| 编辑推荐: |
| 本文来自于cloud.tencent.com,CynosDB是腾讯云自研的新一代高性能高可用的企业级分布式云数据库。融合了传统数据库、云计算与新硬件的优势,100%兼容开源数据库,百万级QPS的高吞吐。 |
|
前言
CynosDB是架构在CynosFS之上的分布式关系数据库系统,为最大化利用存储资源,平衡资源之间的竞争,检查资源使用情况,需要一套高效稳定的分布式集群管理系统(SCM:
Storage Cluster Manager),SCM使用Etcd作为存储,利用Etcd Raft算法完成SCM
Leader的选举,对外提供HTTP API 查询CynosFS 状态,负责CynosFS调度,其包含两类调度:
lPool调度:对SCM 中所有Pool进行调度,每个Pool的调度将根据其状态,产生相关调度操作,包括Pool的初始化,Pool自动扩缩容,以及Pool的销毁等。
lSegment Group调度: 每个Pool内有一个SG调度器,负责该Pool内所有SG的调度,根据每个SG的状态,产生相关的调度操作,包括增减副本,Leader切换,副本迁移,副本离线等。
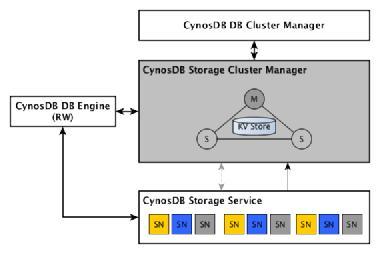
相关组件和名词解释如下:
lDBEngine:数据库引擎,支持一主多从。
lDB Cluster Manager(DCM):数据库集群管理,其负责一主多从DB集群的HA管理。
lStorage Service或Storage Node(SN):Storage Service是个逻辑概念,泛指实际提供服务的Storage
Node。SN则是1个具体的服务进程,负责日志的处理、BLOCK数据的异步回放、读请求的多版本支持等,同时还负责将WALLOG备份到Cold
Backup Storage。
lSegment(Seg):Storage Service管理数据块BLOCK和日志的最小单元(大小为10GB),也是数据复制的实体。通过一致性协议(Raft)进行同步,形成Segment
Group(SG)。
lPool:多个SG从逻辑上构成一个连续的存储数据BLOCK的块设备,供上层的Distributed
File System分配使用。Pool和Seg Group是一对多的关系。
lStorage Cluster Manager(SCM):负责管理Storage Service,维护Pool和SG的对应关系,以及Segment
Group内部成员的调度。
数据模型
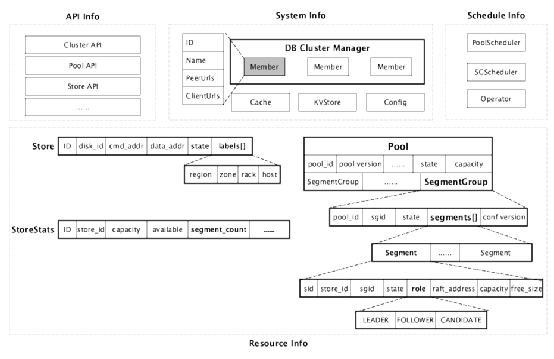
SCM数据模型包含4类信息:API信息,系统信息,调度信息,存储服务信息
lAPI信息(API Info):SCM对外提供服务的接口,包括SCM自身运行情况,Pool信息,以及Storage
Service信息等,提供RESTFul风格的接口(管理类接口)和GRPC接口(数据交互类)。
l系统信息(System Info):SCM自身运行的全局配置信息,以及多个SCM主从Member信息,此外还包括外部系统访问的地址ClientUrls和Member之间的访问地址PeerUrls等信息。
l调度信息(Schedule Info):SCM内部调度的作业信息和状态信息,包括Pool和SG的调度信息,以及相关调度产生的任务,这些任务将会通过心跳下发给Storage
Service。
l存储服务(Store Info):SCM保存的Storage Service信息、调度的状态信息、Storage
Service上报的统计信息以及内部作业定期计算产生的统计信息等,主要包括Pool信息,Storage
Service元数据及Storage Service运行时统计信息,以及SG相关信息。
I/O模型
SCM Master主要与如下模块进行交互:
lStorage Service:进行资源调度,接收心跳,下发命令等交互
lDistributed File System:为其提供对应Pool和pool下所属SG的信息,以帮助其完成读写请求的正确路由
lDCM:为其提供包括创建Pool,查看Pool信息,以及SG调度情况等接口。
lSCM Slave:通过Etcd同步SCM的数据,包括调度信息和资源信息等,维护高可用性的心跳信息。
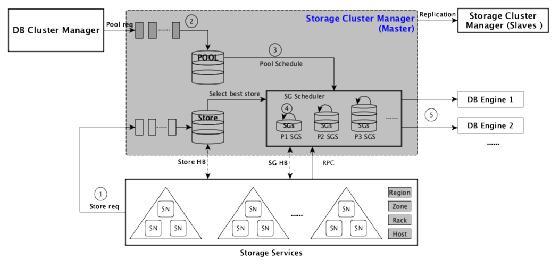
对上图的详细说明:
1.SN注册到SCM,SN的物理布局信息通过标签组labels(每个标签label采用key-value键值对表示)进行定义,标签名依次是Region->Zone->Rack->Host,标签值是具体部署的物理信息,如北京->北京一区->rack_01->host_01。一个SN负责处理一个SSD设备上的数据读写。
2.DCM开始创建Pool,SCM接收到创建操作后,保存该Pool的元数据信息到Etcd上,然后把该Pool加入到内部调度队列。
3.Pool调度器:定期从调度队列上获取各个Pool来调度,调度包括Pool的初始化(分配第一个SG),根据Pool状态及使用情况进行扩缩容,以及Pool的销毁。
4.SG调度器:每个Pool下对应一个SG调度器,负责该Pool内所有SG的调度,包括SG的初始化,增减副本,SG内leader切换,迁移等,通过装箱算法选择最佳Storage
Node作为该SG的成员以及整个存储资源的调度。
5.Distributed File System会定期同步SG的使用情况,Pool信息到SCM,并从SCM获取该Pool的所有SG信息以及SG的变更情况(如SG内leader切换)。
调度原理
通过SCM发送心跳信息来驱动的,包括Store Node(SN)心跳和Segment Group(SG)心跳,心跳消息采用Protobuf
V3定义,GRPC进行交互,由SN发起,SCM负责接收,接收到心跳信息后,将根据SN运行情况产生相关的调度命令,并通过心跳响应信息下发给SN,SN接收命令,并执行命令,然后更新相应的状态信息,通过下一次心跳发送给SCM。
Pool调度
Pool调度将对SCM所有Pool进行调度,每隔5秒轮询一次所有的Pool,检查是否有新的Pool加入,检测每个Pool的状态,根据Pool状态进行调度,如初始化,扩缩容和销毁等。

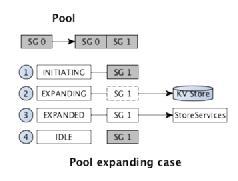
Pool状态包括:UNINITIALIZE,NORMAL,DISABLE,DELETE,其调度状态包括:INITIATING,EXPANDING,EXPANDED,IDLE。Pool调度状态变更如下:
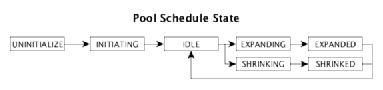
扩容过程如下:
1.当前Pool存在SG0,新增SG1并对SG1进行初始化。
2.当Pool调度器检查到Pool需扩容时,更新其状态为EXPANDING,并持久化该Pool信息,然后添加一个SG的元数据到Pool的SG内部调度队列中,并持久化到Etcd中,SG的ID从0开始编号,依次递增,保持连续性,避免产生空洞,采用一次扩展一个SG的方式,完成后更新其状态为EXPANDED。
3.该Pool的SG调度器进行调度,检测到有新SG,对该SG进行初始化,补充副本。
4.当Pool调度器检查到该Pool的状态为EXPANDED,判断该新的SG是否创建完成(补充完所有副本),如创建完成则更新Pool的调度状态为IDLE,否则忽略本次调度。
调度状态需进行持久化,当SCM发生主从切换时,能恢复到崩溃时的调度状态。
Pool缩容是扩容的逆过程,从id最大的SG开始往0方向收缩,以免产生空洞,具体的操作由SG调度器执行每个SG回收。
Pool释放是对该Pool的所有SG进行释放,回收将从从id最大的SG开始回收,回收过程将通过心跳信息下发指令给SN,具体的操作由SG调度器执行每个SG的回收。
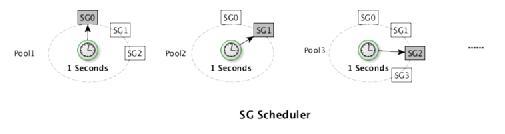
SG调度
CynosDB每个Pool都对应一个SG调度器,每个调度器按1秒轮询一次该Pool内的所有SG,每个Segment
Group之间是相互隔离的,其调度不受影响,调度主要通过SN的心跳和SG心跳完成的,调度包括segment的添加,删除,切主等。
SG状态包括:UNINITIALIZE,NORMAL,DISABLE。
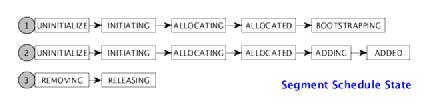
Segment调度状态包括:UNINITIALIZE,INITIATING,ALLOCATING,ALLOCATED,BOOTSTRAPPING,ADDING,ADDED,REMOVING,RELEASING,调度状态如下:
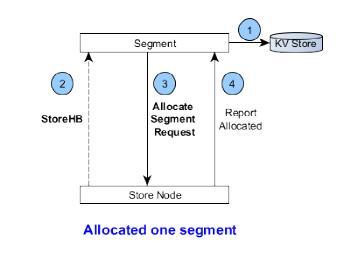
SN心跳:SCM接收store的统计信息,然后下发Segment操作(分配和销毁Segment)和SG操作(启动和销毁Segment
Group)给Store,然后Store执行操作,而Store操作的结果通过GRPC API汇报给元数据。如分配一个Segment给某个Pool的SG过程:
1.保存Segment的元数据信息到KV系统中。
2.接收到Store的心跳信息。
3.下发分配Segment信息。
4.接收到分配Segment信息,进行本地操作,操作完成后直接通过grpc汇报分配结果给元数据。
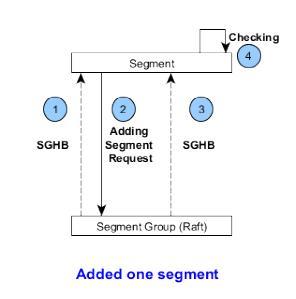
SG心跳:SCM获取SG的心跳信息,更新SG的元数据信息,然后根据SG的状态,产生相应操作(如添加,删除副本)或空操作,通过心跳的响应信息反馈给SN,如有下发操作,SCM通过下一次心跳信息来检查本次操作是否成功,如往某个SG中添加一个副本的过程:
1.SCM接收到SG上报的心跳信息,更新该SG的信息到KV系统。
2.SCM通过响应下发添加Segment请求给SG。
3.SG接收到请求后,向该SG加入新的Segment,添加后,更新SG信息,下一次心跳周期发送更新后的SG信息.
4.SCM接收到SG的心跳信息,检查添加Segment操作是否成功。
装箱算法
假设SCM中存在Region1,该Region1存在Zone1,Zone2两个区域,Zone1有三个机架Rack1,Rack2,Rack3,存在三个主机Host1,Host2,Host3,每个主机有4个SN,每个SN保存已分配的Segment,选择一个Store作为SG
副本分四个步骤:筛选,过滤,打分,比较。
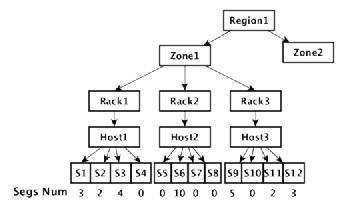
1.筛选:根据Pool注册的标签信息(为一组Key-Value数组),如[{REGION:Region1},{ZONE:Zone1}],选择出可用的PoolStores1集合,如{S1,S2,S3,S4,S5...,S12}。

2.过滤:从PoolStores1集合中过滤不符合规则的store信息,如根据其状态(在线,离线),工作负载(空闲,忙碌),使用率(CPU,内存,磁盘,网络等),以及该Store已在该SG中等进行过滤,得到PoolStores2集合{S1,S2,S4,S7,S8,S9,S10,S12}。
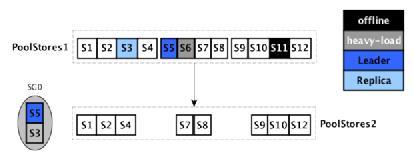
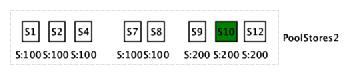
3.打分:假设SG0的segment所在的store的集合为{S5,S3},其中S5为leader所在的store,对PoolStores2中的store进行打分,遍历PoolStores,针对每个pStore,遍历SGStores,比较pStore和sgStore的位置,计算pStore的分值pScore,遍历完SGStores后,得到该pStore在该SG上的分值pScore的总分值,即{100,100,100,100,100,200,200,200}。

4.比较:如选择的Stores的分数相同,则按Store上Segment数量进一步比较,数量少的为选择的Store,如选择出Store10作为为SG0{S5,S3}的另一个副本。
| 








