адФмЯТНЕSQLТ§ЁЂжДааЪБМфГЄЁЂЕШД§ЪБМфГЄ
- ВщбЏгяОфаДЕФРУ
- Ыїв§ЪЇаЇ
- ЙиСЊВщбЏЬЋЖрjoinЃЈЩшМЦШБЯнЛђВЛЕУвбЕФашЧѓЃЌГ§ЗЧФуФмИЩЕФЙ§ФуЕФВњЦЗОРэЃЉ
- ЗўЮёЦїЕїгХМАИїИіВЮЪ§ЩшжУЃЈЛКГхЁЂЯпГЬЪ§ЕШЃЉ
ГЃМћЭЈгУЕФJoinВщбЏ
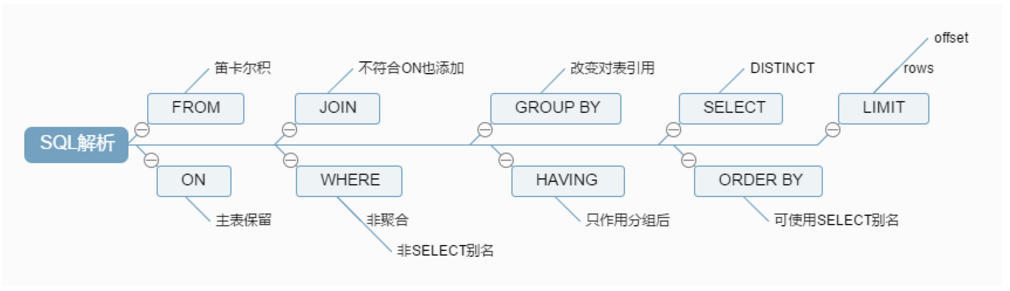
SQLжДааЫГађ
ЪжаД

ЪжаДSQLЫГађ
SELECT DISTINCT
<select_list>
FROM
<left_table> <join_type>
JOIN <right_table> ON <join_condition>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
ORDER BY
<order_by_condition>
LIMIT <limit_number> |
ЛњЖСЃЈMySQLЖСШЁЫГађЃЉ

ЛњЖСЫГађ
FROM
<left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE
<where_condition>
GROUP BY
<group_by_list>
HAVING
<having_condition>
SELECT DISTINCT
<select_list>
ORDER BY
<order_by_condition>
LIMIT <limit_number> |
змНс-SQLНтЮіЫГађ
SQLНтЮі
SQL JOINs
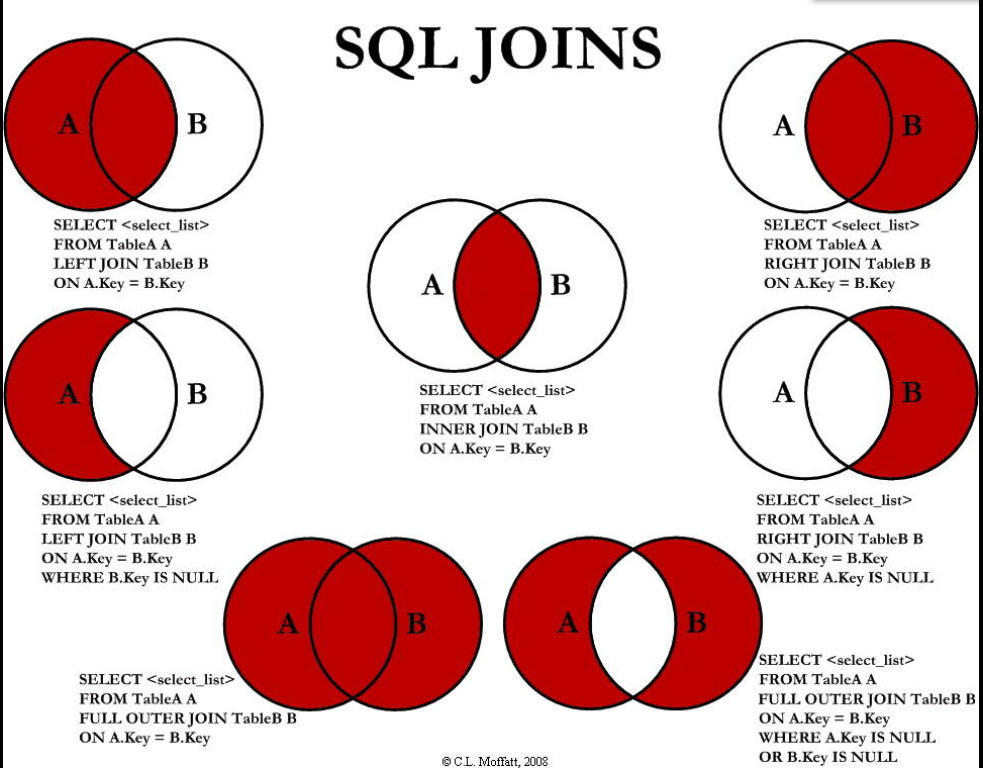
ЦпжжJOINЭМНт
ЪЕбщЃК
-- НЈБэКЭЪ§ОнSQL
CREATE TABLE `tbl_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`locAdd` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `tbl_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `tbl_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_dept(deptName,locAdd) VALUES('RD',11);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('HR',12);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MK',13);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MIS',14); |
СЗЯА
1ЁЂAЁЂBСНБэЙВга
| select * from tbl_emp a inner join tbl_dept b on a.deptId = b.id; |
2ЁЂAЁЂBСНБэЙВга+AЕФЖРга
| select * from tbl_emp a left join tbl_dept b on a.deptId = b.id |
3ЁЂAЁЂBСНБэЙВга+BЕФЖРга
| select * from tbl_emp a right join tbl_dept b on a.deptId = b.id; |
4ЁЂAЕФЖРга
| select * from tbl_emp a left join tbl_dept b on a.deptId = b.id where b.id is null; |
5ЁЂBЕФЖРга
| select * from tbl_emp a right join tbl_dept b on a.deptId = b.id where a.deptId is null; |
6ЁЂABШЋга
MySQL Full JoinЕФЪЕЯж вђЮЊMySQLВЛжЇГжFULL JOIN,ЯТУцЪЧЬцДњЗНЗЈ
left join + union(ПЩШЅГ§жиИДЪ§Он)+ right join
ЪЕЯжШчЯТУцДњТы
7ЁЂAЕФЖРга + BЕФЖРга
-- 6ЁЂABШЋга
SELECT *
FROM tbl_emp a LEFT JOIN tbl_dept b ON a.deptId = b.id
UNION
SELECT *
FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.deptId = b.id;
-- 7ЁЂAЕФЖРга + BЕФЖРга
SELECT *
FROM tbl_emp a LEFT JOIN tbl_dept b ON a.deptId = b.id
WHERE b.id IS NULL
UNION
SELECT *
FROM tbl_emp a RIGHT JOIN tbl_dept b ON a.deptId = b.id
WHERE a.`deptId` IS NULL; |
Ыїв§МђНщ
ЪВУДЪЧЫїв§
MySQLЙйЗНЖдЫїв§ЕФЖЈвхЮЊЃКЫїв§ЃЈIndexЃЉЪЧАяжњMySQLИпаЇЛёШЁЪ§ОнЕФЪ§ОнНсЙЙЁЃ
- ПЩвдЕУЕНЫїв§ЕФБОжЪЃКЫїв§ЪЧЪ§ОнНсЙЙЁЃ
- Ыїв§ЕФФПЕФдкгкЬсИпВщбЏаЇТЪЃЌПЩвдРрБШзжЕфЃЌ
- ШчЙћвЊВщЁАmysqlЁБетИіЕЅДЪЃЌЮвУЧПЯЖЈашвЊЖЈЮЛЕНmзжФИЃЌШЛКѓДгЯТЭљЯТевЕНyзжФИЃЌдйевЕНЪЃЯТЕФsqlЁЃ
- ШчЙћУЛгаЫїв§ЃЌФЧУДФуПЩФмашвЊa----zЃЌШчЙћЮвЯыевЕНJavaПЊЭЗЕФЕЅДЪФиЃПЛђепOracleПЊЭЗЕФЕЅДЪФиЃП
- ЪЧВЛЪЧОѕЕУШчЙћУЛгаЫїв§ЃЌетИіЪТЧщИљБОЮоЗЈЭъГЩЃП
ФуПЩвдМђЕЅРэНтЮЊЁАХХКУађЕФПьЫйВщевНсЙЙЁБ
- дкЪ§ОнжЎЭтЃЌЪ§ОнПтЯЕЭГЛЙЮЌЛЄзХТњзуЬиЖЈВщевЫуЗЈЕФЪ§ОнНсЙЙЃЌетаЉЪ§ОнНсЙЙвдФГжжЗНЪНв§гУЃЈжИЯђЃЉЪ§ОнЃЌетбљОЭПЩвддкетаЉЪ§ОнНсЙЙЩЯЪЕЯжИпМЖВщевЫуЗЈЁЃетжжЪ§ОнНсЙЙЃЌОЭЪЧЫїв§ЁЃ
- ЯТЭМОЭЪЧвЛжжПЩФмЕФЫїв§ЗНЪНЪОР§ЃК
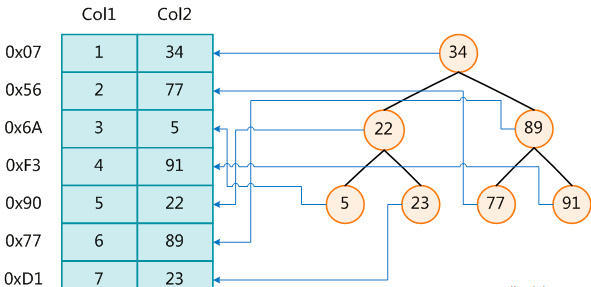
- ЮЊСЫМгПьCol2ЕФВщевЃЌПЩвдЮЌЛЄвЛИігвБпЫљЪОЕФЖўВцВщевЪїЃЌУПИіНкЕуЗжБ№АќКЌЫїв§МќжЕКЭвЛИіжИЯђЖдгІЪ§ОнМЧТМЮяРэЕижЗЕФжИеыЃЌетбљОЭПЩвддЫгУЖўВцВщевдквЛЖЈЕФИДдгЖШФкЛёШЁЕНЯргІЪ§ОнЃЌДгЖјПьЫйЕФМьЫїГіЗћКЯЬѕМўЕФМЧТМЁЃ
вЛАуРДЫЕЫїв§БОЩэвВКмДѓЃЌВЛПЩФмШЋВПДцДЂдкФкДцжаЃЌвђДЫЫїв§ЭљЭљвдЫїв§ЮФМўЕФаЮЪНДцДЂЕФДХХЬЩЯ
ЮвУЧЦНГЃЫљЫЕЕФЫїв§ЃЌШчЙћУЛгаЬиБ№жИУїЃЌЖМЪЧжИB+ЪїНсЙЙзщжЏЕФЫїв§ЁЃЦфжаОлМЏЫїв§ЃЌДЮвЊЫїв§ЃЌИВИЧЫїв§ЃЌИДКЯЫїв§ЃЌЧАзКЫїв§ЃЌЮЈвЛЫїв§ФЌШЯЖМЪЧЪЙгУB+ЪїЫїв§ЃЌЭГГЦЫїв§ЁЃЕБШЛЃЌГ§СЫB+ЪїетжжРраЭЕФЫїв§жЎЭтЃЌЛЙгаЙўЯЁЫїв§(hash index)ЕШЁЃ
Ыїв§ЕФгХЪЦ
РрЫЦДѓбЇЭМЪщЙнНЈЪщФПЫїв§ЃЌЬсИпЪ§ОнМьЫїЕФаЇТЪЃЌНЕЕЭЪ§ОнПтЕФIOГЩБО
ЭЈЙ§Ыїв§СаЖдЪ§ОнНјааХХађЃЌНЕЕЭЪ§ОнХХађЕФГЩБОЃЌНЕЕЭСЫCPUЕФЯћКФ
Ыїв§ЕФСгЪЦ
ЪЕМЪЩЯЫїв§вВЪЧвЛеХБэЃЌИУБэБЃДцСЫжїМќгыЫїв§зжЖЮЃЌВЂжИЯђЪЕЬхБэЕФМЧТМЃЌЫљвдЫїв§СавВЪЧвЊеМгУПеМфЕФ
ЫфШЛЫїв§ДѓДѓЬсИпСЫВщбЏЫйЖШЃЌЭЌЪБШДЛсНЕЕЭИќаТБэЕФЫйЖШЃЌШчЖдБэНјааINSERTЁЂUPDATEКЭDELETEЁЃвђЮЊИќаТБэЪБЃЌMySQLВЛНівЊБЃДцЪ§ОнЃЌЛЙвЊБЃДцвЛЯТЫїв§ЮФМўУПДЮИќаТЬэМгСЫЫїв§СаЕФзжЖЮЃЌЖМЛсЕїећвђЮЊИќаТЫљДјРДЕФМќжЕБфЛЏКѓЕФЫїв§аХЯЂ
Ыїв§жЛЪЧЬсИпаЇТЪЕФвЛИівђЫиЃЌШчЙћФуЕФMySQLгаДѓЪ§ОнСПЕФБэЃЌОЭашвЊЛЈЪБМфбаОПНЈСЂзюгХауЕФЫїв§ЃЌЛђгХЛЏВщбЏгяОф
MySQLЫїв§ЗжРр
ЕЅжЕЫїв§
МДвЛИіЫїв§жЛАќКЌЕЅИіСаЃЌвЛИіБэПЩвдгаЖрИіЕЅСаЫїв§
ЮЈвЛЫїв§
Ыїв§СаЕФжЕБиаыЮЈвЛЃЌЕЋдЪаэгаПежЕ
ИДКЯЫїв§
МДвЛИіЫїАќКЌЖрИіСа
ЛљБОгяЗЈ
ДДНЈЃЌСНжжЗНЪН
| CREATE [UNIQUE ] INDEX indexName ON mytable(columnname(length)); |
ШчЙћЪЧCHARЃЌVARCHARРраЭЃЌlength ПЩвдаЁгкзжЖЮЪЕМЪГЄЖШЃЛ
ШчЙћЪЧ BLOB КЭ TEXT РраЭЃЌБиаыжИЖЈ lengthЁЃ
| ALTER mytable ADD [UNIQUE ] INDEX [indexName] ON (columnname(length)) |
ЩОГ§
| DROP INDEX [indexName] ON mytable; |
ВщПД
| SHOW INDEX FROM table_name\G |
ЪЙгУAlter УќСю
гаЫФжжЗНЪНРДЬэМгЪ§ОнБэЕФЫїв§ЃК
| ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) |
ИУгяОфЬэМгвЛИіжїМќЃЌетвтЮЖзХЫїв§жЕБиаыЪЧЮЈвЛЕФЃЌЧвВЛФмЮЊNULLЁЃ
| ALTER TABLE tbl_name ADD UNIQUE index_name (column_list) |
етЬѕгяОфДДНЈЫїв§ЕФжЕБиаыЪЧЮЈвЛЕФЃЈГ§СЫNULLЭтЃЌNULLПЩФмЛсГіЯжЖрДЮЃЉЁЃ
| ALTER TABLE tbl_name ADD INDEX index_name (column_list) |
ЬэМгЦеЭЈЫїв§ЃЌЫїв§жЕПЩГіЯжЖрДЮЁЃ
| ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list) |
ИУгяОфжИЖЈСЫЫїв§ЮЊ FULLTEXT ЃЌгУгкШЋЮФЫїв§ЁЃ
MySQLЫїв§НсЙЙ
BTreeЫїв§
МьЫїдРэ
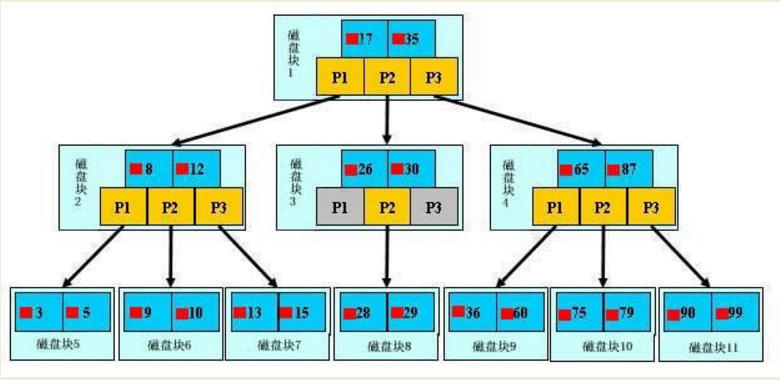
вЛПХb+ЪїЃЌЧГРЖЩЋЕФПщЮвУЧГЦжЎЮЊвЛИіДХХЬПщЃЌПЩвдПДЕНУПИіДХХЬПщАќКЌМИИіЪ§ОнЯюЃЈЩюРЖЩЋЫљЪОЃЉКЭжИеыЃЈЛЦЩЋЫљЪОЃЉЃЌШчДХХЬПщ1АќКЌЪ§ОнЯю17КЭ35ЃЌАќКЌжИеыP1ЁЂP2ЁЂP3ЁЃ P1БэЪОаЁгк17ЕФДХХЬПщЃЌP2БэЪОдк17КЭ35жЎМфЕФДХХЬПщЃЌP3БэЪОДѓгк35ЕФДХХЬПщЁЃ
ецЪЕЕФЪ§ОнДцдкгквЖзгНкЕуМД 3ЁЂ5ЁЂ9ЁЂ10ЁЂ13ЁЂ15ЁЂ28ЁЂ29ЁЂ36ЁЂ60ЁЂ75ЁЂ79ЁЂ90ЁЂ99ЁЃ
ЗЧвЖзгНкЕужЛВЛДцДЂецЪЕЕФЪ§ОнЃЌжЛДцДЂжИв§ЫбЫїЗНЯђЕФЪ§ОнЯюЃЌШч17ЁЂ35ВЂВЛецЪЕДцдкгкЪ§ОнБэжаЁЃ
ШчЙћвЊВщевЪ§ОнЯю29ЃЌФЧУДЪзЯШЛсАбДХХЬПщ1гЩДХХЬМгдиЕНФкДцЃЌДЫЪБЗЂЩњвЛДЮIOЃЌдкФкДцжагУЖўЗжВщевШЗЖЈ29дк17КЭ35жЎМфЃЌЫјЖЈДХХЬПщ1ЕФP2жИеыЃЌФкДцЪБМфвђЮЊЗЧГЃЖЬЃЈЯрБШДХХЬЕФIOЃЉПЩвдКіТдВЛМЦЃЌЭЈЙ§ДХХЬПщ1ЕФP2жИеыЕФДХХЬЕижЗАбДХХЬПщ3гЩДХХЬМгдиЕНФкДцЃЌЗЂЩњЕкЖўДЮIOЃЌ29дк26КЭ30жЎМфЃЌЫјЖЈДХХЬПщ3ЕФP2жИеыЃЌЭЈЙ§жИеыМгдиДХХЬПщ8ЕНФкДцЃЌЗЂЩњЕкШ§ДЮIOЃЌЭЌЪБФкДцжазіЖўЗжВщевевЕН29ЃЌНсЪјВщбЏЃЌзмМЦШ§ДЮIOЁЃ
ецЪЕЕФЧщПіЪЧЃЌ3ВуЕФb+ЪїПЩвдБэЪОЩЯАйЭђЕФЪ§ОнЃЌШчЙћЩЯАйЭђЕФЪ§ОнВщевжЛашвЊШ§ДЮIOЃЌадФмЬсИпНЋЪЧОоДѓЕФЃЌШчЙћУЛгаЫїв§ЃЌУПИіЪ§ОнЯюЖМвЊЗЂЩњвЛДЮIOЃЌФЧУДзмЙВашвЊАйЭђДЮЕФIOЃЌЯдШЛГЩБОЗЧГЃЗЧГЃИпЁЃ |









