| БрМЭЦМі: |
| БОЮФРДздгкjuejin.im,жївЊДгЛљДЁЕНдРэЃЌМЏШКЕНВПЪ№ЕШЕШЗНУцНщЩмЕФЕФЁЃ |
|
1. redisНщЩм
redisЪЧвЛИіЛљгкФкДцЕФK-VДцДЂЪ§ОнПтЁЃжЇГжДцДЂЕФРраЭгаstring,list,set,zset(sorted
set),hashЕШЁЃетаЉЪ§ОнРраЭЖМжЇГжpush/popЁЂadd/removeМАШЁНЛМЏВЂМЏКЭВюМЏМАИќЗсИЛЕФВйзїЃЌЖјЧветаЉВйзїЖМЪЧдзгадЕФЁЃredisжЇГжИїжжВЛЭЌЗНЪНЕФХХађЁЃБЃжЄаЇТЪЕФЧщПіЯТЃЌЪ§ОнЛКДцдкФкДцжаЁЃЭЌЪБredisЬсЙЉСЫГжОУЛЏВпТдЃЌВЛЭЌЕФВпТдДЅЗЂЭЌВНЕНДХХЬЛђепАбаоИФВйзїаДШызЗМгЕФМЧТМЮФМўЃЌдкДЫЛљДЁЩЯЪЕЯжСЫmaster-slaveЁЃ
ЫќЪЧвЛИіИпадФмЕФДцДЂЯЕЭГЃЌФмжЇГжГЌЙ§ 100K+ УПУыЕФЖСаДЦЕТЪЁЃЭЌЪБЛЙжЇГжЯћЯЂЕФЗЂВМ/ЖЉдФЃЌДгЖјШУФудкЙЙНЈИпадФмЯћЯЂЖгСаЯЕЭГЪБЖрСЫСэвЛжжбЁдёЁЃ
RedisжЇГжжїДгЭЌВНЁЃЪ§ОнПЩвдДгжїЗўЮёЦїЯђШЮвтЪ§СПЕФДгЗўЮёЦїЩЯЭЌВНЃЌДгЗўЮёЦїПЩвдЪЧЙиСЊЦфЫћДгЗўЮёЦїЕФжїЗўЮёЦїЁЃетЪЙЕУRedisПЩжДааЕЅВуЪїИДжЦЁЃДцХЬПЩвдгавтЮовтЕФЖдЪ§ОнНјаааДВйзїЁЃгЩгкЭъШЋЪЕЯжСЫЗЂВМ/ЖЉдФЛњжЦЃЌЪЙЕУДгЪ§ОнПтдкШЮКЮЕиЗНЭЌВНЪїЪБЃЌПЩЖЉдФвЛИіЦЕЕРВЂНгЪежїЗўЮёЦїЭъећЕФЯћЯЂЗЂВММЧТМЁЃЭЌВНЖдЖСШЁВйзїЕФПЩРЉеЙадКЭЪ§ОнШпгрКмгаАяжњЁЃ
2. жїДг
redisжЇГжmaster-slaveФЃЪНЃЌвЛжїЖрДгЃЌredis serverПЩвдЩшжУСэЭтЖрИіredis
serverЮЊslaveЃЌДгЛњЭЌВНжїЛњЕФЪ§ОнЁЃХфжУКѓЃЌЖСаДЗжРыЃЌжїЛњИКд№ЖСаДЗўЮёЃЌДгЛњжЛИКд№ЖСЁЃМѕЧсжїЛњЕФбЙСІЁЃredisЪЕЯжЕФЪЧзюжеЛсвЛжТадЃЌОпЬхбЁдёЧПвЛжТадЛЙЪЧШѕвЛжТадЃЌШЁОігквЕЮёГЁОАЁЃ
redis жїДгЭЌВНгаСНжжЗНЪНЃЈЛђепЫљСНИіНзЖЮЃЉЃКШЋЭЌВНКЭВПЗжЭЌВНЁЃ
жїДгИеИеСЌНгЕФЪБКђЃЌНјааШЋЭЌВНЃЛШЋЭЌВННсЪјКѓЃЌНјааВПЗжЭЌВНЁЃЕБШЛЃЌШчЙћгаашвЊЃЌslave дкШЮКЮЪБКђЖМПЩвдЗЂЦ№ШЋЭЌВНЁЃredis
ВпТдЪЧЃЌЮоТлШчКЮЃЌЪзЯШЛсГЂЪдНјааВПЗжЭЌВНЃЌШчВЛГЩЙІЃЌвЊЧѓДгЛњНјааШЋЭЌВНЃЌВЂЦєЖЏ BGSAVEЁЁBGSAVE
НсЪјКѓЃЌДЋЪф RDB ЮФМўЃЛШчЙћГЩЙІЃЌдЪаэДгЛњНјааВПЗжЭЌВНЃЌВЂДЋЪфЛ§бЙПеМфжаЕФЪ§ОнЁЃМђЕЅРДЫЕЃЌжїДгЭЌВНОЭЪЧ
RDB ЮФМўЕФЩЯДЋЯТдиЃЛжїЛњгааЁВПЗжЕФЪ§ОнаоИФЃЌОЭАбаоИФМЧТМДЋВЅИјУПИіДгЛњЁЃ
3. redisМЏШК
жїДгФЃЪНДцдкЕФЮЪЬтЪЧЃЌmasterхДЛњжЎКѓЃЌДгЛњжЛФмЖСЃЌВЛПЩаДЃЌВЛФмБЃжЄИпПЩгУЁЃredisМЏШКММЪѕЪЧЙЙНЈИпадФмЭјеОМмЙЙЕФживЊЪжЖЮЃЌЪдЯыдкЭјеОГаЪмИпВЂЗЂЗУЮЪбЙСІЕФЭЌЪБЃЌЛЙашвЊДгКЃСПЪ§ОнжаВщбЏГіТњзуЬѕМўЕФЪ§ОнЃЌВЂПьЫйЯьгІЃЌЮвУЧБиШЛЯыЕНЕФЪЧНЋЪ§ОнНјааЧаЦЌЃЌАбЪ§ОнИљОнФГжжЙцдђЗХШыЖрИіВЛЭЌЕФЗўЮёЦїНкЕуЃЌРДНЕЕЭЕЅНкЕуЗўЮёЦїЕФбЙСІЁЃ
Redis ClusterВЩгУЮожааФНсЙЙЃЌУПИіНкЕуБЃДцЪ§ОнКЭећИіМЏШКзДЬЌ,УПИіНкЕуЖМКЭЦфЫћЫљгаНкЕуСЌНгЁЃНкЕужЎМфЪЙгУgossipавщДЋВЅаХЯЂвдМАЗЂЯжаТНкЕуЁЃ
Redis МЏШКЪЧвЛИіЗжВМЪНЃЈdistributedЃЉЁЂШнДэЃЈfault-tolerantЃЉЕФ Redis
ЪЕЯжЃЌМЏШКПЩвдЪЙгУЕФЙІФмЪЧЦеЭЈЕЅЛњ Redis ЫљФмЪЙгУЕФЙІФмЕФвЛИізгМЏЃЈsubsetЃЉЁЃ
Redis МЏШКжаВЛДцдкжааФЃЈcentralЃЉНкЕуЛђепДњРэЃЈproxyЃЉНкЕуЃЌМЏШКЕФЦфжавЛИіжївЊЩшМЦФПБъЪЧДяЕНЯпадПЩРЉеЙадЃЈlinear
scalabilityЃЉЁЃ
Redis МЏШКЮЊСЫБЃжЄвЛжТадЃЈconsistencyЃЉЖјЮўЩќСЫвЛВПЗжШнДэадЃКЯЕЭГЛсдкБЃжЄЖдЭјТчЖЯЯпЃЈnet
splitЃЉКЭНкЕуЪЇаЇЃЈnode failureЃЉОпгагаЯоЃЈlimitedЃЉЕжПЙСІЕФЧАЬсЯТЃЌОЁПЩФмЕиБЃГжЪ§ОнЕФвЛжТадЁЃ
4. АВзАВПЪ№
redisАВзАНЯЮЊМђЕЅЃЌЙйЭјЯТдибЙЫѕАќНтбЙЁЃМЏШКФЃЪНашвЊrubyЕФБрвыЛЗОГЃЌМЏШКзюаЁЕФХфжУЮЊ3ЬЈmasterЃЌаЁгк3дђЦєЖЏМЏШКБЈДэЁЃ
redisАцБОЃК3.2.4
4.1 жїДгФЃЪНЭиЦЫЭМ
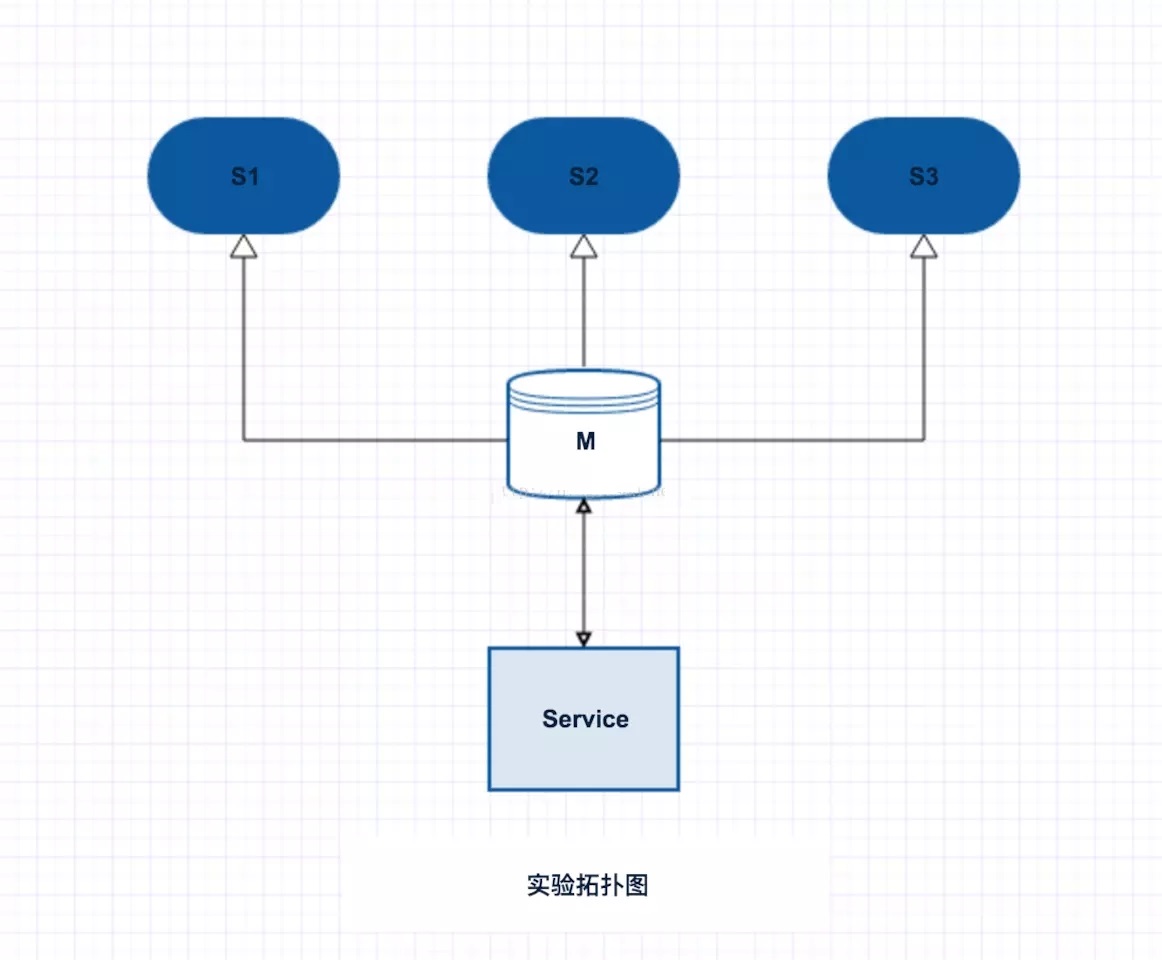
жїДгФЃЪНЭиЦЫЭМ
жїДгФЃЪНВЩгУвЛжїШ§ДгЃЌжїДгЖМХфжУauthШЯжЄЃЌЖСаДЗжРыЁЃ
жївЊЪЕбщЕФЖЏзїЃК
1ЃЉЖрИіapp ЭЌЪБаДЃЌВтЖЈаДЫйТЪЃЛ
2ЃЉЖрИіapp ЭЌЪБаДЃЌЭЌЪБгаЖСЕФНјГЬЃЌВтЖЈЖСаДЫйТЪЃЛ
3ЃЉmasterжїЛњхДЛњЃЌappвРШЛНјааЖСаДЁЃ
4.2 clusterЭиЦЫЭМШчЯТ
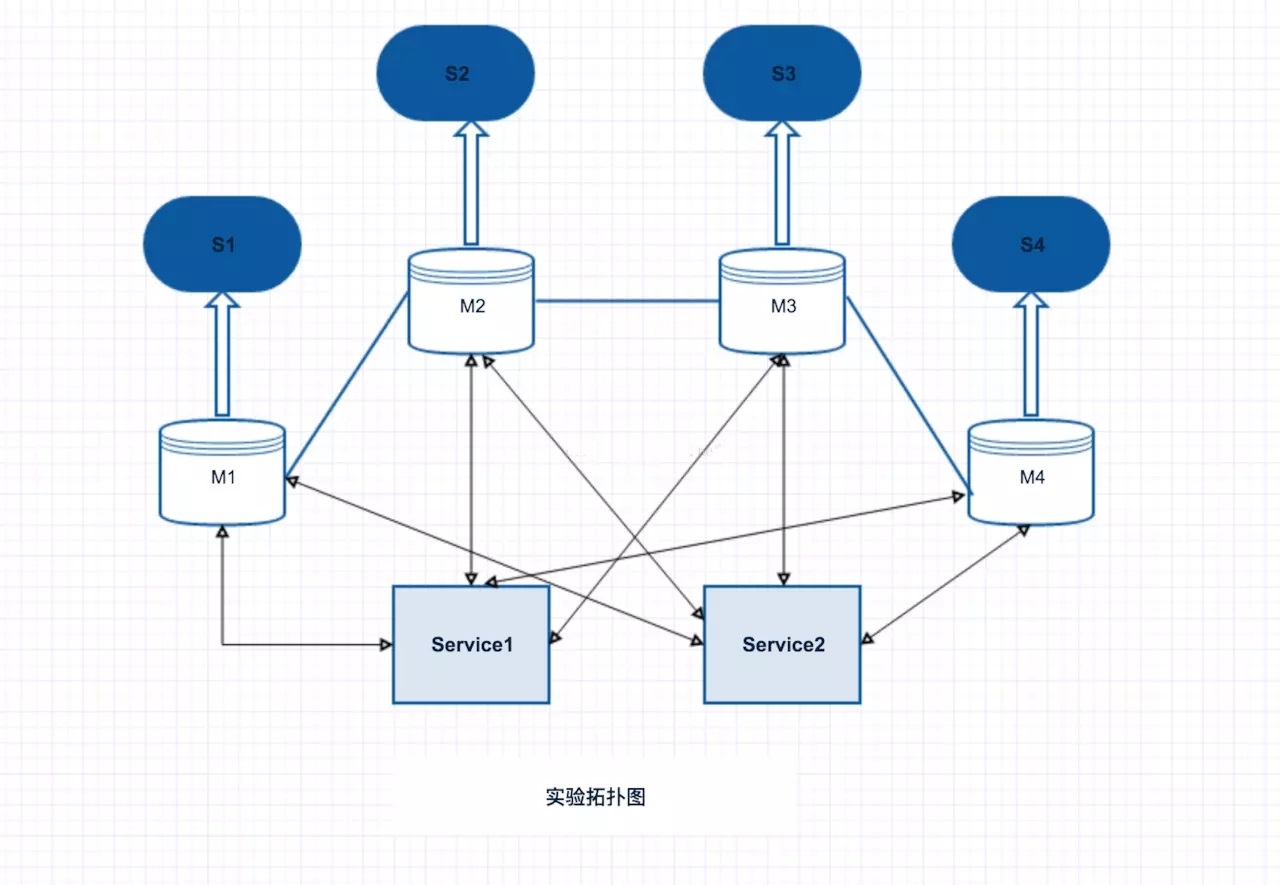
cluster
МЏШКФЃЪНВЩгУЫФжїЫФДгЃЌвВЪЧВЩгУЖСаДЗжРыЁЃ
жївЊЪЕбщЕФЖЏзїЃК
1ЃЉгавЛИіmasterхДЛњЃЌЙлВьШежОЃЌаТЕФslaveГЩЮЊmasterЃЛ
2ЃЉmasterхДЛњКѓЃЌжиаТЦєЖЏЃЌmasterГЩЮЊslaveЃЛ
3ЃЉМЏШКШЋВПхДЛњЃЌredisжїЛњжиЦєЃЌЪ§ОнЮДЖЊЪЇЁЃ
5. дРэ
5.1 вЛжТад
filesnapshot:ФЌШЯredisЪЧЛсвдПьееЕФаЮЪННЋЪ§ОнГжОУЛЏЕНДХХЬ,дкХфжУЮФМўжаЕФИёЪНЪЧЃКsave
N MБэЪОдкNУыжЎФкЃЌredisжСЩйЗЂЩњMДЮаоИФдђredisзЅПьееЕНДХХЬЁЃ
ЙЄзїдРэЃКЕБredisашвЊзіГжОУЛЏЪБЃЌredisЛсforkвЛИізгНјГЬЃЛзгНјГЬНЋЪ§ОнаДЕНДХХЬЩЯвЛИіСйЪБRDBЮФМўжаЃЛЕБзгНјГЬЭъГЩаДСйЪБЮФМўКѓЃЌНЋдРДЕФRDBЬцЛЛЕєЃЌетбљЕФКУДІОЭЪЧПЩвдcopy-on-writeЁЃ
Append-onlyЃКfilesnapshottingЗНЗЈдкredisвьГЃЫРЕєЪБЃЌ зюНќЕФЪ§ОнЛсЖЊЪЇЃЈЖЊЪЇЪ§ОнЕФЖрЩйЪгФуsaveВпТдЕФХфжУЃЉЃЌЫљвдетЪЧЫќзюДѓЕФШБЕуЃЌЕБвЕЮёСПКмДѓЪБЃЌЖЊЪЇЕФЪ§ОнЪЧКмЖрЕФЁЃAppend-onlyЗНЗЈПЩ
вдзіЕНШЋВПЪ§ОнВЛЖЊЪЇЃЌЕЋredisЕФадФмОЭвЊВюаЉЁЃAOFОЭПЩвдзіЕНШЋГЬГжОУЛЏЃЌжЛашвЊдкХфжУЮФМўжаПЊЦєЃЈФЌШЯЪЧnoЃЉЃЌappendonly
yesПЊЦєAOFжЎКѓЃЌredisУПжДаавЛИіаоИФЪ§ОнЕФУќСюЃЌЖМЛсАбЫќЬэМгЕНaofЮФМўжаЃЌЕБredisжиЦєЪБЃЌНЋЛсЖСШЁAOFЮФМўНјааЁАжиЗХЁБвдЛжИДЕН
redisЙиБеЧАЕФзюКѓЪБПЬЁЃ
AOFЮФМўЫЂаТЕФЗНЪНЃЌгаШ§жжЃЌВЮПМХфжУВЮЪ§appendfsync ЃК
appendfsync alwaysУПЬсНЛвЛИіаоИФУќСюЖМЕїгУfsyncЫЂаТЕНAOFЮФМўЃЌЗЧГЃЗЧГЃТ§ЃЌЕЋвВЗЧГЃАВШЋЃЛ
appendfsync everysecУПУыжгЖМЕїгУfsyncЫЂаТЕНAOFЮФМўЃЌКмПьЃЌЕЋПЩФмЛсЖЊЪЇвЛУывдФкЕФЪ§ОнЃЛ
appendfsync noвРППOSНјааЫЂаТЃЌredisВЛжїЖЏЫЂаТAOFЃЌетбљзюПьЃЌЕЋАВШЋадОЭВюЁЃФЌШЯВЂЭЦМіУПУыЫЂаТЃЌетбљдкЫйЖШКЭАВШЋЩЯЖМзіЕНСЫМцЙЫЁЃ
SlaveЭЌбљПЩвдНгЪмЦфЫќSlavesЕФСЌНгКЭЭЌВНЧыЧѓЃЌетбљПЩвдгааЇЕФЗждиMasterЕФЭЌВНбЙСІЁЃвђДЫЮвУЧПЩвдНЋRedisЕФReplicationМмЙЙЪгЮЊЭМНсЙЙЁЃ
Master ServerЪЧвдЗЧзшШћЕФЗНЪНЮЊSlavesЬсЙЉЗўЮёЁЃЫљвддкMaster-SlaveЭЌВНЦкМфЃЌПЭЛЇЖЫШдШЛПЩвдЬсНЛВщбЏЛђаоИФЧыЧѓЁЃ
Slave ServerЭЌбљЪЧвдЗЧзшШћЕФЗНЪНЭъГЩЪ§ОнЭЌВНЁЃдкЭЌВНЦкМфЃЌШчЙћгаПЭЛЇЖЫЬсНЛВщбЏЧыЧѓЃЌRedisдђЗЕЛиЭЌВНжЎЧАЕФЪ§ОнЁЃ
ЮЊСЫЗждиMasterЕФЖСВйзїбЙСІЃЌSlaveЗўЮёЦїПЩвдЮЊПЭЛЇЖЫЬсЙЉжЛЖСВйзїЕФЗўЮёЃЌаДЗўЮёШдШЛБиаыгЩMasterРДЭъГЩЁЃМДБуШчДЫЃЌЯЕЭГЕФЩьЫѕадЛЙЪЧЕУЕНСЫКмДѓЕФЬсИпЁЃ
MasterПЩвдНЋЪ§ОнБЃДцВйзїНЛИјSlavesЭъГЩЃЌДгЖјБмУтСЫдкMasterжавЊгаЖРСЂЕФНјГЬРДЭъГЩДЫВйзїЁЃ
RedisдкmasterЪЧЗЧзшШћФЃЪНЃЌвВОЭЪЧЫЕдкslaveжДааЪ§ОнЭЌВНЕФЪБКђЃЌmasterЪЧПЩвдНгЪмПЭЛЇЖЫЕФЧыЧѓЕФЃЌВЂВЛгАЯьЭЌВНЪ§ОнЕФвЛжТадЃЌШЛЖјдкslaveЖЫЪЧзшШћФЃЪНЕФЃЌslaveдкЭЌВНmasterЪ§ОнЪБЃЌВЂВЛФмЙЛЯьгІПЭЛЇЖЫЕФВщбЏЁЃ
5.2 ReplicationЕФЙЄзїдРэ
(1)SlaveЗўЮёЦїСЌНгЕНMasterЗўЮёЦїЁЃ
(2)SlaveЗўЮёЦїЗЂЫЭSYCNУќСюЁЃ
(3)MasterЗўЮёЦїБИЗнЪ§ОнПтЕН.rdbЮФМўЁЃ
(4)MasterЗўЮёЦїАб.rdbЮФМўДЋЪфИјSlaveЗўЮёЦїЁЃ
(5)SlaveЗўЮёЦїАб.rdbЮФМўЪ§ОнЕМШыЕНЪ§ОнПтжаЁЃ
дкSlaveЦєЖЏВЂСЌНгЕНMasterжЎКѓЃЌЫќНЋжїЖЏЗЂЫЭвЛИіSYNCУќСюЁЃДЫКѓMasterНЋЦєЖЏКѓЬЈДцХЬНјГЬЃЌЭЌЪБЪеМЏЫљгаНгЪеЕНЕФгУгкаоИФЪ§ОнМЏ
ЕФУќСюЃЌдкКѓЬЈНјГЬжДааЭъБЯКѓЃЌMasterНЋДЋЫЭећИіЪ§ОнПтЮФМўЕНSlaveЃЌвдЭъГЩвЛДЮЭъШЋЭЌВНЁЃЖјSlaveЗўЮёЦїдкНгЪеЕНЪ§ОнПтЮФМўЪ§ОнжЎКѓНЋЦф
ДцХЬВЂМгдиЕНФкДцжаЁЃДЫКѓЃЌMasterМЬајНЋЫљгавбОЪеМЏЕНЕФаоИФУќСюЃЌКЭаТЕФаоИФУќСювРДЮДЋЫЭИјSlavesЃЌSlaveНЋдкБОДЮжДааетаЉЪ§ОнаоИФУќСюЃЌДгЖјДяЕНзюжеЕФЪ§ОнЭЌВНЁЃШчЙћMasterКЭSlaveжЎМфЕФСДНгГіЯжЖЯСЌЯжЯѓЃЌSlaveПЩвдздЖЏжиСЌMasterЃЌЕЋЪЧдкСЌНгГЩЙІжЎКѓЃЌвЛДЮЭъШЋЭЌВННЋБЛздЖЏжДааЁЃ
5.3 вЛжТадЙўЯЃ
МЏШКвЊЪЕЯжЕФФПЕФЪЧвЊНЋВЛЭЌЕФ key ЗжЩЂЗХжУЕНВЛЭЌЕФ redis НкЕуЃЌетРяЮвУЧашвЊвЛИіЙцдђЛђепЫуЗЈЃЌЭЈГЃЕФзіЗЈЪЧЛёШЁ
key ЕФЙўЯЃжЕЃЌШЛКѓИљОнНкЕуЪ§РДЧѓФЃЃЌЕЋетжжзіЗЈгаЦфУїЯдЕФБзЖЫЃЌЕБЮвУЧашвЊдіМгЛђМѕЩйвЛИіНкЕуЪБЃЌЛсдьГЩДѓСПЕФ
key ЮоЗЈУќжаЃЌетжжБШР§ЪЧЯрЕБИпЕФЃЌЫљвдОЭгаШЫЬсГіСЫвЛжТадЙўЯЃЕФИХФюЁЃ
вЛжТадЙўЯЃгаЫФИіживЊЬиеїЃК
ОљКтадЃКвВгаШЫАбЫќЖЈвхЮЊЦНКтадЃЌЪЧжИЙўЯЃЕФНсЙћФмЙЛОЁПЩФмЗжВМЕНЫљгаЕФНкЕужаШЅЃЌетбљПЩвдгааЇЕФРћгУУПИіНкЕуЩЯЕФзЪдДЁЃ
ЕЅЕїадЃКЖдгкЕЅЕїадгаКмЖрЗвыШУЮвЗЧГЃЕФВЛНтЃЌЖјЮвЯывЊЕФЪЧЕБНкЕуЪ§СПБфЛЏЪБЙўЯЃЕФНсЙћгІОЁПЩФмЕФБЃЛЄвбЗжХфЕФФкШнВЛЛсБЛжиаТЗжХЩЕНаТЕФНкЕуЁЃ
ЗжЩЂадКЭИКдиЃКетСНИіЦфЪЕЪЧВюВЛЖрЕФвтЫМЃЌОЭЪЧвЊЧѓвЛжТадЙўЯЃЫуЗЈЖд key ЙўЯЃгІОЁПЩФмЕФБмУтжиИДЁЃ
Redis МЏШКжаФкжУСЫ 16384 ИіЙўЯЃВлЃЌЕБашвЊдк Redis МЏШКжаЗХжУвЛИі key-value
ЪБЃЌredis ЯШЖд key ЪЙгУ crc16 ЫуЗЈЫуГівЛИіНсЙћЃЌШЛКѓАбНсЙћЖд 16384 ЧѓгрЪ§ЃЌетбљУПИі
key ЖМЛсЖдгІвЛИіБрКХдк 0-16383 жЎМфЕФЙўЯЃВлЃЌredis ЛсИљОнНкЕуЪ§СПДѓжТОљЕШЕФНЋЙўЯЃВлгГЩфЕНВЛЭЌЕФНкЕуЁЃ
ЪЙгУЙўЯЃВлЕФКУДІОЭдкгкПЩвдЗНБуЕФЬэМгЛђвЦГ§НкЕуЁЃ
ЕБашвЊдіМгНкЕуЪБЃЌжЛашвЊАбЦфЫћНкЕуЕФФГаЉЙўЯЃВлХВЕНаТНкЕуОЭПЩвдСЫЃЛ
ЕБашвЊвЦГ§НкЕуЪБЃЌжЛашвЊАбвЦГ§НкЕуЩЯЕФЙўЯЃВлХВЕНЦфЫћНкЕуОЭааСЫЃЛ
ЕБЩшжУСЫжїДгЙиЯЕКѓЃЌslave дкЕквЛДЮСЌНгЛђепжиаТСЌНг master ЪБЃЌslave ЖМЛсЗЂЫЭвЛЬѕЭЌВНжИСюИј
masterЃЛ
master НгЕНжИСюКѓЃЌПЊЪМЦєЖЏКѓЬЈБЃДцНјГЬБЃДцЪ§ОнЃЌНгзХЪеМЏЫљгаЕФЪ§ОнаоИФжИСюЁЃКѓЬЈБЃДцЭъСЫЃЌmaster
ОЭАбетЗнЪ§ОнЗЂЫЭИј slaveЃЌslave ЯШАбЪ§ОнБЃДцЕНДХХЬЃЌШЛКѓАбЫќМгдиЕНФкДцжаЃЌmaster
НгзХОЭАбЪеМЏЕФЪ§ОнаоИФжИСювЛаавЛааЕФЗЂИј slaveЃЌslave НгЪеЕНжЎКѓжиаТжДааИУжИСюЃЌетбљОЭЪЕЯжСЫЪ§ОнЭЌВНЁЃ
slave дкгы master ЪЇШЅСЊЯЕКѓЃЌздЖЏЕФжиаТСЌНгЁЃШчЙћ master ЪеЕНСЫЖрИі slave
ЕФЭЌВНЧыЧѓЃЌЫќЛсжДааЕЅИіКѓЬЈБЃДцРДЮЊЫљгаЕФ slave ЗўЮёЁЃ
5.4 НкЕуЪЇаЇМьВт
вдЯТЪЧНкЕуЪЇаЇМьВщЕФЪЕЯжЗНЗЈЃК
ЕБвЛИіНкЕуЯђСэвЛИіНкЕуЗЂЫЭ PING УќСюЃЌЕЋЪЧФПБъНкЕуЮДФмдкИјЖЈЕФЪБЯоФкЗЕЛи PING УќСюЕФЛиИДЪБЃЌФЧУДЗЂЫЭУќСюЕФНкЕуЛсНЋФПБъНкЕуБъМЧЮЊPFAIL
ЃЈpossible failureЃЌПЩФмвбЪЇаЇЃЉЁЃ
ЕШД§ PING УќСюЛиИДЕФЪБЯоГЦЮЊЁАНкЕуГЌЪБЪБЯоЃЈnode timeoutЃЉЁБЃЌЪЧвЛИіНкЕубЁЯюЃЈnode-wise
settingЃЉЁЃ
УПДЮЕБНкЕуЖдЦфЫћНкЕуЗЂЫЭ PING УќСюЕФЪБКђЃЌЫќЖМЛсЫцЛњЕиЙуВЅШ§ИіЫќЫљжЊЕРЕФНкЕуЕФаХЯЂЃЌетаЉаХЯЂРяУцЕФЦфжавЛЯюОЭЪЧЫЕУїНкЕуЪЧЗёвбОБЛБъМЧЮЊ
PFAIL Лђеп FAIL ЁЃ
ЕБНкЕуНгЪеЕНЦфЫћНкЕуЗЂРДЕФаХЯЂЪБЃЌЫќЛсМЧЯТФЧаЉБЛЦфЫћНкЕуБъМЧЮЊЪЇаЇЕФНкЕуЁЃетГЦЮЊЪЇаЇБЈИцЃЈfailure
reportЃЉЁЃ
ШчЙћНкЕувбОНЋФГИіНкЕуБъМЧЮЊ PFAIL ЃЌВЂЧвИљОнНкЕуЫљЪеЕНЕФЪЇаЇБЈИцЯдЪНЃЌМЏШКжаЕФДѓВПЗжЦфЫћжїНкЕувВШЯЮЊФЧИіНкЕуНјШыСЫЪЇаЇзДЬЌЃЌФЧУДНкЕуЛсНЋФЧИіЪЇаЇНкЕуЕФзДЬЌБъМЧЮЊ
FAIL ЁЃ
вЛЕЉФГИіНкЕуБЛБъМЧЮЊ FAIL ЃЌЙигкетИіНкЕувбЪЇаЇЕФаХЯЂОЭЛсБЛЙуВЅЕНећИіМЏШКЃЌЫљгаНгЪеЕНетЬѕаХЯЂЕФНкЕуЖМЛсНЋЪЇаЇНкЕуБъМЧЮЊ
FAIL ЁЃ
МђЕЅРДЫЕЃЌвЛИіНкЕувЊНЋСэвЛИіНкЕуБъМЧЮЊЪЇаЇЃЌБиаыЯШбЏЮЪЦфЫћНкЕуЕФвтМћЃЌВЂЧвЕУЕНДѓВПЗжжїНкЕуЕФЭЌвтВХааЁЃвђЮЊЙ§ЦкЕФЪЇаЇБЈИцЛсБЛвЦГ§ЃЌЫљвджїНкЕувЊНЋФГИіНкЕуБъМЧЮЊ
FAIL ЕФЛАЃЌБиаывдзюНќНгЪеЕНЕФЪЇаЇБЈИцзїЮЊИљОнЁЃ
дквдЯТСНжжЧщПіжаЃЌНкЕуЕФ FAIL зДЬЌЛсБЛвЦГ§ЃК
ШчЙћБЛБъМЧЮЊ FAIL ЕФЪЧДгНкЕуЃЌФЧУДЕБетИіНкЕужиаТЩЯЯпЪБЃЌ FAIL БъМЧОЭЛсБЛвЦГ§ЁЃБЃГжЃЈretaningЃЉДгНкЕуЕФ
FAIL зДЬЌЪЧУЛгавтвхЕФЃЌвђЮЊЫќВЛДІРэШЮКЮВлЃЌвЛИіДгНкЕуЪЧЗёДІгк FAIL зДЬЌЃЌОіЖЈСЫетИіДгНкЕудкгаашвЊЪБФмЗёБЛЬсЩ§ЮЊжїНкЕуЁЃ
ШчЙћвЛИіжїНкЕуБЛДђЩЯ FAIL БъМЧжЎКѓЃЌОЙ§СЫНкЕуГЌЪБЪБЯоЕФЫФБЖЪБМфЃЌдйМгЩЯЪЎУыжгжЎКѓЃЌеыЖдетИіжїНкЕуЕФВлЕФЙЪеЯзЊвЦВйзїШдЮДЭъГЩЃЌВЂЧветИіжїНкЕувбОжиаТЩЯЯпЕФЛАЃЌФЧУДвЦГ§ЖдетИіНкЕуЕФ
FAIL БъМЧЁЃ
дкЕкЖўжжЧщПіжаЃЌШчЙћЙЪеЯзЊвЦЮДФмЫГРћЭъГЩЃЌВЂЧвжїНкЕужиаТЩЯЯпЃЌФЧУДМЏШКОЭМЬајЪЙгУдРДЕФжїНкЕуЃЌДгЖјУтШЅЙмРэдБНщШыЕФБивЊЁЃ
5.5 ДгНкЕубЁОй
вЛЕЉФГИіжїНкЕуНјШы FAIL зДЬЌЃЌШчЙћетИіжїНкЕугавЛИіЛђЖрИіДгНкЕуДцдкЃЌФЧУДЦфжавЛИіДгНкЕуЛсБЛЩ§МЖЮЊаТЕФжїНкЕуЃЌЖјЦфЫћДгНкЕудђЛсПЊЪМЖдетИіаТЕФжїНкЕуНјааИДжЦЁЃ
аТЕФжїНкЕугЩвбЯТЯпжїНкЕуЪєЯТЕФЫљгаДгНкЕужаздаабЁОйВњЩњЃЌвдЯТЪЧбЁОйЕФЬѕМўЃК
етИіНкЕуЪЧвбЯТЯпжїНкЕуЕФДгНкЕуЁЃ
вбЯТЯпжїНкЕуИКд№ДІРэЕФВлЪ§СПЗЧПеЁЃ
ДгНкЕуЕФЪ§ОнБЛШЯЮЊЪЧПЩППЕФЃЌвВМДЪЧЃЌжїДгНкЕужЎМфЕФИДжЦСЌНгЃЈreplication linkЃЉЕФЖЯЯпЪБГЄВЛФмГЌЙ§НкЕуГЌЪБЪБЯоЃЈnode
timeoutЃЉГЫвдREDIS_CLUSTER_SLAVE_VALIDITY_MULT ГЃСПЕУГіЕФЛ§ЁЃ
ШчЙћвЛИіДгНкЕуТњзуСЫвдЩЯЕФЫљгаЬѕМўЃЌФЧУДетИіДгНкЕуНЋЯђМЏШКжаЕФЦфЫћжїНкЕуЗЂЫЭЪкШЈЧыЧѓЃЌбЏЮЪЫќУЧЃЌЪЧЗёдЪаэздМКЃЈДгНкЕуЃЉЩ§МЖЮЊаТЕФжїНкЕуЁЃ
ШчЙћЗЂЫЭЪкШЈЧыЧѓЕФДгНкЕуТњзувдЯТЪєадЃЌФЧУДжїНкЕуНЋЯђДгНкЕуЗЕЛи FAILOVER_AUTH_GRANTED
ЪкШЈЃЌЭЌвтДгНкЕуЕФЩ§МЖвЊЧѓЃК
ЗЂЫЭЪкШЈЧыЧѓЕФЪЧвЛИіДгНкЕуЃЌВЂЧвЫќЫљЪєЕФжїНкЕуДІгк FAIL зДЬЌЁЃ
дквбЯТЯпжїНкЕуЕФЫљгаДгНкЕужаЃЌетИіДгНкЕуЕФНкЕу ID дкХХађжаЪЧзюаЁЕФЁЃ
ДгНкЕуДІгке§ГЃЕФдЫаазДЬЌЃКЫќУЛгаБЛБъМЧЮЊ FAIL зДЬЌЃЌвВУЛгаБЛБъМЧЮЊ PFAIL зДЬЌЁЃ
вЛЕЉФГИіДгНкЕудкИјЖЈЕФЪБЯоФкЕУЕНДѓВПЗжжїНкЕуЕФЪкШЈЃЌЫќОЭЛсПЊЪМжДаавдЯТЙЪеЯзЊвЦВйзїЃК
ЭЈЙ§ PONG Ъ§ОнАќЃЈpacketЃЉИцжЊЦфЫћНкЕуЃЌетИіНкЕуЯждкЪЧжїНкЕуСЫЁЃ
ЭЈЙ§ PONG Ъ§ОнАќИцжЊЦфЫћНкЕуЃЌетИіНкЕуЪЧвЛИівбЩ§МЖЕФДгНкЕуЃЈpromoted slaveЃЉЁЃ
НгЙмЃЈclaimingЃЉЫљгагЩвбЯТЯпжїНкЕуИКд№ДІРэЕФЙўЯЃВлЁЃ
ЯдЪНЕиЯђЫљгаНкЕуЙуВЅвЛИі PONG Ъ§ОнАќЃЌМгЫйЦфЫћНкЕуЪЖБ№етИіНкЕуЕФНјЖШЃЌЖјВЛЪЧЕШД§ЖЈЪБЕФ PING
/ PONG Ъ§ОнАќЁЃ
ЫљгаЦфЫћНкЕуЖМЛсИљОнаТЕФжїНкЕуЖдХфжУНјааЯргІЕФИќаТЃЌЬиБ№ЕиЃК
a. ЫљгаБЛаТЕФжїНкЕуНгЙмЕФВлЛсБЛИќаТЁЃ
b. вбЯТЯпжїНкЕуЕФЫљгаДгНкЕуЛсВьОѕЕН PROMOTED БъжОЃЌВЂПЊЪМЖдаТЕФжїНкЕуНјааИДжЦЁЃ
c.ШчЙћвбЯТЯпЕФжїНкЕужиаТЛиЕНЩЯЯпзДЬЌЃЌФЧУДЫќЛсВьОѕЕН PROMOTED БъжОЃЌВЂНЋздЩэЕїећЮЊЯжШЮжїНкЕуЕФДгНкЕуЁЃ
дкМЏШКЕФЩњУќжмЦкжаЃЌШчЙћвЛИіДјга PROMOTED БъЪЖЕФжїНкЕувђЮЊФГаЉдвђзЊБфГЩСЫДгНкЕуЃЌФЧУДИУНкЕуНЋЖЊЪЇЫќЫљДјгаЕФ
PROMOTED БъЪЖЁЃ
6. змНс
RedisМЏШКОпгаИпПЩгУЃЌвзгкЧЈвЦЃЌДцШЁЫйЖШПьЕШЬиЕуЁЃвВПЩвдзїЮЊЯћЯЂЖгСаЪЙгУЃЌжЇГжpub/subФЃЪНЃЌОпЬхгХШБЕузмНсШчЯТЃК
ЪзЯШгХЕу:
redis дкжїНкЕуЯТЯпКѓЃЌДгНкЕуЛсздЖЏЬсЩ§ЮЊжїНкЕуЃЌЬсЙЉЗўЮё
redis хДЛњНкЕуЛжИДКѓЃЌздЖЏЛсЬэМгЕНМЏШКжаЃЌБфГЩДгНкЕу
ЖЏЬЌРЉеЙКЭЩОГ§НкЕуЃЌrehash slotЕФЗжХфЃЌЛљгкЭАЕФЪ§ОнЗжВМЗНЪНДѓДѓНЕЕЭСЫЧЈвЦГЩБОЃЌжЛашНЋЪ§ОнЭАДгвЛИіRedis
NodeЧЈвЦЕНСэвЛИіRedis NodeМДПЩЭъГЩЧЈвЦЁЃ
Redis ClusterЪЙгУвьВНИДжЦЁЃ
ЦфШБЕуЮЊ:
гЩгкredisЕФИДжЦЪЙгУвьВНЛњжЦЃЌдкздЖЏЙЪеЯзЊвЦЕФЙ§ГЬжаЃЌМЏШКПЩФмЛсЖЊЪЇаДУќСюЁЃШЛЖј redis
МИКѕЪЧЭЌЪБжДаа(НЋУќСюЛжИДЗЂЫЭИјПЭЛЇЖЫЃЌвдМАНЋУќСюИДжЦЕНДгНкЕу)етСНИіВйзїЃЌЫљвдЪЕМЪжаЃЌУќСюЖЊЪЇЕФДАПкЗЧГЃаЁЁЃ
ЦеЭЈЕФжїДгФЃЪНжЇГжauthМгУмШЯжЄЃЌЫфШЛБШНЯШѕЃЌЕЋаДЛђепЖСЖМвЊЭЈЙ§УмТыбщжЄЃЌclusterЖдУмТыжЇГжВЛЬЋгбКУЃЌШчЙћЖдМЏШКЩшжУУмТыЃЌФЧУДrequirepassКЭmasterauthЖМашвЊЩшжУЃЌЗёдђЗЂЩњжїДгЧаЛЛЪБЃЌОЭЛсгіЕНЪкШЈЮЪЬтЃЌПЩвдФЃФтВЂЙлВьШежОЁЃ |









