| ���ܵ��ڵ�Ŀ����ͨ����������ͨ������
I/O �� CPU ʱ�������С��ʹÿ����ѯ����Ӧʱ����̲�����ȵ�����������ݿ����������������Ϊ�ﵽ��Ŀ�ģ���Ҫ�˽�Ӧ�ó������������ݵ����������ṹ���������ͻ�����ݿ�ʹ��֮�䣨������������
(OLTP) �����֧�֣�Ȩ�⡣ ����������Ŀ���Ӧ�ᴩ�ڿ����ε�ȫ���̣���Ӧֻ�����ʵ��ϵͳʱ�ſ����������⡣����ʹ���ܵõ�������ߵ��������˿�ͨ����ʼʱ��ϸ��Ƶ���ʵ�֡�Ϊ����Ч���Ż�
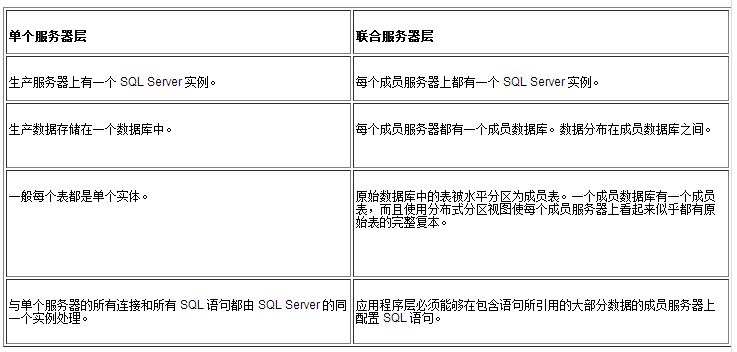
Microsoft? SQL Server? 2000 �����ܣ������ڼ�Ϊ��������������ʶ�����ʹ��������������������Щ�����з����� ��Ȼ����ϵͳ���������⣨���ڴ桢Ӳ���ȣ�Ҳ���о����������������Щ�����õ���������ͨ����������ͨ������£�SQL
Server �Զ��������õ�Ӳ����Դ���Ӷ����ٶԴ�����ϵͳ���ֶ���������������Լ��������õ����棩�� Ŀ¼�� ����������ݿ���������������ͨ�����������ɷ�̯�ڶ������������ﵽ�����ܼ�������� Web վ�����������ܼ��𣩡� ���ݿ���ƣ��������ݿ������γ�Ϊ����������ܵ�����Ч;�������ݿ���ư��������ݿ�ܹ��������Լ�������������ԣ������ϵͳ������λ�ú��������� ��ѯ�Ż���������ȷ��ƵIJ�ѯ������Ӧ�ó����������������ܡ� Ӧ�ó�����ƣ�������ȷ��Ƶ��û�Ӧ�ó����������������ܡ�Ӧ�ó�����ư�������߽硢��������������ʹ�á� �Ż�ʵ�ù��ߺ������ܣ����� Microsoft SQL Server 2000 �ṩ��ʵ�ù��ߺ��ߵ�һЩ����ѡ�������Щѡ�����ͻ��˵�������Щ���ߵ����ܵķ������Լ�ͬʱ������Щ���ߺ�Ӧ�ó����Ч���� �Ż����������ܣ�������θ��IJ���ϵͳ��Microsoft Windows NT?��Microsoft Windows?
95��Microsoft Windows 98 �� Microsoft Windows 2000���� SQL
Server ������������������ܡ� ����ϵͳ����Ż�:��������ϵͳ�����ݿ�֮��ɸ��Ƶķ��桭������������������������������������7 ����������ݿ������ Ϊ�ﵽ���� Web վ������ĸ����ܼ��𣬶��ϵͳһ���ڶ��������֮��ƽ��ÿһ��Ĵ������ɡ�Microsoft?
SQL Server? 2000 ͨ���� SQL Server ���ݽ���ˮƽ��������һ�������֮���̯���ݿ�����ɡ���Щ���������������Ҳ�����Э���Դ�������Ӧ�ó�������ݿ�����������һ��Э����������Ϊ�����塣 ֻ�е�Ӧ�ó���ÿ�� SQL ��䷢�͵�ӵ�и��������Ĵ����ݵij�Ա������ʱ���������ݿ��ſ��Դﵽ�dz��ߵ����ܼ������Ϊʹ������������������
SQL ��䡣ʹ��������������� SQL ��䲻�����Ϸ����������е�Ҫ����Ⱥ��ϵͳ��ͬ���д�Ҫ�� ��Ȼ�������������뵥�����ݿ���������ָ�Ӧ�ó����ͼ����ͬ������ʵ�����ݿ�����ķ�ʽ�ϴ����ڲ����졣
��ȻĿ����������ݿ������������������ȫ���Ĺ������ɣ����ǿ�ͨ�����һ���ڲ�ͬ�ķ�����֮��ֲ����ݵķֲ�ʽ������ͼ���ﵽ��Ŀ�ġ�
���ݿ���� ���ݿ����ư���������ɲ��֣�����ƺ�������ơ������ݿ���ư���ʹ�����ݿ�����������Լ����Ϊҵ����������ݽ�ģ�������뿼����λ������������洢��Щ���ݡ��������ݿ���ư����������ӳ�䵽����ý���ϡ����ÿ��õ�Ӳ������������ʹ�þ����ܿ�ض����ݽ����������ʺ�ά��������������������Ҫ����ƺ������Щ��������ѣ���������ݿ�Ӧ�ó��������ڽ���ȷ������ݿ⡢ʹ��Ϊҵ������ģ������Ӳ�����������ܺ���Ҫ�� ʵ��SQL Server���ݿ���Ż�������Ҫ��һ���õ����ݿ���Ʒ�������ʵ�ʹ����У�����SQL Server�����������������ݿ���Ƶò��õ������ܺܲʵ�����õ����ݿ���Ʊ��뿼����Щ����: 1.1������淶������ һ����˵�������ݿ���ƻ�����淶����ǰ3����: 1.��1�淶:û���ظ�������ֵ���С� 2.��2�淶:ÿ���ǹؼ��ֶα������������ؼ��֣�����������1�����ʽ���ؼ��ֵ�ijЩ��ɲ��֡� 3.��3�淶:1���ǹؼ��ֶβ�����������1���ǹؼ��ֶΡ� ������Щ�������ƻ�������ٵ��к���ı������Ҳ�ͼ������������࣬Ҳ���������ڴ洢���ݵ�ҳ��������ϵҲ����Ҫͨ�����ӵĺϲ��������������ή��ϵͳ�����ܡ�ij�̶ֳ��ϵķǹ淶�����Ը���ϵͳ�����ܣ��ǹ淶�����̿��Ը������ܷ��治ͬ�Ŀ����ö��ֲ�ͬ�ķ������У������·�����ʵ����֤������������ܡ� 1.����淶����Ʋ���������4·�����·�ϲ���ϵ���Ϳ��Կ��������ݿ�ʵ��(��)�м����ظ�����(��) 2.���õļ����ֶ�(���ܼơ����ֵ��)���Կ��Ǵ洢�����ݿ�ʵ���С� ����ijһ����Ŀ�ļƻ�����ϵͳ���мƻ��������ֶ�Ϊ:��Ŀ��š�����ƻ������μƻ��������ƻ������мƻ��������ƻ�����(����ƻ�+���μƻ�+�����ƻ�+���мƻ�)���û�������Ҫ�ڲ�ѯ�ͱ������õ��ģ��ڱ��ļ�¼���ܴ�ʱ���б�Ҫ�Ѽƻ�������Ϊ1���������ֶμ��뵽���С�������Բ��ô��������ڿͻ��˱������ݵ�һ���ԡ� 3.���¶���ʵ���Լ����ⲿ�������ݻ������ݵĿ�֧����Ӧ�ķǹ淶��������: (1)��1��ʵ��(��)�ָ��2����(�����е����Էֳ�2��)�������Ͱ�Ƶ�������ʵ�����ͬ���ٱ����ʵ����ݷֿ��ˡ����ַ���Ҫ����ÿ�����и�����Ҫ�ؼ��֡�������������������ڲ��д��������������������ٵı��� (2)��1��ʵ��(��)�ָ��2����(�����е��зֳ�2��)�����ַ�����������Щ�������������ݵ�ʵ��(��)����Ӧ���г�Ҫ������ʷ��¼��������ʷ��¼�����õ�����˿���Ƶ�������ʵ�����ͬ���ٱ����ʵ���ʷ���ݷֿ��������������������Ϊ�Ӽ�����������(���š����۷��������������)���ʵģ���ô���ַ���Ҳ�Ǻ��кô��ġ� 1.2�������������ݿ� Ҫ����ȷѡ���������ʵ�ֲ��ԣ����붮�����ݿ���ʸ�ʽ��Ӳ����Դ�IJ����ص㣬��Ҫ���ڴ�ʹ�����ϵͳI/O������һ����Χ�㷺�Ļ��⣬�����µ�����ܻ����������� 1.��ÿ��������ص���������Ӧ�÷�ӳ�����������С�洢�ռ䣬�ر��Ƕ��ڱ��������и�����ˡ�������ʹ��smallint���;Ͳ�Ҫ��integer���ͣ����������ֶο��Ա�����ض�ȡ�����ҿ�����1������ҳ�Ϸ��ø���������У����Ҳ�ͼ�����I/O������ 2.��1��������ij�������豸�ϣ���ͨ��SQL Server�ΰ����IJ��ִ���������1����ͬ�������豸�ϣ�������������ܡ�������ϵͳ�����˶�������ʹ��̿����������ݷ��뼼��������£��������ĺô��������ԡ� 3.��SQL Server�ΰ�һ��Ƶ��ʹ�õĴ���ָ��������2�������������ʹ��̿����������ݿ��豸�ϣ�����Ҳ����������ܡ���Ϊ�ж����ͷ�ڲ��ң��������ݷ���Ҳ��������ܡ� 4.��SQL Server�ΰ��ı���ͼ���е����ݴ����1�������������豸�Ͽ���������ܡ�1��ר�õ������͵Ŀ������ܽ�һ��������ܡ� ��ѯ�Ż� ��ѯ�ٶ�����ԭ��ܶ࣬�������¼��֣����� 1��û����������û���õ�����(���Dz�ѯ����������⣬�dz�����Ƶ�ȱ��)���� 2��I/O������С���γ���ƿ��ЧӦ������ 3��û�д��������е��²�ѯ���Ż������� 4���ڴ治�㡡�� 5�������ٶ������� 6����ѯ���������������Բ��ö�β�ѯ�������ķ������������������� 7������������(��Ҳ�Dz�ѯ����������⣬�dz�����Ƶ�ȱ��)���� 8��sp_lock,sp_who,����û��鿴,ԭ���Ƕ�д������Դ������ 9�������˲���Ҫ���к��С��� 10����ѯ��䲻�ã�û���Ż� ����ͨ�����·������Ż���ѯ :���� 1�������ݡ���־�������ŵ���ͬ��I/O�豸�ϣ����Ӷ�ȡ�ٶȣ���ǰ���Խ�TempdbӦ����RAID0�ϣ�SQL2000����֧�֡����������ߴ磩Խ�����I/OԽ��Ҫ.���� 2��������ָ�������ٱ��ijߴ�(sp_spaceuse)���� 3������Ӳ������ 4�����ݲ�ѯ����,��������,�Ż��������Ż����ʷ�ʽ�����ƽ��������������ע���������Ҫ�ʵ��������ʹ��Ĭ��ֵ0��������Ӧ�þ���С��ʹ���ֽ���С���н������ã����������Ĵ�����,��Ҫ�����ļ���ֵ���ֶν���һ�������Ա��ֶΡ��� 5���������;���� 6��������������ڴ�,Windows 2000��SQL server 2000��֧��4-8G���ڴ档���������ڴ棺�����ڴ��СӦ���ڼ�����ϲ������еķ���������á�����
Microsoft SQL Server? 2000 ʱ���ɿ��ǽ������ڴ��С����Ϊ������а�װ�������ڴ��
1.5 ����������ⰲװ��ȫ�ļ������ܣ����������� Microsoft ���������Ա�ִ��ȫ�������Ͳ�ѯ���ɿ��ǣ��������ڴ��С����Ϊ�����Ǽ�����а�װ�������ڴ��
3 ������ SQL Server max server memory ����������ѡ������Ϊ�����ڴ�� 1.5
���������ڴ��С���õ�һ�룩������ 7�����ӷ����� CPU����;���DZ������ײ��д������д�������Ҫ��Դ�����ڴ档ʹ�ò��л��Ǵ��г���MsSQL�Զ�����ѡ��ġ���������ֽ�ɶ�����Ϳ����ڴ����������С����絢���ѯ���������ӡ�ɨ���GROUP
BY�־�ͬʱִ�У�SQL SERVER����ϵͳ�ĸ�������������ŵIJ��еȼ������ӵ���Ҫ���Ĵ�����CPU�IJ�ѯ���ʺϲ��д��������Ǹ��²���Update,Insert��
Delete�����ܲ��д��������� 8�������ʹ��like���в�ѯ�Ļ�����ʹ��index�Dz��еģ�����ȫ���������Ŀռ䡣 like
'a%' ʹ������ like '%a' ��ʹ�������� like '%a%' ��ѯʱ����ѯ��ʱ���ֶ�ֵ�ܳ��ȳ�����,���Բ�����CHAR���ͣ�����VARCHAR�������ֶε�ֵ�ܳ��Ľ�ȫ������������ 9��DB Server ��APPLication Server ���룻OLTP��OLAP���롡�� 10���ֲ�ʽ������ͼ������ʵ�����ݿ�����������塣��������һ��ֿ������ķ��������������Э���ֵ�ϵͳ�Ĵ������ɡ�����ͨ�����������γ����ݿ������������Ļ����ܹ�����һ�����������֧�ִ��͵Ķ��
Web վ��Ĵ�����Ҫ���йظ�����Ϣ���μ�����������ݿ��������������SQL�����ļ�'������ͼ'������ a����ʵ�ַ�����ͼ֮ǰ��������ˮƽ���������� b���ڴ�����Ա������ÿ����Ա�������϶���һ���ֲ�ʽ������ͼ������ÿ����ͼ������ͬ�����ơ����������÷ֲ�ʽ������ͼ���IJ�ѯ�������κ�һ����Ա�����������С�ϵͳ������ͬÿ����Ա�������϶���һ��ԭʼ���ĸ���һ��������ʵÿ����������ֻ��һ����Ա����һ���ֲ�ʽ������ͼ�����ݵ�λ�ö�Ӧ�ó��������ġ����� 11���ؽ����� DBCC REINDEX ,DBCC INDEXDEFRAG,�������ݺ���־ DBCC
SHRINKDB,DBCC SHRINKFILE. �����Զ�������־.���ڴ�����ݿⲻҪ�������ݿ��Զ����������ή�ͷ����������ܡ���T-sql��д�����кܴ�Ľ����������г�������Ҫ�㣺���ȣ�DBMS������ѯ�ƻ��Ĺ����������ģ����� 1����ѯ���Ĵʷ������顡�� 2��������ύ��DBMS�IJ�ѯ�Ż������� 3���Ż����������Ż��ʹ�ȡ·�����Ż����� 4����Ԥ����ģ�����ɲ�ѯ�滮���� 5��Ȼ���ں��ʵ�ʱ���ύ��ϵͳ����ִ�С��� 6�����ִ�н�����ظ��û���Σ���һ��SQL SERVER�����ݴ�ŵĽṹ��һ��ҳ��Ĵ�СΪ8K(8060)�ֽڣ�8��ҳ��Ϊһ������������B����š����� 12��Commit��rollback������ Rollback:�ع����е���� Commit:�ύ��ǰ������.
û�б�Ҫ�ڶ�̬SQL��д������Ҫд��д�������磺 begin tran exec(@s) commit
trans ���߽���̬SQL д�ɺ������ߴ洢���̡����� 13���ڲ�ѯSelect�������Where�־����Ʒ��ص�����,�����ɨ��,������ز���Ҫ�����ݣ��˷��˷�������I/O��Դ������������ĸ����������ܡ�������ܴ��ڱ�ɨ����ڼ佫����ס����ֹ���������ӷ��ʱ�,������ء����� 14��SQL��ע��������ִ��û���κ�Ӱ�� 15�������ܲ�ʹ�ù�꣬��ռ�ô�������Դ�������Ҫrow-by-row��ִ�У��������÷ǹ�꼼��,�磺�ڿͻ���ѭ��������ʱ����Table���������Ӳ�ѯ����Case���ȵȡ��α����������֧�ֵ���ȡѡ����з��ֻࣺ�����밴�մӵ�һ�е����һ�е�˳����ȡ�С�FETCH
NEXT ��Ψһ��������ȡ����,Ҳ��Ĭ�Ϸ�ʽ���ɹ����Կ������α����κεط������ȡ�����С��α�ļ�����SQL2000�±�ù��ܺ�ǿ������Ŀ����֧��ѭ�������ĸ�����ѡ��
READ_ONLY��������ͨ���α궨λ����(Update)��������ɽ����������û������ OPTIMISTIC
WITH valueS:�ֹ۲�������������������۵�һ�������֡��ֹ۲��������������������Σ����ڴ��α꼰�����еļ���У�ֻ�к�С�Ļ����õڶ����û�����ijһ�С���ij���α��Դ�ѡ���ʱ��û�����������е��У��⽫����������䴦������������û���ͼ��ijһ�У�����еĵ�ǰֵ�������һ����ȡ����ʱ��ȡ��ֵ���бȽϡ�����κ�ֵ�����ı䣬��������ͻ�֪���������Ѹ����˴��У����᷵��һ���������ֵ��һ���ģ���������ִ���ġ�ѡ���������ѡ���OPTIMISTIC
WITH ROW VERSIONING:���ֹ۲�������ѡ������а汾���ơ�ʹ���а汾���ƣ����еı��������ij�ְ汾��ʶ������������������ȷ�������ڶ����α���Ƿ��������ġ���
SQL Server �У���������� timestamp ���������ṩ������һ�����������֣���ʾ���ݿ��и��ĵ����˳��ÿ�����ݿⶼ��һ��ȫ�ֵ�ǰʱ���ֵ��@@DBTS��ÿ�����κη�ʽ���Ĵ���
timestamp �е���ʱ��SQL Server ����ʱ������д洢��ǰ�� @@DBTS ֵ��Ȼ������
@@DBTS ��ֵ�����ij�������� timestamp �У���ʱ����ᱻ�ǵ��м����������Ϳ��ԱȽ�ij�еĵ�ǰʱ���ֵ���ϴ���ȡʱ���洢��ʱ���ֵ���Ӷ�ȷ�������Ƿ��Ѹ��¡����������رȽ������е�ֵ��ֻ��Ƚ�
timestamp �м��ɡ����Ӧ�ó����û�� timestamp �еı�Ҫ������а汾���Ƶ��ֹ۲��������α�Ĭ��Ϊ������ֵ���ֹ۲������ơ�
SCROLL LOCKS ���ѡ��ʵ�ֱ��۲������ơ��ڱ��۲��������У��ڰ����ݿ���ж����α�����ʱ��Ӧ�ó�����ͼ�������ݿ��С���ʹ�÷������α�ʱ�����ж����α�ʱ�������Ϸ���һ��������������������ڴ��α꣬��������������һֱ���ֵ������ύ��ع�������ȡ��һ��ʱ������ȥ�α������������������α꣬����ȡ��һ��ʱ�����ͱ���������ˣ�ÿ���û���Ҫ��ȫ�ı��۲�������ʱ���α궼Ӧ�������ڴ�����������ֹ�κ����������ȡ�����������������Ӷ���ֹ����������¸��С�Ȼ����������������ֹ��������������������ֹ���������ȡ�У����ǵڶ�������Ҳ��Ҫ����������Ķ�ȡ���������������α궨���
Select �����ָ��������ʾ����Щ�α겢��ѡ��������ɹ�����������������ȡʱ��ÿ���ϻ�ȡ�������ֵ��´���ȡ�����α�رգ����ȷ�����Ϊ���´���ȡʱ��������Ϊ����ȡ�е��л�ȡ�����������ͷ��ϴ���ȡ���еĹ��������������������������������Ա��ֵ�һ���ύ��ع�����֮������ύʱ�ر��α��ѡ��Ϊ�أ���
COMMIT ��䲢���ر��κδ��α꣬���ҹ��������������ύ֮����ά��������ȡ���ݵĸ��롣����ȡ������������ȡ�����α겢��ѡ����α�
Select ����е�����ʾ������ʾֻ���ֹ���ֵ�ֹ��а汾������������ʾδ����δ����δ�������� NOLOCK
δ����δ����δ����δ���� HOLDLOCK ���������������� UPDLOCK ������¸��¸��� TABLOCKX
����δ����δ������������δ����δ����δ�������� *ָ�� NOLOCK ��ʾ��ʹָ���˸���ʾ�ı����α�����ֻ���ġ����� 16����Profiler�����ٲ�ѯ���õ���ѯ�����ʱ�䣬�ҳ�SQL����������;�������Ż����Ż��������� 17��ע��UNion��UNion all ������UNION all�á��� 18��ע��ʹ��DISTINCT����û�б�Ҫʱ��Ҫ�ã���ͬUNIONһ����ʹ��ѯ�������ظ��ļ�¼�ڲ�ѯ����û������ġ��� 19����ѯʱ��Ҫ���ز���Ҫ���С��С��� 20����sp_configure 'query governor cost limit'����SET
QUERY_GOVERNOR_COST_LIMIT�����Ʋ�ѯ���ĵ���Դ����������ѯ���ĵ���Դ��������ʱ���������Զ�ȡ����ѯ,�ڲ�ѯ֮ǰ�Ͷ�ɱ����
SET LOCKTIME��������ʱ�䡡�� 21����select top 100 / 10 Percent �������û����ص���������SET ROWCOUNT�����Ʋ������С��� 22����SQL2000��ǰ��һ�㲻Ҫ�����µ��־�: "IS NULL", "<>",
"!=", "!>", "!<",
"NOT", "NOT EXISTS", "NOT IN",
"NOT LIKE", and "LIKE '%500'"����Ϊ���Dz�������ȫ�DZ�ɨ�衣Ҳ��Ҫ��Where�־��е������Ӻ�������Convert��substring��,��������ú�����ʱ�����������ٴ������������.�����Ա�ͨд����Where
SUBSTRING(firstname,1,1) = 'm'��ΪWhere firstname like
'm%'������ɨ�裩��һ��Ҫ�������������ֿ��������������ܽ���̫���̫��NOT IN����ɨ�����ʹ��EXISTS��NOT
EXISTS ��IN , LEFT OUTER JOIN ��������ر���������,��Exists��IN���죬��������NOT����.����е�ֵ���пգ���ǰ���������������ã�����2000���Ż����ܹ������ˡ���ͬ����IS
NULL��"NOT", "NOT EXISTS", "NOT
IN"���Ż�������"<>"�Ȼ��Dz����Ż����ò������������� 23��ʹ��Query Analyzer���鿴SQL���IJ�ѯ�ƻ������������Ƿ����Ż���SQL��һ���20%�Ĵ���ռ����80%����Դ�������Ż����ص�����Щ���ĵط������� 24�����ʹ����IN����OR��ʱ���ֲ�ѯû����������ʹ����ʾ����ָ�������� Select * FROM
PersonMember (INDEX = IX_Title) Where processid IN ('��'��'Ů')���� 25������Ҫ��ѯ�Ľ��Ԥ�ȼ���÷��ڱ��У���ѯ��ʱ����Select������SQL7.0��ǰ������Ҫ���ֶΡ�����ҽԺ��סԺ�Ѽ��㡣���� 26��MIN() �� MAX()��ʹ�õ����ʵ����������� 27�����ݿ���һ��ԭ���Ǵ���������Խ��Խ�ã���������ѡ��Default,����ΪRules,Triggers,
Constraint��Լ�����⽡����CheckUNIQUE����,�������͵���ȵȵȶ���Լ����,Procedure.��������ά������С����д���������ߣ�����ִ�е��ٶȿ졣���� 28�����Ҫ�����Ķ�����ֵ��Image�У�ʹ�ô洢���̣�ǧ��Ҫ����ǶInsert������(��֪JAVA�Ƿ�)����Ϊ����Ӧ�ó������Ƚ�������ֵת�����ַ������ߴ����������������������ܵ��ַ����ֽ���ת���ɶ�����ֵ.�洢���̾�û����Щ����:
������Create procedure p_insert as insert into table(Fimage)
values (@image), ��ǰ̨��������洢���̴�������Ʋ��������������ٶ����Ը��ơ����� 29��Between��ijЩʱ���IN �ٶȸ���,Between�ܹ�����ظ��������ҵ���Χ���ò�ѯ�Ż����ɼ������
select * from chineseresume where title in ('��','Ů')
Select * from chineseresume where between '��' and 'Ů'
��һ���ġ�����in���ڱȽ϶�Σ�������ʱ����Щ������ 30���ڱ�Ҫ�Ƕ�ȫ�ֻ��߾ֲ���ʱ��������������ʱ�ܹ�����ٶȣ�������һ������������Ϊ����Ҳ�ķѴ�������Դ�����Ĵ���ͬ��ʵ�ʱ�һ�������� 31����Ҫ��û�����õ����������������ʱ���˷���Դ��ֻ���ڱ�Ҫʹ������ʱʹ���������� 32����OR���־���Էֽ�ɶ����ѯ������ͨ��UNION ���Ӷ����ѯ�����ǵ��ٶ�ֻͬ�Ƿ�ʹ�������й�,�����ѯ��Ҫ�õ�������������UNION
allִ�е�Ч�ʸ���.���OR���־�û���õ���������д��UNION����ʽ����ͼ������ƥ�䡣һ���ؼ��������Ƿ��õ����������� 33������������ͼ������Ч�ʵ͡�����ͼ������ֱ�ӶԱ�������,������stored procedure�����������ر���Dz�Ҫ����ͼǶ��,Ƕ����ͼ������Ѱ��ԭʼ���ϵ��Ѷȡ����ǿ���ͼ�ı��ʣ����Ǵ���ڷ������ϵı��Ż����˵��Ѿ������˲�ѯ�滮��SQL���Ե�������������ʱ����Ҫʹ��ָ����������ͼ��ֱ�Ӵӱ��������߽����������������ͼ�϶������������˲���Ҫ�Ŀ���,��ѯ�ܵ�����.Ϊ�˼ӿ���ͼ�IJ�ѯ��MsSQL��������ͼ�����Ĺ��ܡ����� 34��û�б�Ҫʱ��Ҫ��DISTINCT��ORDER BY����Щ�������Ը��ڿͻ���ִ�С����������˶���Ŀ�������ͬUNION
��UNION ALLһ���ĵ����������� 35����IN����ֵ���б��У���������Ƶ����ֵ������ǰ�棬���ֵ����ٵķ�������棬�����жϵĴ��������� 36������Select INTOʱ��������סϵͳ��(sysobjects��sysindexes�ȵ�)���������������ӵĴ�ȡ��������ʱ��ʱ����ʾ������䣬������
select INTO. drop table t_lxh begin tran select * into
t_lxh from chineseresume where name = 'XYZ' --commit
����һ��������Select * from sysobjects���Կ��� Select INTO ����סϵͳ����Create
table Ҳ����ϵͳ��(��������ʱ������ϵͳ��)������ǧ��Ҫ��������ʹ���������������Ļ�����Ǿ���Ҫ�õ���ʱ����ʹ��ʵ����������ʱ������������ 37��һ����GROUP BY ��HAVING�־�֮ǰ������������У����Ծ�����Ҫ�������������еĹ��������ǵ�ִ��˳��Ӧ���������ţ�select
��Where�־�ѡ�����к��ʵ��У�Group By���������ͳ���У�Having�־�����������ķ��顣����Group
By ��Having�Ŀ���С����ѯ��.���ڴ�������н��з����Havingʮ��������Դ�����Group
BY��Ŀ�IJ��������㣬ֻ�Ƿ��飬��ô��Distinct���졡�� 38��һ�θ��¶�����¼�ȷֶ�θ���ÿ��һ����,����˵�������á��� 39��������ʱ���������ý������Table���Եı�����������,Table ���͵ı�������ʱ���á��� 40����SQL2000�£������ֶ��ǿ��������ģ���Ҫ������������£����� a�������ֶεı�����ȷ���ġ��� b����������TEXT,Ntext��Image�������͡��� c��������������ѡ�� ANSI_NULLS = ON, ANSI_PADDINGS = ON, ����.���� 41�����������ݵĴ����������ڷ������ϣ���������Ŀ�������ʹ�ô洢���̡��洢�����DZ���á��Ż��������ұ���֯��һ��ִ�й滮��Ҵ洢�����ݿ��е�SQL��䣬�ǿ��������Եļ��ϣ��ٶȵ�Ȼ�졣����ִ�еĶ�̬SQL,����ʹ����ʱ�洢���̣��ù��̣���ʱ����������Tempdb�С���ǰ����SQL
SERVER�Ը��ӵ���ѧ���㲻֧�֣����Բ��ò�������������������IJ��϶���������Ŀ�����SQL2000֧��UDFs,����֧�ָ��ӵ���ѧ���㣬�����ķ���ֵ��Ҫ̫�������Ŀ����ܴ��û��Զ��庯������һ��ִ�е����Ĵ�������Դ��������ش�Ľ�����ô洢���̡��� 42����Ҫ��һ�仰��������ʹ����ͬ�ĺ������˷���Դ,��������ڱ������ٵ��ø��졡�� 43��Select COUNT(*)��Ч�ʽ̵ͣ�������ͨ����д������EXISTS��.ͬʱ��ע������
select count(Field of null) from Table �� select count(Field
of NOT null) from Table �ķ���ֵ�Dz�ͬ�ģ��������� 44�������������ڴ湻��ʱ�������߳����� = ���������+5�������ܷ�������Ч�ʣ�����ʹ�������߳�����<�������������SQL
SERVER���̳߳������,����������� = ���������+5�����ص������������ܡ����� 45������һ���Ĵ�����������ı������������ס��A������ס��B����ô�����еĴ洢�����ж�Ҫ�������˳�����������ǡ�����㣨������ģ�ij���洢��������������B����������A������ܾͻᵼ��һ���������������˳��û�б�Ԥ����ϸ����ƺã��������ѱ����֡��� 46��ͨ��SQL Server Performance Monitor������ӦӲ���ĸ��� Memory:
Page Faults / sec�����������ֵż���߸ߣ�������ʱ���߳̾����ڴ档��������ܸߣ����ڴ������ƿ���� Process:���� 1��% DPC Time ָ�ڷ�������ڼ䴦�������ڻ��ӳ������(DPC)���պ��ṩ����İٷֱȡ�(DPC
�������е�Ϊ�ȱ��������Ȩ�͵ļ��)������ DPC ������Ȩģʽִ�еģ�DPC ʱ��İٷֱ�Ϊ��Ȩʱ��ٷֱȵ�һ���֡���Щʱ�䵥�����㲢�Ҳ����ڼ������������һ���֡����������ʾ����Ϊʵ��ʱ��ٷֱȵ�ƽ��æʱ������ 2��%Processor Time������������ò���ֵ��������95%������ƿ����CPU�����Կ�������һ����������һ������Ĵ����������� 3��% Privileged Time ָ�����ô�����ʱ��������Ȩģʽ�İٷֱȡ�(��Ȩģʽ��Ϊ����ϵͳ����Ͳ���Ӳ�������������Ƶ�һ�ִ���ģʽ��������ֱ�ӷ���Ӳ���������ڴ档��һ��ģʽΪ�û�ģʽ������һ��ΪӦ�ó�������ϵͳ��������ϵͳ��Ƶ�һ��������ģʽ������ϵͳ��Ӧ�ó����߳�ת������Ȩģʽ�Է��ʲ���ϵͳ����)����Ȩʱ���
% ����Ϊ��Ϻ� DPC �ṩ�����ʱ�䡣��Ȩʱ����ʸ߿���������ʧ���豸�����Ĵ������ļ��������ġ������������ƽ��æʱ��Ϊ����ʱ���һ������ʾ������ 4��% User Time��ʾ�ķ�CPU�����ݿ������������ִ��aggregate functions�ȡ������ֵ�ܸߣ��ɿ�����������������ʹ�üı����ӣ�ˮƽ�ָ�����ȷ���������ֵ��
Physical Disk: Curretn Disk Queue Length��������ֵӦ��������������1.5~2����Ҫ������ܣ������Ӵ��̡�
SQLServer:Cache Hit Ratio��������ֵԽ��Խ�á������������80%��Ӧ���������ڴ档ע��ò���ֵ�Ǵ�SQL
Server������һֱ�ۼӼ������������о���һ��ʱ���ֵ�����ܷ�ӳϵͳ��ǰֵ������ 47������select emp_name form employee where salary >
3000 �ڴ��������salary��Float���͵ģ����Ż�����������Ż�ΪConvert(float,3000)����Ϊ3000�Ǹ�����������Ӧ�ڱ��ʱʹ��3000.0����Ҫ������ʱ��DBMS����ת����ͬ���ַ����������ݵ�ת�������� 48����ѯ�Ĺ���ͬд��˳�� select a.personMemberID, * from chineseresume a,personmember
b where personMemberID = b.referenceid and a.personMemberID
= 'JCNPRH39681' ��A = B ,B = '����'������ select a.personMemberID, * from chineseresume a,personmember
b where a.personMemberID = b.referenceid and a.personMemberID
= 'JCNPRH39681' and b.referenceid = 'JCNPRH39681' ��A
= B ,B = '����'�� A = '����'������ select a.personMemberID, * from chineseresume a,personmember
b where b.referenceid = 'JCNPRH39681' and a.personMemberID
= 'JCNPRH39681' ��B = '����'�� A = '����'������ 49������ (1)IF û�����븺���˴��� THEN code1=0 code2=9999 ELSE code1=code2=�����˴���
END IF ִ��SQL���Ϊ: Select �������� FROM P2000 Where �����˴���>=:code1
AND�����˴��� <=:code2���� (2)IF û�����븺���˴��� THEN ��Select �������� FROM P2000 ELSE
code= �����˴��� Select �����˴��� FROM P2000 Where �����˴���=:code
END IF ��һ�ַ���ֻ����һ��SQL���,�ڶ��ַ�����������SQL��䡣��û�����븺���˴���ʱ,�ڶ��ַ�����Ȼ�ȵ�һ�ַ���ִ��Ч�ʸ�,��Ϊ��û����������;
�������˸����˴���ʱ,�ڶ��ַ�����Ȼ�ȵ�һ�ַ���Ч�ʸ�,����������һ����������,����������������IJ�ѯ���㡣����д����Ҫ���鷳���� 50������JOBCN���ڲ�ѯ��ҳ���·��������£����������Ż����������ܵ�ƿ���������I/O����������ٶ��ϣ����µķ����Ż���ʵ��Ч�������CPU�����ڴ��ϣ������ڵķ������á����������µķ�����˵������ԽСԽ�á����� begin���� DECLARE @local_variable table (FID int identity(1,1),ReferenceID
varchar(20))���� insert into @local_variable (ReferenceID)���� select top 100000 ReferenceID from chineseresume order
by ReferenceID���� select * from @local_variable where Fid > 40 and
fid <= 60���� end �� begin���� DECLARE @local_variable table (FID int identity(1,1),ReferenceID
varchar(20))���� insert into @local_variable (ReferenceID)���� select top 100000 ReferenceID from chineseresume order
by updatedate���� select * from @local_variable where Fid > 40 and
fid <= 60���� end �IJ�ͬ begin���� create table #temp (FID int identity(1,1),ReferenceID
varchar(20))���� insert into #temp (ReferenceID)���� select top 100000 ReferenceID from chineseresume order
by updatedate���� select * from #temp where Fid > 40 and fid <=
60 drop table #temp���� end ��ȫͨ��ϵͳ�������������Ż������ڴ��С���ļ�ϵͳ���͡�����������Ŀ�����͵ȣ��������������ܺ����ˡ����������������������ⲻ�������ַ������������ͨ����Щ��������������⣺����Ӧ�ó����Լ�Ӧ�ó����ύ�����ݿ�IJ�ѯ���£���������Щ��ѯ������������ݿ�ܹ������� ����ʱ������س��IJ�ѯ���¿���������ԭ������ ������ͨѶ�ٶ����� ����������������ڴ治��� Microsoft? SQL Server? 2000 ���õ��ڴ治�㡣 ��ȱ�����õ�ͳ�����ݡ� ��ͳ�����ݹ��ڡ� ��ȱ�����õ����� ��ȱ�����õ������������� ����ѯ����»��ѵ�ʱ���Ԥ�ڵij�ʱ��ʹ������ļ���嵥������ܣ� ˵���������뼼��֧���ṩ����ϵ֮ǰ�Ȳο��ü���嵥�� 1.�����������ѯ���������Ƿ��йأ����磬�����Ƿ�Ϊ�������������Ƿ����κ���������������ӵ��������½������������ʹ��
Windows NT ���ܼ����������� SQL Server ��غ��� SQL Server ����ص�������ܡ��йظ�����Ϣ����μ�ʹ��ϵͳ���������м��ӡ� 2.��������������ѯ��أ��漰�ĸ���ѯ�������ѯ��ʹ�� SQL �¼�̽��������ʶ�����ٲ�ѯ���йظ�����Ϣ����μ�ʹ��
SQL �¼�̽�������м��ӡ� ͨ��ʹ�� SET ������� SHOWPLAN��STATISTICS IO��STATISTICS TIME
�� STATISTICS PROFILE ѡ�����ȷ�����ݿ��ѯ���ܡ� ��SHOWPLAN ���� SQL Server ��ѯ�Ż���ѡ������ݼ����������йظ�����Ϣ����μ� SET
SHOWPLAN_ALL�� ��STATISTICS IO ��������������õ�ÿ������ɨ����������ȡ�����ڸ��ٻ����з��ʵ�ҳ������������ȡ�������ʴ��̵Ĵ������йص���Ϣ���йظ�����Ϣ����μ�
SET STATISTICS IO�� ��STATISTICS TIME ��ʾ�����������ִ�в�ѯ�����ʱ�䣨�Ժ���Ϊ��λ�����йظ�����Ϣ����μ�
SET STATISTICS TIME�� ��STATISTICS PROFILE ��ʾÿ����ѯִ�к�Ľ������������ѯִ�е������ļ����йظ�����Ϣ����μ�
SET STATISTICS PROFILE�� �� SQL ��ѯ�������У������Դ� graphical execution plan ѡ��鿴���� SQL
Server ��μ������ݵ�ͼ�α�ʾ�� ����Щ�����ռ�����Ϣʹ������ȷ�� SQL Server ��ѯ�Ż����������ִ�в�ѯ�Լ�����ʹ����Щ������������Щ��Ϣ������ȷ��ͨ����д��ѯ�����ı��ϵ������������ݿ���Ƶȷ����ܷ�������ܡ��йظ�����Ϣ����μ�������ѯ�� 3.�Ƿ��Ѿ������õ�ͳ�������Ż���ѯ�� SQL Server �Զ����������ϴ��������ڵ�ֵ�ֲ������ͳ�ơ�Ҳ����ʹ�� SQL ��ѯ�������� CREATE
STATISTICS ����ڷ����������ֶ�����ͳ�ƣ���������� auto create statistics
���ݿ�ѡ������Ϊ true�����Զ��ڷ��������ϴ���ͳ�ơ���ѯ����������������Щͳ��ȷ����ѵIJ�ѯ�������ԡ������Ӳ������漰�ķ���������ά�����ӵ�ͳ����Ϣ������߲�ѯ���ܡ��йظ�����Ϣ����μ�ͳ����Ϣ�� ʹ�� SQL �¼�̽������ SQL ��ѯ�������ڵ�ͼ��ִ�мƻ������Ӳ�ѯ����ȷ����ѯ�Ƿ����㹻��ͳ����Ϣ���йظ�����Ϣ����μ�����;����¼����ࡣ 4.��ѯͳ����Ϣ�Ƿ�Ϊ���£�ͳ����Ϣ�Ƿ��Զ����£� SQL Server �Զ����������ϴ��������²�ѯͳ�ƣ�ֻҪû�н����Զ���ѯͳ�Ƹ������ԣ������⣬����ʹ��
SQL ��ѯ�������� UPDATE STATISTICS ����ڷ����������ֹ�����ͳ�ƣ�������� auto
update statistics ���ݿ�ѡ������Ϊ true�����Զ��ڷ��������ϸ���ͳ�ơ����µ�ͳ�Ʋ�ȡ�������ڻ�ʱ�����ݡ������δ����
UPDATE ���������ѯͳ����Ϣ�������µġ� ���û�н�ͳ������Ϊ�Զ����£���Ӧ����Ϊ�Զ����¡��йظ�����Ϣ����μ�ͳ����Ϣ�� 5.�Ƿ��к��ʵ�����������һ�����������Ƿ����߲�ѯ���ܣ��йظ�����Ϣ����μ������Ż����顣 6.�Ƿ����κ������ȵ�������ȵ㣿����У�����ʹ�ô������������йظ�����Ϣ����μ�ʹ���ļ���������ݺ�
RAID�� 7.�Ƿ�Ϊ��ѯ�Ż����ṩ���Ż����Ӳ�ѯ���������������йظ�����Ϣ����μ���ѯ�Ż����顣 �洢���̵��Ż��� һ��ǰ�ԣ��ھ���һ��ʱ��Ĵ洢���̿���֮��д����һЩ����ʱ���С��;������ҹ�����ϣ���Դ�����棬��Ҫ�����Sybase��SQL
Server���ݿ⣬���������ݿ�Ӧ����һЩ���ԡ� �����ʺ϶��߶������ݿ������Ա�����ݿ���������ܶ࣬�漰����SP���洢���̣����Ż�����Ŀ������Ա�������ݿ���Ũ����Ȥ���ˡ� �������ܣ������ݿ�Ŀ��������У��������������ӵ�ҵ�����Ͷ����ݿ�IJ��������ʱ��ͻ���SP����װ���ݿ�����������Ŀ��SP�϶࣬��д��û��һ���Ĺ淶������Ӱ���Ժ��ϵͳά�����Ѻʹ�SP�����������⣬����������ݿ���������������Ŀ��SP������Ҫ��ܣ��ͻ������Ż������⣬�����ٶ��п��ܺ����������������飬һ�������Ż�����SPҪ��һ�����ܲ��SP��Ч���������ٱ��� �ġ����ݣ� 1��������Ա����õ��������Table��View������ڵ�ǰ���н���View��ʵ�ֿ���������ò�Ҫֱ��ʹ�á�databse.dbo.table_name������Ϊsp_depends������ʾ����SP��ʹ�õĿ��table��view��������У�顣 2��������Ա���ύSPǰ�������Ѿ�ʹ��set showplan on��������ѯ�ƻ������������IJ�ѯ�Ż���顣 3���߳�������Ч�ʣ��Ż�Ӧ�ó�����SP��д������Ӧ��ע�����¼��㣺 a) SQL��ʹ�ù淶�� i. ����������������������holdlock�Ӿ䣬���ϵͳ���������� ii. �������ⷴ������ͬһ�Ż��ű����������������ϴ�ı������Կ����ȸ���������ȡ���ݵ���ʱ���У�Ȼ���������ӡ� iii.��������ʹ���α꣬��Ϊ�α��Ч�ʽϲ����α���������ݳ���1���У���ô��Ӧ�ø�д�����ʹ�����α꣬��Ҫ�����������α�ѭ�����ٽ��б����ӵIJ����� iv. ע��where�־�д�������뿼�����˳��Ӧ�ø�������˳��Χ��С��ȷ�������Ӿ��ǰ��˳�����ܵ����ֶ�˳��������˳����һ�£���Χ�Ӵ�С�� v. ��Ҫ��where�Ӿ��еġ�=����߽��к����������������������ʽ���㣬����ϵͳ����������ȷʹ�������� vi. ����ʹ��exists����select count(1)���ж��Ƿ���ڼ�¼��count����ֻ����ͳ�Ʊ�����������ʱʹ�ã�����count(1)��count(*)����Ч�ʡ� vii.����ʹ�á�>=������Ҫʹ�á�>���� viii.ע��һЩor�Ӿ��union�Ӿ�֮����滻 ix.ע���֮�����ӵ��������ͣ����ⲻͬ��������֮������ӡ� x. ע��洢�����в������������͵Ĺ�ϵ�� xi.ע��insert��update����������������ֹ������Ӧ�ó�ͻ���������������200������ҳ�棨400k������ôϵͳ���������������ҳ�����������ɱ������� b) ������ʹ�ù淶�� i. �����Ĵ���Ҫ��Ӧ�ý�Ͽ��ǣ�������OLTP����Ҫ����6�������� ii. �����ܵ�ʹ�������ֶ���Ϊ��ѯ�����������Ǿ۴���������Ҫʱ����ͨ��index index_name��ǿ��ָ������ iii.����Դ����ѯʱ����table scan����Ҫʱ�����½������� iv. ��ʹ�������ֶ���Ϊ����ʱ�������������������������ô����ʹ�õ��������еĵ�һ���ֶ���Ϊ����ʱ���ܱ�֤ϵͳʹ�ø���������������������ᱻʹ�á� v. Ҫע��������ά�����������ؽ����������±���洢���̡� c)tempdb��ʹ�ù淶�� i. ��������ʹ��distinct��order by��group by��having��join��cumpute����Ϊ��Щ�������tempdb�ĸ����� ii. ����Ƶ��������ɾ����ʱ��������ϵͳ����Դ�����ġ� iii.���½���ʱ��ʱ�����һ���Բ����������ܴ���ô����ʹ��select into����create table������log������ٶȣ��������������Ϊ�˻���ϵͳ������Դ��������create
table��Ȼ��insert�� iv. �����ʱ�����������ϴ���Ҫ������������ôӦ�ý�������ʱ���ͽ��������Ĺ��̷��ڵ���һ���Ӵ洢�����У��������ܱ�֤ϵͳ�ܹ��ܺõ�ʹ�õ�����ʱ���������� v. ���ʹ�õ�����ʱ�����ڴ洢���̵������ؽ����е���ʱ����ʽɾ������truncate table��Ȼ��drop
table���������Ա���ϵͳ���Ľϳ�ʱ�������� vi. ���ô����ʱ����������������Ӳ�ѯ���ģ�����ϵͳ����������Ϊ���ֲ�������һ������ж��ʹ��tempdb��ϵͳ���� d)�������㷨ʹ�ã� �����������ᵽ��SQL�Ż�������ASE Tuning�ֲ��е�SQL�Ż�����,���ʵ��Ӧ��,���ö����㷨���бȽ�,�Ի��������Դ���١�Ч����ߵķ������������ASE�������set
statistics io on, set statistics time on , set showplan
on �ȡ� ������һЩ���õ��Ż���Ҫע��ķ��棺 �������Ż� IN ��������INд������SQL���ŵ��DZȽ�����д������������Ƚ��ʺ��ִ����������ķ������IN��SQL�������DZȽϵ͵ģ���ORACLEִ�еIJ�����������IN��SQL�벻��IN��SQL����������
ORACLE��ͼ����ת���ɶ���������ӣ����ת�����ɹ�����ִ��IN������Ӳ�ѯ���ٲ�ѯ���ı���¼�����ת���ɹ���ֱ�Ӳ��ö���������ӷ�ʽ��ѯ���ɴ˿ɼ���IN��SQL���ٶ���һ��ת���Ĺ��̡�һ���SQL������ת���ɹ��������ں��з���ͳ�Ƶȷ����SQL�Ͳ���ת���ˡ�
�Ƽ���������ҵ���ܼ���SQL���о���������IN�������� NOT IN������ �˲�����ǿ���Ƽ���ʹ�õģ���Ϊ������Ӧ�ñ����������Ƽ���������NOT EXISTS ��������+�ж�Ϊ�գ���������
<> �������������ڣ������ڲ���������Զ�����õ������ģ���˶����Ĵ���ֻ�����ȫ��ɨ�衣�Ƽ���������������ͬ���ܵIJ���������棬��
a<>0 ��Ϊ a>0 or a<0 a<>���� ��Ϊ a>����
IS NULL ��IS NOT NULL�������ж��ֶ��Ƿ�Ϊ�գ��ж��ֶ��Ƿ�Ϊ��һ���Dz���Ӧ�������ģ���ΪB�������Dz�������ֵ�ġ�
�Ƽ���������������ͬ���ܵIJ���������棬�� a is not null ��Ϊ a>0 ��a>�����ȡ��������ֶ�Ϊ�գ�����һ��ȱʡֵ�����ֵ����ҵ��������״̬�ֶβ�����Ϊ�գ�ȱʡΪ���롣����λͼ�������з����ı����ܽ���λͼ�����Ƚ��ѿ��ƣ����ֶ�ֵ̫��������ʹ�����½������˸��²������������ݿ���������
> �� < �����������ڻ�С�ڲ������� ���ڻ�С�ڲ�����һ��������Dz��õ����ģ���Ϊ���������ͻ�����������ң����е�����¿��Զ��������Ż�����һ������100���¼��һ����ֵ���ֶ�A��30���¼��A=0��30���¼��A=1��39���¼��A=2��1���¼��A=3����ôִ��A>2��A>=3��Ч�����кܴ�������ˣ���ΪA>2ʱORACLE�����ҳ�Ϊ2�ļ�¼�����ٽ��бȽϣ���A>=3ʱORACLE��ֱ���ҵ�=3�ļ�¼������
LIKE������ LIKE����������Ӧ��ͨ�����ѯ�������ͨ�����Ͽ��ܴﵽ����������IJ�ѯ����������õò��������������ϵ����⣬��LIKE
��%5400%�� ���ֲ�ѯ����������������LIKE ��X5400%��������÷�Χ������һ��ʵ�����ӣ���YW_YHJBQK����Ӫҵ��ź���Ļ���ʶ�ſ�����ѯӪҵ���
YY_BH LIKE ��%5400%�� ������������ȫ��ɨ�裬����ij�YY_BH LIKE ��X5400%��
OR YY_BH LIKE ��B5400%�� �������YY_BH����������������Χ�IJ�ѯ�����ܿ϶������ߡ�
UNION������ UNION�ڽ��б����Ӻ��ɸѡ���ظ��ļ�¼�������ڱ����Ӻ����������Ľ���������������㣬ɾ���ظ��ļ�¼�ٷ��ؽ����ʵ�ʴ�Ӧ�����Dz�������ظ��ļ�¼��������ǹ��̱�����ʷ��UNION���磺
select * from gc_dfys union select * from ls_jg_dfys
���SQL������ʱ��ȡ���������Ľ������������ռ��������ɾ���ظ��ļ�¼����ؽ�������������������Ļ����ܻᵼ���ô��̽��������Ƽ�����������UNION
ALL���������UNION����ΪUNION ALL����ֻ�ǼĽ���������ϲ���ͷ��ء� select * from gc_dfys union all select * from ls_jg_dfys
SQL��д��Ӱ��ͬһ����ͬһ���ܲ�ͬд��SQL��Ӱ����һ��SQL��A����Աд��Ϊ Select * from
zl_yhjbqk B����Աд��Ϊ Select * from dlyx.zl_yhjbqk�����������ߵ�ǰ��
C����Աд��Ϊ Select * from DLYX.ZLYHJBQK����д������ D����Աд��Ϊ Select
* from DLYX.ZLYHJBQK���м���˿ո������ĸ�SQL��ORACLE��������֮������Ľ����ִ�е�ʱ����һ���ģ����Ǵ�ORACLE�����ڴ�SGA��ԭ�������Եó�ORACLE��ÿ��SQL
����������һ�η���������ռ�ù����ڴ棬�����SQL���ַ�������ʽд����ȫ��ͬ��ORACLEֻ�����һ�Σ������ڴ�Ҳֻ������һ�εķ���������ⲻ�����Լ��ٷ���SQL��ʱ�䣬���ҿ��Լ��ٹ����ڴ��ظ�����Ϣ��ORACLEҲ����ȷͳ��SQL��ִ��Ƶ�ʡ�
WHERE���������˳��Ӱ�� WHERE�Ӿ���������˳��Դ����������IJ�ѯ�����ֱ�ӵ�Ӱ�죬�� Select * from zl_yhjbqk
where dy_dj = '1KV����' and xh_bz=1 Select * from zl_yhjbqk
where xh_bz=1 and dy_dj = '1KV����' ��������SQL��dy_dj����ѹ�ȼ�����xh_bz��������־�������ֶζ�û��������������ִ�е�ʱ����ȫ��ɨ�裬��һ��SQL��dy_dj
= '1KV����'�����ڼ�¼���ڱ���Ϊ99%����xh_bz=1�ı���ֻΪ0.5%���ڽ��е�һ��SQL��ʱ��99%����¼������dy_dj��xh_bz�ıȽϣ����ڽ��еڶ���SQL��ʱ��0.5%����¼������dy_dj��xh_bz�ıȽϣ��Դ˿��Եó��ڶ���SQL��CPUռ�������Աȵ�һ���͡�
��ѯ��˳���Ӱ����FROM����ı��е��б�˳����SQLִ������Ӱ�죬��û��������ORACLEû�жԱ�����ͳ�Ʒ����������ORACLE�ᰴ�����ֵ�˳��������ӣ��ɴ���Ϊ����˳�Ի����ʮ�ֺķ�������Դ�����ݽ��档��ע������Ա�������ͳ�Ʒ�����ORACLE���Զ��Ƚ�С�������ӣ��ٽ��д�������ӣ�
SQL������������öԲ��������Ż������Ͻڣ� �������ֶε�һЩ�Ż����ú����������ֶβ��������������磺 substr(hbs_bh,1,4)=��5400�����Ż�������hbs_bh like ��5400%�� trunc(sk_rq)=trunc(sysdate)���Ż�������
sk_rq>=trunc(sysdate) and sk_rq<trunc(sysdate+1)
��������ʽ����ʽ��������ֶβ��ܽ����������磺 ss_df+20>50���Ż�������ss_df>30
��X��||hbs_bh>��X5400021452�����Ż�������hbs_bh>��5400021542��
sk_rq+5=sysdate���Ż�������sk_rq=sysdate-5 hbs_bh=5401002554���Ż�������hbs_bh=�� 5401002554����ע����������hbs_bh
������ʽ��to_numberת������Ϊhbs_bh�ֶ����ַ��͡� �����ڰ����˶���������ֶ�����ʱ���ܽ����������磺 ys_df>cx_df���������Ż� qc_bh||kh_bh=��5400250000�����Ż�������qc_bh=��5400�� and kh_bh=��250000��
Ӧ��ORACLE��HINT����ʾ������ ��ʾ��������ORACLE������SQL����ִ��·��������������Ҫ�õ��ġ������Զ�SQL�������·������ʾ
Ŀ�귽�����ʾ�� COST�����ɱ��Ż��� RULE���������Ż��� CHOOSE��ȱʡ����ORACLE�Զ�ѡ��ɱ����������Ż��� ALL_ROWS�����е��о��췵�أ� FIRST_ROWS����һ�����ݾ��췵�أ� ִ�з�������ʾ�� USE_NL��ʹ��NESTED LOOPS��ʽ���ϣ� USE_MERGE��ʹ��MERGE
JOIN��ʽ���ϣ� USE_HASH��ʹ��HASH JOIN��ʽ���ϣ�������ʾ�� INDEX��TABLE INDEX����ʹ����ʾ�ı��������в�ѯ�� ��������ʾ���粢�д����ȵȣ� ORACLE����ʾ�����DZȽ�ǿ�Ĺ��ܣ�Ҳ�DZȽϸ��ӵ�Ӧ�ã�������ʾֻ�Ǹ�ORACLEִ�е�һ�����飬��ʱ������ڳɱ�����Ŀ���ORACLEҲ���ܲ��ᰴ��ʾ���С�����ʵ��Ӧ�ã�һ�㲻���鿪����ԱӦ��ORACLE��ʾ����Ϊ�������ݿ⼰���������������һ�����ܿ���һ���ط����������ˣ�����һ���ط�ȴ�½��ˣ�ORACLE��SQLִ�з��������Ѿ��Ƚϳ��죬�������ִ�е�·����������Ӧ�����ݿ�ṹ����Ҫ������������������ǰ���ܣ������ڴ桢�����ļ���Ƭ�������ݿ������������ͳ����Ϣ�Ƿ���ȷ�⼸��������� ��û���Ż����ݿ����վ��ȣ����ݿ�Ĵ�ȡ�ή�����ϵͳ���ܡ����Ǵ��������£���վ�����ݿ����ܲ��ɷֵĹ�ϵ���������ݿ��վ���ṩ�˴������������ԡ����Ի�����ɫ����ʵ���˺ܶ�����Ĺ��ܡ�
1 ��Ҫ���Ǹ����ݿ�������������������������������������ݿ�����ϵͳ�����ܡ����Բο��й�SQL���ܵ����鼮��ѧ����������ѯ��ʽ����������������������ʽ�Ľ���ѯ��䡣
2 ���ʵ�������£������ܵ��ô洢���̶�����SQL��ѯ����Ϊǰ���Ѿ�����Ԥ���룬�����ٶȸ��졣ͬʱ�����ݿ��������������Ҫ����Щ���ݣ������Ƿ��ش�����������ASP������ˡ���֮Ҫ��ֺ���Ч�ط������ݿ��ǿ���ܣ������������ǵ�Ҫ��������������ʺ��������Ϣ��
3 �ڿ������������Ӧ��ʹ��SQL Server������Access����ΪAccess�����ǻ����ļ������ݿ⣬���û����ܺܲ���ݿ����Ӿ���ʹ��OLEDB�ͷ�DSN��ʽ����Ϊ�������ӷ�ʽ�и��õIJ������ܡ� 4 ����ʹ��DAO��Data Access Objects����RDO��Remote Data Objects������Դ����Ϊ������ҪӦ���ڵ��û��Ĵ���ϵͳ�ADO��ActiveX
Data Objects������ΪWebӦ����Ƶġ� 5 ������¼��Rescordset��ʱ��Ҫ�������������������α�(cursort)��������ʽ(locktype)����Ϊ�ڲ�ͬ�ķ�ʽ��ASP���Բ�ͬ�ķ�ʽ�������ݿ⣬��ִ���ٶ�Ҳ�кܴ����������ڴ���������ʱ�������ֻ��������ݣ���ôĬ���α꣨ǰ����ֻ�����������õ����ܡ�
6 ��������ADO������ʱ�����Ľ϶��CPU���ڡ���ˣ������һ��ASPҳ���ж���������ݿ���ֶα�����һ���Ϻõķ�ʽ�ǽ��ֶ�ֵ�ȷ��뱾�ر�����Ȼ�����ֱ�ӵ��ñ��ر������������ʾ���ݡ�
7 ����ADO Connection����Ҳ������һ�������⡣���һ�����ӣ�Connection�����洢��Application�����ж�������ASPҳ��ʹ�ã���ô����ҳ��ͻ�����ʹ��������ӡ�����������Ӷ��洢��Session�����У���ҪΪÿ���û�����һ�����ݿ����ӣ���ͼ�С�����ӳص����ã�����������Web�����������ݿ��������ѹ������������ÿ��ʹ��ADO��ASPҳ�������ͷ�ADO����������������ݿ����ӡ���ΪIIS�ڽ������ݿ����ӳأ��������ַ����dz���Ч��ȱ����ÿ��ASPҳ�涼��Ҫ����һЩ�������ͷŲ�����
8 ASP��ǿ�����Ҫ����;֮һ���Ƕ����ݿ���в����������ݿ����������Ҫע�⣺��Ҫ����ʹ�á�SELECT
�� ......�� ��ʽ��SQL��ѯ��䡣Ӧ�þ�������������Ҫ����Щ�ֶΡ�����һ��������10���ֶΣ�������ֻ���õ����е�һ���ֶΣ�name������ʹ�á�select
name from mytable�����������á�select �� from mytable�������ֶ����Ƚ��ٵ�ʱ�����ߵ�������ܲ������ԣ����ǵ�һ������ӵ�м�ʮ���ֶε�ʱ�����ݿ�������ܶ��㲢����Ҫ�����ݡ����������������ò�ҪΪ�˽�ʡ����ʱ����ߺ��²��Ҷ�Ӧ�ֶ����Ƶ��鷳����Ҫ����ʵʵ��ʹ�á�select
id,name,age... from mytable���� 9 ��ʱ�رմļ�¼�������Լ�����(Connection)����¼����������Ӷ���ķ�ϵͳ��Դ�൱��������ǵĿ������������ġ���������̫��ļ�¼�������Լ����Ӷ�������ȴû�йر����ǣ����ܻ����ASP����տ�ʼ��ʱ�������ٶȺܿ죬�������м����Խ��Խ���������������·�������������ʹ�����·������йرգ�
MyRecordSet.closeSet MyRecordSet=Nothing Set MyConnection=Nothing
10 �������ݿ���Ȼʹ��ODBCϵͳ�����ļ�DSN���������ݿ⣬����ʹ�úܿ��OLEDB���������ӡ�ʹ�ú��ߣ����ƶ�Web�ļ�ʱ��������Ҫ�����á�
OLEDBλ��Ӧ�ó�����ODBC��֮�䡣��ASPҳ���У�ADO����λ��OLEDB֮�ϵij�����ADOʱ�����ȷ���OLEDB��Ȼ���ٷ���ODBC�㡣����ֱ�����ӵ�OLEDB�㣬��ô������߷������˵����ܡ���ôֱ�����ӵ�OLEDB�أ����ʹ��SQLServer
7��ʹ������Ĵ�����Ϊ�����ַ����� strConnString = "DSN='';DRIVER={SQL
SERVER};" & _ "UID=myuid;PWD=mypwd;" & _ "DATABASE=MyDb;SERVER=MyServer;"
����Ҫ�IJ������ǡ�DRIVER=�����֡���������ƹ�ODBC��ʹ��OLEDB������SQL Server��ʹ����������
strConnString ="Provider=SQLOLEDB.1;Password=mypassword;"
& _ "Persist Security Info=True;User ID=myuid;"
& _ "Initial Catalog=mydbname;" &
_ "Data Source=myserver;Connect Timeout=15"
Ϊʲô�����Ҫ������������Ϊʲôѧϰ�����µ����ӷ����ܹؼ���Ϊʲô��ʹ�ñ���DSN����ϵͳDSN�������ã�����Wrox�����ǵ�ADO
2.0����Ա�ο��鼮�������IJ��ԣ����ʹ��OLEDB���ӣ�Ҫ��ʹ��DSN����DSN��less���ӣ������µ�������߱��֣����ܱȽϣ�
----------------------------------------------------------------------
SQL Access ����ʱ��: 18 82 �ظ�1��000����¼��ʱ�䣺2900 5400 OLEDB DSN OLEDB DSN ����ʱ�䣺62 99 �ظ�1��000����¼��ʱ�䣺100 950
----------------------------------------------------------------------
���������Wrox��ADO 2.0����Ա�ο�������ʱ�����Ժ���Ϊ��λ���ظ�1��000����¼��ʱ�����Է������ͱ�ķ�ʽ����ġ� ��һ�����ӣ� select a. *, m.amount from tableA a, ( select b.fieldD,
sum(c.total_amount) amount from tableA b, tableB c where
b.fieldC = 100 and b.fieldA in ('AA', 'BB', 'CC', 'DD',
'EE', 'FF') and b.fieldId = c.fieldId group by b.fieldD
) m where a.fieldC = 100 and a.fieldD = m.fieldD and
a.fieldA = 'GG'
���sql���ж�ͬһ����ɨ��������,����Ч��̫��,��ʲô�취���Ա�������д��? tableA,tableB
�����ӱ���ϵ���벻Ҫ��sql server ��̫����������ΪҪ�õ�oracle�С���oracle�����˻ش� ------------------------------------------ SQL����д���Ǹ������ҵ��Ҫ��д����Ч�����ܺ����ԡ� �ȷ���һ�����SQL��ִ��·���� 1�����Ȼ�ֱ��tableA��tableBӦ��filter������ʹ��m�Ӳ�ѯ�е�where��������Ȼ��������ӣ����ܻ���nestloop��hash
join...��ȡ������ �����������ݹ��������Ȼ����л��ܣ�group by�����m������� 2���������Ὣm�������tableA����㣩���˺�a.fieldC = 100 and a.fieldA
= 'GG'���Ľ�����������ӣ������ж������ӷ�ʽ������� ��a. *, m.amount ���·�����һ��ִ�е�·�����ͻ��������������ɻ���ͬһ����ɨ�������Ρ��϶�ָ����tableA�ˡ�������û�н�����ص��������� ��˵���IJ�ѯ���㽨������Ҳ��ͨ��rowid��λ�����У�����Ȩ�����ǡ���ɨ�衱�������ڲ�IJ�ѯӦ�ò��ᷢ��������ɨ�裨all
table access���������Ӧ��������ɨ�裨index scan���Ŷԡ�������һ�㣬���ǿ������ȿ��ǽ������������Ч�ʡ� ���Կ��ǽ����������� create index idx_1 on tableA(fieldC,fieldA,fieldId,fieldD) create index idx_2 on tableB(fieldId,total_amount) ���������������������������ִ�з������Ա�֤ͳ��ֵȷ�� �������������������ڲ��ִ�мƻ�Ӧ���Ƕ�idx_1��idx_2��������ɨ�裨index scan��Ȼ���������m��������������ľ�������ɨ�裨 index scan + rowid to table���Ľ�����������ӡ� �����ѯ�ƻ����ԣ���������Ż����������ã���Ҫʹ��rboҪʹ��cbo���������û�в�������/* index*/��ʾǿ��ָ��.... ������ǵ������������濼�ǡ�������Dz�������ٶȣ����ǽ���ʵ�廯��ͼ���ﻯ��ͼ��������ֻ��m���ֽ���ʵ�廯�����tableA��tableB �������ھ�̬�������Կ��ǽ��������ʵ�廯�� �����и��dz��õ����Ӳ��ܽ��ˣ� SERVER���ݿ���ʵ�ֿ��ٵ�������ȡ�����ݷ�ҳ�����´���˵��������ʵ�������ݿ�ġ���ͷ�ļ���һ���IJ������ݽṹ�� CREATE table [dbo].[TGongwen] (����--TGongwen�Ǻ�ͷ�ļ����� [Gid] [int] ideNTITY (1, 1) NOT NULL , --������id�ţ�Ҳ������ [title] [varchar] (80) COLLATE Chinese_PRC_CI_AS NULL
, --��ͷ�ļ��ı��� [fariqi] [datetime] NULL , --�������� [neibuYonghu] [varchar] (70) COLLATE Chinese_PRC_CI_AS
NULL , --�����û� [reader] [varchar] (900) COLLATE Chinese_PRC_CI_AS NULL
, --��Ҫ������û���ÿ���û��м��÷ָ�����,���ֿ� ) ON [PRIMARY] TEXTimage_ON [PRIMARY] GO ���棬�����������ݿ�������1000�������ݣ� declare @i int set @i=1 while @i<=250000 begin insert into Tgongwen(fariqi,neibuyonghu,reader,title)
values('2004-2-5','ͨ�ſ�','ͨ�ſ�,�칫��,���ֳ�,���ֳ�,�žֳ�,admin,����֧��,����֧��,��Ѳ��֧��,����֧��,������,�ΰ�֧��,���¿�','�������ȵ�25������¼') set @i=@i+1 end GO declare @i int set @i=1 while @i<=250000 begin insert into Tgongwen(fariqi,neibuyonghu,reader,title)
values('2004-9-16','�칫��','�칫��,ͨ�ſ�,���ֳ�,���ֳ�,�žֳ�,admin,����֧��,����֧��,��Ѳ��֧��,����֧��,������,���¿�','�����м��25������¼') set @i=@i+1 end GO declare @h int set @h=1 while @h<=100 begin declare @i int set @i=2002 while @i<=2003 begin declare @j int set @j=0 while @j<50 begin declare @k int set @k=0 while @k<50 begin insert into Tgongwen(fariqi,neibuyonghu,reader,title)
values(cast(@i as varchar(4))+'-8-15 3:'+cast(@j as
varchar(2))+':'+cast(@j as varchar(2)),'ͨ�ſ�','�칫��,ͨ�ſ�,���ֳ�,���ֳ�,�žֳ�,admin,����֧��,����֧��,��Ѳ��֧��,����֧��,������,���¿�','��������50������¼') set @k=@k+1 end set @j=@j+1 end set @i=@i+1 end set @h=@h+1 end GO declare @i int set @i=1 while @i<=9000000 begin insert into Tgongwen(fariqi,neibuyonghu,reader,title)
values('2004-5-5','ͨ�ſ�','ͨ�ſ�,�칫��,���ֳ�,���ֳ�,�žֳ�,admin,����֧��,����֧��,��Ѳ��֧��,����֧��,������,�ΰ�֧��,���¿�','����������ӵ�900������¼') set @i=@i+1000000 end GO ͨ��������䣬���Ǵ�����25��������2004��2��5�շ����ļ�¼��25�����ɰ칫����2004��9��6�շ����ļ�¼��2002���2003���100��2500����ͬ���ڡ���ͬ����ļ�¼����50��������������ͨ�ſ���2004��5��5�շ�����900������¼���ϼ�1000������ һ���������ˣ��������ʵ����������������ʵ�����������ʵ�ֲ�ѯ�Ż�����Ҫǰ�ᡣ ������index���dz���֮����һ��Ҫ�ġ��û�����Ĵ洢�����������ϵ����ݽṹ���������������ֵ��������ʱ�������ṩ�˶����ݵĿ��ٷ��ʡ���ʵ�ϣ�û������,���ݿ�Ҳ�ܸ���select���ɹ��ؼ���������������ű����Խ��Խ��ʹ�á��ʵ�����������Ч����Խ��Խ���ԡ�ע�⣬����仰�У��������ˡ��ʵ�������ʣ�������Ϊ�����ʹ������ʱ�����濼����ʵ�ֹ��̣������ȿ������Ҳ���ƻ����ݿ�Ĺ������ܡ� ��һ������dz�����������ṹ ʵ���ϣ���������������Ϊһ�������Ŀ¼������SQL SERVER�ṩ�������������ۼ�������clustered
index��Ҳ�ƾ����������ؼ��������ͷǾۼ�������nonclustered index��Ҳ�ƷǾ����������Ǵؼ������������棬���Ǿ�����˵��һ�¾ۼ������ͷǾۼ����������� ��ʵ�����ǵĺ����ֵ�����ı�������һ���ۼ����������磬����Ҫ�顰�����֣��ͻ����Ȼ�ط����ֵ��ǰ��ҳ����Ϊ��������ƴ���ǡ�an����������ƴ�������ֵ��ֵ�����Ӣ����ĸ��a����ͷ���ԡ�z����β�ģ���ô�������־���Ȼ�������ֵ��ǰ��������������������ԡ�a����ͷ�IJ�����Ȼ�Ҳ�������֣���ô��˵�������ֵ���û������֣�ͬ���ģ�����顰�š��֣�����Ҳ�Ὣ�����ֵ䷭����֣���Ϊ���š���ƴ���ǡ�zhang����Ҳ����˵���ֵ�����IJ��ֱ�������һ��Ŀ¼��������Ҫ��ȥ������Ŀ¼���ҵ�����Ҫ�ҵ����ݡ� ���ǰ������������ݱ�������һ�ְ���һ���������е�Ŀ¼��Ϊ���ۼ��������� �������ʶij���֣������Կ��ٵش��Զ��в鵽����֡�����Ҳ���ܻ�����������ʶ���֣���֪�����ķ�������ʱ�����Ͳ��ܰ��ողŵķ����ҵ���Ҫ����֣�����Ҫȥ���ݡ�ƫ�Բ��ס��鵽��Ҫ�ҵ��֣�Ȼ���������ֺ��ҳ��ֱ�ӷ���ijҳ���ҵ���Ҫ�ҵ��֡�������ϡ�����Ŀ¼���͡����ֱ������鵽���ֵ����������������ĵ��������������顰�š��֣����ǿ��Կ����ڲ鲿��֮��ļ��ֱ��С��š���ҳ����672ҳ�����ֱ��С��š��������ǡ��ۡ��֣���ҳ��ȴ��63ҳ�����š��������ǡ����֣�ҳ����390ҳ������Ȼ����Щ�ֲ����������ķֱ�λ�ڡ��š��ֵ����·��������������������ġ��ۡ��š�������ʵ���Ͼ��������ڷǾۼ������е��������ֵ������е����ڷǾۼ������е�ӳ�䡣���ǿ���ͨ�����ַ�ʽ���ҵ�������Ҫ���֣�������Ҫ�������̣����ҵ�Ŀ¼�еĽ����Ȼ���ٷ���������Ҫ��ҳ�롣 ���ǰ�����Ŀ¼������Ŀ¼�����Ĵ��������ĵ�����ʽ��Ϊ���Ǿۼ��������� ͨ���������ӣ����ǿ������ʲô�ǡ��ۼ��������͡��Ǿۼ��������� ��һ������һ�£����ǿ��Ժ��������⣺ÿ����ֻ����һ���ۼ���������ΪĿ¼ֻ�ܰ���һ�ַ����������� ��������ʱʹ�þۼ�������Ǿۼ����� ����ı��ܽ��˺�ʱʹ�þۼ�������Ǿۼ�����������Ҫ���� ��������ʹ�þۼ�����ʹ�÷Ǿۼ����� �о�������������ӦӦ ����ij��Χ�ڵ�����Ӧ��Ӧ һ�����ٲ�ֵͬ��Ӧ��Ӧ С��Ŀ�IJ�ֵͬӦ��Ӧ ����Ŀ�IJ�ֵͬ��ӦӦ Ƶ�����µ��в�ӦӦ �����ӦӦ ������ӦӦ Ƶ���������в�ӦӦ ��ʵ�ϣ����ǿ���ͨ��ǰ��ۼ������ͷǾۼ������Ķ���������������ϱ����磺����ij��Χ�ڵ�����һ���������ij������һ��ʱ���У�ǡ�����Ѿۺ������������˸��У���ʱ����ѯ2004��1��1����2004��10��1��֮���ȫ������ʱ������ٶȾͽ��Ǻܿ�ģ���Ϊ�����Ȿ�ֵ������ǰ����ڽ�������ģ���������ֻ��Ҫ�ҵ�Ҫ���������������еĿ�ͷ�ͽ�β���ݼ��ɣ�������Ǿۼ������������Ȳ鵽Ŀ¼�в鵽ÿһ�����ݶ�Ӧ��ҳ�룬Ȼ���ٸ���ҳ��鵽�������ݡ� ���������ʵ�ʣ�̸����ʹ�õ����� ���۵�Ŀ����Ӧ�á���Ȼ���Ǹղ��г��˺�ʱӦʹ�þۼ�������Ǿۼ�����������ʵ�������Ϲ���ȴ�����ױ����ӻ��ܸ���ʵ����������ۺϷ������������ǽ�������ʵ����������ʵ��������̸һ������ʹ�õ��������Ա��ڴ���������������ķ����� 1���������Ǿۼ����� �����뷨������Ϊ�Ǽ��˴���ģ��ǶԾۼ�������һ���˷ѡ���ȻSQL SERVERĬ�����������Ͻ����ۼ������ġ� ͨ�������ǻ���ÿ�����ж�����һ��ID�У�������ÿ�����ݣ��������ID�����Զ�����ģ�����һ��Ϊ1�����ǵ�����칫�Զ�����ʵ���е���Gid������ˡ���ʱ��������ǽ��������Ϊ������SQL
SERVER�Ὣ����Ĭ��Ϊ�ۼ��������������кô������ǿ������������������ݿ��а���ID������������������Ϊ���������岻�� �Զ������ۼ������������Ǻ����Եģ���ÿ������ֻ����һ���ۼ������Ĺ�����ʹ�þۼ�������ø������ ������ǰ��̸���ľۼ������Ķ������ǿ��Կ�����ʹ�þۼ����������ô������ܹ����ݲ�ѯҪ��Ѹ����С��ѯ��Χ������ȫ��ɨ�衣��ʵ��Ӧ���У���ΪID�����Զ����ɵģ����Dz���֪��ÿ����¼��ID�ţ��������Ǻ�����ʵ������ID�������в�ѯ�����ʹ��ID�����������Ϊ�ۼ�������Ϊһ����Դ�˷ѡ���Σ���ÿ��ID�Ŷ���ͬ���ֶ���Ϊ�ۼ�����Ҳ�����ϡ�����Ŀ�IJ�ֵͬ����²�Ӧ�����ۺ�����������Ȼ���������ֻ������û������ļ�¼���ݣ��ر����������ʱ��Ḻ���ã������ڲ�ѯ�ٶȲ�û��Ӱ�졣 �ڰ칫�Զ���ϵͳ�У�������ϵͳ��ҳ��ʾ����Ҫ�û�ǩ�յ��ļ������黹���û������ļ���ѯ���κ�����½������ݲ�ѯ���벻���ֶε��ǡ����ڡ������û������ġ��û������� ͨ�����칫�Զ�������ҳ����ʾÿ���û���δǩ�յ��ļ�����顣��Ȼ���ǵ�where�����Խ������Ƶ�ǰ�û���δǩ�յ���������������ϵͳ�ѽ����˺ܳ�ʱ�䣬�����������ܴ���ô��ÿ��ÿ���û�����ҳ��ʱ����һ��ȫ��ɨ�裬�����������Dz���ģ�����������û�1����ǰ���ļ����Ѿ�������ˣ�������ֻ��ͽ�����ݿ�Ŀ������ѡ���ʵ�ϣ�������ȫ�������û���ϵͳ��ҳʱ�����ݿ������ѯ����û���3������δ�������ļ���ͨ�������ڡ�����ֶ������Ʊ�ɨ�裬��߲�ѯ�ٶȡ�������İ칫�Զ���ϵͳ�Ѿ�������2�꣬��ô������ҳ��ʾ�ٶ������Ͻ���ԭ���ٶ�8�����������졣 ������֮�����ᵽ�������ϡ����֣�����Ϊ������ľۼ���������äĿ�ؽ���ID���������ʱ�����IJ�ѯ�ٶ���û����ô�ߵģ���ʹ���ڡ����ڡ�����ֶ��Ͻ������������Ǿۺ����������������Ǿ�����һ����1000����������������¸��ֲ�ѯ���ٶȱ��֣�3�����ڵ�����Ϊ25�������� ��1�����������Ͻ����ۼ����������Ҳ�����ʱ��Σ� Select gid,fariqi,neibuyonghu,title from tgongwen ��ʱ��128470���루����128�룩 ��2���������Ͻ����ۼ���������fariq�Ͻ����Ǿۼ������� select gid,fariqi,neibuyonghu,title from Tgongwen where fariqi> dateadd(day,-90,getdate()) ��ʱ��53763���루54�룩 ��3�����ۺ����������������У�fariqi���ϣ� select gid,fariqi,neibuyonghu,title from Tgongwen where fariqi> dateadd(day,-90,getdate()) ��ʱ��2423���루2�룩 ��Ȼÿ�������ȡ�����Ķ���25�������ݣ���������IJ���ȴ�Ǿ�ģ��ر��ǽ��ۼ�����������������ʱ�IJ��졣��ʵ�ϣ�����������ݿ������1000�������Ļ���������������ID���ϣ��������ϵĵ�1��2�����������ҳ�ϵı��־��dz�ʱ������������ʾ����Ҳ��������ID����Ϊ�ۼ�������һ������Ҫ�����ء� �ó������ٶȵķ����ǣ��ڸ���select���ǰ�ӣ�declare @d datetime set @d=getdate() ����select����ӣ� select [���ִ�л���ʱ��(����)]=datediff(ms,@d,getdate()) 2��ֻҪ������������������߲�ѯ�ٶ� ��ʵ�ϣ����ǿ��Է�������������У���2��3�������ȫ��ͬ���ҽ����������ֶ�Ҳ��ͬ����ͬ�Ľ���ǰ����fariqi�ֶ��Ͻ������ǷǾۺ������������ڴ��ֶ��Ͻ������Ǿۺ�����������ѯ�ٶ�ȴ��������֮�����ԣ����������κ��ֶ��ϼؽ�������������߲�ѯ�ٶȡ� �ӽ���������У����ǿ��Կ����������1000�����ݵı���fariqi�ֶ���5003����ͬ��¼���ڴ��ֶ��Ͻ����ۺ��������ٺ��ʲ����ˡ�����ʵ�У�����ÿ�춼�ᷢ�����ļ����⼸���ļ��ķ������ھ���ͬ������ȫ���Ͻ����ۼ�����Ҫ��ģ����Ȳ��ܾ����������ͬ���ֲ���ֻ�м�������ͬ���Ĺ����ɴ˿��������ǽ������ʵ����ľۺ���������������߲�ѯ�ٶ��Ƿdz���Ҫ�ġ� 3����������Ҫ��߲�ѯ�ٶȵ��ֶζ��ӽ��ۼ�����������߲�ѯ�ٶ� �����Ѿ�̸�����ڽ������ݲ�ѯʱ���벻���ֶε��ǡ����ڡ������û������ġ��û���������Ȼ�������ֶζ�����˵���Ҫ�����ǿ������Ǻϲ�����������һ������������compound
index���� �ܶ�����ΪֻҪ���κ��ֶμӽ��ۼ�������������߲�ѯ�ٶȣ�Ҳ���˸е��Ի�����Ѹ��ϵľۼ������ֶηֿ���ѯ����ô��ѯ�ٶȻ�����𣿴���������⣬��������һ�����µIJ�ѯ�ٶȣ����������25�������ݣ�����������fariqi�������ڸ��Ͼۼ���������ʼ�У��û���neibuyonghu���ں��У� ��1��select gid,fariqi,neibuyonghu,title from Tgongwen
where fariqi>'2004-5-5' ��ѯ�ٶȣ�2513���� ��2��select gid,fariqi,neibuyonghu,title from Tgongwen
where fariqi>'2004-5-5' and neibuyonghu='�칫��' ��ѯ�ٶȣ�2516���� ��3��select gid,fariqi,neibuyonghu,title from Tgongwen
where neibuyonghu='�칫��' ��ѯ�ٶȣ�60280���� �����������У����ǿ��Կ���������þۼ���������ʼ����Ϊ��ѯ������ͬʱ�õ����Ͼۼ�������ȫ���еIJ�ѯ�ٶ��Ǽ���һ���ģ�����������ȫ���ĸ��������л�Ҫ�Կ죨�ڲ�ѯ�������Ŀһ��������£�����������ø��Ͼۼ������ķ���ʼ����Ϊ��ѯ�����Ļ�����������Dz����κ����õġ���Ȼ�����1��2�IJ�ѯ�ٶ�һ������Ϊ��ѯ����Ŀ��һ����������������������ж����ϣ����Ҳ�ѯ����ٵĻ��������ͻ��γɡ��������ǡ���������ܿ��Դﵽ���š�ͬʱ�����ס���������Ƿ�ʹ�þۺ������������У�����ǰ����һ��Ҫ��ʹ����Ƶ�����С� ���ģ���������û�е�����ʹ�þ����ܽ� 1���þۺ��������ò��Ǿۺ������������ٶȿ� ������ʵ����䣺��������ȡ25�������ݣ� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi='2004-9-16' ʹ��ʱ�䣺3326���� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where gid<=250000 ʹ��ʱ�䣺4470���� ����þۺ��������ò��Ǿۺ������������ٶȿ��˽�1/4�� 2���þۺ���������һ���������order byʱ�ٶȿ죬�ر�����С����������� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
order by fariqi ��ʱ��12936 select gid,fariqi,neibuyonghu,reader,title from Tgongwen
order by gid ��ʱ��18843 ����þۺ���������һ���������order byʱ���ٶȿ���3/10����ʵ�ϣ������������С�Ļ����þۼ�������Ϊ������Ҫ��ʹ�÷Ǿۼ������ٶȿ�����ԵĶࣻ������������ܴ�Ļ�����10�����ϣ�����ߵ��ٶȲ�����ԡ� 3��ʹ�þۺ������ڵ�ʱ��Σ�����ʱ��ᰴ����ռ�������ݱ��İٷֱȳɱ������٣������۾ۺ�����ʹ���˶��ٸ� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi>'2004-1-1' ��ʱ��6343���루��ȡ100������ select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi>'2004-6-6' ��ʱ��3170���루��ȡ50������ select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi='2004-9-16' ��ʱ��3326���루���Ͼ�Ľ��һģһ��������ɼ�������һ������ô�ô��ںź͵��ں���һ���ģ� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi>'2004-1-1' and fariqi<'2004-6-6' ��ʱ��3280���� 4 �������в�����Ϊ�з���������������ѯ�ٶ� ����������У�����100�������ݣ�2004��1��1���Ժ��������50��������ֻ��������ͬ�����ڣ����ھ�ȷ���գ�֮ǰ������50��������5000����ͬ�����ڣ����ھ�ȷ���롣 select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi>'2004-1-1' order by fariqi ��ʱ��6390���� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi<'2004-1-1' order by fariqi ��ʱ��6453���� ���壩����ע������ ��ˮ�����ۣ���ɸ��ۡ�������Ҳһ����������������������ܣ��������������Ҳ�ᵼ��ϵͳ��Ч����Ϊ�û��ڱ���ÿ�ӽ�һ�����������ݿ��Ҫ������Ĺ�������������������ᵼ��������Ƭ�� ����˵������Ҫ����һ�����ʵ�����������ϵ���ر��ǶԾۺ������Ĵ�������Ӧ��������ʹ�������ݿ��ܵõ������ܵķ��ӡ� ��Ȼ����ʵ���У���Ϊһ����ְ�����ݿ����Ա������Ҫ�����һЩ�������ҳ����ַ���Ч����ߡ���Ϊ��Ч�� ��������SQL���ܶ��˲�֪��SQL�����SQL SERVER�������ִ�еģ����ǵ����Լ���д��SQL���ᱻSQL
SERVER��⡣���磺 select * from table1 where name='zhangsan' and tID >
10000 ��ִ��: select * from table1 where tID > 10000 and name='zhangsan' һЩ�˲�֪��������������ִ��Ч���Ƿ�һ������Ϊ����Ĵ�����Ⱥ��Ͽ�������������ȷ�Dz�һ�������tID��һ���ۺ���������ô��һ������ӱ���10000���Ժ�ļ�¼�в��Ҿ����ˣ���ǰһ����Ҫ�ȴ�ȫ���в��ҿ��м���name='zhangsan'�ģ������ٸ���������������tID>10000�������ѯ����� ��ʵ�ϣ������ĵ����Dz���Ҫ�ġ�SQL SERVER����һ������ѯ�����Ż������������Լ����where�Ӿ��е�����������ȷ���ĸ���������С��ɨ��������ռ䣬Ҳ����˵������ʵ���Զ��Ż��� ��Ȼ��ѯ�Ż������Ը���where�Ӿ��Զ��Ľ��в�ѯ�Ż����������Ȼ�б�Ҫ�˽�һ�¡���ѯ�Ż������Ĺ���ԭ���������������ʱ��ѯ�Ż����ͻ�������ı�����п��ٲ�ѯ�� �ڲ�ѯ�����Σ���ѯ�Ż����鿴��ѯ��ÿ���β�����������Ҫɨ����������Ƿ����á����һ���ο��Ա�����һ��ɨ�������SARG������ô�ͳ�֮Ϊ���Ż��ģ����ҿ��������������ٻ���������ݡ� SARG�Ķ��壺��������������һ����������Ϊ��ͨ����ָһ���ض���ƥ�䣬һ��ֵ�÷�Χ�ڵ�ƥ�������������������AND���ӡ���ʽ���£� ���������� <���������> �� <���������> ���������� �������Գ����ڲ�������һ�ߣ�����������������ڲ���������һ�ߡ��磺 Name=�������� �۸�>5000 5000<�۸� Name=�������� and �۸�>5000 ���һ������ʽ��������SARG����ʽ�������������������ķ�Χ�ˣ�Ҳ����SQL SERVER�����ÿһ�ж��ж����Ƿ�����WHERE�Ӿ��е���������������һ���������ڲ�����SARG��ʽ�ı���ʽ��˵�����õġ� ������SARG���������ܽ�һ��ʹ��SARG�Լ���ʵ���������ĺ�ijЩ�����Ͻ��۲�ͬ�ľ��飺 1��Like����Ƿ�����SARGȡ������ʹ�õ�ͨ��������� �磺name like ����%�� ���������SARG ����name like ��%�š� ,�Ͳ�����SARG�� ԭ����ͨ���%���ַ����Ŀ�ͨʹ��������ʹ�á� 2��or ������ȫ��ɨ�� Name=�������� and �۸�>5000 ����SARG������Name=�������� or �۸�>5000
����SARG��ʹ��or������ȫ��ɨ�衣 3���Dz���������������IJ�����SARG��ʽ����� ������SARG��ʽ���������͵�������ǰ����Dz���������䣬�磺NOT��!=��<>��!<��!>��NOT
EXISTS��NOT IN��NOT LIKE�ȣ�����к�����������Ǽ���������SARG��ʽ�����ӣ� ABS(�۸�)<5000 Name like ��%���� ��Щ����ʽ���磺 WHERE �۸�*2>5000 SQL SERVERҲ����Ϊ��SARG��SQL SERVER�Ὣ��ʽת��Ϊ�� WHERE �۸�>2500/2 �����Dz��Ƽ�����ʹ�ã���Ϊ��ʱSQL SERVER���ܱ�֤����ת����ԭʼ����ʽ����ȫ�ȼ۵ġ� 4��IN �������൱��OR ��䣺 Select * from table1 where tid in (2,3) �� Select * from table1 where tid=2 or tid=3 ��һ���ģ���������ȫ��ɨ�裬���tid����������������Ҳ��ʧЧ�� 5����������NOT 6��exists �� in ��ִ��Ч����һ���� �ܶ������϶���ʾ˵��existsҪ��in��ִ��Ч��Ҫ�ߣ�ͬʱӦ�����ܵ���not exists������not
in������ʵ�ϣ���������һ�£����ֶ���������ǰ�������not������֮���ִ��Ч�ʶ���һ���ġ���Ϊ�漰�Ӳ�ѯ���������������SQL
SERVER�Դ���pubs���ݿ⡣����ǰ���ǿ���SQL SERVER��statistics I/O״̬�� ��1��select title,price from titles where title_id in
(select title_id from sales where qty>30) �þ��ִ�н��Ϊ�� �� 'sales'��ɨ����� 18������ 56 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� �� 'titles'��ɨ����� 1������ 2 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� ��2��select title,price from titles where exists (select
* from sales where sales.title_id=titles.title_id and
qty>30) �ڶ����ִ�н��Ϊ�� �� 'sales'��ɨ����� 18������ 56 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� �� 'titles'��ɨ����� 1������ 2 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� ���ǴӴ˿��Կ�����exists����in��ִ��Ч����һ���ġ� 7���ú���charindex()��ǰ���ͨ���%��LIKEִ��Ч��һ�� ǰ�棬����̸���������LIKEǰ�����ͨ���%����ô��������ȫ��ɨ�裬������ִ��Ч���ǵ��µġ����е����Ͻ���˵���ú���charindex()������LIKE�ٶȻ��д���������������飬��������˵��Ҳ�Ǵ���ģ� select gid,title,fariqi,reader from tgongwen where charindex('����֧��',reader)>0
and fariqi>'2004-5-5' ��ʱ��7�룬���⣺ɨ����� 4������ 7155 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� select gid,title,fariqi,reader from tgongwen where reader
like '%' + '����֧��' + '%' and fariqi>'2004-5-5' ��ʱ��7�룬���⣺ɨ����� 4������ 7155 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� 8��union�������Ա�or��ִ��Ч�ʸ� ����ǰ���Ѿ�̸������where�Ӿ���ʹ��or������ȫ��ɨ�裬һ��ģ��������������϶����Ƽ�������union������or����ʵ֤��������˵�����ڴֶ������õġ� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi='2004-9-16' or gid>9990000 ��ʱ��68�롣ɨ����� 1������ 404008 �Σ������� 283 �Σ�Ԥ�� 392163 �Ρ� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi='2004-9-16' union select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where gid>9990000 ��ʱ��9�롣ɨ����� 8������ 67489 �Σ������� 216 �Σ�Ԥ�� 7499 �Ρ� ��������union��ͨ������±���or��Ч��Ҫ�ߵĶࡣ ���������飬���߷������or���ߵIJ�ѯ����һ���Ļ�����ô��union������or��ִ���ٶȲ�ܶ࣬��Ȼ����unionɨ�������������orɨ�����ȫ���� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi='2004-9-16' or fariqi='2004-2-5' ��ʱ��6423���롣ɨ����� 2������ 14726 �Σ������� 1 �Σ�Ԥ�� 7176 �Ρ� select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where fariqi='2004-9-16' union select gid,fariqi,neibuyonghu,reader,title from Tgongwen
where��fariqi='2004-2-5' ��ʱ��11640���롣ɨ����� 8������ 14806 �Σ������� 108 �Σ�Ԥ�� 1144 �Ρ� 9���ֶ���ȡҪ���ա�����١�����١���ԭ���⡰select *�� ��������һ�����飺 select top 10000 gid,fariqi,reader,title from tgongwen
order by gid desc ��ʱ��4673���� select top 10000 gid,fariqi,title from tgongwen order
by gid desc ��ʱ��1376���� select top 10000 gid,fariqi from tgongwen order by gid
desc ��ʱ��80���� �ɴ˿���������ÿ����ȡһ���ֶΣ����ݵ���ȡ�ٶȾͻ�����Ӧ���������������ٶȻ�Ҫ�����������ֶεĴ�С���жϡ� 10��count(*)����count(�ֶ�)�� ijЩ������˵����*��ͳ�������У���ȻҪ��һ�����������Ч�ʵ͡�����˵����ʵ��û�и��ݵġ����������� select count(*) from Tgongwen ��ʱ��1500���� select count(gid) from Tgongwen ��ʱ��1483���� select count(fariqi) from Tgongwen ��ʱ��3140���� select count(title) from Tgongwen ��ʱ��52050���� �����Ͽ��Կ����������count(*)����count(����)���ٶ����൱�ģ���count(*)ȴ�������κγ�����������ֶλ����ٶ�Ҫ�죬�����ֶ�Խ�������ܵ��ٶȾ�Խ�������룬�����count(*)��
SQL SERVER���ܻ��Զ�������С�ֶ������ܵġ���Ȼ�������ֱ��дcount(����)�������ĸ�ֱ��Щ�� 11��order by���ۼ�����������Ч����� ������������gid��������fariqi�Ǿۺ������У� select top 10000 gid,fariqi,reader,title from tgongwen ��ʱ��196 ���롣ɨ����� 1������ 289 �Σ������� 1 �Σ�Ԥ�� 1527 �Ρ� select top 10000 gid,fariqi,reader,title from tgongwen
order by gid asc ��ʱ��4720���롣ɨ����� 1������ 41956 �Σ������� 0 �Σ�Ԥ�� 1287 �Ρ� select top 10000 gid,fariqi,reader,title from tgongwen
order by gid desc ��ʱ��4736���롣ɨ����� 1������ 55350 �Σ������� 10 �Σ�Ԥ�� 775 �Ρ� select top 10000 gid,fariqi,reader,title from tgongwen
order by fariqi asc ��ʱ��173���롣ɨ����� 1������ 290 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� select top 10000 gid,fariqi,reader,title from tgongwen
order by fariqi desc ��ʱ��156���롣ɨ����� 1������ 289 �Σ������� 0 �Σ�Ԥ�� 0 �Ρ� ���������ǿ��Կ�������������ٶ��Լ������������Ǻ͡�order by �ۼ������С� ���ٶ����൱�ģ�����Щ���ȡ�order
by �Ǿۼ������С��IJ�ѯ�ٶ��ǿ�ö�ġ� ͬʱ������ij���ֶν��������ʱ�������������ǵ����ٶ��ǻ����൱�ġ� 12����Ч��TOP ��ʵ�ϣ��ڲ�ѯ����ȡ�������������ݼ�ʱ��Ӱ�����ݿ���Ӧʱ���������ز������ݲ��ң�����������I/0�������磺 select top 10 * from ( select top 10000 gid,fariqi,title from tgongwen where neibuyonghu='�칫��' order by gid desc) as a order by gid asc ������䣬�������Ͻ�����������ִ��ʱ��Ӧ�ñ��Ӿ��ִ��ʱ�䳤������ʵ�෴����Ϊ���Ӿ�ִ�кص���10000����¼����������������10����䣬����Ӱ�����ݿ���Ӧʱ����������������I/O����������������I/O�����˴�������Ч����֮һ����ʹ��TOP�ؼ����ˡ�TOP�ؼ�����SQL
SERVER�о���ϵͳ�Ż�����һ��������ȡǰ������ǰ�����ٷֱ����ݵĴʡ���������ʵ���е�Ӧ�ã�����TOPȷʵ�ܺ��ã�Ч��Ҳ�ܸߡ��������������һ���������ݿ�ORACLE��ȴû�У��ⲻ��˵����һ���ź�����Ȼ��ORACLE�п����������������磺rownumber������������Ժ�Ĺ��ڡ�ʵ��ǧ�����ݵķ�ҳ��ʾ�洢���̡��������У����Ǿͽ��õ�TOP����ؼ��ʡ� ����Ϊֹ�������������������ʵ�ִӴ����������ݿ��п��ٵز�ѯ��������Ҫ�����ݷ�������Ȼ�����ǽ��ܵ���Щ�������ǡ�������������ʵ���У����ǻ�Ҫ���Ǹ��֡�Ӳ�����أ��磺�������ܡ������������ܡ�����ϵͳ�����ܣ������������������ȡ� ����ʵ��С�������ͺ������ݵ�ͨ�÷�ҳ��ʾ�洢���̽���һ��web Ӧ�ã���ҳ������ܱز����١�������������ݿ����ʮ�ֳ��������⡣��������ݷ�ҳ������:ADO
��¼����ҳ����Ҳ��������ADO�Դ��ķ�ҳ���ܣ������α꣩��ʵ�ַ�ҳ�������ַ�ҳ�����������ڽ�С�����������Σ���Ϊ�α걾����ȱ�㣺�α��Ǵ�����ڴ��У��ܷ��ڴ档�α�һ�������ͽ���صļ�¼��ס��ֱ��ȡ���αꡣ�α��ṩ�˶��ض�����������ɨ����ֶΣ�һ��ʹ���α������б������ݣ�����ȡ�����������IJ�ͬ���в�ͬ�IJ����������ڶ���ʹ���ж�����α꣨������ݼ��ϣ�ѭ��������ʹ�������һ�������ĵȴ����������� ����Ҫ���ǣ����ڷdz��������ģ�Ͷ��ԣ���ҳ����ʱ��������մ�ͳ��ÿ�ζ�������������Դ�ķ����Ƿdz��˷���Դ�ġ��������еķ�ҳ����һ���Ǽ���ҳ���С�Ŀ��������ݣ����Ǽ������е����ݣ�Ȼ��ִ�е�ǰ�С� ����Ϻõ�ʵ�����ָ���ҳ���С��ҳ������ȡ���ݵķ�����ž��ǡ�����˹�洢���̡�������洢���������α꣬�����α�ľ����ԣ��������������û�еõ���ҵ��ձ��Ͽɡ� �������������˸����˴˴洢���̣�����Ĵ洢���̾��ǽ�����ǵİ칫�Զ���ʵ��д�ķ�ҳ�洢���̣� CREATE procedure pagination1 (@pagesize int,��--ҳ���С����ÿҳ�洢20����¼ @pageindex int�� --��ǰҳ�� ) as set nocount on begin declare @indextable table(id int identity(1,1),nid int)��--��������� declare @PageLowerBound int��--�����ҳ�ĵ��� declare @PageUpperBound int��--�����ҳ�Ķ��� set @PageLowerBound=(@pageindex-1)*@pagesize set @PageUpperBound=@PageLowerBound+@pagesize set rowcount @PageUpperBound insert into @indextable(nid) select gid from TGongwen
where fariqi >dateadd(day,-365,getdate()) order by
fariqi desc select O.gid,O.mid,O.title,O.fadanwei,O.fariqi from
TGongwen O,@indextable t where O.gid=t.nid and t.id>@PageLowerBound and t.id<=@PageUpperBound
order by t.id end set nocount off ���ϴ洢����������SQL SERVER�����¼����D�D��������Ӧ��˵����洢����Ҳ��һ���dz�����ķ�ҳ�洢���̡���Ȼ������������У���Ҳ�������еı�����д����ʱ����CREATE
TABLE #Temp���������ԣ���SQL SERVER�У�����ʱ����û���ñ�������ġ����Ա��߸տ�ʼʹ������洢����ʱ���о��dz��IJ������ٶ�Ҳ��ԭ����ADO�ĺá������������ַ����˱ȴ˷������õķ����� �����������Ͽ�����һƪС���ġ������ݱ���ȡ����n������m���ļ�¼�ķ�������ȫ�����£� ��publish ����ȡ���� n ������ m ���ļ�¼�� SELECT TOP m-n+1 * FROM
publish WHERE (id NOT IN (SELECT TOP n-1 id FROM publish)) id Ϊpublish ���Ĺؼ��� �ҵ�ʱ������ƪ���µ�ʱ������Ǿ���Ϊ֮һ����˼·�dz��úá��ȵ��������������칫�Զ���ϵͳ��ASP.net+
C#��SQL SERVER����ʱ��Ȼ��������ƪ���£�������������������һ�£���Ϳ�����һ���dz��õķ�ҳ�洢���̡������Ҿ�����������ƪ���£�û�뵽�����»�û�ҵ���ȴ�ҵ���һƪ���ݴ����д��һ����ҳ�洢���̣�����洢����Ҳ��Ŀǰ��Ϊ���е�һ�ַ�ҳ�洢���̣��Һܺ��û�����Ȱ�������ָ���ɴ洢���̣� CREATE PROCEDURE pagination2 ( @SQL nVARCHAR(4000),����--������������SQL���
@Page int,��������������--ҳ�� @RecsPerPage int,������ --ÿҳ���ɵļ�¼��
@ID VARCHAR(255),������ --��Ҫ����IJ��ظ���ID�� @Sort VARCHAR(255)������--�����ֶμ�����
) AS DECLARE @Str nVARCHAR(4000) SET @Str='SELECT�� TOP '+CAST(@RecsPerPage AS VARCHAR(20))+'
* FROM ('+@SQL+') T WHERE T.'+@ID+'NOT IN (SELECT�� TOP
'+CAST((@RecsPerPage*(@Page-1)) AS VARCHAR(20))+' '+@ID+'
FROM ('+@SQL+') T9 ORDER BY '+@Sort+') ORDER BY '+@Sort PRINT @Str EXEC sp_ExecuteSql @Str GO ��ʵ�����������Լ�Ϊ�� SELECT TOP ҳ��С * FROM Table1 WHERE (ID NOT IN (SELECT TOP ҳ��С*ҳ�� id FROM �� ORDER BY id)) ORDER BY ID ������洢������һ��������ȱ�㣬����������NOT IN��������Ȼ�ҿ���������Ϊ�� SELECT TOP ҳ��С * FROM Table1 WHERE not exists (select * from (select top (ҳ��С*ҳ��) * from table1 order
by id) b where b.id=a.id ) order by id ������not exists������not in��������ǰ���Ѿ�̸���ˣ����ߵ�ִ��Ч��ʵ������û������ġ� �ȱ���ˣ���TOP ���NOT IN������������DZ����α�Ҫ���ÿ�һЩ�� ��Ȼ��not exists����������ϸ��洢���̵�Ч�ʣ���ʹ��SQL SERVER�е�TOP�ؼ���ȴ��һ���dz����ǵ�ѡ����Ϊ��ҳ�Ż�������Ŀ�ľ��DZ����������ļ�¼������������ǰ��Ҳ�Ѿ��ᵽ��TOP�����ƣ�ͨ��TOP
����ʵ�ֶ��������Ŀ��ơ� �ڷ�ҳ�㷨�У�Ӱ�����Dz�ѯ�ٶȵĹؼ����������㣺TOP��NOT IN��TOP����������ǵIJ�ѯ�ٶȣ���NOT
IN��������ǵIJ�ѯ�ٶȣ�����Ҫ�������������ҳ�㷨���ٶȣ���Ҫ������NOT IN��ͬ����������������� ����֪���������κ��ֶΣ����Ƕ�����ͨ��max(�ֶ�)��min(�ֶ�)����ȡij���ֶ��е�������Сֵ�������������ֶβ��ظ�����ô�Ϳ���������Щ���ظ����ֶε�max��min��Ϊ��ˮ�룬ʹ���Ϊ��ҳ�㷨�зֿ�ÿҳ�IJ������������ǿ����ò�������>����<������������ʹ����ʹ��ѯ������SARG��ʽ���磺 Select top 10 * from table1 where id>200 ���Ǿ��������·�ҳ������ select top ҳ��С * from table1 where id> (select max (id) from (select top ((ҳ��-1)*ҳ��С) id from table1 order by id)
as T ) order by id ��ѡ���ظ�ֵ�������ֱ��С����ʱ������ͨ����ѡ���������±��г��˱���������1000�����ݵİ칫�Զ���ϵͳ�еı�������GID��GID���������������Ǿۼ���������Ϊ�����С���ȡgid,fariqi,title�ֶΣ��ֱ��Ե�1��10��100��500��1000��1��10��25��50��ҳΪ���������������ַ�ҳ������ִ���ٶȣ�����λ�����룩 ҳ���뷽��1 ����2 ����3 1 60 30 76 10 46 16 63 100 1076 720 130 500 540 12943 83 1000 17110 470 250 1�� 24796 4500 140 10�� 38326 42283 1553 25�� 28140 128720 2330 50�� 121686 127846 7168 ���ϱ��У����ǿ��Կ��������ִ洢������ִ��100ҳ���µķ�ҳ����ʱ�����ǿ������εģ��ٶȶ��ܺá�����һ�ַ�����ִ�з�ҳ1000ҳ���Ϻ��ٶȾͽ����������ڶ��ַ�����Լ����ִ�з�ҳ1��ҳ���Ϻ��ٶȿ�ʼ�����������������ַ���ȴʼ��û�д�Ľ��ƣ�����Ȼ���㡣 ��ȷ���˵����ַ�ҳ���������ǿ��Ծݴ�дһ���洢���̡����֪��SQL SERVER�Ĵ洢���������ȱ���õ�SQL��䣬����ִ��Ч��Ҫ��ͨ��WEBҳ�洫����SQL����ִ��Ч��Ҫ�ߡ�����Ĵ洢���̲������з�ҳ�������������ҳ�洫���IJ�����ȷ���Ƿ������������ͳ�ơ� -- ��ȡָ��ҳ������ CREATE PROCEDURE pagination3 @tblName�� varchar(255),������ -- ���� @strGetFields varchar(1000) = '*',��-- ��Ҫ���ص��� @fldName varchar(255)='',������-- ������ֶ��� @PageSize�� int = 10,����������-- ҳ�ߴ� @PageIndex��int = 1,���������� -- ҳ�� @doCount��bit = 0,�� -- ���ؼ�¼����, �� 0 ֵ�� @OrderType bit = 0,��-- ������������, �� 0 ֵ���� @strWhere��varchar(1500) = ''��-- ��ѯ���� (ע��: ��Ҫ�� where) AS declare @strSQL�� varchar(5000)������ -- ����� declare @strTmp�� varchar(110)��������-- ��ʱ���� declare @strOrder varchar(400)��������-- �������� if @doCount != 0 begin if @strWhere !='' set @strSQL = "select count(*) as Total from ["
+ @tblName + "] where "+@strWhere else set @strSQL = "select count(*) as Total from ["
+ @tblName + "]" end --���ϴ������˼�����@doCount���ݹ����IJ���0����ִ������ͳ�ơ����µ����д��붼��@doCountΪ0�����
| else
begin
if @OrderType != 0
begin
set @strTmp = "<(select
min"
set @strOrder = " order by
[" + @fldName +"] desc"
|
--���@OrderType����0����ִ�н���������Ҫ��
| end
else
begin
set @strTmp = ">(select
max"
set @strOrder = " order by
[" + @fldName +"] asc"
end
if @PageIndex = 1
begin
if @strWhere != ''
set @strSQL = "select top
" + str(@PageSize) +" "+@strGetFields+
"��from [" + @tblName + "] where
" + @strWhere + " " + @strOrder
else
set @strSQL = "select top
" + str(@PageSize) +" "+@strGetFields+
"��from ["+ @tblName + "] "+
@strOrder
|
--����ǵ�һҳ��ִ�����ϴ��룬������ӿ�ִ���ٶ�
--���´��븳����@strSQL������ִ�е�SQL����
set @strSQL = "select top " + str(@PageSize) +"
"+@strGetFields+ "��from ["
+ @tblName + "] where [" + @fldName + "]" + @strTmp +
"(["+ @fldName + "]) from (select top " +
str((@PageIndex-1)*@PageSize) +
" ["+ @fldName + "] from [" + @tblName + "]"
+ @strOrder + ") as tblTmp)"+ @strOrder
if @strWhere != ''
set @strSQL = "select top " + str(@PageSize) +"
"+@strGetFields+ "��from ["
+ @tblName + "] where [" + @fldName + "]" + @strTmp + "(["
+ @fldName + "]) from (select top " +
str((@PageIndex-1)*@PageSize) + " ["
+ @fldName + "] from [" + @tblName + "] where " + @strWhere + " "
+ @strOrder + ") as tblTmp) and " + @strWhere + " " + @strOrder
end
end
exec (@strSQL)
GO |
���������洢������һ��ͨ�õĴ洢���̣���ע����д�������ˡ� �ڴ�������������£��ر����ڲ�ѯ���ҳ��ʱ��ѯʱ��һ�㲻�ᳬ��9�룻���������洢���̣���ʵ���оͻᵼ�³�ʱ����������洢���̷dz������ڴ��������ݿ�IJ�ѯ�� ����ϣ���ܹ�ͨ�������ϴ洢���̵Ľ������ܸ���Ҵ���һ������ʾ��������������һ����Ч��������ͬʱϣ��ͬ������������ʵʱ���ݷ�ҳ�㷨�� �ġ��ۼ���������Ҫ�Ժ����ѡ��ۼ���������һ�ڵı����У�����д���ǣ�ʵ��С�������ͺ������ݵ�ͨ�÷�ҳ��ʾ�洢���̡�������Ϊ�ڽ����洢����Ӧ���ڡ��칫�Զ�����ϵͳ��ʵ����ʱ�����߷���������ִ洢������С������������£����������� 1����ҳ�ٶ�һ��ά����1���3��֮�䡣 2���ڲ�ѯ���һҳʱ���ٶ�һ��Ϊ5����8�룬���·�ҳ����ֻ��3ҳ��30��ҳ�� ��Ȼ�ڳ�����������£������ҳ��ʵ�ֹ����Ǻܿ�ģ����ڷ�ǰ��ҳʱ�����1��3����ٶȱ����һ������û�о����Ż��ķ�ҳ�����ٶȻ�Ҫ�������û��Ļ�˵���ǡ���û��ACCESS���ݿ��ٶȿ족�������ʶ���Ե����û�����ʹ����������ϵͳ�� ���߾ʹ˷�����һ�£�ԭ���������������֢������˵ļ�������˵���Ҫ��������ֶβ��Ǿۼ������� ��ƪ���µ���Ŀ�ǣ�����ѯ�Ż�����ҳ�㷨������������ֻ���ѡ���ѯ�Ż����͡���ҳ�㷨����������ϵ���Ǻܴ���������һ�𣬾�����Ϊ���߶���Ҫһ���dz���Ҫ�Ķ����D�D�ۼ������� ��ǰ��������������Ѿ��ᵽ�ˣ��ۼ������������������ƣ� 1���������ٶ���С��ѯ��Χ�� 2���������ٶȽ����ֶ����� ��1�������ڲ�ѯ�Ż�ʱ������2�������ڽ��з�ҳʱ���������� ���ۼ�������ÿ��������ֻ�ܽ���һ������ʹ�þۼ������Եø��ӵ���Ҫ���ۼ���������ѡ����˵��ʵ�֡���ѯ�Ż����͡���Ч��ҳ������ؼ����ء� ��Ҫ��ʹ�ۼ������мȷ��ϲ�ѯ�е���Ҫ���ַ��������е���Ҫ����ͨ����һ��ì�ܡ� ����ǰ�桰�������������У���fariqi�����û�����������Ϊ�˾ۼ���������ʼ�У����ڵľ�ȷ��Ϊ���ա��������������ŵ㣬ǰ���Ѿ��ᵽ�ˣ��ڽ��л�ʱ��εĿ��ٲ�ѯ�У�����ID�������кܴ�����ơ� ���ڷ�ҳʱ����������ۼ������д������ظ���¼��������ʹ��max��min����Ϊ��ҳ�IJ����������ʵ�ָ�Ϊ��Ч�����������ID��������Ϊ�ۼ���������ô�ۼ�����������������֮�⣬û���κ��ô���ʵ�������˷��˾ۼ���������������Դ�� Ϊ������ì�ܣ����ߺ�����������һ�������У���Ĭ��ֵΪgetdate()���û���д���¼ʱ��������Զ�д�뵱ʱ��ʱ�䣬ʱ�侫ȷ�����롣��ʹ������Ϊ�˱�������Ժ�С���غϣ���Ҫ�ڴ����ϴ���UNIQUEԼ����������������Ϊ�ۼ������С� �������ʱ���;ۼ�������֮���û��ͼȿ���������в����û��ڲ�������ʱ��ij��ʱ��εIJ�ѯ���ֿ�����ΪΨһ����ʵ��max��min����Ϊ��ҳ�㷨�IJ���� �����������Ż������߷��֣������Ǵ�������������»���С������������£���ҳ�ٶ�һ�㶼�Ǽ�ʮ���룬����0���롣�������ڶ���С��Χ�IJ�ѯ�ٶȱ�ԭ��Ҳû���κγٶۡ� �ۼ���������˵���Ҫ��������Ա����ܽ���һ�£�һ��Ҫ���ۼ����������ڣ� 1������Ƶ��ʹ�õġ�������С��ѯ��Χ���ֶ��ϣ� 2������Ƶ��ʹ�õġ���Ҫ������ֶ��ϡ� Ӧ�ó������ Ӧ�ó�������ھ���ʹ�� Microsoft? SQL Server? 2000 ��ϵͳ�����ܷ�����ؼ����á����ͻ�����Ϊ����ʵ��������ݿ���������ͻ���ȷ����ѯ���͡���ʱ�ύ��ѯ�Լ���δ�����ѯ������ⷴ�����Է������ϵ������ͺͳ���ʱ�䡢I/O
����Լ����� (CPU) ���ɵȲ�����ҪӰ�죬���ɴ�Ӱ���������ܵ����ӡ� ����Ϊ��ˣ���Ӧ�ó������ƽ�������ȷ����ʮ����Ҫ��Ȼ������ʹ��ʹ���ܿ�Ӧ�ó���ʱ������������ƺ������ܸ��Ŀͻ���Ӧ�ó������������⣬Ҳ����ı�Ӱ�����ܵĸ������أ��ͻ��˾���֧�����ã���������Ŀͻ����������������ⶼ���������������Ӧ�ó�������
SQL Server ֧�ֳ�ǧ����IJ����û�����֮����Ʋ��Ӧ�ó���������ʹ����ǿ��ķ�����ƽ̨���������û������� �ͻ���Ӧ�ó�������������� ��������������������� �ͻ��˺� SQL Server ֮�����������ͨ�������ݿ�Ӧ�ó������ܽϲ����Ҫԭ�����������˷������Ϳͻ���֮�䴫�͵���������һ���ص�Ӱ�졣�������������ڿͻ���Ӧ�ó����
SQL Server ֮��Ϊÿ���������ͽ�������͵ĻỰ������ͨ��ʹ�ô洢���̣����Խ���������������С�����磬���Ӧ�ó�����ݴ�
SQL Server �յ�������ֵ��ȡ��ͬ�IJ�����ֻҪ���ܾ�Ӧֱ���ڴ洢�����������������Ӷ�������������������� ����洢�������ж����䣬��Ĭ������£�SQL Server ��ÿ��������ʱ���ͻ���Ӧ�ó�����һ����Ϣ����ϸ˵��ÿ�������Ӱ��������������Ӧ�ó�����Ҫ��Щ��Ϣ�����ȷ��Ӧ�ó�����Ҫ���ǣ����Խ�����Щ��Ϣ�������������������ܡ���ʹ��
SET NOCOUNT �Ự����ΪӦ�ó��������Щ��Ϣ���йظ�����Ϣ����μ� SET NOCOUNT�� ��ʹ��С������� ����û��Ҫ��Ľ�������������ǧ�У����ڿͻ������������ CPU ������ I/O �ĸ��أ�ʹӦ�ó����Զ��ʹ���������Ͳ����ƶ��û��������ԡ���ý�Ӧ�ó������Ϊ��ʾ�û������㹻����Ϣ���Ա��ѯ�ύ�����ɴ�С���еĽ�������йظ�����Ϣ����μ�ʹ�ø�Ч���ݼ����Ż�Ӧ�ó������ܡ� �ɰ���ʵ������Ŀ���Ӧ�ó�����Ƽ��������������ɲ�ѯʱ��ͨ������п��ƣ�ǿ��ijЩ�����ֶΣ������������ѯ���Լ�ʹ��
TOP��PERCENT �� SET ROWCOUNT �� Transact-SQL ������Ʋ�ѯ���ص��������йظ�����Ϣ����μ�ʹ��
TOP �� PERCENT ���ƽ������ SET ROWCOUNT�� ���������û���Ҫ���¿���Ӧ�ó���ʱȡ������ִ�еIJ�ѯ�� Ӧ�ó������Ӧǿ���û����������ͻ�����ȡ����ѯ��������һ�㽫������������������⡣���Ӧ�ó���ȡ����ѯ������ʹ�ÿ���ʽ���ݿ�����
(ODBC) sqlcancel ����ȡ����ѯ����Ӧ�����������ʵ��Ŀ��ǡ����磬ȡ����ѯ�������ύ��ع��û����������ȡ����ѯ�������������ڻ�ȡ����������������ˣ���ȡ����ѯ��ʼ��Ҫ�ύ��ع�����ͬ�������Ҳ�����ڿ�����ȡ����ѯ��
DB-Library ������Ӧ�ó���ӿ� (API)�� ��ʼ��ʵ�ֲ�ѯ��������ʱ�� ��Ҫ�ò�ѯ���������С������ʵ��� API �����ò�ѯ��ʱ�����磬ʹ�� ODBC SQLSetStmtOption
������ �й����ò�ѯ��ʱ�ĸ�����Ϣ����μ� ODBC API �ĵ��� �й�����������ʱ�ĸ�����Ϣ����μ��Զ�������ʱ�� ����Ҫʹ�ò�������ʽ���Ʒ��͵� SQL Server �� SQL ����Ӧ�ó������ߡ� ��������ڸ����Ķ����������� Transact-SQL ��䣬���Ҳ��ṩ�����ѯȡ������ѯ��ʱ����ȫ������Ƶȹؼ����ܣ���Ҫʹ������ߡ����Ӧ�ó�����������
SQL ��䣬ͨ��������ά���õ����ܻ����������⣬��Ϊ����������²�������������������������ʽ���ƣ�����һ�������״��������Ҫ�� ����Ҫ������֧�ֺ����������� (OLTP) ��ѯ����һ���йظ�����Ϣ����μ����������������֧�֡� ��ֻ�ڱ�Ҫʱ��ʹ���αꡣ �α��ǹ�ϵ���ݿ��е����ù��ߣ���ʹ���α��������ʼ�ձ�ʹ�����ϵ� SQL ��仨�Ѷࡣ ��ʹ�����ϵ� SQL ���ʱ���ͻ���Ӧ�ó����÷�������������ָ�������ļ�¼�������������������Ϊ����������Ԫ��ɸ��¡���ͨ���α����ʱ���ͻ���Ӧ�ó���Ҫ�������Ϊÿ��ά��������汾��Ϣ������ֻ��Ϊ�˿ͻ�������ȡ�к���������С� ���ң�ʹ���α���ζ�ŷ�����ͨ��Ҫ����ʱ�洢��ά���ͻ��˵�״̬��Ϣ�����û��ڷ������ϵĵ�ǰ�м���Ϊ�ڶ�ͻ���ά������״̬��Ϣ�����Ĵ����ķ�������Դ�����ڹ�ϵ���ݿ⣬���õIJ������ÿͻ���Ӧ�ó�����ٽ������Ա��ڸ��ε���֮�䲻�ڷ�������ά���ͻ��˵�״̬��Ϣ�����ϵ�
SQL ���֧�ִ˲��ԡ� Ȼ���������ѯʹ���α꣬��ȷ�����ʹ�ø���Ч���α����ͣ������ֻ���α꣩����ѯ�ܷ����Ч�ر�д�α��ѯ���йظ�����Ϣ����μ�ʹ�ø�Ч���ݼ����Ż�Ӧ�ó������ܡ� ��ʹ�����ܼ�̡��йظ�����Ϣ����μ��������������Ӧ�ó������ܵ�Ӱ�졣 ��ʹ�ô洢���̡��йظ�����Ϣ����μ��洢���̶�Ӧ�ó������ܵ�Ӱ�졣 ��ʹ�� Prepared Execution ��ִ�в����� SQL ��䡣�йظ�����Ϣ����μ� Prepared
Execution (ODBC)�� ��ʼ�մ��������н���� ��Ҫ��ƻ�ʹ����δȡ����ѯʱ��ֹͣ��������е�Ӧ�ó�����ͨ���ᵼ�������ͽ������ܡ��йظ�����Ϣ����μ��˽�ͱ��������� ��ȷ����Ӧ�ó������Ϊ�ɱ����������йظ�����Ϣ����μ��������������١� ��ȷ�������������ܹ��Ż��ֲ�ʽ��ѯ���ܵ��ʵ�ѡ��йظ�����Ϣ����μ��Ż��ֲ�ʽ��ѯ�� ��Ӧ��ϵͳ������У�Ҫ���ؿ������¼��㣺 1������ʹ������ ���������ݿ�����Ҫ�����ݽṹ�����ĸ���Ŀ�ľ���Ϊ����߲�ѯЧ�ʡ����ڴ���������ݿ��Ʒ������IBM���������ISAM�����ṹ��������ʹ��Ҫǡ���ô�����ʹ��ԭ�����£� ���ھ����������ӣ�����û��ָ��Ϊ��������Ͻ��������������������ӵ��ֶ������Ż����Զ����������� ����Ƶ�������������飨������group by��order by�����������Ͻ��������� ������������ʽ�о����õ��IJ�ֵͬ�϶�����Ͻ����������ڲ�ֵͬ�ٵ����ϲ�Ҫ���������������ڹ�Ա���ġ��Ա�����ֻ�С��С��롰Ů��������ֵͬ����˾��ޱ�Ҫ�������������������������������߲�ѯЧ�ʣ����������ؽ������ٶȡ� ���������������ж������������Щ���Ͻ�������������compound index���� ��ʹ��ϵͳ���ߡ���Informix���ݿ���һ��tbcheck���ߣ������ڿ��ɵ������Ͻ��м�顣��һЩ���ݿ�������ϣ���������ʧЧ������ΪƵ��������ʹ�ö�ȡЧ�ʽ��ͣ����һ��ʹ�������IJ�ѯ��������������������������tbcheck����������������ԣ���Ҫʱ�����������⣬�����ݿ�����´������ݺ�ɾ�����ؽ�����������߲�ѯ�ٶȡ� 2������������ Ӧ�������Դ��ͱ������ظ��������ܹ����������Զ����ʵ��Ĵ���������ʱ���Ż����ͱ���������IJ��衣������һЩӰ�����أ� �������в�����һ������������У� ��group by��order by�Ӿ����еĴ����������Ĵ���һ���� ������������Բ�ͬ�ı��� Ϊ�˱��ⲻ��Ҫ������Ҫ��ȷ�����������������غϲ����ݿ����������ʱ����Ӱ����Ĺ淶�����������Ч�ʵ������ֵ�õģ���������ɱ��⣬��ôӦ����ͼ����������С������еķ�Χ�ȡ� 3�������Դ��ͱ������ݵ�˳���ȡ ��Ƕ�ײ�ѯ�У��Ա���˳���ȡ�Բ�ѯЧ�ʿ��ܲ���������Ӱ�졣�������˳���ȡ���ԣ�һ��Ƕ��3��IJ�ѯ�����ÿ�㶼��ѯ1000�У���ô�����ѯ��Ҫ��ѯ10�������ݡ����������������Ҫ�������Ƕ����ӵ��н������������磬��������ѧ������ѧ�š����������䡭������ѡ�α���ѧ�š��γ̺š��ɼ��������������Ҫ�����ӣ���Ҫ�ڡ�ѧ�š���������ֶ��Ͻ��������� ������ʹ�ò���������˳���ȡ�����������еļ�����϶�����������ijЩ��ʽ��where�Ӿ�ǿ���Ż���ʹ��˳���ȡ������IJ�ѯ��ǿ�ȶ�orders��ִ��˳������� SELECT �� FROM orders WHERE (customer_num=104 AND order_num>1001)
OR order_num=1008 ��Ȼ��customer_num��order_num�Ͻ��������������������������Ż�������ʹ��˳���ȡ·��ɨ������������Ϊ������Ҫ�������Ƿ�����еļ��ϣ�����Ӧ�ø�Ϊ������䣺 SELECT �� FROM orders WHERE customer_num=104 AND order_num>1001 UNION SELECT �� FROM orders WHERE order_num=1008 ����������������·��������ѯ�� 4����������Ӳ�ѯ һ���еı�ǩͬʱ������ѯ��where�Ӿ��еIJ�ѯ�г��֣���ô�ܿ��ܵ�����ѯ�е���ֵ�ı�֮���Ӳ�ѯ�������²�ѯһ�Ρ���ѯǶ�ײ��Խ�࣬Ч��Խ�ͣ����Ӧ�����������Ӳ�ѯ������Ӳ�ѯ���ɱ��⣬��ôҪ���Ӳ�ѯ�й��˵������ܶ���С� 5���������ѵ��������ʽ MATCHES��LIKE�ؼ���֧��ͨ���ƥ�䣬�����Ͻ��������ʽ��������ƥ���ر�ķ�ʱ�䡣���磺SELECT
�� FROM customer WHERE zipcode LIKE ��98_ _ _�� ��ʹ��zipcode�ֶ��Ͻ����������������������Ҳ���Dz���˳��ɨ��ķ�ʽ�����������ΪSELECT
�� FROM customer WHERE zipcode >��98000������ִ�в�ѯʱ�ͻ�������������ѯ����Ȼ��������ٶȡ� ���⣬��Ҫ����ǿ�ʼ���Ӵ���������䣺SELECT �� FROM customer WHERE zipcode[2��3]
>��80������where�Ӿ��в����˷ǿ�ʼ�Ӵ������������Ҳ����ʹ�������� 6��ʹ����ʱ�����ٲ�ѯ �ѱ���һ���Ӽ�������������ʱ������ʱ�ܼ��ٲ�ѯ���������ڱ����������������������������滹�ܼ��Ż����Ĺ��������磺
| SELECT
cust.name��rcvbles.balance������other columns
FROM cust��rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
AND rcvblls.balance>0
AND cust.postcode>��98000��
ORDER BY cust.name
|
��������ѯҪ��ִ�ж�ζ���ֹһ�Σ���������δ����Ŀͻ��ҳ�������һ����ʱ�ļ��У������ͻ������ֽ�������
| SELECT
cust.name��rcvbles.balance������other columns
FROM cust��rcvbles
WHERE cust.customer_id = rcvlbes.customer_id
|
�Ż�ʵ�ù��ߺ������� �����������ݿ���ִ���Ի���������������������������� �����ݺͻ�ԭ������ �������ݴ��������Ƶ����С� ��ִ�����ݿ����̨���� (DBCC) ������ һ������£�����Ҫ�Ż���Щ������Ȼ���������ܹܺؼ��������У��ɲ���һЩ�����Ż����ܡ� Microsoft SQL Server���ݿ��ں���1�����ڷ��õIJ�ѯ�Ż����Զ��Ż���SQL�ύ�����ݲ�ѯ���������ݲ�����ѯ��ָ֧��SQL�ؼ���WHERE��HAVING�IJ�ѯ����SELECT��DELETE��UPDATE�����ڷ��õIJ�ѯ�Ż�������ͳ����Ϣ�����Ӿ�ķ��ù��㡣 �˽��Ż������ݴ������̵ļ����Ǽ��SHOWPLAN�����������������û����ַ��Ĺ���(����isql)������ͨ������SHOW
SHOWPLAN ON���õ�SHOWPLAN�������������ʹ��ͼ�λ���ѯ������SQL Enterprise
Manager�еIJ�ѯ����isql/w�������趨����ѡ�����ṩ��һ��Ϣ�� SQL Server���Ż�ͨ��3�������:��ѯ����������ѡ�ϲ�ѡ��: 1.��ѯ���� �ڲ�ѯ�����Σ�SQL Server�Ż����鿴ÿһ���������ѯ���������Ӿ䣬���ж����Ƿ��ܱ��Ż���SQL
Serverһ��ᾡ���Ż���Щ����ɨ����Ӿ䡣���磬������/��ϲ��Ӿ䡣���Dz������кϷ���SQL������Էֳɿ��Ż����Ӿ䣬�纬��SQL���ȹ�ϵ����<>�����Ӿ䡣��Ϊ��<>����1���ų��ԵIJ�������������1�������ԵIJ�����������ɨ��������֮ǰ��ȷ���Ӿ��ѡ��Χ���ж��1����ϵ�Ͳ�ѯ�к��в����Ż����Ӿ�ʱ��ִ�мƻ��ñ�ɨ�������ʲ�ѯ��������֣����ڲ�ѯ���п��Ż���SQL
Server�Ӿ䣬�����Ż���ִ������ѡ�� 2.����ѡ�� ����ÿ�����Ż����Ӿ䣬�Ż������鿴���ݿ�ϵͳ������ȷ���Ƿ�����ص����������ڷ������ݡ�ֻ�е������е��е�1��ǰ���ѯ�Ӿ��е�����ȫƥ��ʱ����������ű���Ϊ�����õġ���Ϊ�����Ǹ����е�˳����ģ�����Ҫ��ƥ���Ǿ�ȷ��ƥ�䡣���ڷִ�������ԭ��������Ҳ�Ǹ���������˳������ġ����������Ĵ�Ҫ�з������ݣ��������ڵ绰���в���������Ϊij�����ϵ���Ŀһ�������������û��ʲô�ã���Ϊ�㻹�ǵò鿴ÿһ����ȷ�����Ƿ�������������1���Ӿ��п��õ���������ô�Ż����ͻ�Ϊ��ȷ��ѡ���ԡ� ��������ƹ����У�Ҫ���ݲ�ѯ�������ϸ������еIJ�ѯ���Բ�ѯ���Ż��ص�Ϊ������������� (1)�Ƚ�խ���������бȽϸߵ�Ч�ʡ����ڱȽ�խ��������˵��ÿҳ���ܴ�Ž϶�������У����������ļ���Ҳ���١����ԣ��������ܷ��ø��������ҳ������Ҳ������I/O������ (2)SQL Server�Ż����ܷ��������������ͺϲ������ԡ���������ٵĿ�������ȣ��϶��խ���������Ż����ṩ�����ѡ���Dz�Ҫ��������Ҫ����������Ϊ���ǽ����Ӵ洢��ά���Ŀ�֧�����ڸ���������������������������SQL
Se �Ż����������� Microsoft? SQL Server? 2000 �Զ������ܶ����������ѡ����ϵͳ����Աֻ�������ٵĵ���������У�����Щ����ѡ�������ϵͳ����Ա�ģ���һ�㽨�鱣��ΪĬ��ֵ����ʹ
SQL Server �ܸ�������ʱ������Զ����������е����� �����������Ҫ��������������������Ż����������ܣ� ��SQL Server �ڴ� ��I/O ��ϵͳ ��Microsoft Windows NT? ѡ�� MSSQL������ʹ���ڴ��: ���Ŀ���һ�����������ݻ��棬����ڴ��㹻��������ù������ݺ;�������õ�������ͳͳ�ӵ��ڴ��У�ֱ���ڴ治���ʱ�Ű������ʵ͵����ݸ����������һ�������ڿ�statistics
io��ʱ������physics read����0�� ��ξ��Dz�ѯ�Ŀ�����һ���˵��hash join�ǻ�����Ƚϴ���ڴ濪���ģ���merge join��nested
loop�Ŀ����Ƚ�С������������м�����α�Ҳ�ǻ��бȽϴ�Ŀ����ġ� �������ڹ��������������һ����Ҫ�������� ����ξ��Ƕ�ִ�мƻ���ϵͳ���ݵĴ洢����Щ���DZȽ�С�ġ� �������������ݻ�������ܵ�Ӱ�죬���ϵͳ��û������Ӧ�ó����������ڴ棬���ݻ���һ����Խ��Խ�ã�������Щʱ�����ǻ�ǿ�а�һЩ����pin�ڸ��ٻ����С��������������Ӧ�ó�����Ȼ����Ҫ��ʱ��MSSQL���ͷ��ڴ棬�����߳��л���IO�ȴ���Щ����Ҳ����Ҫʱ��ģ����Ծͻ�������ܵĽ��͡��������Ǿͱ�������MSSQL������ڴ�ʹ�á�������SQL
Server ���ԣ��ڴ�ѡ������ҵ��������ʹ���ڴ�ĵط�������Ҳ����ʹ��sp_configure����ɡ����û������Ӧ�ó�����ô�Ͳ�Ҫ����MSSQL���ڴ��ʹ�á� Ȼ��������ѯ�Ŀ��������������Ȼ��Խ��Խ�ã���Ϊ���Dz��ܴ��еõ��ô����෴��ʹ����Խ����ڴ�����ζ�Ų�ѯ�ٶȵĽ��͡���������һ��Ҫ�����м�����α��ʹ�ã��ھ�������������������Ͻ��������� �����Ĵ�������������Ż����ݿ�ϵͳ �������ܶ�DBA���ܶ��������ɣ�����ս���һ������ϵͳ��ԭ���ij��̲������Դ����ģ�������ϵͳӦ�ñȽϹؼ������������ģ�������Դ���������ҵĿ�ģ�������һ���̶ȵļ��ܣ����е�ʱ���������������--�쵼Ϊ�˱������Σ����������������������ʱ��ϵͳ�������ϵ�����Ƚ����أ����������취��ô��ϵͳ�����Ż�ô? �������ҳ����ܽ�һ�¿����е�;���� ����ض���SQL����"�������" (Metalink 122812.1)���Ľ�ִ�мƻ� ������ͳ����Ϣ (����������/��״ͼͳ��) ���������� (���ӻ�������ʵ�������ɾ������Ҫ������) �������ﻯ��ͼ(�ÿռ俪������ȡʱ������) �Ż�OS�����ݿ�������������� �����Ż�����ϵͳ-������IJ����ĺ�������������ϵͳ��Դ�ĺ�������; ����IO�ĵ���,���Ǻ���Ҫ��һ���֣���Ϊ����IO�ٶȺ��������ϵͳƿ��;������Դ���Ż�-TCP/IP�IJ�������; ����Oracle��ʼ������ �Ż���ģʽ���趨,db_cache �������趨,sga ��С�Ȳ����趨���������ݿ�����������Ҫ��Ӱ�졣 ������ϵͳ��Դ���� ��һЩ����������Ϊ����ϵͳ�У�ϵͳ��Դ�ĵ����DZȽ���Ҫ�ģ����Ȳ������������������Դ���á��е�ϵͳ������ϵͳ����֮�������DZȽϺ����ģ�����һ��ʱ������֮������Ϊ�������ı仯��SQL����ִ�мƻ��仯�Ȼ���ɲ���ʱ���ϵ��ص�����϶����ϵͳ����ѹ���ϵ����⡣ �������ݿ���� ������pctfree ,freelist ���洢���� ���������ռ��ļ������ݿ�������������Ĵ��̷ֲ��� ��cache һЩ���õ����ݿ���� ϵͳBug���������Ӱ��/�����Ľ����� Oracle����Bug��࣬ϵͳ���г����е�Bug������Σ�����������ԣ�����ʱ������ƣ������Bug���ϵͳ����������⡣���ʱ���ϵͳ��Bug
���Ѿ������ݿ�ϵͳ�����������DZ�Ҫ�ġ�ͨ������������Oracle����ȱ�ݣ�ͬʱ��������Ҳ���ܻ���ǿ���ݿ������Ч�ʡ���Ȼ��ҲҪע���������ܴ����IJ�����Ӱ�졣 �� ����ϵͳ����Ż� 1. ����ϵͳ���ܵĺû�ֱ��Ӱ�����ݿ��ʹ�����ܣ��������ϵͳ�������⣬��CPU���ء������ڴ潻��������I/Oƿ���ȣ�����������£������������ݿ��ڲ����ܵ����Dz������ϵͳ���ܵġ����ǿ���ͨ��Windows
NT��ϵͳ������(System Monitor)����ظ����豸����������ƿ��������CPU һ�ֳ����������������ȱ������������ϵͳ�Ĵ�����������ϵͳ��CPU���������ͺ��ٶȾ����ġ����ϵͳû���㹻��CPU�������������Ͳ����㹻��ش���������������Ҫ�����ǿ���ʹ��System
Monitorȷ��CPU��ʹ���ʣ������75%����ߵ����ʳ�ʱ�����У��Ϳ���������CPUƿ�����⣬��ʱӦ������CPU����������ǰ�������ϵͳ���������ԣ��������ΪSQL���Ч�ʷdz��ͣ��Ż����������ڽ���ϵ͵�CPU�����ʡ�����ȷ����Ҫ��ǿ�Ĵ�����������������CPU�����ø����CPU
�滻�������ڴ� SQL Server��ʹ�õ��ڴ�����SQL Server������ؼ�����֮һ�����ڴ�ͬI/O��ϵͳ�Ĺ�ϵҲ��һ���dz���Ҫ�����ء����磬��I/O����Ƶ����ϵͳ�У�SQL
Server�����������ݵĿ����ڴ�Խ�࣬����ִ�е�����I/OҲ��Խ�١�������Ϊ���ݽ������ݻ����ж�ȡ�����ǴӴ��̶�ȡ��ͬ�����ڴ����IJ�����������ԵĴ��̶�дƿ������Ϊϵͳ�����������������������������I/O��������������System
Monitor���SQL Server��Buffer Cache Hit Ratio����������������ʾ�������90%����Ӧ�����Ӹ�����ڴ档����I/O��ϵͳ��I/O��ϵͳ������ƿ�����������ݿ�ϵͳ���������������ͬӲ���йص����⡣���úܲ��I/O��ϵͳ����������������س̶Ƚ����ڱ�д�ܲ��SQL��䡣I/O��ϵͳ���������������ģ�һ�������������ܹ�ִ�е�I/O���������ģ�һ��һ����ͨ�Ĵ���������ÿ��ֻ�ܴ���85��I/O����������������������أ�����Щ������������I/O������Ҫ�Ŷӣ�SQL��I/O�ӳٽ��ܳ�������ܻ�ʹ��������ʱ�����������ʹ�߳��ڵȴ���Դ�Ĺ����б��ֿ���״̬��������������ϵͳ�������ܵ�Ӱ�졣 ���I/O��ϵͳ�йص�����Ҳ���������ģ���������£����Ӵ����������Ϳ��Խ������������⡣�� ��Ȼ��Ӱ�����ܵ����غܶ࣬��Ӧ���ָ�����ͬ���ҳ�һ��ͨ�õ��Ż������Ǻ����ѵģ�ֻ������ϵͳ������ά���Ĺ�����������еľ�����������ϼ��Ե����� 2����SQL Server��ص�Ӳ��ϵͳ ��SQL Server�йص�Ӳ����ư���ϵͳ���������ڴ桢������ϵͳ�����磬��4�����ֻ����Ϲ�����Ӳ��ƽ̨��Windows
NT��SQL Server���������ϡ� 2.1��ϵͳ������(CPU) �����Լ��ľ�����Ҫȷ��CPU�ṹ�Ĺ��̾��ǹ�����Ӳ��ƽ̨��ռ��CPU�Ĺ������Ĺ��̡��������ľ��鿴��CPU��������Ӧ��1��80586/100�����������ֻ��2��3���û�������㹻�ˣ����������֧�ָ�����û��ؼ�Ӧ�ã��Ƽ�����Pentium
Pro��P��CPU�� 2.2���ڴ�(RAM) ΪSQL Server����ȷ�����ʵ��ڴ����ö���ʵ�����õ�������������Ҫ�ġ�SQL Server���ڴ������̻��桢���ݺ�������桢��̬��������֧�����ÿ�֧��SQL
Server���������2GB�����ڴ棬��Ҳ����������ֵ������һ����뿼�ǵ���Windows NT������������صķ���ҲҪռ���ڴ档 Windows NTΪÿ��WIN32Ӧ�ó����ṩ��4GB�������ַ�ռ䡣��������ַ�ռ���Windows
NT�����ڴ������(VMM)ӳ�䵽�����ڴ��ϣ���ijЩӲ��ƽ̨�Ͽ��Դﵽ4GB��SQL ServerӦ�ó���ֻ֪�������ַ�����Բ���ֱ�ӷ��������ڴ棬�����������VMM���Ƶġ�Windows
NT���������������õ������ڴ�������ַ�ռ䣬��������SQL Server����������ڴ���ڿ��õ������ڴ�ʱ���ή��SQL
Server�����ܡ� ��Щ��ַ�ռ���ר��ΪSQL Serverϵͳ���õģ����������ͬһӲ��ƽ̨�ϻ�����������(���ļ��ʹ�ӡ������Ӧ�ó�������)�����У���ôӦ�ÿ��ǵ�����Ҳռ��һ�����ڴ档һ����˵Ӳ��ƽ̨����Ҫ����32MB���ڴ棬���У�Windows
NT����Ҫռ��16MB��1���ķ����ǣ���ÿһ���������û�����100KB���ڴ档���磬�����100���������û�����������Ҫ32MB+100�û�*100KB=42MB�ڴ棬ʵ�ʵ�ʹ����������Ҫ�������е�ʵ���������������˵������ڴ������ϵͳ���ܵ���õ�;���� 2.3��������ϵͳ ���1���õĴ���I/Oϵͳ��ʵ�����õ�SQL Server������һ������Ҫ�ķ��档�������۵Ĵ�����ϵͳ������1�����̿����豸��1������Ӳ�̵�Ԫ�����жԴ������ú��ļ�ϵͳ�Ŀ��ǡ�������SCSI-2���̿������������������Dz�����ѡ�����ص�����: (1)���������ٻ��档����(2)�����������д����������Լ��ٶ�ϵͳCPU���жϡ�����(3)�첽��д֧�֡�����(4)32λRAID֧�֡�����(5)����SCSI��2����������(6)��ǰ�����ٻ���(����1���ŵ�)�� 3���������� �ھ���ѡ����Ӳ��ƽ̨����ʵ����1�����õ����ݿⷽ�������Ҿ߱����û������Ӧ�÷����֪ʶ������Ӧ����Ʋ�ѯ�������ˡ���2�����������SQL
Server��ȡ�����õIJ�ѯ������������ʮ����Ҫ�ģ���1�Ǹ���SQL Server�Ż��������֪ʶ���ɲ�ѯ������;��2������SQL
Server�������ص㣬��ǿ���ݷ��ʲ�����
|






