| БрМЭЦМі: |
| БОЮФРДздгкCSDNЃЌБОЮФжївЊНщЩмЪ§ОнЗжЮіММЪѕЃКЖдгІЗжЮіЁЂдЄВтадЪ§ОнЗжЮіЗНЗЈвдМАЪБМфађСаЕШЯрЙиФкШнЁЃ |
|
вЛЁЂжїГЩЗжЗжЮіPCA
1. ЛљБОЫМЯы
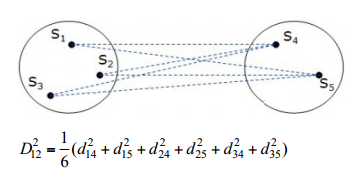
жїГЩЗжЗжЮіЪЧвЛРрГЃгУЕФеыЖдСЌајБфСПЕФНЕЮЌЗНЗЈЃЌбЁШЁФмЙЛзюДѓЛЏНтЪЭЪ§ОнБфвьЕФГЩЗжЃЌНЋЪ§ОнДгИпЮЌНЕЕНЕЭЮЌЃЌЭЌЪББЃжЄИїИіЮЌЖШжЎМфе§НЛЁЃ
жїГЩЗжЗжЮіЕФОпЬхЗНЗЈЪЧЖдБфСПЕФаЗНВюОиеѓЛђЯрЙиЯЕЪ§ОиеѓЧѓШЁЬиеїжЕКЭЬиеїЯђСПЃЌОжЄУїЃЌЖдгІзюДѓЬиеїжЕЕФЬиеїЯђСПЃЌЦфЗНЯђе§ЪЧаЗНВюОиеѓБфвьзюДѓЕФЗНЯђЃЌвРДЮРрЭЦЃЌЕкЖўДѓЬиеїжЕЖдгІЕФЬиеїЯђСПЃЌЪЧгыЕквЛИіЬиеїЯђСПе§НЛЧвФмзюДѓГЬЖШНтЪЭЪ§ОнЪЃгрБфвьЕФЗНЯђЃЌЖјУПИіЬиеїжЕдђФмЙЛКтСПИїЗНЯђЩЯБфвьЕФГЬЖШЁЃвђДЫЃЌНјаажїГЩЗжЗжЮіЪБЃЌбЁШЁзюДѓЕФМИИіЬиеїжЕЖдгІЕФЬиеїЯђСПЃЌВЂНЋЪ§ОнгГЩфдкетМИИіЬиеїЯђСПзщГЩЕФВЮПМЯЕжаЃЌДяЕННЕЮЌЕФФПЕФЃЈбЁдёЕФЬиеїЯђСПЪ§СПЕЭгкдЪМЪ§ОнЕФЮЌЪ§ЃЉЁЃ
ЕБЗжЮіжаЫљбЁЕФБфСПОпгаВЛЭЌЕФСПИйЃЌЧвВюБ№БШНЯДѓЕФЧщПіЯТЃЌгІбЁдёЯрЙиЯЕЪ§ОиеѓНјаажїГЩЗжЗжЮіЁЃ
жїГЩЗжЗжЮіЪЪгУгкБфСПжЎМфОпгаЯрЙиЙиЯЕЃЌБфСПдкШ§ЮЌПеМфжаГЪЯжЭжЧђаЮЗжВМЁЃЖрБфСПжЎМфгаЯджјЕФЧПЯпадЯрЙиЃЌБэУїжїГЩЗжЗжЮіЪЧгавтвхЕФЁЃ
2.жїГЩЗжЕФМЦЫуЙЋЪН
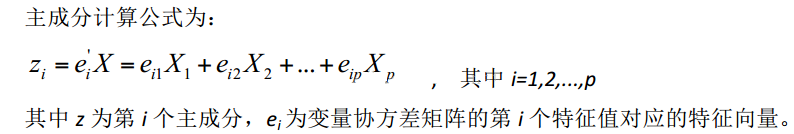
3.ЩЂЕуЭМНт
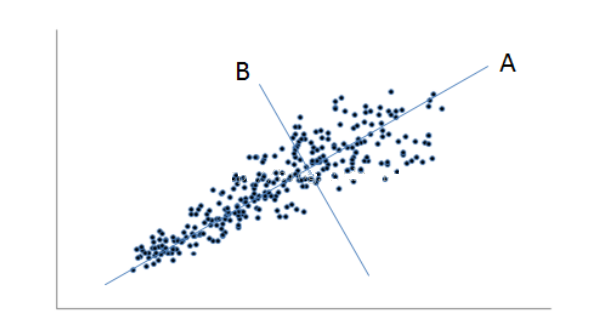
дЪМЪ§ОнПЩвдЪЙгУдзјБъЯЕжаЕФЯђСПРДБэЪОЃЌаЗНВюОиеѓЕФЬиеїЯђСПЮЊAКЭBЃЌгЩгкAЗНЯђЕФБфвьдЖДѓгкBЗНЯђЃЌвђДЫЃЌНЋЫљгаЕугГЩфЕНAЩЯЃЌВЂЪЙгУAзїЮЊВЮПМЯЕРДЪіЪ§ОнЃЌетбљКіТдСЫЪ§ОндкBЗНЯђЩЯЕФБфвьЃЌЕЋШДНЋЖўЮЌЕФЪ§ОнНЕЕЭЕНСЫвЛЮЌЁЃ
4. жїГЩЗжЗжЮіЕФВНжш

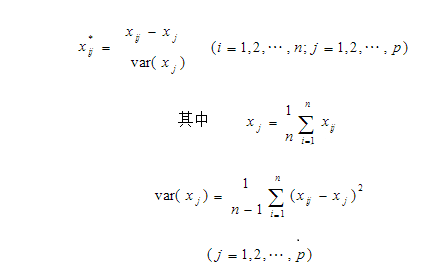





5. бЁдёжїГЩЗжИіЪ§
жїГЩЗжЗжЮіЕФФПЕФЪЧМђЛЏБфСПЃЌвЛБщБЃСєЕФжїГЩЗжгІИУаЁгкдЪМБфСПЕФИіЪ§ЁЃИљОнжїГЩЗжЗжЮіЕФФПЕФЃЌИіЪ§бЁШЁЕФЗНЗЈЪЧгаЧјБ№ЕФЁЃ
ОпЬхБЃСєМИИіжїГЩЗжЃЌгІИУзёбСНИіддђЃЈСНИіддђЭЌЪБЪЙгУЃЌПЩжЛПМТЧвЛИіЃЉЃК
1. ЕЅИіжїГЩЗжНтЪЭЕФБфвьВЛгІИУаЁгк1ЃЈЬиеїИљжЕВМаЁгк1ЃЉ
2. бЁШЁЕФжїГЩЗжЕФРлМЦБфвьгІИУДяЕН80% ~ 90%ЃЈРлМЦЬиеїИљжЕеМзмЬиеїИљжЕ80%вдЩЯЃЉ
6. гІгУГЁОА
жїГЩЗжЗЈЕФгІгУДѓжТЗжЮЊШ§ИіЗНУцЃК 1ЁЂЖдЪ§ОнзізлКЯДђЗжЃЛ 2ЁЂ НЕЮЌвдБуЖдЪ§ОнНјааУшЪіЃЛ3ЁЂЮЊОлРрЛђЛиЙщЕШЗжЮіЬсЙЉБфСПбЙЫѕЁЃдкгІгУЪБвЊФмЙЛХаЖЯжїГЩЗжЗЈЕФЪЪгУадЃЌФмЙЛИљОнашЧѓбЁШЁКЯЪЪЕФжїГЩЗжЪ§СПЁЃ
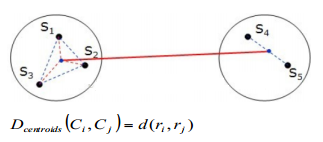
ЖўЁЂвђзгЗжЮі
1. ЛљБОЫМЯы
жїГЩЗжЗжЮіЪБвЛАуЧщПіЯТВЛФмЖджїГЩЗжЫљДњБэКЌвхНјаавЕЮёЩЯЕФНтЖСЃЌвђЮЊжїГЩЗжЗНЯђЩЯвЛАуВЛЛсЧЁКУФГаЉБфСПШЈжиДѓЃЌЖјСэЭтвЛаЉБфСПШЈжиЖМаЁЃЌетвВБэЯждкжїГЩЗжШЈжиЕФаЮГЩЕФЩЂЕуЭМЛсЦЋРызјБъжсЁЃ
ШчЙћПЩвдНЋжїГЩЗжЕФзјБъжсНјааа§зЊЃЌЪЙвЛаЉБфСПЕФШЈжиЕФОјЖджЕдквЛИіжїГЩЗжЩЯДяЕНзюДѓЃЌЖјдкЦфЫћжїГЩЗжЩЯОјЖджЕзюаЁЃЌетбљОЭДяЕНСЫБфСПЗжРрЕФФПЕФЁЃЖдгІЕиЃЌетжжЮЌЖШЗжЮіЗНЗЈБЛГЦЮЊвђзгЗжЮіЁЃ
вђзгЗжЮіЪЧвЛРрГЃгУЕФСЌајБфСПНЕЮЌВЂНјааЮЌЖШЗжЮіЕФЗНЗЈЃЌЦфОГЃВЩгУжїГЩЗжЗЈзїЮЊЦфвђзгдиКЩОиеѓЕФЙРМЦЗНЗЈЃЌдкЬиеїЯђСПЗНЯђЩЯЃЌЪЙгУЬиеїжЕЕФЦНЗНИљНјааМгШЈЃЌзюКѓЭЈЙ§вђзга§зЊЃЌЪЙЕУБфСПЕФШЈжидкВЛЭЌвђзгЩЯИќМгСНМЋЗжЛЏЁЃГЃгУзюДѓЗНВюЗЈНјаавђзга§зЊЃЌетжжЗНЗЈЪЧвЛжже§НЛа§зЊЁЃ
2. е§НЛа§зЊвђзгФЃаЭ

3. вђзгЗжЮіЕФвЛАуВНжш

4. вђзгдиКЩОиеѓЕФЙРМЦ
вЛАуЪЙгУжїГЩЗжЗжЮіЗНЗЈЁЃбЁдёКЯЪЪЕФвђзгЪ§СПЃЌетвЛВНашвЊжїГЩЗжЗжЮіЕФНсЙћЃЌвђзгИіЪ§ЕФШЗЖЈБъзМБШжїГЩЗжЗжЮіПэЃЌБШШчЃЌЬиеїИљДѓгк0.7ОЭПЩвдПМТЧБЃСєЁЃ
5. вђзга§зЊ
а§зЊЕФФПЕФЪЧЪЙвђзгИККЩСНМЖЗжЛЏЃЌвЊУДНгНќ0ЃЌвЊУДНгНќ-1Лђ1ЃЌетбљвзгкЖдвђзгзіГіНтЪЭЁЃ
ЗжЮЊЃКе§НЛа§зЊКЭаБНЛа§зЊЁЃ
е§НЛа§зЊЃЌвђзгМфЕФаХЯЂВЛЛсжиЕўЁЃзюГЃгУЕФЪЧзюДѓЗНВюа§зЊЃЌЪЧвЛжже§НЛа§зЊЃЌФПЕФЪЧЪЙдиКЩЦНЗНЕФЗНВюзюДѓЛЏЁЃ
6. вђзгЗжЮіЕФгІгУ
вђзгЗжЮіЭЈжїГЩЗжЗжЮіРрЫЦЃЌЪЪгУгкБфСПжЎМфДцдкНЯЧПЕФЯпадЙиЯЕЕФЧщПіЃЌФмЙЛзлКЯГіМИЯюЗДгГБфСПЙВЭЌЬиБ№ЕФжИБъЁЃзюМђЕЅЕФЗНЗЈОЭЪЧМЦЫуБфСПЕФЯрЙиЯЕЪ§ОиеѓЃЌвЊЪЧДѓВПЗжЯрЙиЯЕЪ§жЕаЁгк0.3ЃЌОЭВЛЪЪгУвђзгЗжЮіЁЃЛЙгавЛаЉМьбщЗНЗЈЃЌШчАЭЬиРћЬиЧђаЮМьбщЃЌKMOМьбщЕШЁЃ
вђзгЗжЮізїЮЊЮЌЖШЗжЮіЕФЪжЖЮЃЌЪЧЙЙдьКЯРэЕФОлРрФЃаЭКЭЮШНЁЕФЗжРрФЃаЭЕФБиШЛВНжшЃЌгУгкНЕЕЭНтЪЭБфСПЙВЯпадДјРДЕФФЃаЭВЛЮШЖЈадЁЃ
Ш§ЁЂОлРрЗжЮі
ОлРрЗжЮіЪЧвЛжжЗжРрЕФЖрдЊЭГМЦЗжЮіЗНЗЈЁЃАДееИіЬхЛђбљЦЗЕФЬиеїНЋЫќУЧЗжРрЃЌЪЙЭЌвЛРрБ№ФкЕФИіЬхОпгаОЁПЩФмИпЕФЭЌжЪад(homogeneity)ЃЌЖјРрБ№жЎМфдђгІОпгаОЁПЩФмИпЕФвьжЪадЁЃ
1.ОлРрЗжЮіЕФЛљБОТпМ
ОлРрЗжЮіЕФЛљБОТпМЪЧМЦЫуЙлВтжЕжЎМфЕФОрРыЛђепЯрЫЦЖШЁЃОрРыНЯаЁЁЂЯрЫЦЖШНЯИпЃЌАДееЯрЫЦЖШНјааЗжзщЁЃ
ОпЬхПЩвдЗжЮЊШ§ИіВНжшЃК
1. ДгNИіЙлВтКЭKИіЪьЯЄЪ§ОнПЊЪМЃЛ
2. МЦЫуNИіЙлВтСНСНжЎМфЕФОрРыЃЛ
3. НЋОрРыНќЕФЙлВтОлЮЊвЛРрЃЌНЋОрРыдЖЕФЗжЮЊВЛЭЌЕФРрЃЌзюжеДяЕНзщМфЕФОрРызюДѓЛЏЃЌзщФкЕФОрРызюаЁЛЏЁЃ
2.ОлРрЗжЮіЕФЗНЗЈжжРр
ЯЕЭГОлРрЗЈЃЈВуДЮОлРрЃЉЃКИУЗНЗЈПЩвдЕУЕННЯРэЯыЕФЗжРрЃЌЕЋЪЧФбвдДІРэДѓСПбљБОЁЃ
K-meansОлРрЃЈЗЧВуДЮОлРрЁЂПьЫйОлРрЃЉЃКПЩвдДІРэДѓСПбљБОЃЌЕЋЪЧВЛФмЬсЙЉРрЯрЫЦЖШаХЯЂЃЌВЛФмНЛЛЅЕФОіЖЈОлРрИіЪ§ЁЃ
СНВНЗЈОлРрЃЈЯШЪЙгУK-meansОлРрЃЌКѓЪЙгУВуДЮОлРрЃЉ
3. ЯЕЭГОлРр
ЯЕЭГОлРрЃЌвВОЭЪЧВуДЮОлРрЃЌжИЕФЪЧаЮГЩРрЯрЫЦЖШВуДЮЭМЦзЃЌБугкжБЙлЕФШЗЖЈРржЎМфЕФЛЎЗжЁЃ ЦфЛљБОЫМЯыдкгкСю
n ИібљБОздГЩвЛРрЃЌМЦЫуЦфСНСНжЎМфЕФЯрЫЦадЃЌДЫЪБРрМфОрРыгыбљБОМфОрРыЪЧЕШМлЕФЁЃАбВтЖШзюаЁЕФСНИіРрКЯВЂЃЌ
ШЛКѓАДееФГжжОлРрЗНЗЈМЦЫуРрМфЕФОрРыЃЌдйАДзюаЁОрРызМдђВЂРрЁЃетбљУПДЮМѕЩйвЛРрЃЌГжајЯТШЅЃЌ жБЕНЫљгабљБОЖМЙщЮЊвЛРрЮЊжЙЁЃ
ИУЗНЗЈПЩвдЕУЕННЯРэЯыЕФЗжРрЃЌЕЋЪЧФбвдДІРэДѓСПбљБОЁЃ
1. ЛљБОВНжш
ЃЈ1ЃЉЖдЪ§ОнНјааБфЛЛДІРэЃЛЃЈВЛЪЧБиаыЕФЃЌЕБЪ§СПМЖЯрВюКмДѓЛђжИБъБфСПОпгаВЛЭЌЕЅЮЛЪБЪЧБивЊЕФЃЉ
ЃЈ2ЃЉЙЙдьnИіРрЃЌУПИіРржЛАќКЌвЛИібљБОЃЛ
ЃЈ3ЃЉМЦЫуnИібљБОСНСНМфЕФОрРыЃЛ
ЃЈ4ЃЉКЯВЂОрРызюНќЕФСНРрЮЊвЛаТРрЃЛ
ЃЈ5ЃЉМЦЫуаТРргыЕБЧАИїРрЕФОрРыЃЌШєРрЕФИіЪ§ЕШгк1ЃЌзЊЕН6ЃЛЗёдђЛи4ЃЛ
ЃЈ6ЃЉЛОлРрЭМЃЛ
ЃЈ7ЃЉОіЖЈРрЕФИіЪ§ЃЌДгЖјЕУГіЗжРрНсЙћЁЃ2. Ъ§ОндЄДІРэ
ВЛЭЌвЊЫиЕФЪ§ОнЭљЭљОпгаВЛЭЌЕФЕЅЮЛКЭСПИйЃЌЦфЪ§жЕЕФБфвьПЩФмЪЧКмДѓЕФЃЌетОЭЛсЖдЗжРрНсЙћВњЩњгАЯьЃЌвђДЫЕБЗжРрвЊЫиЕФЖдЯѓШЗЖЈжЎКѓЃЌдкНјааОлРрЗжЮіжЎЧАЃЌЪзЯШвЊЖдСЌајБфСПНјааДІРэЁЃ
дкОлРрЗжЮіжаЃЌГЃгУЕФОлРрвЊЫиЕФЪ§ОнДІРэЗНЗЈгаШчЯТМИжжЃК
ЂйZ soroesБъзМЛЏ
ЂкБъзМВюБъзМЛЏ
Ђле§ЬЌБъзМЛЏ
ОЙ§етжжБъзМЛЏЫљЕУЕФаТЪ§ОнЃЌИївЊЫиЕФМЋДѓжЕЮЊ1ЃЌМЋаЁжЕЮЊ0ЃЌЦфгрЕФЪ§жЕОљдк0гы1жЎМфЁЃ
ЮЊСЫЕУЕНКЯРэЕФОлРрНсЙћЃЌВЛЕЋвЊЖдЪ§ОнНјааБъзМЛЏЃЌЛЙвЊЖдБфСПНјааЮЌЖШЗжЮіЁЃвЛАуВЩгУвђзгЗжЮіНјааЮЌЖШЗжЮіЃЌИљОнбљБОЕФЬиеїбЁдёвђзгзЊЛЛЕФЗНЗЈЃЌЖдЙлВтЪ§ОнНјааДІРэЃЌВЂдкБЃДцЕФвђзгНсЙћЩЯНјааОлРрЗжЮіЁЃ
ШчЙћБфСПГЪЦЋЬЌЗжВМЃЌПЩвдЖдЪ§ОнНјааКЏЪ§БфЛЛРДПЫЗўЦЋЬЌадЃЌШчЖдЪ§БфЛЛЁЃ
3.ЙлВтЕуМфОрРыЕФМЦЫу
дкОлРрЪБЕФвЛИіживЊЮЪЬтЪЧЖЈвхбљБООрРыЃЌвЛАуЪЙгУХЗЪНОрРыЛђуЩПЩЗђЫЙЛљОрРыЃЌуЩПЩЗђЫЙЛљОрРыЙЋЪНШчЯТЃК
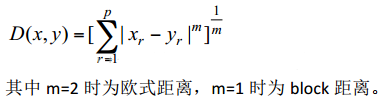
4. ЙлВтРрМфОлРрЕФМЦЫу
СэвЛИіживЊЮЊЬтЪЧЖЈвхСНИіРржЎМфЕФОрРыЃЌЗНЗЈАќРЈЦНОљСЊНгЗЈЁЂжиаФЗЈКЭ Ward зюаЁЗНВюЗЈЁЃ
ЃЈ1ЃЉЦНОљСЌНгЗЈгжГЦШЋСЌНгЗЈЃЌМДНЋвЛРрЕФЫљгаЙлВтжЕгыСэвЛРрЕФЫљгаЙлВтжЕЗжБ№зіСНСНжЎМфЕФОрРыЃЌЧѓЫљгаОрРыЕФЦНОљжЕзїЮЊРрМфОрРыЃК
ЃЈ2ЃЉжиаФЗЈМЦЫуЕФЪЧЙлВтРрИїзджиаФжЎМфЕФОрРыЃК
ЃЈ3ЃЉWard зюаЁЗНВюЗЈЃК ЛљгкЗНВюЗжЮіЕФЫМЯыЃЌШчЙћЗжРрКЯРэЃЌдђЭЌРрбљБОМфРыВюЦНЗНКЭгІЕБНЯаЁЃЌРргыРрМфРыВюЦНЗНКЭгІЕБНЯДѓЁЃ
Ward зюаЁЗНВюЗЈВЂРрЪБЃЌ змЪЧЪЙВЂРрЕМжТЕФРрФкРыВюЦНЗНКЭдіСПзюаЁЁЃвђДЫЃЌИУЗНЗЈКмЩйЪмЕНвьГЃжЕЕФгАЯьЃЌдкЪЕМЪгІгУжаЕФЗжРраЇЙћНЯКУЃЌЪЪгУЗЖЮЇЙуЁЃЕЋИУЗНЗЈвЊЧѓбљЦЗМфЕФОрРыБиаыЪЧХЗЪЯОрРыЁЃ
4. K-meansОлРр
K-means ОлРрЪЧвЛжжПьЫйОлРрЗЈЃЌЪЪКЯгІгУгкДѓбљБОСПЕФЪ§ОнЁЃЦфЗНЗЈПЩвдзмНсЮЊЃК ЪзЯШЫцЛњбЁдё K
ИіЕузїЮЊжааФЕуЃЌЫљгабљБОгыет K ИіжааФЕуМЦЫуОрРыЃЌОрРызюНќЕФбљБОБЛЙщЮЊгыжааФЕуЭЌРрЕФЕуЃЌШЛКѓжиаТМЦЫуУПИіРрЕФжааФЃЌдйДЮМЦЫуУПИібљБОгыРржааФЕФОрРыЃЌВЂАДеезюЖЬОрРыддђжиаТЛЎЗжРрЃЌШчДЫЕќДњжБжСРрВЛдйБфЛЏЮЊжЙЁЃ
1. ЛљБОВНжш
ЃЈ1ЃЉЩшЖЈKжЕЃЌШЗЖЈОлРрЪ§ЃЈШэМўЫцЛњЗжХфОлРржааФЫљашЕФжжзгЃЉЁЃ
ЃЈ2ЃЉМЦЫуУПИіМЧТМЕНРржааФЕФОрРыЃЈХЗЪНОлРрЃЉЃЌВЂЗжГЩKРрЁЃ
ЃЈ3ЃЉШЛКѓАбKРржааФЃЈОљжЕЃЉзїЮЊаТЕФжааФЃЌжиаТМЦЫуОрРыЁЃ
ЃЈ4ЃЉЕќДњЕНЪеСВБъзМЭЃжЙЁЃ
2. гХШБЕу
ИУЗНЗЈЕФгХЕуЪЧМЦЫуЫйЖШПьЃЌПЩгУгкбљБОСПНЯДѓЕФЪ§ОнЃЌШБЕуЪЧашвЊШЫЮЊЩшЖЈОлРрЕФЪ§СП KЃЌЭЌЪБЦфГѕЪМЕуЕФВЛЭЌбЁдёПЩФмЛсаЮГЩВЛЭЌЕФОлРрНсЙћЃЌвђДЫГЃГЃЪЙгУЖрДЮбЁдёГѕЪМжааФЕуЃЌВЂЖдзюжеЕФЖрИіОлРрНсЙћШЁЦНОљЕФЗНЗЈРДЙЙНЈЮШЖЈЕФФЃаЭЁЃ
3. гІгУЪЕР§
ЗЂЯжвьГЃжЕЃКШчЫЂаХгУМЖБ№ЕФЮЅЙцепЕФааЮЊЛсгые§ГЃЯћЗбааЮЊдкЯћЗбЦЕДЮЁЂЦНОљЯћЗбН№ЖюЕШЗНУцВювьБШНЯДѓЃЌЖдЦфНјааЖЈЮЛЯрЕБгкЗЂЯжвьГЃЕуЃЌвђДЫвЊЧѓЖдБфСПЕФзЊЛЛВЛФмИФБфЦфдгаЗжВМаЮЬЌЁЃГЃгУЕФБъзМЛЏЗНЗЈШчжааФБъзМЛЏЁЂМЋВюБъзМЛЏВЛЛсИФБфЗжВМаЮЬЌЃЌЖјЧвдкОлРрЧАЭљЭљашвЊЪЙгУБъзМЛЏРДЯћГ§БфСПЕФСПИйЁЃ
ЫФЁЂЖдгІЗжЮі
ЖдгІЗжЮіЪЧвЛжжЪ§ОнЗжЮіММЪѕЃЌЫќФмЙЛАяжњЮвУЧбаОПгЩЖЈадБфСПЙЙГЩЕФНЛЛЅЛузмБэРДНвЪОБфСПМфЕФСЊЯЕЁЃНЛЛЅБэЕФаХЯЂвдЭМаЮЕФЗНЪНеЙЪОЁЃжївЊЪЪгУгкгаЖрИіРрБ№ЕФЖЈРрБфСПЃЌПЩвдНвЪОЭЌвЛИіБфСПЕФИїИіРрБ№жЎМфЕФВювьЃЌвдМАВЛЭЌБфСПИїИіРрБ№жЎМфЕФЖдгІЙиЯЕЁЃЪЪгУгкСНИіЛђЖрИіЖЈРрБфСПЁЃ
1. РраЭ
МђЕЅЖдгІЗжЮіЃКЖдСНИіЗжРрБфСПНјааЕФЖдгІЗжЮі
ЖржиЖдгІЗжЮіЃКЖдЖрИіЗжРрБфСПНјааЕФЖдгІЗжЮіЃЈзюгХГпЖШЃЉ
СЌајаЭБфСПЕФЗжЮіКЭЗжРрБфСПЕФЗжЮіЃЌСЌајаЭБфСППЩвдЯШЗжЯфКѓдйНјааЖдгІЗжЮіЁЃ
2. ЖдгІЗжЮіКЭСаСЊБэЗжЮіЕФЙиЯЕ
дкЖдСНИіЗжРрБфСПНјааЗжЮіЪБЃЌСаСЊБэЪЧГЃгУЕФЗНЪНЃЌЕЋШчЙћБфСПЗжРрЫЎЦННЯЖрЃЌЭљЭљКмФбжБЙлЕиЗЂЯжЗжРрЫЎЦНжЎМфЕФЯрЛЅСЊЯЕЃЌЮЊДЫЛсЪЙгУЖдгІЗжЮіЗНЗЈРДДІРэетИіЮЪЬтЁЃ
ЖдгІЗжЮіЪЧгУгкбАЧѓСаСЊБэЕФааКЭСажЎМфЕФЙиЯЕЕФвЛжжЕЭЮЌЭМаЮБэЪОЗЈЃЌЫќПЩвдДгжБОѕЩЯНвЪОЭЌвЛЗжРрБфСПЕФИїИіРрБ№жЎМфЕФВювьЃЌвдМАВЛЭЌЗжРрБфСПИїИіРрБ№жЎМфЕФЖдгІЙиЯЕЁЃ
дкЖдгІЗжЮіжаЃЌСаСЊБэЕФУПвЛааЖдгІЃЈЭЈГЃЪЧЖўЮЌЃЉЭМжаЕФвЛЕуЃЌУПвЛСавВЖдгІЭЌвЛЭМжаЕФвЛЕуЁЃБОжЪЩЯЃЌетаЉЕуЖМЪЧСаСЊБэЕФИїааИїСаЯђвЛИіЖўЮЌХЗЪНПеМфЕФЭЖгАЃЌетжжЭЖгАзюДѓЯоЖШЕФБЃГжСЫИїааЛђИїСажЎМфЕФЙиЯЕЁЃ
3. ЖдгІЗжЮіКЭСаСЊБэЗжЮіЕФЙиЯЕ
ЖдгІЗжЮіЪЧдкжїГЩЗжЗЈЛљДЁЩЯЗЂеЙЦ№РДЕФвЛжжММЪѕЃЌЦфЭЈЙ§ЖдСаСЊБэНјаазЊЛЛЃЌЪЙЕУаагыСаИїздЕФЬиеїжЕЗжБ№ЯрЕШЃЌЗжБ№ЖдаагыСаНјаажїГЩЗжЗжНтЪБЃЌПЩвдЪЙЕУИїздЕФаЗНВюОиеѓЕФЬиеїжЕЯрЕШЃЌЪЙгУЬиеїжЕЕФЦНЗНИљЖджїГЩЗжЗНЯђЕФЪ§ОнНјааМгШЈЃЌБЃжЄСЫаагыСаПЩвддкЭЌвЛГпЖШЯТНјааБШНЯЁЃ

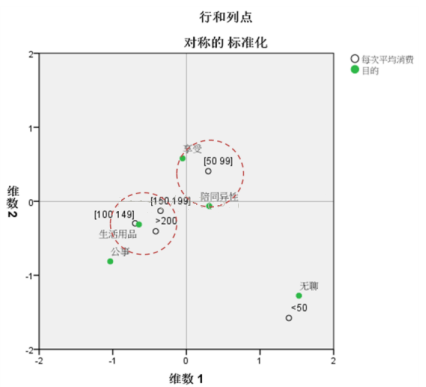
4.ЖдгІЭМЕФНтЖСЗНЗЈ
1-змЬхЙлВьЃК
2-ЙлВьСкНќЧјгђ
3-ЯђСПЗжЮіЁЊЁЊЦЋКУХХађ
4-ЯђСПЕФМаНЧЁЊЁЊгрЯвЖЈРэ
5-ДгОрРыжаЕФЮЛжУПД
6-зјБъжсЖЈвхКЭЯѓЯоЗжЮі
7-ВњЦЗЖЈЮЛЃКРэЯыЕугыЗДРэЯыЕуФЃаЭ
8-ЪаГЁЯИЗжКЭЖЈЮЛ
5.гХШБЕу
МђЕЅЖдгІЗжЮіЕФгХЕуЃК
ЖЈадБфСПЛЎЗжЕФРрБ№дНЖрЃЌетжжЗНЗЈЕФгХЪЦдНУїЯдЁЃ
НвЪОааБфСПРрБ№МфгыСаБфСПРрБ№МфЕФСЊЯЕЁЃ
НЋРрБ№СЊЯЕжБЙлЕиБэЯждкЖўЮЌЭМаЮжаЃЈЖдгІЭМЃЉЁЃ
ПЩвдНЋУћвхБфСПЛђДЮађБфСПзЊБфЮЊМфОрБфСПЁЃ
МђЕЅЖдгІЗжЮіЕФШБЕуЃК
ВЛФмгУгкЯрЙиЙиЯЕЕФМйЩшМьбщЁЃ
ЮЌЖШвЊгЩбаОПепОіЖЈЁЃ
гаЪБКђЖдгІЭМНтЪЭБШНЯРЇФбЁЃ
ЖдМЋЖЫжЕБШНЯУєИаЁЃ
ЮхЁЂЖрЮЌГпЖШЗжЮі
ЖрЮЌГпЖШЗжЮіЃЈMDS)ЃЌЪЧЛљгкбаОПЖдЯѓжЎМфЕФЯрЫЦадЛђОрРыЃЌНЋбаОПЖдЯѓдквЛИіЕЭЮЌЃЈЖўЮЌЛђШ§ЮЌЃЉЕФПеМфаЮЯѓЕиБэЪОГіРДЃЌНјааОлРрЛђЮЌЖШЗжЮіЕФвЛжжЭМЪОЗЈЁЃЭЈЙ§ЖрЮЌГпЖШЗжЮіЫљГЪЯжЕФПеМфЖЈЮЛЭМЃЌФмМђЕЅУїСЫЕиЫЕУїИїбаОПЖдЯѓжЎМфЕФЯрЖдЙиЯЕЁЃ
1.ЯрЫЦадЛђОрРыВтСП
ЖрЮЌГпЖШЗжЮігУгкКтСПбљБОМфЯрвьадЃЈОрРыЃЉЛђЯрЫЦадГЬЖШЁЃгЩгкБфСПРраЭЕФВЛЭЌЃЌбљБОМфЕФОрРыЛђЯрЫЦадЭљЭљвВашвЊВЩгУВЛЭЌЕФЗНЗЈРДКтСПЃЌБШШчуЩПЩЗђЫЙЛљОрРыЁЂПЈЗНОрРыЁЂгрЯвЯрЫЦЖШЕШЕШЃЌгІЕБЪьжЊОрРы/ЯрЫЦадВтСПЕФдРэКЭЪЪгУадЃЌ
ВЂе§ШЗЪЙгУЁЃ

2ЁЂЖрЮЌГпЖШЗжЮідРэ

3ЁЂЖрЮЌГпЖШЗжЮіЕФгІгУ
дкЪаГЁбаОПСьгђжївЊбаОПЯћЗбепЕФЬЌЖШЃЌКтСПЯћЗбепЕФжЊОѕМАЦЋКУЁЃЩцМАЕФбаОПЖдЯѓЗЧГЃЙуЗКЃЌР§ШчЃКЦћГЕЁЂЯДЭЗЫЎЁЂвћСЯЁЂПьВЭЪГЦЗЁЂЯубЬКЭЙњМвЁЂЦѓвЕЦЗХЦЁЂеўЕГКђбЁШЫЕШЁЃЭЈЙ§MDSЗжЮіФмЙЛЮЊЪаГЁбаОПЬсЙЉгаЙиЯћЗбепЕФжЊОѕКЭЦЋКУаХЯЂдкЪаГЁбаОПСьгђжївЊбаОПЯћЗбепЕФЬЌЖШЃЌКтСПЯћЗбепЕФжЊОѕМАЦЋКУЁЃ
дкашвЊБШНЯбљБОМфЯрвьадЛђЯрЫЦадЕФГЁКЯЯТЃЌПЩвдЪЙгУЖрЮЌГпЖШЗжЮіЃЌР§ШчБШНЯВЛЭЌЦЗХЦ/ВњЦЗМфЯрЫЦадЃЌгУвдбАевЧБдкЕФОКељЖдЪжЁЃзюжеЕФНсЙћЭљЭљЪЧдкЖўЮЌИажЊЭМЩЯРДеЙЪОЁЃ
4ЁЂЖрЮЌГпЖШЗжЮігыЖдгІЗжЮіЕФЧјБ№
ЖрЮЌГпЖШЗжЮіУшЪіЕФЪЧааБфСПжЎМфЕФЙиЯЕЃЌЖдгІЗжЮіЪЧУшЪіааБфСПКЭСаБфСПжЎМфЕФЙиЯЕЁЃ
СљЁЂдЄВтадЪ§ОнЗжЮіЗНЗЈ
1. МђЕЅЯпадЛиЙщ
2. ЖрдЊЯпадЛиЙщ
1.ЖрдЊЛиЙщЗНГЬ2. ЯпадЛиЙщЕФЮхИіМйЩш
ЯпадЛиЙщЕФжиЕугыФбЕудкгкФЃаЭЕїгХЃЌећИігХЛЏЙ§ГЬПЩвдПДзіЪЧдкНЋФЃаЭж№ВНЕїећЕНЗћКЯЯпадЛиЙщЮхИіОЕфМйЩшЕФЙ§ГЬЃЌвђЮЊФЃаЭдНЗћКЯЦфЧАМйЩшЃЌдђдЄВтНсЙћдНПЩППЁЃЯпадЛиЙщЕФЮхИіМйЩшЮЊЃК
Ёё МйЩшвЛЃК НтЪЭБфСПКЭБЛНтЪЭБфСПжЎМфДцдкЯпадЙиЯЕЃЛЃЈЮЅЗДЃЌдђФЃаЭдЄВтФмСІВюЃЉ
Ёё МйЩшЖўЃКНтЪЭБфСПКЭШХЖЏЯюВЛФмЯрЙиЃЛЃЈЮЅЗДдђЛиЙщЯЕЪ§ЙРМЦгаЦЋЃЉ
Ёё МйЩшШ§ЃКНтЪЭБфСПжЎМфВЛФмЧПЯпадЯрЙиЃЈХђеЭЯЕЪ§ЃЉЃЛЃЈЮЅЗЈдђЛиЙщЯЕЪ§ЕФБъзМЮѓВюБЛЗХДѓЃЉ
Ёё МйЩшЫФЃКШХЖЏЯюЖРСЂЭЌЗжВМЃЈвьЗНВюМьбщЁЂ DW МьбщЃЉЃЛЃЈЮЅЗДдђШХЖЏЯюЕФБъзМЮѓВюЙРМЦВЛзМЃЌTМьбщЪЇаЇЃЉ
Ёё МйЩшЮхЃКШХЖЏЯюЗўДге§ЬЌЗжВМЃЈ QQ МьбщЃЉЁЃЃЈЮЅЗДдђTМьбщЪЇаЇЃЉ
3. ФЃаЭБфСПЕФбЁдё
ФЃаЭБфСПбЁдёЕФЗНЗЈжївЊгаЃКЯђЧАЛиЙщЗЈЁЂЯђКѓЛиЙщЗЈЁЂж№ВНЛиЙщЗЈ
4.ЯпадЛиЙщЗжЮіЕФВНжш
ЃЈ 1ЃЉ вЊЖдЪ§ОнзіЛљБОЕФЗжЮіЃЌЗжЮіЕФЪЧЧБдкЕФНтЪЭБфСПКЭБЛНтЪЭБфСПжЎМфПЩФмДцдкЕФЛљБОЙиЯЕЃЛ
ЃЈ 2ЃЉ ПЩвдИљОнГѕВНЗжЮіЕФНсЙћЙЙНЈКђбЁФЃаЭЃЛ
ЃЈ 3ЃЉ ЖдКђбЁФЃаЭНјаагааЇадМйЩшМьбщЃЛ
ЃЈ 4ЃЉЖдФЃаЭЕФЙВЯпадКЭгАЯьЕуНјааМьВтЃЌаое§ФЃаЭПЩФмДцдкЕФЦЋВюЃЛ
ЃЈ 5ЃЉИљОнМьВтЕФНсЙћЖдФЃаЭНјаааое§ЃЛ
ЃЈ 6ЃЉЖдаое§КѓЕФФЃаЭжиаТНјааБивЊЕФгааЇадМйЩшМьбщЁЂ ЙВЯпадКЭгАЯьЕуМьВтЃЌ жБЕНФЃаЭВЛдйашвЊНјвЛВНаое§ЮЊжЙЃЛ
ЃЈ 7ЃЉ Ждаое§КѓЕФФЃаЭНјаадЄВтМьбщЁЃ НЈСЂгааЇЕФНЈФЃбЛЗВХФмБЃжЄФЃаЭЕФе§ШЗадЁЂгааЇадКЭОЋШЗадЁЃ5.
ВаВюМйЩшЕФМьВщ
ВаВюашвЊТњзуЖРСЂЭЌЗжВМКЭе§ЬЌЗжВМСНИіМйЩшЁЃ
ПЩвдЭЈЙ§МьВщВаВюЩЂЕуЭМКЭВаВюЭМЖдВаВюЕФЯпадЛиЙщМйЩшНјааМьВщЁЃВаВюЩЂЕуЭМжївЊПДВаВюЪЧЗёКЭФГИіНтЪЭБфСПДцдкЧњЯпЙиЯЕЃЌвдМАВаВюЕФРыЩЂГЬЖШЪЧЗёКЭФГИіНтЪЭБфСПгаЙиЁЃВаВюЭМжївЊЪЧПДВаВюЪЧЗёгаРыШКжЕЁЃ
ЃЈ1ЃЉВаВюгыздБфСПЩЂЕуЭМГЪХзЮяЯпЁЃЫЕУїНтЪЭБфСПXКЭБЛНтЪЭБфСПYДцдкИпНзЗЧЯпадЙиЯЕЁЃаое§ЕФЗНЗЈЪЧдкФЃаЭжаМгШоНтЪЭБфСПXЕФИпНзаЮЪНЃЌШчX2
ЃЈ2ЃЉВаВюЗжВМГЪвьЗНВюЁЃаое§ЕФЗНЗЈзюМђЕЅЕФЪЧЖдYШЁЖдЪ§ЁЃ
ЃЈ3ЃЉВаВюГЪздЯрЙиЁЃаое§ЕФЗНЗЈНЯМђЕЅЕФЪЧМгШыБЛНтЪЭБфСПYЕФвЛНзжЭКѓЯюНјааЛиЙщЁЃЪЙгУDWМьбщШЗШЯВаВюЕФздЯрЙиЙиЯЕЁЃ
гЩгкЮоЗЈЙлВьЕНЮѓВюЯю u t,жЛФмЭЈЙ§ВаВюЯю e tРДХаЖЯ u t ЕФааЮЊЁЃШчЙћ u tЛђ e tГЪГіЯТЭМ(a)
-(d) аЮЪНЃЌдђБэЪОu t ДцдкздЯрЙиЃЌШчЙћ ut Лђet ГЪЯжЭМжа (e) аЮЪНЃЌдђ БэЪО u
tВЛДцдкздЯрЙиЁЃ
DW=2 ВЛЯрЙиЃЛDW=0ЃЌШХЖЏЭъШЋИКЯрЙиЃЛDW=4ЃЌШХЖЏЭъШЋе§ЯрЙиЁЃВаВюЪЧЗёе§ЬЌЗжВМПЩвдЙлВьQQЭМЗжВМЁЃ
6.РыШКжЕ
РыШКжЕПЩФмЛсЕМжТФтКЯЧњЯпВњЩњЦЋВюЁЃвЛАуЪЙгУЭГМЦСПРДЪЖБ№ПЩФмЕФРыШКжЕЁЃ
ЭГМЦСПЃКбЇЩњЛЏВаВюЁЂRSTUDENTВаВюЁЂCOOKЁЎs DЁЂDFBETASЁЂDFFITS
ДІРэРыШКжЕЃКжиаТМьВщЪ§ОнЃЌШЗШЯЪ§ОнЕФгааЇадЁЃШчЙћгааЇЃЌвЊЗжЮіАќКЌКЭЩОГ§РыШКжЕЕФНсЙћЁЃЮЊСЫИќКУЕФФтКЯЪ§ОнЃЌПЩФмашвЊдкФЃаЭжаНјШыИпНзЯюЁЃ
7. ЙВЯпад
ЪЖБ№БфСПЙВЯпадЕФЙЄОпЃКЗНВюХђеЭжЕЁЂЙВЯпадЗжЮіЃЈЬиеїжЕКЭЬѕМўжИЪ§ЃЉЁЂЮоНиОрЕФЙВЯпадЗжЮі
ЗНВюХђеЭжЕVIДѓгк10ЃЌЧПЯпадЯрЙи
3.ТпМЛиЙщ
ЕБЗДгІБфСПЪЧЗжРрБфСПЪБЃЌЙЙдьФЃаЭашвЊгУЕНТпМЛиЙщЁЃ
1. ЗжРрБфСПЕФЯрЙиадМьбщ
ЗжРрБфСПжЎМфЕФЯрЙиадвЛАуПЩвдВЩгУСаСЊБэЗжЮіЛђПЈЗНМьбщЕФЗНЗЈЁЃ
1. СаСЊБэ
СаСЊБэЪЧСНИіЗжРрБфСПЕФЗжРрЫЎЦНжЎМфаЮГЩЕФНЛВцЦЕЪ§БэЃЌЭЈЙ§МЦЫуааАйЗжБШЛђСаАйЗжБШЃЌЖдЪЕМЪЦЕТЪКЭЦкЭћЦЕТЪНјааЖдБШЗжЮіЁЃ
2,.ПЈЗНМьбщ
ПЈЗНМьбщПЩгУгкСНЗжРрБфСПЯрЙиадЕФМьбщЃЌПЈЗНЭГМЦСПШчЯТЃК
ПЩвдПДЕНЭГМЦСПЪіЕФЪЕМЪЩЯЪЧЙлВьЦЕЪ§гыЦкЭћЦЕЪ§жЎМфЕФВюжЕЁЃ
2.ТпМЛиЙщЗНГЬ3. ЦРХаФЃаЭБэЯжгХСгЕФЗНЗЈ
ЃЈ1ЃЉвЛжТадЗжЮіЃКМЦЫувЛ жТЕФЖдЪ§ЃЌВЛвЛжТЕФЖдЪ§ЁЂЯрЕШЕФЖдЪ§РДЦРЙРФЃаЭЪЧЗёКмКУЕФдЄВтСЫздЩэЕФЪ§ОнЁЃCжЕдНДѓФЃаЭБэЯжСІдНКУЁЃ
ЃЈ2ЃЉЛьЯ§ОиеѓЕФНтЖСКЭЭЈЙ§ ROC ЧњЯпЦРХаФЃаЭЕФЗНЗЈЁЃ
ЭЈЙ§ЛьЯ§ОиеѓЃЌФмЙЛШЗЖЈдЄВтФЃаЭЕФСщУєЖШКЭЬивьЖШЁЃСщУєЖШжИЕФЪЧФЃаЭЁАЛїжаЁБЕФИХТЪЃЌЖјЬивьЖШжИЕФЪЧФЃаЭЁАе§ШЗЗёЖЈЁБЕФИХТЪЁЃЙЋЪНЮЊСщУєЖШ=A/ЃЈA+BЃЉЃЛЬивьЖШ=D/ЃЈC+DЃЉЁЃ
ROC ЧњЯпЪЧЛљгкСщУєЖШКЭЬивьЖШЛГіЕФЧњЯпЁЃROC ЧњЯпЯТУцЛ§жИЕФЪЧ ROC ЧњЯпКЭЕзЯпЁЂгвЯпЮЇГЩЕФУцЛ§ЁЃгЩгкСщУєЖШКЭЬивьЖШЕФШЁжЕЗЖЮЇЖМдк[0,1]жЎМфЃЌ
ROC ЧњЯпЯТУцЛ§жЕдННгНќ1ЃЌБэУїФЃаЭдЄВтФмСІдНЧПЁЃ
Цп ЁЂЪБМфађСа
ЪБМфађСаЃКЯЕЭГжаФГвЛБфСПЛђжИБъЕФЪ§жЕЛђЭГМЦЙлВтжЕЃЌАДЪБМфЫГађХХСаГЩвЛИіЪ§жЕађСаЃЌОЭГЦЮЊЪБМфађСа(Time
Series)ЃЌгжГЦЖЏЬЌЪ§ОнЁЃ
1. ЧїЪЦЗжНтЗЈ
1. ЪБМфађСаБфЛЏаЮЪН
ЪБМфађСажївЊПМТЧЕФвђЫиЪЧЃК
ГЄЦкЧїЪЦ(Long-term trend)
ЪБМфађСаПЩФмЯрЕБЮШЖЈЛђЫцЪБМфГЪЯжФГжжЧїЪЦЁЃ
ЪБМфађСаЧїЪЦвЛАуЮЊЯпадЕФ(linear)ЃЌЖўДЮЗНГЬЪНЕФ (quadratic)ЛђжИЪ§КЏЪ§(exponential
function)ЁЃ
МОНкадБфЖЏ(Seasonal variation)
АДЪБМфБфЖЏЃЌГЪЯжжиИДадааЮЊЕФађСаЁЃ
МОНкадБфЖЏЭЈГЃКЭШеЦкЛђЦјКђгаЙиЁЃ
МОНкадБфЖЏЭЈГЃКЭФъжмЦкгаЙиЁЃ
жмЦкадБфЖЏ(Cyclical variation)
ЯрЖдгкМОНкадБфЖЏЃЌЪБМфађСаПЩФмОРњЁАжмЦкадБфЖЏЁБЁЃ
жмЦкадБфЖЏЭЈГЃЪЧвђЮЊОМУБфЖЏЁЃ
ЫцЛњгАЯь(Random effects)
ШчЭМЫљЪОЃЌКкЩЋЕФЧњЯпДњБэЪБМфађСаЕФдЪМШЁжЕЃЌ ЖјИљОндЪМађСаЕФЪБМфзпЪЦОЭФмШЗЖЈИУЪБМфађСаЕФГЄЦкЧїЪЦБфЖЏЁЃ
ЖјКмЖраавЕЖМЪЧДцдкМОНкадБфЖЏЕФЧїЪЦЕФЁЃБШШчЃЌ дЫЪфаавЕЁЂЗчСІЗЂЕчаавЕЁЃгжБШШчЃЌ ЫЎЙћКЭЪпВЫМлИёЕШЁЃ
ЖјбЛЗЧїЪЦвВГЩЮЊжмЦкЧїЪЦЁЃБШШчОМУжмЦкЧїЪЦЁЃЯрЖдЖјбдЃЌ бЛЗКЭМОНкадЧїЪЦЪЧдЪМађСажаНЯЮЊЮШНЁЕФЧїЪЦБфЖЏЁЃ
ЖјЮоЙцдђЕФЫцЛњЧїЪЦЪЧФбвдНјаадЄВтЕФЃЌЧвВЈЖЏНЯДѓЁЃвђДЫЃЌ ЖдгкЪБМфађСаЕФВ№ЗжЃЌЭЈГЃЪЧНЋНЯЮЊЮШНЁЕФГЄЦкбЛЗвдМАМОНкадЧїЪЦВ№ЗжГіРДЃЌЖјВЛПМТЧЫцЛњЧїЪЦЕФгАЯьЁЃ
2. ЪБМфађСаФЃаЭ
2. ЪБМфађСаЗжЮідЄВтЗЈЕФЗжРр
ЦНЛЌдЄВтЗЈ
АќРЈвЦЖЏЦНОљЗЈКЭжИЪ§ЦНЛЌЗЈСНжжЃЌЦфОпЬхЪЧАбЪБМфађСазїЮЊЫцЛњБфСПЃЌдЫгУЫуЪѕЦНОљКЭМгШЈЦНОљЕФЗНЗЈзіЮДРДЧїЪЦЕФдЄВтЁЃетбљЕУЕНЕФЧїЪЦЯпБШЪЕМЪЪ§ОнЕуЕФСЌЯпвЊЦНЛЌвЛаЉЃЌЙЪГЦЦНЛЌдЄВтЗЈЁЃ
ЧїЪЦЭтЭЦдЄВтЗЈ
ИљОндЄВтЖдЯѓРњЪЗЗЂеЙЕФЭГМЦзЪСЯЃЌФтКЯГЩдЄЯШжИЖЈЕФФГжжЪБМфКЏЪ§ЃЌВЂгУЫќРДУшЪідЄВтФПБъЕФЗЂеЙЧїЪЦЁЃ
ЦНЮШЪБМфађСадЄВтЗЈ
гЩгкЦНЮШЪБМфађСаЕФЫцЛњЬиеїВЛЫцЪБМфБфЛЏЃЌЫљвдПЩРћгУЙ§ШЅЕФЪ§ОнЙРМЦИУЪБМфађСаФЃаЭЕФВЮЪ§ЃЌДгЖјПЩвддЄВтЮДРДЁЃ
3.ЦНЮШЪБМфађСа ARMA ФЃаЭ | 








