| Īŗľ≠Õ∆ľŲ: |
| Īĺőńņī◊‘”ŕľÚ ť,◊ų’Ŗ’ĺ‘ŕ≥Ő–Ú‘ĪĶńĹ«∂»“‘MySQLő™ņżŐĹňų żĺ›Ņ‚Ķńį¬√ō£°Ō£ÕŻőń’¬ń໛ŝ…‹Ņ…Ļ©≤őŅľ°£ |
|
żĺ›Ņ‚ĽýĪĺ‘≠ņŪ
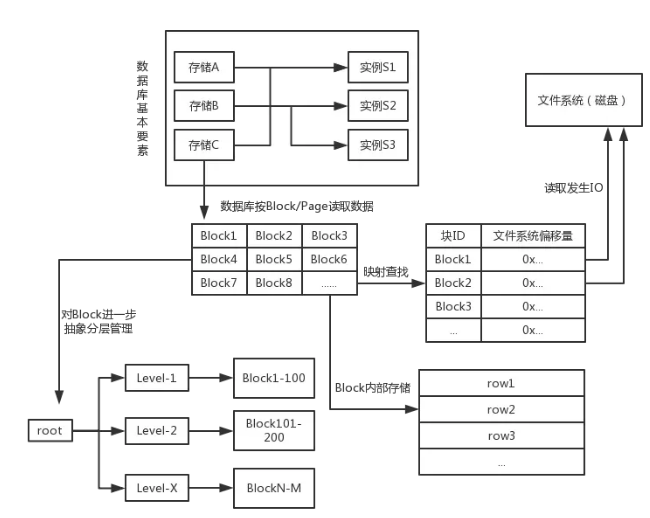
ő“∂‘DBĶńņŪĹ‚
Ķŕ“Ľ£¨ żĺ›Ņ‚Ķń◊ť≥…£ļīśīĘ + Ķņż
≤ĽĪō∂ŗňĶ£¨ żĺ›ĶĪ»Ľ–Ť“™īśīĘ£ĽīśīĘŃňĽĻ≤ĽĻĽ£¨Ō‘»Ľ–Ť“™ŐŠĻ©≥Ő–Ú∂‘īśīĘĶń≤Ŕ◊ųĹÝ––∑‚◊į£¨∂‘Õ‚ŐŠĻ©‘Ų…ĺłń≤ťĶńAPI£¨ľī Ķņż°£
“ĽłŲīśīĘ£¨Ņ…“‘∂‘”¶∂ŗłŲ Ķņż£¨’‚ĹęŐŠłŖ’‚łŲīśīĘĶńłļ‘ōń‹Ń¶“‘ľįłŖŅ…”√£Ľ∂ŗłŲīśīĘŅ…“‘∑÷≤ľ‘ŕ≤ĽÕ¨ĶńĽķ∑Ņ°ĘĶō”Ú£¨Ĺę ĶŌ÷»›‘÷°£
Ķŕ∂Ģ£¨įīBlock or Page∂Ń»° żĺ›
”√īůÕ»ŌŽ“≤÷™Ķņ£¨ żĺ›Ņ‚≤ĽŅ…ń‹įī––∂Ń»° żĺ›£®Why? ? ^_^£©°£ Ķ÷ …Ō£¨ żĺ›Ņ‚£¨»ÁOracle/MySQL£¨∂ľ «Ľý”ŕĻŐ∂®īů–°£®Ī»»Á16K£©ĶńőÔņŪŅť£®Block
or Page£¨ő“’‚ņÔĺÕ≤Ľ«Ý∑÷Õ≥“Ľ≥∆ő™Block£©ņī ĶŌ÷Ķų∂»ļÕĻ‹ņŪĶń°£“™÷™ĶņBlock « żĺ›Ņ‚ĶńłŇńÓ£¨»Áļő∂‘”¶ĶĹőńľĢŌĶÕ≥ńō£ŅŌ‘»Ľ–Ť“™÷ł≥Ų°į’‚łŲBlockĶńĶō÷∑‘ŕńńņÔ°Ī£¨ĶĪ≤ť’“ĶĹĶō÷∑ļů£¨∂Ń»°ĻŐ∂®īů–°Ķń żĺ›ĺÕŌŗĶĪ”ŕÕÍ≥…ŃňBlockĶń∂Ń»°Ńň°£
żĺ›Ņ‚ļ‹īŌ√ųĶń£¨ňŁ≤ĽĽŠĹŲĹŲ÷Ľ∂Ń»°–Ť“™∂Ń»°ĶńBlock£¨ňŁĽĻĽŠŐśő“√«į—łĹĹŁĶńBlockŅť∂ľ∂Ń»°ľ”‘ō÷Ńńŕīś°£ Ķľ …Ō£¨’‚ «ő™Ńňľű…ŔIOīő ż£¨ŐŠłŖ√Ł÷–¬ °£ ¬ Ķ…Ō£¨“ĽłŲBlockŅťĶńłĹĹŁBlock“≤ «»»Ķ„ żĺ›£¨’‚÷÷ī¶ņŪ∑Ĺ Ĺļ‹”–Īō“™£°
Ķ໿£¨īŇŇŐIO « żĺ›Ņ‚Ķń–‘ń‹∆ŅĺĪ
ļŃőř“…ő £¨ żĺ›‘ŕīŇŇŐ…Ō£¨…Ŕ≤ĽŃňīŇŇŐIO°£ ≤√īīŇÕ∑–ż◊™£¨∂®őĽīŇĶņ£¨—į÷∑ĶńĻż≥Ő£¨ĺÕ≤ĽňĶŃň£¨ő“√« «≥Ő–Ú‘Ī£¨“≤Ļ‹≤ĽŃň’‚–©°£Ķę «’‚łŲĻż≥Ő»∑ Ķ «∑«≥£ļń ĪĶń£¨ļÕńŕīś∂Ń»°≤Ľ «“ĽłŲ żŃŅľ∂£¨ňý“‘ļůņī≥ŲŌ÷Ńňļ‹∂ŗ∑Ĺ Ĺņīľű…ŔIO£¨ŐŠ…ż żĺ›Ņ‚–‘ń‹°£
Ī»»Á£¨‘Ųľ”ńŕīś£¨»√ żĺ›Ņ‚į— żĺ›łŁ∂ŗĶńľ”‘ō÷Ńńŕīś°£ńŕīśňšļ√£¨Ķę“≤≤Ľń‹ņń”√£¨ő™ ≤√ī’‚√īňĶńō£ŅľŔ…Ť żĺ›Ņ‚÷–”–100G żĺ›£¨»ÁĻŻ∂ľľ”‘ō÷Ńńŕīś£¨“≤ĺÕňĶ żĺ›Ņ‚“™Ļ‹ņŪ100GīŇŇŐ żĺ›+100Gńŕīś żĺ›£¨ń„ňĶņŘ≤ĽņŘ£Ņ£® żĺ›Ņ‚“™ī¶ņŪīŇŇŐļÕńŕīśĶń”≥…šĻōŌĶ£¨ żĺ›ĶńÕ¨≤Ĺ£¨ĽĻ“™∂‘ńŕīś żĺ›ĹÝ––«ŚņŪ£¨»ÁĻŻ…śľį żĺ›Ņ‚ ¬őŮ£¨”÷ «“ĽŌĶŃ–łī‘”≤Ŕ◊ų......£©≤ĽĻż’‚ņÔ–Ť“™÷ł≥ŲĶń «£¨ő™Ńňľ”Ņžńŕīś≤ť’“ňŔ∂»£¨ żĺ›Ņ‚“Ľį„∂‘ńŕīśĹÝ––HASHīś∑Ň°£
Ī»»Á£¨ņŻ”√ňų“ż£¨ňų“żŌŗĪ»ńŕīś£¨ «“ĽłŲ–‘ľŘĪ»∑«≥£łŖĶń∂ęőų£¨ļůőńŌÍŌłĹť…‹MySQLĶńňų“ż‘≠ņŪ°£
Ī»»Á£¨ņŻ”√–‘ń‹łŁļ√ĶńīŇŇŐ...£®ļÕ‘Ř√«ĺÕ√ĽĻōŌĶńō£©
Ķŕňń£¨ŐŠ≥Ų“Ľ–©ő Ő‚ňľŅľŌ¬£ļ
ő™ ≤√īő“√«ňĶņŻ”√delete…ĺ≥ż“ĽłŲĪŪĶń żĺ›ĹŌtrancate“ĽłŲĪŪ“™¬ż£Ņ
°ĺ“ĽłŲįī––≤ť’“…ĺ≥ż£¨∂ŗ∑—ĺĘ£Ľ“ĽłŲĽý”ŕBlockĶńŐŚŌĶĹŠĻĻ…ĺ≥ż°Ņ
ő™ ≤√īő“√«ňĶ“™–°ĪŪ«ż∂ĮīůĪŪ£Ņ
°ĺ–°ĪŪ«ż∂ĮīůĪŪĽŠŅž£Ņ ≤√īĻŪ£ŅM*NļÕN*M≤Ľ «“Ľ—ýĶń√ī£Ņ”–ĻŪĶńĶō∑Ĺ£¨ĺÕ”–ňų“ż£°°Ņ
ŐĹňųMySQLňų“żĪ≥ļůĶń‘≠ņŪ
∂‘”ŕĺÝīů żĶń”¶”√ŌĶÕ≥£¨∂Ń–īĪ»ņż‘ŕ10:1£¨…ű÷Ń100:1£¨∂Ý«“insert/updateļ‹ń—≥ŲŌ÷–‘ń‹ő Ő‚£¨”ŲĶĹ◊Ó∂ŗĶń£¨◊Óľ¨ ÷ĶńĺÕ «selectŃň£¨select”ŇĽĮ «÷ō÷–÷ģ÷ō£¨Ō‘»Ľ…Ŕ≤ĽŃňňų“ż£°
ňĶ∆ūMySQLĶńňų“ż£¨ő“√«ĽŠ√į≥Ųļ‹∂ŗ’‚–©∂ęőų£ļBTreeňų“ż/B+Treeňų“ż/Hashňų“ż/ĺŘľĮňų“ż/∑«ĺŘľĮňų“ż...’‚√ī∂ŗ£¨‘őÕ∑£°
ňų“żĶĹĶ◊ « ≤√ī£¨ŌŽĹ‚ĺŲ ≤√īő Ő‚£Ņ
ņŌ…ķ≥£ŐłŃň£¨ĻŔÕÝňĶMySQLňų“ż «“Ľ÷÷ żĺ›ĹŠĻĻ£¨ňų“żĶńńŅĶńĺÕ «ő™ŃňŐŠłŖ≤ť—Į–߬ °£
ňĶį◊Ńň£¨≤Ľ Ļ”√ňų“żĶńĽį£¨īŇŇŐIOīő żĪ»ĹŌ∂ŗ£°“™ŌŽľű…ŔīŇŇŐIOīő ż£¨‘ű√īįž£Ņ
ő“√«ŌŽÕ®Ļż≤Ľ∂Ōňű–°ŌŽ“™ĽŮ»°Ķń żĺ›Ķń∑∂őßņī…ł—°≥Ų◊Ó÷’ŌŽ“™ĶńĹŠĻŻ£¨į—√Ņīő≤ť’“ żĺ›ĶńīŇŇŐIOīő żŅō÷∆‘ŕ“ĽłŲļ‹–°Ķń żŃŅľ∂£¨◊Óļ√ «≥£ ż żŃŅľ∂°£
ő™Ńň”¶∂‘…Ō Ųő Ő‚£¨B+Treeňų“ż≥ŲņīŃň£°
Hello£¨B+Tree
‘ŕMySQL÷–£¨≤ĽÕ¨īśīĘ“ż«ś∂‘ňų“żĶń ĶŌ÷∑Ĺ Ĺ «≤ĽÕ¨Ķń£¨’‚ņÔĹę÷ōĶ„∑÷őŲMyISAMļÕInnodb°£
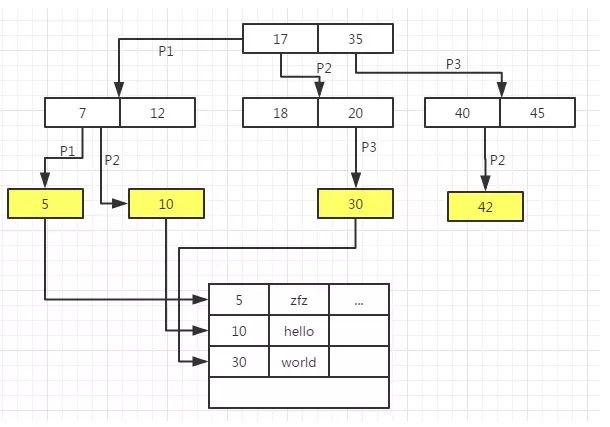
MyISAM“ż«śĶńB+Treeňų“żĹŠĻĻ
ő“√«÷™Ķņ∂‘”ŕMyISAM“ż«ś∂Ý—‘£¨ żĺ›őńľĢļÕňų“żőńľĢ «∑÷ņŽĶń°£ī”Õľ÷–“≤Ņ…“‘Ņī≥Ų£¨Õ®Ļżňų“ż≤ť’“ĶĹļů£¨ĺÕĶ√ĶĹŃň żĺ›ĶńőÔņŪĶō÷∑£¨»Ľļůłýĺ›Ķō÷∑∂®őĽ żĺ›őńľĢ÷–Ķńľ«¬ľľīŅ…°£’‚÷÷∑Ĺ Ĺ“≤Ĺ–"∑«ĺŘľĮňų“ż"°£
∂Ý∂‘”ŕInnodb“ż«ś∂Ý—‘£¨ żĺ›őńľĢĪĺ…Ū «ňų“żőńľĢ£°Õ®ň◊Ķ„ňĶ£¨“∂◊”ĹŕĶ„…Ō£¨MyISAMīśīĘĶń «ľ«¬ľĶńőÔņŪĶō÷∑£¨∂ÝInnodb…ŌīśīĘĶń « żĺ›ńŕ»›£¨’‚÷÷∑Ĺ Ĺľī"ĺŘľĮňų“ż"°£
ŃŪÕ‚“ĽĶ„–Ť“™◊Ę“‚Ķń «£¨∂‘”ŕInnodb∂Ý—‘£¨÷ųľŁňų“ż÷–“∂◊”ĹŕĶ„īśīĘĶń « żĺ›ńŕ»›£¨∂Ý∆’Õ®ňų“żĶń“∂◊”ĹŕĶ„÷–īśīĘĶń «÷ųľŁ÷Ķ£°“≤ĺÕ «ňĶ£¨∂‘”ŕInnodbĶń∆’Õ®ňų“ż◊÷∂ő≤ť’“£¨Ō»Õ®Ļż∆’Õ®ňų“żĶńB+Tree≤ť’“ĶĹ÷ųľŁļů£¨»ĽļůÕ®Ļż÷ųľŁňų“żĶńB+TreeĹÝ––≤ť’“°£ī”’‚ņÔń„Ņ…“‘Ņī≥Ų£¨∂‘”ŕInnodb∂Ý—‘£¨÷ųľŁĶńĹ®ŃĘ∑«≥£÷ō“™£°
∂Ý∂‘”ŕMyISAM∂Ý—‘£¨÷ųľŁňų“żļÕ∆’Õ®ňų“żĹŲĹŲĶń«ÝĪū‘ŕ”ŕ÷ųľŁ÷Ľ–Ť“™≤ť’“ĶĹ“ĽŐűľ«¬ľľīŅ…Õ£÷Ļ£¨∂Ý∆’Õ®ňų“ż‘ –Ū÷ōłī£¨’“ĶĹ“ĽŐűľ«¬ľļů–Ť“™ľŐ–Ý≤ť’“£¨‘ŕĹŠĻĻ…Ō√Ľ”–«ÝĪū£¨»Á…ŌÕľňý ĺ°£
…Ó»ŽB+Tree
ŐŠľłłŲő Ő‚£ļ
ő™ ≤√īB+Treeį—’ś ĶĶń żĺ›∑ŇĶĹ“∂◊”ĹŕĶ„£¨∂Ý≤Ľ «ńŕ≤„ĹŕĶ„£Ņ
ő™ ≤√īő“√«ňĶňų“ż◊÷∂ő“™ĺ°Ņ…ń‹∂Ő£¨◊Óļ√ «Ķ•ĶųĶ›‘ŲĶń£Ņ
ő™ ≤√īłīļŌňų“żīś‘ŕ◊Ó◊ů∆•Ňš‘≠‘Ú£Ņ
∑∂őß≤ť—Į£®>,<,between,like£©∂‘◊Ó◊ů∆•Ňš”– ≤√ī”įŌž£Ņ
Ļō”ŕB+TreeĶń“Ľ–© ż—ßņŪ¬Ř£¨‘Ř√«ĺÕ≤ĽÕśŃň£¨÷Ń…Ŕ“ĽĶ„Ņ…“‘ŅŌ∂®Ķń «£ļ żĺ›ĪŪĶń żĺ›ŃŅN=F( ųĶńłŖ∂»h£¨√ŅłŲBlockīśīĘĶńňų“żĶńłŲ żm)°£‘ŕN“Ľ∂®Ķń«ťŅŲŌ¬£¨ňų“ż◊÷∂ő‘Ĺ–°£¨ń«√īmĽŠ‘Ĺīů£¨’‚“‚ő∂◊ŇhĹę‘Ĺ–°£° ų‘ĹĶÕ£¨ĶĪ»Ľ≤ť’“ĶńłŁŅž£°
»ÁĻŻńŕ≤„ĹŕĶ„īś∑Ň’ś ĶĶń żĺ›£¨Ō‘»ĽmĽŠĪš–°£¨ ųĹęĪšłŖ°£
‘ŕ Ķľ ”¶”√÷–£¨ő“√«”¶ł√ĺ°Ņ…ń‹≤…”√Ķ•ĶųĶ›‘ŲĶń◊÷∂ő◊ųő™÷ųľŁ£¨“Ľ∑Ĺ√ś≤ĽĽŠ ĻĶ√ňų“żĶń żĺ›ĹŠĻĻĪšīů£¨ľű–°Ńňňų“ż’ľ”√ĶńŅ’ľš£ĽŃŪ“Ľ∑Ĺ√ś“≤≤ĽĽŠ∆Ķ∑ĪĶń∑÷Ń—B+Tree£¨ ĻĶ√–߬ Ō¬ĹĶ°£
Ī»»ÁłīļŌňų“ż(name,age,sex)£¨B+TreeĽŠ”ŇŌ»Ī»ĹŌnameņī»∑∂®Ō¬“Ľ≤ĹĶńň—ňų∑ĹŌÚ°£»ÁĻŻÕĽ»ĽņīŃňłŲ(age,sex)£¨łýĪĺ…ŌĺÕőřī”Ō¬ ÷°£’‚“≤ «∑ŻļŌ≥£ņŪĶń£¨∂‘”ŕ“ĽĪĺ ť£¨ő“√«ňĶ°į’“ĶĹĶŕľł’¬ĶŕľłĹŕĶńXXX°Ī£¨ī”√Ľ”–ŐżňĶĻż°į’“ĶĹĶŕľłĹŕĶńXXX°Ī£°’‚ «łīļŌňų“żĶń÷ō“™Őō–‘£¨ľī◊Ó◊ů∆•ŇšŐō–‘°£
ľŔ…Ťīś‘ŕłīļŌňų“ż(name,age,sex)£¨ő“√«‘ŕĹÝ––selectĶń ĪļÚ£¨≤Ę√Ľ”–įī’’’‚łŲň≥–ÚĹÝ––£¨∂Ý «sex
= 'man' and name = 'zfz' and age = 27£¨ «∑ŮĽŠ Ļ”√ňų“żńō£Ņ żĺ›Ņ‚ «ļ‹īŌ√ųĶń£¨‘ŕSQL”ŇĽĮĶń ĪļÚ£¨ĽŠ◊‘∂ĮįÔ÷ķő“√«Ķų’Ż£°Ķę «»ÁĻŻ»Ī ßŃňłīļŌňų“żĶńĶŕ“ĽŃ–£¨ żĺ›Ņ‚“≤Ĺęőřń‹ő™Ń¶ńō°£
∂‘”ŕ◊Ó◊ů∆•Ňš£¨MySQLĽŠ“Ľ÷ĪŌÚ”“∆•Ňš÷ĪĶĹ”ŲĶĹ∑∂őß≤ť—ĮĺÕÕ£÷Ļ∆•Ňš°£ ≤√ī“‚ňľ£ŅĪ»»ÁłīļŌňų“ż(name,age,sex)£¨∂‘”ŕname
= 'zhangfengzhe' and age > 26 and sex = 'man'£¨ Ķľ …Ō÷ĽņŻ”√ĶĹŃňłīļŌňų“żĶńnameŃ–°£
ŌŽņŻ”√ňų“ż£¨ĺÕĶ√°įł…弰Ī
≤√īĹ–°įł…弰Ī£ŅĺÕ «≤Ľ“™»√ňų“ż≤ő”Žľ∆ň„£°Ī»»Á‘ŕňų“ż…Ō”¶”√ļĮ ż£¨ļ‹Ņ…ń‹Ķľ÷¬ňų“ż ß–ß°£ő™ ≤√īńō£Ņ
∆š Ķ≤Ľ”√ŌŽ£¨B+Tree…ŌīśīĘĶń « żĺ›£¨“™Ī»ĹŌĶńĽį£¨–Ť“™į—ňý”–Ķń żĺ›∂ľ”¶”√…ŌļĮ ż£¨Ō‘»Ľ≥…ĪĺŐęīů°£
ŌŽĹ®ŃĘňų“ż£¨ŅīŅī«Ý∑÷∂»
ňų“żňš»ĽőÔ√ņľŘŃģ£¨Ķę «“≤Īū¬“ņī°£count(distinct col) / count(*)Ņ…“‘ň„“ĽŌ¬colĶń«Ý∑÷∂»£¨Ō‘»Ľ∂‘”ŕ÷ųľŁ∂Ý—‘£¨ĺÕ «1°£«Ý∑÷∂»ŐęĶÕĶńĽį£¨Ņ…“‘Ņľ¬«Ō¬£¨ «∑ŮĽĻ”–Īō“™Ĺ®ŃĘňų“żńō£Ņ
Hashňų“ż
’‚ņÔ≤Ę≤Ľ «“™…Ó»Ž∑÷őŲHashňų“ż£¨∂Ý «“™ňĶ√ų“ĽŌ¬HashĶńňľŌŽ’ś «őřī¶≤Ľ‘ŕ£°
‘ŕMySQLĶńMemoryīśīĘ“ż«ś÷–£¨īś‘ŕhashļĮ ż£¨łÝ“ĽłŲkey£¨Õ®ĻżhashļĮ żĹÝ––ľ∆ň„Ķ√ĶĹĶō÷∑£¨ňý“‘Õ®≥£«ťŅŲŌ¬£¨hashňų“ż≤ť’“£¨ĽŠ∑«≥£Ņž£¨O£®1£©ĶńňŔ∂»°£Ķę «“≤īś‘ŕhash≥ŚÕĽ£¨ļÕHashMap“Ľ—ý£¨Õ®ĻżĶ•ŃīĪŪĶń–ő ĹĹ‚ĺŲ°£
ňľŅľŌ¬£¨hashňų“ż «∑Ů÷ß≥÷∑∂őß≤ť—Įńō£Ņ
Ō‘»Ľ «≤Ľ÷ß≥÷Ķń£¨ňŁ÷Ľń‹łÝ“ĽłŲKEY»•≤ť’“°£ĺÕ»ÁÕ¨HashMap“Ľ—ý£¨≤ť’“keyįŁļ¨"zhangfengzhe"Ķń£¨ĽŠļ‹Ņž√ī£Ņ
SQL”ŇĽĮ…Ů∆ų£ļexplain
SQL”ŇĽĮĶń≥°ĺįļ‹∂ŗ£¨ÕÝ…ŌĶńľľ«…“≤ļ‹∂ŗ£¨Õͻ꾫≤Ľ◊°£°
“™ŌŽ≥ĻĶ◊Ĺ‚ĺŲ’‚łŲő Ő‚£¨ő“ŌŽ÷Ľ”–į—ňų“żĪ≥ļůĶń żĺ›ĹŠĻĻļÕ‘≠ņŪ◊Ų ĶĪĶńņŪĹ‚£¨”ŲĶĹ ť–īSQLĽÚ’ŖSQL¬ż≤ť—ĮĶń ĪļÚ£¨ő“√«”–Ľýī°»•∑÷őŲ£¨‘ŔņŻ”√ļ√explainĻ§ĺŖ»•—ť÷§£¨ĺÕ”¶ł√ő Ő‚≤Ľīůńō°£
explain≤ť—ĮĶńĹŠĻŻ£¨Ņ…“‘łśňŖń„ńń–©ňų“ż’ż‘ŕĪĽ Ļ”√£¨ĪŪ «»ÁļőĪĽ…®√ŤĶńĶ»Ķ»°£’‚ņÔő“Ĺę—› ĺłŲDemo°£
żĺ›ĪŪstudent£ļ
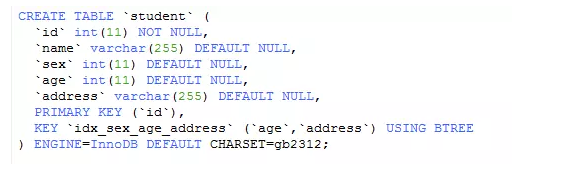
◊Ę“‚łīļŌňų“ż(age,address)
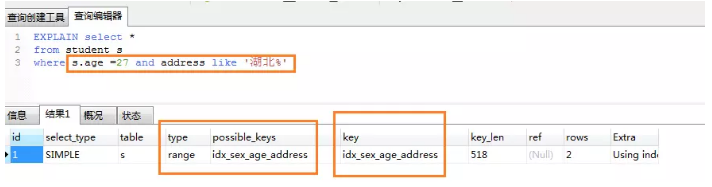
∑ŻļŌ◊Ó◊ů«į◊ļ∆•Ňš
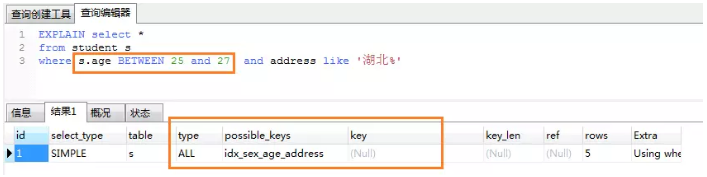
łīļŌňų“ż ß–ß
OK£¨ĶĹ’‚ņÔ£¨◊ľĪłĹŠ ÝŃň£¨≤ť—Į»›“◊£¨”ŇĽĮ≤Ľ“◊£¨«“–ī«“’šŌߣ° | 





