| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌжївЊНщЩмСЫЪВУДЪЧЛКДцЛїДЉЃЌНтОіЗНАИЃКЪЙгУЛЅГтЫјЃЌвьВНЙЙНЈЛКДцЃЌВМТЁЙ§ТЫЦїЕШЁЃ |
|
ЪВУДЪЧЛКДцЛїДЉ
дкЬИТлЛКДцЛїДЉжЎЧАЃЌЮвУЧЯШРДЛивфЯТДгЛКДцжаМгдиЪ§ОнЕФТпМЃЌШчЯТЭМЫљЪО 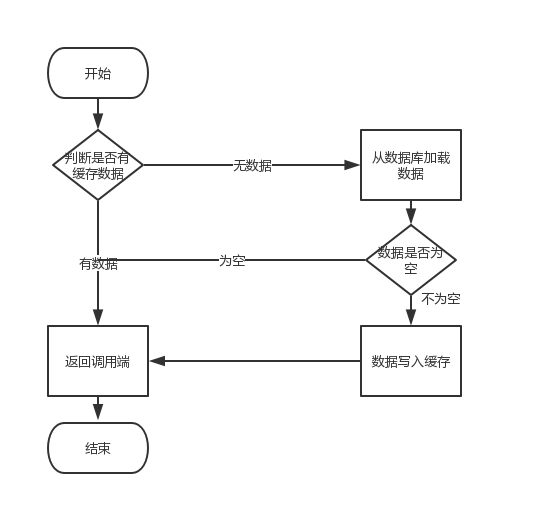
вђДЫЃЌШчЙћКкПЭУПДЮЙЪвтВщбЏвЛИідкЛКДцФкБиШЛВЛДцдкЕФЪ§ОнЃЌЕМжТУПДЮЧыЧѓЖМвЊШЅДцДЂВуШЅВщбЏЃЌетбљЛКДцОЭЪЇШЅСЫвтвхЁЃШчЙћдкДѓСїСПЯТЪ§ОнПтПЩФмЙвЕєЁЃетОЭЪЧЛКДцЛїДЉЁЃ
ГЁОАШчЯТЭМЫљЪО:
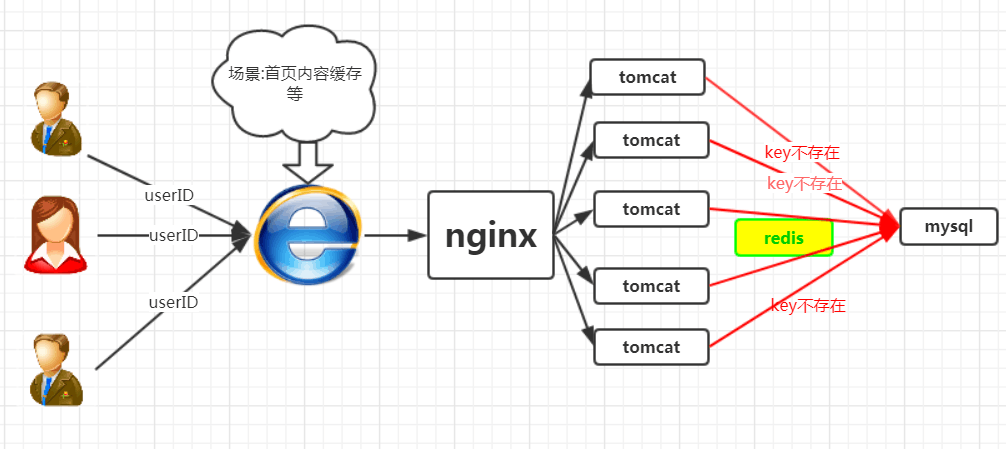
ЮвУЧе§ГЃШЫдкЕЧТМЪзвГЕФЪБКђЃЌЖМЪЧИљОнuserIDРДУќжаЪ§ОнЃЌШЛЖјКкПЭЕФФПЕФЪЧЦЦЛЕФуЕФЯЕЭГЃЌКкПЭПЩвдЫцЛњЩњГЩвЛЖбuserID,ШЛКѓНЋетаЉЧыЧѓэЁЕНФуЕФЗўЮёЦїЩЯЃЌетаЉЧыЧѓдкЛКДцжаВЛДцдкЃЌОЭЛсДЉЙ§ЛКДцЃЌжБНгэЁЕНЪ§ОнПтЩЯ,ДгЖјдьГЩЪ§ОнПтСЌНгвьГЃЁЃ
НтОіЗНАИ
дкетРяЮвУЧИјГіШ§ЬзНтОіЗНАИЃЌДѓМвИљОнЯюФПжаЕФЪЕМЪЧщПіЃЌбЁдёЪЙгУ.
НВЯТЪіШ§жжЗНАИЧАЃЌЮвУЧЯШЛивфЯТredisЕФsetnxЗНЗЈ
SETNX key value
НЋ key ЕФжЕЩшЮЊ value ЃЌЕБЧвНіЕБ key ВЛДцдкЁЃ
ШєИјЖЈЕФ key вбОДцдкЃЌдђ SETNX ВЛзіШЮКЮЖЏзїЁЃ
SETNX ЪЧЁКSET if Not eXistsЁЛ(ШчЙћВЛДцдкЃЌдђ SET)ЕФМђаДЁЃ
ПЩгУАцБОЃК>= 1.0.0
ЪБМфИДдгЖШЃК O(1)
ЗЕЛижЕЃК ЩшжУГЩЙІЃЌЗЕЛи 1ЁЃЩшжУЪЇАмЃЌЗЕЛи 0 ЁЃ
аЇЙћШчЯТ
redis> EXISTS
job # job ВЛДцдк
(integer) 0
redis> SETNX job "programmer"
# job ЩшжУГЩЙІ
(integer) 1
redis> SETNX job "code-farmer"
# ГЂЪдИВИЧ job ЃЌЪЇАм
(integer) 0
redis> GET job # УЛгаБЛИВИЧ
"programmer" |
1ЁЂЪЙгУЛЅГтЫј
ИУЗНЗЈЪЧБШНЯЦеБщЕФзіЗЈЃЌМДЃЌдкИљОнkeyЛёЕУЕФvalueжЕЮЊПеЪБЃЌЯШЫјЩЯЃЌдйДгЪ§ОнПтМгдиЃЌМгдиЭъБЯЃЌЪЭЗХЫјЁЃШєЦфЫћЯпГЬЗЂЯжЛёШЁЫјЪЇАмЃЌдђЫЏУп50msКѓжиЪдЁЃ
жСгкЫјЕФРраЭЃЌЕЅЛњЛЗОГгУВЂЗЂАќЕФLockРраЭОЭааЃЌМЏШКЛЗОГдђЪЙгУЗжВМЪНЫј( redisЕФsetnx)
МЏШКЛЗОГЕФredisЕФДњТыШчЯТЫљЪО:
String get(String
key) {
String value = redis.get(key);
if (value == null) {
if (redis.setnx(key_mutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis.expire(key_mutex, 3 * 60)
value = db.get(key);
redis.set(key, value);
redis.delete(key_mutex);
} else {
//ЦфЫћЯпГЬанЯЂ50КСУыКѓжиЪд
Thread.sleep(50);
get(key);
}
}
} |
гХЕу:
1.ЫМТЗМђЕЅ
2.БЃжЄвЛжТад
ШБЕу
1.ДњТыИДдгЖШдіДѓ
2.ДцдкЫРЫјЕФЗчЯе
2ЁЂвьВНЙЙНЈЛКДц
дкетжжЗНАИЯТЃЌЙЙНЈЛКДцВЩШЁвьВНВпТдЃЌЛсДгЯпГЬГижаШЁЯпГЬРДвьВНЙЙНЈЛКДцЃЌДгЖјВЛЛсШУЫљгаЕФЧыЧѓжБНгэЁЕНЪ§ОнПтЩЯЁЃИУЗНАИredisздМКЮЌЛЄвЛИіtimeoutЃЌЕБtimeoutаЁгкSystem.currentTimeMillis()ЪБЃЌдђНјааЛКДцИќаТЃЌЗёдђжБНгЗЕЛиvalueжЕЁЃ
МЏШКЛЗОГЕФredisДњТыШчЯТЫљЪО:
String get(final
String key) {
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout < = System.currentTimeMillis())
{
// вьВНИќаТКѓЬЈвьГЃжДаа
threadPool.execute (new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
if (redis.setnx(keyMutex, "1")) {
// 3 min timeout to avoid mutex holder crash
redis. expire (keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
} |
гХЕу:
адМлзюМбЃЌгУЛЇЮоашЕШД§
ШБЕу
ЮоЗЈБЃжЄЛКДцвЛжТад
3ЁЂВМТЁЙ§ТЫЦї
1ЁЂдРэ
ВМТЁЙ§ТЫЦїЕФОоДѓгУДІОЭЪЧЃЌФмЙЛбИЫйХаЖЯвЛИідЊЫиЪЧЗёдквЛИіМЏКЯжаЁЃвђДЫЫћгаШчЯТШ§ИіЪЙгУГЁОА:
1.ЭјвГХРГцЖдURLЕФШЅжиЃЌБмУтХРШЁЯрЭЌЕФURLЕижЗ
2.ЗДРЌЛјгЪМўЃЌДгЪ§ЪЎвкИіРЌЛјгЪМўСаБэжаХаЖЯФГгЪЯфЪЧЗёРЌЛјгЪЯфЃЈЭЌРэЃЌРЌЛјЖЬаХЃЉ
3.ЛКДцЛїДЉЃЌНЋвбДцдкЕФЛКДцЗХЕНВМТЁЙ§ТЫЦїжаЃЌЕБКкПЭЗУЮЪВЛДцдкЕФЛКДцЪБбИЫйЗЕЛиБмУтЛКДцМАDBЙвЕєЁЃ
OKЃЌНгЯТРДЮвУЧРДЬИЬИВМТЁЙ§ТЫЦїЕФдРэ
ЦфФкВПЮЌЛЄвЛИіШЋЮЊ0ЕФbitЪ§зщЃЌашвЊЫЕУїЕФЪЧЃЌВМТЁЙ§ТЫЦїгавЛИіЮѓХаТЪЕФИХФюЃЌЮѓХаТЪдНЕЭЃЌдђЪ§зщдНГЄЃЌЫљеМПеМфдНДѓЁЃЮѓХаТЪдНИпдђЪ§зщдНаЁЃЌЫљеМЕФПеМфдНаЁЁЃ
МйЩшЃЌИљОнЮѓХаТЪЃЌЮвУЧЩњГЩвЛИі10ЮЛЕФbitЪ§зщЃЌвдМА2ИіhashКЏЪ§ЃЈf1,f2
ЃЉЃЌШчЯТЭМЫљЪО(ЩњГЩЕФЪ§зщЕФЮЛЪ§КЭhashКЏЪ§ЕФЪ§СПЃЌЮвУЧВЛгУШЅЙиаФЪЧШчКЮЩњГЩЕФЃЌгаЪ§бЇТлЮФНјааЙ§зЈвЕЕФжЄУї)ЁЃ

МйЩшЪфШыМЏКЯЮЊ(N1,N2 ),ОЙ§МЦЫуf1(N1)ЕУЕНЕФЪ§жЕЕУЮЊ2ЃЌf2(N1)
ЕУЕНЕФЪ§жЕЮЊ5ЃЌдђНЋЪ§зщЯТБъЮЊ2КЭЯТБэЮЊ5ЕФЮЛжУжУЮЊ1ЃЌШчЯТЭМЫљЪО
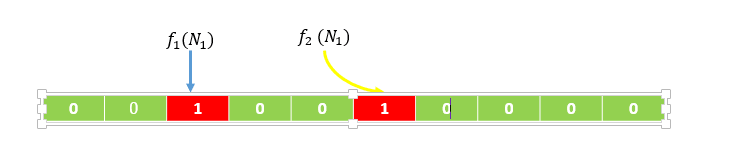
ЭЌРэЃЌОЙ§МЦЫуf1(N2)
ЕУЕНЕФЪ§жЕЕУЮЊ3ЃЌf2(N2)
ЕУЕНЕФЪ§жЕЮЊ6ЃЌдђНЋЪ§зщЯТБъЮЊ3КЭЯТБэЮЊ6ЕФЮЛжУжУЮЊ1ЃЌШчЯТЭМЫљЪО

етИіЪБКђЃЌЮвУЧгаЕкШ§ИіЪ§N3
ЃЌЮвУЧХаЖЯN3дкВЛдкМЏКЯ(N1,N2)жаЃЌОЭНјааf1(N3)ЃЌf2(N3)
ЕФМЦЫу
1.ШєжЕЧЁЧЩЖМЮЛгкЩЯЭМЕФКьЩЋЮЛжУжаЃЌЮвУЧдђШЯЮЊЃЌN3
дкМЏКЯ(N1,N2
)жа
2.ШєжЕгавЛИіВЛЮЛгкЩЯЭМЕФКьЩЋЮЛжУжаЃЌЮвУЧдђШЯЮЊЃЌN3
ВЛдкМЏКЯ(N1,N2)жа
вдЩЯОЭЪЧВМТЁЙ§ТЫЦїЕФМЦЫудРэЃЌЯТУцЮвУЧНјааадФмВтЪдЃЌ
2ЁЂадФмВтЪд
ДњТыШчЯТ:
(1)аТНЈвЛИіmavenЙЄГЬЃЌв§ШыguavaАќ
<dependencies>
<dependency>
<groupId> com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>
</dependencies>
|
(2)ВтЪдвЛИідЊЫиЪЧЗёЪєгквЛИіАйЭђдЊЫиМЏКЯЫљашКФЪБ
package bloomfilter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.Charset;
public class Test {
private static int size = 1000000;
private static BloomFilter <Integer> bloomFilter
= BloomFilter .create(Funnels.integerFunnel(),
size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // ЛёШЁПЊЪМЪБМф
//ХаЖЯетвЛАйЭђИіЪ§жаЪЧЗёАќКЌ29999етИіЪ§
if (bloomFilter.mightContain(29999)) {
System.out.println("УќжаСЫ");
}
long endTime = System.nanoTime(); // ЛёШЁНсЪјЪБМф
System.out.println("ГЬађдЫааЪБМфЃК " +
(endTime - startTime) + "ФЩУы");
}
} |
ЪфГіШчЯТЫљЪО
УќжаСЫ
ГЬађдЫааЪБМфЃК 219386ФЩУы |
вВОЭЪЧЫЕЃЌХаЖЯвЛИіЪ§ЪЧЗёЪєгквЛИіАйЭђМЖБ№ЕФМЏКЯЃЌжЛвЊ0.219msОЭПЩвдЭъГЩЃЌадФмМЋМбЁЃ
(3)ЮѓХаТЪЕФвЛаЉИХФю
ЪзЯШЃЌЮвУЧЯШВЛЖдЮѓХаТЪзіЯдЪОЕФЩшжУЃЌНјаавЛИіВтЪдЃЌДњТыШчЯТЫљЪО
package bloomfilter;
import java.util.ArrayList;
import java.util.List;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class Test {
private static int size = 1000000;
private static BloomFilter <Integer> bloomFilter
= BloomFilter .create(Funnels.integerFunnel(),
size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
//ЙЪвтШЁ10000ИіВЛдкЙ§ТЫЦїРяЕФжЕЃЌПДПДгаЖрЩйИіЛсБЛШЯЮЊдкЙ§ТЫЦїРя
for (int i = size + 10000; i < size + 20000;
i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("ЮѓХаЕФЪ§СПЃК" + list.size());
}
} |
ЪфГіНсЙћШчЯТ
ШчЙћЩЯЪіДњТыЫљЪОЃЌЮвУЧЙЪвтШЁ10000ИіВЛдкЙ§ТЫЦїРяЕФжЕЃЌШДЛЙга330ИіБЛШЯЮЊдкЙ§ТЫЦїРяЃЌетЫЕУїСЫЮѓХаТЪЮЊ0.03.МДЃЌдкВЛзіШЮКЮЩшжУЕФЧщПіЯТЃЌФЌШЯЕФЮѓХаТЪЮЊ0.03ЁЃ
ЯТУцЩЯдДТыРДжЄУїЃК 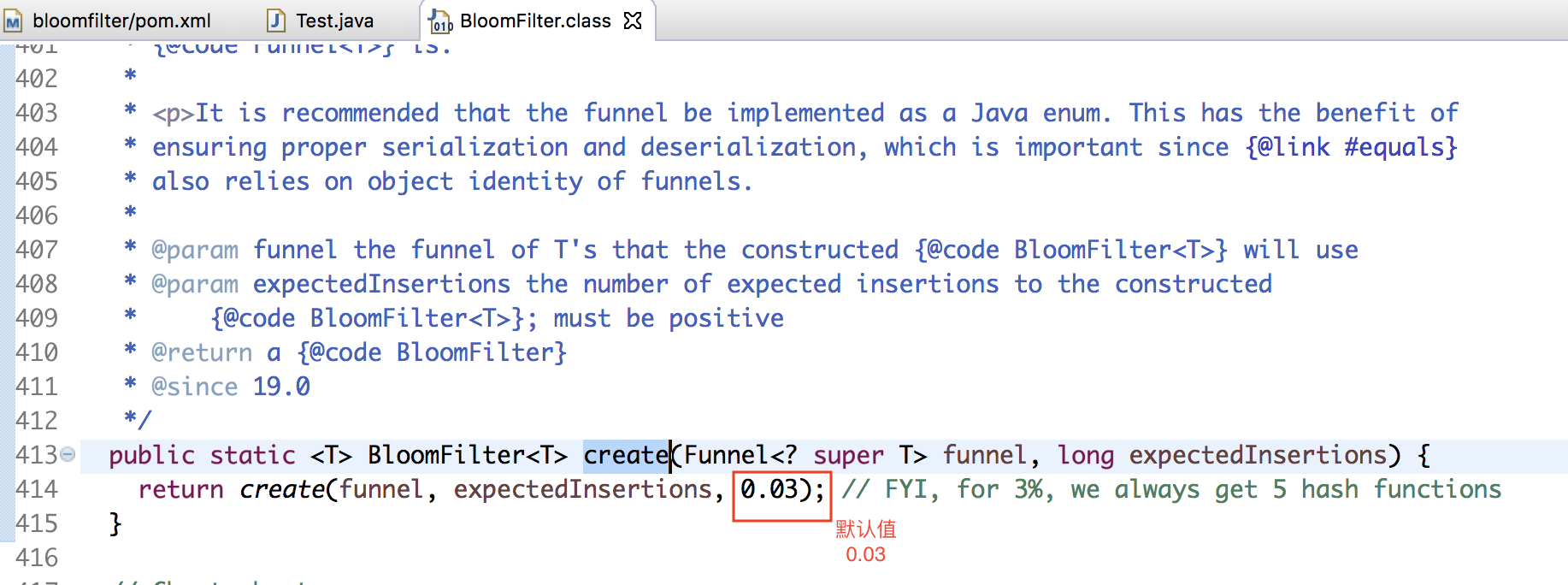
НгЯТРДЮвУЧРДПДвЛЯТЃЌЮѓХаТЪЮЊ0.03ЪБЃЌЕзВуЮЌЛЄЕФbitЪ§зщЕФГЄЖШШчЯТЭМЫљЪО 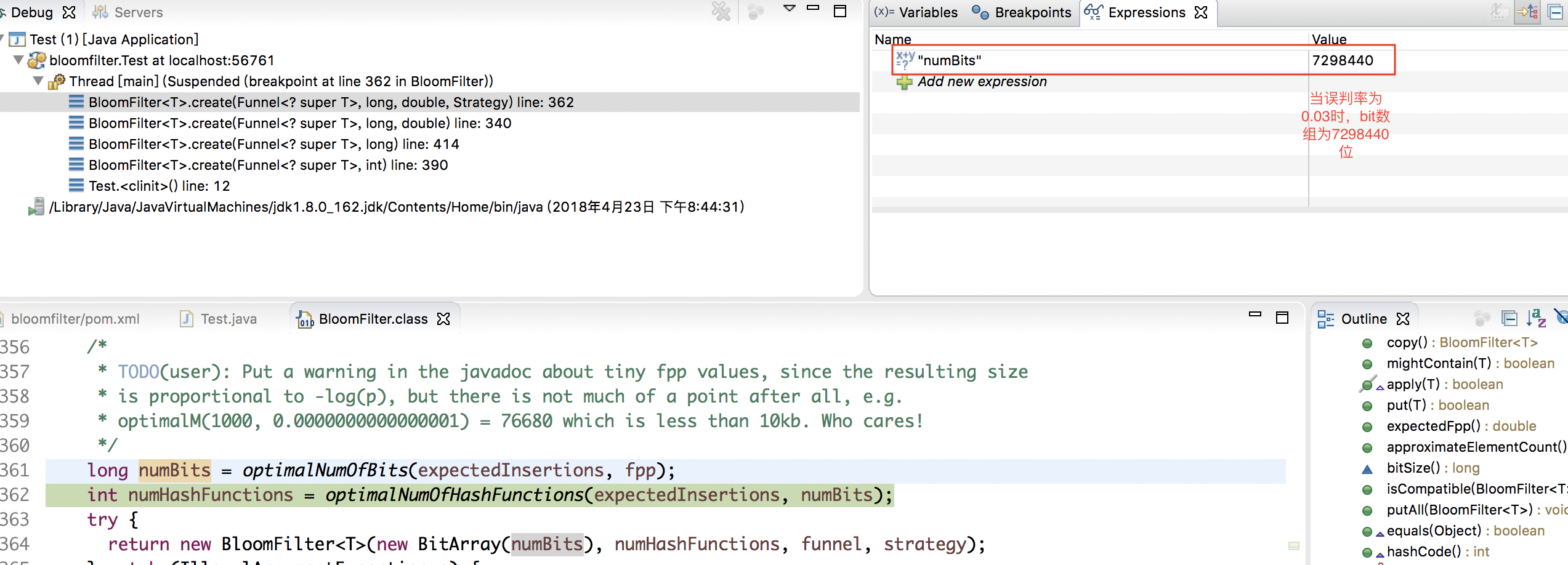
НЋbloomfilterЕФЙЙдьЗНЗЈИФЮЊ
| private static
BloomFilter<Integer> bloomFilter = BloomFilter
.create (Funnels.integerFunnel(), size, 0. 01); |
МДЃЌДЫЪБЮѓХаТЪЮЊ0.01ЁЃдкетжжЧщПіЯТЃЌЕзВуЮЌЛЄЕФbitЪ§зщЕФГЄЖШШчЯТЭМЫљЪО 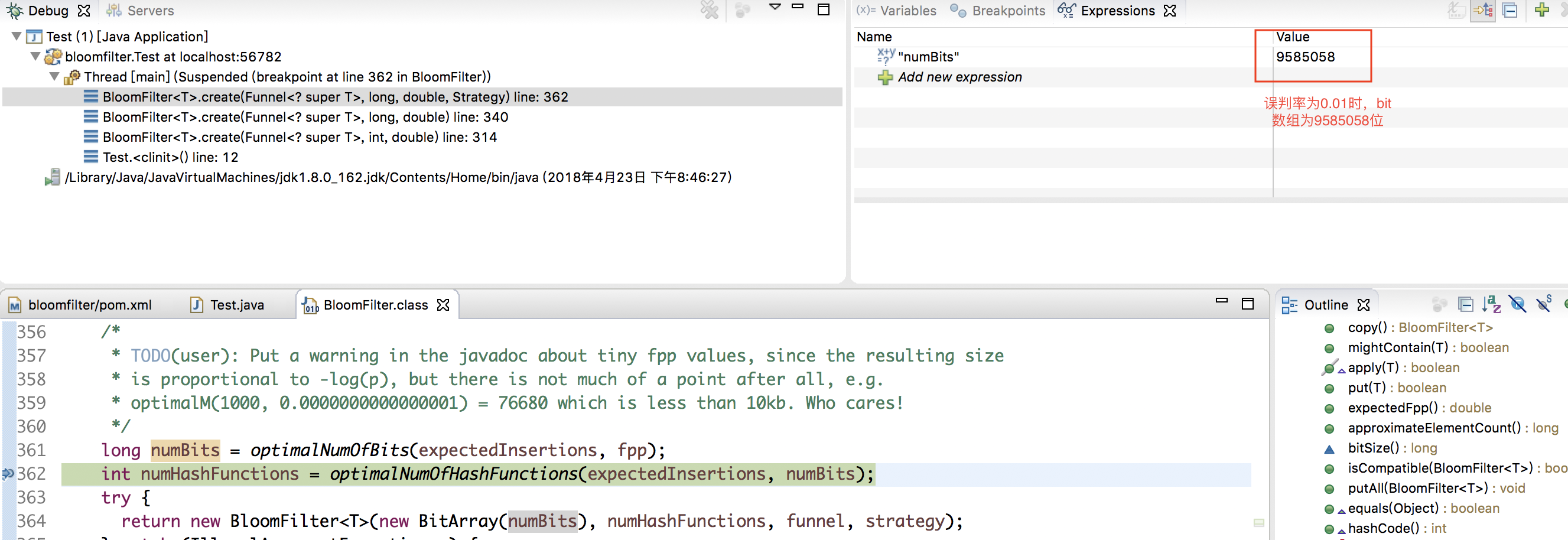
гЩДЫПЩМћЃЌЮѓХаТЪдНЕЭЃЌдђЕзВуЮЌЛЄЕФЪ§зщдНГЄЃЌеМгУПеМфдНДѓЁЃвђДЫЃЌЮѓХаТЪЪЕМЪШЁжЕЃЌИљОнЗўЮёЦїЫљФмЙЛГаЪмЕФИКдиРДОіЖЈЃЌВЛЪЧХФФдДќЯЙЯыЕФЁЃ
3ЁЂЪЕМЪЪЙгУ
redisЮБДњТыШчЯТЫљЪО
String get(String
key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
return null;
}else{
value = db.get(key);
redis.set(key, value);
}
}
return valueЃЛ
} |
гХЕу:
1.ЫМТЗМђЕЅ
2.БЃжЄвЛжТад
3.адФмЧП
ШБЕу
1.ДњТыИДдгЖШдіДѓ
2.ашвЊСэЭтЮЌЛЄвЛИіМЏКЯРДДцЗХЛКДцЕФKey
3.ВМТЁЙ§ТЫЦїВЛжЇГжЩОжЕВйзї
змНс
дкзмНсВПЗжЃЌРДИіТўЛАбЁЃЯЃЭћЖдДѓМвевЙЄзїгаАяжњ 
| 








