| БрМЭЦМі: |
| БОЮФРДдДВЎРждкЯпЃЌ
НщЩмСЫеЙЪОЙњЭтвЦЖЏжЇИЖЗўЮёЩЬ Stripe ШчКЮАВШЋЕиЖдЪ§вдвкМЦЕФ SubscriptionsЃЈЖЉдФЗўЮёЃЉЖдЯѓНјааДѓЙцФЃЧЈвЦЁЃ |
|
ШчКЮНјааДѓЙцФЃдкЯпЪ§ОнЧЈвЦ
ЙЄГЬЭХЖгГЃУцСйвЛЯюЙВЭЌЬєеНЃКжиаТЩшМЦЪ§ОнФЃаЭвджЇГжЧхЮњзМШЗЕФГщЯѓКЭИќИДдгЕФЙІФмЁЃетвтЮЖзХЃЌдкЩњВњЛЗОГжаЃЌашвЊЧЈвЦЪ§вдАйЭђМЦЕФЛюдОЪ§ОнЖдЯѓЃЌВЂЧвжиЙЙЩЯЧЇааДњТыЁЃ
гУЛЇЦкЭћ Stripe API БЃеЯПЩгУадКЭвЛжТадЁЃЫљвддкНјааЧЈвЦЪБЃЌашвЊИёЭтНїЩїЃЌБиаыБЃжЄЪ§ОнЕФЪ§жЕе§ШЗЮоЮѓЃЌВЂЧв
Stripe ЕФЗўЮёЪМжеБЃГжПЩгУЁЃ
БОЮФНЋеЙЪОЙњЭтвЦЖЏжЇИЖЗўЮёЩЬ Stripe ШчКЮАВШЋЕиЖдЪ§вдвкМЦЕФ SubscriptionsЃЈЖЉдФЗўЮёЃЉЖдЯѓНјааДѓЙцФЃЧЈвЦЁЃ
ЮЊЪВУДЧЈвЦРЇФбЃП
1.Ъ§ОнЙцФЃ
Ъ§вдвкМЦЕФ Subscriptions ЖдЯѓЁЃдкЩњВњЛЗОГЪ§ОнПтЩЯНјааЩцМАЕНЫљгаетаЉЖдЯѓЕФДѓЙцФЃЧЈвЦЛсгаОоДѓЕФЙЄзїСПЁЃ
ЯыЯѓвЛЯТЃЌЧЈвЦвЛИі Subscription ЖдЯѓашвЊЛЈЗбвЛУыжгЃЌШєвдЫГађЗНЪНЧЈвЦвЛвкИіЖдЯѓНЋЛЈЗбГЌЙ§Ш§ФъЕФЪБМфЁЃ
2.ЗўЮёдЫааЪБМф
ЩЬвЕЛњЙЙГжајЭЈЙ§ Stripe ЕФЗўЮёНјааНЛвзЁЃЫљгаЕФЛљДЁЩшЪЉЩ§МЖЖМЪЧдкЯпНјааЃЌЖјВЛвРРЕгкгаМЦЛЎЕФЮЌЛЄЪБЖЮЁЃвђЮЊВЛФмдкЧЈвЦЙ§ГЬжажаЖЯ
Subscriptions ЗўЮёЃЌдкетИіЧЈвЦЙ§ГЬжаБиаывЊБЃжЄЫљгаЗўЮё 100% ДІгкПЩгУзДЬЌЁЃ
3.Ъ§Оне§ШЗад
ДњТыПтжаЕФКмЖрДњТыЖМдкЪЙгУ Subscriptions Ъ§ОнПтБэЁЃШчЙћЪдЭМвЛДЮадаоИФећИі Subscriptions
ЗўЮёжаЪ§вдЧЇМЦЕФДњТыааЃЌФЧМИКѕПЯЖЈЛсКіЪгвЛаЉБпНчЧщПі ЁЃЙЄГЬЭХЖгБиаыШЗБЃУПЯюЗўЮёЖМФмЙЛГжајЛёШЁе§ШЗЮоЮѓЕФЪ§ОнЁЃ
дкЯпЧЈвЦЕФФЃЪН
НЋЪ§АйЭђИіЖдЯѓДгОЩЪ§ОнПтБэЧЈвЦЕНаТБэЪЧКмгаФбЖШЕФЃЌЕЋаэЖрЙЋЫОашвЊШЅзіетбљЕФЪТЧщЁЃ
вдЯТЪЧдкНјааДѓаЭдкЯпЧЈвЦжаГЃгУЕФ 4 ВНЁБЫЋаДФЃЪНЁАЃЌОпЬхВНжшЪЧЃК
1.ЯђОЩБэКЭаТБэЫЋаДЪ§ОнвдБЃжЄЫќУЧжЎМфЕФЪ§ОнЪЧЭЌВНЕФЁЃ
2.аоИФДњТыПтжаЫљгаЕФЪ§ОнЖСШЁТЗОЖвдДгаТБэЖСШЁЪ§ОнЁЃ
3.аоИФДњТыПтжаЫљгаЕФЪ§ОнаДШыТЗОЖвдНЋЪ§ОнжЛаДШыаТБэЁЃ
4.ЩОГ§вРРЕЙ§ЪБЪ§ОнФЃаЭЕФОЩЪ§ОнЁЃ
ЧЈвЦЪОР§ЃКSubscriptions
ЪВУДЪЧSubscriptionsЃПЮЊЪВУДашвЊНјааЪ§ОнЧЈвЦЃП
Stripe ЕФ Subscriptions гУгкАяжњ DigitalOcean КЭ Squarespace
етРргУЛЇЙЙНЈВЂЙмРэЫћУЧПЭЛЇЕФбЛЗМЦЗбЁЃдкЙ§ШЅМИФъжаЃЌЮвУЧЮШВНдіМгСЫвЛаЉЙІФмРДжЇГжИќИДдгЕФМЦЗбФЃЪНЃЌР§ШчЖрЖЉдФЁЂЪдгУЁЂгХЛнШЏКЭЗЂЦБЁЃ
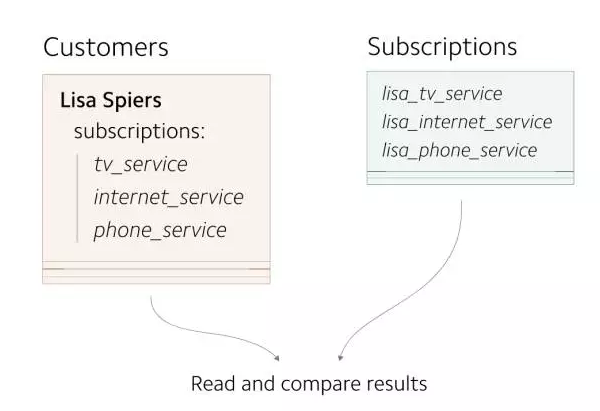
дкдчЦкЃЌУПИі Customer ЖдЯѓзюЖржЛгавЛИі subscription ЁЃ customers
аХЯЂДцДЂЮЊЕЅЖРЕФМЧТМЁЃвђЮЊ customers ЕН subscriptions жЎМфЕФгГЩфЙиЯЕЗЧГЃМђЕЅЃЌЫљвдsubscriptions
аХЯЂгы customers аХЯЂДцДЂдквЛЦ№ЁЃ
| class
Customer
Subscription subscription
end |
зюжеЃЌЮвУЧЕФгУЛЇЯывЊОпгаЖрИі subscriptions ЕФ customers ЁЃЮвУЧОіЖЈНЋЕЅвЛЕФ
subscription зжЖЮзЊЛЛЮЊ subscriptions зжЖЮЃЌвдБуДцДЂОпгаЖрИі subscription
ЕФЪ§зщЁЃ
| class
Customer
def subscriptions
hard_assertion_failed("Accessing subscriptions
array on customer")
end
end |
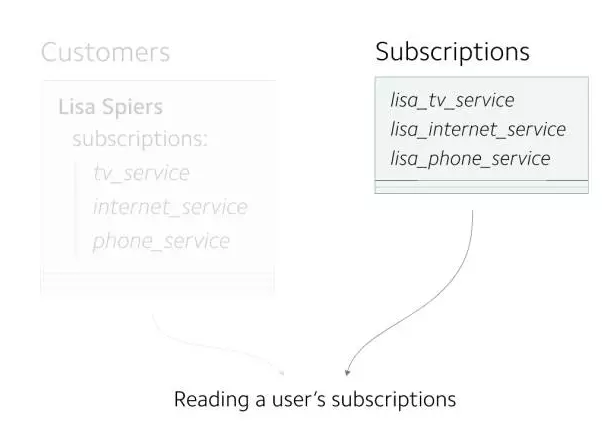
ЕБЬэМгаТЙІФмЪБЃЌетИіЪ§ОнФЃаЭБуГіЯжЮЪЬтСЫЁЃШЮКЮЖд subscriptions
ЕФаоИФЖМЛсв§ЗЂећЬѕ Customer МЧТМЕФИќаТЃЌвдМА subscriptions ЯрЙиЕФВщбЏЖМвЊЭЈЙ§ЩЈУш
customer ЖдЯѓЪЕЯжЁЃЫљвдЮвУЧОіЖЈНЋ subscriptions ЖРСЂДцДЂЁЃ
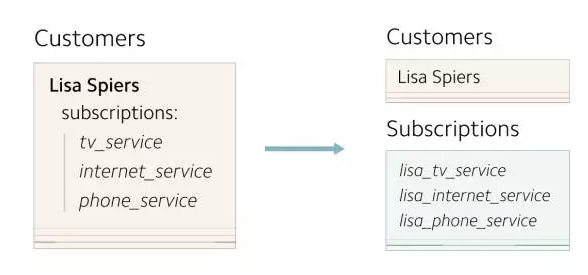
ЃЈжиаТЩшМЦЕФЪ§ОнФЃаЭНЋ subscriptions
зЊвЦЕНЖРСЂЕФЪ§ОнБэжаЃЉ
ЬсабвЛЯТЃЌЫФВНЧЈвЦЗНАИШчЯТЃК
1.ЯђОЩБэКЭаТБэЫЋаДЪ§ОнвдБЃжЄЫќУЧжЎМфЕФЪ§ОнЪЧЭЌВНЕФЁЃ
2.аоИФДњТыПтжаЫљгаЕФЪ§ОнЖСШЁТЗОЖвдДгаТБэЖСШЁЪ§ОнЁЃ
3.аоИФДњТыПтжаЫљгаЕФЪ§ОнаДШыТЗОЖвдНЋЪ§ОнжЛаДШыаТБэЁЃ
4.ЩОГ§вРРЕЙ§ЪБЪ§ОнФЃаЭЕФОЩЪ§ОнЁЃ
ЯТУцНщЩметЫФИіВНжшЕФОпЬхЪЕМљЁЃ
ЕквЛВНЃКЫЋаД
ДДНЈвЛеХаТЕФЪ§ОнПтБэЃЌзїЮЊЧЈвЦЕФПЊЪМЁЃЕквЛВНЪЧПЊЪМИДжЦаТЪ§ОнЃЌЭЌЪБаДШыаТОЩСНДІДцДЂжаЁЃжЎКѓЃЌдйНЋШБЪЇЕФЪ§ОнЛиЬюжСаТДцДЂЃЌвбЪЙСНДІДцДЂОпгаЯрЭЌЕФЪ§Он
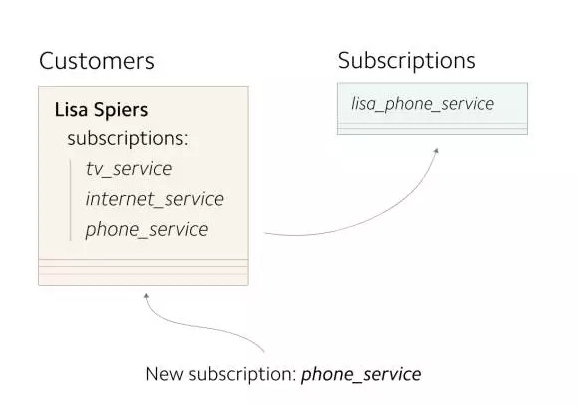
ЃЈЫљгааТаДШыЕФЪ§ОнЖМгІИќаТаТОЩСНДІДцДЂЃЉ
дк Stripe ЕФАИР§жаЃЌЮвУЧНЋЫљгааТДДНЈЕФ subscriptions ЭЌЪБаДШы Customers
БэКЭ Subscriptions БэЁЃдкПЊЪМЫЋаДСНеХБэжЎЧАЃЌашвЊЦРЙРЖюЭтЕФаДШыВйзїЖдЩњВњЛЗОГЪ§ОнПтадФмЕФЧБдкгАЯьЁЃПЩвдЭЈЙ§ЛКТ§ЬсИпжиИДЖдЯѓЕФАйЗжБШРДЛКНтадФмЮЪЬтЃЌЭЌЪБГжајЙизЂЯЕЭГдЫаажИБъЁЃ
НјааЕНДЫЪБЃЌаТДДНЈЕФЖдЯѓвбЭЌЪБДцдкгкСНеХБэжаЃЌЖјОЩЖдЯѓжЛФмдкОЩБэжаевЕНЁЃНгЯТРДНЋвдРСЖшЗНЪНЃЈ lazy
fashion ЃЉПЊЪМИДжЦвбДцдкЕФОЩЖдЯѓЃКУПЕБЖдЯѓИќаТЪБЃЌНЋЫќУЧздЖЏИДжЦЕНаТБэжаЁЃетжжЗНЪНПЩж№ВНзЊвЦвбДцдкЕФЪ§ОнЁЃ
зюКѓЃЌНЋЪЃгрЕФ subscriptions Ъ§ОнЛиЬюжСаТБэЁЃ
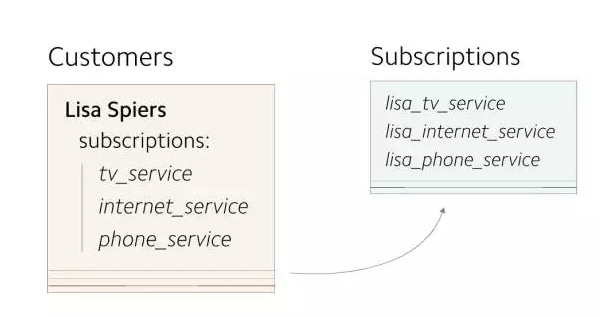
ЃЈЛиЬювбДцдк subscriptions
Ъ§ОнжСаТБэЃЉ
дке§дкЖдЭтЬсЙЉЗўЮёЕФЪ§ОнПтЩЯевЕНЫљгаашвЊЧЈвЦЕФЪ§ОнЪЧЛиЬюВйзїжаДњМлзюДѓЕФВПЗжЁЃЭЈЙ§ВщбЏЪ§ОнПтВщевЫљгаЖдЯѓЕФЗНЪННЋашвЊдкЩњВњЛЗОГЪ§ОнПтЩЯжДааЯрЕБЖрЕФВщбЏВйзїЃЌетНЋКФЗбКмЖрЪБМфЁЃавдЫЕФЪЧЃЌПЩвдНЋЪ§ОнДгЯпЩЯЕМШыЖдЩњВњЛЗОГЪ§ОнПтЭъШЋЮогАЯьЕФРыЯпСїГЬжаЁЃЮвУЧДДНЈЪЪгУгкЮвУЧ
Hadoop МЏШКЕФЪ§ОнПтПьееЃЌетШУЮвУЧПЩвдЪЙгУ MapReduce вдРыЯпЁЂЗжВМЪНЕФЗНЪНПьЫйДІРэЪ§ОнЁЃ
ЮвУЧЪЙгУ Scalding РДЙмРэ MapReduce зївЕЁЃ Scalding ЪЧгУ Scala
БраДЕФЗЧГЃЪЕгУЕФПтЃЌПЩвдКмШнвзЕиБраДMapReduceзївЕЃЈ10ааДњТыМДПЩЪЕЯжвЛИіМђЕЅЕФзївЕЃЉЁЃ дкетжжЧщПіЯТЃЌЪЙгУ
Scalding АяжњЙЄГЬЭХЖгевГіЫљгаsubscriptions Ъ§ОнЁЃОпЬхВНжшШчЯТЃК
1.БраДвЛЗн Scalding зївЕЃЌЬсЙЉЫљгаашвЊИДжЦЕФ subscription
ID ЕФСаБэЁЃ
2.ЭЈЙ§вЛзщНјГЬВЂаажДааРДДѓЙцФЃЕФИДжЦ subscriptions
Ъ§ОнЁЃ
3.ЧЈвЦЭъГЩКѓЃЌашдйДЮдЫаа Scalding зївЕЃЌвдШЗБЃЫљга subscriptions
Ъ§ОнЖМвбДцдкгк Subscriptions БэжаЁЃ
ЕкЖўВНЃКИФБфЫљгаЖСВйзїТЗОЖ
ЕНФПЧАЮЊжЙЃЌаТОЩЪ§ОнБэвбЪЧЭЌВНзДЬЌЁЃЯТвЛВНвЊзіЕФЪЧдкаТБэЩЯНјааЫљгаЕФЖСВйзїЁЃ
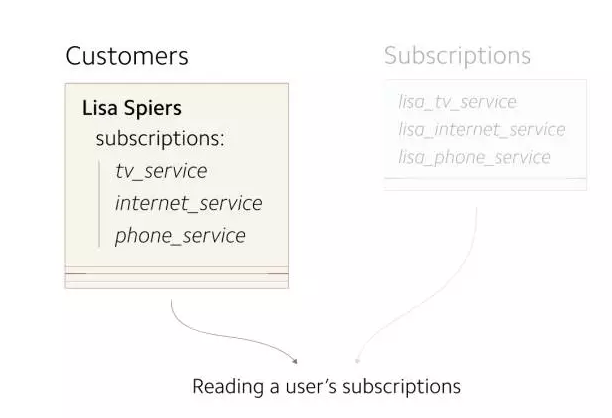
ЃЈФПЧАЃЌЫљгаЕФЖСВйзїдк Customers
БэЩЯНјааЃЌашвЊНЋетаЉВйзїзЊвЦЕН Subscriptions БэЩЯЃЉ
ашвЊШЗБЃДгаТБэЖСЪ§ОнЪЧАВШЋЕФЃЌsubscription дкаТОЩБэжаЕФЪ§ОнгІИУЪЧвЛжТЕФЁЃПЩвдЪЙгУ GitHub
ГіЦЗЕФ Scientist РДИЈжњбщжЄЖСВйзїЁЃScientist ЪЧвЛИі Ruby ПтЃЌ ЫќПЩвдШУЮвУЧдкЩњВњЛЗОГдЫааЪЕбщЃЌБШЖдВЛЭЌДњТыЕФдЫааНсЙћВЂЖдВЛвЛжТЕФНсЙћЗЂГіОЏИц
ЁЃЭЈЙ§ Scientist ЃЌПЩЪЕЪБЩњГЩеыЖдВЛвЛжТНсЙћЕФОЏИцКЭжИБъЁЃЕБЪЕбщДњТыжаЗЂЩњДэЮѓЃЌЦфгрЕФгІгУГЬађЪЧВЛЛсЪмЕНШЮКЮгАЯьЕФЁЃ
ЪЕбщАДШчЯТНјааЃК
1.ЪЙгУ Scientist Дг Subscriptions БэКЭ
Customers БэЭЌЪБЖСШЁЪ§ОнЁЃ
2.ШчЙћЖСШЁЕНЕФЪ§ОнВЛвЛжТЃЌдђЯђЙЄГЬЭХЖгЗЂГіОЏИцЁЃ
GitHub ЕФ Scientist ПЩдЫааЖСШЁСНеХБэВЂЖдЪ§ОнзіЖдБШЕФЪЕбщЁЃ
дкШЗШЯЫљгаЪ§ОнЪЧвЛжТЕФКѓЃЌОЭПЩвдПЊЪМДгаТБэЖСШЁЪ§ОнСЫЁЃ
ЃЈЪЕбщГЩЙІЃЌЯждкЫљгаЕФЖСВйзїЖМдк Subscriptions
БэЩЯНјааЃЉ
ЕкШ§ВНЃКИФБфЫљгааДВйзїТЗОЖ
НгЯТРДЃЌашвЊИќаТаДВйзїТЗОЖЃЌНЋЪ§ОнаДШыаТЕФ Subscriptions БэЁЃ ЪЕЪЉЕФФПБъЪЧж№ВНЭЦНјетаЉИФБфЃЌЫљвдашвЊВЩШЁНїЩїЕФВпТдЁЃ
жБЕНЯждкЃЌЪ§ОнвЛжБаДШыОЩБэЃЌШЛКѓБЛИДжЦЕНаТБэЃК

ЯждквЊЕпЕЙетИіЫГађЃКЯШНЋЪ§ОнаДШыаТБэЃЌШЛКѓНЋЦфаДШыОЩБэжаЁЃ ЭЈЙ§БЃГжетСНеХБэЕФвЛжТадЃЌЮвУЧПЩвдНјаадіСПИќаТВЂзаЯИЙлВьУПИіИќИФЁЃ
жиЙЙ subscriptions ЕФЫљгааДВйзїДњТыПЩвдЫЕЪЧЧЈвЦжазюОпЬєеНадЕФВПЗжЁЃ Stripe
ЗўЮёжаДІРэ subscriptions ВйзїЕФТпМЃЈР§ШчИќаТЃЌЗжЦкИЖПюЁЂајЗбЃЉЩцМАЖрИіЗўЮёЕФЪ§ЧЇааДњТыЁЃ
ГЩЙІжиЙЙЕФЙиМќЪЧдіСПДІРэЃКНЋОЁПЩФмЖрЕФДњТыТЗОЖЗжИєГЩПЩФмЕФзюаЁЕЅдЊЃЌвдБуПЩвдзаЯИгІгУУПИіИќИФЁЃ аТОЩСНеХБэЕФЪ§ОндкжиЙЙЕФШЮКЮвЛИіНзЖЮЖМашвЊБЃГжвЛжТЁЃ
ЖдгкУПИіДњТыТЗОЖЃЌЮвУЧашвЊЪЙгУећЬхЗНЗЈРДШЗБЃЮвУЧЕФИќИФЪЧАВШЋЕФЁЃ ЮвУЧВЛФмНіНіжЛЪЙгУаТЪ§ОнЬцДњОЩЪ§ОнЃКУПвЛИіТпМПщЖМашвЊзаЯИехзУЁЃ
ШчЙћДэЙ§СЫШЮКЮЧщПіЃЌПЩФмОЭЛсдьГЩЪ§ОнВЛвЛжТЁЃ жЕЕУЧьавЕФЪЧЃЌПЩвддЫааИќЖрЕФ Scientist ЪЕбщРДЬсабЙЄГЬЭХЖгПЩФмДцдкЕФШЮКЮВЛвЛжТЁЃ
аТЕФЃЌМђЛЏЕФаДЪ§ОнТЗОЖШчЯТЫљЪОЃК

ПЩЭЈЙ§дкЕїгУ subscriptions Ъ§зщЪБДЅЗЂБЈДэЕФЗНЗЈЃЌШЗБЃУЛгаДњТыМЬајЪЙгУЙ§ЪБЕФsubscriptions
Ъ§зщЃК
| class
Customer
def subscriptions
hard_assertion_failed("Accessing subscriptions
array on customer")
end
end |
ЕкЫФВНЃКЩОГ§ОЩЪ§Он
зюКѓЕФЃЈвВЪЧзюСюШЫТњвтЕФЃЉВНжшЪЧвЦГ§ОЩЕФаДВйзїДњТыЃЌВЂзюжеЩОГ§ЁЃ
вЛЕЉШЗЖЈУЛгаШЮКЮДњТывРРЕЙ§ЪБЪ§ОнФЃаЭЕФ subscriptions зжЖЮЃЌОЭВЛдйашвЊНЋЪ§ОнаДШыОЩБэЃК

ЫцзХетвЛБфЛЏЃЌДњТыВЛдйЪЙгУОЩЪ§ОндДЃЌаТЪ§ОндДГЩЮЊЮЈвЛЪ§ОндДЁЃ
ЯждкЃЌПЩвдЩОГ§Ыљга Customer ЖдЯѓЩЯЕФ subscriptions Ъ§зщЃЌВЂЧвж№НЅвдРСЖшЕФЗНЪНДІРэЁАЩОГ§ЁБВйзїЁЃ
УПДЮ subscription БЛМгдиКѓЃЌЖМЛсздЖЏЧхПеетИі subscriptions Ъ§зщЃЌШЛКѓдЫаа
Scalding зївЕВЂЧЈвЦЃЌвдВщевШЮКЮЪЃгрЕФвЊЩОГ§ЕФЖдЯѓЁЃ зюжеЕФЪ§ОнФЃаЭШчЯТЃК

НсТл
дкБЃжЄ Stripe API Ъ§ОнвЛжТадЕФЭЌЪБНјааЧЈвЦЪЧЗЧГЃИДдгЕФЙЄзїЁЃАВШЋНјааетЯюЧЈвЦЕФМИИівЊЕуЪЧЃК
ЮвУЧжЦЖЈСЫвЛИіЫФНзЖЮЧЈвЦВпТдЃЌПЩвдШУЮвУЧдкЩњВњЛЗОГжаВЛЭЃЗўНјааЪ§ОнЧаЛЛЁЃ
1.ЪЙгУHadoopРыЯпДІРэЪ§ОнЃЌЪЙгУMapReduceвдВЂааЗНЪНДІРэДѓСПЪ§ОнЃЌЖјВЛЪЧвРРЕдкЩњВњЛЗОГЪ§ОнПтЩЯжДааЕФДњМлИпАКЕФВщбЏЁЃ
2.ЫљзіЕФЫљгаИќИФЖМЪЧНЅНјЪНЕФЁЃ ЮвУЧДгЮДЪдЭМвЛДЮИќИФМИАйааДњТыЁЃ
3.ЫљгаЕФБфЛЏЖМЪЧИпЖШЭИУїКЭПЩЙлВьЕФЁЃ Scientist ЕФЪЕбщжЛвЊгавЛЬѕЪ§ОндкЩњВњЛЗОГжаЪЧВЛвЛжТЕФЃЌОЭСЂМДЬсабЙЄГЬЭХЖгЁЃ
дкећИіЧЈвЦЙ§ГЬжаЃЌЮвУЧЖМЖдАВШЋЕФЧЈвЦЛГгааХаФЁЃ
4.ЮвУЧЗЂЯжетжжЗНЗЈдкЮвУЧжДааЙ§ЕФаэЖрдкЯпЪ§ОнЧЈвЦжаЖМКмгааЇЁЃЮвУЧЯЃЭћетаЉЪЕМљзіЗЈЖдгкЦфЫћЭХЖгНјааДѓЙцФЃЧЈвЦвВЪЧгаАяжњЕФЁЃ
|









