| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊВћЪіСЫвђRedisЕФRehashЛњжЦгіЕНЕФСНИіЮЪЬтЃЌДгЯжЯѓЕНдРэНјааСЫЯъЯИЕФНщЩмЁЃ |
|
БГОА
SquirrelЃЈЫЩЪѓЃЉЪЧУРЭХММЪѕЭХЖгЛљгкRedis ClusterДђдьЕФЛКДцЯЕЭГЁЃОЙ§ВЛЖЯЕФЕќДњбаЗЂЃЌФПЧАвбаЮГЩвЛећЬзздЖЏЛЏдЫЮЌЬхЯЕЃККИЧвЛМќдЫЮЌМЏШКЁЂЯИСЃЖШЕФМрПиЁЂжЇГжздЖЏРЉЫѕШнвдМАШШЕуKeyМрПиЕШЭъећЕФНтОіЗНАИЁЃЭЌЪБЗўЮёЖЫЭЈЙ§DockerНјааВПЪ№ЃЌзюДѓГЬЖШЕФЬсИпдЫЮЌЕФСщЛюадЁЃЗжВМЪНЛКДцSquirrelВњЦЗзд2015ФъЩЯЯпжСНёЃЌвбдкУРЭХФкВПЙуЗКЪЙгУЃЌДцДЂШнСПГЌЙ§60TЃЌШеОљЕїгУСПвВГЌЙ§ЭђвкДЮЃЌж№ВНГЩЮЊУРЭХФПЧАзюжївЊЕФЛКДцЯЕЭГжЎвЛЁЃ
ЫцзХЪЙгУЕФСПКЭГЁОАВЛЖЯЩюШыЃЌSquirrelЭХЖгвВВЛЖЯЗЂЯжRedisЕФШєИЩЁБПгЁБКЭВЛзуЃЌвђДЫвВдкГжајЕФИФНјRedisвджЇГХУРЭХФкВППьЫйЗЂеЙЕФвЕЮёашЧѓЁЃБОЮФГЂЪдЗжЯэдкдЫЮЌЙ§ГЬжаВШЙ§ЕФRedis
RehashЛњжЦЕФвЛаЉПгвдМАЮвУЧЕФНтОіЗНАИЃЌЦфжадкИпИКдиЧщПіЯТЮяРэЛњЗЂЩњЖЊАќЕФЯжЯѓКЭНтОіЗНАИвбОаДГЩВЉПЭЁЃ
АИР§
Redis ТњШнзДЬЌЯТгЩгкRehashЕМжТДѓСПKeyЧ§ж№
ЮвУЧЯШРДПДвЛеХМрПиЭМЃЈЩЯЭМЃЌЮвУЧЯпЩЯецЪЕАИР§ЃЉЃЌRedisдкТњШнгаЧ§ж№ВпТдЕФЧщПіЯТЃЌMaster/Slave
ОљгаДѓСПЕФKeyЧ§ж№ЬдЬЃЌЕМжТMaster/Slave жїДгВЛвЛжТЁЃ
Root Cause ЖЈЮЛ
гЩгкSlaveФкДцЧјгђБШMasterЩйвЛИіrepl-backlog bufferЃЈЯпЩЯвЛАуХфжУЮЊ128MЃЉЃЌе§ГЃЧщПіЯТMasterЕНДяТњШнКѓИљОнЧ§ж№ВпТдЬдЬKeyВЂЭЌВНИјSlaveЁЃЫљвдSlaveетжжЧщПіЯТВЛЛсвђТњШнДЅЗЂЧ§ж№ЁЃ
АДеевдЭљОбщЃЌХХВщЫМТЗжївЊОлНЙдкдьГЩSlaveФкДцЖИдіЕФЮЪЬтЩЯЃЌАќРЈПЭЛЇЖЫСЌНгЁЂЪфШы/ЪфГіЛКГхЧјЁЂвЕЮёЪ§ОнДцШЁЗУЮЪЁЂЭјТЗЖЖЖЏЕШЕМжТRedisФкДцЖИдіЕФЫљгаЭтВПвђЫиЃЌЭЈЙ§RedisМрПиКЭвЕЮёСДТЗМрПиОљУЛгаЖЈЮЛГЩЙІЁЃ
гкЪЧЃЌЭЈЙ§ЪсРэRedisдДТыЃЌЮвУЧГЂЪдНЋФПЙтЭЖЯђСЫRedisЛсеМгУФкДцПЊЯњЕФвЛИіживЊЛњжЦЁЊЁЊRedis
RehashЁЃ
Redis Rehash ФкВПЪЕЯж
дкRedisжаЃЌМќжЕЖдЃЈKey-Value PairЃЉДцДЂЗНЪНЪЧгЩзжЕфЃЈDictЃЉБЃДцЕФЃЌЖјзжЕфЕзВуЪЧЭЈЙ§ЙўЯЃБэРДЪЕЯжЕФЁЃЭЈЙ§ЙўЯЃБэжаЕФНкЕуБЃДцзжЕфжаЕФМќжЕЖдЁЃРрЫЦJavaжаЕФHashMapЃЌНЋKeyЭЈЙ§ЙўЯЃКЏЪ§гГЩфЕНЙўЯЃБэНкЕуЮЛжУЁЃ
НгЯТРДЮвУЧвЛВНВНРДЗжЮіRedis Dict ReashЕФЛњжЦКЭЙ§ГЬЁЃ
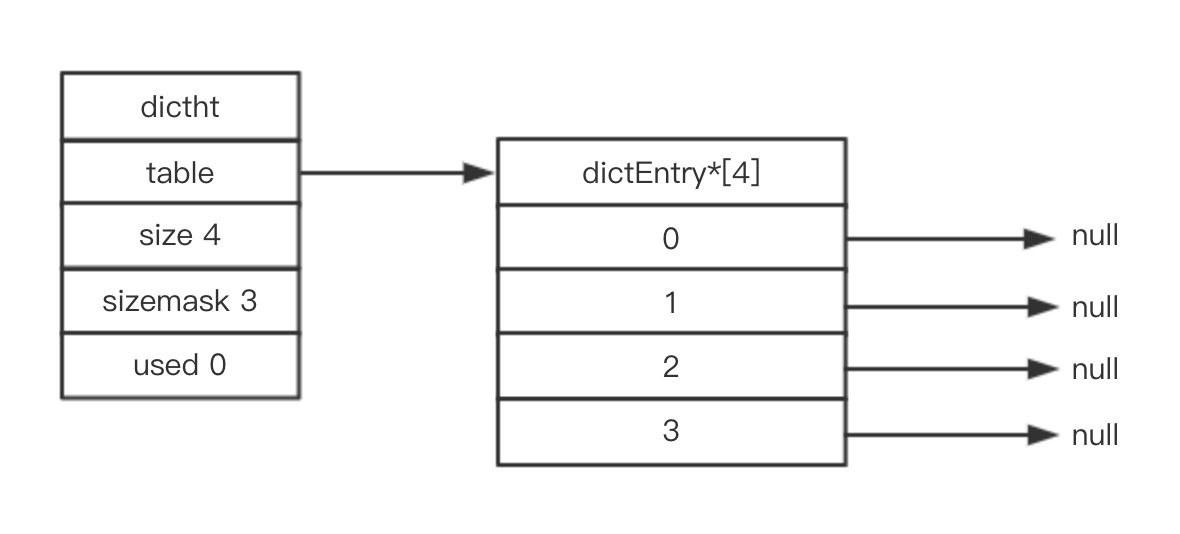
(1) Redis ЙўЯЃБэНсЙЙЬхЃК
/* hashБэНсЙЙЖЈвх
*/
typedef struct dictht {
dictEntry **table; // ЙўЯЃБэЪ§зщ
unsigned long size; // ЙўЯЃБэЕФДѓаЁ
unsigned long sizemask; // ЙўЯЃБэДѓаЁбкТы
unsigned long used; // ЙўЯЃБэЯжгаНкЕуЕФЪ§СП
} dictht; |
ЪЕЬхЛЏвЛЯТЃЌШчЯТЭМЫљжИвЛИіДѓаЁЮЊ4ЕФПеЙўЯЃБэЃЈRedisФЌШЯГѕЪМЛЏжЕЮЊ4ЃЉЃК
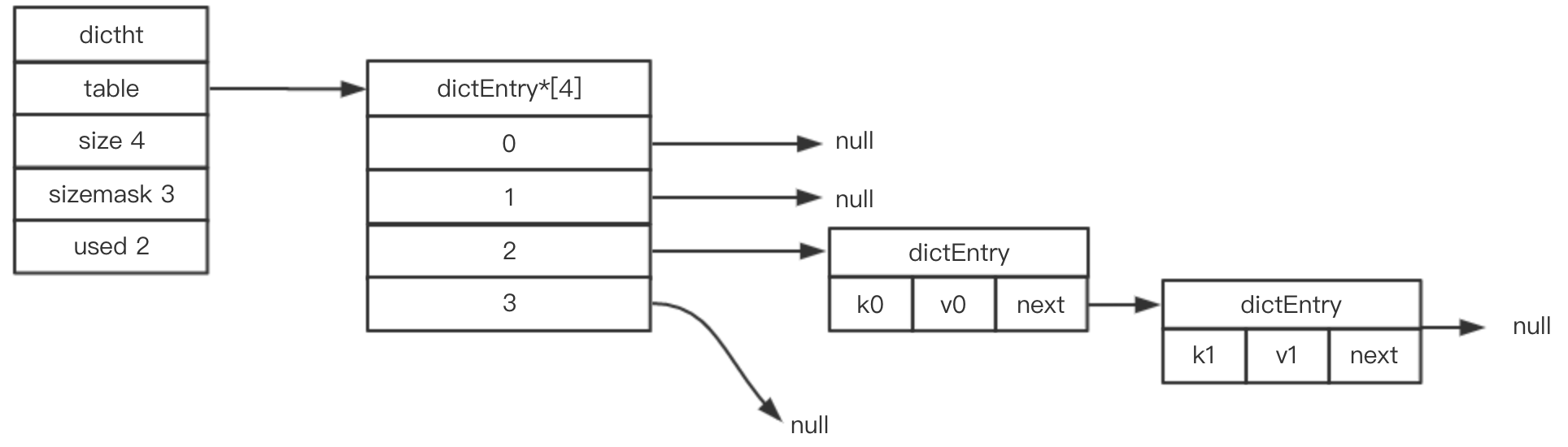
(2) Redis ЙўЯЃЭА
Redis ЙўЯЃБэжаЕФtableЪ§зщДцЗХзХЙўЯЃЭАНсЙЙЃЈdictEntryЃЉЃЌРяУцОЭЪЧRedisЕФМќжЕЖдЃЛРрЫЦJavaЪЕЯжЕФHashMapЃЌRedisЕФdictEntryвВЪЧЭЈЙ§СДБэЃЈnextжИеыЃЉЗНЪНРДНтОіhashГхЭЛЃК
/* ЙўЯЃЭА */
typedef struct dictEntry {
void *key; // МќЖЈвх
// жЕЖЈвх
union {
void *val; // здЖЈвхРраЭ
uint64_t u64; // ЮоЗћКХећаЮ
int64_t s64; // гаЗћКХећаЮ
double d; // ИЁЕуаЭ
} v;
struct dictEntry *next; //жИЯђЯТвЛИіЙўЯЃБэНкЕу
} dictEntry; |
(3) зжЕф
Redis Dict жаЖЈвхСЫСНеХЙўЯЃБэЃЌЪЧЮЊСЫКѓајзжЕфЕФРЉеЙзїRehashжЎгУЃК
/* зжЕфНсЙЙЖЈвх */
typedef struct dict {
dictType *type; // зжЕфРраЭ
void *privdata; // ЫНгаЪ§Он
dictht ht[2]; // ЙўЯЃБэ[СНИі]
long rehashidx; // МЧТМrehash НјЖШЕФБъжОЃЌжЕЮЊ-1БэЪОrehashЮДНјаа
int iterators; // ЕБЧАе§дкЕќДњЕФЕќДњЦїЪ§
} dict; |
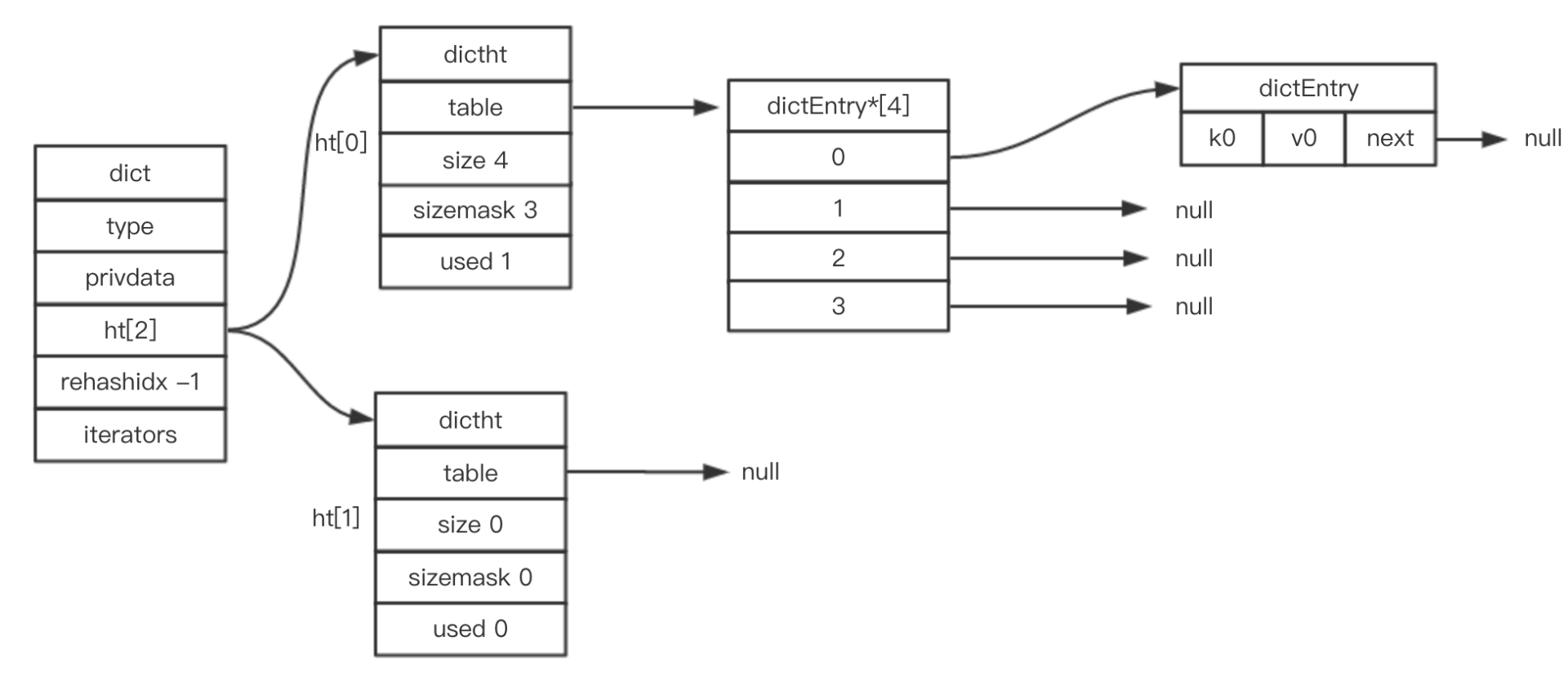
змНсвЛЯТЃК
- дкClusterФЃЪНЯТЃЌвЛИіRedisЪЕР§ЖдгІвЛИіRedisDB(db0);
- вЛИіRedisDBЖдгІвЛИіDict;
- вЛИіDictЖдгІ2ИіDicthtЃЌе§ГЃЧщПіжЛгУЕНht[0]ЃЛht[1] дкRehashЪБЪЙгУЁЃ
ШчЩЯЃЌЮвУЧЛиЙЫСЫвЛЯТRedis KVДцДЂЕФЪЕЯжЁЃЃЈRedisФкВПЛЙгаЦфЫћНсЙЙЬхЃЌгЩгкИњRehashВЛЩцМАЃЌВЛдйзИЪіЃЉ
ЮвУЧжЊЕРЕБHashMapжагЩгкHashГхЭЛЃЈИКдивђзгЃЉГЌЙ§ФГИіуажЕЪБЃЌГігкСДБэадФмЕФПМТЧЃЌЛсНјааResizeЕФВйзїЁЃRedisвВвЛбљЁОRedisжаЭЈЙ§dictExpand()ЪЕЯжЁПЁЃЮвУЧПДвЛЯТRedisжаЕФЪЕЯжЗНЪНЃК
/* ИљОнЯрЙиДЅЗЂЬѕМўРЉеЙзжЕф
*/
static int _dictExpandIfNeeded(dict *d)
{
if (dictIsRehashing(d)) return DICT_OK; // ШчЙће§дкНјааRehashЃЌдђжБНгЗЕЛи
if (d->ht[0].size == 0) return dictExpand(d,
DICT_HT_INITIAL_SIZE); // ШчЙћht[0]зжЕфЮЊПеЃЌдђДДНЈВЂГѕЪМЛЏht[0]
/* (ht[0].used/ht[0].size)>=1ЧАЬсЯТЃЌ
ЕБТњзуdict_can_resize=1Лђht[0].used/t[0].size>5ЪБЃЌБуЖдзжЕфНјааРЉеЙ
*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2); // РЉеЙзжЕфЮЊдРДЕФ2БЖ
}
return DICT_OK;
}
...
/* МЦЫуДцДЂKeyЕФbucketЕФЮЛжУ */
static int _dictKeyIndex(dict *d, const void
*key)
{
unsigned int h, idx, table;
dictEntry *he;
/* МьВщЪЧЗёашвЊРЉеЙЙўЯЃБэЃЌВЛзудђРЉеЙ */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* МЦЫуKeyЕФЙўЯЃжЕ */
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask; //МЦЫуKeyЕФbucketЮЛжУ
/* МьВщНкЕуЩЯЪЧЗёДцдкаТдіЕФKey */
he = d->ht[table].table[idx];
/* дкНкЕуСДБэМьВщ */
while(he) {
if (key==he->key || dictCompareKeys(d, key,
he->key))
return -1;
he = he->next;
}
if (!dictIsRehashing(d)) break; // ЩЈЭъht[0]КѓЃЌШчЙћЙўЯЃБэВЛдкrehashingЃЌдђЮоашдйЩЈht[1]
}
return idx;
}
...
/* НЋKeyВхШыЙўЯЃБэ */
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
// ШчЙћЙўЯЃБэдкrehashingЃЌдђжДааЕЅВНrehash
/* ЕїгУ_dictKeyIndex() МьВщМќЪЧЗёДцдкЃЌШчЙћДцдкдђЗЕЛиNULL */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] :
&d->ht[0];
entry = zmalloc(sizeof(*entry)); // ЮЊаТдіЕФНкЕуЗжХфФкДц
entry->next = ht->table[index]; // НЋНкЕуВхШыСДБэБэЭЗ
ht->table[index] = entry; // ИќаТНкЕуКЭЭАаХЯЂ
ht->used++; // ИќаТht
/* ЩшжУаТНкЕуЕФМќ */
dictSetKey(d, entry, key);
return entry;
}
...
/* ЬэМгаТМќжЕЖд */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key); // ЬэМгаТМќ
if (!entry) return DICT_ERR; // ШчЙћМќДцдкЃЌдђЗЕЛиЪЇАм
dictSetVal(d, entry, val); // МќВЛДцдкЃЌдђЩшжУНкЕужЕ
return DICT_OK;
} |
МЬајdictExpandЕФдДТыЪЕЯжЃК
int dictExpand(dict
*d, unsigned long size)
{
dictht n; // аТЙўЯЃБэ
unsigned long realsize = _dictNextPower(size);
// МЦЫуРЉеЙЛђЫѕЗХаТЙўЯЃБэЕФДѓаЁ(ЕїгУЯТУцКЏЪ§_dictNextPower())
/* ШчЙће§дкrehashЛђепаТЙўЯЃБэЕФДѓаЁаЁгкЯжвбЪЙгУЃЌдђЗЕЛиerror */
if (dictIsRehashing(d) || d->ht[0].used >
size)
return DICT_ERR;
/* ШчЙћМЦЫуГіЙўЯЃБэsizeгыЯжЙўЯЃБэДѓаЁвЛбљЃЌвВЗЕЛиerror */
if (realsize == d->ht[0].size) return DICT_ERR;
/* ГѕЪМЛЏаТЙўЯЃБэ */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
// ЮЊtableжИЯђdictEntry ЗжХфФкДц
n.used = 0;
/* ШчЙћht[0] ЮЊПеЃЌдђГѕЪМЛЏht[0]ЮЊЕБЧАМќжЕЖдЕФЙўЯЃБэ */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* ШчЙћht[0]ВЛЮЊПеЃЌдђГѕЪМЛЏht[1]ЮЊЕБЧАМќжЕЖдЕФЙўЯЃБэЃЌВЂПЊЦєНЅНјЪНrehashФЃЪН
*/
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
...
static unsigned long _dictNextPower(unsigned
long size) {
unsigned long i = DICT_HT_INITIAL_SIZE; // ЙўЯЃБэЕФГѕЪМжЕЃК4
if (size >= LONG_MAX) return LONG_MAX;
/* МЦЫуаТЙўЯЃБэЕФДѓаЁЃКЕквЛИіДѓгкЕШгкsizeЕФ2ЕФN ДЮЗНЕФЪ§жЕ */
while(1) {
if (i >= size)
return i;
i *= 2;
}
} |
змНсвЛЯТОпЬхТпМЪЕЯжЃК
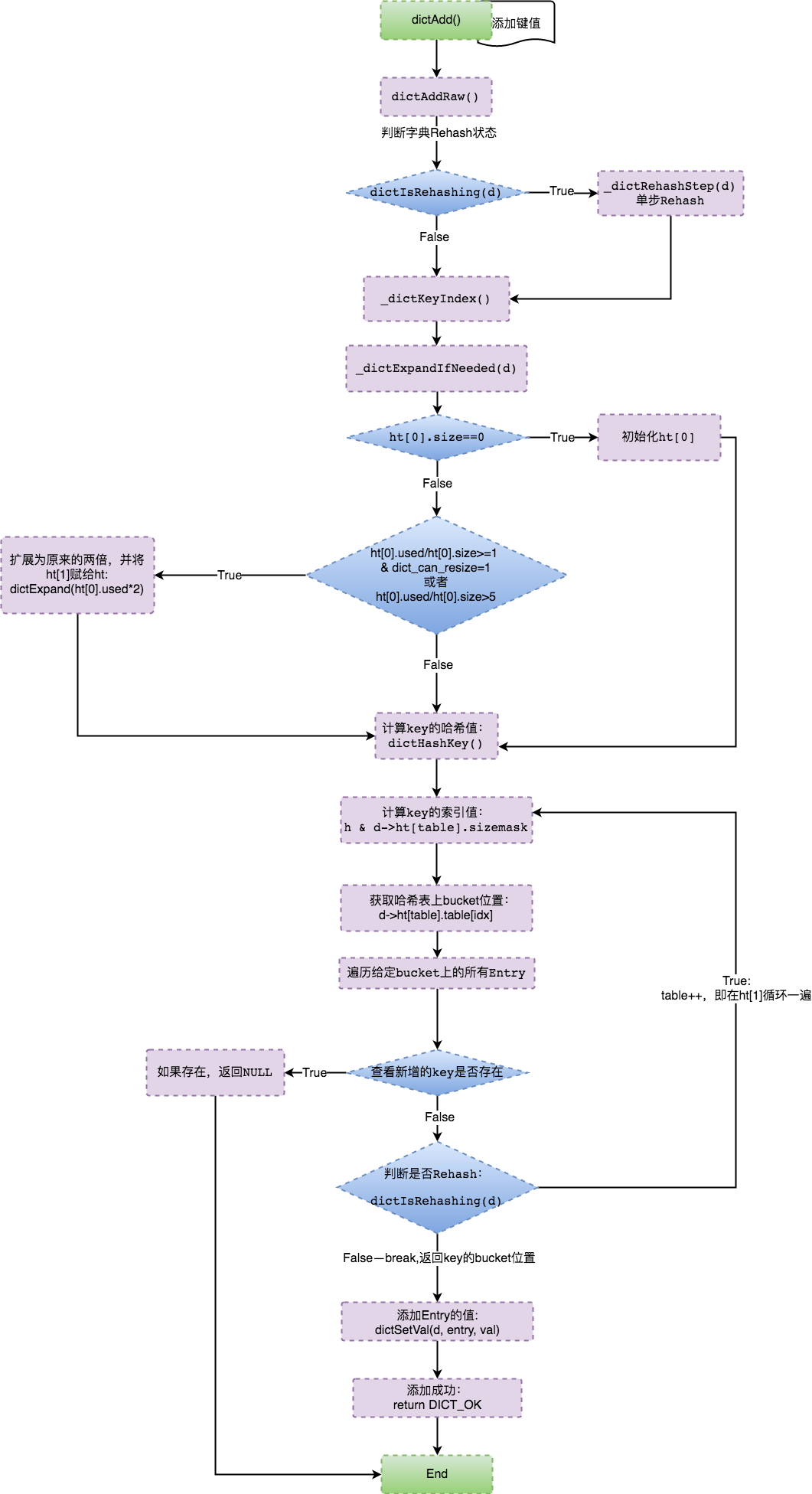
ПЩвдШЗШЯЕБRedis HashГхЭЛЕНДяФГИіЬѕМўЪБОЭЛсДЅЗЂdictExpand()КЏЪ§РДРЉеЙHashTableЁЃ
DICT_HT_INITIAL_SIZEГѕЪМЛЏжЕЮЊ4ЃЌЭЈЙ§ЩЯЪіБэДяЪНЃЌШЁЕБ4*2^n >=
ht[0].used*2ЕФжЕзїЮЊзжЕфРЉеЙЕФsizeДѓаЁЁЃМДЮЊЃКht[1].size ЕФжЕЕШгкЕквЛИіДѓгкЕШгкht[0].used*2ЕФ2^nЕФЪ§жЕЁЃ
RedisЭЈЙ§dictCreate()ДДНЈДЪЕфЃЌдкГѕЪМЛЏжаЃЌtableжИеыЮЊNullЃЌЫљвдСНИіЙўЯЃБэht[0].tableКЭht[1].tableЖМЮДеце§ЗжХфФкДцПеМфЁЃжЛгадкdictExpand()зжЕфРЉеЙЪБВХИјtableЗжХфжИЯђdictEntryЕФФкДцЁЃ
гЩЩЯПЩжЊЃЌЕБRedisДЅЗЂResizeКѓЃЌОЭЛсЖЏЬЌЗжХфвЛПщФкДцЃЌзюжегЩht[1].tableжИЯђЃЌЖЏЬЌЗжХфЕФФкДцДѓаЁЮЊЃКrealsize*sizeof(dictEntry*)ЃЌtableжИЯђdictEntry*ЕФвЛИіжИеыЃЌДѓаЁЮЊ8bytesЃЈ64ЮЛOSЃЉЃЌМДht[1].tableашЗжХфЕФФкДцДѓаЁЮЊЃК8*2*2^n
ЃЈnДѓгкЕШгк2ЃЉЁЃ
ЪсРэвЛЯТЙўЯЃБэДѓаЁКЭФкДцЩъЧыДѓаЁЕФЖдгІЙиЯЕЃК
ИДЯжбщжЄ
ЮвУЧЭЈЙ§ВтЪдЛЗОГЪ§ОнРДбщжЄвЛЯТЃЌЕБRedis RehashЙ§ГЬжаЃЌФкДцеце§ЕФеМгУЧщПіЁЃ
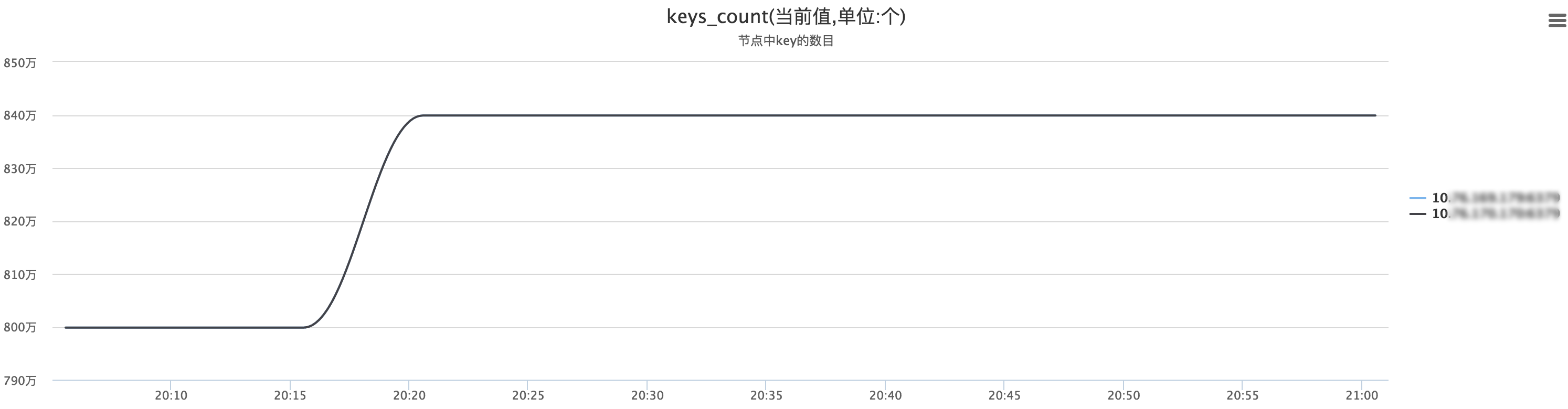
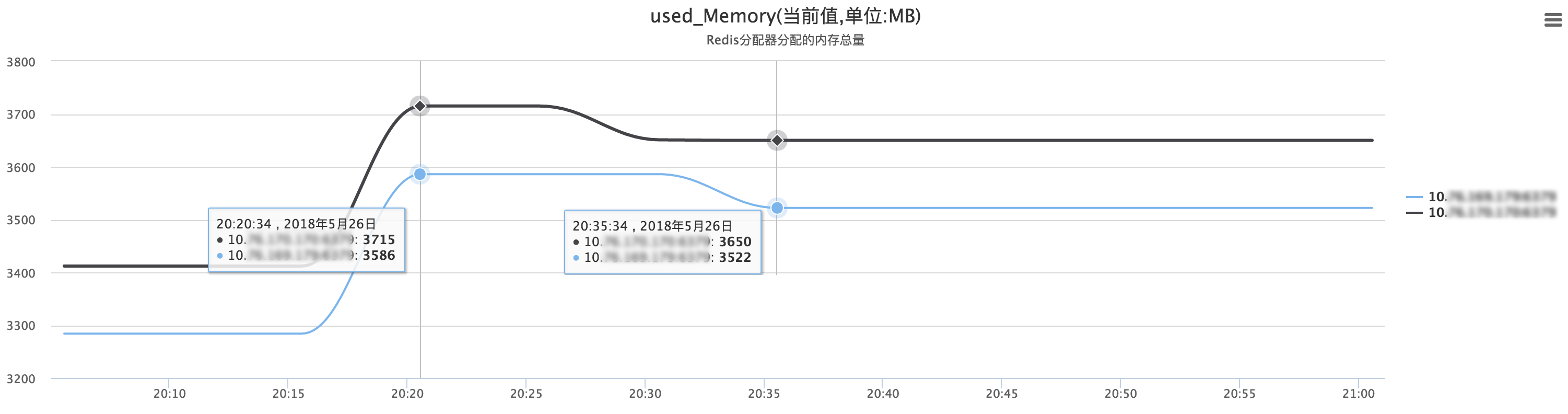
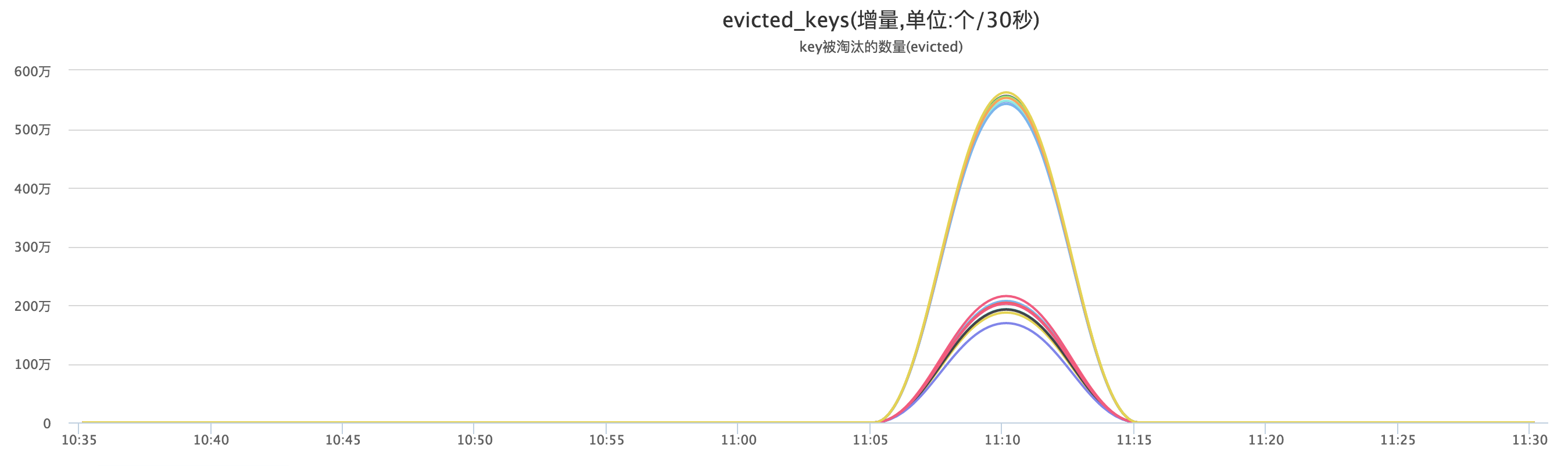
ЩЯЪіСНЗљЭМжаЃЌRedis KeyИіЪ§ЭЛЦЦRedis ResizeЕФСйНчЕуЃЌЕБKeyзмЪ§ЮШЖЈЧвRehashЭъГЩКѓЃЌRedisФкДцЃЈSlaveЃЉДг3586MНЕжСЮЊ3522MЃК3586-3522=64MЁЃМДбщжЄЩЯЪіRedisдкResizeжСЭъГЩЕФжаМфзДЬЌЃЌЛсЮЌГжвЛЖЮЪБМфФкДцЯћКФЃЌЧвеМгУФкДцЕФжЕЮЊЩЯЮФСаБэЯргІЕФФкДцПеМфЁЃ
НјвЛВНЙлВьвЛЯТRedisФкВПЭГМЦаХЯЂЃК
/* RedisНкЕу800ЭђзѓгвKeyЪБКђЕФDictзДЬЌаХЯЂ:жЛгаht[0]аХЯЂЁЃ*/
"[Dictionary HT]
Hash table 0 stats (main hash table):
table size: 8388608
number of elements: 8003582
different slots: 5156314
max chain length: 9
avg chain length (counted): 1.55
avg chain length (computed): 1.55
Chain length distribution:
0: 3232294 (38.53%)
1: 3080243 (36.72%)
2: 1471920 (17.55%)
3: 466676 (5.56%)
4: 112320 (1.34%)
5: 21301 (0.25%)
6: 3361 (0.04%)
7: 427 (0.01%)
8: 63 (0.00%)
9: 3 (0.00%)
"
/* RedisНкЕу840ЭђзѓгвKeyЪБКђЕФDictзДЬЌаХЯЂе§дкRehasingжаЃЌАќКЌСЫht[0]КЭht[1]аХЯЂЁЃ*/
"[Dictionary HT]
[Dictionary HT]
Hash table 0 stats (main hash table):
table size: 8388608
number of elements: 8019739
different slots: 5067892
max chain length: 9
avg chain length (counted): 1.58
avg chain length (computed): 1.58
Chain length distribution:
0: 3320716 (39.59%)
1: 2948053 (35.14%)
2: 1475756 (17.59%)
3: 491069 (5.85%)
4: 123594 (1.47%)
5: 24650 (0.29%)
6: 4135 (0.05%)
7: 553 (0.01%)
8: 78 (0.00%)
9: 4 (0.00%)
Hash table 1 stats (rehashing target):
table size: 16777216
number of elements: 384321
different slots: 305472
max chain length: 6
avg chain length (counted): 1.26
avg chain length (computed): 1.26
Chain length distribution:
0: 16471744 (98.18%)
1: 238752 (1.42%)
2: 56041 (0.33%)
3: 9378 (0.06%)
4: 1167 (0.01%)
5: 119 (0.00%)
6: 15 (0.00%)
"
/* RedisНкЕу840ЭђзѓгвKeyЪБКђЕФDictзДЬЌаХЯЂ(RehashЭъГЩКѓ);ht[0].sizeДг8388608РЉеЙЕНСЫ16777216ЁЃ*/
"[Dictionary HT]
Hash table 0 stats (main hash table):
table size: 16777216
number of elements: 8404060
different slots: 6609691
max chain length: 7
avg chain length (counted): 1.27
avg chain length (computed): 1.27
Chain length distribution:
0: 10167525 (60.60%)
1: 5091002 (30.34%)
2: 1275938 (7.61%)
3: 213024 (1.27%)
4: 26812 (0.16%)
5: 2653 (0.02%)
6: 237 (0.00%)
7: 25 (0.00%)
" |
ОЙ§Redis RehashФкВПЛњжЦЕФЩюШыЁЂRedisзДЬЌМрПиКЭRedisФкВПЭГМЦаХЯЂЃЌЮвУЧПЩвдЕУГіНсТлЃК
ЕБRedis НкЕужаЕФKeyзмСПЕНДяСйНчЕуКѓЃЌRedisОЭЛсДЅЗЂDictЕФРЉеЙЃЌНјааRehashЁЃЩъЧыРЉеЙКѓЯргІЕФФкДцПеМфДѓаЁЁЃ
ШчЩЯЃЌRedisдкТњШнЧ§ж№зДЬЌЯТЃЌRedis RehashЪЧЕМжТRedis MasterКЭSlaveДѓСПДЅЗЂЧ§ж№ЬдЬЕФИљБОдвђЁЃ
Г§СЫЕМжТТњШнЧ§ж№ЬдЬЃЌRedis RehashЛЙЛсв§Ц№ЦфЫћвЛаЉЮЪЬтЃК
- дкtablesizeМЖБ№гыЯжгаKeysЪ§СПВЛдкЭЌвЛИіЧјМфФкЃЌжїДгЧаЛЛКѓЃЌгЩгкRedisШЋСПЭЌВНЃЌДгПтtablesizeНЕЮЊгыЯжгаKeyЦЅХфжЕЃЌЕМжТФкДцЧуаБЃЛ
- Redis ClusterЯТЕФФГИіЗжЦЌгЩгкKeyЪ§СПЯрЖдНЯЖрЬсЧАResizeЃЌЕМжТМЏШКЗжЦЌФкДцВЛОљЁЃ
ЕШЕШЁ
Redis RehashЛњжЦгХЛЏ
ФЧУДеыЖддкRedisТњШнЧ§ж№зДЬЌЯТЃЌШчКЮБмУтвђRehashЖјЕМжТRedisЖЖЖЏЕФетжжЮЪЬтЁЃ
- ЮвУЧдкRedis RehashдДТыЪЕЯжЕФТпМЩЯЃЌМгЩЯСЫвЛИіХаЖЯЬѕМўЃЌШчЙћЯжгаЕФЪЃгрФкДцВЛЙЛДЅЗЂRehashВйзїЫљашЩъЧыЕФФкДцДѓаЁЃЌМДВЛНјааResizeВйзїЃЛ
- ЭЈЙ§ЬсЧАдЫгЊНјааЙцБмЃЌБШШчШнСПдЄЙРЪБНЋRehashеМгУЕФФкДцПМТЧдкФкЃЌЛђепЭЈЙ§МрПиЖЈЪБРЉШнЁЃ
Redis RehashЛњжЦГ§СЫЛсгАЯьЩЯЪіФкДцЙмРэКЭЪЙгУЭтЃЌвВЛсгАЯьRedisЦфЫћФкВПгыжЎЯрЙиСЊЕФЙІФмФЃПщЁЃЯТУцЮвУЧЗжЯэвЛЯТгЩгкRehashЛњжЦЖјВШЕНЕФЕкЖўИіПгЁЃ
RedisЪЙгУScanЧхРэKeyгЩгкRehashЕМжТЧхРэЪ§ОнВЛГЙЕз
SquirrelЦНЬЈЬсЙЉИјвЕЮёЧхРэKeyЕФAPIКѓЬЈТпМЃЌЪЧЭЈЙ§ScanРДЪЕЯжЕФЁЃЪЕМЪЯпЩЯдЫаааЇЙћВЂВЛЪЧУПДЮЖМФмЭъШЋЧхРэИЩОЛЁЃМДЭЈЙ§ScanЩЈУшЧхРэЯрЦЅХфЕФKeyЃЌНЯЕЭЦЕТЪЛсгавХТЉЁЂKeyЮДБЛШЋВПЧхРэЕєЕФЯжЯѓЁЃгаСЫЧАМИДЮЕФЯрЙиОбщКѓЃЌЮвУЧжБНгДгдРэШыЪжЁЃ
ScanдРэ
ЮЊСЫИпаЇЕиЦЅХфГіЪ§ОнПтжаЫљгаЗћКЯИјЖЈФЃЪНЕФKeyЃЌRedisЬсЙЉСЫScanУќСюЁЃИУУќСюЛсдкУПДЮЕїгУЕФЪБКђЗЕЛиЗћКЯЙцдђЕФВПЗжKeyвдМАвЛИігЮБъжЕCursorЃЈГѕЪМжЕЪЙгУ0ЃЉЃЌЪЙгУУПДЮЗЕЛиCursorВЛЖЯЕќДњЃЌжБЕНCursorЕФЗЕЛижЕЮЊ0ДњБэБщРњНсЪјЁЃ
RedisЙйЗНЖЈвхScanЬиЕуШчЯТЃК
1. ећИіБщРњДгПЊЪМЕННсЪјЦкМфЃЌ вЛжБДцдкгкRedisЪ§ОнМЏФкЕФЧвЗћКЯЦЅХфФЃЪНЕФЫљгаKeyЖМЛсБЛЗЕЛиЃЛ
2. ШчЙћЗЂЩњСЫrehashЃЌЭЌвЛИідЊЫиПЩФмЛсБЛЗЕЛиЖрДЮЃЌБщРњЙ§ГЬжааТдіЛђепЩОГ§ЕФKeyПЩФмЛсБЛЗЕЛиЃЌвВПЩФмВЛЛсЁЃ
ОпЬхЪЕЯж
ЩЯЪіЬсМАRedisЕФKeysЪЧвдDictЗНЪНРДДцДЂЕФЃЌе§ГЃжЛвЊвЛДЮБщРњDictжаЫљгаHashЭАОЭПЩвдЭъећЩЈУшГіЫљгаKeyЁЃЕЋЪЧдкЪЕМЪЪЙгУжаЃЌRedis
DictЪЧгазДЬЌЕФЃЌЛсЫцзХKeyЕФдіЩОВЛЖЯБфЛЏЁЃ
НгЯТРДИљОнDictЫФжжзДЬЌРДЗжЮівЛЯТScanЕФВЛЭЌЪЕЯжЁЃ
DictЕФЫФжжзДЬЌГЁОАЃК
1. зжЕфtablesizeБЃГжВЛБфЃЌУЛгаРЉЫѕШнЃЛ
2. зжЕфResizeЃЌDictРЉДѓСЫЃЈЭъГЩзДЬЌЃЉЃЛ
3. зжЕфResizeЃЌDictЫѕаЁСЫЃЈЭъГЩзДЬЌЃЉЃЛ
4. зжЕфе§дкRehashingЃЈРЉеЙЛђЪеЫѕЃЉЁЃ
(1) зжЕфtablesizeБЃГжВЛБфЃЌдкRedis DictЮШЖЈЕФзДЬЌЯТЃЌжБНгЫГађБщРњМДПЩЃЛ
(2) зжЕфResizeЃЌDictРЉДѓСЫЃЌШчЙћЛЙЪЧАДееЫГађБщРњЃЌОЭЛсЕМжТЩЈУшДѓСПжиИДKeyЁЃБШШчзжЕфtablesizeДг8БфГЩСЫ16ЃЌМйЩшжЎЧАЗУЮЪЕФЪЧ3КХЭАЃЌФЧУДБэРЉеЙКѓдђЪЧМЬајЗУЮЪ4~15КХЭАЃЛЕЋЪЧЃЌдЯШЕФ0~3КХЭАжаЕФЪ§ОндкDictГЄЖШБфДѓКѓБЛЧЈвЦЕН8~11КХЭАжаЃЌвђДЫЃЌБщРњ8~11КХЭАЕФЪБКђЛсгаДѓСПЕФжиИДKeyБЛЗЕЛиЃЛ
(3) зжЕфResizeЃЌDictЫѕаЁСЫЃЌШчЙћЛЙЪЧАДееЫГађБщРњЃЌОЭЛсЕМжТДѓСПЕФKeyБЛвХТЉЁЃБШШчзжЕфtablesizeДг8БфГЩСЫ4ЃЌМйЩшЕБЧАЗУЮЪЕФЪЧ3КХЭАЃЌФЧУДЯТвЛДЮдђЛсжБНгЗЕЛиБщРњНсЪјСЫЃЛЕЋЪЧжЎЧА4~7КХЭАжаЕФЪ§ОндкЫѕШнКѓЧЈвЦДјПЩ0~3КХЭАжаЃЌвђДЫетВПЗжKeyОЭЮоЗЈЩЈУшЕНЃЛ
(4) зжЕфе§дкRehashingЃЌетжжЧщПіШч(2)КЭ(3)ЧщПівЛЯТЃЌвЊУДДѓСПжиИДЩЈУшЁЂвЊУДвХТЉКмЖрKeyЁЃ
ФЧУДдкDictЗЧЮШЖЈзДЬЌЃЌМДЗЂЩњRehashЕФЧщПіЯТЃЌScanвЊШчКЮБЃжЄдгаЕФKeyЖМФмБщРњГіРДЃЌгжОЁЩйПЩФмжиИДЩЈУшФиЃПRedis
ScanЭЈЙ§HashЭАбкТыЕФИпЮЛЫГађЗУЮЪРДНтОіЁЃ
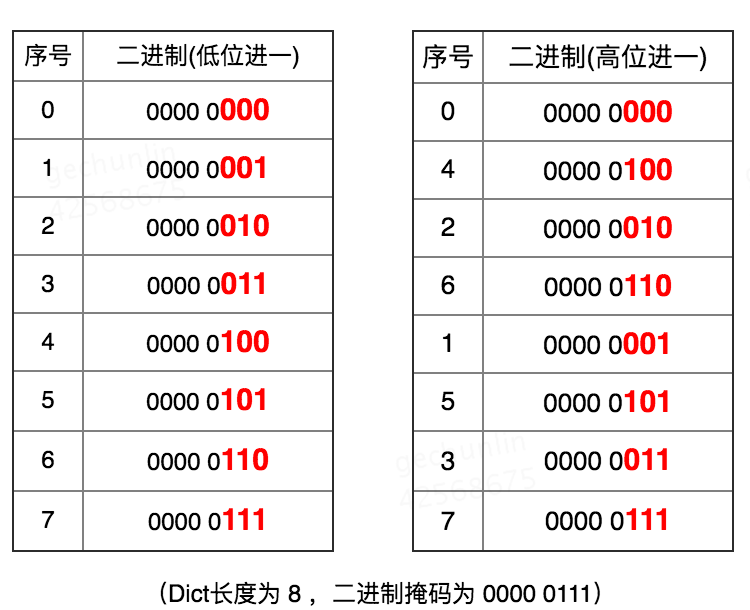
ИпЮЛЫГађЗУЮЪМДАДееDict sizemaskЃЈбкТыЃЉЃЌдкгааЇЮЛЃЈЩЯЭМжаDict sizemaskЮЊ3ЃЉЩЯДгИпЮЛПЊЪММгвЛУЖОйЃЛЕЭЮЛдђАДеегааЇЮЛЕФЕЭЮЛж№ВНМгвЛЗУЮЪЁЃ
ЕЭЮЛађЃК0Ёњ1Ёњ2Ёњ3Ёњ4Ёњ5Ёњ6Ёњ7
ИпЮЛађЃК0Ёњ4Ёњ2Ёњ6Ёњ1Ёњ5Ёњ3Ёњ7
ScanВЩгУИпЮЛађЗУЮЪЕФдвђЃЌОЭЪЧЮЊСЫЪЕЯжRedis DictдкRehashЪБОЁПЩФмЩйжиИДЩЈУшЗЕЛиKeyЁЃ
ОйИіР§згЃЌШчЙћDictЕФtablesizeДг8РЉеЙЕНСЫ16ЃЌЪсРэвЛЯТScanЩЈУшЗНЪН:
Dict(8) ДгCursor 0ПЊЪМЩЈУшЃЛ
зМБИЩЈУшCursor 6ЪБЗЂЩњResizeЃЌРЉеЙЮЊжЎЧАЕФ2БЖЃЌВЂЭъГЩRehashЃЛ
ПЭЛЇЖЫетЪБПЊЪМДгDict(16)ЕФCursor 6МЬајЕќДњЃЛ
етЪБАДее 6Ёњ14Ёњ1Ёњ9Ёњ5Ёњ13Ёњ3Ёњ11Ёњ7Ёњ15 ScanЭъГЩЁЃ
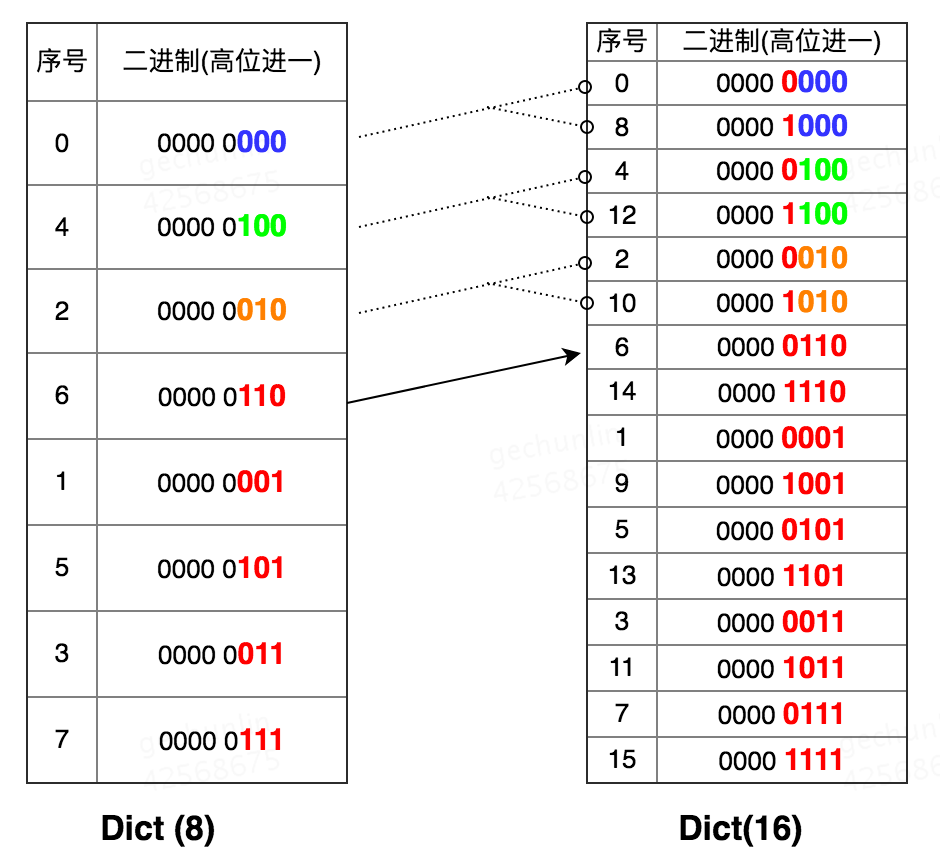
ПЩвдПДГіЃЌИпЮЛађScanдкDict RehashЪБМДПЩвдБмУтжиИДБщРњЃЌгжФмЭъећЗЕЛидЪМЕФЫљгаKeyЁЃЭЌРэЃЌзжЕфЫѕШнЪБвВвЛбљЃЌзжЕфЫѕШнПЩвдПДГіЪЧЗДЯђРЉШнЁЃ
ЩЯЪіЪЧScanЕФРэТлЛљДЁЃЌЮвУЧПДвЛЯТRedisдДТыШчКЮЪЕЯжЁЃ
(1) ЗЧRehashing зДЬЌЯТЕФЪЕЯжЃК
if (!dictIsRehashing(d))
{ // ХаЖЯЪЧЗёе§дкrehashingЃЌШчЙћВЛдкдђжЛгаht[0]
t0 = &(d->ht[0]); // ht[0]
m0 = t0->sizemask; // бкТы
/* Emit entries at cursor */
de = t0->table[v & m0]; // ФПБъЭА
while (de) {
fn(privdata, de);
de = de->next; // БщРњЭАжаЫљгаНкЕуЃЌВЂЭЈЙ§ЛиЕїКЏЪ§fn()ЗЕЛи
}
...
/* ЗДЯђЖўНјжЦЕќДњЫуЗЈОпЬхЪЕЯжТпМЁЊЁЊгЮБъЪЕЯжЕФОЋЫш */
/* Set unmasked bits so incrementing the reversed
cursor
* operates on the masked bits of the smaller
table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
} |
дДТыжаRedisНЋCursorЕФМЦЫуЭЈЙ§Reverse Binary IterationЃЈЗДЯђЖўНјжЦЕќДњЫуЗЈЃЉРДЪЕЯжЩЯЪіЕФИпЮЛађЩЈУшЗНЪНЁЃ
(2) Rehashing зДЬЌЯТЕФЪЕЯжЃК
...
else { // ЗёдђЫЕУїе§дкrehashingЃЌОЭДцдкСНИіЙўЯЃБэht[0]ЁЂht[1]
t0 = &d->ht[0];
t1 = &d->ht[1]; // жИЯђСНИіЙўЯЃБэ
/* Make sure t0 is the smaller and t1 is the
bigger table */
if (t0->size > t1->size) { ШЗБЃt0аЁгкt1
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask; // ЯрЖдгІЕФбкТы
/* Emit entries at cursor */
/* ЕќДњ(аЁБэ)t0ЭАжаЕФЫљгаНкЕу */
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Iterate over indices in larger table that
are the expansion
* of the index pointed to by the cursor in the
smaller table */
/* */
do {
/* Emit entries at cursor */
/* ЕќДњ(ДѓБэ)t1 жаЫљгаНкЕуЃЌбЛЗЕќДњЃЌЛсАбаЁБэУЛгаИВИЧЕФslotШЋВПЩЈУшвЛБщ */
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller
mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference
is non-zero */
} while (v & (m0 ^ m1));
}
/* Set unmasked bits so incrementing the reversed
cursor
* operates on the masked bits of the smaller
table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v; |
ШчЩЯRehashingЪБЃЌRedis ЭЈЙ§elseЗжжЇЪЕЯжИУЙ§ГЬжаЖдСНеХHashБэНјааЩЈУшЗУЮЪЁЃ
ЪсРэвЛЯТТпМСїГЬЃК
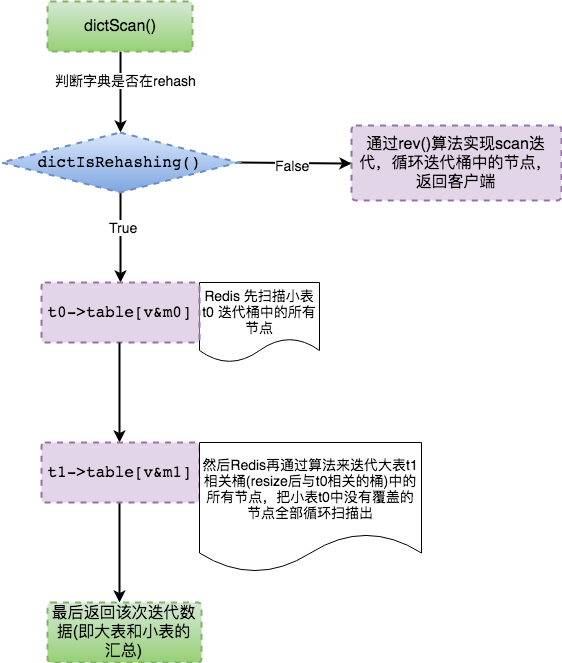
RedisдкДІРэdictScan()ЪБЃЌЩЯУцЯИЗжЕФЫФИіГЁОАЕФЪЕЯжЗжГЩСЫСНИіТпМЃК
1. ДЫЪБВЛдкRehashingЕФзДЬЌЃК
етжжзДЬЌЃЌМДDictЪЧОВжЙЕФЁЃеыЖдетжжзДЬЌЯТЕФЩЯЪіШ§жжГЁОАЃЌRedisВЩгУЩЯЪіЕФReverse Binary
IterationЃЈЗДЯђЖўНјжЦЕќДњЫуЗЈЃЉЃК
Ђё. ЪзЯШЖдгЮБъЃЈCursorЃЉЖўНјжЦЮЛЗзЊЃЛ
Ђђ. дйЖдЗзЊКѓЕФжЕМг1ЃЛ
Ђѓ. зюКѓдйДЮЖдЂђЕФНсЙћНјааЗзЊЁЃ
ЭЈЙ§ЧюОйИпЮЛЃЌвРДЮЯђЕЭЮЛЭЦНјЕФЗНЪНЃЈМДИпЮЛађЗУЮЪЕФЪЕЯжЃЉРДШЗБЃЫљгадЊЫиЖМЛсБЛБщРњЕНЁЃ
етжжЫуЗЈвбООЁПЩФмМѕЩйжиИДдЊЫиЕФЗЕЛиЃЌЕЋЪЧЪЕМЪЪЕЯжКЭТпМжаЛЙЪЧЛсгаПЩФмДцдкжиИДЗЕЛиЃЌБШШчдкDictЫѕШнЪБЃЌИпЮЛКЯВЂЕНЕЭЮЛЭАжаЃЌЕЭЮЛЭАжаЕФдЊЫиОЭЛсБЛжиИДШЁГіЁЃ
е§дкRehashingЕФзДЬЌЃК
RedisдкRehashingзДЬЌЕФЪБКђЃЌdictScan()ЪЕЯжЭЈЙ§вЛДЮадЩЈУшЯжгаЕФСНжжзжЕфБэЃЌБмУтжаМфзДЬЌЮоЗЈЮЌЛЄЁЃ
ОпЬхЪЕЯжОЭЪЧдкБщРњЭъаЁБэCursorЮЛжУКѓЃЌНЋаЁБэCursorЮЛжУПЩФмRehashЕНЕФДѓБэЫљгаЮЛжУШЋВПБщРњвЛБщЃЌШЛКѓдйЗЕЛиБщРњдЊЫиКЭЯТвЛИіаЁБэБщРњЮЛжУЁЃ
Root Cause ЖЈЮЛ
RehashingзДЬЌЪБЃЌгЮБъЕќДњжївЊТпМДњТыЪЕЯжЃК
/* Increment
bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
//BUG |
Ђё. vЕЭЮЛМг1ЯђИпЮЛНјЮЛЃЛ
Ђђ. ШЅЕєvзюЧАУцКЭзюКѓУцЕФВПЗжЃЌжЛБЃСєvЯрНЯгкm0ЕФИпЮЛВПЗжЃЛ
Ђѓ. БЃСєvЕФЕЭЮЛЃЌИпЮЛВЛЖЯМг1ЁЃМДЕЭЮЛВЛБфЃЌИпЮЛВЛЖЯМг1ЃЌЪЕЯжСЫаЁБэЕНДѓБэЭАЕФЙиСЊЁЃ
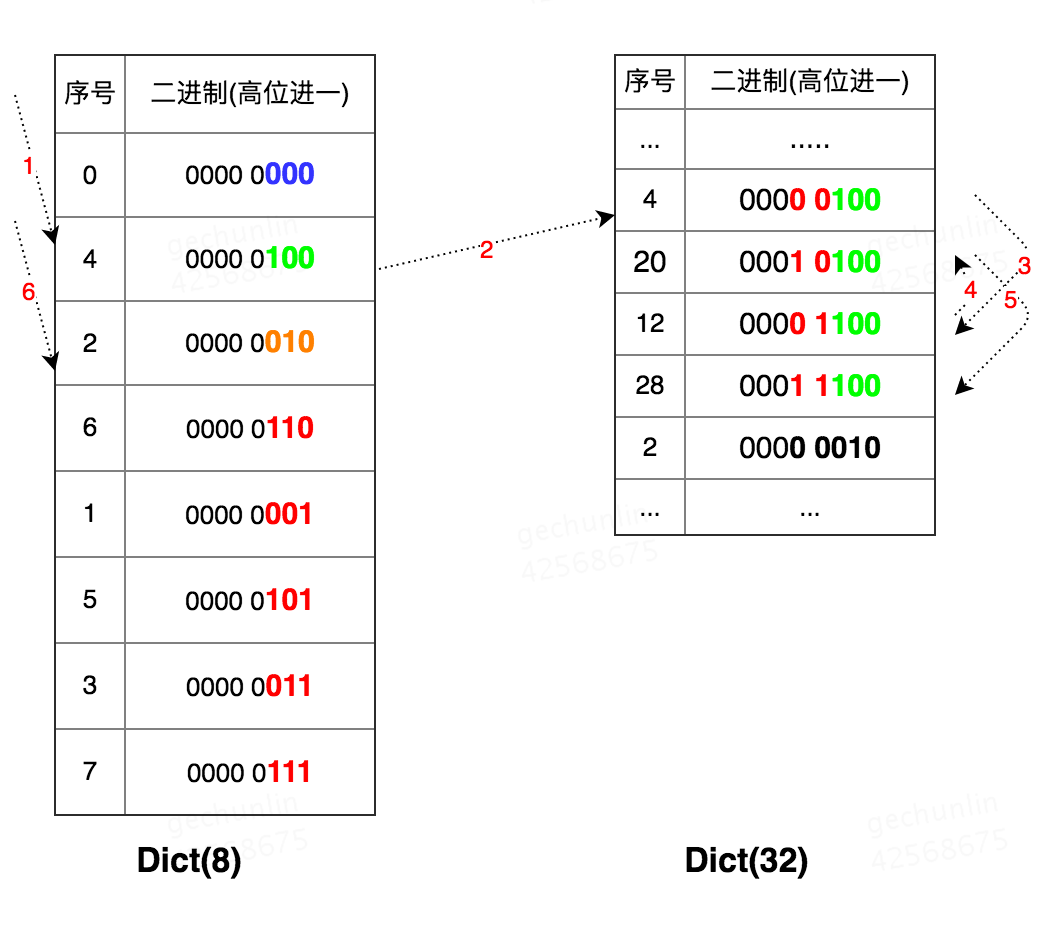
ОйИіР§згЃЌШчЙћDictЕФtablesizeДг8РЉеЙЕНСЫ32ЃЌЪсРэвЛЯТScanЩЈУшЗНЪН:
Dict(8) ДгCursor 0ПЊЪМЩЈУшЃЛ
зМБИЩЈУшCursor 4ЪБЗЂЩњResizeЃЌРЉеЙЮЊжЎЧАЕФ4БЖЃЌRehashingЃЛ
ПЭЛЇЖЫЯШЗУЮЪDict(8)жаЕФ4КХЭАЃЛ
ШЛКѓдйЕНDict(32)ЩЯЗУЮЪ:4Ёњ12Ёњ20Ёњ28ЁЃ
етРяПЩвдПДЕНДѓБэЕФЯрЙиЭАЕФЫГађВЂЗЧЪЧАДеежЎЧАЫљЪіЕФЖўНјжЦИпЮЛађЃЌЪЕМЪЩЯЪЧАДееЕЭЮЛађРДБщРњДѓБэжаИпГіаЁБэЕФгааЇЮЛЁЃ
ДѓБэt1ИпЮЛЖМЪЧЯђЕЭЮЛМг1МЦЫуЕУГіЕФЃЌЩЈУшЕФЫГађШДЪЧДгЕЭЮЛМг1ЃЌЯђИпЮЛНјЮЛЁЃRedisеыЖдRehashingЪБетжжТпМЪЕЯждкРЉШнЪБЪЧПЩвддЫаае§ГЃЕФЃЌЕЋЪЧдкЫѕШнЪБИпЮЛађКЭЕЭЮЛађЕФБщРњдкДѓаЁБэЩЯЕФЛьгУдквЛЖЈЬѕМўЯТЛсГіЯжЮЪЬтЁЃ
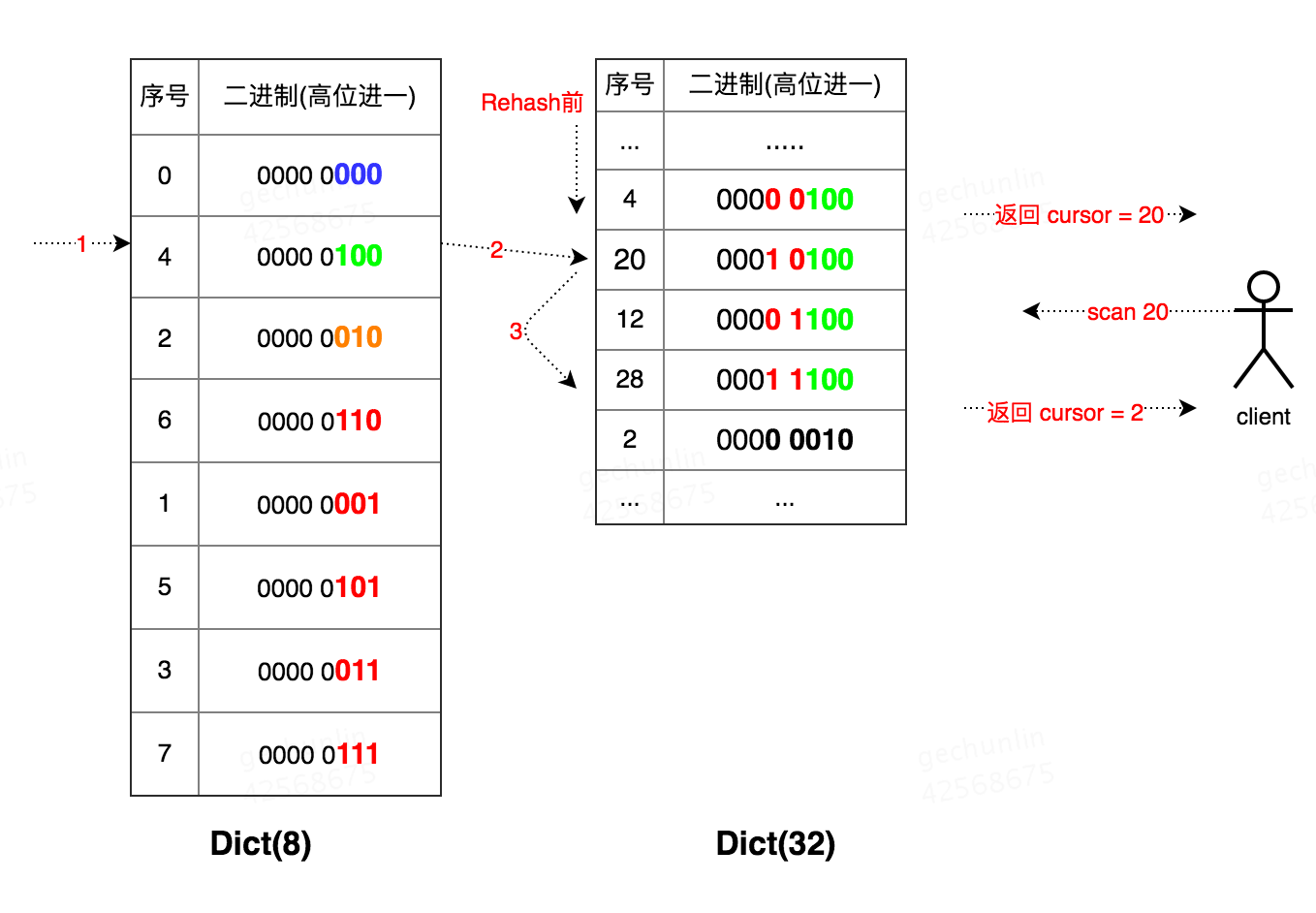
дйДЮЪОР§ЃЌDictЕФtablesizeДг32ЫѕШнЕН8ЃК
1. Dict(32) ДгCursor 0ПЊЪМЩЈУшЃЛ
2. зМБИЩЈУшCursor 20ЪБЗЂЩњResizeЃЌЫѕШнжСдРДЕФЫФЗжжЎвЛМДtablesizeЮЊ8ЃЌRehashingЃЛ
3. ПЭЛЇЖЫЗЂЦ№Cursor 20,ЪзЯШЗУЮЪDict(8)жаЕФ4КХЭАЃЛ
4. дйЕНDict(32)ЩЯЗУЮЪ:20Ёњ28;
5. зюКѓЗЕЛиCursor = 2ЁЃ
ПЩвдПДГіДѓБэжаЕФ12КХЭАУЛгаБЛЗУЮЪЕНЃЌМДБщРњДѓБэЪБЃЌАДееЕЭЮЛађЗУЮЪЛсвХТЉЖдФГаЉЭАЕФЗУЮЪЁЃ
ЩЯЪіетжжЧщПіЗЂЩњашвЊОпБИвЛЖЈЕФЬѕМўЃК
1. дкDictЫѕШнRehashЪБScan;
2. DictЫѕШнжСжСЩйдDict tablesizeЕФЫФЗжжЎвЛЃЌжЛгадкетжжЧщПіЯТЃЌДѓБэЯрЖдаЁБэЕФгааЇЮЛВХЛсИпГіЖўЮЛвдЩЯЃЌДгЖјДЅЗЂЬјЙ§ФГИіЭАЕФЧщПіЃЛ
3. ШчЙћдкRehashПЊЪМЧАЗЕЛиЕФCursorЪЧдкаЁБэФмБэЪОЕФЗЖЮЇФкЃЈМДВЛГЌЙ§7ЃЉЃЌФЧУДдкНјааИпЮЛгааЇЮЛЕФМгвЛВйзїЪБЃЌБиШЛЖМЪЧДг0ПЊЪММЦЫуЃЌУПДЮМгвЛвВБиШЛФмЙЛЗУЮЪЕФШЋЫљгаЕФЯрЙиЭАЃЛШчЙћдкRehashПЊЪМЧАЗЕЛиЕФcursorВЛдкаЁБэФмБэЪОЕФЗЖЮЇФкЃЈБШШч20ЃЉЃЌФЧУДдкНјааИпЮЛгааЇЮЛМгвЛВйзїЕФЪБКђЃЌОЭгаПЩФмЬјЙ§
ЃЌЛђепжиИДЗУЮЪФГаЉЭАЕФЧщПіЁЃ
ПЩМћЃЌжЛгаТњзуЩЯЪіШ§жжЧщПіВХЛсЗЂЩњScanБщРњЙ§ГЬжаТЉЕєСЫвЛаЉKeyЕФЧщПіЁЃдкжДааЧхРэKeyЕФЪБКђЃЌШчЙћЧхРэЕФKeyЪ§СПКмДѓЃЌЕМжТСЫRedisФкВПЕФHashБэЫѕШнжСЩйдDict
tablesizeЕФЫФЗжжЎвЛЃЌОЭПЩФмДцдквЛаЉKeyБЛТЉЕєЕФЗчЯеЁЃ
ScanдДТыгХЛЏ
аоИДТпМОЭЪЧШЋВПЖМДгИпЮЛПЊЪМдіМгНјааБщРњЃЌМДДѓаЁБэЖМЪЙгУИпЮЛађЗУЮЪЃЌаоИДдДТыШчЯТЃК
unsigned long
dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de, *next;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v
& m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Set unmasked bits so incrementing the reversed
cursor
* operates on the masked bits */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the
bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v
& m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Iterate over indices in larger table that
are the expansion
* of the index pointed to by the cursor in the
smaller table */
do {
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t1->table[v
& m1]);
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Increment the reverse cursor not covered
by the smaller mask.*/
v |= ~m1;
v = rev(v);
v++;
v = rev(v);
/* Continue while bits covered by mask difference
is non-zero */
} while (v & (m0 ^ m1));
}
return v;
} |
ЮвУЧЭХЖгвбОНЋДЫPR PushЕНRedisЙйЗНЃКFix dictScan(): It canЁЏt scan
all buckets when dict is shrinkingЃЌВЂвбОБЛЙйЗНMergeЁЃ
жСДЫЃЌЛљгкRedis RehashвдМАScanЪЕЯжжаЩцМАRehashЕФСНИіЛњжЦвбОЛљБОСЫНтКЭгХЛЏЭъГЩЁЃ
змНс
БОЮФжївЊВћЪіСЫвђRedisЕФRehashЛњжЦВШЕНЕФСНИіПгЃЌДгЯжЯѓЕНдРэНјааСЫЯъЯИЕФНщЩмЁЃетРяМђЕЅзмНсвЛЯТЃЌЕквЛИіАИР§ЛсдьГЩЯпЩЯМЏШКНјааДѓСПЬдЬЃЌЖјЧвВњЩњжїДгВЛвЛжТЕФЧщПіЃЌдквЕЮёВуУцвВЛсЗЂЩњДѓСПГЌЪБЃЌгАЯьвЕЮёПЩгУадЃЌЮЪЬтбЯжиЃЌЗЧГЃжЕЕУДѓМвЙизЂЃЛЕкЖўИіАИР§ЛсдьГЩЪ§ОнЧхРэЮоЗЈЭъШЋЧхРэЃЌЕЋЪЧПЩвддйРћгУScanЧхРэвЛБщвВФмЙЛЧхРэЭъБЯЁЃ
зЂЃКБОЮФжадДТыЛљгкRedis 3.2.8ЁЃ | 








