БГОА
ЕБНёITНче§ДІгквЦЖЏЛЅСЊРЫГБжаЃЌгПЯжГівЛХњХњгХауЕФУХЛЇЭјеОКЭЕчЩЬЦНЬЈЁЃдкОоДѓЕФРћШѓЧ§ЖЏЯТЃЌетаЉЙЋЫОЖМШЋСІДђдьИїздЕФЯЕЭГвдЪЪгІЛЅСЊЭјЪаГЁЗЂеЙЕФашвЊЃЌЖјЧвдкДЫЙ§ГЬжаИїИіЯЕЭГЛЙВЛЭЃЕиНгЪмзХвкЭђЭјУёЕФМьбщЁЃОРњЙ§ЧЇДИАйСЖКѓЃЌФЧаЉЁАУћУХДѓГЇЁБЖМЗзЗззмНсГіЁАИпПЩгУЃЌИпПЩППЃЌИпВЂЗЂЯТЕЭбгГйЁБЕФгХауЪЕМљЁЃ
ЖјФЯКНЕчЩЬгЊЯњЦНЬЈетжжДјгаЙњЦѓБГОАКЭДЋЭГаавЕЬиЩЋЕФЕчЩЬЯЕЭГдкетЙЩРЫГБЕФв§СьжЎЯТЃЌвВж№ВНЯђетаЉЁАДѓГЇЁБбЇЯАЃЌНсКЯздЩэЕФЪЕМЪЧщПіЃЌдкЁАИпПЩгУЃЌИпПЩППЃЌИпВЂЗЂЯТЕЭбгГйЁБЕФЯЕЭГгХЛЏжЎТЗЩЯеЙПЊвЛЗЌгЮРњЬНЫїЃЌЦкМфвВгЮРРСЫВЛЩйДѓПгАЕЙЕЁЃ
ЮвУЧЩЬЮёвЦЖЏЭХЖгзїЮЊВПУХРяЯШЗцВПЖгЃЌдкДђдьвЛЬзвдRedisЮЊЛљДЁЕФЛКДцЯЕЭГЃЈШЁУћЮЊЁАКкъзЪЏЁБЃЉгУгкжЇГХФЯКНЕчЩЬгЊЯњЦНЬЈЃЌАяжњЙЋЫОЪЕЯжЁАФЯКНeааЁБеНТдФПБъЕФЙ§ГЬжаЖдRedisЛЗОГжаЕФПгНЇЧ№лжеЙПЊСЫвЛЗЌгЮРњЁЃ
ГѕВНЫМПМ
2015ФъЪЧвЦЖЏЕчЩЬЕФЁАОЎХчЪНЁБЗЂеЙФъЗнЃЌФЯКНЕФЙйЗНAPPГаЪЦЖјЦ№ЃЌВЛЙ§ЪТЪЕгЁжЄСЫФЧОфЛАЁЊЁЊЁАРэЯыКмЗсТњЃЌЯжЪЕКмЙЧИаЁБЁЃФЧИіЪБКђAPPЕФКѓЬЈМмЙЙЪЧАДДЋЭГЕФЦѓвЕФкВПгІгУЫМТЗДюНЈЕФЃЌЯЕЭГЕФбаЗЂЫМТЗЪЧжЛЙмЪЕЯжЙІФмЃЌВЛзЂжиНгПкадФмЁЃ
ШУШЫОРНсЕФЕиЗНБШНЯЖрЃЌвЛЪБШ§ПЬФбвдЖдЦфНјааШЋУцгХЛЏИФдьЃЌЕЋЩЯМЖЯТДяЕФKPIвЊдкЖЬЦкФкЭъГЩЃЌБиаывЊдкЖЬЪБМфФкЬсЩ§вЛаЉЙиМќНгПкЕФадФмЃЌЮвУЧЕквЛЪБМфЯыЕНЕФЖјЧвзюКУПЊЕЖЕФФЊЙ§гкРрЫЦКНАрЖЏЬЌКЭЛњЦБаХЯЂЕШВщбЏРрЙІФмНгПкЃЌвђЮЊжЛвЊМгЩЯЛКДцЃЌадФмТэЩЯФмДѓЗљЖШЬсЩ§ЁЃ
ЛљгкетЗНУцПМТЧЃЌЮвУЧЕБЪБШЯЮЊЕквЛвЊЮёОЭЪЧвЊДюНЈвЛЬзФмУцЯђЛЅСЊЭјЕФЛКДцЯЕЭГЃЌОЙ§МИЗЌбЁаЭКѓЃЌФПЙтПЊЪММЏжаЕНRedis-ClusterЩЯЁЃ
ЩюШыЬНЫї
ЮвУЧдкЬНЫїЦкМфвЛБпЗзЪСЯЃЌвЛБпдкВтЪдЛЗОГДюНЈСЫвЛЬзRedis-ClusterЃЌОЙ§вЛЖЮЪБМфелЬкКѓЃЌдк2016Фъ3дТЗне§ЪНЭЖВњЪЙгУЁЃ
дкЭЖВњГѕЦкаХаФВЛДѓЃЌЫљвдевСЫаЁНгПкРДГЂЪдЃЌЛКДцЕФЪ§ОнСПаЁЃЈаЁгк1KBЃЉЃЌНсЙЙМђЕЅЃЌЛљБОЖМЪЧвЛаЉЯЕЭГХфжУаХЯЂЃЌШчЙІФмПЊЙиЃЌAPPАцБОаХЯЂЕШЃЌRedis-ClusterЖдДЫБэЪОКСЮобЙСІЁЃ
НєНгзХЃЌдк16Фъ3дТЕзЃЌЮвУЧПЊЪМАбRedis-ClusterЭЖЗХЕНе§ЙцеНГЁЩЯЃЌБШШчЛКДцЛњЦБаХЯЂЃЌКНАрЖЏЬЌИќаТЁЃетИіНгПкЪ§ОнСПБШжЎЧАЕФДѓЃЈ50-100KBЃЉЃЌНсЙЙБШНЯИДдгЃЌЖјЧвЪЧЮвУЧЙиМќЙІФмЕФКЫаФНгПкЁЃЪЙгУRedis-ClusterЛКДцЛњЦБаХЯЂвдМАгХЛЏСЫНгПкЕФЭЈбЖавщКѓЃЌЖдВщЦБНгПкМгЫйаЇЙћЪЎЗжЯджјЃЌНгПкЕФЯьгІЪБМфДг7-8УыНЕЕНвЛАйЖрКСУыЃЌдйХфКЯIOSКЭАВзПЖЫЕФдЩњвГУцфжШОЗНЪНгХЛЏКѓЃЌЪЕЯжЛњЦБаХЯЂ"УыГі"ЃЌетБъжОзХФЯКНЯЕЭГПЊЪМЬЄНјЁАУыМЋОуРжВПЁБЕФУХМїЁЃдквЛДЮИњШЋУРКНПеЕФНЛСїжаЃЌЛњЦБВщбЏЕФЫйЖШАбЫћУЧЯХСЫвЛЬјЁЃЃЈЕБЪБШЋУРappВщвЛЯТЛњЦБаХЯЂашвЊ8-9УыЃЉ
гІЖдДѓСїСП
ЮвУЧНтОідкГЃЙцЗўЮёзДЬЌЯТЕФКЫаФЙІФмВщбЏРрНгПкЕФЗЕЛиЛКТ§ЕФЮЪЬтЃЌЕЋетНіНіЪЧПЊЪМЃЌвђЮЊвЦЖЏЕчЩЬзюДѓЕФЬиЩЋОЭЪЧИуДйЯњЛюЖЏЃЌЯёУыЩБЁЂГщНБЁЂХЩШЏЕШЕШЃЌетаЉЛюЖЏЖМЛсв§ЗЂЫВЪБЕФЗУЮЪИпЗхЃЌЗУЮЪСПЭљЭљЪЧГЃЙцЗўЮёзДЬЌЯТЕФЪЎБЖЛђвдЩЯЃЌФЯКНзд2015Фъ10дТ28ШеИуСЫЕквЛДЮЛсдБШеЛюЖЏКѓЃЌЭљКѓЕФУПдТ28ШеЖМЛсИувЛДЮЃЌУПДЮЕФСуЕуЗхжЕЖМЛсЖдЮвУЧЯЕЭГдьГЩЛйУ№адДђЛїЃЌЦфЪЕетОЭКУЯёвЛИіУЛДЉвТЗўЕФШЫдкБљЬьбЉЕижааазпвЛбљЃЌЫљвдМИКѕдкЭъГЩНгПкЬсЫйЕФЭЌвЛЪБМфЃЌЮвУЧгУRedis-ClusterзіСЫМўЁАУоАРЁБШУЯЕЭГЁАДЉЁБЩЯЁЊЁЊАбЫљгаСїСПзЊМоЕНRedis-ClusterЩЯЁЃ
РћгУRedisЕФЕЅЯпГЬдзгадЙмРэЗУЮЪаэПЩжЄГиЃЌаэПЩжЄГиЕФДѓаЁИљОнЛюЖЏНгПкЕФадФмСщЛюЕїећЁЃжЛгаЕУЕНаэПЩжЄЕФЧыЧѓВХФмЗУЮЪЯрЙиНгПкЃЌЕБНгПкЗЕЛиКѓАбаэПЩжЄЪЭЗХЛиаэПЩжЄГижаЃЌЖјЕУВЛЕНаэПЩжЄЕФЧыЧѓдђНјШыRedis
blpopЕФЕШД§ЖгСажаЁЃ етЯюДыЪЉНсКЯNginx-LuaЕФЗўЮёЩ§НЕМЖКЭЯоСїШлЖЯЛњжЦЃЈжївЊБЃЛЄФЧаЉаДВйзїЙІФмЃЌБШШчЯТЕЅЃЉЃЌШЗБЃСЫФЯКНгЊЯњЦНЬЈдкЭљКѓЕФЛсдБШеЛђЦфЫћДѓДйЛюЖЏЦкМфГаЪмЧЇЭђМЖЕФЗУЮЪСїСПЪБШдФмЦНЮШЕиЬсЙЉЗўЮёЁЃ
ЭЈЙ§етжжАьЗЈЃЌдкITЭХЖгЙцФЃдЖдЖВЛШчФЧаЉгаУћЦјЕФЕчЩЬЙЋЫОЭЌРрЯЕЭГбаЗЂЭХЖгЕФЧщПіЯТЃЌОЙ§вЛИідТЕФИФдьЃЌЮвУЧАбвЛИіУПДЮЖМЪЧЬЩзХЙ§СуЕуИпЗхЕФЯЕЭГЃЌБфГЩЛљБОЩЯФмАВАВЮШЮШЕиеОзХЙ§СуЕуИпЗхЕФЯЕЭГЁЃ
ШЋЬьКђЗўЮё
гЩгкЕБЪБгІгУЕФЮЪЬтНЯЖрЃЌЕЅСДТЗЛљБОФбвдБЃжЄ7*24аЁЪБВЛМфЖЯЗўЮёЃЌШ§ЭЗСНШеЛсЙђвЛЯТЃЌзюжБНгЕФДІРэЗНЪНОЭЪЧЕБМрПиБЈОЏЪБШУдЫЮЌАяУІжиЦєЁЃОЁЙмЮвУЧгаЖрЬѕСДТЗЃЌЕЋвЛЕЉФГЬѕСДТЗdownЛњжиЦєЃЌЙ§ГЬжаПЯЖЈЛсгАЯьЕНВПЗжгУЛЇЁЃЮвУЧЭХЖгЕФбаЗЂзЪдДЪЕдкгаЯоЃЌЖјЧвФЧЖЮЪБМфШЋВПОЋСІЗХдкШЗБЃЛсдБШеетжжДйЯњЛюЖЏЩЯЃЈжЇГХвЕЮёВПУХГхKPIЃЉЃЌЕЋетИіЮЪЬтгжВЛФмЗХШЮВЛЙмЃЌЫљвдВЩгУБШНЯЪЁЪТЕФЗНЪНЁЊЁЊдк16ФъЕФ4дТГѕЃЌЮвУЧАбИїЬѕСДТЗЕФsessionзДЬЌаХЯЂЭГвЛЛКДцЕНRedis-ClusterжаЃЌетбљПЩвдАбИіБ№СДТЗЕФdownЛњЖдгУЛЇЕФгАЯьНЕЕНзюЕЭЃЌСэЭтаДСЫМђЕЅМрПиНгПкШУМрПиЯЕЭГЕїгУЃЌЕБМрПиЯЕЭГЭЈЙ§етИіНгПкЗЂЯжФГЬѕСДТЗdownСЫОЭЕївЛЯТИУСДТЗЩЯЕФжиЦєНХБОЁЃ
етбљзівЛЗНУцЮЊЭХЖгељШЁСЫанЯЂЪБМфЃЌВЛгУЮЊЙЪеЯЦЃгкБМУќЃЌМѕЧсбаЗЂШЫдБбЙСІЃЌСэвЛЗНУцЦфЪЕвВЫуАбЯЕЭГаоГЩ7*24ВЛМфЖЯЗўЮёСЫЃЌзюживЊЕФЪЧФмШУЭХЖггаИќГфЗжЕФЪБМфжЦЖЈгХЛЏИФдьМЦЛЎКЭЗНАИЃЌЪЙЕУКѓРДЮвУЧФмдкБШНЯДгШнЕФЧщПіЯТЭЈЙ§ДњТыВуУцЕФгХЛЏКЭJVMЕїгХЕШДыЪЉАбгІгУГіЯжЕФИїжжЮЪЬтвЛвЛНтОіЁЃ
НјвЛВНгХЛЏ
ЕБСДТЗФмБЃжЄ7*24аЁЪБВЛМфЖЯЗўЮёКѓЃЌЮвУЧгжЛиЙ§ЭЗРДгХЛЏФЧаЉЛсдБШеКЭЦфЫћДйЯњЛюЖЏжагУЕНЕФаДВйзїЙІФмНгПкЃЌШчЯТЖЉЕЅЁЂХЩгХЛнШЏКЭСьгХЛнШЏжЎРрЃЌгШЦфгХЛнШЏЯрЙиЕФНгПкВЛЕЋЩцМАЫЋБэаХЯЂаДШыЃЌЖјЧвЛЙДјЪТЮёЃЌВЂЗЂвЛИпЪ§ОнПтСЌНгОЭеМТњЁЃ
зюГѕжЛФмЭЈЙ§ЯоСїЕФЗНЪНЯШДІРэЃЌЕЋетбљзіМЋВЛКЯРэЃЌЛюЖЏЦкМфДѓВПЗжгУЛЇЕФИаЪмЪЧМШХЩВЛСЫШЏгжСьВЛСЫШЏЁЃ
КѓРДДѓИХдк16Фъ7дТИФГЩАбШыПтЪ§ОнЖЊНјЖгСаРяЃЌХХЖгШыПтЃЌВЛЙ§етбљгУЛЇЬхбщвВВЛКУЃЌБШШчгаШЫЕуСЫСьШЏАДХЅЃЌШЛКѓТэЩЯШЅШЏАќВщПДЃЌЩѕжСТэЩЯЪЙгУЪБЗЂЯжУЛШЏЃЌвЊЕШЩЯвЛЖЮЪБМфВХПДЕНИеВХЫљСьШЏЃЌдвђЪЧЪ§ОнЛЙдкЖгСаРяЃЌЛЙУЛШыПтЁЃ
дйКѓРДЮвУЧОЭЯыФмЗёЯШаДЛКДцЃЌЖСЕФЪБКђвВЪЧЯШЖСЛКДцЃЌетбљОЭФмТњзугУЛЇашвЊЁЃПЩЪЧПДПДЮвУЧЕФRedisЃК
1.ВЛФмжЇГжНсЙЙЛЏДцДЂ
2.ВЛжЇГжЪТЮёЁЃ
ЕБЪБmongoDBПЩвджЇГжНсЙЙЛЏДцДЂЃЌЖјЧвжЇГжSqlВщбЏЃЌВЂЧвГаХЕМДНЋжЇГжЪТЮёЃЌШЛЖјЮвУЧЕФДцДЂжаМфМўвбОгаMysqlКЭRedisЃЌГігкЭХЖгЙцФЃКЭММЪѕеЛЕФЙмРэЃЌЮвУЧВЛЬЋЯЃЭћАбММЪѕеЛИуЕУЬЋгЗжзЃЌвђЮЊВЛЯыНЕЕЭБОРДОЭВЛЫуИпЕФбаЗЂаЇТЪЃЌБмУтГіЯжММЪѕЪЕЯжЪБГіЯжбЁдёРЇФбЃЌЖјЧвОЭФЧУДвЛСНИіаДМмЙЙДњТыЁЂЗтзАДюНЈЕзВузщМўЕФШЫЃЌЮЌЛЄЖрЬзММЪѕЦёВЛЭТбЊЁЃ
ЕБЪБгаИіЭЌЪТЬсвщАбНсЙЙЛЏДцДЂзЊЛЏГЩk-vЃЌдйРћгУkeyЕФУќУћЙцдђРДФЃЗТЪТЮёЃЌетбљЭъШЋПЩвдзіГіЛљгкRedisзїЮЊЕзВуДцДЂЕФФкДцЪ§ОнПтЁЃгкЪЧЮвУЧНјааСЫвЛаЉpojoНсЙЙзЊЛЛКЭkeyБъЧЉЗтзАЃЌВЂАбЫљгаЯрЙиЕФAPIЭЈЙ§JDBCРДЗтзАЃЌзюжеЕФаЇЙћВЛЕЋжЇГжPOJOЕФНсЙЙЛЏДцДЂвдМАSQLгяОфВйзїЃЌЖјЧвЛЙжЇГжЪТЮёЁЃЭЈЙ§етжжЗНЪНАбгХЛнШЏаХЯЂЯШЛКДцЕНRedis-ClusterКѓдйИљОнЮвУЧЗтзАЕФЁБЪТЮёЁАГжОУЛЏЕНMysqlжаЃЌетбљОЭЛљБОТњзуСЫИїЗНашЧѓЁЃ
дкДњТыЩЯПДЃЌдкServiceВуАбPOJOГжОУЛЏЕНЪ§ОнПтгыЛКДцЕНRedisЪЧЮоВюБ№ЕФЃЌЮЊДЫЮвЕФЭЌЪТАбетЬзЪЕЯжГЦЮЊФкДцЪ§ОнПтФЃПщЁЃ
| /**
* @author DeanPhipray
* OBSI DBДцДЂЪОР§
*
* */
@Transactional
public int saveToRedis(String fieldName,Student
student,Teacher Teacher) throws RdbException{
Row row=new Row();
try {
row.setValue(fieldName, SeqFactory.getOID());
rStudentDao.insert("dual", row);
row.setValue(fieldName, SeqFactory.getOID());
rStudentDao.insert("dual", row);
row.setValue(fieldName, SeqFactory.getOID());
rStudentDao.insert(student);
row.setValue(fieldName, SeqFactory.getOID());
rTeacherDao.insert(teacher);
}catch (Exception e) {
log.error("ЛКДцЪЕР§ЪЇАм");
throw new RdbException("Rdb save fail",e);
}
return 2;
}
/**
* @author DeanPhipray
* OBSI DB queryЪОР§
*
* */
public Student query(@RequestParam("id")
Long id,String tableName) throws RdbException{
Student student= null;
try {
String sql = "select * from "+ tableName
+ "where id = ?";
List params = new LinkedList<>();
params.add(id);
student= (Student) rStudentDao.query(sql,params);
} catch (Exception e) {
log.error("ВщбЏЪЕР§ЪЇАм");
throw new RdbException("Rdb query fail",e);
}
return student;
} |
НќЦкЭХЖгПЊЪМИуУєНнзЊаЭЃЌЮвУЧИњвЛаЉУєНнЙЫЮЪЕФНЛСїжаЬсЕНЮвУЧвЛжБЮЊММЪѕеЛзіkeepfitЕФРэФюЃЌЛљБОЕУЕНЖдЗНЕФШЯЭЌЁЃ
ВШПгОРњ
вЛКХПгЃКНЉЪЌСЌНг
дквЛИідТКкЗчИпЕФЩЯЯпвЙЃЌЕБДѓМвЖМвдЮЊЩЯЯпШЮЮёПьЭъГЩЪБЃЌЭЛШЛгаЭЌЪТИцЫпЮвЗЂВМаТАќжиЦєЯЕЭГКѓЃЌЯЕЭГЮоЗЈЛёШЁRedis-ClusterСДНгЃЌжиЦєЙ§КУМИДЮЛЙЪЧетбљЃЌЮвТэЩЯМьВщМЏШКзДЬЌЃЌЗЂЯжвЛЧае§ГЃЃЌЕЋМьВщСЌНгЪ§ЪБОЭОЊЦцЕиЗЂЯжЫљгаНкЕуЕФСЌНгЪ§ЕНДяСЫЩЯЯоЁЃЮвУЧЫуСЫвЛЯТОѕЕУКмЦцЙжЃЌвђЮЊНгШыЕФЯЕЭГЪЎИљЪжжИЭЗЪ§ЕУЭъЃЌЖјЧвУПИіЯЕЭГЕФХфжУЖМЪЧАДЮвУЧжЦЖЈЕФФЃАхХфВЮЪ§ЃЌЮвУЧзюДѓСЌНгЪ§ВХХфСЫ200ЃЌПеЯазюДѓСЌНгЪ§50ЃЌПеЯазюаЁСЌНгЪ§ЪЧ10ЃЌвЛАуИїИігІгУЪЕР§жЛЛсвд10ИіСЌНгСЌЕНRedis-ClusterИїИіНкЕужаЃЌдѕУДЫуЖМЕНВЛСЫСЌНгЪ§ЕФЩЯЯоАЁЁЃЮЊСЫОЁПьЛжИДЃЌЮвУЧЯШЭЈЙ§НХБОУќСюдкRedisЗўЮёЦїЩЯЧхçэНгЃЌНтШЅШМУМжЎМБЃЌВЛЙ§жЮБъВЛжЮБОЃЌавПїУПДЮЧхГ§ЭъСЌНгЃЌПЭЛЇЖЫЛсздЖЏжиСЌЃЌВЛгАЯьЗўЮёЃЌЖјСЌНгЪ§дйДЮЕНДяЩЯЯоЃЌДѓИХвЊСНЬьЪБМфЁЃ
| echo
"client list" | redis-cli -c -p {port}|awk
-F '=|
' '$12>3600{print $4}' | sed "s/^/client
kill /g" | redis-cli -c -p {port} |
ЬюПгЙЅТдЃКЯћГ§НЉЪЌСДНг
дкЫцКѓМИЬьРяЃЌЮвУЧЗЂЯжПЭЛЇЖЫЩшСЫзюДѓГЌЪБЃЌШчЙћСЌНгвЛжБДІгкПеЯазДЬЌЃЌДѓИХ5ЗжжгОЭЛсЖЯПЊгыЗўЮёЦїжЎМфЕФГЄСЌНгЃЌЕЋЦцЙжЕФЪЧЗўЮёЖЫВЛГаШЯПЭЛЇЖЫЕФЖЯСЌзДЬЌЃЌвЛжББЃГжИУСЌНгЃЌНсЙћДгПЭЛЇЖЫЕФЗўЮёЦїПДВЛЕНетжжСЌНгЃЌЕЋдкRedisЗўЮёЦїЩЯШДПДЕНДѓСПетжжСЌНгЃЌзюжеЕМжТЗўЮёЖЫСЌНгЪ§БЛеМТњЃЌЮоЗЈдйДДНЈаТСЌНгЖдЭтЬсЙЉЗўЮёЁЃЮЊСЫШУСДНггавЛЖЈЕФЕЏадЃЌЮвУЧдкПЭЛЇЖЫЩшжУСЌНгГЌЪБЪБМфЁЂСЌНгГиДѓаЁЁЂзюДѓПеЯаСЌНгЪ§ЁЂзюаЁПеЯаСЌНгЪ§ЕШЁЃ
| <!--
jedis configuration starts -->
<bean id="config" class="org.apache.commons.pool2.
impl.Generic
ObjectPoolConfig">
<property name="maxTotal" value="200"></property>
<property name="maxIdle" value="50"></property>
<property name="minIdle" value="10"></property>
<property name="maxWaitMillis"
value="15000">
</property>
<property name="lifo" value="true"></property>
<property name="blockWhenExhausted"
value="true">
</property>
<property name="testOnBorrow" value="false">
</property>
<property name="testOnReturn" value="false">
</property>
<property name="testWhileIdle"
value="true">
</property>
<property name="timeBetweenEvictionRunsMillis"
value="30000"></property>
</bean>
<bean id="jedisCluster" class="com.csair.csmbp.
util.JedisClusterFactory">
<property name="addressKeyPrefix"
value="address"
/>
<property name="timeout" value="300000"
/>
<property name="maxRedirections"
value="6"
/>
<property name="config" ref="config"
/>
</bean> |
дкЗўЮёЖЫИљОнЪЕМЪЧщПіЩшжУtcp-keepalivedКЭTimeoutетСНИіВЮЪ§ЃЌЦфжаНЈвщTimeoutЕФжЕИњПЭЛЇЖЫЕФГЌЪБЪБМфвЛжТЁЃ
ЖўКХПгЃКПЭЛЇЖЫЙ§Жр
ЫцзХгІгУГЁОАЕФж№НЅдіЖрЃЌетЬзЛКДцЯЕЭГв§Ц№СЫВПУХФкКмЖрЯюФПзщЕФаЫШЄКЭЙизЂЃЌНгзХОЭЪЧЗзЗзгЛдОНгШыЃЌвЛЯТзгЕЎЩњСЫКмЖрПЭЛЇЖЫЃЌДјРДЕФЮЪЬтОЭЪЧСЌНгЪ§ХфжУФбвдЭГвЛЙцЙмЃЌСЌНгЪ§БЉдіЃЌНсЙћФГаЉЯЕЭГ/ИіБ№СДТЗЗжВЛЕНСЌНгЃЌетвЛРДОЭв§ГівЛИіБШНЯОЕфЕФГЁОАЃЌФГДѓСьЕМгУЮвУЧЕФЯЕЭГзмЪЧБЈДэЃЌЖјЮвУЧФЃЗТВйзїЯыжиЯжДэЮѓЪБЃЌЛљБОЪЧе§ГЃ(ШУЮвУЧМЋЖШБРРЃ)ЁЃ
ЬюПгЙЅТдЃКДюНЈДњРэВу
етИіЮЪЬтЗЂЩњЪБМрПиЯЕЭГЪЧВЛЛсБЈОЏЕФЃЌвђЮЊМрПиЯЕЭГЪЧЙЬЖЈЦЕТЪЗЂЫЭМьВтЧыЧѓЃЌвЛжБЙЬЖЈеМгУзХвЛЬѕСДТЗЃЌЖјЧвДЫЪБЕФМрПиЯЕЭГЛЙУЛШЅМрПиМЏШКЕФСЌНгЪ§ЁЃКѓРДЮвУЧЭЈЙ§ПчСДТЗЕФШежОЗжЮіЯЕЭГМьВщШежОЪБЗЂЯжИіБ№гІгУСЌВЛЩЯRedis-Cluster,дйПДПДRedisЗўЮёЦїЩЯЕФСЌНгЪ§ЪЧДІгкБЌТњзДЬЌЃЌВЛЙ§ОјЖдДѓВПЗжСЌНгЪЧПеЯазДЬЌЃЌУЛЪ§ОнСїЖЏЕФЃЌгЩДЫОЭЕЎЩњСЫгУДњРэАбСЌНгЭГвЛЙмРэЕФЯыЗЈЁЃ
НгЯТРДОЭДюНЈСЫвЛЬзЧсСПМЖЕФДњРэВуМЏШКЭГвЛЙмРэRedis-ClusterСДНгЃЌВЩгУNettyПђМмДІРэИїИіЯЕЭГ/ИїЬѕСДТЗЕФПЭЛЇЖЫЧыЧѓЁЃ
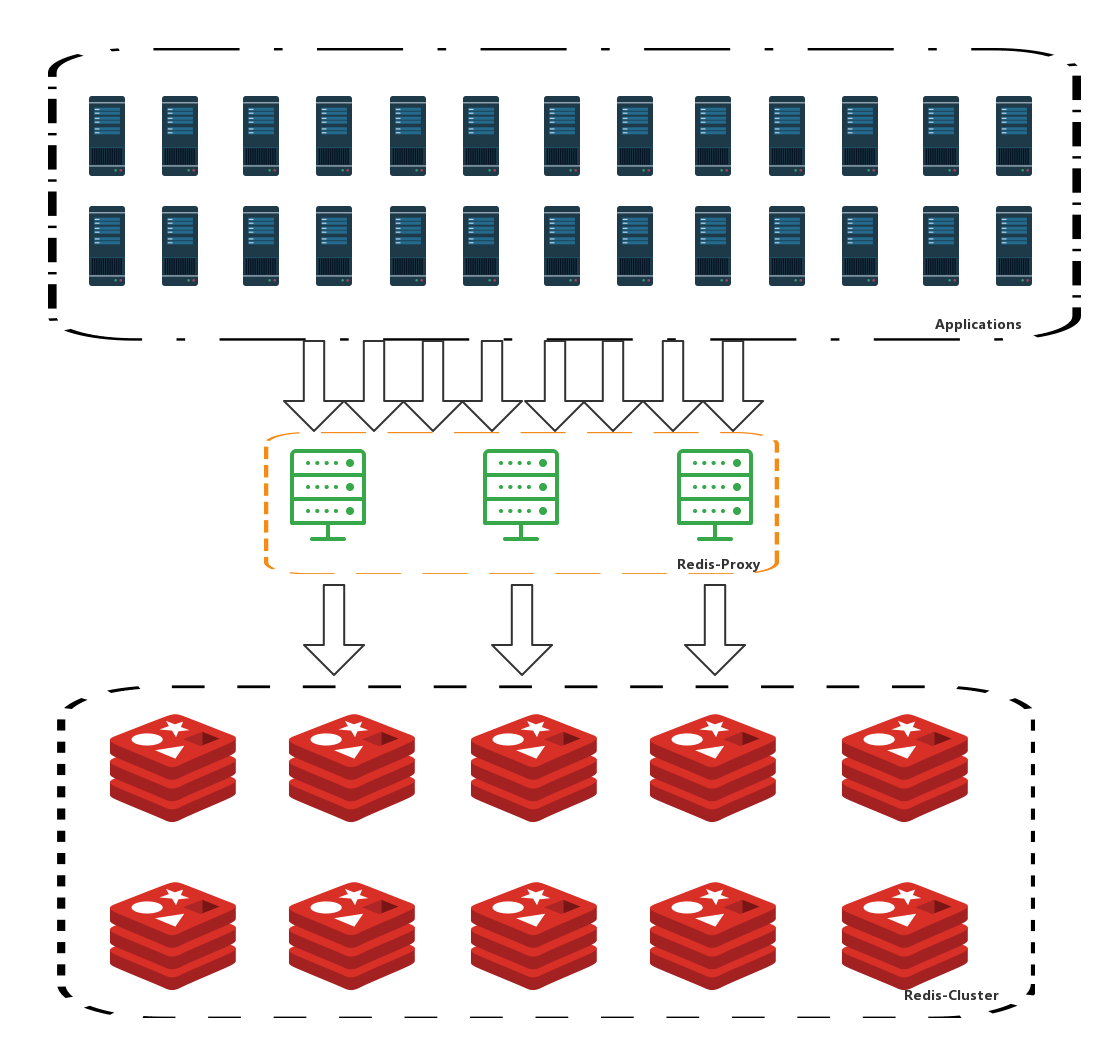
дкПЭЛЇЖЫКЭДњРэжЎМфЃЌДњРэФЃФтJedisИњRedisжЎМфЕФЭЈбЖавщЃЌвдnioЕФЗНЪНДІРэВЂЗЂЧыЧѓЃЌдкДњРэгыRedis-ClusterжЎМфВЩгУsocketГЄСЌНгИДгУЗНЪНзіЧыЧѓзЊЗЂЃЌдБОЕФПЭЛЇЖЫЭъШЋЮоашзіШЮКЮДњТыИФЖЏОЭФмНгШыДњРэМЏШКЁЃ
ДњРэМЏШКЛсдкRedis-ClusterжаЛКДцДњРэМЏШКЕФНкЕуаХЯЂКЭЫЂаТИїИіНкЕуЕФНЁПЕзДЬЌЃЌвђЮЊJedisПЭЛЇЖЫЛсЖЈЪБбЏЮЪМЏШКНкЕуаХЯЂЃЌЖјДњРэМЏШКжЛашАбMasterНкЕуЬцЛЛЮЊДњРэМЏШКНкЕуЃЌВЂЧвЖдДњРэМЏШКНкЕузівЛДЮЦНОљЕФHash
SlotЗжЦЌОЭФмШЗБЃЃК
1.ПЭЛЇЖЫЧыЧѓМЏжаСЌНгЕНДњРэМЏШКЩЯ
2.ДњРэМЏШКдкЖЏЬЌРЉеЙаТНкЕуЪБФмБЛПЭЛЇЖЫздЖЏЗЂЯж
Ш§КХПгЃКФкДцзюДѓжЕЯожЦ
Ц№ГѕЛКДцЕФЪ§ОнБШНЯЩйЃЌвЛжБУЛХфзюДѓФкДцЯожЦЃЌЫцзХНгШыЯЕЭГдНРДдНЖрЃЌЛКДцЪ§ОнСПВЛЖЯдіДѓЃЌНсЙћдкФГИіЗчКЭШеРіЕФАзЬьЃЌФкДцБЛМЗБЌЃЌЯЕЭГГ§СЫБЈCluster
downЭтЃЌВЂУЛИќЧхЮњЕФБЈДэЃЌЕБЪБЮвУЧвЛСГУдуЏЃЌФЊУћЦфУюЕиВщСЫ1ИіЖраЁЪБКѓВХЗЂЯжЗўЮёЦїФкДцБЛКФЙтСЫЁЃ
ЬюПгЙЅТдЃКЩшжУзюДѓФкДцЯожЦ
дкЗўЮёЖЫИљОнЗўЮёЦїзЪдДЕФЪЕМЪЧщПіЩшжУmaxmemoryЕФДѓаЁЃЌетбљгаИіКУДІОЭЪЧЕБГЌЙ§етИіжЕЪБЃЌRedisЛсШУsetВйзїЪЇАмЃЌЖјЧвгаУїШЗЕФвьГЃаХЯЂЗЕЛиЁЃетИіПгНтОіАьЗЈЫфШЛЗЧГЃМђЕЅЃЌЕЋМЋвзБЛКіТдЃЌЪєгкАЕЙЕЁЃ
ЫФКХПгЃКaofЮФМўеМТњДХХЬПеМф
гавЛЬьЮвУЧИеКУЭъГЩСЫвЛИіМОЖШЕФШЮЮёЃЌе§зМБИЯэЪмФЧЗнФбЕУЕФАДЪБЯТАрДјРДЕФаЁгфдУЃЌЫЕЪБГйЃЌФЧЪБПьЃЌМрПиБЈОЏЃЁМЏШКжаФГЬЈЗўЮёЦїЩЯЕФЫљгаЪЕР§ЭЃжЙЗўЮёЃЌЮвУЧТэЩЯГЂЪджиЦєЩЯУцЕФЪЕР§ЃЌЕЋгкЪТЮоВЙЁЃгкЪЧЮвУЧжЛКУАДВПОЭАрЃЌРЯРЯЪЕЪЕДгcpuЁЂФкДцЁЂДХХЬПеМфЁЂRedisШежОЕШЕШж№ИіМьВщЃЌНсЙћЗЂЯжДХХЬПеМфТњСЫЃЌAOFвЛжБзшШћЃЌвЛИіaofЮФМўЬхЛ§ОЙШЛгаЪЎМИGЃЈЦфЫће§ГЃЕФЪЕР§ЩЯaofЮФМўВХ2-3GЃЉЃЌЮЊСЫОЁПьЛжИДЮвУЧЙћЖЯАбЦфжаСНИіДгНкЕуЪЕР§ЕФaofЮФМўЩОЕєЃЌШЛКѓдйжиЦєЪЕР§ЃЌШЛКѓОЭЛжИДе§ГЃСЫЃЌВЛЙ§ЕБЮвУЧЫГЪжжиЦєетЬЈЗўЮёЦївЛИіУЛгаЩОГ§aofЮФМўЕФЪЕР§КѓЃЌетИіЪЕР§ЕФaofЮФМўдкжиЦєКѓНгНќ1ЗжжгКѓДгЪЎМИGБфГЩСЫ2GЃЌдкДЫЦкМфИУЪЕР§НјШыНЉЫРзДЬхЃЈЕЅЯпГЬЕФБзЖЫЃЉЃЌетУїЯдНјааСЫaofжиаДАЁЁЃ
ЬюПгЙЅТдЃКПижЦaofЮФМўДѓаЁ
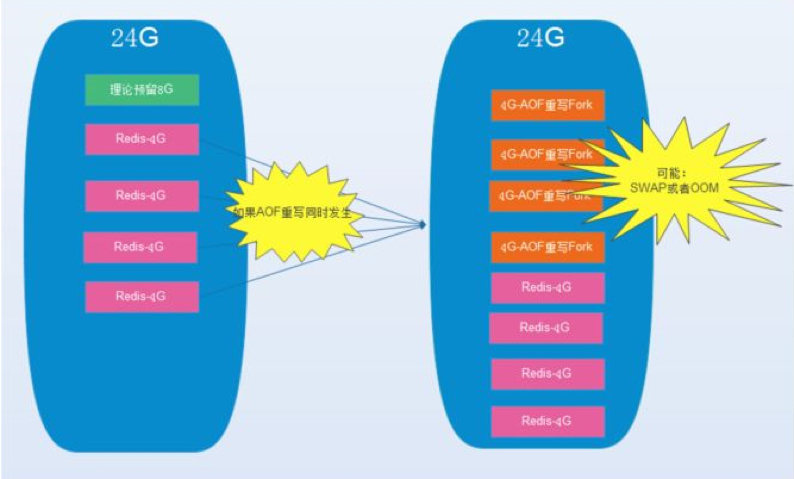
ДЫКѓУПЬьжДааBGREWRITEAOFжИСюНХБОЃЌМрПиДХХЬПеМфЃЌМѕЩйЗўЮёЦїЩЯRedisЕФЪЕР§Ъ§ВЂЬкПевЛАыФкДцЃЌвђЮЊвЛЬЈЛњЩЯВПЪ№ЖрИіRedisЪЕР§ЛсгаИівўЛМЃЌЭђвЛЖрИіЪЕР§дњЖбзіAOFжиаДЛсЕМжТswapЛђепoomЃЌЕМжТжиаДЪЇАмЃЌетжжЪЇАмЛсВЛЖЯжиИДЃЌжБжСaofЮФМўЯёЙібЉЧђЫЦЕФБфДѓЃЌзюжеШћТњДХХЬЃЌСэЭтжиаДЬхЛ§НЯДѓЕФaofЮФМўЪБЃЌRedisЛсНјШыIOзшШћзДЬЌЃЌЭЃжЙЖдЭтЗўЮёЁЃ
НсгяКЭМФЭћ
дкНќвЛФъАыЕФЬНЫїКЭЪЕМљЙ§ГЬжаЃЌЮвУЧЭХЖгвЛТЗПгПгЭнЭнЃЌМИОЕпХцЕизпЕНЯждкЃЌДѓЬхЩЯУўЫїГівЛЬзЁАИпПЩгУЃЌИпПЩППЃЌИпВЂЗЂЯТЕЭбгГйЁБЕФЛКДцНтОіЗНАИЁЃ
ЯЃЭћетЬзЭбЬЅгкRedis(КьБІЪЏ)ЕФЁАКкъзЪЏЁБЯЕЭГЃЌГЫзХЁАФЯКНeааЁБетЙЩЖЋЗчЃЌФмЕУЕНИќКУЕФГжајЕФгХЛЏЃЌдкЮДРДЕФШезгРязпЕУИќЮШЁЂИќдЖЁЃ |









