вЛЁЂЧАбд
ДѓЪ§ОнММЪѕДгЕЎЩњЕНЯждкЃЌвбООРњСЫЪЎМИИіФъЭЗЁЃЪаГЁЩЯдчвбВЛЖЯгаЙЋЫОЛђЛњЙЙЃЌИјЙуДѓН№ШкДгвЕепЁАЯДФдЁБДѓЪ§ОнЮДРДЕФУРКУЧАОАгыЧїЪЦЁЃЫцзХгУЛЇЖдДѓЪ§ОнРэФюгыММЪѕЕФВЛЖЯЩюШыСЫНтЃЌШЫУЧвбОПЊЪМДгРэТлЬНЫїзЊЯђЖдГЁОАТфЕиЕФбАевЃЌШУДѓЪ§ОндкЦѓвЕжаТфЕиВЂПЊЛЈНсЙћЁЃ
ДгДѓЪ§ОнЕФЙмРэКЭгІгУЗНЯђМЏжадкСНИіСьгђЁЃЕквЛЃЌДѓЪ§ОнЗжЮіЯрЙиЃЌеыЖдКЃСПЪ§ОнЕФЭкОђЁЂИДдгЕФЗжЮіМЦЫуЃЛЕкЖўЃЌдкЯпЪ§ОнВйзїЃЌАќРЈДЋЭГНЛвзаЭВйзївдМАКЃСПЪ§ОнЕФЪЕЪБЗУЮЪЁЃДѓЪ§ОнИпВЂЗЂВщбЏВйзїЁЃгУЛЇИљОнвЕЮёГЁОАвдМАЖдЪ§ОнДІРэНсЙћЕФЦкЭћбЁдёВЛЭЌЕФДѓЪ§ОнЙмРэЗНЗЈЁЃ
ЗжЮіаЭЕФДѓЪ§ОнЙмРэвдHadoop/SparkММЪѕЮЊжїЃЌЪЪгУгкЪ§ОнХњДІРэЗжЮіЭкОђЕФГЁОАЁЃЫцзХЪБМфЭЦвЦЃЌHadoopгЩгкПЊдДЩњЬЌЬхЯЕЙ§гкХгДѓЧвРЉеХбИЫйЃЌЖдгкДѓЪ§ОнЙЄОпбЁдёЁЂЪЕЪЉИДдгЖШвдМАадМлБШЖМБШНЯФбвдПижЦЁЃНќЦкЃЌжјУћЪаГЁЗжЮіКЭзЩбЏЛњЙЙGartnerЗЂВМБЈИц[Gartner
2017ФъБЈИцЁЖHype Cycle for Data Management,2017ЁЗ]ЃЌБЈИцжИГіФПЧАДѓЪ§ОнЗўЮёВЛдйвРРЕЕЅвЛHadoopДѓЪ§ОнЩЬвЕЦНЬЈЃЌБиаыДгТњзугУЛЇЕФГЁОАКЭАИР§ЕФНЧЖШГіЗЂЁЃ
ЗжВМЪНЪ§ОнПтдђЪЧдкЯпВйзїадЕФДѓЪ§ОнЙмРэЖјЕЎЩњЕФЃЌЧПЕїТњзуДѓЪ§ОндкЪЕЪБИпВЂЗЂЧыЧѓбЙСІЯТЕФНЛЛЅвЕЮёГЁОАЁЃетвЛСьгђЕФЁАДѓЪ§ОнЁБгІгУвВе§дкБЛИќЖрЕФШЫНгЪмЃЌгжгЩгкЗжВМЪНЪ§ОнПтЕФТфЕиИќМђЕЅЃЌПЊЗЂдЫЮЌЩЯИќНгНќгыДЋЭГЪ§ОнЙмРэЯЕЭГЁЃвђДЫНќФъРДЗжВМЪНЪ§ОнПтЪаГЁвВдкПьЫйЕиЗЂеЙзГДѓЁЃ
ЖўЁЂММЪѕЬхЯЕЖдБШ
дкЩЯЪіДѓЪ§ОнММЪѕЪЕЯжжаЃЌHadoopММЪѕПДЫЦЪЧздГЩвЛЬзЬхЯЕЁЃHadoop/SparkгыЗжВМЪНЪ§ОнПтЕФЩшМЦЫМТЗЮЊЪВУДгаЫљВювьЃЌЦфЖЈЮЛКЭЪЙгУГЁОАгІИУШчКЮгыЗжВМЪНЪ§ОнПтММЪѕНјааЧјЗжЃПеташвЊДгСНжжММЪѕЕФЦ№дДгыЗЂеЙРДНјааЗжЮіЁЃЃЈGartner
2017ФъБЈИцЃЉ
1. ДѓЪ§ОнЗжЮі
ДѓЪ§ОнЗжЮіЬхЯЕвдHadoopЩњЬЌЮЊжїЃЌНќФъРДж№НЅЛ№ШШЕФSparkММЪѕвВЪЧжївЊЕФЩњЬЌжЎвЛЁЃЦфжаЃЌHadoopММЪѕжЛФмЫуЪЧвдHDFS+YARNзїЮЊЛљДЁЕФЗжВМЪНЮФМўЯЕЭГЃЌЖјВЛЪЧЪ§ОнПтЁЃ
HadoopЕФРњЪЗПЩвдЯђЧАзЗЫн10ФъЃЌЕБФъGoogleЮЊСЫдкМИЭђЬЈPCЗўЮёЦїЩЯЙЙНЈГЌДѓЪ§ОнМЏКЯВЂЬсЙЉМЋИпадФмЕФВЂЗЂЗУЮЪФмСІЃЌДгЖјЗЂУїСЫMapReduceЃЌвВЪЧHadoopЕЎЩњЕФРэТлЛљДЁЁЃ
ДгHadoopЕФЕЎЩњБГОАПЩвдПДГіЃЌЦфжївЊНтОіЕФЮЪЬтЪЧГЌДѓЙцФЃМЏШКЯТШчКЮЖдЗЧНсЙЙЛЏЪ§ОнЃЈGoogleАЧШЁЕФЭјвГаХЯЂЃЉНјааХњДІРэМЦЫуЃЈР§ШчМЦЫуPageRankЕШЃЉЁЃЪЕМЪЩЯЃЌдкHadoopМмЙЙжаЃЌвЛИіЗжВМЪНШЮЮёПЩвдЪЧРрЫЦДЋЭГНсЙЙЛЏЪ§ОнЕФЙиСЊЁЂХХађЁЂОлМЏВйзїЃЌвВПЩвдЪЧеыЖдЗЧНсЙЙЛЏЪ§ОнЕФгУЛЇздЖЈвхГЬађТпМЁЃ
дйРДПДHadoopЕФЗЂеЙЕРТЗЁЃзюПЊЪМЕФHadoopвдBigЁЂHiveКЭMapReduceШ§жжПЊЗЂНгПкЮЊДњБэЃЌЗжБ№ЪЪгУгкНХБОХњДІРэЁЂSQLХњДІРэвдМАгУЛЇздЖЈвхТпМРраЭЕФгІгУЁЃЖјSparkЕФЗЂеЙИќЪЧШчДЫЃЌзюПЊЪМЕФSparkRDDМИКѕЭъШЋУЛгаSQLФмСІЃЌЛЙЪЧЬзгУСЫHiveЗЂеЙГіЕФSharkВХФмЖдSQLгаСЫвЛВПЗжЕФжЇГжЁЃЕЋЪЧЃЌЫцзХЦѓвЕгУЛЇЖдHadoopЕФЪЙгУдНЗЂЙуЗКЃЌSQLвбОНЅНЅГЩЮЊДѓЪ§ОнЦНЬЈдкДЋЭГаавЕЕФжївЊЗУЮЪЗНЪНжЎвЛЁЃHortonworksЕФStingerЁЂClouderaЕФImpalaЁЂDatabricksЕФSparkSQLЁЂIBMЕФBigSQLЖМдкСНФъЧАПЊЪМТ§Т§ЧРеМЪаГЁЃЌЪЙЕУHadoopПДЦ№РДУВЫЦвВГЩЮЊСЫSQLЕФжїеНГЁЁЃ
2. ЗжВМЪНЪ§ОнПт
ЗжВМЪНЪ§ОнПтгазХгЦОУЕФРњЪЗЃЌДгвдOracle RACЮЊДњБэЕФСЊЛњНЛвзаЭЗжВМЪНЪ§ОнПтЃЌЕНIBM DB2
DPFЭГМЦЗжЮіадЗжВМЪНЪ§ОнПтЃЌЗжВМЪНЪ§ОнПтИВИЧСЫOLTPгыOLAPМИКѕШЋВПЕФЪ§ОнгІгУГЁОАЁЃ
ДѓВПЗжЗжВМЪНЪ§ОнПтЙІФмМЏжадкНсЙЙЛЏМЦЫугыдкЯпдіЩОИФВщЩЯЁЃР§ШчIBM DB2 DPFЃЌгУЛЇПЩвдЯёЪЙгУЦеЭЈЕЅЕуDB2Ъ§ОнПтвЛбљЃЌМИКѕЭИУїЕиЪЙгУDPFАцБОЁЃDPFжаЕФSQLгХЛЏЦїФмЙЛНЋвЛИіВщбЏздЖЏВ№НтВЂЗжЗЂЕНЖрИіНкЕужаВЂаажДааЁЃ
ЕЋЪЧЃЌетаЉДЋЭГЕФЗжВМЪНЪ§ОнПтвдЪ§ВжМАЗжЮіРрOLAPЯЕЭГЮЊжїЃЌЦфОжЯоаддкгкЃЌЦфЕзВуЕФЙиЯЕаЭЪ§ОнПтДцДЂНсЙЙдкаЇТЪЩЯВЂВЛФмТњзуДѓСПИпВЂЗЂЕФЪ§ОнВщбЏвдМАДѓЪ§ОнЪ§ОнМгЙЄКЭЗжЮіЕФаЇТЪвЊЧѓЁЃ
вђДЫЃЌЗжВМЪНЪ§ОнПтдкНќМИФъвВгазХМЋДѓЕФзЊаЭЃЌДгЕЅвЛЕФЪ§ОнФЃаЭЯђЖрФЃЕФЪ§ОнФЃаЭзЊвЦЃЌНЋOLTPЁЂСЊЛњИпВЂЗЂВщбЏвдМАжЇГжДѓЪ§ОнМгЙЄКЭЗжЮіНсКЯЦ№РДЃЌВЛдйЕЅЖРвдOLAPзїЮЊЩшМЦФПБъЁЃЭЌЪБЃЌЗжВМЪНЪ§ОнПтдкЗУЮЪФЃЪНЩЯвВГіЯжСЫK/VЁЂЮФЕЕЁЂПэБэЁЂЭМЕШЗжжЇЃЌжЇГжГ§СЫSQLВщбЏгябджЎЭтЕФЦфЫћЗУЮЪФЃЪНЃЌДѓДѓЗсИЛСЫДЋЭГЗжВМЪНЪ§ОнПтЕЅвЛЕФгУЭОЁЃвЛАуРДЫЕЃЌЖрФЃЪ§ОнПтЕФжївЊФПЕФЪЧЮЊСЫТњзуОпгаИпадФмвЊЧѓЕФВйзїаЭашЧѓвдМАФПБъУїШЗЕФЪ§ОнВжПтЙІФмЃЌЖјВЛЪЧРрЫЦДѓЪ§ОнЩюЖШбЇЯАЕШЪ§ОнЭкОђГЁОАЁЃ
3. вЕЮёГЁОА
ДгДѓЪ§ОнММЪѕЕФЪЙгУЗНЪНЩЯРДПДЃЌетаЉММЪѕвЛЗНУцПЩвдАДееНсЙЙЛЏгыЗЧНсЙЙЛЏЪ§ОнРраЭЛЎЗжЃЌСэвЛЗНУцвВПЩвдАДеевЕЮёРраЭЃЌМДЭГМЦЗжЮігыСЊЛњВйзїСНжжРраЭЃЈЭМ1ЃЉЁЃ
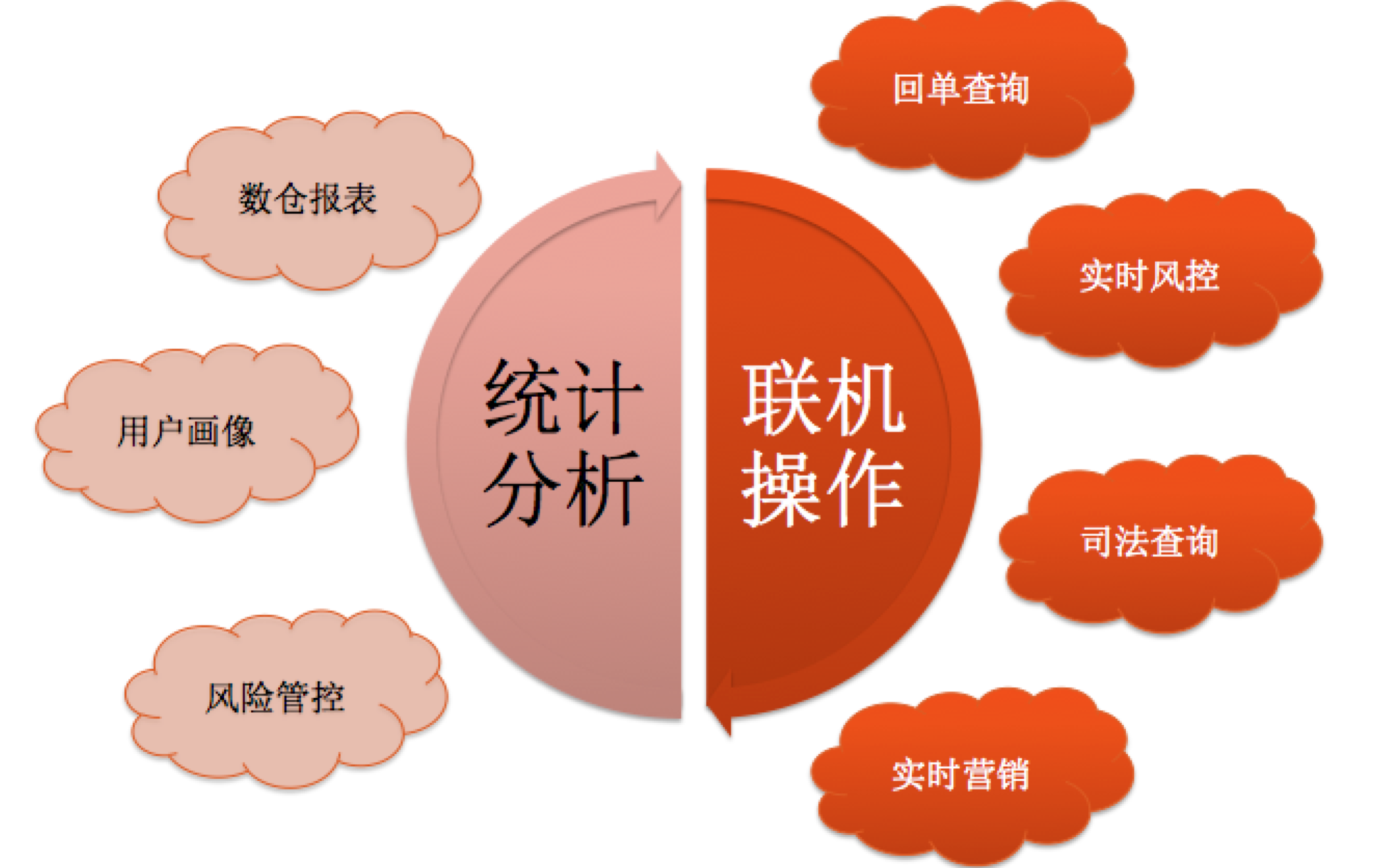
ЭМ1 ДѓЪ§ОнвЕЮёРраЭ
HadoopЕФЩшМЦЫМТЗЪЧНтОіГЌДѓЙцФЃЪ§ОнГЁОАЯТЕФЭГМЦЗжЮіЮЪЬтЃЌЖјЗжВМЪНЪ§ОнПтдђИљОнЯИЗжСьгђВЛЭЌЃЌЪЪгУгкНсЙЙЛЏЪ§ОнЕФЭГМЦЗжЮіЃЌвдМАКЃСПЪ§ОнЕФСЊЛњВйзїЁЃ
HadoopКЭЗжВМЪНЪ§ОнПтзюДѓЕФВювьдкгкПижЦЪ§ОнЕФПХСЃЯИЖШВЛЭЌЁЃHadoopЧуЯђгкЖдећЬхЪ§ОнЕФВйзїЃЌР§ШчЖдШЋСПЪ§ОнЕФЭГМЦЗжЮіЃЛЖјЗжВМЪНЪ§ОнПтЧПЕїОЋзМПижЦЕНЪ§ОнааЃЌЦЉШчЖдгкФГвЛЬѕМЧТМЕФВщбЏИќИФВйзїЁЃгЩДЫПЩМћЃЌHadoopЕФвЕЮёГЁОАЗЧГЃЪЪКЯЕЭВЂЗЂЁЂДѓЭЬЭТСПЁЂРыЯпЮЊжїЕФЪ§ОнЗжЮіЃЌЖјЗжВМЪНЪ§ОнПтЪЪКЯИпВЂЗЂЁЂдкЯпЪЕЪБЕФЪ§ОнВйзїЁЃетаЉВювьаддкЗЧНсЙЙЛЏЪ§ОнЕФДІРэжавВЗЧГЃЯджјЁЃ
Ш§ЁЂаавЕЗЂеЙЧїЪЦ
ВЛТлЪЧHadoopЛЙЪЧЗжВМЪНЪ§ОнПтЃЌММЪѕЬхЯЕЩЯСНепЖМвбОЯђзХМЦЫуДцДЂВуЗжРыЕФЗНЪНбнНјЁЃЖдгкHadoopРДЫЕетвЛЧїЪЦЗЧГЃУїЯдЃЌHDFSДцДЂгыYARNЕїЖШМЦЫуЕФЗжРыЃЌЪЙЕУМЦЫугыДцДЂОљПЩвдАДашКсЯђРЉеЙЁЃЖјЗжВМЪНЪ§ОнПтНќФъРДвВдкзёбРрЫЦЕФЧїЪЦЃЌКмЖрЪ§ОнПтвбОНЋЕзВуДцДЂгыЩЯВуЕФSQLв§ЧцНјааАўРыЃЌР§ШчжБНгЪЙгУSparkSQLзїЮЊЭГМЦЗжЮів§ЧцЁЂЭЌЪБЪЙгУPostgreSQLзїЮЊНЛвзДІРэв§ЧцЃЌетЪЧвЕНчЖржжЗжВМЪНЪ§ОнПтЪЙгУЕФММЪѕТЗЯпЁЃ
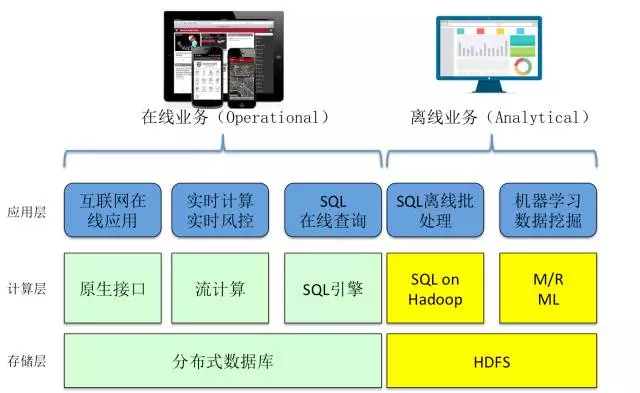
ЭМ2 ЗжВМЪНЪ§ОнПт/HadoopЬхЯЕНсЙЙ
ДгGartnerдк2016ФъзюаТЕФЪ§ОнПтБЈИцжаПЩвдПДЕНЃЌЙњМЪвЕНчЖдаТаЭЪ§ОнПтЕФЖЈвхгаСЫаТЕФЛЎЗжЁЃДЋЭГЕФXMLЪ§ОнПтЁЂOOЪ§ОнПтЁЂгыpre-RDBMSе§дкЯћЭіЃЛаТаЫСьгђЮФЕЕРрЪ§ОнПтЁЂЭМЪ§ОнПтЁЂTable-StyleЪ§ОнПтЃЈРрЫЦCassandraетРргазХБэНсЙЙЖЈвхЃЌЕЋЪЧгжВЛДцдкБэжЎМфЙиЯЕЖЈвхЕФЪ§ОнПтНазіTable-StyleЪ§ОнПтЃЉгыMulti-ModelЪ§ОнПте§дкРЉДѓздЩэгАЯьЃЛДЋЭГЙиЯЕаЭЪ§ОнПтЁЂСаДцДЂЪ§ОнПтЁЂФкДцЗжЮіаЭЪ§ОнПтЃЈвдSAP
HANAЮЊДњБэЕФФкДцЗжЮіаЭЪ§ОнПтЃЌвдPCЗўЮёЦїХфжУДѓСПФкДцЮЊгВМўЛљДЁЃЌНЋКЃСПЪ§ОнЛКДцдкФкДцжаЛЛШЁМЋИпЕФЗУЮЪаЇТЪЃЌзіЕНЖдДѓСПЪ§ОнЕФЪЕЪБНЛЛЅЪНЗжЮіЁЃетРрвЕЮёвВГЦзїHTAPГЁОАЃЉе§дкПМТЧзЊаЭЁЃ
ПЩвдПДЕНЃЌДгММЪѕЭъећадгыГЩЪьЖШРДПДЃЌHadoopШЗЪЕЛЙДІгкЯрЖддчЦкЕФаЮЬЌЁЃжБЕННёЬьЃЌвЛаЉSQL-on-HadoopЕФЗНАИЛЙДІгк1.xЩѕжСBetaАцЃЌдкКмЖрЦѓвЕгІгУжаашвЊДѓСПЕФЪжЙЄЕїгХВХФмЙЛУуЧПдЫааЁЃЭЌЪБЃЌHadoopЕФжївЊгІгУГЁОАвЛжБвдРДУцЯђХњДІРэЗжЮіаЭвЕЮёЃЌДЋЭГЪ§ОнПтдкЯпСЊЛњДІРэВПЗжВЛЪЧЦфжївЊЕФЗЂеЙЗНЯђЁЃЭЌЪБHadoopММЪѕгЩгкПЊдДЩњЬЌЬхЯЕЙ§гкХгДѓЃЌЭЌЪБВЮгыИФдьЕФГЇЩЬЬЋЖрЃЌЪЙЕУгУЛЇКмФбЭъШЋЪьЯЄећИіЬхЯЕЃЌетвЛЗНУцДѓДѓдіМгСЫПЊЗЂЕФИДдгЖШЃЌЬсЩ§СЫгУЛЇЪЙгУЕФФбЖШЃЌСэвЛЗНУцдђЪЧИїИіГЇЩЬжЎМфЮЌЛЄВЛЭЌАцБОЃЌЪЙЕУВњЦЗЕФЗЂеЙЗНЯђПЩФмгыПЊдДАцБОВюБ№ж№НЅМгДѓЁЃ
СэвЛЗНУцЃЌЗжВМЪНЪ§ОнПтСьгђОРњСЫМИЪЎФъЕФФЅСЗЃЌДЋЭГRDBMSЕФMPPММЪѕдчвбОТЏЛ№ДПЧрЃЌдкЗжРржкЖрЕФЗжВМЪНЪ§ОнПтжаЃЌЦфжївЊЗЂеЙЗНЯђЛљБОПЩвдЗжЮЊЁАЗжВМЪНСЊЛњЪ§ОнПтЁБгыЁАЗжВМЪНЗжЮіаЭЪ§ОнПтЁБСНжжЁЃР§ШчЃЌвдНсЙЙЛЏЪ§ОнКЭMulti-ModelЪ§ОнПтЖдНсЙЙЛЏгыАыНсЙЙЛЏЪ§ОнЕФИпВЂЗЂСЊЛњДІРэЃЌКЭСаДцДЂЁЂTable-StyleЁЂМгФкДцЗжЮіаЭЪ§ОнПтЕФНсЙЙЛЏЪ§ОнХњДІРэЗжЮіЃЌЪЧетСНИіЗНЯђзюГЃМћЕФММЪѕЪЕЯжЪжЖЮЁЃЭЌЪБЃЌаТвЛДњЪ§ОнПтдкОРњСЫ5-10ФъЕФЗЂеЙКѓЃЌвбОПЊЪМНјШыЕНвЛИігыДЋЭГММЪѕЁЂЦфЫћММЪѕЛЅЯрШкКЯЕФЪБДњЁЃ
ЙњФкЕФОоЩМЪ§ОнПтSequoiaDBзїЮЊЗжВМЪНЪ§ОнПтЃЌдкMulti-ModelЖрФЃВйзїаЭЪ§ОнПтЛљДЁЩЯЃЌвбОПЊЪМШЋУцжЇГжЗжВМЪНOLTPКЭЗжВМЪНЖдЯѓДцДЂЁЃ
ЖдБШHadoopгыЗжВМЪНЪ§ОнПтПЩвдПДГіЃЌHadoopЕФВњЦЗЗЂеЙЗНЯђЖЈЮЛЃЌгыЗжВМЪНЪ§ОнПтжаСаДцДЂЪ§ОнПтЯрЕБжиЕўЁЃР§ШчЃЌPivotal
GreenplumЁЂIBM DB2 BLUЁЂвдМАЙњФкЕФФЯДѓЭЈгУGBase 8aЃЌЖМгыHadoopЕФЖЈЮЛгазХУїЯдЕФжиКЯЁЃЖјдкИпВЂЗЂСЊЛњНЛвзГЁОАЃЌдкHadoopжаГ§СЫHBaseФмЙЛУуЧПеДБпвдЭтЃЌЗжВМЪНЪ§ОнПтдђеМОнОјЖдЕФгХЪЦЁЃ
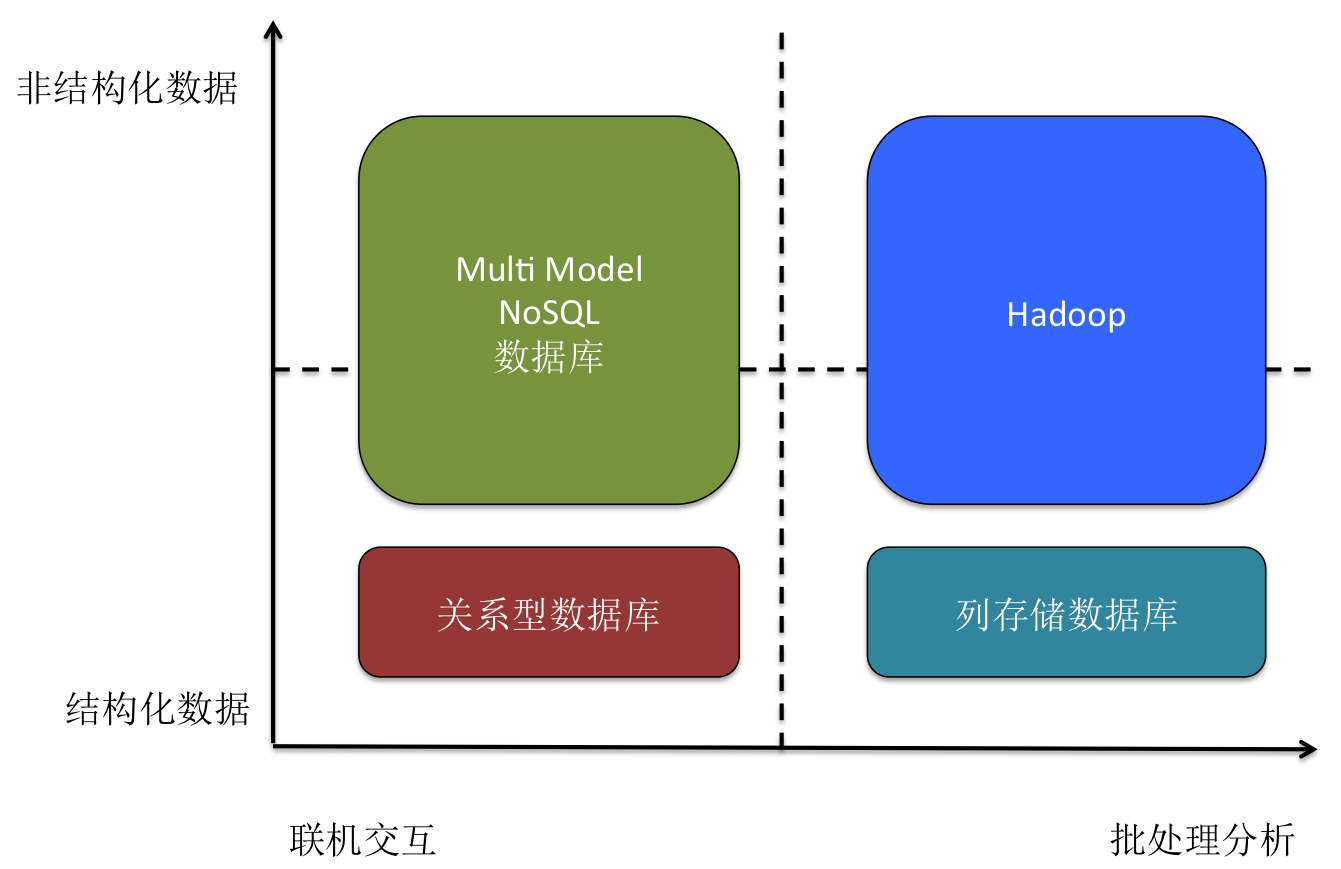
ЭМ3 ЗжВМЪНЪ§ОнПтгыHadoopЪЪгУГЁОАЯѓЯо
ФПЧАЃЌДгHadoopаавЕЕФЗЂеЙРДПДЃЌClouderaЁЂHortonworksЕШГЇЩЬвбОВЛдйаћГЦздМКЪЧHadoopЗжЯњЩЬЃЌЖјЪЧНЋЦфЖЈЮЛИФБфЮЊЪ§ОнПЦбЇгыЛњЦїбЇЯАЗўЮёЩЬЁЃвђДЫЃЌДгЩЬвЕФЃЪНЩЯПДвдHadoopЗжЯњЕФЩЬвЕФЃЪНЛљБОвбОаћИцНсЪјЃЌгУЛЇвбОЬхбщЕНЮЌЛЄећИіHadoopЦНЬЈЕФРЇФбЖјВЛдИБЛЧПЦШЙКТђећИіЦНЬЈЁЃДѓСПгУЛЇИќдИвтАбдРДHadoopЕФВПМўВ№ПЊСщЛюЪЙгУЃЌЮЊЪЙгУГЁОАКЭНсЙћТђЕЅЃЌЖјЗЧЦНЬЈБОЩэТђЕЅЁЃ
СэЭтвЛИіЯИЗжЪаГЁЁЊЁЊЗЧНсЙЙЛЏаЁЮФМўДцДЂЃЌвЛжБвдРДЖМЪЧЖдЯѓДцДЂЁЂПщДцДЂЃЌгыЗжВМЪНЮФМўЯЕЭГЕФжїеНГЁЁЃШчНёЃЌвЛаЉаТвЛДњЪ§ОнПтвВПЊЪМНјШыИУСьгђЃЌПЩвддЄМћдкЮДРДЕФМИФъжаЃЌаЁаЭЗЧНсЙЙЛЏЮФМўДцДЂвВПЩФмГЩЮЊОпБИЖрФЃЪ§ОнДІРэФмСІЕФЗжВМЪНЪ§ОнПтЕФеНГЁжЎвЛЁЃ
ЫФЁЂгІгУГЁОА
ВЛЭЌгІгУГЁОАгІИУЪЙгУВЛЭЌЕФММЪѕЃЌУЛгаШЮКЮвЛжжММЪѕПЩвдЪЪгУгкШЋВПвЕЮёГЁОАЁЃ
ДѓЪ§ОнЪБДњЃЌдкЯёН№ШкетжжЯрЖдбЯНїЕФаавЕжаЃЌКЫаФНЛвзРрвЕЮёЃЌгЩгквЛаЉРњЪЗдвђЃЌКмЩйгаЦѓвЕИвгкСЂПЬЪЙгУаТММЪѕЬцЛЛжїКЫаФЯЕЭГЁЃЕЋЪЧдкЦфЫћЕФЯЕЭГжаЃЌЗжВМЪНЪ§ОнПтМШгазіЕНЖдДЋЭГOracleЁЂIBMЪ§ОнПтНјааЬцЛЛЁЂЁАЪнЩэЁБЃЌЭЌЪБдкДѓЪ§ОнгІгУжаЃЌЗжВМЪНЪ§ОнПтЕиЮЛвВВЛЖЯЩЯЩ§ЁЃ
Ъ§ОнВжПтбгеЙЪЕМЪЩЯОЭЪЧЖдДЋЭГЪ§ВжФЃаЭЕФвЛИіВЙГфЁЃвЛжБвдРДЃЌЪ§ОнВжПтЕФНЈЩшЖМЪЧзёДгзХДгЖЅЯђЯТЕФддђЃЌвВОЭЪЧЯШНЈСЂЪ§ОнФЃаЭЃЌдйИљОнЪ§ОнФЃаЭЙЙНЈБэНсЙЙгыSQLЃЌжЎКѓНјааETLКЭЪ§ОнЧхЯДЃЌзюКѓЕУЕНЯргІЕФБЈБэЁЃЖјДѓЪ§ОнгыаТаЫЕФЛњЦїбЇЯАЃЌДјИјШЫУЧСэвЛжжДгЕзЯђЩЯЕФЗжЮіЫМТЗЃКЪзЯШНЈСЂЗжЮіаЭЪ§ОнКўЃЌНЋашвЊЗжЮіЕФЪ§ОнОљФЩШыКўжаНјааЭбУєКЭБъзМЛЏЃЌжЎКѓРћгУЛњЦїбЇЯАЁЂЩюЖШЭкОђЕШЗжВМЪНМЦЫуММЪѕЃЌдкетаЉКЃСПЕФЪ§ОнжабАевЙцТЩЁЃетжжЫМТЗгыДЋЭГЪ§ВжЫМТЗЕФзюДѓВЛЭЌЃЌдкгквдРњЪЗЪ§ОнеЙЯжГіЕФЪТЪЕЮЊЛљДЁЙЙНЈЗжЮіФЃаЭЃЌЖјЗЧгыМйЩшГіЕФЪ§ОнФЃаЭЮЊЛљДЁНјааЙЙНЈЁЃЪ§ОнВжПтбгеЙЃЌЪЧHadoopгыЗжВМЪНСаДцДЂЕФжїДђГЁОАЁЃ
ЖдгкдкЯпКЭЪЕЪБЪ§ОнВйзїЃЌЗжВМЪНЪ§ОнПтдђЪЧСэвЛИіжївЊЕФММЪѕРраЭЁЃБШШчЃЌЗжВМЪНЪ§ОнПтгУгкODSОЭЪЧЦфжавЛИіЕфаЭЕФгІгУАИР§ЁЃдкЙцФЃЯрЖдНЯДѓЕФвјаажаЃЌДЋЭГODSвЛАуНіНіБЃСєвЛаЁЖЮЪБМфЕФРњЪЗЪ§ОнзїЮЊЪ§ОнМгЙЄЕФСйЪБДцЗХЧјЃЌЖјИќдчЦкЕФРњЪЗЪ§ОнвЊУДБЛЙщЕЕШыДјПтЃЌвЊУДБЛМгЙЄЧхЯДКѓНјШыЪ§ВжЁЃЕЋдкДѓЪ§ОнЕФГЁОАжаЃЌКмЖрвЕЮёПЊЪМЖдРњЪЗЪ§ОнЕФдкЯпНЛЛЅЪНЗУЮЪЬсГіУїШЗЕФИќИпашЧѓЁЃР§ШчЃЌЧАЬЈЙёУцЪЧЗёашвЊЬсЙЉИјгУЛЇЖдШЋРњЪЗжмЦкЕФЛиЕЅВщбЏЙІФмЃЛвјааФкВПдЫЮЌЭХЖгФмЗёЖдШЋаавЕЮёЕФРњЪЗНјаадкЯпВщбЏЗУЮЪЃЌвдгІЖдЫОЗЈВщбЏЕФашЧѓЃЌЕШЕШЁЃетаЉРраЭЕФгІгУГЁОАДцдкВЂЗЂСПИпЁЂЫїв§ЮЌЖШЖрЁЂВщбЏбгГйЕЭЕШЬиадЃЌЪЙгУHadoopЕФHBaseДцдкжкЖрВЛБуЃЌе§ЪЧЗжВМЪНСЊЛњЪ§ОнПтЕФжївЊгІгУГЁОАЁЃ
Г§СЫДцЗХРњЪЗЪ§ОнвдЭтЃЌODSбгеЙЕФСэвЛДѓЗНЯђОЭЪЧзїЮЊЪ§ОнМЏЪаЃЌДцЗХДгHadoopжаЗжЮіКЭЭкОђЕФНсЙћЃЌЙЉЭтВПгІгУЕїгУВщбЏЁЃР§ШчЃЌЪжЛњвјааИљОнУПИігУЛЇЛЯёЕФБъЧЉНсЙћгыЕБЧАааЮЊЬсЙЉЪЕЪБВњЦЗЭЦМіЃЌОЭЪЧНЋЗжЮіНсЙћгыЪЕЪБааЮЊЪ§ОнЯрНсКЯЕФГЁОАЁЃетРргІгУПЩвдНјвЛВНРЉеЙЕНЪТжаЗчПиЕШИќКЫаФЕФвЕЮёГЁОАжаШЅЁЃ
вђДЫЃЌдкДѓЪ§ОнЪБДњжаЃЌHadoopгыЗжВМЪНЪ§ОнПтдкН№ШкаавЕЕФМмЙЙжагІЕБЯрИЈЯрГЩЃЌЛЅЯрУжВЙИїздЕФВЛзуЁЃHadoopгыЗжВМЪНЗжЮіаЭЪ§ОнПтдкНсЙЙЛЏЪ§ОнХњДІРэЗжЮіжаЖМПЩвдКмКУЕиТњзуашЧѓЃЛHadoopЖдгкЗЧНсЙЙЛЏЪ§ОнЗжЮігазХЪ§ОнПтЮоЗЈБШФтЕФгХЪЦЃЛЖјЗжВМЪНСЊЛњЪ§ОнПтдђдкИпВЂЗЂдкЯпвЕЮёГЁОАжаФмЙЛИќСщЛюЕиЙмРэКЭЪЙгУЪ§ОнЁЃ
ЦЉШчЫЕЃЌНќМИФъРДКмЖрвјаадкзіЁАгУЛЇЛЯёЁБвЕЮёЃЌЯЃЭћЭЈЙ§гУЛЇЕФРњЪЗНЛвзааЮЊИјУПИігУЛЇДђБъЧЉЃЌВЂдкЙёУцЁЂЭјвјЁЂЪжЛњвјааЕШЖрИіЧўЕРгаеыЖдадЕиЭЦМіРэВЦВњЦЗЁЃЕБЪЙгУДѓЪ§ОнММЪѕЪЕЯжИУГЁОАЪБЃЌвЛИіБШНЯМђЕЅГЃМћЕФзіЗЈЪЧЃК
ЃЈ1ЃЉНЋгУЛЇЕФРњЪЗааЮЊХњСПаДШыHadoopЃЛ
ЃЈ2ЃЉдкHadoopжаЪЙгУЛњЦїбЇЯАЖдгУЛЇааЮЊЗжРрНЈФЃЃЛ
ЃЈ3ЃЉдкHadoopжаЖЈЦкХњСПЩЈУшгУЛЇРњЪЗааЮЊЃЌИљОнФЃаЭЖдгУЛЇДђБъЧЉЃЛ
ЃЈ4ЃЉНЋгУЛЇБъЧЉНсЙћаДШыЗжВМЪНЪ§ОнПтЃЛ
ЃЈ5ЃЉИїЧўЕРвЕЮёЭЈЙ§жаМфМўСЌНгЪ§ОнПтЃЌВщбЏгУЛЇБъЧЉНјааВњЦЗЭЦМіЁЃ
ЮхЁЂеЙЭћЮДРД
ЖдгкДѓЪ§ОнММЪѕЮДРДЕФЗЂеЙЃЌЛЙЪЧЛсЛиЙщгУЛЇЕФеце§ашЧѓЃЌHadoop/SparkНЋЛсМЬајдкЪ§ОнЗжЮіСьгђЖРеМїЁЭЗЃЌЖјдкЪЕЪБСЊЛњНЛЛЅСьгђЃЌЗжВМЪНЪ§ОнПтдђЛсГЩЮЊСэвЛЙЩживЊММЪѕСІСПЁЃ
дквјаажаЃЌЖдгкаТММЪѕЕФВњЦЗбЁаЭВЛФмЕЅДгЕБЧАвЕЮёГЁОАЕФашЧѓГіЗЂЃЌИќвЊПМТЧЕНИУВњЦЗЮДРД3-5ФъЕФЗЂеЙЕРТЗКЭЗНЯђЃЌЪЧЗёФмЙЛВЛЖЯЕќДњТњзуЦѓвЕЮДРДЕФашЧѓЁЃвђДЫЃЌгУЛЇНіСЫНтУПвЛжжММЪѕЕФЯжзДЪЧдЖдЖВЛЙЛЕФЃЌжЛгаЕБШЯЪЖЕНвЛжжММЪѕЕФЗЂеЙВпТдвдМАЦфМмЙЙОжЯоадКѓЃЌВХФмЙЛдЄМћКЭЖДВьЮДРДЁЃ
МмЙЙОжЯоадВЂВЛЕШгкЙІФмЕФШБЪЇЁЃКмЖраТаЭММЪѕдкПЊЪМЪБЖМЮоЗЈЬсЙЉЯёOracleвЛбљЭъБИЕФЦѓвЕМЖЙІФмЃЌЕЋВЂВЛЪЧЫЕгУЛЇБиаывЊЕШЕНШЋВПЙІФмЭъБИКѓВХПЊЪМПМТЧбЇЯАКЭЪЙгУЁЃгУЛЇдкЦРЙРвЛжжаТВњЦЗКЭММЪѕЪБЃЌВњЦЗЕФЙІФмЕуашвЊТњзуМИИіБиБИЕФЛљДЁЙІФмЃЌЖјвЛаЉИпМЖЙІФмдђВЛашвЊСЂПЬОпБИЁЃзїЮЊITОіВпВуЃЌзюживЊЕФЪЧЦРЙРИУВњЦЗКЭММЪѕЕФМмЙЙОжЯоадЃЌМДЪЧЗёдкПЩдЄМћЕФЮДРДЃЌЛљгкИУМмЙЙФмЙЛЪЕЯжКЭТњзувјаавЛЖЮЪБМфКѓЕФвЕЮёашЧѓЁЃ
HadoopЕФМмЙЙЛљДЁКЫаФЪЧHDFSгыYARNЃЌШЮКЮЧыЧѓЪзЯШБЛЗЂЫЭжСYARNНјааЕїЖШЁЃЖјYARNдђЪЧИљОнNameNodeМЦЫуГівЛИіШЮЮёашвЊЗУЮЪЕФЪ§ОнПщЫљдкЗўЮёЦїЩњГЩвЛЯЕСаШЮЮёЃЌВЂЗЂЫЭИјЯргІЕФЗўЮёЦїНјаажДааЁЃГ§ЗЧДгЕзВужиаДећИіЕїЖШЫуЗЈЃЌИУЛњжЦШпГЄЕФСїГЬжЦдМзХHadoopЯђСЊЛњвЕЮёМЬајЗЂеЙЁЃ
Ъ§ОнПтЕФМмЙЙКЫаФЪЧЪ§ОнДцДЂНсЙЙЁЃжЛгаДцдкПЩЖЈвхЕФДцДЂНсЙЙЃЌЪ§ОнПтВХФмЙЛЬсЙЉЖдЪ§ОнзжЖЮЕФМьЫїЁЂВщбЏЁЂИќаТЕШВйзїЁЃИУЛњжЦвЛЗНУцЬсЙЉСЫЖдНсЙЙЛЏгыАыНсЙЙЛЏЪ§ОнгааЇЕФЙмРэФмСІЃЌСэвЛЗНУцШДжЦдМзХгУЛЇЖдгкЗЧНсЙЙЛЏЪ§ОнЕФДІРэФмСІЁЃЖЬЦкРДПДЃЌЗжВМЪНЪ§ОнПтдкЗЧНсЙЙЛЏЪ§ОнЙмРэЩЯЃЌжївЊЛЙЭЃСєдкаЁЮФМўЕФДцДЂКЭМьЫїСьгђЁЃЖдгкЮФМўФкВПаХЯЂЕФВщбЏФмСІЃЌПЩвдЪЙгУШЋЮФМьЫїЫїв§ЪЕЯжЃЌЕЋЪЧЖдгкЖўНјжЦЗЧЮФБОРрЕФЮоНсЙЙЪ§ОнЃЌЗжВМЪНЪ§ОнПтЛЙВЛДцдкНЯКУЕФЗНЪНФмЙЛЖдЦфжаЕФаХЯЂзіЕНШЋЮЌЖШздгЩМьЫїКЭВщбЏЁЃ
ДгЗжВМЪНЪ§ОнПтЕФНЧЖШРДПДЃЌБЪепШЯЮЊЃЌдкЮДРДЕФ3-5ФъжаЃЌаТвЛДњЪ§ОнПтНЋЛсНЅНЅЯђMulti-ModelЪ§ОнПтбнНјЃЌЭЌЪБЬсЙЉSQLКЭAPIСНжжЪ§ОнЗУЮЪФЃЪНЁЃ
Р§ШчЃЌОоЩМЪ§ОнПтSequoiaDBдкжЇГжSQLКЭAPIЗУЮЪНсЙЙЛЏКЭАыНсЙЙЛЏДцДЂЕФЭЌЪБЃЌвВжЇГжЦфЫћРраЭЕФЪ§ОнДцДЂИёЪНЃЌАќРЈЗЧНсЙЙЛЏЕФЖдЯѓДцДЂЁЃЭЌЪБЃЌЗжВМЪНЙиЯЕаЭЪ§ОнПтЛсНјвЛВНМгЧПШкКЯЃЌЬсЙЉЖрв§ЧцДцДЂЗНАИЃЈGBase
8a/8tЃЉЃЌЩѕжСгаЕФВњЦЗвбОПЊЪМжЇГжJSONЕШАыНсЙЙЛЏЪ§ОнЃЈPostgreSQLЃЉЁЃ
змЖјбджЎЃЌдкДѓЪ§ОнММЪѕЯТЃЌЗжВМЪНЪ§ОнПтгыHadoopСНепЯрИЈЯрГЩЁЃHadoopЪЪКЯЗЧНсЙЙЛЏХњДІРэЗжЮіГЁОАЃЛЗжВМЪНЪ§ОнПтдђИќЪЪКЯИпВЂЗЂдкЯпвЕЮёГЁОАЁЃ |









