| БрМЭЦМі: |
| БОЮФРДздгкyq.aliyun.comЃЌЗжЯэСЫШчКЮгУзюМђЕЅПьНнЕФЗНЪННтОігУЛЇЪЙгУSQL
ServerЪ§ОнПтЙ§ГЬжаЕФЕфаЭЮЪЬтЃЌЪЙSQL ServerФмЙЛЮШЖЈЕиЬсЙЉГжајЗўЮёЁЃ
|
|

ЙЄгћЩЦЦфЪТЃЌБиЯШРћЦфЦїЁЃГЃМћЕФЗжЮіадФмЮЪЬтЕФЙЄОпгаШ§жжЃКеяЖЯгВМўзЪдДЃЌЕШД§РраЭЃЌадФмгяОфЁЃ
гВМўзЪдДЭЈГЃгаЫФИіЗНУцХаЖЯЃК
CPUМрПиЃЌадФмМЦЪ§ЦїжївЊАќРЈ%Processor TimeЁЂProcessor
Queue LengthЁЂBatch request /secЁЂ Transactions /sec(
total_ )ЁЃетаЉВЮЪ§ФмЙЛХаЖЯCPUЕФДІРэФмСІЃЌЛђепЫЕвЛИіЪЕР§ЕФЭЬЭТСПЁЃ
MemoryМрПиЃЌадФмМЦЪ§ЦїжївЊЮЊЃК Buffer Cache Hit
RatioЁЂ Page Life ExpectancyЁЂLazy Writes / secЁЃетМИИіадФмВЮЪ§ЛљБОЩЯФмЗДгГФкДцЮЪЬтЃЌЙлВьФкДцзДЬЌЁЃ
IOМрПиЃЌадФмВЮЪ§жївЊЮЊЃКCurrent Disk Queue LengthЁЂAvg.Disk
Sec /ReadЁЂAvg.Disk Sec/WriteЁЃ
Network МрПиЃЌОЁЙмФПЧАЭјТчЗНУцКмЩйГіЯжЦПОБЃЌЕЋШдашМрПиBytes
Total /secКЭ% Net UtilizationЃЌЦфжаNet UtilizationЪЧвЛИіЯЕЭГМЖБ№ЕФВЮЪ§ЁЃ
МрПигВМўзЪдДЕФадФмМЦЪ§ЦїгаШ§ИіЙЄОпПЩвдЪЙгУЃЌЗжБ№ЪЧЃКLogmanЁЂPerfmonЁЂsys
.dm_ os_ performance_ counters ЁЃЦфжа LogmanЪЧвЛИіУќСюааЙЄОпЃЌЪЎЗжвзгУЃЌЧвПЩЩшжУКмЖрВЮЪ§ЃЌТњзуВЛЭЌгУЛЇЕФашЧѓЃЛPerfmonЪЧвЛИіUIЙЄОпЃЌвВЪЧФПЧАзюГЃгУЕФЙЄОпжЎвЛЃЛsys.dm_
os_ performance_ countersЪЧSQL Server ФкжУЕФЫбМЏадФмМЦЪ§ЦїЕФЯЕЭГЪгЭМЃЌЫќПЩвдЖЈжЦадФмВЮЪ§ЪеМЏЃЌЕЋOSЕФадФмВЮЪ§ЪЧЮоЗЈЪеМЏЕФЁЃ
ЭЈГЃБИЪмЙизЂЕФЕШД§РраЭжївЊгаШ§жжЃКЗЕЛижДааЕФЯпГЬЫљгіЕНЕФЫљгаЕШД§ЕФЯрЙиаХЯЂЁЂгаЙиАДРрзщжЏЕФЫљгауХЫјЕШД§ЕФаХЯЂЁЂПЩвдЪЙгУЯЕЭГЪгЭМРДеяЖЯSQL
Server вдМАЬиЖЈВщбЏКЭХњДІРэЕФадФмЮЪЬтЁЃЦфжаЃЌЩЯЪіУПвЛЯюЖдгІЕФеяЖЯЙЄОпШчЯТЃК
sys.dm_os_wait_stats ЃКЗўЮёЦїМЖБ№ЕФЪеМЏЪ§Он
sys.dm_os_latch_stats ЃКЗўЮёЦїМЖБ№ЪеМЏЕФуХЫјЕШД§аХЯЂ
sys.sysprocesses /sys.dm_exec_requests:
ПЩвдгУдкSESSIONМЖБ№ЛђепгяОфМЖБ№ЕФЕШД§РраЭЗжЮі
етРявЊзЂвтСНЕуЃКЕквЛЕуЃЌsys.dm_os_wait_stats ЪеМЏЕФЪ§ОнЪЧРлМЦЕФНсЙћЃЌШєашзМШЗЕиХаЖЯЕБЧАЮЪЬтЃЌдђвЊЧхРэЕєетаЉЪ§ОнЃЛЗёдђЃЌвдЧАЕФФГИіЪ§Он/ВЮЪ§жЕПЩФмЛсИпгкЯждкЕФжЕЃЛЕкЖўЕуЃЌsys.dm_os_wait_stats/sys.dm_os_latch_stats
ШЗЖЈЪЧЗёашвЊЧхГ§ЛКДцЪ§ОнЃЌЪЙгУDBCC SQLPERFЁЃ
адФмгяОфЗНУцЃЌТ§SQLЪЧЪ§ОнПтадФмБэЯжзюЭЛГіЕФЗНЪНЃЌвђДЫИњзйТ§SQLЪЧадФмЕїгХБиаызіЕФЙЄзїЁЃвЛАуПЩгУЙЄОпШчЯТЃК
SQL Server ProfilerЃКПЩИњзйЪ§ОнПтЫљгаЪТМўЕФЙЄОпЃЌдкРЉеЙЪТМўГіЯжЧАЃЌЪЧзюГЃгУЕФЙЄОпЁЃ
ЛюЖЏМрЪгЦїЃКЫќЪЧПьЫйеяЖЯЮЪЬтЕФвЛжжЙЄОпЃЌSSMSПЩЗНБуВщПДзЪдДЦПОБЁЃ
ЯЕЭГЪгЭМЃКsys.dm_exec_ query_stats /sys.dm_exec_requests/sys.dm_
exec _sql_ textЕШЃЌФмИљОнИіШЫашЧѓЖЈжЦЯЕЭГаХЯЂЃЌАќРЈВщбЏЕШД§ЧщПіЃЌВщбЏжДааМЦЛЎЃЌжДааЧыЧѓЯрЙиаХЯЂЃЌжДааSQL
ЕФЮФБОаХЯЂЕШЁЃ
РЉеЙЪТМўЃКНЈвщSQL Server 2012жЎКѓЕФАцБОЪЙгУЃЌДЫЧАЕФАцБОжаЃЌРЉеЙЪТМўЪЧВЛЭъЩЦЕФЁЃ
ЮЂШэЙЄОпSQLDIAG/ PSSDIAG/ SQLNexus/ Perfmance
Dashboard
етРягавЛЕуашвЊЪЙгУепЬиБ№зЂвтЃЌЪЙгУSQL Server ProfilerЪЧвЛжжБШНЯжиЕФЗНЪНЃЌЖдЯЕЭГадФмгАЯьЮЊ5ЁЋ10%зѓгвЃЌЮЊСЫМѕЩйадФмгАЯьЃЌПЩвдВЩгУвдЯТМИИіЗНУцНјаагХЛЏЃК
ЪЙгУНХБОДДНЈВЂЩњГЩЮФМўЃЌВЛвЊдЖГЬЪеМЏЪ§ОнЃЛ
ЪеМЏЪ§ОнЪБОЁПЩФмЪЙгУЖрЕФЙ§ТЫЬѕМўЃЌВЂШЅЕєВЛБивЊЕФЪфГіСаЃЛ
ЪеМЏЕФЪЧдЪМЪ§ОнЃЌашвЊОлКЯКЭДІРэЪ§ОнЃЌПЩвдздМКаДе§дђБэДяЪНДІРэЁЃ
ЯТЭМЫљЪОЕФЪЧвЛИіИњзйЕБЧАжДаагяОфЕФЪОР§ЃК

ИУSQLгяОфМђЕЅгааЇЃЌгУРДзЅШЁЕБЧАжДаагяОфЕФSQLЃЌПЩвдЗНБуЕиПДЕНЕБЧАжДааНЯГЄЕФгяОфЃЌвдМАетаЉгяОфЕФзЪдДПЊЯњЧщПіЁЃ
НгЯТРДЯъЯИПДвЛЯТОпЬхЕФАИР§ЁЃ
АИР§вЛЃКЪЕР§ВЮЪ§ЕїЪдгыбЁдё

ВЛЭЌЕФвЕЮёГЁОАЃЌЪЕР§МЖБ№ЕФВЮЪ§вВВЛЭЌЁЃдкАЂРядЦЪ§ОнПтжаЕФЪЕР§МЖБ№ЃЌЫљгізюЖрашвЊЕїећЕФЪЧВЂааЖШЁЃВЂааВЮЪ§ШчЯТЃЌАќРЈСНИіЪЕР§МЖБ№КЭвЛИігяОфМЖБ№ЃК
max degree of parallelism : ЪЕР§МЖВЂааЖШ ЁЃ
cost threshold for parallelism ЃКВЂаажДааЕФДмааПЊЯњуажЕЃЌЦфжаПЊЯњЮЊдкЬиЖЈгВМўХфжУжадЫааДЎааМЦЛЎЙРМЦЫљашЪБМфЃЌЕЅЮЛЪЧУыЃЌШєДЎаажДааМЦЛЎГЌЙ§СЫИУжЕЃЌОЭЦєгУВЂаажДааМЦЛЎЁЃ
option (dopmax N )ЃКгяОфМЖВЂаажДааПижЦЁЃ
Г§СЫВЂааВЮЪ§жЎЭтЃЌВЂааММЪѕЗНУцЛЙвЊСЫНтЦфЫћММЪѕвЊЕуЃКЪзЯШЃЌВЂаажДааБОжЪЩЯЪЧРћгУЖрИіТпМCPUжДааФГИігяОфЃЛЭЌЪБЃЌВЂаажДааашвЊГѕЪМЛЏЁЂЭЌВНЁЂжажЙВЂааЕШПЊЯњЃЌДгЖјПЊЯњдіМгЃЛДЫЭтЃЌВщбЏЕФПЊЯњМЦЛЎаЁгкПЊЯњуажЕвВПЩФмВЂаажДааЃЛГ§ДЫжЎЭтЃЌoption
(dopmax N )ЬсЪОЛсИВИЧЪЕР§МЖБ№ЕФВЂааЩшжУЃЛзюКѓЃЌЕБЩшжУЯрЙибкТыгГЩфТпМCPUЮЊ1ЪБВЛЛсВЂаажДааЁЃ

ЯТУцРДПДвЛИіОпЬхЕФАИР§ЃЌИУАИР§ЕФжївЊЯжЯѓЪЧЯЕЭГгАЯьКмТ§ЃЌИДжЦбгГй6ИіаЁЪБЃЌЧыЧѓЪ§КЭЪТЮёДІРэКмЕЭЃЛЭЌЪБДѓСПЕФCXPACKETЕШД§ЃЌДѓСПSESSIONБЛзшШћЃЛДЫЭтЃЌЫќЕФВЂааЖШЩшжУЪЧ0ЁЃ
ДЫДІЕШД§РраЭЮЊCXPACKETЃЌдкВЂааВщбЏГЂЪдЪЙгУЭЌВНВщбЏДІРэЦїЃЌНЛЛЛЕќДњЦїЪБЗЂЩњЃЌетОЭвЊПМТЧЕїећВЂааЖШЕФПЊЯњуажЕЃЌЛђНЕЕЭВЂааЖШЁЃОпЬхВйзївВЪЧЗЧГЃШнвзЕФЃЌЪЙгУЭМжаsp_configureгяОфЃЌжЛвЊЕїећетИіжЕЃЌОЭЛсНтОігіЕНЕФадФмЮЪЬтЁЃ
ГЃМћЕФзюМбЪЕМљАќРЈЃК
ЕквЛЕуЃЌЪЙгУЛюЖЏМрЪгЦїПьЫйеяЖЯЃЌСЫНтЙЃИХЃЛ
ЕкЖўЕуЃЌВщПДЪЕР§ЕФTOP 10ЕШД§РраЭЃЌВщПДSESSIONЕФЕШД§РраЭЃЛ
ЕкШ§ЕуЃЌНщгкOLTPКЭOLAPЕФЪ§ОнПтЃЌНЈвщНЋЪЕЧ€ааЖШЩшжУЮЊ2ЃЌЪЧИіОбщжЕЃЛ
ЕкЫФЕуЃЌДДНЈадФмМЦЪ§ЦїЃЌОЋШЗЖЈЮЛЮЪЬтЁЃ
АИР§ЖўЃКЮЊКЮtempdbЕФЩшжУШчДЫживЊ

АИР§ЖўЪЧЪ§ОнПтМЖБ№ЕФАИР§ЃЌвЛАуЧщПіЯТЮвУЧИќЙизЂЕФЪЧгУЛЇЕФЪ§ОнПтЁЃЃЌдкЯЕЭГЪ§ОнПтжаЃЌTempdbЕФжївЊзїгУЮЊЃКtempdb
ЪЧвЛИіЯЕЭГЪ§ОнПтЃЌЪЧвЛИіШЋОжзЪдД ЁЃЫќПЩвдЯдЪНДДНЈЕФСйЪБгУЛЇЖдЯѓЃКР§ШчСйЪББэЁЂСйЪБДцДЂЙ§ГЬЁЂБэБфСПЛђгЮБъЃЛЪ§ОнПтв§ЧцДДНЈЕФФкВПЖдЯѓ:Р§ШчДцДЂМйЭбЛњЛђХХађЕФжаМфНсЙћЕФЙЄзїБэЃЛааАцБОКХЃКР§ШчааАцБОПижЦИєРыЛђПьееИєРыЪТЮёЛђепСЊЛњЫїв§ВйзїЁЂДЅЗЂЦїЕШЁЃTempdbЛЙПЩвдНјааадФмЬсЩ§ЃЌБШШчПЩЛКДцСйЪБЖдЯѓЁЂЗжХфЛьКЯвГЫуЗЈИФЩЦадФмЁЂзюаЁШежОаДШыЁЃ
TempdbдкЪЙгУжаГЃЕМжТШ§жжЮЪЬтЃКПеМфЮЪЬтЁЂзЪдДељЧРЃЌPAGELATCHЕШД§ЁЂИпВЂЗЂЮЪЬтЁЃ
ЯТУцРДПДвЛИіОпЬхАИР§ЁЃ
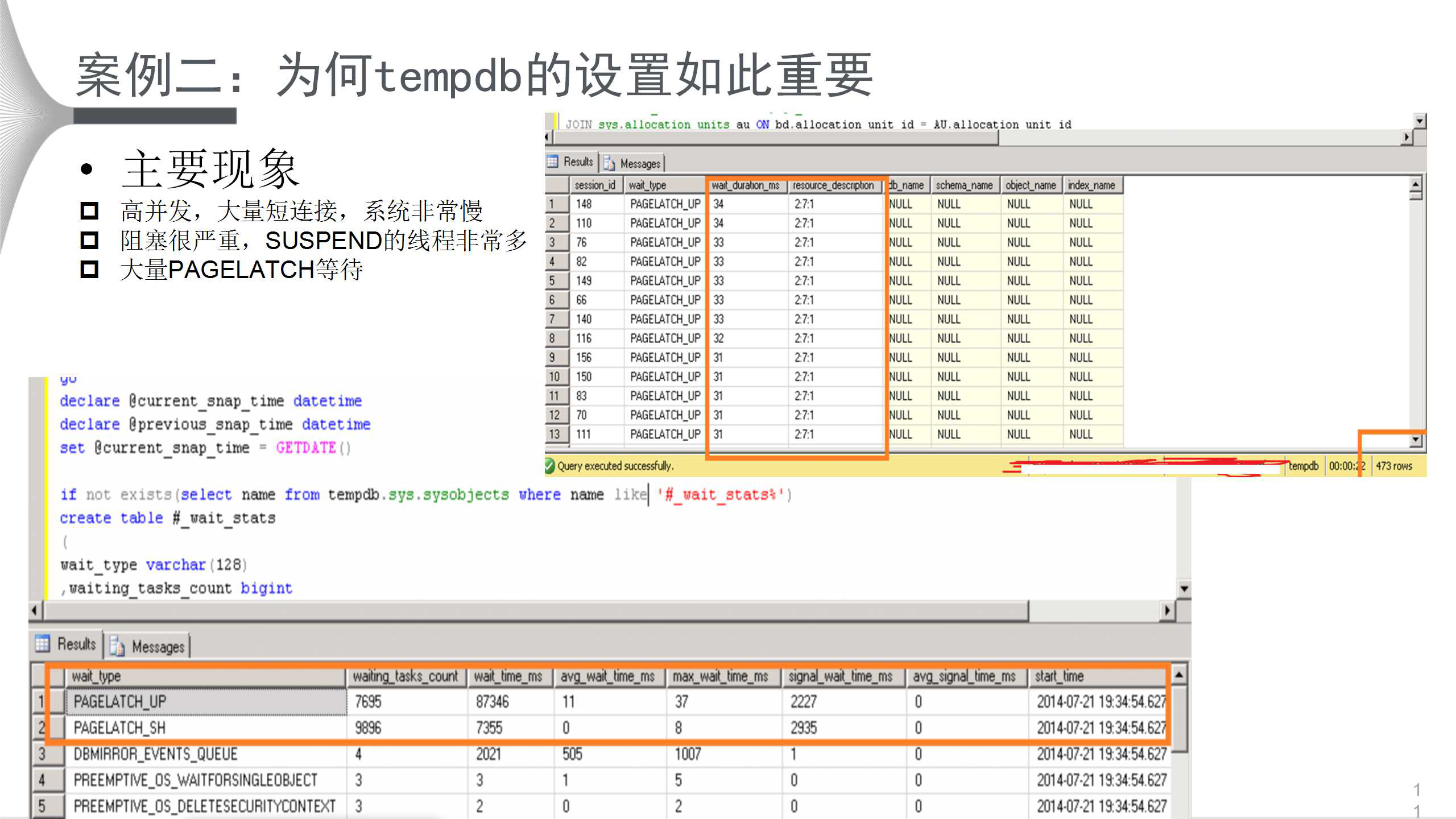
ИУАИР§ЕФжївЊЯжЯѓЮЊЃКИпВЂЗЂЃЌДѓСПЖЬСЌНгЃЌЯЕЭГЗЧГЃТ§ЃЛзшШћКмбЯжиЃЌSUSPENDЕФЯпГЬЗЧГЃЖрЃЛДѓСПPAGELATCH
ЕШД§ЁЃ
ЩЯЭМЪЧдкЪЕР§МЖБ№ЭГМЦЕФЕШД§РраЭЃЌКмУїЯдЃЌзюЖрЕФЪЧLATCH_UPЕШД§ЃЌФЧСаКьЩЋПђЭМЕФУшЪіЗЧГЃживЊЁЃЦфжа2:7:1жаЕФ2жИЕФЪЧЪ§ОнПтЃЌЪ§ОнПтЕФIDЮЊ2ЃЌМДtempdbЃЛ7ЪЧЫќЕФЕк8ИіЮФМўЃЛ1ЪЧвЛИіЬиЪтвГЃЌЦфЪЕОЭЪЧPFS
ЃЌМДУПИіЪ§ОнПтЮФМўЖМгаЕФвГУцЩшжУПеМфЁЃвђДЫЃЌИпВЂЗЂЯТЃЌВЛЖЯЗУЮЪЃЈЩЈУшЃЉtempdb ЕФЮФМўЕФPFSвГЪЙЦфБфЕУгШЮЊживЊЁЃ
ЙигкPFSвГЕФељгУЃЌзюМбЪЕМљЮЊЃК
ДђПЊИњзйБъМЧ1118,ЯћГ§ЕЅвГЗжХф
ЪЙгУЖрИіЮФМўПЩвдМѕЩй tempdb ДцДЂељгУВЂЛёЕУИќДѓЕФПЩЩьЫѕад
ЮФМўЖрЩйвЛАугыЖдгІЕФТпМCPUЖдЦыЃЌЕЋВЂЗЧЭъШЋАДееетИіЙцТЩ
ЖрИіЮФМўДѓаЁЩшжУЯрЭЌЃЌАДБШР§ЬюГфЫуЗЈИљОнЮФМўДѓаЁЪЙгУGAMвГЗжХфЕНзюДѓЮФМў
ЮФМўдіСПЩшжУЮЊКЯРэЕФДѓаЁвдБмУт tempdb Ъ§ОнПтЮФМўЕФдіСПЙ§аЁЃЌ200~500M(10%)
ДХХЬОЁПЩФмЪЙгУгУЛЇЪ§ОнПтЪЙгУЕФДХХЬвдЭтЕФДХХЬ
зіЕНвдЩЯетаЉвЊЧѓЃЌtempdbЕФОКељОЭЛсМѕЩйЛђЯћГ§ЃЌЪЙгУепШчЙћгаетЗНУцЕФЦПОБЃЌПЩвдГЂЪдвЛЯТЁЃ
АИР§Ш§ЃКИєРыМЖБ№ЕФе§ШЗбЁгУ
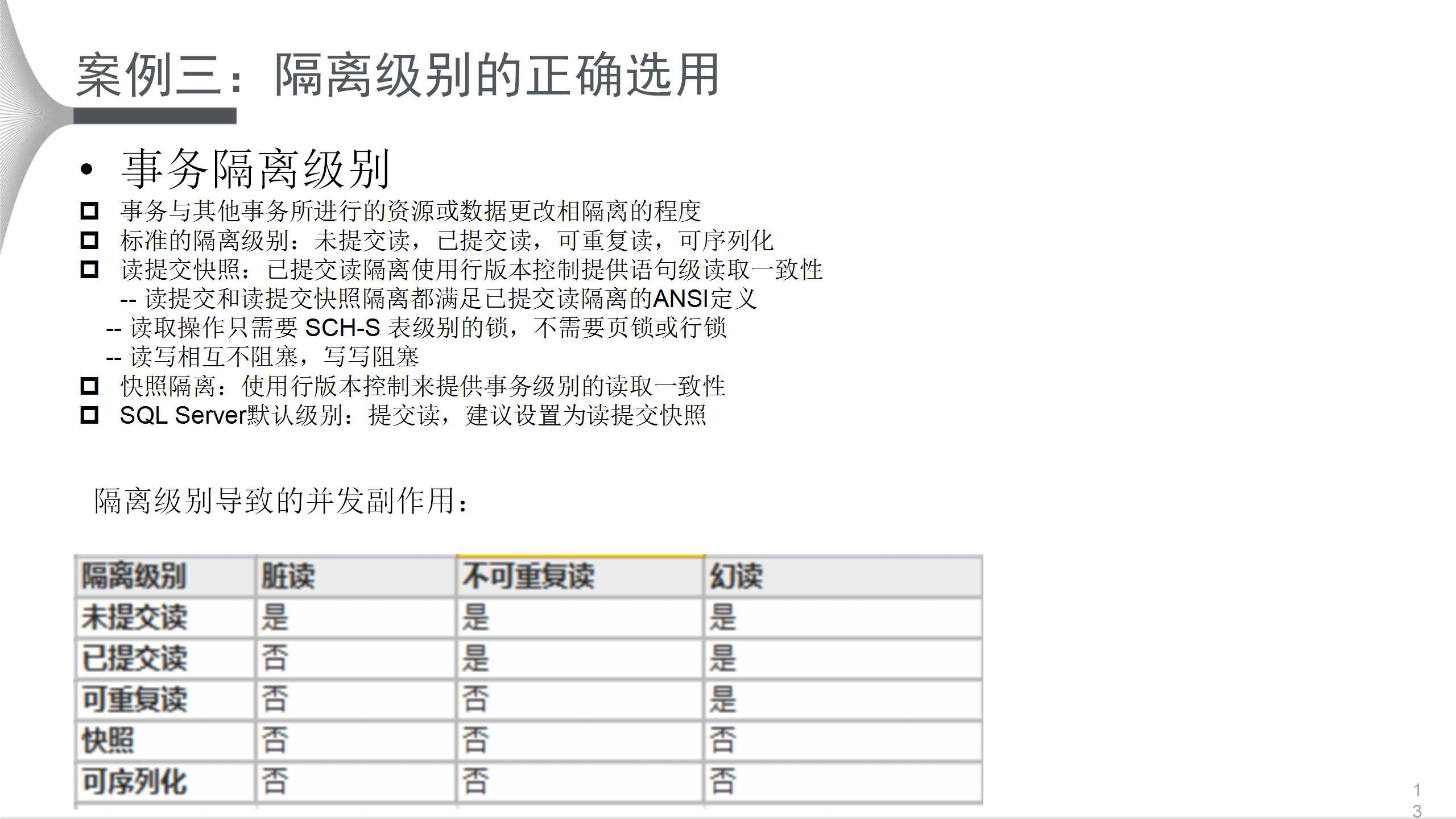
АИР§Ш§ЮЊЪ§ОнПтИєРыМЖБ№ЕФгАЯьЁЃЪТЮёИєРыМЖБ№ЪЧжИЪТЮёгыЦфЫћЪТЮёЫљНјааЕФзЪдДЛђЪ§ОнИќИФЯрИєРыЕФГЬЖШЁЃБъзМЕФИєРыМЖБ№гаЫФжжЃКЮДЬсНЛЖСЃЌвбЬсНЛЖСЃЌПЩжиИДЖСЃЌПЩађСаЛЏЁЃГ§ДЫжЎЭтЃЌSQL
ServerЛЙдіМгСЫЖСЬсНЛПьееКЭПьееИєРыЃК
ЖСЬсНЛПьееЪЧжИвбЬсНЛЖСИєРыЪЙгУааАцБОПижЦЬсЙЉгяОфМЖЖСШЁвЛжТадЃК
ЖСЬсНЛКЭЖСЬсНЛПьееИєРыЖМТњзувбЬсНЛЖСИєРыЕФANSIЖЈвх
ЖСШЁВйзїжЛашвЊ SCH-S БэМЖБ№ЕФЫјЃЌВЛашвЊвГЫјЛђааЫј
ЖСаДЯрЛЅВЛзшШћЃЌаДаДзшШћ
ПьееИєРыЪЧЪЙгУааАцБОПижЦРДЬсЙЉЪТЮёМЖБ№ЕФЖСШЁвЛжТадЁЃ
SQL ServerФЌШЯМЖБ№ЪЧЬсНЛЖСЃЌЕЋНЈвщЩшжУЮЊЖСЬсНЛПьееЁЃБъзМИєРыМЖБ№ПЩФмЕМжТВЂЗЂЕФИБзїгУЃЌОпЬхЧщаЮШчЩЯЭМБэИёЫљЪОЁЃ
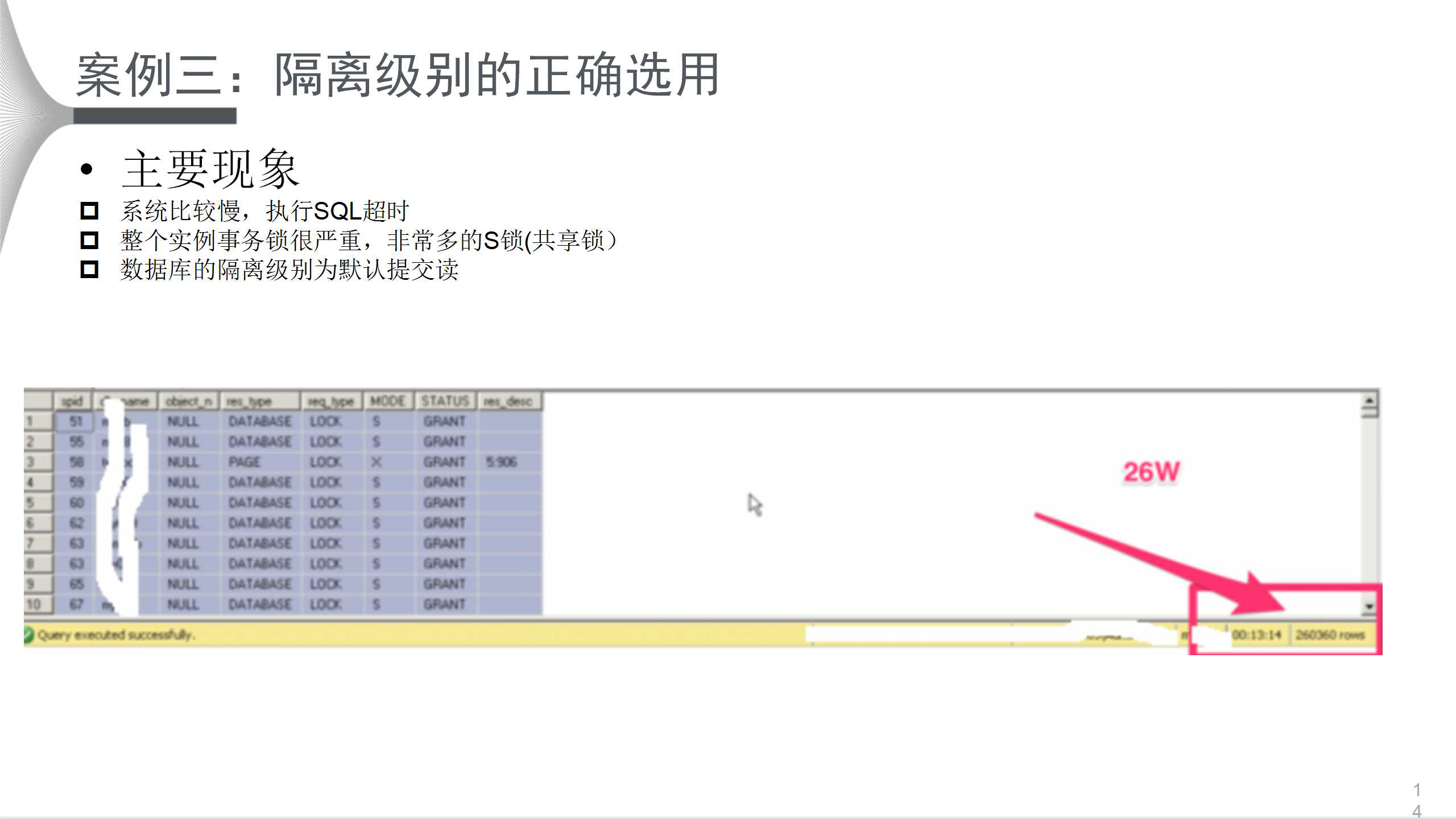
ИУАИР§ЕФжївЊЯжЯѓЪЧЃКЯЕЭГБШНЯТ§ЃЌжДааSQLГЌЪБЃЛећИіЪЕР§ЪТЮёЫјКмбЯжиЃЌЗЧГЃЖрЕФSЫј(ЙВЯэЫјЃЉЃЛЪ§ОнПтЕФИєРыМЖБ№ЮЊФЌШЯЬсНЛЖСЁЃ
ШчЩЯЭМЫљЪОЃЌгУЛЇЕФЪТЮёЫјаХЯЂДяЕНСЫ26WжЎЖрЃЌНјЖјбЯжигАЯьећЬхадФмЁЃЖдгкетаЉећЬхадЮЪЬтЃЌПМТЧЩшжУИєРыМЖБ№ЁЂЖСЬсНЛПьееПЩвдгааЇНтОіЁЃЫјЙ§ЖрЕФдвђдкгкЃКБэЕФЩшМЦВЛКЯРэЃЌSQLаДЕУВЛЙЛгХЛЏЃЛЛђепДгЪЕР§МЖБ№ећЬхЩЯРДПДЃЌЪ§ОнПтИєРыМЖБ№ЩшжУВЛКЯРэЁЃ
вђДЫзюМбЪЕМљЮЊНЋЪ§ОнПтЩшжУЮЊЖСЬсНЛПьееЃЌЛёШЁадФмВЮЪ§ЃЌЖдБШНсЙћЃКЫјДг5WНЕМЖЕН2KЃЌTPSДг1000діМгЕН1600ЁЃЫљвдгХЛЏЪБЃЌЭЈЙ§ЩшжУЪ§ОнПтЕФИєРыМЖБ№ЃЌФмЙЛЬсИпЯрЕБПЩЙлЕФадФмЁЃ
АИР§ЫФЃКБэЕФГЃМћЮЪЬт

ГЃМћЕФЕфаЭЕФБэЮЪЬтАќРЈЃКЗЖЪНгыЗДЗЖЪНгІгУВЛКЯРэЁЂЪ§ОнРраЭбЁдёВЛКЯРэЁЂжїМќбЁдёВЛЕБЁЂЖбБэКЭОлМЏЫїв§БэЗжВЛЧхЁЂжїБэДгБэСЌНгзжЖЮЩшМЦРраЭВЛвЛжТЁЃ
ЯТУцПДвЛИіФЃФтгУЛЇАИР§ЁЃ
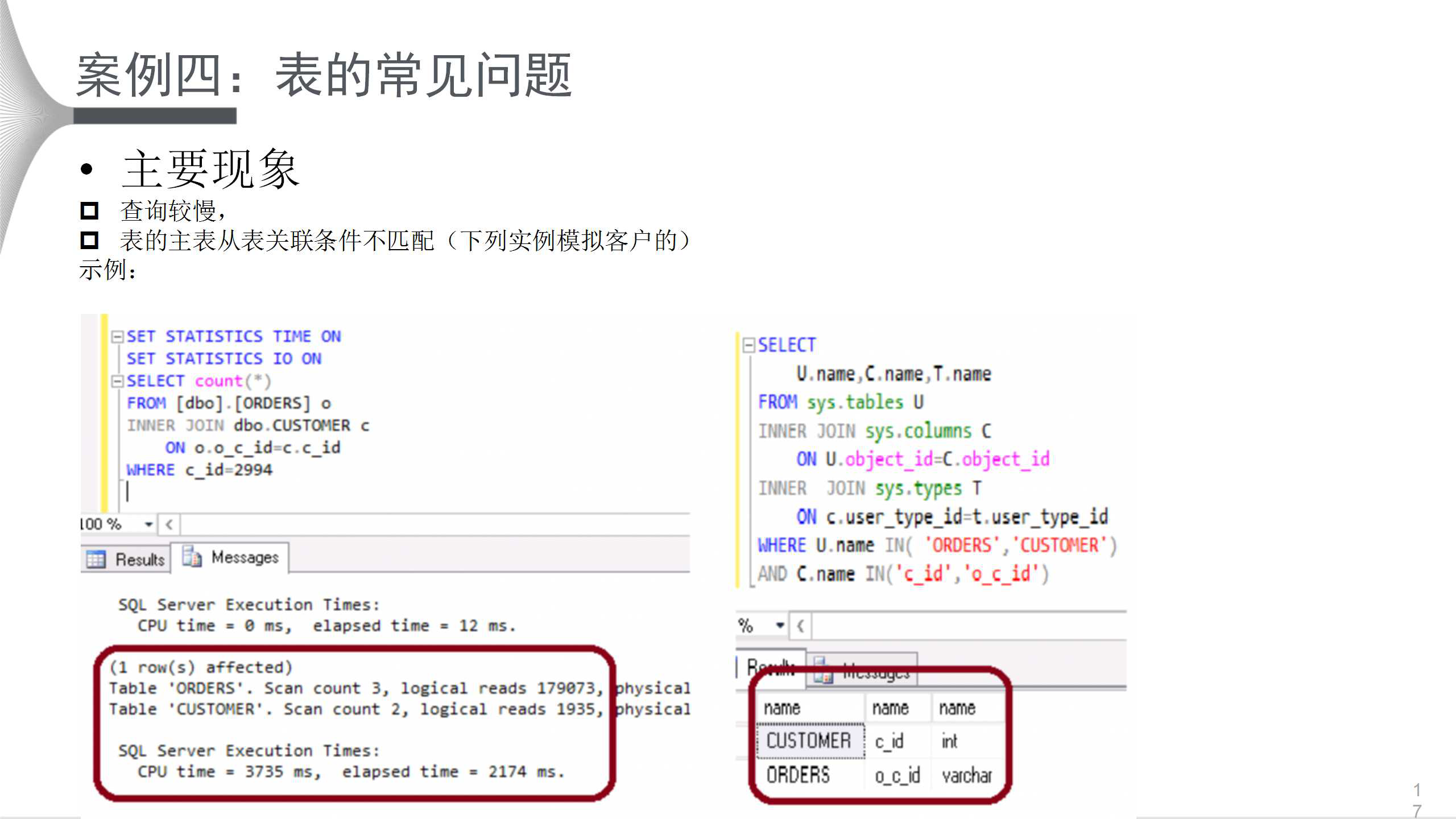
ИУгУЛЇЕФжївЊЯжЯѓЪЧВщбЏНЯТ§ЃЛБэЕФжїБэКЭДгБэЙиСЊЬѕМўВЛЦЅХфЁЃЩЯЭМзѓВргяОфЗЧГЃМђЕЅЃЌжДааНсЙћжаЃЌCPUгУЪБ3.735УыЃЌжДааЪБМф2.174УыЃЌЪБМфНЯГЄЁЃВщПДЯЕЭГЪгЭМЃЌЗЂЯжБэЕФРраЭвЛИіЪЧintаЭЁЂвЛИіЪЧvarcharаЭЃЌжБНгКмФбПДГіРДЃЌЕЋЪЧВщПДжДааМЦЛЎОЭКмЧхГўЁЃ
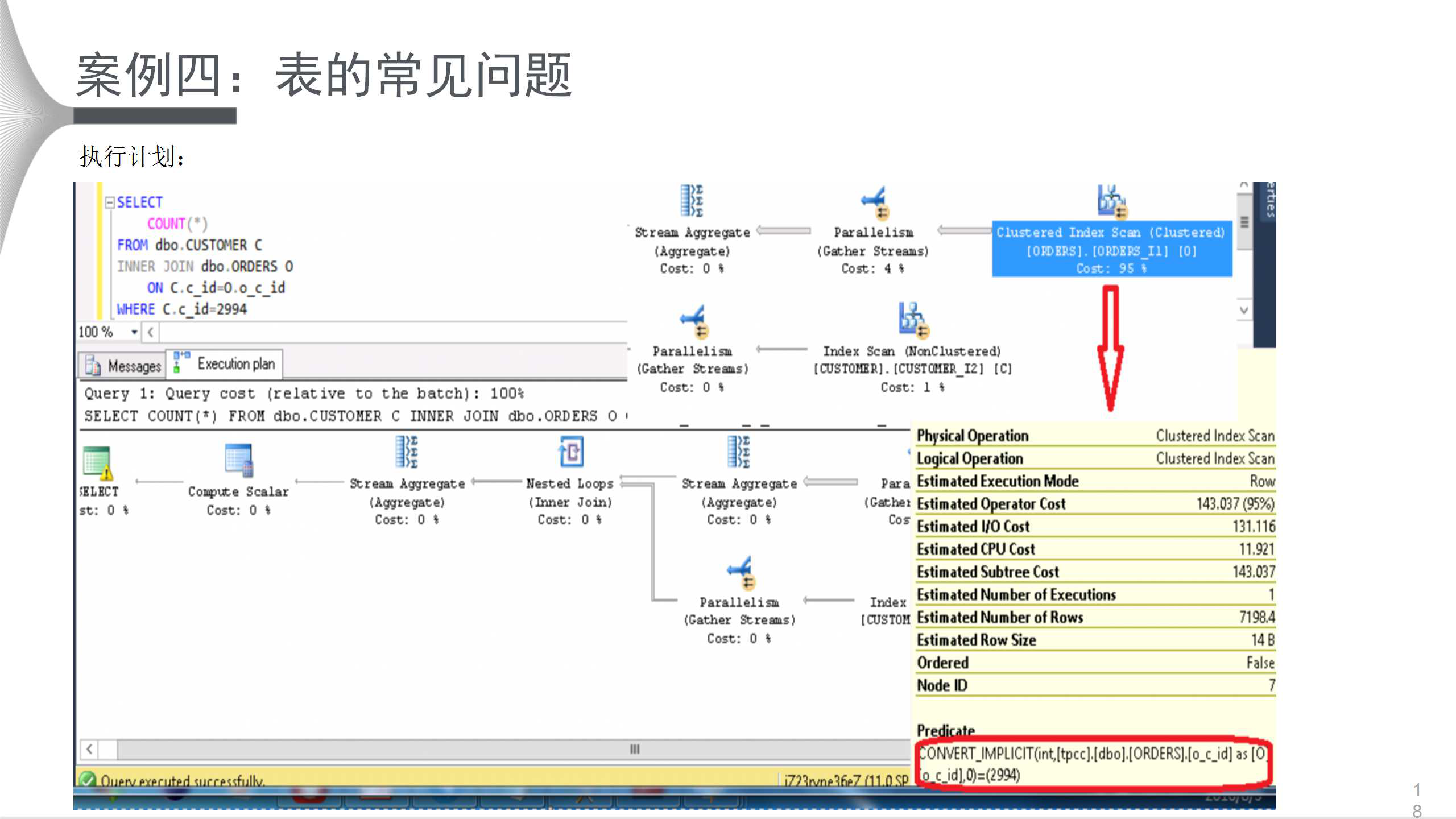
КмУїЯдЃЌЙиСЊЬѕМўДцдкРраЭВЛвЛжТЃЌЕМжТжДаааЇТЪЕЭЯТЁЃвђДЫЃЌНЋЙиСЊЬѕМўРраЭЕїећвЛжТЃЌаоИФБэЕФНсЙЙЪЧзюКУЕФЗНЪНЁЃВЛЙ§аоИФЪБЧызЂвтЃЌЪМжедквЕЮёПеЯаЪБВйзїЃЌШчЙћСагаINDEXЃЌашвЊЯШDROP
ЕєЫїв§ВХПЩвдИќИФЁЃ
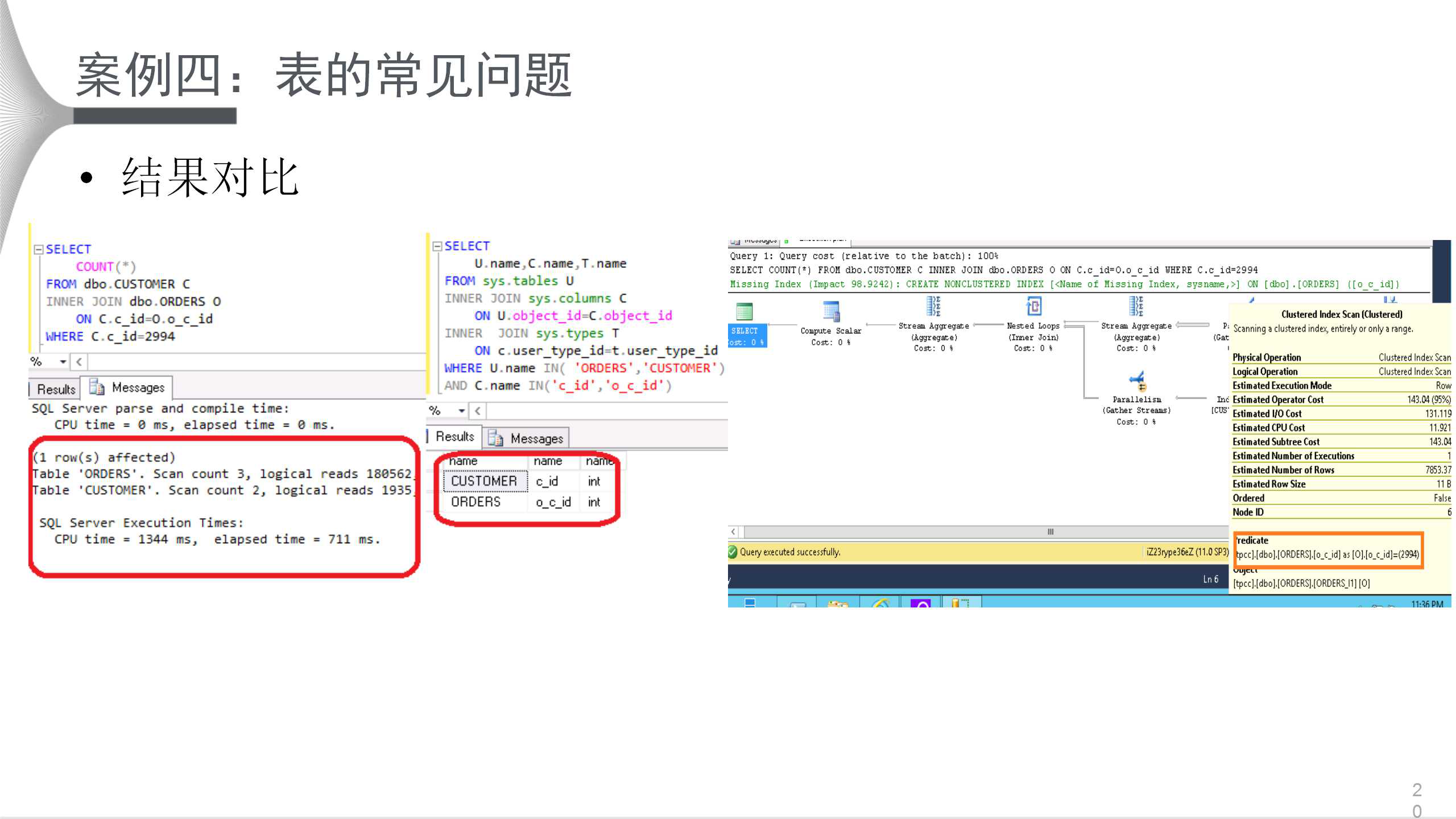
НсЙћЖдБШШчЩЯЭМЫљЪОЁЃЯдШЛЃЌНсЙћЕУЕНЬсЩ§ЃЌCPUПЊЯњДг4УыЕН1УыЖрЃЌЪ§ОнНсЙЙРраЭвВБфвЛжТЃЌетОЭЪЧSQL
ServerЧПДѓЕФЕиЗНЁЃ
ЙигкБэЕФЩшМЦЃЌЛЙгавЛаЉНЈвщШчЯТЃК
вЛАувЊЧѓЕкШ§ЗЖЪНЃЌПЩЪЪЕБШпгрЃЛ
гІИУгХЯШПМТЧЪ§зжРраЭЃЌЦфДЮЪЧШеЦкЛђЖўНјжЦРраЭЃЌзюКѓЪЧзжЗћРраЭЃЛ
БэЕФСаГЄЖШОЁПЩФмЖЬЃЌМДПЩМѕЩйПеМфЃЌвВПЩвдЬсИпадФмЃЛ
зжЗћБфГЄПЩФмГіЯжаавчГіЃЌЖЈГЄЯћКФИќЖрЕФПеМфЕМжТЗжИюИќЖрЕФвГЃЌашШЈКтЃЛ
LOBЪ§ОнРраЭЧыЪЙгУnvarchar(max) /varchar(max)
/varbanary(max)ЃЛ
е§ШЗШЯЪЖUNICODEзжЗћДјРДЕФКУДІКЭЛЕДІЃЛ
ВщбЏКЭБфИќЦЕЗБЕФБэНЈвщЩшМЦЮЊОлМЏЫїв§БэЃЌВхШыИќаТКЭВщбЏашвЊЦНКтЃЛ
ЭтМќПЩвдЬсЩ§адФмЃЌЕЋКѓЦкЮЌЛЄБШНЯТщЗГЃЌНЈвщвЕЮёЩЯЙцЗЖжїЭтМќЙиЯЕЃЛ
БмУтЙиСЊЬѕМўГіЯжЪ§ОнРраЭВЛвЛжТЃЌЗЧГЃживЊЃЛ
АИР§ЮхЃКЫїв§ЕФГЃМћЮЪЬт
ДгБэдйЯИЗжвЛВуЃЌДгЫїв§ЕФНЧЖШГіЗЂЁЃЙигкЫїв§ЃЌЪЙгУепашвЊСЫНтвдЯТМИИіИХФюЃК
ЪВУДЪЧОлМЏЫїв§КЭОлМЏЫїв§Бэ
ЪВУДЪЧЗЧОлМЏЫїв§КЭЖбБэ
ОлМЏЫїв§КЭЗЧОлМЏЫїв§ЕФЙиЯЕЮЪЬт
ЪщЧЉВщевЮЪЬт
ИпМЖЫїв§ММЪѕ
ЦфжаОлМЏЫїв§КЭЗЧОлМЏЫїв§ЕФЙиЯЕШчЩЯЭМЫљЪОЃЌОлМЏЫїв§гавЛИіжИеыЃЌжИеыМДЮЊааЖЈЮЛЦїЃЌгыЖбБэКЭОлМЏЫїв§БэЖМгаЙиЯЕЁЃ
ЯТУцРДПДвЛИіОпЬхР§згЁЃ
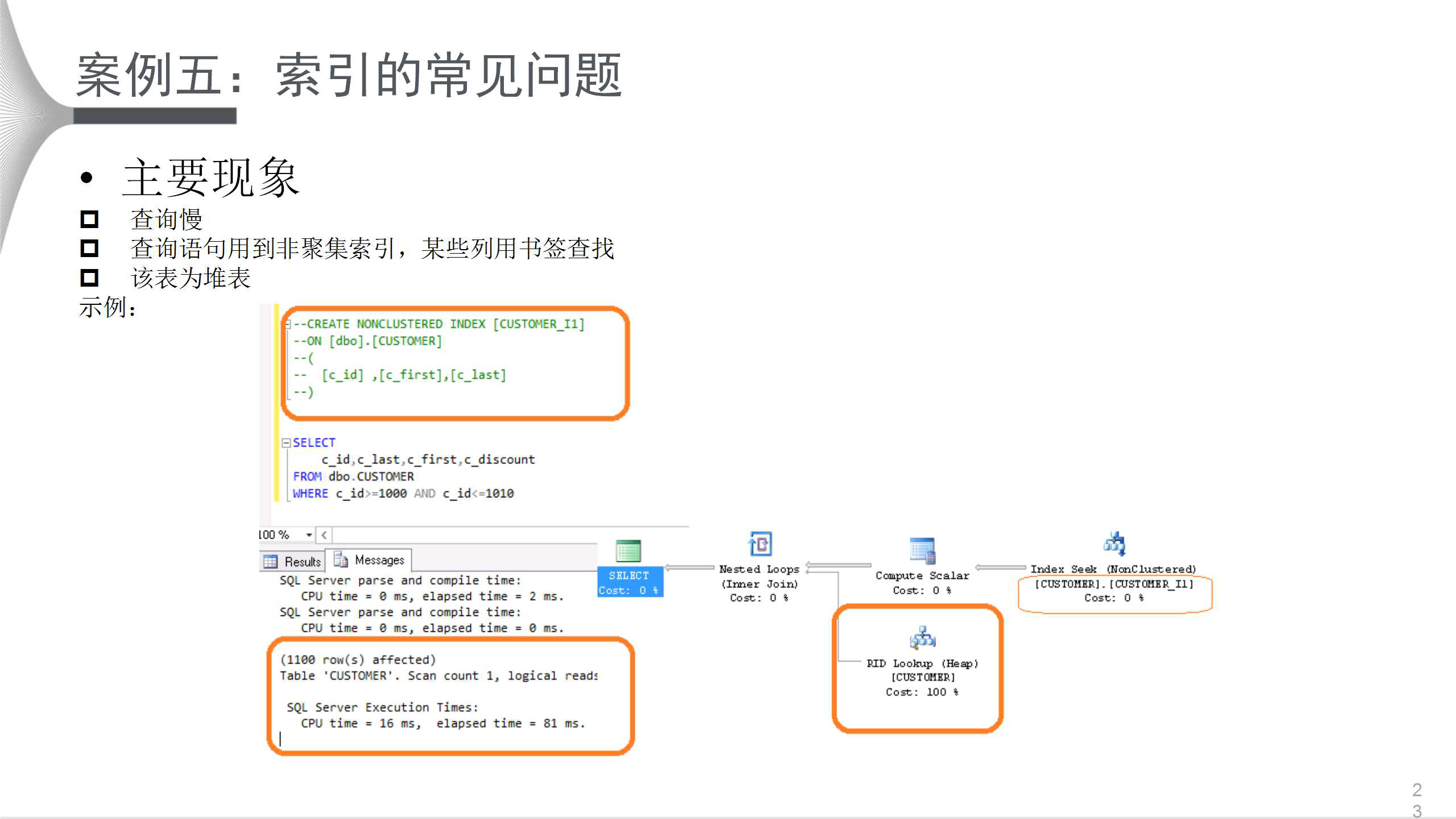
ИУЕфаЭАИР§жївЊЯжЯѓЪЧВщбЏТ§ЃЛВщбЏгяОфгУЕНЗЧОлМЏЫїв§ЃЌФГаЉгУЪщЧЉВщевЁЃетЪЧЪщЧЉВщевЕФЕфаЭЮЪЬтЃЌгяОфКмМђЕЅЃЌВщбЏФГаЉЗЖЮЇЕФПЩЛёЕУаХЯЂЃЌИУЗЧОлМЏЫїв§АќКЌШ§ИіСаЃЌВЛАќРЈc_discountЃЌжДааЧщПіЮЊ1100ааЪ§ОнЃЌCPUПЊЯњЮЊ16msЃЌжДааЪБМф81msЁЃИУжДааМЦЛЎУЛгаЪЙгУЕНЫїв§ЕФСаЃЌЭЈЙ§ааКХВщевЃЌПЩвдПДЕУГіПЊЯњ100%ЁЃ
ЪњЯпВщевгаСНИіНтОіАьЗЈЃК
ЃЈ1ЃЉЯћГ§ЪщЧЉЃЌИВИЧЫљгаСаЃЌАбc_discountСаАќКЌНјРДЃЌгяОфВЛБфЃЌЧщПіТэЩЯЕУЕНИФЩЦЁЃ
ЃЈ2ЃЉАбБэИќИФЮЊОлМЏЫїв§БэЁЃ
Ыїв§ЩшМЦНЈвщШчЯТЃК
МьВщWHEREзгОфКЭСЌНгЬѕМўСа
ЪЙгУеЕФЫїв§
МьВщСаЕФЮЈвЛад
МьВщСаЕФЪ§ОнРраЭ
ПМТЧСаЕФЫГађ
гХЛЏЪщЧЉВщевЃЌЪЙгУИВИЧЫїв§ЃЌОлМЏЫїв§ЛђепЫїв§СЌНгЯћГ§ЪщЧЉВщев
МьЫївЛЖЈЗЖЮЇКЭдЄЯШХХађЪ§ОнЪЪКЯОлМЏЫїв§
ЦЕЗБИќаТЕФСаЩЯВЛвЊЩшМЦОлМЏЫїв§ЃЌЫћНЋЕМжТЫљгаЕФЗЧОлМЏЫїв§ЕФИќаТ
ЪзЯШДДНЈОлМЏЫїв§ЃЌдйДДНЈЗЧОлМЏЫїв§ЃЌећРэЫїв§ЫщЦЌвВЪЧШчДЫ
АИЧњЃКзшШћЗжЮі
зшШћПЩФмгаКмЖржжЃЌетДгЯЕЭГЪгЭМжаПЩвдПДЕУКмЧхГўЁЃЗжЮізшШћЃЌзюживЊЕФЪЧПДЕБЧАзшШћЕФзЪдДЪЧЪВУДЃЌдкЕШД§ЪВУДзЪдДЪЭЗХЃЌФЧУДЙигкзшШћЃЌашвЊСЫНтЕФЛљБОжЊЪЖШчЯТЃК
ЫјФмгааЇЙмРэЪ§ОнПтзЪдДЕФВЂЗЂЃЌВЂЧвБЃжЄЪ§ОнЕФвЛжТад
ЫРЫјЪЧСЌНгВЛПЩЭЫШУЕФНЉЫРОжУцЃЌЪЧвЛжжгРОУЕФзшШћ
ЫјСЃЖШЪЧЪВУД
ЫјФЃЪНгаЪЧЪВУД
БиаыСЫНтЪТЮяЕФACIDЪєад
ИєРыМЖБ№ЖдзшШћЕФгАЯь
ЦфЪЕзшШћжївЊЛЙЪЧвђЮЊгаЫјЃЌвђЮЊЫјФмгааЇЙмРэЪ§ОнПтзЪдДЕФВЂЗЂЃЌВЂЧвБЃжЄЪ§ОнЕФвЛжТадЁЃЫРЫјЪЧСЌНгВЛПЩЭЫШУЕФНЉЫРОжУцЃЌЪЧвЛжжгРОУЕФзшШћЃЌвЛЕЉГіЯжЫРЫјЃЌЛсБЃСєЛиЙізЪдДзюДѓЕФСЌНгЁЃжЛвЊЩцМАЪ§ОнПтЃЌЪТЮёЕФACDIЪєадОЭБиаывЊСЫНтЁЃЯТУцПДвЛИіОпЬхЕФгУЛЇецЪЕАИР§ЃЌГЬађжДааЗЧГЃЛКТ§ЃЌКмЖрСЌНгГЌЪБЁЃ
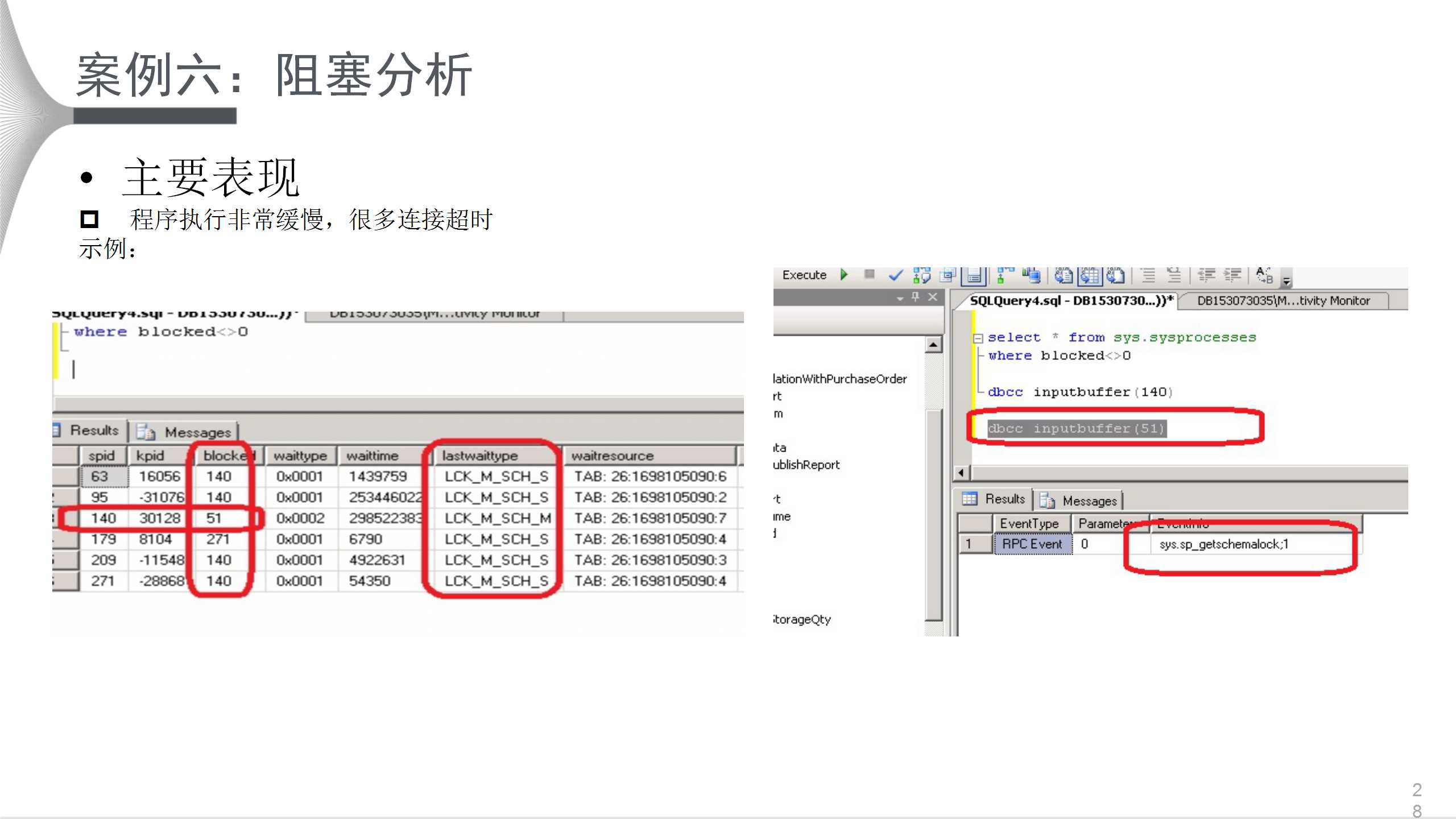
ЩЯЭМЕФжДааНХБОЗЧГЃМђЕЅЃЌгвЭМЕФsys.sysprocessesЧхГўЕиУшЪіСЫзшШћЧщПіЃЌ51КХНјГЬзшШћСЫ140КХЃЌ140КХгжДѓСПзшШћСЫЦфЫћНјГЬЁЃ51КХSESSIONдкХЌСІЕУЕНМмЙЙЫјЃЌ140КХдкзіREBUILD
INDEXЃЌДгЖј51КХSESSIONБЛЯЕЭГзЪдДзшШћЃЌЖјЮоЗЈЪЭЗХЃЌ140КХSESSION ЕФREBUILD
INDEX БиШЛгАЯьвЕЮёЕФе§ГЃдЫзЊЁЃвђДЫжБНгKILL 51ОЭПЩвдНтОіЮЪЬтЁЃЭЈГЃkillвЛИіНјГЬЃЌБ№ЭќСЫПДЦфГЩБОЁЃ

зшШћЗжЮіЕФМИЕуНЈвщШчЯТЃК
БЃГжЖЬЕФЪТЮё
ЪТЮёжаОЁПЩФмжДааЩйЕФТпМ
ЪТЮёжаВЛвЊИЩЗЧЪ§ОнДІРэЯрЙиЕФЪТ
ЪЙгУЫїв§МгПьжДаа
ЪЙгУИВИЧЫїв§НтОіВщбЏадФм
ЪЙгУЗжЧјЬсЩ§ељгУЕФБэ
ЪЙгУааАцБОКХПижЦзЪдДељгУ
ПижЦКУЪТЮёДІРэЃЌЧаФЊШУЪТЮёЪЇШЅПижЦ
ЪЙгУЬсНЛЖСПьееИєРыМЖБ№
СэЭтЃЌзшШћзюбЯжиЕФОЭЪЧЫРЫјЮЪЬтЃЌПЩДђПЊ1222/1204ИњзйКЭЗжЮіЫРЫјаХЯЂЁЃ
АИР§ЦпЃКSQLгяОфгХЛЏ
ЕБгаЮЪЬтГіЯжЃЌЪзЯШВщПДmySQLЃЌШчЙћЪЧЫќГіЯжЕФЮЪЬтЃЌдђдйПМТЧвдЯТМИИіЮЪЬтЃК
ЮоЫїв§ЛђепЫїв§ВЛе§ШЗ
вўЪНзЊЛЛШУSQLжДаааЇТЪЕЭЯТ
СаЩЯЪЙгУКЏЪ§НјЖјЫуЪѕдЫЫу
LIKEгяОфЕМжТШЋБэЩЈУш
WHEREЬѕМўЕФЪЙгУORСЌНг
ЯждкПДвЛЯТАИР§ЁЃЕквЛИіАИР§ЫЕУїСЫЪЙгУКЏЪ§ЕМжТадФмЕЭЯТЁЃ
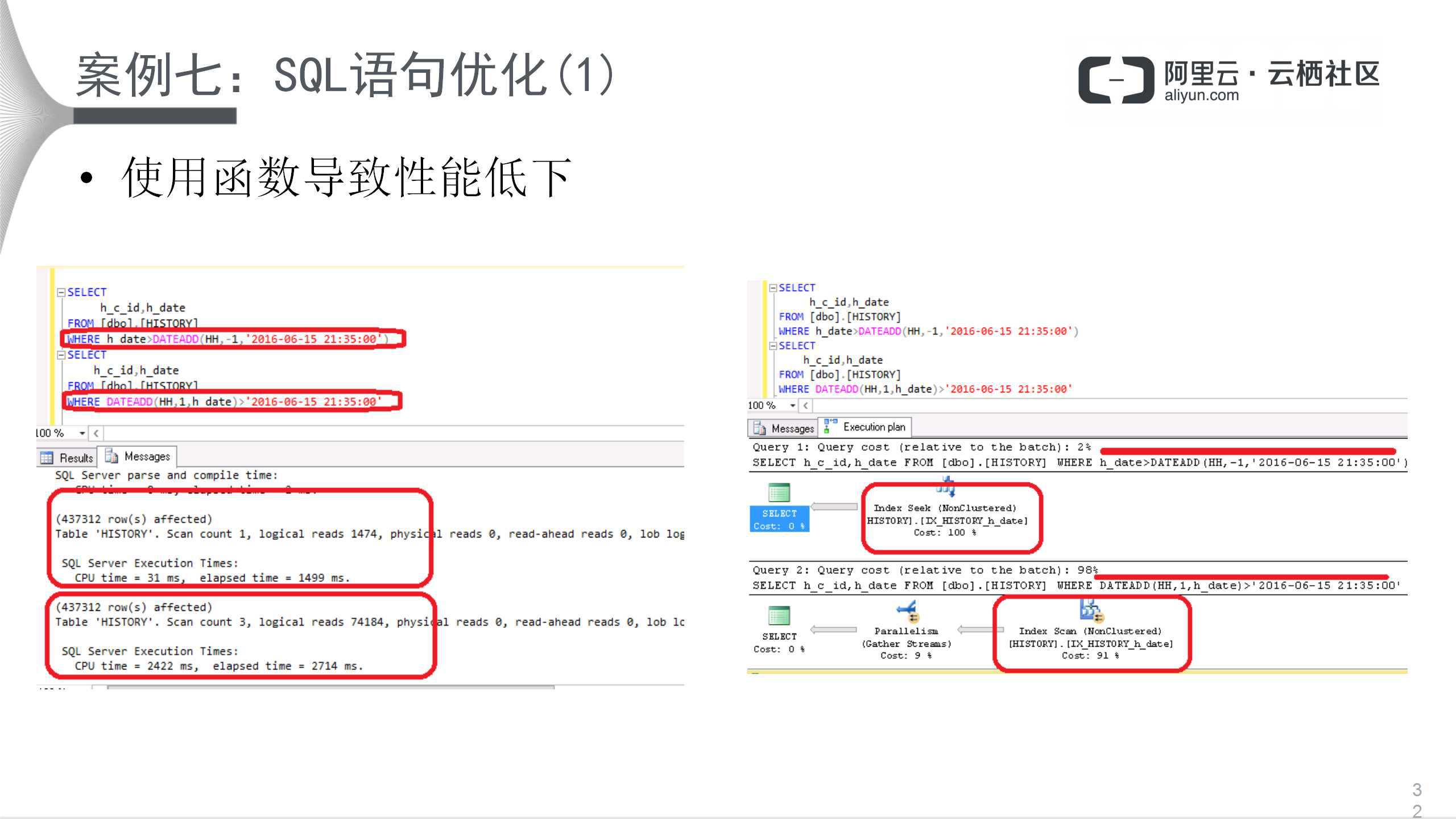
ЩЯУцЕФгяОфЪЧе§ШЗЕФаДЗЈЃЌЯТУцгяОфЪЧДэЮѓЕФЁЂЪЙгУКЏЪ§ЕФаДЗЈЁЃзѓЭМЯТЗНЃЌЪ§ОнСПЭЌбљЪЧ437312ЃЌЃЌжДаааЇТЪДѓЯрОЖЭЅЃЌЫЕУїЪЙгУКЏЪ§ЕФЮЃКІЗЧГЃДѓЃЛЭЌЪБПДвЛЯТгвБпЃЌКЭзѓБпЯрКєгІЃЌindex
seekКЭscanЛсЩЈУшИќЖрЕФТпМвГЃЌвђДЫЛсЯджјНЕЕЭадФмЃЌКмЖретжжЧщПіЖМПЩвдБмУтЁЃ

АИР§2НтЪЭСЫЕБWHEREЬѕМўЪЙгУСЫORСЌНгЃЌЩЯУцКЭЯТУцЕФгяОфжДааНсЙћвЛжТЃЌЕЋЪЧЩЈУшЕФУїЯдВЛвЛбљЃЌПЊЯњвВВЛвЛбљЃКЩЯУцЕФCPUЪЙгУСЫ9msзѓгвЃЌЯТУцЕФНгНќ200msЁЃгвБпЮЊжДааМЦЛЎЃЌКмУїЯдЃЌЪЙгУСЫORСЌНгЃЌжДааМЦЛЎвЊИДдгЕФЖрЃЌетвВЪЧадФмВювьЕФжївЊдвђЁЃ
ЯТЭМЪЧзмНсЕФЯрЙиНЈвщЃК

АИР§АЫЃКМмЙЙгХЛЏЕФбнНј
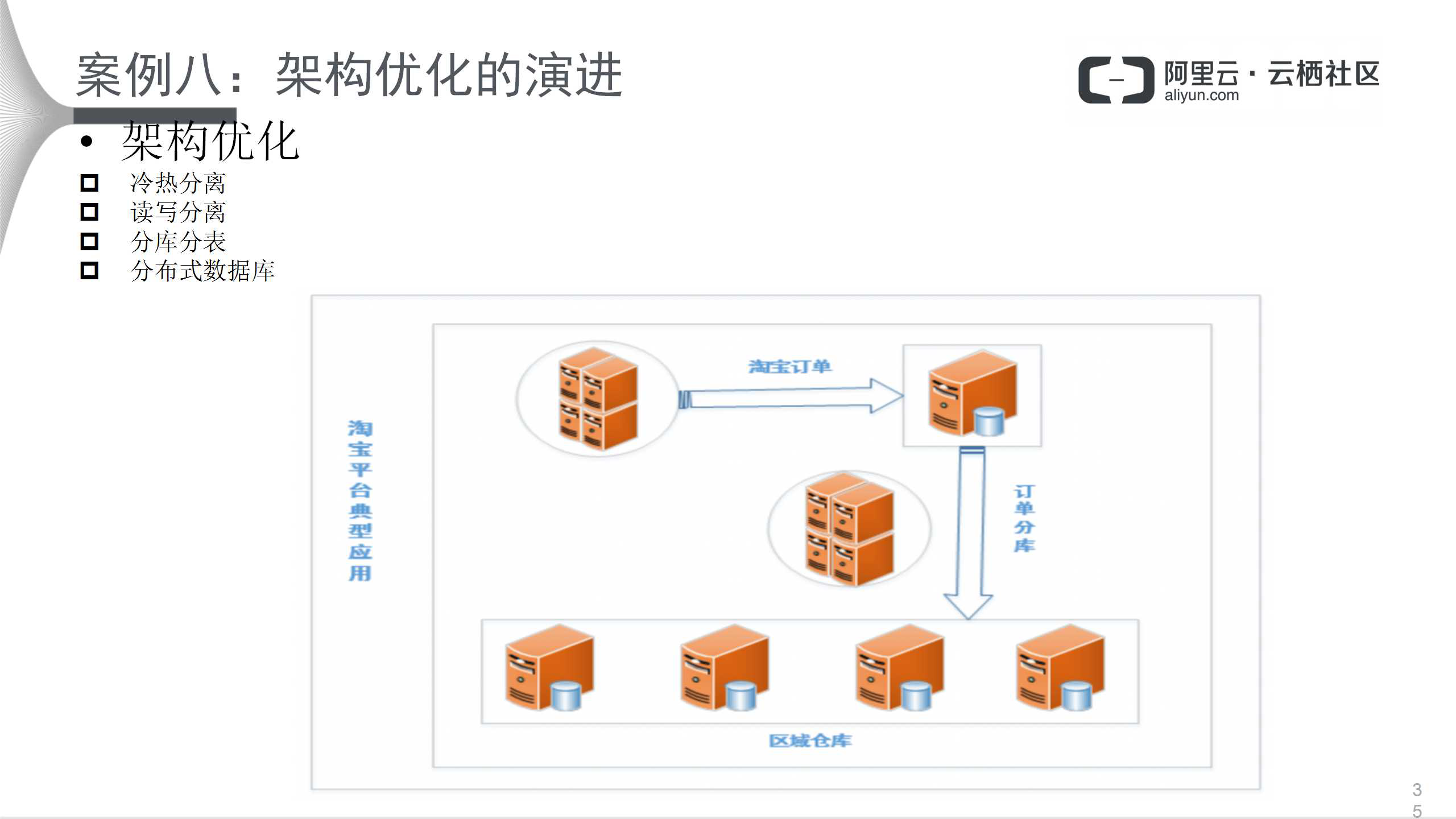
зюКѓПДвЛЯТМмЙЙЁЃЧАУцДгЪ§ОнПтЕФНЧЖШПМТЧЃЌШчЙћадФмУЛгаЬсЩ§ЃЌФЧОЭДгМмЙЙПМТЧЁЃМмЙЙгХЛЏЗНЪНгавдЯТМИжжЃК
РфШШЗжРыЁЃР§ШчЃЌвЛИіДѓБэЃЌПЩвдАбИїИіЪ§ОнБШШчЫЕШ§ИідТЪ§ОнЗХШыЕБЧАБэЃЌШ§ИідТжЎЭтЕФЪ§ОнЗХШыРњЪЗБэЃЌетбљПЩвдЯджјМѕЩйБэЕФДѓаЁЁЃ
ЖСаДЗжРыФмЙЛМѕЩйЖСКЭаДЕФбЙСІЁЃ
ЗжПтЗжБэПЩДгвЕЮёЩЯРДПДЃЌвВПЩДгЪ§ОнЩЯРДПДЁЃвЕЮёЩЯЃЌБШШчЫЕвЛИіЙКЮяСїГЬЃЌгаЖЉЕЅЯЕЭГЁЂгУЛЇаХЯЂЁЂжЭКѓаХЯЂЛЙгаВжПтХфЫЭЁЃФЧУДЃЌЯЕЭГГѕЪМНзЖЮЗХдквЛИіЭМЩЯЃЌЕБвЕЮёРЉДѓЃЌашвЊДгвЕЮёЩЯНЋЦфЗжПЊЃЌНЋвЕЮёЗХЕНВЛЭЌЕФВуДЮЩЯЃЌВЛЭЌЕФЪ§ОнПтЪЕР§ЩЯШЅЃЌДгЖјМѕаЁбЙСІЁЃШчЙћЛЙВЛЙЛЃЌОЭдйНјааРфШШЗжРыКЭЖСаДЗжРыЁЃ
ЗжВМЪНЪ§ОнПтЮЊЧАШ§ИіЕФбгЩьЃЌАбВЛЭЌЕФвЕЮёКЭЪ§ОнЗХЕНВЛЭЌЕФЪЕР§жаШЅЁЃ
ЩЯЭМЫљЪОЕФЬдБІЦНЬЈОЭЪЧЕфаЭЕФАИР§ЃЌМДвЕЮёМгЪ§ОнЕФЗжПтЗжБэЁЃЪЕМЪЩЯЃЌНЋВжПтЃЌГіПтЃЌШыПтЕФећИіСїГЬЗжХфЕНСЫВЛЭЌЕФЪЕР§ЃЌДгЖјМѕаЁбЙСІЃЌЯджјЬсИпЖЉЕЅЕФДІРэЁЃ | 








