| 背景介绍
身处大数据时代,在数据库领域,我们要分析处理的数据越来越多,我们分析处理数据的速度也要越来越快,但是传统数据库基于磁盘的计算模型,已经难以满足我们的需求。幸运的是随着硬件的发展,内存设备的性能在不断提高,而价格却在不断下降。内存计算技术将带着我们“飞”起来!
内存计算(In-Memory Computing),实质上是 CPU 直接从内存而非硬盘上读取数据,并对数据进行计算、分析。在数据库上引入内存计算技术,意味着去除磁盘
IO 的消耗,利用内存随机访问的特性可以制定更高效的算法等等。这都极大的提高数据的处理速度。
目前很多商业数据库已经拥有了内存计算功能,如 SAP HANA、DB2
BLU、Oracle 12C、SQL Server 2014。但是商业数据库的价格毕竟不菲,在开源产品飞速发展的今天,利用开源的内存计算产品是一个好主意。
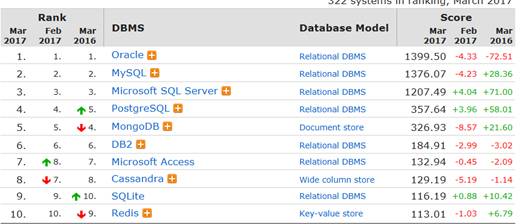
图 1 数据库产品使用排名
从图 1 我们可以看到,目前开源的数据库使用比较多的是 MySQL、Redis、PostgreSQL
等等。Redis、MemCached 是 KV 类型的内存数据库,不支持关系模型,仅作为关系型数据库的缓存。MySQL
支持 In-Memory 引擎,但是不支持数据的持久化,不支持列存储。基于这种情况,我们打算开发一套基于开源关系型数据库之上的内存计算引擎,实现支持内存计算,数据持久化,并行计算等特性。
为什么选择 PostgreSQL?
虽然决定自开发,但是站在巨人的肩膀上是一个好主意!我们决定基于 PostgreSQL 开发一个内存计算的引擎,具体理由如下:
1.PostgreSQL 的许可证非常开放(BSD 协议),简单来说,你可以忘记许可证的问题。
2.PostgreSQL 提供完善的外部表(FDW:Foreign
Data Wrapper)扩展开发机制,可以很容易的开发满足自身需求的插件。
3.PostgreSQL 的自身稳定性很高,基于 PostgreSQL
开发产品,不用担心稳定性的问题。
4.在开源社区上有很多 PostgreSQL 的扩展插件,可以借鉴。
5.可以随着 PostgreSQL 的社区版本进行迭代。
6.由于 PostgreSQL 的学院派风格。PostgreSQL
的代码质量很高,便于阅读学习。
内存计算引擎的设计思路
数据需要存储在内存上,由于 PostgreSQL 提供了外部表(FDW)概念,可以通过 API 来对数据进行管理,普通思维是外部表对应的是远程数据库或者其他数据来源,但是我们提出一个概念是将这个
FDW 对应成内存,这样通过开发扩展插件来实现,不影响 PostgreSQL 升级带来的迭代问题,也不需要修改内核源码。数据常驻内存,只是简单的解决了数据库
IO 的问题,只能节省 IO 的时间,并不能带来计算上质的飞跃,我们测试过,只是将数据 Cache
到内存中,性能只有 1-2 倍的提升。如果说设计好存储,利用列式存储将数据分条带分块,通过多线程对数据进行计算,每个线程互不干扰的扫描并计算所分配的条带,这样对内存计算来说能够达到质的飞跃,这也是所有常见数据库所追求的。
外部表 (FDW)
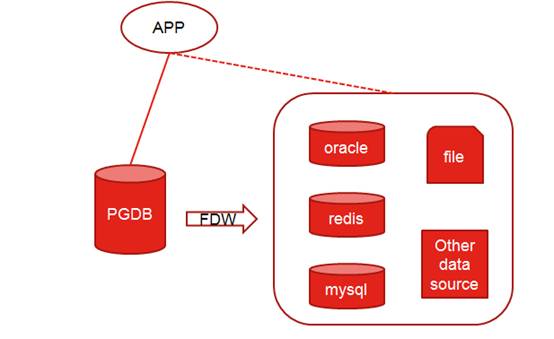
图 2 外部表透明访问
外部表:在 PostgreSQL 内部提供一种表类型,能够提供用户访问外部源数据的一种方式,这是
PostgreSQL 作为学院派设计比较优美的地方,努力打造成世界的中心,提供给开发人员遐想的空间。
列式存储
如图 3 所示,将一张表进行横向切割产生了 stripe,stripe 是由多个块数组构成,blockArray
是多列的 block 数据,block 是由单列的多个行数据组成,在对数据进行索引时,只需要通过 stripeNum、blockArrayNum、blockRowNum
能索引到行,这样组成了 RowID。
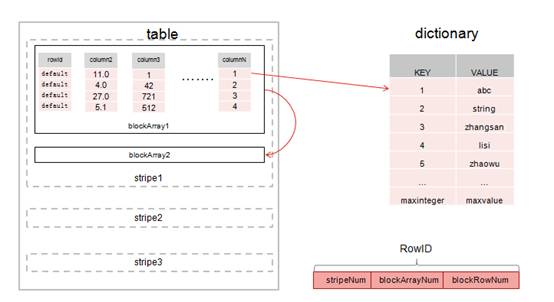
图 3 内存列式存储
注:blockArrayNum:DEFAULT is 15blockRowNum:DEFAULT
is 10000RowID = stripeNum + blockNum + blockRowNum(“+”号是拼接)
对字符串存储使用了 Hash 字典表,字符串存储过程中会在 Hash 表中对应一个 8 字节的 MapCode,在进行字符串比较过滤或者对字符串进行
Join 计算时,只需要对 MapCode 值进行比较或者对 MapCode 值进行排序而不是对字符串进行比较或者排序,这样不仅带来了效率上的提升,而且还节省了空间。在存储中采用分条带分块的概念,这样的存储模型为多线程计算做好了完美铺垫。
内存计算
在对内存计算分析之前需要提出一个概念,对数据列单个的取出或者两个列的取出都称之为序列
(Time Series),序列是自定义的一种类型,我们打造是所有类型皆序列,如下面的例子:
| SQL:select
sum(c1 + 1) from table where c2>10;->
select cs_sum(cs_filter(c2>10,c1) + 1) from
table_get();
|
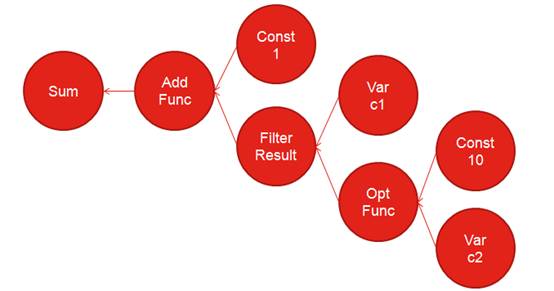
图 4 内存计算流程
对图 4 的分析如下:
我们是将整个 SQL 语句翻译成 UDF 函数来进行执行,通过这样的翻译会生成如图 4 所示的一个树形结构,当中的每个节点都是对应的一个
Iterator,当键入带有 UDF 的 SQL 语句后,准备工作先生成 Iterator 的结构树,在对
SUM 值输出时才开始进行计算。
C2>10 是一个公式,在迭代器中进行的是 C2 与常数 10 的比较,满足条件的会返回序列
(Time Series), 在过滤过程中返回的序列其实是一个 Bitmap,通过这个 Bitmap
可以知道 C1 这个序列哪些记录被选中,再对选中返回的序列进行 Add 操作,最终返回 SUM 结果。
并行计算
首先多线程是通过参数配置启动多少个线程来完成这次计算,配置选项在 postgres.conf 文件,默认情况是单线程计算,如果配置了会根据配置数量来进行启动
nthreads 个线程。
之前也提到过由于使用了分条带分块,因此并行计算不是问题了,以下是拆分条带的间隔
| Interval
= (stripe_last – stripe_first + nthreads)/nthreads |
并行中按照这个间隔来对条带进行扫描并计算,还是以 SUM 为例。
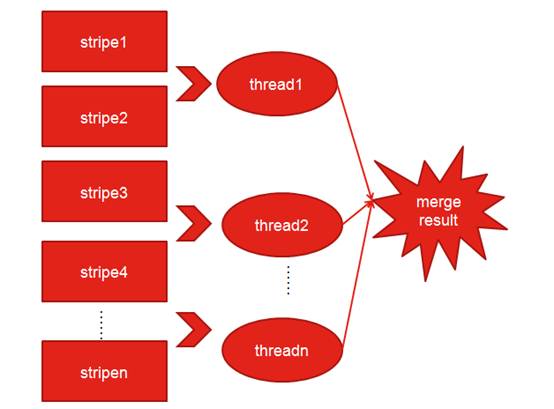
图 5 并行计算分析
如图 5 所示,每个线程都只扫描所分配的条带号并进行计算,最终将各个线程的计算结果 merge,最终得到计算结果。
内存计算引擎的优化 Join
由于使用的是列式存储,因此与原生 PostgreSQL 行式计算引擎有很大的不同,但是实现的原理以及算法都是模仿
PostgreSQL 内部实现,支持三种 Join 方式:Nestloop Join、Sort Merge
Join、Hash Join。
Nestloop
实现方式:

参见伪代码,Nestloop 实现的方式比较简单,通过 for 循环进行嵌套实现,所以复杂度是 O(N*M)。
分析: 比较通用的连接方式,分为内外表,每扫描外表的一行数据都要在内表中查找与之相匹配的行,对于被连接的数据子集较小的情况,Nestloop
连接是个较好的选择。
Sort Merge Join
实现方式:

参考 PostgreSQL 中提供的伪代码分析,首先对两个表做 Join 的两列进行排序,由于我们是列存储,这个操作非常容易。接下来遍历两个表,如果合适放入结果集,依次处理直到将两表的数据取完。
分析:merge join 需要在排序上花一部分开销,排序后运算成本接近全表扫描两个表的成本之和。在已经排序的条件下,这种
join 方式具有巨大优势。
hash join
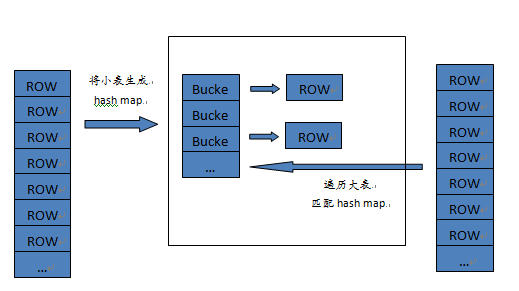
图 6 hash join 实现分析
实现方式:对于要做 join 的两张表,首先将小表转换成 hash map,然后扫描大表的每一行数据,计算行数据的
hash 值,映射 hash map,可以得到匹配的行。
分析:当表比较大的时候,采用 hash join 是比较有优势的。运算成本接近全表扫描两个表的成本之和。当然这会浪费一定的内存空间,不过既然我们是内存计算引擎,内存空间显然不是问题。由于采用
hash 字典技术,字符串数据在表中实际上存储的是字符串对应的 hash 值,这样在做 hash join
的时候,我们选择字符串的列去做 join 的话,我们将更快的得到结果。
持久化
既然是内存引擎会出现断电数据丢失的问题,因此我们在设计之初考虑到了这个问题,添加一个可配置的功能持久化,只要配置该选项是把持久化
switch 打开,在创建内存外部表时,会同时创建 PostgreSQL 原生表,该表的插入操作是会进行
Wal 日志记录以及落盘,在对内存进行增删改操作时,会先将 sql 拷贝一份,并将在 PostgreSQL
原生表中先执行一遍,然后再对内存外部表操作,这样保证了数据的持久化了,数据都可以从原生表以及 Wal
日志中获取。
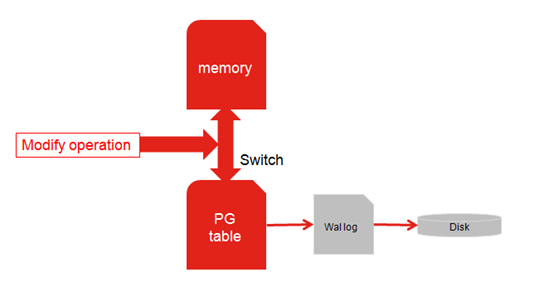
图 7 数据持久化过程
测试对比
测试环境:
| Server
Specs: Physical Server, 24 Cores, 128G RAM
Test Products: LeMCS; PostgreSQL ; DB2
Data Volume: 2 tables , 30GB,800w 条记录和 1300w
条记录 |
测试结果:
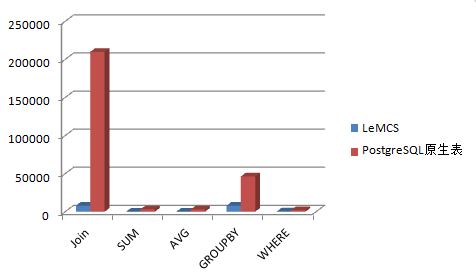
图 8 测试对比
如图 8 所示,LeMCS 在对比 PostgreSQL 原生表测试中,计算速度都能够快到 5x-30x。
附测试 sql:
注:LeMCS 均使用的是 UDF 函数替换进行测试
后续开发
通过运用以上的技术手段实现的内存计算引擎,以插件的形式嵌入 PostgreSQL 数据库中,目前通过测试使用正常,达到我们之前制定的目标。当然很多问题需要后续开发进行解决。目前所有对内存中表的访问都是通过自定义函数(UDF)来实现的,为了便于使用,我们正在开发对于标准
SQL 的支持。后续我们会将这款工具发布出来,与有需要的同学分享,大家一起使用并持续开发,把这款工具打造的更加强大,帮助更多的人。 |









