| БрМЭЦМі: |
| БОЮФРДздгкinfoqЃЌПЊЗЂШЫдБвРПП
Statsboard РДМрПиЯЕЭГВЂЗЂЯжЮЪЬтЃЌвђДЫЃЌПЩППгааЇЕФМрПиЯЕЭГЖдгкПЊЗЂЫйЖШРДЫЕЗЧГЃживЊЁЃ |
|
Pinterest ЪЙгУ OpenTSDB РДЬсШЁКЭЬсЙЉжИБъЪ§ОнЁЃШЛЖјЃЌЫцзХ
Pinterest ЕФЗЂеЙЃЌЗўЮёЦївВДгЪ§АйИідіМгЕНЪ§ЧЇИіЃЌУПУыВњЩњЪ§АйЭђИіЪ§ОнЕуЃЌЖјЧветИіЪ§зжЛЙдкМЬајдіГЄЁЃ
ЫфШЛ OpenTSDB дкЙІФмЩЯдЫааСМКУЃЌЕЋЦфадФмЫцзХ Pinterest ЕФдіГЄЖјНЕЕЭЃЌЕМжТдЫгЊПЊЯњЃЈР§ШчбЯжиЕФ
GC ЮЪЬтКЭ HBase ОГЃБРРЃЃЉЁЃЮЊСЫНтОіетИіЮЪЬтЃЌPinterest ПЊЗЂСЫздМКЕФФкВПЪБМфађСаЪ§ОнПтЁЊЁЊGokuЃЌЦфжаАќКЌгУ
C ++ БраДЕФ OpenTSDB МцШн APIЃЌвджЇГжИпаЇЕФЪ§ОнЬсШЁКЭГЩБОАКЙѓЕФЪБМфађСаВщбЏЁЃ
е§ЮФЃК
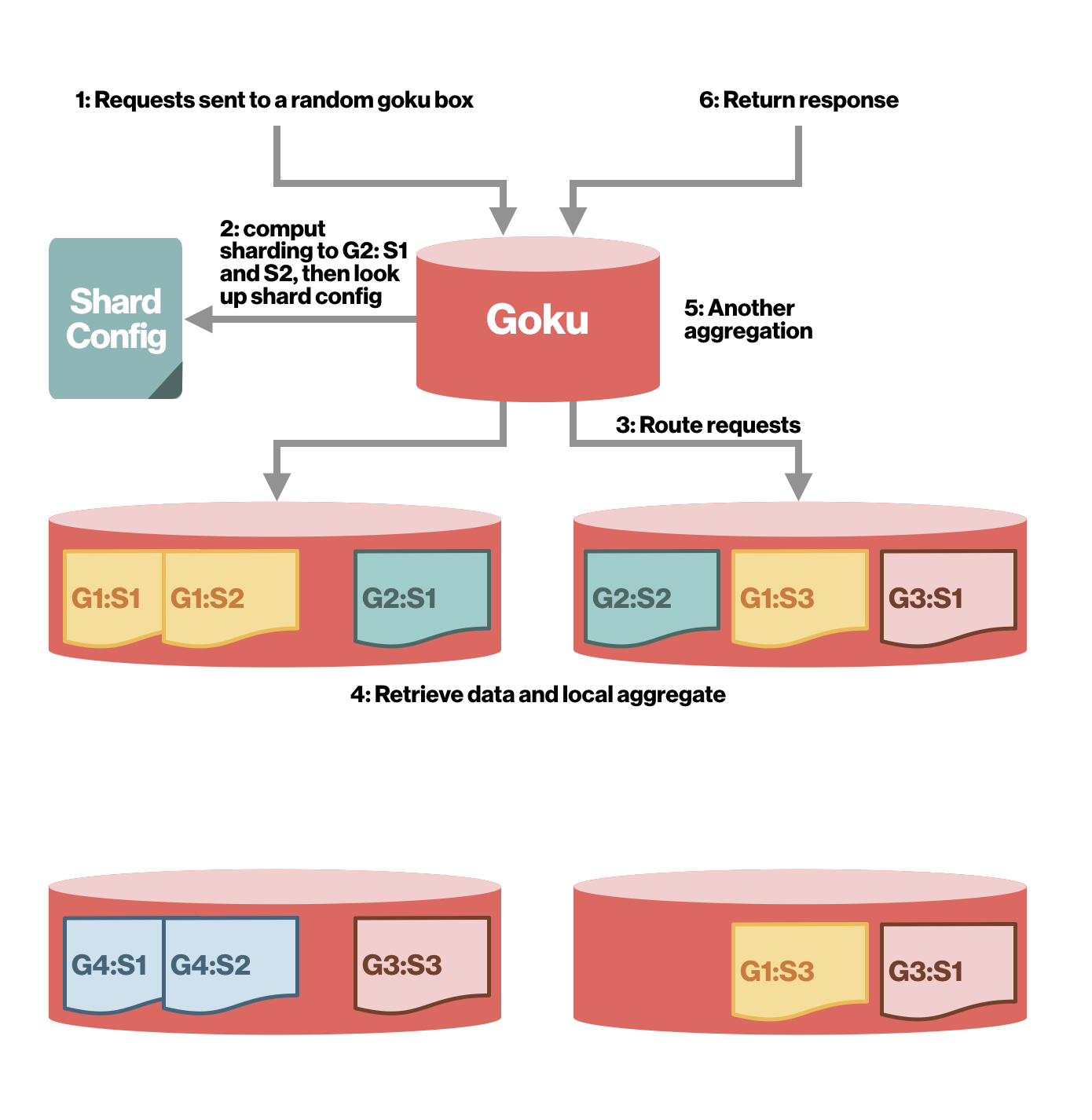
ЃЈЪЙгУ Goku НјааСНМЖЗжЦЌЃЉ
ЪБМфађСаЪ§ОнФЃаЭ
ЪБМфађСаЪ§Он
Goku зёб OpenTSDB ЕФЪБМфађСаЪ§ОнФЃаЭЁЃЪБМфађСагЩвЛИіМќКЭвЛЯЕСаЪБМфЪ§зжЪ§ОнЕузщГЩЁЃkey
= metric name + вЛзщБъМЧМќжЕЖдЁЃР§ШчЃЌЁАtc.proc.stat.cpu.total.infra-goku-a-prod
{host = infra-goku-a-prod-001ЃЌcell_id = aws-us-east-1}ЁБЁЃЪ§ОнЕу
= Мќ + жЕЁЃжЕЪЧЪБМфДСКЭжЕЖдЁЃР§ШчЃЌЃЈ1525724520,174706.61ЃЉЃЌЃЈ1525724580,173456.08ЃЉЁЃ
ЪБМфађСаВщбЏ
Г§СЫПЊЪМЪБМфКЭНсЪјЪБМфжЎЭтЃЌУПИіВщбЏЖМгЩвдЯТВПЗжЛђШЋВПзщГЩЃКЖШСПБъзМУћГЦЁЂЙ§ТЫЦїЁЂОлКЯЦїЁЂНЕВЩбљЦїЁЂЫйТЪбЁЯюЁЃ
1ЃЉЖШСПУћГЦЪОР§ЃКЁАtc.proc.stat.cpu.total.infra-goku-a-prodЁБЁЃ
2ЃЉЖдБъМЧжЕгІгУЙ§ТЫЦїЃЌвдМѕЩйдкВщбЏЛђзщжаЪАШЁЯЕСаЕФДЮЪ§ЃЌВЂдкИїжжБъМЧЩЯОлКЯЁЃGoku жЇГжЕФЙ§ТЫЦїЪОР§АќРЈЃКЭъШЋЦЅХфЁЂЭЈХфЗћЁЂOrЁЂNot
Лђ RegexЁЃ
3ЃЉОлКЯЦїЙцЖЈНЋЖрИіЪБМфађСаКЯВЂЮЊЕЅИіЪБМфађСаЕФЪ§бЇЗНЗЈЁЃGoku жЇГжЕФОлКЯЦїЪОР§АќРЈЃКSumЁЂMax
/ MinЁЂAvgЁЂZimsumЁЂCountЁЂDevЁЃ
4ЃЉНЕВЩбљЦїашвЊвЛИіЪБМфМфИєКЭвЛИіОлКЯЦїЁЃОлКЯЦїгУгкМЦЫужИЖЈЪБМфМфИєФкЫљгаЪ§ОнЕуЕФаТЪ§ОнЕуЁЃ
5ЃЉЫйТЪбЁЯюПЩбЁдёМЦЫуБфЛЏТЪЁЃгаЙиЯъЯИаХЯЂЃЌЧыВЮдФ OpenTSDB Ъ§ОнФЃаЭЁЃ
ЬєеН
Goku НтОіСЫ OpenTSDB жаЕФаэЖрЯожЦЃЌАќРЈЃК
1ЃЉВЛБивЊЕФЩЈУшЃКGoku гУЕЙХХЫїв§в§ЧцШЁДњСЫ OpenTSDB ЕФЕЭаЇЩЈУшЁЃ
2ЃЉЪ§ОнДѓаЁЃКOpenTSDB жаЕФЪ§ОнЕуЪЧ 20 зжНкЁЃPinterest ВЩгУ Gorilla
бЙЫѕРДЪЕЯж 12 БЖбЙЫѕЁЃ
3ЃЉЕЅЛњОлКЯЃКOpenTSDB НЋЪ§ОнЖСШЁЕНвЛИіЗўЮёЦїЩЯВЂНјааОлКЯЃЌЖј Goku ЕФаТВщбЏв§ЧцЪЧНЋМЦЫуЧЈвЦЕНИќНгНќДцДЂВуЕФЮЛжУЃЌИУДцДЂВудквЖНкЕуЩЯНјааВЂааДІРэЃЌШЛКѓдкИљНкЕуЩЯОлКЯВПЗжНсЙћЁЃ
4ЃЉађСаЛЏЃКOpenTSDB ЪЙгУ JSONЃЌЕБгаЬЋЖрЪ§ОнЕувЊЗЕЛиЪБЃЌJSON ЛсКмТ§ЃЛGoku
ЪЙгУ thrift ЖўНјжЦДњЬцЁЃ
МмЙЙ
ДцДЂв§Чц
Goku дкФкДцДцДЂв§ЧцжаЪЙгУСЫ Facebook Gorilla РДДцДЂЙ§ШЅ 24 аЁЪБФкЕФзюаТЪ§ОнЁЃ
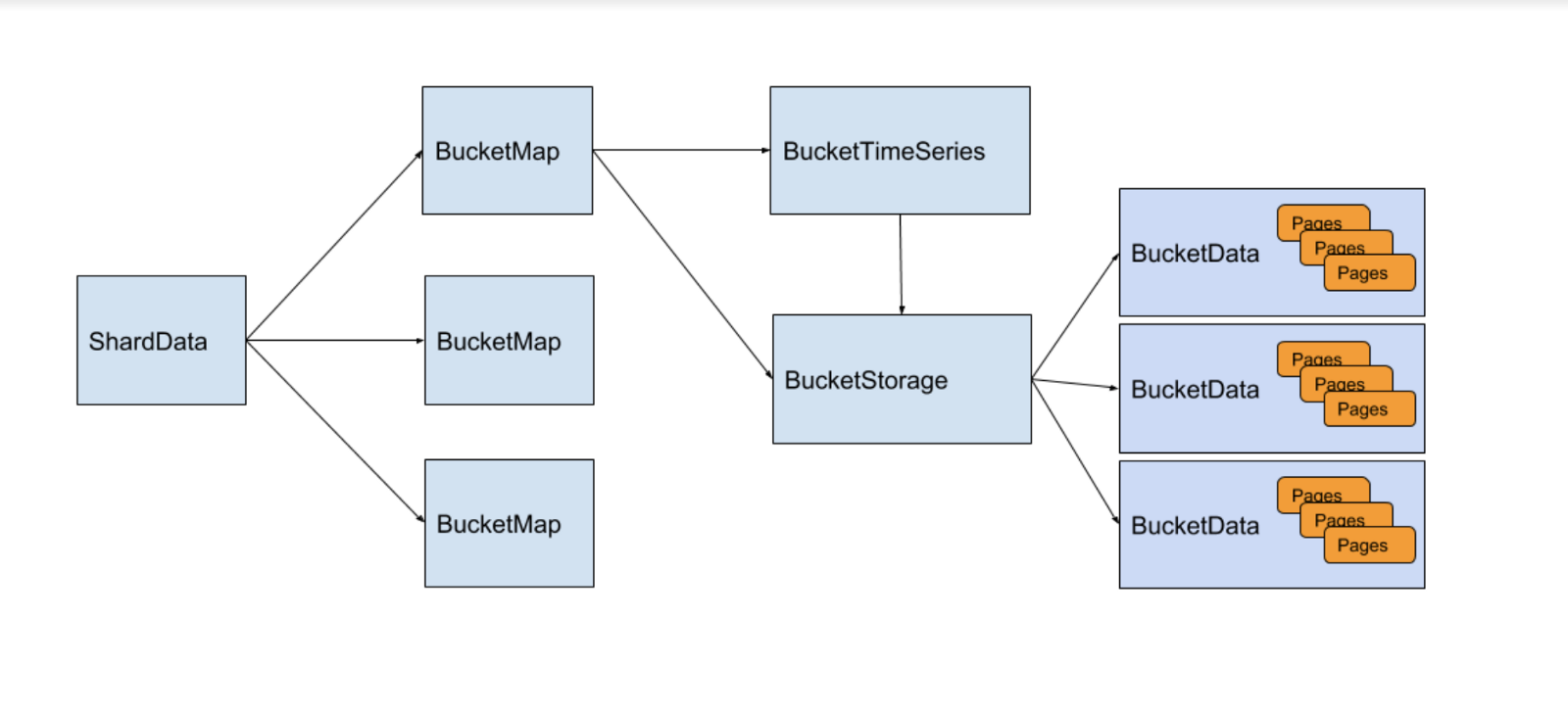
ЃЈДцДЂв§ЧцМђНщЁЃЧыВщПД GorillaТлЮФМАЦф GitHubДцДЂПтРДСЫНтЯъЯИаХЯЂЃЉ
ШчЩЯЫљЪіЃЌдкДцДЂв§ЧцжаЃЌЪБМфађСаБЛЗжГЩГЦЮЊ BucketMap ЕФВЛЭЌЗжЦЌЁЃЖдгквЛИіЪБМфађСаЃЌвВБЛЗжЮЊПЩвдЕїећЪБГЄЕФ
bucketЃЈPinterest ФкВПвдУП 2 аЁЪБЮЊвЛИі bucketЃЉЁЃдкУПИі BucketMap
жаЃЌУПИіЪБМфађСаЖМБЛЗжХфвЛИіЮЈвЛЕФ ID ВЂСДНгЕНвЛИі BucketTimeSeries ЖдЯѓЁЃBucketTimeSeries
НЋзюаТЕФПЩаоИФЛКГхЧјДцДЂЧјКЭДцДЂ ID БЃДцЕН BucketStorage жаЕФВЛПЩБфЪ§ОнДцДЂЧјЁЃдкХфжУДцДЂ
bucket ЪБМфжЎКѓЃЌBucketTimeSeries жаЕФЪ§ОнНЋБЛаДШы BucketStorageЃЌБфЮЊВЛПЩБфЪ§ОнЁЃ
ЮЊСЫЪЕЯжГжОУадЃЌBucketData вВЛсаДШыДХХЬЁЃЕБ Goku жиаТЦєЖЏЪБЃЌЫќЛсНЋЪ§ОнДгДХХЬЖСШыФкДцЁЃPinterest
ЪЙгУ NFS РДДцДЂЪ§ОнЃЌДгЖјЪЕЯжМђЕЅЕФЗжЦЌЧЈвЦЁЃ
ЗжЦЌКЭТЗгЩ
ЮвУЧЪЙгУСНВуЗжЦЌВпТдЁЃЪзЯШЃЌЮвУЧЖдЖШСПУћГЦНјааЩЂСаЃЌвдШЗЖЈФГвЛЪБМфађСаЪєгкФФИіЗжЦЌзщЁЃЮвУЧдкЖШСПУћГЦ
+ БъМЧМќжЕМЏЩЯНјааЩЂСаЃЌвдШЗЖЈЪБМфађСадкЫљдкзщжаЕФФФИіЗжЦЌЁЃДЫВпТдПЩШЗБЃЪ§ОндкЗжЦЌжЎМфБЃГжЦНКтЁЃЭЌЪБЃЌгЩгкУПИіВщбЏНіНјШывЛИізщЃЌвђДЫЩШГіБЃГжНЯЕЭЫЎЦНЃЌвдМѕЩйЭјТчПЊЯњКЭЮВВПбгГйЁЃСэЭтЃЌЮвУЧПЩвдЖРСЂЕиРЉеЙУПИіЗжЦЌзщЁЃ
ВщбЏв§Чц
ЕЙХХЫїв§
Goku ЭЈЙ§жИЖЈБъМЧМќКЭБъМЧжЕРДжЇГжВщбЏЁЃР§ШчЃЌШчЙћЮвУЧЯыжЊЕРвЛИіжїЛњhost1ЕФ CPU ЪЙгУТЪЃЌЮвУЧПЩвдНјааВщбЏcpu.usage
{host = host1}ЁЃЮЊСЫжЇГжетжжВщбЏЃЌPinterest ЪЕЯжСЫЕЙХХЫїв§ЁЃЃЈдк Pinterest
ФкВПЃЌЫќЪЧДгЫбЫїЯюЕНЮЛМЏЕФЩЂСагГЩфЁЃЃЉЫбЫїЯюПЩвдЪЧЯёcpu.usageетбљЕФЖШСПУћГЦЃЌвВПЩвдЪЧЯёhost
= host1етбљЕФБъМЧМќжЕЖдЁЃЪЙгУетИіЕЙХХЫїв§в§ЧцЃЌЮвУЧПЩвдПьЫйжДааANDЁЂORЁЂNOTЁЂWILDCARDКЭREGEXВйзїЃЌгыдЪМЕФЛљгк
OpenTSDB ЩЈУшЕФВщбЏЯрБШЃЌетвВМѕЩйСЫаэЖрВЛБивЊЕФВщевЁЃ
ОлКЯ
ДгДцДЂв§ЧцМьЫїЪ§ОнКѓЃЌПЊЪМНјааОлКЯКЭЙЙНЈзюжеНсЙћЕФВНжшЁЃ
Pinterest зюГѕГЂЪдСЫ OpenTSDB ЕФФкжУВщбЏв§ЧцЁЃНсЙћЗЂЯжЃЌгЩгкЫљгадЪМЪ§ОнЖМашвЊдкЭјТчЩЯдЫааЃЌадФмЛсбЯжиЯТНЕЃЌЖјЧветаЉЖЬЦкЖдЯѓвВЛсЕМжТКмЖр
GCЁЃ
вђДЫЃЌPinterest дк Goku жаИДжЦСЫ OpenTSDB ЕФОлКЯВуЃЌВЂОЁПЩФмЕидчЕиНјааМЦЫуЃЌвдОЁСПМѕЩйЯпЩЯЕФЪ§ОнЁЃ
ЕфаЭЕФВщбЏСїГЬШчЯТЃК
гУ Statsboard ПЭЛЇЖЫВщбЏЃЈPinterest ЕФФкВПЖШСПМрПи UIЃЉШЮКЮДњРэ goku
ЪЕР§
ДњРэ goku ЛљгкЗжЦЌХфжУНЋВщбЏЩШГіЕНЭЌвЛзщФкЕФЯрЙи goku ЪЕР§
УПИі goku ЖСШЁЕЙХХЫїв§вдЛёШЁЯрЙиЕФЪБМфађСа ID ВЂЛёШЁЦфЪ§Он
УПИі goku ЛљгкВщбЏОлКЯЪ§ОнЃЌШчОлКЯЦїЁЂНЕВЩбљЦїЕШ
ДњРэ goku дкЪеМЏУПИі goku ЕФНсЙћВЂЗЕЛиПЭЛЇЖЫКѓНјааЕкЖўТжОлКЯ
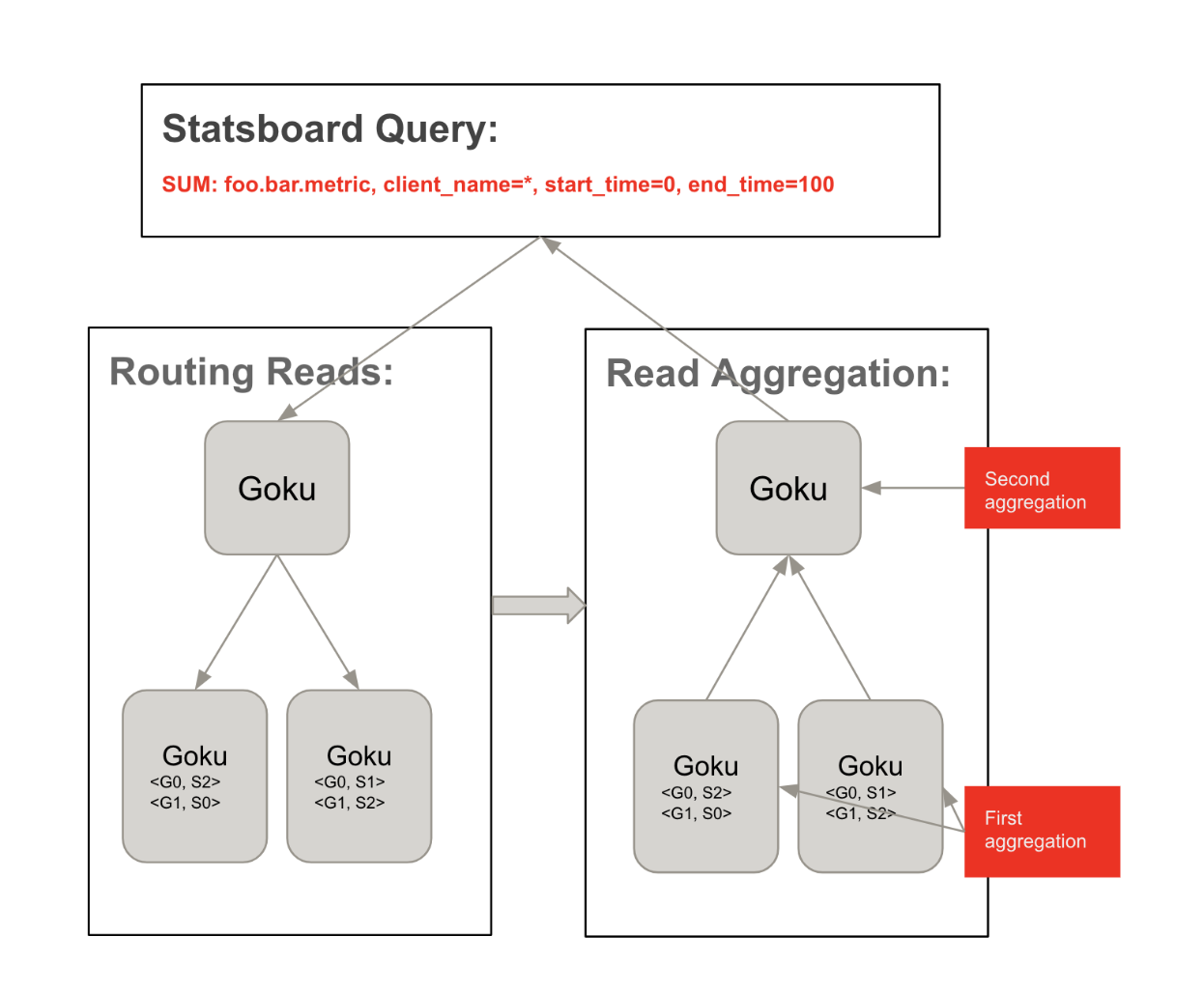
адФм
гыжЎЧАЪЙгУЕФ OpenTSDB / HBase НтОіЗНАИЯрБШЃЌGoku дкМИКѕЫљгаЗНУцЖМБэЯжИќКУЁЃ

СэвЛИідкЪЙгУ Goku ЧАКѓИпЛљЪ§ВщбЏбгГйЖдБШЭМЃЌШчЯТЭМЫљЪОЃК
ЯТвЛВН
ЛљгкДХХЬЕФГЄЦкЪ§ОнДцДЂ
Goku зюжеНЋжЇГжГЌЙ§вЛЬьЪБМфЪ§ОнЕФВщбЏЁЃЖдгкЯёвЛФъетбљЕФЪБГЄВщбЏЃЌPinterest НЋВЛЛсЙ§ЗжЧПЕївЛУыжгФкЗЂЩњЕФЪТЧщЃЌЖјЪЧЙизЂећЬхЧїЪЦЁЃвђДЫЃЌPinterest
НЋНјааНЕВЩбљКЭбЙЫѕЃЌАбвдаЁЪБМЦЕФ bucket КЯВЂЮЊИќГЄЦкЕФЪБГЄЃЌДгЖјМѕаЁЪ§ОнСПВЂЬсИпВщбЏадФмЁЃ
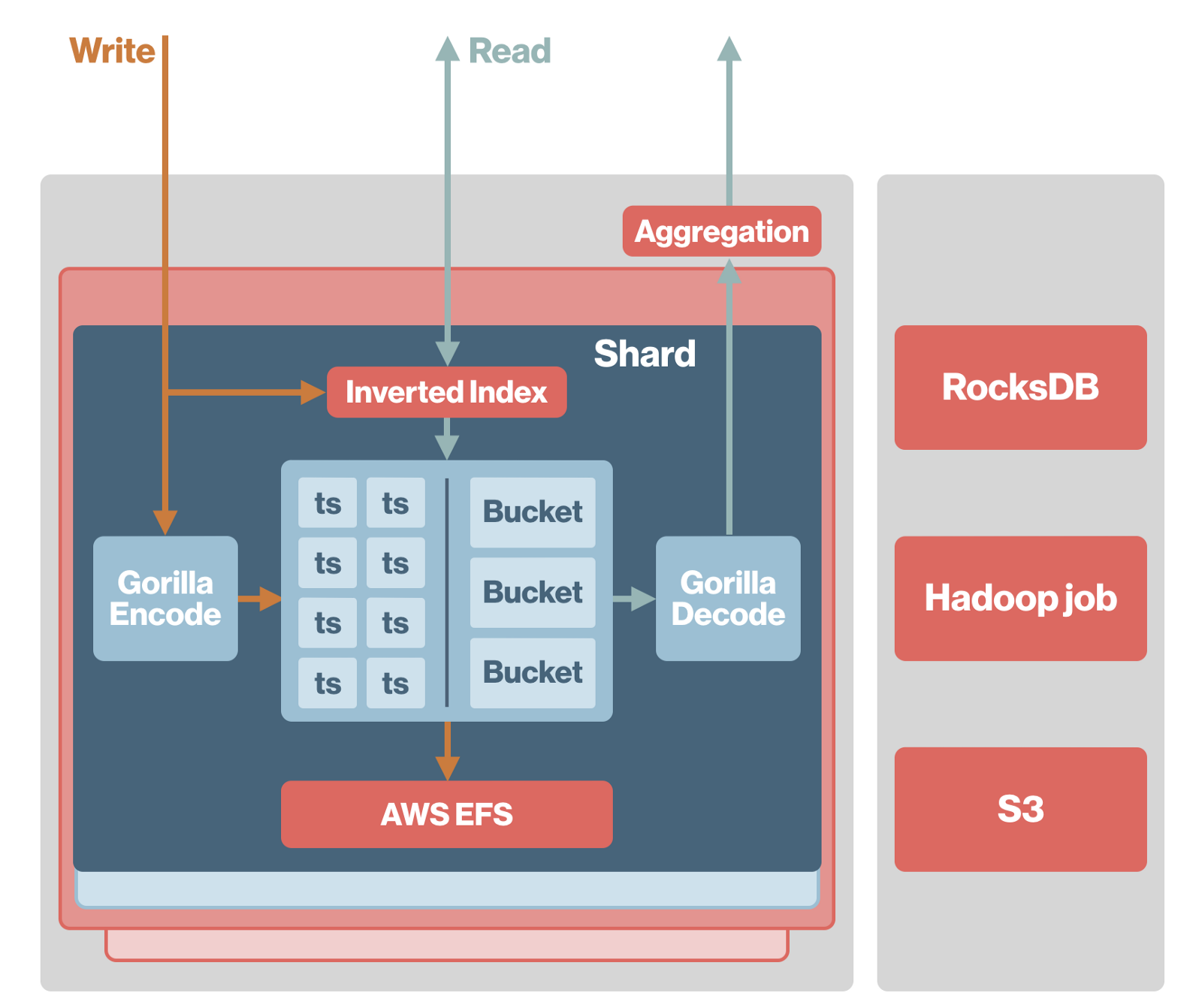
ЃЈGoku НзЖЮЃЃ2ЁЊЁЊЛљгкДХХЬЃКЪ§ОнАќРЈЫїв§Ъ§ОнКЭЪБМфађСаЪ§ОнЃЉ
ИДжЦ
ФПЧАЃЌPinterest гаСНИі goku МЏШКНјааЫЋаааДШыЁЃДЫЩшжУЬсИпСЫПЩгУадЃКЕБвЛИіМЏШКжаДцдкЮЪЬтЪБЃЌПЩвдЧсЫЩЕиНЋСїСПЧаЛЛЕНСэвЛИіМЏШКЁЃЕЋЪЧЃЌгЩгкетСНИіМЏШКЪЧЖРСЂЕФЃЌвђДЫКмФбШЗБЃЪ§ОнЕФвЛжТадЁЃР§ШчЃЌШчЙћаДШывЛИіМЏШКГЩЙІЖјСэвЛИіЮДГЩЙІЪБЃЌдђЪ§ОнаДШыЪЇАмЃЌЪ§ОнгЩДЫБфЕУВЛвЛжТЁЃСэвЛИіШБЕуЪЧЙЪеЯзЊвЦзмЪЧдкМЏШКВуУцЗЂЩњЁЃЮЊДЫЃЌPinterest
е§дкПЊЗЂЛљгкШежОЕФМЏШКФкИДжЦЃЌвджЇГжжїДгЗжЦЌЁЃетНЋЬсИпЖСШЁПЩгУадЃЌБЃГжЪ§ОнвЛжТадЃЌВЂжЇГжЗжЦЌМЖЕФЙЪеЯзЊвЦЁЃ
ЗжЮігУР§
ЫљгааавЕЖМашвЊЙуЗКЕФЗжЮіЃЌPinterest вВВЛР§ЭтЃЌР§ШчУцСйбЏЮЪЪЕбщКЭЙуИцЭЦЙуаЇЙћЕШЮЪЬтЁЃФПЧАЃЌPinterest
жївЊВЩгУРыЯпзївЕКЭ HBase НјааЗжЮіЃЌетвтЮЖзХВЛЛсгаЪЕЪБЪ§ОнВњЩњЃЌВЂБмУтДѓСПВЛБивЊЕФдЄОлКЯЁЃгЩгкЪБМфађСаЪ§ОнЕФаджЪЃЌGoku
ПЩвдКмШнвзЕиЪЪгІЫќЃЌВЛНіПЩвдЬсЙЉЪЕЪБЪ§ОнЃЌЛЙПЩвдЬсЙЉАДашОлКЯЁЃ
Pinterest БэЪОНЋМЬајЬНЫї Goku ЕФгУР§ЃЌШчЙћФуЖдДЫРрЯюФПИааЫШЄЃЌЧыВщПД | 








