|
ЫцзХДѓЪ§ОнетИіИХФюЕФаЫЦ№вдМАецЪЕашЧѓдкИїИіаавЕЕФТфЕиЃЌКмЖрШЫЖМШШждгкЬжТлЗжВМЪНЪ§ОнПтЃЌНёЬьОЭетИіЛАЬтЃЌжївЊЗжЮЊШ§ВПЗжЃКЕквЛВПЗжНВвЛЯТЗжВМЪНЪ§ОнПтЕФЙ§ШЅКЭЯжзДЃЌЯЃЭћДѓМвФмЖдетИіСьгђгавЛИіШЋУцЕФСЫНт;ЕкЖўВПЗжНВвЛЯТTiDBЕФМмЙЙвдМАзюНќЕФвЛаЉНјеЙ;зюКѓНсКЯЮвУЧПЊЗЂTiDBЙ§ГЬжаЕФвЛаЉЫМПМНВвЛЯТЗжВМЪНЪ§ОнПтЮДРДПЩФмЕФЧїЪЦЁЃ
вЛЁЂЗжВМЪНЪ§ОнПтЕФРњЪЗКЭЯжзД
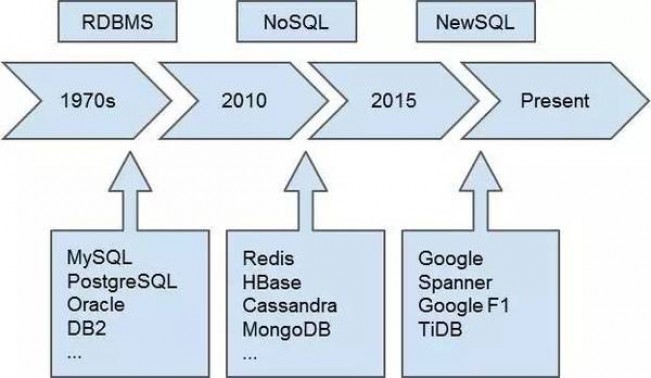
1ЁЂДгЕЅЛњЪ§ОнПтЫЕЦ№
ЙиЯЕаЭЪ§ОнПтЦ№дДзд1970ФъДњЃЌЦфзюЛљБОЕФЙІФмгаСНИіЃК
АбЪ§ОнДцЯТРДЃЛ
ТњзугУЛЇЖдЪ§ОнЕФМЦЫуашЧѓЁЃ
ЕквЛЕуЪЧзюЛљБОЕФвЊЧѓЃЌШчЙћвЛИіЪ§ОнПтУЛАьЗЈАбЪ§ОнАВШЋЭъећДцЯТРДЃЌФЧУДКѓајЕФШЮКЮЙІФмЖМУЛгавтвхЁЃЕБТњзуЕквЛЕуКѓЃЌгУЛЇНєНгзХОЭЛсвЊЧѓФмЙЛЪЙгУЪ§ОнЃЌПЩФмЪЧМђЕЅЕФВщбЏЃЌБШШчАДееФГИіKeyРДВщевValue;вВПЩФмЪЧИДдгЕФВщбЏЃЌБШШчвЊЖдЪ§ОнзіИДдгЕФОлКЯВйзїЁЂСЌБэВйзїЁЂЗжзщВйзїЁЃЭљЭљЕкЖўЕуЪЧвЛИіБШЕквЛЕуИќФбТњзуЕФашЧѓЁЃ
дкЪ§ОнПтЗЂеЙдчЦкНзЖЮЃЌетСНИіашЧѓЦфЪЕВЛФбТњзуЃЌБШШчгаКмЖргХауЕФЩЬвЕЪ§ОнПтВњЦЗЃЌШчOracle/DB2ЁЃдк1990ФъжЎКѓЃЌГіЯжСЫПЊдДЪ§ОнПтMySQLКЭPostgreSQLЁЃетаЉЪ§ОнПтВЛЖЯЕиЬсЩ§ЕЅЛњЪЕР§адФмЃЌдйМгЩЯзёбФІЖћЖЈТЩЕФгВМўЬсЩ§ЫйЖШЃЌЭљЭљФмЙЛКмКУЕижЇГХвЕЮёЗЂеЙЁЃ
НгЯТРДЃЌЫцзХЛЅСЊЭјЕФВЛЖЯЦеМАЬиБ№ЪЧвЦЖЏЛЅСЊЭјЕФаЫЦ№ЃЌЪ§ОнЙцФЃБЌеЈЪНдіГЄЃЌЖјгВМўетаЉФъЕФНјВНЫйЖШШДдкж№НЅМѕТ§ЃЌШЫУЧвВдкЕЃаФФІЖћЖЈТЩЛсЪЇаЇЁЃдкДЫЯћБЫГЄЕФЧщПіЯТЃЌЕЅЛњЪ§ОнПтдНРДдНФбвдТњзугУЛЇашЧѓЃЌМДЪЙЪЧНЋЪ§ОнБЃДцЯТРДетИізюЛљБОЕФашЧѓЁЃ
2ЁЂЗжВМЪНЪ§ОнПт
Ыљвд2005ФъзѓгвЃЌШЫУЧПЊЪМЬНЫїЗжВМЪНЪ§ОнПтЃЌДјЦ№СЫNoSQLетВЈРЫГБЁЃетаЉЪ§ОнПтНтОіЕФЪзвЊЮЪЬтЪЧЕЅЛњЩЯЮоЗЈБЃДцШЋВПЪ§ОнЃЌЦфжавдHBase/Cassadra/MongoDBЮЊДњБэЁЃЮЊСЫЪЕЯжШнСПЕФЫЎЦНРЉеЙЃЌетаЉЪ§ОнПтЭљЭљвЊЗХЦњЪТЮёЃЌЛђепЪЧжЛЬсЙЉМђЕЅЕФKVНгПкЁЃДцДЂФЃаЭЕФМђЛЏЮЊДцДЂЯЕЭГЕФПЊЗЂДјРДСЫБуРћЃЌЕЋЪЧНЕЕЭСЫЖдвЕЮёЕФжЇГХЁЃ
(1)NoSQLЕФНјЛї
HBaseЪЧЦфжаЕФЕфаЭДњБэЁЃHBaseЪЧHadoopЩњЬЌжаЕФживЊВњЦЗЃЌGoogle BigTableЕФПЊдДЪЕЯжЃЌЫљвдетРяЯШЫЕвЛЯТBigTableЁЃ
BigTableЪЧGoogleФкВПЪЙгУЕФЗжВМЪНЪ§ОнПтЃЌЙЙНЈдкGFSЕФЛљДЁЩЯЃЌУжВЙСЫЗжВМЪНЮФМўЯЕЭГЖдгкаЁЖдЯѓЕФВхШыЁЂИќаТЁЂЫцЛњЖСЧыЧѓЕФШБЯнЁЃHBaseвВАДееетИіМмЙЙЪЕЯжЃЌЕзВуЛљгкHDFSЁЃHBaseБОЩэВЂВЛЪЕМЪДцДЂЪ§ОнЃЌГжОУЛЏЕФШежОКЭSST fileДцДЂдкHDFSЩЯЃЌRegion ServerЭЈЙ§ MemTable ЬсЙЉПьЫйЕФВщбЏЃЌаДШыЖМЪЧЯШаДШежОЃЌКѓЬЈНјааCompactЃЌНЋЫцЛњаДзЊЛЛЮЊЫГађаДЁЃЪ§ОнЭЈЙ§ Region дкТпМЩЯНјааЗжИюЃЌИКдиОљКтЭЈЙ§ЕїНкИїИіRegion ServerИКд№ЕФRegionЧјМфЪЕЯжЃЌRegionдкГжајаДШыКѓЃЌЛсНјааЗжСбЃЌШЛКѓБЛИКдиОљКтВпТдЕїЖШЕНЖрИіRegion ServerЩЯЁЃ
ЧАУцЬсЕНСЫЃЌHBaseБОЩэВЂВЛДцДЂЪ§ОнЃЌетРяЕФRegionНіЪЧТпМЩЯЕФИХФюЃЌЪ§ОнЛЙЪЧвдЮФМўЕФаЮЪНДцДЂдкHDFSЩЯЃЌHBaseВЂВЛЙиаФИББОИіЪ§ЁЂЮЛжУвдМАЫЎЦНРЉеЙЮЪЬтЃЌетаЉЖМвРРЕгкHDFSЪЕЯжЁЃКЭBigTableвЛбљЃЌHBaseЬсЙЉааМЖЕФвЛжТадЃЌДгCAPРэТлЕФНЧЖШРДПДЃЌЫќЪЧвЛИіCPЕФЯЕЭГЃЌВЂЧвУЛгаИќНјвЛВНЬсЙЉ ACID ЕФПчааЪТЮёЃЌвВЪЧКмвХКЖЁЃ
HBaseЕФгХЪЦдкгкЭЈЙ§РЉеЙRegion ServerПЩвдМИКѕЯпадЬсЩ§ЯЕЭГЕФЭЬЭТЃЌМАHDFSБОЩэОЭОпгаЕФЫЎЦНРЉеЙФмСІЃЌЧвећИіЯЕЭГГЩЪьЮШЖЈЁЃЕЋHBaseвРШЛгавЛаЉВЛзуЁЃЪзЯШЃЌHadoopЪЙгУJavaПЊЗЂЃЌGCбгГйЪЧвЛИіЮоЗЈБмУтЮЪЬтЃЌетЖдЯЕЭГЕФбгГйдьГЩвЛаЉгАЯьЁЃСэЭтЃЌгЩгкHBaseБОЩэВЂВЛДцДЂЪ§ОнЃЌКЭHDFSжЎМфЕФНЛЛЅЛсЖрвЛВуадФмЫ№КФЁЃЕкШ§ЃЌHBaseКЭBigTableвЛбљЃЌВЂВЛжЇГжПчааЪТЮёЃЌЫљвддкGoogleФкВПгаЭХЖгПЊЗЂСЫMegaStoreЁЂPercolatorетаЉЛљгкBigTableЕФЪТЮёВуЁЃJeff DeanГаШЯКмКѓЛкУЛгадкBigTableжаМгШыПчааЪТЮёЃЌетвВЪЧSpannerГіЯжЕФвЛИідвђЁЃ
(2)RDMSЕФОШЪъ
Г§СЫNoSQLжЎЭтЃЌRDMSЯЕЭГвВзіСЫВЛЩйХЌСІРДЪЪгІвЕЮёЕФБфЛЏЃЌвВОЭЪЧЙиЯЕаЭЪ§ОнПтЕФжаМфМўКЭЗжПтЗжБэЗНАИЁЃзівЛПюжаМфМўашвЊПМТЧКмЖрЃЌБШШчНтЮі SQLЃЌНтЮіГіShardKeyЃЌШЛКѓИљОнShardKeyЗжЗЂЧыЧѓЃЌдйКЯВЂНсЙћЁЃСэЭтдкжаМфМўетВуЛЙашвЊЮЌЛЄSessionМАЪТЮёзДЬЌЃЌЖјЧвДѓЖрЪ§ЗНАИВЂВЛжЇГжПчshardЕФЪТЮёЃЌетОЭВЛПЩБмУтЕиЕМжТСЫвЕЮёЪЙгУЦ№РДЛсБШНЯТщЗГЃЌашвЊздМКЮЌЛЄЪТЮёзДЬЌЁЃДЫЭтЃЌЛЙгаЖЏЬЌЕФРЉШнЫѕШнКЭздЖЏЕФЙЪеЯЛжИДЃЌдкМЏШКЙцФЃдНРДдНДѓЕФЧщПіЯТЃЌдЫЮЌКЭDDLЕФИДдгЖШЪЧжИЪ§МЖЩЯЩ§ЁЃ
ЙњФкПЊЗЂепдкетИіСьгђгаЙ§КмЖрЕФжјУћЕФЯюФПЃЌБШШчАЂРяЕФCobarЁЂTDDLЃЌКѓРДЩчЧјЛљгкCobarИФНјЕФMyCATЃЌ360ПЊдДЕФAtlasЕШЃЌЖМЪєгкетвЛРржаМфМўВњЦЗЁЃдкжаМфМўетИіЗНАИЩЯгавЛИіжЊУћЕФПЊдДЯюФПЪЧYoutubeЕФVitessЃЌетЪЧвЛИіМЏДѓГЩЕФжаМфМўВњЦЗЃЌФкжУСЫШШЪ§ОнЛКДцЁЂЫЎЦНЖЏЬЌЗжЦЌЁЂЖСаДЗжРыЕШЃЌЕЋетвВдьГЩСЫећИіЯюФПЗЧГЃИДдгЁЃ
СэЭтвЛИіжЕЕУвЛЬсЕФЪЧPostgreSQL XCетИіЯюФПЃЌЦфећЬхЕФМмЙЙгаЕуЯёдчЦкАцБОЕФOceanBaseЃЌгЩвЛИіжабыНкЕуРДДІРэаЕїЗжВМЪНЪТЮёЃЌЪ§ОнЗжЩЂдкИїИіДцДЂНкЕуЩЯЃЌгІИУЪЧФПЧАPG ЩчЧјзюКУЕФЗжВМЪНРЉеЙЗНАИЃЌВЛЩйШЫдкЛљгкетИіЯюФПзіздМКЕФЯЕЭГЁЃ
3ЁЂNewSQLЕФЗЂеЙ
2012~2013ФъGoogle ЯрМЬЗЂБэСЫSpannerКЭF1СНЬзЯЕЭГЕФТлЮФЃЌШУвЕНчЕквЛДЮПДЕНСЫЙиЯЕФЃаЭКЭNoSQLЕФРЉеЙаддквЛИіДѓЙцФЃЩњВњЯЕЭГЩЯШкКЯЕФПЩФмадЁЃ Spanner ЭЈЙ§ЪЙгУгВМўЩшБИ(GPSЪБжг+дзгжг)ЧЩУюЕиНтОіЪБжгЭЌВНЕФЮЪЬтЃЌЖјдкЗжВМЪНЯЕЭГРяЃЌЪБжге§ЪЧзюШУШЫЭЗЭДЕФЮЪЬтЁЃSpannerЕФЧПДѓжЎДІдкгкМДЪЙСНИіЪ§ОнжааФИєЕУЗЧГЃдЖЃЌвВФмБЃжЄЭЈЙ§TrueTime APIЛёШЁЕФЪБМфЮѓВюдквЛИіКмаЁЕФЗЖЮЇФк(10ms)ЃЌВЂЧвВЛашвЊЭЈбЖЁЃSpannerЕФЕзВуШдШЛЛљгкЗжВМЪНЮФМўЯЕЭГЃЌВЛЙ§ТлЮФРявВЫЕЪЧПЩвдЮДРДгХЛЏЕФЕуЁЃ
GoogleЕФФкВПЕФЪ§ОнПтДцДЂвЕЮёЃЌДѓЖрЪЧ3~5ИББОЃЌживЊЕФЪ§ОнашвЊ7ИББОЃЌЧветаЉИББОБщВМШЋЧђИїДѓжоЕФЪ§ОнжааФЃЌгЩгкЦеБщЪЙгУСЫPaxosЃЌбгГйЪЧПЩвдЫѕЖЬЕНвЛИіПЩвдНгЪмЕФЗЖЮЇ(аДШыбгГй100msвдЩЯ)ЃЌСэЭтгЩPaxosДјРДЕФAuto-FailoverФмСІЃЌИќЪЧШУећИіМЏШКМДЪЙЪ§ОнжааФЬБЛОЃЌвЕЮёВуЖМЪЧЭИУїЮоИажЊЕФЁЃF1ЪЧЙЙНЈдкSpannerжЎЩЯЃЌЖдЭтЬсЙЉСЫSQLНгПкЃЌF1ЪЧвЛИіЗжВМЪНMPP SQLВуЃЌЦфБОЩэВЂВЛДцДЂЪ§ОнЃЌЖјЪЧНЋПЭЛЇЖЫЕФSQLЗвыГЩЖдKVЕФВйзїЃЌЕїгУSpannerРДЭъГЩЧыЧѓЁЃ
SpannerКЭF1ЕФГіЯжБъжОзХЕквЛИіNewSQLдкЩњВњЛЗОГжаЬсЙЉЗўЮёЃЌНЋЯТУцМИИіЙІФмдквЛЬзЯЕЭГжаЬсЙЉЃК
SQLжЇГж
ACIDЪТЮё
ЫЎЦНРЉеЙ
Auto Failover
ЖрЛњЗПвьЕиШндж
е§вђЮЊОпБИШчДЫЖрЕФгеШЫЬиадЃЌдкGoogleФкВПЃЌДѓСПЕФвЕЮёвбОДгдРДЕФ BigTableЧаЛЛЕНSpannerжЎЩЯЁЃЯраХетЖдвЕНчЕФЫМТЗЛсгаОоДѓЕФгАЯьЃЌОЭЯёЕБФъЕФHadoopвЛбљЃЌGoogleЕФЛљДЁШэМўЕФММЪѕЧїЪЦЪЧзпдкЩчЧјЧАУцЕФЁЃ
Spanner/F1ТлЮФв§Ц№СЫЩчЧјЕФЙуЗКЕФЙизЂЃЌКмПьПЊЪМГіЯжСЫзЗЫцепЁЃЕквЛИіЭХЖгЪЧCockroachLabsзіЕФCockroachDBЁЃCockroachDBЕФЩшМЦКЭSpannerКмЯёЃЌЕЋЪЧУЛгабЁдёTrueTime API ЃЌЖјЪЧЪЙгУHLC(Hybrid logical clock)ЃЌвВОЭЪЧNTP +ТпМЪБжгРДДњЬцTrueTimeЪБМфДСЃЌСэЭтCockroachDBбЁгУRaftзіЪ§ОнИДжЦавщЃЌЕзВуДцДЂТфЕидкRocksDBжаЃЌЖдЭтЕФНгПкбЁдёСЫPGавщЁЃ
CockroachDBЕФММЪѕбЁаЭБШНЯМЄНјЃЌБШШчвРРЕСЫHLCРДзіЪТЮёЃЌЪБМфДСЕФОЋШЗЖШВЂУЛгаАьЗЈзіЕН10msФкЕФбгГйЃЌЫљвдCommit WaitашвЊгУЛЇздМКжИЖЈЃЌЦфбЁдёШЁОігкгУЛЇЕФNTPЗўЮёЪБжгЮѓВюЃЌетЕуЖдгкгУЛЇРДЫЕЗЧГЃВЛгбКУЁЃЕБШЛ CockroachDBЕФетаЉММЪѕбЁдёвВДјРДСЫКмКУЕФвзгУадЃЌЫљгаТпМЖМдквЛИізщМўжаЃЌВПЪ№ЗЧГЃМђЕЅЃЌетИіЪЧЗЧГЃДѓЕФгХЕуЁЃ
СэвЛИізЗЫцепОЭЪЧЮвУЧзіЕФTiDBЁЃетИіЯюФПвбОПЊЗЂСЫСНФъЪБМфЃЌЕБШЛдкПЊЪМЖЏЪжЧАЮвУЧвВзМБИСЫКмГЄЪБМфЁЃНгЯТРДЮвЛсНщЩмвЛЯТетИіЯюФПЁЃ
ЖўЁЂTiDBЕФМмЙЙКЭзюНќНјеЙ
TiDBБОжЪЩЯЪЧвЛИіИќМге§ЭГЕФSpannerКЭF1ЪЕЯжЃЌВЂВЛCockroachDBФЧбљбЁдёНЋSQLКЭKVШкКЯЃЌЖјЪЧЯёSpannerКЭF1вЛбљбЁдёЗжРыЁЃЯТУцЪЧTiDBЕФМмЙЙЭМЃК
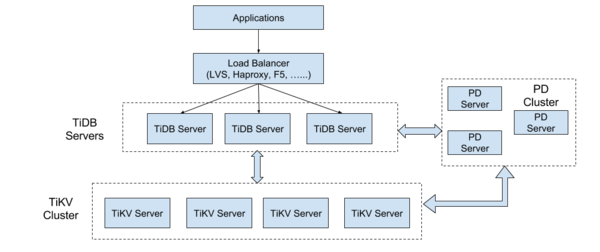
етбљЗжВуЕФЫМЯывВЪЧЙсДЉећИіTiDBЯюФПЪМжеЕФЃЌЖдгкВтЪдЃЌЙіЖЏЩ§МЖвдМАИїВуЕФИДдгЖШПижЦЛсБШНЯгагХЪЦЃЌСэЭтTiDBбЁдёСЫMySQLавщКЭгяЗЈЕФМцШнЃЌMySQLЩчЧјЕФORMПђМмЁЂдЫЮЌЙЄОпЃЌжБНгПЩвдгІгУдкTiDBЩЯЃЌСэЭтКЭ SpannerвЛбљЃЌTiDBЪЧвЛИіЮозДЬЌЕФMPP SQL LayerЃЌећИіЯЕЭГЕФЕзВуЪЧвРРЕ TiKV РДЬсЙЉЗжВМЪНДцДЂКЭЗжВМЪНЪТЮёЕФжЇГжЃЌTiKVЕФЗжВМЪНЪТЮёФЃаЭВЩгУЕФЪЧGoogle PercolatorЕФФЃаЭЃЌЕЋЪЧдкДЫжЎЩЯзіСЫКмЖргХЛЏЃЌPercolatorЕФгХЕуЪЧШЅжааФЛЏГЬЖШЗЧГЃИпЃЌећИіМЬајВЛашвЊвЛИіЖРСЂЕФЪТЮёЙмРэФЃПщЃЌЪТЮёЬсНЛзДЬЌетаЉаХЯЂЦфЪЕЪЧОљдШЗжЩЂдкЯЕЭГЕФИїИіkeyЕФmetaжаЃЌећИіФЃаЭЮЈвЛвРРЕЕФЪЧвЛИіЪкЪБЗўЮёЦїЃЌдкЮвУЧЕФЯЕЭГЩЯЃЌМЋЯоЧщПіетИіЪкЪБЗўЮёЦїУПУыФмЗжХф 400wвдЩЯИіЕЅЕїЕндіЕФЪБМфДСЃЌДѓЖрЪ§ЧщПіЛљБОЙЛгУСЫ(БЯОЙгаGoogleСПМЖЕФГЁОАВЂВЛЖрМћ)ЃЌЭЌЪБдкTiKVжаЃЌетИіЪкЪБЗўЮёБОЩэЪЧИпПЩгУЕФЃЌвВВЛДцдкЕЅЕуЙЪеЯЕФЮЪЬтЁЃ
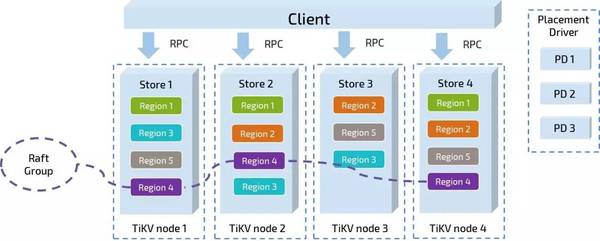
ЩЯУцЪЧTiKVЕФМмЙЙЭМЁЃTiKVКЭCockroachDBвЛбљвВЪЧбЁдёСЫRaftзїЮЊећИіЪ§ОнПтЕФЛљДЁЃЌВЛвЛбљЕФЪЧЃЌTiKVећЬхВЩгУRustгябдПЊЗЂЃЌзїЮЊвЛИіУЛгаGCКЭ RuntimeЕФгябдЃЌдкадФмЩЯПЩвдЭкОђЕФЧБСІЛсИќДѓЁЃВЛЭЌTiKVЪЕР§ЩЯЕФЖрИіИББОвЛЦ№ЙЙГЩСЫвЛИіRaft GroupЃЌPDИКд№ЖдИББОЕФЮЛжУНјааЕїЖШЃЌЭЈЙ§ХфжУЕїЖШВпТдЃЌПЩвдБЃжЄвЛИіRaft GroupЕФЖрИіИББОВЛЛсБЃДцдкЭЌвЛЬЈЛњЦї/ЛњМм/ЛњЗПжаЁЃ
Г§СЫКЫаФЕФTiDBЁЂTiKVжЎЭтЃЌЮвУЧЛЙЬсЙЉСЫВЛЩйвзгУЕФЙЄОпЃЌБугкгУЛЇзіЪ§ОнЧЈвЦКЭБИЗнЁЃБШШчЮвУЧЬсЙЉЕФSyncerЃЌВЛЕЋФмНЋЕЅИіMySQLЪЕР§жаЕФЪ§ОнЭЌВНЕНTiDBЃЌЛЙФмНЋЖрИіMySQLЪЕР§жаЕФЪ§ОнЛузмЕНвЛИіTiDBМЏШКжаЃЌЩѕжСЪЧНЋвбОЗжПтЗжБэЕФЪ§ОндйКЯПтКЯБэЁЃетбљЪ§ОнЕФЭЌВНЗНЪНИќМгСщЛюКУгУЁЃ
TiDBФПЧАМДНЋЗЂВМRC3АцБОЃЌдЄМЦСљдТЗнФмЙЛЗЂВМGAАцБОЁЃдкМДНЋЕНРДЕФ RC3АцБОжаЃЌЖдMySQLМцШнадЁЂSQLгХЛЏЦїЁЂЯЕЭГЮШЖЈадЁЂадФмзіСЫДѓСПЕФЙЄзїЁЃЖдгкOLTPГЁОАЃЌжиЕугХЛЏаДШыадФмЁЃСэЭтЬсЙЉСЫШЈЯоЙмРэЙІФмЃЌгУЛЇПЩвдАДееMySQLЕФШЈЯоЙмРэЗНЪНПижЦЪ§ОнЗУЮЪШЈЯоЁЃЖдгкOLAPГЁОАЃЌвВЖдгХЛЏЦїзіСЫДѓСПЕФЙЄзїЃЌАќРЈИќЖргяОфЕФгХЛЏЁЂжЇГжSortMergeJoinЫузгЁЂIndexLookupJoinЫузгЁЃСэЭтЖдФкДцЪЙгУвВзіСЫДѓСПЕФгХЛЏЃЌвЛаЉГЁОАЯТЃЌФкДцЪЙгУЯТНЕ75%ЁЃ
Г§СЫTiDBБОЩэЕФгХЛЏжЎЭтЃЌЮвУЧЛЙдкзівЛИіаТЕФЙЄГЬЃЌУћзжНаTiSparkЁЃМђЕЅРДНВЃЌОЭЪЧШУSparkИќКУЕиНгШыTiDBЁЃЯждкЦфЪЕSparkвбОПЩвдЭЈЙ§JDBCНгПкЖСШЁTiDBжаЕФЪ§ОнЃЌЕЋЪЧетРягаСНИіЮЪЬтЃК1. жЛФмЭЈЙ§ЕЅИіTiDBНкЕуЖСШЁЪ§ОнЧвЪ§ОнашвЊДгTiKVжаОЙ§ TiDB жазЊЁЃ2. ВЛФмКЭSparkЕФгХЛЏЦїЯрНсКЯЃЌЮвУЧЦкЭћФмКЭSparkЕФгХЛЏЦїећКЯЃЌНЋFilterЁЂОлКЯФмЭЈЙ§TiKVЕФЗжВМЪНМЦЫуФмСІЬсЫйЁЃетИіЯюФПвбОПЊЪМПЊЗЂЃЌдЄМЦНќЦкПЊдДЃЌЮхдТЗнОЭФмгаЕквЛИіАцБОЁЃ
Ш§ЁЂЗжВМЪНЪ§ОнПтЕФЮДРДЧїЪЦ
ЙигкЮДРДЃЌЮвОѕЕУЮДРДЕФЪ§ОнПтЛсгаМИИіЧїЪЦЃЌвВЪЧTiDBЯюФПзЗЧѓЕФФПБъЃК
1ЁЂЪ§ОнПтЛсЫцзХвЕЮёдЦЛЏЃЌЮДРДвЛЧаЕФвЕЮёЖМЛсХмдкдЦЖЫЃЌВЛЙмЪЧЫНгадЦЛђепЙЋгадЦЃЌдЫЮЌЭХЖгНгДЅЕФПЩФмдйвВВЛЪЧецЪЕЕФЮяРэЛњЃЌЖјЪЧвЛИіИіИєРыЕФШнЦїЛђепЁИМЦЫузЪдДЁЙЃЌетЖдЪ§ОнПтвВЪЧвЛИіЬєеНЃЌвђЮЊЪ§ОнПтЬьЩњОЭЪЧгазДЬЌЕФЃЌЪ§ОнзмЪЧвЊДцДЂдкЮяРэЕФДХХЬЩЯЃЌЖјЪ§ОнвЦЖЏЕФДњМлБШвЦЖЏШнЦїЕФДњМлПЩФмДѓКмЖрЁЃ
2ЁЂЖрзтЛЇММЪѕЛсГЩЮЊБъХфЃЌвЛИіДѓЪ§ОнПтГадивЛЧаЕФвЕЮёЃЌЪ§ОндкЕзВуДђЭЈЃЌЩЯВуЭЈЙ§ШЈЯоЃЌШнЦїЕШММЪѕНјааИєРыЃЌЕЋЪЧЪ§ОнЕФДђЭЈКЭРЉеЙЛсБфЕУвьГЃМђЕЅЃЌНсКЯЕквЛЕуЬсЕНЕФдЦЛЏЃЌвЕЮёВуПЩвддйвВВЛгУЙиаФЮяРэЛњЕФШнСПКЭЭиЦЫЃЌжЛашвЊШЯЮЊЕзВуЪЧвЛИіЮоЧюДѓЕФЪ§ОнПтЦНЬЈМДПЩЃЌВЛгУдйЕЃаФЕЅЛњШнСПКЭИКдиОљКтЕШЮЪЬтЁЃ
3ЁЂOLAPКЭOLTPвЕЮёЛсШкКЯЃЌгУЛЇНЋЪ§ОнДцДЂНјШЅКѓЃЌашвЊБШНЯЗНБуИпаЇЕФЗНЪНЗУЮЪетПщЪ§ОнЃЌЕЋЪЧOLTPКЭOLAPдкSQLгХЛЏЦї/жДааЦїетВуЕФЪЕЯжвЛЖЈЪЧЧЇВюЭђБ№ЕФЁЃвдЭљЕФЪЕЯжжаЃЌгУЛЇЭљЭљЪЧЭЈЙ§ETLЙЄОпНЋЪ§ОнДгOLTPЪ§ОнПтЭЌВНЕНOLAPЪ§ОнПтЃЌетвЛЗНУцдьГЩСЫзЪдДЕФРЫЗбЃЌСэвЛЗНУцвВНЕЕЭСЫOLAPЕФЪЕЪБадЁЃЖдгкгУЛЇЖјбдЃЌШчЙћФмЪЙгУЭЌвЛЬзБъзМЕФгяЗЈКЭЙцдђРДНјааЪ§ОнЕФЖСаДКЭЗжЮіЃЌЛсгаИќКУЕФЬхбщЁЃ
4ЁЂдкЮДРДЗжВМЪНЪ§ОнПтЯЕЭГЩЯЃЌжїДгШежОЭЌВНетбљТфКѓЕФБИЗнЗНЪНЛсБЛMulti-Paxos / RaftетбљИќЧПЕФЗжВМЪНвЛжТадЫуЗЈЬцДњЃЌШЫЙЄЕФЪ§ОнПтдЫЮЌдкЙмРэДѓЙцФЃЪ§ОнПтМЏШКЪБЪЧВЛПЩФмЕФЃЌЫљгаЕФЙЪеЯЛжИДКЭИпПЩгУЖМНЋЪЧИпЖШздЖЏЛЏЕФЁЃ
|









