| Īŗľ≠Õ∆ľŲ: |
| Īĺőńņī◊‘”ŕcsdn,ĪĺőńĹť…‹ŃňMySQLĶń≤ť—Į”ŇĽĮĶńľľ«…“‘ľįĻ§◊ų‘≠ņŪ£¨ Ķľ ≥°ĺįŌ¬–‘ń‹»ÁļőŐŠ…ż£¨Ō£ÕŻŌŽ∂‘ńķĶń—ßŌį”–ňýįÔ÷ķ°£ |
|
MySQL¬Ŗľ≠ľ‹ĻĻ
»ÁĻŻń‹‘ŕÕ∑ń‘÷–ĻĻĹ®“Ľ∑ýMySQLłų◊ťľĢ÷ģľš»Áļő–≠Õ¨Ļ§◊ųĶńľ‹ĻĻÕľ£¨”–÷ķ”ŕ…Ó»ŽņŪĹ‚MySQL∑ĢőŮ∆ų°£Ō¬Õľ’Ļ ĺŃňMySQLĶń¬Ŗľ≠ľ‹ĻĻÕľ°£
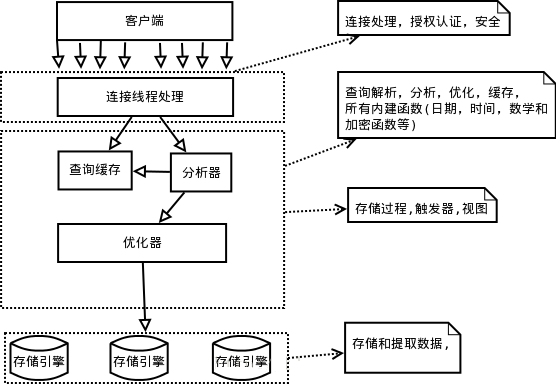
MySQL¬Ŗľ≠ľ‹ĻĻ’ŻŐŚ∑÷ő™»ż≤„£¨◊Ó…Ō≤„ő™ŅÕĽß∂ň≤„£¨≤Ę∑«MySQLňý∂ņ”–£¨÷Ó»Á£ļѨŔī¶ņŪ°Ę ŕ»®»Ō÷§°Ęį≤»ęĶ»Ļ¶ń‹ĺý‘ŕ’‚“Ľ≤„ī¶ņŪ°£
MySQLīů∂ŗ żļň–ń∑ĢőŮĺý‘ŕ÷–ľš’‚“Ľ≤„£¨įŁņ®≤ť—ĮĹ‚őŲ°Ę∑÷őŲ°Ę”ŇĽĮ°ĘĽļīś°Ęńŕ÷√ļĮ ż(Ī»»Á£ļ Īľš°Ę ż—ß°Ęľ”√‹Ķ»ļĮ ż)°£ňý”–ĶńŅÁīśīĘ“ż«śĶńĻ¶ń‹“≤‘ŕ’‚“Ľ≤„ ĶŌ÷£ļīśīĘĻż≥Ő°Ęī•∑Ę∆ų°Ę ”ÕľĶ»°£
◊ÓŌ¬≤„ő™īśīĘ“ż«ś£¨∆šłļ‘ūMySQL÷–Ķń żĺ›īśīĘļÕŐŠ»°°£ļÕLinuxŌ¬ĶńőńľĢŌĶÕ≥ņŗň∆£¨√Ņ÷÷īśīĘ“ż«ś∂ľ”–∆š”Ň ∆ļÕŃ” ∆°£÷–ľšĶń∑ĢőŮ≤„Õ®ĻżAPI”ŽīśīĘ“ż«śÕ®–Ň£¨’‚–©APIĹ”Ņŕ∆ŃĪőŃň≤ĽÕ¨īśīĘ“ż«śľšĶń≤Ó“ž°£
√Ņ“ĽłŲŅÕĽß∂ň∑Ę∆ū“ĽłŲ–¬Ķń«Ž«ů∂ľ”…∑ĢőŮ∆ų∂ňĶńѨŔ/ŌŖ≥Őī¶ņŪĻ§ĺŖłļ‘ūĹ” ’ŅÕĽß∂ňĶń«Ž«ů≤ĘŅ™ĪŔ“ĽłŲ–¬ĶńńŕīśŅ’ľš£¨‘ŕ∑ĢőŮ∆ų∂ňĶńńŕīś÷–…ķ≥…“ĽłŲ–¬ĶńŌŖ≥Ő£¨ĶĪ√Ņ“ĽłŲ”√ĽßѨŔĶĹ∑ĢőŮ∆ų∂ňĶń ĪļÚĺÕĽŠ‘ŕĹÝ≥ŐĶō÷∑Ņ’ľšņÔ…ķ≥…“ĽłŲ–¬ĶńŌŖ≥Ő”√”ŕŌž”¶ŅÕĽß∂ň«Ž«ů£¨”√Ľß∑Ę∆ūĶń≤ť—Į«Ž«ů∂ľ‘ŕŌŖ≥ŐŅ’ľšńŕ‘ň––£¨
ĹŠĻŻ“≤‘ŕ’‚ņÔ√śĽļīś≤Ę∑ĶĽōłÝ∑ĢőŮ∆ų∂ň°£ŌŖ≥ŐĶń÷ō”√ļÕŌķĽŔ∂ľ «”…ѨŔ/ŌŖ≥Őī¶ņŪĻ‹ņŪ∆ų ĶŌ÷Ķń°£
◊Ř…Ōňý Ų£ļ”√Ľß∑Ę∆ū«Ž«ů£¨Ń¨Ĺ”/ŌŖ≥Őī¶ņŪ∆ųŅ™ĪŔńŕīśŅ’ľš£¨Ņ™ ľŐŠĻ©≤ť—ĮĶńĽķ÷∆°£
MySQL≤ť—ĮĻż≥Ő
”√Ľß◊‹ «Ō£ÕŻMySQLń‹ĻĽĽŮĶ√łŁłŖĶń≤ť—Į–‘ń‹£¨◊Óļ√Ķńįž∑® «Ň™«Ś≥ĢMySQL «»Áļő”ŇĽĮļÕ÷ī––≤ť—ĮĶń°£“ĽĶ©ņŪĹ‚Ńň’‚“ĽĶ„£¨ĺÕĽŠ∑ĘŌ÷£ļļ‹∂ŗĶń≤ť—Į”ŇĽĮĻ§◊ų Ķľ …ŌĺÕ «◊Ů—≠“Ľ–©‘≠‘Ú»√MySQLĶń”ŇĽĮ∆ųń‹ĻĽįī’’‘§ŌŽĶńļŌņŪ∑Ĺ Ĺ‘ň––∂Ý“—°£
ĶĪŌÚMySQL∑ĘňÕ“ĽłŲ«Ž«ůĶń ĪļÚ£¨MySQLĶĹĶ◊◊ŲŃň–© ≤√īńō£ŅŌ¬Õľ’Ļ ĺŃňMySQLĶń≤ť—ĮĻż≥Ő°£
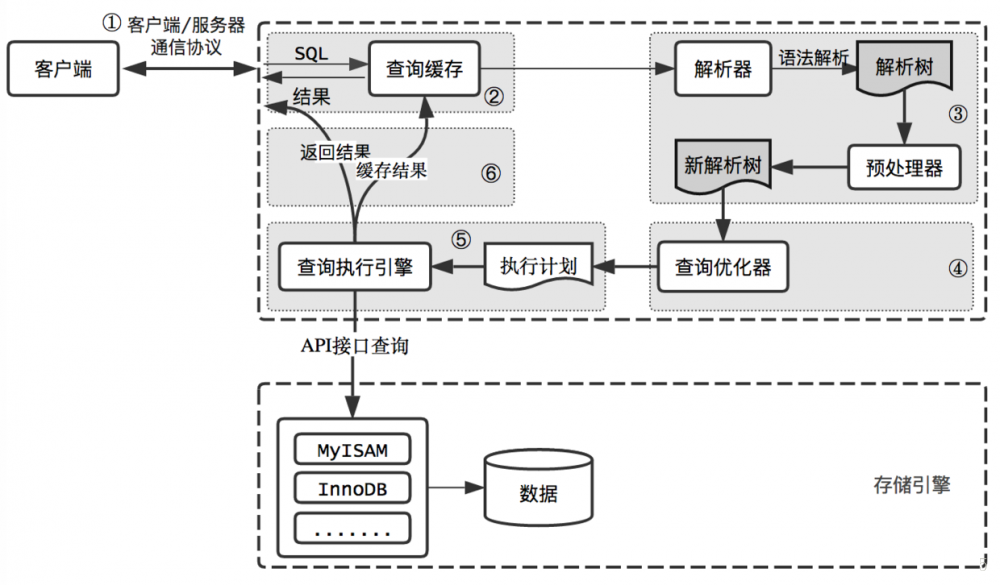
ŅÕĽß∂ň/∑ĢőŮ∂ňÕ®–Ň–≠“ť
MySQLŅÕĽß∂ň/∑ĢőŮ∂ňÕ®–Ň–≠“ť «°įįŽňęĻ§°ĪĶń£ļ‘ŕ»ő“Ľ ĪŅŐ£¨“™√ī «∑ĢőŮ∆ųŌÚŅÕĽß∂ň∑ĘňÕ żĺ›£¨“™√ī «ŅÕĽß∂ňŌÚ∑ĢőŮ∆ų∑ĘňÕ żĺ›£¨’‚ŃĹłŲ∂Į◊ų≤Ľń‹Õ¨ Ī∑Ę…ķ°£“ĽĶ©“Ľ∂ňŅ™ ľ∑ĘňÕŌŻŌĘ£¨ŃŪ“Ľ∂ň“™Ĺ” ’ÕÍ’ŻłŲŌŻŌĘ≤Ňń‹Ōž”¶ňŁ£¨ňý“‘ő“√«őř∑®“≤őř–ŽĹę“ĽłŲŌŻŌĘ«–≥…–°Ņť∂ņŃĘ∑ĘňÕ£¨“≤√Ľ”–įž∑®ĹÝ––ŃųŃŅŅō÷∆°£
ŅÕĽß∂ň”√“ĽłŲĶ•∂ņĶń żĺ›įŁĹę≤ť—Į«Ž«ů∑ĘňÕłÝ∑ĢőŮ∆ų£¨ňý“‘ĶĪ≤ť—Į”Ôĺšļ‹≥§Ķń ĪļÚ£¨–Ť“™…Ť÷√max_allowed_packet≤ő ż°£Ķę «–Ť“™◊Ę“‚Ķń «£¨»ÁĻŻ≤ť—Į Ķ‘ŕ «Őęīů£¨∑ĢőŮ∂ňĽŠĺ‹ĺÝĹ” ’łŁ∂ŗ żĺ›≤ĘŇ◊≥Ų“ž≥£°£
”Ž÷ģŌŗ∑īĶń «£¨∑ĢőŮ∆ųŌž”¶łÝ”√ĽßĶń żĺ›Õ®≥£ĽŠļ‹∂ŗ£¨”…∂ŗłŲ żĺ›įŁ◊ť≥…°£Ķę «ĶĪ∑ĢőŮ∆ųŌž”¶ŅÕĽß∂ň«Ž«ů Ī£¨ŅÕĽß∂ňĪō–ŽÕÍ’ŻĶńĹ” ’’ŻłŲ∑ĶĽōĹŠĻŻ£¨∂Ý≤Ľń‹ľÚĶ•Ķń÷Ľ»°«į√śľłŐűĹŠĻŻ£¨»Ľļů»√∑ĢőŮ∆ųÕ£÷Ļ∑ĘňÕ°£“Ú∂Ý‘ŕ Ķľ Ņ™∑Ę÷–£¨ĺ°ŃŅĪ£≥÷≤ť—ĮľÚĶ•«“÷Ľ∑ĶĽōĪō–ŤĶń żĺ›£¨ľű–°Õ®–Ňľš żĺ›įŁĶńīů–°ļÕ żŃŅ «“ĽłŲ∑«≥£ļ√ĶńŌįĻŖ£¨’‚“≤ «≤ť—Į÷–ĺ°ŃŅĪ‹√‚ Ļ”√SELECT
*“‘ľįľ”…ŌLIMITŌř÷∆Ķń‘≠“Ú÷ģ“Ľ°£
≤ť—ĮĽļīś
‘ŕĹ‚őŲ“ĽłŲ≤ť—Į”Ôĺš«į£¨»ÁĻŻ≤ť—ĮĽļīś «īÚŅ™Ķń£¨ń«√īMySQLĽŠľž≤ť’‚łŲ≤ť—Į”Ôĺš «∑Ů√Ł÷–≤ť—ĮĽļīś÷–Ķń żĺ›°£»ÁĻŻĶĪ«į≤ť—Į«°ļ√√Ł÷–≤ť—ĮĽļīś£¨‘ŕľž≤ť“Ľīő”√Ľß»®Ōřļů÷ĪĹ”∑ĶĽōĽļīś÷–ĶńĹŠĻŻ°£’‚÷÷«ťŅŲŌ¬£¨≤ť—Į≤ĽĽŠĪĽĹ‚őŲ£¨“≤≤ĽĽŠ…ķ≥…÷ī––ľ∆Ľģ£¨łŁ≤ĽĽŠ÷ī––°£
MySQLĹęĽļīśīś∑Ň‘ŕ“ĽłŲ“ż”√ĪŪ£®≤Ľ“™ņŪĹ‚≥…table£¨Ņ…“‘»Ōő™ «ņŗň∆”ŕHashMapĶń żĺ›ĹŠĻĻ£©£¨Õ®Ļż“ĽłŲĻĢŌ£÷Ķňų“ż£¨’‚łŲĻĢŌ£÷ĶÕ®Ļż≤ť—ĮĪĺ…Ū°ĘĶĪ«į“™≤ť—ĮĶń żĺ›Ņ‚°ĘŅÕĽß∂ň–≠“ťįśĪĺļŇĶ»“Ľ–©Ņ…ń‹”įŌžĹŠĻŻĶń–ŇŌĘľ∆ň„Ķ√ņī°£ňý“‘ŃĹłŲ≤ť—Į‘ŕ»őļő◊÷∑Ż…ŌĶń≤ĽÕ¨£®ņż»Á£ļŅ’łŮ°Ę◊Ę Õ£©£¨∂ľĽŠĶľ÷¬Ľļīś≤ĽĽŠ√Ł÷–°£
»ÁĻŻ≤ť—Į÷–įŁļ¨»őļő”√Ľß◊‘∂®“ŚļĮ ż°ĘīśīĘļĮ ż°Ę”√ĽßĪšŃŅ°ĘŃŔ ĪĪŪ°ĘmysqlŅ‚÷–ĶńŌĶÕ≥ĪŪ£¨∆š≤ť—ĮĹŠĻŻ∂ľ≤ĽĽŠĪĽĽļīś°£Ī»»ÁļĮ żNOW()ĽÚ’ŖCURRENT_DATE()ĽŠ“Úő™≤ĽÕ¨Ķń≤ť—Į Īľš£¨∑ĶĽō≤ĽÕ¨Ķń≤ť—ĮĹŠĻŻ£¨‘ŔĪ»»ÁįŁļ¨CURRENT_USERĽÚ’ŖCONNECION_ID()Ķń≤ť—Į”Ô嚼Š“Úő™≤ĽÕ¨Ķń”√Ľß∂Ý∑ĶĽō≤ĽÕ¨ĶńĹŠĻŻ£¨Ĺę’‚—ýĶń≤ť—ĮĹŠĻŻĽļīś∆ūņī√Ľ”–»őļőĶń“‚“Ś°£
ľ»»Ľ «Ľļīś£¨ĺÕĽŠ ߖߣ¨ń«≤ť—ĮĽļīśļő Ī ß–ßńō£ŅMySQLĶń≤ť—ĮĽļīśŌĶÕ≥ĽŠłķ◊Ŕ≤ť—Į÷–…śľįĶń√ŅłŲĪŪ£¨»ÁĻŻ’‚–©ĪŪ£® żĺ›ĽÚĹŠĻĻ£©∑Ę…ķĪšĽĮ£¨ń«√īļÕ’‚’ŇĪŪŌŗĻōĶńňý”–Ľļīś żĺ›∂ľĹę ß–ß°£’ż“Úő™»Áīň£¨‘ŕ»őļőĶń–ī≤Ŕ◊ų Ī£¨MySQLĪō–ŽĹę∂‘”¶ĪŪĶńňý”–Ľļīś∂ľ…Ť÷√ő™ ß–ß°£»ÁĻŻ≤ť—ĮĽļīś∑«≥£īůĽÚ’Ŗňť∆¨ļ‹∂ŗ£¨’‚łŲ≤Ŕ◊ųĺÕŅ…ń‹īÝņīļ‹īůĶńŌĶÕ≥ŌŻļń£¨…ű÷ŃĶľ÷¬ŌĶÕ≥Ĺ©ňņ“ĽĽŠ∂ý°£∂Ý«“≤ť—ĮĽļīś∂‘ŌĶÕ≥Ķń∂ÓÕ‚ŌŻļń“≤≤ĽĹŲĹŲ‘ŕ–ī≤Ŕ◊ų£¨∂Ń≤Ŕ◊ų“≤≤ĽņżÕ‚£ļ°°
1. »őļőĶń≤ť—Į”Ôĺš‘ŕŅ™ ľ÷ģ«į∂ľĪō–Žĺ≠Ļżľž≤ť£¨ľī Ļ’‚ŐűSQL”Ôĺš”ņ‘∂≤ĽĽŠ√Ł÷–Ľļīś
2. »ÁĻŻ≤ť—ĮĹŠĻŻŅ…“‘ĪĽĽļīś£¨ń«√ī÷ī––ÕÍ≥…ļů£¨ĽŠĹęĹŠĻŻīś»ŽĽļīś£¨“≤ĽŠīÝņī∂ÓÕ‚ĶńŌĶÕ≥ŌŻļń
Ľý”ŕīň£¨ő“√«“™÷™Ķņ≤Ę≤Ľ « ≤√ī«ťŅŲŌ¬≤ť—ĮĽļīś∂ľĽŠŐŠłŖŌĶÕ≥–‘ń‹£¨ĽļīśļÕ ß–ß∂ľĽŠīÝņī∂ÓÕ‚ŌŻļń£¨÷Ľ”–ĶĪĽļīśīÝņīĶń◊ ‘īĹŕ‘ľīů”ŕ∆šĪĺ…ŪŌŻļńĶń◊ ‘ī Ī£¨≤ŇĽŠłÝŌĶÕ≥īÝņī–‘ń‹ŐŠ…ż°£»ÁĻŻŌĶÕ≥»∑ Ķīś‘ŕ“Ľ–©–‘ń‹ő Ő‚£¨Ņ…“‘≥Ę ‘īÚŅ™≤ť—ĮĽļīś£¨≤Ę‘ŕ żĺ›Ņ‚…Ťľ∆…Ō◊Ų“Ľ–©”ŇĽĮ£¨Ī»»Á£ļ
1. ∂ŗłŲ–°ĪŪīķŐś“ĽłŲīůĪŪ£¨◊Ę“‚≤Ľ“™Ļż∂»…Ťľ∆
2. ŇķŃŅ≤Ś»ŽīķŐś—≠Ľ∑Ķ•Őű≤Ś»Ž
3. ļŌņŪŅō÷∆ĽļīśŅ’ľšīů–°£¨“Ľį„ņīňĶ∆šīů–°…Ť÷√ő™ľł ģ’◊Ī»ĹŌļŌ
4. Ņ…“‘Õ®ĻżSQL_CACHEļÕSQL_NO_CACHEņīŅō÷∆ń≥łŲ≤ť—Į”Ôĺš «∑Ů–Ť“™ĹÝ––Ľļīś
◊ÓļůĶń÷“łś «≤Ľ“™«Š“◊īÚŅ™≤ť—ĮĽļīś£¨ŐōĪū «–ī√‹ľĮ–Õ”¶”√°£»ÁĻŻń„ Ķ‘ŕ «»Ő≤Ľ◊°£¨Ņ…“‘Ĺęquery_cache_type…Ť÷√ő™DEMAND£¨’‚ Ī÷Ľ”–ľ”»ŽSQL_CACHEĶń≤ť—Į≤ŇĽŠ◊ŖĽļīś£¨∆šňŻ≤ť—Į‘Ú≤ĽĽŠ£¨’‚—ýŅ…“‘∑«≥£◊‘”…ĶōŅō÷∆ńń–©≤ť—Į–Ť“™ĪĽĽļīś°£
”Ô∑®Ĺ‚őŲļÕ‘§ī¶ņŪ
MySQLÕ®ĻżĻōľŁ◊÷ĹęSQL”ÔĺšĹÝ––Ĺ‚őŲ£¨≤Ę…ķ≥…“ĽŅŇ∂‘”¶ĶńĹ‚őŲ ų°£’‚łŲĻż≥ŐĹ‚őŲ∆ų÷ų“™Õ®Ļż”Ô∑®Ļś‘Úņī—ť÷§ļÕĹ‚őŲ°£Ī»»ÁSQL÷– «∑Ů Ļ”√ŃňīŪőůĶńĻōľŁ◊÷ĽÚ’ŖĻōľŁ◊÷Ķńň≥–Ú «∑Ů’ż»∑Ķ»Ķ»°£‘§ī¶ņŪ‘ÚĽŠłýĺ›MySQLĻś‘ÚĹÝ“Ľ≤Ĺľž≤ťĹ‚őŲ ų «∑ŮļŌ∑®°£Ī»»Áľž≤ť“™≤ť—ĮĶń żĺ›ĪŪļÕ żĺ›Ń– «∑Ůīś‘ŕĶ»Ķ»°£
≤ť—Į”ŇĽĮ
ĺ≠Ļż«į√śĶń≤Ĺ÷Ť…ķ≥…Ķń”Ô∑® ųĪĽ»Ōő™ «ļŌ∑®ĶńŃň£¨≤Ę«“”…”ŇĽĮ∆ųĹę∆š◊™ĽĮ≥…≤ť—Įľ∆Ľģ°£∂ŗ ż«ťŅŲŌ¬£¨“ĽŐű≤ť—ĮŅ…“‘”–ļ‹∂ŗ÷÷÷ī––∑Ĺ Ĺ£¨◊Óļů∂ľ∑ĶĽōŌŗ”¶ĶńĹŠĻŻ°£”ŇĽĮ∆ųĶń◊ų”√ĺÕ «’“ĶĹ’‚∆š÷–◊Óļ√Ķń÷ī––ľ∆Ľģ°£
MySQL Ļ”√Ľý”ŕ≥…ĪĺĶń”ŇĽĮ∆ų£¨ňŁ≥Ę ‘‘§≤‚“ĽłŲ≤ť—Į Ļ”√ń≥÷÷÷ī––ľ∆Ľģ ĪĶń≥…Īĺ£¨≤Ę—°‘Ů∆š÷–≥…Īĺ◊Ó–°Ķń“ĽłŲ°£‘ŕMySQLŅ…“‘Õ®Ļż≤ť—ĮĶĪ«įĽŠĽįĶńlast_query_costĶń÷ĶņīĶ√ĶĹ∆šľ∆ň„ĶĪ«į≤ť—ĮĶń≥…Īĺ°£
| mysql>
select * from t_message limit 10;
... °¬‘ĹŠĻŻľĮ
mysql> show status like 'last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 6391.799000 |
+-----------------+-------------+
---------------------
|
ĺņż÷–ĶńĹŠĻŻĪŪ ĺ”ŇĽĮ∆ų»Ōő™īůłŇ–Ť“™◊Ų6391łŲ żĺ›“≥ĶńňśĽķ≤ť’“≤Ňń‹ÕÍ≥……Ō√śĶń≤ť—Į°£’‚łŲĹŠĻŻ «łý囓Ľ–©Ń–ĶńÕ≥ľ∆–ŇŌĘľ∆ň„Ķ√ņīĶń£¨’‚–©Õ≥ľ∆–ŇŌĘįŁņ®£ļ√Ņ’ŇĪŪĽÚ’Ŗňų“żĶń“≥√śłŲ ż°Ęňų“żĶńĽý ż°Ęňų“żļÕ żĺ›––Ķń≥§∂»°Ęňų“żĶń∑÷≤ľ«ťŅŲĶ»Ķ»°£
”–∑«≥£∂ŗĶń‘≠“ÚĽŠĶľ÷¬MySQL—°‘ŮīŪőůĶń÷ī––ľ∆Ľģ£¨Ī»»ÁÕ≥ľ∆–ŇŌĘ≤Ľ◊ľ»∑°Ę≤ĽĽŠŅľ¬«≤Ľ ‹∆šŅō÷∆Ķń≤Ŕ◊ų≥…Īĺ£®”√Ľß◊‘∂®“ŚļĮ ż°ĘīśīĘĻż≥Ő£©°ĘMySQL»Ōő™Ķń◊Ӕҳķő“√«ŌŽĶń≤Ľ“Ľ—ý£®ő“√«Ō£ÕŻ÷ī–– Īľšĺ°Ņ…ń‹∂Ő£¨ĶęMySQL÷Ķ—°‘ŮňŁ»Ōő™≥…Īĺ–°Ķń£¨Ķę≥…Īĺ–°≤Ę≤Ľ“‚ő∂◊Ň÷ī–– Īľš∂Ő£©Ķ»Ķ»°£
”–∑«≥£∂ŗĶń‘≠“ÚĽŠĶľ÷¬MySQL—°‘ŮīŪőůĶń÷ī––ľ∆Ľģ£¨Ī»»ÁÕ≥ľ∆–ŇŌĘ≤Ľ◊ľ»∑°Ę≤ĽĽŠŅľ¬«≤Ľ ‹∆šŅō÷∆Ķń≤Ŕ◊ų≥…Īĺ£®”√Ľß◊‘∂®“ŚļĮ ż°ĘīśīĘĻż≥Ő£©°ĘMySQL»Ōő™Ķń◊Ӕҳķő“√«ŌŽĶń◊Ó”Ň≤Ę≤Ľ“Ľ—ý£®ő“√«Ō£ÕŻ÷ī–– Īľšĺ°Ņ…ń‹∂Ő£¨ĶęMySQL÷Ķ—°‘ŮňŁ»Ōő™≥…Īĺ–°Ķń£¨Ķę≥…Īĺ–°≤Ę≤Ľ“‚ő∂◊Ň÷ī–– Īľš∂Ő£©Ķ»Ķ»°£
MySQLĶń≤ť—Į”ŇĽĮ∆ų «“ĽłŲ∑«≥£łī‘”Ķń≤ŅľĢ£¨ňŁ Ļ”√Ńň∑«≥£∂ŗĶń”ŇĽĮ≤Ŗ¬‘ņī…ķ≥…“ĽłŲ◊Ó”ŇĶń÷ī––ľ∆Ľģ£ļ
°°°°
1. ÷ō–¬∂®“ŚĪŪĶńĻōŃ™ň≥–Ú£®∂ŗ’ŇĪŪĻōŃ™≤ť—Į Ī£¨≤Ę≤Ľ“Ľ∂®įī’’SQL÷–÷ł∂®Ķńň≥–ÚĹÝ––£¨Ķę”–“Ľ–©ľľ«…Ņ…“‘÷ł∂®ĻōŃ™ň≥–Ú£©
2. ”ŇĽĮMIN()ļÕMAX()ļĮ ż£®’“ń≥Ń–Ķń◊Ó–°÷Ķ£¨»ÁĻŻł√Ń–”–ňų“ż£¨÷Ľ–Ť“™≤ť’“B+Treeňų“ż◊Ó◊ů∂ň£¨∑ī÷ģ‘ÚŅ…“‘’“ĶĹ◊Óīů÷Ķ£¨ĺŖŐŚ‘≠ņŪľŻŌ¬őń£©
3. ŐŠ«į÷’÷Ļ≤ť—Į£®Ī»»Á£ļ Ļ”√Limit Ī£¨≤ť’“ĶŬķ◊„ żŃŅĶńĹŠĻŻľĮļůĽŠŃĘľī÷’÷Ļ≤ť—Į£©
4. ”ŇĽĮŇŇ–Ú£®‘ŕņŌįśĪĺMySQLĽŠ Ļ”√ŃĹīőīę šŇŇ–Ú£¨ľīŌ»∂Ń»°––÷ł’ŽļÕ–Ť“™ŇŇ–ÚĶń◊÷∂ő‘ŕńŕīś÷–∂‘∆šŇŇ–Ú£¨»Ľļů‘Ŕłýĺ›ŇŇ–ÚĹŠĻŻ»•∂Ń»° żĺ›––£¨∂Ý–¬įśĪĺ≤…”√Ķń «Ķ•īőīę šŇŇ–Ú£¨“≤ĺÕ «“Ľīő∂Ń»°ňý”–Ķń żĺ›––£¨»Ľļůłý図Ý∂®ĶńŃ–ŇŇ–Ú°£∂‘”ŕI/O√‹ľĮ–Õ”¶”√£¨–߬ ĽŠłŖļ‹∂ŗ£©
≤ť—Į÷ī––“ż«ś
‘ŕÕÍ≥…Ĺ‚őŲļÕ”ŇĽĮĹ◊∂ő“‘ļů£¨MySQLĽŠ…ķ≥…∂‘”¶Ķń÷ī––ľ∆Ľģ£¨≤ť—Į÷ī––“ż«śłýĺ›÷ī––ľ∆ĽģłÝ≥ŲĶń÷łŃÓ÷ū≤Ĺ÷ī––Ķ√≥ŲĹŠĻŻ°£’ŻłŲ÷ī––Ļż≥ŐĶńīů≤Ņ∑÷≤Ŕ◊ųĺý «Õ®ĻżĶų”√īśīĘ“ż«ś ĶŌ÷ĶńĹ”ŅŕņīÕÍ≥…£¨’‚–©Ĺ”ŅŕĪĽ≥∆ő™handler
API°£≤ť—ĮĻż≥Ő÷–Ķń√Ņ“Ľ’ŇĪŪ”…“ĽłŲhandler ĶņżĪŪ ĺ°£ Ķľ …Ō£¨MySQL‘ŕ≤ť—Į”ŇĽĮĹ◊∂őĺÕő™√Ņ“Ľ’ŇĪŪīīĹ®Ńň“ĽłŲhandler Ķņż£¨”ŇĽĮ∆ųŅ…“‘łýĺ›’‚–© ĶņżĶńĹ”ŅŕņīĽŮ»°ĪŪĶńŌŗĻō–ŇŌĘ£¨įŁņ®ĪŪĶńňý”–Ń–√Ż°Ęňų“żÕ≥ľ∆–ŇŌĘĶ»°£īśīĘ“ż«śĹ”ŅŕŐŠĻ©Ńň∑«≥£∑ŠłĽĶńĻ¶ń‹£¨Ķę∆šĶ◊≤„ĹŲ”–ľł ģłŲĹ”Ņŕ£¨’‚–©Ĺ”ŅŕŌŮīÓĽżńĺ“Ľ—ýÕÍ≥…Ńň“Ľīő≤ť—ĮĶńīů≤Ņ∑÷≤Ŕ◊ų°£
∑ĶĽōĹŠĻŻłÝŅÕĽß∂ň
≤ť—Į÷ī––Ķń◊Óļů“ĽłŲĹ◊∂őĺÕ «ĹęĹŠĻŻ∑ĶĽōłÝŅÕĽß∂ň°£ľī Ļ≤ť—Į≤ĽĶĹ żĺ›£¨MySQL»‘»ĽĽŠ∑ĶĽō’‚łŲ≤ť—ĮĶńŌŗĻō–ŇŌĘ£¨Ī»»Áł√≤ť—Į”įŌžĶĹĶń–– ż“‘ľį÷ī–– ĪľšĶ»Ķ»°£
»ÁĻŻ≤ť—ĮĽļīśĪĽīÚŅ™«“’‚łŲ≤ť—ĮŅ…“‘ĪĽĽļīś£¨MySQL“≤ĽŠĹęĹŠĻŻīś∑ŇĶĹĽļīś÷–°£
ĹŠĻŻľĮ∑ĶĽōŅÕĽß∂ň «“ĽłŲ‘ŲŃŅ«“÷ū≤Ĺ∑ĶĽōĶńĻż≥Ő°£”–Ņ…ń‹MySQL‘ŕ…ķ≥…Ķŕ“ĽŐűĹŠĻŻ Ī£¨ĺÕŅ™ ľŌÚŅÕĽß∂ň÷ū≤Ĺ∑ĶĽōĹŠĻŻľĮŃň°£’‚—ý∑ĢőŮ∂ňĺÕőř–ŽīśīĘŐę∂ŗĹŠĻŻ∂ÝŌŻļńĻż∂ŗńŕīś£¨“≤Ņ…“‘»√ŅÕĽß∂ňĶŕ“Ľ ĪľšĽŮĶ√∑ĶĽōĹŠĻŻ°£–Ť“™◊Ę“‚Ķń «£¨ĹŠĻŻľĮ÷–Ķń√Ņ“Ľ––∂ľĽŠ“‘“ĽłŲ¬ķ◊„ŅÕĽß∂ň/∑ĢőŮ∆ųÕ®–Ň–≠“ťĶń żĺ›įŁ∑ĘňÕ£¨‘ŔÕ®ĻżTCP–≠“ťĹÝ––īę š£¨‘ŕīę šĻż≥Ő÷–£¨Ņ…ń‹∂‘MySQLĶń żĺ›įŁĹÝ––Ľļīś»ĽļůŇķŃŅ∑ĘňÕ°£
ĽōÕ∑◊‹ĹŠ“ĽŌ¬MySQL’ŻłŲ≤ť—Į÷ī––Ļż≥Ő£¨◊‹ĶńņīňĶ∑÷ő™6łŲ≤Ĺ÷Ť£ļ
1. ŅÕĽß∂ňŌÚMySQL∑ĢőŮ∆ų∑ĘňÕ“ĽŐű≤ť—Į«Ž«ů
2. ∑ĢőŮ∆ų ◊Ō»ľž≤ť≤ť—ĮĽļīś£¨»ÁĻŻ√Ł÷–Ľļīś£¨‘ÚŃĘŅŐ∑ĶĽōīśīĘ‘ŕĽļīś÷–ĶńĹŠĻŻ°£∑Ů‘ÚĹÝ»ŽŌ¬“ĽĹ◊∂ő
3. ∑ĢőŮ∆ųĹÝ––SQLĹ‚őŲ°Ę‘§ī¶ņŪ°Ę‘Ŕ”…”ŇĽĮ∆ų…ķ≥…∂‘”¶Ķń÷ī––ľ∆Ľģ
4. MySQLłýĺ›÷ī––ľ∆Ľģ£¨Ķų”√īśīĘ“ż«śĶńAPIņī÷ī––≤ť—Į
5. ĹęĹŠĻŻ∑ĶĽōłÝŅÕĽß∂ň£¨Õ¨ ĪĽļīś≤ť—ĮĹŠĻŻ
–‘ń‹”ŇĽĮĹ®“ť
Ō¬√śĽŠī”3łŲ≤ĽÕ¨∑Ĺ√śłÝ≥Ų“Ľ–©”ŇĽĮĹ®“ť°£Ķę«ŽĶ»Ķ»£¨“Ľĺš÷“łś£ļ≤Ľ“™Őż–Ň◊‘ľļŅīĶĹĶńĻō”ŕ”ŇĽĮĶń°įĺÝ∂‘’śņŪ°Ī£¨įŁņ®ĪĺőńňýŐ÷¬ŘĶńńŕ»›£¨∂Ý”¶ł√ «‘ŕ Ķľ Ķń“ĶőŮ≥°ĺįŌ¬Õ®Ļż≤‚ ‘ņī—ť÷§ń„Ļō”ŕ÷ī––ľ∆Ľģ“‘ľįŌž”¶ ĪľšĶńľŔ…Ť°£
ĪŪĶń…Ťľ∆”Ž żĺ›ņŗ–Õ”ŇĽĮ
—°‘Ů żĺ›ņŗ–Õ÷Ľ“™◊Ů—≠–°∂ÝľÚĶ•Ķń‘≠‘ÚĺÕļ√£¨‘Ĺ–°Ķń żĺ›ņŗ–ÕÕ®≥£ĽŠłŁŅž£¨’ľ”√łŁ…ŔĶńīŇŇŐ°Ęńŕīś£¨ī¶ņŪ Ī–Ť“™ĶńCPU÷‹∆ŕ“≤łŁ…Ŕ°£‘ĹľÚĶ•Ķń żĺ›ņŗ–Õ‘ŕľ∆ň„ Ī–Ť“™łŁ…ŔĶńCPU÷‹∆ŕ£¨Ī»»Á£¨’Ż–ÕĺÕĪ»◊÷∑Ż≤Ŕ◊ųīķľŘĶÕ£¨“Ú∂ÝĽŠ Ļ”√’Ż–ÕņīīśīĘipĶō÷∑£¨ Ļ”√DATETIMEņīīśīĘ Īľš£¨∂Ý≤Ľ « Ļ”√◊÷∑Żīģ°£
’‚ņÔ◊‹ĹŠľłłŲŅ…ń‹»›“◊ņŪĹ‚īŪőůĶńľľ«…£ļ
1. Õ®≥£ņīňĶį—Ņ…ő™NULLĶńŃ–łńő™NOT NULL≤ĽĽŠ∂‘–‘ń‹ŐŠ…ż”–∂ŗ…ŔįÔ÷ķ£¨÷Ľ «»ÁĻŻľ∆Ľģ‘ŕŃ–…ŌīīĹ®ňų“ż£¨ĺÕ”¶ł√Ĺęł√Ń–…Ť÷√ő™NOT
NULL°£
2. ∂‘’Ż żņŗ–Õ÷ł∂®ŅŪ∂»£¨Ī»»ÁINT(11)£¨√Ľ”–»őļő¬—”√°£INT Ļ”√4◊÷ĹŕīśīĘŅ’ľš£¨ń«√īňŁňýĪŪ ĺĶń ż÷Ķ∑∂őß“—ĺ≠»∑∂®£¨ňý“‘INT(1)ļÕINT(20)∂‘”ŕīśīĘļÕľ∆ň„ «ŌŗÕ¨Ķń°£
3. UNSIGNEDĪŪ ĺ≤Ľ‘ –Ūłļ÷Ķ£¨īů÷¬Ņ…“‘ Ļ’ż żĶń…ŌŌřŐŠłŖ“ĽĪ∂°£Ī»»ÁTINYINTīśīĘ∑∂őß «-128
~ 127£¨∂ÝUNSIGNED TINYINTīśīĘĶń∑∂őß»ī «0 ®C 255°£
4. Õ®≥£ņīĹ≤£¨√Ľ”–ŐęīůĶńĪō“™ Ļ”√DECIMAL żĺ›ņŗ–Õ°£ľī Ļ «‘ŕ–Ť“™īśīĘ≤∆őŮ żĺ› Ī£¨»‘»ĽŅ…“‘ Ļ”√BIGINT°£Ī»»Á–Ť“™ĺę»∑ĶĹÕÚ∑÷÷ģ“Ľ£¨ń«√īŅ…“‘Ĺę żĺ›≥ň“‘“ĽįŔÕÚ»Ľļů Ļ”√BIGINTīśīĘ°£’‚—ýŅ…“‘Ī‹√‚ł°Ķ„ żľ∆ň„≤Ľ◊ľ»∑ļÕDECIMALĺę»∑ľ∆ň„īķľŘłŖĶńő Ő‚°£
5. TIMESTAMP Ļ”√4łŲ◊÷ĹŕīśīĘŅ’ľš£¨DATETIME Ļ”√8łŲ◊÷ĹŕīśīĘŅ’ľš°£“Ú∂Ý£¨TIMESTAMP÷Ľń‹ĪŪ ĺ1970
®C2038ńÍ£¨Ī»DATETIMEĪŪ ĺĶń∑∂őß–°Ķ√∂ŗ£¨∂Ý«“TIMESTAMPĶń÷Ķ“Ú Ī«Ý≤ĽÕ¨∂Ý≤ĽÕ¨°£
6. īů∂ŗ ż«ťŅŲŌ¬√Ľ”– Ļ”√√∂ĺŔņŗ–ÕĶńĪō“™£¨∆š÷–“ĽłŲ»ĪĶ„ «√∂ĺŔĶń◊÷∑ŻīģŃ–ĪŪ «ĻŐ∂®Ķń£¨ŐŪľ”ļÕ…ĺ≥ż◊÷∑Żīģ£®√∂ĺŔ—°ŌÓ£©Īō–Ž Ļ”√ALTER
TABLE£®»ÁĻŻ÷Ľ÷Ľ «‘ŕŃ–ĪŪń©ő≤◊∑ľ”‘™ňō£¨≤Ľ–Ť“™÷ōĹ®ĪŪ£©°£
7. ĪŪĶńŃ–≤Ľ“™Őę∂ŗ°£‘≠“Ú «īśīĘ“ż«śĶńAPIĻ§◊ų Ī–Ť“™‘ŕ∑ĢőŮ∆ų≤„ļÕīśīĘ“ż«ś≤„÷ģľšÕ®Ļż––Ľļ≥ŚłŮ ĹŅĹĪī żĺ›£¨»Ľļů‘ŕ∑ĢőŮ∆ų≤„ĹęĽļ≥Śń໛ł¬Ž≥…łųłŲŃ–£¨’‚łŲ◊™ĽĽĻż≥ŐĶńīķľŘ «∑«≥£łŖĶń°£»ÁĻŻŃ–Őę∂ŗ∂Ý Ķľ Ļ”√ĶńŃ–”÷ļ‹…ŔĶńĽį£¨”–Ņ…ń‹ĽŠĶľ÷¬CPU’ľ”√ĻżłŖ°£
8.īůĪŪALTER TABLE∑«≥£ļń Ī£¨MySQL÷ī––īů≤Ņ∑÷–řłńĪŪĹŠĻŻ≤Ŕ◊ųĶń∑Ĺ∑® «”√–¬ĶńĹŠĻĻīīĹ®“ĽłŲ’ŇŅ’ĪŪ£¨ī”ĺ…ĪŪ÷–≤ť≥Ųňý”–Ķń żĺ›≤Ś»Ž–¬ĪŪ£¨»Ľļů‘Ŕ…ĺ≥żĺ…ĪŪ°£”»∆šĶĪńŕīś≤Ľ◊„∂ÝĪŪ”÷ļ‹īů£¨∂Ý«“ĽĻ”–ļ‹īůňų“żĶń«ťŅŲŌ¬£¨ļń ĪłŁĺ√°£
īīĹ®łŖ–‘ń‹ňų“ż
ňų“ż «ŐŠłŖMySQL≤ť—Į–‘ń‹Ķń“ĽłŲ÷ō“™Õĺĺ∂£¨ĶęĻż∂ŗĶńňų“żŅ…ń‹ĽŠĶľ÷¬ĻżłŖĶńīŇŇŐ Ļ”√¬ “‘ľįĻżłŖĶńńŕīś’ľ”√£¨ī”∂Ý”įŌž”¶”√≥Ő–ÚĶń’ŻŐŚ–‘ń‹°£”¶ĶĪĺ°ŃŅĪ‹√‚ ¬ļů≤ŇŌŽ∆ūŐŪľ”ňų“ż£¨“Úő™ ¬ļůŅ…ń‹–Ť“™ľŗŅōīůŃŅĶńSQL≤Ňń‹∂®őĽĶĹő Ő‚ňý‘ŕ£¨∂Ý«“ŐŪľ”ňų“żĶń ĪľšŅŌ∂® «‘∂īů”ŕ≥ű ľŐŪľ”ňų“żňý–Ť“™Ķń Īľš£¨Ņ…ľŻňų“żĶńŐŪľ”“≤ «∑«≥£”–ľľ űļ¨ŃŅĶń°£
ňų“żŌŗĻōĶń żĺ›ĹŠĻĻļÕň„∑®
Õ®≥£ő“√«ňýňĶĶńňų“ż «÷łB-Treeňų“ż£¨ňŁ «ńŅ«įĻōŌĶ–Õ żĺ›Ņ‚÷–≤ť’“ żĺ›◊Óő™≥£”√ļÕ”––ßĶńňų“ż£¨īů∂ŗ żīśīĘ“ż«ś∂ľ÷ß≥÷’‚÷÷ňų“ż°£ Ļ”√B-Tree’‚łŲ ű”Ô£¨ «“Úő™MySQL‘ŕCREATE
TABLEĽÚ∆šňŁ”Ôĺš÷– Ļ”√Ńň’‚łŲĻōľŁ◊÷£¨Ķę Ķľ …Ō≤ĽÕ¨ĶńīśīĘ“ż«śŅ…ń‹ Ļ”√≤ĽÕ¨Ķń żĺ›ĹŠĻĻ£¨Ī»»ÁInnoDBīśīĘ“ż«śĺÕ « Ļ”√ĶńB+Tree°£
B+Tree÷–ĶńB «÷łbalance£¨“‚ő™∆Ĺļ‚°£–Ť“™◊Ę“‚Ķń «£¨B+ ųňų“ż≤Ę≤Ľń‹’“ĶĹ“ĽłŲłÝ∂®ľŁ÷ĶĶńĺŖŐŚ––£¨ňŁ’“ĶĹĶń÷Ľ «ĪĽ≤ť’“ żĺ›––ňý‘ŕĶń“≥£¨Ĺ”◊Ň żĺ›Ņ‚ĽŠį—“≥∂Ń»ŽĶĹńŕīś£¨‘Ŕ‘ŕńŕīś÷–ĹÝ––≤ť’“£¨◊ÓļůĶ√ĶĹ“™≤ť’“Ķń żĺ›°£
ňś◊Ň żĺ›Ņ‚÷– żĺ›Ķń‘Ųľ”£¨ňų“żĪĺ…Ūīů–°ňś÷ģ‘Ųľ”£¨≤ĽŅ…ń‹»ę≤ŅīśīĘ‘ŕńŕīś÷–£¨“Úīňňų“żÕýÕý“‘ňų“żőńľĢĶń–ő ĹīśīĘĶńīŇŇŐ…Ō°£’‚—ýĶńĽį£¨ňų“ż≤ť’“Ļż≥Ő÷–ĺÕ“™≤ķ…ķīŇŇŐI/OŌŻļń£¨Ōŗ∂‘”ŕńŕīśīś»°£¨I/Oīś»°ĶńŌŻļń“™łŖľłłŲ żŃŅľ∂°£Ņ…“‘ŌŽŌů“ĽŌ¬“ĽŅ√ľłįŔÕÚĹŕĶ„Ķń∂Ģ≤ś ųĶń…Ó∂» «∂ŗ…Ŕ£Ņ»ÁĻŻĹę’‚√īīů…Ó∂»Ķń“ĽŅŇ∂Ģ≤ś ų∑ŇīŇŇŐ…Ō£¨√Ņ∂Ń»°“ĽłŲĹŕĶ„£¨–Ť“™“ĽīőīŇŇŐĶńI/O∂Ń»°£¨’ŻłŲ≤ť’“Ķńļń ĪŌ‘»Ľ «≤Ľń‹ĻĽĹ” ‹Ķń°£ń«√ī»Áļőľű…Ŕ≤ť’“Ļż≥Ő÷–ĶńI/Oīś»°īő ż£Ņ
“Ľ÷÷––÷ģ”––ßĶńĹ‚ĺŲ∑Ĺ∑® «ľű…Ŕ ųĶń…Ó∂»£¨Ĺę∂Ģ≤ś ųĪšő™m≤ś ų£®∂ŗ¬∑ň—ňų ų£©£¨∂ÝB+TreeĺÕ «“Ľ÷÷∂ŗ¬∑ň—ňų ų°£ņŪĹ‚B+Tree Ī£¨÷Ľ–Ť“™ņŪĹ‚∆š◊Ó÷ō“™ĶńŃĹłŲŐō’ųľīŅ…£ļĶŕ“Ľ£¨ňý”–ĶńĻōľŁ◊÷£®Ņ…“‘ņŪĹ‚ő™ żĺ›£©∂ľīśīĘ‘ŕ“∂◊”ĹŕĶ„£®Leaf
Page£©£¨∑«“∂◊”ĹŕĶ„£®Index Page£©≤Ę≤ĽīśīĘ’ś’żĶń żĺ›£¨ňý”–ľ«¬ľĹŕĶ„∂ľ «įīľŁ÷Ķīů–°ň≥–Úīś∑Ň‘ŕÕ¨“Ľ≤„“∂◊”ĹŕĶ„…Ō°£∆šīő£¨ňý”–Ķń“∂◊”ĹŕĶ„”…÷ł’ŽŃ¨Ĺ”°£»ÁŌ¬Õľő™łŖ∂»ő™3ĶńľÚĽĮŃňĶńB+Tree°£
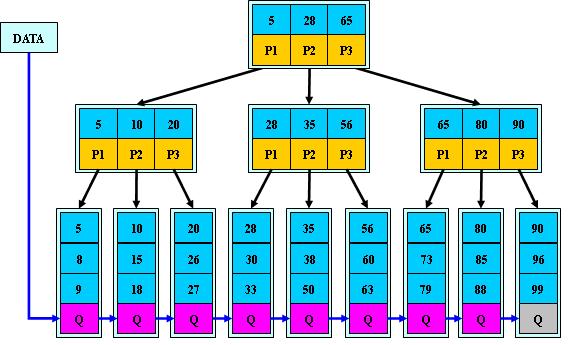
∂‘B+ ųŅ…“‘ĹÝ––ŃĹ÷÷≤ť’“‘ňň„£ļ
1. ī”◊Ó–°ĻōľŁ◊÷∆ūň≥–Ú≤ť’“
2. ī”łýĹŠĶ„Ņ™ ľ£¨ĹÝ––ňśĽķ≤ť’“
‘ŕňśĽķ≤ť’“ Ī£¨ī”łýĹŠĶ„≥Ų∑Ę£¨”ŽB ųĶń≤ť’“∑Ĺ ĹŌŗÕ¨£¨÷Ľ≤ĽĻżľī Ļ‘ŕ∑«÷’∂ňĹŠĶ„…Ō’“ĶĹŃňīż≤ťĶńĻōľŁ◊÷£¨“≤≤Ľ÷’÷Ļ£¨∂Ý «ľŐ–ÝŌÚŌ¬“Ľ÷ĪĶĹīÔįŁļ¨īż≤ťĻōľŁ◊÷Ķń“∂◊”ĹŠĶ„°£“Úīň£¨‘ŕB+ ų÷–£¨≤ĽĻ‹ňśĽķ≤ť’“≥…Ļ¶”Ž∑Ů£¨√ŅīőňśĽķ≤ť’“∂ľ «◊ŖŃň“ĽŐűī”łýĶĹ“∂◊”ĹŠĶ„Ķń¬∑ĺ∂°£»ÁĻŻ–Ť“™ĹÝ––ň≥–Ú≤ť’“£¨ī”◊Ó◊ů≤ŗįŁļ¨◊Ó–°ĻōľŁ◊÷Ķń“∂◊”ĹŠĶ„≥Ų∑Ę£¨≤Ľĺ≠Ļż∑÷÷ßĹŠĶ„£®ľī∑«÷’∂ňĹŠĶ„£©£¨—ō◊Ň÷łŌÚŌ¬“Ľ“∂◊”ĹŠĶ„Ķń÷ł’ŽŅ…Īťņķňý”–ĶńĻōľŁ◊÷°£
Ō¬Õľ’Ļ ĺŃň“Ľ÷÷Ņ…ń‹Ķńňų“ż∑Ĺ Ĺ°£◊ůĪŖ « żĺ›ĪŪ£¨“ĽĻ≤”–ŃĹŃ–∆ŖŐűľ«¬ľ£¨◊Ó◊ůĪŖĶń « żĺ›ľ«¬ľĶńőÔņŪĶō÷∑£®◊Ę“‚¬Ŗľ≠…ŌŌŗŃŕĶńľ«¬ľ‘ŕīŇŇŐ…Ō≤Ę≤Ľ «“Ľ∂®őÔņŪŌŗŃŕĶń£©°£ő™Ńňľ”ŅžCol2Ķń≤ť’“£¨Ņ…“‘ő¨Ľ§“ĽłŲ”“ĪŖňý ĺĶń∂Ģ≤ś≤ť’“ ų£¨√ŅłŲĹŕĶ„∑÷ĪūįŁļ¨ňų“żľŁ÷ĶļÕ“ĽłŲ÷łŌÚ∂‘”¶ żĺ›ľ«¬ľőÔņŪĶō÷∑Ķń÷ł’Ž£¨’‚—ýĺÕŅ…“‘‘ň”√∂Ģ≤ś≤ť’“‘ŕO(log2N)Ķńłī‘”∂»ńŕĽŮ»°ĶĹŌŗ”¶ żĺ›°£°°
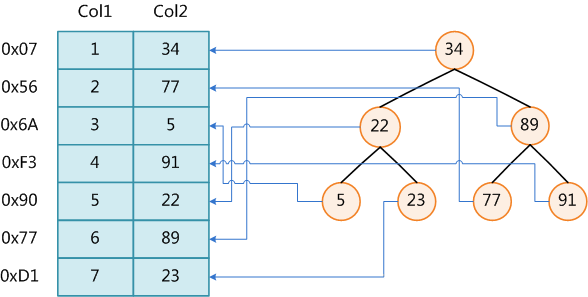
°° żĺ›Ņ‚ňų“ż≤…”√B+ ųĶń÷ų“™‘≠“Ú «B ų‘ŕŐŠłŖŃňīŇŇŐIO–‘ń‹ĶńÕ¨ Ī≤Ę√Ľ”–Ĺ‚ĺŲ‘™ňōĪťņķĶń–߬ ĶÕŌ¬Ķńő Ő‚°£’ż «ő™ŃňĹ‚ĺŲ’‚łŲő Ő‚£¨B+ ų”¶‘ň∂Ý…ķ°£B+ ų÷Ľ“™Īťņķ“∂◊”ĹŕĶ„ĺÕŅ…“‘ ĶŌ÷’ŻŅ√ ųĶńĪťņķ°£∂Ý«“‘ŕ żĺ›Ņ‚÷–Ľý”ŕ∑∂őßĶń≤ť—Į «∑«≥£∆Ķ∑ĪĶń£¨∂ÝB ų≤Ľ÷ß≥÷’‚—ýĶń≤Ŕ◊ų£®ĽÚ’ŖňĶ–߬ ŐęĶÕ£©°£B+ ų‘™ňōĪťņķ–߬ ľęłŖ£¨B+ ųĶńĹŠĻĻ“≤ŐōĪū ļŌīÝ”–∑∂őßĶń≤ť’“°£Ī»»Á≤ť’“—ß–£18-22ňÍĶń—ß…ķ»ň ż£¨Ņ…“‘Õ®Ļżī”łýĹŠĶ„≥Ų∑ĘĹÝ––ňśĽķ≤ť’“£¨’“ĶĹĶŕ“ĽłŲ18ňÍĶń—ß…ķ£®īň ĪĶĹīÔŃň“∂◊”ĹŠĶ„£©£¨»Ľļů‘Ŕ‘ŕ“∂◊”ĹŠĶ„≥Ų∑Ęň≥–Ú≤ť’“ĶĹ∑ŻļŌ∑∂őßĶńňý”–ľ«¬ľ°£
ő™ĪŪ…Ť÷√ňų“ż «“™ł∂≥ŲīķľŘĶń£ļ“Ľ «‘Ųľ”Ńň żĺ›Ņ‚ĶńīśīĘŅ’ľš£¨∂Ģ «‘ŕ≤Ś»ŽļÕ–řłń żĺ› Ī“™Ľ®∑—ĹŌ∂ŗĶń Īľš£®“Úő™ňų“ż“≤“™ňś÷ģĪš∂Į£©°£
łŖ–‘ń‹≤Ŗ¬‘
Õ®Ļż…Ōőń£¨Ōŗ–Ňń„∂‘B+TreeĶń żĺ›ĹŠĻĻ“—ĺ≠”–Ńňīů÷¬ĶńŃňĹ‚£¨ĶęMySQL÷–ňų“ż «»Áļő◊ť÷Į żĺ›ĶńīśīĘńō£Ņ“‘“ĽłŲľÚĶ•Ķń ĺņżņīňĶ√ų£¨ľŔ»Á”–»ÁŌ¬ żĺ›ĪŪ£ļ
| CREATE
TABLE People(
last_name varchar(50) not ,
first_name varchar(50) not ,
dob date not ,
gender enum(`m`,`f`) not ,
key(last_name,first_name,dob)
);
|
∂‘”ŕĪŪ÷–√Ņ“Ľ–– żĺ›£¨ňų“ż÷–įŁļ¨Ńňlast_name°Ęfirst_name°ĘdobŃ–Ķń÷Ķ£¨Ō¬Õľ’Ļ ĺŃňňų“ż «»Áļő◊ť÷Į żĺ›īśīĘĶń°£

Ņ…“‘ŅīĶĹ£¨ňų“ż ◊Ō»łýĺ›Ķŕ“ĽłŲ◊÷∂őņīŇŇŃ–ň≥–Ú£¨ĶĪ√Ż◊÷ŌŗÕ¨ Ī£¨‘Úłýĺ›Ķ໿łŲ◊÷∂ő£¨ľī≥Ų…ķ»’∆ŕņīŇŇ–Ú£¨’ż «“Úő™’‚łŲ‘≠“Ú£¨≤Ň”–Ńňňų“żĶń°į◊Ó◊ů‘≠‘Ú°Ī°£
1°ĘMySQL≤ĽĽŠ‘ŕ°į∑«∂ņŃĘĶńŃ–°Ī…ŌĹ®ŃĘňų“ż°£ °Ī∂ņŃĘĶńŃ–°Ī «÷łňų“żŃ–≤Ľń‹ «ĪŪīÔ ĹĶń“Ľ≤Ņ∑÷£¨“≤≤Ľń‹ «ļĮ żĶń≤ő ż°£Ī»»Á£ļ
| select
* from where id + 1 = 5 |
ő“√«ļ‹»›“◊Ņī≥Ų∆šĶ»ľŘ”ŕ id = 4£¨Ķę «MySQLőř∑®◊‘∂ĮĹ‚őŲ’‚łŲĪŪīÔ Ĺ£¨ Ļ”√ļĮ ż «Õ¨—ýĶńĶņņŪ°£
2°Ę«į◊ļňų“ż
»ÁĻŻŃ–ļ‹≥§£¨Õ®≥£Ņ…“‘ňų“żŅ™ ľĶń≤Ņ∑÷◊÷∑Ż£¨’‚—ýŅ…“‘”––ßĹŕ‘ľňų“żŅ’ľš£¨ī”∂ÝŐŠłŖňų“ż–߬ °£
3°Ę∂ŗŃ–ňų“żļÕňų“żň≥–Ú
‘ŕ∂ŗ ż«ťŅŲŌ¬£¨‘ŕ∂ŗłŲŃ–…ŌĹ®ŃĘ∂ņŃĘĶńňų“ż≤Ę≤Ľń‹ŐŠłŖ≤ť—Į–‘ń‹°£ņŪ”…∑«≥£ľÚĶ•£¨MySQL≤Ľ÷™Ķņ—°‘ŮńńłŲňų“żĶń≤ť—Į–߬ łŁļ√£¨ňý“‘‘ŕņŌįśĪĺ£¨Ī»»ÁMySQL
5.0÷ģ«įĺÕĽŠňśĪ„—°‘Ů“ĽłŲŃ–Ķńňų“ż£¨∂Ý–¬ĶńįśĪ弊≤…”√ļŌ≤Ęňų“żĶń≤Ŗ¬‘°£ĺŔłŲľÚĶ•Ķńņż◊”£¨‘ŕ“Ľ’ŇĶÁ”į—›‘ĪĪŪ÷–£¨‘ŕactor_idļÕfilm_idŃĹłŲŃ–…Ō∂ľĹ®ŃĘŃň∂ņŃĘĶńňų“ż£¨»Ľļů”–»ÁŌ¬≤ť—Į£ļ
| select
film_id,actor_id from film_actor where actor_id
= 1 or film_id = 1 |
ņŌįśĪĺĶńMySQLĽŠňśĽķ—°‘Ů“ĽłŲňų“ż£¨Ķę–¬įśĪĺ◊Ų»ÁŌ¬Ķń”ŇĽĮ£ļ
| select
film_id,actor_id from film_actor where actor_id
= 1
union all
select film_id,actor_id from film_actor where
film_id = 1 and actor_id <> 1
|
1.ĶĪ≥ŲŌ÷∂ŗłŲňų“ż◊ŲŌŗĹĽ≤Ŕ◊ų Ī£®∂ŗłŲANDŐűľĢ£¨Ī»»Á…Ōņż÷–»ÁĻŻłń≥…where
film_id = 1 and actor_id = 1£©£¨Õ®≥£ņīňĶ“ĽłŲįŁļ¨ňý”–ŌŗĻōŃ–Ķńňų“ż“™”Ň”ŕ∂ŗłŲ∂ņŃĘňų“ż°£
2.ĶĪ≥ŲŌ÷∂ŗłŲňų“ż◊ŲŃ™ļŌ≤Ŕ◊ų Ī£®∂ŗłŲORŐűľĢ£¨»Á…Ōņż÷–≤ť—Į”Ôĺš£©£¨∂‘ĹŠĻŻľĮĶńļŌ≤Ę°ĘŇŇ–ÚĶ»≤Ŕ◊ų–Ť“™ļń∑—īůŃŅĶńCPUļÕńŕīś◊ ‘ī£¨ŐōĪū «ĶĪ∆š÷–Ķńń≥–©ňų“żĶń—°‘Ů–‘≤ĽłŖ£¨–Ť“™∑ĶĽōļŌ≤ĘīůŃŅ żĺ› Ī£¨≤ť—Į≥…Ī峣łŖ°£ňý“‘’‚÷÷«ťŅŲŌ¬ĽĻ≤Ľ»Á◊Ŗ»ęĪŪ…®√Ť°£
“Úīňexplain Ī»ÁĻŻ∑ĘŌ÷”–ňų“żļŌ≤Ę£®Extra◊÷∂ő≥ŲŌ÷Using
union£©£¨”¶ł√ļ√ļ√ľž≤ť“ĽŌ¬≤ť—ĮļÕĪŪĹŠĻĻ «≤Ľ «“—ĺ≠ «◊Ó”ŇĶń£¨»ÁĻŻ≤ť—ĮļÕĪŪ∂ľ√Ľ”–ő Ő‚£¨ń«÷Ľń‹ňĶ√ųňų“żĹ®Ķń∑«≥£‘„ł‚£¨”¶ĶĪ…ų÷ōŅľ¬«ňų“ż «∑ŮļŌ £¨”–Ņ…ń‹“ĽłŲįŁļ¨ňý”–ŌŗĻōŃ–Ķń∂ŗŃ–ňų“żłŁ ļŌ°£
«į√śő“√«ŐŠĶĹĻżňų“ż»Áļő◊ť÷Į żĺ›īśīĘĶń£¨ī”Õľ÷–Ņ…“‘ŅīĶĹ∂ŗŃ–ňų“ż Ī£¨∂ŗŃ–ňų“żĶńň≥–Ú∂‘”ŕ≤ť—Į «÷ŃĻō÷ō“™Ķń£¨ļ‹√ųŌ‘”¶ł√į——°‘Ů–‘łŁłŖĶń◊÷∂ő∑ŇĶĹňų“żĶń«į√ś£¨’‚—ýÕ®ĻżĶŕ“ĽłŲ◊÷∂őĺÕŅ…“‘Ļż¬ňĶŰīů∂ŗ ż≤Ľ∑ŻļŌŐűľĢĶń żĺ›°£
ņŪĹ‚ňų“ż—°‘Ů–‘ĶńłŇńÓļů£¨ĺÕ≤Ľń—»∑∂®ńńłŲ◊÷∂őĶń—°‘Ů–‘ĹŌłŖŃň£¨≤ť“ĽŌ¬ĺÕ÷™ĶņŃň£¨Ī»»Á£ļ
| SELECT
* FROM payment where staff_id = 2 and customer_id
= 584 |
«”¶ł√īīĹ®(staff_id,customer_id)Ķńňų“żĽĻ «”¶ł√ĶŖĶĻ“ĽŌ¬ň≥–Ú£Ņ÷ī––Ō¬√śĶń≤ť—Į£¨ńńłŲ◊÷∂őĶń—°‘Ů–‘łŁĹ”ĹŁ1ĺÕį—ńńłŲ◊÷∂őňų“ż«į√śĺÕļ√°£
| select
count(distinct staff_id)/count(*) as staff_id_selectivity,
count(distinct customer_id)/count(*) as customer_id_selectivity,
count(*) from payment
|
∂ŗ ż«ťŅŲŌ¬ Ļ”√’‚łŲ‘≠‘Ú√Ľ”–»őļőő Ő‚°£
4°ĘĪ‹√‚∂ŗłŲ∑∂őßŐűľĢ
Ķľ Ņ™∑Ę÷–£¨ő“√«ĽŠĺ≠≥£ Ļ”√∂ŗłŲ∑∂őßŐűľĢ£¨Ī»»ÁŌŽ≤ť—Įń≥łŲ Īľš∂őńŕĶ«¬ľĻżĶń”√Ľß£ļ
| select
user.* from user where login_time > '2017-04-01'
and age between 18 and 30; |
’‚łŲ≤ť—Į”–“ĽłŲő Ő‚£ļňŁ”–ŃĹłŲ∑∂őßŐűľĢ£¨login_timeŃ–ļÕageŃ–£¨MySQLŅ…“‘ Ļ”√login_timeŃ–Ķńňų“żĽÚ’ŖageŃ–Ķńňų“ż£¨Ķęőř∑®Õ¨ Ī Ļ”√ňŁ√«°£
5°Ę»Ŗ”ŗļÕ÷ōłīňų“ż
»Ŗ”ŗňų“ż «÷ł‘ŕŌŗÕ¨ĶńŃ–…Ōįī’’ŌŗÕ¨Ķńň≥–ÚīīĹ®ĶńŌŗÕ¨ņŗ–ÕĶńňų“ż£¨”¶ĶĪĺ°ŃŅĪ‹√‚’‚÷÷ňų“ż£¨∑ĘŌ÷ļůŃĘľī…ĺ≥ż°£Ī»»Á”–“ĽłŲňų“ż(A,B)£¨‘ŔīīĹ®ňų“ż(A)ĺÕ «»Ŗ”ŗňų“ż°£»Ŗ”ŗňų“żĺ≠≥£∑Ę…ķ‘ŕő™ĪŪŐŪľ”–¬ňų“ż Ī£¨Ī»»Á”–»ň–¬Ĺ®Ńňňų“ż(A,B)£¨Ķę’‚łŲňų“ż≤Ľ «ņ©’Ļ“—”–Ķńňų“ż(A)°£
īů∂ŗ ż«ťŅŲŌ¬∂ľ”¶ł√ĺ°ŃŅņ©’Ļ“—”–Ķńňų“ż∂Ý≤Ľ «īīĹ®–¬ňų“ż°£Ķę”–ľę…Ŕ«ťŅŲŌ¬≥ŲŌ÷–‘ń‹∑Ĺ√śĶńŅľ¬«–Ť“™»Ŗ”ŗňų“ż£¨Ī»»Áņ©’Ļ“—”–ňų“ż∂ÝĶľ÷¬∆šĪšĶ√Ļżīů£¨ī”∂Ý”įŌžĶĹ∆šňŻ Ļ”√ł√ňų“żĶń≤ť—Į°£
6°Ę…ĺ≥ż≥§∆ŕőī Ļ”√Ķńňų“ż
∂®∆ŕ…ĺ≥ż“Ľ–©≥§ Īľšőī Ļ”√ĻżĶńňų“ż «“ĽłŲ∑«≥£ļ√ĶńŌįĻŖ°£
Ļō”ŕňų“ż’‚łŲĽįŐ‚īÚň„ĺÕīňīÚ◊°£¨◊Óļů“™ňĶ“Ľĺš£¨ňų“ż≤Ę≤Ľ◊‹ «◊Óļ√ĶńĻ§ĺŖ£¨÷Ľ”–ĶĪňų“żįÔ÷ķŐŠłŖ≤ť—ĮňŔ∂»īÝņīĶńļ√ī¶īů”ŕ∆šīÝņīĶń∂ÓÕ‚Ļ§◊ų Ī£¨ňų“ż≤Ň «”––ßĶń°£∂‘”ŕ∑«≥£–°ĶńĪŪ£¨ľÚĶ•Ķń»ęĪŪ…®√ŤłŁłŖ–ß°£∂‘”ŕ÷–ĶĹīů–ÕĶńĪŪ£¨ňų“żĺÕ∑«≥£”––ß°£∂‘”ŕ≥¨īů–ÕĶńĪŪ£¨Ĺ®ŃĘļÕő¨Ľ§ňų“żĶńīķľŘňś÷ģ‘Ų≥§£¨’‚ ĪļÚ∆šňŻľľ ű“≤–ŪłŁ”––ߣ¨Ī»»Á∑÷«ÝĪŪ°£◊ÓļůĶń◊Óļů£¨explainļů‘ŔŐŠ≤‚ «“Ľ÷÷√ņĶ¬°£
‘ŕĻ§◊ų÷–£¨ő“√«”√”ŕ≤∂◊Ĺ–‘ń‹ő Ő‚◊Ó≥£”√ĶńĺÕ «īÚŅ™¬ż≤ť—Į£¨∂®őĽ÷ī–––߬ ≤ÓĶńSQL£¨ń«√īĶĪő“√«∂®őĽĶĹ“ĽłŲSQL“‘ļůĽĻ≤Ľň„ÕÍ ¬£¨ő“√«ĽĻ–Ť“™÷™Ķņł√SQLĶń÷ī––ľ∆Ľģ£¨Ī»»Á «»ęĪŪ…®√Ť£¨ĽĻ «ňų“ż…®√Ť£¨’‚–©∂ľ–Ť“™Õ®ĻżEXPLAIN»•ÕÍ≥…°£EXPLAIN√ŁŃÓ «≤ťŅī”ŇĽĮ∆ų»ÁļőĺŲ∂®÷ī––≤ť—ĮĶń÷ų“™∑Ĺ∑®°£Ņ…“‘įÔ÷ķő“√«…Ó»ŽŃňĹ‚MySQLĶńĽý”ŕŅ™ŌķĶń”ŇĽĮ∆ų£¨ĽĻŅ…“‘ĽŮĶ√ļ‹∂ŗŅ…ń‹ĪĽ”ŇĽĮ∆ųŅľ¬«ĶĹĶń∑√ő ≤Ŗ¬‘ĶńŌłĹŕ£¨“‘ľįĶĪ‘ň––SQL”Ôĺš Īńń÷÷≤Ŗ¬‘‘§ľ∆ĽŠĪĽ”ŇĽĮ∆ų≤…”√°£
◊‹ĹŠ
ņŪĹ‚≤ť—Į «»Áļő÷ī––“‘ľį Īľš∂ľŌŻļń‘ŕńń–©Ķō∑Ĺ£¨‘Ŕľ”…Ō“Ľ–©”ŇĽĮĻż≥ŐĶń÷™ ∂”–÷ķ”ೣļ√ĶńņŪĹ‚MySQL£¨ņŪĹ‚≥£ľŻ”ŇĽĮľľ«…Ī≥ļůĶń‘≠ņŪ°£
| 





