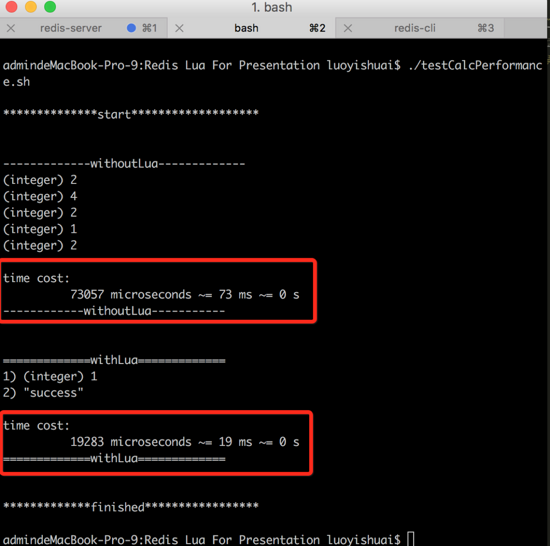
вЛЭђСљЧЇзжЬИЬИШчКЮЪЕЯжОЕфЁАЫФдђдЫЫуЁБЫуЗЈгХЛЏ
Redis МЏКЯдЫЫу
вЛЭђСљЧЇзжЬИЬИШчКЮЪЕЯжОЕфЁАЫФдђдЫЫуЁБЫуЗЈгХЛЏ Redis МЏКЯдЫЫу
ЖўЁЂЮЊЪВУДвЊЁАгХЛЏЁБ Redis МЏКЯдЫЫу
2.1 Redis МЏКЯдЫЫуМђНщ
2.1.1 ЮоађМЏКЯ set УќСю
2.1.2 гаађМЏКЯ sorted set УќСю
2.2.1 ЦеЭЈдЩњМЏКЯУќСюЪЕЯж
2.2.2 ЦеЭЈдЩњМЏКЯУќСю+ЪТЮёЪЕЯж
2.2.3 МЏКЯИіЪ§ВЛЖЈЁЂашЧѓГЁОАЖрБфЕФМЏКЯдЫЫу
2.2.4 змНсашвЊЁАгХЛЏЁБЕФдвђ
2.2.4 lua НХБОЕФМђЕЅЪОР§
Ш§ЁЂRedis МА Lua ЛљДЁжЊЪЖ
3.1 Redis ПЭЛЇЖЫгыЗўЮёЖЫНЛЛЅ
3.1.1 ПЭЛЇЖЫгыЗўЮёЖЫНЛЛЅ
3.1.2 ПЭЛЇЖЫЛКГхЧјвдМАШэгВадЯожЦ
3.2 Redis жа Lua ЛЗОГ
3.2.1 ЮвЖд Lua гябдЕФРэНт
3.2.2 ПЭЛЇЖЫЪЙгУ Lua НХБОгы Redis НЛЛЅЕФМђЕЅЪОР§
3.2.3 Lua гябдШчКЮ "ЧЖШы" Redis ЛЗОГ
3.2.4 eval УќСюИёЪНМАЦфжДааЙ§ГЬ
ЫФЁЂЁАЫФдђдЫЫуЁБЫуЗЈЛљДЁжЊЪЖ
4.1.1 жазКБэДяЪНгыКѓзКБэДяЪН
4.1.3 еЛЁЂЖгСагыВйзїЗћгХЯШМЖ
4.2 жазКБэДяЪНзЊКѓзКБэДяЪНЕФЙ§ГЬ
4.2.2 зЊЛЛЙ§ГЬЯъЯИЪОР§
4.3 МЦЫуКѓзКБэДяЪНЙ§ГЬ
ЮхЁЂLua НХБОЪЕЯж ЁАЫФдђдЫЫуЁБЫуЗЈЁАгХЛЏЁБМЏКЯдЫЫу
5.1 ДгРэТлЕН lua НХБОЪЕеНИХЪі
вЛЁЂБОЮФИХЪі
БОЮФжївЊНщЩмЮЊЪВУДвЊЪЙгУ Lua НХБОдк Redis ЛЗОГжагХЛЏМЏКЯдЫЫуЃЌвдМАШчКЮЪЙгУ Lua НХБОдк
Redis ЛЗОГжагХЛЏМЏКЯдЫЫуЁЃдкНщЩметСНВПЗжФкШнжаМфЃЌЛЙЛсДЉВхзХНщЩм Redis Ъ§ОнПт КЭ Lua
гябдЕФвЛаЉЛљДЁжЊЪЖЃЌвдМАОЕфЁАЫФдђдЫЫуЁБЫуЗЈЕФЛљДЁжЊЪЖЁЃ
ЖўЁЂЮЊЪВУДвЊЁАгХЛЏЁБ Redis МЏКЯдЫЫу
2.1 Redis МЏКЯдЫЫуМђНщ
Redis жагаСНжжМЏКЯРраЭЃК set ЃЈЮоађМЏКЯЃЉ КЭ sorted set ЃЈгаађМЏКЯЃЉЃЌеыЖдМЏКЯЕФЕЅДЮдЫЫуЃЈНЛЃЌВЂЃЌВюЃЉгадЩњЕФ
Redis УќСюжЇГжЁЃ
2.1.1 ЮоађМЏКЯ set УќСю
sadd key member [member ...]
sinter key [key ...]
sinterstore destination key [key ...]
sunion key [key ...]
sunionstore destination key [key ...]
sdiff key [key ...]
sdiffstore destination key [key ...]
sismember key member
smembers key
...
ИќЖр Redis ЮоађМЏКЯЯрЙиУќСюЧыВЮМћЃКЃК Redis set
2.1.2 гаађМЏКЯ sorted set УќСю
zadd key [NX|XX] [CH] [INCR] score member [score
member ...]
zinterstore destination numkeys key
[key ...] [WEIGHTS weight [weight ...]] [AGGREGATE
SUM|MIN|MAX]
zunionstore destination numkeys key
[key ...] WEIGHTS weight [weight ...]] [AGGREGATE
SUM|MIN|MAX]
...
sorted set УЛга zinter ЁЂ zunion ЃЌвВУЛга zdiffstore ЁЃ ЦфжаЃЌ
zdiffstore ЕФгявхашвЊЭЈЙ§зщКЯЦфЫћУќСюРДЪЕЯжЁЃ
ИќЖрRedis гаађМЏКЯЯрЙиУќСюЧыВЮМћЃК Redis zset
2.1.3 МЏКЯдЫЫуЪОР§
ЮвУЧЯШМђЕЅЕиПДвЛЯТ sadd ЁЂ sunionstore УќСюЁЃ setX ЃЈАќКЌ[a,b,c]ЃЉ
КЭ setY ЃЈАќКЌ[c,d]ЃЉ ЪЧЮоађМЏКЯЃЌЭЈЙ§Чѓ setX КЭ setY ЕФВЂМЏЃЌВЂАбНсЙћДцШыМЏКЯ
setZ ЁЃПЩвдЕУжЊЃЌдкМЏКЯ setX Лђепдк setY жаЕФдЊЫига[a,b,c,d]ЁЃ
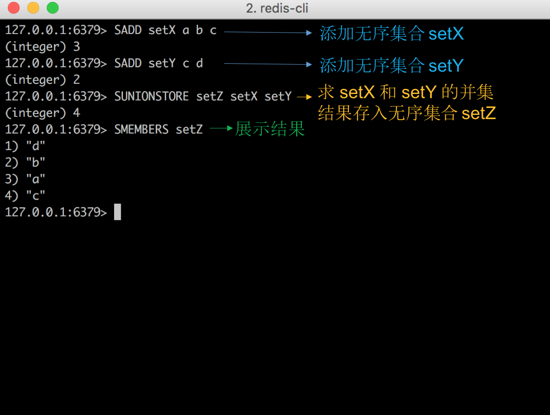
ЭМ1ЃКЮоађМЏКЯ set ЕФ ЧѓВЂМЏ ЪОР§
ШЛКѓдйПДвЛЯТ zadd ЁЂ zinterstore УќСюЁЃ zsetX
ЃЈАќКЌ[a:1,b:2,c:3]ЃЉ КЭ zsetY ЃЈАќКЌ[c:3,d:6]ЃЉ ЪЧгаађМЏКЯЃЌЭЈЙ§Чѓ
zsetX КЭ zsetY ЕФНЛМЏЃЌВЂАбНсЙћДцШыМЏКЯ zsetZ ЁЃПЩвдЕУжЊЃЌдкМЏКЯ zsetX ВЂЧвдк
zsetY жаЕФдЊЫига[c:6]ЁЃ
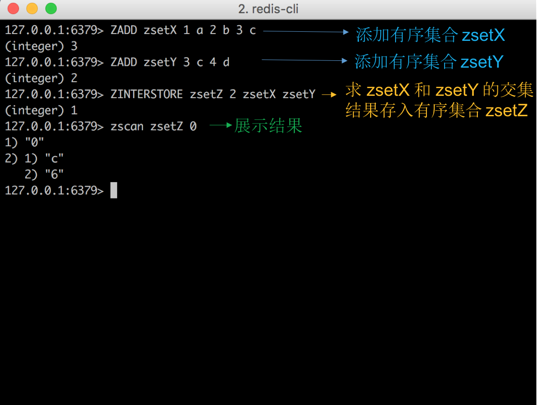
ЭМ2ЃКгаађМЏКЯ sorted set
ЕФ ЧѓНЛМЏ ЪОР§
2.2 ЮЊЪВУДвЊЁАгХЛЏЁБ
МйЩшгаетбљЕФашЧѓГЁОА
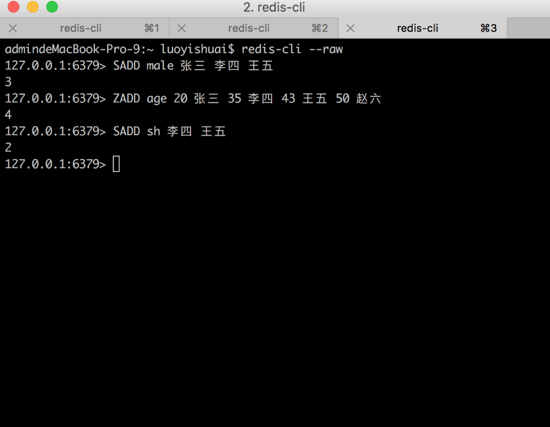
гаБэЪОадБ№ЮЊФаадЕФЮоађМЏКЯ male ЃЌдЊЫига [ еХШ§ЃЌРюЫФЃЌЭѕЮх ]ЃЌ
гаБэЪОФъСфЕФгаађМЏКЯ age ЃЌдЊЫига [ еХШ§:20ЃЌРюЫФ:35ЃЌЭѕЮх:43ЃЌедСљ:50 ]
гаБэЪОзЁжЗдкЩЯКЃЕФЮоађМЏКЯ sh ЃЌдЊЫига [ РюЫФЃЌЭѕЮх ]ЁЃ
ЯждкашвЊевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад ЁБЁЃ
2.2.1 ЦеЭЈдЩњМЏКЯУќСюЪЕЯж
ЯШевГіФъСфДѓгк30ЫъЕФФаадЃЌСйЪБНсЙћДцЮЊгаађМЏКЯ tempSet1 ЃЌдЊЫига [ РюЫФ:35ЃЌЭѕЮх:43ЃЌедСљ:50
]ЃЛ
НгзХНЋ tempSet1 КЭ male зїНЛМЏЃЌСйЪБНсЙћДцЮЊгаађМЏКЯ tempSet2 ЃЌдЊЫига [
РюЫФ:35ЃЌЭѕЮх:43 ]ЃЛ
ШЛКѓНЋ tempSet2 КЭ sh зїНЛМЏЃЌзюжеНсЙћДцЮЊгаађМЏКЯ resultSet ЃЌдЊЫига [
РюЫФ:35ЃЌЭѕЮх:43 ]ЃЛ
ЫљвдЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад ЁБга РюЫФКЭЭѕЮх ЁЃ
ШчЭМЫљЪОЃК
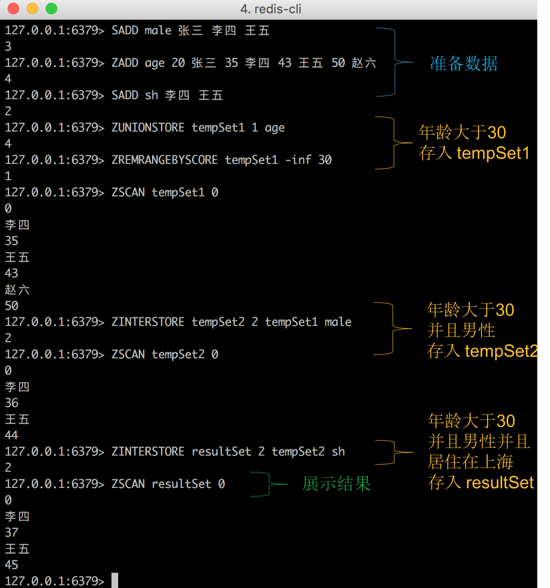
ЭМ3ЃКдЩњУќСюевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад
ЁБЪОР§
ДгЭМжаЮвУЧПЩвдПДГіЃЌвЊевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад ЁБашвЊЖрДЮНјааМЏКЯдЫЫуЃЌЙ§ГЬжагыЗўЮёЦїгаЖрДЮНЛЛЅЃЌВЂЧвЮоЗЈБЃжЄдзгадЁЃ
2.2.2 ЦеЭЈдЩњМЏКЯУќСю+ЪТЮёЪЕЯж
ЕБШЛЃЌЮвУЧПЩвдЪЙгУ Redis ЪТЮёРДБЃжЄМЦЫу tempSet1 ЃЌ tempSet2 КЭ resultSet
ЕФдзгадЃЌЕЋЪЧЃЌШдОЩУЛЗЈБмУтПЭЛЇЖЫгыЗўЮёЖЫЕФЖрДЮНЛЛЅЁЃШчЭМЫљЪОЃК
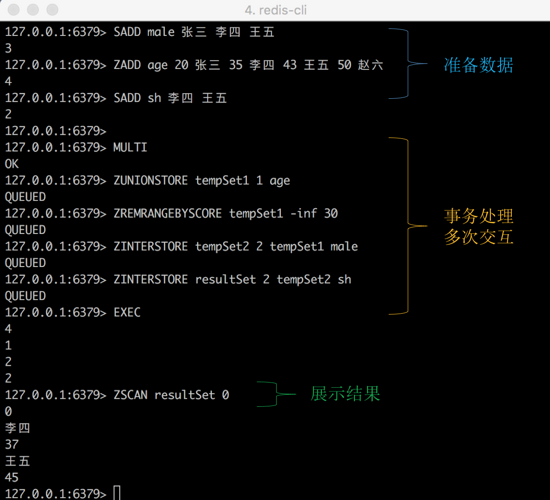
ЭМ4ЃКдЩњУќСю+ЪТЮёевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад
ЁБЪОР§
2.2.3 МЏКЯИіЪ§ВЛЖЈЁЂашЧѓГЁОАЖрБфЕФМЏКЯдЫЫу
СэЭтЃЌЮвУЧдйПДвЛЯТСэМИжжашЧѓЃЌевГіЁА ФъСфДѓгк40ЫъЧвВЛОгзЁдкЩЯКЃЕФФаад ЁБЃЌевГіЁА ФъСфаЁгк30ЫъОгзЁдкЩЯКЃЕФФаад
ЁБЕШЕШЁЃЦфжаЃЌЮвУЧЛсЗЂЯжЃЌеыЖдУПвЛжжашЧѓЃЌЮвУЧашвЊаДЖрЬз redis дЩњУќСюЕФзщКЯТпМ(ЛђепдйМгЩЯ
redis ЪТЮё)ЃЛ
дйепЃЌШчЙћЮвУЧЛЙгаБ№ЕФМЏКЯЃЌБШШчБэЪОадБ№ЮЊХЎадЕФЮоађМЏКЯ female ЃЌдЊЫига[ ЭѕРіЃЌРюКьЃЌеХгЂ
]ЃЌБэЪОжЅТщаХгУЗжЕФгаађМЏКЯ credit ЃЌдЊЫига[ ЭѕРі:550ЃЌРюКь:650ЃЌеХгЂ:730 ]ЃЛЃЈзЂЃКаХгУЗжЃЌФъСфЕШгаађМЏКЯБэЪОЕФЪЧгУЛЇЕФШЋМЏЃЌЪЕМЪЩЯМЏКЯгІЮЊ
age :[ЭѕРі:18ЃЌРюКь:19ЃЌеХгЂ:19ЃЌеХШ§:20ЃЌРюЫФ:35ЃЌЭѕЮх:43ЃЌедСљ:50]ЃЌ
credit :[ЭѕРі:550ЃЌРюКь:650ЃЌеХШ§:675ЃЌРюЫФ:693ЃЌеХгЂ:730ЃЌедСљ:740ЃЌЭѕЮх:751]ЃЉЕШЕШЁЃ
ЯждкзмЕФМЏКЯаХЯЂШчЯТЃК
male : [ еХШ§ЃЌРюЫФЃЌЭѕЮх ]
female : [ ЭѕРіЃЌРюКьЃЌеХгЂ ]
sh : [ РюЫФЃЌЭѕЮх ]ЁЃ
age : [ ЭѕРі:18ЃЌРюКь:19ЃЌеХгЂ:19ЃЌеХШ§:20ЃЌРюЫФ:35ЃЌЭѕЮх:43ЃЌедСљ:50
]
credit : [ ЭѕРі:550ЃЌРюКь:650ЃЌеХШ§:675ЃЌРюЫФ:693ЃЌеХгЂ:730ЃЌедСљ:740ЃЌЭѕЮх:751
]
ФЧУДШчЙћЯждкашвЊевГіЃЌЁАФмПДАзСьШеМЧЧвОгзЁдкЩЯКЃЕФФаадЁБЃЌФЧУДЯШевЕНФаадЃЌдйевЕНОгзЁдкЩЯКЃЕФЃЌШЛКѓевЕНжЅТщаХгУЗжДѓгк750ЕФЃЈзЂЃКжЛгаЗжЪ§ДѓгкЕШгк750ВХФмПДАзСьШеМЧЃЌаЃдАШеМЧЕШЃЉЃЌгУ
Redis дЩњУќСюМгЪТЮёгыЗўЮёЖЫЖрДЮНЛЛЅЃЌМИИіМЏКЯзїдЫЫуКѓЮвУЧвЛЯТзгОЭжЊЕРжЛгаИєБкРЯЭѕЁЊЁЊ ЭѕЮх
ФмПД"АзСьШеМЧ"ЁЃ
ДгДЫПЩвдПДГіЃЌЕБЮвУЧЕФМЏКЯИіЪ§ВЛЖЈЃЌашЧѓГЁОАЖрБфЕФЧщПіЯТЃЌгУдЩњМЏКЯУќСюЛђепЪТЮёашвЊПЭЛЇЖЫЖрЬзБраДИДдгЕФТпМЁЃЃЈетаЉЖМЪЧЮвЪЕМЪПЊЗЂжагіЕНЕФашЧѓЮЪЬтЁЃЃЉ
2.2.4 змНсашвЊЁАгХЛЏЁБЕФдвђ
ФЧУДЮвУЧДѓжТПЩвдЕУГіНсТлЃЌЮЊЪВУДашвЊЁАгХЛЏЁБ Redis МЏКЯдЫЫуЁЃ
дЩњМЏКЯУќСю ВЛжЇГжЖрДЮ НЛВЂВюМЏКЯ ЛьКЯ дЫЫуЃЛ
ЪЙгУдЩњМЏКЯУќСюЖрДЮМЏКЯдЫЫу ВЛФмБЃжЄдзгад ЃЛ
ЪЙгУдЩњМЏКЯУќСюЖрДЮгыЗўЮёЖЫНЛЛЅ ЗЧГЃКФЪБ ЃЛ
ЪЙгУ Redis ЪТЮёЭЌбљЮоЗЈБмУтгыЗўЮёЖЫЖрДЮНЛЛЅ ЃЛ
ЪЙгУдЩњМЏКЯУќСюЛђепЪТЮёашвЊ ПЭЛЇЖЫБраДИДдгТпМ ЁЃ
МШШЛжЊЕРСЫЮЊЪВУДвЊЁАгХЛЏЁБЃЌВЛгХЛЏУЛЗЈБЃжЄвЛДЮНЛЛЅзїЖрДЮМЏКЯЛьКЯдЫЫуЃЌВЛгХЛЏУЛЗЈБЃжЄЖрДЮМЏКЯдЫЫудзгадЃЌВЛгХЛЏУЛЗЈМѕЩйНЛЛЅДЋЪфЕФКФЪБЃЌВЛгХЛЏашвЊПЭЛЇЖЫБраДЖрЬзИДдгТпМЃЌФЧУДЮвУЧШчКЮШЅзігХЛЏФиЃПетЪБКђОЭИУ
" Lua НХБО "вдМАОЕф "ЫФдђдЫЫу" ЫуЗЈЕЧГЁСЫЁЃ Lua
НХБО ЪЧНтОівЛДЮНЛЛЅЃЌКФЪБвдМАдзгадЮЪЬтЕФЃЌЖјОЕф "ЫФдђдЫЫу" ЫуЗЈдђНтОіМЏКЯИіЪ§ВЛЖЈЃЌвЕЮёГЁОАЖрБфЕФЮЪЬтЕФЁЃ
2.2.4 lua НХБОЕФМђЕЅЪОР§
ЯТУцЕФеТНкЛсжиЕуНщЩм " Lua НХБО "вдМАОЕф "ЫФдђдЫЫу"
ЫуЗЈЁЃетРяЯШРДПДвЛИіМђЕЅЕФР§згЃЌЛЙЪЧИеВХЕФашЧѓГЁОАЃЌевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад ЁБЁЃ
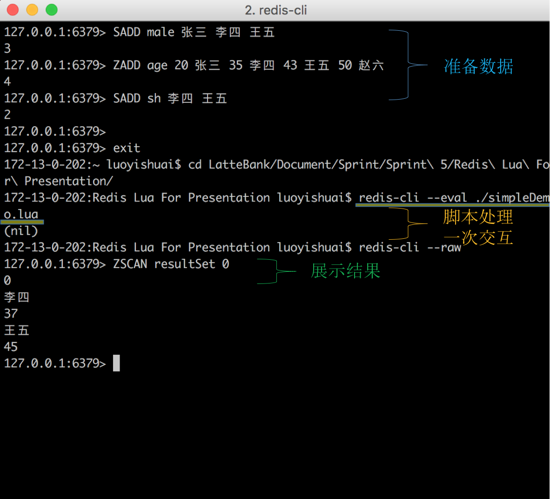
ЭМ5ЃКlua НХБОзщКЯУќСюевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад
ЁБЪОР§
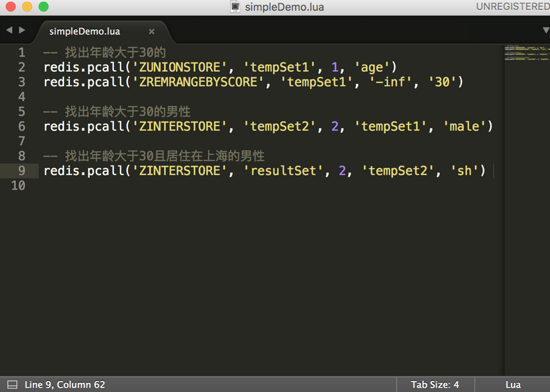
ЭМ6ЃКевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад
ЁБЕФМђЕЅlua НХБО
ЪЙгУ lua НХБОзщКЯСЫЖрЬѕ redis УќСюЃЌдкПЭЛЇЖЫЕїгУЕФЪБКђЃЌжЛашвЊгыЗўЮёЖЫНЛЛЅвЛДЮЃЌАбНХБОДЋЕНЗўЮёЖЫЃЌетРяжЛгавЛДЮДЋЪфЃЌЗўЮёЖЫНгЪмЕННХБОКѓЃЌдзгадЕижДаа
lua НХБОРяЕФЖрЬѕ redis УќСюЁЃ
етРяШчЙћАбМЏКЯЕФНЛВЂВювдМАДѓгкаЁгкЕШБШНЯЗћгГЩфГЩЗћКХ &&ЃЌIIЃЌ^ЃЌ>ЃЌ<
ЕШЃЌФЧУДевГіЁА ОгзЁдкЩЯКЃВЂЧвФъСфДѓгк30ЫъЕФФаад ЁБЕФМЏКЯдЫЫуБэДяЪНОЭПЩвдБэЪОЮЊ age:score>30
&& male && sh ЃЌевГіЁА ФмПДАзСьШеМЧЧвОгзЁдкЩЯКЃЕФФаад
ЁБЕФМЏКЯдЫЫуБэДяЪНОЭПЩвдБэЪОЮЊ credit:score>=750 && male
&& sh ЃЛЦфЫћашЧѓГЁОАгыДЫРрЫЦЃЌЖМПЩвдГщЯѓГЩвЛИіетбљЕФМЏКЯдЫЫуБэДяЪНЁЃ
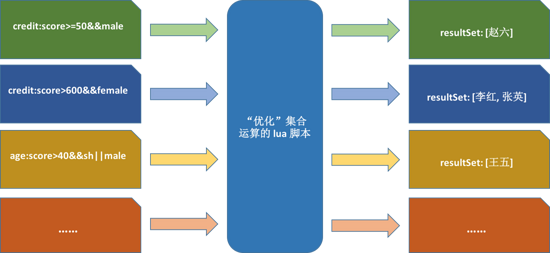
ЭМ7ЃКlua НХБОДІРэМЏКЯИіЪ§ВЛЖЈЃЌвЕЮёашЧѓЖрБфЕФЧщПі
ФЧУДЃЌжЛвЊНХБОЗтзАКУСЫЮоађМЏКЯКЭгаађМЏКЯЕФНЛВЂВюЕШУќСюЃЌНгЪеЩЯЪіФЧбљЕФМЏКЯдЫЫуБэДяЪНЃЌВЂЧвгаЫуЗЈТпМДІРэНЛВЂВюЕШМЏКЯдЫЫуЕФЯШКѓЫГађЃЌФЧУДОЭФмжЇГжЖрИіМЏКЯдЫЫувдМАТњзуВЛЭЌЕФашЧѓГЁОАСЫЃЌетРяЫуЗЈОЭЪЧОЕфЕФЁАЫФдђдЫЫуЁБЫуЗЈЃЌжЛВЛЙ§ЮЊСЫТњзуОпЬхЕФашЧѓЃЌЮвУЧЩдЮЂзіСЫвЛЯТЫуЗЈЕФБфаЮЃЌЩдКѓЛсЯъЯИНщЩмЁЃ
Ш§ЁЂRedis МА Lua ЛљДЁжЊЪЖ
дкНщЩмгУ lua НХБОЪЕЯжОЕфЫФдђдЫЫуЫуЗЈЁАгХЛЏЁБМЏКЯдЫЫужЎЧАЃЌЮвУЧЯШРДСЫНтвЛЯТ Redis вдМА
Lua ЯрЙиЕФЛљДЁжЊЪЖЃЌвдБуКѓајЩюШыНщЩмОпЬхЕФНХБОгыЫуЗЈЁЃ
3.1 Redis ПЭЛЇЖЫгыЗўЮёЖЫНЛЛЅ
3.1.1 ПЭЛЇЖЫгыЗўЮёЖЫНЛЛЅ
Redis ЗўЮёЦїЪЧ вЛЖдЖр ЗўЮёЦїГЬађЃЌвЛИіЗўЮёЦїПЩвдгыЖрИіПЭЛЇЖЫНЈСЂЭјТчСЌНгЃЌетРяЕФПЭЛЇЖЫжИЕФЪЧЦеЭЈПЭЛЇЖЫЃЛRedis
ЛЙга ЮБПЭЛЇЖЫ ЃЌЫќДІРэЕФУќСюЧыЧѓРДздЗўЮёЖЫЕФ lua НХБОЃЈжДаа Redis УќСюЃЉЛђеп AOF
ЮФМўЃЈЛЙдЪ§ОнПтзДЬЌЃЉЃЌЮоашЭЈЙ§ЭјТчСЌНгЃЌжБНгдкЗўЮёЖЫжДааЁЃЦфжаЃЌетСНИіЮБПЭЛЇЖЫгжЩдгаВЛЭЌЃК
Lua ЮБПЭЛЇЖЫ
ЗўЮёЦїдЫааЕФећИіЩњУќжмЦкЛсвЛжБДцдк
ЗўЮёЦїЙиБеЪБЙиБе
AOF ЮБПЭЛЇЖЫ
диШы AOF ЮФМўЛЙдЪ§ОнПтЪБДцдк
диШыЭъГЩКѓЙиБе
СэЭтЃЌRedis ЗўЮёЦїЪЙгУ ЕЅЯпГЬЕЅНјГЬ ЗНЪНДІРэУќСюЧыЧѓЕФЃЌЭЌЪБДІРэЖрИіПЭЛЇЖЫУќСюЧыЧѓашвЊХХЖгЕШД§ЁЃ
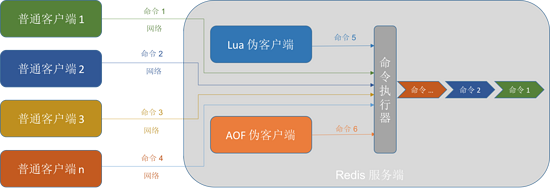
ЭМ8ЃКЦеЭЈПЭЛЇЖЫЃЌЮБПЭЛЇЖЫгыЗўЮёЖЫНЛЛЅ
3.1.2 ПЭЛЇЖЫЛКГхЧјвдМАШэгВадЯожЦ
УПИі Redis ПЭЛЇЖЫгыЗўЮёЖЫСЌНгЪБЃЌЗўЮёЖЫЛсЮЊУПИіПЭЛЇЖЫЕФСЌНгДДНЈЯргІЕФ redisClient
НсЙЙЃЈПЭЛЇЖЫзДЬЌЃЉЃЌЫќБЃДцзХПЭЛЇЖЫЕФЕБЧАзДЬЌаХЯЂЃЈБШНЯЭЈгУЕФЪєадЃЉвдМАжДааЯрЙиЙІФмашвЊгУЕНЕФЪ§ОнНсЙЙЃЈКЭЬиЖЈЙІФмЯрЙиЕФЪєадЃЉЁЃ
| typedef structredisClient{
// ...
intfd; // УшЪіЗћЃК-1-ЮБПЭЛЇЖЫЃЌ Дѓгк-1ЕФећЪ§-ЦеЭЈПЭЛЇЖЫ
robj*name; // Ућзж
intflag; // БъжОЮЛЃЌБэЪОПЭЛЇЖЫНЧЩЋзДЬЌЕШЃК REDIS_SLAVE-ДгЗўЮёЦїЃЌ REDIS_MULTI-е§жДааЪТЮё
sds querybuf; // ЪфШыЛКГхЃЌПеМфИљОнЪфШыЖЏЬЌЩьЫѕЃЌзюДѓЮЊ1GЃЌГЌГіПЭЛЇЖЫЛсБЛЙиБе
/**
* вдЯТСНИіЮЊЙЬЖЈДѓаЁЪфГіЛКГхЧјСНИіЪєад ЃЌ REDIS_REPLY_CHUNK_BYTES
= 16*1024 МД 16 KB
*/
charbuf[REDIS_REPLY_CHUNK_BYTES]; // ЙЬЖЈДѓаЁЛКГхЧјзжНкЪ§зщ
intbufpos; // ЙЬЖЈДѓаЁЛКГхЧјвбЪЙгУзжНкЪ§
list*reply; // ПЩБфДѓаЁЛКГхЧјЃЌСДБэЙЙГЩЃЌ РэТлЩЯПЩБфДѓаЁЛКГхЧјПЩЮоЯоДѓЃЌЪЕМЪЩЯВЛФмГЌЙ§гВадЯожЦ
robj**argv; // УќСюВЮЪ§ЃЌШч "set age 18"
intargc; // УќСюВЮЪ§ИіЪ§ЃЌ ШчЩЯЪіУќСюдђЮЊ 3ЃЌ set БОЩэвВЪЧУќСюВЮЪ§
structredisCommand*cmd; // УќСюЕФЪЕЯжКЏЪ§
intauthenticated; // ЩэЗнбщжЄЃК0-ЮДЭЈЙ§ЃЌ1-ЭЈЙ§
time_tctime; // ПЭЛЇЖЫДДНЈЪБМф
time_tlastinteration; // ПЭЛЇЖЫгыЗўЮёЖЫзюКѓвЛДЮЛЅЖЏЪБМф
time_tobuf_soft_limit_reached_time; // ЪфГіЛКГхЧјЕквЛДЮЕНДяШэадЯожЦЕФЪБМф
// ...
}redisClient |
етРязХжиНВНВЃЌЪфШыЛКГхЧјЃЌЪфГіЛКГхЧјЃЈАќРЈгВадЯожЦгыШэадЯожЦЃЉЁЃ
ЪфШыЛКГхЧј
ПЭЛЇЖЫзДЬЌНсЙЙ redis-cli БЃДцЕФЪфШыЛКГхЧјБЃДцПЭЛЇЖЫЗЂЫЭЕФУќСюЧыЧѓЁЃЛКГхЧјЕФДѓаЁИљОнЪфШыФкШн
ЖЏЬЌЕиЫѕаЁКѓепРЉДѓ ЃЌзюДѓ ВЛФмГЌЙ§ 1G ЁЃ
ШчЙћПЭЛЇЖЫЗЂЫЭЕФУќСюЧыЧѓДѓаЁГЌЙ§СЫЪфШыЛКГхЧјЕФЯожЦДѓаЁЃЈФЌШЯЮЊ1GBЃЉЃЌФЧУДетИіПЭЛЇЖЫНЋЛсБЛЗўЮёЦїЙиБеЁЃ
ЪфГіЛКГхЧј
ЙЬЖЈДѓаЁЛКГхЧј ЁЊЁЊзжНкЪ§зщ
БЃДцГЄЖШНЯаЁЕФЛиИД
БШШч'OK'
БШШчМђЖЬЕФзжЗћДЎжЕ
БШШчећЪ§жЕ
БШШчДэЮѓЛиИДЕШ
ПЩБфДѓаЁЕФЛКГхЧј ЁЊЁЊreplyСДБэ
БЃДцГЄЖШНЯДѓЕФЛиИД
БШШчвЛИіЗЧГЃГЄЕФзжЗћДЎжЕ
БШШчвЛИігаКмЖрЯюзщГЩЕФСаБэ
БШШчАќКЌСЫКмЖрдЊЫиЕФМЏКЯЕШЕШ
ШчЙћЗЂЫЭИјПЭЛЇЖЫЕФУќСюЛиИДДѓаЁГЌЙ§СЫЪфГіЛКГхЧјЕФДѓаЁЃЌФЧУДетИіПЭЛЇЖЫНЋЛсБЛЗўЮёЦїЙиБеЁЃЗўЮёЖЫЪЙгУСНжжФЃЪНРДЯожЦПЭЛЇЖЫЪфГіЛКГхЧјЕФДѓаЁ
гВадЯожЦ
ШчЙћЪфГіЛКГхЧјДѓаЁГЌЙ§СЫгВадЯожЦЩшжУЕФДѓаЁЃЌФЧУДЗўЮёЖЫСЂМДЙиБеПЭЛЇЖЫЁЃ
ШэадЯожЦ
ШчЙћЪфГіЛКГхЧјДѓаЁГЌЙ§СЫШэадЯожЦЩшжУЕФДѓаЁЃЌ ЛЙУЛГЌЙ§гВадЯожЦЃЌФЧУДЗўЮёЖЫНВЪЙгУПЭЛЇЖЫзДЬЌНсЙЙЕФ obuf_soft_limit_reached_time
ЪєадМЧЯТПЭЛЇЖЫЕНДяШэадЯожЦЕФЦ№ЪМЪБМфЃЛ
жЎКѓЗўЮёЖЫЛсМЬајМрПиПЭЛЇЖЫЃЌШчЙћЪфГіЛКГхЧјДѓаЁ вЛжБГЌЙ§ШэадЯожЦ ЃЌВЂЧв ГжајЪБМфГЌЙ§ЗўЮёЦїЩшЖЈЕФЪБГЄ
ЃЌФЧУДЗўЮёЖЫНВЙиБеПЭЛЇЖЫЃЛ
ЯрЗДЕиЃЌШчЙћЪфГіЛКГхЧјДѓаЁдкжИЖЈЪБМфФкВЛдйГЌГіШэадЯожЦЃЌФЧУДПЭЛЇЖЫОЭВЛЛсБЛЙиБеЃЌВЂЧв obuf_soft_limit_reached_time
ЪєаджЕвВЛсБЛЧхСуЁЃ
ЪЙгУ client-output-buffer-limit бЁЯюПЩЮЊЦеЭЈПЭЛЇЖЫЃЌДгЗўЮёЦїПЭЛЇЖЫЃЌжДааЗЂВМгыЖЉдФЕФПЭЛЇЖЫЗжБ№ЩшжУВЛЭЌЕФШэадЯожЦКЭгВадЯожЦЃЌИёЪНШчЯТЃК
client-output-buffer-limit < class
> < hard limit > < soft limit > <
soft seconds >
client-output-buffer-limit normal
0 0 0 ЁЊЁЊ 0 жИВЛЯожЦ
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
ЕБШЛЃЌЭЈЙ§ client list УќСюПЩВщПД redis ПЭЛЇЖЫНсЙЙЕФВПЗжЕБЧАзДЬЌЃЌШчЯТЃК
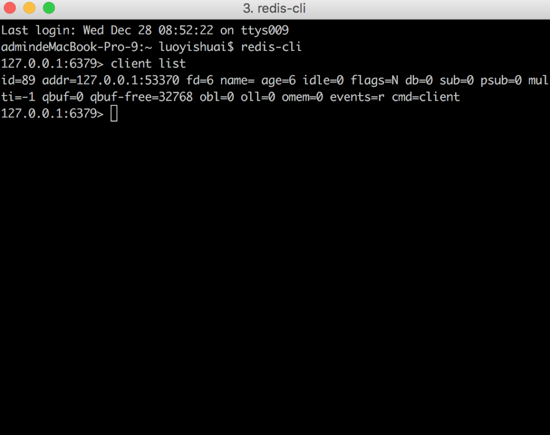
ЭМ9ЃКЭЈЙ§ client list
УќСюВщПЭЛЇЖЫЕБЧАзДЬЌ
3.2 Redis жа Lua ЛЗОГ
3.2.1 ЮвЖд Lua гябдЕФРэНт
Lua гябдЪЧвЛУХЧЖШыЪННХБОгябдЁЃетРягаСНИіЙиМќзжЃК ЧЖШыЪН КЭ НХБО ЁЃ ЁАНХБОЁБ дкетРяЪЧжИЮоашБрвыЃЌАДаажДааЃЌЫќЕФгябдЗчИёИњ
python КЭ perl гябдНЯЮЊРрЫЦЃЛ ЁАЧЖШыЪНЁБ дкетРяЪЧжИЫќЭЈЙ§ЧЖШыФГИіЛЗОГЃЌдйНсКЯЫожїгябдФГаЉЬиадЃЈР§Шчдк
Redis ЛЗОГжаПЩЕїгУ C КЏЪ§ЃЉРДЗЂЛгЫќБОЩэзїЮЊгябдЕФзїгУЁЃ
етРяЖдгкЁАЧЖШыЪНЁБЕФРэНтЃЌШчЙћвд Lua гябдЧЖШыЕН Redis ЛЗОГРДОйР§ЕФЛАЃЌвтЫМЪЧ Redis
ЗўЮёЖЫжага Lua ЛЗОГЃЌЭЈЙ§дк Redis ЗўЮёЖЫжДаа lua НХБОЃЌФмЙЛЪЕЯжгаИДдгТпМЕФЖрИі redis
УќСюЕФдзгжДааЁЃ
3.2.2 ПЭЛЇЖЫЪЙгУ Lua НХБОгы Redis НЛЛЅЕФМђЕЅЪОР§
Redis Дг 2.6 АцБО ПЊЪМв§ШыЖд Lua НХБОЕФжЇГжЃЌЭЈЙ§дкЗўЮёЦїжаЧЖШы Lua ЛЗОГЃЌRedis
ПЭЛЇЖЫПЩвдЪЙгУ Lua НХБОЃЌжБНгдкЗўЮёЦї дзгЕи жДааЖрИіУќСюЁЃ
3.2.2.1 lua НХБОЪфГі Hello World ЕФР§зг
ЯШРДПДИіМђЕЅЕФР§згЃК
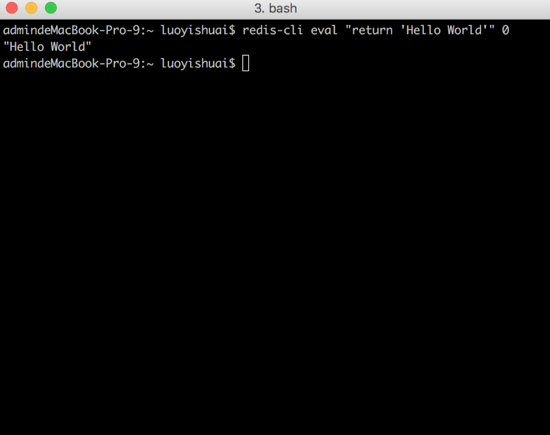
ЭМ10ЃКlua НХБОЪфГі hello
world
ДгЩЯЭМПЩжЊЃЌЕБЗўЮёЖЫПЊЦєЕФзДЬЌЯТЃЌredis ПЭЛЇЖЫЭЈЙ§ eval УќСюжДааСЫ lua НХБОЃЌНХБОФкШнЮЊ
return 'Hello World' ЃЌНХБОДЋШыВЮЪ§жа KEY ЕФИіЪ§ЮЊ 0 ИіЃЛЮвУЧПДЕНПЭЛЇЖЫДђгЁСЫНХБОРяЗЕЛиЕФзжЗћДЎ
Hello World ЁЃ
3.2.2.2 lua НХБОгы Redis НЛЛЅЕФР§зг
дйПДвЛИі lua НХБОгы Redis НЛЛЅЕФР§згЃК
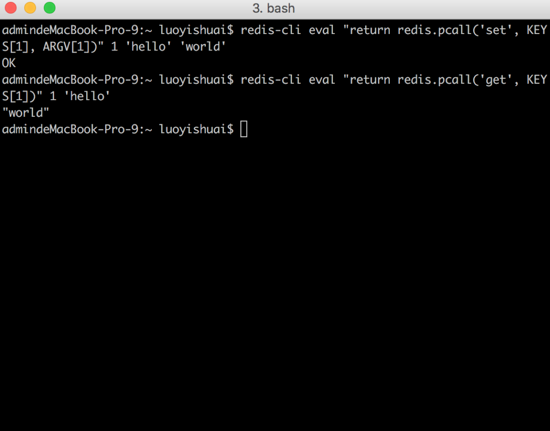
ЭМ11ЃКlua НХБОгы redis
НЛЛЅЃЌ set hello world КЭ get hello
ДгЩЯЭМПЩжЊЃЌЕквЛДЮНЛЛЅжаЃЌredis ПЭЛЇЖЫЭЈЙ§ eval УќСюжДааСЫ lua НХБОЃЌНХБОФкШнЮЊ
return redis.pcall('set', KEYS[1], ARGV[1]) ЃЌНХБОДЋШыВЮЪ§жа
KEY ЕФИіЪ§ЮЊ 1 ЃЌетИіKEYЪЧжИНгдк 1 КѓУцЕФ 'hello' ЃЌетИі 'hello' ЕШ
KEY БЛНХБОРяЕФ KEY[] Ъ§зщНгЪеЃЌ KEY[1] БэЪОЕквЛИі KEY ЃЌМД 'hello'
ЃЌШЛКѓ 'hello' НєНгзХЪЧВЮЪ§ 'world' ЃЌетИі 'world' ЕШ ARGV БЛНХБОРяЕФ
ARGV[] Ъ§зщНгЪеЃЌARGV[1] БэЪОЕквЛИі ARGVЃЌМД 'world' ЃЌНХБОРя redis.pcall()
ЕїгУ set УќСюЃЛЮвУЧПДЕНПЭЛЇЖЫДђгЁСЫНХБОРяжДаа set УќСюЗЕЛиЕФ ok ЃЌШчЭЌжБНггУ redis-cli
аД set УќСюЕУЕНЕФЗЕЛивЛбљЁЃ
ЕкЖўДЮНЛЛЅжаЃЌredis ПЭЛЇЖЫЭЌбљЭЈЙ§ eval УќСюжДааСЫ lua НХБОЃЌНХБОФкШнЮЊ return
redis.pcall('get', KEYS[1]) ЃЌНХБОДЋШыВЮЪ§жа KEY ЕФИіЪ§ЮЊ 1 ЃЌетИі
KEY ЪЧжИНгдк 1 КѓУцЕФ 'hello' ЃЌгыЕквЛДЮжДаа set УќСюЕФНЛЛЅвЛбљЃЌетИі 'hello'
ОЭЪЧ KEYS[1] ЃЌетРяУЛгаВЮЪ§ ARGV[]ЃЌНХБОРя redis.pcall() ЕїгУ get
УќСюЃЛЮвУЧПДЕНПЭЛЇЖЫДђгЁСЫНХБОРяжДаа get УќСюЗЕЛиЕФ 'world' ЃЌШчЭЌжБНггУ redis-cli
аД get УќСюЕУЕНЕФЗЕЛивЛбљЁЃ
ДгвдЩЯСНИіР§згПЩвдПДЕНЃЌredis ПЭЛЇЖЫЭЈЙ§ eval УќСюАб lua НХБОДЋЫЭЕН redis
ЗўЮёЖЫжДааЃЌВЂЧвПЩвдЪЙгУ redis.pcall() КЏЪ§ЕїгУ redis ЕФУќСюЁЃ
ФЧУДетИіЙ§ГЬЪЧдѕУДбљЕФФиЃПНгЯТРДвЛаЁНкзіИіДѓИХЕФВћЪіЁЃ
3.2.3 Lua гябдШчКЮ "ЧЖШы" Redis ЛЗОГ
дкНщЩм eval УќСюДгЗЂЫЭНХБОЕНЗўЮёЖЫЕНЗўЮёЖЫжДааНХБОжЎЧАЃЌЮвУЧЯШПДвЛЯТжДаа lua НХБОЧА Redis
ЕФвЛаЉзМБИЙЄзїЁЃ
3.2.3.1 lua ЛЗОГзМБИЙЄзїЁЊЁЊЮБПЭЛЇЖЫ
ШчжЎЧАЫљЪіЃЌЗўЮёЖЫЪЧЭЈЙ§ДДдьвЛИіЮБПЭЛЇЖЫРДзЈУХжДаа lua НХБОЕФЁЃЗўЮёЦїФкЧЖвЛИі Lua ЛЗОГЃЌВЂЖдетИіЛЗОГНјаавЛЯЕСааоИФЃЌДгЖјШЗБЃетИі
Lua ЛЗОГПЩвдТњзу Redis ЗўЮёЦїЕФашвЊЃЈОЭЮвИіШЫЕФРэНтЃЌетИіЛЗОГПЩвдРрБШ JavaгябджаЕФ
JVMЃЉЁЃ
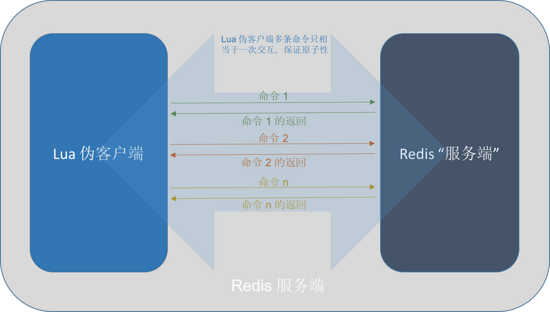
ЭМ12ЃКlua ЮБПЭЛЇЖЫ
Redis ЗўЮёЦїДДНЈКЭаоИФ Lua ЛЗОГЕФећИіЙ§ГЬАќРЈвдЯТВНжшЃК
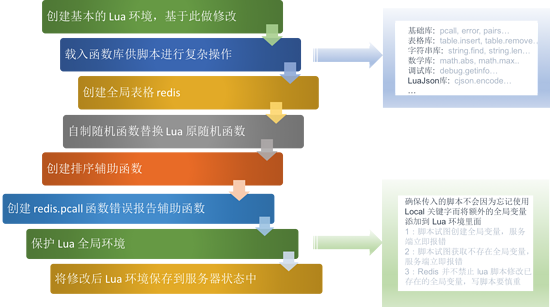
ЭМ13ЃКДДНЈКЭаоИФ Lua ЛЗОГЙ§ГЬ
ДгЩЯЭМЕУжЊЃЌRedis ДДНЈКЭаоИФ Lua ЛЗОГОЙ§СЫАЫИіВНжшЃЌПЩвдЗжЮЊ ДДНЈ -> аоИФ
-> ЬэМг Ш§ДѓЙ§ГЬЃЛжївЊЕФЙ§ГЬПЩвдИХЪіЮЊЃКДДНЈЛљБОЕФ lua ЛЗОГЃЌ ЮЊЛЗОГдиШыКЏЪ§ПтЃЌЛљгк
Redis ЛЗОГЖд lua НХБОдгаЕФКЏЪ§зіЕїећВЂЧвНћжЙВПЗж lua НХБОЕФЙІФмвдБЃЛЄ Redis
жа lua ЕФШЋОжЛЗОГЃЌШЛКѓАбОЙ§етИіаоИФКѓЕФ lua ЛЗОГЬэМгЕНЗўЮёЦїзДЬЌНсЙЙжаЁЃ
КУСЫЃЌФЧУДЖрИіПЭЛЇЖЫЖМЕїгУСЫ lua НХБОЃЌФЧашвЊЖрЩйИіЛЗОГФиЃП
ИеВХЮвУЧвбОСЫНтЙ§СЫ Redis ЪЙгУДЎааЛЏЃЈЕЅЯпГЬЃЉЗНЪНжДаа Redis УќСюЕФЃЌЫљвдД№АИЪЧЃЌдкЬиЖЈЪБМфФкЃЌ
зюЖржЛгавЛИіНХБОФмЗХдк lua ЛЗОГжа ЃЌФЧУДећИі Redis ЗўЮёЦї жЛашвЊДДНЈвЛИі Lua ЛЗОГ
МДПЩЁЃ
ФЧУДЮвУЧРДПДвЛЯТЃЌНХБОЕїгУЗНЁЂlua ЛЗОГЁЂЮБПЭЛЇЖЫгыЗўЮёЖЫЃЈЦфЪЕЪЧжИУќСюжДааЦїЃЉжЎМфЕФНЛЛЅЙиЯЕЁЃ
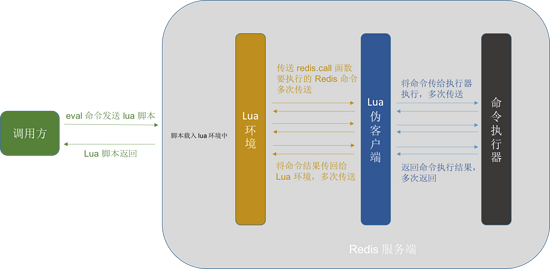
ЭМ14ЃКНХБОЕїгУЗНЁЂlua ЛЗОГЁЂЮБПЭЛЇЖЫгыЗўЮёЖЫЃЈЦфЪЕЪЧжИУќСюжДааЦїЃЉНЛЛЅЙиЯЕ
ЗўЮёЖЫзМБИКУ Lua ЛЗОГКѓЃЌJedis Лђеп redis-cli ЕШЕїгУЗНЭЈЙ§ eval УќСюАб
Lua НХБОЗЂЫЭЕНЗўЮёЖЫЃЌЗўЮёЖЫдиШыНХБОЕН lua ЛЗОГЃЌlua ЛЗОГАб redis.call()
КЏЪ§вЊжДааЕФ redis УќСюЗЂЫЭЕН lua ЮБПЭЛЇЖЫЃЌЮБПЭЛЇЖЫОЭКЭЦеЭЈПЭЛЇЖЫвЛбљЕигыУќСюжДааЦїНЛЛЅЁЊЁЊЁЊЁЊЗЂЫЭУќСюгыЛёШЁУќСюНсЙћЁЃЦфжаЃЌ
redis.call() КЏЪ§ПЩФмЪЧдк lua НХБОжаЖрДЮБЛЕїгУЕФЃЌЫљвдЛсгаЖрДЮЕФгы redis УќСюжДааЦїЕФ
НЛЛЅ ЁЃ
3.2.3.2 lua ЛЗОГжЎНХБОзжЕф
дк Lua ЛЗОГгыЗўЮёЖЫЕФНЛЛЅЕФЙ§ГЬжаЃЌГ§СЫЮБПЭЛЇЖЫетИізщМўЃЌЛЙгаСэвЛИізщМўЪЧ НХБОзжЕф ЃЈlua_sriptsЃЉЁЃетИізжЕфЕФМќЪЧФГИі
Lua НХБОЕФ SHA1 аЃбщКЭЃЌзжЕфЕФжЕЪЧетИіНХБОЃЌФЧУДзжЕфОЭПЩвдЮЌЛЄЖрИі lua НХБОЁЃ
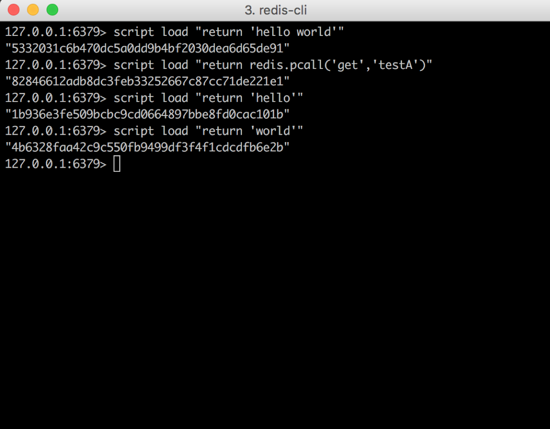
ЭМ15ЃКЭЈЙ§ script load
УќСюМгди lua НХБОЕФ SHA1 жЕ

ЭМ16ЃКredisServer НсЙЙжаЕФ
lua_scripts
3.2.4 eval УќСюИёЪНМАЦфжДааЙ§ГЬ
3.2.4.1 eval УќСюИёЪН
Redis ЭЈЙ§ eval УќСюжДаа lua НХБОЃЌeval УќСюИёЪНЮЊЃК EVAL script
numkeys key [key ...] arg [arg ...]
УќСюЕквЛИіВЮЪ§ scipts ЪЧНХБОЃЌЕкЖўИіВЮЪ§ numkeys ЪЧМќУћ key ЕФИіЪ§ЃЌКѓУцИњзХМќ
keyЃЌНгзХЪЧНХБОЫљашВЮЪ§ argЁЃБШШчЃК
> eval "return {KEYS[1],KEYS[2],ARGV[1]}"
2key1 key2 first
1) "key1"
2) "key2"
3) "first"
етРя numkeys ЮЊ2БэЪОга key1 key2 СНИіМќЃЌkey1 key2 ДЋШыЕННХБОжаЃЌБЛ
KEYS[] Ъ§зщНгЪеЃЌfirst НХБОВЮЪ§БЛ ARGV[] Ъ§зщНгЪеЁЃЯъЧыЧыВЮПМЃК Redis eval
command
Redis НЈвщЫљгагУЕНЕФ key (жИredisЕФkey)ЃЌЖМашвЊДЋЕН KEYS[] Ъ§зщЃЌЖјВЛЪЧДЋЕН
ARGV[] Ъ§зщЃЌетИігІИУЪЧЛљгк Redis МЏШКЕФПМТЧЁЃ
зЂвтЃКlua НХБОКЭЪТЮёЦфжагаУќСюГіДэЃЌЖМЛсМЬајЭљЯТжДааЃЌВЂУЛгаЛиЙіЁЃ
ЮЊСЫБЃжЄдзгадЃЌгУscanЃЌzscan Лђеп sscan ЕШУќСюЛсЁАзшШћЁБЗўЮёЖЫЃЌетРяЕФЁАзшШћЁБЪЧжИЖд
redis Ъ§ОнПтЕФаДВйзїЮоЗЈЩњаЇЁЃ
3.2.4.2 eval УќСюжДааЙ§ГЬ
КУСЫЃЌЯждкдйРДЛиД№ЧАУцЫЕЃЌeval УќСюЗЂЫЭНХБОЕНЗўЮёЖЫЕНЗўЮёЖЫжДааНХБОетИіЙ§ГЬЪЧдѕУДбљЕФФЧИіЮЪЬтЁЃ
eval УќСюжДааЙ§ГЬПЩвдЗжЮЊвдЯТШ§ИіВНжшЃК
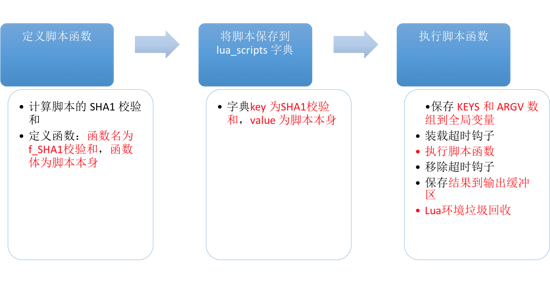
ЭМ17ЃКeval УќСюжДааЙ§ГЬ
ИљОнПЭЛЇЖЫИјЖЈЕФ Lua НХБОЃЌдк Lua ЛЗОГжаЖЈвхвЛИі Lua КЏЪ§ЁЃ
МЦЫуНХБОЕФ SHA1 аЃбщКЭ
КЏЪ§УћЮЊ f_SHA1аЃбщКЭЃЌКЏЪ§ЬхЮЊНХБОБОЩэ
Р§ШчЃКЖдгкУќСю eval "return 'hello world'" 0 ЃЌНХБОЮЊ
return 'hello world' ЃЌМЦЫуЫќЕФ SHA1 аЃбщКЭЮЊ ЁА 5332031c6b470dc5a0dd9b4bf2030dea6d65de91
ЁБЃЌФЧУДКЏЪ§УћЮЊ f_5332031c6b470dc5a0dd9b4bf2030dea6d65de91
ЃЌКЏЪ§ЬхЮЊ return 'hello world' ЁЃ
ЪЙгУКЏЪ§БЃДцДцШыНХБОКУДІЪЧЃК
жДааНХБОКмМђЕЅЃЌЕїгУгыНХБОЯргІЕФКЏЪ§МДПЩЁЃ
ЭЈЙ§КЏЪ§ЕФОжВПадШУ Lua ЛЗОГБЃГжЧхНрЃЌМѕЩйРЌЛјЛиЪеЕФЙЄзїСПЃЌВЂЧвБмУтЪЙгУШЋОжБфСПЁЃ
ШчЙћНХБОЖдгІЕФКЏЪ§БЛЖЈвхЙ§ЃЌФЧУДжЛвЊМЧзЁетИіНХБОЕФ SHA1 аЃбщКЭЃЌОЭПЩвддкВЛжЊЕРНХБОЕФЧщПіЯТЃЌжБНгЭЈЙ§ЕїгУ
lua КЏЪ§жДааКЏЪ§ЁЃетвВЪЧ eval УќСюЕФЪЕЯждРэЁЃ
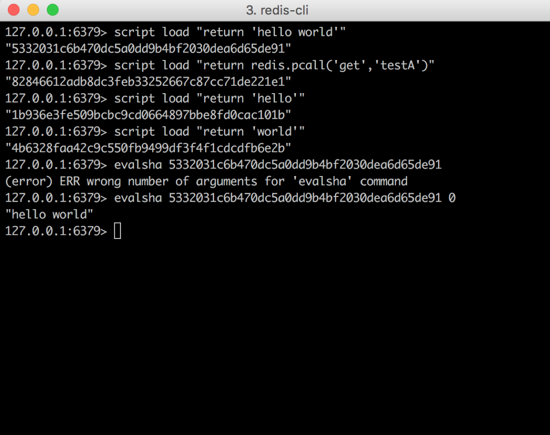
ЩЯЭМжаЃЌЕБЕУжЊНХБОЕФ SHA1 аЃбщКЭЃЌжБНгЭЈЙ§ evelsha УќСюПЩвджБНгЕїгУ SHA1 аЃбщКЭЖдгІЕФНХБО
ЃЌМДЩЯУцЕФ return 'hello world'
НЋПЭЛЇЖЫИјЖЈЕФ Lua НХБОБЃДцЕН lua_scripts зжЕфЃЌЕШД§НЋРДНјвЛВНЪЙгУЁЃ
НХБОЕФ SHA1 аЃбщКЭзїЮЊ key ЃЌ НХБОБОЩэзїЮЊ value жЕДцШы lua_scripts
зжЕфЁЃ

жДааИеИедк Lua ЛЗОГжаЖЈвхЕФКЏЪ§ЃЌвдДЫРДжДааПЭЛЇЖЫИјЖЈЕФ Lua НХБОЁЃ
зМБИКЭжДааНХБОЙ§ГЬШчЯТЃК
НЋ eval УќСюДЋШыЕФМќУћВЮЪ§КЭНХБОВЮЪ§ЗжБ№ДцЕН KEYS Ъ§зщКЭ ARGV Ъ§зщ ЃЌзїЮЊ ШЋОжБфСП
ДЋЕН Lua ЛЗОГРяУцЁЃ
НЋ Lua ЛЗОГзАдиГЌЪБДІРэЙГзгЃЌдкНХБОГіЯжГЌЪБЧщПіЯТЃЌПЭЛЇЖЫПЩЭЈЙ§ script kill УќСюЭЃжЙНХБОЛђеп
shutdown nosave УќСюжБНгЙиБеЗўЮёЦї
НХБОгазюДѓжДааЪБМфЃЌФЌШЯЮЊ 5 УыЃЌБЃДцдкХфжУЮФМўЕФ lua-time-limit ХфжУЯюРяЁЃ
жДааНХБОКЏЪ§
НХБОжЛПЩДЋВЮКЭаоИФ Redis Ъ§ОнЃЌВЛПЩЗУЮЪЭтВПЯЕЭГЃЈЗУЮЪЮФМўЯЕЭГКЭЯЕЭГЕїгУЃЉ
вЦçÍЪБЙГзг
НЋжДааКЏЪ§ЫљЕУ НсЙћБЃДцЕНЪфГіЛКГхЧј ЃЌЕШЕНЗўЮёЦїНЋНсЙћЗЕЛиИјПЭЛЇЖЫ
Жд Lua ЛЗОГжДаа РЌЛјЛиЪе Вйзї
ЫФЁЂЁАЫФдђдЫЫуЁБЫуЗЈЛљДЁжЊЪЖ
Ъ§бЇвтвхЩЯЃЌМгМѕГЫГ§дЫЫуБЛГЦЮЊЁАЫФдђдЫЫуЁБЃЌШч 1+2*3-4 ЃЌЁАЫФдђдЫЫуЁБЫуЗЈжївЊЗжСНВНЃКЕквЛВНЪЧ
жазКБэДяЪНзЊКѓзКБэДяЪН ЃЌЕкЖўВНЪЧ МЦЫуКѓзКБэДяЪНЕУЕННсЙћ ЁЃ
4.1 ЛљБОИХФюНщЩм
4.1.1 жазКБэДяЪНгыКѓзКБэДяЪН
вЛАуЧщПіЯТЃЌЫФдђдЫЫуЕФБэДяЪНЮЊжазКБэДяЪНЃЌБШШчБэДяЪН A+(B-C/D)*E ЃЌИУБэДяЪНЕФжазКБэДяЪНгыКѓзКБэДяЪНШчЯТЃК
жазКБэДяЪНЃК A+(B-C/D)*E
КѓзКБэДяЪНЃК ABCD/-E*+
жазКБэДяЪННЋ ВйзїЗћ жУгкСНИіВйзїЪ§ жа ЃЛ КѓзКБэДяЪН НЋ ВйзїЗћ жУгкСНИіВйзїЪ§жЎ Кѓ ЃЛСэЭтЃЌКѓзКБэДяЪНвбО
ؽçУКХ ЃЌВЂЧв ЖЈвхСЫдЫЫуЕФЯШКѓЫГађ ЃЌЩдКѓЮвУЧРДЗжЮіЁЃ
4.1.2 ВйзїЗћгыВйзїЪ§
жаКѓзКБэДяЪНжаЕФзжЗћгаВйзїЪ§КЭВйзїЗћжЎЗжЃК
ВйзїЗћЃКБэДяЪНжаЕФ +-*/() ЃЈЩдКѓдЫЫугУЕНЕФ # ЗћКХвВЪЧЃЉ
ВйзїЪ§ЃКБэДяЪНжаЕФ ABCDE
вВОЭЪЧЫЕЃЌЮвУЧНЋМг(+)ЁЂМѕ(-)ЁЂГЫ(*)ЁЂГ§(/)ЁЂКЭРЈКХ("()")ГЦзї
ВйзїЗћ ЃЌНЋдЫЫуЕФзжЗћAЁЂBЁЂCЁЂDЁЂEГЦзї ВйзїЪ§ ЁЃ
4.1.3 еЛЁЂЖгСагыВйзїЗћгХЯШМЖ
НЋжазКБэДяЪНзЊЮЊКѓзКБэДяЪНЃЌашвЊ
вЛИіВйзїЗћеЛ ЁЊЁЊ КѓНјЯШГі LIFO
вЛИізжЗћЖгСа ЁЊЁЊ ЯШНјЯШГі FIFO
ЖЈвхВйзїЗћгХЯШМЖ
ЦфжаЃЌ ВйзїЗћеЛ ДцДЂВйзїЗћЃЌВЂЖдВйзїЗћНјааШыеЛГіеЛВйзїЃЛ зжЗћЖгСа ДцДЂзЊЛЛЧАКѓЕФБэДяЪНЃЛ ВйзїЗћгХЯШМЖ
ЖЈвхСЫеЛФквдМАеЛЭтИїИіВйзїЗћЕФгХЯШМЖЁЃ
ВйзїЗћгХЯШМЖЙцдђШчЯТЃК
* / гХЯШМЖЯрЭЌЃЌ + - гХЯШМЖЯрЭЌ
гХЯШМЖЃК * / > + - ЃЛ
ЭЌвЛгХЯШМЖ(БШШч + - )ЃКЯШНјеЛ < КѓНјеЛЃЛ
ОЎКХ # гХЯШМЖзюЕЭ
дкеЛЭтЃЌзѓРЈКХ ( гХЯШМЖзюИпЃЛдкеЛФкЃЌ ( гХЯШМЖГ§ОЎКХ # ЭтзюЕЭ
змЕФРДЫЕЃЌдкеЛЭт ( > * / > + - > ) > '#'ЃЛдкеЛФк *
/ > + - > ) > ( > #
МЦЫуКѓзКБэДяЪНЃЌашвЊ
вЛИіВйзїЪ§еЛ ЁЊЁЊ КѓНјЯШГі LIFO
вЛИізжЗћЖгСа ЁЊЁЊ ЯШНјЯШГі FIFO
4.2 жазКБэДяЪНзЊКѓзКБэДяЪНЕФЙ§ГЬ
4.2.1 зЊЛЛЙ§ГЬСїГЬЭМ
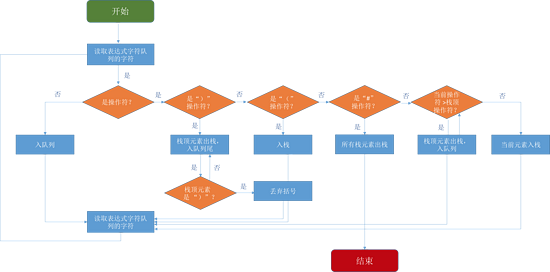
ЭМ18ЃКжазКБэДяЪНзЊКѓзКБэДяЪНЙ§ГЬ
жївЊЕФЙ§ГЬЮЊЃК
бЛЗЖСШЁБэДяЪНзжЗћЖгСаЕФзжЗћ
ШчЙћЪЧВйзїЪ§
жБНгШыЖгСа
ШчЙћЪЧВйзїЗћ
ШчЙћЪЧ ")" ВйзїЗћ
еЛЖЅдЊЫиГіеЛЃЌШыЖгСаЃЌжБЕНгіЕНЕквЛИі ЁА(ЁБ
ШчЙћЛЙУЛЖСШЁЕН ЁБ(ЁАЃЌОЭвбОЖСЕНСЫ "#"ЃЌЫЕУїБэДяЪНзѓРЈКХКЭгвРЈКХВЛЦЅХф
ЗёдђЃЌШчЙћЪЧ ЁА(ЁБ ВйзїЗћ
жБНгШыеЛ
ЗёдђЃЌБШНЯжИеыЖСШЁЕФЕБЧАВйзїЗћЃЌгыеЛЖЅВйзїЗћЕФгХЯШМЖ
ШчЙћЕБЧАдЊЫи <= еЛЖЅдЊЫи
еЛЖЅдЊЫиГіеЛЃЌШыЖгСа
жБЕНгіЕНгХЯШМЖ > ЕБЧАдЊЫиЕФеЛЖЅЕЅДЪЃЌЛђепгіЕНЁА#ЁБЃЌЕБЧАдЊЫиШыеЛ
ЗёдђЃЌЃЈЕБЧАдЊЫигХЯШМЖ > еЛЖЅдЊЫиЃЉЕБЧАдЊЫиШыеЛ
ЕБЖгСаЖСШЁЕНФЉЮВЃЌеЛжаЫљгадЊЫивРДЮГіеЛЃЌВЂШыЖгСаЃЈ#вВШыЖгСаЃЉ
4.2.2 зЊЛЛЙ§ГЬЯъЯИЪОР§
БэДяЪН A+(B-C/D)*E жазКзЊКѓзКСїГЬВЮМћШчЯТ PPT бнЪОЃК жазКзЊКѓзКСїГЬ
4.3 МЦЫуКѓзКБэДяЪНЙ§ГЬ
4.3.1 МЦЫуЙ§ГЬСїГЬЭМ
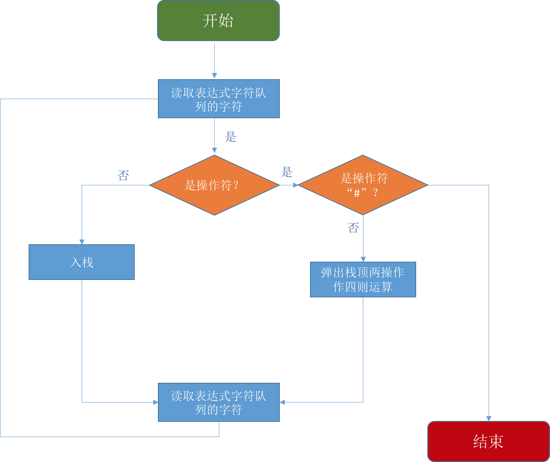
ЭМ19ЃКМЦЫуЙ§ГЬСїГЬЭМ
жївЊЕФЙ§ГЬЮЊЃК
бЛЗЖСШЁБэДяЪНзжЗћЖгСаЕФзжЗћ
ШчЙћЪЧВйзїЪ§ЃЈВЛЪЧВйзїЗћЃЉ
жБНгШыеЛ
ЗёдђЪЧВйзїЗћ
еЛЖЅЕЏГіСНИіВйзїЗћЃЌзіЫФдђдЫЫуЃЌНсЙћжиаТШыеЛ
ШчЙћгіЕНЖгСаЮВЃЌНсЪј
4.3.2 МЦЫуЙ§ГЬЪОР§
БэДяЪН ABCD/-E*+ МЦЫуКѓзКБэДяЪНСїГЬВЮМћШчЯТ PPT бнЪОЃК МЦЫуКѓзКБэДяЪНСїГЬ
4.4 МђЕЅЪОР§
ЯТУцбнЪОвЛИіМђЕЅЕФЪОР§ЃЌбнЪОЭЈЙ§жазКБэДяЪНзЊКѓзКБэДяЪНЃЌВЂМЦЫуКѓзКБэДяЪНРДМЦЫу 1+(3-4/2)*5
ЕФЙ§ГЬЃК
БэДяЪН 1+(3-4/2)*5 жазКзЊКѓзКСїГЬВЮМћШчЯТ PPT бнЪОЃК жазКзЊКѓзКЪОР§
БэДяЪН 1342/-5*+ МЦЫуКѓзКБэДяЪНСїГЬВЮМћШчЯТ PPT бнЪОЃК МЦЫуКѓзКБэДяЪНЪОР§
ЮхЁЂLua НХБОЪЕЯж ЁАЫФдђдЫЫуЁБЫуЗЈЁАгХЛЏЁБМЏКЯдЫЫу
5.1 ДгРэТлЕН lua НХБОЪЕеНИХЪі
МШШЛвбОевЕНСЫ Redis гы Lua ЕФЛљДЁжЊЪЖЃЌвВжЊЕРЁАЫФдђдЫЫуЁБЫуЗЈЕФЛљДЁжЊЪЖЃЌФЧУДНгЯТРДЮвУЧПДПДШчКЮгУ
Lua НХБОРДЪЕЯжЃЌВЂЧвЙ§ГЬжаашвЊзіФФаЉТфЕиЪЕеНЕФИФдьЁЃ
дйПДвЛЯТжЎЧАЕФ Lua НХБОДІРэМЏКЯИіЪ§ВЛЖЈЃЌвЕЮёашЧѓЖрБфЕФЧщПіЕФЭМЁЃ
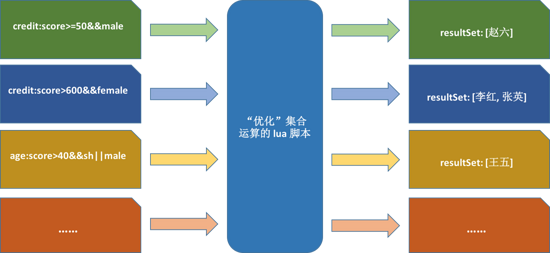
ЭМ20ЃКlua НХБОДІРэМЏКЯИіЪ§ВЛЖЈЃЌвЕЮёашЧѓЖрБфЕФЧщПі
ДгЭМЕФзѓБпвЛРИЮвУЧПЩвдПДЕНЃЌУПвЛРИЮЛЖМЪЧвЛИіБэДяЪНЃЌЮвУЧПЩвдЖдЦфжаЕФБэДяЪНзіВ№ЗжЃЌвдЗћКЯЁАЫФдђдЫЫуЁБЫуЗЈжаЁАзжЗћЁБЕФЖЈвхЃЌетРяЮвУЧвдЪОР§РДНВНтЃЌ
credit:score >= 50 && male ПЩвдВ№ЗжЮЊ credit:score
ЁЂ >= ЁЂ 50 ЁЂ && КЭ male ЮхВПЗжЃЌЦфжаЃК
ВйзїЗћЃК >= &&
ВйзїЪ§ЃК credit:score ЁЂ 50 ЁЂ male
ЮвУЧАбВйзїЗћКЭВйзїЪ§зїЮЊзюЛљБОЕФЕЅдЊЃЌЯрЕБгкОЕфЁАЫФдђдЫЫуЁБЫуЗЈЕФЁАзжЗћЁБЃЌетРяЮвУЧГЦзїЁАЕЅДЪЁБЃЌМДвдЁАЕЅДЪЁБзізюЛљБОЕЅдЊзїдЫЫуЁЃ
ЮвУЧПЩвдЯыЕНЃЌШчЙћАбОЕфЁАЫФдђдЫЫуЁБЫуЗЈЕФВйзїЗћ + - * / ЛЛГЩ && ||
^ >= > <= < = != ЕШВйзїЗћЃЌАбОЕфЁАЫФдђдЫЫуЁБЫуЗЈЕФВйзїЪ§
A B C D E ЃЌЬцЛЛЮЊ Redis МЏКЯНЛВЂВюдЫЫуашвЊЕФ male ЁЂ age ЁЂКЭ credit:score
ЕШВйзїЪ§ЃЌФЧУДЮвУЧОЭПЩвдЪЕЯжетИі Lua НХБОТњзуМЏКЯЕФНЛВЂВюЕШЛьКЯдЫЫуЁЃ
5.2 lua НХБОЪЕеН
5.2.1 МђЕЅбнЪО
ЛЙЪЧЕквЛНкОйР§ЕФР§згЃК
ЭМ21ЃКзМБИЮоађМЏКЯ maleЃЌshЃЌгаађМЏКЯ
age

ЭМ22ЃКЪЙгУ lua НХБОдЫЫу sh
&& male && age:score >40 ЪОР§
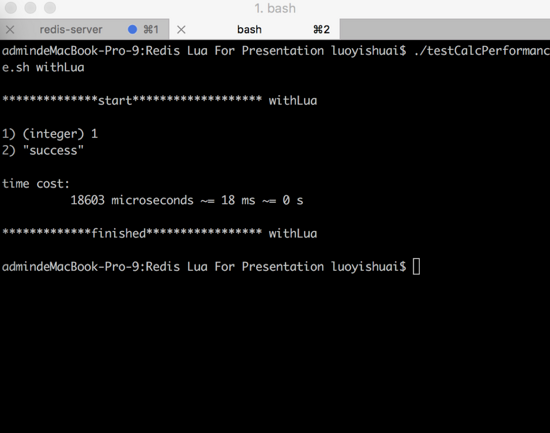
ЭМ23ЃКХм shell НХБОЕїгУ lua
НХБО
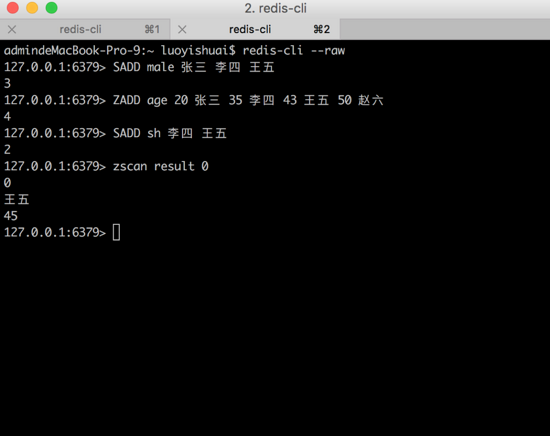
ЭМ24ЃКВщПД lua НХБОдЫЫуЕУЕНЕФгаађМЏКЯ
result
ДгвдЩЯМИИіЭМПЩвдПДЕНЃЌдЫЫу sh && male && age:score
>40 втЫМЪЧевГі ОгзЁдкЩЯКЃЧвФъСфДѓгк40ЫъЕФФаад ЃЌДгНсЙћПЩжЊЃЌОЭЪЧ ЭѕЮх ЃЌЦфФъСфЮЊ45ЫъЁЃДгетИіМђЕЅЕФЪОР§ЮвУЧПЩвдЭЦВтЃЌжЛвЊгаЯргІЕФМЏКЯЃЌЕБаДКУБэДяЪНЃЌЖМФмвЛДЮадЕигыЗўЮёЖЫНЛЛЅЃЌЫуГіЯывЊЕФБэДяЪННсЙћЁЃ
НгЯТРДЮвУЧДгЩшМЦКЭДњТыВуУцРДЪЕЯжетИіНХБОЁЃ
5.2.2 ЩшМЦВуУц
ЮвУЧашвЊЃК
СНжжЪ§ОнНсЙЙЃК
еЛ
ЖгСа
жївЊЕФСНИіСїГЬЃК
жазКБэДяЪНзЊКѓзКБэДяЪН
МЦЫуКѓзКБэДяЪНЕУЕННсЙћ
ИЈжњЕФвЛИіСїГЬЃК
зжЗћађСазЊЕЅДЪађСа
ВйзїЗћгХЯШМЖ
5.2.3 ДњТыВуУц
5.2.3.1 еЛЖЈвх
--[[
еЛЖЈвх
ИёЪНЪОР§ЃК{stack_table={"A","B","C"}
}
КЏЪ§ЃК
аТНЈВЂГѕЪМЛЏеЛЃКnew(o) --oЮЊЛљДЁеЛЃЌПЩЮЊ nil
ШыеЛЃКpush(element)
ГіеЛЃКpop()
ЛёШЁеЛЖЅдЊЫиЃКtop()
ХаЖЯЪЧЗёПееЛЃКisEmpty()
еЛДѓаЁЃКsize()
ЧхПееЛЃКclear()
ДђгЁеЛдЊЫиЃКprintElement()
--]] |
5.2.3.2 ЖгСаЖЈвх
--[[
ЖгСаЖЈвх
ИёЪНЪОР§ЃК{queue_table={"A","B","C"},capacity=
10000,size_= 3,head= 0,rear= 0}
КЏЪ§ЃК
аТНЈВЂГѕЪМЛЏЖгСаЃКnew(o) --oЮЊЛљДЁЖгСаЃЌПЩЮЊ nil
ШыЖгСаЃКenQueue(element)
ГіЖгСаЃКdeQueue()
ХаЖЯЪЧЗёПеЖгСаЃКisEmpty()
ЖгСаДѓаЁЃКsize()
ЧхПеЖгСаЃКclear()
ДђгЁЖгСадЊЫиЃКprintElement()
--]] |
5.2.3.3 ТпМБэДяЪНРрЖЈвх
--[[
ТпМБэДяЪНМЦЫуЦїЖЈвх ЃЈРћгУБеАќЕФЗНЪНФЃФтУцЯђЖдЯѓБрГЬЕФРрЃЉ
ЫНгаГЩдБЪєадЃК
logic_exprЃКТпМБэДяЪН
key_final_setЃКзюжеНсЙћМЏЕФkey
is_sorted_set_calcЃКЪЧЗёЪЧгаађМЏКЯЕФдЫЫу
ЫНгаГЩдБКЏЪ§ЃК
ХаЖЯЪЧЗёЮЊВйзїЗћЃКisOperator(key)
ХаЖЯБэДяЪНЪЧЗёгаБЃСєзж'#'ЃКhasNoSharpInExpr()
аЃбщБэДяЪНРЈКХЪЧЗёГЩЖдГіЯжЃКisBracketsMatch()
strБэДяЪНзЊqueue_tableЃКstrToQueueTable(str_expr)
жазКБэДяЪНзЊКѓзКЃКinfix2Suffix(expr_queue)
ДгЕЅДЪжаЛёШЁkeyЃКgetKeyFromWord(word)
ХаЖЯЕЅДЪЪЧЗёЮЊЪ§зжЃКis_operand_a_num(operand)
МЦЫуКѓзКТпМБэДяЪНЃКcalcInRedis()
ЙЋгаГЩдБКЏЪ§ЃК
МЦЫуТпМБэДяЪНжїСїГЬЃКcalc()
--]] |
5.2.3.4 ВйзїЗћгХЯШМЖЖЈвх
-- еЛЭтгХЯШМЖ
localopr_priority_out_table= { ["("]
= 4, [">"] = 3, ["<"]
= 3, [">="] = 3, ["<="]
= 3, ["="] = 3, ["!="] = 3,
["||"] = 2, ["&&"]
= 2, ["^"] = 2, [")"] = 1,
["#"] = -1 }
-- еЛФкгХЯШМЖ
localopr_priority_in_table= { ["("]
= 0, [">"] = 3, ["<"]
= 3, [">="] = 3, ["<="]
= 3, ["="] = 3, ["!="] =
3, ["||"] = 2, ["&&"]
= 2, ["^"] = 2, [")"] =
1, ["#"] = -1 }
-- гХЯШМЖДцЗХдкtableжаЃЌ ЯрЕБгквЛИіhashmap ЃЌ keyгаВйзїЗћЃЌ valueЮЊгХЯШМЖЃЌ Ъ§зждНДѓЃЌ гХЯШМЖдНИпЃЈМД
4 > 3 > 2 > 1 > 0 > -1ЃЉ
|
5.2.3.5 жїСїГЬЪЕЯж
-- МЦЫуТпМБэДяЪНжїСїГЬ
localcalc= function ()
--strБэДяЪНзЊqueue_table
localstatus,queue_table_=pcall(strToQueueTable)
if notstatusthen
return {-1,queue_table_}
end
-- ГѕЪМЛЏБэДяЪНЖгСа
localorigin_queue= {queue_table=queue_table_}
localexpr_queue= Queue:new(origin_queue)
-- жазКБэДяЪНзЊКѓзК
localstatus,suffix_queue= pcall(infix2Suffix,expr_queue)
if notstatusthen
return {-1,suffix_queue}
end
--МЦЫуКѓзКБэДяЪНЃЌ ЕУЕННсЙћМЏЕФдЊЫиИіЪ§
localstatus,num_final_set =pcall (calcInRedis,suffix_queue)
if notstatusthen
return {-1,num_final_set}
end
returnnum_final_set
-- return {1, "success"}
end |
5.2.3.6 НХБОжДааШыПк
--[[
НХБОжДааШыПк
KEYS[1] зюжеНсЙћМЏЕФkey
ARGV[1] ТпМБэДяЪН
calc_resultзюжеНсЙћ
--]]
-- localkey_final_set= "result"
-- locallogic_expr= "sh&Ёс&&age:score>40"
-- localis_sorted_set_calc= true
-- НгЪеЕїгУНХБОДЋШыЕФKEYгыВЮЪ§
localkey_final_set=KEYS[1]
locallogic_expr=ARGV[1]
localis_sorted_set_calc=ARGV[2]
localcalc_result= {-1, "logic_expr or key_final_set
is nil."}
ifkey_final_set~= nil andlogic_expr~= nil then
-- ГѕЪМЛЏТпМБэДяЪНМЦЫуЦї
locallogicExprCalculator= LogicExprCalculator (key_final_set,logic_expr, is_sorted_set_calc)
-- ПЊЪММЦЫу
calc_result=logicExprCalculator.calc()
end
returncalc_result |
вдЩЯДњТыЪЧећИі lua НХБОЕФВПЗжДњТыЦЌЖЮЃЌ НХБОШыПк ЪЧ eval УќСюДЋВЮЪ§КЭНгЪеВЮЪ§ЕФШыПкЃЌНХБОДгетРяПЊЪМЕїгУ
жїСїГЬ ЃЛ жїСїГЬ АќКЌМИДѓВНжшЃЈвд sh&&male&&age:score>40
ОйР§ЃЉЃК
str БэДяЪНзЊ queue_table 1.1. queue_table = {sh,male,&&,age:score,>,40,#}
ГѕЪМЛЏБэДяЪНЖгСа 2.1. expr_queue = queue_table = {sh,male,&&,age:score,>,40,#}
жазКБэДяЪНзЊКѓзК 3.1. suffix_queue = {sh,male,&&,age:score,40,>,&&,#}
МЦЫуКѓзКБэДяЪНЃЌЕУЕННсЙћМЏЕФдЊЫиИіЪ§ 4.1. ЯШЫу sh && male ЕУЕН result1ЃЈМД
sinterstore result1 ЃЉЃЌ дйЫу age:score > 40 ЕУЕН result2ЃЌзюКѓЫу
result1 && result2 ЕУЕН resultЁЃ
ЗЕЛиНсЙћЁЃ 5.1. ЗЕЛи result ЕФИіЪ§
Lua НХБОЭъећДњТыЧыВЮПМЃК lua НХБОЁАгХЛЏЁБ Redis МЏКЯдЫЫуЭъећДњТы
5.2.4 ЛиЙЫ Lua НХБОФмЙЛЁАгХЛЏЁБЕФЕиЗН
5.2.4.1 ЮхИігХЛЏЕу
Redis МЏКЯдЫЫуашвЊЁАгХЛЏЁБЕФдвђгавЛЯТМИИіЃК
дЩњМЏКЯУќСю ВЛжЇГжЖрДЮ НЛВЂВюМЏКЯ ЛьКЯ дЫЫуЃЛ
ЪЙгУдЩњМЏКЯУќСюЖрДЮМЏКЯдЫЫу ВЛФмБЃжЄдзгад ЃЛ
ЪЙгУдЩњМЏКЯУќСюЖрДЮгыЗўЮёЖЫНЛЛЅ ЗЧГЃКФЪБ ЃЛ
ЪЙгУ Redis ЪТЮёЭЌбљЮоЗЈБмУтгыЗўЮёЖЫЖрДЮНЛЛЅ ЃЛ
ЪЙгУдЩњМЏКЯУќСюЛђепЪТЮёашвЊ ПЭЛЇЖЫБраДИДдгТпМ ЁЃ
ФЧУДЯждкРДПДПДЪЕЯжСЫОЕфЁАЫФдђдЫЫуЁБЫуЗЈЕФ Lua НХБОФмЙЛЁАгХЛЏЁБФФаЉЕуЁЃ
Lua НХБОФмжЇГж && ЁЂ || ЁЂ ^ ЁЂ >= ЁЂ > ЁЂ <=
ЁЂ < ЁЂ = ЁЂ != ЕШВйзїЗћЕФЛьКЯЪЙгУЃЈБШШч ( male && sh
&& age:score<40||credit:score>=750 ЃЉЁЃ
НтОіЩЯЪіЕФЕк 1 ЕуЃК ВЛжЇГжЖрДЮ НЛВЂВюМЏКЯ ЛьКЯ дЫЫуЃЛ
Lua НХБОДЋЫЭЕНЗўЮёЖЫКѓЃЌЗўЮёЖЫЪЧдзгадЕижДааећИі Lua НХБОЃЌжДааНХБОЙ§ГЬжаЦфЫћЕНДяЕФУќСюНЋБЛзшШћЁЃ
НтОіЩЯЪіЕк2ЕуЃК ВЛФмБЃжЄдзгад ЃЛ
Lua НХБОвЛДЮадДЋЪфЕНЗўЮёЖЫЃЌЕїгУЗНЪЙгУПЭЛЇЖЫжЛгыЗўЮёЖЫзівЛДЮНЛЛЅЃЌВЂЧвдкЕїгУЙ§НХБОжЎКѓЃЌЗўЮёЖЫгаНХБОЖдгІЕФ
SHA1 аЃбщКЭ ПЩЙЉПЭЛЇЖЫжБНгЪЙгУ evalsha УќСюДЋШы SHA1 аЃбщКЭ жБНгЕїгУНХБОЃЌЙ§ГЬжавЛДЮНЛЛЅЃЌЧвВЛашвЊдйДЋЪфНХБОЃЌМѕЩйСЫЭјТчДЋЪфЕФКФЪБЁЃетИіЩдКѓгаЯъЯИНщЩмЁЃ
НтОіСЫЩЯЪіЕФЕк3ЕуЃК ЗЧГЃКФЪБ
Lua НХБОвЛДЮадДЋЪфЕНЗўЮёЖЫЃЌЕїгУЗНЪЙгУПЭЛЇЖЫжЛгыЗўЮёЖЫзівЛДЮНЛЛЅЁЃ
НтОіЩЯЪіЕФЕк4ЕуЃК ЮоЗЈБмУтгыЗўЮёЖЫЖрДЮНЛЛЅ
Lua НХБОДЋЫЭЕНЗўЮёЖЫКѓЃЌНХБООЭГЃзЄдкЗўЮёЖЫЃЈШчЙћУЛгаБЛ script flush ЕФЛАЃЉЃЌПЭЛЇЖЫжЛашвЊДЋШыМђЕЅЕФБэДяЪНЃЌЖјВЛгУБраДИДдгЕФТпМЁЃ
НтОіЩЯЪіЕФЕк5ЕуЃК ПЭЛЇЖЫБраДИДдгТпМ
5.2.4.2 Lua НтОіКФЪБЮЪЬт
НгЯТРДзаЯИНщЩмвЛЯТ Lua НХБОЁАгХЛЏЁБЕФЕк3ЕуЃЌЯждкга3ИіМЏКЯШчЯТЃК

ЭМ25ЃКзМБИЮоађМЏКЯ maleЃЌshЃЌгаађМЏКЯ
age
ЯждкдЫаа sh НХБОЗжБ№ВщПДЪЙгУ Lua НХБОвдМАВЛЪЙгУ Lua НХБО евГі ОгзЁдкЩЯКЃЧвФъСфДѓгк40ЫъЕФФаад
ЃЌЗжБ№ЕФКФЪБЁЃ
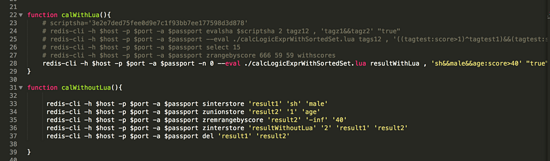
ЭМ26ЃКЪЙгУКЭВЛЪЙгУ lua НХБОдЫЫу
sh && male && age:score >40 ЪОР§
ЭМ27ЃКХм shell НХБОЕїгУ lua
НХБОВЂВщПДКФЪБЁЃ
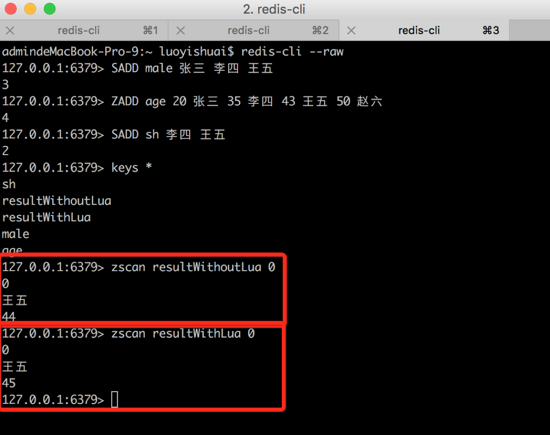
ЭМ28ЃКВщПДНсЙћ
ДгЭМ24ПЩвдПДГіЃЌЪЙгУ Lua НХБОзіМЏКЯдЫЫуЃЌЕФШЗМѕЩйСЫКФЪБЁЃЕБШЛетжЛЪЧвЛДЮЕФдЫЫуНсЙћЯдЪОЃЌЮвУЧПЩвдВЛЖЯЕиБфЛЛБэДяЪНЃЌШЅзіЪЙгУ
Lua НХБОвдМАВЛЪЙгУ Lua НХБОКФЪБЕФЖдБШЁЃ
СэЭтЃЌЫцзХБэДяЪНЩцМАдЫЫуЕФМЏКЯИіЪ§ЕФдіМгЃЌВЛЪЙгУ Lua НХБОвЊзіЕФНЛЛЅДЮЪ§діЖрЃЌЭјТчКФЪБНЋЛсЫцжЎдіЖрЃЌШчЙћЪЧЪЙгУ
Lua НХБОЃЌФЧУДжЛгавЛДЮЕФНЛЛЅНЋЗЧГЃНкЪЁЪБМфЁЃ
ТпМдЫЫуЭъећЕФ Lua НХБО МЦЫуКФЪБ sh НХБО
5.2.5 НХБОЪЕеНЕФМИИізЂвтЕу
Lua "вЛЧа" ЖМЪЧ tableЃЌетРяЕФ"вЛЧа"жївЊЪЧжИ
arrayЁЂhashmapЁЂlist ЕШМЏКЯРраЭЁЃ
Redis ВЛжЇГж Lua НХБОФЃПщЛЏЃЌВЛФмЭЈЙ§ import в§гУФЃПщЃЌЫљвдећИіНХБОЖМЪЧдквЛИіЮФМўжаЁЃ
еЛЕФЪЕЯжБШНЯМђЕЅЃЌОЭЪЧЖдЪ§зщЕФдіЩОИФЃЛЖгСаЕФЪЕЯжИДдгвЛЕуЃЌЕЋвВЪЧЖдЪ§зщЕФдіЩОИФЃЌЩшМЦЕНвЛЖЈЕФЫуЗЈЃЌПЩвдЯъПДДњТыЁЃ
БэДяЪНзжЗћДЎзЊзжЗћЖгСаЪБЃЌзЂвтЗжДЪЃЈБШШчдѕУДАб sh&&male&&age:score>40
ЗжГі sh ЁЂ && ЁЂ male ЁЂ age:score ЁЂ >= ЁЂ 40
РДЃЉЁЃ
дкМЦЫуКѓзКБэДяЪНЪБЃЌзЂвтгы redis НЛЛЅЕФЪБКђЃЌШчЙћУЛгадЩњУќСюжБНгжЇГжЃЌШчКЮЭЈЙ§зщКЯУќСюРДЪЕЯжЃЈБШШч
zdiffstore ,, гаађМЏКЯЕФ >= ЃЌ > ЃЌ != ЕШЃЌетРяВЛЯыЫЕЃЌНХБОРягаЯъЯИЕФзЂЪЭЫЕУїЃЉЁЃ
дкМЦЫуКѓзКБэДяЪНЪБЃЌзЂвтгы redis НЛЛЅЕФЪБКђЃЌЛсгаКмЖрСйЪБНсЙћМЏЕФВњЩњЃЌашвЊЧхРэЕєСйЪБНсЙћМЏЃЌВХФмБЃжЄгыВЛЪЙгУ
lua НХБОЕФаЇЙћЪЧвЛбљЕФЁЃ |









