| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌНщЩмСЫДцДЂЙ§ГЬдЫааСїГЬЃЌГЃгУЯЕЭГДцДЂЙ§ГЬЃЌДДНЈВЛДјВЮЪ§ДцДЂЙ§ГЬЃЌДјЭЈХфЗћВЮЪ§ДцДЂЙ§ГЬЕШжЊЪЖЁЃ
|
|
вЛ. ЪВУДЪЧДцДЂЙ§ГЬ
ЯЕЭГДцДЂЙ§ГЬЪЧЯЕЭГДДНЈЕФДцДЂЙ§ГЬЃЌФПЕФдкгкФмЙЛЗНБуЕФДгЯЕЭГБэжаВщбЏаХЯЂЛђЭъГЩгыИќаТЪ§ОнПтБэЯрЙиЕФЙмРэШЮЮёЛђЦфЫћЕФЯЕЭГЙмРэШЮЮёЁЃЯЕЭГДцДЂЙ§ГЬжївЊДцДЂдкmasterЪ§ОнПтжаЃЌвдЁАspЁБЯТЛЎЯпПЊЭЗЕФДцДЂЙ§ГЬЁЃОЁЙметаЉЯЕЭГДцДЂЙ§ГЬдкmasterЪ§ОнПтжаЃЌЕЋЮвУЧдкЦфЫћЪ§ОнПтЛЙЪЧПЩвдЕїгУЯЕЭГДцДЂЙ§ГЬЁЃгавЛаЉЯЕЭГДцДЂЙ§ГЬЛсдкДДНЈаТЕФЪ§ОнПтЕФЪБКђБЛздЖЏДДНЈдкЕБЧАЪ§ОнПтжаЁЃ
Жў. ДцДЂЙ§ГЬдЫааСїГЬ
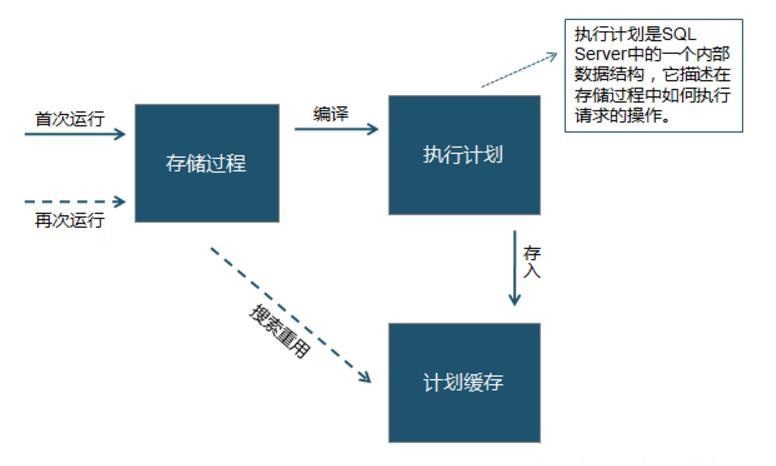
ДцДЂЙ§ГЬЪЧгЩвЛаЉSQLгяОфКЭПижЦгяОфзщГЩЕФБЛЗтзАЦ№РДЕФЙ§ГЬЃЌЫќзЄСєдкЪ§ОнПтжаЃЌПЩвдБЛПЭЛЇгІгУГЬађЕїгУЃЌвВПЩвдДгСэвЛИіЙ§ГЬЛђДЅЗЂЦїЕїгУЁЃЫќЕФВЮЪ§ПЩвдБЛДЋЕнКЭЗЕЛиЁЃгыгІгУГЬађжаЕФКЏЪ§Й§ГЬРрЫЦЃЌДцДЂЙ§ГЬПЩвдЭЈЙ§УћзжРДЕїгУЃЌЖјЧвЫќУЧЭЌбљгаЪфШыВЮЪ§КЭЪфГіВЮЪ§ЁЃ
ИљОнЗЕЛижЕРраЭЕФВЛЭЌЃЌЮвУЧПЩвдНЋДцДЂЙ§ГЬЗжЮЊШ§РрЃК
ЗЕЛиМЧТММЏЕФДцДЂЙ§ГЬЕФжДааНсЙћЪЧвЛИіМЧТММЏЃЌЕфаЭЕФР§згЪЧДгЪ§ОнПтжаМьЫїГіЗћКЯФГвЛИіЛђМИИіЬѕМўЕФМЧТМЃЛ
ЗЕЛиЪ§жЕЕФДцДЂЙ§ГЬжДааЭъвдКѓЗЕЛивЛИіжЕЃЌР§ШчдкЪ§ОнПтжажДаавЛИігаЗЕЛижЕЕФКЏЪ§ЛђУќСю;
ааЮЊДцДЂЙ§ГЬНіНіЪЧгУРДЪЕЯжЪ§ОнПтЕФФГИіЙІФмЃЌЖјУЛгаЗЕЛижЕЃЌР§ШчдкЪ§ОнПтжаЕФИќаТКЭЩОГ§ВйзїЁЃ
ИіШЫШЯЮЊЃЌДцДЂЙ§ГЬЫЕАзСЫОЭЪЧвЛЖб SQL ЕФКЯВЂЁЃжаМфМгСЫЕуТпМПижЦЁЃ
1.ЕЋЪЧДцДЂЙ§ГЬДІРэБШНЯИДдгЕФвЕЮёЪББШНЯЪЕгУЁЃБШШчЫЕЃЌ
вЛИіИДдгЕФЪ§ОнВйзїЁЃШчЙћФудкЧАЬЈДІРэЕФЛАЁЃПЩФмЛсЩцМАЕНЖрДЮЪ§ОнПтСЌНгЁЃЕЋШчЙћФугУДцДЂЙ§ГЬЕФЛАЁЃОЭжЛгавЛДЮЁЃДгЯьгІЪБМфЩЯРДЫЕгагХЪЦЁЃ
1.вВОЭЪЧЫЕДцДЂЙ§ГЬПЩвдИјЮвУЧДјРДдЫаааЇТЪЬсИпЕФКУДІЁЃ
СэЭтЃЌГЬађШнвзГіЯж BUG ВЛЮШЖЈЃЌЖјДцДЂЙ§ГЬЃЌжЛвЊЪ§ОнПтВЛГіЯжЮЪЬтЃЌЛљБОЩЯЪЧВЛЛсГіЯжЪВУДЮЪЬтЕФЁЃвВОЭЪЧЫЕДгАВШЋЩЯНВЃЌЪЙгУСЫДцДЂЙ§ГЬЕФЯЕЭГИќМгЮШЖЈЁЃ
ФЧУДЮЪЬтРДСЫЃЌЪВУДЪБКђВХПЩвдгУДцДЂЃПЖдгкЪ§ОнСПВЛЪЧКмДѓвдМАвЕЮёДІРэВЛЪЧКмИДдгЕФаЁЯюФПОЭЮоашвЊСЫУДЃП
Д№ЃКДэЁЃДцДЂЙ§ГЬВЛНіНіЪЪгУгкДѓаЭЯюФПЃЌЖдгкжааЁаЭЯюФПЃЌЪЙгУДцДЂЙ§ГЬвВЪЧЗЧГЃгаБивЊЕФЁЃЦфЭўСІКЭгХЪЦжївЊЬхЯждкЃК
1.ДцДЂЙ§ГЬжЛдкДДдьЪБНјааБрвыЃЌвдКѓУПДЮжДааДцДЂЙ§ГЬЖМВЛашдйжиаТБрвыЃЌЖјвЛАу
SQL гяОфУПжДаавЛДЮОЭБрвывЛДЮ,ЫљвдЪЙгУДцДЂЙ§ГЬПЩЬсИпЪ§ОнПтжДааЫйЖШЁЃ
2.ЕБЖдЪ§ОнПтНјааИДдгВйзїЪБ(ШчЖдЖрИіБэНјаа Update,Insert,Query,Delete
ЪБЃЉЃЌПЩНЋДЫИДдгВйзїгУДцДЂЙ§ГЬЗтзАЦ№РДгыЪ§ОнПтЬсЙЉЕФЪТЮёДІРэНсКЯвЛЦ№ЪЙгУЁЃетаЉВйзїЃЌШчЙћгУГЬађРДЭъГЩЃЌОЭБфГЩСЫвЛЬѕЬѕЕФ
SQL гяОфЃЌПЩФмвЊЖрДЮСЌНгЪ§ОнПтЁЃЖјЛЛГЩДцДЂЃЌжЛашвЊСЌНгвЛДЮЪ§ОнПтОЭПЩвдСЫЁЃ
3.ДцДЂЙ§ГЬПЩвджиИДЪЙгУ,ПЩМѕЩйЪ§ОнПтПЊЗЂШЫдБЕФЙЄзїСПЁЃ
4.АВШЋадИп,ПЩЩшЖЈжЛгаФГДЫгУЛЇВХОпгаЖджИЖЈДцДЂЙ§ГЬЕФЪЙгУШЈЁЃ
5.МѕЩйЭјТчЭЈаХСПЁЃЕїгУвЛИіааЪ§ВЛЖрЕФДцДЂЙ§ГЬгыжБНгЕїгУSQLгяОфЕФЭјТчЭЈаХСППЩФмВЛЛсгаКмДѓЕФВюБ№ЃЌПЩЪЧШчЙћДцДЂЙ§ГЬАќКЌЩЯАйааSQLгяОфЃЌФЧУДЦфадФмОјЖдБШвЛЬѕвЛЬѕЕФЕїгУSQLгяОфвЊИпЕУЖрЁЃ
6.жДааЫйЖШИќПьЁЃгаСНИідвђЃКЪзЯШЃЌдкДцДЂЙ§ГЬДДНЈЕФЪБКђЃЌЪ§ОнПтвбОЖдЦфНјааСЫвЛДЮНтЮіКЭгХЛЏЁЃЦфДЮЃЌДцДЂЙ§ГЬвЛЕЉжДааЃЌдкФкДцжаОЭЛсБЃСєвЛЗнетИіДцДЂЙ§ГЬЃЌетбљЯТДЮдйжДааЭЌбљЕФДцДЂЙ§ГЬЪБЃЌПЩвдДгФкДцжажБНгЕїгУЁЃ
7.ИќЧПЕФЪЪгІадЃКгЩгкДцДЂЙ§ГЬЖдЪ§ОнПтЕФЗУЮЪЪЧЭЈЙ§ДцДЂЙ§ГЬРДНјааЕФЃЌвђДЫЪ§ОнПтПЊЗЂШЫдБПЩвддкВЛИФЖЏДцДЂЙ§ГЬНгПкЕФЧщПіЯТЖдЪ§ОнПтНјааШЮКЮИФЖЏЃЌЖјетаЉИФЖЏВЛЛсЖдгІгУГЬађдьГЩгАЯьЁЃ
8.ВМЪНЙЄзїЃКгІгУГЬађКЭЪ§ОнПтЕФБрТыЙЄзїПЩвдЗжБ№ЖРСЂНјааЃЌЖјВЛЛсЯрЛЅбЙжЦЁЃ
ДцДЂЙ§ГЬЕФЪЙгУЃЌКУЯёвЛжБЪЧвЛИіељТлЁЃ
ЮвВЛЧуЯђгкОЁПЩФмЪЙгУДцДЂЙ§ГЬЃЌЪЧетУДШЯЮЊЕФЃК
1.дЫааЫйЖШЃК ДѓЖрЪ§ИпМЖЕФЪ§ОнПтЯЕЭГЖМгаstatement cacheЕФЃЌЫљвдБрвыsqlЕФЛЈЗбУЛЪВУДгАЯьЁЃЕЋЪЧжДааДцДЂЙ§ГЬвЊБШжБНгжДааsqlЛЈЗбИќЖрЃЈМьВщШЈЯоЕШЃЉЃЌЫљвдЖдгкКмМђЕЅЕФsqlЃЌДцДЂЙ§ГЬУЛгаЪВУДгХЪЦЁЃ
2.ЭјТчИККЩЃКШчЙћдкДцДЂЙ§ГЬжаУЛгаЖрДЮЪ§ОнНЛЛЅЃЌФЧУДЪЕМЪЩЯЭјТчДЋЪфСПКЭжБНгsqlЪЧвЛбљЕФЁЃ
3.ЭХЖгПЊЗЂЃККмвХКЖЃЌБШЦ№ГЩЪьЕФIDEЃЌУЛгаЪВУДКмКУДцДЂЙ§ГЬЕФIDEЙЄОпРДжЇГжЃЌвВОЭЪЧЫЕЃЌетаЉБиаыЪжЙЄЭъГЩЁЃ
4.АВШЋЛњжЦЃКЖдгкДЋЭГЕФC/SНсЙЙЃЌСЌНгЪ§ОнПтЕФгУЛЇПЩвдВЛЭЌЃЌЫљвдАВШЋЛњжЦгагУЃЛЕЋЪЧдкwebЕФШ§ВуМмЙЙжаЃЌЪ§ОнПтгУЛЇВЛЪЧИјгУЛЇгУЕФЃЌЫљвдЛљБОЩЯЃЌжЛгавЛИігУЛЇЃЌгЕгаЫљгаШЈЯоЃЈзюЖрЛЙгавЛИіПЊЗЂгУЛЇЃЉЁЃетИіЪБКђЃЌАВШЋЛњжЦгаЕуЖргрЁЃ
5.гУЛЇТњвтЃКЪЕМЪЩЯетИіжЛЪЧвЊНЋЗУЮЪЪ§ОнПтЕФНгПкЭГвЛЃЌЪЧгУДцДЂЙ§ГЬЃЌЛЙЪЧEJBЃЌУЛЬЋДѓЙиЯЕЃЌвВОЭЪЧЫЕЃЌдкШ§ВуНсЙЙжаЃЌЕЅЖРЩшМЦГівЛИіЪ§ОнЗУЮЪВуЃЌЭЌбљФмЪЕЯжетИіФПБъЁЃ
6.ПЊЗЂЕїЪдЃКвЛбљгЩгкIDEЕФЮЪЬтЃЌДцДЂЙ§ГЬЕФПЊЗЂЕїЪдвЊБШвЛАуГЬађРЇФбЃЈРЯАцБОDB2ЛЙжЛФмгУCаДДцДЂЙ§ГЬЃЌИќЪЧвЛИіджФбЃЉЁЃ
7.вЦжВадЃКЫуСЫЃЌетИіВЛгУЬсЃЌЗДе§вЛАуЕФгІгУзмЪЧАѓЖЈФГИіЪ§ОнПтЕФЃЌВЛШЛОЭЮоЗЈППгХЛЏЪ§ОнПтЗУЮЪРДЬсИпадФмСЫЁЃ
8.ЮЌЛЄадЃКЕФШЗЃЌДцДЂЙ§ГЬгааЉЪБКђБШГЬађШнвзЮЌЛЄЃЌетЪЧвђЮЊПЩвдЪЕЪБИќаТDBЖЫЕФДцДЂЙ§ГЬЃЌЕЋЪЧдк3ВуНсЙЙЯТЃЌИќаТserverЖЫЕФЪ§ОнЗУЮЪВувЛбљФмЪЕЯжетИіФПБъЃЌПЩЯЇЯждкКмЖрЦНЬЈВЛжЇГжЪЕЪБИќаТЖјвбЁЃ
ГЃгУЯЕЭГДцДЂЙ§ГЬгаЃК
exec sp_databases
; --ВщПДЪ§ОнПт
exec sp_tables ; --ВщПДБэ
exec sp_columns student ;--ВщПДСа
exec sp_helpIndex student ;--ВщПДЫїв§
exec sp_helpConstraint student ;--дМЪј
exec sp_stored_procedures;
exec sp_helptext 'sp_ stored_ procedures';--ВщПДДцДЂЙ§ГЬДДНЈЁЂЖЈвхгяОф
exec sp_rename student, stuInfo;--аоИФБэЁЂЫїв§ЁЂСаЕФУћГЦ
exec sp_renamedb myTempDB , myDB;--ИќИФЪ§ОнПтУћГЦ
exec sp_defaultdb 'master', 'myDB';--ИќИФЕЧТМУћЕФФЌШЯЪ§ОнПт
exec sp_helpdb;-- Ъ§ОнПтАяжњЃЌВщбЏЪ§ОнПтаХЯЂ
exec sp_helpdb master; |
ЯЕЭГДцДЂЙ§ГЬЪОР§:
--БэжиУќУћ
exec sp_rename 'stu', 'stud';
select * from stud;
--СажиУќУћ
exec sp_ rename 'stud.name', 'sName', 'column';
exec sp_ help 'stud';
--жиУќУћЫїв§
exec sp_ rename N'student.idx_ cid', N'idx_ cidd',
N'index';
exec sp_ help 'student';
--ВщбЏЫљгаДцДЂЙ§ГЬ
select * from sys.objects where type = 'P';
select * from sys.objects where type_ desc like
'%pro % ' and name like 'sp %'; |
гУЛЇздЖЈвхДцДЂЙ§ГЬ
create proc
| procedure pro_ name
[ {@ВЮЪ§Ъ§ОнРраЭ} [= ФЌШЯжЕ] [output],
{@ВЮЪ§Ъ§ОнРраЭ} [= ФЌШЯжЕ] [output],
....
]
as
SQL_ statements |
2ЁЂ ДДНЈВЛДјВЮЪ§ДцДЂЙ§ГЬ
--ДДНЈДцДЂЙ§ГЬ
if (exists (select * from sys.objects where name
= 'proc _ get_ student'))
drop proc proc_ get_ student
go
create proc proc_ get_ student
as
select * from student;
--ЕїгУЁЂжДааДцДЂЙ§ГЬ
exec proc_ get_ student; |
3ЁЂ аоИФДцДЂЙ§ГЬ
--аоИФДцДЂЙ§ГЬ
alter proc proc_get_student
as
select * from student; |
4ЁЂ ДјВЮДцДЂЙ§ГЬ
--ДјВЮДцДЂЙ§ГЬ
if (object_id ('proc_find_stu', 'P') is not null)
drop proc proc_find_stu
go
create proc proc_find_stu (@startId int, @endId
int)
as
select * from student where id between @startId
and @endId
go
exec proc_find_stu 2, 4; |
5ЁЂ ДјЭЈХфЗћВЮЪ§ДцДЂЙ§ГЬ
--ДјЭЈХфЗћВЮЪ§ДцДЂЙ§ГЬ
if (object_ id('proc_ findStudentByName', 'P')
is not null )
drop proc proc_findStudentByName
go
create proc proc_findStudentByName (@name varchar
(20) = '% j %', @nextName varchar (20) = '%')
as
select * from student where name like @name and
name like @nextName;
go
exec proc_ findStudentByName;
exec proc_ findStudentByName '%o%', 't%'; |
6ЁЂ ДјЪфГіВЮЪ§ДцДЂЙ§ГЬ
if (object_id('proc_getStudentRecord',
'P') is not null )
drop proc proc_getStudentRecord
go
create proc proc_getStudentRecord(
@ id int, --ФЌШЯЪфШыВЮЪ§
@name varchar(20) out, --ЪфГіВЮЪ§
@age varchar(20) output--ЪфШыЪфГіВЮЪ§
)
as
select @name = name, @age = age from student where
id = @id and sex = @age;
go
--
declare @id int,
@name varchar(20),
@temp varchar(20);
set @id = 7;
set @temp = 1;
exec proc_getStudentRecord @ id, @ name out, @
temp output ;
select @name, @temp;
print @name + '#' + @temp; |
7ЁЂ ВЛЛКДцДцДЂЙ§ГЬ
--WITH RECOMPILE
ВЛЛКДц
if (object_id('proc_temp', 'P') is not null)
drop proc proc_temp
go
create proc proc_temp
with recompile
as
select * from student;
go
exec proc_temp; |
8ЁЂ МгУмДцДЂЙ§ГЬ
--МгУмWITH ENCRYPTION
if (object_id ('proc_temp_encryption', 'P') is
not null )
drop proc proc_temp_ encryption
go
create proc proc_temp_ encryption
with encryption
as
select * from student;
go
exec proc_temp_encryption;
exec sp_helptext 'proc_temp';
exec sp_helptext 'proc_temp_ encryption'; |
9ЁЂ ДјгЮБъВЮЪ§ДцДЂЙ§ГЬ
if (object_id('proc_cursor',
'P') is not null)
drop proc proc_cursor
go
create proc proc_cursor
@cur cursor varying output
as
set @cur = cursor forward_only static for
select id, name, age from student;
open @cur;
go
--ЕїгУ
declare @exec_cur cursor;
declare @id int,
@name varchar(20),
@age int;
exec proc_cursor @cur = @exec_cur output;--ЕїгУДцДЂЙ§ГЬ
fetch next from @exec_cur into @id, @name, @age;
while (@@fetch_status = 0)
begin
fetch next from @exec_cur into @id, @name, @age;
print 'id: ' + convert(varchar, @id) + ', name:
' + @name + ', age: ' + convert(char, @age);
end
close @exec_cur;
deallocate @exec_cur;--ЩОГ§гЮБъ |
10ЁЂ ЗжвГДцДЂЙ§ГЬ
---ДцДЂЙ§ГЬЁЂrow_numberЭъГЩЗжвГ
if (object_id('pro_page', 'P') is not null)
drop proc proc_cursor
go
create proc pro_page
@startIndex int,
@endIndex int
as
select count(*) from product
;
select * from (
select row_number() over(order by pid) as rowId,
* from product
) temp
where temp.rowId between @startIndex and @endIndex
go
--drop proc pro_page
exec pro_page 1, 4
--
--ЗжвГДцДЂЙ§ГЬ
if (object_id('pro_page', 'P') is not null)
drop proc pro_stu
go
create procedure pro_stu(
@pageIndex int,
@pageSize int
)
as
declare @startRow int, @endRow int
set @startRow = (@pageIndex - 1) * @pageSize +1
set @endRow = @startRow + @pageSize -1
select * from (
select *, row_number() over (order by id asc)
as number from student
) t
where t.number between @startRow and @endRow;
exec pro_stu 2, 2; |
RaiserrorЗЕЛигУЛЇЖЈвхЕФДэЮѓаХЯЂЃЌПЩвджИЖЈбЯжиМЖБ№ЃЌЩшжУЯЕЭГБфСПМЧТМЫљЗЂЩњЕФДэЮѓЁЃ
Raiserror ({msg_id
| msg_str | @local_variable}
{, severity, state}
[,argument[,Ёn]]
[with option[,Ёn]]
) |
# msg_id:дкsysmessagesЯЕЭГБэжажИЖЈЕФгУЛЇЖЈвхДэЮѓаХЯЂ
# msg_str:гУЛЇЖЈвхЕФаХЯЂЃЌаХЯЂзюДѓГЄЖШдк2047ИізжЗћЁЃ
# severityЃКгУЛЇЖЈвхгыИУЯћЯЂЙиСЊЕФбЯжиМЖБ№ЁЃЕБЪЙгУmsg_idв§ЗЂЪЙгУsp_addmessageДДНЈЕФгУЛЇЖЈвхЯћЯЂЪБЃЌraiserrorЩЯжИЖЈбЯжиадНЋИВИЧsp_addmessageжаЖЈвхЕФбЯжиадЁЃ
ШЮКЮгУЛЇПЩвджИЖЈ0-18жБНгЕФбЯжиМЖБ№ЁЃжЛгаsysadminЙЬЖЈЗўЮёЦїНЧЩЋГЃгУЛђОпгаalter traceШЈЯоЕФгУЛЇВХФмжИЖЈ19-25жБНгЕФбЯжиМЖБ№ЁЃ19-25жЎМфЕФАВШЋМЖБ№ашвЊЪЙгУwith
logбЁЯюЁЃ
# stateЃКНщгк1жС127жБНгЕФШЮКЮећЪ§ЁЃStateФЌШЯжЕЪЧ1ЁЃ
raiserror ('is
error', 16, 1);
select * from sys. messages;
-- ЪЙгУsysmessages жаЖЈвхЕФЯћЯЂ
raiserror (33003, 16, 1);
raiserror (33006, 16, 1); |
|









