| БрМЭЦМі: |
| БОЮФРДздгкcloud.tencent.com,CynosDB
for PostgreSQLЪЧЬкбЖдЦздбаЕФвЛПюдЦдЩњЪ§ОнПтЃЌЦфжївЊКЫаФЫМЯыРДздгкбЧТэбЗЕФдЦЪ§ОнПтЗўЮёAuroraЁЃ |
|
ЦѓвЕITЯЕЭГЧЈвЦЕНЙЋгадЦЩЯвбШЛЪЧе§дкЗЂЩњЕФЧїЪЦЁЃЪ§ОнПтЗўЮёЃЌзїЮЊЙЋгадЦЩЯЬсЙЉЕФЙиМќзщМўЃЌЪЧЦѓвЕПЭЛЇЪЧЗёдИвтНЋздМКдЫааЖрФъЕФЯЕЭГАсЕНдЦЩЯЕФЙиМќПМСПжЎвЛЁЃСэвЛЗНУцЃЌздДгSystem
RПЊЪМЃЌЙиЯЕЪ§ОнПтЯЕЭГвбОДѓдМЫФЪЎФъЕФРњЪЗСЫЁЃгШЦфЪЧЫцзХЛЅСЊЭјЕФЗЂеЙЃЌвЕЮёЖдЪ§ОнПтЪЕР§ЕФЭЬЭТСПвЊЧѓдНРДдНИпЁЃЖдгкКмЖрвЕЮёРДЫЕЃЌЕЅИіЮяРэЛњЦїЫљФмЬсЙЉЕФзюДѓЭЬЭТСПвбОВЛФмТњзувЕЮёЕФИпЫйЗЂеЙЁЃвђДЫЃЌЪ§ОнПтМЏШКЪЧКмЖрITЯЕЭГШЦВЛЙ§ШЅЕФПВЁЃ
CynosDB for PostgreSQLЪЧЬкбЖдЦздбаЕФвЛПюдЦдЩњЪ§ОнПтЃЌЦфжївЊКЫаФЫМЯыРДздгкбЧТэбЗЕФдЦЪ§ОнПтЗўЮёAuroraЁЃетжжКЫаФЫМЯыОЭЪЧЁАЛљгкШежОЕФДцДЂЁБКЭЁАДцДЂМЦЫуЗжРыЁБЁЃЭЌЪБЃЌCynosDBдкМмЙЙКЭЙЄГЬЪЕЯжЩЯШЗЪЕгаКмЖрКЭAuroraВЛвЛбљЕФЕиЗНЁЃCynosDBЯрБШДЋЭГЕФЕЅЛњЪ§ОнПтЃЌжївЊНтОіШчЯТЮЪЬтЃК
ДцЫуЗжРы
ДцЫуЗжРыЪЧдЦЪ§ОнПтЧјБ№гкДЋЭГЪ§ОнПтЕФжївЊЬиЕужЎвЛЃЌжївЊЪЧЮЊСЫ1ЃЉЬсЩ§зЪдДРћгУаЇТЪЃЌгУЛЇгУЖрЩйзЪдДОЭИјЖрЩйзЪдДЃЛ2ЃЉМЦЫуНкЕуЮозДЬЌИќгаРћгкЪ§ОнПтЗўЮёЕФИпПЩгУадКЭМЏШКЙмРэЃЈЙЪеЯЛжИДЁЂЪЕР§ЧЈвЦЃЉЕФБуРћадЁЃ
ДцДЂздЖЏРЉЫѕШн
ДЋЭГЙиЯЕаЭЪ§ОнПтЛсЪмЕНЕЅИіЮяРэЛњЦїзЪдДЕФЯожЦЃЌАќРЈЕЅЛњЩЯДцДЂПеМфЕФЯожЦКЭМЦЫуФмСІЕФЯожЦЁЃCynosDBВЩгУЗжВМЪНДцДЂРДЭЛЦЦЕЅЛњДцДЂЯожЦЁЃСэЭтЃЌДцДЂжЇГжЖрИББОЃЌЭЈЙ§RAFTавщРДБЃжЄЖрИББОЕФвЛжТадЁЃ
ИќИпЕФЭјТчРћгУТЪ
ЭЈЙ§ЛљгкШежОЕФДцДЂЩшМЦЫМТЗЃЌДѓЗљЖШНЕЕЭЪ§ОнПтдЫааЙ§ГЬжаЕФЭјТчСїСПЁЃ
ИќИпЕФЭЬЭТСП
ДЋЭГЕФЪ§ОнПтМЏШКЃЌУцСйЕФвЛИіЙиМќЮЪЬтЪЧЃКЗжВМЪНЪТЮёКЭМЏШКЭЬЭТСПЯпадРЉеЙЕФУЌЖмЁЃвВОЭЪЧЫЕЃЌКмЖрЪ§ОнПтМЏШКЃЌвЊУДжЇГжЭъећЕФACIDЃЌвЊУДзЗЧѓМЋКУЕФЯпадРЉеЙадЃЌДѓВПЗжЪБКђгуКЭамеЦВЛПЩМцЕУЁЃЧАепБШШчOracle
RACЃЌЪЧФПЧАЪаГЁЩЯзюГЩЪьзюЭъЩЦЕФЪ§ОнПтМЏШКЃЌЬсЙЉЖдвЕЮёЭъШЋЭИУїЕФЪ§ОнЗУЮЪЗўЮёЁЃЕЋЪЧOracle RACЕФЯпадРЉеЙадШДБЛЪаГЁжЄУїЛЙВЛЙЛЃЌвђДЫЃЌИќЖргУЛЇжївЊгУRACРДЙЙНЈИпПЩгУМЏШКЃЌЖјВЛЪЧИпРЉеЙЕФМЏШКЁЃКѓепБШШчProxy+ПЊдДDBЕФЪ§ОнПтМЏШКЗНАИЃЌЭЈГЃФмЬсЙЉКмКУЕФЯпадРЉеЙадЃЌЕЋЪЧвђЮЊВЛжЇГжЗжВМЪНЪТЮёЃЌЖдЪ§ОнПтгУЛЇДцдкНЯДѓЕФЯожЦЁЃгжЛђепПЩвджЇГжЗжВМЪНЪТЮёЃЌЕЋЪЧЕБПчНкЕуаДШыБШР§КмДѓЪБЃЌЗДЙ§РДНЕЕЭСЫЯпадРЉеЙФмСІЁЃCynosDBЭЈЙ§ВЩгУвЛаДЖрЖСЕФЗНЪНЃЌРћгУжЛЖСНкЕуЕФЯпадРЉеЙРДЬсЩ§ећИіЯЕЭГЕФзюДѓЭЬЭТСПЃЌЖдгкОјДѓВПЗнЙЋгадЦгУЛЇРДЫЕЃЌетОЭвбОзуЙЛСЫЁЃ
ЯТЭМЮЊCynosDB for PostgreSQLЕФВњЦЗМмЙЙЭМЃЌCynosDBЪЧвЛИіЛљгкЙВЯэДцДЂЁЂжЇГжвЛаДЖрЖСЕФЪ§ОнПтМЏШКЁЃ
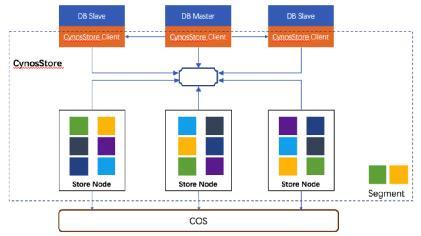
ЭМвЛCynosDB for PostgreSQLВњЦЗМмЙЙЭМ
CynosDBЛљгкCynosStoreжЎЩЯЃЌCynosStoreЪЧвЛИіЗжВМЪНДцДЂЃЌЮЊCynosDBЬсЙЉМсЪЕЕФЕззљЁЃCynosStoreгЩЖрИіStore
NodeКЭCynosStore ClientзщГЩЁЃCynosStore ClientвдЖўНјжЦАќЕФаЮЪНгыDBЃЈPostgreSQLЃЉвЛЦ№БрвыЃЌЮЊDBЬсЙЉЗУЮЪНгПкЃЌвдМАИКд№жїДгDBжЎМфЕФШежОСїДЋЪфЁЃГ§ДЫжЎЭтЃЌУПИіStore
NodeЛсздЖЏНЋЪ§ОнКЭШежОГжајЕиБИЗнЕНЬкбЖдЦЖдЯѓДцДЂЗўЮёCOSЩЯЃЌгУРДЪЕЯжPITRЃЈМДЪБЛжИДЃЉЙІФмЁЃ
вЛЁЂCynosStoreЪ§ОнзщжЏаЮЪН
CynosStoreЛсЮЊУПвЛИіЪ§ОнПтЗжХфвЛЖЮДцДЂПеМфЃЌЮвУЧГЦжЎЮЊPoolЃЌвЛИіЪ§ОнПтЖдгІвЛИіPoolЁЃЪ§ОнПтДцДЂПеМфЕФРЉЫѕШнЪЧЭЈЙ§PoolЕФРЉЫѕШнРДЪЕЯжЕФЁЃвЛИіPoolЛсЗжГЩЖрИіSegment
GroupЃЈSGЃЉЃЌУПИіSGЙЬЖЈДѓаЁЮЊ10GЁЃЮвУЧвВАбУПИіSGНазівЛИіТпМЗжЦЌЁЃвЛИіSegment
GroupЃЈSGЃЉгЩЖрИіЮяРэЕФSegmentзщГЩЃЌвЛИіSegmentЖдгІвЛИіЮяРэИББОЃЌЖрИіИББОЭЈЙ§RAFTавщРДЪЕЯжвЛжТадЁЃSegmentЪЧCynosStoreжазюаЁЕФЪ§ОнЧЈвЦКЭБИЗнЕЅЮЛЁЃУПИіSGБЃДцЪєгкЫќЕФЪ§ОнвдМАЖдетВПЗжЪ§ОнзюНќвЛЖЮЪБМфЕФаДШежОЁЃ
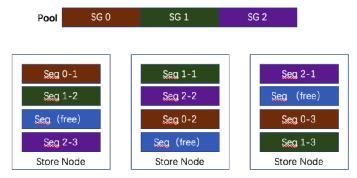
ЭМЖў CynosStore Ъ§ОнзщжЏаЮЪН
ЭМЖўжаCynosStoreвЛЙВга3ИіStore NodeЃЌCynosStoreжаДДНЈСЫвЛИіPoolЃЌетИіPoolгЩ3ИіSGзщГЩЃЌУПИіSGга3ИіИББОЁЃCynosStoreЛЙгаПеЯаЕФИББОЃЌПЩвдгУРДИјЕБЧАPoolРЉШнЃЌвВПЩвдДДНЈСэвЛИіPoolЃЌНЋетПеЯаЕФ3ИіSegmentзщГЩвЛИіSGВЂЗжХфИіетИіаТЕФPoolЁЃ
ЖўЁЂЛљгкШежОвьВНаДЕФЗжВМЪНДцДЂ
ДЋЭГЕФЪ§ОнЭЈГЃВЩгУWALЃЈШежОЯШаДЃЉРДЪЕЯжЪТЮёКЭЙЪеЯЛжИДЁЃетбљзізюжБЙлЕФКУДІЪЧ1ЃЉЪ§ОнПтdownЛњКѓПЩвдИљОнГжОУЛЏЕФWALРДЛжИДЪ§ОнвГЁЃ2ЃЉЯШаДШежОЃЌЖјВЛЪЧжБНгаДЪ§ОнЃЌПЩвддкЪ§ОнПтаДВйзїЕФЙиМќТЗОЖЩЯНЋЫцЛњIOЃЈаДЪ§ОнвГЃЉБфГЩЫГађIOЃЈаДШежОЃЉЃЌБугкЬсЩ§Ъ§ОнПтадФмЁЃ
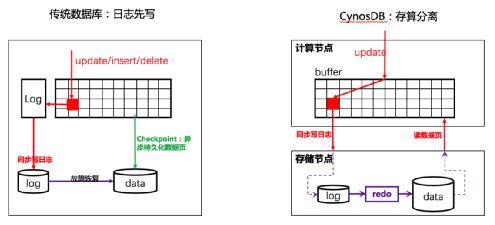
ЭМШ§ ЛљгкШежОЕФДцДЂ
ЭМШ§ЃЈзѓЃЉМЋЖШГщЯѓЕиУшЪіСЫДЋЭГЪ§ОнПтаДЪ§ОнЕФЙ§ГЬЃКУПДЮаоИФЪ§ОнЕФЪБКђЃЌБиаыБЃжЄШежОЯШГжОУЛЏжЎКѓВХПЩвдЖдЪ§ОнвГНјааГжОУЛЏЁЃДЅЗЂШежОГжОУЛЏЕФЪБЛњЭЈГЃга
1ЃЉЪТЮёЬсНЛЪБЃЌетИіЪТЮёВњЩњЕФзюДѓШежОЕужЎЧАЕФЫљгаШежОБиаыГжОУЛЏжЎКѓВХФмЗЕЛиИјПЭЛЇЖЫЪТЮёЬсНЛГЩЙІЃЛ
2ЃЉЕБШежОЛКДцПеМфВЛЙЛгУЪБЃЌБиаыГжОУЛЏжЎКѓВХФмЪЭЗХШежОЛКДцПеМфЃЛ
3ЃЉЕБЪ§ОнвГЛКДцПеМфВЛЙЛгУЪБЃЌБиаыЬдЬВПЗжЪ§ОнвГРДЪЭЗХЛКДцПеМфЁЃБШШчИљОнЬдЬЫуЗЈБиаывЊЬдЬдрвГAЃЌФЧУДзюКѓаоИФAЕФШежОЕужЎЧАЕФЫљгаШежОБиаыЯШГжОУЛЏЃЌШЛКѓВХПЩвдГжОУЛЏAЕНДцДЂЃЌзюКѓВХФмеце§ДгЪ§ОнЛКДцПеМфжаНЋAЬдЬЁЃ
ДгРэТлЩЯРДЫЕЃЌЪ§ОнПтжЛашвЊГжОУЛЏШежООЭПЩвдСЫЁЃвђЮЊжЛвЊгЕгаДгЪ§ОнПтГѕЪМЛЏЪБПЬЕНЕБЧАЕФЫљгаШежОЃЌЪ§ОнПтОЭФмЛжИДГіЕБЧАШЮКЮвЛИіЪ§ОнвГЕФФкШнЁЃвВОЭЪЧЫЕЃЌЪ§ОнПтжЛашвЊаДШежОЃЌЖјВЛашвЊаДЪ§ОнвГЃЌОЭФмБЃжЄЪ§ОнЕФЭъећадКЭе§ШЗадЁЃЕЋЪЧЃЌЪЕМЪЩЯЪ§ОнПтЪЕЯжепВЛЛсетУДзіЃЌвђЮЊ1ЃЉДгЭЗЕНЮВБщРњШежОЛжИДГіУПИіЪ§ОнвГНЋЪЧЗЧГЃКФЪБЕФЃЛ2ЃЉШЋСПШежОБШЪ§ОнБОЩэЙцФЃвЊДѓЕУЖрЃЌашвЊИќЖрЕФДХХЬПеМфШЅДцДЂЁЃ
ФЧУДЃЌШчЙћГжОУЛЏШежОЕФДцДЂЩшБИВЛНіНіОпгаДцДЂФмСІЃЌЛЙгЕгаМЦЫуФмСІЃЌФмЙЛздааНЋШежОжиЗХЕНзюаТЕФвГЕФЛАЃЌНЋЛсдѕУДбљЃПЪЧЕФЃЌШчЙћетбљЕФЛАЃЌЪ§ОнПтв§ЧцОЭУЛгаБивЊНЋЪ§ОнвГДЋЕнИјДцДЂСЫЃЌвђЮЊДцДЂПЩвдздааМЦЫуГіаТвГВЂГжОУЛЏЁЃетОЭЪЧCynosDBЁАВЩгУЛљгкШежОЕФДцДЂЁБЕФКЫаФЫМЯыЁЃЭМШ§ЃЈгвЃЉМЋЖШГщЯѓЕиУшЪіСЫетжжЫМЯыЁЃЭМжаМЦЫуНкЕуКЭДцДЂНкЕужУгкВЛЭЌЕФЮяРэЛњЃЌДцДЂНкЕуГ§СЫГжОУЛЏШежОвдЭтЃЌЛЙОпБИЭЈЙ§applyШежОЩњГЩзюаТЪ§ОнвГУцЕФФмСІЁЃШчДЫвЛРДЃЌМЦЫуНкЕужЛашвЊаДШежОЕНДцДЂНкЕуМДПЩЃЌЖјВЛашвЊдйНЋЪ§ОнвГДЋЕнИјДцДЂНкЕуЁЃ
ЯТЭМУшЪіСЫВЩгУЛљгкШежОДцДЂЕФCynosStoreЕФНсЙЙЁЃ
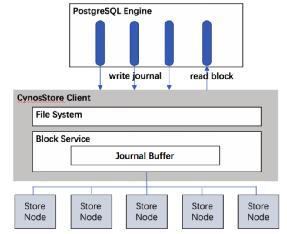
ЭМЫФ CynosStoreЃКЛљгкШежОЕФДцДЂ
ДЫЭМУшЪіСЫЪ§ОнПтв§ЧцШчКЮЗУЮЪCynosStoreЁЃЪ§ОнПтв§ЧцЭЈЙ§CynosStore ClientРДЗУЮЪCynosStoreЁЃзюКЫаФЕФСНИіВйзїАќРЈ1ЃЉаДШежОЃЛ2ЃЉЖСЪ§ОнвГЁЃ
Ъ§ОнПтв§ЧцНЋЪ§ОнПтШежОДЋЕнИјCynosStoreЃЌCynosStore ClientИКд№НЋЪ§ОнПтШежОзЊЛЛГЩCynosStore
JournalЃЌВЂЧвИКд№НЋетаЉВЂЗЂаДШыЕФJournalНјааађСаЛЏЃЌзюКѓИљОнJournalаоИФЕФЪ§ОнвГТЗгЩЕНВЛЭЌЕФSGЩЯШЅЃЌВЂЗЂЫЭИјSGЫљЪєStore
NodeЁЃСэЭтЃЌCynosStore ClientВЩгУвьВНЕФЗНЪНМрЬ§ИїИіStore NodeЕФШежОГжОУЛЏШЗШЯЯћЯЂЃЌВЂНЋЙщВЂжЎКѓЕФзюаТЕФГжОУЛЏШежОЕуИцЫпЪ§ОнПтв§ЧцЁЃ
ЕБЪ§ОнПтв§ЧцЗУЮЪЕФЪ§ОнвГдкЛКДцжаВЛУќжаЪБЃЌашвЊЯђCynosStoreЖСШЁашвЊЕФвГЃЈread blockЃЉЁЃread
blockЪЧЭЌВНВйзїЁЃВЂЧвЃЌCynosStoreжЇГжвЛЖЈЪБМфЗЖЮЇЕФЖрАцБОвГЖСШЁЁЃвђЮЊИїИіStore
NodeдкжиЗХШежОЪБЕФВНЕїВЛФмЭъШЋзіЕНвЛжТЃЌзмЛсгаЯШгаКѓЃЌвђДЫашвЊЖСЧыЧѓЗЂЦ№епЬсЙЉвЛжТадЕуРДБЃжЄЪ§ОнПтв§ЧцЫљвЊЧѓЕФвЛжТадЃЌЛђепФЌШЯЧщПіЯТгЩCynosStoreгУзюаТЕФвЛжТадЕуЃЈЖСЕуЃЉШЅЖСЪ§ОнвГЁЃСэЭтЃЌдквЛаДЖрЖСЕФГЁОАЯТЃЌжЛЖСЪ§ОнПтЪЕР§вВашвЊгУЕНCynosStoreЬсЙЉЕФЖрАцБОЬиадЁЃ
CynosStoreЬсЙЉСНИіВуУцЕФЗУЮЪНгПкЃКвЛИіЪЧПщЩшБИВуУцЕФНгПкЃЌСэвЛИіЪЧЛљгкПщЩшБИЕФЮФМўЯЕЭГВуУцЕФНгПкЁЃЗжБ№НазіCynosBSКЭCynosFSЃЌЫћУЧЖМВЩгУетжжвьВНаДШежОЁЂЭЌВНЖСЪ§ОнЕФНгПкаЮЪНЁЃФЧУДЃЌCynosDB
for PostgreSQLЃЌВЩгУЛљгкШежОЕФДцДЂЃЌЯрБШвЛжїЖрДгPostgreSQLМЏШКРДЫЕЃЌЕНЕзФмДјРДФФаЉКУДІЃП
1ЃЉМѕЩйЭјТчСїСПЁЃЪзЯШЃЌжЛвЊДцЫуЗжРыОЭБмУтВЛСЫМЦЫуНкЕуЯђДцДЂНкЕуЗЂЫЭЪ§ОнЁЃШчЙћЮвУЧЛЙЪЧЪЙгУДЋЭГЪ§ОнПт+ЭјТчгВХЬЕФЗНЪНРДзіДцЫуЗжРыЃЈМЦЫуКЭДцДЂНщжЪЕФЗжРыЃЉЃЌФЧУДЭјТчжаГ§СЫашвЊДЋЕнШежОвдЭтЃЌЛЙашвЊДЋЕнЪ§ОнЃЌДЋЕнЪ§ОнЕФДѓаЁгЩВЂЗЂаДШыСПЁЂЪ§ОнПтЛКДцДѓаЁЁЂвдМАcheckpointЦЕТЪРДОіЖЈЁЃвдCynosStoreзїЮЊЕззљЕФCynosDBжЛашвЊНЋШежОДЋЕнИјCynosStoreОЭПЩвдСЫЃЌНЕЕЭЭјТчСїСПЁЃ
2ЃЉИќМггаРћгкЛљгкЙВЯэДцДЂЕФМЏШКЕФЪЕЯжЃКвЛИіЪ§ОнПтЕФЖрИіЪЕР§ЃЈвЛаДЖрЖСЃЉЗУЮЪЭЌвЛИіPoolЁЃЛљгкШежОаДЕФCynosStoreФмЙЛБЃжЄжЛвЊDBжїНкЕуЃЈЖСаДНкЕуЃЉаДШыШежОЕНCynosStoreЃЌОЭФмШУДгНкЕуЃЈжЛЖСНкЕуЃЉФмЙЛЖСЕНБЛетВПЗжШежОаоИФЙ§ЕФЪ§ОнвГзюаТАцБОЃЌЖјВЛашвЊЕШД§жїНкЕуЭЈЙ§checkpointЕШВйзїНЋЪ§ОнвГГжОУЛЏЕНДцДЂВХФмШУЖСНкЕуМћЕНзюаТЪ§ОнвГЁЃетбљФмЙЛДѓДѓНЕЕЭжїДгЪ§ОнПтЪЕР§жЎМфЕФбгЪБЁЃВЛШЛЃЌДгНкЕуашвЊЕШД§жїНкЕуНЋЪ§ОнвГГжОУЛЏжЎКѓЃЈcheckpointЃЉВХФмЭЦНјЖСЕуЁЃШчЙћетбљЃЌЖдгкжїНкЕуРДЫЕЃЌcheckpointЕФМфИєЬЋОУЕФЛАЃЌОЭЛсЕМжТжїДгбгЪБМгДѓЃЌШчЙћcheckpointМфИєЬЋаЁЃЌгжЛсЕМжТжїНкЕуаДЪ§ОнЕФЭјТчСїСПдіДѓЁЃ
ЕБШЛЃЌapplyШежОжЎКѓЕФаТЪ§ОнвГЕФГжОУЛЏЃЌетВПЗжЙЄзїзмЪЧвЊзіЕФЃЌВЛЛсЦОПеЯћЪЇЃЌжЛЪЧДгЪ§ОнПтв§ЧцЯТвЦЕНСЫCynosStoreЁЃЕЋЪЧе§ШчЧАЮФЫљЪіЃЌГ§СЫНЕЕЭВЛБивЊЕФЭјТчСїСПвдЭтЃЌCynosStoreЕФИїИіSGЪЧВЂааРДзіredoКЭГжОУЛЏЕФЁЃВЂЧввЛИіPoolЕФSGЪ§СППЩвдАДашРЉеЙЃЌSGЕФЫожїStore
NodeПЩвдЖЏЬЌЕїЖШЃЌвђДЫПЩвдгУЗЧГЃСщЛюКЭИпаЇЕФЗНЪНРДЭъГЩетВПЗжЙЄзїЁЃ
Ш§ЁЂCynosStore JournalЃЈCSJЃЉ
CynosStore JournalЃЈCSJЃЉЭъГЩРрЫЦЪ§ОнПтШежОЕФЙІФмЃЌБШШчPostgreSQLЕФWALЁЃCSJгыPostgreSQL
WALВЛЭЌЕФЕиЗНдкгкЃКCSJгЕгаздМКЕФШежОИёЪНЃЌгыЪ§ОнПтгявхНтёюКЯЁЃPostgreSQL WALжЛгаPostgreSQLв§ЧцПЩвдЩњГЩКЭНтЮіЃЌвВОЭЪЧЫЕЃЌЕБЦфЫћДцДЂв§ЧцФУЕНPostgreSQL
WALЦЌЖЮКЭетВПЗжЦЌЖЮЫљаоИФЕФЛљДЁвГФкШнЃЌвВУЛгаАьЗЈЛжИДГізюаТЕФвГФкШнЁЃCSJжТСІгкЖЈвхвЛжжгыИїжжДцДЂв§ЧцТпМЮоЙиЕФШежОИёЪНЃЌБугкНЈСЂвЛИіЭЈгУЕФЛљгкШежОЕФЗжВМЪНДцДЂЯЕЭГЁЃCSJЖЈСЫ5жжJournalРраЭЃК
1.SetByteЃКгУJournalжаЕФФкШнИВИЧжИЖЈЪ§ОнвГжаЁЂжИЖЈЦЋвЦЮЛжУЁЂжИЖЈГЄЖШЕФСЌајДцДЂПеМфЁЃ
2. SetBitЃКгыSetByteРрЫЦЃЌВЛЭЌЕФЪЧSetBitЕФзюаЁСЃЖШЪЧBitЃЌР§ШчPostgreSQLжаhitbitаХЯЂЃЌПЩвдзЊЛЛГЩSetBitШежОЁЃ
3. ClearPageЃКЕБаТЗжХфPageЪБЃЌашвЊНЋЦфГѕЪМЛЏЃЌДЫЪБаТЗжХфвГЕФдЪМФкШнВЂВЛживЊЃЌвђДЫВЛашвЊНЋЦфДгЮяРэЩшБИжаЖСГіРДЃЌЖјНіНіашвЊгУвЛИіШЋСувГаДШыМДПЩЃЌClearPageОЭЪЧУшЪіетжжаоИФЕФШежОРраЭЁЃ
4. DataMoveЃКгавЛаЉаДШыВйзїНЋвГУцжавЛВПЗжЕФФкШнвЦЖЏЕНСэвЛИіЕиЗНЃЌDataMoveРраЭЕФШежОгУРДУшЪіетжжВйзїЁЃБШШчPostgreSQLдкVacuumЙ§ГЬжаЖдPageНјааcompactВйзїЃЌДЫЪБгУDataMoveБШгУSetByteШежОСПИќаЁЁЃ
5. UserDefinedЃКЪ§ОнПтв§ЧцзмЛсгавЛаЉВйзїВЂВЛЛсаоИФФГИіОпЬхЕФвГУцФкШнЃЌЕЋЪЧашвЊДцЗХдкШежОжаЁЃБШШчPostgreSQLЕФзюаТЕФЪТЮёidЃЈxidЃЉОЭЪЧДцДЂдкWALжаЃЌБугкЪ§ОнПтЙЪеЯЛжИДЪБжЊЕРДгФЧИіxidПЊЪМЗжХфЁЃетжжРраЭШежОИњЪ§ОнПтв§ЧцгявхЯрЙиЃЌВЛашвЊCynosStoreШЅРэНтЃЌЕЋЪЧгжашвЊШежОНЋЦфГжОУЛЏЁЃUserDefinedОЭЪЧРДУшЪіетжжШежОЕФЁЃCynosStoreеыЖдетжжШежОжЛИКд№ГжОУЛЏКЭЬсЙЉВщбЏНгПкЃЌapply
CSJЪБЛсКіТдЫќЁЃ
вдЩЯ5жжРраЭЕФJournalЪЧДцДЂзюЕзВуЕФШежОЃЌжЛвЊЖдЪ§ОнЕФаДЪЧЛљгкПщ/вГЕФЃЌЖМПЩвдзЊЛЛГЩет5жжШежОРДУшЪіЁЃЕБШЛЃЌвВгавЛаЉв§ЧцВЛЬЋЪЪКЯзЊЛЛГЩетжжзюЕзВуЕФШежОИёЪНЃЌБШШчЛљгкLSMЕФДцДЂв§ЧцЁЃ
CSJЕФСэвЛИіЬиЕуЪЧТвађГжОУЛЏЃЌвђЮЊвЛИіPoolЕФCSJЛсТЗгЩЕНЖрИіSGЩЯЃЌВЂЧвВЩгУвьВНаДШыЕФЗНЪНЁЃЖјУПИіSGЗЕЛиЕФjournal
ackВЂВЛЭЌВНЃЌВЂЧвЯрЛЅДЉВхЃЌвђДЫCynosStore ClientЛЙашвЊНЋетаЉackНјааЙщВЂВЂЭЦНјСЌајCSJЕуЃЈVDLЃЉЁЃ
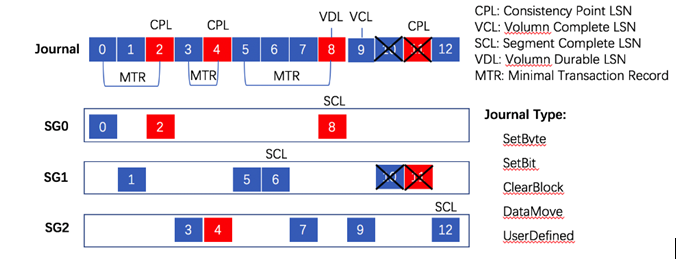
ЭМЮх CynosStoreШежОТЗгЩКЭТвађACK
жЛвЊЪЧСЌајШежОИљОнЪ§ОнЗжЦЌТЗгЩЃЌОЭЛсгаШежОТвађackЕФЮЪЬтЃЌДгЖјБиаыЖдШежОackНјааЙщВЂЁЃAuroraгаетИіЛњжЦЃЌCynosDBЭЌбљгаЁЃЮЊСЫБугкРэНтЃЌЮвУЧЖдJournalжаЕФИїИіЙиМќЕуЕФУќУћВЩгУИњAuroraЭЌбљЕФЗНЪНЁЃ
етРяашвЊжиЕуУшЪіЕФЪЧMTRЃЌMTRЪЧCynosStoreЬсЙЉЕФдзгаДЕЅЮЛЃЌCSJОЭЪЧгЩвЛИіMTRНєАЄзХвЛИіMTRзщГЩЕФЃЌШЮвтвЛИіШежОБиаыЪєгквЛИіMTRЃЌвЛИіMTRжаЕФЖрЬѕШежОКмгаПЩФмЪєгкВЛЭЌЕФSGЁЃеыЖдPostgreSQLв§ЧцЃЌПЩвдНќЫЦРэНтЮЊЃКвЛИіXLogRecordЖдгІвЛИіMTRЃЌвЛИіЪ§ОнПтЪТЮёЕФШежОгЩвЛИіЛђепЖрИіMTRзщГЩЃЌЖрИіЪ§ОнПтВЂЗЂЪТЮёЕФMTRПЩвдЯрЛЅДЉВхЁЃЕЋЪЧCynosStoreВЂВЛРэНтКЭИажЊЪ§ОнПтв§ЧцЕФЪТЮёТпМЃЌЖјжЛРэНтMTRЁЃЗЂЫЭИјCynosStoreЕФЖСЧыЧѓЫљЬсЙЉЕФЖСЕуБиаыВЛФмдквЛИіMTRЕФФкВПФГИіШежОЕуЁЃМђЖјбджЎЃЌMTRОЭЪЧCynosStoreЕФЪТЮёЁЃ
ЫФЁЂЙЪеЯЛжИД
ЕБжїЪЕР§ЗЂЩњЙЪеЯКѓЃЌгаПЩФметИіжїЪЕР§ЩЯPoolжаИїИіSGГжОУЛЏЕФШежОЕудкШЋОжЗЖЮЇФкВЂВЛСЌајЃЌЛђепЫЕгаПеЖДЁЃЖјетаЉПеЖДЫљЖдгІЕФШежОФкШнвбОЮоДгЕУжЊЁЃБШШчга3ЬѕСЌајЕФШежОj1,
j2, j3ЗжБ№ТЗгЩЕНШ§ИіSGЩЯЃЌЗжБ№ЮЊsg1, sg2, sg3ЁЃдкЗЂЩњЙЪеЯЕФФЧвЛПЬЃЌj1КЭj3вбОГЩЙІЗЂЫЭЕНsg1КЭsg3ЁЃЕЋЪЧj2ЛЙдкCynosStore
ClientЫљдкЛњЦїЕФЭјТчЛКГхЧјжаЃЌВЂЧвЫцзХжїЪЕР§ЙЪеЯЖјЖЊЪЇЁЃФЧУДЕБаТЕФжїЪЕР§ЦєЖЏКѓЃЌетИіPoolЩЯОЭЛсгаВЛСЌајЕФШежОj1,
j3ЃЌЖјj2вбОЖЊЪЇЁЃ
ЕБетжжЙЪеЯГЁОАЗЂЩњКѓЃЌаТЦєЖЏЕФжїЪЕР§НЋЛсИљОнЩЯДЮГжОУЛЏЕФСЌајШежОVDLЃЌдкУПИіSGЩЯВщбЏздДгетИіVDLжЎКѓЕФЫљгаШежОЃЌВЂНЋетаЉШежОНјааЙщВЂЃЌМЦЫуГіаТЕФСЌајГжОУЛЏЕФШежОКХVDLЁЃетОЭЪЧаТЕФвЛжТадЕуЁЃаТЪЕР§ЭЈЙ§CynosStoreЬсЙЉЕФTruncateНгПкНЋУПИіSGЩЯДѓгкVDLЕФШежОtruncateЕєЃЌФЧУДаТЪЕЧœٜЕФЕквЛЬѕjournalНЋДгетИіаТЕФVDLЕФЯТвЛЬѕПЊЪМЁЃ
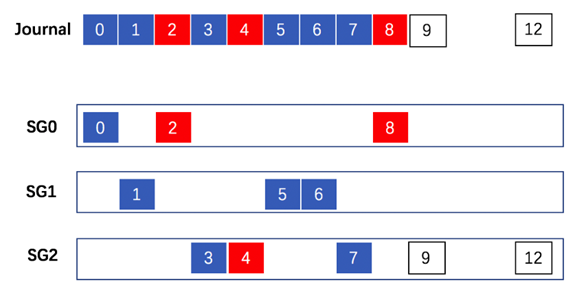
ЭМСљЃКЙЪеЯЛжИДЪБШежОЛжИДЙ§ГЬ
ШчЙћЭМЮхИеКУЪЧФГИіЪ§ОнПтЪЕР§ЙЪеЯЗЂЩњЕФЪБМфЕуЃЌЕБжиаТЦєЖЏвЛИіЪ§ОнПтЖСаДЪЕР§жЎКѓЃЌЭМСљОЭЪЧМЦЫуаТЕФвЛжТадЕуЕФЙ§ГЬЁЃCynosStore
ClientЛсМЦЫуЕУГіаТЕФвЛжТадЕуОЭЪЧ8ЃЌВЂЧвАбДѓгк8ЕФШежОЖМTruncateЕєЁЃвВОЭЪЧАбSG2ЩЯЕФ9КЭ10truncateЕєЁЃЯТвЛИіВњЩњЕФШежОНЋЛсДг9ПЊЪМЁЃ
ЮхЁЂЖрИББОвЛжТад
CynosStoreВЩгУMulti-RAFTРДЪЕЯжSGЕФЖрИББОвЛжТадЃЌ CynosStoreВЩгУХњСПКЭвьВНСїЫЎЯпЕФЗНЪНРДЬсЩ§RAFTЕФЭЬЭТСПЁЃЮвУЧВЩгУCynosStoreздЖЈвхЕФbenchmarkВтЕУЕЅИіSGЩЯШежОГжОУЛЏЕФЭЬЭТСПЮЊ375ЭђЬѕ/УПУыЁЃCynosStore
benchmarkВЩгУвьВНаДШыШежОЕФЗНЪНВтЪдCynosStoreЕФЭЬЭТСПЃЌШежОРраЭАќКЌSetByteКЭSetBitСНжжЃЌаДШежОЯпГЬГжајВЛЖЯЕиаДШыШежОЃЌМрЬ§ЯпГЬИКд№ДІРэackЛиАќВЂЭЦНјVDLЃЌШЛКѓbenchmarkВтСПЕЅЮЛЪБМфФкVDLЕФЭЦНјЫйЖШЁЃ375ЭђЬѕ/УывтЮЖзХУПУыжгвЛИіSGГжОУЛЏ375ЭђЬѕSetByteКЭSetBitШежОЁЃдквЛИіSGЕФГЁОАЯТЃЌCynosStore
ClientЕНStore NodeЕФЦНОљЭјТчСїСП171MB/УПУыЃЌетвВЪЧвЛИіLeaderЕНвЛИіFollowerЕФЭјТчСїСПЁЃ
СљЁЂвЛаДЖрЖС
CynosDBЛљгкЙВЯэДцДЂCynosStoreЃЌЬсЙЉЖдЭЌвЛИіPoolЩЯЕФвЛаДЖрЖСЪ§ОнПтЪЕР§ЕФжЇГжЃЌвдЬсЩ§Ъ§ОнПтЕФЭЬЭТСПЁЃЛљгкЙВЯэДцДЂЕФвЛаДЖрЖСашвЊНтОіСНИіЮЪЬтЃК
1. жїНкЕуЃЈЖСаДНкЕуЃЉШчКЮНЋЖдвГЕФаоИФЭЈжЊИјДгНкЕуЃЈжЛЖСНкЕуЃЉЁЃвђЮЊДгНкЕувВЪЧгаBufferЕФЃЌЕБДгНкЕуЛКДцЕФвГУцдкжїНкЕужаБЛаоИФЪБЃЌДгНкЕуашвЊвЛжжЛњжЦРДЕУжЊетИіБЛаоИФЕФЯћЯЂЃЌДгЖјдкДгНкЕуBufferжаИќаТетИіаоИФЛђепДгCynosStoreжажиЖСетИівГЕФаТАцБОЁЃ
2. ДгНкЕуЩЯЕФЖСЧыЧѓШчКЮЖСЕНЪ§ОнПтЕФвЛжТадЕФПьееЁЃПЊдДPostgreSQLЕФжїБИФЃЪНжаЃЌБИЛњЭЈЙ§РћгУжїЛњЭЌВНЙ§РДЕФПьееаХЯЂКЭЪТЮёаХЯЂЙЙдьвЛИіПьееЃЈЛюЖЏЪТЮёСаБэЃЉЁЃCynosDBЕФДгНкЕуГ§СЫашвЊЪ§ОнПтПьееЃЈЛюЖЏЪТЮёСаБэЃЉвдЭтЃЌЛЙашвЊвЛИіCynosStoreЕФПьееЃЈвЛжТадЖСЕуЃЉЁЃвђЮЊЗжЦЌЕФШежОЪБВЂааapplyЕФЁЃ
ШчЙћвЛИівЛаДЖрЖСЕФЙВЯэДцДЂЪ§ОнПтМЏШКЕФДцДЂБОЩэВЛОпБИШежОжизіЕФФмСІЃЌжїДгФкДцвГЕФЭЌВНгаСНжжБИбЁЗНАИЃК
ЕквЛжжБИбЁЗНАИЃЌжїДгжЎМфжЛЭЌВНШежОЁЃДгЪЕР§НЋжСЩйашвЊБЃСєжїЪЕР§здДгЩЯДЮcheckpointвдРДЫљгаВњЩњЕФШежОЃЌвЛЕЉДгЪЕЧœٜcache
missЃЌжЛФмДгДцДЂЩЯЖСШЁЩЯДЮcheckpointЕФbaseвГЃЌВЂдкДЫЛљДЁЩЯжиЗХШежОЛКДцжаздЩЯДЮcheckpointвдРДЕФЫљгаЙигкетИівГЕФаоИФЁЃетжжЗНЗЈЕФЙиМќЮЪЬтдкгкШчЙћжїЪЕР§checkpointжЎМфЕФЪБМфМфИєЬЋГЄЃЌЛђепШежОСПЬЋДѓЃЌЛсЕМжТДгЪЕР§дкУќжаТЪВЛИпЕФЧщПіЯТдкapplyШежОЩЯКФЗбЗЧГЃЖрЕФЪБМфЁЃЩѕжСЃЌМЋЖЫГЁОАЯТЃЌЕМжТДгЪЕР§ЖдЭЌвЛИівГЛсЗДИДЖрДЮapplyЭЌвЛЖЮШежОЃЌГ§СЫДѓЗљдіДѓВщбЏЪБбгЃЌЛЙВњЩњСЫКмЖрУЛБивЊЕФCPUПЊЯњЃЌЭЌЪБвВЛсЕМжТжїДгжЎМфЕФбгЪБгаПЩФмДѓЗљдіМгЁЃ
ЕкЖўжжБИбЁЗНАИЃЌжїЪЕР§ЯђДгЪЕР§ЬсЙЉЖСШЁФкДцЛКГхЧјЪ§ОнвГЕФЗўЮёЃЌжїЪЕР§ЖЈЦкНЋБЛаоИФЕФвГКХКЭШежОЭЌВНИјДгЪЕР§ЁЃЕБЖСвГЪБЃЌДгЪЕР§ЪзЯШИљОнжїЪЕР§ЭЌВНЕФБЛаоИФЕФвГКХаХЯЂРДХаЖЯЪЧ1ЃЉжБНгЪЙгУДгЪЕР§здМКЕФФкДцвГЃЌЛЙЪЧ2ЃЉИљОнФкДцвГКЭШежОжиЗХаТЕФФкДцвГЃЌЛЙЪЧ3ЃЉДгжїЪЕР§РШЁзюаТЕФФкДцвГЃЌЛЙЪЧ4ЃЉДгДцДЂЖСШЁвГЁЃетжжЗНЗЈгаЕуРрЫЦOracle
RACЕФМђЛЏАцЁЃетжжЗНАИвЊНтОіСНИіЙиМќЮЪЬтЃК1ЃЉВЛЭЌЕФДгЪЕР§ДгжїЪЕР§ЛёШЁЕФвГПЩФмЪЧВЛЭЌАцБОЃЌжїЪЕР§ФкДцвГЗўЮёгаПЩФмашвЊЬсЙЉЖрАцБОЕФФмСІЁЃ2ЃЉЖСФкДцвГЗўЮёПЩФмЖджїЪЕЧœٜНЯДѓИКЕЃЃЌвђЮЊГ§СЫЖрИіДгЪЕР§ЕФгАЯьвдЭтЃЌЛЙгавЛЕуОЭЪЧУПДЮжїЪЕР§жаЕФФГИівГФФХТаоИФКмаЁЕФвЛВПЗжФкШнЃЌДгЪЕР§ШчЙћЖСЕНДЫвГдђБиаыРШЁећвГФкШнЁЃДѓжТРДЫЕЃЌжїЪЕР§аоИФдНЦЕЗБЃЌДгЪЕР§РШЁвВЛсИќЦЕЗБЁЃ
ЯрБШНЯРДЫЕЃЌCynosStoreвВашвЊЭЌВНдрвГЃЌЕЋЪЧCynosStoreЕФДгЪЕР§ЛёШЁаТвГЕФЗНЪНвЊСщЛюЕФЖргаСНжжбЁдё1ЃЉДгШежОжиЗХФкДцвГЃЛ2ЃЉДгStoreNodeЖСШЁЁЃДгЪЕР§ЖдЭЌВНдрвГашвЊЕФзюаЁаХЯЂНіНіЪЧЕНЕзФФаЉвГБЛжїЪЕР§ИјаоИФЙ§ЃЌжїДгЭЌВНШежОФкШнЪЧЮЊСЫШУДгЪЕР§МгЫйЃЌвдМАНЕЕЭStore
NodeЕФИКЕЃЁЃ
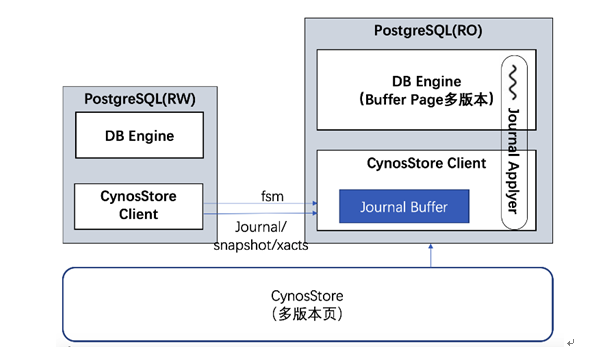
ЭМЦп CynosDBвЛаДЖрЖС
ЭМЦпУшЪіСЫвЛаДвЛЖСЃЈвЛжївЛДгЃЉЕФЛљБОПђМмЃЌвЛаДЖрЖСЃЈвЛжїЖрДгЃЉОЭЪЧвЛаДвЛЖСЕФЕўМгЁЃCynosStore
ClientЃЈCSClientЃЉдЫааЬЌЧјЗжжїДгЃЌжїCSClientдДдДВЛЖЯЕиНЋCynosStore
JournalЃЈCSJЃЉДгжїЪЕР§ЗЂЫЭЕНДгЪЕР§ЃЌгыПЊдДPostgreSQLжїБИФЃЪНВЛЭЌЕФЪЧЃЌжЛвЊетаЉСЌајЕФШежОЕНДяДгЪЕР§ЃЌВЛгУЕШЕНетаЉШежОШЋВПapplyЃЌDB
engineОЭПЩвдЖСЕНетаЉШежОЫљаоИФЕФзюаТАцБОЁЃДгЖјНЕЕЭжїДгжЎМфЕФЪБбгЁЃетРяЬхЯжЁАЛљгкШежОЕФДцДЂЁБЕФгХЪЦЃКжЛвЊжїЪЕР§НЋШежОГжОУЛЏЕНStore
NodeЃЌДгЪЕР§МДПЩЖСЕНетаЉШежОЫљаоИФЕФзюаТАцБОЪ§ОнвГЁЃ
ЦпЁЂНсгя
CynosStoreЪЧвЛИіЭъШЋДгСуДђдьЁЂЪЪгІдЦЪ§ОнПтЕФЗжВМЪНДцДЂЁЃCynosStoreдкМмЙЙЩЯОпБИвЛаЉЬьШЛгХЪЦЃК1ЃЉДцДЂМЦЫуЗжРыЃЌВЂЧвАбДцДЂМЦЫуЕФЭјТчСїСПНЕЕНзюЕЭЃЛ
2ЃЉЬсЩ§зЪдДРћгУТЪЃЌНЕЕЭдЦГЩБОЃЌ3ЃЉИќМггаРћгкЪ§ОнПтЪЕР§ЪЕЯжвЛаДЖрЖСЃЌ4ЃЉЯрБШвЛжїСНДгЕФДЋЭГRDSМЏШКОпБИИќИпЕФадФмЁЃГ§ДЫжЎЭтЃЌКѓајЮвУЧЛсдкадФмЁЂИпПЩгУЁЂзЪдДИєРыЕШЗНУцЖдCynosStoreНјааНјвЛВНЕФдіЧПЁЃ | 








