| БрМЭЦМі: |
| БОЮФРДздгкcnblogЃЌБОЮФжївЊНщЩмMySQLМмЙЙЁЂmysqlЕФВщбЏжДааСїГЬвдМАSQLНтЮіЫГађЕШЯрЙижЊЪЖЁЃ |
|
ЧАбдЃК вЛжБЪЧЯыжЊЕРвЛЬѕSQLгяОфЪЧдѕУДБЛжДааЕФЃЌЫќжДааЕФЫГађЪЧдѕбљЕФЃЌШЛКѓВщПДзмНсИїЗНзЪСЯЃЌОЭгаСЫЯТУцетвЛЦЊВЉЮФСЫЁЃ БОЮФНЋДгMySQLзмЬхМмЙЙ--->ВщбЏжДааСїГЬ--->гяОфжДааЫГађРДЬНЬжвЛЯТЦфжаЕФжЊЪЖЁЃ
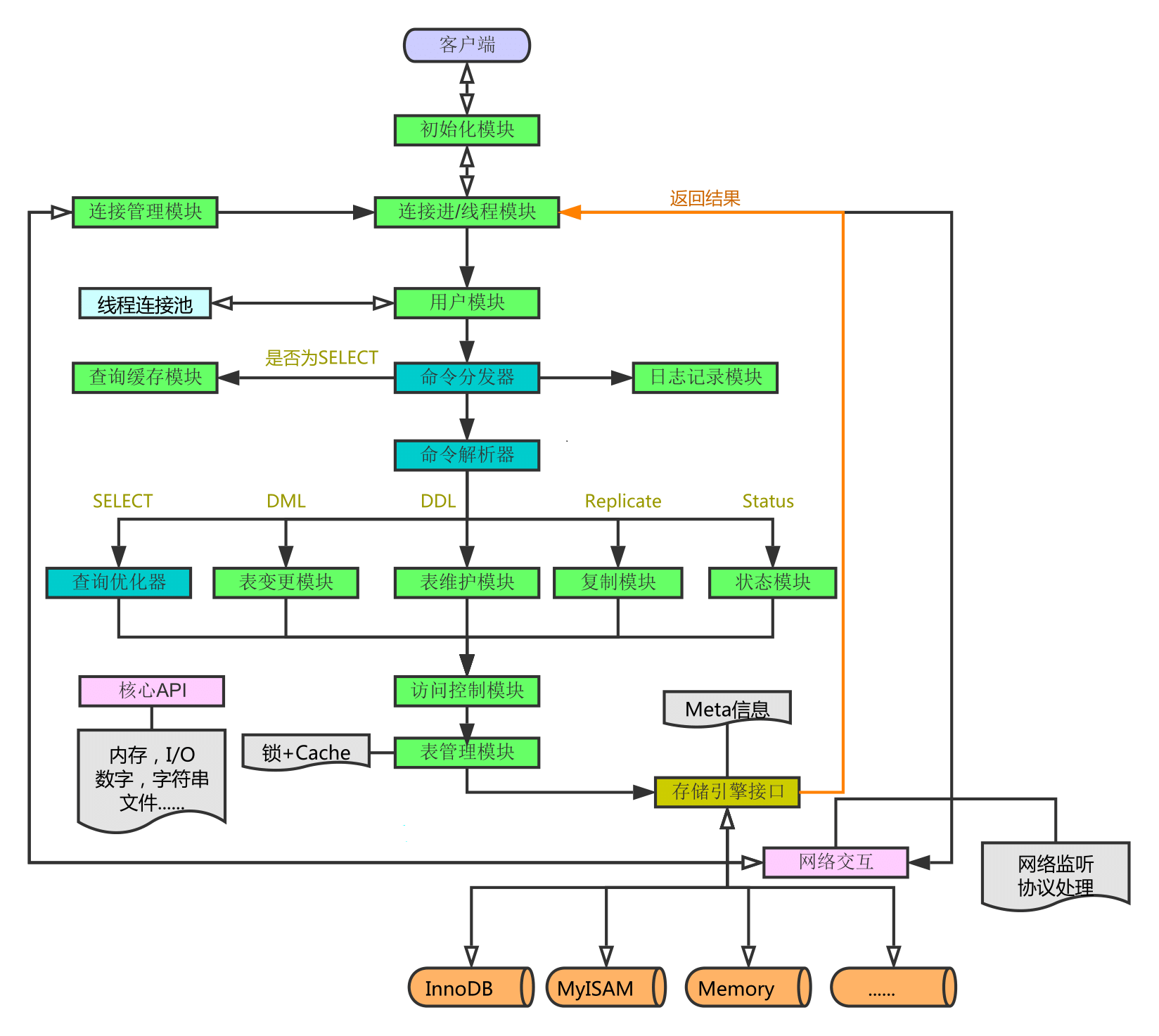
ДгЩЯЭМжаЮвУЧПЩвдПДЕНЃЌећИіМмЙЙЗжЮЊСНВуЃЌЩЯВуЪЧMySQLDЕФБЛГЦЮЊЕФЁЎSQL
LayerЁЏЃЌЯТВуЪЧИїжжИїбљЖдЩЯЬсЙЉНгПкЕФДцДЂв§ЧцЃЌБЛГЦЮЊЁЎStorage Engine LayerЁЏЁЃЦфЫќИїИіФЃПщКЭзщМўЃЌДгУћзжЩЯОЭПЩвдМђЕЅСЫНтЕНЫќУЧЕФзїгУЃЌетРяОЭВЛдйРлЪіСЫ
вЛЁЂMySQLМмЙЙзмРРЃК МмЙЙзюКУПДЭМЃЌдйХфЩЯБивЊЕФЫЕУїЮФзжЁЃ ЯТЭМИљОнВЮПМЪщМЎжавЛЭМЮЊдБОЃЌдйдкЦфЩЯЬэМгЩЯСЫздМКЕФРэНтЁЃ
ДгЩЯЭМжаЮвУЧПЩвдПДЕНЃЌећИіМмЙЙЗжЮЊСНВуЃЌЩЯВуЪЧMySQLDЕФБЛГЦЮЊЕФЁЎSQL LayerЁЏЃЌЯТВуЪЧИїжжИїбљЖдЩЯЬсЙЉНгПкЕФДцДЂв§ЧцЃЌБЛГЦЮЊЁЎStorage
Engine LayerЁЏЁЃЦфЫќИїИіФЃПщКЭзщМўЃЌДгУћзжЩЯОЭПЩвдМђЕЅСЫНтЕНЫќУЧЕФзїгУЃЌетРяОЭВЛдйРлЪіСЫЁЃ
ЖўЁЂВщбЏжДааСїГЬ ЯТУцдйЯђЧАзпвЛаЉЃЌШнЮвИљОнздМКЕФШЯЪЖЫЕвЛЯТВщбЏжДааЕФСїГЬЪЧдѕбљЕФЃК
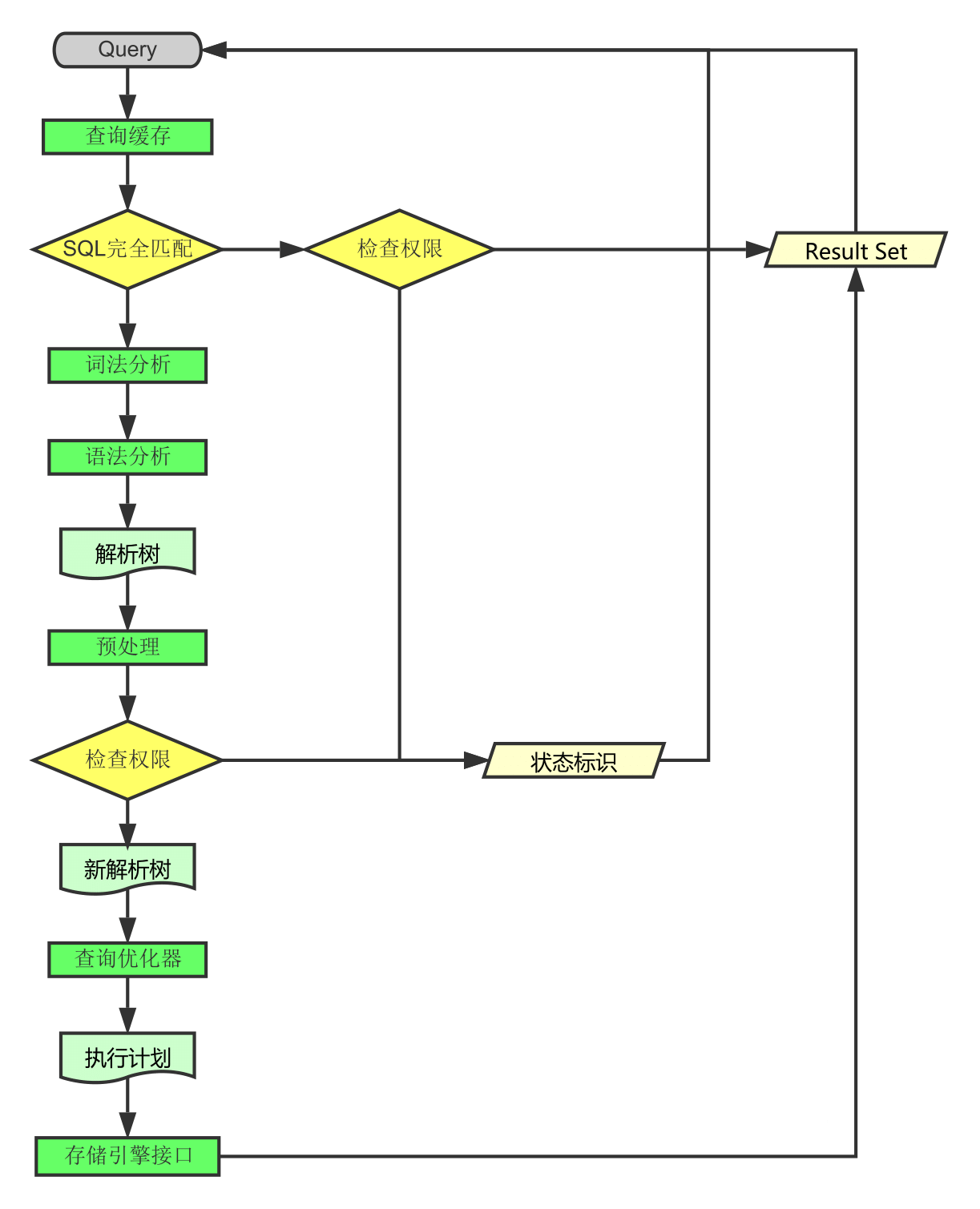
1.СЌНг 1.1ПЭЛЇЖЫЗЂЦ№вЛЬѕQueryЧыЧѓЃЌМрЬ§ПЭЛЇЖЫЕФЁЎСЌНгЙмРэФЃПщЁЏНгЪеЧыЧѓ 1.2НЋЧыЧѓзЊЗЂЕНЁЎСЌНгНј/ЯпГЬФЃПщЁЏ 1.3ЕїгУЁЎгУЛЇФЃПщЁЏРДНјааЪкШЈМьВщ 1.4ЭЈЙ§МьВщКѓЃЌЁЎСЌНгНј/ЯпГЬФЃПщЁЏДгЁЎЯпГЬСЌНгГиЁЏжаШЁГіПеЯаЕФБЛЛКДцЕФСЌНгЯпГЬКЭПЭЛЇЖЫЧыЧѓЖдНгЃЌШчЙћЪЇАмдђДДНЈвЛИіаТЕФСЌНгЧыЧѓ
2.ДІРэ
2.1ЯШВщбЏЛКДцЃЌМьВщQueryгяОфЪЧЗёЭъШЋЦЅХфЃЌНгзХдйМьВщЪЧЗёОпгаШЈЯоЃЌЖМГЩЙІдђжБНгШЁЪ§ОнЗЕЛи 2.2ЩЯвЛВНгаЪЇАмдђзЊНЛИјЁЎУќСюНтЮіЦїЁЏЃЌОЙ§ДЪЗЈЗжЮіЃЌгяЗЈЗжЮіКѓЩњГЩНтЮіЪї 2.3НгЯТРДЪЧдЄДІРэНзЖЮЃЌДІРэНтЮіЦїЮоЗЈНтОіЕФгявхЃЌМьВщШЈЯоЕШЃЌЩњГЩаТЕФНтЮіЪї 2.4дйзЊНЛИјЖдгІЕФФЃПщДІРэ 2.5ШчЙћЪЧSELECTВщбЏЛЙЛсОгЩЁЎВщбЏгХЛЏЦїЁЏзіДѓСПЕФгХЛЏЃЌЩњГЩжДааМЦЛЎ 2.6ФЃПщЪеЕНЧыЧѓКѓЃЌЭЈЙ§ЁЎЗУЮЪПижЦФЃПщЁЏМьВщЫљСЌНгЕФгУЛЇЪЧЗёгаЗУЮЪФПБъБэКЭФПБъзжЖЮЕФШЈЯо 2.7гадђЕїгУЁЎБэЙмРэФЃПщЁЏЃЌЯШЪЧВщПДtable cacheжаЪЧЗёДцдкЃЌгадђжБНгЖдгІЕФБэКЭЛёШЁЫјЃЌЗёдђжиаТДђПЊБэЮФМў 2.8ИљОнБэЕФmetaЪ§ОнЃЌЛёШЁБэЕФДцДЂв§ЧцРраЭЕШаХЯЂЃЌЭЈЙ§НгПкЕїгУЖдгІЕФДцДЂв§ЧцДІРэ 2.9ЩЯЪіЙ§ГЬжаВњЩњЪ§ОнБфЛЏЕФЪБКђЃЌШєДђПЊШежОЙІФмЃЌдђЛсМЧТМЕНЯргІЖўНјжЦШежОЮФМўжа 3.НсЙћ 3.1QueryЧыЧѓЭъГЩКѓЃЌНЋНсЙћМЏЗЕЛиИјЁЎСЌНгНј/ЯпГЬФЃПщЁЏ 3.2ЗЕЛиЕФвВПЩвдЪЧЯргІЕФзДЬЌБъЪЖЃЌШчГЩЙІЛђЪЇАмЕШ 3.3ЁЎСЌНгНј/ЯпГЬФЃПщЁЏНјааКѓајЕФЧхРэЙЄзїЃЌВЂМЬајЕШД§ЧыЧѓЛђЖЯПЊгыПЭЛЇЖЫЕФСЌНг вЛЭМаЁзмНс
Ш§ЁЂSQLНтЮіЫГађ НгЯТРДдйзпвЛВНЃЌШУЮвУЧПДПДвЛЬѕSQLгяОфЕФЧАЪРНёЩњЁЃ ЪзЯШПДвЛЯТЪОР§гяОф
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition
>
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number > |
ШЛЖјЫќЕФжДааЫГађЪЧетбљЕФ
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number> |
ЫфШЛздМКУЛЯыЕНЪЧетбљЕФЃЌВЛЙ§вЛПДЛЙЪЧКмздШЛКЭаГЕФЃЌДгФФРяЛёШЁЃЌВЛЖЯЕФЙ§ТЫЬѕМўЃЌвЊбЁдёвЛбљЛђВЛвЛбљЕФЃЌХХКУађЃЌФЧВХжЊЕРвЊШЁЧАМИЬѕФиЁЃ МШШЛШчДЫСЫЃЌФЧОЭШУЮвУЧвЛВНВНРДПДПДЦфжаЕФЯИНкАЩЁЃ зМБИЙЄзї 1.ДДНЈВтЪдЪ§ОнПт
| create database
testQuery |
2.ДДНЈВтЪдБэ
CREATE TABLE
table1
(
uid VARCHAR(10) NOT NULL,
name VARCHAR(10) NOT NULL,
PRIMARY KEY(uid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8;
CREATE TABLE table2
(
oid INT NOT NULL auto_increment,
uid VARCHAR(10),
PRIMARY KEY(oid)
)ENGINE=INNODB DEFAULT CHARSET=UTF8; |
3.ВхШыЪ§Он
INSERT INTO
table1(uid,name) VALUES('aaa','mike'),('bbb','jack'),('ccc','mike'),('ddd','mike');
INSERT INTO table2(uid) VALUES('aaa'),('aaa'),('bbb'),('bbb'),('bbb'),('ccc'),(NULL); |
4.зюКѓЯывЊЕФНсЙћ
SELECT
a.uid,
count(b.oid) AS total
FROM
table1 AS a
LEFT JOIN table2 AS b ON a.uid = b.uid
WHERE
a. NAME = 'mike'
GROUP BY
a.uid
HAVING
count(b.oid) < 2
ORDER BY
total DESC
LIMIT 1; |
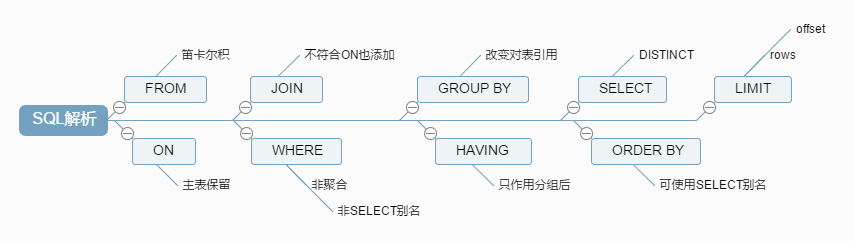
ЃЁЯждкПЊЪМSQLНтЮіжЎТУАЩЃЁ 1. FROM ЕБЩцМАЖрИіБэЕФЪБКђЃЌзѓБпБэЕФЪфГіЛсзїЮЊгвБпБэЕФЪфШыЃЌжЎКѓЛсЩњГЩвЛИіащФтБэVT1ЁЃ (1-J1)ЕбПЈЖћЛ§
МЦЫуСНИіЯрЙиСЊБэЕФЕбПЈЖћЛ§(CROSS JOIN) ЃЌЩњГЩащФтБэVT1-J1ЁЃ
mysql> select
* from table1,table2;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| bbb | jack | 1 | aaa |
| ccc | mike | 1 | aaa |
| ddd | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 2 | aaa |
| ccc | mike | 2 | aaa |
| ddd | mike | 2 | aaa |
| aaa | mike | 3 | bbb |
| bbb | jack | 3 | bbb |
| ccc | mike | 3 | bbb |
| ddd | mike | 3 | bbb |
| aaa | mike | 4 | bbb |
| bbb | jack | 4 | bbb |
| ccc | mike | 4 | bbb |
| ddd | mike | 4 | bbb |
| aaa | mike | 5 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 5 | bbb |
| ddd | mike | 5 | bbb |
| aaa | mike | 6 | ccc |
| bbb | jack | 6 | ccc |
| ccc | mike | 6 | ccc |
| ddd | mike | 6 | ccc |
| aaa | mike | 7 | NULL |
| bbb | jack | 7 | NULL |
| ccc | mike | 7 | NULL |
| ddd | mike | 7 | NULL |
+-----+------+-----+------+
rows in set (0.00 sec) |
(1-J2)ONЙ§ТЫ ЛљгкащФтБэVT1-J1етвЛИіащФтБэНјааЙ§ТЫЃЌЙ§ТЫГіЫљгаТњзуON ЮНДЪЬѕМўЕФСаЃЌЩњГЩащФтБэVT1-J2ЁЃ
зЂвтЃКетРявђЮЊгяЗЈЯожЦЃЌЪЙгУСЫ'WHERE'ДњЬцЃЌДгжаЖСепвВПЩвдИаЪмЕНСНепжЎМфЮЂУюЕФЙиЯЕЃЛ
mysql> SELECT
-> *
-> FROM
-> table1,
-> table2
-> WHERE
-> table1.uid = table2.uid
-> ;
+-----+------+-----+------+
| uid | name | oid | uid |
+-----+------+-----+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
+-----+------+-----+------+
rows in set (0.00 sec) |
(1-J3)ЬэМгЭтВПСа
ШчЙћЪЙгУСЫЭтСЌНг(LEFT,RIGHT,FULL)ЃЌжїБэЃЈБЃСєБэЃЉжаЕФВЛЗћКЯONЬѕМўЕФСавВЛсБЛМгШыЕНVT1-J2жаЃЌзїЮЊЭтВПааЃЌЩњГЩащФтБэVT1-J3ЁЃ
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| bbb | jack | 3 | bbb |
| bbb | jack | 4 | bbb |
| bbb | jack | 5 | bbb |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
rows in set (0.00 sec) |
ЯТУцДгЭјЩЯевЕНвЛеХКмаЮЯѓЕФЙигкЁЎSQL JOINS'ЕФНтЪЭЭМЃЌШчШєЧжЗИСЫФуЕФШЈвцЃЌЧыРЭЗГИцжЊЩОГ§ЃЌаЛаЛЁЃ
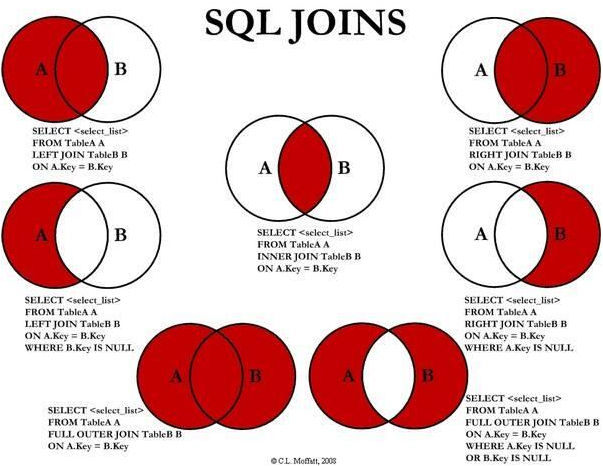
2. WHERE ЖдVT1Й§ГЬжаЩњГЩЕФСйЪББэНјааЙ§ТЫЃЌТњзуWHEREзгОфЕФСаБЛВхШыЕНVT2БэжаЁЃ зЂвтЃК ДЫЪБвђЮЊЗжзщЃЌВЛФмЪЙгУОлКЯдЫЫуЃЛвВВЛФмЪЙгУSELECTжаДДНЈЕФБ№УћЃЛ гыONЕФЧјБ№ЃК ШчЙћгаЭтВПСаЃЌONеыЖдЙ§ТЫЕФЪЧЙиСЊБэЃЌжїБэЃЈБЃСєБэЃЉЛсЗЕЛиЫљгаЕФСаЃЛ ШчЙћУЛгаЬэМгЭтВПСаЃЌСНепЕФаЇЙћЪЧвЛбљЕФЃЛ гІгУЃК ЖджїБэЕФЙ§ТЫгІИУЗХдкWHEREЃЛ
ЖдгкЙиСЊБэЃЌЯШЬѕМўВщбЏКѓСЌНгдђгУONЃЌЯШСЌНгКѓЬѕМўВщбЏдђгУWHEREЃЛ
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike';
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| aaa | mike | 2 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
rows in set (0.00 sec) |
3. GROUP BY етИізгОфЛсАбVT2жаЩњГЩЕФБэАДееGROUP BYжаЕФСаНјааЗжзщЁЃЩњГЩVT3БэЁЃ зЂвтЃК ЦфКѓДІРэЙ§ГЬЕФгяОфЃЌШчSELECT,HAVINGЃЌЫљгУЕНЕФСаБиаыАќКЌдкGROUP BYжаЃЌЖдгкУЛгаГіЯжЕФЃЌЕУгУОлКЯКЏЪ§ЃЛ двђЃК GROUP BYИФБфСЫЖдБэЕФв§гУЃЌНЋЦфзЊЛЛЮЊаТЕФв§гУЗНЪНЃЌФмЙЛЖдЦфНјааЯТвЛМЖТпМВйзїЕФСаЛсМѕЩйЃЛ ЮвЕФРэНтЪЧЃК
ИљОнЗжзщзжЖЮЃЌНЋОпгаЯрЭЌЗжзщзжЖЮЕФМЧТМЙщВЂГЩвЛЬѕМЧТМЃЌвђЮЊУПвЛИіЗжзщжЛФмЗЕЛивЛЬѕМЧТМЃЌГ§ЗЧЪЧБЛЙ§ТЫЕєСЫЃЌЖјВЛдкЗжзщзжЖЮРяУцЕФзжЖЮПЩФмЛсгаЖрИіжЕЃЌЖрИіжЕЪЧЮоЗЈЗХНјвЛЬѕМЧТМЕФЃЌЫљвдБиаыЭЈЙ§ОлКЯКЏЪ§НЋетаЉОпгаЖржЕЕФСазЊЛЛГЩЕЅжЕЃЛ
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| aaa | mike | 1 | aaa |
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
rows in set (0.00 sec) |
4. HAVING
етИізгОфЖдVT3БэжаЕФВЛЭЌЕФзщНјааЙ§ТЫЃЌжЛзїгУгкЗжзщКѓЕФЪ§ОнЃЌТњзуHAVINGЬѕМўЕФзгОфБЛМгШыЕНVT4БэжаЁЃ
mysql> SELECT
-> *
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+------+------+------+
| uid | name | oid | uid |
+-----+------+------+------+
| ccc | mike | 6 | ccc |
| ddd | mike | NULL | NULL |
+-----+------+------+------+
rows in set (0.00 sec) |
5. SELECT етИізгОфЖдSELECTзгОфжаЕФдЊЫиНјааДІРэЃЌЩњГЩVT5БэЁЃ (5-J1)МЦЫуБэДяЪН МЦЫуSELECT згОфжаЕФБэДяЪНЃЌЩњГЩVT5-J1 (5-J2)DISTINCT бАевVT5-1жаЕФжиИДСаЃЌВЂЩОЕєЃЌЩњГЩVT5-J2
ШчЙћдкВщбЏжажИЖЈСЫDISTINCTзгОфЃЌдђЛсДДНЈвЛеХФкДцСйЪББэЃЈШчЙћФкДцЗХВЛЯТЃЌОЭашвЊДцЗХдкгВХЬСЫЃЉЁЃетеХСйЪББэЕФБэНсЙЙКЭЩЯвЛВНВњЩњЕФащФтБэVT5ЪЧвЛбљЕФЃЌВЛЭЌЕФЪЧЖдНјааDISTINCTВйзїЕФСадіМгСЫвЛИіЮЈвЛЫїв§ЃЌвдДЫРДГ§жиИДЪ§ОнЁЃ
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
rows in set (0.00 sec) |
6.ORDER BY ДгVT5-J2жаЕФБэжаЃЌИљОнORDER BY згОфЕФЬѕМўЖдНсЙћНјааХХађЃЌЩњГЩVT6БэЁЃ зЂвтЃК
ЮЈвЛПЩЪЙгУSELECTжаБ№УћЕФЕиЗНЃЛ
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT OUTER JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
| ddd | 0 |
+-----+-------+
rows in set (0.00 sec) |
7.LIMIT LIMITзгОфДгЩЯвЛВНЕУЕНЕФVT6ащФтБэжабЁГіДгжИЖЈЮЛжУПЊЪМЕФжИЖЈааЪ§ОнЁЃ зЂвтЃК offsetКЭrowsЕФе§ИКДјРДЕФгАЯьЃЛ ЕБЦЋвЦСПКмДѓЪБаЇТЪЪЧКмЕЭЕФЃЌПЩвдетУДзіЃК ВЩгУзгВщбЏЕФЗНЪНгХЛЏЃЌдкзгВщбЏРяЯШДгЫїв§ЛёШЁЕНзюДѓidЃЌШЛКѓЕЙађХХЃЌдйШЁNааНсЙћМЏ
ВЩгУINNER JOINгХЛЏЃЌJOINзгОфРявВгХЯШДгЫїв§ЛёШЁIDСаБэЃЌШЛКѓжБНгЙиСЊВщбЏЛёЕУзюжеНсЙћ
mysql> SELECT
-> a.uid,
-> count(b.oid) AS total
-> FROM
-> table1 AS a
-> LEFT JOIN table2 AS b ON a.uid = b.uid
-> WHERE
-> a. NAME = 'mike'
-> GROUP BY
-> a.uid
-> HAVING
-> count(b.oid) < 2
-> ORDER BY
-> total DESC
-> LIMIT 1;
+-----+-------+
| uid | total |
+-----+-------+
| ccc | 1 |
+-----+-------+
row in set (0.00 sec) |
жСДЫSQLЕФНтЮіжЎТУОЭНсЪјСЫЃЌЩЯЭМзмНсвЛЯТЃК
ЮВЩљЃК рХЃЌЕНетРяетвЛДЮЕФЩюШыСЫНтжЎТУОЭВюВЛЖрецЕФНсЪјСЫЃЌЫфШЛвВВЛЪЧКмЩюШыЃЌжЛЪЧвЛаЉЖЋЮїНЋЦфЖЋЦДЮїДедквЛЦ№ЖјвбЃЌВЮПМСЫвЛаЉвдЧАПДЙ§ЕФЪщМЎЃЌДѓЪІжЎБЪЙћШЛВЛвЛбљЁЃЖјЧвдкетЙ§ГЬжавВЪЧgetЕНСЫТљЖрЖЋЮїЕФЃЌзюживЊЕФЪЧИќНјвЛВНвтЪЖЕНЃЌМЦЫуЛњШэМўЪРНчЕФКъДѓбН~ СэгЩгкБОШЫВХЪшбЇЧГЃЌЦфжаФбУтДцдкчЂТЉДэЮѓжЎДІЃЌШєЗЂЯжРЭЗГИцжЊаоИФЃЌИааЛ~ | 








