ЗжВМЪНЮФМўЯЕЭГДцДЂФПБъвдЗЧНсЙЙЛЏЪ§ОнЮЊжїЃЌЕЋдкЪЕМЪгІгУжаЃЌДцдкДѓСПЕФНсЙЙЛЏКЭАыНсЙЙЛЏЕФЪ§ОнДцДЂашЧѓЁЃЗжВМЪНМќжЕЯЕЭГЪЧвЛжжгаБ№гкЮвУЧЫљЪьЯЄЕФЗжВМЪНЪ§ОнПтЯЕЭГЕФЃЌгУгкДцДЂЙиЯЕМђЕЅЕФАыНсЙЙЛЏЪ§ОнЕФДцДЂгІгУЁЃ
дкЗжВМЪНМќжЕЯЕЭГжаЃЌАыНсЙЙЛЏЪ§ОнБЛЗтзАГЩгЩ<keyЃЌvalueЃЌtimestamp>МќжЕЖдзщГЩЕФЖдЯѓЃЌЦфжаkeyЮЊЮЈвЛБъЪОЗћ;valueЮЊЪєаджЕЃЌПЩвдЮЊШЮКЮРраЭЃЌШчЮФзжЁЂЭМЦЌЃЌвВПЩвдЮЊПе;timestampЮЊЪБМфДСЃЌПЩвдЬсЙЉЪ§ОнЕФЖрАцБОжЇГжЁЃЗжВМЪНМќжЕЯЕЭГвдМќжЕЖдДцДЂЃЌЫќЕФНсЙЙВЛЙЬЖЈЃЌУПвЛдЊзщПЩвдгаВЛвЛбљЕФзжЖЮЃЌПЩИљОнашвЊдіМгМќжЕЖдЃЌДгЖјВЛОжЯогкЙЬЖЈЕФНсЙЙЃЌЪЪгУУцИќДѓЃЌПЩРЉеЙадИќКУЁЃ

ЗжВМЪНМќжЕЯЕЭГжЇГжеыЖдЕЅИі<keyЃЌvalueЃЌtimestamp>МќжЕЖдЕФдіЁЂЩОЁЂВщЁЂИФВйзїЃЌПЩвддЫаадкPCЗўЮёЦїМЏШКЩЯЃЌВЂЪЕЯжМЏШКАДашРЉеЙЃЌДгЖјДІРэДѓЙцФЃЪ§ОнЃЌВЂЭЈЙ§Ъ§ОнБИЗнБЃеЯШнДэадЃЌБмУтСЫЗжИюЪ§ОнДјРДЕФИДдгадКЭГЩБОЁЃ
змЬхРДЫЕЃЌЗжВМЪНМќжЕЯЕЭГДгДцДЂЪ§ОнНсЙЙЕФНЧЖШПДЃЌЗжВМЪНМќжЕЯЕЭГгыДЋЭГЕФЙўЯЃБэБШНЯРрЫЦЃЌВЛЭЌЕФЪЧЃЌЗжВМЪНМќжЕЯЕЭГжЇГжНЋЪ§ОнЗжВМЕНМЏШКжаЕФЖрИіДцДЂНкЕуЁЃЗжВМЪНМќжЕЯЕЭГПЩвдХфжУЪ§ОнЕФБИЗнЪ§ФПЃЌПЩвдНЋвЛЗнЪ§ОнЕФЫљгаИББОДцДЂЕНВЛЭЌЕФНкЕуЩЯЃЌЕБгаНкЕуЗЂЩњвьГЃЮоЗЈе§ГЃЬсЙЉЗўЮёЪБЃЌЦфгрЕФНкЕуЛсМЬајЬсЙЉЗўЮёЁЃ
ЯТУцЃЌЮвУЧРДПДПДвЕНчжїСїЕФЗжВМЪНМќжЕЯЕЭГЕФМмЙЙФЃЪНЁЃ
Amazon Dynamo
DynamoЪЧAWSЩЯзюЛљДЁЕФЗжВМЪНДцДЂгІгУжЎвЛЃЌвВЪЧAWSзюдчЭЦГіЕФдЦЗўЮёжЎвЛЃЌЫќЙЙНЈдкAWSЕФS3ЛљДЁжЎЩЯЃЌВЩгУШЅжааФНкЕуЛЏЕФP2PЗНЪНЃЌВЩгУетжжФЃЪНЕФЃЌЛЙгаFacebookЭЦГіЕФCassandraЁЃ
1ЁЂЪ§ОнЗжВМ
DynamoЪЙгУСЫИФНјЕФвЛжТадЙўЯЃЫуЗЈЃКУПИіЮяРэНкЕуИљОнЦфадФмЕФВювьЗжХфЖрИіtokenЃЌУПИіtokenЖдгІвЛИіЁАащФтНкЕуЁБЁЃЫљгаНкЕуУПИєЙЬЖЈЪБМф(БШШч1s)ЭЈЙ§GossipавщЕФЗНЪНДгЦфЫћНкЕужаШЮвтбЁдёвЛИігыжЎЭЈаХЕФНкЕуЁЃШчЙћСЌНгГЩЙІЃЌЫЋЗННЛЛЛИїздБЃДцЕФМЏШКаХЯЂЁЃ
GossipавщгУгкP2PЯЕЭГжазджЮЕФНкЕуаЕїЖдећИіМЏШКЕФШЯЪЖЃЌБШШчМЏШКЕФНкЕузДЬЌЁЂИКдиЧщПіЁЃгЩгкжжзгНкЕуЕФДцдкЃЌаТНкЕуМгШыПЩвдзіЕУБШНЯМђЕЅЃКаТНкЕуМгШыЪБЪзЯШгыжжзгНкЕуНЛЛЛМЏШКаХЯЂЃЌДгЖјСЫНтећИіМЏШКЁЃ
2ЁЂвЛжТадгыИДжЦ
вЛАуРДЫЕЃЌДгЛњЦїK+iхДЛњПЊЪМЕНБЛШЯЖЈЮЊгРОУЪЇаЇЕФЪБМфВЛЛсЬЋГЄЃЌЛ§РлЕФаДВйзївВВЛЛсЬЋЖрЃЌПЩвдРћгУMerkleЪїЖдЛњЦїЕФЪ§ОнЮФМўНјааПьЫйЭЌВНЁЃDynamoв§ШыЯђСПЪБжг(Vector
lock)ЕФММЪѕЪжЖЮРДГЂЪдНтОіГхЭЛЃЌетИіВпТдвРРЕМЏШКФкНкЕужЎМфЕФЪБжгЭЌВНЫуЗЈЃЌЕЋВЛФмЭъШЋБЃжЄзМШЗадЁЃDynamoжЛБЃжЄзюжевЛжТадЃЌШчЙћЖрИіНкЕужЎМфЕФИќаТЫГађВЛвЛжТЃЌПЭЛЇЖЫПЩФмЖСШЁВЛЕНЦкЭћЕФНсЙћЁЃ
3ЁЂШнДэ
КЫаФЛњжЦОЭЪЧЃКЪ§ОнЛиДЋ+MerkleЪїЭЌВН+ЖСШЁаоИД
DynamoдкЪ§ОнЖСаДжаВЩгУСЫвЛжжГЦЮЊШѕquorum (Sloppy quorum)ЕФЛњжЦЃЌЩцМАШ§ИіВЮЪ§WЁЂRЁЂN,МћЦфжаWДњБэвЛДЮГЩЙІЕФаДВйзїжСЩйашвЊаДШыЕФИББОЪ§ЃЌRДњБэвЛДЮГЩЙІЖСВйзїашгЩЗўЮёЦїЗЕЛиИјгУЛЇЕФзюаЁИББОЪ§ЃЌNЪЧУПИіЪ§ОнДцДЂЕФИББОЪ§ЁЃDynamoвЊЧѓR+WЁЕNЃЌТњзуетИівЊЧѓЃЌБЃжЄгУЛЇЖСШЁЪ§ОнЪБЃЌЪМжеПЩвдЛёЕУвЛИізюаТЕФЪ§ОнАцБОЁЃ
еыЖдСйЪБЙЪеЯЃЌвЛЕЉФГИіНкЕуГіЯжЮЪЬтЃЌдђНЋетИіНкЕужЕДЋЫЭИјЁАЭЌзщЁБжаЕФЯТвЛИіе§ГЃНкЕуЃЌВЂдкетИіЪ§ОнИББОЕФдЊЪ§ОнжаМЧТМЪЇаЇЕФНкЕуЮЛжУЃЌБугкЪ§ОнЛиДЋ;ШЛКѓЃЌгЩетИіНкЕуЩЯвЛИіСйЪБПеМфНјааДцДЂКЭДІРэЪ§ОнЃЌЭЌЪБИУНкЕуЛЙЖдЪЇаЇЕФНкЕуНјааМрВтЃЌвЛЕЉЪЇаЇЕФНкЕужиаТПЩгУЃЌдђНЋздМКЫљБЃДцЕФзюаТЪ§ОнЛиДЋИјЫќЃЌШЛКѓЩОГ§здМКПЊБйЕФСйЪБПеМфЪ§ОнЁЃ
еыЖдгРОУадЙЪеЯЃЌDynamoБиаыМьЫКЭБЃГжЪ§ОнЕФЭЌВН ЃЌDynamoВЩгУвЛжжГЦЮЊЗДьиавщЕФЪжЖЮРДБЃжЄЪ§ОнЕФЭЌВНЁЃЮЊСЫМѕЩйЪ§ОнЭЌВНМьВтжаашвЊДЋЪфЕФЪ§ОнСПЃЌМгПьМьВтЫйЖШЃЌDynamoЪЙгУСЫMerkleЙўЯЃЪїММЪѕЃЌУПИіащФтНкЕуБЃДцШ§ПХMerkleЪїЃЌМДУПИіМќжЕЧјМфНЈСЂвЛИіMerkleЪїЁЃDynamoжаMerkleЙўЯЃЪїЕФвЖзгНкЕуЪЧДцДЂУПИіЪ§ОнЗжЧјФкЫљгаЪ§ОнЖдгІЕФЙўЯЃжЕЃЌИИНкЕуЪЧЦфЫљгазгНкЕуЕФЙўЯЃжЕЁЃ
4ЁЂИКдиОљКт
ВЩгУИФНјЕФвЛжТадHash+ащФтНкЕуФЃЪНЁЃ
дкДЋЭГЕФвЛжТадЙўЯЃЫуЗЈЩЯЃЌЗўЮёНкЕуИњЙўЯЃЛЗЩЯЕФЕуЪЧвЛвЛЖдгІЕФЁЃетРяЛсДцдквЛИіЮЪЬтЃЌОЭЪЧУПвЛИіНкЕуЕФИКдизюКѓЪЧВЛОљдШЕФЃЌЖјЮвУЧвВЮоЗЈНјааЕїећЁЃDynamoЭЈЙ§вЛИіЗўЮёНкЕуПЩвдгаЖрИіЙўЯЃЛЗЩЯЕФащФтНкЕуЕФЗНЗЈЃЌЪЙЕУУПвЛИіЗўЮёНкЕуЕФИКдиЖМЪЧОљдШЕФЁЃВЂЧвМйШчЗЂЯжСЫФГвЛИіНкЕуЕФИКдиЙ§ИпЃЌЩйЗжХфащФтНкЕуИјЫќБуПЩвдНЕЕЭИУЗўЮёНкЕуЕФИКдиЃЌДгЖјЪЕЯжСЫздЖЏЕиИКдиОљКтЁЃ
5ЁЂЖСаДСїГЬ
гЩгкВЩгУСЫШЅжааФЛЏЕФФЃЪНЃЌвђДЫЃЌашвЊВЩгУНЯИДдгЕФФЃЪНРДПижЦВЂЗЂЃЌDynamoЪЙгУPaxosавщНсКЯGossipРДНјааВЂЗЂДІРэЁЃОпЬхДІРэФЃЪНШчЭМ1ЫљЪОЁЃ
ЭМ1 Dynamo аДШыКЭЖСШЁСїГЬ
DynamoВЩгУШЅжааФНкЕуЕФP2PЩшМЦЃЌдіМгСЫЯЕЭГПЩРЉеЙадЃЌЕЋЭЌЪБДјРДСЫвЛжТадЮЪЬтЃЌгАЯьЩЯВугІгУЁЃвЛжТадЮЪЬтЪЙЕУвьГЃЧщПіЯТЕФВтЪдБфЕУИќМгРЇФбЃЌгЩгкDynamoжЛБЃжЄзюЛљБОЕФзюжевЛжТадЃЌЖрПЭЛЇЖЫВЂЗЂВйзїЕФЪБКђКмФбдЄВтВйзїНсЙћЃЌвВКмФбдЄВтВЛвЛжТЕФЪБМфДАПкЃЌгАЯьВтЪдгУР§ЩшМЦЁЃ
гЩгкШЅжааФЛЏФЃЪНЫљЕМжТЕФИДдгадКЭВЛШЗЖЈадЁЃФПЧАжїСїЕФЗжВМЪНЯЕЭГвЛАуЖМДјгажааФНкЕуЃЌетбљФмЙЛМђЛЏЩшМЦЃЌЖјЧвжааФНкЕужЛЮЌЛЄЩйСПдЊЪ§ОнЃЌвЛАуВЛЛсГЩЮЊадФмЦПОБЁЃ
ЬдБІTair
TairЪЧАЂРяАЭАЭЭЦГіЕФвЛИіИпадФмЃЌЗжВМЪНЃЌПЩРЉеЙЃЌИпПЩППЕФkey/valueНсЙЙДцДЂЯЕЭГЃЌЫќзЈУХеыЖдаЁЮФМўЕФДцДЂзіСЫгХЛЏЃЌВЂЬсЙЉМђЕЅвзгУЕФНгПк(РрЫЦMap)ЁЃ
1ЁЂећЬхМмЙЙ
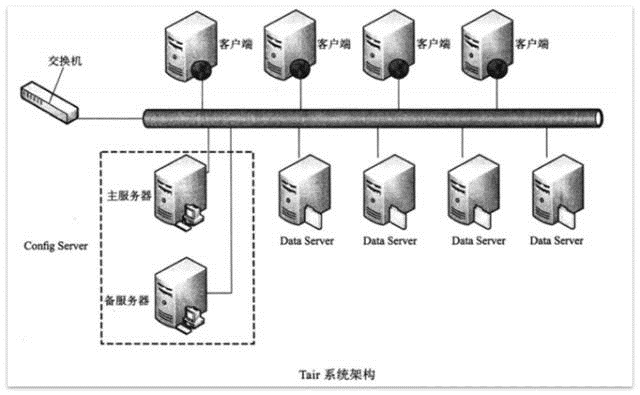
TairзїЮЊвЛИіЗжВМЪНЯЕЭГЃЌЪЧгЩвЛИіжааФПижЦНкЕуКЭШєИЩИіЗўЮёНкЕузщГЩЁЃConfig
ServerЪЧПижЦЕуЃЌЖјЧвЪЧЕЅЕуЃЌФПЧАВЩгУвЛжївЛБИЕФаЮЪНРДБЃжЄПЩППадЃЌЫљгаЕФData ServerЕиЮЛЖМЪЧЕШМлЕФЁЃ
ЭМ2 TairЯЕЭГМмЙЙ
2ЁЂЪ§ОнЗжВМ
TairИљОнЪ§ОнЕФжїМќМЦЫуЙўЯЃжЕКѓЃЌЗжВМЕНQИіЭАжаЃЌИљОнDynamoТлЮФжаЕФЪЕбщНсТлЃЌQШЁжЕашвЊдЖДѓгкМЏШКЕФЮяРэЛњЦїЪ§ЃЌР§ШчQШЁжЕ102400ЁЃ
3ЁЂШнДэ
ШчЙћЪЧБИИББОЃЌдђжБНгЧЈвЦ;ШчЙћЪЧжїИББОЃЌдђЯШЧаЛЛдйЧЈвЦЁЃ
4ЁЂЪ§ОнЧЈвЦ
ЛњЦїМгШыЛђепИКдиВЛОљКтПЩФмЕМжТЭАЧЈвЦЃЌЧЈвЦЕФЙ§ГЬжаашвЊБЃжЄЖдЭтЗўЮёЁЃЕБЧЈвЦЗЂЩњЪБЃЌМйЩшData Server
AвЊАбЭА1ЁЂ2ЁЂ3ЧЈвЦЕНData Server BЁЃЧЈвЦЭъГЩЧАЃЌПЭЛЇЖЫЕФТЗгЩБэУЛгаБфЛЏЃЌПЭЛЇЖЫЖд1ЁЂ2ЁЂ3ЕФЗУЮЪЧыЧѓЖМЛсТЗгЩЕНAЁЃЯждкМйЩш1ЛЙУЛПЊЪМЧЈвЦЃЌ2е§дкЧЈвЦжаЃЌ3вбОЧЈвЦЭъГЩЁЃФЧУДШчЙћЖд1ЗУЮЪЃЌAжБНгЗўЮё;ШчЙћЖд3ЗУЮЪЃЌAЛсАбЧыЧѓзЊЗЂИјBЃЌВЂЧвНЋBЕФЗЕЛиНсЙћЗЕЛиИјгУЛЇ;ШчЙћЖд2ЗУЮЪЃЌгЩAДІРэЃЌЭЌЪБШчЙћЪЧЖд2ЕФаоИФВйзїЃЌЛсМЧТМаоИФШежОЃЌЕШЕНЭА2ЧЈвЦЭъГЩЪБЃЌЛЙвЊАбаоИФШежОЗЂЫЭЕНBЃЌдкBЩЯгІгУетаЉаоИФВйзїЃЌжБЕНAКЭBжЎМфЪ§ОнЭъШЋвЛжТЧЈвЦВХеце§ЭъГЩЁЃ
5ЁЂХфжУЗўЮёЦї(Config Server)
ПЭЛЇЖЫЛКДцТЗгЩБэЃЌДѓЖрЪ§ЧщПіЯТЃЌПЭЛЇЖЫВЛашвЊЗУЮЪХфжУЗўЮёЦї(Config Server)ЃЌConfig
ServerхДЛњвВВЛгАЯьПЭЛЇЖЫе§ГЃЗУЮЪЁЃШчЙћData ServerЗЂЯжПЭЛЇЖЫЕФАцБОКХЙ§ОЩЃЌдђЛсЭЈжЊПЭЛЇЖЫШЅConfig
ServerЛёШЁвЛЗнаТЕФТЗгЩБэЁЃШчЙћПЭЛЇЖЫЗУЮЪФГЬЈData ServerЗЂЩњСЫВЛПЩДяЕФЧщПі(ИУData
ServerПЩФмхДЛњСЫ)ЃЌПЭЛЇЖЫЛсжїЖЏШЅConfig ServerЛёШЁаТЕФТЗгЩБэЁЃ
6ЁЂЪ§ОнЗўЮёЦї(Data Server)
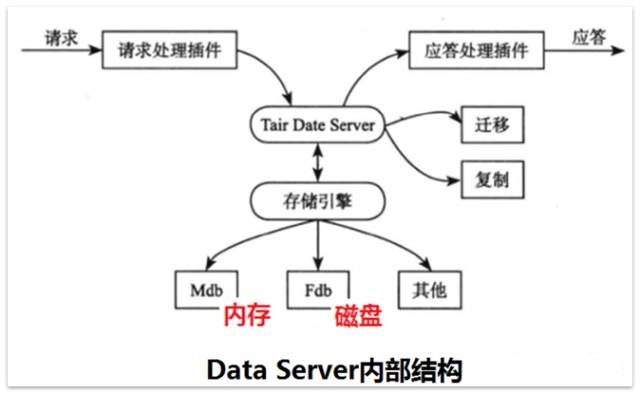
TairДцДЂв§ЧцгавЛИіГщЯѓВуЃЌжЛвЊТњзуДцДЂв§ЧцашвЊЕФНгПкЃЌОЭПЩвдКмЗНБуЕиЬцЛЛTairЕзВуЕФДцДЂв§ЧцЁЃ
TairзюжївЊЕФгУЭОдкгкЗжВМЪНЛКДцЃЌГжОУЛЏДцДЂЦ№ВНБШНЯЭэЃЌдкЪЕЯжЯИНкЩЯвВгавЛаЉВЛОЁШчШЫвтЕФЕиЗНЁЃР§ШчЃЌTairГжОУЛЏДцДЂЭЈЙ§ИДжЦММЪѕРДЬсИпПЩППадЃЌШЛЖјЃЌетжжИДжЦЪЧвьВНЕФЁЃвђДЫЃЌЕБгаData
ServerЗЂЩњЙЪеЯЪБЃЌПЭЛЇгаПЩФмдквЛЖЈЪБМфФкЖСВЛЕНзюаТЕФЪ§ОнЃЌЩѕжСЗЂЩњзюаТаоИФЕФЪ§ОнЖЊЪЇЕФЧщПіЁЃ |









