| Ъ§ОнвЛжТадЪЧЙЙНЈвЕЮёЯЕЭГашвЊПМТЧЕФживЊЮЪЬт
ЃЌ вдЭљЮвУЧЪЧвРППЪ§ОнПтРДБЃжЄЪ§ОнЕФвЛжТадЁЃЕЋЪЧдкЮЂЗўЮёМмЙЙвдМАЗжВМЪНЛЗОГЯТЪЕЯжЪ§ОнвЛжТадЪЧвЛИіКмгаЬєеНЕФЕФЮЪЬтЁЃServiceCombзїЮЊПЊдДЕФЮЂЗўЮёПђМмжТСІНтОіЮЂЗўЮёПЊЗЂЙ§ГЬжаЕФЮЪЬтЁЃЮвУЧзюНќЗЂЦ№ЕФServiceComb-SagaЯюФПРДНтОіЗжВМЪНЛЗОГЯТЕФЪ§ОнзюжевЛжТадЮЪЬтЁЃБОЮФНЋЯђДѓМвНщЩмЮЊЪВУДЪ§ОнвЛжТадШчДЫживЊЃПSagaгжЪЧЪВУДЃП
ЕЅЬхгІгУЕФЪ§ОнвЛжТад
ЯыЯѓвЛЯТШчЙћЮвУЧОгЊзХвЛМвДѓаЭЦѓвЕЃЌЯТЪєгаКНПеЙЋЫОЁЂзтГЕЙЋЫОЁЂКЭСЌЫјОЦЕъЁЃЮвУЧЮЊПЭЛЇЬсЙЉвЛеОЪНЕФТУгЮааГЬЙцЛЎЗўЮёЃЌетбљПЭЛЇжЛашвЊЬсЙЉГіааФПЕФЕиЃЌ
ЮвУЧАяжњПЭЛЇдЄЖЉЛњЦБЁЂзтГЕЁЂвдМАдЄЖЉОЦЕъЁЃДгвЕЮёЕФНЧЖШЃЌЮвУЧБиаыБЃжЄЩЯЪіШ§ИіЗўЮёЕФдЄЖЉЖМЭъГЩВХФмТњзувЛИіГЩЙІЕФТУгЮааГЬЃЌЗёдђВЛФмГЩааЁЃ
ЮвУЧЕФЕЅЬхгІгУвЊТњзуетИіашЧѓЗЧГЃМђЕЅЃЌжЛашНЋетИіШ§ИіЗўЮёЧыЧѓЗХЕНЭЌвЛИіЪ§ОнПтЪТЮёжаЃЌЪ§ОнПтЛсАяЮвУЧБЃжЄШЋВПГЩЙІЛђепШЋВПЛиЙіЁЃ
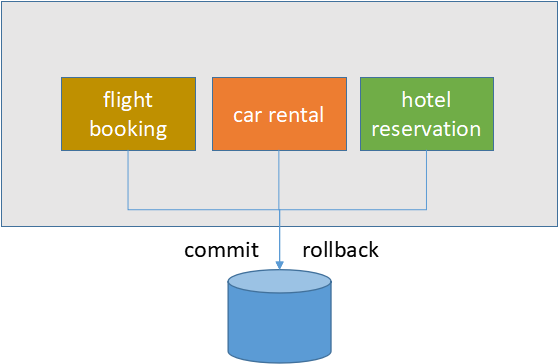
ЕБетИіЙІФмЩЯЯпвдКѓЃЌЙЋЫОЗЧГЃТњвтЃЌПЭЛЇвВЗЧГЃИпаЫЁЃ
ЮЂЗўЮёГЁОАЯТЕФЪ§ОнвЛжТад
етМИФъжаЃЌЮвУЧЕФааГЬЙцЛЎЗўЮёЗЧГЃГЩЙІЃЌЦѓвЕеєеєШеЩЯЃЌгУЛЇСПвВЗСЫЪ§ЪЎБЖЁЃЦѓвЕЕФЯТЪєКНПеЙЋЫОЁЂзтГЕЙЋЫОЁЂКЭСЌЫјОЦЕъвВЯрМЬЭЦГіСЫИќЖрЗўЮёвдТњзуПЭЛЇашЧѓЃЌ
ЮвУЧЕФгІгУКЭПЊЗЂЭХЖгвВвђДЫШеНЅХгДѓЁЃШчНёЮвУЧЕФЕЅЬхгІгУвбБфЕУШчДЫИДдгЃЌвджСгкУЛШЫСЫНтећИігІгУЪЧдѕУДдЫзїЕФЁЃИќдуЕФЪЧаТЙІФмЕФЩЯЯпЯждкашвЊЫљгабаЗЂЭХЖгКЯзїЃЌ
ШевЙЗмеНЪ§жмВХФмЭъГЩЁЃПДзХЪаГЁеМгаТЪУППігњЯТЃЌЙЋЫОИпВуЖдбаЗЂВПУХдНРДдНВЛТњвтЁЃ
ОЙ§Ъ§ТжЬжТлЃЌЮвУЧзюжеОіЖЈНЋХгДѓЕФЕЅЬхгІгУвЛЗжЮЊЫФЃКЛњЦБдЄЖЉЗўЮёЁЂзтГЕЗўЮёЁЂОЦЕъдЄЖЉЗўЮёЁЂКЭжЇИЖЗўЮёЁЃЗўЮёИїздЪЙгУздМКЕФЪ§ОнПтЃЌВЂЭЈЙ§HTTPавщЭЈаХЁЃ
ИКд№ИїЗўЮёЕФЭХЖгИљОнЪаГЁашЧѓАДеездМКЕФПЊЗЂНкзрЗЂАцЩЯЯпЁЃШчНёЮвУЧУцСйаТЕФЬєеНЃКШчКЮБЃжЄзюГѕШ§ИіЗўЮёЕФдЄЖЉЖМЭъГЩВХФмТњзувЛИіГЩЙІЕФТУгЮааГЬЃЌ
ЗёдђВЛФмГЩааЕФвЕЮёЙцдђЃПЯждкЗўЮёгаИїздЕФБпНчЃЌЖјЧвЪ§ОнПтбЁаЭвВВЛОЁЯрЭЌЃЌЭЈЙ§Ъ§ОнПтБЃжЄЪ§ОнвЛжТадЕФЗНАИвбВЛПЩааЁЃ
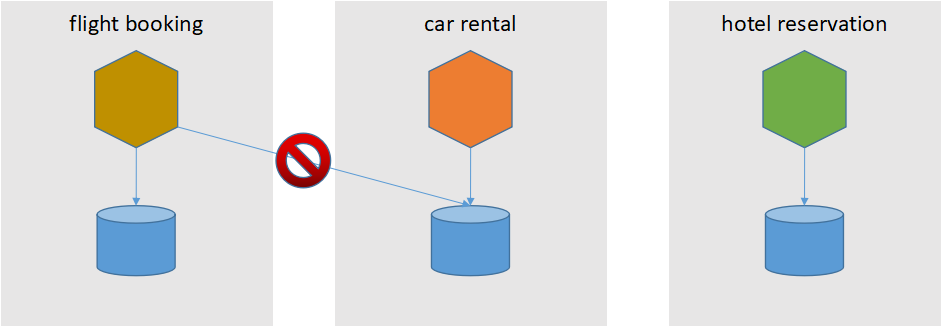
Sagas
авдЫЕФЪЧЮвУЧдкЛЅСЊЭјевЕНвЛЦЊОЋВЪЕФТлЮФЃЌЮФжаЬсГіЕФЪ§ОнвЛжТадНтОіЗНАИSagaЧЁКУТњзуЮвУЧЕФвЕЮёвЊЧѓЁЃ
SagaЪЧвЛИіГЄЛюЪТЮёЃЌПЩБЛЗжНтГЩПЩвдНЛДэдЫааЕФзгЪТЮёМЏКЯЁЃЦфжаУПИізгЪТЮёЖМЪЧвЛИіБЃГжЪ§ОнПтвЛжТадЕФецЪЕЪТЮёЁЃ
дкЮвУЧЕФвЕЮёГЁОАЯТЃЌвЛИіааГЬЙцЛЎЕФЪТЮёОЭЪЧвЛИіSagaЃЌЦфжаАќКЌЫФИізгЪТЮёЃКЛњЦБдЄЖЉЁЂзтГЕЁЂОЦЕъдЄЖЉЁЂКЭжЇИЖЁЃ
Chris RichardsonдкЫћЕФЮФеТPattern: SagaжаЖдSagaгаЫљУшЪіЁЃ Caitie
McCaffreyвВдкЫ§ЕФбнНВжаЬсЕНШчКЮдкЮЂШэЕФЙтдЮ 4гЮЯЗжаШчКЮгІгУsagaНтОіЪ§ОнвЛжТадЮЪЬтЁЃ
SagaЕФдЫаадРэ
SagaжаЕФЪТЮёЯрЛЅЙиСЊЃЌгІзїЮЊЃЈЗЧдзгЃЉЕЅЮЛжДааЁЃШЮКЮЮДЭъШЋжДааЕФSagaЪЧВЛТњзувЊЧѓЕФЃЌШчЙћЗЂЩњЃЌБиаыЕУЕНВЙГЅЁЃвЊаое§ЮДЭъШЋжДааЕФВПЗжЃЌ
УПИіsagaзгНЛвзT1гІЬсЙЉЖдгІВЙГЅЪТЮёC1
ЮвУЧИљОнЩЯЪіЙцдђЖЈвхвдЯТЪТЮёМАЦфЯргІЕФЪТЮёВЙГЅЃК 
ЕБУПИіsagaзгЪТЮё T1, T2, Ё, Tn ЖМгаЖдгІЕФВЙГЅЖЈвх C1, C2, Ё, Cn-1,
ФЧУДsagaЯЕЭГПЩвдБЃжЄ [1]
згЪТЮёађСа T1, T2, Ё, TnЕУвдЭъГЩ (зюМбЧщПі)
ЛђепађСа T1, T2, Ё, Tj, Cj, Ё, C2, C1, 0 < j < n,
ЕУвдЭъГЩ
ЛЛОфЛАЫЕЃЌЭЈЙ§ЩЯЪіЖЈвхЕФЪТЮё/ВЙГЅЃЌsagaБЃжЄТњзувдЯТвЕЮёЙцдђЃК
ЫљгаЕФдЄЖЉЖМБЛжДааГЩЙІЃЌШчЙћШЮКЮвЛИіЪЇАмЃЌЖМЛсБЛШЁЯћ
ШчЙћзюКѓвЛВНИЖПюЪЇАмЃЌЫљгадЄЖЉвВНЋБЛШЁЯћ
SagaЕФЛжИДЗНЪН
дТлЮФжаУшЪіСЫСНжжРраЭЕФSagaЛжИДЗНЪНЃК
ЯђКѓЛжИД ВЙГЅЫљгавбЭъГЩЕФЪТЮёЃЌШчЙћШЮвЛзгЪТЮёЪЇАм
ЯђЧАЛжИД жиЪдЪЇАмЕФЪТЮёЃЌМйЩшУПИізгЪТЮёзюжеЖМЛсГЩЙІ
ЯдШЛЃЌЯђЧАЛжИДУЛгаБивЊЬсЙЉВЙГЅЪТЮёЃЌШчЙћФуЕФвЕЮёжаЃЌзгЪТЮёЃЈзюжеЃЉзмЛсГЩЙІЃЌЛђВЙГЅЪТЮёФбвдЖЈвхЛђВЛПЩФмЃЌЯђЧАЛжИДИќЗћКЯФуЕФашЧѓЁЃ
РэТлЩЯВЙГЅЪТЮёгРВЛЪЇАмЃЌШЛЖјЃЌдкЗжВМЪНЪРНчжаЃЌЗўЮёЦїПЩФмЛсхДЛњЃЌЭјТчПЩФмЛсЪЇАмЃЌЩѕжСЪ§ОнжааФвВПЩФмЛсЭЃЕчЁЃдкетжжЧщПіЯТЮвУЧФмзіаЉЪВУДЃП
зюКѓЕФЪжЖЮЪЧЬсЙЉЛиЭЫДыЪЉЃЌБШШчШЫЙЄИЩдЄЁЃ
ЪЙгУSagaЕФЬѕМў
SagaПДЦ№РДКмгаЯЃЭћТњзуЮвУЧЕФашЧѓЁЃЫљгаГЄЛюЪТЮёЖМПЩвдетбљзіТ№ЃПетРягавЛаЉЯожЦЃК
SagaжЛдЪаэСНИіВуДЮЕФЧЖЬзЃЌЖЅМЖЕФSagaКЭМђЕЅзгЪТЮё [1]
дкЭтВуЃЌШЋдзгадВЛФмЕУЕНТњзуЁЃвВОЭЪЧЫЕЃЌsagasПЩФмЛсПДЕНЦфЫћsagasЕФВПЗжНсЙћ [1]
УПИізгЪТЮёгІИУЪЧЖРСЂЕФдзгааЮЊ [2]
дкЮвУЧЕФвЕЮёГЁОАЯТЃЌКНАрдЄЖЉЁЂзтГЕЁЂОЦЕъдЄЖЉКЭИЖПюЪЧздШЛЖРСЂЕФааЮЊЃЌЖјЧвУПИіЪТЮёЖМПЩвдгУЖдгІЗўЮёЕФЪ§ОнПтБЃжЄдзгВйзїЁЃ
ЮвУЧдкааГЬЙцЛЎЪТЮёВуУцвВВЛашвЊдзгадЁЃвЛИігУЛЇПЩвддЄЖЉзюКѓвЛеХЛњЦБЃЌЖјКѓгЩгкаХгУПЈгрЖюВЛзуЖјБЛШЁЯћЁЃЭЌЪБСэвЛИігУЛЇПЩФмПЊЪМЛсПДЕНвбЮогрЦБЃЌ
НгзХгЩгкЧАепдЄЖЉБЛШЁЯћЃЌзюКѓвЛеХЛњЦББЛЪЭЗХЃЌЖјЧРЕНзюКѓвЛИізљЮЛВЂЭъГЩааГЬЙцЛЎЁЃ
ВЙГЅвВгаашПМТЧЕФЪТЯюЃК
ВЙГЅЪТЮёДггявхНЧЖШГЗЯћСЫЪТЮёTiЕФааЮЊЃЌЕЋЮДБиФмНЋЪ§ОнПтЗЕЛиЕНжДааTiЪБЕФзДЬЌЁЃЃЈР§ШчЃЌШчЙћЪТЮёДЅЗЂЕМЕЏЗЂЩфЃЌ
дђПЩФмЮоЗЈГЗЯћДЫВйзїЃЉ
ЕЋетЖдЮвУЧЕФвЕЮёРДЫЕВЛЪЧЮЪЬтЁЃЦфЪЕФбвдГЗЯћЕФааЮЊвВгаПЩФмБЛВЙГЅЁЃР§ШчЃЌЗЂЫЭЕчгЪЕФЪТЮёПЩвдЭЈЙ§ЗЂЫЭНтЪЭЮЪЬтЕФСэвЛЗтЕчгЪРДВЙГЅЁЃ
ЯждкЮвУЧгаСЫЭЈЙ§SagaРДНтОіЪ§ОнвЛжТадЮЪЬтЕФЗНАИЁЃЫќдЪаэЮвУЧГЩЙІЕижДааЫљгаЪТЮёЃЌЛђдкШЮКЮЪТЮёЪЇАмЕФЧщПіЯТЃЌВЙГЅвбГЩЙІЕФЪТЮёЁЃ
ЫфШЛSagaВЛЬсЙЉACIDБЃжЄЃЌЕЋШдЪЪгУгкаэЖрЪ§ОнзюжевЛжТадЕФГЁОАЁЃФЧЮвУЧШчКЮЩшМЦвЛИіSagaЯЕЭГЃП
Saga Log
SagaБЃжЄЫљгаЕФзгЪТЮёЖМЕУвдЭъГЩЛђВЙГЅЃЌЕЋSagaЯЕЭГБОЩэвВПЩФмЛсБРРЃЁЃSagaБРРЃЪБПЩФмДІгквдЯТМИИізДЬЌЃК
SagaЪеЕНЪТЮёЧыЧѓЃЌЕЋЩаЮДПЊЪМЁЃвђзгЪТЮёЖдгІЕФЮЂЗўЮёзДЬЌЮДБЛSagaаоИФЃЌЮвУЧЪВУДвВВЛашвЊзіЁЃ
вЛаЉзгЪТЮёвбОЭъГЩЁЃжиЦєКѓЃЌSagaБиаыНгзХЩЯДЮЭъГЩЕФЪТЮёЛжИДЁЃ
згЪТЮёвбПЊЪМЃЌЕЋЩаЮДЭъГЩЁЃгЩгкдЖГЬЗўЮёПЩФмвбЭъГЩЪТЮёЃЌвВПЩФмЪТЮёЪЇАмЃЌЩѕжСЗўЮёЧыЧѓГЌЪБЃЌsagaжЛФмжиаТЗЂЦ№жЎЧАЮДШЗШЯЭъГЩЕФзгЪТЮёЁЃетвтЮЖзХзгЪТЮёБиаыУнЕШЁЃ
згЪТЮёЪЇАмЃЌЦфВЙГЅЪТЮёЩаЮДПЊЪМЁЃSagaБиаыдкжиЦєКѓжДааЖдгІВЙГЅЪТЮёЁЃ
ВЙГЅЪТЮёвбПЊЪМЕЋЩаЮДЭъГЩЁЃНтОіЗНАИгыЩЯвЛИіЯрЭЌЁЃетвтЮЖзХВЙГЅЪТЮёвВБиаыЪЧУнЕШЕФЁЃ
ЫљгазгЪТЮёЛђВЙГЅЪТЮёОљвбЭъГЩЃЌгыЕквЛжжЧщПіЯрЭЌЁЃ
ЮЊСЫЛжИДЕНЩЯЪізДЬЌЃЌЮвУЧБиаызЗзйзгЪТЮёМАВЙГЅЪТЮёЕФУПвЛВНЁЃЮвУЧОіЖЈЭЈЙ§ЪТМўЕФЗНЪНДяЕНвдЩЯвЊЧѓЃЌВЂНЋвдЯТЪТМўБЃДцдкУћЮЊsaga
logЕФГжОУДцДЂжаЃК
Saga started event БЃДцећИіsagaЧыЧѓЃЌЦфжаАќРЈЖрИіЪТЮё/ВЙГЅЧыЧѓ
Transaction started event БЃДцЖдгІЪТЮёЧыЧѓ
Transaction ended event БЃДцЖдгІЪТЮёЧыЧѓМАЦфЛиИД
Transaction aborted event БЃДцЖдгІЪТЮёЧыЧѓКЭЪЇАмЕФдвђ
Transaction compensated event БЃДцЖдгІВЙГЅЧыЧѓМАЦфЛиИД
Saga ended event БъжОзХsagaЪТЮёЧыЧѓЕФНсЪјЃЌВЛашвЊБЃДцШЮКЮФкШн 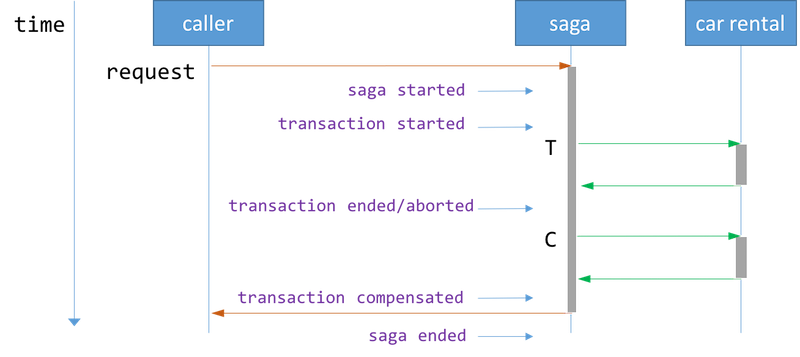
ЭЈЙ§НЋетаЉЪТМўГжОУЛЏдкsaga logжаЃЌЮвУЧПЩвдНЋsagaЛжИДЕНЩЯЪіШЮКЮзДЬЌЁЃ
гЩгкSagaжЛашвЊзіЪТМўЕФГжОУЛЏЃЌЖјЪТМўФкШнвдJSONЕФаЮЪНДцДЂЃЌSaga logЕФЪЕЯжЗЧГЃСщЛюЃЌЪ§ОнПтЃЈSQLЛђNoSQLЃЉЃЌГжОУЯћЯЂЖгСаЃЌЩѕжСЦеЭЈЮФМўПЩвдгУзїЪТМўДцДЂЃЌ
ЕБШЛгааЉФмИќПьЕУАяsagaЛжИДзДЬЌЁЃ
SagaЧыЧѓЕФЪ§ОнНсЙЙ
дкЮвУЧЕФвЕЮёГЁОАЯТЃЌКНАрдЄЖЉЁЂзтГЕЁЂКЭОЦЕъдЄЖЉУЛгавРРЕЙиЯЕЃЌПЩвдВЂааДІРэЃЌЕЋЖдгкЮвУЧЕФПЭЛЇРДЫЕЃЌжЛдкЫљгадЄЖЉГЩЙІКѓвЛДЮИЖЗбИќМггбКУЁЃ
ФЧУДетЫФИіЗўЮёЕФЪТЮёЙиЯЕПЩвдгУЯТЭМБэЪОЃК
НЋааГЬЙцЛЎЧыЧѓЕФЪ§ОнНсЙЙЪЕЯжЮЊгаЯђЗЧбЛЗЭМЧЁКУКЯЪЪЁЃ ЭМЕФИљЪЧsagaЦєЖЏШЮЮёЃЌвЖЪЧsagaНсЪјШЮЮёЁЃ
Parallel Saga
ШчЩЯЫљЪіЃЌКНАрдЄЖЉЃЌзтГЕКЭОЦЕъдЄЖЉПЩвдВЂааДІРэЁЃЕЋЪЧетбљзіЛсдьГЩСэвЛИіЮЪЬтЃКШчЙћКНАрдЄЖЉЪЇАмЃЌЖјзтГЕе§дкДІРэдѕУДАьЃПЮвУЧВЛФмвЛжБЕШД§зтГЕЗўЮёЛигІЃЌ
вђЮЊВЛжЊЕРашвЊЕШЖрОУЁЃ
зюКУЕФАьЗЈЪЧдйДЮЗЂЫЭзтГЕЧыЧѓЃЌЛёЕУЛигІЃЌвдБуЮвУЧФмЙЛМЬајВЙГЅВйзїЁЃЕЋШчЙћзтГЕЗўЮёгРВЛЛигІЃЌЮвУЧПЩФмашвЊВЩШЁЛиЭЫДыЪЉЃЌБШШчЪжЖЏИЩдЄЁЃ
ГЌЪБЕФдЄЖЉЧыЧѓПЩФмзюКѓШдБЛзтГЕЗўЮёЪеЕНЃЌетЪБЗўЮёвбОДІРэСЫЯрЭЌЕФдЄЖЉКЭШЁЯћЧыЧѓЁЃ
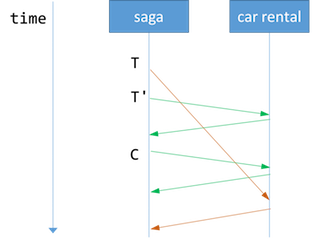
вђДЫЃЌЗўЮёЕФЪЕЯжБиаыБЃжЄВЙГЅЧыЧѓжДаавдКѓЃЌдйДЮЪеЕНЕФЖдгІЪТЮёЧыЧѓЮоаЇЁЃ Caitie McCaffreyдкЫ§ЕФбнНВDistributed
Sagas: A Protocol for Coordinating MicroservicesжаАбетИіГЦЮЊПЩНЛЛЛЕФВЙГЅЧыЧѓ
(commutative compensating request)ЁЃ
ACID and Saga
ACIDЪЧОпгавдЯТЪєадЕФвЛжТадФЃаЭ:
дзгадЃЈAtomicityЃЉ
вЛжТадЃЈConsistencyЃЉ
ИєРыадЃЈIsolationЃЉ
ГжОУадЃЈDurabilityЃЉ
SagaВЛЬсЙЉACIDБЃжЄЃЌвђЮЊдзгадКЭИєРыадВЛФмЕУЕНТњзуЁЃдТлЮФУшЪіШчЯТЃК
full atomicity is not provided. That is, sagas may
view the partial results of other sagas [1]
ЭЈЙ§saga logЃЌsagaПЩвдБЃжЄвЛжТадКЭГжОУадЁЃ
Saga МмЙЙ
зюКѓЃЌЮвУЧЕФSagaМмЙЙШчЯТЃК
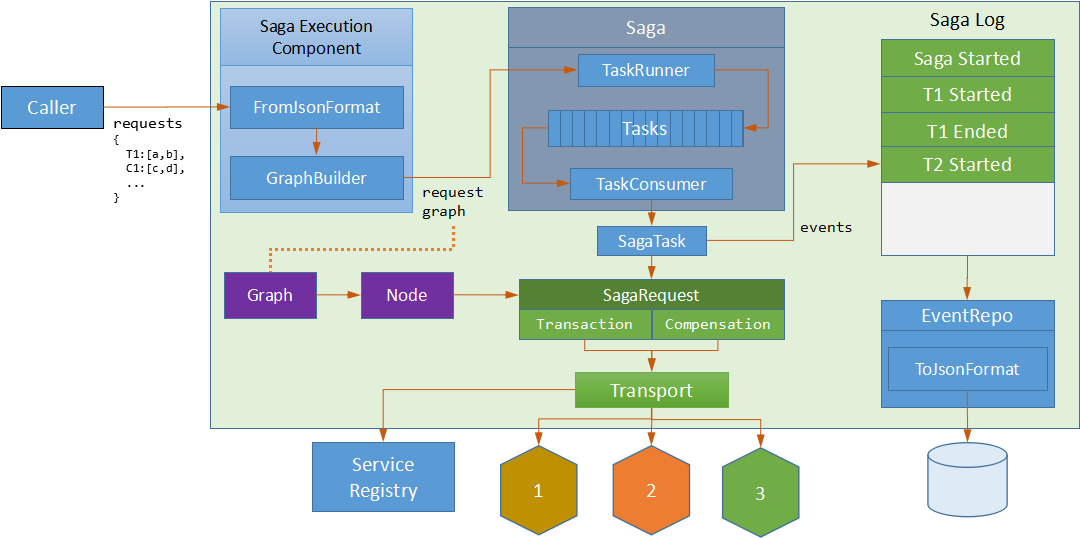
Saga Execution ComponentНтЮіЧыЧѓJSONВЂЙЙНЈЧыЧѓЭМ
TaskRunner гУШЮЮёЖгСаШЗБЃЧыЧѓЕФжДааЫГађ
TaskConsumer ДІРэSagaШЮЮёЃЌНЋЪТМўаДШыsaga logЃЌВЂНЋЧыЧѓЗЂЫЭЕНдЖГЬЗўЮё
дкЩЯЮФжаЃЌЮвЬИЕНСЫServiceCombЯТЕФSagaЪЧдѕУДЩшМЦЕФЁЃ ШЛЖјЃЌвЕНчЛЙгаЦфЫћЪ§ОнвЛжТадНтОіЗНАИЃЌШчСННзЖЮЬсНЛЃЈ2PCЃЉКЭTry-Confirm
/ CancelЃЈTCCЃЉЁЃФЧsagaЯрБШжЎЯТгаЪВУДЬиБ№ЃП
СННзЖЮЬсНЛ Two-Phase Commit (2PC)
СННзЖЮЬсНЛавщЪЧвЛжжЗжВМЪНЫуЗЈЃЌгУгкаЕїВЮгыЗжВМЪНдзгЪТЮёЕФЫљгаНјГЬЃЌвдБЃжЄЫћУЧОљЭъГЩЬсНЛЛђжажЙЃЈЛиЙіЃЉЪТЮёЁЃ
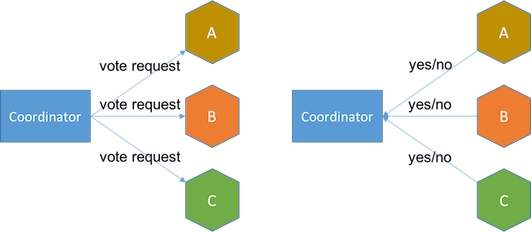
2PCАќКЌСНИіНзЖЮЃК
ЭЖЦБНзЖЮ аЕїЦїЯђЫљгаЗўЮёЗЂЦ№ЭЖЦБЧыЧѓЃЌЗўЮёЛиД№yesЛђnoЁЃШчЙћгаШЮКЮЗўЮёЛиИДnoвдОмОјЛђГЌЪБЃЌаЕїЦїдђдкЯТвЛНзЖЮЗЂЫЭжажЙЯћЯЂЁЃ
ОіЖЈНзЖЮ ШчЙћЫљгаЗўЮёЖМЛиИДyesЃЌаЕїЦїдђЯђЗўЮёЗЂЫЭcommitЯћЯЂЃЌНгзХЗўЮёИцжЊЪТЮёЭъГЩЛђЪЇАмЁЃШчЙћШЮКЮЗўЮёЬсНЛЪЇАмЃЌ
аЕїЦїНЋЦєЖЏЖюЭтЕФВНжшвджажЙИУЪТЮёЁЃ 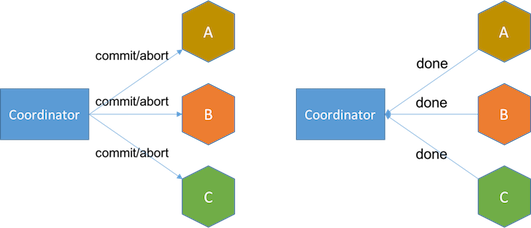
дкЭЖЦБНзЖЮНсЪјжЎКѓгыОіВпНзЖЮНсЪјжЎЧАЃЌЗўЮёДІгкВЛШЗЖЈзДЬЌЃЌвђЮЊЫћУЧВЛШЗЖЈНЛвзЪЧЗёМЬајНјааЁЃЕБЗўЮёДІгкВЛШЗЖЈзДЬЌВЂгыаЕїЦїЪЇШЅСЌНгЪБЃЌ
ЫќжЛФмбЁдёЕШД§аЕїЦїЕФЛжИДЃЌЛђепзЩбЏЦфЫћдкШЗЖЈзДЬЌЯТЕФЗўЮёРДЕУжЊаЕїЦїЕФОіЖЈЁЃдкзюЛЕЕФЧщПіЯТЃЌ nИіДІгкВЛШЗЖЈзДЬЌЕФЗўЮёЯђЦфЫћn-1ИіЗўЮёзЩбЏНЋВњЩњO(n2)ИіЯћЯЂЁЃ
СэЭтЃЌ2PCЪЧвЛИізшШћавщЁЃЗўЮёдкЭЖЦБКѓашвЊЕШД§аЕїЦїЕФОіЖЈЃЌДЫЪБЗўЮёЛсзшШћВЂЫјЖЈзЪдДЁЃгЩгкЦфзшШћЛњжЦКЭзюВюЪБМфИДдгЖШИпЃЌ
2PCВЛФмЪЪгІЫцзХЪТЮёЩцМАЕФЗўЮёЪ§СПдіМгЖјРЉеЙЕФашвЊЁЃ
гаЙи2PCЪЕЯжЕФИќЖрЯИНкПЩВЮПМ2КЭ3ЁЃ
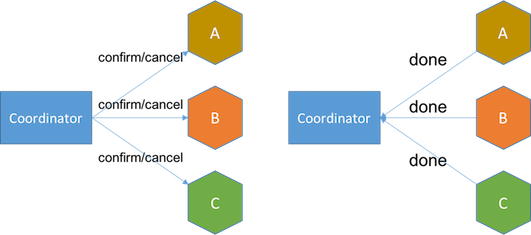
Try-Confirm/Cancel (TCC)
TCCвВЪЧВЙГЅаЭЪТЮёФЃЪНЃЌжЇГжСННзЖЮЕФЩЬвЕФЃаЭЁЃ
ГЂЪдНзЖЮ НЋЗўЮёжУгкД§ДІРэзДЬЌЁЃР§ШчЃЌЪеЕНГЂЪдЧыЧѓЪБЃЌКНАрдЄЖЉЗўЮёНЋЮЊПЭЛЇдЄСєвЛИізљЮЛЃЌВЂдкЪ§ОнПтВхШыПЭЛЇдЄЖЉМЧТМЃЌНЋМЧТМЩшЮЊдЄСєзДЬЌЁЃ
ШчЙћШЮКЮЗўЮёЪЇАмЛђГЌЪБЃЌаЕїЦїНЋдкЯТвЛНзЖЮЗЂЫЭШЁЯћЧыЧѓЁЃ 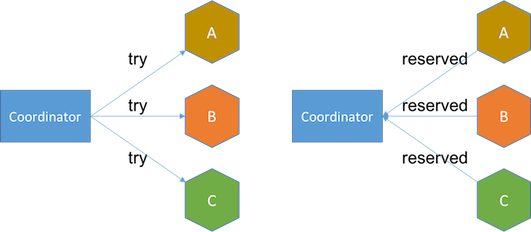
ШЗШЯНзЖЮ НЋЗўЮёЩшЮЊШЗШЯзДЬЌЁЃШЗШЯЧыЧѓНЋШЗШЯПЭЛЇдЄЖЉЕФзљЮЛЃЌетЪБЗўЮёвбПЩЯђПЭЛЇЪеШЁЛњЦБЗбгУЁЃЪ§ОнПтжаЕФПЭЛЇдЄЖЉМЧТМвВЛсБЛИќаТЮЊШЗШЯзДЬЌЁЃ
ШчЙћШЮКЮЗўЮёЮоЗЈШЗШЯЛђГЌЪБЃЌаЕїЦїНЋжиЪдШЗШЯЧыЧѓжБЕНГЩЙІЃЌЛђдкжиЪдСЫвЛЖЈДЮЪ§КѓВЩШЁЛиЭЫДыЪЉЃЌБШШчШЫЙЄИЩдЄЁЃ
гыsagaЯрБШЃЌTCCЕФгХЪЦдкгкЃЌГЂЪдНзЖЮНЋЗўЮёзЊЮЊД§ДІРэзДЬЌЖјВЛЪЧзюжезДЬЌЃЌетЪЙЕУЩшМЦЯргІЕФШЁЯћВйзїЧсЖјвзОйЁЃ
Р§ШчЃЌЕчгЪЗўЮёЕФГЂЪдЧыЧѓПЩНЋгЪМўБъМЧЮЊзМБИЗЂЫЭЃЌВЂЧвНідкШЗШЯКѓЗЂЫЭгЪМўЃЌЦфЯргІЕФШЁЯћЧыЧѓжЛашНЋгЪМўБъМЧЮЊвбЗЯЦњЁЃЕЋШчЙћЪЙгУsagaЃЌ
ЪТЮёНЋЗЂЫЭЕчзггЪМўЃЌМАЦфЯргІЕФВЙГЅЪТЮёПЩФмашвЊЗЂЫЭСэвЛЗтЕчзггЪМўзїГіНтЪЭЁЃ
TCCЕФШБЕуЪЧЦфСННзЖЮавщашвЊЩшМЦЖюЭтЕФЗўЮёД§ДІРэзДЬЌЃЌвдМАЖюЭтЕФНгПкРДДІРэГЂЪдЧыЧѓЁЃСэЭтЃЌTCCДІРэЪТЮёЧыЧѓЫљЛЈЗбЕФЪБМфПЩФмЪЧsagaЕФСНБЖЃЌ
вђЮЊTCCашвЊгыУПИіЗўЮёНјааСНДЮЭЈаХЃЌВЂЧвЦфШЗШЯНзЖЮжЛФмдкЪеЕНЫљгаЗўЮёЖдГЂЪдЧыЧѓЕФЯьгІКѓПЊЪМЁЃ
гаЙиTCCЕФИќЖрЯИНкПЩВЮПМTransactions for the REST of Us.
ЪТМўЧ§ЖЏЕФМмЙЙ
КЭTCCвЛбљЃЌдкЪТМўЧ§ЖЏЕФМмЙЙжаЃЌГЄЛюЪТЮёЩцМАЕФУПИіЗўЮёЖМашвЊжЇГжЖюЭтЕФД§ДІРэзДЬЌЁЃНгЪеЕНЪТЮёЧыЧѓЕФЗўЮёЛсдкЦфЪ§ОнПтжаВхШывЛЬѕаТЕФМЧТМЃЌ
НЋИУМЧТМзДЬЌЩшЮЊД§ДІРэВЂЗЂЫЭвЛИіаТЕФЪТМўИјЪТЮёађСажаЕФЯТвЛИіЗўЮёЁЃ
вђЮЊдкВхШыМЧТМКѓЗўЮёПЩФмБРРЃЃЌЮвУЧЮоЗЈШЗЖЈЪЧЗёаТЪТМўвбЗЂЫЭЃЌЫљвдУПИіЗўЮёЛЙашвЊЖюЭтЕФЪТМўБэРДИњзйЕБЧАГЄЛюЪТЮёДІгкФФвЛВНЁЃ
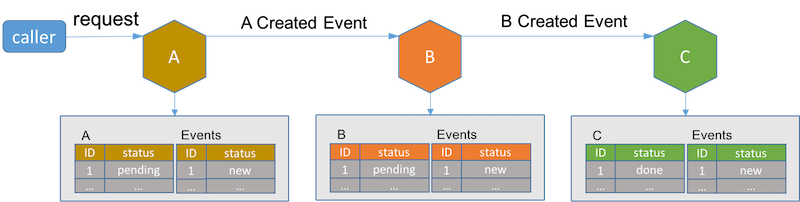
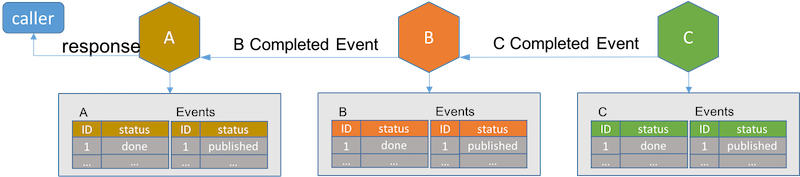
вЛЕЉГЄЛюЪТЮёжаЕФзюКѓвЛИіЗўЮёЭъГЩЦфзгЪТЮёЃЌЫќНЋЭЈжЊЫќдкЪТЮёжаЕФЧАвЛИіЗўЮёЁЃНгЪеЕНЭъГЩЪТМўЕФЗўЮёНЋЦфдкЪ§ОнПтжаЕФМЧТМзДЬЌЩшЮЊЭъГЩЁЃ
ШчЙћзаЯИБШНЯЃЌЪТМўЧ§ЖЏЕФМмЙЙОЭЯёЗЧМЏжаЪНЕФЛљгкЪТМўЕФTCCЪЕЯжЁЃШчЙћШЅЕєД§ДІРэзДЬЌЖјжБНгАбЗўЮёМЧТМЩшЮЊзюжезДЬЌЃЌетИіМмЙЙОЭЯёЗЧМЏжаЪНЕФЛљгкЪТМўЕФsagaЪЕЯжЁЃ
ШЅжааФЛЏФмДяЕНЗўЮёзджЮЃЌЕЋвВдьГЩСЫЗўЮёжЎМфИќНєУмЕФЕФёюКЯЁЃМйЩшаТЕФвЕЮёашЧѓдкЗўЮёBКЭCжЎМфЕФдіМгСЫаТЕФСїГЬDЁЃдкЪТМўЧ§ЖЏМмЙЙЯТЃЌЗўЮёBКЭCБиаыИФЖЏДњТывдЪЪгІаТЕФСїГЬDЁЃ
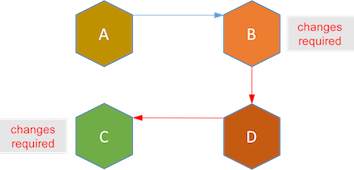
Sagaдђе§КУЯрЗДЃЌЫљгаетаЉёюКЯЖМдкsagaЯЕЭГжаЃЌЕБдкГЄЛюЪТЮёжаЬэМгаТСїГЬЪБЃЌЯжгаЗўЮёВЛашвЊШЮКЮИФЖЏЁЃ
ИќЖрЯИНкПЩВЮПМEvent-Driven Data Management for Microservices.
МЏжаЪНгыЗЧМЏжаЪНЪЕЯж
етИіSagaЯЕСаЕФЮФеТЬжТлЕФЖМЪЧМЏжаЪНЕФsagaЩшМЦЁЃЕЋsagaвВПЩгУЗЧМЏжаЪНЕФЗНАИРДЪЕЯжЁЃФЧУДЗЧМЏжаЪНЕФАцБОгаЪВУДВЛЭЌЃП
ЗЧМЏжаЪНsagaУЛгазЈжАЕФаЕїЦїЁЃЦєЖЏЯТвЛИіЗўЮёЕїгУЕФЗўЮёОЭЪЧЕБЧАЕФаЕїЦїЁЃР§ШчЃЌ
ЗўЮёAЪеЕНвЊЧѓЗўЮёAЃЌBКЭCжЎМфЕФЪ§ОнвЛжТадЕФЪТЮёЧыЧѓЁЃ
AЭъГЩЦфзгЪТЮёЃЌВЂНЋЧыЧѓДЋЕнИјЪТЮёжаЕФЯТвЛИіЗўЮёЃЌЗўЮёB.
BЭъГЩЦфзгЪТЮёЃЌВЂНЋЧыЧѓДЋЕнИјCЃЌвРДЫРрЭЦЁЃ
ШчЙћCДІРэЧыЧѓЪЇАмЃЌBгад№ШЮЦєЖЏВЙГЅЪТЮёЃЌВЂвЊЧѓAЛиЙіЁЃ 
гыМЏжаЪНЯрБШЃЌЗЧМЏжаЪНЕФЪЕЯжОпгаЗўЮёзджЮЕФгХЪЦЁЃЕЋУПИіЗўЮёЖМашвЊАќКЌЪ§ОнвЛжТадавщЃЌВЂЬсЙЉЦфЫљашЕФЖюЭтГжОУЛЏЩшЪЉЁЃ
ЮвУЧИќЧуЯђгкзджЮЕФвЕЮёЗўЮёЃЌЕЋЗўЮёЛЙЙиСЊКмЖргІгУЕФИДдгадЃЌШчЪ§ОнвЛжТадЃЌЗўЮёМрПиКЭЯћЯЂДЋЕнЃЌ НЋетаЉМЌЪжЮЪЬтМЏжаДІРэЃЌФмНЋвЕЮёЗўЮёДггІгУЕФИДдгаджаЪЭЗХЃЌзЈзЂгкДІРэИДдгЕФвЕЮёЃЌвђДЫЮвУЧВЩгУСЫМЏжаЪНЕФsagaЩшМЦЁЃ
СэЭтЃЌЫцзХГЄЛюЪТЮёжаЩцМАЕФЗўЮёЪ§СПдіГЄЃЌЗўЮёжЎМфЕФЙиЯЕБфЕУдНРДдНФбРэНтЃЌКмПьБуЛсГЪЯжЯТЭМЕФЫРаЧаЮзДЁЃ

ЭМЦЌРДдД: http://www.slideshare.net/BruceWong3/the-case-for-chaos
(s12)
ЭЌЪБЃЌдкГЄЛюЪТЮёжаЖЈЮЛЮЪЬтвВБфЕУИќМгИДдгЃЌвђЮЊЗўЮёШежОБщВМШКМЏНкЕуЁЃ
Summary
БОЮФНЋsagaгыЦфЫћЪ§ОнвЛжТадНтОіЗНАИНјааСЫБШНЯЁЃSagaБШСННзЖЮЬсНЛИќвзРЉеЙЁЃдкЪТЮёПЩВЙГЅЕФЧщПіЯТЃЌ
ЯрБШTCCЃЌsagaЖдвЕЮёТпММИКѕУЛгаИФЖЏЕФашвЊЃЌЖјЧвадФмИќИпЁЃМЏжаЪНЕФsagaЩшМЦНтёюСЫЗўЮёгыЪ§ОнвЛжТадТпММАЦфГжОУЛЏЩшЪЉЃЌ
ВЂЪЙХХВщЪТЮёжаЕФЮЪЬтИќШнвзЁЃ |









