| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌНщЩмСЫMySqlЕФИДжЦЃЌДДНЈЫљгУЕФИДжЦеЫКХЃЌХфжУmasterЃЌХфжУslaveЕФЙ§ГЬЁЃ |
|
вЛЁЂMySqlЕФИДжЦ
Ъ§ОнПтИДжЦЕФЛљБОЮЪЬтОЭЪЧШУвЛЬЈЗўЮёЦїЕФЪ§ОнгыЦфЫћЗўЮёЦїБЃГжЭЌВНЁЃMySqlФПЧАжЇГжСНжжИДжЦЗНЪНЃКЛљгкааЕФИДжЦКЭЛљгкгяОфЕФИДжЦЃЌетСНепЕФЛљБОЙ§ГЬЖМЪЧдкжїПтЩЯМЧТМЖўНјжЦЕФШежОЁЂдкБИПтЩЯжиЗХШежОЕФЗНЪНРДЪЕЯжвьВНЕФЪ§ОнИДжЦЁЃЦфЙ§ГЬЗжЮЊШ§ВНЃК
(1)masterНЋИФБфМЧТМЕНЖўНјжЦШежО(binary log)жаЃЈетаЉМЧТМНазіЖўНјжЦШежОЪТМўЃЌbinary
log events ЃЉЃЛ
(2)slaveНЋmasterЕФbinary log eventsПНБДЕНЫќЕФжаМЬШежО(relay log)ЃЛ
(3)slaveжизіжаМЬШежОжаЕФЪТМўЃЌНЋИФБфЗДгГЫќздМКЕФЪ§ОнЁЃ
![] (http: //image.wenzhihuai.com
/images /20171118040843.png)
ИУЙ§ГЬЕФЕквЛВПЗжОЭЪЧmasterМЧТМЖўНјжЦШежОЁЃдкУПИіЪТЮёИќаТЪ§ОнЭъГЩжЎЧАЃЌmasterдкЖўШежОМЧТМетаЉИФБфЁЃMySQLНЋЪТЮёДЎааЕФаДШыЖўНјжЦШежОЃЌМДЪЙЪТЮёжаЕФгяОфЖМЪЧНЛВцжДааЕФЁЃдкЪТМўаДШыЖўНјжЦШежОЭъГЩКѓЃЌmasterЭЈжЊДцДЂв§ЧцЬсНЛЪТЮёЁЃ
ЯТвЛВНОЭЪЧslaveНЋmasterЕФbinary logПНБДЕНЫќздМКЕФжаМЬШежОЁЃЪзЯШЃЌslaveПЊЪМвЛИіЙЄзїЯпГЬЁЊЁЊI/OЯпГЬЁЃI/OЯпГЬдкmasterЩЯДђПЊвЛИіЦеЭЈЕФСЌНгЃЌШЛКѓПЊЪМbinlog
dump processЁЃBinlog dump process Дгmaster ЕФЖўНјжЦШежОжаЖСШЁЪТМўЃЌШчЙћвбОИњЩЯmasterЃЌЫќЛсЫЏУпВЂЕШД§masterВњЩњаТЕФЪТМўЁЃI/OЯпГЬНЋетаЉЪТМўаДШыжаМЬШежОЁЃ
SQL slave threadДІРэИУЙ§ГЬЕФзюКѓвЛВНЁЃSQLЯпГЬДгжаМЬШежОЖСШЁЪТМўЃЌИќаТslaveЕФЪ§ОнЃЌЪЙЦфгыmaster
жаЕФЪ§ОнвЛжТЁЃжЛвЊИУЯпГЬгыI/OЯпГЬБЃГжвЛжТЃЌжаМЬШежОЭЈГЃЛсЮЛгкOSЕФЛКДцжаЃЌЫљвджаМЬШежОЕФПЊЯњКмаЁЁЃ
ДЫЭтЃЌдкmasterжавВгавЛИіЙЄзїЯпГЬЃККЭЦфЫќMySQLЕФСЌНгвЛбљЃЌslaveдкmasterжаДђПЊвЛИіСЌНгвВЛсЪЙЕУmaster
ПЊЪМвЛИіЯпГЬЁЃИДжЦЙ§ГЬгавЛИіКмживЊЕФЯожЦЁЊЁЊИДжЦдкslaveЩЯЪЧДЎааЛЏЕФЃЌвВОЭЪЧЫЕmasterЩЯЕФВЂааИќаТВйзїВЛФмдкslaveЩЯВЂааВйзїЁЃ
MySqlЕФЛљБОИДжЦЗНЪНгажїДгИДжЦЁЂжїжїИДжЦЃЌжїжїИДжЦМДАбжїДгИДжЦЕФХфжУЕЙЙ§РДдйХфжУвЛБщМДПЩЃЌЯТУцЕФХфжУдђЪЧжїДгИДжЦЕФЙ§ГЬЃЌЕНЪБКђПЩздааИФЮЊжїжїИДжЦЁЃЦфЫћЕФМмЙЙШчЃКвЛжїПтЖрБИПтЁЂЛЗаЮИДжЦЁЂЪїЛђепН№зжЫўаЭЖМЪЧЛљгкетСНжжЗНЪНЃЌПЩВЮПМЁЖИпадФмMySqlЁЗЁЃ
ЖўЁЂХфжУЙ§ГЬ
2.1 ДДНЈЫљгУЕФИДжЦеЫКХ
гЩгкЪЧИіздМКЕФаЁЭјеОЃЌОЭВЛзіЙ§ЖрЕФВйзїСЫЃЌжБНгЪЙгУrootеЫКХ
2.2 ХфжУmaster
НгЯТРДвЊЖдmysqlЕФserverIDЃЌШежОЮЛжУЃЌИДжЦЗНЪНЕШНјааВйзїЃЌЪЙгУvimДђПЊmy.cnfЁЃ
[client]
default- character-set=utf8
[mysqld]
character_set_server=utf8
init_connect = SET NAMES utf8
datadir=/var/lib/mysql
socket=/var /lib/mysql/mysql.sock
symbolic-links =0
log-error=/var /log/mysqld.log
pid-file=/var /run/mysqld/mysqld.pid
# master
log-bin=mysql-bin
# ЩшЮЊЛљгкааЕФИДжЦ
binlog-format=ROW
# ЩшжУserverЕФЮЈвЛid
server-id=2
# КіТдЕФЪ§ОнПтЃЌВЛЪЙгУБИЗн
binlog- ignore-db=information_schema
binlog- ignore-db=cluster
binlog- ignore-db=mysql
# вЊНјааБИЗнЕФЪ§ОнПт
binlog-do-db=myblog |
жиЦєMysqlжЎКѓЃЌВщПДжїПтзДЬЌЃЌshow master statusЁЃ

ЦфжаЃЌFileЮЊШежОЮФМўЃЌжИЖЈSlaveДгФФИіШежОЮФМўПЊЪМЖСИДжЦЪ§ОнЃЌPositionЮЊЦЋвЦЃЌДгФФИіPOSITIONКХПЊЪМЖСЃЌBinlog_Do_DBЮЊвЊБИЗнЕФЪ§ОнПтЁЃ
2.3 ХфжУslave
ДгПтЕФХфжУИњжїПтРрЫЦЃЌvim /etc/my.cnfХфжУДгПтаХЯЂЁЃ
[client]
default-character-set=utf8
[mysqld]
character_set_server=utf8
init_connect= SET NAMES utf8
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
# slave
log-bin=mysql-bin
# ЗўЮёЦїЮЈвЛid
server-id=3
# ВЛБИЗнЕФЪ§ОнПт
binlog-ignore-db=information_schema
binlog-ignore-db=cluster
binlog-ignore-db=mysql
# ашвЊБИЗнЕФЪ§ОнПт
replicate-do-db=myblog
# ЦфЫћЯрЙиаХЯЂ
slave-skip-errors=all
slave-net-timeout=60
# ПЊЦєжаМЬШежО
relay_log = mysql-relay-bin
#
log_slave_updates = 1
# ЗРжЙИФБфЪ§Он
read_only = 1 |
жиЦєslaveЃЌЭЌЪБЦєЖЏИДжЦЃЌЛЙашвЊЕїећвЛЯТУќСюЁЃ
| mysql> CHANGE
MASTER TO MASTER_HOST = '119.23.46.71', MASTER
_USER = 'root', MASTER_ PASSWORD = 'helloroot',
MASTER_ PORT = 3306, MASTER_ LOG_FILE = 'mysql-bin.
000009 ' , MASTER_LOG_ POS = 346180; |
ПЩвдПДМћslaveвбОПЊЪМНјааЭЌВНСЫЁЃЮвУЧЪЙгУshow slave
status\GРДВщПДslaveЕФзДЬЌЁЃ
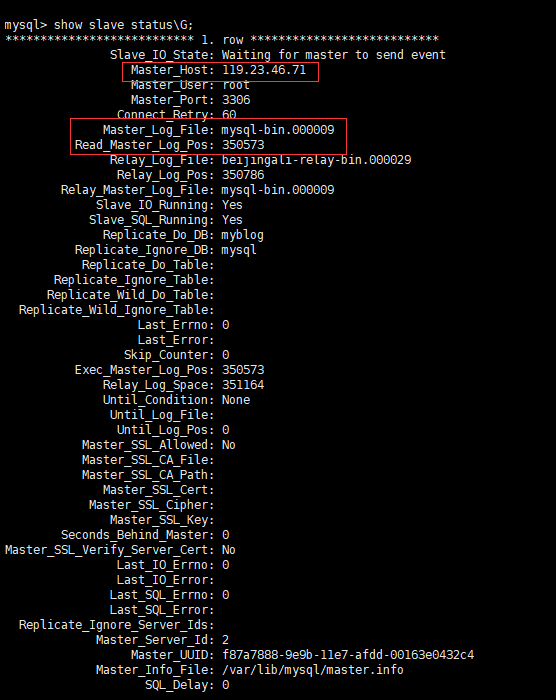
ЦфжаШежОЮФМўКЭPOSITIONВЛвЛжТЪЧКЯРэЕФЃЌХфжУКУСЫЕФЛАЃЌМДЪЙжиЦєЃЌвВВЛЛсгАЯьЕНжїДгИДжЦЕФХфжУЁЃ
ФГЬьдкGithubЩЯЦЏгЮЃЌЗЂЯжСЫАЂРяЕФcanalЃЌЭЌЪБВХжЊЕРЩЯУцетИівЕЮёЪЧНавьЕиПчЛњЗПЭЌВНЃЌдчЦкЃЌАЂРяАЭАЭB2BЙЋЫОвђЮЊДцдкКМжнКЭУРЙњЫЋЛњЗПВПЪ№ЃЌДцдкПчЛњЗПЭЌВНЕФвЕЮёашЧѓЁЃВЛЙ§дчЦкЕФЪ§ОнПтЭЌВНвЕЮёЃЌжївЊЪЧЛљгкtriggerЕФЗНЪНЛёШЁдіСПБфИќЃЌВЛЙ§Дг2010ФъПЊЪМЃЌАЂРяЯЕЙЋЫОПЊЪМж№ВНЕФГЂЪдЛљгкЪ§ОнПтЕФШежОНтЮіЃЌЛёШЁдіСПБфИќНјааЭЌВНЃЌгЩДЫбмЩњГіСЫдіСПЖЉдФ&ЯћЗбЕФвЕЮёЁЃЯТУцЪЧЛљБОЕФдРэЃК
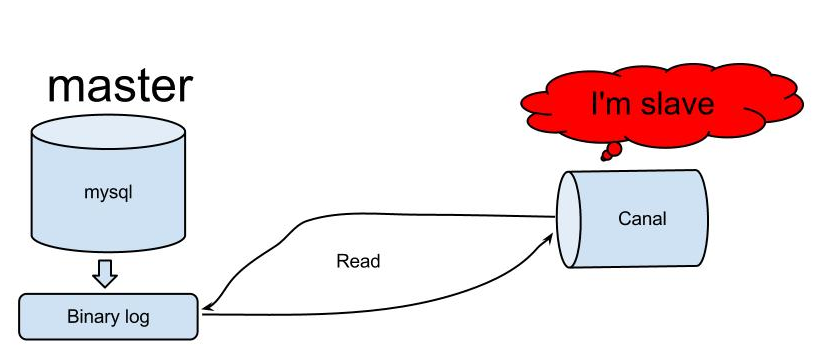
дРэЯрЖдБШНЯМђЕЅЃК
1.canalФЃФтmysql slaveЕФНЛЛЅавщЃЌЮБзАздМКЮЊmysql slaveЃЌЯђmysql
masterЗЂЫЭdumpавщ
2.mysql masterЪеЕНdumpЧыЧѓЃЌПЊЪМЭЦЫЭbinary logИјslave(вВОЭЪЧcanal)
3.canalНтЮіbinary logЖдЯѓ(дЪМЮЊbyteСї)
ЦфжаЃЌХфжУЙ§ГЬШчЯТЃКhttps://github.com/alibaba/canalЃЌПЩвдДюХфZookeeperЪЙгУЁЃдкZKUIжаФмЙЛВщПДЕННкЕуЃК

вЛАуЧщПіЯТЃЌЛЙвЊХфКЯАЂРяЕФСэвЛИіПЊдДВњЦЗЪЙгУotterЃЌЯрЙиЮФЕЕЛЙЪЧевевGitHubАЩЃЌИіШЫДюНЈЭъСЫжЎКѓЃЌгУЦ№РДЛЙЪЧВЛШчжБНгЪЙгУmysqlЕФжїжїИДжЦЃЌЖјЧввьЕиЛњЗПЭЌВНетжжДѓЦѓвЕВХгаЕФвЕЮёЁЃ | 








