
ЦфжаЃЌЙиМќЕугаЃК
ГЌЪБЪБМфЃКЮЊБмУтЫРЫјЃЌЫјБиаыгаГЌЪБЪБМфЃЛЮЊБмУтЫјГЌЪБЕМжТЪТЮёВЂааЃЌЪТЮёБиаыгаГЌЪБЪБМфЃЌЖјЧвЫјГЌЪБЪБМфБиаыДѓгкЪТЮёГЌЪБЪБМфЃЈЪБМфВюзюКУдкУыМЖЃЉЁЃ
МгЫјЪБЛњЃКTiDB жаЁАЫјМьВщЁБЕФвРОнЪЧЪТЮёПЊЦєЪБЛёШЁЕФЁАШЋОжЪБМфДСЁБЃЌЫљвдМгЫјЪБЛњБиаыдкЪТЮёПЊЦєЧАЁЃ
ЪТЮёФЃАхНгПкЩшМЦ
вўВиИДдгЕФЪТЮёжиаДТпМЃЌБЉТЖМђЕЅгбКУЕФ APIЃК
TiDB ВщбЏКЭ MySQL ЕФВювь
дк TiDB ЪЙгУЙ§ГЬжаЃЌХМЖћЛсгаетбљЕФЧщПіЃЌФГМИИізжЖЮНЈСЂСЫЫїв§ЃЌЕЋЪЧВщбЏЙ§ГЬЛЙЪЧКмТ§ЃЌЩѕжСВЛОЙ§Ыїв§МьЫїЁЃ
Ыїв§ЛьЯ§аЭЃЈОйР§ЃЉ
БэНсЙЙЃК
CREATE TABLE `t_test`
(
`id` bigint(20) NOT NULL DEFAULT '0' COMMENT 'жїМќ
id',
`a` int(11) NOT NULL DEFAULT '0' COMMENT 'a',
`b` int(11) NOT NULL DEFAULT '0' COMMENT 'b',
`c` int(11) NOT NULL DEFAULT '0' COMMENT 'c',
PRIMARY KEY (`id`),
KEY `idx_a_b` (`a`,`b`),
KEY `idx_c` (`c`)
) ENGINE=InnoDB; |
ВщбЏЃКШчЙћашвЊВщбЏ (a=1 Чв b=1 ЃЉЛђ c=2 ЕФЪ§ОнЃЌдк
MySQL жаЃЌsql ПЩвдаДЮЊЃКSELECT id from t_test where (a=1
and b=1) or (c=2);ЃЌMySQL зіВщбЏгХЛЏЪБЃЌЛсМьЫїЕН idx_a_b КЭ idx_c
СНИіЫїв§ЃЛЕЋЪЧдк TiDB ЃЈ v2.0.8-9 ЃЉжаЃЌетИі sql ЛсГЩЮЊвЛИіТ§ SQLЃЌашвЊИФаДЮЊЃК
| SELECT id from
t_test where (a=1 and b=1) UNION SELECT id from
t_test where (c=2); |
аЁНсЃКЕМжТИУЮЪЬтЕФдвђЃЌПЩвдРэНтЮЊ TiDB ЕФ sql НтЮіЛЙгагХЛЏПеМфЁЃ
РфШШЪ§ОнаЭЃЈОйР§ЃЉ
БэНсЙЙЃК
CREATE TABLE
`t_job_record` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT
'жїМќ id',
`job_code` varchar(255) NOT NULL DEFAULT '' COMMENT
'ШЮЮё code',
`record_id` bigint(20) NOT NULL DEFAULT '0' COMMENT
'МЧТМ id',
`status` tinyint(3) NOT NULL DEFAULT '0' COMMENT
'жДаазДЬЌ:0 Д§ДІРэ',
`execute_time` bigint(20) NOT NULL DEFAULT '0'
COMMENT 'жДааЪБМфЃЈКСУыЃЉ',
PRIMARY KEY (`id`),
KEY `idx_status_execute_time` (`status`,`execute_time`),
KEY `idx_record_id` (`record_id`)
) ENGINE=InnoDB COMMENT='вьВНШЮЮё job' |
Ъ§ОнЫЕУїЃК
a. РфЪ§ОнЃЌstatus=1 ЕФЪ§ОнЃЈвбОДІРэЙ§ЕФЪ§ОнЃЉЃЛ
b. ШШЪ§ОнЃЌstatus=0 ВЂЧв execute_time<=
ЕБЧАЪБМф ЕФЪ§ОнЁЃ
Т§ВщбЏЃКЖдгкШШЪ§ОнЃЌЪ§ОнСПвЛАуВЛДѓЃЌЕЋЪЧВщбЏЦЕЖШКмИпЃЌМйЩшЕБЧАЃЈКСУыМЖЃЉЪБМфЮЊЃК1546361579646ЃЌдђдк
MySQL жаЃЌВщбЏ sql ЮЊЃК
| SELECT * FROM
t_job_record where status =0 and execute_time< =
1546361579646 |
етИідк MySQL жаКмИпаЇЕФВщбЏЃЌдк TiDB жаЫфШЛвВПЩДгЫїв§МьЫїЃЌЕЋЦфКФЪБШДВЛОЁШЫвтЃЈАйЭђМЖЪ§ОнСПЃЌКФЪБАйКСУыМЖЃЉЁЃ
двђЗжЮіЃКдк TiDB жаЃЌЕзВуЫїв§НсЙЙЮЊ LSM-TreeЃЌШчЯТЭМЃК
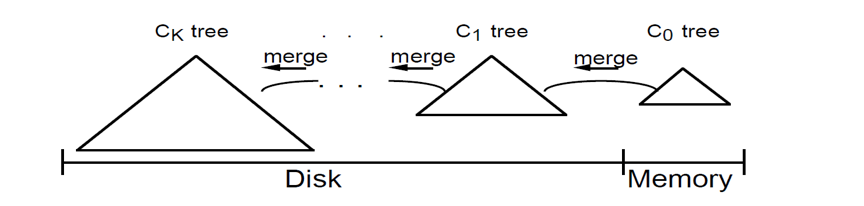
ЕБДгФкДцМЖЕФ C0 ВуВщбЏВЛЕНЪ§ОнЪБЃЌЛсж№ВуЩЈУшгВХЬжаИїВуЃЛЧв merge
ВйзїЮЊвьВНВйзїЃЌЫїв§Ъ§ОнИќаТЛсДцдквЛЖЈЕФбгГйЃЌПЩФмДцдкЮоаЇЫїв§ЁЃгЩгкж№ВуЩЈУшКЭвьВН mergeЃЌЪЙЕУВщбЏаЇТЪНЯЕЭЁЃ
гХЛЏЗНЪНЃКОЁПЩФмЫѕаЁЙ§ТЫЗЖЮЇЃЌБШШчНсКЯвьВН job ЛёШЁМЧТМЦЕТЪЃЌдкБЃжЄВЛвХТЉЪ§ОнЕФЧАЬсЯТЃЌКЯРэЩшжУ
execute_time ЩИбЁЧјМфЃЌР§Шч 1 аЁЪБЃЌsql ИФаДЮЊЃК
| SELECT * FROM
t_job_record where status =0 and execute_time> 1546357979646
and execute_time<= 1546361579646 |
гХЛЏаЇЙћЃККФЪБ 10 КСУыМЖБ№ЃЈвдЯТЃЉЁЃ
ЙигкВщбЏЕФЦєЗЂ
дкЛљгк TiDB ЕФвЕЮёПЊЗЂжаЃЌЯШо№ЦњДЋЭГЙиЯЕаЭЪ§ОнПтДјРДЕФЖд sql
ЯШШыЮЊжїЕФРэНтЛђОбщЃЌНїЩїЩшМЦУПвЛИі sqlЃЌШч DBA ЫљЬсГЋЃКЩшМЦ sql ЪБЮёБиЙизЂжДааМЦЛЎЃЌБивЊЪБЧыНЬ
DBAЁЃ
КЭ MySQL ЯрБШЃЌTiDB ЕФЕзВуДцДЂКЭНсЙЙОіЖЈСЫЦфЬиЪтадКЭВювьадЃЛЕЋЪЧЃЌTiDB
жЇГж MySQL авщЃЌЫќУЧвВДцдквЛаЉЙВЭЌжЎДІЃЌБШШчдк TiDB жаЪЙгУЁАдЄБрвыЁБКЭЁАХњДІРэЁБЃЌЭЌбљПЩвдЛёЕУвЛЖЈЕФадФмЬсЩ§ЁЃ
ЗўЮёЖЫдЄБрвы
дк MySQL жаЃЌПЩвдЪЙгУ PREPARE stmt_name
FROM preparable_stm Жд sql гяОфНјаадЄБрвыЃЌШЛКѓЪЙгУ EXECUTE stmt_name
[USING @var_name [, @var_name] ...] жДаадЄБрвыгяОфЁЃШчДЫЃЌЭЌвЛ
sql ЕФЖрДЮВйзїЃЌПЩвдЛёЕУБШГЃЙц sql ИќИпЕФадФмЁЃ
mysql-jdbc дДТыжаЃЌЪЕЯжСЫБъзМЕФ Statement КЭ
PreparedStatement ЕФЭЌЪБЃЌЛЙгавЛИіServerPreparedStatement
ЪЕЯжЃЌServerPreparedStatement ЪєгкPreparedStatementЕФЭиеЙЃЌШ§епЖдБШШчЯТЃК
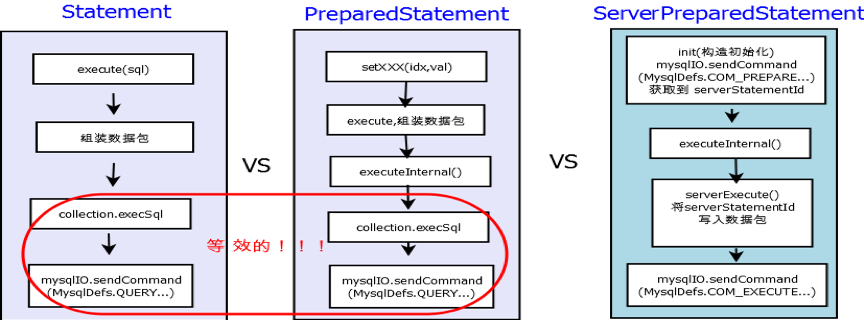
ШнвзЗЂЯжЃЌPreparedStatement КЭ Statement
ЕФЧјБ№жївЊЧјБ№дкгкВЮЪ§ДІРэЃЌЖјЖдгкЗЂЫЭЪ§ОнАќЃЌЕїгУЗўЮёЖЫЕФДІРэТпМЪЧвЛбљЃЈЛђРрЫЦЃЉЕФЃЛОВтЪдЃЌЖўепЫйЖШЯрЕБЁЃЦфЪЕЃЌPreparedStatement
ВЂВЛЪЧЗўЮёЖЫдЄДІРэЕФЃЛServerPreparedStatement ВХЪЧеце§ЕФЗўЮёЖЫдЄДІРэЃЌЫйЖШвВНЯ
PreparedStatement ПьЃЛЦфЪЙгУГЁОАвЛАуЪЧЃКЦЕЗБЕФЪ§ОнПтЗУЮЪЃЌsql Ъ§СПгаЯоЃЈгаЛКДцЬдЬВпТдЃЌЪЙгУВЛвЫЛсЕМжТСНДЮ
IO ЃЉЁЃ
ХњДІРэ
ЖдгкЖрЬѕЪ§ОнаДШыЃЌГЃгУ sql ЮЊ insert Ё values
(Ё),(Ё)ЃЛЖјЖдгкЖрЬѕЪ§ОнИќаТЃЌврПЩвдЪЙгУ update Ё case Ё when Ё then
Ё end РДМѕЩй IO ДЮЪ§ЁЃЕЋЫќУЧЖМгавЛИіЬиЕуЃЌЪ§ОнЬѕЪ§дНЖрЃЌsql дНМгИДдгЃЌsql НтЮіГЩБОвВИќИпЃЌКФЪБдіГЄПЩФмИпгкЯпаддіГЄЁЃЖјХњДІРэЃЌПЩвдИДгУвЛЬѕМђЕЅ
sqlЃЌЪЕЯжХњСПЪ§ОнЕФаДШыЛђИќаТЃЌЮЊЯЕЭГДјРДИќЕЭЁЂИќЮШЖЈЕФКФЪБЁЃ
ЖдгкХњДІРэЃЌзїЮЊПЭЛЇЖЫЃЌjava.sql.Statement жївЊЖЈвхСЫСНИіНгПкЗНЗЈЃЌaddBatch
КЭ executeBatch РДжЇГжХњДІРэЁЃ
ХњДІРэЕФМђвЊСїГЬЫЕУїШчЯТЃК

ОвЕЮёжаЪЕМљЃЌЪЙгУХњДІРэЗНЪНЕФаДШыЃЈЛђИќаТЃЉЃЌБШГЃЙц insert
Ё values(Ё),(Ё)ЃЈЛђ update Ё case Ё when Ё then Ё endЃЉадФмИќЮШЖЈЃЌКФЪБвВИќЕЭЁЃ
| 








