ЗжЯэДѓИй
1.ЪВУДЪЧЁКЪ§ОнПтМДЗўЮёЁЛ
2.MongoDB
3.ШчКЮДюНЈвЛИіMongoDBЁКЪ§ОнПтМДЗўЮёЁЛ
ЪВУДЪЧЁКЪ§ОнПтМДЗўЮёЁЛ


ЪзЯШНщЩмвЛЯТЁКЪ§ОнПтМДЗўЮёЁЛЁЃЁКЪ§ОнПтМДЗўЮёЁЛЦфЪЕЪЧЁКDatabase-as-a-serviceЁЛЕФжаЮФЗвыЃЌЮвУЧПДПДЫќдкЮЌЛљАйПЦжаЕФЖЈвхЃКЁКЪ§ОнПтМДЗўЮёЁЛЪЧетбљвЛжжЗўЮёФЃЪНЃЌЫќЪЙЕУгІгУПЊЗЂепВЛдйашвЊздМКАВзАКЭЮЌЛЄЪ§ОнПтЃЌЖјЪЧгЩзЈУХЕФЪ§ОнПтЗўЮёЬсЙЉЩЬРДзіЃЌгІгУПЊЗЂепПЩвдИљОнздМКЕФашвЊШЅжБНгЪЙгУЪ§ОнПтЗўЮёЃЌВЂЮЊЪЙгУСПжЇИЖЗбгУМДПЩЁЃЮвУЧжЊЕРЃЌЯждкгаКмЖрЕФas-a-serviceЃЌБШШчInfrastructure
as a ServiceЃЈIaaSЃЉЁЂPlatform as a ServiceЃЈPaasЃЉЛЙгаSoftware
as a ServiceЃЈSaasЃЉЁЃЫћУЧЕНЕзЖМЪЧЪВУДФиЃПгаЪВУДЧјБ№ЃП
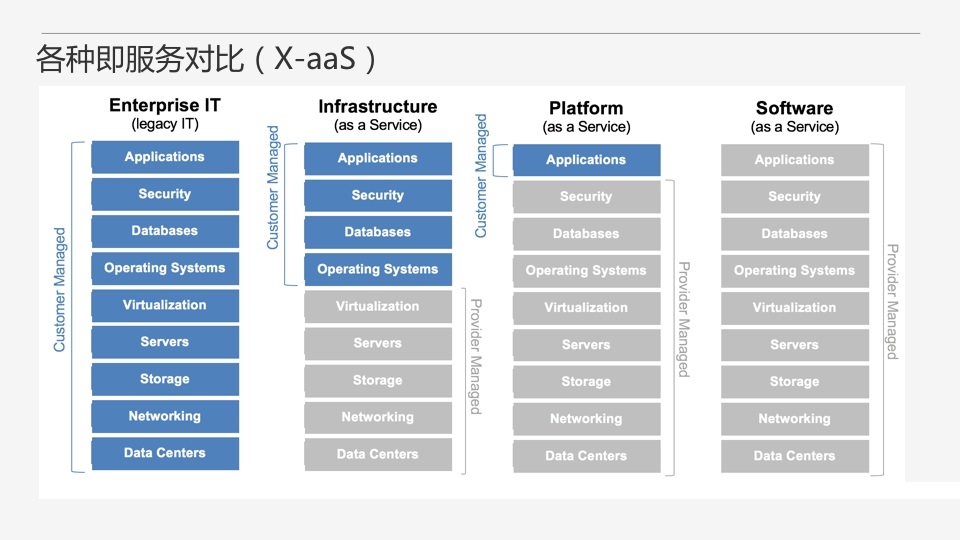
етеХЭМгІИУПЩвдКмКУЕФНтЪЭетаЉX-aaSЁЃзюзѓБпЪЧДЋЭГЦѓвЕЕФITЃЌЫљгаЕФЛюЖМвЊздМКИЩЃЌДгЪ§ОнжааФЗўЮёЦїЕНВйзїЯЕЭГЪ§ОнПтдйЕНЩЯВувЕЮёЯЕЭГЁЃIaaSПЊЪМОЭНјШыдЦМЦЫуЕФЗЖГыСЫЃЌзюЛљДЁЕФЪЧдЦЗўЮёЦїЃЌВЛашвЊдйЙиаФЛњЗПАЁгВМўРЃЌжБНгОЭПЩвдгУЁЃШЛКѓдйЭљгвПЭЛЇашвЊЙизЂЕФдНРДдНЩйЃЌдрЛюРлЛюЖМНЛИјЗўЮёЬсЙЉЩЬРДИЩЁЃ
ФЧУДЁКЪ§ОнПтМДЗўЮёЁЛЕФЧщПіЪЧдѕУДбљФиЃП
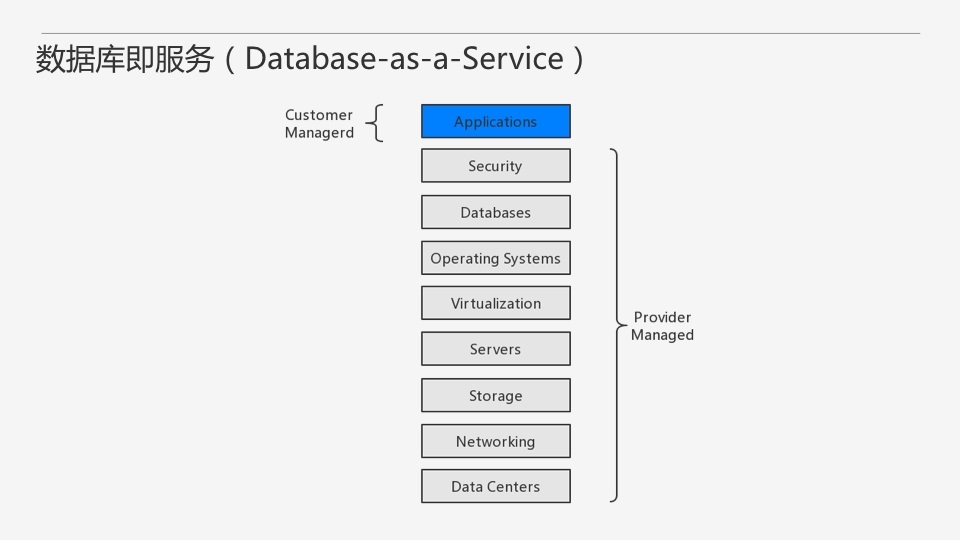
ЁКЪ§ОнПтМДЗўЮёЁЛЦфЪЕПЩвдШЯЮЊЪЧPaaSЕФвЛжжБфжжЃЌжївЊЙизЂЕудкЪ§ОнПтЩЯЃЌПЭЛЇВЛдйашвЊШЅздМКВПЪ№Ъ§ОнПтЃЌЖјЪЧжЛашвЊАДашЪЙгУгЩЗўЮёЬсЙЉЩЬЬсЙЉЕФЪ§ОнПтМДПЩЃЌЪ§ОнПтЕФЮЌЛЄЖМНЛИјЗўЮёЬсЙЉЩЬРДЭъГЩЃЌетбљПЭЛЇжЛашЙизЂгІгУБОЩэМДПЩЁЃ
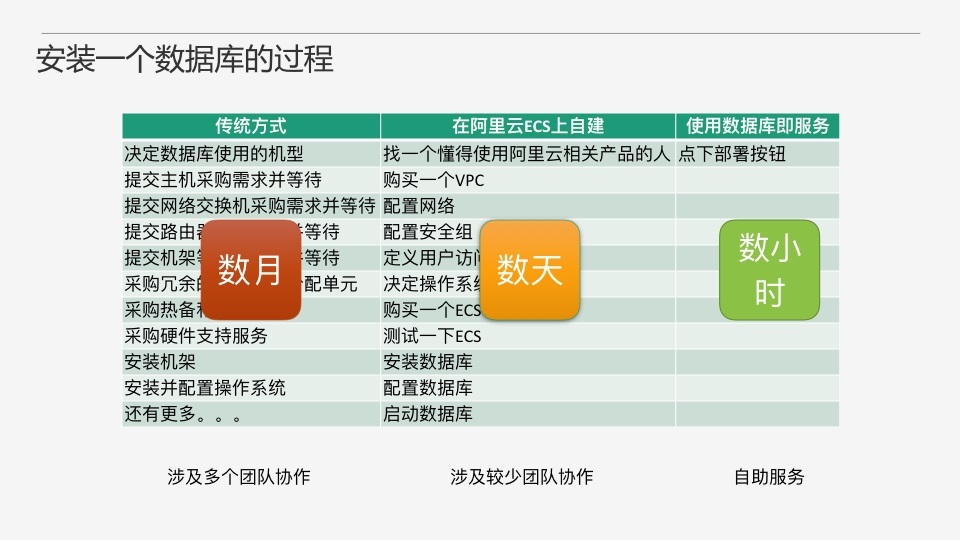
ЮвУЧРДОпЬхПДвЛЯТЪЙгУЁКЪ§ОнПтМДЗўЮёЁЛКЭдРДгаЪВУДВЛЭЌЃЌетРяГ§СЫСаОйДЋЭГШЋВПDIYЕФЗНЪНжЎЭтЃЌЛЙЖдБШСЫвЛжжРћгУIaaSРДздНЈЪ§ОнПтЕФЗНЪНЃЌетвВЪЧЯждкБШНЯГЃМћЕФвЛжжзіЗЈЁЃЮвУЧПДЕНДЋЭГЗНЪНЃЌашвЊзіКмЖрЪТЧщЃЌетЕБжаЛЙашвЊЩцМАЖрИіЭХЖгРДазїЃЌЗЧГЃВЛШнвзЁЃШЛКѓПДПДЕкЖўжжЗНЪНЃЌРћгУIaaSРДздНЈЃЌетРявдАЂРядЦЕФдЦЗўЮёЦїECSЮЊР§ЃЌетжжЗНЪНКЭИеИеЯрБШЃЌЪЁСЫВЛЩйЪТЃЌЕЋЪЧШдШЛЪЧБШНЯТщЗГЕФЃЌвВПЩФмЛЙашвЊЩцМАПчЭХЖгазїЁЃЮвУЧдйРДПДПДШчЙћЪЧЪЙгУЁКЪ§ОнПтМДЗўЮёЁЛФиЃПжЛашвЊЕуЯТвГУцЩЯЕФВПЪ№АДХЅЃЌОЭПЩвдЕШзХгУСЫЃЌвбОНјЛЏЮЊЭъШЋзджњЗўЮёСЫЁЃДгЪБМфЩЯРДПДЃЌЕквЛжжЗНЪНПЩФмашвЊЛЈЗбЪ§дТЃЌЕкЖўжжПЩФмашвЊЛЈЗбЪ§ЬьЃЌЕкШ§жждђжЛашвЊЪ§аЁЪБМДПЩЁЃПЩМћЁКЪ§ОнПтМДЗўЮёЁЛЕФгХЪЦЛЙЪЧКмУїЯдЕФЁЃ

ЫљвдЫЕЮЊЪВУДвЊЁКМДЗўЮёЁЛЃЌЦфЪЕЪЧвЛИіНјЛЏЕФЧїЪЦЁЃЮвУЧОГЃЫЕШЫВЛФмЬЋРСЃЌЕЋЪЧРСетИізжгУдкГЬађдГЩэЩЯПЩФмВЂВЛЪЧВЛКУЕФЖЋЮїЃЌвђЮЊРСЃЌДйЪЙЮвУЧЛсШЅздЖЏЛЏЁЃзюдчЮвУЧЭЈЙ§ШЫШтВйзїЃЌЯТдиШэМўЃЌБрвыВПЪ№ЃЌШЛКѓХфжУЁЃгавЛЬьЮвУЧЗЂЯжОГЃашвЊетУДИЩКмРлКмРЫЗбЪБМфЃЌОЭПЊЪМаДНХБОРДЭъГЩетаЉВйзїЃЌЩњВњСІПЊЪМЬсИпЁЃЕШЕНЙцФЃИќДѓЕФЪБКђЃЌБШШчвЊЭЌЪБЙмРэЪ§ЪЎЬЈЪ§АйЬЈЛњЦїЃЌетЪБКђПЩФмЗжЗЂНХБОвВЯгТщЗГСЫЃЌПЊЪМаДвЛаЉздЖЏЛЏЕФЙЄОпРДзіетИіЪТЧщЁЃЕНзюИпМЖНзЖЮЃЌОЭЪЧЭъШЋЪЕЯжзджњЗўЮёЃЌетЪЧРСЕФзюИпОГНчЁЃ

MongoDBМђНщ
ЫЕЭъСЫЁКМДЗўЮёЁЛвдМАЦфживЊадЃЌНгЯТРДЮвУЧПДвЛЯТНёЬьЕФСэвЛИіжїНЧЃКMongoDBЃЌвђЮЊгааЉЭЌбЇПЩФмЖдетИіВЛСЫНтЃЌЫљвдЛЙЪЧМђЕЅНщЩмвЛЯТЁЃ
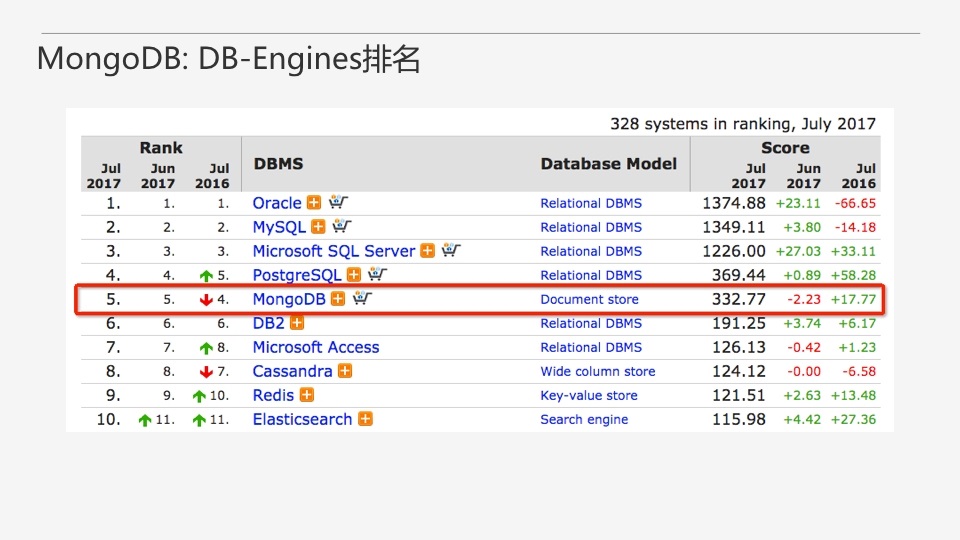
ЪзЯШЃЌMongoDBЪЧЪВУДФиЃЌЫќЪЧвЛИіDocument StoreЃЌЮФЕЕаЭЪ§ОнПтЃЌвВЪЧЮвУЧОГЃЫЕЕФNoSQLЁЃИљОнDB-EnginesЕФЪ§ОнПтХХУћЃЌMongoDBГЄЦкАдеМзХNoSQLРЯДѓЕФЕиЮЛЃЌЯждкЪЧЪ§ОнПтНчвЛЮЛжиСПМЖбЁЪжЁЃ
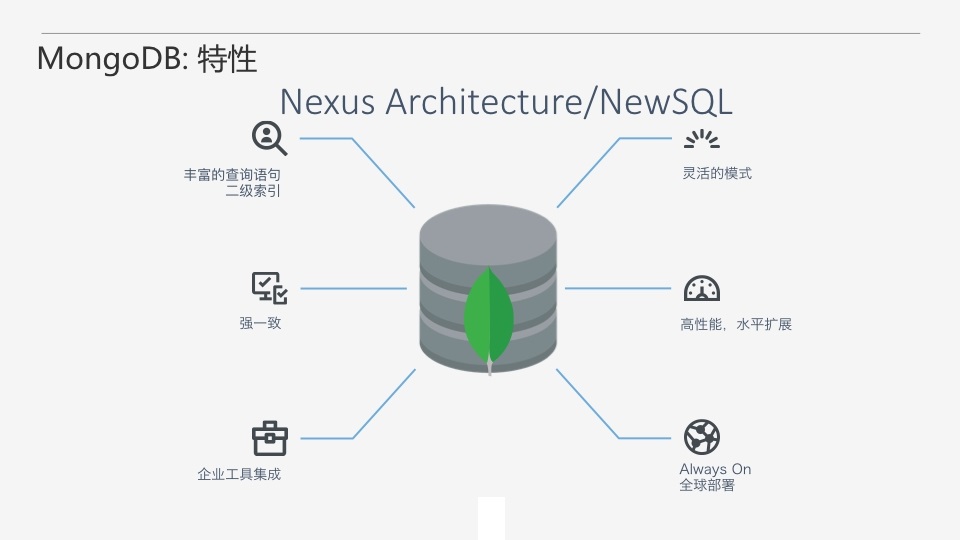
ЪТЪЕЩЯЃЌMongoDBПЩвдГЦЮЊЪЧвЛжжNewSQLЃЌЫќШкКЯСЫДЋЭГЙиЯЕаЭЪ§ОнПтКЭNoSQLЕФвЛаЉгХЕуЁЃзюзѓБпЕФ3ИіФмСІЪЧРДздгкЙиЯЕаЭЪ§ОнПтЁЃЪзЯШЃЌЫќОпБИЗсИЛЕФВщбЏгяОфКЭЖўМЖЫїв§ЁЃЭЈЙ§етЕуЃЌгУЛЇПЩвдвдзуЙЛИДдгЕФЗНЪНРДЗУЮЪКЭзщжЏЪ§ОнЁЃЕкЖўЕуЃЌЧПвЛжТадЁЃMongoDBжЇГжвЛИіСщЛюЕФвЛжТадФЃаЭЁЃФуПЩвдбЁдёЪЙгУЧПвЛжТадЃЌЛђзюжевЛжТадЃЌШЁОігкФуЕФвЕЮёГЁОАЁЃЕкШ§ЕуЃЌMongoDBФмКмКУЕФМЏГЩЕНЖрЦѓвЕЯжгаММЪѕМмЙЙжаЁЃгвБп3ИіФмСІ
РДздNoSQLЃЌЪзЯШЪЧСщЛюЕФЪ§ОнФЃаЭЃЌMongoDBЕФЮФЕЕФЃаЭдЪаэЖЏЬЌаоИФschemaЃЌВЛгУЕЃаФгаШЮКЮЕФадФмгАЯьЁЃЦфДЮЪЧИпадФмКЭИпПЩРЉеЙадЃЌMongoDBПЩвдЧсЫЩНјааЫЎЦНРЉеЙЃЌДгЖјДјРДИќИпЕФЭЬЭТКЭИќЕЭЕФбгГйЁЃзюКѓЃЌЪЧШЋЧђВПЪ№ЃЌвВОЭЪЧИпПЩгУЁЃНгЯТРДЮвУЧОЭРДОпЬхНВЯТMongoDBЕФМИИіЙиМќЬиадЁЃ
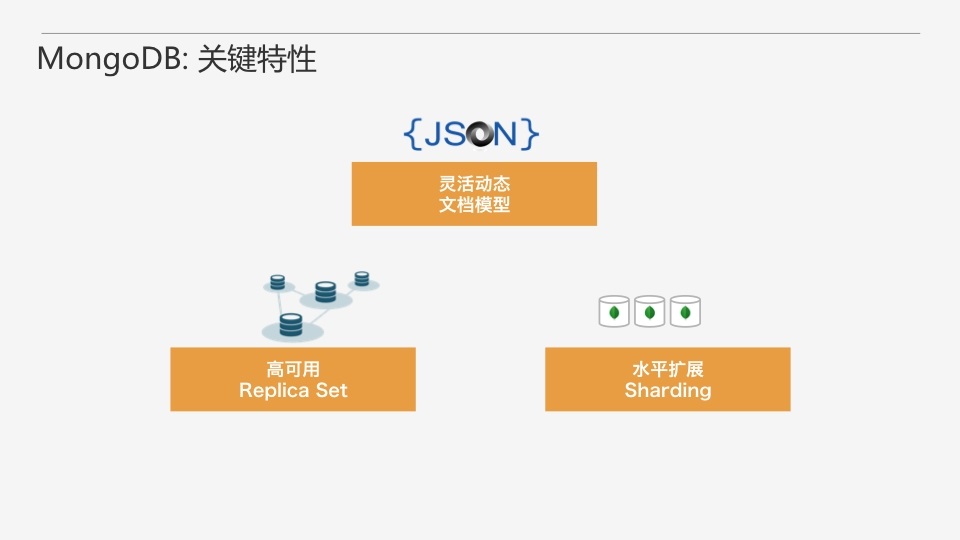
MongoDBЕФЙиМќЬиаджївЊЪЧ3ИіЃЌЕквЛИіОЭЪЧСщЛюЖЏЬЌЕФЮФЕЕФЃаЭЃЌЕкЖўИіЪЧИпПЩгУИББОМЏЃЌЕкШ§ИіЪЧMongoDBЕФЫЎЦНРЉеЙЃЌвВОЭЪЧshardingЁЃ

MongoDBвдвЛжжНазіBSONЃЈЖўНјжЦJSONЃЉЕФДцДЂаЮЪННЋЪ§ОнзїЮЊЮФЕЕДцДЂЁЃОпгаЯрЫЦНсЙЙЕФЮФЕЕЭЈГЃБЛзщжЏГЩМЏКЯЁЃПЩвдАбМЏКЯПДГЩРрЫЦгкЙиЯЕЪ§ОнПтжаЕФЕФБэЃКЮФЕЕЖдгІЕФЪЧааЃЌзжЖЮЖдгІЕФЪЧСаЁЃ
MongoDBНЋвЛЬѕМЧТМЕФЫљгаЪ§ОнОлКЯдквЛИіЮФЕЕжаЃЌЖјдкЙиЯЕЪ§ОнПтжадђЧуЯђгкНЋЪ§ОнЗжВМдкЖрИіБэжаЁЃетбљзігаМИИіКУДІЃЌвЛЪЧгЩгкЪ§ОнОлМЏЃЌМѕЩйСЫЖрБэJOINЕФашЧѓЃЌетбљжЛашвЊЖСвЛДЮОЭПЩвдЖСЕНЫљгаЪ§ОнЃЌдкадФмЩЯЛсгаКмДѓгХЪЦЁЃ
СэЭтЃЌетжжФЃаЭИќМгНгНќЮвУЧЦНЪББрГЬгябджаЕФЖдЯѓНсЙЙЃЌПЩвдЗНБуПЊЗЂепНјааЪ§ОнгГЩфЁЃ
зюКѓОЭЪЧетжжФЃаЭЪЧschema-lessЕФЃЌвВОЭЪЧдкMongoDBжаВЛашвЊЯёЙиЯЕЪ§ОнПтвЛбљШЅЪТЯШЖЈвхУПИіБэЕФschemaЁЃMongoDBвЛИіМЏКЯФкЕФЮФЕЕжЎМфПЩвдгЕгаВЛЭЌЕФНсЙЙЃЌПЩвдЧсЫЩЮЊвЛИіаТЕФЮФЕЕЬэМгКЭМѕЩйзжЖЮЃЌВЛЛсгаШЮКЮЕФадФмгАЯьЁЃетИіЬиадЗЧГЃЪЪКЯПЊЗЂвЛаЉаТВњЦЗЃЌПЩвдПьЫйЕќДњЁЃ
ЕБШЛЃЌЙ§гкСщЛюОЭПЩФмЕМжТЛьТвЁЃгаЪБКђЮвУЧЯывЊЧѓЮФЕЕБиаывЊгаФГаЉзжЖЮЃЌФГаЉзжЖЮБиаывЊгаЙЬЖЈЕФРраЭЁЃЮЊДЫЃЌMongoDBЬсЙЉСЫвЛИіЮФЕЕбщжЄЙІФмРДЖдЮФЕЕЕФИёЪННјаадМЪјЁЃ
НгЯТРДЫЕMongoDBЕФЕкЖўИіЙиМќЬиадЃЌИпПЩгУИББОМЏЃЈвВПЩвдЗвыГЩИДжЦМЏЃЉЁЃ
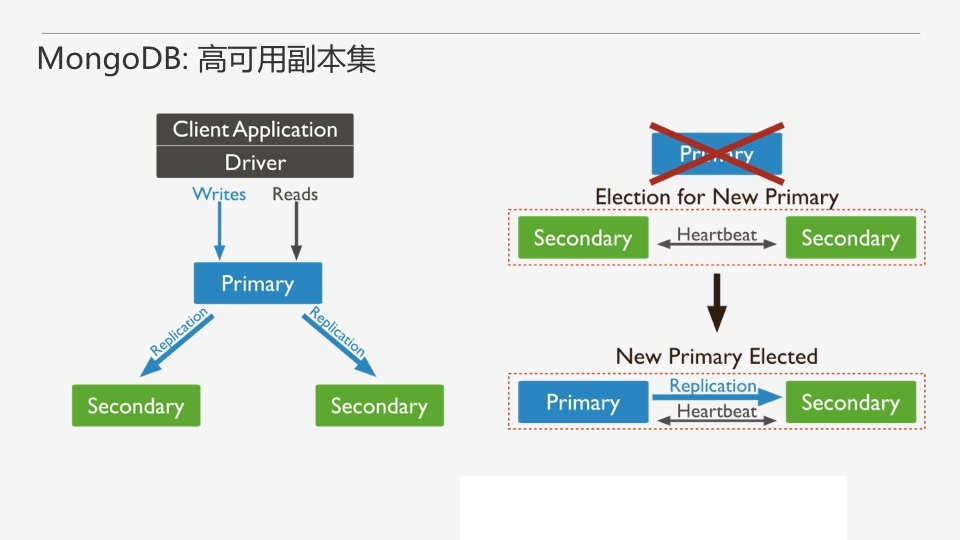
MongodbИББОМЏгЩвЛзщMongodЪЕР§ЃЈНјГЬЃЉзщГЩЃЌАќКЌвЛИіPrimaryНкЕуКЭЖрИіSecondaryНкЕуЃЌMongodb
DriverЃЈПЭЛЇЖЫЃЉЕФЫљгаЪ§ОнЖМаДШыPrimaryЃЌSecondaryДгPrimaryЭЌВНаДШыЕФЪ§ОнЃЌвдБЃГжИББОМЏФкЫљгаГЩдБДцДЂЯрЭЌЕФЪ§ОнМЏЃЌЬсЙЉЪ§ОнЕФИпПЩгУЁЃ
ЩЯЭМЪЧвЛИіЕфаЭЕФMongdbИББОМЏЃЌАќКЌвЛИіPrimaryНкЕуКЭ2ИіSecondaryНкЕуЁЃ
ИББОМЏЭЈЙ§replSetInitiateУќСюЃЈЛђmongo shellЕФrs.initiate()ЃЉНјааГѕЪМЛЏЃЌГѕЪМЛЏКѓИїИіГЩдБМфПЊЪМЗЂЫЭаФЬјЯћЯЂЃЌВЂЗЂЦ№PrimaryбЁОйВйзїЃЌЛёЕУЁКДѓЖрЪ§ЁЛГЩдБЭЖЦБжЇГжЕФНкЕуЃЌЛсГЩЮЊPrimaryЃЌЦфгрНкЕуГЩЮЊSecondaryЁЃ
етРяЁКДѓЖрЪ§ЁЛЕФЖЈвхЪЧИББОМЏФкПЩЭЖЦБГЩдБЕФвЛАывдЩЯЃЌЕБИББОМЏФкДцЛюГЩдБЪ§СПВЛзуДѓЖрЪ§ЪБЃЌећИіИББОМЏНЋЮоЗЈбЁОйГіPrimaryЃЌДЫЪБИББОМЏНЋЮоЗЈЬсЙЉаДЗўЮёЃЌДІгкжЛЖСзДЬЌЁЃЭЈГЃНЈвщНЋИББОМЏГЩдБЪ§СПЩшжУЮЊЦцЪ§ЃЌвђЮЊХМЪ§ИіНкЕуФмШнШЬЕФНкЕуЪЇаЇКЭБШЫћЩй1ИіНкЕуЕФЦцЪ§ИіНкЕуЪЧвЛбљЕФЃЌЕЋЪЧПЩвдНкЪЁвЛИіНкЕуЕФЪ§ОнДцДЂГЩБОЁЃ
Г§СЫГѕЪМЛЏЕФЪБКђЛсНјаабЁОйЃЌMongoDBИББОМЏЕФИпПЩгУЗўЮёЬхЯждкЃЌЕБИББОМЏжаУЛгаPrimaryНкЕуЪБЃЌбЁОйЖМЛсНјааЁЃБШШчЕБPrimaryНкЕухДЛњЪБЃЌЪЃЯТЕФSecondaryНкЕужаЛсбЁОйГіаТЕФPrimaryЃЈжЛашвЊТњзуДѓЖрЪ§ГЩдБДцЛюЕФЬѕМўЃЉЁЃбЁОйЪЙгУЕФЫуЗЈЪЧЛљгкRaftавщЃЌЕЋЪЧПЩвдЭЈЙ§ЮЊНкЕуХфжУбЁОйгХЯШМЖЖдбЁОйНсЙћНјааПижЦЁЃ
ДЫЭташвЊЬсвЛЯТЃЌгавЛаЉБШНЯГЃМћЕФЬиЪтЕФSecondaryЁЃвЛИіЪЧHiddenЃЌHiddenНкЕуКЭЦеЭЈЕФSecondaryЕФЧјБ№ЪЧЫќЪЧЖдDriverвўВиЕФНкЕуЃЌвВОЭЪЧПЭЛЇЖЫЮоЗЈЗУЮЪЕНHiddenЃЌСэЭтОЭЪЧЫќЕФбЁОйгХЯШМЖЪЧ0ЃЌвВОЭЪЧЫќВЛФмБЛбЁОйЮЊPrimaryЁЃHiddenНкЕуЩЯгЕгаЪ§ОнЃЌвђДЫЭЈГЃЛсгУРДзївЛаЉдЫЮЌШЮЮёЃЌШчЪ§ОнБИЗнЁЂМЦЫуЗжЮіЕШЁЃ
СэЭтЛЙгавЛИіЪЧArbiterЃЌArbiterЪЧжЛВЮгыЭЖЦБЃЌЕЋЪЧВЛДцДЂЪ§ОнЕФНкЕуЃЌетПЩвдгУдкЖдПЩгУадгавЊЧѓЃЌгжвЊбЯИёПижЦГЩБОЕФГЁОАЁЃ
ДЫЭтЛЙгаШчPriority0НкЕуЁЂDelayedНкЕуЕШЁЃ
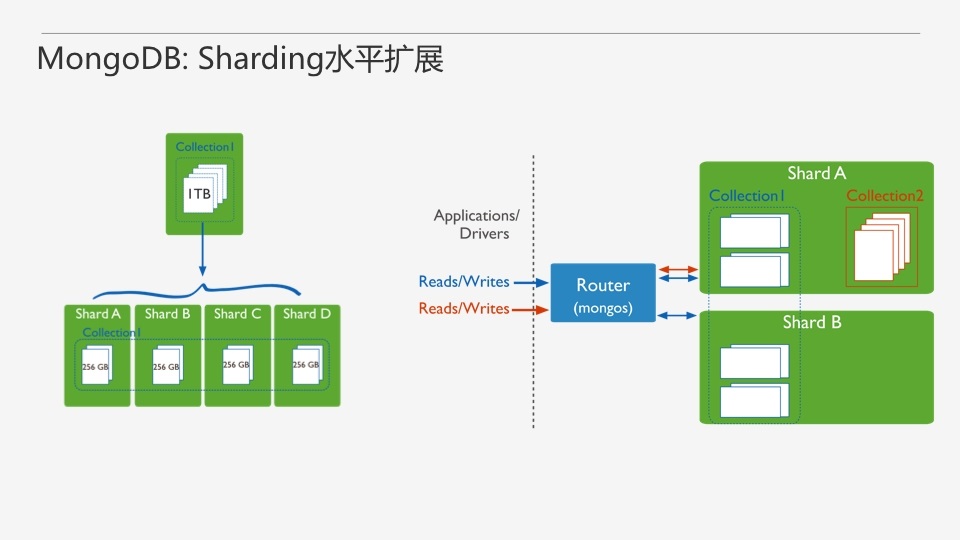
MongoDBЬсЙЉСЫвЛжжЫЎЦНРЉеЙЕФЗНЪНЃЌНазіshardingЃЌЭЈЙ§етжжЗНЪНЖдЪ§ОнПтНјааРЉШнЃЌЖдгІгУЪЧЭИУїЕФЁЃЭЈЙ§shardingЃЌПЩвдНЋвЛИіМЏКЯЕФЪ§ОнЩЂЕНЖрИіshardНкЕуЩЯЁЃетРяУПИіshardЖМПЩвдЪЧвЛзщИББОМЏЁЃгІгУГЬађЭЈЙ§вЛИіТЗгЩНкЕуЃЈmongosЃЉРДЗУЮЪshardingМЏШКЕФЪ§ОнЁЃгаСЫshardingЃЌmongodbОЭПЩвдЭЛЦЦЕЅЛњЕФЯожЦЃЌБШШчДХХЬЁЂФкДцКЭIOPSЕШЃЌДгЖјЬсЙЉИќЧПДѓЕФЗўЮёФмСІЁЃ
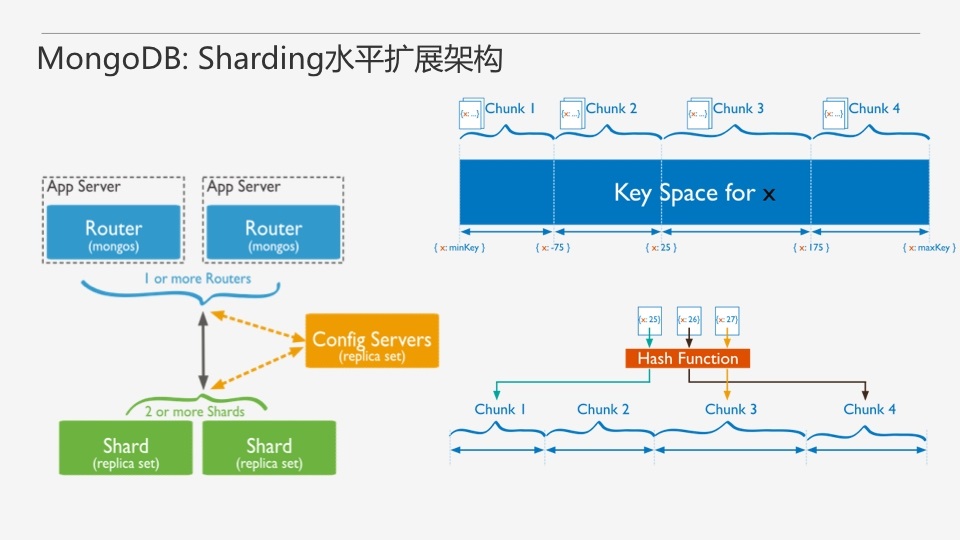
Sharded clusterгЩShardЁЂMongosКЭConfig server 3ИізщМўЙЙГЩЁЃMongosБОЩэВЂВЛГжОУЛЏЪ§ОнЃЌSharded
clusterЫљгаЕФдЊЪ§ОнЖМЛсДцДЂЕНConfig ServerЃЌЖјгУЛЇЕФЪ§ОндђЛсЗжЩЂДцДЂЕНИїИіshardЁЃMongosЦєЖЏКѓЃЌЛсДгconfig
serverМгдидЊЪ§ОнЃЌПЊЪМЬсЙЉЗўЮёЃЌНЋгУЛЇЕФЧыЧѓе§ШЗТЗгЩЕНЖдгІЕФShardЁЃ
Sharded clusterжЇГжНЋЕЅИіМЏКЯЕФЪ§ОнЗжЩЂДцДЂдкЖрИіshardЩЯЃЌгУЛЇПЩвджИЖЈИљОнМЏКЯФкЮФЕЕЕФФГИізжЖЮМДshard
keyРДЗжВМЪ§ОнЃЌФПЧАжївЊжЇГж2жжЪ§ОнЗжВМЕФВпТдЃЌЗЖЮЇЗжЦЌЃЈRange based shardingЃЉЛђhashЗжЦЌЃЈHash
based shardingЃЉЁЃ
ЗЖЮЇЗжЦЌЯТЃЌЮФЕЕЪЧИљОнЦфshard keyЕФжЕНјааЗжЦЌЁЃshard keyЕФжЕЯрСкНќЕФЮФЕЕБШНЯгаПЩФмЛсБЛЗХдкЭЌвЛИіshardЩЯЃЌетжжЗНЪНЪЪгУгкашвЊЪЙгУЗЖЮЇВщбЏЕФвЕЮёЁЃ
ЙўЯЃЗжЦЌЯТЃЌЮФЕЕИљОнЦфshard keyЕФhashжЕНјааЗжЦЌЁЃетЛсБЃжЄЪ§ОнЗжВМБШНЯОљдШЃЌЕЋЪЧВЛРћгкЗЖЮЇВщбЏЁЃ
ЫцзХЪ§ОнСПЕФдіЖрЃЌMongoDBвВЛсздЖЏдкКѓЬЈЖдЪ§ОнвдchunkЮЊЕЅЮЛНјааИКдиОљКтЁЃ

ШчКЮДюНЈвЛИіMongoDBЁКЪ§ОнПтМДЗўЮёЁЛ
НгЯТРДНщЩмвЛЯТНёЬьЕФжиЕуФкШнЃЌШчКЮДюНЈвЛИіMongoDBЪ§ОнПтМДЗўЮёЁЃ

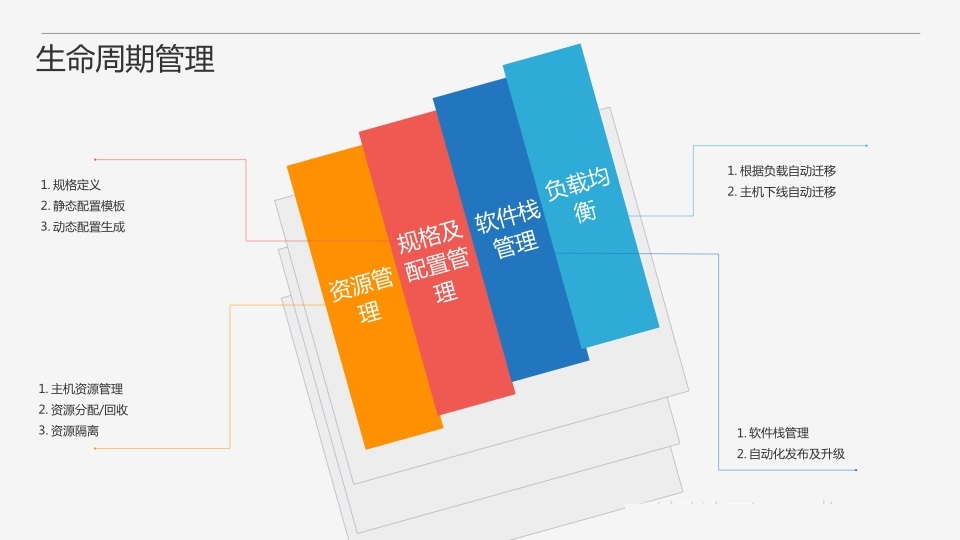
ЪзЯШЃЌдкЮвПДРДЃЌЪ§ОнПтМДЗўЮёЃЌгІИУОпБИетаЉЬиадЃКздЖЏЛЏЁЂАДашЗўЮёЁЂЕЏадЁЂАВШЋЁЂИпПЩгУКЭПЩСПЛЏЁЃЕквЛИіЃЌздЖЏЛЏЃЌетЪЧЗЧГЃЙиМќЕФЃЌЪЧЪЕЯжзджњЗўЮёЕФЛљДЁЃЌЫљгаПЩвдБЛздЖЏЛЏВйзїЕФСїГЬЖМгІИУБЛздЖЏЛЏЃЌВЛашвЊШЫЙЄИЩдЄЁЃЕкЖўИіЃЌАДашЗўЮёЃЌЪ§ОнПтМДЗўЮёгІИУЪЧгЩгУЛЇЧ§ЖЏЕФЃЌКѓЬЈгІИУвЊгавЛИіЙЄзїСїЕФЛњжЦРДЖдашЧѓНјааЯьгІЁЃЕкШ§ИіЃЌЕЏадЃЌПЩвдАДашЖЏЬЌРЉЫѕШнЁЃЕкЫФИіЃЌАВШЋЃЌетЪЧЮугЙжУвЩЕФЁЃЕкЮхИіЃЌИпПЩгУЃЌхДЛњздЖЏЧаЛЛЁЃЕкСљИіЃЌПЩСПЛЏЃЌЗўЮёЕФЪЙгУСППЩвдБЛКтСПЁЂБЈИцВЂЧвЪЧПЩПиЕФЁЃ
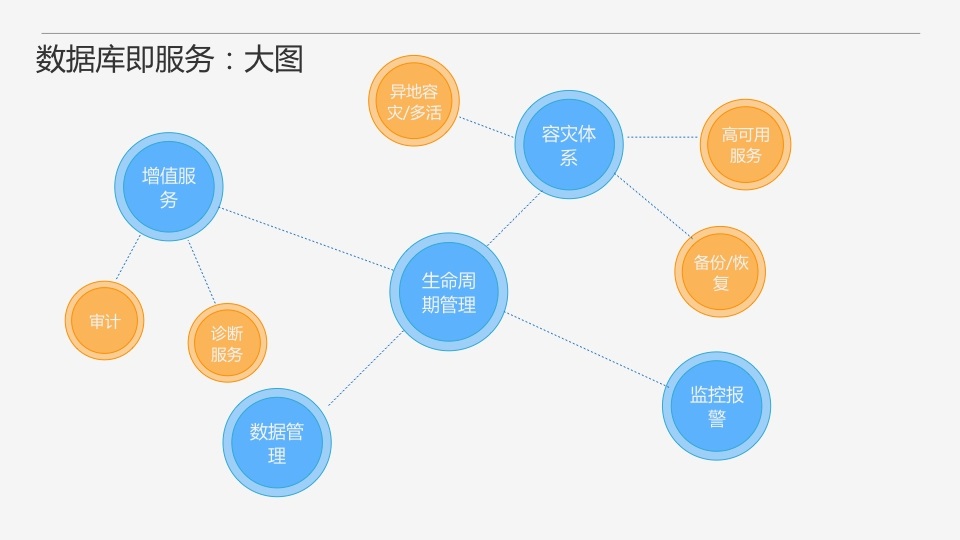
ДЫЭМЮЊЪ§ОнПтМДЗўЮёгІОпБИЕФЙІФмДѓЭМЁЃжївЊАќРЈЩњУќжмЦкЙмРэЁЂШнджЬхЯЕЁЂМрПиБЈОЏЁЂЪ§ОнЙмРэКЭдіжЕЗўЮёЁЃЩњУќжмЦкЙмРэАќРЈЪ§ОнПтЪЕР§ЕФаТНЈЁЂЪЭЗХЁЂРЉЫѕШнЕШЃЌетЪЧЪ§ОнПтМДЗўЮёзюЛљДЁЕФЙІФмЁЃШнджЬхЯЕАќРЈИпПЩгУЁЂБИЗнЛжИДЃЌЩѕжСИќИпМЖЕФШчвьЕиШндж/ЖрЛюЕШЕШЁЃМрПиБЈОЏвЛЗНУцОЭЪЧЗўЮёЪЙгУСПЕФМрПиЃЌСэвЛЗНУцдђЪЧБЈОЏЃЌАќРЈЗўЮёВЛПЩгУЕФБЈОЏЃЌвдМАвЛаЉМрПиЪ§ОнвьГЃЕФБЈОЏЁЃЪ§ОнЙмРэжИЕФОЭЪЧПЩвдЗНБуЕФЖдЪ§ОнНјааЙмРэЃЌШчПЩвдЬсЙЉвЛаЉЭМаЮЛЏНчУцЕШЁЃдіжЕЗўЮёАќРЈЩѓМЦЁЂеяЖЯЗўЮёЕШЁЃЦфжаЩѓМЦЪЧЪ§ОнПтЕФвЛИіЗЧГЃживЊЕФЙІФмЃЌвЛЗНУцПЩвдАяжњВщжЄЮЪЬтЃЌСэвЛЗНУцПЩвдЮЊвЛаЉЪ§ОнЗжЮіЛђеяЖЯЬсЙЉЪ§ОндДЁЃеяЖЯЗўЮёвЛЗНУцИњзйЗўЮёЕФзЪдДЪЙгУСПЃЌЮЊЪЧЗёашвЊРЉЫѕШнЬсЙЉОіВпвРОнЃЌСэвЛЗНУцжївЊЮЊТ§ВщбЏЬсЙЉгХЛЏНЈвщЁЃ
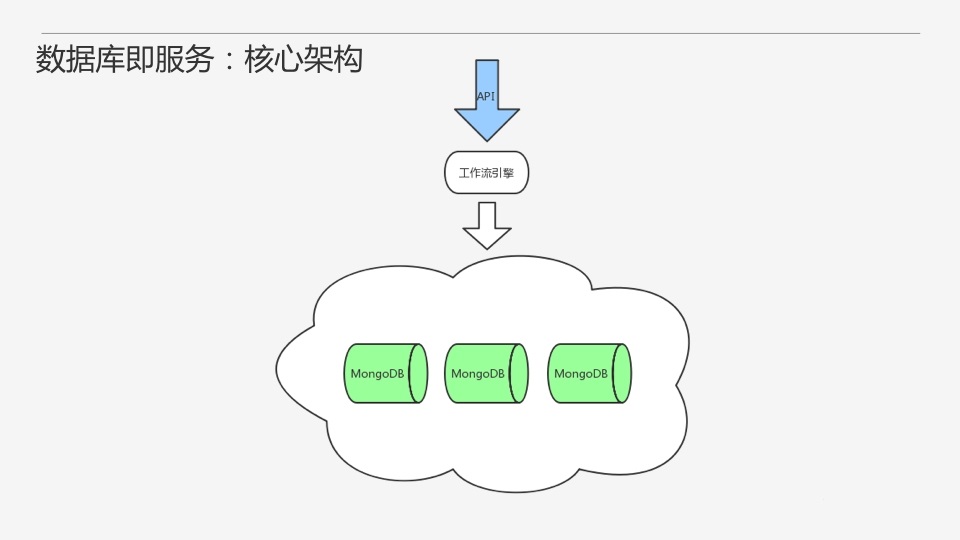
Ъ§ОнПтМДЗўЮёЕФКЫаФМмЙЙОЭЪЧЙЄзїСїв§ЧцЃЌетЪЧЪЕЯжздЖЏЛЏМААДашЗўЮёЕФЛљДЁЁЃ
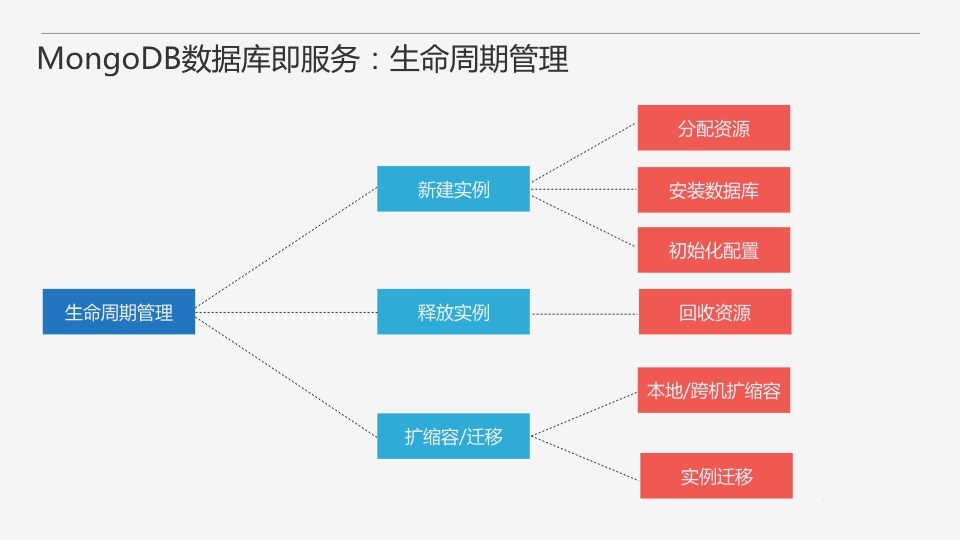
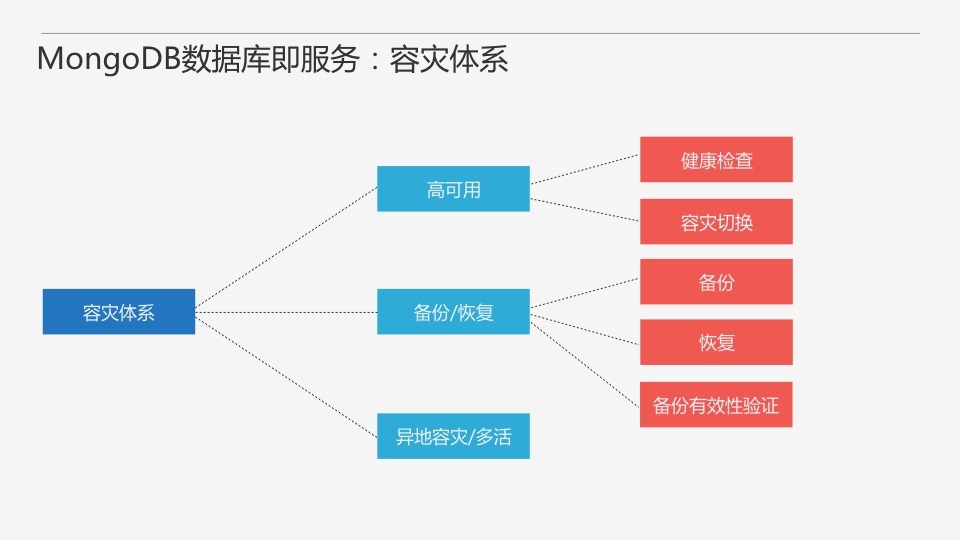
ЩњУќжмЦкЙмРэЙІФмАќРЈЪ§ОнПтЪЕР§ЕФаТНЈЁЂЪЭЗХЁЂРЉЫѕШнвдМАЧЈвЦЁЃаТНЈвЛИіЪ§ОнПтЪЕР§АќРЈЗжХфзЪдДЃЈжївЊЪЧжїЛњзЪдДЃЉЁЂАВзАЪ§ОнПтЁЂГѕЪМЛЏХфжУЁЃЖдMongoDBРДЫЕЃЌИББОМЏЩцМАЖрИіНкЕуЃЌЩцМАЕНзЪдДЕФЗжХфВпТдЃЌShardingИќЖрЁЃСэЭтИББОМЏЛЙашвЊвЛаЉГѕЪМЛЏЙЄзїЃЌshardingашвЊгавЛИіИїзщМўЕФзщКЯЁЃЪЭЗХЪЕР§БШНЯМђЕЅЃЌжївЊЪЧзЪдДЕФЛиЪеЁЃРЉЫѕШнПЩвдЗжЮЊБОЕиКЭПчЛњЕФРЉЫѕШнЃЌЦфЪЕПчЛњЕФРЉЫѕШнОЭЪЧЧЈвЦЁЃЖдгкMongoDBРДЫЕЃЌЧЈвЦПЩвджБНгРћгУMongoDBЕФЬэМгНкЕуздЖЏЭЌВНЕФЬиадЃЌЛЙЪЧБШНЯЗНБуЕФЁЃ
ЩњУќжмЦкЙмРэЙІФмжївЊЩцМАетМИИізщМўЃЌАќРЈзЪдДЙмРэЁЂЙцИёМАХфжУЙмРэЁЂШэМўеЛЙмРэКЭИКдиОљКтЁЃзЪдДЙмРэжївЊЪЧжИжїЛњзЪдДЕФЙмРэЃЌетРяжїЛњПЩвдЪЧЮяРэЛњЃЌвВПЩвдЪЧащФтЛњЃЌШчдЦжїЛњЕШЁЃзЪдДЙмРэжївЊИКд№зЪдДЕФЗжХфКЭЛиЪеЃЌДЫЭтЛЙАќРЈШчКЮЪЕЪЉзЪдДИєРыЁЃЙцИёМАХфжУЙмРэвЛИіЪЧашвЊЮЊЪ§ОнПтЪЕР§жЦЖЈвЛаЉЙцИёЃЌвдЗНБуРЉШнКЭЫѕШнЃЌСэвЛЗНУцЪЧИКд№Ъ§ОнПтЯрЙиХфжУЕФЮЌЛЄЁЃШэМўеЛЙмРэдђАќРЈЪ§ОнПтШэМўвдМАЦфвРРЕЕФШэМўЕФАВзАЮЌЛЄЕШЃЌАќРЈВйзїЯЕЭГЁЃГ§СЫетаЉЃЌЛЙашвЊвЛИіИКдиОљКтзщМўРДБЃжЄЪ§ОнПтЪЕР§дкзЪдДЩЯЕФЗжВМЕФОљКтЃЌЕБгажїЛњзЪдДашвЊЯТЯпЕФЪБКђЃЌФмЙЛзіЕНздЖЏЖдЦфЩЯЕФЪ§ОнПтЪЕР§НјааЧЈвЦЁЃ
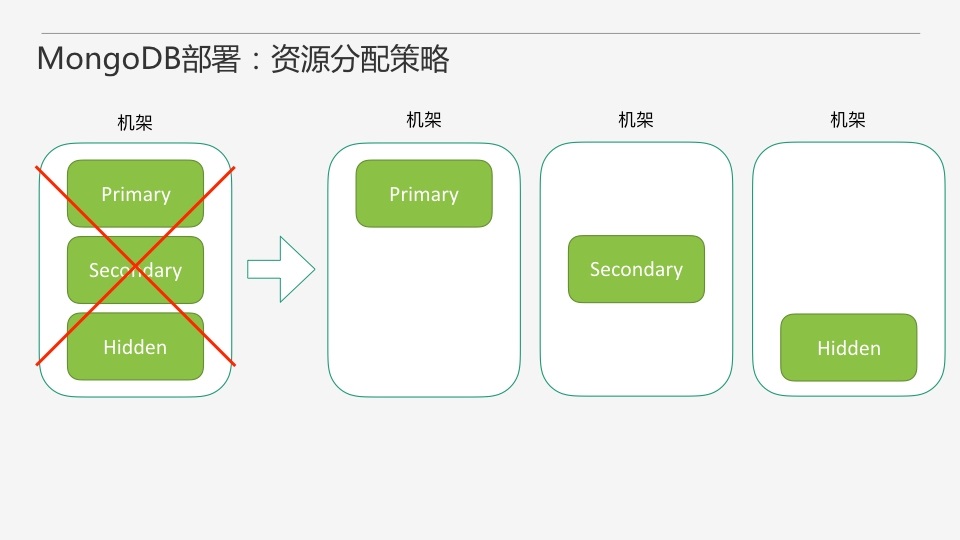
ЖдгкMongoDBРДЫЕЃЌдкЪЕЪЉзЪдДЗжХфВпТдЪБашвЊзЂвтЕФвЛЕуЪЧашвЊБЃжЄВЛвЊЦЦЛЕИББОМЏдБОЕФИпПЩгУЬиадЁЃЫфШЛMongoDBИББОМЏздДјСЫИпПЩгУЃЌЕЋЪЧШчЙћФуАбИББОМЏЕФЫљгаНкЕуЖМЗжВМдквЛЬЈЮяРэЛњЩЯЃЌФЧШчЙћетИіЮяРэЛњЙвСЫЃЌећИіИББОМЏЖМУЛгУСЫЁЃЫљвдвЛИіЦ№ТыЕФддђЪЧвЊБЃжЄMongoDBЖрИББОЕФжїЛњАВШЋадЃЌОЁПЩФмЙЛзіЕНЛњМмАВШЋЁЃ

ЯждкЮвУЧЕФMongoDBЪ§ОнПтМДЗўЮёЕФМмЙЙПЩвдЩдЮЂРЉГфвЛЯТСЫЃЌЖрСЫзЪдДЗўЮёЁЂЙцИёМАХфжУЗўЮёЁЂШэМўеЛЗўЮёвдМАИКдиОљКтЗўЮёетМИИізщМўЁЃ
НгЯТРДПДвЛЯТШнджЬхЯЕЃЌетАќРЈИпПЩгУЁЂБИЗн/ЛжИДЁЂвьЕиШндж/ЖрЛюЁЃИпПЩгУашвЊгавЛИіИКд№НЁПЕМьВщЕФбВМьЗўЮёЃЌСэЭтЛЙашвЊгавЛИіШнджЧаЛЛЕФзщМўЁЃБИЗн/ЛжИДвВЪЧШнджЬхЯЕЗЧГЃживЊЕФвЛЛЗЃЌетРягавЛИіКмШнвзБЛКіЪгЕФЪТЧщЪЧашвЊзіБИЗнЕФгааЇадбщжЄЁЃШчЙћБИЗнВЛЪЧгааЇЕФЃЌФЧЕШгкУЛгаБИЗнЁЃвьЕиШндж/ЖрЛюЪЧБШНЯИпМЖЕФШнджФмСІЃЌЪЕЪЉЦ№РДБШНЯИДдгЃЌгааЫШЄЕФЭЌбЇПЩвдВЮПМЮвжЎЧАзіЙ§ЕФвЛИіЗжЯэ
MongoDBвьЕиШнджЖрЛюЪЕМљ
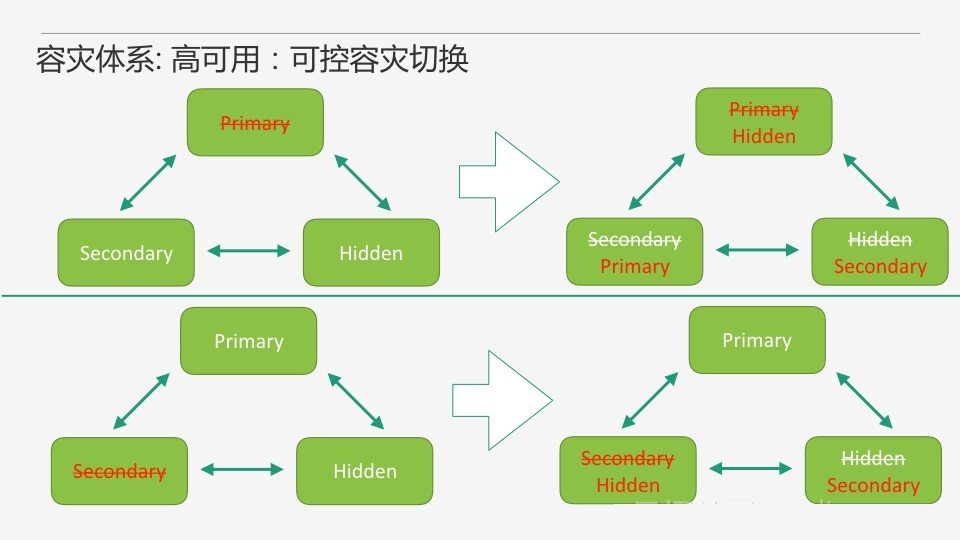
MongoDBИББОМЏздДјСЫИпПЩгУЃЌЮвУЧЛЙашвЊзіЪВУДЙЄзїФиЃПжївЊЪЧашвЊБЃжЄШнджЧаЛЛЕФвЛИіПЩПиЁЃвдвЛИіОЕфЕФ3НкЕуP/S/HИББОМЏЮЊР§ЃЌвЛЗНУцЮвУЧПЩвдЭЈЙ§ХфжУбЁОйгХЯШМЖЕФЗНЪНРДБЃГжPrimaryКЭSecondaryЕФНЧЩЋЮШЖЈадЁЃСэвЛЗНУцЃЌЮвУЧЯЃЭћдкШЮвтЪБПЬЃЌгУЛЇЖМПЩвдгаСНИіНкЕуЪЧПЩЗУЮЪЕФЃЌвђДЫЮвУЧашвЊЖдНкЕухДЛњКѓЕФИББОМЏзівЛаЉreconfigВйзїЃЌБЃжЄхДЛњНкЕузюжеЖМЛсБфГЩHiddenЃЌШЛКѓЭГвЛЖдHiddenНјааДІРэЃЌБШШчжиДюЕШЁЃ

ШнджЬхЯЕЕкЖўИіБШНЯживЊЕФЕуОЭЪЧБИЗнЛжИДЁЃБИЗнжївЊашвЊзіЕФЪЧашвЊЬсЙЉздЖЏ/ЪжЖЏЕФБИЗнЗНЪНвдМАжЇГжвЛаЉСщЛюЕФБИЗнВпТджЦЖЈЃЌШчБИЗнжмЦк/БИЗнБЃСєЪБМфЕШЁЃЛжИДжївЊЪЧПДЖдЛжИДЕФаЮЬЌзіГЩЪВУДбљЃЌЪЧИВИЧдРДЕФЪЕР§ЛЙЪЧПЫТЁГівЛИіаТЕФЪЕР§РДЃЌЛЙгаОЭЪЧЛжИДЕФСЃЖШЃЌетШЁОігкБИЗнФмСІЃЌЪЧжЛФмЛжИДЕНФГИіШЋСПБИЗнЃЌЛЙЪЧПЩвдЛжИДЕНШЮвтЪБМфЕуЁЃЙигкБИЗнДцДЂЃЌЮвУЧвЊЧѓЕФзювЊ
ФмСІЪЧИпПЩППадЁЃСэЭтОЭЪЧИеИеЬсЙ§ЕФБИЗнгааЇадбщжЄЃЌВЛФмЕШЕНЛ№ЩеУМУЋСЫВХЗЂЯжБИЗнВЛПЩгУЃЌашвЊЗРЗЖгкЮДШЛЁЃ
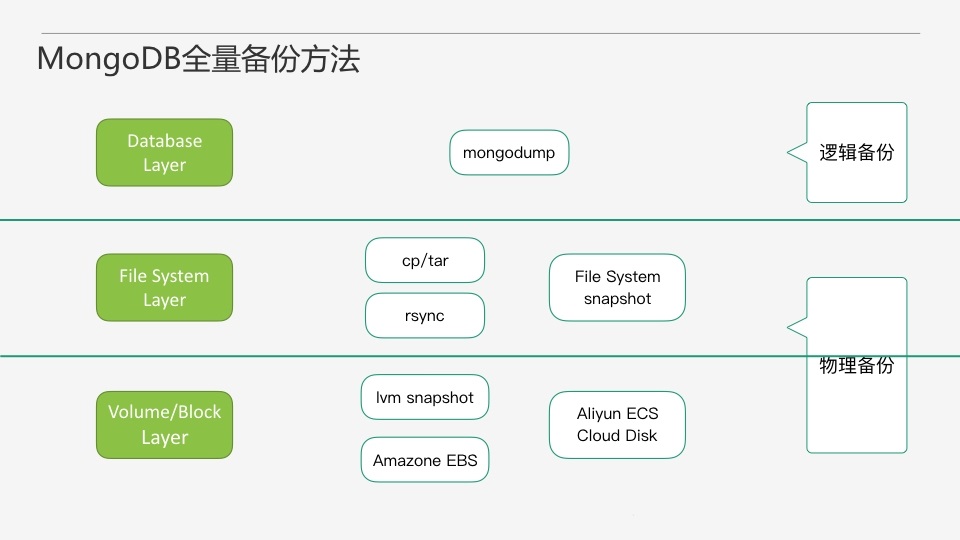
??ЙигкMongoDBЕФБИЗнЗНЗЈЃЌЯрЙиЕФЮФЕЕКЭЗжЯэвбОгаКмЖрСЫЃЌетРядйМђЕЅЬсвЛЯТЁЃШЋСПБИЗнДгЪЕЪЉЗНЪНЩЯПЩвдЗжЮЊСНжжЃЌТпМБИЗнКЭЮяРэБИЗнЁЃЦфжаТпМБИЗнжївЊЪЙгУЙйЗНЬсЙЉЕФmongodump/mongorestoreЙЄОпЁЃЮяРэБИЗндђПЩвддкЮФМўЯЕЭГЛђЪЧИќЕзВуЕФТпМОэЁЂПщЩшБИетВуШЅзіЁЃ
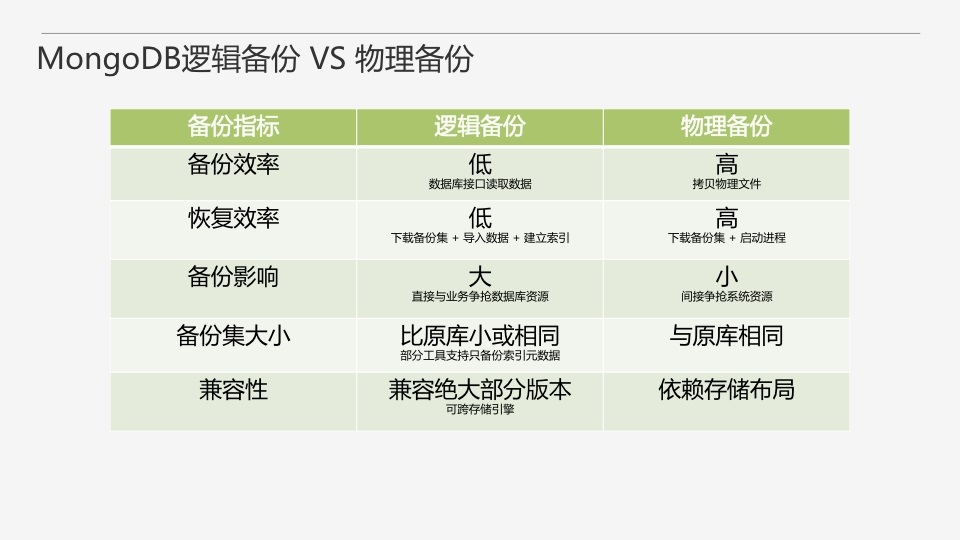
ДгИїИіжИБъЩЯЖдБШТпМБИЗнКЭЮяРэБИЗнЃЌдкБИЗнКЭЛжИДаЇТЪЩЯЃЌЮяРэБИЗнЕФгХЪЦБШНЯУїЯдЃЌВЛЙ§ТпМБИЗндкМцШнадЩЯЛсБШНЯКУЁЃ

MongoDBЕФдіСПБИЗнжївЊЭЈЙ§ГжајЕФзЅШЁoplogРДЪЕЯжЁЃгаСЫШЋСПБИЗнМгдіСПБИЗнЃЌОЭПЩвдЪЕЯжЛжИДЕНШЮвтЪБМфЕуЁЃ
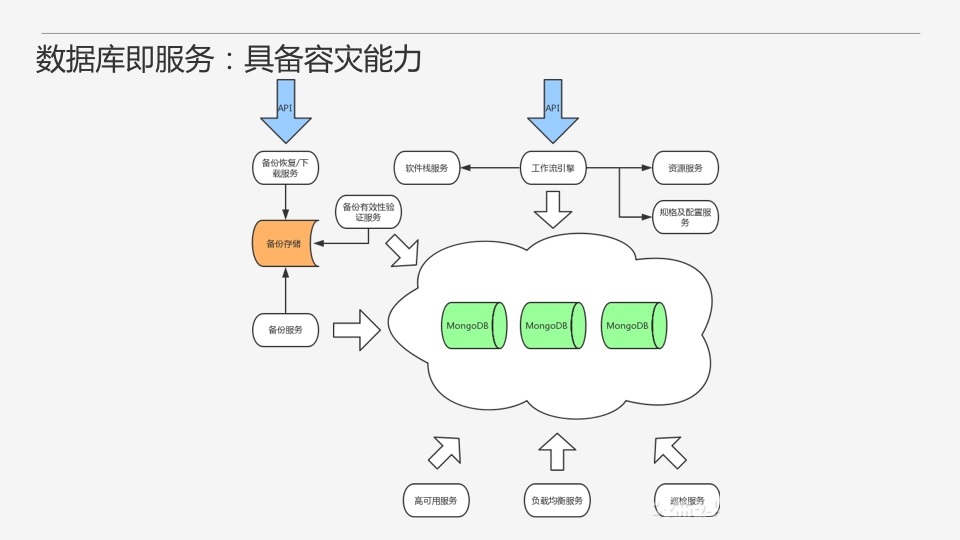
жСДЫЃЌЮвУЧЕФMongoDBЪ§ОнПтМДЗўЮёЕФМмЙЙгжПЩвдЕУЕНвЛИіБШНЯДѓЕФРЉГфЃЌжївЊдіМгСЫИпПЩгУвдМАБИЗнЯрЙиЕФвЛаЉЗўЮёЁЃ
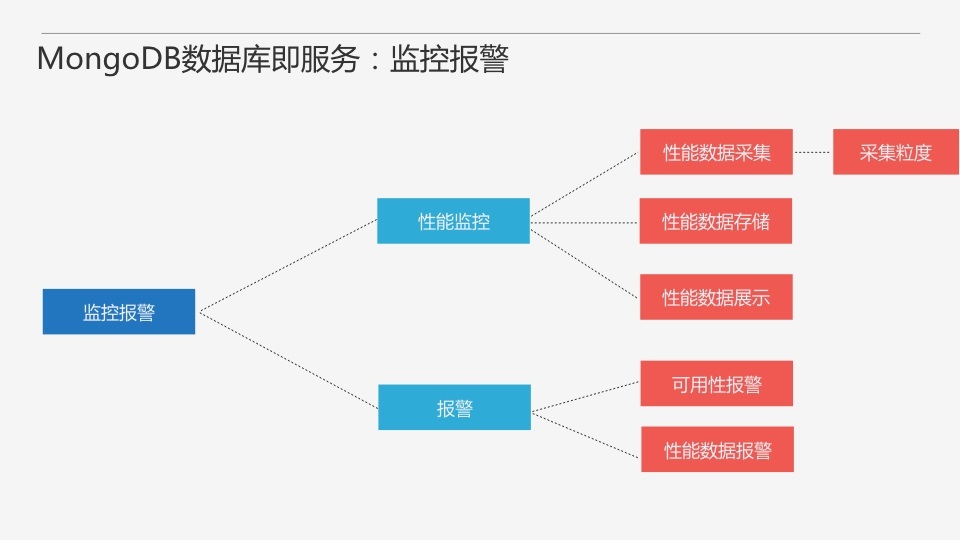
НгЯТРДПДЯТЪ§ОнПтЕФМрПиБЈОЏЃЌадФмМрПи?жївЊЩцМАадФмЪ§ОнЕФВЩМЏЁЂДцДЂКЭеЙЪОЁЃВЩМЏСЃЖШдНЯИдНКУЃЌзюКУФмзіЕНУыМЖЁЃБЈОЏдђПЩвдЗжЮЊПЩгУадЕФБЈОЏКЭадФмЪ§ОнЕФБЈОЏЁЃ
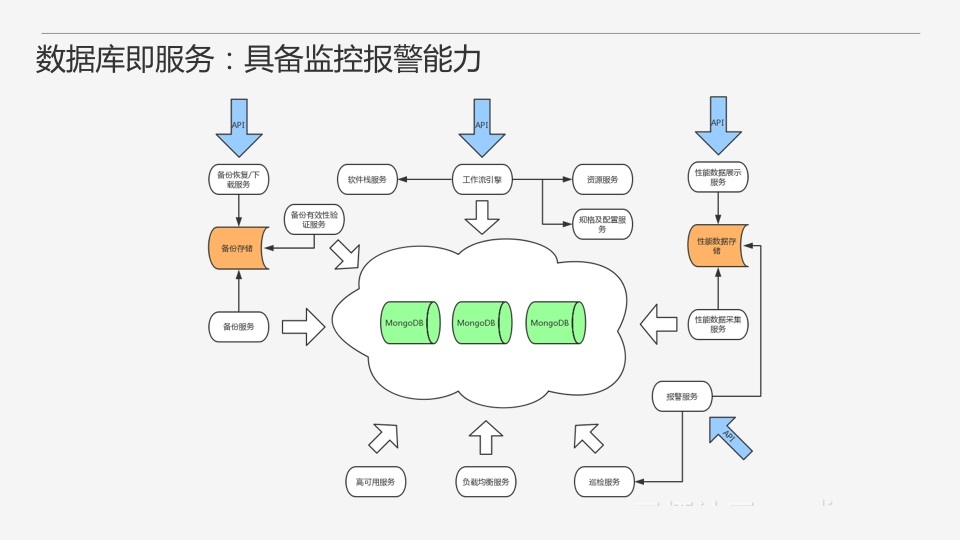
ОпБИМрПиБЈОЏФмСІКѓЕФМмЙЙЭМвбОгаЕуТњСЫЃЌетРяБЈОЏЗўЮёПЩвдЭЈЙ§бВМьЗўЮёКЭадФмЪ§ОнДцДЂЪеМЏЯрЙиЪ§ОнЁЃ
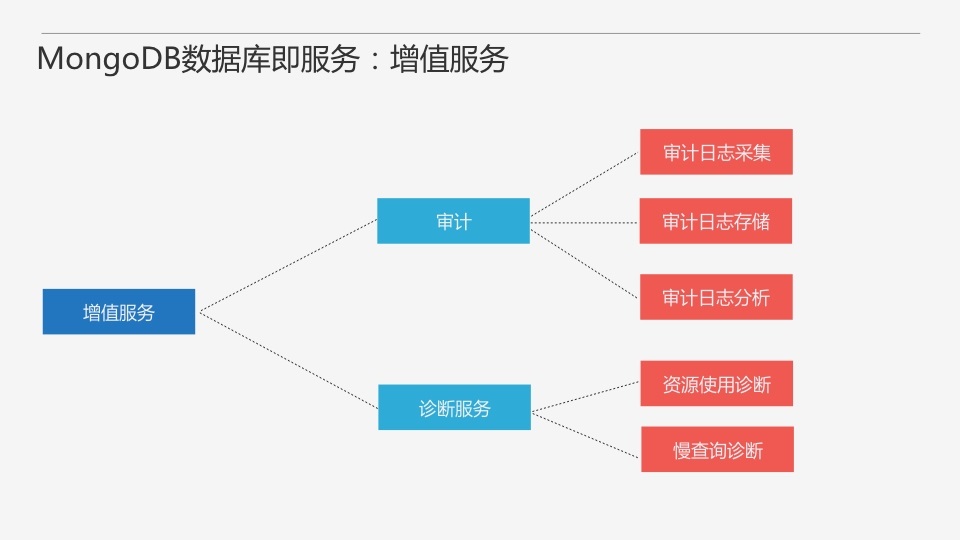
РДПДзюКѓвЛИідіжЕЗўЮёЃЌвЛИіЪЧЩѓМЦЃЌжївЊЩцМАЩѓМЦШежОЕФВЩМЏЁЂДцДЂКЭЗжЮіЁЃСэвЛИіЪЧеяЖЯЗўЮёЃЌвЛИіЪЧзЪдДЪЙгУСПЩЯЕФеяЖЯЃЌСэЭтвЛИіЪЧТ§ВщбЏЕФеяЖЯЃЌПЩвдзівЛаЉЫїв§ЭЦМіЕШЁЃ
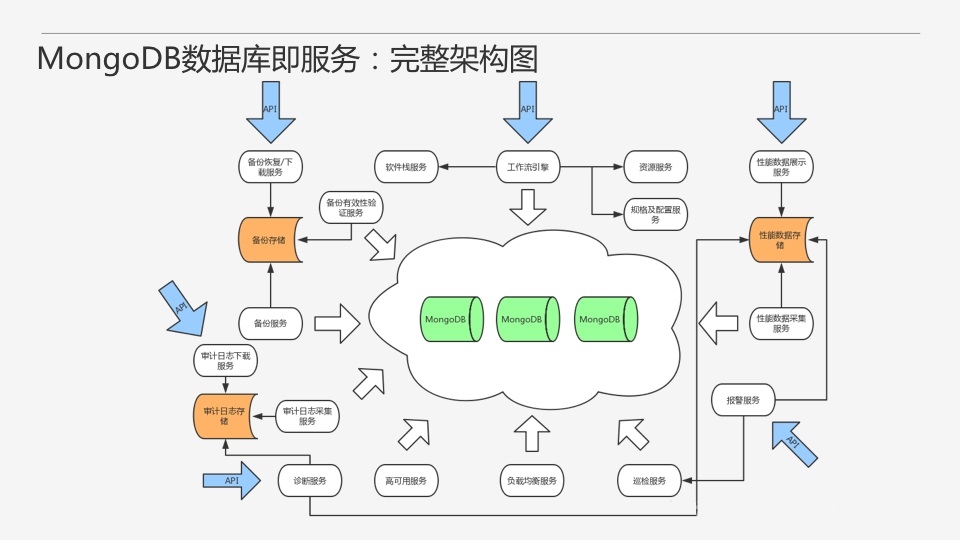
етОЭЪЧЮвУЧЕФMongoDBЪ§ОнПтМДЗўЮёЕФЭъећМмЙЙЃЌПЩвдПДЕНзщМўЛЙЪЧБШНЯЖрЕФЃЌзівЛИіЪ§ОнПтМДЗўЮёЛЙВЛЪЧФЧУДШнвзЙўЁЃ

??????зюКѓзівЛЯТзмНсЃЌЮвШЯЮЊЪ§ОнПтМДЗўЮёЕФКЫаФЬиадгаСНЕуЃЌвЛИіЪЧзЪдДГиЛЏЃЌСэЭтвЛИіЪЧЗўЮёПЩСПЛЏЁЃзЪдДГиЛЏКѓВХПЩвдНјаазЪдДЕФздЖЏЙмРэЃЌЖјЮвУЧашвЊЕФЗўЮёЪЧвЊФмЙЛБЛСПЛЏЕФЃЌВЂЧвЪЧПЩПиЕФЁЃЯждкЛиЙЫвЛЯТжЎЧАЕФвЛМќАВзАЪ§ОнПтЃЌЦфЪЕБГКѓгааэЖрЙЄзївЊзіЁЃетРяЫГБузіЯТЙуИцЃЌШчЙћОѕЕУздМКДюНЈвЛИіЪ§ОнПтМДЗўЮёЬЋТщЗГЃЌПЩвдПМТЧЪЙгУЯжГЩЕФдЦЗўЮёЃЌБШШчАЂРядЦMongoDBЪ§ОнПтЗўЮёЃКЃЉФуЯывЊЕФШЋЖМгаЃЁ |









