| БрМЭЦМі: |
| БОЮФРДздгкcsdn,КмЖрГѕбЇепШЯЮЊдкMongoDBжаеыЖдвЛЖдЖрНЈФЃЮЈвЛЕФЗНАИОЭЪЧдкИИЮФЕЕжаФкЧЖвЛИіЪ§зщзгЮФЕЕЃЌЕЋЪЧетЪЧВЛзМШЗЕФЁЃ |
|
Part 1
ЁАЮвгаЗсИЛЕФsqlЪЙгУОбщЃЌЕЋЪЧЮвЪЧИіMongoDBЕФГѕбЇепЁЃЮвгІИУШчКЮдкMongoDBжаеыЖдвЛЖдЖрЙиЯЕНјааНЈФЃЃПЁБетЪЧЮвБЛЮЪМАзюЖрЕФЮЪЬтжЎвЛЁЃ
ЮвУЛЗЈМђЕЅЕФИјГіД№АИЃЌвђЮЊетгаКмЖрЗНАИШЅЪЕЯжЁЃНгЯТРДЮвЛсНЬЕМФуШчКЮеыЖдвЛЖдЖрНјааНЈФЃЁЃ
етИіЛАЬтгаКмЖрФкШнашвЊЬжТлЃЌЮвЛсгУШ§ИіВПЗжНјааЫЕУїЁЃдкЕквЛВПЗжЃЌЮвЛсЬжТлеыЖдвЛЖдЖрЙиЯЕНЈФЃЕФШ§жжЛљДЁЗНАИЁЃдкЕкЖўВПЗжЮвНЋЛсИВИЧИќЖрИпМЖФкШнЃЌАќРЈЗДЗЖЪНЛЏКЭЫЋЯђв§гУЁЃдкзюКѓвЛВПЗжЃЌЮвНЋЛсЛиЙЫИїжжбЁдёЃЌВЂИјГізіОіЖЈЪБашвЊПМТЧЕФвђЫиЁЃ
КмЖрГѕбЇепШЯЮЊдкMongoDBжаеыЖдвЛЖдЖрНЈФЃЮЈвЛЕФЗНАИОЭЪЧдкИИЮФЕЕжаФкЧЖвЛИіЪ§зщзгЮФЕЕЃЌЕЋЪЧетЪЧВЛзМШЗЕФЁЃвђЮЊФуПЩвддкMongoDBФкЧЖвЛИіЮФЕЕВЛДњБэФуОЭБиаыетУДзіЁЃ
ЕБФуЩшМЦвЛИіMongoDBЪ§ОнПтНсЙЙЃЌФуашвЊЯШЮЪздМКвЛИідкЪЙгУЙиЯЕаЭЪ§ОнПтЪБВЛЛсПМТЧЕФЮЪЬтЃКетИіЙиЯЕжаМЏКЯЕФДѓаЁЪЧЪВУДбљЕФЙцФЃЃПФуашвЊвтЪЖЕНвЛЖдКмЩйЃЌвЛЖдаэЖрЃЌвЛЖдЗЧГЃЖрЃЌетаЉЯИЮЂЕФЧјБ№ЁЃВЛЭЌЕФЧщПіЯТФуЕФНЈФЃвВНЋВЛЭЌЁЃ
Basics: Modeling One-to-Few : вЛЖдКмЩй
еыЖдИіШЫашвЊБЃДцЖрИіЕижЗНјааНЈФЃЕФГЁОАЯТЪЙгУФкЧЖЮФЕЕЪЧКмКЯЪЪЃЌПЩвддкpersonЮФЕЕжаЧЖШыaddressesЪ§зщЮФЕЕЃК
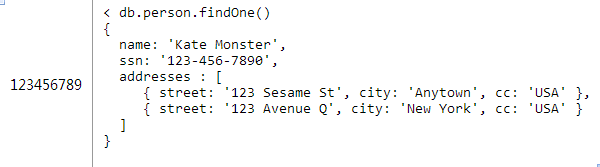
етжжЩшМЦОпгаФкЧЖЮФЕЕЩшМЦжаЫљгаЕФгХШБЕуЁЃзюжївЊЕФгХЕуОЭЪЧВЛашвЊЕЅЖРжДаавЛЬѕгяОфШЅЛёШЁФкЧЖЕФФкШнЁЃзюжївЊЕФШБЕуЪЧФуЮоЗЈАбетаЉФкЧЖЮФЕЕЕБзіЕЅЖРЕФЪЕЬхШЅЗУЮЪЁЃ
Р§ШчЃЌШчЙћФуЪЧдкЖдвЛИіШЮЮёИњзйЯЕЭГНјааНЈФЃЃЌУПИігУЛЇНЋЛсБЛЗжХфШєИЩИіШЮЮёЁЃФкЧЖетаЉШЮЮёЕНгУЛЇЮФЕЕдкгіЕНЁАВщбЏзђЬьЫљгаЕФШЮЮёЁБетбљЕФЮЪЬтЪБНЋЛсЗЧГЃРЇФбЁЃЮвЛсдкЯТвЛЦЊЮФеТеыЖдетИігУР§ЬсЙЉвЛаЉЪЪЕБЕФЩшМЦЁЃ
Basics: One-to-Many:вЛЖдаэЖр
вдВњЦЗСуМўЖЉЛѕЯЕЭГЮЊР§ЁЃУПИіЩЬЦЗгаЪ§АйИіПЩЬцЛЛЕФСуМўЃЌЕЋЪЧВЛЛсГЌЙ§Ъ§ЧЇИіЁЃетИігУР§КмЪЪКЯЪЙгУМфНгв§гУ---НЋСуМўЕФobjectidзїЮЊЪ§зщДцЗХдкЩЬЦЗЮФЕЕжа(дкетИіР§згжаЕФObjectIDЮвЪЙгУИќМгвзЖСЕФ2зжНкЃЌЯжЪЕЪРНчжаЫћУЧПЩФмЪЧгЩ12ИізжНкзщГЩЕФ)ЁЃ
УПИіСуМўЖМНЋгаЫћУЧздМКЕФЮФЕЕЖдЯѓ
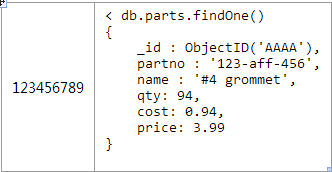
УПИіВњЦЗЕФЮФЕЕЖдЯѓжаpartsЪ§зщжаНЋЛсДцЗХЖрИіСуМўЕФObjectID ЃК

дкЛёШЁЬиЖЈВњЦЗжаЫљгаСуМўЃЌашвЊвЛИігІгУВуМЖБ№ЕФjoin
ЮЊСЫФмПьЫйЕФжДааВщбЏЃЌБиаыШЗБЃproducts.catalog_numberгаЫїв§ЁЃЕБШЛгЩгкСуМўжаparts._idвЛЖЈЪЧгаЫїв§ЕФЃЌЫљвдетвВЛсКмИпаЇЁЃ
етжжв§гУЕФЗНЪНЪЧЖдФкЧЖгХШБЕуЕФВЙГфЁЃУПИіСуМўЪЧИіЕЅЖРЕФЮФЕЕЃЌПЩвдКмШнвзЕФЖРСЂШЅЫбЫїКЭИќаТЫћУЧЁЃашвЊвЛЬѕЕЅЖРЕФгяОфШЅЛёШЁСуМўЕФОпЬхФкШнЪЧЪЙгУетжжНЈФЃЗНЪНашвЊПМТЧЕФвЛИіЮЪЬтЃЈЧызаЯИЫМПМетИіЮЪЬтЃЌдкЕкЖўеТЗДЗДЗЖЪНЛЏжаЃЌЮвУЧЛЙЛсЬжТлетИіЮЪЬтЃЉ
етжжНЈФЃЗНЪНжаЕФСуМўВПЗжПЩвдБЛЖрИіВњЦЗЪЙгУЃЌЫљвддкЖрЖдЖрЪБВЛашвЊвЛеХЕЅЖРЕФСЌНгБэЁЃ
Basics: One-to-Squillions: вЛЖдЗЧГЃЖр
ЮвУЧгУвЛИіЪеМЏИїжжЛњЦїШежОЕФР§згРДЬжТлвЛЖдЗЧГЃЖрЕФЮЪЬтЁЃгЩгкУПИіmongodbЕФЮФЕЕга16MЕФДѓаЁЯожЦЃЌЫљвдМДЪЙФуЪЧДцДЂObjectIDвВЪЧВЛЙЛЕФЁЃЮвУЧПЩвдЪЙгУКмОЕфЕФДІРэЗНЗЈЁАИИМЖв§гУЁБ---гУвЛИіЮФЕЕДцДЂжїЛњЃЌдкУПИіШежОЮФЕЕжаБЃДцетИіжїЛњЕФObjectIDЁЃ
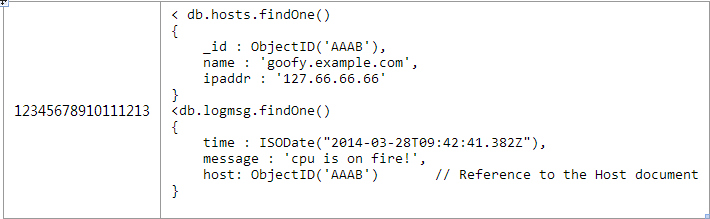
вдЯТЪЧИіКЭЕкЖўжаЗНАИЩдЮЂВЛЭЌЕФгІгУМЖБ№ЕФjoinгУРДВщеввЛЬЈжїЛњзюНќ5000ЬѕЕФШежОаХЯЂ

ЫљвдЃЌМДЪЙетжжМђЕЅЕФЬжТлвВгаФмВьОѕГіmongobdЕФНЈФЃКЭЙиЯЕФЃаЭНЈФЃЕФВЛЭЌжЎДІЁЃФуБиаывЊзЂвтвЛЯТСНИівђЫиЃК
1.вЛЖдЖржаЕФЖрЪЧЗёашвЊвЛИіЕЅЖРЕФЪЕЬхЁЃ
2.етИіЙиЯЕжаМЏКЯЕФЙцФЃЪЧвЛЖдКмЩйЃЌКмЖрЃЌЛЙЪЧЗЧГЃЖрЁЃ
ЛљгквдЩЯвђЫиРДОіЖЈВЩШЁвЛЯТШ§жжНЈФЃЕФЗНЪН
1.вЛЖдКмЩйЧвВЛашвЊЕЅЖРЗУЮЪФкЧЖФкШнЕФЧщПіЯТПЩвдЪЙгУФкЧЖЖрЕФвЛЗНЁЃ
2.вЛЖдЖрЧвЖрЕФвЛЖЫФкШнвђЮЊИїжжРэгЩашвЊЕЅЖРДцдкЕФЧщПіЯТПЩвдЭЈЙ§Ъ§зщЕФЗНЪНв§гУЖрЕФвЛЗНЕФЁЃ
3.вЛЖдЗЧГЃЖрЕФЧщПіЯТЃЌЧыНЋвЛЕФФЧЖЫв§гУЧЖШыНјЖрЕФвЛЖЫЖдЯѓжаЁЃ
ЯТвЛДЮЮвУЧНЋЛсПДЕНШчКЮЪЙгУЫЋЯђЙиЯЕКЭЗДЗЖЪНЛЏШЅЬсЩ§вдЩЯШ§жжЛљБОЗНАИЕФадФмЁЃ
Part 2
дкЩЯвЛЦЊЮФеТжаЮвНщЩмСЫШ§жжЛљБОЕФЩшМЦЗНАИЃКФкЧЖЃЌзгв§гУЃЌИИв§гУЃЌЭЌЪБЫЕУїСЫдкбЁдёЗНАИЪБашвЊПМТЧЕФСНИіЙиМќвђЫиЁЃ
вЛЖдЖржаЕФЖрЪЧЗёашвЊвЛИіЕЅЖРЕФЪЕЬхЁЃ
етИіЙиЯЕжаМЏКЯЕФЙцФЃЪЧвЛЖдКмЩйЃЌКмЖрЃЌЛЙЪЧЗЧГЃЖрЁЃ
дкеЦЮеСЫвдЩЯЛљДЁММЪѕКѓЃЌЮвНЋЛсНщЩмИќЮЊИпМЖЕФжїЬтЃКЫЋЯђЙиСЊКЭЗДЗЖЪНЛЏЁЃ
ЫЋЯђЙиСЊ
ШчЙћФуЯыШУФуЕФЩшМЦИќПсЃЌФуПЩвдШУв§гУЕФЁАoneЁБЖЫКЭЁАmanyЁБЖЫЭЌЪББЃДцЖдЗНЕФв§гУЁЃ
вдЩЯвЛЦЊЮФеТЬжТлЙ§ЕФШЮЮёИњзйЯЕЭГЮЊР§ЁЃгаpersonКЭtaskСНИіМЏКЯЃЌone-to-nЕФЙиЯЕЪЧДгpersonЖЫЕНtaskЖЫЁЃдкашвЊЛёШЁpersonЫљгаЕФtaskетИіГЁОАЯТашвЊдкpersonетИіЖдЯѓжаБЃДцгаtaskЕФidЪ§зщЃЌШчЯТУцДњТыЫљЪОЁЃ
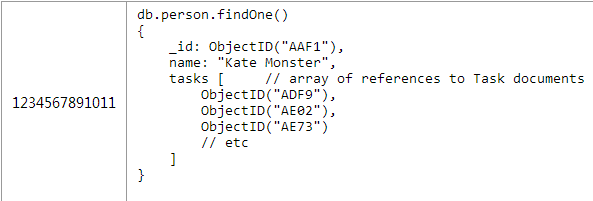
дкФГаЉГЁОАжаетИігІгУашвЊЯдЪОШЮЮёЕФСаБэЃЈР§ШчЯдЪОвЛИіЖрШЫазїЯюФПжаЫљгаЕФШЮЮёЃЉЃЌЮЊСЫФмЙЛПьЫйЕФЛёШЁФГИігУЛЇИКд№ЕФЯюФППЩвддкtaskЖдЯѓжаЧЖШыИНМгЕФpersonв§гУЙиЯЕЁЃ
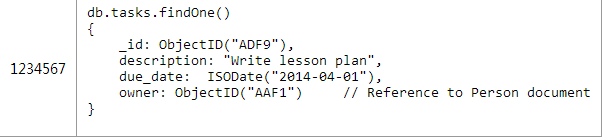
етИіЗНАИОпгаЫљгаЕФвЛЖдЖрЗНАИЕФгХШБЕуЃЌЕЋЪЧЭЈЙ§ЬэМгИНМгЕФв§гУЙиЯЕЁЃдкtaskЮФЕЕЖдЯѓжаЬэМгЖюЭтЕФЁАownerЁБв§гУПЩвдКмПьЕФевЕНФГИіtaskЕФЫљгаепЃЌЕЋЪЧШчЙћЯыНЋвЛИіtaskЗжХфИјЦфЫћpersonОЭашвЊИќаТв§гУжаЕФpersonКЭtaskетСНИіЖдЯѓЃЈЪьЯЄЙиЯЕЪ§ОнПтЕФЭЏаЌЛсЗЂЯжетбљОЭУЛЗЈБЃжЄВйзїЕФдзгадЁЃЕБШЛЃЌетЖдШЮЮёИњзйЯЕЭГРДЫЕВЂУЛгаЪВУДЮЪЬтЃЌЕЋЪЧФуБиаыПМТЧФуЕФгУР§ЪЧЗёФмЙЛШнШЬЃЉ
дквЛЖдЖрЙиЯЕжагІгУЗДЗЖЪН
дкФуЕФЩшМЦжаМгШыЗДЗЖЪНЃЌПЩвдЪЙФуБмУтгІгУВуМЖБ№ЕФjoinЖСШЁЃЌЕБШЛЃЌДњМлЪЧетвВЛсШУФудкИќаТЪЧашвЊВйзїИќЖрЪ§ОнЁЃЯТУцЮвЛсОйИіР§згРДНјааЫЕУї
ЗДЗЖЪНMany -< One
вдВњЦЗКЭСуМўЮЊР§ЃЌФуПЩвддкpartsЪ§зщжаШпгрДцДЂСуМўЕФУћзжЁЃвдЯТЪЧУЛгаМгШыЗДЗЖЪНЩшМЦЕФНсЙЙЁЃ

ЗДЗЖЪНЛЏвтЮЖзХФуВЛашвЊжДаавЛИігІгУВуМЖБ№ЕФjoinШЅЯдЪОвЛИіВњЦЗЫљгаЕФСуМўУћзжЃЌЕБШЛШчЙћФуЭЌЪБЛЙашвЊЦфЫћСуМўаХЯЂФЧетИігІгУВуЕФjoinЪЧБмУтВЛСЫЕФЁЃ

дкЪЙЕУЛёШЁСуМўУћзжМђЕЅЕФЭЌЪБЃЌжДаавЛИігІгУВуМЖБ№ЕФjoinЛсКЭжЎЧАЕФДњТыгааЉЧјБ№ЃЌОпЬхШчЯТЃК

ЗДЗЖЪНЛЏдкНкЪЁФуЖСЕФДњМлЕФЭЌЪБЛсДјРДИќаТЕФДњМлЃКШчЙћФуНЋСуМўЕФУћзжШпгрЕНВњЦЗЕФЮФЕЕЖдЯѓжаЃЌФЧУДФуЯыИќИФФГИіСуМўЕФУћзжФуОЭБиаыЭЌЪБИќаТЫљгаАќКЌетИіСуМўЕФВњЦЗЖдЯѓЁЃ
дквЛИіЖСБШаДЦЕТЪИпЕФЖрЕФЯЕЭГРяЃЌЗДЗЖЪНЪЧгаЪЙгУЕФвтвхЕФЁЃШчЙћФуКмОГЃЕФашвЊИпаЇЕФЖСШЁШпгрЕФЪ§ОнЃЌЕЋЪЧМИКѕВЛШЅБфИќЫћdЛАЃЌФЧУДИЖГіИќаТЩЯЕФДњМлЛЙЪЧжЕЕУЕФЁЃИќаТЕФЦЕТЪдНИпЃЌетжжЩшМЦЗНАИЕФДјРДЕФКУДІдНЩйЁЃ
Р§ШчЃКМйЩшСуМўЕФУћзжБфЛЏЕФЦЕТЪКмЕЭЃЌЕЋЪЧСуМўЕФПтДцБфЛЏКмЦЕЗБЃЌФЧУДФуПЩвдШпгрСуМўЕФУћзжЕНВњЦЗЖдЯѓжаЃЌЕЋЪЧБ№ШпгрСуМўЕФПтДцЁЃ
ашвЊзЂвтЕФЪЧЃЌвЛЕЉФуШпгрСЫвЛИізжЖЮЃЌФЧУДЖдгкетИізжЖЮЕФИќаТНЋВЛдкЪЧдзгЕФЁЃКЭЩЯУцЫЋЯђв§гУЕФР§згвЛбљЃЌШчЙћФудкСуМўЖдЯѓжаИќаТСЫСуМўЕФУћзжЃЌФЧУДИќаТВњЦЗЖдЯѓжаБЃДцЕФУћзжзжЖЮЧАНЋЛсДцдкЖЬЪБМфЕФВЛвЛжТЁЃ
ЗДЗЖЪНOne -< Many
ФувВПЩвдШпгрoneЖЫЕФЪ§ОнЕНmanyЖЫЃК
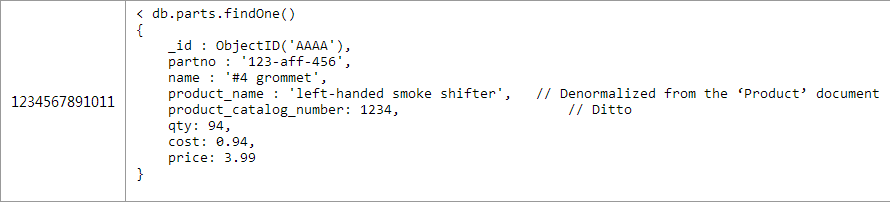
ШчЙћФуШпгрВњЦЗЕФУћзжЕНСуМўБэжаЃЌФЧУДвЛЕЉИќаТВњЦЗЕФУћзжОЭБиаыИќаТЫљгаКЭетИіВњЦЗгаЙиЕФСуМўЃЌетБШЦ№жЛИќаТвЛИіВњЦЗЖдЯѓРДЫЕДњМлУїЯдИќДѓЁЃетжжЧщПіЯТЃЌИќгІИУЩїжиЕФПМТЧЖСаДЦЕТЪЁЃ
дквЛЖдКмЖрЕФЙиЯЕжагІгУЗДЗЖЪН
дкШежОЯЕЭГетИівЛЖдаэЖрЕФР§згжавВПЩвдгІгУЗДЗЖЪНЛЏЕФММЪѕЁЃФуПЩвдНЋoneЖЫЃЈжїЛњЖдЯѓЃЉШпгрЕНШежОЖдЯѓжаЃЌЛђепЗДжЎЁЃ
ЯТУцЕФР§згНЋжїЛњжаЕФIPЕижЗШпгрЕНШежОЖдЯѓжаЁЃ
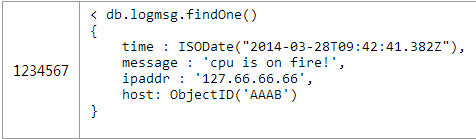
ШчЙћЯыЛёШЁзюНќФГИіipЕижЗЕФШежОаХЯЂОЭБфЕФКмМђЕЅЃЌжЛашвЊвЛЬѕгяОфЖјВЛЪЧжЎЧАЕФСНЬѕОЭФмЭъГЩЁЃ

ЪТЪЕЩЯЃЌШчЙћoneЖЫжЛгаЩйСПЕФаХЯЂДцДЂЃЌФуЩѕжСПЩвдШЋВПШпгрДцДЂЕНЖрЖЫЩЯЃЌКЯВЂСНИіЖдЯѓЁЃ
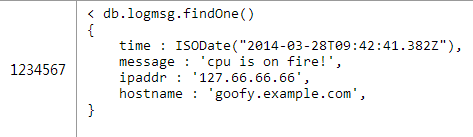
СэвЛЗНУцЃЌвВПЩвдШпгрЪ§ОнЕНoneЖЫЁЃБШШчЫЕФуЯыдкжїЛњЮФЕЕжаБЃДцзюНќЕФ1000ЬѕШежОЃЌПЩвдЪЙгУMongoDB
2.4жааТМгШыЕФ$eache/$sliceЙІФмРДБЃжЄlistгаађЖјЧвжЛБЃДц1000ЬѕЁЃ
ШежОЖдЯѓБЃДцдкlogmsgМЏКЯжаЃЌЭЌЪБШпгрЕНhostsЖдЯѓжаЁЃетбљМДЪЙhostsЖдЯѓжаГЌЙ§1000ЬѕЕФЪ§ОнвВВЛЛсЕМжТШежОЖдЯѓЖЊЪЇЁЃ
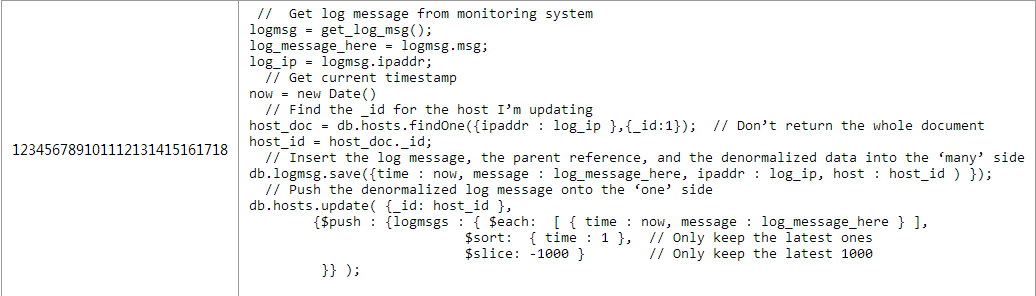
ЭЈЙ§дкВщбЏжаЪЙгУЭЖгАВЮЪ§ ЃЈРрЫЦ{_id:1}ЃЉЕФЗНЪНдкВЛашвЊЪЙгУlogmsgsЪ§зщЕФЧщПіЯТБмУтЛёШЁећИіmongodbЖдЯѓЃЌ1000ИіШежОаХЯЂДјРДЕФЭјТчПЊЯњЪЧКмДѓЕФЁЃ
дквЛЖдЖрЕФЧщПіЯТЃЌашвЊЩїжиЕФПМТЧЖСКЭИќаТЕФЦЕТЪЁЃШпгрШежОаХЯЂЕНжїЛњЮФЕЕЖдЯѓжажЛгадкШежОЖдЯѓМИКѕВЛЛсЗЂЩњИќаТЕФЧщПіЯТВХЪЧИіКУЕФОіЖЈЁЃ
змНс
дкетЦЊЮФеТРяЃЌЮвНщЩмСЫЖдШ§жжЛљДЁЗНАИЃКФкЧЖЮФЕЕЃЌзгв§гУЃЌИИв§гУЕФВЙГфбЁдёЁЃ
ЪЙгУЫЋЯђв§гУРДгХЛЏФуЕФЪ§ОнПтМмЙЙЃЌЧАЬсЪЧФуФмНгЪмЮоЗЈдзгИќаТЕФДњМлЁЃ
ПЩвддкв§гУЙиЯЕжаШпгрЪ§ОнЕНoneЖЫЛђепNЖЫЁЃ
дкОіЖЈЪЧЗёВЩгУЗДЗЖЪНЛЏЪБашвЊПМТЧЯТУцЕФвђЫиЃК
ФуНЋЮоЗЈЖдШпгрЕФЪ§ОнНјаадзгИќаТЁЃ
жЛгаЖСаДБШНЯИпЕФЧщПіЯТВХгІИУВЩШЁЗДЗЖЪНЛЏЕФЩшМЦЁЃ
ЯТДЮЃЌЮвНЋЛсИцЫпФудкУцЖдетаЉЗНАИЪБИУШчКЮОёдёЁЃ
Part 3
етЦЊЮФеТЪЧЯЕСаЕФзюКѓвЛЦЊЁЃдкЕквЛЦЊЮФеТРяЃЌЮвНщЩмСЫШ§жжеыЖдЁАвЛЖдЖр ЁБЙиЯЕНЈФЃЕФЛљДЁЗНАИЁЃдкЕкЖўЦЊЮФеТжаЃЌЮвНщЩмСЫЖдЛљДЁЗНАИЕФРЉеЙЃКЫЋЯђЙиСЊКЭЗДЗЖЪНЛЏЁЃ
ЗДЗЖЪНПЩвдШУФуБмУтвЛаЉгІгУВуМЖБ№ЕФjoinЃЌЕЋЪЧетвВЛсШУИќаТБфЕФИќИДдгЃЌПЊЯњИќДѓЁЃВЛЙ§ШпгрФЧаЉЖСШЁЦЕТЪдЖдЖДѓгкИќаТЦЕТЪЕФзжЖЮЛЙЪЧжЕЕУЕФЁЃ
ШчЙћФуЛЙУЛгаЖСЙ§ЧАСНЦЊЮФеТЃЌЛЖгвЛРРЁЃ
ШУЮвУЧЛиЙЫЯТетаЉЗНАИ
ФуПЩвдВЩШЁФкЧЖЃЌЛђепНЈСЂoneЖЫЛђепNЖЫЕФв§гУЃЌвВПЩвдШ§епМцЖјгажЎЁЃ
ФуПЩвддкoneЖЫЛђепNЖЫШпгрЖрИізжЖЮ
ЯТУцетаЉЪЧФуашвЊНїМЧЕФЃК
1ЁЂгХЯШПМТЧФкЧЖЃЌГ§ЗЧгаЪВУДЦШВЛЕУвбЕФдвђЁЃ
2ЁЂашвЊЕЅЖРЗУЮЪвЛИіЖдЯѓЃЌФЧетИіЖдЯѓОЭВЛЪЪКЯБЛФкЧЖЕНЦфЫћЖдЯѓжаЁЃ
3ЁЂЪ§зщВЛгІИУЮоЯожЦдіГЄЁЃШчЙћmanyЖЫгаЪ§АйИіЮФЕЕЖдЯѓОЭВЛвЊШЅФкЧЖЫћУЧПЩвдВЩгУв§гУObjectIDЕФЗНАИЃЛШчЙћгаЪ§ЧЇИіЮФЕЕЖдЯѓЃЌФЧУДОЭВЛвЊФкЧЖObjectIDЕФЪ§зщЁЃИУВЩШЁФФаЉЗНАИШЁОігкЪ§зщЕФДѓаЁЁЃ
4ЁЂВЛвЊКІХТгІгУВуМЖБ№ЕФjoinЃКШчЙћЫїв§НЈЕФе§ШЗВЂЧвЭЈЙ§ЭЖгАЬѕМўЃЈЕкЖўеТЬсМАЃЉЯожЦЗЕЛиЕФНсЙћЃЌФЧУДгІгУВуМЖБ№ЕФjoinВЂВЛЛсБШЙиЯЕЪ§ОнПтжаjoinПЊЯњДѓЖрЩйЁЃ
5ЁЂдкНјааЗДЗЖЪНЩшМЦЪБЧыЯШШЗШЯЖСаДБШЁЃвЛИіМИКѕВЛИќИФжЛЪЧЖСШЁЕФзжЖЮВХЪЪКЯШпгрЕНЦфЫћЖдЯѓжаЁЃ
6ЁЂдкMongoDBжаШчКЮЖдФуЕФЪ§ОнНЈФЃЃЌШЁОігкФуЕФгІгУГЬађШчКЮШЅЗУЮЪЫќУЧЁЃЪ§ОнЕФНсЙЙвЊШЅЪЪгІФуЕФГЬађЕФЖСаДГЁОАЁЃ
ЩшМЦжИФЯ
ЕБФудкMongoDBжаЖдЁАвЛЖдЖрЁБЙиЯЕНјааНЈФЃЃЌФугаКмЖрЕФЗНАИПЩЙЉбЁдёЃЌЫљвдФуБиаыКмНїЩїЕФШЅПМТЧЪ§ОнЕФНсЙЙЁЃЯТУцетаЉЮЪЬтЪЧФуБиаыШЯецЫМПМЕФЃК
ЙиЯЕжаМЏКЯЕФЙцФЃгаЖрДѓЃКЪЧвЛЖдКмЩйЃЌКмЖрЃЌЛЙЪЧЗЧГЃЖрЃП
ЖдгквЛЖдЖржаЁБЖрЁАЕФФЧвЛЖЫЃЌЪЧЗёашвЊЕЅЖРЕФЗУЮЪЫќУЧЃЌЛЙЪЧЫЕЫќУЧжЛЛсдкИИЖдЯѓЕФЩЯЯТЮФжаБЛЗУЮЪЁЃ
БЛШпгрЕФзжЖЮЕФЖСаДЕФБШР§ЪЧЖрЩйЃП
Ъ§ОнНЈФЃЩшМЦжИФЯ
дквЛЖдКмЩйЕФЧщПіЯТЃЌФуПЩвддкИИЮФЕЕжаФкЧЖЪ§зщЁЃ
дквЛЖдКмЖрЛђепашвЊЕЅЖРЗУЮЪЁАNЁБЖЫЕФЪ§ОнЪБЃЌФуПЩвдВЩгУЪ§зщв§гУObjectIDЕФЗНЪНЁЃШчЙћПЩвдМгЫйФуЕФЗУЮЪвВПЩвддкЁАNЁБЖЫЪЙгУИИв§гУЁЃ
дквЛЖдЗЧГЃЖрЕФЧщПіЯТЃЌПЩвддкЁАNЁБЖЫЪЙгУИИв§гУЁЃ
ШчЙћФуДђЫудкФуЕФЩшМЦжав§ШыШпгрЕШЗДЗЖЪНЩшМЦЃЌФЧУДФуБиаыШЗБЃФЧаЉШпгрЕФЪ§ОнЖСШЁЕФЦЕТЪдЖдЖДѓгкИќаТЕФЦЕТЪЁЃЖјЧвФувВВЛашвЊКмЧПЕФвЛжТадЁЃвђЮЊЗДЗЖЪНЛЏЕФЩшМЦЛсШУФудкИќаТШпгрзжЖЮЪБИЖГівЛЖЈЕФДњМлЃЈИќТ§ЃЌЗЧдзгЛЏЃЉ | 








