| 编辑推荐: |
| 本文来自于网络,主要介绍了流数据处理、流-表二元性以及KSQL基于Kafka的Stream
API构建等相关知识。 |
|
本文要点
大多数的流处理技术,需要开发人员使用Java或Scala等编程语言编写代码。
KSQL是Apache Kafka的数据流SQL引擎,它使用SQL语句替代编写大量代码去实现流处理任务。
KSQL基于Kafka的Stream API构建,它支持过滤、转换、聚合、连接、加窗操作和Sessionization(即捕获单一会话期间的所有的流事件)等流处理操作。
KSQL的用例涉及实现实时报表和仪表盘、基础设施和物联网设备监控、异常检测和欺骗行为报警等。
你会根据一分钟前的交通信号灯过马路吗?当然不会!当前,现代企业或者出于竞争上的压力,或者因为企业的客户对产品或服务的交互方式有着更高的期望,它们也面对着同样的需求。
如果人们在iPad上轻点按钮就可以租赁和观看最新的影片,那么为什么还要因为银行账户吃紧而必须等待数小时?
数据在现代企业中处于核心地位,数据的量也在不断增加中,并且持续快速变化。流处理技术正是支持企业实时利用这些洪流信息的一种技术。目前为重新塑造自身的业务,Netflix、奥迪、PayPal、Airbnb、Uber和纽约时报等上万家企业已经选择了Apache
Kafka?作为流处理平台的事实标准。
人们的很多日常活动,例如阅读报纸、在线购物、预订酒店或航班、搭乘出租车、玩电子游戏或是拨打电话,其后台都已由Kafka提供支持。
为什么需要流处理?
为了说明流处理技术的作用,我在此给出一个适用于多个不同行业的很好例子。假设我们需要去实时创建并维护客户的全面档案。这样做出于很多的原因,包括:
为创造更好的客户体验。例如,“这位高级客户在过去五分钟内尝试多次结账购物车,但由于我们最近的网站更新错误而产生失败。因此,我们需要立即向该客户提供折扣,并对所造成的不良用户体验致歉。”
为尽量降低风险。例如,“这笔新的付款操作似乎存在欺诈。因为该付款是在美国境外发起的,但客户的手机应用报告她身处纽约市。我们应立即阻止这笔付款,并第一时间联系该客户。”
该用例需要实时汇集来自各种内部渠道的以及一些可能外部渠道的数据,然后将这些信息整合到全面客户档案(也称为客户的“360度档案”)中。而且一旦任何渠道有新的信息可用,档案都会得到立即更新。
下图描绘了我们如何使用Kafka实现该用例的高层设置。其中,客户数据从各种来源的数据流中持续收集。全面客户档案保持在表中,表根据这些数据来源构建并持续更新。所有这些操作都是实时的,并具有一定的规模。
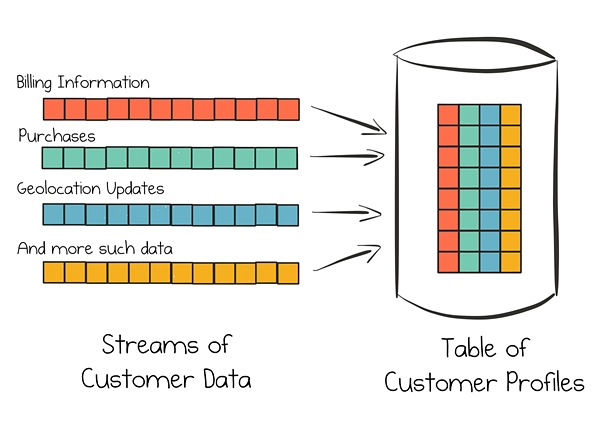
图1 从内部和外部客户数据流实时构建全面客户档案
上图的概念非常简单,它与人们对人体神经系统工作方式的理解几乎匹配。神经系统将来自眼睛、耳朵、四肢等传感器的数据传输到大脑,以便人们能够快速做出明智的决定,例如过马路是否安全。这就是为什么Kafka常被认为是数字原生公司的“中枢神经系统”。
然而,从目前的情况看,流处理领域入门的门槛还是相当高的。当前最广为使用的一些流处理技术,包括Apache
Kafka的Streams API,仍然需要用户使用Java或Scala等编程语言编写代码,即使是实现最简单的任务也是如此。对编程技巧的这种苛刻要求,已经阻碍了许多企业充分利用流处理所能提供的优势。但值得庆幸的是,现在我们有了一种更简单的方法。
KSQL简介,Apache Kafka的数据流SQL引擎
KSQL于2017年推出,是Apache Kafka的数据流SQL引擎。KSQL降低了人们进入流处理的门槛。用户不必编写大量的代码,只需使用简单的SQL语句就可以开始处理流处理。例如:
CREATE STREAM
fraudulent_payments AS
SELECT * FROM payments-kafka-stream
WHERE fraud_probability > 0.8 |
就这么简单!虽然我们可能无法一眼看出,上面给出的KSQL流数据查询在实现上是分布式的、容错的、弹性的、可扩展的和实时的,这些特性可以满足现代企业对数据的需求。KSQL实现了这一目标,它是建立在Kafka的Streams
API之上的,充分地利用了Kafka在分布式流处理方面的强大技术基础。
如果我们想使用Java或Scala直接调用Kafka的Stream API实现上述KSQL查询,那么我们的应用代码段可能需要做如下编写。当然,这一代码段还需要编译、打包并应用部署。
// Using Kafka’s
Streams API
object FraudFilteringApplication extends App {
val builder: StreamsBuilder = new StreamsBuilder()
val fraudulentPayments: KStream[String, Payment]
= builder
.stream[String, Payment]("payments-kafka-topic")
.filter((_ ,payment) => payment.fraudProbability
> 0.8)
fraudulentPayments.to("fraudulent-payments-topic")
val config = new java.util.Properties
config.put(StreamsConfig.APPLICATION_ID_CONFIG,
"fraud-filtering-app")
config.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,
"kafka-broker1:9092")
val streams: KafkaStreams = new KafkaStreams(builder.build(),
config)
streams.start()
} |
对于Java或Scala开发人员而言,Kakfa Streams API是一个强大的软件库,它实现了将流数据处理集成到应用中。但是KSQL为开发人员提供了更宽广的基础,即一种仅使用SQL即可表达流数据处理需求的方式。
当然,读者还可以使用KSQL实现更多功能,不必局限于上面所展示的简单例子。KSQL是采用Apache
2.0许可开源的,构建于Kakfa的Streams API之上。这意味着,KSQL支持很大范围的流数据处理操作,包括过滤、转换、聚合、连接、加窗操作和Sessionization(即捕获单一会话期间的所有的流事件)等。使用KSQL,可轻松实现:
驱动实时报告和仪表盘;
监控基础设施和物联网设备;
检测异常,并对欺诈活动报警;
分析基于会话的用户活动;
执行实时ETL;
以及更多操作……
下面给出几个使用KSQL的例子。
例子一:使用KSQL实现在线数据集成和扩充
企业开展的大部分数据处理,都可归为数据扩充(Data Enrichment)或数据整理(Data
Wrangling),即如何从多个系统中提取、转换和连接数据,并存储到键值存储、RDBMS、搜索索引、缓存等数据服务系统中。KSQL可与Kafka
Connect的连接器一起使用,操作Oracle、MySQL、Elasticsearch、HDFS或S3等存储系统,实现将批量数据集成转换为实时数据集成。
下面的KSQL查询使用了流数据表连接,将存储在数据表中的元数据扩充到数据流中:
CREATE STREAM
vip_users_clickstream AS
SELECT user_id, user_country, web_page, action
FROM website_clickstream c
LEFT JOIN users u ON u.user_id = c.user_id
WHERE u.level = 'Platinum'; |
为符合GDPR规范,,我们需要在加载数据流到其它系统之前将其中的PII(个人验证信息,personally
identifiable information)数据过滤掉。在此,我们需要移除上例中建立的vip_users数据流中的usr_id域。具体做法是,将不将该域添加到结果数据流中,在结果数据流中只保留了user_country、web_page和action域:
CREATE STREAM
anonymized_vip_clickstream AS
SELECT user_country, web_page, action
FROM vip_users_clickstream; |
例子二:使用KSQL实现实时监控和分析
尽管实时监控和实时分析是两种完全不同的用例,但是它们所需要实现的流数据处理功能是非常类似的。KSQL可以直接对原始事件流定义一些适当的度量,无论数据流是生成自数据库更新、应用、移动设备、车辆等来源。
下例给出的查询基于在五分钟窗口内观察到车辆遥测数据中的错误数,实时计算可能出故障的车辆。该例是一类特殊的聚合操作,即窗口聚合。数据首先被分组为窗口数据(在本例的查询中,分组和加窗操作是基于输入数据中的时间戳信息),然后每个窗口做单独聚合。
CREATE TABLE
possibly_failing_vehicles AS
SELECT vehicle, COUNT(*)
FROM vehicle_monitoring_stream
WINDOW TUMBLING (SIZE 5 MINUTES)
WHERE event_type = 'ERROR'
GROUP BY vehicle
HAVING COUNT(*) >= 3; |
KSQL的另一个用法是自定义业务层面的度量,这些度量是从监控和报警中实时计算得到的。例如,展示一个AAA电子游戏特许经营商(“最近的游戏扩展是否增加了游戏时间?”)的并发在线玩家数量,报告电子商务网站中放弃购买的购物车数量(“我们最新的在线商店更新是否更加方便了客户结账?”)。类似,也可以使用KSQL为用户的业务应用定义一个用于表示是否正确的概念,进而检查该概念是否符合生产中的要求。
上面的查询例子正好也是一个有状态查询的例子。有状态的流处理可以说是流处理中最常用的功能,同时在实现与正确处理上非常具有挑战性。下面我将做详细介绍。
实现流数据处理中的记忆:有状态流处理
例子二中的查询对输入流数据执行聚合操作。聚合操作是一种有状态的操作,即在操作中需要维护和更新状态。例子二的查询在观测到新的错误前,需要记住每个时间窗口和每辆车的上一次错误计数情况,否则就无法确定查询结果是否会超出五分钟窗口期内的车辆错误阈值。分布式流处理的一个主要挑战,就是要在保证这种有状态操作可以高效且正确工作的同时,考虑到诸如机器崩溃、网络错误和大规模运行等因素。
相比之下,无状态操作更为简单。计算可以在机器间自由迁移,这样操作的代价很低,易于实现。而有状态操作要实现计算的迁移,还需要执行诸如将历史状态从故障机器移动到活动机器,并且要有效地完成,期间还可能会涉及以GB为单位的数据迁移。其中最重要的是,数据迁移必须正确地完成。例如,在例子二给出的KSQL查询中,没有人会希望仅仅因为相同的错误信息已经得到多次处理,因此就向汽车司机发出引擎即将故障的虚假警报!
为实现更快的处理和更好的容错能力,KSQL通常会运行在多台机器、虚拟机或容器上。那么KSQL如何解决有状态的挑战?答案是,KSQL建立是在Kafka的Streams
API上的,这使得所有的KSQL查询(包括有状态查询)具有如下特征:
容错:在机器出现故障时,状态和计算需要从故障机器自动迁移到活动的机器上。实现容错,一方面需要持续地对从KSQL到Kafka的状态做“流备份”,另一方面应在需要时自动地从Kakfa将状态恢复回KSQL。
弹性:用户可以在操作现场中随时添加并移除新机器,扩展或缩小处理规模,而不会造成数据丢失,依然给出正确的处理结果。
扩展性:将处理负载和状态自动地扩展到各台机器,实现对数据的协作处理。扩展性是通过使用Kafka的处理协议和分区数据存储实现的。其中,处理任务根据数据的分区情况扩展到各台机器做并行处理。
由于这些属性在KSQL中是开箱即可用的,因此用户只需要专注于为自己的流处理需求,编写所需的SQL语句。出于同一原因,KSQL非常适合构建现代部署环境,例如基于Docker、Kubernetes或云原生的环境。
流-表二元性(Stream-Table Duality)
对数据流和表提供头等支持,这是Kafka的一个独有特性。读者是否注意到,我们在前面的的例子中同时给出了数据流和表?例如,虽然例子二的输入是一个数据流,但是该有状态查询的结果是一个表:
CREATE TABLE
possibly_failing_vehicles AS
SELECT vehicle, COUNT(*)
FROM vehicle_monitoring_stream
WINDOW TUMBLING (SIZE 5 MINUTES)
WHERE event_type = 'ERROR'
GROUP BY vehicle
HAVING COUNT(*) >= 3; |
读者可能会思考,“数据流和表两者间有何差别?”,并且更为重要的是,“这种特性如何可用于我的日常工作中?”。简而言之,该特性非常有用。表和数据流为用户提供了必要的原语,可用于对数据建立推理和建模,回答对数据的业务问题。下面给出我能想到的一些最直观的英文类比:
Kafka中的数据流是世界(或业务)从一开始至今的完整历史。它表示了过去和当前。当我们从当前走向未来时,新的事件会不断地添加到世界历史中。在Kafka中,事件写入、存储并读取自Kafka主题(Topic)。由于我们无法更改过去,因此Kafka是一种对事件不可变的、只添加的日志记录。从分析RDBMS角度看,我们可以认为数据流是对“事实”(Fact)的建模。
Kafka中的表是世界的当前状态(更通用的表述是某一时刻的状态)。它表示现在或过去的某个时刻,是世界事件历史的一个聚合,该聚合在我们从当前走向未来时会持续改变。表通过对数据流的处理而从流中获取,更准确地说是通过聚合这些数据流。在处理中使用了Kafka的Streams
API和KSQL等工具。从分析RDBMS的角度看,我们可以认为表是对“维度”(Dimension)的建模,保持了一个键的当前值。
我们将这种内在关系称为“流-表二元性”(Stream-Table Duality)。如果读者希望更深入了解这种数据流和表间的有意思关系,推荐大家阅读我的一篇文章“Kafka和流数据处理中的数据流和表”。
稍等,那么表的概念出自何处?答案是,表来自于我们数十年在构建应用和服务中成功使用的数据库。在数据库中,表是首先需要构建的结构,它是各项工作的基础。数据流实际上也存在于数据库中,表现为构建数据库的交易日志(例如,MySQL的binlog,或者Oracle的Redo
Log)。但这对用户而言是不可见的,用户并不直接操作这些数据流。我继续使用前面的类比,一个数据库知道现在,但它不知道过去。如果用户需要过去,那么请取出备份磁带。磁带实际上可以看成是一种硬件流……
这样,Kafka和流数据处理是数据库的完全反转。正如上文所说,我们首先要构建数据流。而表是从数据流生成的。Pat
Helland将此归纳为“所有变化均源自于不可变性”(“Immutability Changes Everything”),“真相是日志(数据流),数据库是日志子集的一个缓存”。Kafka知道当前,但也知道过去。这就是为什么纽约时报将其所有已发表的文章(可回溯至19世纪50年代的160年间的新闻报道)存储在Kafka中,作为事实来源(Source
of Truth)。
简而言之,数据库认为表是最重要的,数据流次之;而Kafka认为数据流最重要,表次之。在Kafka
Streams和KSQL中,通过提供对数据流和表的原生支持,帮助用户构建了流数据处理和数据库之间的桥梁。为使该特性更为强大,用户可以使用Kafka
Connnect将现有数据库和表实时挂接到Kafka中。根据上面的陈述,我们完全可以给出这样一个结论,即Kafka是一种“数据流关系”系统,而非“仅是数据流”的系统。
数据流和表的进一步阐述
出于下述两个重要原因,流-表二元性在实践中是至关重要的。首先,企业现有数据库中可能已经存在了大量的数据,并且企业希望能将这些数据应用于一些由流数据处理驱动的用例。其次,用户一旦着手实现自己的流处理应用,他们很快就会意识到,即使并不存在一个“真实”的数据库,大多数用例实际上还是需要将数据建模为流和表。这是因为表代表“状态”。无论何时要实现任何有状态处理,包括执行聚合(例如,计算某个关键业务度量的五分钟平均值)或连接(例如,通过维度表连接事实“流”实现实时数据扩充),表都会涉及其中。
下面给出一个流和表的例子。该例子使用KSQL实时计算用户地理位置的变更次数。例如,Strava这样的移动应用允许用户手动签到某个位置,并自动定期发送地理位置更新。查询的输入是一个地理位置更新数据流,输出结果是一个不断更新的表。由于COUNT()是一种聚合操作,因此查询是一个有状态操作,即为了累加当前计数,首先必须记住当前的计数值!下面给出KSQL查询,它每秒执行会数次地理位置更新。对于每秒数十万次乃至更多此更新,操作也是同样的。
CREATE TABLE
geo_location_checkins_per_user AS
SELECT username, COUNT(*)
FROM geo_location_updates
GROUP BY username; |
在下一个例子中,我们根据订单状态计算“订单”流的每小时汇总情况。这也是一个实践中常见的用例。同样,计算的结果是一个表('orders_hourly_aggregates')。一旦有新订单到达,该表就会持续更新。该查询还展示了一些可在KSQL中使用的标量函数。
CREATE TABLE
orders_hourly_aggregates AS
SELECT
order_status,
COUNT(*) AS order_count,
MAX(ORDER_TOTAL) AS max_order_total,
MIN(ORDER_TOTAL) AS min_order_total,
SUM(ORDER_TOTAL) AS sum_order_total,
FROM orders
WINDOW TUMBLING (SIZE 1 HOUR)
GROUP BY order_status |
功能齐备(Batteries Included)的流数据处理
Kafka提供了一个功能齐备的流媒体平台,可用于构建应用和系统。无论实施简单的流数据扩充,还是实现类似于欺诈检测或360度用户配置文件等更为复杂的操作,我们都需要一个易于使用的流处理解决方案,这正是所有功能和核心数据结构齐备Kafka,特别是Kafka包括对流和表的头等支持。如果缺乏这种支持,用户最终需要构建一些不必要的复杂架构,将流(或仅支持流的)处理技术与Cassandra或MySQL等远程数据存储结合在一起,才能启用有状态处理,并且可能还必须添加Hadoop
/ HDFS才能启用支持容错的处理。那么用户需要同时抛接多少个科技球?
总结
本文是一次对使用KSQL(Apache Kafka的流SQL引擎)进行流处理的旋风之旅。文中给出了多个具体的例子,从更高层面介绍了KSQL是如何解决有状态流处理的挑战,以及Kafka和KSQL是如何通过对数据流和表提供很好的支持,为搭建数据流和数据库世界之间的桥梁提供帮助。KSQL更易于读者端到端地实现自己的用例。
如果读者对KSQL产生了浓厚的兴趣,我推荐如下资源:
下载KSQL,并按快速指南操作。
阅读KSQL文档。文档中详细介绍了KSQL的结构、SQL语法指南,并提供了更多的例子和教程,其中包括一些基于Docker的变体。
加入GitHub上的KSQL社区,或者加入Confluent上Slack社区 Community Slack组的“#ksql”频道。 | 








