| БрМЭЦМі: |
| БОЮФРДздгк51ctoЃЌжївЊНщЩмСЫдѕбљЩшМЦЛКДцИјЪ§ОнПтМѕИКвдМАЛКДцЪЙгУЕФвЛаЉГЃМћЮЪЬтЕШЯрЙижЊЪЖЁЃ |
|
здЙХБјМвЖрФБЃЌЁЖФБЙЅЦЊЁЗЃЌЁАЙЪЩЯБјЗЅФБЃЌЦфДЮЗЅНЛЃЌЦфДЮЗЅБјЃЌЦфЯТЙЅГЧЁЃЙЅГЧжЎЗЈЃЌЮЊВЛЕУвбЁБЃЌПЩМћЙЅГЧжЎМЦгаКмЖржжЃЌЖјХРЧНЙЅГЧЪЧзюВЛУїжЧЕФзіЗЈЃЌОќЖгЦЃБЙЪмЫ№ЁЂЧЎСИЫ№КФЁЂАйаедтбъЁЃЙЪЖјЮвУЧгаКмЖргиЛижЎВпЃЌФБТдЁЂЭтНЛЁЂОќЪТЪжЖЮЕШЕШЃЌУПвЛжжЖМБШЙЅГЧЕФДњМлаЁЃЌИќЧсСПМЖЃЌЛКДцЩшМЦврЪЧШчДЫЁЃ
вЛЁЂЮЊЪВУДвЊЩшМЦЛКДц?
ЦфЪЕИпВЂЗЂгІЖдЕФНтОіЗНАИВЛЪЧЛЅСЊЭјЖРДДЕФЃЌМЦЫуЛњЯШзцУЧКмдчОЭЖдРрЫЦЕФГЁОАзіСЫЗНАИЁЃБШШчЁЖМЦЫуЛњзщГЩдРэЁЗетбљЬсЕНЕФCPUЛКДцИХФю:ЫќЪЧвЛжжИпЫйЛКДцЃЌШнСПБШФкДцаЁЕЋЪЧЫйЖШШДПьКмЖрЃЌетжжЛКДцЕФГіЯжжївЊЪЧЮЊСЫНтОіCPUдЫЫуЫйЖШдЖДѓгкФкДцЖСаДЫйЖШЃЌЩѕжСДяЕНЧЇЭђБЖЕФЮЪЬтЁЃ
ДЋЭГЕФCPUЭЈЙ§fsbжБСЌФкДцЕФЗНЪНЯдШЛОЭЛсвђЮЊФкДцЗУЮЪЕФЕШД§ЃЌЕМжТCPUЭЬЭТСПЯТНЕЃЌФкДцГЩЮЊадФмЦПОБЁЃЭЌЪБгжгЩгкФкДцЗУЮЪЕФШШЕуЪ§ОнМЏжаадЃЌЫљвдашвЊдкCPUгыФкДцжЎМфзівЛВуСйЪБЕФДцДЂЦїзїЮЊИпЫйЛКДцЁЃ
ЫцзХЯЕЭГИДдгадЕФЬсЩ§ЃЌетжжИпЫйЛКДцКЭФкДцжЎМфЕФЫйЖШНјвЛВНРПЊЃЌгЩгкММЪѕФбЖШКЭГЩБОЕШдвђЃЌЫљвдгаСЫИќДѓЕФЖўМЖЁЂШ§МЖЛКДцЁЃИљОнЖСШЁЫГађЃЌОјДѓЖрЪ§ЕФЧыЧѓЪзЯШТфдквЛМЖЛКДцЩЯЃЌЦфДЮЖўМЖ...
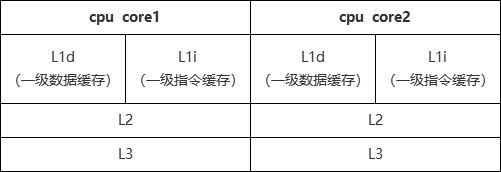
ЙЪЖјгІгУгкSOAЩѕжСЮЂЗўЮёЕФГЁОАЃЌФкДцЯрЕБгкДцДЂвЕЮёЪ§ОнЕФГжОУЛЏЪ§ОнПтЃЌЦфЭЬЭТСППЯЖЈЪЧдЖдЖаЁгкЛКДцЕФЃЌЖјЖдгкjavaГЬађРДНВЃЌБОЕиЕФJVMЛКДцгХгкМЏжаЪНЕФRedisЛКДцЁЃ
ЙиЯЕаЭЪ§ОнПтВйзїЗНБуЁЂвзгкЮЌЛЄЧвЗУЮЪЪ§ОнСщЛюЃЌЕЋЪЧЫцзХЪ§ОнСПЕФдіМгЃЌЦфМьЫїЁЂИќаТЕФаЇТЪЛсдНРДдНЕЭЁЃЫљвддкИпВЂЗЂЕЭбгГйвЊЧѓИДдгЕФГЁОАЃЌвЊИјЪ§ОнПтМѕИКЃЌМѕЩйЦфбЙСІЁЃ
ЖўЁЂИјЪ§ОнПтМѕИК
1.ЛКДцЗжВМЪНЃЌзіЖрМЖЛКДц
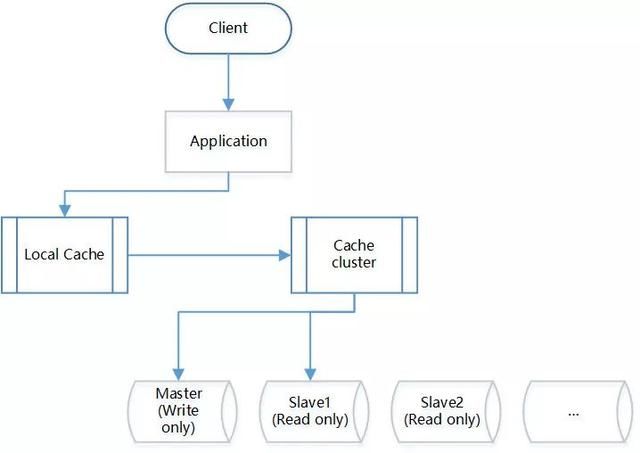
ЖСЧыЧѓЪБаДЛКДц
аДЛКДцЪБвЛМЖвЛМЖаДЃЌЯШаДБОЕиЛКДцЃЌдйаДМЏжаЪНЛКДцЁЃОпЬхаЉЛКДцЕФЗНЗЈПЩвдгаКмЖржжЃЌЕЋЪЧашвЊзЂвтМИЯюддђ:
ВЛвЊИДжЦеГЬљЃЌБмУтжиИДДњТы;
ЧаМЩКЭвЕЮёёюКЯЬЋНєЃЌВЛРћгкКѓЦкЮЌЛЄ;
ПЊЗЂГѕЦкИеИеЩЯЯпНзЖЮЃЌЮЊСЫХХВщЮЪЬтЃЌГЃГЃЛсИјЛКДцЩшжУПЊЙиЃЌЕЋЪЧПЊЙиЩшжУЖрСЫдђЛсЭЌЪБЩ§ИпЯЕЭГЕФИДдгЖШЃЌашвЊНсКЯвЛЬзЭГвЛХфжУЙмРэЯЕЭГЃЌР§ШчОЉЖЋЮяСїОЭгавЛЬзНазіUCCЁЃ
злЩЯЫљЪіЃЌИпёюКЯДјРДЕФЭДЃЌУжВЙЕФДњМлЪЧКмДѓЕФЃЌЫљвдПЩвдНшМјSpring cacheРДЪЕЯжЃЌЪЕЯжвВБШНЯМђЕЅЃЌЪЙгУЪБвЛИізЂНтОЭИуЖЈСЫЁЃ
аДЛКДцЪЇАмСЫдѕУДАь?гІИУЯШаДЛКДцЛЙЪЧЪ§ОнПтФи?
МШШЛЪЧЛКДцЕФЩшМЦЃЌФЧУДВпТдвЛЖЈЪЧБЃжЄзюжевЛжТадЃЌФЧУДЮвУЧжЛашвЊВЩгУвьВНЯћЯЂРДВЙГЅОЭКУСЫЁЃ
ДѓВПЗжЛКДцгІгУЕФГЁОАЪЧЖСаДБШВювьКмДѓЕФЃЌЖСдЖДѓгкаДЃЌдкетжжГЁОАЯТЃЌжЛашвЊвдЪ§ОнПтЮЊжїЃЌЯШаДЪ§ОнПтЃЌдйаДЛКДцОЭКУСЫЁЃ
зюКѓВЙГфвЛЕуЃЌЪ§ОнПтГіЯжвьГЃЪБЃЌВЛвЊвЛЙЩФдЕФcatch RuntimeExceptionЃЌЖјЪЧАбОпЬхЙиаФЕФвьГЃЭљЭтХзЃЌШЛКѓНјаагаеыЖдадЕФвьГЃДІРэЁЃ
ЙигкЦфЫћадФмЗНУц
ЛКДцЩшМЦЖМЪЧеМгУдНЩйдНКУЃЌФкДцзЪдДАКЙѓвдМАЬЋДѓВЛКУЮЌЛЄЖМЧ§ЪЙЮвУЧетбљЩшМЦЁЃЫљвдвЊОЁПЩФмМѕЩйЛКДцВЛБивЊЕФЪ§ОнЃЌгаЕФЭЌбЇЭМЪЁЪТАбећИіЖдЯѓађСаЛЏДцДЂЁЃСэЭтЃЌађСаЛЏгыЗДађСаЛЏвВЪЧЯћКФадФмЕФЁЃ
2.vsИїжжЛКДцЭЌВНЗНАИ
ЛКДцЭЌВНЗНАИгаКмЖржжЃЌдкПМТЧвЛжТадЁЂЪ§ОнПтЗУЮЪбЙСІЁЂЪЕЪБадЕШЗНУцзіШЈКтЁЃзмЕФРДЫЕгавдЯТМИжжЗНЪН:
РСМгдиЪН
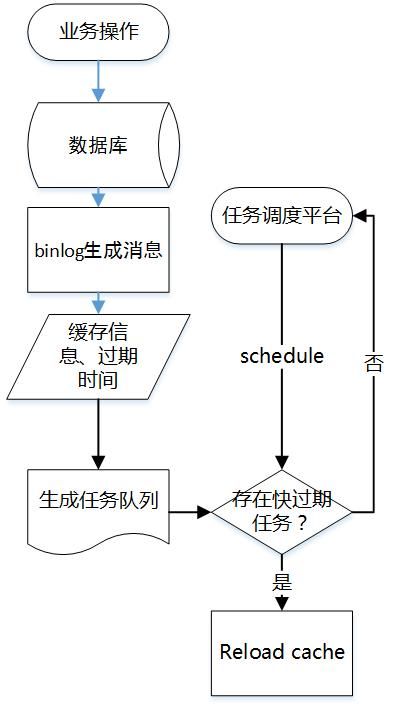
ШчЩЯЖЮЬсЕНЕФЗНЪНЃЌЖСЪБЫГБуМгдиЃЌЮЊСЫИќаТЛКДцЪ§ОнЃЌашвЊЙ§ЦкЛКДцЁЃ
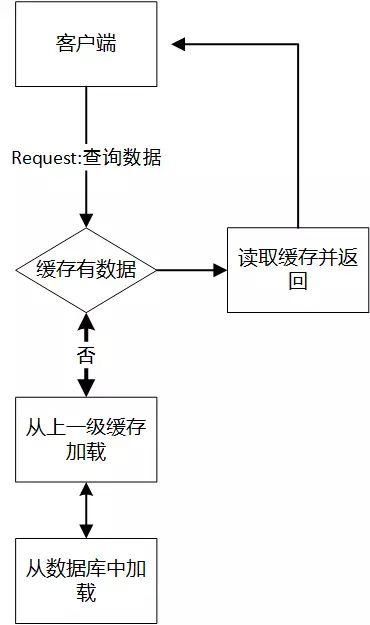
гХЕу:МђЕЅжБНгЁЃ
ШБЕу:
ЛсдьГЩвЛДЮЛКДцВЛУќжа;
етбљЕБгУЛЇВЂЗЂКмДѓЪБЃЌЧЁКУЛКДцжаЮоЪ§ОнЃЌЪ§ОнПтГаЕЃЫВЪБСїСПЙ§ДѓЛсдьГЩЗчЯеЁЃ
РСМгдиЪНЬЋМђЕЅСЫЃЌУЛгаздЖЏМгдиЃЌвьВНЫЂаТЕШЛњжЦЃЌЮЊСЫУжВЙЦфШБЯнЃЌЧыВЮМћНгЯТРДЕФСНжжЗНЗЈ:
ВЙГфЪН
ПЩвддкЛКДцЪБЃЌАбЙ§ЦкЪБМфЕШаХЯЂаДЕНвЛИівьВНЖгСаРяЃЌКѓЬЈЦ№ИіЯпГЬГиЖЈЦкЩЈУшетИіЖгСаЃЌдкПьЙ§ЦкЪБжїЖЏreloadЛКДцЃЌЪЙЕУЪ§ОнЛсвЛжББЃГждкЛКДцжаЃЌШчЙћЛКДцУЛгавВУЛгаБивЊШЅЪ§ОнПтВщбЏСЫЁЃГЃМћЕФДІРэЗНЪНгаЪЙгУbinlogМгЙЄГЩЯћЯЂЙЉдіСПДІРэЁЃ
гХЕу:ЫЂаТЛКДцБфЮЊвьВНЕФШЮЮёЃЌЖдЪ§ОнПтЕФбЙСІЫВМфгЩгкШЮЮёЖгСаЕФНщШыЖјНЕЕЭСЫЃЌЯїЦНВЂЗЂЕФВЈЗхЁЃ
ШБЕу:ЯћЯЂвЛЕЉЛ§бЙЛсдьГЩЭЌВНбгГйЃЌв§ШыИДдгЖШЁЃ
ЖЈЪБМгдиЪН
етОЭашвЊгаИівьВНЯпГЬГиЖЈЦкАбЪ§ОнПтЕФЪ§ОнЫЂЕНМЏжаЪНЛКДцЃЌШчRedisРяЁЃ
гХЕу:БЃжЄЫљгаЪ§ОнзюаЁЪБМфВюЭЌВНЕНЛКДцжаЃЌбгГйКмЕЭЁЃ
ШБЕу:ШчВЙГфЪНЃЌашвЊвЛИіШЮЮёЕїЖШПђМмЃЌИДдгЖШЬсЩ§ЃЌЧввЊБЃжЄШЮЮёЕФЫГађЁЃШчЙћЕнНјвЛВНЛЙЯыМгдиЕНБОЕиЛКДцЃЌОЭЕУБОЕигІгУздМКЦ№ЯпГЬзЅШЁЃЌЗНАИЮЌЛЄГЩБОИпЁЃПЩвдПМТЧЪЙгУmqЛђепЦфЫћвьВНШЮЮёЕїЖШПђМмЁЃ
ps:ЮЊСЫЗРжЙЖгСаЙ§ДѓЕїЖШГіЯжЮЪЬтЃЌДІРэЭъЕФЪ§ОнвЊОЁПьНсзЊЃЌЧввЊЖдЛ§бЙЪ§ОнвдМАаДШыЧщПізіМрПиЁЃ
3.ЗРжЙЛКДцДЉЭИ
ЛКДцДЉЭИЪЧжИВщбЏЕФkeyбЙИљВЛДцдкЃЌДгЖјЛКДцВщбЏВЛЕНЖјВщбЏСЫЪ§ОнПтЁЃШєЪЧетбљЕФkeyЧЁКУВЂЗЂЧыЧѓКмДѓЃЌФЧУДОЭЛсЖдЪ§ОнПтдьГЩВЛБивЊЕФбЙСІЁЃдѕУДНтОіФи?
АбЫљгаДцдкЕФkeyЖМДцЕНСэЭтвЛИіДцДЂЕФSetМЏКЯРяЃЌВщбЏЪБПЩвдЯШВщбЏkeyЪЧЗёДцдк;
ИЩДрМђЕЅвЛаЉЃЌИјВщбЏВЛЕНЕФkeyвВМгвЛИіБъЪЖПежЕЕФValueЃЌетбљОЭВЛЛсШЅВщбЏЪ§ОнПтСЫЃЌБШШчГЁОАЮЊВщбЏЪЁЪаЧјНжЕРЖдгІЕФвЦЖЏгЊвЕЬќЃЌШєЪЧФГНжЕРШЗЪЕУЛгавЦЖЏгЊвЕЬќЃЌkeyЙцдђВЛБфЃЌvalueПЩвдЩшжУЮЊ"0"ЕШЮовтвхЕФзжЗћЁЃЕБШЛДЫжжЗНАИвЊБЃжЄЛКДцМЏШКЕФИпПЩгУ;
етаЉKeyПЩФмВЛЪЧгРдЖВЛДцдкЃЌЫљвдашвЊИљОнвЕЮёГЁОАРДЩшжУЙ§ЦкЪБМфЁЃ
4.ШШЕуЛКДцгыЛКДцЬдЬВпТд
гавЛаЉГЁОАЃЌашвЊжЛБЃГжвЛВПЗжЕФШШЕуЛКДцЃЌВЛашвЊШЋСПЛКДцЃЌБШШчШШТєЕФЩЬЦЗаХЯЂЃЌЙКТђФГРрЩЬЦЗЕФШШУХЩЬШІаХЯЂЕШЕШЁЃ
злКЯРДНВЃЌЛКДцЙ§ЦкЕФВпТдгавдЯТШ§жж:
FIFO(First InЃЌFirst Out)
МДЯШНјЯШГіЃЌЬдЬзюдчНјРДЕФЛКДцЪ§ОнЃЌвЛИіБъзМЕФЖгСаЁЃ

вдЖгСаЮЊЛљБОЪ§ОнНсЙЙЃЌДгЖгЪзНјШыаТЪ§ОнЃЌДгЖгЮВЬдЬЁЃ
LRU(Least RecentlyUsed)
МДзюНќзюЩйЪЙгУЃЌЬдЬзюНќВЛЪЙгУЕФЛКДцЪ§ОнЁЃШчЙћЪ§ОнзюНќБЛЗУЮЪЙ§ЃЌдђВЛЬдЬЁЃ
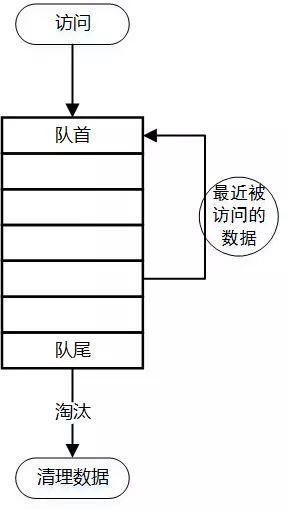
КЭFIFOВЛЭЌЕФЪЧЃЌашвЊЖдСДБэзіЛљБОФЃаЭЃЌЖСаДЕФЪБМфИДдгЖШЪЧO(1)ЃЌаДШыаТЪ§ОнНјШыЭЗВПЃЌСДБэТњСЫЪ§ОнДгЮВВПЬдЬ;
зюНќЪБМфБЛЗУЮЪЕФЪ§ОнвЦЖЏЕНЭЗВПЃЌЪЕЯжЫуЗЈгаКмЖрЃЌШчhashmap+ЫЋЯђСДБэЕШЕШ;
ЮЪЬтдкгкШєЪЧХМЗЂадФГаЉkeyБЛзюНќЦЕЗБЗУЮЪЃЌЖјЗЧГЃЬЌЃЌдђЪ§ОнЪмЕНЮлШОЁЃ
LFU(Least Frequently used)
МДзюНќЪЙгУДЮЪ§зюЩйЕФЪ§ОнБЛЬдЬЃЌзЂвтКЭLRUЕФЧјБ№дкгкLRUЕФЬдЬЙцдђЪЧЛљгкЗУЮЪЪБМфЁЃ
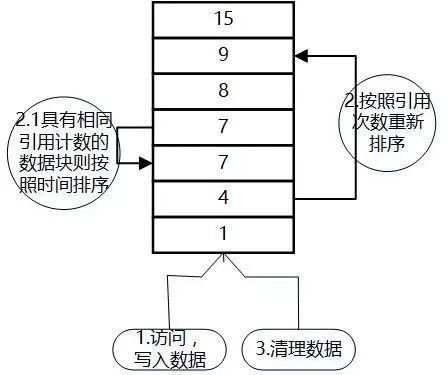
LFUжаЕФУПИіЪ§ОнПщЖМгавЛИів§гУМЦЪ§ЃЌЪ§ОнПщАДеев§гУМЦЪ§ХХађЃЌШєЪЧЧЁКУОпгаЯрЭЌв§гУМЦЪ§ЕФЪ§ОнПщдђАДееЪБМфХХађ;
вђЮЊаТМгШыЕФЪ§ОнЗУЮЪДЮЪ§ЮЊ1ЃЌЫљвдВхШыЕНЖгСаЮВВП;
ЖгСажаЕФЪ§ОнБЛаТЗУЮЪКѓЃЌв§гУМЦЪ§діМгЃЌЖгСажиаТХХађ;
ЕБашвЊЬдЬЪ§ОнЪБЃЌНЋвбОХХађЕФСаБэзюКѓЕФЪ§ОнПщЩОГ§;
гаКмУїЯдЮЪЬтЪЧШєЖЬЪБМфФкБЛЦЕЗБЗУЮЪЖрДЮЃЌБШШчЗУЮЪвьГЃЛђепбЛЗУЛгаПижЦзЁЃЌЖјКѓКмГЄЪБМфЮДЪЙгУЃЌдђДЫЪ§ОнЛсвђЮЊЦЕТЪИпЖјБЛДэЮѓЕФБЃСєЯТРДЃЌУЛгаБЛЬдЬЁЃгШЦфЖдгкаТРДЕФЪ§ОнЃЌгЩгкЦфЦ№ЪМЕФДЮЪ§ЪЧ1ЃЌЫљвдМДБуБЛе§ГЃЪЙгУвВЛсвђЮЊБШВЛЙ§РЯЕФЪ§ОнЖјБЛЬдЬЁЃЫљвдЮЌЛљАйПЦЫЕДПДтЕФLFUЫуЗЈВЛОГЃЕЅЖРЪЙгУЖјЪЧзщКЯдкЦфЫћВпТджаЪЙгУЁЃ
5.ЛКДцЪЙгУЕФвЛаЉГЃМћЮЪЬт
Q1:ФЧУДгІИУбЁдёгУБОЕиЛКДц(local cache)ЛЙЪЧМЏжаЪНЛКДц(Cache cluster)Фи?
A1:ЪзЯШПДЪ§ОнСПЃЌПДЛКДцИќаТЕФГЩБОЃЌШчЙћећЬхЛКДцЪ§ОнСПВЛЪЧКмДѓЃЌЖјЧвБфЛЏЕФВЛЦЕЗБЃЌФЧУДНЈвщБОЕиЛКДцЁЃ
Q2:дѕУДХњСПИќаТвЛХњЛКДцЪ§Он?
A2:вРДЮДгЪ§ОнПтЖСШЁЃЌШЛКѓХњСПаДШыЛКДцЃЌХњСПИќаТЃЌЩшжУАцБОЙ§ЦкkeyЛђепжїЖЏЩОГ§ЁЃ
Q3:ШчЙћВЛжЊЕРгаФФаЉkeyдѕУДЖЈЦкЩОГ§?
A3:ФУRedisРДЫЕkeys * ЬЋЫ№КФадФмЃЌВЛЭЦМіЁЃПЩвджИЖЈвЛИіМЏКЯЃЌАбЫљгаЕФkeyЖМДцЕНетИіМЏКЯРяЃЌШЛКѓЖдећИіМЏКЯНјааЩОГ§ЃЌетбљБуФмЭъШЋЧхРэСЫЁЃ
Q4:вЛИіkeyАќКЌЕФМЏКЯКмДѓЃЌRedisЮоЗЈзіЕНФкДцПеМфЩЯЕФОљдШShard?
A4:1ЁЂПЩвдМђЕЅЕФЩшжУkeyЙ§ЦкЃЌетбљОЭвЊдЪаэгаЛКДцВЛУќжаЕФЧщПі;2ЁЂИјkeyЩшжУАцБОЃЌБШШчЮЊСНЬьКѓЕФЕБЧАЪБМфЃЌШЛКѓЖСШЁЛКДцЪБгУЪБМфХаЖЯвЛЯТЪЧЗёашвЊжиаТМгдиЛКДцЃЌзїЮЊАцБОЙ§ЦкЕФВпТдЁЃ | 








