| БрМЭЦМі: |
| БОЮФРДздгкinfoq,БОЮФЮЊСЫНтОіЗжВМЪНЪ§ОнПтЯТЃЌИДдгЕФ
SQLЃЈШчШЋОжадЕФХХађЁЂЗжзщЁЂjoinЁЂзгВщбЏЃЌЬиБ№ЪЧЗЧОљКтзжЖЮЕФетаЉТпМВйзїЃЉФбвдЪЕЯжЕФЮЪЬтЃЛ |
|
ЩшМЦЫМЯы
ЮЊСЫНтОіЗжВМЪНЪ§ОнПтЯТЃЌИДдгЕФ SQLЃЈШчШЋОжадЕФХХађЁЂЗжзщЁЂjoinЁЂзгВщбЏЃЌЬиБ№ЪЧЗЧОљКтзжЖЮЕФетаЉТпМВйзїЃЉФбвдЪЕЯжЕФЮЪЬтЃЛдкгаСЫвЛаЉЗжВМЪНЪ§ОнПтКЭ
Hadoop ЪЕМЪгІгУОбщЕФЛљДЁЩЯЃЌЖдБШСНепЕФгХЕуКЭВЛзуЃЌМгЩЯздМКЕФвЛаЉЬсСЖКЭЫМПМ, ЩшМЦСЫвЛЬззлКЯСНепЕФЯЕЭГЃЌРћгУСНепЕФгХЕуЃЌ
ВЙГфСНепЕФВЛзуЁЃОпЬхЕФЫЕЃЌ ЪЙгУЪ§ОнПтЫЎЦНЗжИюЕФЫМЯыЪЕЯжЪ§ОнДцДЂЃЌЪЙгУ MapReduceЕФЫМЯыЪЕЯж
SQL МЦЫуЁЃ
етРяЕФЪ§ОнПтЫЎЦНЗжИюЕФвтЫМЪЧжЛЗжПтВЛЗжБэЃЌЖдгкВЛЭЌЪ§СПМЖБ№ЕФБэЃЌЗжПтЕФЪ§СППЩвдВЛвЛбљЃЌР§Шч 1 вкЕФЪ§ОнСПЗж
10 ИіЗжПтЃЌ10 вкЕФЗж 50 ИіЗжПтЁЃЖдгкЪЙгУ MapReduceЕФЫМЯыЪЕЯжМЦЫу ; ЖдгквЛИіашЧѓЃЌзЊЛЛГЩвЛИіЛђЖрИігавРРЕЙиЯЕЕФSQLЃЌЦфжаЕФУПИіSQLЗжНтГЩвЛИіЛђЖрИі
MapReduceШЮЮёЃЌУПИі MapReduceШЮЮёгжАќКЌ mapsqlЁЂЯДХЦЃЈshuffleЃЉЁЂreducesqlЃЌетИіЙ§ГЬПЩвдРэНтЮЊРрЫЦ
hiveЃЌЧјБ№ЪЧСЌ MapReduceШЮЮёжаЕФ map КЭ reduce ВйзївВЪЧЭЈЙ§ SQL ЪЕЯж,
ЖјЗЧ Hadoop жаЕФ map КЭ reduce Вйзї.
етЪЧЛљБОЕФ MapReduceЕФЫМЯыЃЌЕЋЪЧдк Hadoop ЕФЩњЬЌШІжа, ЕквЛДњЕФ MapReduceНЋНсЙћДцДЂгкДХХЬЃЌЕкЖўДњЕФ
MapReduceИљОнФкДцЪЙгУЧщПіНЋНсЙћДцДЂгкФкДцЛђДХХЬЃЌРрБШвЛЯТгУЪ§ОнПтРДДцДЂЃЌФЧУД MapReduce
ЕФНсЙћОЭЪЧДцДЂдкБэжаЃЌЖјЪ§ОнПтЕФЛКДцЛњжЦЬьШЛжЇГжИљОнФкДцЧщПіОіЖЈДцДЂдкФкДцЛЙЪЧДХХЬ ; СэЭтЃЌHadoop
ЩњЬЌШІжа, МЦЫуФЃаЭвВВЂЗЧвЛжжЃЌетРяЕФ MapReduceЕФМЦЫуЫМЯыЃЌПЩвдгУРрЫЦ spark ЕФ RDD
ЕќДњМЦЫуЗНЪНРДЬцДњ ; БОЯЕЭГЛЙЪЧЛљгк MapReduceРДЫЕУїЕФЁЃ
МмЙЙ
ИљОнвдЩЯЕФЫМЯы, ЯЕЭГЕФМмЙЙШчЯТЃК
УЛгаДњРэНкЕу
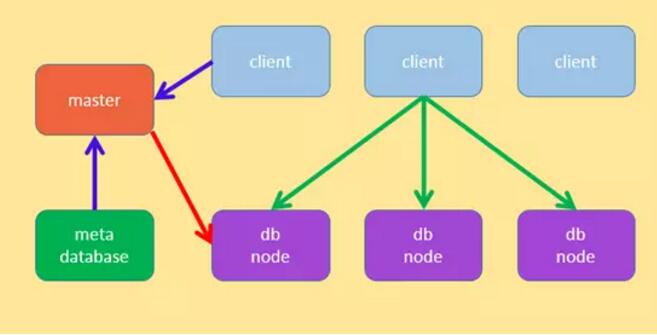
гаДњРэНкЕу
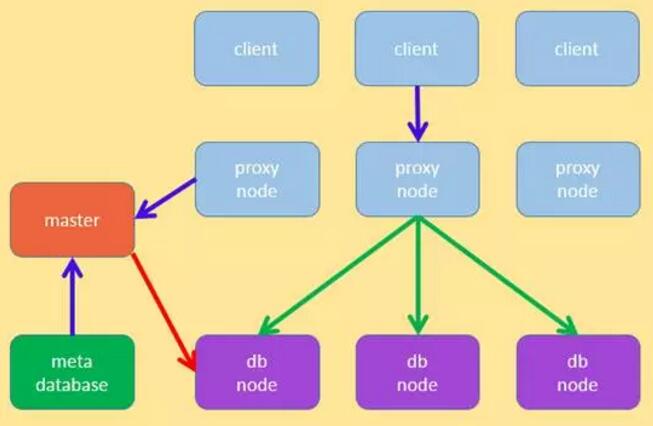
ФЃПщЫЕУї
ЙигкЯЕЭГжаЕФФЃПщЃЌгЩгкКЭОјДѓВПЗжЕФЗжВМЪНЯЕЭГРрЫЦЃЌетРяНізіМђвЊЫЕУїЃК
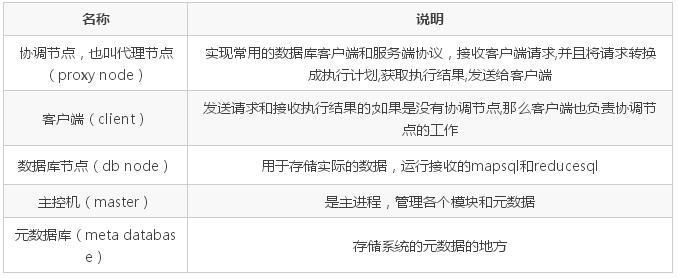
СНжжМмЙЙЕФЧјБ№
ЮоДњРэНкЕуЕФЪБКђЃЌПЭЛЇЖЫЕЃИКзХБШНЯДѓЕФЙЄзїЃЌАќРЈЃКЗЂЫЭЧыЧѓЁЂНтЮі SQLЁЂЩњГЩжДааМЦЛЎЁЂЩъЧызЪдДЁЂАВХХжДааЁЂЛёШЁНсЙћЕШЃЛгаДњРэНкЕуЕФЪБКђЃЌДњРэНкЕуЕЃИКзХНгЪмЧыЧѓЁЂНтЮі
SQLЁЂЩњГЩжДааМЦЛЎЁЂЩъЧызЪдДЁЂАВХХжДааЁЂЗЕЛиНсЙћИјПЭЛЇЖЫЕШДѓВПЗжд№ШЮЃЌСэЭтДњРэНкЕуЬсЙЉжЇГжЭтВПавщЕФНгПкЃЌШч
mysql ЕФ c/s авщЃЌЪЙгУ mysql ЕФУќСюааПЩвджБНгСЌНгНјРДжДаа SQLЃЌећИіЯЕЭГОЭЯёЦеЭЈЕФ
mysql server вЛбљЁЃ
гІгУМмЙЙ
ЪЕМЪгІгУЛЗОГПЩФмЪЧе§ЪНЛЗОГвЛЬз, е§ЪНБИЗнЛЗОГвЛЬз, ЯпЯТЛЗОГвЛЬз, ПЩвдАДееШчЯТЕФМмЙЙНјааВПЪ№ЁЃ
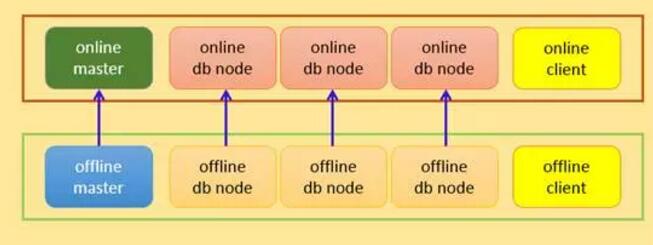
ЛљБОИХФю ЫЕУї
ЯТУцеыЖдМмЙЙжаЕФвЛаЉИХФюзіаЉЫЕУї
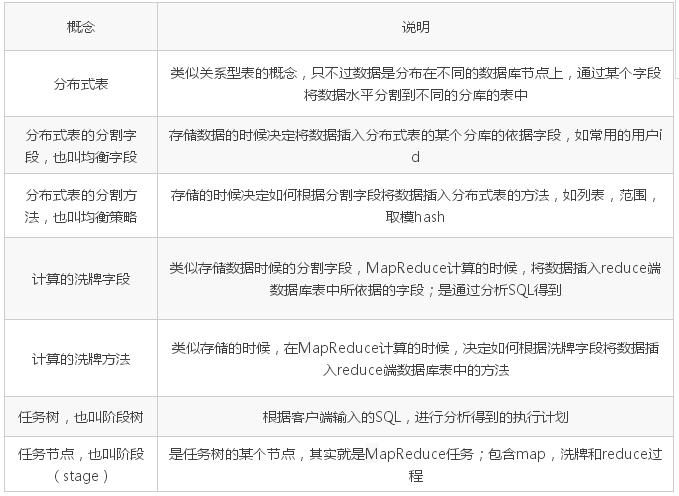
діЩОИФВйзї
ЕБВхШыЪ§ОнЕФЪБКђЃЌИљОнОљКтзжЖЮКЭОљКтВпТдНЋМЧТМВхШыЕНЖдгІЕФЪ§ОнПтНкЕужаЁЃ
ЕБИќаТЪ§ОнЕФЪБКђЃЌашвЊИљОнОљКтВпТдХаЖЯЪ§ОнИќаТЧАЕФКЭИќаТКѓЕФЪ§ОнПтНкЕуЪЧЗёБфЛЏЃКШчЙћУЛгаБфЛЏЃЌжБНгИќаТЃЛШчЙћгаБфЛЏЃЌдкИќаТЧАЕФЪ§ОнПтНкЕужаЩОГ§РЯЪ§ОнЃЌдкИќаТКѓЕФЪ§ОнПтНкЕужаВхШыаТЪ§ОнЁЃ
ЕБЩОГ§Ъ§ОнЕФЪБКђЃЌИљОнОљКтВпТддкЯргІЕФЪ§ОнПтНкЕужаЩОГ§ЁЃ
етШ§жжБфИќЪ§ОнЕФВйзїЃЌжЛвЊЩцМАЕНЖрИіНкЕуЕФЪ§ОнБфИќЃЌЖМашвЊЪЙгУЗжВМЪНЪТЮёБЃжЄвЛжТадЁЂдзгадЕШЪТЮёЬиадЁЃ
ВщбЏВйзї
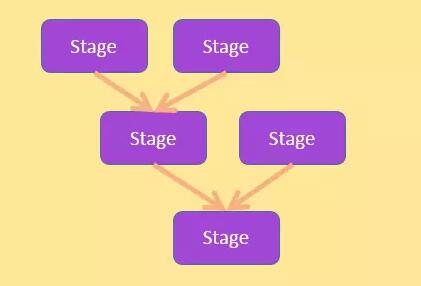
ВщбЏВйзїЕФдРэРрЫЦ hiveЃЌДѓМвПЩвдЖдБШРДРэНт ; ЮЊСЫЗНБуНтЪЭВщбЏВйзї, ЪзЯШРДЫЕУїНзЖЮЪїКЭНзЖЮЕФНсЙЙЃЌШчЯТЭМЫљЪОЃК
НзЖЮЪї
НзЖЮ
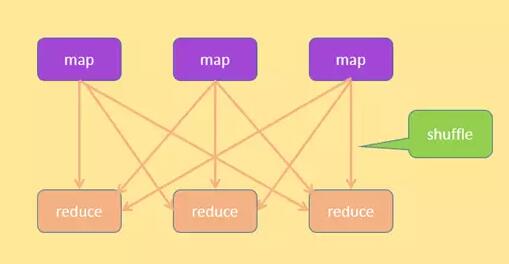
ВщбЏВНжш
НсКЯЩЯУцЕФЭМ, ВщбЏВйзїЕФОпЬхЙ§ГЬШчЯТ:
НЋЪфШы SQL ОЙ§ДЪЗЈЁЂгяЗЈЁЂгявхЗжЮіЃЌМЏКЯБэНсЙЙаХЯЂКЭЪ§ОнЗжВМаХЯЂЃЌЩњГЩАќКЌЖрИіНзЖЮЃЈМђГЦ stageЃЉЕФжДааМЦЛЎЃЌетаЉНзЖЮОпгавЛЖЈЕФвРРЕЙиЯЕЃЌаЮГЩЖрЪфШыЕЅЪфГіЕФШЮЮёЪїЁЃ
УПИіНзЖЮАќРЈСНжж SQLЃЌГЦЮЊ mapsql КЭ reducesqlЃЌСэЭтУПИіНзЖЮАќРЈШ§ИіВйзїЃЌmapЁЂЪ§ОнЯДХЦКЭ
reduceЃЛmap КЭ reduce ЗжБ№жДаа mapsql КЭ reducesqlЁЃ
ЯШдкВЛЭЌЕФЪ§ОнПтНкЕужажДаа map ВйзїЃЌmap ВйзїжДаа mapsqlЃЌЫќЕФЪфШыЪЧУПИіЪ§ОнПтНкЕуЩЯЕФБэФкВПЕФЪ§ОнЃЌЪфГіИљОнФГИізжЖЮАДеевЛЖЈЕФЙцдђНјааЗжИюЃЌЗХЕНВЛЭЌЕФНсЙћМЏжаЃЌНсЙћМЏзїЮЊЪ§ОнЯДХЦЕФЪфШыЁЃ
ШЛКѓжДааЪ§ОнЯДХЦЕФЙ§ГЬЃЌНЋВЛЭЌНсЙћМЏПНБДЕНВЛЭЌЕФНЋвЊжДаа reduce ЕФЪ§ОнПтНкЕуЩЯЁЃ
дкВЛЭЌЕФЪ§ОнПтНкЕужажДаа reduce ВйзїЃЌreduce ВйзїжДаа reducesqlЃЛ
зюКѓЗЕЛиНсЙћЁЃ
Р§зг
гЩгкЯЕЭГКЫаФдкгкДцДЂКЭМЦЫу, ЯТУцЖдДцДЂКЭМЦЫуЯрЙиЕФИХФюОйР§ЫЕУї
ОљКтВпТд
ОйР§ЫЕУїОљКтВпТдЃЌЛљБОаХЯЂШчЯТЃКБэУћзжЃКtab_user_loginБэУшЪіЃКгУгкДцДЂгУЛЇЕЧТМаХЯЂНкЕуЪ§ЃК4ЃЌЗжЮЊ
0ЁЂ1ЁЂ2ЁЂ3
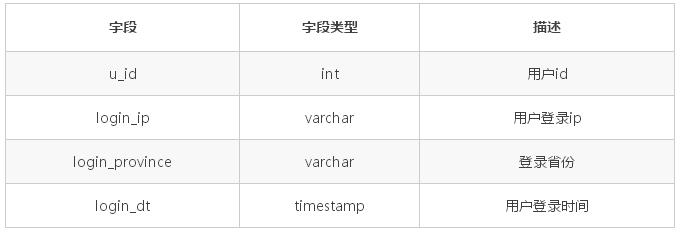
ОйР§ЫЕЯТШчЯТЕФМИжжВпТдЃК
СаБэЃКвдЕЧТМЪЁЗнзїЮЊОљКтзжЖЮЮЊР§
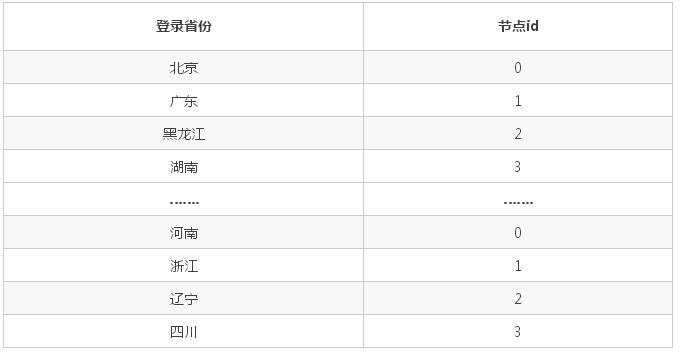
ШЁФЃ hashЃКАД 4 ШЁФЃ, вдгУЛЇ id зїЮЊОљКтзжЖЮ
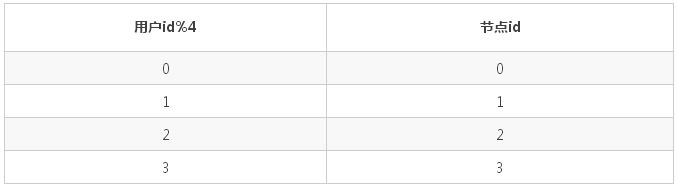
ЗЖЮЇ: Дг 0 ЕНвЛвкЃЌвдгУЛЇ id зїЮЊОљКтзжЖЮ

ШЁФЃ hash КЭЗЖЮЇНсКЯЃКЯШЗЖЮЇЃЌдйШЁФЃ, вдгУЛЇ id зїЮЊОљКтзжЖЮ

ВщбЏ
ОйР§ЫЕУїВщбЏВйзїЃЌЛљБОаХЯЂШчЯТЃК
гУЛЇБэ tab_user_info ШчЯТЃК
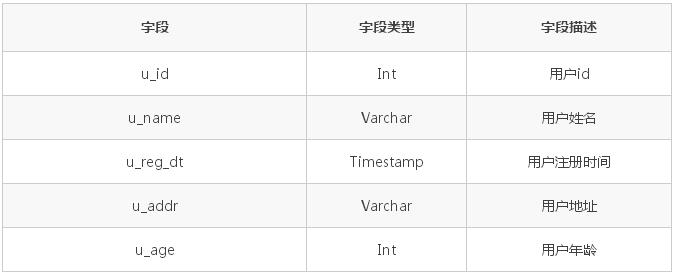
гУЛЇЕЧТМБэ tab_login_info ЕФНсЙЙШчЯТЃК
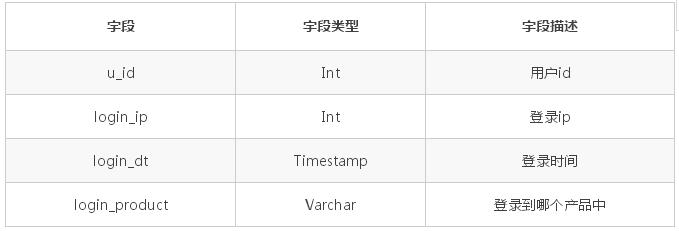
ХХађ
ХХађЕФЙиМќЕуЪЧНкЕужЎМфДцдкДѓаЁЙиЯЕЃЌДѓЕФ key Лђеп key ЗЖЮЇЗХЕННкЕу id ДѓЕФНкЕуЩЯЃЌШЛКѓдкНкЕуЩЯХХађЃЌЛёШЁЪ§ОнЕФЪБКђИљОнНкЕу
id ДѓаЁвРДЮЛёШЁЁЃ
вдШчЯТ sql ЮЊР§ЃЌФГвЛзЂВсЪБМфЗЖЮЇФкЕФгУЛЇаХЯЂЃЌАДееФъСфКЭ id ХХађЃК
| select * from
tab_user_info t where u_reg_dt> =? and u_reg_dt<=?
order by u_id |
жДааМЦЛЎПЩФмЮЊЃК
MapЃК
| select * from
tab_user_info t where u_reg_dt>=? and u_reg_dt<=?
order by u_id |
ShuffleЃК
жДааЭъГЩжЎКѓЃЌетжжЧщПіЯТгЩгкашвЊАДее u_id НјааЪ§ОнЯДХЦЃЌЫљвдИїИіДцДЂНкЕуЩЯашвЊАДее u_id
НјааЛЎЗжЁЃР§Шчга N ИіМЦЫуНкЕуЃЌФЧУДАДееЃЈзюДѓ u_id- зюаЁ u_idЃЉ/N ЦНОљЛЎЗжЃЌНЋВЛЭЌДцДЂНкЕуЩЯЕФЭЌвЛЗЖЮЇЕФ
u_idЃЌЛЎЗжЕНЭЌвЛИіМЦЫуНкЕуЩЯМДПЩЃЈетРяЕФМЦЫуНкЕуДцдкДѓаЁЙиЯЕЃЉЁЃ
ReduceЃК
| select * from
tab_user_info t order by u_id |
ЗжзщОлКЯ
ЙиМќЕуКЭХХађРрЫЦЃЌНкЕужЎМфДцдкДѓаЁЙиЯЕЃЌДѓЕФ key Лђеп key ЗЖЮЇЗХЕННкЕу id ДѓЕФНкЕуЩЯЃЌШЛКѓдкНкЕуЩЯЗжзщОлКЯЃЌЛёШЁЪ§ОнЕФЪБКђИљОнНкЕу
id ДѓаЁвРДЮЛёШЁЁЃ
вдШчЯТ sql ЮЊР§ЃЌФГвЛзЂВсЪБМфЗЖЮЇФкЕФгУЛЇЃЌАДееФъСфЗжзщЃЌМЦЫуУПИіЗжзщФкЕФгУЛЇЪ§ЃК
| select age,count(u_id)
v from tab_user_info t where u_reg_dt>=? and
u_reg_dt<=? group by age |
жДааМЦЛЎПЩФмЮЊЃК
MapЃК
| select age,count(u_id)
v from tab_user_info t where u_reg_dt>=? and
u_reg_dt<=? group by age |
ShuffleЃК
жДааЭъГЩжЎКѓЃЌетжжЧщПіЯТгЩгкашвЊАДее age НјааЪ§ОнЯДХЦЃЌПМТЧЕН age ЕФЮЈвЛжЕБШНЯЩйЃЌЫљвдЪ§ОнЯДХЦПЩвдНЋЫљгаЕФМЧТМПНБДЕНЭЌвЛИіМЦЫуНкЕуЩЯЁЃ
ReduceЃК
| select age,sum(v)
from t where group by age |
СЌНг
ЪзЯШУїШЗ join ЕФзжЖЮРраЭЮЊЪ§зжРраЭКЭзжЗћДЎРраЭЃЌЦфЫћРраЭШчШеЦкПЩвдзЊЛЛЮЊетСНжжЁЃЪ§зжРраЭЕФХХађКмМђЕЅЃЌзжЗћДЎРраЭЕФЪ§ОнХХађашвЊШЗЖЈЙцдђЃЌРрЫЦ
mysql жаЕФ collationЃЌБШНЯГЃгУЕФЪЧАДее unicode БрТыЫГађЃЌАДееЪЕМЪДцДЂНкЕуЕФДѓаЁЕШЃЛЦфДЮ
join ЕФЗНЪНгаЕШжЕ join КЭЗЧЕШжЕ joinЃЛвдШчЯТГЃгУЧвБШНЯМђЕЅЕФЧщПіЮЊР§ЁЃ
вдШчЯТ sql ЮЊР§ЃЌФГвЛзЂВсЪБМфЗЖЮЇФкЕФгУЛЇЕФЫљгаЕЧТМаХЯЂЃК
select t1.u_id,t1.u_name,t2.login_product
from tab_user_info t1 join tab_login_info t2
on (t1.u_id=t2.u_id and t1.u_reg_dt>=? and
t1.u_reg_dt<=?) |
жДааМЦЛЎПЩФмЮЊЃК
MapЃК
гЩгкЪЧ joinЃЌЫљгаЕФБэЖМвЊНјааВщбЏВйзїЃЌВЂЧвЮЊУПеХБэДђЩЯздМКЕФБъЧЉЃЌОпЬхЪЕЪЉЕФЪБКђПЩвдМгИіБэУћзжзжЖЮЃЌдкЫљгаДцДЂНкЕуЩЯжДаа
select u_id,u_name
from tab_user_info t where u_reg_dt>=? and
t1.u_reg_dt<=?
select u_id, login_product from tab_login_info
t |
ShuffleЃКетжжЧщПіЯТгЩгкашвЊАДее u_id НјааЪ§ОнЯДХЦЃЌПМТЧЕН u_id ЕФЮЈвЛжЕБШНЯЖрЃЌЫљвдИїИіДцДЂНкЕуЩЯашвЊАДее
u_id НјааЛЎЗжЃЌР§Шчга N ИіМЦЫуНкЕуЃЌФЧУДАДееЃЈзюДѓ u_id- зюаЁ u_idЃЉ/N ЦНОљЛЎЗжЃЌНЋВЛЭЌДцДЂНкЕуЩЯЕФЭЌвЛЗЖЮЇЕФ
u_idЃЌЛЎЗжЕНЭЌвЛИіМЦЫуНкЕуЩЯЁЃ
ReduceЃК
select t1.u_id,t1.u_name,t2.login_product
from tab_user_info t1 join tab_login_info t2
on (t1.u_id=t2.u_id) |
згВщбЏ
гЩгкзгВщбЏПЩвдЗжНтГЩОпгавРРЕЙиЯЕЕФВЛАќКЌзгВщбЏЕФ SQLЃЌЫљвдЩњГЩЕФжДааМЦЛЎЃЌОЭЪЧЖрИі SQL ЕФжДааМЦЛЎАДеевЛЖЈЕФвРРЕЙиЯЕНјаавРДЮжДааЁЃ
гывбгаЯЕЭГЕФЧјБ№КЭгХЕу
ЯрБШ hdfs РДЫЕЃЌЪ§ОнЕФЗжВМЪЧгаЙцдђЕФЃЌhdfs ашвЊЦєЖЏжЎКѓжДааУќСюШЅВщбЏЮФМўОпЬхдкЪВУДНкЕуЩЯЃЛдЊЪ§ОнЕФНЯаЁЃЌМЧТМЙцдђМДПЩЃЌЙмРэГЩБОНЯЕЭЃЌдкЦєЖЏЫйЖШЗНУцКмПьЁЃ
Ъ§ОнЪЧЗХдкЪ§ОнПтжаЕФЃЌПЩвдКмКУЕФЪЙгУЫїв§КЭЪ§ОнПтБОЩэЕФЛКДцЛњжЦЃЌДѓДѓЬсИпЪ§ОнВщбЏЕФаЇТЪЃЌЬиБ№ЪЧдкДѓСПЪ§ОнЕФЧщПіЯТЃЌРћгУЫїв§ВщбЏЗЕЛиЩйСПЕФЪ§ОнЁЃ
Ъ§ОнПЩвдНјааЩОГ§КЭаоИФЃЌетдкЛљгк hdfs ЕФЯЕЭГжавЛАуБШНЯТщЗГКЭЕЭаЇЁЃ
дкМЦЫуЗНУцЃЌКЭ MapReduce ЛђепЦфЫћЕФЗжВМЪНМЦЫуПђМмЃЈШч sparkЃЉВЂУЛгаБОжЪЕФЧјБ№ЃЈашвЊНјаа
shuffleЃЉЁЃЕЋЪЧгЩгкЪ§ОнЕФЗжВМЪЧгаЙцдђЕФЃЌдкгааЉЕиЗНПЩвдзіЕФИќКУЃЌдкЗжВМЪНШЋЮФЫїв§ЬхЯжЁЃ
гЩгкЯпЩЯЯЕЭГвЛАуЪЙгУЪ§ОнПтзїЮЊзюжеЕФДцДЂЮЛжУЃЌЖјАбЪ§ОнПтЭЌВНЕН hdfs жаЪЧБШНЯТщЗГЕФЃЌВЂЧвЖдгкгаЩОГ§КЭИќаТЕФЧщПіЃЌЭЌВНЪ§ОнТщЗГЕЭаЇЃЌЫйЖШНЯТ§ЃЛЯрБШжЎЯТЃЌетИіЗНАИПЩвдЪЙгУЪ§ОнПтБОЩэЬсЙЉЕФОЕЯёИДжЦЙІФмРДЭЌВНЃЌЛљБОУЛгаЖюЭтЕФТщЗГКЭЕЭаЇЕФЙЄзїЁЃ
ЛљгквдЩЯЃЌПЩвдАбЯпЩЯЯЕЭГЃЈжїЯЕЭГЃЉКЭЯпЯТЕФЪ§ОнЗжЮіЭкОђЃЈДгЯЕЭГЃЉзіГЩЭГвЛЕФЗНАИ, ВЮМћгІгУМмЙЙЭМЁЃ
гІгУГЁОА
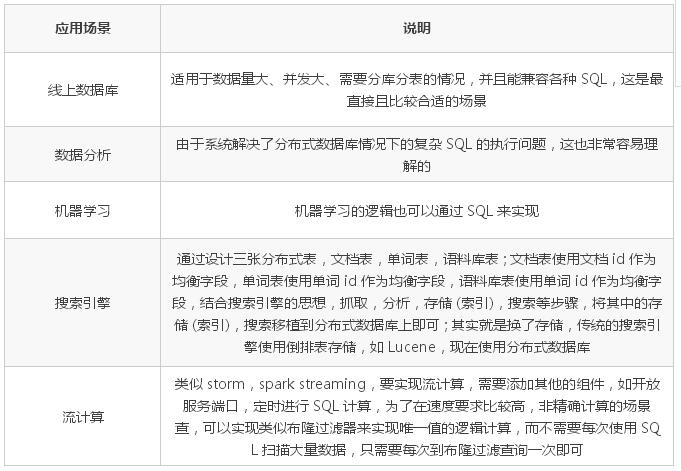
зюКѓСаОйвЛаЉгІгУГЁОА
| 








