Talk
is cheapЃЌshow me the demoЁЃMySQL ЕНЕзФмВЛФмЗХЕН Docker РяХмЃПЭЌГЬТУгЮФПЧАвбОгаГЌЙ§вЛЧЇИі
MySQL ЪЕР§АВШЋЮШЖЈЕиХмдк Docker ЦНЬЈЩЯЁЃ
ЧАбд
ЧАМИдТОГЃПДЕНга MySQL ЕНЕзФмВЛФмЗХЕН Docker РяХмЕФИїжжЬжТлЁЃетбљзіЪЧДэЕФЃЁетбљзіЪЧЖдЕФЃЁЫЕДэЕФРэгЩвВЫЕСЫвЛДѓЖбЃЌЫЕЖдЕФЫМЯывВКмУїШЗЁЃДѓМвЖМгаЕРРэЁЃЕЋЪЧЮвБОШЫОѕЕУетбљЕФЬжТлТфЕивтвхВЛДѓЁЃвђЮЊЖдгыДэЛЙЪЧвЊЪЕМљРДЕУГіЕФЁЃ
ЫљвдЭЌГЬТУгЮвВКмдчПЊЪМСЫ MySQL ЕФ Docker ЛЏЪЕМљЃЌЕНФПЧАвбОгаГЌвЛЧЇЖрИі
MySQL ЪЕР§дк Docker ЦНЬЈАВШЋЮШЖЈЕиХмзХЃЌDB дЫЮЌФмСІЗЂЩњСЫжЪЕФЬсИпЃЈDBA дйвВВЛгУЕЃаФЩОПтХмТЗСЫЃЉЁЃ
ЕБШЛетбљЪЧВЛЪЧПЩвджЄУїжЎЧАЕФЬжТлНсТлЁЊЁЊЪЧЖдЕФЁЃЮвЯывВВЛвЛЖЈЃЌвђЮЊЮвУЧЛЙжЛЪЧвЛжЛдкбЇЗЩааЕФаЁФёЃЌЛЙвЊИќЖрЕФбЇЯАЃЌЫљвдЮвУЧЬиНЋЮвУЧдк
MySQL ЕФ Docker ЛЏЩЯЕФЪЕМљЗжЯэИјДѓМвЁЃ
БГОАНщЩм
ЭЌГЬТУгЮдчЦкЕФЪ§ОнПтЖМвд MSSQL ЮЊжїЃЌетИіВњЦЗгаИіЬиЕуОЭЪЧ UI ВйзїКмАєЁЃЕЋЪЧХњСПКЭздЖЏЛЏЙмРэКмФбзіЃЌШЫСІЕФЙЄзїКмЖрЁЃКѓРДж№НЅЬцЛЛЮЊ
MySQL КѓвВЪЧАДееДЋЭГЕФдЫЮЌЗНЪНЙмРэЁЃЕМжТДѓВПЗжЕФЙЄзїашвЊШЫШтдЫЮЌЁЃ
ЕБШЛЯёЮвУЧдчЦкЪЙгУЙ§ЕФ MSSQL вВЪЧгагХЕуЕФЃКОЭЪЧЕЅЛњадФмБШНЯКУЃЌдкЕБФъФЧИізЪдДВЛЙЛЕФФъДњРяЮвУЧГЃПЩвддкИпПЩгУЕФЪЕР§ЩЯдЫааЖрИіПтЁЃетжжЧщПіЯТЮяРэЛњЪ§СПгыЪЕР§Ъ§СПЛЙЪЧБШНЯПЩПиЕФЃЌЯрЖдЪ§СПБШНЯЩйЃЌШЫШтдЫЮЌЭъШЋПЩвдгІЖдЁЃ
ЕЋЪЧ MSSQL ЕФШБЯнвВКмЖрЃЌБШШчзіЫЎЦНВ№ЗжБШНЯРЇФбЃЌЕМжТЪ§ОнПтГЩЮЊЯЕЭГжазюДѓЕФвЛИіЦПОБЁЃЕЋдкЮвУЧЪЙгУ
MySQL+ жаМфМўЃЈЮвУЧзіетИіжаМфМўвВЪЧЯТСЫВЛЩйаФЫМЕФЃЌвдКѓПЩвдЗжЯэвЛЯТЃЉзіЫЎЦНВ№ЗжКѓОЭПЊЪМНтОіСЫетИіЦПОБЁЃ
ЫЎЦНВ№ЗжЕФв§ШывВДјРДСЫвЛИіаЁШБЕуЃЌОЭЪЧЛсдьГЩЪ§ОнПтЪЕР§Ъ§СПДѓЗљЩЯЩ§ЁЃОйИіР§згЮвУЧзі 1024 ЗжЦЌЕФЛАвЛАуЪЧзі
32 Иі nodeЃЌвЛжївЛДгЪЧБиаыЕФЃЈДѓВПЗжЧщПіЪЧвЛжїСНДгЃЉЃЌФЧУДжСЩй 64 ИіЪЕР§ЃЌдйМгЩЯгІМБРЉеЙКЭБИЗнгУЕФНкЕуФЧОЭИќЖрСЫЃЈжаМфМўЕФПЊЗЂепИќЯЃЭћЪЧ
1024 ЦЌОЭЪЧ 1024 ИіЪЕР§ЃЉЁЃ
вЛДЮЩЯЯпзівЛИі 32node ЗжЦЌРЉеЙДгПтЃЌСНИі DBA зузуЛЈСЫ 4 ИіаЁЪБЁЃСэЭтЃЌШчЙћзіЕЅЛњЕЅЪЕР§ФЧПЯЖЈИќВЛааСЫЃЌБ№ЕФВЛЫЕЃЌГЩБОвВЛсЪЧИіДѓЮЪЬтЃЌЧвЮяРэЛњЕФзЪдДвВЮДФмзюДѓЛЏРћгУЁЃПіЧввђЮЊ
MySQL ЕЅЬхЕФадФмУЛгХЪЦЫљвдЗжЦЌОгЖрЫљвдДѓВПЗжЧщПіЯТВЂВЛЪЧУПИіПтЖМФмХмТњећИіЮяРэЛњЕФЁЃМДЪЙгаВПЗжФмХмТњећЛњзЪдДЕФПтЃЌЫќЕФЖрНкЕуБИЗнЃЌЛЗОГвЛжСадКЭдЫЮЌЖЏзїЭГвЛЕШЮЪЬтвВЛсШУ
DBA вЛЭЗдуЃЌУІТЕгжШнвзГіДэЕФЙЄзїЦфЪЕЪЧЮовтвхЕФЁЃ
гаСЫЕЅЛњЖрЪЕР§дЫаа MySQL ЪЕР§ЕФашЧѓЁЃЕЅЛњЖрЪЕР§вЊЫМПМЕФжївЊЮЪЬтОЭЪЧШчЙћНјаазЪдДИєРыКЭЯожЦЃЌЪЕЯжЗНАИгаКмЖрЃЌдѕУДбЁЃПKVMЃЌDockerЃЌCgroups
ЪЧФПЧАЕФПЩвдЪЕЯжИєРыжїСїЗНАИЁЃ
KVM ЖдвЛИі DB ЕФИєРыРДЫЕЬЋжиСЫЃЌадФмгАЯьЬЋДѓЃЌдкЩњВњЛЗОГгУВЛКЯЪЪЁЃетЪЧвђЮЊ MySQL дЫааЕФОЭЪЧИіНјГЬЖјЧвЖд
IO вЊЧѓБШНЯИпЃЌЫљвд KVM ВЛТњзувЊЧѓ (ЫфШЛгХЛЏвдКѓ IO ФмгаЕуЬсЩ§)ЁЃ
cgroups БШНЯЧсЃЌЫфШЛИєРыадВЛЪЧКмИпЃЌЕЋЖдгкЮвУЧЕФ MySQL ЖрЪЕР§ИєРыРДЫЕЪЧЭъШЋЙЛгУСЫЃЈDocker
ЕФзЪдДЯожЦгУЕФОЭЪЧ cgroupsЃЉЁЃЕЋЪЧЮвУЧЛЙЯыеыЖдУПИі MySQL ЪЕР§дЫааЖюЭтЕФЙмРэНјГЬ (БШШчМрПиЕШЕШ)ЁЃгУ
cgroups ЪЕЯжЦ№РДЛсБШНЯИДдгЃЌВЂЧвЮвУЧЛЙЯыШУЪЕР§ЙмРэКЭЮяРэЛњЧјЗжПЊЃЌФЧ cgroups вВЗХЦњЁЃ
жСгк DockerЃЌФЧОЭКмВЛДэСЫЃЌФЧаЉТугУ cgroups ЕФТщЗГЫќЖМИјИуЖЈСЫЁЃВЂЧвга API ПЩвдЬсЙЉжЇГжЃЌПЊЗЂГЩБОЕЭЁЃЖјЧвЮвУЧПЩвдЛљгк
Docker ОЕЯёРДзіВПЪ№здЖЏЛЏЃЌФЧУДЛЗОГЕФвЛжСадвВПЩЧсЫЩНтОіЁЃЫљвдзюжеЮвУЧбЁдёСЫ Docker зїЮЊдЦЦНЬЈЕФзЪдДИєРыЗНАИ
(ЕБШЛЙ§ГЬжавВзіСЫКмЖрадФмЁЂЮШЖЈадЕШЕФЪЪХфЙЄзїЃЌетРяОЭВЛзИЪіСЫ)ЁЃ
ЯТУцСНИіЭМПЩвдаЮЯѓеЙЪОетПюВњЦЗДјРДЕФИяУќадвтвхЃК

ЕБШЛвЊФмГЦжЎЮЊдЦЃЌФЧУДЦНЬЈзюЛљБОЕФвЊЧѓОЭЪЧОпБИзЪдДМЦЫуЁЂзЪдДЕїЖШЙІФмЃЌЧвзЪдДЗжХфЮоашШЫЙЄВЮгыЁЃЖдгУЛЇРДНВЃЌФУЕНЕФгІИУЪЧжБНгПЩгУЕФзЪдДЃЌВЂЧвЬьЩњздДјИпПЩгУЁЂздЖЏБИЗнЁЂМрПиИцОЏЁЂТ§ШежОЗжЮіЕШЙІФмЃЌЮоашгУЛЇЙиаФзЪдДБГКѓЕФЪТЧщЁЃЦфДЮВХЪЧИїжжШеГЃЕФ
DBA дЫЮЌВйзїашЧѓЗўЮёЛЏЪфГіЁЃЯТУцЮвУЧОЭРДНВНВЮвУЧетИіЦНЬЈЪЧШчКЮвЛВНВНЪЕЯжЕФЁЃ
ЦНЬЈЪЕЯжЙ§ГЬ
еОдкОоШЫЕФМчАђЩЯ
ЮввЛжБШЯЮЊЦРМлвЛПюЪ§ОнПтЕФгХСгЃЌВЛФмжЛЦРМлЪ§ОнПтБОЩэЁЃЮвУЧвЊзлКЯЫќЕФжмБпЩњЬЌЪЧЗёНЁШЋЃЌБШШчЃКИпПЩгУЗНАИЁЂБИЗнЗНАИЁЂШеГЃЮЌЛЄФбЖШЁЂШЫВХДЂБИЕШЕШЁЃЕБШЛЖдгквЛИідЦЦНЬЈвВвЛбљЃЌЫљвдЮвУЧНјааСЫЖЬЦНПьЕФЪдДэЙЄзїЃЌНЋЦНЬЈЗжЮЊЖрЦкАцБОПЊЗЂЁЃЕквЛИіАцБОЕФПЊЗЂжмЦкБШНЯЖЬЃЌжївЊгУРДЪдбщЃЌЫљвдЮвУЧвЊОЁПЩФмдЫгУвбгаЕФПЊдДВњЦЗРДЪЕЯжЮвУЧЕФашЧѓЃЌЛђепЖдвбгаПЊдДВњЦЗНјааЖўДЮПЊЗЂвдКѓЪЕЯжЖЈжЦЛЏЕФашЧѓЁЃвдЯТЪЧЮвУЧЕБЪБгУЕНЕФВПЗжПЊдДВњЦЗКЭММЪѕЁЃ

ЯТУцбЁМИИіВњЦЗМђЕЅЫЕвЛЯТЮвУЧЭЈЙ§ЫќЪЕЯжЪВУДЙІФмЃК
1.PerconaЃКЮвУЧЕФБИЗнЁЂТ§ШежОЗжЮіЁЂЙ§диБЃЛЄЕШЙІФмЖМЪЧЛљгк
pt-tools ЙЄОпАќРДЪЕЯжЕФЁЃ
2.PrometheusЃКадФмгХдНЧвЙІФмЧПДѓЕФ TSDBЃЌгУгкЪЕЯжећИіЦНЬЈЪЕР§ЕФМрПиИцОЏЁЃШБЕуЪЧУЛгаМЏШКЙІФмЃЌЕЅЛњадФмЪЧИіЦПОБ
(ЫфШЛЕЅЛњЕФДІРэФмСІвбОКмЧПСЫ)ЃЌЫљвдЮвУЧдквЕЮёВуУцНјааСЫ DB В№ЗжЃЌЪЕЯжСЫЗжВМЪНДцДЂМАРЉеЙЁЃ
3.ConsulЃКЗжВМЪНЕФЗўЮёЗЂЯжКЭХфжУЙВЯэШэМўЃЌХфКЯ prometheus
ЪЕЯжМрПиНкЕузЂВсЁЃ
4.PythonЃКЙмРэ Docker ШнЦїжа MySQL ЪЕР§ЕФ agent
вдМАВПЗжВйзїНХБОЁЃ
5.DockerЃКГади MySQL ЪЕЧ€ЪЕЯжзЪдДИєРыКЭзЪдДЯожЦЁЃ
змЬхМмЙЙ
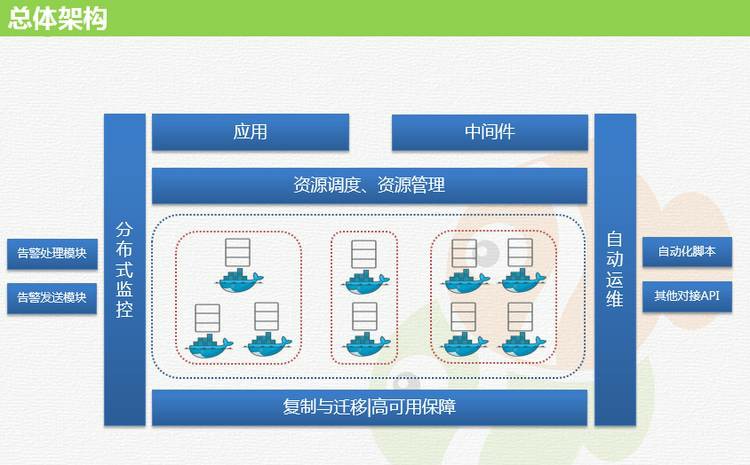
ШнЦїЕїЖШЯЕЭГШчКЮбЁдё
ШнЦїЕїЖШЕФПЊдДВњЦЗжївЊга Kubernetes КЭ mesosЃЌЕЋЪЧЮвУЧВЂУЛгабЁгУетСНИіЁЃжївЊдвђЪЧЮвУЧФкВПвбОПЊЗЂСЫвЛЬзЛљгк
Docker ЕФзЪдДЙмРэЁЂЕїЖШЕФЯЕЭГЃЌжСНёЮШЖЈдЫаа 2 ФъЖрСЫЁЃетЬзМмЙЙЩдзїаоИФЪЧЗћКЯашЧѓЕФЁЃ
СэЭтЕкШ§ЗНЕФзЪдДЕїЖШЯЕЭГМцШнЮвУЧФПЧАЕФИпПЩгУМмЙЙЃЌЦфЫћздЖЏЛЏЙмРэгааЉФбЖШЃЌЭЌЪБзЪдДЗжХфВпТдвВашвЊЖЈжЦЛЏЁЃЫљвдзюжеЛЙЪЧбЁдёВЩгУСЫздбаЕФзЪдДЕїЖШЙмРэЁЃЪЪКЯздМКЯжзДЕФашЧѓВХЪЧзюКУЕФЁЃЕБШЛКѓУцгаЛњЛсзіЕНМЦЫуЕїЖШКЭДцДЂЕїЖШЗжРыЕФЧщПіЯТЮвУЧПЩФмЛсзЊЯђ
Kubernetes ЕФЗНАИЁЃ
ЙЄзїдРэ
ЮвУЧОЭФУДДНЈМЏШКРДОйР§АЩЁЃЕБЦНЬЈЗЂЦ№вЛИіДДНЈМЏШКЕФШЮЮёКѓЃЌЪзЯШЛсИљОнМЏШКЙцФЃ (вЛжївЛДгЛЙЪЧвЛжїЖрДгЃЌЛђепЪЧЗжЦЌМЏШК)
ШЗЖЈвЊДДНЈЕФЪЕР§Ъ§СПЃЌШЛКѓИљОнетИіашЧѓАДееЮвУЧЕФзЪдДЩИбЁЙцдђ (БШШчжїДгВЛФмдкЭЌвЛЬЈЛњЦїЁЂФкДцХфжУВЛдЪаэГЌТєЕШЕШ)ЃЌДгЯжгаЕФзЪдДГижаЦЅХфГіПЩгУзЪдДЃЌШЛКѓвРДЮДДНЈжїДгЙиЯЕЁЂДДНЈИпПЩгУЙмРэЁЂМьВщМЏШКИДжЦзДЬЌЁЂЭЦЫЭМЏШКаХЯЂЕНжаМфМў
(бЁгУСЫжаМфМўЕФЧщПіЯТ) ПижЦжааФЁЂзюКѓНЋвдЩЯЯрЙиаХЯЂЖМЭЌВНЕН CMDBЁЃ
вдЩЯЕФУПвЛИіЙЄзїЖМЪЧЭЈЙ§ЗўЮёЖЫЗЂЫЭЯћЯЂЕН agentЃЌШЛКѓгЩ agent жДааЖдгІЕФНХБОЃЌНХБОЛсЗЕЛижИЖЈИёЪНЕФжДааНсЙћЃЌетаЉНХБОЪЧгЩ
DBA ПЊЗЂЕФЁЃетжжЗНЪНЕФгХЪЦдкгкЃЌDBA БШШЮКЮШЫЖМСЫНтЪ§ОнПтЃЌЫљвдЭЈЙ§етжжЗНЪНПЩвдгааЇЬсЩ§ЯюФППЊЗЂаЇТЪЃЌвВФмШУ
DBA ВЮгыЕНЯюФПЕБжаШЅЁЃПЊЗЂжЛашвЊаДЧАЬЈТпМЃЌDBA ИКд№КѓЖЫОпЬхжДааЕФжИСюЁЃШчЙћЮДРДЙІФмгаБфИќЛђЕќДњЕФЛАЃЌжЛашвЊЕќДњНХБОМДПЩЃЌЮЌЛЄСПМЋаЁЁЃ
зЪдДЕФЕїЖШЗжХфддђ
ОЙ§ЖдЭЌГЬЖрФъЕФ DB дЫЮЌЪ§ОнЗжЮіЕУЕНШчЯТОбщЃК
1.CPU зюДѓГЌТє 3 БЖЃЌФкДцВЛГЌТєЃЛ
2.ЭЌвЛЛњЗПгХЯШбЁдёзЪдДзюПеЯаЕФЛњЦїЃЛ
3.жїДгНЧЩЋВЛдЪаэдкЭЌвЛЬЈЛњЦїЩЯЃЛ
4.Шєга VIP ашЧѓЕФжїДгЖЫПкашвЊвЛжТЃЌЮо VIP ашЧѓжБНгЖдНгжаМфМўЕФЮоЖЫПквЛжТЕФЯожЦЃЛ
5.ЗжЦЌЕФМЏШКНЋНкЕуЗжВМдкЖрЬЈЮяРэЛњЩЯЃЛ
ВњЦЗЗжРр
КЫаФЙІФм
вдЩЯЪЧвбОЩЯЯпЕФВПЗжКЫаФЙІФмЃЌЛЙгаКмЖрЙІФмОЭВЛдйвЛвЛеЙЪОЁЃ
БИЗнЛжИДЯЕЭГ
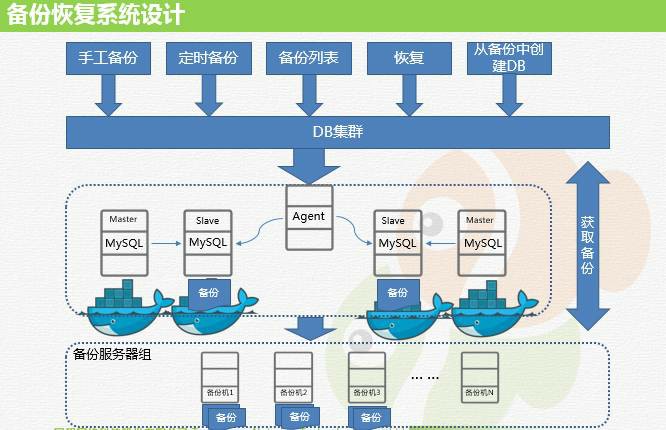
БИЗнЙЄОпЮвУЧЪЧгУ percona-xtrabackupЁЃЭЈЙ§СїБИЗнЕФЗНЪННЋЪ§ОнБИЗнЕНдЖЖЫЕФБИЗнЗўЮёЦїЁЃБИЗнЗўЮёЦїгаЖрЬЈЃЌЗжБ№АДееЫљЪєЛњЗПЛЎЗжЁЃ
ЮвУЧЬсЙЉСЫЪжЙЄБИЗнКЭЖЈЪББИЗнРДТњзуВЛЭЌГЁОАЕФашЧѓЁЃЖрЪЕР§БИЗнвЛЖЈвЊЙизЂДХХЬ IO КЭЭјТчЃЌЫљвдЮвУЧЕФБИЗнВпТдЛсЯожЦЕЅИіЮяРэЛњЩЯВЂааБИЗнЕФЪ§СПЃЌСэЭтЕЅИіЛњЗПБИЗнШЮЮёЖгСаЕФВЂааЖШвВгаПижЦЃЌШЗБЃВЂааБИЗнШЮЮёЪМжеБЃГжЕНЮвУЧжИЖЈЕФЪ§СПЁЃ
МйШчећИіЛњЗПВЂааЕФЪЧ 50 ИіШЮЮёЃЌФЧУДет 50 ИіЕБжаШчЙћга 5 ИіЬсЧАБИЗнЭъГЩЃЌФЧУДЛсаТМгШы
5 ИіЕШД§БИЗнЕФШЮЮёНјШыетИіБИЗнЖгСаЁЃЮвУЧКѓРДИФдьСЫБИЗнЕФДцДЂЗНЪНЃЌжБНгНЋБИЗнСїШыЗжЪНДцДЂЁЃ
МрПиИцОЏЯЕЭГ
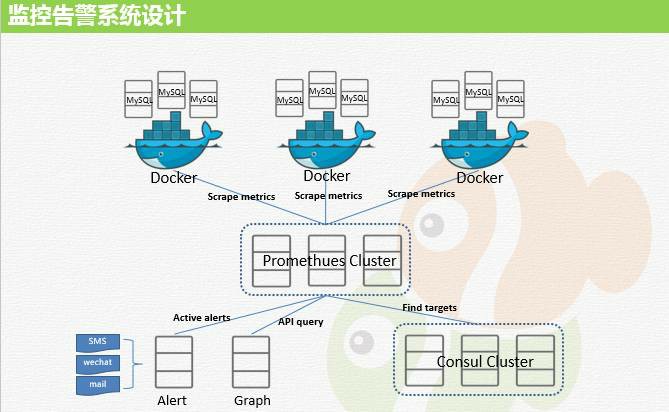
дкЩЯЯпетЬздЦЦНЬЈЧАЃЌЮвУЧЛЙЪЧгУДЋЭГЕФ zabbix РДЪЕЯжМрПиИцОЏЕФЁЃzabbix ЕФЙІФмЕФШЗЗЧГЃЧПДѓЃЌЕЋЪЧКѓЖЫЕФЪ§ОнПтЪЧИіЦПОБЃЌЕБШЛПЩвдЭЈЙ§Ъ§ОнПтВ№ЗжЕФЗНЪННтОіЁЃ
Ъ§ОнПтвЊМрПиЕФжИБъБШНЯЖрЃЌШчЙћВЩМЏЕФЯюФПБШНЯЖрЃЌzabbix ОЭашвЊМг proxyЃЌМмЙЙдНРДдНИДдгЃЌдйМгЩЯКЭЮвУЧЦНЬЈЖдНгЕФГЩБОБШНЯИпЃЌЖдвЛаЉИДдгЕФЭГМЦРрВщбЏ
(95 жЕЁЂдЄВтжЕЕШ) адФмБШНЯВюЁЃ
ЫљвдЮвУЧбЁСЫвЛПю TSDBЁЊЁЊprometheusЃЌетЪЧвЛПюадФмМЋЧПЁЂМЋЦфЪЪКЯМрПиЯЕЭГЪЙгУЕФЪБађадЪ§ОнПтЁЃprometheus
гХЕуОЭЪЧЕЅЛњадФмГЌЧПЁЃЕЋЗВЪТгжгаСНУцадЃЌЫќЕФШБЕуОЭЪЧВЛжЇГжМЏШКМмЙЙ (ВЛЙ§ЮвУЧНтОіСЫРЉеЙЕФЮЪЬтЃЌЯТУцЛсНВЕН)ЁЃ
prometheus ЕФЪЙгУгІИУЪЧДгвЛФъЧАОЭПЊЪМЕФЃЌФЧЪБКђЮвУЧжЛЪЧАбЫќзїЮЊИЈжњЕФМрПиЯЕЭГРДЪЙгУЕФЃЌЫцзХж№НЅЪьЯЄЃЌдНРДдНОѕЕУетИіЪЧШнЦїМрПиЕФОјМбНтОіЗНАИЁЃЫљвддкЩЯдЦЦНЬЈЕФЪБКђОЭбЁдёСЫЫќзїЮЊећИіЦНЬЈЕФМрПиЯЕЭГЁЃ
МрПиЪ§ОнВЩМЏ
prometheus ЪЧжЇГж pushgateway КЭ pull ЕФЗНЪНЁЃЮвУЧбЁгУСЫ pull ЕФЗНЪНЁЃвђЮЊНсЙЙМђЕЅЃЌПЊЗЂГЩБОЕЭЕФЭЌЪБЛЙФмКЭЮвУЧЕФЯЕЭГЭъУРЖдНгЁЃconsul
МЏШКИКд№зЂВсЪЕР§аХЯЂКЭЗўЮёаХЯЂЃЌБШШч MySQL ЪЕР§жїДгЖдгІЕФЗўЮёЁЂLinux жїДгЖдгІЕФЗўЮёЁЂШнЦїзЂВсЖдгІЕФЗўЮёЁЃШЛКѓ
prometheus ЭЈЙ§ consul ЩЯзЂВсЕФаХЯЂРДЛёШЁМрПиФПБъЃЌШЛКѓШЅ pull МрПиЪ§ОнЁЃМрПиПЭЛЇЖЫЪЧвд
agent ЕФаЮЪНДцдкЃЌprometheus ЭЈЙ§ HTTP авщЛёШЁ agent ЖЫВЩМЏЕНЕФЪ§ОнЁЃ
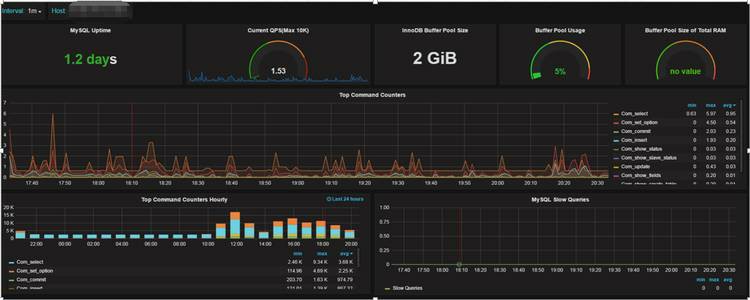
МрПижИБъЛЭМ
ВЛЕУВЛЫЕ grafana ЪЧМрПиЛЭМНчЕФПИАбзгЃЌЙІФмЦыШЋЕФЖШСПвЧБэХЬКЭЭМаЮБрМЦїЃЌОЙ§МђЕЅХфжУОЭФмЭъГЩИїжжМрПиЭМаЮЕФеЙЪОЁЃШЛКѓЮвУЧДђЭЈСЫдЦЦНЬЈКЭ
grafana ЕФЙиСЊЃЌгУЛЇдкдЦЦНЬЈашвЊВщПДЪЕР§ЛђМЏШКаХЯЂЃЌжЛвЊЕуЛїАДХЅМДПЩЁЃ

ИцОЏЙмРэ
ИцОЏЙмРэЗжЮЊЃКИцОЏЗЂЫЭЁЂИцОЏНгЪеШЫЙмРэЁЂИцОЏОВФЌЕШЙІФмЁЃprometheus гавЛИіИцОЏЗЂЫЭФЃПщ alertmanagerЃЌЮвУЧЭЈЙ§
webhook ЕФЗНЪНШУ alertmanager АбИцОЏаХЯЂЗЂЫЭЕНдЦЦНЬЈЕФИцОЏ APIЃЌШЛКѓдкдЦЦНЬЈРДИљОнКѓУцЕФТпМНјааИцОЏФкШнЗЂЫЭЁЃ
alertmanager ЭЦЙ§РДЕФжЛЪЧЪЕР§ЮГЖШЕФИцОЏЃЌЫљвдЮвУЧНсКЯИцОЏЦНЬЈЕФЪЕР§ЯрЙиаХЯЂЃЌЛсЦДГівЛИіЖрЮЌаХЯЂЕФИцОЏФкШнЁЃШУ
DBA вЛПДОЭжЊЕРЪЧЫЕФФФИіМЏШКдкЪВУДЪБМфДЅЗЂСЫЪВУДЕШМЖЕФЪВУДИцОЏЁЃИцОЏЛжИДКѓвВЛсдйЗЂвЛДЮЛжИДЕФЭЈжЊЁЃ
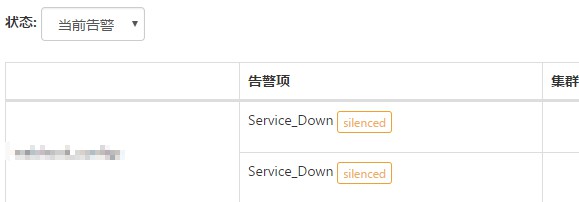
alertmanager вВЪЧЙІФмЧПДѓЕФЙЄОпЃЌжЇГжИцОЏвжжЦЁЂИцОЏТЗгЩВпТдЁЂЗЂЫЭжмЦкЁЂОВФЌИцОЏЕШЕШЁЃгаашвЊПЩвдздааХфжУЁЃЕЋЪЧетжжКЭЦНЬЈЗжРыЕФЙмРэЗНЪНВЛЪЧЮвУЧЯывЊЕФЃЌЫљвдОЭЯыАб
alertmanager ЖдИцОЏаХЯЂДІРэЕФетВПЗжЙІФмМЏГЩЕНдЦЦНЬЈФкЁЃ
ЕЋЪЧЙйЗНЮФЕЕВЂУЛгаЬсМАЕН alertmanager ЕФ APIЃЌЭЈЙ§ЖддДТыЕФЗжЮіЃЌЮвУЧевЕНСЫИцОЏЙмРэЯрЙиЕФ
APIЁЃШЛКѓ alertmanager ЕФдЩњ UI ЩЯВйзїЕФЙІФмЭъУРвЦжВЕНСЫЮвУЧЕФдЦЦНЬЈЃЌЭЌЪБаТдіСЫЪЕР§ЯрЙиМЏШКУћГЦЁЂИКд№ШЫЕШИќЖрЮГЖШЕФаХЯЂЁЃ
ЯТУцЪЧвЛаЉВйзїбљР§ЃК
ЕБЧАИцОЏЃК
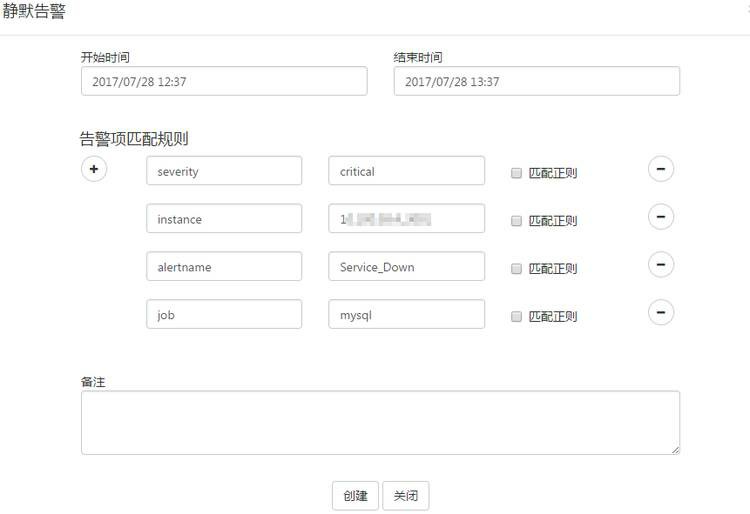
ЬэМгИцОЏОВФЌЃК
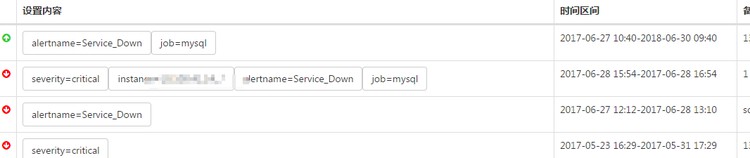
вбДДНЈЕФОВФЌЙцдђЃК
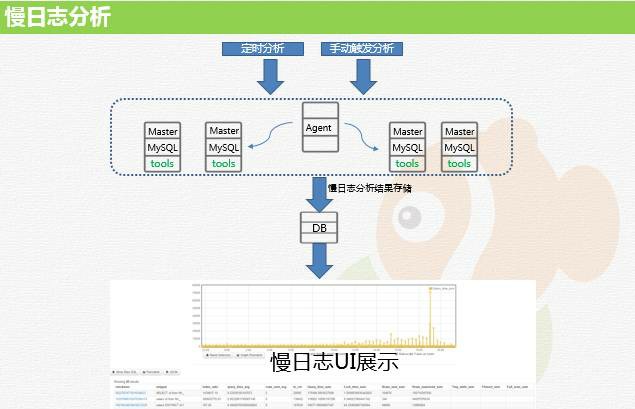
Т§ШежОЗжЮіЯЕЭГ
Т§ШежОЕФЪеМЏЪЧЭЈЙ§ pt-query-digest УПаЁЪБНјааБОЕиЗжЮіЃЌЗжЮіЭъГЩвдКѓНЋНсЙћаДШыТ§ШежОДцДЂЕФЪ§ОнПтРДЭъГЩЕФЁЃЕБШЛШчЙћгУЛЇашвЊСЂПЬВщПДЕБЧАТ§ШежОЕФЧщПіЃЌвВПЩвддкНчУцЕуЛїТ§ШежОЗжЮіЁЃЗжЮіЭъГЩКѓПЩвддк
UI НчУцЕуЛїТ§ШежОВщПДЃЌОЭФмПДЕНИУЪЕР§ЕФТ§ШежОЗжЮіНсЙћЁЃЫќЭЌЪБМЏГЩСЫ explainЁЂВщПД table
status ЕШЙІФмЁЃ
МЏШКЙмРэ
МЏШКЙмРэзїЮЊИУЦНЬЈЕФКЫаФЙІФмжЎвЛЃЌеМОнСЫећИіЦНЬЈ 70% ЕФЙЄзїЁЃетаЉЙІФмОЭЪЧ DBA дЫЮЌжаОГЃашвЊгУЕНЕФЁЃЮвУЧЕФЩшМЦЫМТЗЪЧвдМЏШКЮЊЕЅЮЛЃЌЫљвдЭЌЪБжЛФмВйзївЛИіМЏШКЩЯЕФЪЕР§ЁЃетбљОЭВЛЛсдквЛИівГУцЩЯЯдЪОЙ§ЖрЮогУЕФаХЯЂЃЌПДзХТвЛЙгаПЩФмЕМжТЮѓВйзїЁЃПДСЫЯТЭМжаЕФетаЉЙІФмОЭФмИќУїАзЮЊЪВУДвЊетУДЩшМЦСЫЁЃ
ЭМжажЛЪЧвЛВПЗжЃЌЛЙгаВПЗжЮДеЙЪОГіЕФЙІФм (МЏГЩжаМфМўЁЂDashboardЁЂКкЦСеяЖЯДАПкЕШ)ЃЌдкКѓАцжаЙІФмИќЖрЁЃ
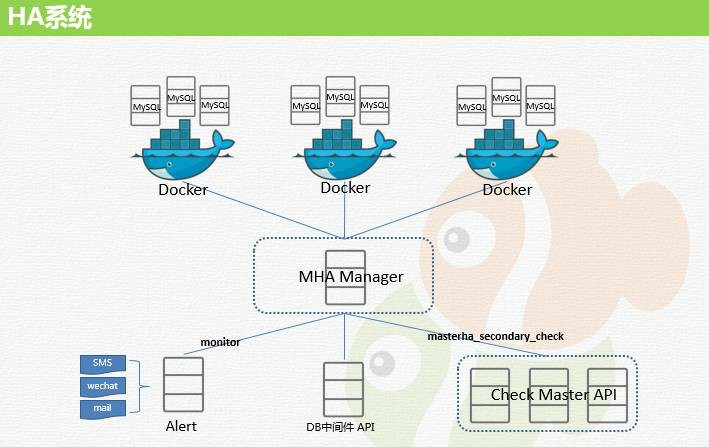
ИпПЩгУ
ИпПЩгУЗНАИЮвУЧЪЙгУСЫФПЧАзюСїааЕФ MySQL ИпПЩгУЗНАИ MHAЁЃMHA ЕФгХШБЕуОЭВЛдкетРяНВСЫЃЌга
DBA ЭЌбЇЕФгІИУЖМвбОКмЪьЯЄСЫЁЃетРяЮвЫЕвЛЯТЮвУЧЛљгкЭЌГЬвЕЮёзіЕФЕїећЁЃ
GTID
вђЮЊЮвУЧжївЊЪЙгУЕФ MariaDBЃЌЕЋЪЧ MHA зюаТАцБОвВЪЧВЛФмжЇГж MariaDB ЕФ GTID
ЧаЛЛЁЃЫљвдЮвУЧдкдгаЕФЛљДЁЩЯзіСЫИФНјЃЌжЇГжСЫ MariaDB ЕФ GTIDЁЃЪЙгУ GTID вдКѓСщЛюЧаЛЛЪЧвЛИіЗНУцЃЌСэЭтвЛИіЗНУцЪЧ
sync_master_info КЭ sync_relay_log_info ОЭВЛашвЊЩшжУГЩ 1 СЫ
(MariaDB ВЛжЇГжаД tableЃЌжЛФмаД file)ЃЌМЋДѓМѕЩйСЫДгПтИДжЦДјРДЕФ IOPSЁЃ
ЧаЛЛЪБЕїећЯрЙиВЮЪ§
ЮвУЧдкЧаЛЛЪБЕїећ sync_binlog КЭ innodb_flush_log_at_trx_commit
ВЮЪ§ЃЌетСНИіВЮЪ§ЪЧОіЖЈЪ§ОнТфХЬЗНЪНЕФЃЌФЌШЯДѓМвЖМЪЧЩшжУЫЋ 1ЁЃетбљЯрЖдЪ§ОнзюАВШЋЃЌЕЋЪЧ IO вВзюИпЁЃ
дЦЗўЮёЕФЖрЪЕР§ВПЪ№ЛсЕМжТвЛЬЈЮяРэЛњЩЯМШга master гжга slaveЁЃЮвУЧПЯЖЈВЛЯЃЭћ slave
ВњЩњЬЋИпЕФ IO гАЯьЕНЭЌЛњЦїЕФЦфЫћ slave(ЫфШЛПЩвд IO ИєРыЃЌЕЋЪЧгХЯШНЕЕЭВЛБивЊ IO ВХППЦз)ЁЃЫљвдРэТлЩЯРДЫЕ
Master ЩЯУцЩшжУЫЋ 1ЃЌslave дђПЩвдВЛетбљЩшжУЁЃЕЋЪЧЧаЛЛКѓдРДЕФ salve ПЩФмЛсБфГЩСЫ
masterЁЃЫљвдЮвУЧФЌШЯ slave ЗЧЫЋ 1ЃЌдк MHA ЧаЛЛЕФЪБКђЛсздЖЏНЋаТ master ЕФетСНИіВЮЪ§ЩшжУЮЊ
1ЁЃ
ЩкБј
ЮвУЧдкЖрИіЕуВПЪ№СЫЩкБјЗўЮёЁЃетИіЩкБјЪЧвЛИіМђЕЅЕФ API ЗўЮёЃЌДјЩЯЯьгІЕФВЮЪ§ПЩвдЧыЧѓЕНжИЖЈЕФЪЕР§ЁЃЕБ
MHA manager МьВтЕНга Master ЮоЗЈСЌНгЪБЃЌЛсДЅЗЂ secondary check
ЛњжЦЃЌДјзХ master ЯрЙиаХЯЂЧыЧѓЩкБјНкЕуЕФ APIЃЌИљОнЩкБјНкЕуЗЕЛиЧщПіЃЌШєГЌЙ§АыЪ§ЮоЗЈСЌНгдђЧаЛЛЁЃЗёдђЗХЦњЧаЛЛЁЃ
ИпПЩгУЧаЛЛЖдНгDB жаМфМў
(ЕуЛїЗХДѓЭМЯё)
DB жаМфМўКЭ DB ЭЈЙ§ЮяРэ IP СЌНгЃЌЕБЗЂЩњИпПЩгУЧаЛЛЪБНЋзюаТЕФ Master IPЁЂMaster
port аХЯЂЭЦЫЭЕН DB жаМфМўПижЦжааФЃЌDB жаМфМўФУЕНХфжУКѓСЂПЬЯТЗЂВЂЩњаЇЁЃ
ЪЕР§ЁЂПтЧЈвЦ
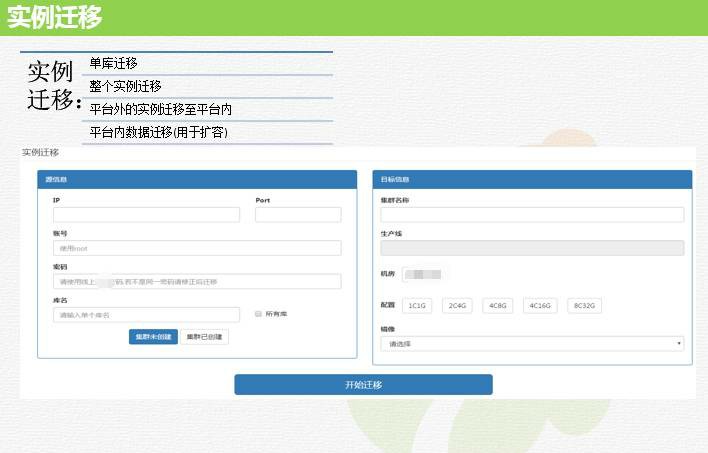
ЧЈвЦЙІФмГѕждЪЧЮЊСЫНЋЦНЬЈЭтЕФЪЕР§ЛђепПтЧЈвЦЕНЦНЬЈРяУцРДЃЌКѓРДЫцзХж№НЅЪЙгУЗЂЯжетИіЙІФмПЩЭкОђЕФПеМфКмДѓЃЌБШШчПЩвдзіЦНЬЈФкПтБэВ№ЗжЕШашЧѓЁЃЪЕЯждРэвВКмМђЕЅЃЌгУ
mydumper НЋжИЖЈЪ§ОнБИЗнЯТРДвдКѓЃЌдйгУ myloader ЛжИДЕНжИЖЈЪ§ОнПтЁЃ
етЪЧвЛИіШЋСПЕФЙ§ГЬЃЌдіСПИДжЦгУЕФЪЧгУЮвУЧздМКПЊЗЂЕФвЛИіжЇГжВЂааИДжЦЕФЙЄОпЃЌетИіЙЄОпЛЙжЇГжЕШУнДІРэЃЌЪЙгУИќСщЛюЁЃУЛгагУдЩњИДжЦЕФдвђЪЧЃЌМйШчвЊНЋдДЪЕР§ЖрИіПтжаЕФвЛИіПтЧЈвЦЕНФПБъЪЕР§ЃЌФЧУДдЩњИДжЦОЭашвЊЖд
binlog зіИДжЦЙ§ТЫЃЌетРяУцЩцМАЕНХфжУаоИФЃЌЪЕР§жиЦєЃЌЫљвдЙћЖЯВЛПМТЧЁЃ
ЪЕЯжЙ§ГЬВЂУЛгаИпДѓЩЯЃЌЕЋЪЧЭъШЋТњзуашЧѓЁЃЕБШЛ mydumper КЭ myloader вВгавЛаЉЮЪЬтЃЌЮвУЧвВзіСЫаЁИФЖЏвдКѓВХЪЕЯжЕФЁЃКѓУцЮвУЧМЦЛЎгУСїЕФЗНЪНШЅзіЪ§ОнЕМГіЕМШы
(РрЫЦгкАЂРяПЊдДЕФ datax)ЁЃ
ЧЈвЦЭъГЩЃЌдіСПЮобгГйЕФЧщПіЯТЃЌДѓМвЛсЙиаФЧЈвЦЧАКѓЪ§ОнвЛжТадЕФЮЪЬтЃЌЮвУЧЬсЙЉСЫздбаЕФЪ§ОнаЃбщЙЄОпЁЃЪЕВт
300G ЕФЪ§ОнаЃбщЪБМфдМЮЊ 2 жС 3 ЗжжгЃЌПьТ§ШЁОігкПЊЖрЩйЯпГЬЁЃ
ЦСБЮЕзВуЮяРэзЪдД
ЖдгУЛЇРДНВЃЌЦНЬЈЬсЙЉЕФЪЧвЛИіЛђвЛзщЪ§ОнПтЗўЮёЃЌВЛашвЊЙиЯЕКѓЖЫЕФЪЕР§ЪЧдкФФЬЈЛњЦїЩЯЁЃзЪдДМЦЫуКЭЕїЖШШЋВПгЩЯЕЭГЕФЫуЗЈНјааЙмРэЁЃ
ЬсЩ§зЪдДРћгУТЪ (CPUЁЂФкДц)
ЭЈЙ§ЕЅЛњЖрЪЕР§ЃЌCPU зЪдДПЩГЌТєЃЌгааЇЬсИп CPU зЪдДЕФРћгУЁЃФкДцзЪдДЮДГЌТєЃЌЕЋЪЧПЩвдПижЦЕНУПИіЪЕР§ЕФФкДцЪЙгУЃЌШЗБЃУПИіЪЕР§ЖМФмгазуЙЛЕФФкДцЁЃШєгаЪЃгрФкДцЃЌдђМЬајЗжХфШнЦїМДПЩЃЌВЛ
OOM ЕФЧщПіЯТбЙеЅФкДцзЪдДЁЃ
ЬсЩ§дЫЮЌаЇТЪ
аЇТЪЕФЬсЩ§ЕУвцгкБъзМЛЏвдКѓДјРДЕФздЖЏЛЏЁЃХњСПдЫЮЌЕФГЩБОКмЕЭЁЃвдЧАВПЪ№вЛЬзЗжЦЌМЏШКашвЊЛЈЗбНЋНќ 6
ИіаЁЪБ (ВЛАќКЌЖдНгжаМфМўЕФ 1 ЕН 2 ИіаЁЪБ)ЃЌЖјЯждкжЛашвЊ 5 ЗжжгМДПЩВПЪ№ЭъГЩЁЃВЂЧвВПЪ№ЭъГЩвдКѓЛсНЋЬсЙЉвЛЬзжаМфМў
+DB ЗжЦЌМЏШКЕФЗўЮёЁЃ
ОЋЯИЛЏЙмРэ
ЦНЬЈЩЯЯпКѓгааЇЬсИпСЫзЪдДРћгУТЪЃЌЭЌЪБЮвУЧАДее 1 Пт 1 ЪЕР§ЕФЗНЪНЃЌПЩвдгааЇБмУтВЛЭЌПтЕФбЙСІВЛОљЕМжТЯрЛЅгАЯьЕФЮЪЬтЁЃВЂЧвадФмМрПивВФмОЋзМЕНПтМЖБ№ЁЃ
Нсгя
вдЩЯетаЉжЛЪЧвЛИіПЊЪМ, КѓУцЛЙгаКмЖрЙІФмашвЊЭъЩЦЃЌЯТУцЪЧНќЦкВпЛЎЕФвЛаЉЙІФмЃЌЦфжагааЉвбОдкКѓАцжаПЊЗЂЭъГЩЁЃ
ЫцзХЙІФмЕФВЛЖЯЕќДњЃЌЮвУЧЛсДђдьвЛИіИќМгЭъУРЕФЫНгадЦЦНЬЈЁЃ

Ъ§ОнПтЫНгадЦЦНЬЈЕФЩЯЯпЖдЭЌГЬ DB РДЫЕЃЌвтЮЖзХвЛИіЪБДњЕФНсЪјЃЌвВвтЮЖзХвЛИіЪБДњЕФПЊЪМЁЃНсЪјЕФЪЧДЋЭГдЫЮЌЕЭаЇЁЂИпГЩБОЕФдЫЮЌЪБДњЃЌПЊЪМЕФЪЧвЛИіЕЭГЩБОЁЂИпаЇТЪЁЂИпБЃеЯЕФдЫЮЌЪБДњЁЃЮвУЧЯраХЮДРДЛсИќУРКУЃЁ |









