| вЛЁЂвЕЮёБГОА
ЬсЕНМЦЫуДцДЂЗжРыЃЌБиаывЊЬсЕНЁАдЦЁБЃЌвђЮЊМЦЫуДцДЂЗжРыЪЧЁАдЦЁБДцдкЕФФЃЪНКЭаЮЬЌжЎвЛЃЌвВЪЧзюгаГЩБОгХЪЦЕФЗНЪНжЎвЛЁЃ
ЁАдЦЁБЪБДњвбОеце§РДСйЃЌЫќдкВЛЖЯЕФЮЊПЭЛЇДДдьМлжЕЃЌвђДЫЫќЪЧвЛжжаТЕФЩЬвЕФЃЪНЁЃСэЭтЃЌЁАдЦЁБвВЪЧвЛжжЗўЮёЃЌЪЧвЛжжITЗўЮёЃЌШчДѓМвГЃМћIaaSЃЌPaaSЃЌSaaSЕШЁЃ
ДгАВШЋНЧЖШРДНВЃЌгжПЩвдЗжЮЊЁАЙЋгадЦЁБКЭЁАЫНгадЦЁБЁЃСэЭтЃЌЫќЦфЪЕвВЪЧДѓМвЫљЬсГЋЕФЁАЙВЯэОМУЁБКЭЁАЙцФЃОМУЁАЕФвЛжжЁЃ
1.1 дЦМЦЫу
ФЧУДЁАдЦЁБЕЙЕзЪЧЪВУДЃЌЛђепЫЕгЩФФаЉММЪѕЫљЙЙГЩФиЃПвЊЛиД№етИіЮЪЬтЃЌЪзЯШЮвУЧРДПДЁАдЦЁБММЪѕЕФЗжВуМмЙЙЃЌвЛАуПЩвдДѓжТЗжЮЊвдЯТШ§ВуЃК
ЕквЛВуЪЧЛљДЁЩшЪЉВуЃЌШчIDCЛњЗПЃЌЗўЮёЦївдМАЭјТчЁЃЦфжаЃЌЁАШэМўЖЈвхЭјТчЁБЗЂЩњдкетвЛВужаЃЌащФтЭјТчЩцМАЕНЗЧГЃЖрЕФММЪѕЃЌШчащФтЭјПЈЛђепswitchЃЌoverlayЃЌvxlanЕШЁЃIaaSЃЈInfrastructure
As a Service: ЛљДЁЩшЪЉЗўЮёЃЉвЛАуОЭЪЧжИНЋетвЛВуЕФФмСІНјааащФтЛЏЃЌЬсЙЉЁАдЦЁБЗўЮёЁЃвЛАуЁАЙЋгадЦЁБПЭЛЇАДЪБМфНјаазтгУЁЃ
ЕкЖўВуЪЧДцДЂВуЃЌНЋЫљгаЖРСЂЕФДцДЂЗўЮёЦїНјааМЏжаЪНЭГвЛЙмРэЁЃЖјЖдЭГвЛДцДЂРДНВЃЌвЛАуОЭЪЧДѓМвЫљЪьжЊЕФЗжВМЪНДцДЂСЫЃЌШчПЊдДЩчЧјЕФCephЃЌGoogleЕФGFSЃЌHadoopЩњЬЌЕФHDFSЕШЁЃвЕНчЫљЮНЕФЁАШэМўЖЈвхДцДЂЁБЃЌОЭЪЧжИетвЛВуЁЃ
ЕкШ§ВуЪЧМЦЫуВуЃЌМЦЫуВуЩцМАЕНЕФУцЪЧзюЙуЕФЁЃШчжаМфМўЃЌгІгУЃЌДѓЪ§ОнМЦЫу(MaxCompute)ЃЌвдМАМЦЫуДцДЂЗжРыКѓЕФЪ§ОнПтЕШЁЃ
етУДЗжВуКѓЃЌДјРДЕФКУДІОЭЪЧУПвЛВуПЩвдАДИїздЕФФмСІНјааМЋЯоРЉеЙЃЌащФтЛЏКѓЃЌАДзтЛЇИєРыЃЌЬсЙЉИпаЇТЪЕФЕЏадвдМАГЩБОЫѕМѕЕШЁЃШчAmazonЃЌGoogleЃЌAzureвдМААЂРядЦЕШЁЃ
ЖдгкетжжЁАдЦЁБММЪѕМмЙЙЗжВуЕФМлжЕЃЌДгITЕФНЧЖШРДНВжСЩйПЩвдгавдЯТСНДѓгХЪЦЃК
НкдМВЦЮёГЩБО
бЇЙ§ITIL V3ЕФЭЌбЇжЊЕРЃЌДгЙЋЫОЛђепЦѓвЕМмЙЙРДНВЃЌЛЅСЊЭјЙЋЫОЪзЯШБиаыНтОіITЗўЮёеНТдЮЪЬтЃЌЖјЗўЮёеНТджазюЮЊКЫаФжЎвЛОЭЪЧВЦЮёГЩБОПижЦЁЃ
ЕБвЛИіЦѓвЕЗЂеЙЕНвЛЖЈЙцФЃКѓЃЌЮЊITИЖГіЕФГЩБОБиаыгЩДжЗХаЭзЊЕНМЏдМаЭФЃЪНЁЃЗёдђЃЌвЛИіЙЋЫОЕФгЏРћНЋБЛОоЖюЕФITГЩБОЫљЭЬЪЩЁЃЫљвдвЛИіДѓЙЋЫОЕФITЗўЮёздЩэОЭПЩвдаЮГЩЫНгадЦЗжВуМмЙЙЁЃ
ЗжВуКѓЃЌЬсИпIDCзЪдДЃЌЭјТчЃЌДцДЂЕФЪЙгУТЪЃЌДгЖјНкЪЁГЩБОЁЃСэЭтЃЌвВЬсИпСЫITЗўЮёЕФСщЛюадКЭаЇТЪЁЃЕБдквЕЮёЦНЗхНзЖЮЪБЃЌвдзюаЁITЭЖШыГЩБОдЫааЃЛЕБгаМЦЛЎЕФвЕЮёЛюЖЏЪБЃЌШчЁАЕчЩЬДѓДйЁБЕШЃЌдђПЩвдЖдзЪдДНјааЕЏадЃЈРыЯпзЪдДЕШЃЉЃЌДгЖјНкЪЁГЩБОЁЃ
ЪЙФмITЗўЮё
КмЖрЦѓвЕЃЌгШЦфЪЧЗЧЛЅСЊЭјЙЋЫОЃЌКмЩйОпБИДѓЖјШЋЕФЫљгаITЗўЮёЃЌвђДЫЃЌПЩвдНшдЦЕФЗўЮёЃЌРДЮЊвЕЮёЬсЙЉПЩФмЃЌРЉеЙвЕЮёЕФБпНчЁЃ
ШчSaaSЗўЮёЛђепPaaSЗўЮёЃЌПЭЛЇПЩвдЭЈЙ§зтгУетаЉЗўЮёЃЌДгЖјОпБИСЫФГаЉITЗўЮёЕФФмСІЁЃШчGPSЗўЮёЃЌДѓЪ§ОнЗўЮёЃЌШЫЙЄжЧФмЕШЁЃ
1.2 МЦЫуДцДЂЗжРы
ДгЩЯУцЗжЮіПЩжЊЃЌМЦЫуКЭДцДЂЗжРыЪЧвЛжжаТЕФММЪѕМмЙЙЧїЪЦЃЌгШЦфдкITЙцФЃЗЂеЙЕНвЛЖЈГЬЖШКѓЁЃИїВузіЕНМЋжТЃЌДгЖјЪЕЯжЙцФЃКЭЙВЯэОМУЃЌвдИќЩйЕФВЦЮёГЩБОЪЕЯжвЕЮёЗўЮёЁЃетвВЪЧетРяНшЪБЯТСїааЕФЁАдЦЁБЕФММЪѕЗжВуМмЙЙЃЌв§ГіМЦЫуДцДЂЗжРыЕФМлжЕЁЃ
ЛиЕНе§ЬтЃЌМЦЫуДцДЂЗжРыНіЪЧвЛжжММЪѕМмЙЙЪжЖЮЃЌЕЋЪЧдкТѕЯђетИіЗжВуЕФЬхЯЕжЎЧАЃЌИїИівЕЮёЖМашвЊзіДѓСПЪЪКЯздМКвЕЮёЬиадЕФгХЛЏЁЃдкЮвУЧЪ§ОнПтСьгђЃЌгШЦфШчДЫЃЌЖјЧввЊЧѓИќМгПСПЬЃЌФбЖШИќДѓЁЃ
дкЪ§ОнПтЪЕЯжМЦЫуДцДЂЗжРыЪБЃЌЮвУЧдкИїВузіСЫжюЖрЕФгХЛЏЃЌЪЙЕУЪ§ОнПтЕФМЦЫуДцДЂЗжРыГЩЮЊПЩФмЃЌЮвУЧашвЊШэгВМўНсКЯгХЛЏЃЌашвЊЪ§ОнПтЭЬЭТгХЛЏЃЌашвЊЭГвЛДцДЂЕїЖШЕШЁЃ
ЯТУцНЋвЛвЛеЙПЊЃЌЕЋВЛзіММЪѕЯИНкВћЪіЃЌгааЫШЄЕФЭЌбЇЃЌЛЖгДѓМвЯпЯТКЭЮвНЛСїВЂАяУІжИе§ЁЃ
ЖўЁЂЗжВМЪНДцДЂгХЛЏ
дкПЊЪМНВЗжВМЪНДцДЂЧАЃЌЯШНтЪЭМИИіживЊЕФИХФюЃК
ЗўЮёПЩгУад
ЪЧжИФмЬсЙЉСЌајЗўЮёЕФФмСІЃЌP=ЃЈЗўЮёзмЪБМф - ЙЪеЯЪБМфЃЉ/ ЗўЮёзмЪБМф * 100ЁЃвЛАувдЖрЩйИіЁА9ЁБРДБэЪОЁЃШчДцДЂЗўЮёЬсЙЉ8ИіЁА9ЁБЕФИпПЩгУадЁЃ
ЗўЮёПЩППад
ЪЧжИСНДЮЙЪеЯМфЕФЪБМфЃЌT=ЙЪеЯзмЪБМф/ЙЪеЯДЮЪ§ЁЃ
ЗўЮёПЩЛжИДад
вЛАувдRPOЃЈRecovery Point ObjectЃЉКЭRTO(Recovery Time Object)СНИіжИБъРДБэЪОЁЃ
ЁАRPOЁАЪЧжИЗўЮёЛђепЪ§ОнФмЛжИДЕНвЕЮёЗЂЩњЙЪеЯЪБМфЕуЕФОрРыЁЃRPOдНаЁдНКУЃЌШчЙћЁБRPOЁАЮЊЁБ0ЁАЃЌОЭЪЧЮоЫ№ЛжИДЁЃШчЙћгаЫ№ЃЌОЭЪЧЛљгкЪБМфЕуЕФЛжИДЃЈPITRЃК
Point In Time RecoveryЃЉЁЃ
ЁАRTOЁБЪЧжИвЕЮёЛжИДе§ГЃЪБЃЌЗўЮёЛђепЪ§ОнЛжИДЫљЛЈЕФЪБМфЁЃвЛАугаЯрЙиЕФSLAжИБъЃЌШчЁА5ЁБЗжжгЛжИДЃЌЁАУыЁБМЖЛжИДЕШЁЃ
вЛАуДѓМвНЋЁАПЩгУадЁБКЭЁАПЩППадЁБИуЛьЯ§СЫЃЌЦфЪЕЪЧЭъШЋВЛЭЌЕФСНИіИХФюЁЃ
БШШчЫЕЃЌвЛИігІгУвЛУыФкгаЁА1ЁБКСУыГіЯжвЛДЮЗўЮёЙЪеЯЁЃФЧУДетИігІгУЕФИпПЩгУадЮЊ6ИіЁБ9ЁАЃЌЕЋЪЧЪЕМЪЩЯЗўЮёПЩППадЪЧЗЧГЃВюЕФЃЌУПУыЖМЗЂЩњЙЪеЯСЫЁЃ
СэЭтЃЌШчЙћвЛИігІгУвЛФъжаЃЌга1аЁЪБЗЂЩњЙЪеЯЃЌЦфЫќЪБМфЖМе§ГЃЃЌФЧУДИпПЩгУадБШНЯЕЭЃЌдМЮЊ4ИіЁА9ЁАЃЌБШНЯВюЃЛЖјПЩППадБШНЯКУЃЌжЛЗЂЩњвЛДЮЁЃ
2.1 діСПКЭвьВНЛжИД
дРДЃЌЮвУЧЕЅвЛЕФЗўЮёЦїЃЌЦфДХХЬЙЪеЯТЪЭљЭљЖМБШНЯЕЭЃЌMTTFЃЈMean Time To FailureЃЉвЛАуЮЊ100wаЁЪБЁЃШЛЖјЃЌЕБДѓЙцФЃЕФДХХЬЛђепSSDЃЈЭЈГЃ1000ЃЉзщКЯдквЛЦ№ЗХШыЕНЭГвЛЗжВМЪНДцДЂМЏШКжажЎКѓЃЌЦфЙЪеЯТЪНЋУїЯдБфДѓЁЃ
ЮвУЧПЩвдМђЕЅзівЛИіМЦЫуЃЌвЛИіДХХЬдквЛИіаЁЪБФкЕФПЩгУТЪЮЊЃК1/1,000,000ЃЌ99.9999%ЃЌ6ИіЁА9ЁАЁЃЖјЕБвЛИіМЏШКДХХЬДяЕН1000ИіЙцФЃЃЌУПвЛИіаЁЪБЗЂЩњДХХЬЙЪеЯЕФИХТЪЮЊ0.01
%ЁЃвЛЬь24ИіаЁЪБЃЌФЧУДУПЬьНЋга 14.4ЗжжгЪЧгаПЩФмдкетИіМЏШКжаЗЂЩњДХХЬЙЪеЯЁЃетвбОЪЧЗЧГЃДѓЕФвЛИіЪ§зжЁЃдквЛИіДѓМЏШКжаЃЌАДетбљзгЕФИХТЪЃЌМИКѕУПЬьЖМгаПЩФмЛсгаДХХЬfaultЗЂЩњЁЃетЪЧвЛИіВЛПЩБмУтЖјгжЪБГЃЗЂЩњЕФЪТМўЁЃ
дкЗжВМЪНЯЕЭГЩшМЦдРэжаЃЌЙЪеЯВЂВЛПЩХТЁЃБШЙЪеЯИќживЊЕФЪЧзіКУЗўЮёИпПЩгУадКЭЪ§ОнЕФИпПЩППадЁЃ
вђДЫЃЌвЛАуЗжВМЪНДцДЂЖМЬсЙЉСЫШ§ИББОЃЈreplicaЃЉРДБЃжЄЪ§ОнЕФПЩППадвдМАДцДЂЗўЮёЕФИпПЩгУадЁЃШ§ИіИББОЕФЪ§ОнЃЌАДШ§ИіЛњМмЮЛВПЪ№КѓЃЌЦфИпПЩгУадвЛАуФмДяЕН8Иі9ЁЃЕЋЪЧШ§ИіИББОжаЃЌвђвЛЬЈЛњЦїDownЛњЃЌЖјЗЂЩњИББОднЪБадМѕЩйЛђепгРдЖЖЊЪЇЪБЃЌЮвУЧОЭашвЊАбЪ§ОнПьЫйЛжИДЛиРДЁЃШчЙћВЛМАЪБНјааЛжИДЃЌГЄЪБМфДІгкdegradeзДЬЌЃЌдйЗЂЩњХЬЕФЙЪеЯКѓЃЌЦфПЩгУадЛсДѓДѓНЕЕЭЁЃ
вђДЫдкетжжГЁОАЯТЃЌЛжИДЖдгкЗжВМЪНДцДЂРДНВЃЌдѕУДВЛШЅгАЯьвЕЮёЕФаДШыЪЧвЛИіЗЧГЃЙиМќЕФЮЪЬтЁЃ
дкНјааМЏШККѓЬЈЪ§ОнЛжИДЪБЃЌЮвУЧвЕЮёвЊЧѓзмЬхЭЬЭТВЛФмЯТНЕЮЊдРДЕФ80%ЃЌЛжИДЪБВЛФмЪЙДцДЂЗўЮёЗЂЩњжаЖЯЁЃвђЮЊетаЉЖМЛсгАЯьПЩгУадгыПЩППадЁЃ
вђДЫЃЌЮвУЧзіСЫдіСПЛжИДКЭвьВНЛжИДЃЌаЇЙћЧАКѓЖдБШШчЯТЁЃЦфжаЁАКьЩЋЁБЕФЮЊгХЛЏКѓЕФIOPSЧњЯпЭМЃЌЁАРЖЩЋЁБЕФЮЊгХЛЏЧАЕФIOPSЧњЯпЭМЃЌДѓДѓЬсИпСЫДцДЂМЏШКЕФИпПЩгУадЁЃ
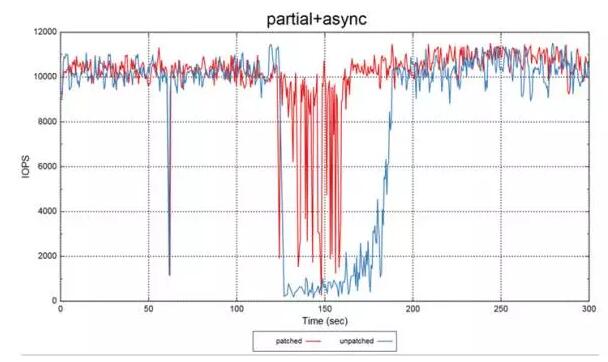
2.2 ГЄЮВгХЛЏ
МЦЫуДцДЂЗжРыКѓЃЌЫљгаЕФIOЖМБфГЩСЫЭјТчIOЃЌвђДЫЖдгкЕЅТЗIOЪБбггАЯьЕФвђЫиЗЧГЃЖрЃЌШчЭјТчЖЖЖЏЃЌТ§ХЬЃЌИКдиЕШЃЌЖјетаЉвђЫивВЪЧВЛПЩБмУтЕФЁЃвђДЫЃЌЮвУЧБиаыгавЛжжЗНЗЈЃЌФмЙЛБШНЯКЯРэЕиЙцБметаЉгАЯьЁЃ
ЮвУЧЩшМЦСЫЁАИББОДяГЩЖрЪ§аДШыМДЗЕЛиЕФВпТдЃЈcommit majority featureЃЉЁБЃЌФмЙЛБШНЯгааЇЕФЪЙГЄЮВЪБбгЖЖЖЏзіЕНКЯРэЕФПижЦЃЌвдТњзувЕЮёЕФашЧѓЁЃ
е§ГЃЧщПіЯТЃЌТ§ХЬвђЫиЛсКмПьЯћЪЇЃЌГ§ЗЧГіЯжГжајадЕФТ§ЃЌетПЩФмгЩгВМўЙЪеЯЕШвђЫиЕМжТЁЃ
ЮвУЧзіСЫвЛИіуажЕПижЦЃЌИљОнОбщЃЌЭЈГЃЮЊЁБ200ЁБmsЃЈПЩХфжУЃЉЁЃЕБШ§ИіИББОаДГЩЙІЕФЪБМфдк200msвдФкЪБЃЌЪ§ОнеебљвдШ§ИіИББОаДГЩЙІЕФФЃЪНЗЕЛиЃЌЖјЕБЦфжавЛИіНкЕуТ§ЪБЃЌЧвГЌЙ§200msЃЌдђСНИіИББОаДГЩЙІОЭЗЕЛиИјПЭЛЇЖЫЁЃетбљзіЕФФПЕФЪЧЃЌдкБЃжЄЪ§ОнПЩППадЕФЭЌЪБЃЌгжߞçêЮВбгЪБгАЯьЁЃ
СэЭтЃЌЮвУЧЛсБЃДцperf counterжЕЃЌШчЙћcommit majorityЕФВйзї(operation)ГЌЙ§вЛЖЈЪ§жЕЪБЃЌЧвУЛгаЯћЭЫЕФМЃЯѓЃЌОЭЛсЗЂИцОЏГіРДЃЌШЫЮЊНщШыДІРэЁЃ
вдЯТЪЧcommit majority featureПЊЦ№ЧАКѓЕФаЇЙћЖдБШЁЃЦфжаЁАРЖЩЋЁБЮЊгХЛЏКѓЕФГЄЮВЪБбгЃЌЁАКьЩЋЁБЮЊгХЛЏЧАГЄЮВЪБбгЃЌаЇЙћЗЧГЃЯджјЁЃ
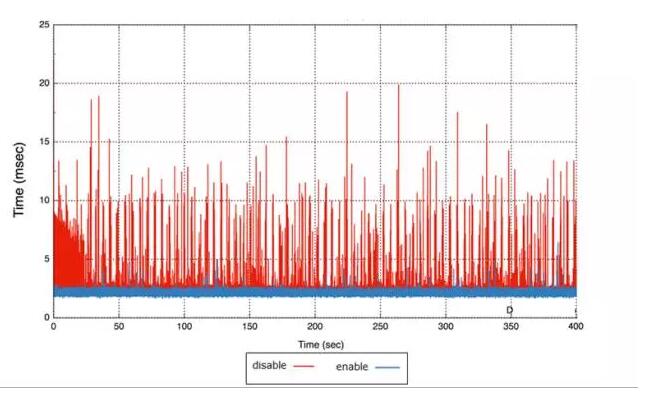
2.3 СїПиЩшМЦ
вЛАуЗжВМЪНЯЕЭГЖМЛсгаСїПиЃЌЛђепЪЧITIL ЙцЗЖжаЬсЕНЕФQoSПижЦЃЈQuality of ServiceЃЉЁЃвЛАуЖМЪЧЖдЗжВМЪНДцДЂКѓЬЈЛюЖЏЕФСїСППижЦЃЌШчЪ§ОнЛжИДЛђепЪ§ОнЦНКтЕШЁЃетЭљЭљЪЧВЛЙЛЕФЃЌЮвУЧашвЊЙизЂЧАЖЫвЕЮёЕФаДШыгыКѓЖЫДцДЂМЏШКЛюЖЏзівЛИіЁАЫйЖШСЊЖЏБШТЪЁБЃЌМђГЦЁАЫйЖЏБШЁБЁЃ
аТЕФСїПиЗНАИЩшМЦЃЌжївЊЙиаФШ§ИіЗНУцЃКЦфвЛЪЧгХЯШМЖПижЦЃЌЦфЖўЪЧquotaПижЦЃЌЦфШ§ЪЧвЕЮёгыКѓЬЈЛюЖЏЕФЫйЖЏБШЁЃ
гХЯШМЖПижЦ
жївЊЪЧжИДцДЂКѓЖЫЛюЖЏНЕЕЭгХЯШМЖЃЌЧАЖЫвЕЮёаДШыгазюИпгХЯШМЖЃЌетжївЊЪЧЮЊСЫБЃжЄвЕЮёаДШыЕФЪБбгзюЕЭЁЃ
QuotaПижЦ
жївЊЪЧжИДцДЂКѓЖЫЛюЖЏНјааЪ§ОнЛжИДКЭЪ§ОнжиЦНКтЪБВЛФмеМОнИпДјПэвдМАIOPSЃЌВЛШЛЛсгАЯьЧАЖЫвЕЮёЕФаДШыЁЃ
ЫйЖЏБШ
жївЊЪЧжИДцДЂКѓЖЫЕФЛюЖЏгывЕЮёаДШыЕФЫйЖШзівЛИіЦНКтЁЃвЛАуШчЙћМЏШККѓЖЫЛюЖЏЬЋЕЭЃЌЛсгАЯьЪ§ОнЛжИДЃЌетЛсЬсИпЖрХЬЙЪеЯЕФИХТЪЃЌНЕЕЭСЫЪ§ОнЕФПЩППадЁЃЫљвдДЋЭГЗжВМЪНДцДЂжЛзіЕНвдЩЯСНжжЃЌЮвУЧОЙ§гХЛЏКѓЃЌЭЈЙ§ЛЌЖЏДАПкЛњжЦЃЌзіЕНСЫЧАКѓЖЫЪ§ОнаДШыЕФЫйЖЏЃЌдкВЛгАЯьвЕЮёаДШыЕФЧщПіЯТЃЌОЁзюДѓПЩФмЬсИпЪ§ОнЛжИДЫйЖШЃЌБЃжЄЖрИББОЪ§ОнЕФЭъећадЁЃ
ЬсИпЪ§ОнжиЦНКтЕФЫйЖШЃЌвВЪЧЮЊСЫБЃжЄећИіМЏШКЕФадФмЁЃвђЮЊвЛГіЯжЪ§ОнЧуаБЪБЃЌВПЗжХЬЕФИКдиНЋБфДѓЃЌДгЖјЛсгАЯьећИіМЏШКЕФећЬхЪБбгКЭЭЬЭТЁЃ
СїПиаЇЙћШчЯТЃК
2.4 зДЬЌЛњМгЫй
Ъ§ОнжааФЕФДцДЂЛњаЭЃЌвЛАуЖМЛсЬсЙЉДѓШнСПЙцИёЕФДцДЂЁЃШчЮвУЧФПЧАЪЙгУЕФV41ЛњаЭЃЌЕЅЛњ12еХПЈЃЌУПеХПЈ4TДцДЂШнСПЁЃдкЗжВМЪНДцДЂжаЃЌвЛАувЛеХПЈЩшМЦЮЊвЛИіЪ§ОнНкЕуЁЃвђДЫЃЌЕБвЛЬЈЛњЦїЙЪеЯЪБЃЌОЭЛсГіЯж12ИіЪ§ОнНкЕуВЛПЩгУЁЃ
ЗжВМЪНЯЕЭГжаЛђепЗжВМЪНДцДЂжаЃЌЕБНкЕуГіЯжheartbeatаХКХЖЊЪЇЪБЃЌЛсНјааpeeringЛюЖЏЃЌетИіЛюЖЏЛсЩцМАЕНМЏШКзДЬЌЛњЕФБфЧЈЃЌЛђепЪЧmetadataдЊЪ§ОнЕФБфИќЁЃШЛЖјетаЉБфИќЮЊСЫдзгадЃЌЖМЪЧГжгаЫјЕФЁЃетОЭЛсЕМжТЧАЖЫЕФвЕЮёаДШыЛсгаЖЬднЕФblockЁЃ
ИљОнЪЕМЪЪ§ОнПтвЕЮёашЧѓЃЌЮвУЧНјааСЫгХЛЏЃЌНЋзДЬЌЛњЕФЙ§ГЬНјааВ№ЗжЃЌЯИСЃЖШЛЏmutexЫјЃЌДгЖјЬсИпВЂЗЂФмСІЃЌНЋpeeringЙ§ГЬПижЦдкУыМЖвдФкЁЃФПЧАОЙ§гХЛЏКѓЃЌЭЬЭТДгдРДЕФ12ДЮЖЖЖЏВЂЁАЕј0ЁББфЮЊжЛЯТНЕЕНе§ГЃЫЎЦНЕФ4/5ЃЌДѓДѓБЃжЄИпПЩгУадЁЃвдЯТЮЊгХЛЏКѓЕФаЇЙћЃК
2.5 ДцДЂГЩБОгХЛЏ
ЮвУЧФУЕНСЫЪ§ОнЖрИББОЕФКьРћЃЌШчЗжВМЪНМЏШКЕФИпПЩгУадвдМАИпПЩППадЃЌЕЋЪЧЫцжЎИЖГіЕФДњМлОЭЪЧДцДЂГЩБОЁЃвђДЫЃЌЮвУЧНгЯТРДЛсЪЙгУECЃЈErasure
CodeЃЉЃЌРДМѕЩйДцДЂГЩБОЕФЪЙгУЁЃECГЩЪьЖШвдМАадФмЩЯЛЙашвЊгХЛЏЁЃЧАУцНВМИИіЕуЮвУЧвбОЪЕЯжСЫЁЃECетИіЙІФмЛЙашвЊНјаажиаТЩшМЦЃЌЖјЧвЖдУїФъЕФЛњаЭбнНјЗЂЛгБШНЯДѓЕФживЊЁЃЯТАыФъЃЌЮвУЧЛсжиЕуРДЙЅПЫетИівЕНчФбЬтЃЌЁАШчКЮдкВЛгАЯьадФмЕФЛљДЁЩЯЃЌЪЕЯжГЩБОЫѕМѕЁБЁЃ
СэЭтЃЌДЋЭГЕФECадФмБШНЯВюЃЌгШЦфЪЧдкГіЯжВПЗжХЬЙЪеЯЪБЃЌЪ§ОнжиЫуКЭЛжИДЕФЪБМфБШНЯОУЃЌЯёЮЂШэвбОв§ШыLRCЃЈLocal
Re-generated CodeЃЉРДЪЕЯжЁЃ
ШчКЮзіЕНЖдЖСаДЮоЫ№ЕФECЃЌвЛжБвдРДЖМЪЧвЛИіЗЧГЃДѓЕФЬєеНЁЃзмЬхЕФЗНАИЮоЗЧОЭЪЧСНжжЃЌвЛжжЭЈЙ§Ъ§ОнЗжВуРДНтОіЃЌвЛжжЭЈЙ§ШпгрПеМфЃЌЖдРњЪЗАцБОНјааECЁЃетСНжжЪЕЯждквЕЮёЖМгаЯргІЕФдаЭЃЌОпЬхЪЕЯжЯИНкетРяднВЛзіеЙПЊЁЃ
Ш§ЁЂЪ§ОнПтЩшМЦ
НВСЫетУДЖрЗжВМЪНДцДЂЕФЮЪЬтвдМАгХЛЏЃЌетЪЧвђЮЊЃЌЗжВМЪНДцДЂЕФЮШЖЈадЪЧЛљЪЏЃЌУЛгаетИіЛљЪЏЕФЮШЖЈадЃЌЦфЫќЖМВЛПЩФмЁЃвђДЫЃЌЮвУЧЩЯАыФъЛЈСЫБШНЯЖрЪБМфдкЗжВМЪНДцДЂБОЩэЕФгХЛЏЩЯЁЃ
ФЧУДЃЌЛиЙщЕНЪ§ОнПтБОЩэЃЌРДПДМЦЫуДцДЂЯТашвЊЙЅПЫЕФвЛаЉФбЕуЁЃЮвЯыЃЌзюживЊЕФЮЪЬтФЊЙ§гкЁАШчКЮЬсИпЪ§ОнПтЕФадФмКЭЭЬЭТЁБЁЃЮвУЧЗжЮЊвдЯТМИИіЕуРДНВЁЃ
3.1RedoгХЛЏ
ЕБЫљгаЕФIOЖМБфГЩЭјТчIOКѓЃЌЮвУЧвЊзіЕФОЭЪЧШчКЮМѕЩйЕЅТЗIOЕФбгГйЃЌЕБШЛетИіЪЧЗжВМЪНДцДЂвдМАЭјТчвЊНтЕФЮЪЬтЁЃЗжВМЪНДцДЂашвЊгХЛЏздЩэЕФШэМўstackвдМАЕзВуSPDKЕФНсКЯЕШЁЃЖјЭјТчВудђашвЊИќИпДјПэвдМАЕЭЪБбгММЪѕЃЌШч25G
TCPЛђеп25G RDMAЃЌЛђеп100GЕШИќИпДјПэЕФЭјТчЕШЁЃ
ЕЋЪЧЮвУЧПЩвдДгСэЭтвЛИіНЧЖШРДПМТЧЮЪЬтЃЌШчКЮдкЪБбгвЛЖЈЕФЧщПіЯТЃЌЬсИпВЂЗЂСПЃЌДгЖјРДЬсИпЭЬЭТЁЃЛђепЫЕдкЙиМќТЗОЖЩЯМѕЩйIOЕїгУЕФДЮЪ§ЃЌДгЖјДгФГжжГЬЖШЩЯЬсИпЯЕЭГЕФЭЬЭТЁЃД№АИЪЧвЛЖЈЕФЁЃ
ДѓМвжЊЕРЃЌгАЯьЪ§ОнПтЪТЮёЪ§ЕФзюЙиМќвђЫиОЭЪЧЪТЮёcommitЕФЫйЖШЃЌcommitЕФЫйЖШвРРЕгкаДREDOЪБЕФIOЭЬЭТЁЃЫљЮНЕФREDOвВОЭЪЧДѓМвЪьжЊЕФWAL(Write
Ahead Log)ШежОЁЃ
дкдрЪ§ОнflushЛиДцДЂЪБЃЌШежОБиаыЯШТфЕиЃЌетЪЧвђЮЊЪ§ОнПтЕФCrash RecoveryЪЧжиЖШвдРДгкДЫЕФЁЃдкrecoveryНзЖЮЃЌЪ§ОнПтЯШРћгУredoНјааroll
forwardЃЛдйРћгУundoНјааroll backwardЃЌзюКѓдйГЗЯњгУЛЇЮДЬсНЛЕФЪТЮёЁЃ
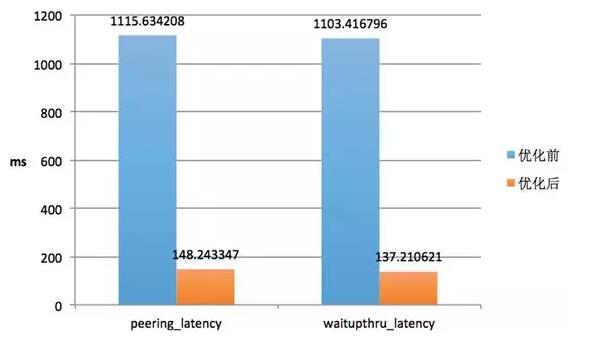
вђДЫЃЌДцДЂМЦЫуЗжРыЯТЃЌвЊЯыдкЕЅТЗIOЪБбгвЛЖЈЪБЬсИпЭЬЭТЃЌОЭБиаывЊгХЛЏcommitЬсНЛЪБЕФаЇТЪЁЃЮвУЧЭЈЙ§гХЛЏredoЕФаДШыЗНЪНЃЌШУећИіЬсИпЭЬЭТ50%зѓгвЃЌаЇЙћШчЯТЃК
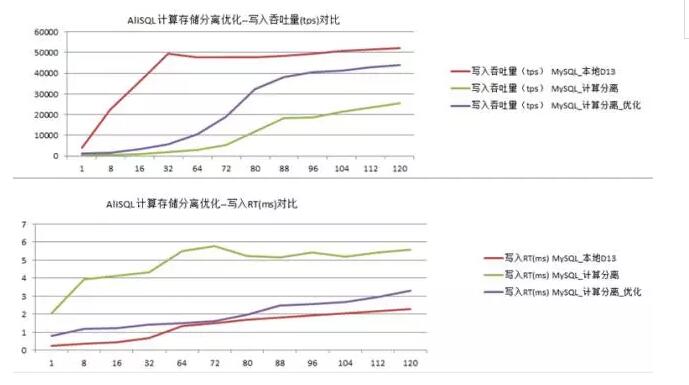
СэЭтЃЌвВПЩвдгХЛЏredo group commitЕФДѓаЁЃЌНсКЯЕзВуДцДЂstripeФмСІЃЌзіВЂЗЂгыЭЬЭТгХЛЏЁЃ
БИзЂЃКЁБD13ЁБЪЧвЛжжвбОзіЙ§raidЕФSATA SSD
3.2 дзгаД
дкЪ§ОнПтФкДцФЃаЭжаЃЌЪ§ОнвГЭЈГЃЪЧвд16KзіЮЊвЛИіbuffer pageРДЙмРэЕФЁЃЕБФкКЫаоИФЭъЪ§ОнжЎКѓЃЌЛсгазЈУХЕФЁАcheckpointЁБЯпГЬАДвЛЖЈЕФЦЕТЪНЋDirty
Page flushЕНДХХЬЩЯЁЃ
ЮвУЧжЊЕРЃЌЭЈГЃosЕФpage cacheЪЧ4KЃЌЖјвЛАуЕФЮФМўЯЕЭГblock sizeвВЪЧ4KЁЃЫљвдвЛИі16kКЭpageЛсБЛЗжГЩ4Иі4kЕФos
filesystem block sizeРДДцДЂЃЌЮяРэЩЯВЛФмБЃжЄСЌајадЁЃ
ФЧУДЛсДјРДвЛИібЯжиЕФЮЪЬтЃЌОЭЪЧЕБfsyncгявхЗЂГіЪБЃЌвЛИі16kЕФpage flushЃЌжЛЭъГЩЦфжаЕФ8kЃЌЖјетИіЪБКђclientЖЫcrashЃЌВЛдйЛсгажиЪдЃЛФЧУДећИіfsyncОЭжЛаДСЫвЛАыЃЌfsyncгявхБЛЦЦЛЕЃЌЪ§ОнВЛЭъећЁЃ
ЩЯУцЕФетИіГЁОАЃЌЮвУЧГЦжЎЮЊЁАpartial writeЁБЁЃвЛАуЮвУЧЭЈЙ§вдЯТСНИіЗНАИРДНтЃК
Ъ§ОнвГСЌај?
OSВуЮЊЪ§ОнПтЗжХфЕФЪ§ОнвГ16kЪЧЗёСЌајЃПШчЙћСЌајЃЌЕзВуblock layerЕїЖШЪБЃЌЪЧЗёзіЮЊвЛИіIO
requestЃП
ШчЙћЪ§ОнвГЮяРэСЌајЃЌПЩвдБЃжЄIO requestЕФдзгадЃЌФЧУДЮвУЧОЭПЩвдЪЙгУext4 ЕФbigallocЬиадЃЌдкЩЯВуЖдЦыаДКѓЃЌРДБЃжЄдзгадЃЌЛђепжСЩйдквЛЖЈГЬЖШРДМѕЩйГіЯжpartial
writeЕФПЩФмадЁЃ
БИзЂЃКOracleЭЈГЃВЛЪЙгУЮФМўЯЕЭГЃЌЪЙгУТуЕФПщДцДЂЛђепASMЃЈAutomatic Storage
ManagementЃЉЃЌПЩвдзіЕНвЛИіIO RequestЕФдзгадЃЛЖјMySQLЪЙгУDouble Write
BufferРДБмУтpartial writeЕФЮЪЬтЁЃ
ЖдгкMySQLЖјбдЃЌдкБОЕиДцДЂЪБЃЌЪЙгУDouble Write BufferЮЪЬтВЛДѓЁЃЕЋЪЧШчЙћЕзВуБфГЩЭјТчIOЃЌIOЪБбгБфИпЪБЃЌЛсЪЙMySQLЕФећЬхЭЬЭТЯТНЕЃЌЖјDouble
Write BufferЛсМгжиетИігАЯьЁЃ
ЫљвдНЋMySQLЕФDouble Write BufferЙиЕєЃЌДгЖјдкТ§ЫйЭјТчIOЯТЃЌЬсИпMySQLЕФЭЬЭТЁЃ
OS FilesystemЪЧЗёжЇГж16k?
Шчext4ЪЧжЇГж16kЕФblock sizeЗжХфЕФЃЌЕЋЪЧmountЪБЛсБЈДэЁЃвђЮЊmountЪБЃЌВЛжЇГжГЌЙ§ФкДцвГДѓаЁ(4k)ЕФЮФМўЯЕЭГЁЃЕБШЛвВПЩвдЭЈЙ§fuse-ext2ЙЄОпmountЦ№РДЃЌЕЋЪЧГЩЪьЖШЩЯЛЙВЛЙЛЁЃ
СэЭтЃЌfuseвВЪЧвЛИіБШНЯКУЕФЗНЗЈЃЌЕЋЪЧПЩФмвЊМцШнPOXISавщЕФФбЖШЛсБШНЯДѓЁЃЕБШЛвЛАувЕЮёИќдИвтЩЯВузівЛаЉИФдьЃЌзівЛИіМђЕЅЕФЮФМўЯЕЭГЃЌШЅЪЪХфЕзВуЗжВМЪНДцДЂЁЃ
3.3 Data Activity offload
МЦЫуДцДЂЗжРыКѓЃЌЖдЭјТчДјПэЪЧвЛИіЗЧГЃДѓЕФбЙСІЃЌгШЦфЪЧInnoDBв§ЧцЃЌdouble write bufferМгЩЯredoЃЌdirty
pageвдМАbinlogЃЌЪ§ОнДцдкЖрДЮаДЁЃЭЈЙ§IOдзгадЙиЕєdouble write bufferЃЌФЧУДЖдгкdirty
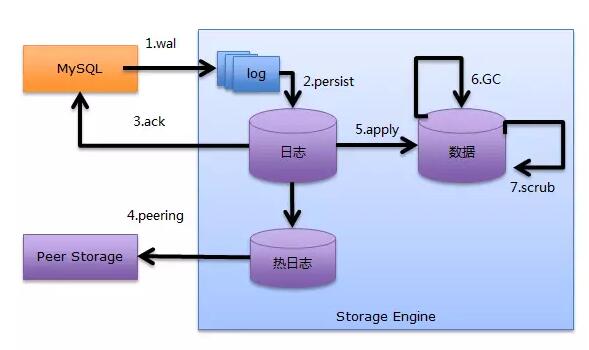
pageЕФДІРэФиЃП AuroraИјСЫЮвУЧвЛИіЗЧГЃЕФР§згЃЌНЋЫљгагыЪ§ОнЯрЙиЕФВйзїЖМЯТЗХЕНДцДЂКѓЖЫЃК
ВНжш1ЃКЧАЖЫМЦЫуНкЕужЛИКд№REDOЯђДцДЂМЏШКЗжЗЂ
ВНжш2ЃКГжОУЛЏДцДЂНгЪеЕНЕФШежОЕНЗжВМЪНДцДЂЩЯ
ВНжш3ЃКЗЕЛиackИјМЦЫуНкЕуЃЌвдБэЪОБОДцДЂНкЕувбОЪеЕНШежОВЂзіГжОУЛЏДцДЂ
ВНжш4ЃКгыЦфЫќДцДЂМЏШКНјааpeeringЃЌРћгУGossipавщаоВЙШБЪЇЕФШежОЃЛвьВНДІРэЃЌЪБМфВЛМЦдкackФк
ВНжш5ЃКНЋШежОгІгУЕНЪ§ОнвГЩЯЃЌЮЊвьВНДІРэ
ВНжш6ЃКНјааGCЛюЖЏЃЌЛиЪеКЭећРэЪ§ОнвГвдМАШежО
ВНжш7ЃКНјааЪ§ОнаЃбщвдМАЖрИББОжЎМфЕФЪ§ОнаЃбщ
СэЭтЃЌЖдгкMySQLЪЕР§crashКѓЕФrecoveryНзЖЮЃЌвВЪЧдкДцДЂНкЕуЩЯДІРэЁЃЦфRTOЃЈRecovery
Time ObjectЃЉдк2ЗжжгвдФкЁЃ
етаЉгыЪ§ОнЯрЙиЕФВйзїЃЌЮвУЧЭГГЦЮЊЁАData ActivityЁБЃЌдкМЦЫуДцДЂЗжРыЕФЧїЪЦЯТЃЌЖМПЩвдзіЕНгХбХЕФЯТЗХЁЃ
ДѓжТДІРэТпМШчЯТЃК
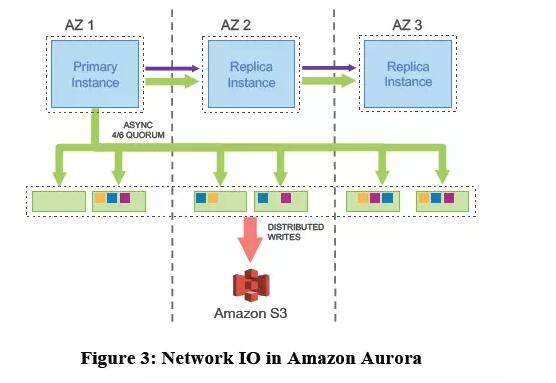
3.4 ЖСФмСІРЉеЙ
ЕБДцДЂгыМЦЫуЗжРыКѓЃЌШчКЮЬсЙЉЁАвЛЗнЪ§ОнЃЌЖрЗнМЦЫуЁБЕФФмСІОЭжСЙиживЊЁЃAuroraвбОгаСЫSDPЃЈShard
Disk ParallelЃЉМмЙЙЃЌгУredoШЅЪЇаЇБИПтcacheЃЌгУгкЖСФмСІЕФРЉеЙЁЃ
ЫФЁЂЭГвЛЕїЖШ
ЭГвЛЕїЖШжївЊЗжЮЊДцДЂЕїЖШгыМЦЫуНкЕуЕФЕїЖШЃЌЩцМАЕФФкШнБШНЯЖрЃЌШчДцДЂШчКЮРЉШнЃПДцДЂVolumeШчКЮЙмРэЃПМЦЫуНкЕуШчКЮЕїЖШЃПвдМАЭјТчЭиЦЫМмЙЙШчКЮЕїМЦЃПЕШЕШЁЃгЩгкЦЊЗљЪмЯоЃЌНЋдкКѓУцеТНкжажиЕуНВЪіЁЃ
СэЭтЃЌЖдгкЭјТчЭиЦЫЩшМЦИааЫШЄЕФЭЌбЇЃЌЧыВЮПМЃКЁЖМЦЫуДцДЂЗжРыжЎЁАЪ§ОнДцДЂИпПЩгУадЩшМЦЁБЁЗ
ЮхЁЂаТММЪѕгыеЙЭћ
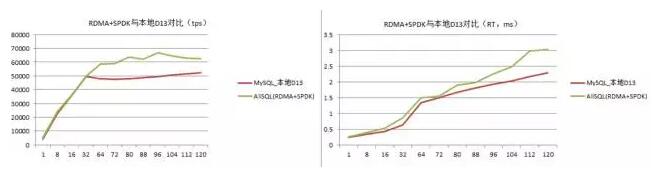
ФПЧАЮвУЧе§дкНјааШэгВМўНсКЯЃЈRDMAЃЌSPDKЃЉвдМАЩЯВуЪ§ОнПтв§ЧцгыЗжВМЪНДцДЂШкКЯгХЛЏЃЌадФмНЋЛсГЌГіДЋЭГSATA
SSDБОЕиХЬЕФадФмЁЃ
ЫфШЛДѓЙцФЃЯТЃЌВПЪ№RDMAЛЗОГЛЙдквЛЖЈГЬЖШЩЯЪмЕНЯожЦЃЌЕЋЪЧдквЛИіPODФкЕФЗжВМЪНДцДЂМЏШКжаЪЙгУRDMAЪЧЭъШЋгаПЩФмЕФЁЃЮЊДЫЃЌЮвУЧВЛНіМмЩшСЫИпДјПэЭјТчШч25GвдМАНЋРДЕФ100GЕШЃЌЖјЧвTCPгыRDMAЭјТчЕФfailoverЗНАИвВеце§дЭФ№жаЁЃ
RDMAКЭSPDKЕФЬиЕуОЭЪЧkernel pass-byЁЃЯТУцЪЧЮвУЧНјааВтЪдЕФвЛзщЪ§ОнЃЌЦфжаБОЕигУЕФЪЧSATA
SSDЃЌВЂЧвзіСЫraidЃЌЕЋЪЧЦфадФмТдЕЭгкЛљгкRDMAКЭSPDKЕФЗжВМЪНДцДЂЁЃ
етаЉЭјТчКЭгВМўММЪѕЕФЗЂеЙЃЌНЋЛсИјЁАдЦМЦЫуЁБДјРДИќЖрЕФПЩФмадЃЌвВЛсИјеце§ЕФЁАдЦМЦЫуЁБаТЕФЩЬвЕФЃЪНДјРДИќЖруПуНЃЌЖјЮвУЧвбОдкетЬѕбєЙтЕФДѓЕРЩЯЁЃ
ЛЖггаИќЖрЕФШЫвЛЦ№ВЮгыНјРДЃЌвЛЦ№аЏЪжТѕНјЮДРДЁЃ
|









