БГОА
дквЛДЮгЮгОЕФЪБКђЃЌЯыЦ№вЛИіЮЪЬтЃЌЮЊЪВУД hdfs ЕФ namenode УЛгаДцДЂПщЕФЖдгІНкЕуаХЯЂЃЌЕМжТЦєЖЏ hdfs ЕФЪБКђЃЌdatanode ашвЊЩЈУшЫљгаЕФЪ§ОнПщЃЌдйНЋИУ datanode ЩЯЕФПщаХЯЂЗЂЫЭИј namenodeЃЌnamenode ВХФмЙЙНЈЭъећЕФдЊЪ§ОнаХЯЂЁЃИљОнЮФМўКЭЪ§ОнПщЕФЖрЩйЃЌЦєЖЏ hdfs ЕФЪБКђашвЊМИЗжжгЕНМИИіаЁЪБЁЃ
ЖдБШЯТЗжВМЪНЪ§ОнПтЃЌШчЙћАбМЧТМЖдгІЕФНкЕуаХЯЂЗЂЫЭИј MasterЃЌФЧОЭВЛПЩЯыЯѓСЫЁЃЫљвддкЗжВМЪНЪ§ОнПтжа hdfs ЕФДцДЂВпТдВЛПЩШЁЁЃЭЌЪБзюНќвЛжББЛФПЧАЕФЗжВМЪНЪ§ОнПтЕФДцДЂЩЯгаМИИіЮЪЬтРЇШХзХ:
- дкНкЕуЪ§ЙЬЖЈЕФЪБКђЃЌHdfs ЕФЪ§ОнЪЧИљОнЛњЦїИКдиРДОіЖЈДцДЂдкФФИіНкЕуЩЯЕФЃЌетбљзіЕФКУДІЪЧЪ§ОнЦНОљЗжВМЃЌПЩвдИљОнЛњЦїЕФДцДЂДѓаЁМгШЈЦНОљЃЌВЂЧввРОнЛњЦїЕФИКдиЧщПіЖЏЬЌЕїећЃЛФПЧАЗжВМЪНЗжВМЪНЪ§ОнПтжазіЕФКмгаЯоЃЌИУШчКЮИФНјФи
- ЬэМгаТНкЕуЕФЪБКђЃЌ Hdfs ХфжУКУаТНкЕужИЯђЕФ namenodeЃЌШЛКѓЦєЖЏаТНкЕуМДПЩЃЌДцДЂЙ§вЛЖЮЪБМфЛсЪеСВЕНЦНОљЃЌШчЙћЯыМгШыКѓТэЩЯЪЙЕУЪ§ОнЦНОљЗжВМЃЌПЩвджДаа rebalance ВйзїЃЛЖјЗжВМЪНЪ§ОнПтЬэМгНкЕуЕФЪБКђЃЌХфжУКУаТНкЕужИЯђЕФ MasterЃЌШЛКѓЦєЖЏаТНкЕужЎКѓЃЌЭЈГЃЛЙашвЊИљОнЗжВМЕФЙцдђНјааЪ§ОнжиаТЗжВМЃЌЩѕжСЙцдђвВПЩФмашвЊНјааВ№ЗжКЯВЂРЉеЙЕШаоИФЃЌЗжВМЪНЪ§ОнПтФмзіЕНЪВУДГЬЖШЃЌШчКЮзі ЕБШЛШчЙћФмзіЕНЪ§ОнжиаТЗжВМЃЌrebalance ЕФВйзївВОЭПЩвдМгШыЕНЗжВМЪНЪ§ОнПтжаЃЌСНепЪЧЙВЭЈЕФЃЌЖМЪЧзіЪ§ОнЕФвЦЖЏЃЌЪ§ОнжиаТЗжВМЙизЂЙ§ГЬЃЌrebalance ЙизЂНсЙћЁЃ
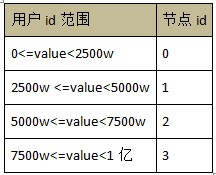
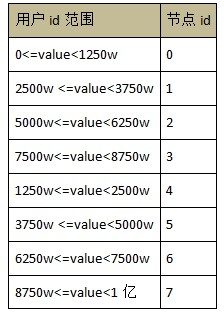
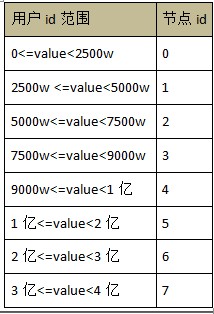
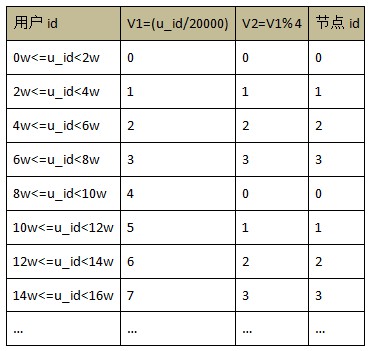
Hadoop жаЕФ hdfs КЭЗжВМЪНЪ§ОнПтЕФЖдБШ
дкНјвЛВНЕФЬжТлШчКЮИФНјЗжВМЪНЪ§ОнПтЕФДцДЂжЎЧАЃЌЯШПДПДЗжВМЪНЪ§ОнПтКЭ hadoop жа hdfs ЕФЖдБШЁЃ
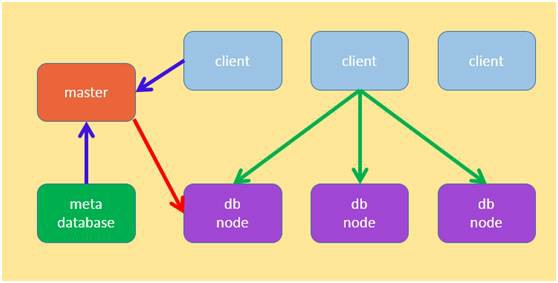
Figure 1: ЗжВМЪНЪ§ОнПтЕФМмЙЙ
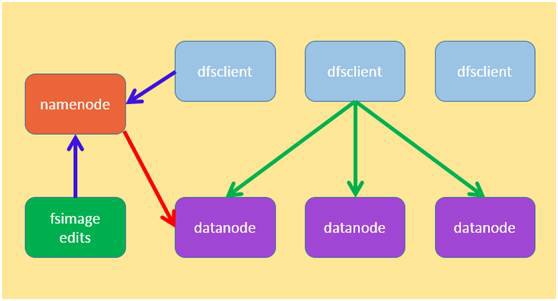
Figure 2:hadoop жа hdfs ЕФМмЙЙ
ЧАУцЬсЕНЗжВМЪНЪ§ОнПтжаАбМЧТМЖдгІЕФНкЕуаХЯЂЩЯБЈИј master ЪЧВЛПЩааЕФЗНАИЃЌетРяЦфЪЕЪЧвЛжжПфДѓЕФЖдБШЃЌСНепжаЕФИХФюАДееШчЯТЕФРрБШИќМгКЯЪЪЃК
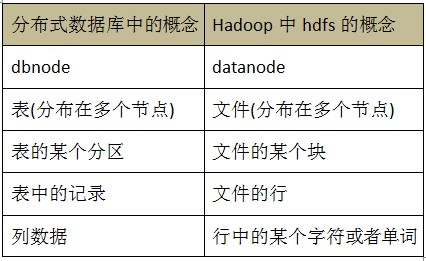
ДгвдЩЯЕФЖдБШПЩвдПДГіЃЌШчЙћЗжВМЪНЪ§ОнПтЕФНкЕуШчЙћКЭ datanode вЛбљЃЌФмЙЛдкЦєЖЏЕФЪБКђЩЈУшИУЪЕР§ЩЯЕФБэаХЯЂЃЌЩЯБЈИј masterЃЌФЧУДЗжВМЪНЪ§ОнПтЕФзіЗЈОЭПЩвдКЭ hadoop жаЕФ hdfs ЗНЪНвЛбљЃЌМДБэЕФЗжЧјЫцЛњЗжЩЂдк dbnode ЩЯЃЌетбљдЊЪ§ОнЕФДѓаЁвВВЛЛсЬиБ№ДѓЁЃЕЋЮвУЧашвЊзЂвтЕНетжжЫцЛњЕФЗНЪНЃЌЪЙЕУЖСаДЪ§ОнЕФЪБКђЃЌПЭЛЇЖЫашвЊжЊЕРЪ§ОнЮЛгкФФИіЛђепФФаЉНкЕуЃЌетбљЖдвбгаЪ§ОнЕФЖСаДашвЊОЙ§СНВНЃЌЪзЯШЧыЧѓ master Ъ§ОнЮЛгкФФИіНкЕуЃЌШч hadoop жа hdfs ашвЊЯђ namenode ЧыЧѓЖСаДЪ§ОнЫљдкЕФ datanode аХЯЂЃЌШЛКѓдкЯђ datanode ЗЂЫЭЖСаДУќСюЃЛШчЙћЪ§ОнЪЧгаЙцдђЕФЗжВМдкНкЕужаЃЌФЧУДПЩвдНЋетаЉЙцдђаХЯЂДцДЂдкПЭЛЇЖЫжаЃЌБмУтЖСаДВйзїЦЕЗБЧыЧѓ masterЃЌетЖдИпВЂЗЂЕФГЁКЯЗЧГЃгааЇЁЃЫљвдетЦЊЮФеТЮвУЧЛЙЪЧХзЦњЫцЛњЕФЗжВМЃЌВЩгУгаЙцдђЕФЗНЪНРДЬжТлЗжВМЪНЪ§ОнПтЕФДцДЂЁЃ
КЫаФЫМЯы
ДгДцДЂМмЙЙКЭИХФюЩЯПДетСНепЗЧГЃЕФЯрЫЦЃЌЩѕжСЖМПЩвдЙщвЛЛЏСЫЃЌЫљвдЗжВМЪНЪ§ОнПтЕФ sql МЦЫувВПЩвдНшМј hadoop жаЕФ mapreduce МЦЫуФЃаЭЃЌетЦЊЮФеТжївЊЬжТлДцДЂЕФИФНјЃЌЮЊМЦЫуДђКУЛљДЁЃЛДгЩЯУцЕФБГОАКЭЮЪЬтПЩвдПДГіЃЌhdfs гаШБЕуЃЌвВгагХЕуЃЛФПЧАЕФЗжВМЪНЪ§ОнПтгаВЛзуЃЌвВгаБШ hdfs зіЕФКУЕиЗНЃЛетЦЊЮФеТЛљгкетаЉгХШБЕуЃЌДјзХетаЉЮЪЬтЃЌВЩжкМвжЎГЄЃЌЖдФПЧАЕФЗжВМЪНЪ§ОнПтЕФДцДЂНјааСЫЗжЮіКЭИФНјЃЌЮЊЛљгкЗжВМЪНЪ§ОнПтЕФЗжВМЪН sql МЦЫуФмЙЛИќКУЕФРћгУ hadoop ЩњЬЌШІжаЕФ mapreduceЃЌspark ЕШЗжВМЪНМЦЫуФЃаЭДђЯТСМКУЕФЛљДЁЁЃ
ДгЩЯУцЕФЮЪЬтжаЃЌОЙ§ЫМПМПЩвдЗЂЯжЃЌЗжВМЪНЪ§ОнПтЕФЪ§ОнЪЧВЛФмЫцЛњЗжВМЕФЃЌЪЧБиаыгаЙцдђЕФЃЌЕЋЪЧЙцдђашвЊФмЙЛЖЏЬЌЕїећЃЌВХФмНтОівдЩЯЮЪЬтЃЌЭЌЪБУЛга hdfs ЦєЖЏЩЈУшЪ§ОнПщЕМжТЦєЖЏЪБМфЙ§ГЄЕФЮЪЬтЁЃе§вђЮЊЙцдђЪЧашвЊФмЙЛЖЏЬЌЕїећЕФЃЌЫљвдашвЊВЩМЏЪ§ОнПтНкЕуЕФИКдиЧщПіЃЌвђЮЊетЪЧЙцдђЖЏЬЌЕїећЕФвРОнЁЃЯТУцОЭОпЬхЗжЮіШчКЮзіЃЌгаФФаЉЗНЪНПЩвдзіЁЃ
ИКдиЧщПі
ашвЊВЩМЏЕФИКдиЪ§ОнЃЌДѓИХАќРЈШчЯТЗНУц:
- ЛњЦїЕФ cpuЃЌФкДцЪЙгУЃЌio ЧщПіЃЌЭјТчСїСПЃЌДХХЬДцДЂДѓаЁЕШ
- Ъ§ОнПтЕФДцДЂДѓаЁЃЌqpsЃЌtpsЃЌТ§ВщбЏЃЌЫјЃЌСйЪББэЃЌСЌНгЪ§ЕШ
етаЉжИБъжаБШНЯЙиМќЕФжИБъШЮКЮвЛИіГЌЙ§СЫЫќЕФуажЕЃЌетНкЕуОЭВЛПЩвддйВхШыЪ§ОнЃЌУПИіжИБъЕФуажЕИљОнЛњЦїЕФХфжУОіЖЈЃЛ
ЯТУцИјГівЛИіжИБъЕФуажЕР§згЃЌШчЯТБэЫљЪО:
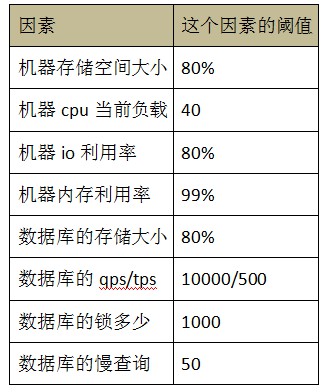
ЭЈЙ§етжЛжИБъПЩвдМЦЫувЛИіжЕ db_node_load(0<=db_node_load<=1ЃЌ0 БэЪОУЛгаИКдиЃЌ1 БэЪОИКдивбТњ)ЃЌВЂЧвЩшжУвЛИіуажЕ insert_load_thresholdЃЌdb_node_load аЁгк insert_load_threshold ЕФЪБКђЃЌетИіНкЕуЪЧПЩвдВхШыЪ§ОнЕФЃЛ db_node_load ДѓгкЕШгк insert_load_threshold ЕФЪБКђЃЌетИіНкЕуЪЧВЛПЩвдВхШыЪ§ОнЕФЃЛетРяжЛПМТЧСЫВхШыЃЛЖдгкЩОГ§ЃЌЖМБиаыдкетИіНкЕужДааЃЛЖдгкИќаТЃЌШчЙћИќаТЧАКЭИќаТКѓЕФЪ§ОнЖМдкИУНкЕуЩЯЃЌвВБиаыдкетИіНкЕужДааЃЛШчЙћВЛдкЭЌвЛИіНкЕуЃЌФЧУДдкЕБЧАНкЕуЩОГ§ЃЌжиаТАДееЙцдђМгИКдиЧщПібЁдёвЛИіаТЕФНкЕуНјааВхШыЁЃМЦЫу db_node_load ЕФЙЋЪНЪЧУПИівђЫиЕФЕБЧАжЕГ§вдИУвђЫиЕФзюДѓжЕЕФМгШЈЦНОљЃЌжИБъЕФзюДѓжЕИљОнЛњЦїЕФХфжУОіЖЈЃЌИїИіжИБъЕФЫљеМБШР§ЕФР§згШчЯТЃК
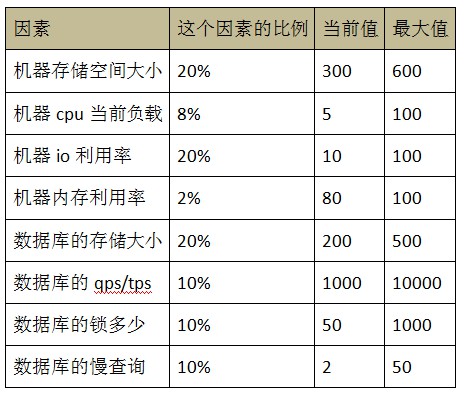
ФЧУД db_node_load = 20%*300/600 +8%*5/100+ 20%*10/100+ 2%*80/100+ 20%*200/500+ 10%*1000/10000+ 10%*50/1000+ 10%*2/50 =0.239
Ъ§ОнЗжВМЙцдђ
ЫљЮНЕФЗжВМЙцдђЃЌАќКЌСНИівЊЫи
- ЗжИюзжЖЮЃЌвВНаОљКтзжЖЮЃЌ ДцДЂЪ§ОнЕФЪБКђОіЖЈНЋЪ§ОнВхШыЗжВМЪНБэЕФФГИіНкЕуЕФвРОнзжЖЮЃЌПЩвдЪЧвЛИіЛђепЖрИігаЫГађЙиЯЕЕФзжЖЮЃЌзжЖЮПЩвдЪЧЪ§зжЃЌвВПЩвдЪЧзжЗћДЎЃЌзжЗћДЎЭЈГЃзЊЛЛЮЊЪ§зжЃЛШчГЃгУЕФгУЛЇ id
- ЗжИюЗНЗЈЃЌвВНаОљКтВпТдЃЌ ДцДЂЕФЪБКђОіЖЈШчКЮИљОнЗжИюзжЖЮНЋЪ§ОнВхШыЗжВМЪНБэЕФФГИіНкЕуЕФЗНЗЈЃЌШчСаБэЃЌЗЖЮЇЃЌШЁгр
ЛљБООљКтВпТд
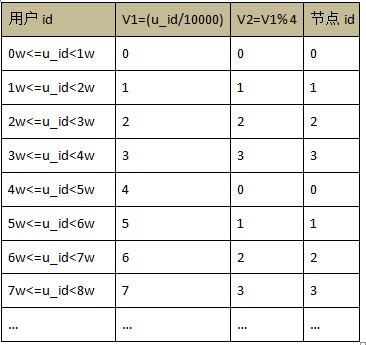
ЯШМђЕЅОйР§ЫЕУїЛљБОЕФОљКтВпТдЃЌЛљБОаХЯЂШчЯТЃКБэУћзжЃКtab_user_loginБэУшЪіЃКгУгкДцДЂгУЛЇЕЧТМаХЯЂНкЕуЪ§ЃК4ЃЌЗжБ№ЮЊ 0ЁЂ1ЁЂ2ЁЂ3зжЖЮаХЯЂЃК
СаБэ
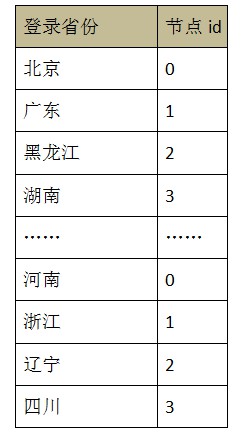
вдЕЧТМЪЁЗнзїЮЊОљКтзжЖЮ
ЗЖЮЇ
Дг 0 ЕНвЛвкЃЌвдгУЛЇ id зїЮЊОљКтзжЖЮ
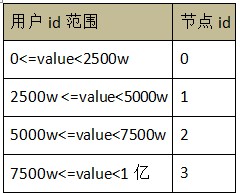
ШЁгр (НкЕуЪ§ЮЊГ§Ъ§ЃЌМДГ§вдНкЕуЪ§ШЁгрЪ§)
вдгУЛЇ id зїЮЊОљКтзжЖЮЃЌНкЕуЪ§ЮЊ 4
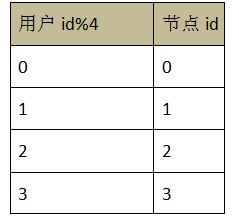
ЛљБООљКтВпТдЕФЗжЮі
- СаБэЕФОљКтВпТдЪЙгУЕФГЁОАжївЊЪЧвРОнМИИіСаБэжЕЃЌШчЪЁЗнЃЌДѓЧјЃЌАДдТДцДЂЕШЃЌЖрИіСаБэжЕПЩвдДцДЂЕНЭЌвЛИіНкЕужаЃЛ
- ЗЖЮЇЕФОљКтВпТдЃЌИљОнашЧѓШЗЖЈЪ§ОнЕФзюДѓзюаЁжЕЃЌШЛКѓИљОнУПИіНкЕуЕФДцДЂМЦЫуФмСІКЭНкЕуЪ§ОіЖЈУПИіНкЕуЗжХфЗЖЮЇЃЌМДАДееНкЕуФмСІНјааМгШЈЦНОљЗжХфЃЌЗЖЮЇаЁЕФЪ§ОнЗжЮЊЕН id аЁЕФНкЕуЩЯЃЛашвЊдіМгНкЕуЕФЪБКђЃЌДгвдЧАзюДѓНкЕуЕФзюДѓжЕПЊЪМЃЌЮЊаТЬэМгЕФНкЕужиаТЗжХфЪ§ОнЕФЗЖЮЇЃЛетжжОљКтВпТдЕФгІгУГЁОАБШНЯЙуЗКЃЌ ПЩвдЪЙгУдкзддіЕФащФт idЃЌгУЛЇ idЃЌЪБМфЕШзжЖЮЩЯУцЃЛЖјЧвдкЗжВМЪНЪ§ОнПтжажДаа select ВщбЏЕФЪБКђЃЌЩцМАЕН orderЃЌgroupЃЌЗЧЕШжЕ join ЕШашвЊХХађЕФВйзїЃЌВЂЧветаЉВйзїЕФзжЖЮЪЧОљКтзжЖЮЕФЪБКђЃЌЯДХЦ (shuffle) ОЭПЩвдКіТдЃЌвђЮЊНкЕу id ЪЧЫГађЕФЃЌНкЕу id аЁЕФНкЕужаДцДЂЕФЪ§ОнаЁЃЌдйМгЩЯОљКтзжЖЮЩЯЭЈГЃгаЫїв§ЃЌХХађЕФВйзїЛсЗЧГЃИпаЇЁЃ етжжОљКтВпТдвВгавЛаЉВЛзуЃЌЪ§ОнЪЧЗёЦНОљЗжВМвРРЕЮЊУПИіНкЕуЗжХфЕФзюДѓзюаЁжЕЃЛШчЙћЪ§ОнЪЧащФт id зїЮЊЗжИюзжЖЮЃЌЕндіЃЌВхШыЕФЪ§ОнЛљБОЩЯЖМЪЧдкзюДѓЕФНкЕужаЃЌЦфЫћНкЕуЛљБОЩЯУЛгаВхШыЃЌжЛгаВщбЏЃЛШчЙћЪ§ОнЪЧгУЛЇ id зїЮЊЗжИюзжЖЮЃЌаТзЂВсЕФгУЛЇ id ЪЧЕндіЃЌФЧУДаТзЂВсЕФгУЛЇЪ§ОнЛљБОЩЯЖМЪЧдкзюДѓЕФНкЕужаЃЌЪ§ОнЗжВНгаИіУїЯдЕФЬиеїЃЌСЌајзЂВсЕФгУЛЇЕФЪ§ОнЛљБОЖМдкЯрЭЌЕФНкЕужаЃЌетбљдкИпЗхЦкЃЌЭЦЙуЦкЃЌЛюЖЏЦкФГаЉНкЕуЕФИКдиБШНЯИпЃЌИКдиОЭЛсГіЯжВЛОљКтЃЛ
- ШЁгрЕФОљКтВпТдФмЙЛНтОіЗЖЮЇЕФОљКтВпТдНкЕуИКдиПЩФмВЛОљКтЕФЮЪЬтЃЌЪ§ОнРэТлЩЯЪЧЦНОљЗжВМЕФЃЛЕЋЪЧШчЙћНкЕужЎМфЕФадФмЪЧВЛЦНОљЕФЃЌФЧУДОЭДцдкФОЭАаЇгІЃЌУПИіНкЕуЕФДцДЂШнСПКЭадФмзюДѓжЕ (адФмЦПОБ) ОЭЪЧадФмзюВюЕФФЧИіНкЕуЃЛЭЌЪБетжжОљКтВпТдВЛОпБИЗЖЮЇЕФОљКтВпТджаФГаЉГЁОАжаЯДХЦКЭХХађЕФИпаЇЬиеїЁЃ
ЛљБООљКтВпТдЯТЕФЪ§ОнжиаТЗжВМ
ЧАУцЬсЕНЙцдђашвЊЖЏЬЌЕїећЃЌЛђепЪ§ОнжиаТЗжВМЃЌетРяжИЕФЪЧЕїећФГИіОљКтВпТдФкВПЕФВЮЪ§ЛђепЙцдђЪ§ОнБОЩэЃЌЖјЗЧзЊЛЛОљКтВпТдЃЌ етШ§жжОљКтВпТдЯТЕФЪ§ОнжиаТЗжВМШчЯТЃК
- СаБэЕФОљКтВпТдашвЊНЋБфЖЏЕФСаБэЪ§ОнжиаТЗжВМЃЌШчЩЯУцЕФР§згжаНЋКкСњНЪЁЕФЪ§ОнДг 2 КХНкЕувЦЖЏЕН 3 КХНкЕуЃЌФЧУДжЛашвЊвЦЖЏКкСњНЪЁЕФЪ§ОнЃЛ
- ЗЖЮЇЕФОљКтВпТдЃЌПЩвдвЦЖЏНкЕужаЕФећИіЗЖЮЇЃЌвВПЩвдвЦЖЏНкЕужаЕФВПЗжЗЖЮЇЃЌДгетЕуРДЫЕЃЌЗЖЮЇЕФОљКтВпЯдЕУИќМгСщЛюЃЌШчЩЯУцР§згжаНЋгУЛЇ id ЗЖЮЇЮЊ 2500w <=value<5000w ЕФећЬхЗЖЮЇДг 2 КХНкЕувЦЖЏЕН 3 КХНкЕуЃЌвВПЩвдНЋгУЛЇ id ЗЖЮЇЮЊ 4500w <=value<5000w ЕФВПЗжЗЖЮЇДг 2 КХНкЕувЦЖЏЕН 3 КХНкЃЌ гУЛЇ id ЗЖЮЇЮЊ 2500w <=value<4500w ЕФВПЗжЗЖЮЇБЃСєдк 2 КХНкЕуЃЛ
- ШЁгрЕФОљКтВпТдБШНЯЬиЪтЃЌ СаБэКЭЗЖЮЇЕФОљКтВпТддкНкЕуЪ§ВЛБфЕФЪБКђПЩвджиаТЗжВМЪ§ОнЃЌЖјШЁгрЕФОљКтВпТддђВЛФмжиаТЗжВМЃЛШчЙћдіМгНкЕуЪ§ЃЌНкЕу id вРДЮдіМгЃЌМЦЫуаТЕФНкЕуЪ§КЭРЯЕФНкЕуЪ§ЕФзюаЁЙЋБЖЪ§ЃЌ вЛЬѕМЧТМЕФОљКтзжЖЮЖдзюаЁЙЋБЖЪ§ШЁгрЃЌШчЙћгрЪ§аЁгкЕШгкРЯЕФНкЕуЪ§ (аЁЕФНкЕуЪ§)ЃЌФЧУДетЬѕМЧТМВЛгУвЦЖЏЃЌЗёдђашвЊвЦЖЏетЬѕМЧТМЕНОљКтзжЖЮЖдаТЕФНкЕуЪ§ЕФгрЪ§ЖдгІЕФНкЕужаЃЛШчЙћМѕЩйНкЕуЪ§ЃЌЩОГ§НкЕу id ЕФДѓЕФНкЕуЃЌ МЦЫуаТЕФНкЕуЪ§КЭРЯЕФНкЕуЪ§ЕФзюаЁЙЋБЖЪ§ЃЌ вЛЬѕМЧТМЕФОљКтзжЖЮЖдзюаЁЙЋБЖЪ§ШЁгрЃЌШчЙћгрЪ§аЁгкЕШгкаТЕФНкЕуЪ§ (аЁЕФНкЕуЪ§)ЃЌФЧУДетЬѕМЧТМВЛгУвЦЖЏЃЌЗёдђашвЊвЦЖЏетЬѕМЧТМЕНОљКтзжЖЮЖдаТЕФНкЕуЪ§ЕФгрЪ§ЖдгІЕФНкЕужаЃЛОйР§ЫЕУїЃЌдіМгНкЕуЕФЪБКђЃЌДг 4 ИіНкЕудіМгЕН 6 ИіНкЕуЃЌ4 КЭ 6 ЕФЙЋБЖЪ§ЪЧ 12ЃЌгУМЧТМЕФОљКтзжЖЮЖдзюаЁЙЋБЖЪ§ШЁгрЃЌНсЙћЮЊ 0 ЕН 11ЃЌФЧУДгрЪ§ 0 ЕН 4 ЕФМЧТМВЛгУвЦЖЏЃЌгрЪ§ЮЊ 5 ЕН 11 ЕФашвЊвЦЖЏЃЛМѕЩйНкЕуЕФЪБКђЃЌДг 8 ИіНкЕуМѕЩйЕН 6 ИіНкЕуЃЌ8 КЭ 6 ЕФЙЋБЖЪ§ЪЧ 24ЃЌгУМЧТМЕФОљКтзжЖЮЖдзюаЁЙЋБЖЪ§ШЁгрЃЌНсЙћЮЊ 0 ЕН 23ЃЌФЧУДгрЪ§ 0 ЕН 6 ЕФМЧТМВЛгУвЦЖЏЃЌгрЪ§ЮЊ 7 ЕН 23 ЕФашвЊвЦЖЏЁЃ
зщКЯОљКтВпТд
СНИіЛљБООљКтВпТдЕФзщКЯ
вдЩЯЕФОљКтВпТдПЩвдШЮвтЕФзщКЯЃЌШчЙћбЁдёСНИіЃЌдђгаСљжжзщКЯЕФОљКтВпТдЁЃ
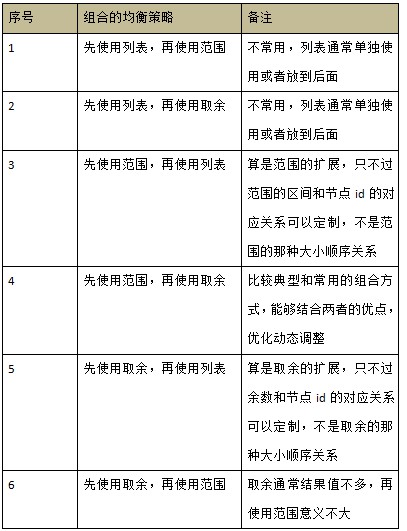
ЬєбЁБШНЯЕфаЭЕФађКХЮЊ 4 ЕФзщКЯЃЌ ЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгрЮЊР§НјааЫЕУї
ЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгр
Р§ШчЃЌвдгУЛЇ id зїЮЊОљКтзжЖЮЃЌУПИіЗЖЮЇга 10000 ИіжЕЃЌНкЕуЪ§ЮЊ 4ЃЌФЧУДНсЙћШчЯТЃК
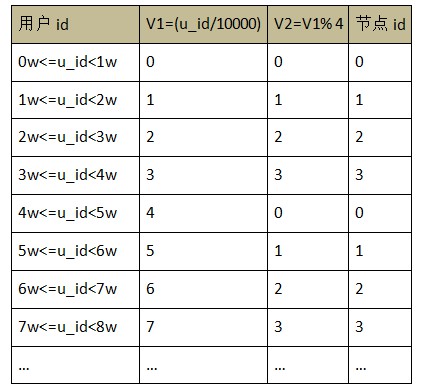
ДгетИіР§згжаЃЌПЩвдЗЂЯжЃЌ ЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгрЕФзщКЯВпТдПЩвдзлКЯСНепЕФгХЪЦЃЌАќКЌЗЖЮЇЕФДѓаЁЫГађКЭШЁгрЕФЪ§ОнЦНОљЗжВМгХЪЦЃЌЕЋЦфЪЕвВдквЛЖЈГЬЖШЩЯЯїШѕСЫгХЪЦЃЌОпЬхЕФЫЕЃЌФГИіБэЕФМЧТМОЭВЛЪЧзмЬхЩЯАДееЫГађДѓаЁДцДЂЃЌЖјЪЧУП 10000 ЬѕМЧТМетИіаЁЗЖЮЇФкЪЧгаЫГађДѓаЁЕФЃЌУП 10000 ИіЕФНкЕуЗжВМЪЧАДееШЁгрЙцдђЕФЗжВМдкВЛЭЌЕФНкЕуЩЯЃЛФГИіБэЕФЪ§ОнвВВЛЪЧдкМЧТММЖБ№ЩЯЦНОљЗжВМЃЌЖјЪЧвд 10000 ЬѕМЧТМЮЊСЃЖШНјааЦНОљЗжВМЕФЃЛЮвУЧЩшМЦЕФЪБКђашвЊИљОнЪЕМЪЧщПіРДШЗЖЈЪЧбЁдё 10000ЃЌЛЙЪЧ 1024 Лђеп 1048576 ЕШЁЃбЁдёЕФдНаЁ (ЯИСЃЖШ)ЃЌдкЖЏЬЌЕїећЕФЪБКђвВПЩвдИќМгСщЛюЃЛдкЪЕМЪжаЃЌНкЕуЪ§ЭЈГЃВЛЖрЃЌФЧУДЯИСЃЖШОЭЛсДђелПлЃЛШч 4 ИіНкЕуЃЌЮвУЧашвЊвЦЖЏ 1 вкЬѕМЧТМжаЕФ 1000 ЭђЃЌФЧУДУПИіНкЕуЦНОљашвЊвЦЖЏЕФЪЧ 250wЃЌ УПИіЗЖЮЇга 10000 ИіжЕОЭЯдЕУаЁСЫЃЌЕМжТЗЖЮЇЪ§ОЭЖрЃЌдЊЪ§ОнОЭЯджјдіМгЃЛШчЙћга 10 ИіНкЕуЃЌФЧУДУПИіНкЕуЦНОљжЛашвЊвЦЖЏ 100w МЧТМЁЃЭЌЪБЙлВьЩЯУцЕФР§згЃЌПЩвдЗЂЯжЃЌШЁгржЎКѓЕФжЕ V2 КЭНкЕу id ЪЧвЛвЛЖдгІВЂЧвЪ§СПвЛжТЁЃЕЋЦфЪЕЮвУЧвВВЩгУЦфЫћЗНЪНЃЌШчСаБэЃЌЗЖЮЇКЭШЁгрЗНЪНЃЛДІРэЗНЗЈЪЧНЋШЁгрМЦЫужаГ§Ъ§ЛЛГЩЕФНкЕуЪ§ЕФБЖЪ§ (ЖјЗЧНкЕуЪ§БОЩэ)ЃЌОпЬхМИБЖвРОнЪ§ОнСПЕФДѓаЁКЭвдКѓЯЕЭГЕФРЉШнашЧѓЃЛ етжжЪЕМЪЩЯвбОЪЧШ§ИіЛљБООљКтВпТдЕФзщКЯСЫЃЌдкЯТУцЕФЬжТлжаЃЌетжжЗНЪНЖддЊЪ§ОнЕФДѓаЁУЛгаЯджјЕФдіМгЃЌ ЭЈГЃбЁдёНЯДѓЕФЪ§БШНЯКУЃЌШчНкЕуЪ§ЕФ 8 БЖЃЌ32 БЖЩѕжС 128 БЖЁЃ
Ш§ИіЛљБООљКтВпТдЕФзщКЯ
АДееЩЯУцЕФЗжЮіЃЌ Ш§ИіЛљБООљКтВпТдЕФзщКЯЪЧЛљгкСНИіИіЛљБООљКтВпТдЕФзщКЯЃЌШчЯТЃК
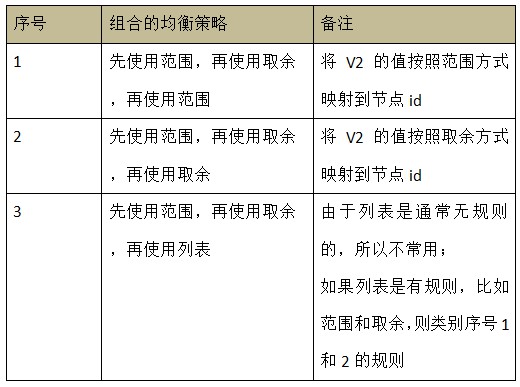
ЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгрЃЌдйЪЙгУЗЖЮЇ
Р§ШчЃЌвдгУЛЇ id зїЮЊОљКтзжЖЮЃЌУПИіЗЖЮЇга 10000 ИіжЕЃЌШЁгрЕФГ§Ъ§ЮЊ 32ЃЌНсЙћШчЯТЃК
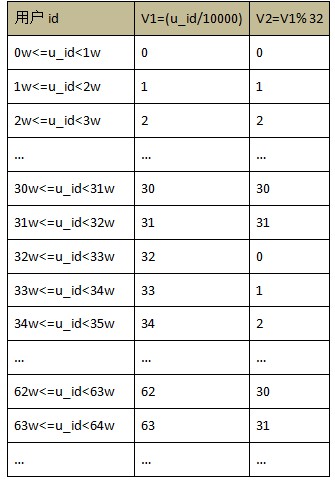
дкЩЯвЛВНЕУЕН V2 ЕФЛљДЁЩЯЃЌШчЙћНкЕуЪ§ЮЊ 4ЃЌ ФЧУДУП 8 ИігрЪ§ЫГађЗХЕННкЕужаЃЌНсЙћШчЯТЃК
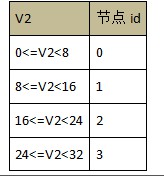
ЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгрЃЌдйЪЙгУШЁгр
Р§ШчЃЌвдгУЛЇ id зїЮЊОљКтзжЖЮЃЌУПИіЗЖЮЇга 10000 ИіжЕЃЌШЁгрЕФГ§Ъ§ЮЊ 32ЃЌНсЙћШчЯТЃК
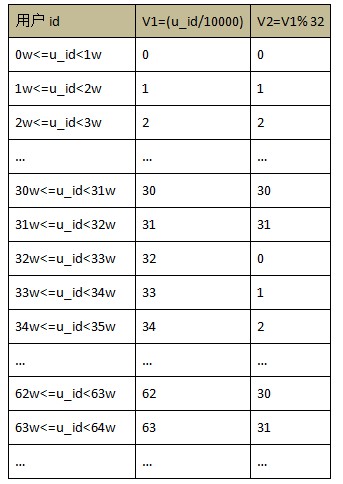
дкЩЯвЛВНЕУЕН V2 ЕФЛљДЁЩЯЃЌШчЙћНкЕуЪ§ЮЊ 4ЃЌ ФЧУД V2 АДее 4 ШЁгрЃЌвтвхЖдгІЕННкЕу idЃЌНсЙћШчЯТЃК
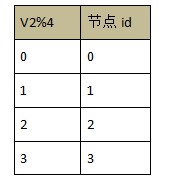
етСНжжОљКтВпТдЕФНсЙћДгаЇЙћЩЯПДЖМЪЧЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгрЃЛзюКѓЪЙгУЗЖЮЇВпТдЕФЪЙЕУУП 8 ЭђвЛИіЗЖЮЇЃЌзюКѓЪЙгУШЁгрВпТдЕФЗЖЮЇЛЙЪЧ 1 ЭђвЛИіЃЌГ§Ъ§ЖМЮЊНкЕуЪ§ЃЌетбљвЛРДЃЌЪЙЕУЪ§ОнжиаТЗжВМЕФСщЛюаддіМгЃЌЭЌЪБВЛЪЇЙцдђадЃЌЮЊЪ§ОнЕФЖЏЬЌжиаТЗжВМДђКУЛљДЁЁЃ
Ъ§ОнЖЏЬЌжиаТЗжВМ
ЪзЯШНщЩмвЛИіИХФювЦЖЏТпМЪ§ОнПщЃЌЛђепНаЪ§ОнДАПк (move logic data chunk)ЃЌ вЦЖЏЪ§ОнЪБЃЌвЛИіНкЕуФкПЩвдвЦЖЏЕНСэЭтвЛИіНкЕуФкЕФСЌајЪЕМЪЪ§ОнМЧТМЪ§ЁЃашвЊИљОнРЯЕФЗжВМЙцдђКЭаТЕФЗжВМЙцдђЕФШЗЖЈЃЌЭЈГЃЪЧеыЖдЗЖЮЇЕФОљКтВпТдЛђепАќКЌЗЖЮЇЕФзщКЯОљКтВпТдЃЌДАПкЕФДѓаЁвЊаЁгкЕШгквЦЖЏЕФЪ§ОнЫљДІЕФФЧИіЗЖЮЇЕФДѓаЁЃЌШчЗЖЮЇЕФОљКтВпТдР§згжаЃЌ0 КХНкЕужа 0<=value<2500w ЃЌ ФЧУДЪ§ОнДАПкПЩвдбЁдё 1 ЕН 2500w жа 2500w ЕФвђзгЃЌШч 1000ЃЌ100w ЕШЃЌЬЋаЁЕМжТДАПкЪ§ЬЋЖрЃЌЬЋДѓЕМжТДАПкЪ§аЁЃЌВЂЗЂЪ§ЬсИпВЛСЫЁЃ НјвЛВНЫЕЃЌДАПкЕФДѓаЁЪЧРЯЕФЗжВМЙцдђКЭаТЕФЗжВМЙцдђжаЪ§ОнЫљДІЕФФЧИіЗЖЮЇЕФДѓаЁЕФЙЋдМЪ§ЃЌЪЕМЪжаСНепЪЧБЖЪ§ЕФЙиЯЕЃЌШЁаЁЕФМДПЩЃЌШчЙћаЁЕФЪ§вВБШНЯДѓЃЌШч 500wЃЌЛЙПЩвдШЁетИіЪ§ЕФзуЙЛаЁЕФФГИідМЪ§ЃЌШч 1wЁЃ
ГЁОА
ЯТУцДгвдЯТМИИіГЁОАЫЕУїЪ§ОнЖЏЬЌжиаТЗжВМ:
1. ВхШыЪ§ОнЕФЪБКђЃЌБОРДетЬѕМЧТМашвЊВхШыНкЕу AЃЌЗЂЯжНкЕу A ЕФИКдиИпЃЌВЛдЪаэВхШыЃЌетЪБЕїећЙцдђЃЌНЋНкЕу A жаЕФетЬѕМЧТМЫљДІЗЖЮЇЕФвЛВПЗжЛђепећЬхвЦЖЏЕН B НкЕуЃЛ
2. МгШыаТНкЕуЕФЪБКђЃЌашвЊНЋдРДФГМИИіНкЕу (Шч A1 ЕН A4) ЩЯФГаЉЗЖЮЇЕФвЛВПЗжЛђепећЬхвЦЖЏЕНаТНкЕуЩЯЃЛЩОГ§НкЕуЕФЪБКђЃЌ ашвЊНЋЩОГ§ЕФНкЕу (Шч A3 ЕН A4) ЩЯЗЖЮЇећЬхвЦЖЏЕНЦфЫћВЛЩОГ§ЕФНкЕуЩЯЃЛ
3. ЗЂЯжЪ§ОнВЛОљКтЃЌШЫЙЄЪжЖЏДЅЗЂЪ§ОнжиаТЗжВМЃЌетжжГЁОАКЭМгШыКЭЩОГ§НкЕуЃЌБОжЪЩЯУЛгаЧјБ№ЃЌОЭЪЧдквбгаЕФНкЕужавЦЖЏЪ§ОнЃЌЖјВЛЩцМАаТМгЕФЛђепвЊЩОГ§ЕФНкЕуЁЃ
вЕЮёгАЯьЗжЮі
Ъ§ОнЕФвЦЖЏЃЌЬиБ№ЪЧДѓСПЪ§ОнЕФвЦЖЏЃЌЪЦБиЖдвЕЮёЕФВйзїДјРДгАЯьЃЌШчЙћПижЦВЛКУЕФЛАЃЌПЩФмЪЧджФбЃЛЮЪЬтСаОйШчЯТ:
ГЁОА 1 ЯТЃЌВхШыЕФЪ§ОнЪЧЯШВхШыРЯНкЕудйвЦЖЏЛЙЪЧЯШвЦЖЏдйВхШыаТНкЕуЃЌЯШВхШыЧщПіЯТПЩФмХМЖћЪ§ОнПтБОЩэИКдиИпЕНВЛФмВхШыЃЌЯШвЦЖЏЧщПіЯТЃЌПЩФмЕМжТВхШыбгГйгжБШНЯДѓЃЌЕМжТгУЛЇЯьгІБШНЯТ§ЃЛ
ГЁОА 1ЃЌ2ЃЌ3 ЯТЃЌвЦЖЏЪ§ОнДАПкЕФЪБКђЃЌвЕЮёЩЯПЩФмЖдетИіДАПкНјааЪ§ОнВйзїЃЌВхШыЃЌИќаТЃЌЩОГ§ЖМгаПЩФмЃЌЪБМфЩЯПЩФмвЕЮёЯШВйзїКЭЫјЖЈМЧТМЃЌШЛКѓвЦЖЏЃЌвВгаПЩФмЯШвЦЖЏЃЌвЦЖЏЙ§ГЬжаЃЌВйзїСЫвбОвЦЖЏЕФЪ§ОнЛђепВйзїКЭЫјЖЈЛЙУЛгавЦЖЏЕФМЧТМЃЛ
ШчКЮДІРэЪ§ОнжиаТЗжВМ
ЩшМЦКУЕФЯЕЭГЃЌПЩФмВЛЬЋашвЊЪ§ОнЕФвЦЖЏЃЌЕЋЪЧДгвЛАуЕФНЧЖШПМТЧЃЌЫќЪЧвЛИіБШНЯЦЕЗБЕФВйзїЃЌЖјЧвЩцМАПчНкЕуЕФВхШыЪ§ОнЃЌЩОГ§Ъ§ОнЃЌаоИФЙцдђдЊЪ§ОнЃЌетШ§епашвЊдквЛИіЪТЮёжаЭъГЩЃЌЫљвдашвЊЪЙгУЗжВМЪНЪТЮёЁЃЮЊСЫБЃжЄвЦЖЏЪ§ОнЕФЪБКђвЕЮёЕФе§ГЃдЫааЃЌЮвУЧашвЊзіШчЯТЕФЩшМЦЃК
- ГЁОА 1 ЕФЯШВхШыЛЙЪЧЯШвЦЖЏЕФЮЪЬтЃЌПЩвдЖЏЬЌЕїећЃЌдкВхШыКмЩйЕФМЧТМЕФЪБКђЃЌЯШВхШыЃЌдйвЦЖЏЃЌШчЙћдЫаажаЯШВхШыЪЇАмЃЌдђЭЫЛЏЮЊЯШвЦЖЏдкВхШыЃЛдкВхШыДѓСПЕФЪ§ОнЕФЪБКђЃЌЯШвЦЖЏЃЌдйВхШыЃЛетжжГЁОАгІИУВЛЖрМћЃЌКмЖрЧщПіПЩвджБНгВхШыЃЌвЦЖЏШЅШУКѓЬЈЯпГЬРДЭъГЩЁЃ
- ГЁОА 1ЃЌ2ЃЌ3 ЯТвЕЮёВйзїСЫашвЊвЦЖЏЕФЪ§ОнЕФЮЪЬтЃЌЕїећвЦЖЏЕФДАПкДѓаЁЃЌЪЙЕУвЛИіДАПкЕФДІРэЪБМфПижЦдкПЩвдНгЪмЕФЪБМфвдФкЃЌвЛИіДАПкЕФФкЕФЪ§ОнвЛДЮЫјЖЈЃЌР§ШчЪБМфЩшжУЮЊ 1sЃЌДАПкДѓаЁбЁдё 2kЃЌЪЙгУ select for update РДЫјЖЈЃЌзюКѓжБНгЩОГ§етаЉМЧТМЃЌзюКѓИќаТЙцдђдЊЪ§ОнЁЃЖдгкДАПкБШНЯДѓЕФЧщПіЃЌПЩвдЪ§ОнВйзїПЩвдНЋДѓДАПкЕїећЮЊаЁДАПкЃЌУПИіаЁДАПкЪЙгУвдЩЯЕФДІРэЗНЪНЃЌЭЌЪБвЕЮёЕФВйзїЪЙгУРрЫЦДЅЗЂЦїЕФМьВщЛњжЦРДЭЌВНИќаТЕНаТНкЕуЩЯЃЌОпЬхЕФЫЕЃК
o ЖдгквбОвЦЖЏЕФаЁДАПкФкЕФВхШыЛђепИВИЧ (replace) ВйзїЃЌВхШыЛђепИВИЧ (replace) ЕНаТНкЕу
o ЖдгквбОвЦЖЏЕФаЁДАПкФкЕФЩОГ§ВйзїЃЌдкаТНкЕуЩОГ§ЖдгІМЧТМ
o ЖдгквбОвЦЖЏЕФаЁДАПкФкЕФИќаТВйзїЃЌдкаТНкЕуИќаТЖдгІМЧТМ
вдЩЯЫљЬжТлЕФЪ§ОнжиаТЗжВМжївЊЪЧШЗЖЈКУЧАКѓЕФЙцдђЃЌКѓУцЕФЙЄзїОЭЪЧИљОнЧАКѓЕФЙцдђШЅЧЈвЦЪ§ОнКЭаоИФдЊЪ§Он
ЪЙгУЗЖЮЇЕФЪ§ОнЖЏЬЌжиаТЗжВМ
ШчРЯЕФОљКтВпТдДг 0 ЕНвЛвкЃЌвдгУЛЇ id зїЮЊОљКтзжЖЮЃЛ ЗжВМШчЯТ:
ГЁОА 1:4 ИіНкЕуДцДЂЛђепадФмЖМДяЕНСЫуажЕЃЌашвЊРЉШнЃЌМЦЛЎУПИіНкЕуВ№ЗжГЩСНИіЯрЕШЕФВПЗжЃЌФЧУДаТЕФЗжВМНсЙћШчЯТЃК
ГЁОАЖўЃК3 КХНкЕугЩгкадФмВЛзуЃЌЬэМгвЛИі 4 КХНкЕуЃЌ 3 КХНкЕуЕФЪ§ОнВ№ЕН 3 КХКЭ 4 КХжаЃЌЭЌЪБРЉДѓгУЛЇЗЖЮЇЕН 4 вкЃЌЪЙгУадФмБШНЯИпЕФ 5ЃЌ6ЃЌ7 КХНкЕуЃЌУПИіНкЕуДцДЂвЛИівкЃЌФЧУДаТЕФЗжВМНсЙћШчЯТ:
ЪЙгУЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгрЕФЪ§ОнЖЏЬЌжиаТЗжВМ
ОйР§ЫЕУїЃЌвдЩЯЕФЯШЪЙгУЗЖЮЇЃЌдйЪЙгУШЁгрзїЮЊРЯЕФЗжВМЃЌШчЯТ:
ГЁОА 1: ЯждкашвЊАДее 20000 вЛИіЗЖЮЇЃЌФЧУДОЭЪЧУП 8w ЬѕМЧТМЦНОљЗжВМдк 4 ИіНкЕужаЃЌаТЕФЗжВМНсЙћШчЯТ:
аЁНс
Ъ§ОнЕФОљКтВпТдЛђепЗжВМЙцдђЪЧвЛАбЫЋШаНЃЃЌHdfs ЕФЪ§ОнЪЧЫцЛњЕФЃЌНкЕуЩЯБЈЕФаЮЪНЃЌЫљвдФмЙЛЖЏЬЌЕїећЃЌЮоашЪ§ОнжиаТЗжВМЃЌШБЕуЪЧЦєЖЏашвЊЩЈУшЃЌЕМжТЦєЖЏТ§ЃЛЗжВМЪНЪ§ОнПтЕФОљКтВпТдЪЧгаЙцдђЕФЃЌЙцдђЭЈГЃДцдкдкдЊЪ§ОнжаЃЌMaster ЦєЖЏЪБМгдидЊЪ§ОнОЭПЩвдЃЌдЊЪ§ОнЭЈГЃКмаЁЃЌЫљвдЦєЖЏКмПьЃЛЕЋЪЧЙцдђЕФЖЏЬЌЕїећБШНЯТщЗГЃЌ Ъ§ОнЕФжиаТЗжВМвВЪЧБиаыЕФЙЄзїЃЛЛљБОЕФЙцдђБШНЯМђЕЅЃЌЕЋЕїећЖЏЬЌЕїећСПБШНЯДѓЃЌКФЪБГЄЃЛзщКЯЕФЙцдђЩдЮЂИДдгЃЌЕЋЕїећЕФЪ§ОнСПЛсЫѕаЁЃЌКФЪБЖЬЁЃ |









