Ъ§ОнБэРраЭ(ДцДЂв§Чц)
Ъ§ОнПтв§ЧцгУгкДцДЂЁЂДІРэКЭБЃЛЄЪ§ОнЕФКЫаФЗўЮёЃЌРћгУЪ§ОнПтв§ЧцПЩПижЦЗУЮЪШЈЯоВЂПьЫйДІРэЪТЮёЃЌРћгУЪ§ОнПтв§ЧцДДНЈгУгкСЊЛњЪТЮёДІРэЛђСЊЛњЗжЮіДІРэЪ§ОнЕФЙиЯЕЪ§ОнПтЃЌАќРЈДДНЈгУгкДцДЂЪ§ОнЕФБэКЭгУгкВщПДЁЂЙмРэЁЂБЃЛЄЪ§ОнАВШЋЕФЪ§ОнПтЖдЯѓ(Ыїв§ЁЂЪгЭМЁЂДцДЂЙ§ГЬ)ЁЃ
ГЃМћв§ЧцБШЖд
| Ьиад |
Myisam |
InnoDB |
Memory |
BDB |
Archive |
| ДцДЂЯожЦ |
ЮоЯожЦ |
64TB |
га |
УЛга |
УЛга |
| ЪТЮёАВШЋ |
- |
жЇГж |
- |
жЇГж |
- |
| ЫјЛњжЦ |
БэЫј |
ааЫј |
БэЫј |
вГЫј |
ааЫј |
| BЪїЫїв§ |
жЇГж |
жЇГж |
жЇГж |
жЇГж |
- |
| ЙўЯЃЫїв§ |
- |
жЇГж |
жЇГж |
- |
- |
| ШЋЮФЫїв§ |
жЇГж |
- |
- |
- |
- |
| МЏШКЫїв§ |
- |
жЇГж |
- |
- |
- |
| Ъ§ОнЛКДц |
- |
жЇГж |
жЇГж |
- |
- |
| Ыїв§ЛКДц |
жЇГж |
жЇГж |
жЇГж |
- |
- |
| Ъ§ОнбЙЫѕ |
жЇГж |
- |
- |
- |
жЇГж |
| ПеМфЪЙгУ |
ЕЭ |
Ип |
N/A |
ЕЭ |
ЗЧГЃЕЭ |
| ФкДцЪЙгУ |
ЕЭ |
Ип |
жа |
ЕЭ |
ЕЭ |
| ХњСПВхШыЫйЖШ |
Ип |
ЕЭ |
Ип |
Ип |
ЗЧГЃИп |
| ЭтМќжЇГж |
- |
жЇГж |
- |
- |
- |
Иїв§ЧцЬиЕу
mysqlФЌШЯДцДЂв§ЧцЃЌдкДХХЬЩЯДцДЂГЩШ§ИіЮФМў.frm(ДцДЂБэЖЈвх).MYD(MYDataДцДЂЪ§Он)ЁЃMYI(MYIndexДцДЂЫїв§);
УЛгаЪТЮёжЇГжЃЌВЛжЇГжааЫјЭтМќЃЌвђДЫЕБinsertЁЂupdateЛсЫјЖЈећИіБэЃЌаЇТЪЛсЕЭвЛаЉЃЌMyIASMжаДцДЂСЫааЪ§ЃЌШчЙћБэЕФЖСВйзїдЖДѓгкаДЧвВЛашвЊЪТЮёЃЌMyISAMгХбЁЁЃ
Ыїв§
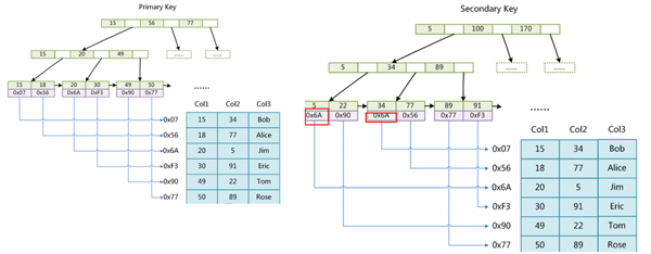
1.MyISAMв§ЧцЫїв§НсЙЙЮЊB+TreeЃЌЦфжаB+TreeЕФЪ§ОнгђДцДЂЕФЮЊЪЕМЪЪ§ОнЕижЗМДЫїв§КЭЪЕМЪЪ§ОнЗжПЊМДЗЧОлМЏЫїв§ЁЃ
2.ШчЭМжїМќЫїв§КЭИЈжњЫїв§НсЙЙвЛжБжЛВЛЙ§жїМќЫїв§вЊЧѓkeyЮЈвЛЁЃ
3.MyISAMжаЫїв§МьЫїЫуЗЈЪзЯШАВзАB+TreeЫбЫїЫуЗЈЫбЫїЫїв§ЃЌШчЙћkeyДцдкЃЌдђШЁГіdataгђЕФжЕЃЌШЛКѓвдdataгђЕФжЕЮЊЕижЗЃЌЖСШЁЯргІЪ§ОнМЧТМЁЃ
ЬсЙЉСЫЖдЪ§ОнПтACIDЪТЮёжЇГжВЂЪЕЯжSQLБъзМЕФЫФжжИєРыМЖБ№ЃЌЬсЙЉааМЖЫјКЭЭтМќдМЪјЁЃMysqlдЫааЪБInnodbЛсдкФкДцжаНЈСЂЛКГхГигУгкЛКГхЪ§ОнКЭЫїв§ЃЌИУв§ЧцВЛжЇГжfulltextРраЭЫїв§ЧвУЛгаБЃДцБэЕФааЪ§ЃЌselect count(*) from table бЊвЉЩЈШЋБэЁЃ
ашвЊЪТЮёВйзїЪБInnodbЪзбЁЃЌЫјСІЖШаЁЃЌаДВйзїВЛЛсЫјЖЈШЈБъЃЌЫљвдВЂЗЂИпЪБInnodbв§ЧцаЇТЪИќИп,
ЯрБШMyisamаДДІРэаЇТЪВювЛаЉЛсеМгУИќЖрЕФДХХЬПеМфБЃДцЪ§ОнКЭЫїв§ЁЃ
Ыїв§
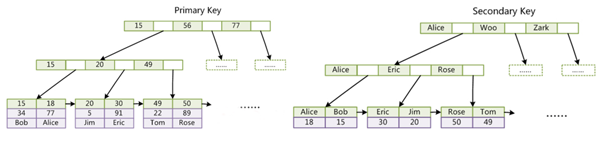
1.InnodbЫїв§ВЩгУB+TreeЧвInnodbЫїв§ЮФМўБОЩэОЭЪЧЪ§ОнЮФМўМДB+TreeЕФЪ§ОнгђДцДЂЕФОЭЪЧЪЕМЪЕФЪ§ОнШчЭМPrimary KeyМДОлМЏЫїв§ЁЃетИіЫїв§ЕФkeyОЭЪЧЪ§ОнБэжїМќЃЌInnodbБэБОЩэОЭЪЧжїЫїв§ЁЃ
2.InnodbИЈжњЫїв§Ъ§ОнгђДцДЂЕФЪЧЯргІЕФжїМќЕФжЕЖјВЛЪЧЕижЗЃЌЭЈЙ§ИЈжњЫїв§ВщевЪБЯШевЕНжїМќдйЭЈЙ§жїМќВщевЪ§ОнЁЃЫљвджїМќВЛНЈвщЙ§ГЄЗёдђИЈжњЫїв§ЛсБфЕУКмДѓЁЃ
3.InnodbБиаыгажїМќШчЙћУЛгаЯдЪОжИЖЈMysqlЛсздЖЏбЁдёвЛИіЮЈвЛБъЪЖЕФЪ§ОнМЧТМЮЊжїМќЁЃ
4.ОлМЏЫїв§АДжїМќЫбЫїаЇТЪЪЎЗжИпаЇЃЌИЈжњЫїв§БиаыМьЫїСНБщЁЃ
5.ЛљгкInnodbЫїв§НсЙЙПЩвдНтЪЭЮЊЪВУДВЛНЈвщЪЙгУЙ§ГЄЕФжїМќЃЌЮЊЪВУДВЛНЈвщЪЙгУЗЧЕЅЕї(ЗЧЕнді)ЕФМЧТМзіжїМќЃЌB+TreeЫїв§НсЙЙЕМжТЪЙгУЗЧЕЅЕїзіжїМќЛсЯрЕБЕЭаЇЁЃ
ГЃгУУќСю
- show engines; ВщПДЕБЧАжЇГжЕФв§ЧцКЭФЌШЯв§Чц
- show table status from mytest; show create table tablename;ВщПДЪ§ОнБэв§Чц
- аоИФФЌШЯв§Чц my.ini [mysqld]ЯТдіМг default-storage-engine=InnoDB
УћДЪИХФю
- ACID: (Atomicity)дзгад,вЊУДШЋВПжДаавЊУДВЛжДаа;(Consistency)вЛжТадЃЌЪТЮёЕФдЫааВЛИФБфЪ§ОнПтжаЪ§ОнЕФвЛжТад;(Isolation)ЖРСЂад,вВГЦИєРыадСНИівдЩЯЕФЪГЮяВЛЛсГіЯжНЛДэжДааЕФзДЬЌ;(Durability)ГжОУад,ЪТЮёжДааГЩЙІКѓЪ§ОнГжОУБЃДцЁЃ
- BTree ЖўВцЫбЫїЪї
1.ЫљгаЗЧвЖзгМИЕузюЖргаСНИізгНкЕу(left right)
2.ЫљгаНкЕуДцДЂвЛИіЙиМќзж
3.ЗЧвЖзгНкЕузѓжИеыжИЯђаЁгкЦфЙиМќзжЕФзгЪїЃЌгвжИеыжИЯђДѓгкЦфЙиМќзжЕФзгЪї
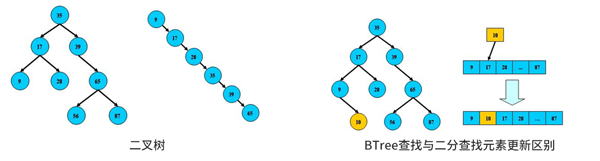
ЖўВцЪїВщев:ДгИњНкЕуПЊЪМВщбЏЙиМќзжгыНкЕуЯрЕШЃЌУќжаЗЕЛиЁЃЗёдђВщбЏЙиМќзжБШНкЕуаЁЃЌНјШызѓзгНкЕуЗёдђНјШыгвНкЕуЁЃШчЙћзѓЛђгвЮЊПеЗДРЁевВЛЕНЁЃШчЙћЪїзѓгвНкЕуБЃГжЦНКтШчЭМ1ЁЂ3ПУЪїВщбЏадФмБЦНќЖўЗжВщевЁЃЪїБШЖўЗжВщевЕФгаЕуЪЧЪ§ОнИќаТЪБВЛашвЊвЦЖЏДѓЖЮФкДцЪ§ОнШч3ЁЂ4ЭМЪ§ОнИќаТЁЃ
ОЙ§вЛЯЕСаЕФИќаТПЩФмЕМжТЭМ2ЕФBTreeЪїЃЌИУЪїЫбЫїГЩЯпадЮоВщбЏгХЪЦЃЌдкЪЕМЪЪЙгУжаЭЈГЃЪЙгУЦНКтЖўВцЪїШчЭМ1ЁЂ3МДЁАЦНКтЖўВцЪїЁБЃЌЦНКтЫуЗЈЪЧвЛжждкBЪїжжВхШыКЭЩОГ§НкЕуЕФВпТдЁЃ
- B-Tree ЖрТЗЫбЫїЪї(ЗЧЖўВцЪї)
1.ШЮвтЗЧвЖзгНкЕузюЖржЛгаMИізгНкЕуЧвM>2
2.ИњНкЕуЕФзгНкЕуЪ§ЮЊ[2, M]
3.Г§ИњНкЕуЭтЕФЗЧвЖзгНкЕуЕФзгНкЕуЪїЮЊ[M/2, M]
4.УПИіНкЕуДцЗХжСЩйM/2-1(ШЁЩЯећ)КЭжСЖрM-1ИіЙиМќзж(жСЩй2ИіЙиМќзж)
5.ЗЧвЖзгНкЕуЕФЙиМќзжИіЪ§=жИЯђЖљзгЕФжИеыИіЪ§-1
6.ЗЧвЖзгНкЕуЕФЙиМќзж:K[1],K[2],Ё,K[M-1]ЧвK[i]<K[i+1]
7.ЗЧвЖзгМИЕуЕФжИеы:P[1],P[2],Ё,P[M],ЦфжаP[1]жИЯђЙиМќзжаЁгкK[1]ЕФзгЪїЃЌP[M]жИЯђЙмЙиМќзжДѓгкK[M-1]ЕФзгЪїЃЌЦфЫћP[i]жИЯђЙиМќзжЪєгк(K[i-1], K[i])ЕФзгЪї
8.ЫљгавЖзгНкЕуЮЛгкЭЌвЛВу
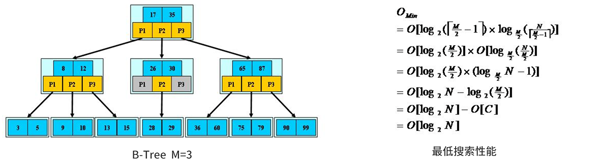
B-TreeВщев:ДгИњНкЕуПЊЪМЃЌЖдНкЕуФкЕФЙиМќзж(гаађ)НјааЖўЗжВщевЃЌУќжаНсЪјЁЃЗёдђНјШыВщбЏЙиМќзжЫљЪєЗЖЮЇЕФЖљзгНкЕу;жиИДжБЕНПеЛђвЖзгНкЕуЁЃ
гЩгкЯожЦГ§ИљНкЕуЭтЕФЗЧвЖзгНкЕужСЩйКЌгаM/2ИіЖљзгЃЌШЗБЃСЫНкЕуЕФжСЩйРћгУТЪЫљвдB-TreeЕФадФмЕШМлгкЖўЗжВщевЃЌвВОЭУЛгаBЪїЦНКтЕФЮЪЬтЁЃгЩгкM/2ЕФЯожЦЃЌВхШыЛђЩОГ§НкЕуЪБашвЊПМТЧЗжСбКЭКЯВЂНкЕуЁЃ
B-TreeЬиад:ЙиМќзжМЏКЯЗжВМдкећПЦЪїжж;ШЮКЮвЛИіЙиМќзжГіЯжЧвжЛГіЯждквЛИіНкЕужа;ЫбЫїгаПЩФмдкЗЧвЖзгНкЕуНсЪј;ЫбЫїадФмЕШМлгкдкЙиМќзжШЋМЏФкзівЛДЮЖўЗжВщев;здЖЏВуДЮПижЦ;
- B+Tree B-TreeБфЬхЖрТЗЫбЫїЪї
1.ЛљБОгыB-TreeЖЈвхЯрЭЌГ§вдЯТЭт
2.ЗЧвЖзгНкЕуЕФзгЪїжИеыгыЙиМќзжИіЪ§ЯрЭЌ
3.ЗЧвЖзгНкЕуЕФзгЪїжИеыP[i]жИЯђЙиМќзжжЕЪєгк(K[i], K[i+1])ЕФзгЪї
4.ЮЊЫљгавЖзгНкЕудіМгвЛИіСДжИеы
5.ЫљгаЙиМќзжЖМдквЖзгНкЕуГіЯж
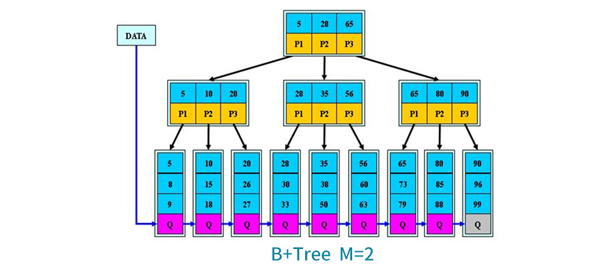
B+TreeВщев:гыB-TreeЯрЭЌЧјБ№B+ЪїжЛгаДяЕНвЖзгНкЕуВХУќжаЃЌЦфадФмЕШМлгкЙиМќзжШЋМЏзівЛДЮЖўЗжВщевЁЃ
B+TreeЬиад:ЫљгаЙиМќзжЖМГіЯждквЖзгНкЕуСДБэжаЃЌСДБэжаЙиМќзжгаађ;ВЛПЩФмдкЗЧвЖзгНкЕуУќжа;ЗЧвЖзгНкЕуЯрЕБгкЪЧвЖзгНкЕуЕФЫїв§ЃЌвЖзгНкЕуЯрЕБгкЪЧДцДЂЙиМќзжЪ§ОнЕФЪ§ОнВу;ИќЪЪКЯЮФМўЫїв§ЯЕЭГ;
1.дкB+TreeЕФЗЧИњКЭЗЧвЖзгНкЕудіМгжИЯђажЕмЕФжИеы
B+TreeЗжСб:ЕБвЛИіНкЕуТњЪБЃЌЗжХфвЛИіаТЕФНкЕуЃЌНЋдНкЕужа1/2ЕФЪ§ОнИДжЦЕНаТНкЕуЃЌзюКѓдкИИНкЕужадіМгаТНкЕужИеы;B+ЪїЗжРржЛгАЯьдНкЕуКЭИИНкЕуВЛгАЯьажЕмНкЕуЁЃ
B*TreeЗжСб:вЛИіНкЕуТњЪБЃЌШчЙћЯТвЛИіажЕмНкЕуЮДТњЃЌНЋвЛВПЗжЪ§ОнвЦЕНажЕмМИЕужаЃЌдйдкдДНкЕуВхШыЙиМќзжЃЌзюКѓаоИФИИНкЕужаажЕмНкЕуЕФЙиМќзж;ШчЙћажЕмНкЕувВТњСЫЃЌдђдкдДНкЕугыажЕмНкЕужЎМфдіМгаТНкЕуЃЌВЂИїИГжЕ1/3ЕФЪ§ОнЕНаТНкЕуЃЌзюКѓдкИИНкЕудіМгаТНкЕуЕФжИеыЁЃB*TreeЗжХфНкЕуЕФИХТЪБШB+TreeвЊЕЭЃЌПеМфЪЙгУТЪИпЁЃ
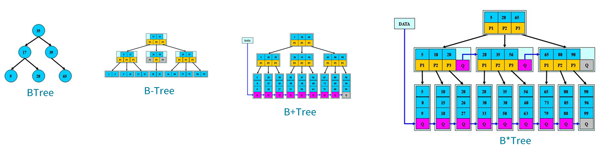
ИїИіЪїБШЖд
| РраЭ |
ЬиЕу |
| BTree |
УПИіНкЕужЛДцДЂвЛИіЙиМќзжЃЌЕШгкУќжаЃЌаЁгкзѓНкЕуЃЌДѓгкгвНкЕу |
| B-Tree |
ЖрТЗЫбЫїЪїЃЌУПИіНкЕуДцДЂM/2ЕНMИіЙиМќзжЃЌЗЧвЖзгНкЕуДцДЂжИЯђЙиМќзжЗЖЮЇЕФзгНкЕуЃЌЫљгаЙиМќзждкећПУЪїжаГіЯжЃЌЧвжЛГіЯжвЛДЮЃЌЗЧвЖзгНкЕуПЩвдУќжа |
| B+Tree |
B-TreeЛљДЁЩЯЮОвЖзгНкЕудіМгСДБэжИеыЃЌЫљгаЙиМќзжЖМдквЖзгНкЕуГіЯжЃЌЗЧвЖзгНкЕузїЮЊвЖзгНкЕуЕФЫїв§ЃЌB+TreeвЖзгНкЕуВХУќжа |
| B*Tree |
B+TreeЛљДЁЩЯЮЊЗЧвВздМКЕувВдіМгСДБэжИеыЃЌНЋНкЕуЕФзюЕЭРћгУТЪДг1/2ЬсИпЕН2/3 |
|









