| БрМЭЦМі: |
| БОЮФРДздгкRicky
Ho,ЮФеТжаШЗЪЕЖдMongoDBгЩФкжСЭтЕФМмЙЙНјааСЫЦЪЮіЁЃ |
|
БОЮФНиШЁСЫЦфЮФеТжаЕФМИеХжиЕуМмЙЙЪОвтЭМЦЌНјааМђЕЅУшЪіЁЃЯЃЭћЖдДѓМвгагУЁЃ
MongoDBЪ§ОнЮФМўФкВПНсЙЙ
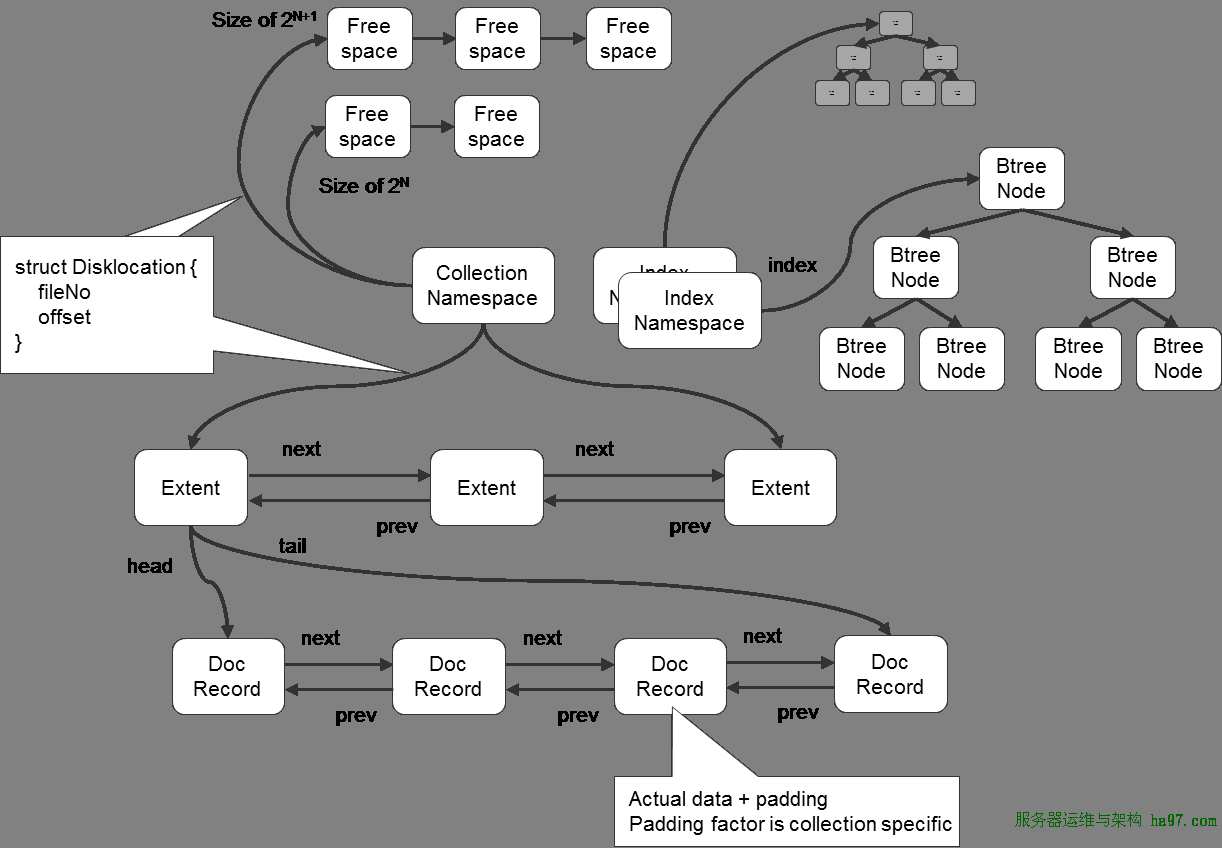
MongoDBдкЪ§ОнДцДЂЩЯАДУќУћПеМфРДЛЎЗжЃЌвЛИіcollectionЪЧвЛИіУќУћПеМфЃЌвЛИіЫїв§вВЪЧвЛИіУќУћПеМф
ЭЌвЛИіУќУћПеМфЕФЪ§ОнБЛЗжГЩКмЖрИіExtentЃЌExtentжЎМфЪЙгУЫЋЯђСДБэСЌНг
дкУПвЛИіExtentжаЃЌБЃДцСЫОпЬхУПвЛааЕФЪ§ОнЃЌетаЉЪ§ОнвВЪЧЭЈЙ§ЫЋЯђСДНгСЌНгЕФ
УПвЛааЪ§ОнДцДЂПеМфВЛНіАќРЈЪ§ОнеМгУПеМфЃЌЛЙПЩФмАќКЌвЛВПЗжИНМгПеМфЃЌетЪЙЕУдкЪ§ОнupdateБфДѓКѓПЩвдВЛвЦЖЏЮЛжУ
Ыїв§вдBTreeНсЙЙЪЕЯж
ЯрЙидФЖСЃКЁЖMongoDBЪ§ОнЮФМўФкВПНсЙЙЁЗ
дкMongoDBжаЪЕЯжЪТЮё
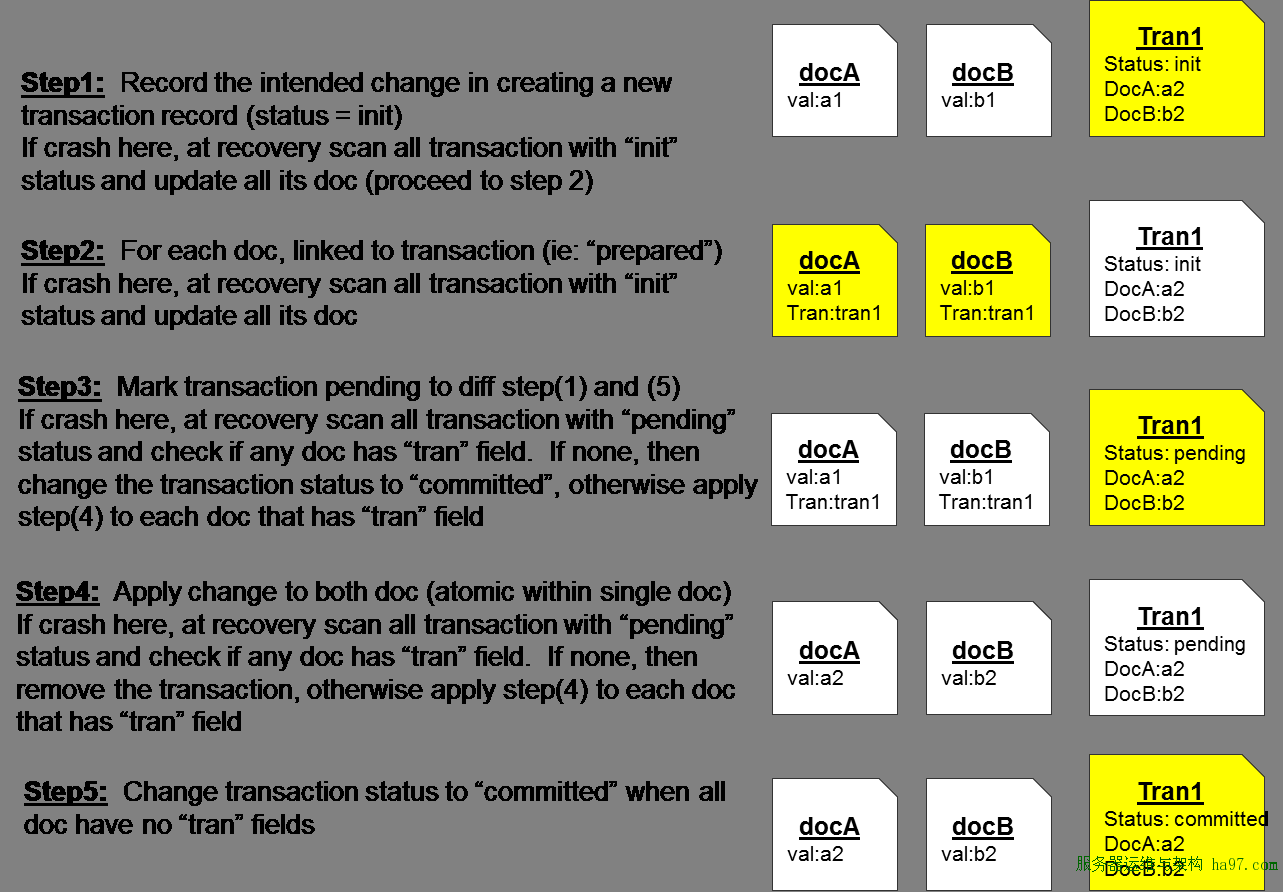
жкЫљжмжЊЃЌMongoDBжЛжЇГжЖдЕЅааМЧТМЕФдзгадаоИФЃЌВЂВЛжЇГжЖдЖрааЪ§ОнЕФдзгВйзїЁЃЕЋЪЧЭЈЙ§ЩЯЭМжаЕФБфЬЌВйзїЃЌЪЕМЪФувВПЩвдздМКЪЕЯжЪТЮёЁЃЦфВНжшШчЭМЫљЮДЃК
Ек1ВНЃКЯШМЧТМвЛЬѕЪТЮёМЧТМЃЌНЋвЊаоИФЕФЖрааМЧТМЕФаоИФжЕаДЕНРяУцЃЌВЂЩшжУЦфзДЬЌЮЊinitЃЈШчЙћетЪБКђВйзїжаЖЯЃЌФЧУДдкжиаТЦєЖЏЪБЃЌЛсХаЖЯЕНЫћДІгкinitзДЬЌЃЌДгЖјНЋЦфБЃДцЕФЖраааоИФВйзїгІгУЕНОпЬхЕФааЩЯЃЉ
Ек2ВНЃКШЛКѓИќаТОпЬхвЊаоИФЕФааЃЌНЋИеВХаДЕФЪТЮёМЧТМЕФБъЪЖаДЕНЫќЕФtranзжЖЮжа
Ек3ВНЃКНЋЪТЮёМЧТМЕФзДЬЌДгinitБфГЩpendingЃЈШчЙћдкетЪБКђВйзїжаЖЯЃЌФЧУДдкжиаТЦєЖЏЪБЃЌЛсХаЖЯЕНЫќЕФзДЬЌЪЧpendingЕФЃЌетЪБКђВщПДЦфЫљгаЖдгІЕФЖрЬѕвЊаоИФЕФМЧТМЃЌШчЙћЦфtranгажЕЃЌФЧУДОЭНјааЕк4ВНЃЌШчЙћУЛжЕЃЌЫЕУїЕк4ВНвбОжДааЙ§СЫЃЌжБНгНЋЦфзДЬЌДгpendingБфГЩcommitedСЫОЭааЃЉ
Ек4ВНЃКНЋашвЊаоИФЕФЖрЬѕМЧТМЕФЯргІжЕаоИФСЫЃЌВЂЧвunsetЕєжЎЧАЕФtranзжЖЮ
Ек5ВНЃКНЋЪТЮёМЧТМФЧвЛЬѕЕФзДЬЌДгpendingБфГЩcommitedЃЌЪТЮёЭъГЩ
ЦфЪЕЩЯУцЕФВНжшВЂВЛКБМћЃЌдкжЇГжЪТЮёЕФDBMSжаЃЌЦфЪТЮёдзгадЬсНЛЕФБЃжЄДѓЖрЖМгыЩЯУцРрЫЦЁЃЦфЪЕЪТЮёМЧТМЕФtranФЧЬѕМЧТМЃЌОЭРрЫЦгкетаЉDBMSжаЕФredologвЛбљЁЃ
MongoDBЪ§ОнЭЌВН
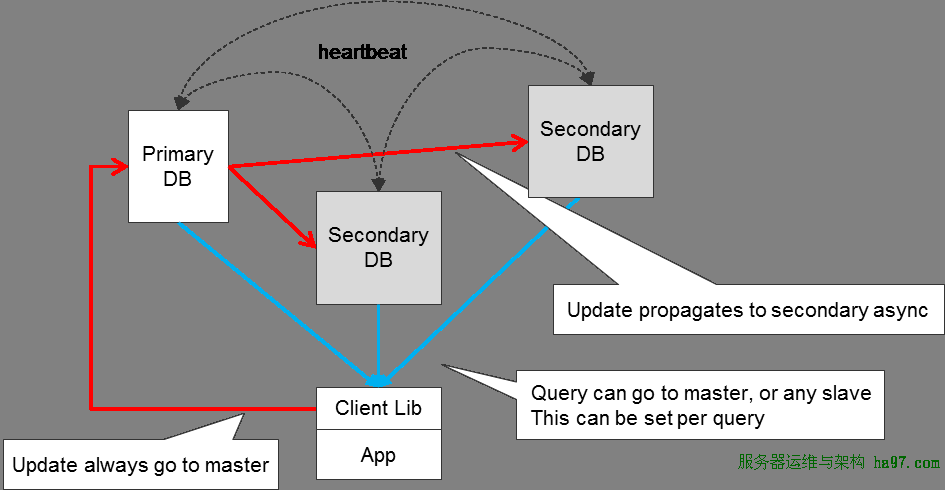
ЩЯЭМЪЧMongoDBВЩгУReplica SetsФЃЪНЕФЭЌВНСїГЬ
КьЩЋМ§ЭЗБэЪОаДВйзїаДЕНPrimaryЩЯЃЌШЛКѓвьВНЭЌВНЕНЖрИіSecondaryЩЯ
РЖЩЋМ§ЭЗБэЪОЖСВйзїПЩвдДгPrimaryЛђSecondaryШЮвтвЛИіЩЯЖС
ИїИіPrimaryгыSecondaryжЎМфвЛжББЃГжаФЬјЭЌВНМьВтЃЌгУгкХаЖЯReplica SetsЕФзДЬЌ
ЗжЦЌЛњжЦ
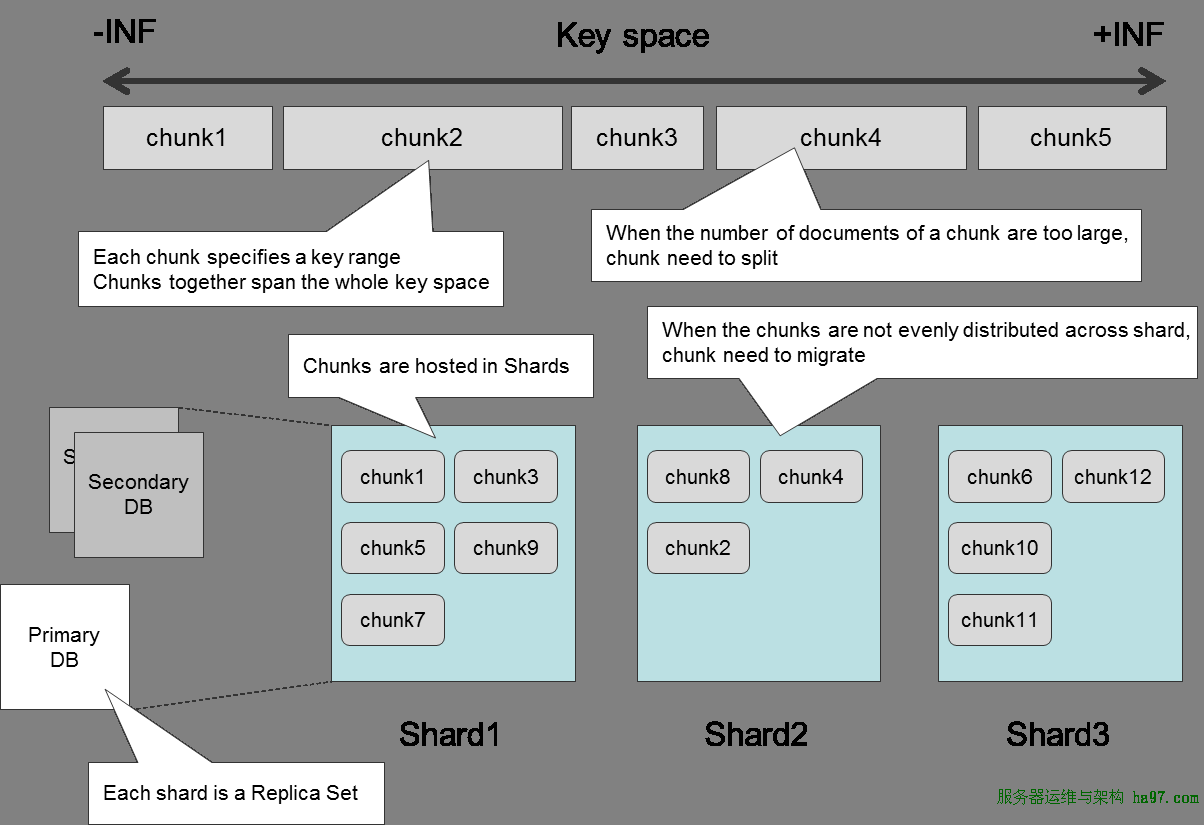
MongoDBЕФЗжЦЌЪЧжИЖЈвЛИіЗжЦЌkeyРДНјааЃЌЪ§ОнАДЗЖЮЇЗжГЩВЛЭЌЕФchunkЃЌУПИіchunkЕФДѓаЁгаЯожЦ
гаЖрИіЗжЦЌНкЕуБЃДцетаЉchunkЃЌУПИіНкЕуБЃДцвЛВПЗжЕФchunk
УПвЛИіЗжЦЌНкЕуЖМЪЧвЛИіReplica SetsЃЌетбљБЃжЄЪ§ОнЕФАВШЋад
ЕБвЛИіchunkГЌЙ§ЦфЯожЦЕФзюДѓЬхЛ§ЪБЃЌЛсЗжСбГЩСНИіаЁЕФchunk
ЕБchunkдкЗжЦЌНкЕужаЗжВМВЛОљКтЪБЃЌЛсв§ЗЂchunkЧЈвЦВйзї
ЗўЮёЦїНЧЩЋ
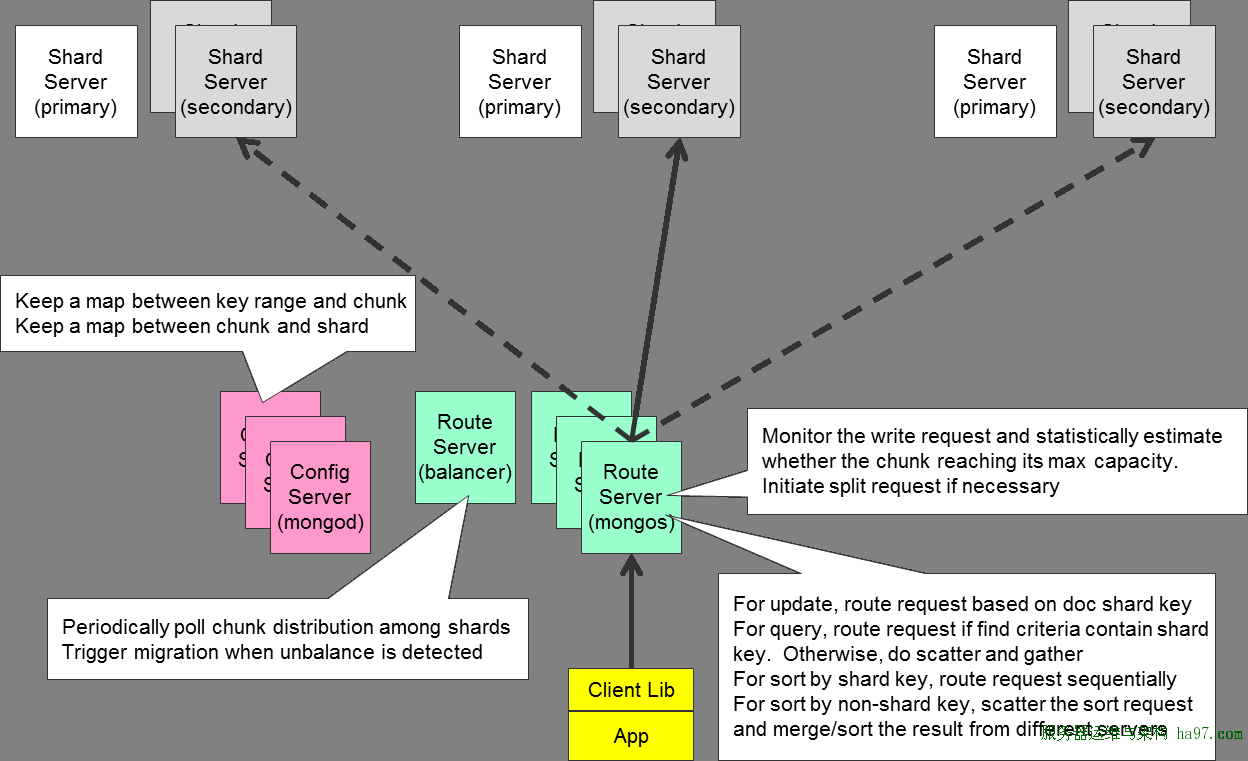
ЩЯУцНВСЫЗжЦЌЕФБъзМЃЌЯТУцЪЧОпЬхдкЗжЦЌЪБЕФМИжжНкЕуНЧЩЋ
ПЭЛЇЖЫЗУЮЪТЗгЩНкЕуmongosРДНјааЪ§ОнЖСаД
configЗўЮёЦїБЃДцСЫСНИігГЩфЙиЯЕЃЌвЛИіЪЧkeyжЕЕФЧјМфЖдгІФФвЛИіchunkЕФгГЩфЙиЯЕЃЌСэвЛИіЪЧchunkДцдкФФвЛИіЗжЦЌНкЕуЕФгГЩфЙиЯЕ
ТЗгЩНкЕуЭЈЙ§configЗўЮёЦїЛёШЁЪ§ОнаХЯЂЃЌЭЈЙ§етаЉаХЯЂЃЌевЕНеце§ДцЗХЪ§ОнЕФЗжЦЌНкЕуНјааЖдгІВйзї
ТЗгЩНкЕуЛЙЛсдкаДВйзїЪБХаЖЯЕБЧАchunkЪЧЗёГЌГіЯоЖЈДѓаЁЃЌШчЙћГЌГіЃЌОЭЗжСаГЩСНИіchunk
ЖдгкАДЗжЦЌkeyНјааЕФВщбЏКЭupdateВйзїРДЫЕЃЌТЗгЩНкЕуЛсВщЕНОпЬхЕФchunkШЛКѓдйНјааЯрЙиЕФЙЄзї
ЖдгкВЛАДЗжЦЌkeyНјааЕФВщбЏКЭupdateВйзїРДЫЕЃЌmongosЛсЖдЫљгаЯТЪєНкЕуЗЂЫЭЧыЧѓШЛКѓдйЖдЗЕЛиНсЙћНјааКЯВЂ | 








