1ЁЂБГОА
RedisЕФГіЯжШЗЪЕДѓДѓЕиЬсИпЯЕЭГДѓВЂЗЂФмСІжЇГХЕФПЩФмадЃЌзЊблМфRedisЕФзюаТАцБОвбОЪЧ3.XАцБОСЫЃЌЕЋЮвУЧЕФЯЕЭГвРШЛМЬајХмзХ2.8ЃЌВЂКмКУЕижЇГХзХЮвУЧЕБЧАУПЬь5вкЗУЮЪСПЕФгІгУЯЕЭГЁЃЯыЕБФъRedisЕФЕЅЕуЕЅЯпГЬЬиадЮоЗЈТњзуЮвУЧШевцзГДѓЕФЯЕЭГЃЌжЛФмгВзХЭЗЦЄАбRedisЁАМЏШКЛЏЁБИКдиЁЃЧветЬзЁАМЏШКЛЏЁБЗНАИСМКУЕидЫаажСНёЁЃЫфФбЖШВЛИпЃЌЪЄдкМђЕЅКЭЪЕгУЁЃЮоТлМђЕЅЛЙЪЧКмМђЕЅЃЌМЧТМетжжОРњЪЧвЛМўЗЧГЃгаШЄЕФЪТЧщЁЃ
2ЁЂЮЪЬт
ЯЕЭГЗУЮЪСПШевцБЖдіЃЌЕБЧАЕФRedisЕЅЕуЗўЮёШЗЪЕПЭЙлДцдкСЌајПЩгУадвдМАжЇГХЦПОБЗчЯеЃЌетжжжї/БИФЃЪНдкЗўЮёЙЪеЯЭЛЗЂЕФЧщПіЯТОЭЛсБЛЖЏЭЃжЙЗўЮёНјааRedisНкЕуЧаЛЛЁЃеыЖдЕЅЕуЮЪЬтЃЌЮвУЧНсКЯздЩэЕФвЕЮёгІгУГЁОАЖдRedisЁАМЏШКЛЏЁБЬсГіМИИіжївЊФПБъЃК
1ЁЂБмУтЕЅЕуЧщПіЃЌШЗБЃЗўЮёИпПЩгУЃЛ
2ЁЂНєПЩФмАбЪ§ОнЗжВМЪНДцДЂЃЌНЕЕЭЙЪеЯгАЯьЗЖЮЇЃЌТњзуЗўЮёСщЛюЩьЫѕЃЛ
3ЁЂПижЦЁАМЏШКЛЏЁБЕФИДдгЖШЃЌДгЖјПижЦБпМЪГЩБОЃЛ
3ЁЂЙ§ГЬ
вдЩЯФПБъ1КЭ2ОЭЪЧЫљЮНЕФЗжВМЪНМЏШКЗНАИЃЌАбДѓЮЪЬтЗжЖјжЮжЎЁЃЕЋзюФбАбПиЕФЪЧФПБъ3ЕФЁАМђЛЏЁБЪЕЯжЁЃЛљгкЕБЪБПЊдДЩчЧјЕФФЧМИжжRedisМЏШКЗНАИЃЌЖдгкЮвУЧЁАМђЛЏЁБЕФвЊЧѓРДЫЕЯрЖдТдЯдгЗжзЁЃЫљвдЛЙЪЧОіЖЈНсКЯздЩэЕФвЕЮёгІгУЕШвђЫиДђдьвЛИіЁАКЯЪЪЁБЕФRedisМЏШКЁЃ
ГѕЪМЃЌЮвУЧЦОНшздМКЖдЗжВМЪНМЏШКЕФШЯЪЖЙДНсКЯгІгУГЁОАЙДРеГівЛИіЮвУЧОѕЕУзуЙЛЁАМђЛЏЁБЕФЩшМЦЭМЃЌШЛКѓдкетИіЁАМђЛЏЁБМмЙЙЕФЛљДЁЩЯМЬајЛїЦЦЮвУЧИїжжгІгУГЁОАЫљДјРДЕФШБЯнЁЃМмЙЙЭМШчЯТЃК
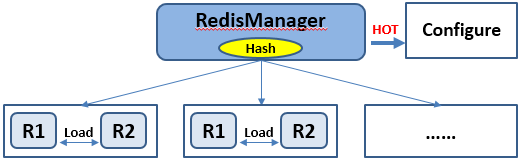
ВЛФбПДГіЃЌЮвУЧЯыОЁСПЭЈЙ§вЛИіRedisManagerРрКЭХфжУЮФМўОЭФмЙмРэећИіМЏШКЃЌВЛашвЊЖјЭтЕФШэМўжЇГжЁЃЕЅР§ЪЙгУЕФЪБКђRedisManagerКЭХфжУЮФМўОЭвбОДцдкЃЌRedisManagerгаИїжжЕЅР§ВйзїЕФAPIжиаДЃЈШчgetЁЂsetЕШЃЉЃЌЯждкЮвУЧЛЙЪЧЯыБЃГжетжжФЃЪНЖдвЕЮёДІРэЬсЙЉМЏШКAPIЃЌБЃГжећИіЗўЮёЛЏгІгУПђМмЃЈРрЫЦгкНёЬьЫљГЋЕМЕФЁАЮЂЗўЮёЁБЃЉЕФЧсСПМЖЬиадЁЃШчЩЯЭМЫљЪОЃЌЪ§ОнИљОнhashЪЕЯжЗжГЩВЛЭЌПщЗХдкВЛЭЌЕФhashНкЕуЩЯЃЌЖјУПИіhashНкЕуБиаыДцдкСНИіRedisЪЕР§зіhashНкЕуМЏШКжЇГХЁЃЮЊЪВУДЛсЪЧСНИіЖјВЛЪЧШ§ИіЛђПЩРЉеЙЖрИіЃПЮвУЧЪЧетбљПМТЧЕФЃК
1ЁЂШЮКЮПЩГжајРЉеЙЛђГщЯѓЪЧеОдкЙцЗЖетИіОоШЫЕФМчАђЩЯЃЌЮвУЧБќГаСЫећИіЯЕЭГМмЙЙЁАдМЖЈдЖдЖДѓгкХфжУЁБЕФддђЃЌЪЪЕБЕиЯожЦСЫБпНчЗЖЮЇЛЛШЁПижЦадЖјгжВЛЪЇСщЛюЁЃ
2ЁЂЖдгкЮвУЧЯЕЭГФПЧАЕФЗўЮёЦїжЪСПРДЫЕЃЌхДЛњЕФИХТЪНЯаЁЃЌЫЋЛњЃЈЫЋЪЕР§ЃЉЭЌЪБхДЛњЕФИХТЪИќаЁЁЃОЭЫуетИіИХТЪГіЯжЃЌЮвУЧжкЖрЕФвЕЮёГЁОАЛЙЪЧдЪаэетжжВПЗжМфНгадЙЪеЯЁЃетОЭЪЧГЩБОгыжЪСПжЎМфЕФЦНКтКЭШЁЩсЁЃ
3ЁЂгЩгкЮвУЧУЛгаЪЙгУЖюЭтЕФШэМўИЈжњЃЌетаЉЖюЭтЕФВйзїЖМвРРЕСЫЯпГЬЖюЭтадФмШЅУжВЙЃЌР§ШчСНИіRedisЪЕР§ИКдижЎМфЕФЭЌВНЕШЃЌЫљвдЮвУЧЪЧгУадФмЛЛШЁВПЗжвЛжТадЁЃИКдиНкЕудНЖрадФмЯћКФдНЖрЃЌЫљвдСНИіЪЕР§зіИКдиЪЧЮвУЧЁАЪЪЕБдМЪјЁБКЭКтСПЕФОіВпЁЃ
4ЁЂГЁОА
4.1 ГЁОА1
дкRedisManagerРржагаСНИізюЛљБОЕФAPIЃЌФЧОЭЪЧc_getКЭc_setЃЌЦфжаcДњБэclusterЁЃетСНИіAPIЕФЛљБОЪЕЯжШчЯТЃК
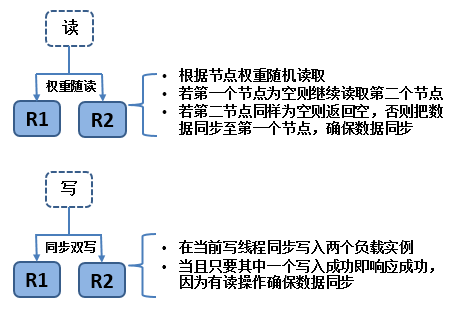
ДгетСНИіЛљБОВйзїПЩвдПДГіЃЌЮвУЧРћгУСЫБщРњhashНкЕуЕФЫљгаИКдиЪЕР§РДЪЕЯжИпПЩгУадЃЌВЂЭЈЙ§ЁАЭЌВНаДЁБРДТњзуRedisЪ§ОнЁАШѕвЛжТадЁБЮЪЬтЁЃЖјетИіЁАЭЌВНаДЁБОЭЪЧЖюЭтЕФадФмЯћКФЃЌЪЧвРРЕгкЫЋаДЙ§ГЬжажЛГЩЙІаДШывЛИіЪЕР§ЕФИХТЪЁЃвђЮЊRedisЕФЮШЖЈадЃЌетжжИХТЪВЛИпЃЌЫљвдЖюЭтадФмЯћКФЕФИХТЪвВВЛИпЁЃвдЩЯВйзїМИКѕЪЪгУЫљгаЛКДцРрМЏШКжЇГжЁЃетРрЛКДцЪ§ОнЕФЧПвЛжТадИќЖрЗХдкЪ§ОнПтЁЃЪ§ОндкПтБэБфИќКѓЃЌжЛашвЊАбЛКДцЪ§ОнdeleteМДПЩЁЃОпЬхГЁОАШчЯТЃК
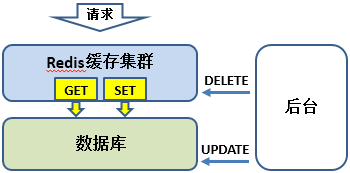
1ЁЂЪ§ОнЕФБфИќЭЈЙ§ЁАКѓЬЈЁБЮЌЛЄЃЌБфИќКѓЭЌВНDELETEЛКДцЕФЯрЛЅЪ§ОнЁЃ
2ЁЂвЕЮёЯпГЬЧыЧѓЛКДцЪ§ОнЮЊПеЃЈc_getЃЉЃЌдђВщбЏЪщПтВЂАбЪ§ОнЭЌВНжСЛКДцЃЈc_setЃЉЁЃ
3ЁЂRedisЕФhashНкЕуМЏШКАВзАМЏШКФкВПЪЕЯжИКд№КЭЪ§ОнЭЌВНЮЪЬтЃЈc_getКЭc_setЕФЪЕЯждРДЃЉЁЃ
ЮвУЧДѓВПЗжвЕЮёЪ§ОнЛКДцЖМЪЧЛљгквдЩЯСїГЬЪЕЯжЃЌетИіСїГЬЛсДцдквЛИідрЪ§ОнЮЪЬтЃЌР§ШчЕБUPDATEПтБэГЩЙІЕЋDELETEЛКДцЪ§ОнВЛГЩЙІЃЌОЭЛсДцдкдрЪ§ОнЁЃЮЊСЫФмОЁПЩФмНЕЕЭдрЪ§ОнЕФПЩФмадЃЌЮвУЧЛсдкЛКДцЩшжУЛКДцЪ§ОнвЛИігааЇЦкЃЈsetexЃЉЃЌОЭЫудрЪ§ОнГіЯжЃЌвВжЛЛсгАЯьsecondsЪБМфЖЮЁЃСэЭтдкКѓЬЈБфИќЙ§ГЬШчЙћDELETEЛКДцЪЇАмЮвУЧЛсгаЪЪЕБЕФЬсЪОгяЬсЪОЃЌКУШУШЯЮЊЗЂЯжМЬајНјвЛВНДІРэЃЈР§ШчжиаТБфИќЃЉЁЃ
4.1 ГЁОА2
Г§СЫГЁОА1ЕФЛКДцгУЭОЭтЃЌЛЙДцдкГжОУЛЏГЁОАЁЃОЭЪЧЛљгкRedisзіЪ§ОнГжОУЛЏМЏШКЃЌМДЫљгаВйзїЖМЪЧЛљгкRedisМЏШКЕФЁЃФЧУДдкЪ§ОнвЛжТадЮЪЬтЩЯОЭашвЊЯТЕуЙІЗђСЫЃЈc_set_syncЃЉЃЌЮБДњТыШчЯТЃК
ЭЈЙ§вдЩЯЮБДњТыПЩвдПДГіЃЌc_set_syncЗНЗЈЪЧЯШЧПжЦШЋВПЩОГ§Ъ§ОнКѓдйc_setЃЌШЗБЃЪ§ОнвЛжТадЁЃЕЋетЛсГіЯжвЛИіЪ§ОнЖЊЪЇЮЪЬтЃЌОЭЪЧc_del_
| c_set_sync(key,value){
if(c_del_sync(key)){
c_set(key,value);
}
}
c_del_sync(key){
if(del(r1,key)&&del(r2,key)){
return true;
}
return false;
} |
syncКѓЕЋsetЪЇАмЃЌФЧЪ§ОнОЭЛсЖЊЪЇЃЌвђЮЊЮвУЧЕФЪ§ОнМИКѕЖМЪЧДгКѓЬЈВйзїЕФЃЌШчЙћГіЯжетжжЪ§ОнЖЊЪЇЃЌМђЕЅЕФЮвУЧПЩвджиаТХфжУЃЌИДдгЕФЮвУЧПЩвдЭЈЙ§ШежОЛжИДЁЃ
5 ЩьЫѕ
вдЩЯСНИіГЁОАИќЖрЮЇШЦCЃЈвЛжТадЃЉКЭAЃЈПЩгУадЃЉЕФЬиадНјааЬжТлЃЌФЧУДНгЯТРДдйНщЩмвЛЯТЮвУЧЁАМЏШКЛЏЁБЕФPЃЈЗжЧјШнДэадЃЉЬиадЁЃЦфЪЕДгЮвЫМПМДЅЗЂОЭПЩвдПДЕУГіЮвУЧЖдPЕФШЈжиЪЧЧсгкCКЭAЕФЁЃЮЊЪВУДетУДЫЕЃПвђЮЊЮвУЧЯЕЭГМмЙЙЪЧЗўЮёЛЏМмЙЙЃЈФЧЪБЮвЛЙУЛНгДЅЕНЁАЮЂЗўЮёЁБИХФюЃЉЃЌвВОЭЪЧДгЮЪЬтНЧЖШАбДѓЮЪЬтЃЈвЕЮёЭГГЦЃЉВ№ЗжИїжжаЁЮЪЬтЃЈЗўЮёЛЏЃЉж№вЛЖРСЂНтОіЁЃИїжжаЁЮЪЬтЕФвЕЮёИДдгЖШЮвУЧНєПЩФмПижЦЕНвЛЖЈЕФЧсСПМЖГЬЖШЃЈШчЙћвЊСПЛЏНтЪЭЕФЛАФЧОЭЪЧЗўЮёБЃГждк10ЕН20ИіAPIЕФЙцФЃЃЌЩѕжСаЁгк10ЃЉЁЃЖјЧвУПИіЗўЮёЕФГадиСПдіГЄТЪдЄЙРжЕвВдкПЩПиЗЖЮЇЃЌЫљвдЕНФПЧАЮЊжЙЃЌМЋЩйгаЖдRedisМЏШКНјааЩьЫѕЕФашЧѓЁЃЕЋЩйЪ§ЕФЩьЫѕЛЙЪЧДцдкЃЌЕЋЦЕТЪВЛИпЁЃЖдгквЛИіЭъећЕФМЏШКЛЏЗНАИЃЌЩьЫѕЙІФмБиаыЕУгаЃЌжЛВЛЙ§ПЩФмашвЊЯёвдЩЯСНжжГЁОАФЧбљеыЖдВЛЭЌвЕЮёЪЙгУГЁОАдкЁАЙцЗЖЛЏЃЈдМмЙЙЛљДЁЩЯЃЉЁБЯТЖЈжЦГіИїжжГЁОАAPIЁЃ
5.1 ГЁОА1
вђЮЊЛКДцГЁОАЯрЖдМђЕЅЃЌРЉеЙЛђЪеЫѕhashНкЕуКѓЃЌШчЙћдкЛКДцжаевВЛЕНЪ§ОнЃЌдђЛсЗУЮЪЪ§ОнПтжиаТLoadЪ§ОнЕНаТЕФhashНкЕуЁЃЩьЫѕЦкЭъГЩГѕЦкПЩФмЛсЖдЪ§ОнПтДјРДвЛЖЈЕФбЙСІЃЌетжжбЙСІЕФДѓаЁРДдДгкЩшМЦhashЪ§ОнЕФБфЛЏДѓаЁЃЌетжжЪ§ОнБфЛЏДѓаЁШЁОігкжиаТетИіhashЪЕЯжЙцдђЕФБфЛЏЕФДѓаЁЁЃЫљвдЃЌПЩИљОнОпЬхЧщПіРДжиаДhashЙцдђЁЃ
ЛЙгавЛИіОЭЪЧЪ§ОнвЛжТадЮЪЬтЃЈCКЭPЃЉЃЌШчКЮдкЖЏЬЌЩьЫѕЙ§ГЬжаЃЌШЗБЃЛКДцЪ§ОнвЛжТадЁЃЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧдкЖЏЬЌРЉеЙЙ§ГЬжаЃЌЭЃжЙИїжжИќаТНгПкВйзїЁЃвђЮЊЮвУЧЕФЪ§ОнБфИќЖМЪЧЭЈЙ§ЙмРэдБЕФЃЌЫљвдетИіДњМлПЩвдКіТдВЛМЦЁЃ
5.2 ГЁОА2
ДЫГЁОА2ЖдгІЪЧШДШДЪЧ4.2ГЁОАЃЌШчЙћгУRedisМЏШКзіГжОУЛЏЙЄОпЃЌШчЙћШЗБЃЗжЧјШнДэадЃЈPЃЉКЭЪ§ОнвЛжТадЃЈCЃЉЁЃЖдгкЪ§ОнвЛжТадЮЪЬтЃЌЮвУЧЭЌбљбЁдёСЫГЁОА1ЕФАьЗЈЃЌдкЩьЫѕЦкМфЭЃжЙЫљгаИќаТВйзїЃЌжЛБЃСєЖСЁЃетОЭБмУтСЫЪ§ОнвЛжТадЮЪЬтЁЃЖдгкЗжЧјШнДэадЮЪЬтЃЌФЧОЭЪЧШчЙћШЗБЃжиаТhashКѓЃЌЪ§ОнФмСїЯђИїжжЕФаТhashНкЕуФиЁЃЮЊСЫМЬајБЃГжетжжЁАМђЛЏадЁБПђМмЃЌЮвУЧМЬајбЁдёСЫЮўЩќвЛЖЈЕФадФмРДТњзуЗжЧјШнДэадЮЪЬтЃЌОпЬхЪЕЯжШчЯТЫљЪОЃК
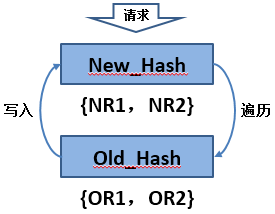
1ЁЂЯШГЂЪдДгNew_HashНкЕуЖСШЁЃЛ
2ЁЂШєВЛДцдкдђМЬајбАевOld_HashНкЕуЃЛ
3ЁЂШєЛЙЪЧВЛДцдкЃЌдђЗЕЛиПеЃЛ
4ЁЂШєДцдкдђc_setЕНNew_HashНкЕуЁЃ
ЭЈЙ§вдЩЯСїГЬЗжЮіПДЕНЃЌЮвУЧЮўЩќСЫВПЗжЯпГЬадФмЃЈЕквЛДЮЗУЮЪЕФБфИќЪ§ОнЕФЯпГЬЃЉЕФадФмЃЌПЩФмЛсЖр2ЕН3ДЫЕФredisЧыЧѓЃЈУПИіRedisЧыЧѓдМ5жС10КСУыЃЉЁЃЕБЩьЫѕЭъГЩКѓЃЌжиаТЗХПЊЪ§ОнИќаТAPIЃЈЮвУЧЗўЮёЛЏПђМмЫљгавЕЮёAPIЖМПЩвдЭЈЙ§ПижЦЬЈПижЦВЂЗЂВЂЩшжУЯрЙиЬсЪОгяЃЌЮоашжиЦєгІгУЃЉЁЃГ§СЫЖСШЁашвЊБщРњаТОЩhashНкЕуЭтЃЌЮЊСЫШЗБЃЪ§ОнвЛжТадЮЪЬтЃЌЮвУЧc_del_syncФкжУСЫвЛИіХаЖЯЪЧЗёДцдкОЩhashНкЕуЁЃЮБДњТыШчЯТЃК
| c_del_sync(key){
if(hash_old){
if(del(nr1,key)&&del(nr2,key) &&del(or1,key)
&&del(or2,key)) {
ЁЁЁЁЁЁЁЁtrue;
ЁЁЁЁЁЁЁЁЁЁЁЁЁЁ}
ЁЁЁЁ}else{
if(del(r1,key)&&del(r2,key)){
true;
ЁЁЁЁЁЁЁЁЁЁ}
ЁЁЁЁ}
ЁЁЁЁreturn false;
}
|
етжжГЁОАБШНЯЪЪгУгкsetВйзїВЛЖрЕФГЁОАЃЌвђЮЊЖрsetВйзїЛсЖрЯћКФдМвЛБЖЕФадФмЃЌШчЙћОѕЕУзЪдДГфзуЃЌетЕБШЛПЩвдПМТЧЁЃетжжЭЌВНЗНЪНЛЙгавЛИіУїЯдШБЕуОЭЪЧЖЬЦкФкЖрДЮЩьЫѕЃЌЛсЖЊЪЇHash_Old_Old_....ЕФЪ§ОнЃЌвђЮЊУПДЮHash_OldЖМЮоЗЈФмШЗБЃдкЯТвЛДЮЩьЫѕЧА1Фм00%ЭЌВНЫљгаЪ§ОнЃЈЭЌВНЪ§ОнашвЊвРРЕЪ§ОнЗУЮЪЃЌВЛХХГ§ВПЗжЪ§ОнвЛжБУЛгаБЛЗУЮЪЃЉЁЃ
6ЁЂзмНс
вдЩЯМЏШКЛЏЗНАИвбОдЫаадМСНФъЃЌЯЕЭГШеЗУЮЪСПдМ5вкЃЌ70%ЙщЙІгкRedisЕФжЇГХЁЃвдЩЯМЏШКЗНАИЪЧЛљгкЮвУЧЕФаавЕвЕЮёГЁОАКЭздЩэПђМмСПЩэЖЈзіЕФЃЌЮвИќЖрЕиЪЧЯыЗжЯэНтОіетИіЮЪЬтЕФЫМТЗКЭЙ§ГЬЁЃЪРНчЩЯУЛгаЁАОјЖдЭЈгУЁБЃЌжЛгаЁАЯрЖдЭЈгУЁБЃЌЭЈгУЗЖЮЇдНЙуЃЌгЗжзГЬЖШдНИпЃЌПЩФмДјРДЕФГЩБООЭЛсдНДѓЁЃЮвУЧИќЖрЕФЪЧУцЖдШчЙћЁАКмКУЕиЁБНтОіЮЪЬтЃЌетИіЁАКмКУЕиЁБвўВизХИїжжИїбљЕФПМТЧвђЫиЁЃОёдёОЭЪЧвЛИіЮЊСЫФмДяЕНзюМбаЇЙћЖјШЅКтСПЁЂбЁдёЁЂЗХЦњЕФЙ§ГЬЁЃ |









