| БрМЭЦМі: |
| БОЮФРДздгкit168ЃЌБОЮФжївЊНщЩмПьЙЗДђГЕЪ§ОнПтМмЙЙЕФвЛжТадЪЕМљЃЌдквЛжТадЪЕМљЕФЙ§ГЬжаЃЌФмЙЛЬхЯжПьЙЗДђГЕЪ§ОнПтМмЙЙЕФбнНјРњГЬЁЃ |
|
ПьЙЗДђГЕ(д58ЫйдЫ)ЪЧвЛИіДДвЕаЭЙЋЫОЃЌММЪѕМмЙЙЁЂММЪѕЬхЯЕЁЂЪ§ОнПтМмЙЙЕФБфЧЈЃЌКЭдкзљКмЖрЙЋЫОЪЧКмЯрНќЕФЃЌНёЬьКЭДѓМвСФвЛСФЃЌЮвУЧдкПьЙЗДђГЕЪ§ОнПтМмЙЙвЛжТадЗНУцХіЕНвЛаЉЮЪЬтЁЃ
ВЛвЛжТЕФгХЛЏРњГЬЃЌвВЪЧЪ§ОнПтМмЙЙбнНјЕФЙ§ГЬ
жїЯпЪЧЮвУЧЕФЪ§ОнПтМмЙЙБфЛЏЕФЙ§ГЬЃЌдкетИіЙ§ГЬжаЃЌЮвСаГіСЫЫФИіИњвЛжТадЯрЙиЕФНкЕуЃЌжїДгЛсВЛвЛжТЁЂЛКДцЛсВЛвЛжТЁЂШпгрЪ§ОнЛсВЛвЛжТЁЂЖрПтЖрЪЕР§ЛсВЛвЛжТЁЃВЛвЛжТЕФгХЛЏРњГЬЃЌвВЪЧЮвУЧЪ§ОнПтМмЙЙбнНјЕФвЛИіЙ§ГЬЁЃДгЕЅПтЕНЯждкЃЌгаФФаЉПгдкЕШзХЮвУЧФиЃП

ЯШПДвЛЯТЃЌзюГѕЕФЪ§ОнПтМмЙЙЃЌзюдчЪЧетИібљзгЕФЁЃФЧИіЪБКђУЛгаЪВУДЮЂЗўЮёЗжВуЃЌ webЭЈЙ§DAOЗУЮЪвЛИіЕЅПтЪ§ОнПтЃЌзюдчЮветУДЭцЕФЁЃЕЅПтЃЌЫќВЛОпБИЪВУДИпПЩгУЃЌИпВЂЗЂЬиадЃЌРЉеЙадвВБШНЯВюЁЃЮвЯраХКмЖрДДвЕЙЋЫОГѕЦквВЪЧетбљЁЃ
ЕЅПтзюдчЛсгіЕНЪВУДбљЕФЦПОБФиЃПдкДДвЕЕФЪБКђЃЌЪ§ОнСПБфДѓСЫЃЌВЂЗЂСПДѓСЫЃЌвЕЮёБфИДдгСЫЃЌећИіЯЕЭГЕФЦПОБзюЯШГіЯждкФФРяЃПЮвЕФОбщЪЧЪ§ОнПтЁЃЪ§ОнПтЕФЦПОБгжЛсдкФФРяЃПЮвЕФОбщЪЧЖСЁЃвђЮЊОјДѓВПЗжЕФвЕЮёЪЧЖСЖраДЩйЕФвЕЮёЃЌЖСЃЌзюШнвзГЦЮЊЯЕЭГЕФЦПОБЁЃ
зюдчдкЪ§ОнПтЖСПИВЛзЁЕФЪБКђЃЌзюЯШЯыЕНЕФгХЛЏЗНЪНЪЧЪВУДЃПЛЅСЊЭјЙЋЫОЖМНВПьЃЌНёЬьГіЮЪЬтЃЌФмВЛФмУїЬьКѓЬьИјЮвИуЖЈЃПзюЯШЯыЕНЕФЗНАИЪЧЪВУДЃЌШчКЮФмПьЫйРЉГфЪ§ОнПтЕФЖСадФмФиЃП
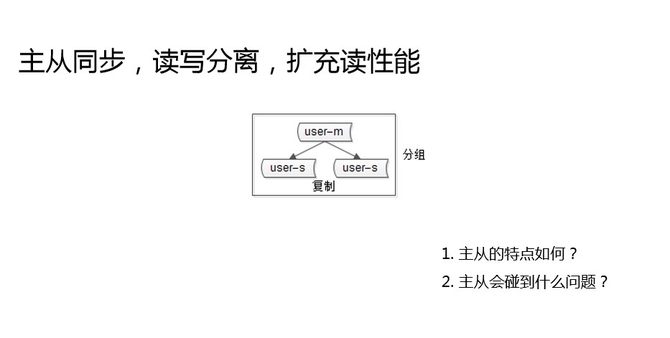
МгСНИіЪЕР§ЃЌжїДгЭЌВНЃЌЖСаДЗжРыЃЌетЪЧДДвЕаЭЙЋЫОЃЌЕБЪ§ОнПтЖСГЩЮЊЦПОБЕФЪБКђЃЌзюЯШЯыЕНЕФЗНАИЃЌПьЫйРЉГфЖСадФмЁЃжїДгЭЌВНХіЕНЕФЮЪЬтЪЧЪВУДЃПетОЭЪЧБОжїЬтвЊНВЕФЕквЛИіЮЪЬтЃЌжїДгвЛжТадЕФЮЪЬтЁЃ
ЕБЪ§ОнСПдНРДдНЖрЃЌЭЬЭТСПдНРДдНДѓЕФЪБКђЃЌаДЕНСЫжїПтЃЌжїПтЭЌВНЕНДгПтЃЌжїДгЭЌВНДцдкбгЪБЃЌдкбгЪБДАПкЦкФкЃЌЖСаДЗжРыШЅЖСДгПтЃЌОЭгаПЩФмЖСЕНвЛИіОЩЪ§ОнЁЃетИіЮЪЬтЃЌЮвЯраХДѓМввВЛсХіЕНЁЃ
ЖдгкетИіЮЪЬтЃЌВЛЩйНгвЕЮёЕФНтЗЈЗНАИЪЧЃЌШЬЃЌгааЉвЕЮёШчЙћЖдвЛжТадЕФвЊЧѓУЛетУДИпЁЃЕЋгаУЛгагХЛЏЗНАИФиЃП
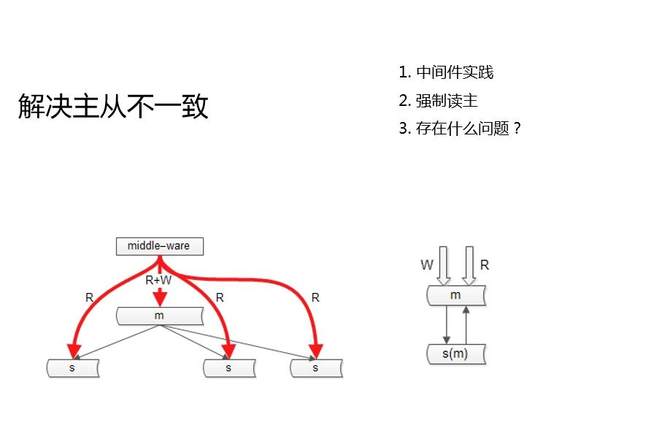
етСНИіЭМЪЧЮвУЧЕФСНИіГЃМћЕФЪЕМљЁЃ
ЕквЛИіЪЧжаМфМўЃЌЮвУЧЕФЗўЮёВуЛђепеОЕуВуВЛжБНгЕїЪ§ОнПтЃЌЭЈЙ§вЛИіжаМфВуЃЌШЅЕїЪ§ОнПтЁЃжаМфВуЫќФмЙЛжЊЕРФФвЛИіПтЃЌФФвЛИіБэЃЌФФвЛИіKEYЗЂЩњСЫаДВйзїЃЌШчЙћЫЕНгЯТРДЕФетвЛЖЮЪБМф(МйЩшжїДгЭЌВНвЛУыжгЭъГЩ)ЃЌгаЖСЧыЧѓТфЕНДгПтЩЯЃЌОЭЛсЖСЕНОЩЪ§ОнЁЃФЧУДДЫЪБЃЌжаМфМўОЭвЊНЋЖСЧыЧѓЃЌТЗгЩЕНжїПтЩЯШЅЃЌЖСаТЪ§ОнЁЃ
ЕкЖўИіЪЧЧПжЦЖСжїЁЃЕкЖўИіЭМЃЌЫЋжїЭЌВНЃЌЧПжЦЖСжїгаЪВУДКУДІЃПЕквЛНтОіСЫИпПЩгУЮЪЬтЃЌЫЋжїЪЙгУЭЌвЛИіVIPЃЌвЛИіжїПтШчЙћЙвСЫЃЌСэвЛИіжїПтФмЫцЪБЖЅЩЯЃЌБЃеЯИпПЩгУЁЃЕкЖўБмУтСЫжїДгжЎМфЕФВЛвЛжТЁЃ
ЧПжЦЖСжїЫќДјРДЕФаТЕФЮЪЬтЪЧЪВУДФиЃПНтОіСЫвЛжТадЮЪЬтЃЌЕЋЖСадФмРЉеЙЕФЮЪЬтгжРДСЫЃЌжїПтПЙЖСаДЃЌЛЙЪЧУЛгаНтОіЖСадЕФРЉДѓЕФЮЪЬтЁЃ
Г§СЫдіМгДгПтЃЌЛЅСЊЭјЙЋЫОЛЙгавЛжжГЃМћЕФЬсЩ§ЯЕЭГЖСадФмЕФЗНЪНЃЌЛКДцМгЗўЮёЛЏЁЃГщЯѓГіЗўЮёВуЃЌЯђЕїгУЗНЦСБЮЕзВуЪ§ОнПтЕФИДдгадЃЌЦСБЮЪ§ОнПтЕФИпПЩгУЕФИДдгадЃЌЦСБЮЛКДцЕФИДдгадЃЌЖдвЕЮёВуЬсЙЉЗўЮёЁЃ
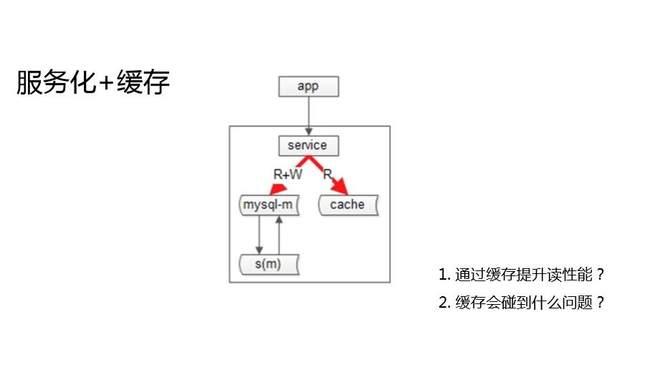
ЗўЮёЛЏМгЛКДцШЗЪЕЪЧЬсЩ§ЯЕЭГЖСШнСПЕФМмЙЙЗНАИЁЃЭЈЙ§ЛКДцРДЬсЩ§ЖСадЃЌгжЛсгіЕНЪВУДаТЕФЮЪЬтФиЃПгУжїДгМмЙЙЃЌгажїДгВЛвЛжТЮЪЬтЃЛгУЛКДцМмЙЙЃЌЕБШЛвВгаЛКДцВЛвЛжТЕФЮЪЬтЁЃжЛвЊФуАбЭЌвЛЗнЪ§ОнЗХдкСЫЖрИіЕиЗНЃЌЖрИіЕиЗНЕФаоИФгаЪБМфВюЃЌетИіЪБМфВюОЭЛсгаЪ§ОнЗУЮЪВЛвЛжТЕФЮЪЬтЁЃ
ЕБЮвУЧГіЯжЪ§ОнПтгыЛКДцжаЕФЪ§ОнВЛвЛжТЕФЪБКђЃЌЮвУЧдѕУДРДНтОіЃП
ЪзЯШРДПДвЛЯТЮЊЪВУДЛсВЛвЛжТЁЃЛКДцЕФГЃгУЭцЗЈЪЧЁАCache Aside PatternЁБЁЃCache
Aside PatternЃЌХдТЗЛКДцЃЌвЛАуЪЧдѕУДЭцЕФЃПЬдЬЛКДцЃЌЖјВЛЪЧИќаТЛКДцЃЌетЪЧCache Aside
PatternЕФНсТлЁЃ
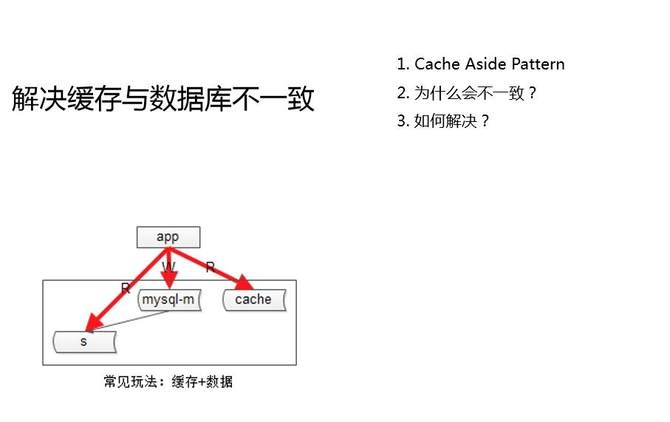
ЖСаДЪБађЪЧЪВУДбљЕФЃПЖдгкЖСЧыЧѓгаЛКДцЃЌКСЮоељвщЕФЃЌЯШЖСЛКДцЃЌШчЙћЪ§ОнУќжаЮвОЭжБНгЗЕЛиЃЌШчЙћЪ§ОнУЛгаУќжаЃЌЖСДгПтЖСаДЗжРыЃЌАбетИіЪ§ОнДгДгПтРяФУГіЃЌЗХЕНЛКДцРяЃЌетЪЧЖСЧыЧѓЕФвЛИіСїГЬЁЃ
ЖдгкаДЧыЧѓЃЌCache Aside PatternЕФзіЗЈЪЧЃЌЯШаДЪ§ОнПтЃЌдйЬдЬЛКДцЁЃдкЪВУДЧщПіЯТЛсГіЯжВЛвЛжТЃПЕБВЂЗЂСПЯрЖдЛсБШНЯИпЪБЃЌЖдгкЭЌвЛИіKEYзіСЫвЛИіаДВйзїЃЌТэЩЯгжРДСЫвЛИіЖСВйзїЃЌЛсГіЯжЪВУДбљЕФЧщПіЃПЯШЗЂЩњвЛИіаДВйзїЃЌЯШИќаТЕНЪ§ОнПтЃЌЬдЬСЫCacheЃЌТэЩЯгжРДСЫвЛИіЖСВйзїЃЌетИіЪБКђжїДгЭЌВНЛЙУЛЭЌВНЭъГЩЃЌЯШЖСЛКДцЃЌЛКДцБЛИеИеЕФаДВйзївбОЬдЬЕєСЫЃЌгжШЅЖСДгПтЃЌАбДгПтЕФдрЪ§ОнФУЙ§РДЗХЕНЛКДцРяШЅЃЌВЛвЛжТОЭГіЯжЁЃ
ИпВЂЗЂзДЬЌЯТЃЌаДКѓСЂМДЖСЕФГЁОАЃЌШнвзГіЯждрЪ§ОнШыCacheЁЃ
ДѓМвЗЂЯжУЛгаЃЌетРяЕФЪ§ОнВЛвЛжТЃЌБШжїДгЕФЪ§ОнВЛвЛжТЕФЧщПіИќбЯжиЁЃжїДгВЛвЛжТЃЌжЛгавЛИіжїЖЏЭЌВНЪБМфВюВЛвЛжТЃЌЭЌВНжЎКѓЃЌДгПтОЭФмЖСЕНаТЪ§ОнСЫЁЃЕЋЪЧЛКДцгыЪ§ОнПтЕФВЛвЛжТЃЌЫќЛсЕМжТКѓајвЛжБВЛвЛжТЃЌвЛЕЉдрЪ§ОнШыСЫЛКДцЃЌдрЪ§ОнЛсбгајЕНЯТвЛИіаДЗЂЩњЕФЪБКђВХЛсБЛЬдЬЕєЃЌЫљвдЫќЦфЪЕИќбЯжиЁЃ
ШчКЮРДНтОіФиЃПЛКДцКЭЪ§ОнПтЕФЪ§ОнВЛвЛжТЃЌЮвУЧЕФСНИіЪЕМљЃКвьВНЬдЬЛКДцЃЌШЗБЃДгПтвбОЭЌВНГЩЙІЃЛЩшЖЈГЌЪБЪБМфЃЌМЋЯоЧщПіЯТгаЛњЛсаое§ЁЃ
ЕквЛИіЃЌЕШДгПтвбОЭъШЋЭЌВНГЩЙІЃЌдйШЅвьВНЬдЬЛКДцЃПжЛвЊМрЬ§ДгПтЕФbinlogЃЌДгПтbinlogЭъГЩЃЌвЛЖЈЪЧаДВйзїжДааЭъБЯЃЌДЫЪБдйЬдЬЛКДцЃЌОЭФмБмУтЪБМфВюЁЃ
ЕкЖўИіЃЌОЭЪЧШчЙћдЪаэCache missЃЌВЛвЊНЋЛКДцЙ§ЦкЪБМфЩшЮЊгРОУЃЌШчЙћФуЩшжУЮЊЮоЯоГЄЕФЙ§ЦкЪБМфЃЌОЭУЛгавЛИіЛњЛсШЅаое§ВЛвЛжТСЫЁЃ
ЫцзХвЕЮёЕФЗЂеЙЃЌГ§СЫСїСПЕФдіМгЃЌЮвУЧвЊЬсЩ§ЯЕЭГЕФЖСадФмЃЌЮвУЧвЊЬсЩ§ЯЕЭГЕФЪ§ОнПтИпПЩгУЃЌЛЙЛсУцСйвЛИіЪВУДЮЪЬтЃПЖдСЫЃЌЪ§ОнСПЛсдіДѓЁЃЮвУЧвЕЮёЪ§ОнСПдНРДдНДѓСЫЃЌЭЈГЃВЩгУЪВУДбљЕФЗНЪНШЅНтОіЃПДДвЕаЭЙЋЫОЃЌетСНИіЗНАИгІИУЪЧДѓМвгУЕУзюЖрЕФЁЃ
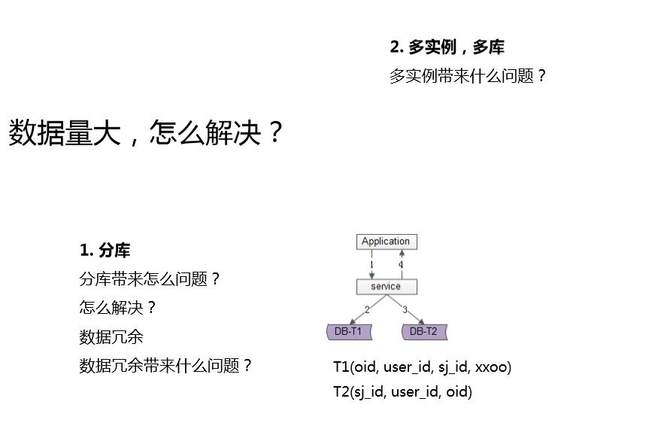
ЕквЛИіЃЌЗжПтЁЃНЕЕЭУПИіПтЃЌНЕЕЭУПИіЪЕР§ЕФЪ§ОнСПЃЌетбљОЭФмЙЛГадиИќЖрЕФЪ§ОнЁЃЗжПтгжДјРДЪВУДаТЕФЮЪЬтЃПОйСЫИіР§згЃЌЖЉЕЅвЛИіПтЃЌЫќгаЖрИіЮЌЖШЕФВщбЏЃЌгаЖЉЕЅIDЕФВщбЏЃЌгагУЛЇIDЕФВщбЏЃЌгаЫОЛњIDЕФВщбЏЃЌвЛИіПтУЛгаШЮКЮЮЪЬтЁЃ
ЕЋЗжПтвдКѓЃЌБфГЩЖрИіПтвдКѓЃЌвЛЕЉгУСЫвЛИіЮЌЖШЗжПтЃЌФуЛсЗЂЯжЦфЫћЕФЮЌЖШЕФВщбЏОЭвЊБфГЩЖрИіПтСЫЃЌЪЧВЛЪЧЃП
вЛАуРДЫЕЪЧЭЈЙ§гУЛЇЕФIDШЅЗжПтЃЌдкЖЉЕЅIDРяШЅЗХЩЯЗжПтвђзгЃЌетбљЭЈЙ§гУЛЇIDвдМАЖЉЕЅIDЖМФмЙЛЖЈЮЛЕНЯрЙиЪ§ОнЁЃЕЋЪЧЖдгкЫОЛњIDОЭВЛЭЌСЫЃЌЫОЛњIDКЭгУЛЇIDЪЧвЛИіЖрЖдЖрЕФЙиЯЕЁЃвЛИігУЛЇЫћПЩФмЯТСЫЖрИіЫОЛњЕФЕЅЃЌвЛИіЫОЛњНгСЫЖрИігУЛЇЕФЕЅЃЌЭЈЙ§ЫОЛњIDШЅВщбЏЃЌВЂВЛФмвЛДЮадВщбЏЕНЫљгаЕФЪ§ОнЃЌЭЌвЛИіЫОЛњЕФЖЉЕЅвЛЖЈЪЧЗжВМдкЖрИіПтРяЁЃдѕУДАьФиЃПДЫЪБзюГЃгУНтОіЗНАИЪЧЃЌЪ§ОнШпгрЁЃ
ЮвгУвЛИіДцДЂдЊЪ§ОнЃЌгУвЛИіДцДЂЙиЯЕЪ§ОнЃЌдЊЪ§ОнЭЈЙ§гУЛЇIDРДЗжПтЃЌБЃжЄЭЌвЛИігУЛЇЕФЫљгаЖЉЕЅдквЛИіПтРяЁЃЙиЯЕЪ§ОнгУЫОЛњIDРДЗжПтЃЌБЃжЄЭЌвЛИіЫОЛњЕФЫљгаЖЉЕЅдквЛИіПтРяЁЃЭЌвЛЗнЪ§ОнЃЌгЩгкЫќДцдкСНИіЮЌЖШЕФВщбЏЃЌетСНИіЮЌЖШВщбЏЖМПЩвдВЛПфПтЃЌЖјЭЈЙ§Ъ§ОнШпгрРДЪЕЯжЃЌетИідквЕФкЪєгкКмГЃМћЕФЗНАИЁЃ
Ъ§ОнШпгрЃЌгжЛсГіЯжЪВУДЮЪЬтЃПвЛЦ№РДПДвЛЯТЁЃЩЯУцЪЧгІгУЃЌжаМфЪЧЗўЮёЃЌвЛИіЪ§ОнДцдкСНИіПтРяЃЌвЛИіПтЪЧЭЈЙ§гУЛЇIDЗжПтЃЌвЛИіПтЪЧЭЈЙ§ЫОЛњIDШЅЗжПтЃЌЕїгУЗНРДСЫвЛИіЧыЧѓЃЌЯШвЊЭљЕквЛЗнЪ§ОнРяаДвЛИіЪ§ОнЃЌдйЭљСэЭтвЛИіПтРяаДвЛИіШпгрЪ§ОнЁЃФмБЃжЄШпгрЪ§ОнЕФвЛжТадУДЃПЪЧВЛФмЙЛБЃжЄЃЌетСНИіПтЭЌЪБаДГЩЙІЕФЃЌФЧдѕУДАьФиЃП
етОЭЪЧШпгрЪ§ОнЕФвЛжТадЮЪЬтЁЃЪ§ОнШпгрЪ§ОнЕФВЛвЛжТгХЛЏЃЌНёЬьНщЩмШ§жжЗНЗЈЃЌЦфЪЕБОжЪЕФЗНЗЈТлЖМЪЧзюжевЛжТадЁЃ
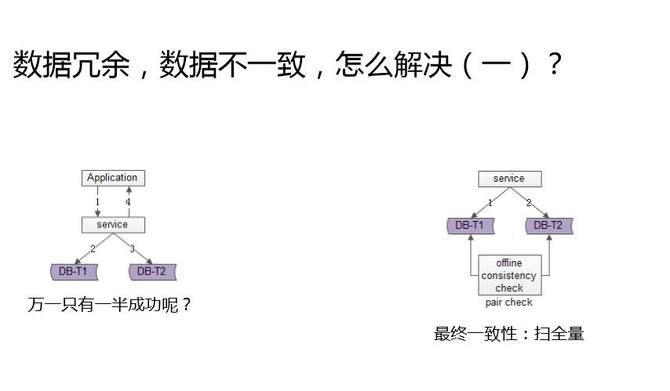
ЕквЛИіЗНАИЪЧЩЈШЋСПЁЃдѕУДЗЂЯжШпгрЪ§ОнВЛвЛжТЃПаДИіНХБОЃЌУПЬьЭэЩЯХмЃЌРэТлЩЯAПтРягаЕФBПтРяУцвВгаЃЌвЛЕЉЩЈПтЗЂЯждѕУДAПтгаBПтРяУЛгаЃЌОЭЪЧГіЯжВЛвЛжТСЫЃЌОЭвЊИљОнвЕЮёЬиадРДзіВЙГЅЁЃЕНЕзЪЧНЋКѓвЛАыВЙНјШЅЃЌЛЙЪЧАбЧАвЛАыЩОЕєЃЌИњвЕЮёЬиадЯрЙиЃЌВЛЙ§ЫМТЗДѓжТЪЧетбљЕФЃЌвЛИівьВНЕФЗНЪНЃЌзюжеРДБЃжЄвЛжТадЁЃ
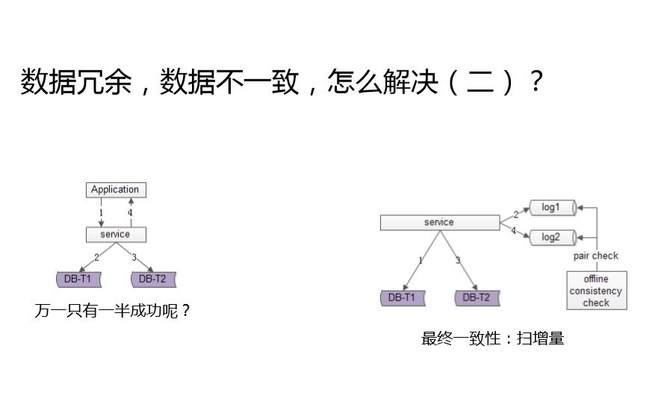
ЕкЖўИіЗНАИЪЧЩЈдіСПЁЃЭЈЙ§ЗўЮёВйзїСНИіПтЃЌаДГЩЙІЕквЛИіПтаДвЛЬѕШежОЃЌаДГЩЙІЕкЖўИіПтдйаДвЛЬѕШежОЁЃетаЉШежОРяЕФОЭЪЧУПЬьИФБфЕФЪ§ОнЃЌУПЬьВЛгУЩЈУшШЋСПЃЌжЛвЊЩЈУшУПЬьИФБфЕФЪ§ОнОЭааСЫЁЃШчЙћЩЈУшШежОВЛЦЅХфЃЌОЭЭЈЙ§вьВНЕФЗНЪНаоИДЃЌБЃжЄзюжевЛжТадЁЃ
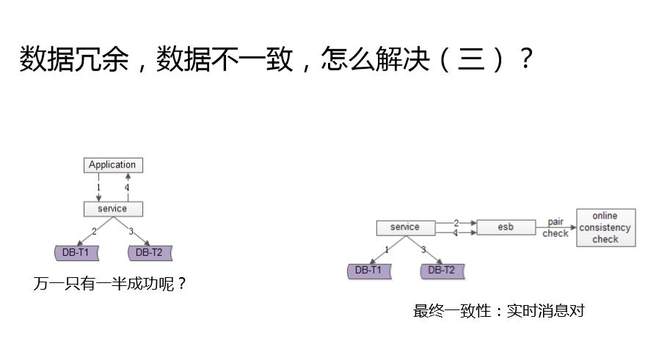
ЕкШ§ИіЗНЪНЃЌБШЧАСНжжЗНЪНИќМгЪЕЪБЁЃВЛаДШежОСЫЃЌЖјЪЧЗЂЯћЯЂЁЃгУвЛИіЯћЯЂзщМўЃЌЪ§ОнПте§ЯђБэВйзїГЩЙІСЫЃЌЗЂвЛИіЯћЯЂЃЌШпгрБэВйзїГЩЙІСЫЃЌЗЂСэвЛИіЯћЯЂЁЃгУвЛИівьВНЕФЗўЮёШЅМрЬ§етСНИіЯћЯЂЃЌШчЙћжЛгавЛЬѕЯћЯЂЕНДяЃЌОЭШЅЪ§ОнПтМьВтвЛжТадЃЌВЂгУвьВНЕФЗНЪНРДВЙГЅЁЃ

зюКѓЪЧЖрЪЕР§ЖрПтЃЌетвВЪЧНтОіЪ§ОнСПДѓЕФвЛИіГЃМћЗНАИЁЃЫќЛсДјРДЪВУДбљЕФВЛвЛжТФиЃПетРягавЛИіАИР§ЃЌЯТЕЅЕФвЛИіВйзїЃЌПЩФмгаШ§ИіЪ§ОнвЊаоИФЃЌвЛИіЪЧгрЖюЕФЪ§ОнЃЌЮвПЩФмвЊПлМѕвЛаЉгрЖюЃЛвЛИіЪЧЖЉЕЅЕФЪ§ОнЃЌвЊаТдівЛЬѕЖЉЕЅЃЛвЛИіЪЧСїЫЎЕФЪ§ОнЃЌвЊаТдівЛЬѕСїЫЎЁЃдРДЪЧЕЅПтЪТЮёРДБЃжЄвЛжТадЃЌЯждкЪ§ОнСПДѓСЫЃЌБфГЩЖрИіПтЃЌгрЖюЪЧвЛИіЕЅЖРЕФЪЕР§ЃЌЖЉЕЅЪЧвЛИіЕЅЖРЕФЪЕР§ЃЌСїЫЎЪЧвЛИіЕЅЖРЕФЪЕР§ЃЌЫљвддРДЕФвЛИіЪТЮёЃЌдкЖрПтзДЬЌЯТЃЌОЭБфГЩШ§ИіЪТЮёЁЃ
ЖрЪЕР§ЃЌЖрПтЪТЮёЃЌВЛвЛжТЃЌдѕУДАьЃПетвЛПщЮвУЧгаСНИігХЛЏЪЕМљЁЃ

ЕквЛИіЪЧВЙГЅЪТЮёЃЌвЕФкгІИУвВОГЃгУЕНВЙГЅЪТЮёЁЃ
грЖюВйзїЃЌе§ЯђЕФВйзїЪЧПлМѕгрЖюЃЌВЙГЅЪТЮёОЭЪЧАбгрЖюМгЛиРДЁЃ
ЖЉЕЅВйзїЃЌе§ЯђЕФВйзїЪЧаТдіЖЉЕЅЃЌВЙГЅЪТЮёОЭЪЧАбЖЉЕЅЩОГ§ЕєЁЃ
СїЫЎВйзїЃЌе§ЯђЕФВйзїЪЧаТдіСїЫЎЃЌВЙГЅЪТЮёОЭЪЧАбСїЫЎЩОГ§ЁЃ
змжЎЃЌВЙГЅЪТЮёОЭЪЧЕБФуЗЂЯжЧАУцЕФЪТЮёжДааЪЇАмЕФЪБКђЃЌвЊжДаавЛИігІгУВуЕФЪТЮёЃЌЛиЙівЛИіЖЏзїЁЃ
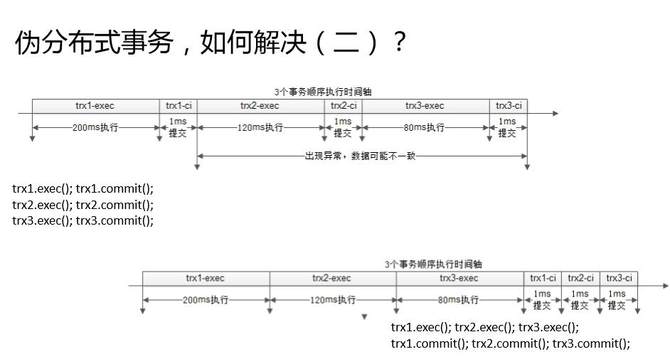
СэЭтвЛжжЗНЪНЃЌЮБЗжВМЪНЪТЮёЕФНтОіЗНАИЃЌЪЧКѓжУЬсНЛЁЃ
ЯШЯИЛЏЕФПДвЛЯТШ§ИіЪТЮёЪЧдѕУДжДааЕФЃПЕквЛИіЪТЮёЯШжДаадйЬсНЛЃЌЕкЖўИіЪТЮёжДаадйЬсНЛЃЌЕкШ§ИіЪТЮёжДаадйЬсНЛЁЃЪТЮёЕФжДааЙ§ГЬКмТ§ЃЌЪТЮёЕФЬсНЛЙ§ГЬКмПьЁЃЩЯЭМетИіР§згЃЌПЩФмжДааЪБМф200КСУыЃЌЬсНЛЪБМфМИКСУыЃЌЪВУДЪБКђЛсГіЯжВЛвЛжТФиЃПЕквЛИіЪТЮёЬсНЛГЩЙІжЎКѓЃЌзюКѓвЛИіЪТЮёЬсНЛГЩЙІжЎЧАЕФжаМфЃЌШЮКЮвЛИіЕиЗНГіЯжвьГЃЖМЛсЕМжТВЛвЛжТЁЃ
гХЛЏЦфЪЕвВКмМђЕЅЃЌКѓжУЬсНЛЁЃЕквЛИіЪТЮёжДааЃЌЕкЖўИіЪТЮёжДааЃЌЕкШ§ИіЪТЮёжДаа;ЕквЛИіЪТЮёЬсНЛЃЌЕкЖўИіЪТЮёЬсНЛЃЌЕкШ§ИіЪТЮёЬсНЛЁЃЪВУДЪБКђЛсГіЯжВЛвЛжТФиЃПШдШЛЪЧЕквЛИіЪТЮёЬсНЛГЩЙІжЎКѓЃЌЕкШ§ИіЪТЮёЬсНЛГЩЙІжЎЧАЕФЪБМфМфИєЃЌШчЙћГіЯжСЫЃЌЭјТчвьГЃЃЌЗўЮёЦїЙвСЫЃЌОЭЛсВЛвЛжТЁЃЕЋЪЧетИіМфИєОЭжЛгаКѓУцЕФСНКСУыЃЌЫљвдећИіВЛвЛжТЕФИХТЪЪЧНЕЕЭСЫАйБЖзѓгвЁЃ
зюКѓзівЛИіМђЕЅЕФзмНсЁЃИљОнЮвЕФОбщЃЌ40Зжжг50ЗжжгЕФвЛИіММЪѕЗжЯэЃЌЕкЖўЬьФмЙЛМЧзЁЕФжЛга10%ЁЃШчЙћжЛМЧзЁ10%ЃЌФЧЮвЯЃЭћДѓМвФмЙЛМЧзЁетвЛвГЕФФкШнЃЌВЂЯЃЭћздМКЕФТпМЪЧЧхЮњЕФЁЃ

Ъ§ОнПтМмЙЙзюГѕЪЧЕЅПтЃЌЕЅПтЛсХіЕНЪВУДЮЪЬтЃПЛсХіЕНЖСадФмЦПОБЕФЮЪЬтЁЃЖСадФмЦПОБзюдчгУЪВУДбљЕФЗНЪНШЅНтОіЃПжїДгЭЌВНЖСаДЗжРыЃЌЫќЛсДјРДЪВУДЮЪЬтЃПжїДгЕФВЛвЛжТЃЌгУЪВУДЗНАИНтОіЃПЮвУЧЕФЪЕМљЪЧжаМфМўЃЌвдМАЧПжЦЖСжїЁЃ
ЬсЩ§ЖСадФмЃЌЗўЮёЛЏМгЛКДцвВЪЧГЃМћЗНАИЃЌДјРДЪВУДаТЕФЮЪЬтЃПЛКДцКЭЪ§ОнПтЕФВЛвЛжТЁЃдкCache Aside
PatternЕФЧщПіЯТЃЌгааДКѓСЂМДЖСЕФЮЪЬтЃЌОЩЪ§ОнПЩФмШыЛКДцЁЃЮвУЧЕФЪЕМљЃЌПЩвдЭЈЙ§вьВНЬдЬЕФЗНЪНЃЌЕБаДВйзїдкДгПтЩЯеце§ЭъГЩЕФЪБКђдйШЅЬдЬЛКДцЁЃЭЌЪБЃЌЮвУЧНЈвщЮЊЫљгадЪаэCache
missЕФЪ§ОнЩшжУГЌЪБЪБМфЁЃ
Ъ§ОнПтМмЙЙЃЌЪ§ОнСПДѓЕФЮЪЬтЃЌдѕУДНтОіЃПГЃгУЕФНтОіЗНАИЪЧЗжПтЃЌЖрЪЕР§ЁЃЗжПтДјРДЪВУДаТЕФЮЪЬтЃПМЧЕУЮвЕФР§згУДЃЌЗжСЫПтжЎКѓЃЌПЩвдБЃжЄЭЌвЛИігУЛЇЕФЪ§ОндкЭЌвЛИіПтРяЃЌВЛФмЙЛБЃжЄЭЌвЛИіЫОЛњЪ§ОнвВдкЭЌвЛИіПтРяЃЌдѕУДНтОіЃПЪЙгУЪ§ОнШпгрЁЃШпгрДјРДЪВУДЮЪЬтЃПШпгрЪ§ОнЕФВЛвЛжТЮЪЬтЃЌЗНЯђЪЧзюжевЛжТадЁЃдѕУДзюжеБЃжЄвЛжТадЃПЩЈШЋСПЃЌЩЈдіСПЃЌЪЕЪБЯћЯЂЖдЁЃГ§СЫЖрПтЃЌЖрЪЕР§вВПЩвдРЉеЙЪ§ОнДцДЂСПЃЌЛсгіЕНЪВУДЮЪЬтЃПЖрПтЕФЪТЮёВЛФмдкБЃжЄддђадЃЌВЙГЅЪТЮёЃЌКѓжУЬсНЛЃЌЖМЪЧЮвУЧЕФгХЛЏЪЕМљЁЃ
| 








