| БрМЭЦМі: |
| БОЮФРДздгкoschinaЃЌБОЮФжївЊНщЩмRocksDBЕФаДШыЕФСїГЬЁЂЖСШЁЕФВуДЮЕШЯрЙиФкШнЁЃ |
|
ЫќЪЧвЛИіИпадФмЕФKey-ValueЪ§ОнПтЁЃЩшМЦСЫЭъЩЦЕФГжОУЛЏЛњжЦЃЌЭЌЪББЃжЄадФмКЭАВШЋадЁЃФмЙЛСМКУЕФжЇГжЗЖЮЇВщбЏЃЌвђЮЊK-VМЧТМОЭЪЧАДееKeyРДХХађЕФЁЃ
ЯТЭМЮЊаДШыЕФСїГЬЃК
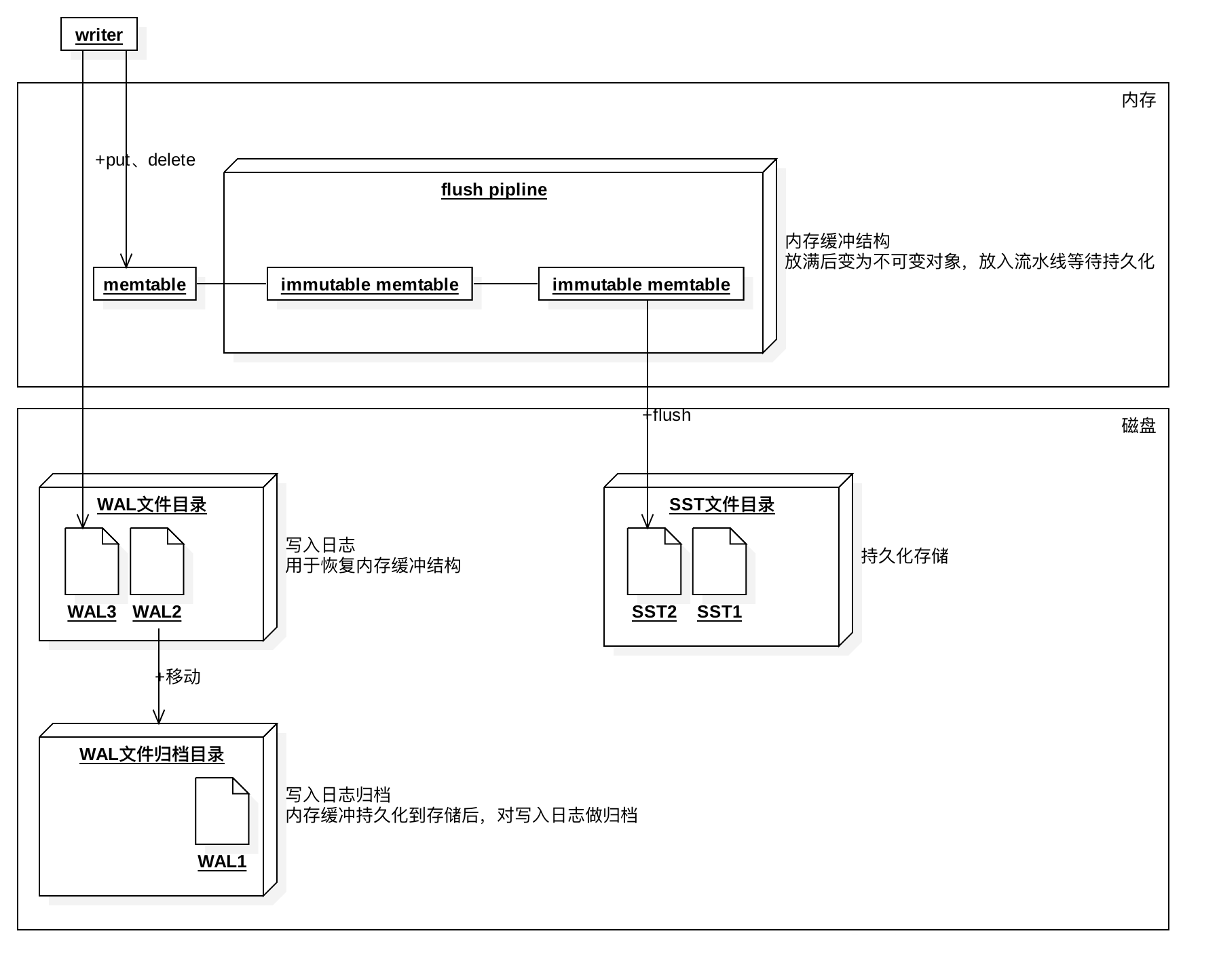
ПЩвдПДЕНжївЊЕФШ§ИізщГЩВПЗжЃЌФкДцНсЙЙmemtableЃЌРрЫЦЪТЮёШежОНЧЩЋЕФWALЮФМўЃЌГжОУЛЏЕФSSTЮФМўЁЃ
Ъ§ОнЛсЗХЕНФкДцНсЙЙmemtableЃЌвЛЖЈЬѕМўЯТДЅЗЂаДЕНЕНSSTЮФМўЁЃаДШыWALЮФМўЪЧПЩбЁЕФЃЌгУРДЛжИДЮДаДШыЕНДХХЬЕФmemtableЁЃ
ЯТЭМеЙЪОСЫЖСШЁЕФВуДЮЃК
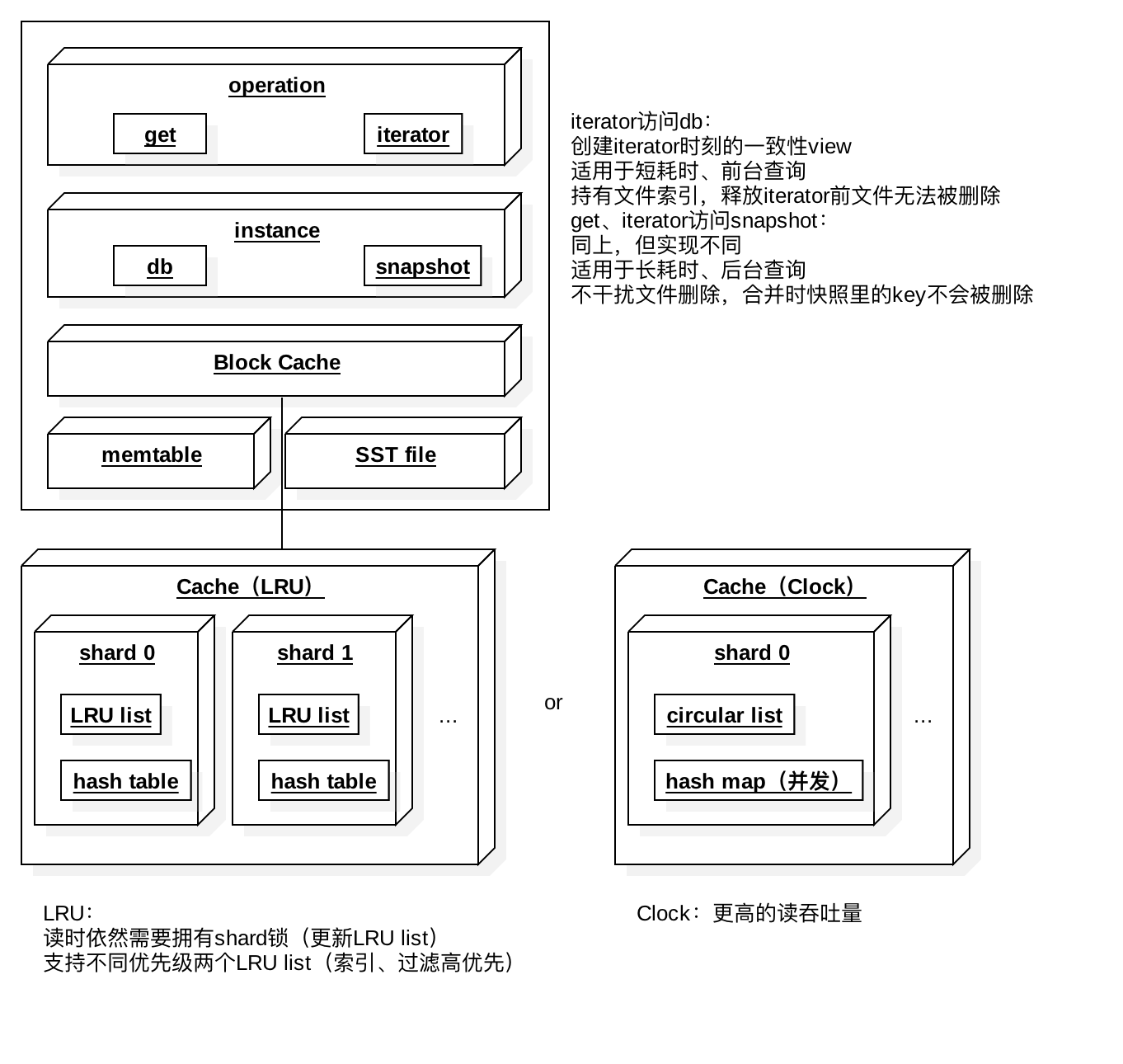
memtableКЭSSTЮФМўзщГЩЪ§ОнЕФШЋМЏЁЃжЎЩЯЪЧЛКДцВуЃЌЛКДцЮЊЬсЩ§ВщбЏадФмзіСЫЗжЦЌЃЌЕзВуЖМВЩгУhashВщбЏЃЌВЛЭЌЛКДцНсЙЙЕФЧјБ№дкгкШШЕуЪ§ОнЕФЬцЛЛТпМЁЃЗУЮЪЪ§ОнПтЪБЃЌЖМЪЧЗУЮЪЕФДђПЊЪБМфЕуЕФviewЃЈЮвВТВтвЛИіkeyгаВЛЭЌЪБМфДСЕФЖрЬѕМЧТМЃЉЁЃГ§СЫжБНгВщбЏdbЃЌЛЙЬсЙЉСЫВщбЏПьееЕФЛњжЦЁЃжБНгЗУЮЪdbЪБЃЌЛсГжгаЮФМўОфБњЃЌетбљЖрИіSSTЮФМўКЯВЂЪБЃЌвбОБЛКЯВЂЕЋБЛЗУЮЪЕФЮФМўОЭВЛФмБЛЩОГ§ЁЃЖјПьееЛњжЦБЃжЄСЫЗУЮЪЙ§ГЬжаЮФМўФмБЛЩОГ§ЃЈЮвВЂЮДЯыУїАзШчКЮзіЕНЕФЃЉЃЌВЛЙ§ДђПЊЦкМфБЛЩОГ§ЕФkeyЕФМЧТМЛЙЛсдкаТКЯВЂЕФЮФМўРяДцдкЁЃ
memtableЕФНсЙЙгаМИжжПЩбЁЃЌБОжЪЖМЪЧХХађЕФНсЙЙЃЈЮЊСЫжЇГжЗЖЮЇВщбЏЃЉ
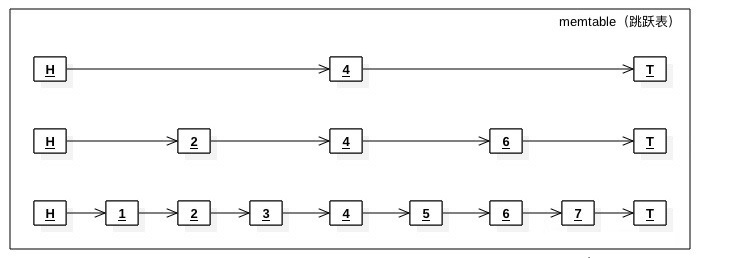
ЦфжажЎвЛЪЧЩЯЭМЕФЬјдОБэЃЌВЛСЫНтЬјдОБэЛњжЦЕФЖСепПЩвдМђЕЅРэНтЮЊгаађжЇГжНќЫЦЖўЗжВщевЕФЪБМфИДдгЖШЮЊlog2(N)ЕФНсЙЙ
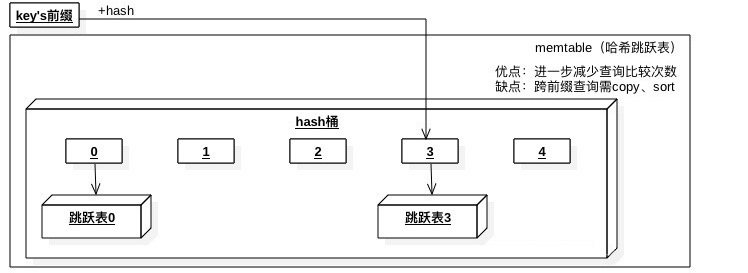
СэЭтвЛжжЪЧhashНсКЯЬјдОБэЃЌЪЧАДееkeyЕФЧАзКзіhashЃЌЕЅЖРЗУЮЪвЛИіkeyЪБадФмИќКУЃЌЗЖЮЇВщбЏадФмЛсВюаЉ
WALЮФМўНсЙЙШчЯТЭМЃЌАДееаДШыЕФЫГађРДДцДЂБфГЄЕФK-VЃЌАДееЙЬЖЈГЄЖШРДЗжзщДцДЂЃЈПЩФмвЛИіK-VПчЖрИіЗжзщЃЉЕФФПЕФЪЧБугкЖСШЁ
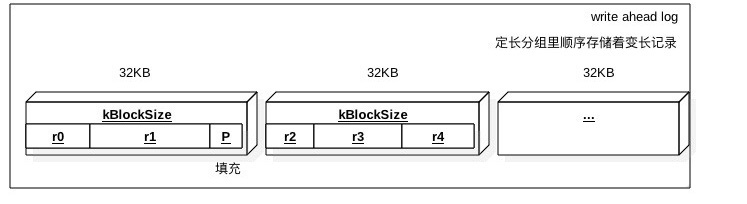
жЇГжМИжжSSTЮФМўНсЙЙ
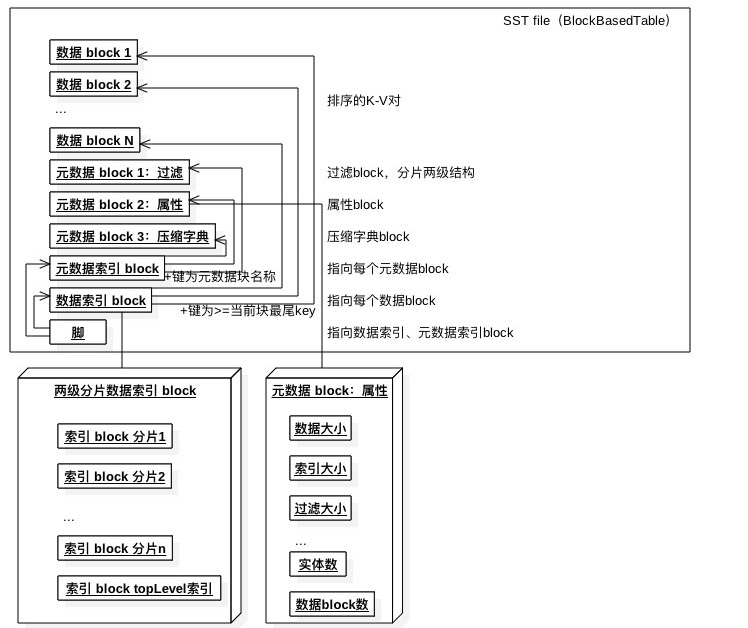
ЩЯЭМЮЊАДееЖрПщРДДцДЂЕФНсЙЙЁЃУППщЕФK-VЖМЪЧгаађЕФЃЌЖјЖрПщвВЪЧгаађЕФЁЃЮФМўжаАќКЌдЊЪ§ОнЯрЙиЕФаХЯЂЃЌАќРЈЪ§ОнбЙЫѕзжЕфЁЂЙ§ТЫЦїЕШЁЃЛсАДееЪ§ОнПщЫљЪєЕФK-VЗЖЮЇРДДДНЈЫїв§ЃЌЮЊЬсЩ§ВщбЏадФмЛсИјЫїв§ЗжЦЌЁЃ
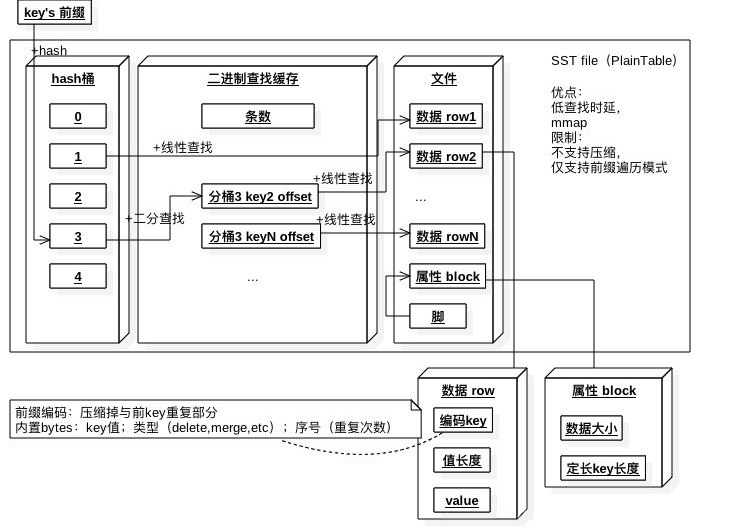
СэЭтвЛжжНсЙЙЪЧУПИіK-VРДДцДЂЁЃЫќЕФЫїв§БШНЯЬиЪтЃЌгЩhashНсЙЙКЭЖўНјжЦВщевЛКДцСНВПЗжзщГЩЁЃвРШЛАДееkeyЕФЧАзКзіhashЃЌШчЙћЭАЖдгІЕФK-VМЧТМКмЩйЃЌдђжБНгжИЯђЕквЛИіkeyЃЈгаЖрИіkeyЪєгкИУЭАЃЉЕФМЧТМЮЛжУЁЃШчЙћЪєгкЭАЕФK-VМЧТМЖргк16ЬѕЃЌЛђепАќКЌЖргквЛИіЧАзКЕФМЧТМЃЌдђЯШжИЯђЖўНјжЦВщевЛКДцЃЈЯШЖўЗжВщевЃЉЃЌЖјКѓжИЯђЕквЛИіkeyЕФМЧТМЮЛжУЁЃ
ЫцзХK-VЕФаДШыЃЌЛсЩњГЩКмЖрЕФSSTЮФМўЃЌетВПЗжЮФМўашвЊБЛКЯВЂЕНвЛЦ№ЁЃДгЖјНЕЕЭДђПЊЮФМўЪ§СПЃЌВЂЧввЦГ§вбОВЛДцдкЕФМЧТМЁЃЭЈГЃПЩвдХфжУСНжжЗНЪНЃЌЭЈгУКЯВЂЃЈЯТЭМзѓВрЃЉгыlevelКЯВЂЃЈгвВрЃЉЁЃ

ЦфжавЛИіИХФюЪЧlevelЃЌПЩвдМђЕЅРэНтГЩдНРЯЕФЪ§ОндкдНИпЕФlevelЃЈвВОЭЪЧЪ§ОнзюГѕаДШыЕНзюЕЭЕФlevelЃЌlevel0ОЭЪЧmemtableЃЉЁЃ
ЮвНЋЭЈгУКЯВЂМђЕЅРэНтЮЊвЛжжМђЕЅДжБЉЕФКЯВЂЃЌПЩвдОЁСПНЕЕЭаДДХХЬЕФбЙСІЃЌЛсдіДѓЖСШЁЕФбЙСІЃЌСйЪБПеМфеМгУДѓЁЃ
вЛАуЖрВЩгУlevelКЯВЂЕФЗНЪНЁЃУПИіlevelЖМгаmaxДѓаЁЃЌГЌГіКѓЛсДЅЗЂБОlevelгыЯТвЛlevelЕФЮФМўКЯВЂЕНвЛЦ№ЁЃВЛЭЌlevelЕФКЯВЂЪЧПЩвдВЂЗЂжДааЕФЁЃ
ЖдrocksdbзіИізмНсЁЃЫљгаМЧТМдквЕЮёЩЯЪЧгаађЕФЃЌЖдkeyЕФВщбЏЦфЪЕЛсжДааРрЫЦЖўЗжВщевЁЃГжОУЛЏЪЧЭЈЙ§аДШыгаађЮФМўРДЪЕЯжЕФЁЃИпадФмЕФаДШыЪЧЭЈЙ§ЯШаДШыФкДцНсЙЙРДБЃжЄЕФЃЈаДТњЕФФкДцНсЙЙЫЂЕНГжОУЛЏЮФМўЃЉЁЃЬсЙЉСЫlevelЛњжЦЖдЪ§ОнзіЗжВуЃЌгХЯШВщбЏзюаТаДШыЕФlevelРДгХЛЏВщбЏадФмЁЃ | 








