��֮ǰ�������У��ҽ����˷ֿ�ֱ��ļ��ֱ�����ʽ���淨��Ҳ�ص�����˴�ֱ�ֿ�������������ͽ����������ƪ�У����ǽ���������ˮƽ�ֿ�ֱ���һЩ���ɡ�
��Ƭ����������
��ϵ�����ݿⱾ���Ƚ����׳�Ϊϵͳ����ƿ���������洢�����������������������ȶ������ޣ����ݿⱾ���ġ���״̬�ԡ���������������Web��Ӧ�÷�������ô������չ���ڻ�������ҵ�������ݺ߲������ʵĿ����£������ļ�����Ա����˷ֿ�ֱ���������Щ�ط�Ҳ��ΪSharding����Ƭ����ͬʱ�����еķֲ�ʽϵͳ�м��������MongoDB��ElasticSearch�ȣ��������Ѻ�֧��Sharding����ԭ����˼�붼�Ǵ�ͬС��ġ�
�ֲ�ʽȫ��ΨһID
�ںܶ���С��Ŀ�У���������ֱ��ʹ�����ݿ�������������������ID������ȷʵ�Ƚϼ����ڷֿ�ֱ��Ļ����У����ݷֲ��ڲ�ͬ�ķ�Ƭ�ϣ������ٽ������ݿ�����������ֱ�����ɣ��������ɲ�ͬ��Ƭ�ϵ����ݱ��������ظ���������ʹ�ú��˽���ļ���ID�����㷨��
Twitter��Snowflake��������ѩ���㷨����
UUID/GUID��һ��Ӧ�ó�������ݿ��֧�֣�
MongoDB ObjectID������UUID�ķ�ʽ��
Ticket Server�����ݿ����淽ʽ��Flickr���õľ������ַ�ʽ��
���У�Twitter ��Snowflake�㷨�DZ��߽������ڷֲ�ʽϵͳ��Ŀ��ʹ�����ģ�δ�����ظ��������⡣���㷨���ɵ���64λΨһId����41λ��timestamp+
10λ�Զ���Ļ�����+ 13λ�ۼӼ�������ɣ������ﲻ��������ܣ�����Ȥ�Ķ��߿����в���������ϡ�
������Ƭ����Ͳ���
��Ƭ�ֶθ����ѡ��
�ڿ�ʼ��Ƭ֮ǰ����������Ҫȷ����Ƭ�ֶΣ�Ҳ�ɳ�Ϊ��Ƭ���������ܶೣ�������Ӻͳ������Dz���ID����ʱ���ֶν��в�֡���Ҳ�������Եģ��ҵĽ����ǽ��ʵ��ҵ��ͨ����ϵͳ��ִ�е�sql������ͳ�Ʒ�����ѡ�����Ҫ��Ƭ���Ǹ�������Ƶ����ʹ�ã���������Ҫ���ֶ�����Ϊ��Ƭ�ֶΡ�
������Ƭ����
�����ķ�Ƭ�����������Ƭ��������Ƭ�����֣�����ͼ��ʾ��
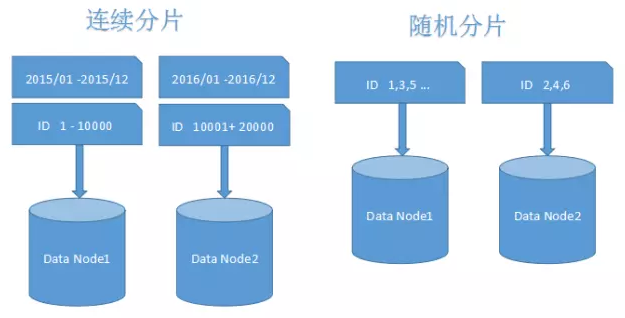
����Ҫʹ�÷�Ƭ�ֶν��з�Χ����ʱ��������Ƭ���Կ��ٶ�λ��Ƭ���и�Ч��ѯ�����������¿�����Ч������Ƭ��ѯ�����⡣����������������Ƭ��Ⱥ����ʱ��ֻ��Ҫ���ӽڵ㼴�ɣ������������Ƭ�����ݽ���Ǩ�ơ����ǣ�������ƬҲ�п��ܴ��������ȵ�����⣬����ͼ�а�ʱ���ֶη�Ƭ�����ӣ���Щ�ڵ���ܻᱻƵ����ѯѹ���ϴ������ݽڵ�ͳ�Ϊ��������Ⱥ��ƿ��������Щ�ڵ���ܴ������ʷ���ݣ�������Ҫ����ѯ����
�����Ƭ��ʵ����������ģ�Ҳ��ѭһ������ͨ�������ǻ����Hashȡģ�ķ�ʽ���з�Ƭ��֣�������Щʱ��Ҳ����Ϊ��ɢ��Ƭ�������Ƭ��������ԱȽϾ��ȣ������׳����ȵ�Ͳ������ʵ�ƿ�������ǣ����ڷ�Ƭ��Ⱥ����������ҪǨ�ƾɵ����ݡ�ʹ��һ����Hash�㷨�ܹ��ܴ�̶ȵı���������⣬���Ժܶ��м���ķ�Ƭ��Ⱥ�������һ����Hash�㷨����ɢ��ƬҲ���������ٿ��Ƭ��ѯ�ĸ������⡣
����Ǩ�ƣ������滮�����ݵ�����
��������Ŀ���ڳ��ھͿ�ʼ���Ƿ�Ƭ��Ƶģ�һ�㶼����ҵ����ٷ�չ�������ܺʹ洢��ƿ��ʱ�Ż���ǰ������ˣ����ɱ���ľ���Ҫ������ʷ����Ǩ�Ƶ����⡣һ����������ͨ�������ȶ�����ʷ���ݣ�Ȼ����ָ���ķ�Ƭ�����ٽ�����д�뵽������Ƭ�ڵ��С�
���⣬������Ҫ���ݵ�ǰ����������QPS�Ƚ��������滮���ۺϳɱ����أ�����������Ҫ���ٷ�Ƭ��һ�㽨�鵥����Ƭ�ϵĵ�����������Ҫ����1000W����
����Dz��������Ƭ������Ҫ���Ǻ��ڵ��������⣬��Ի�Ƚ��鷳������Dz��õķ�Χ��Ƭ��ֻ��Ҫ���ӽڵ�Ϳ����Զ����ݡ�
���Ƭ��������
���Ƭ�������ҳ
һ����������ҳʱ��Ҫ����ָ���ֶν������������ֶξ��Ƿ�Ƭ�ֶε�ʱ������ͨ����Ƭ������ԱȽ�����λ��ָ���ķ�Ƭ�����������ֶηǷ�Ƭ�ֶε�ʱ������ͻ��ñȽϸ����ˡ�Ϊ�����ս����ȷ�ԣ�������Ҫ�ڲ�ͬ�ķ�Ƭ�ڵ��н����ݽ��������أ�������ͬ��Ƭ���صĽ�������л��ܺ��ٴ���������ٷ��ظ��û�������ͼ��ʾ��
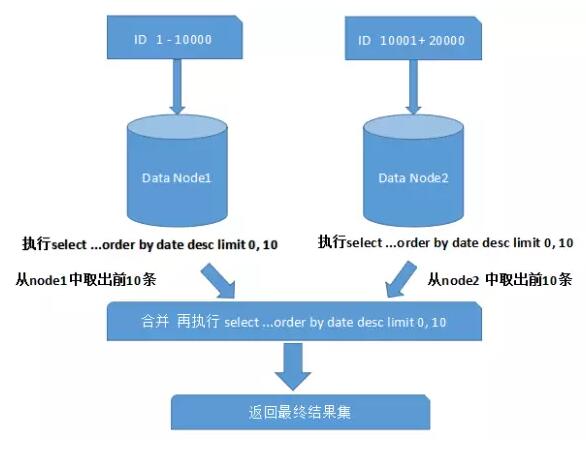
����ͼ����������ֻ�����һ�������ȡ��һҳ���ݣ��������������ܵ�Ӱ�첢�����ǣ������ȡ����10ҳ���ݣ�����ֽ���ø��Ӻܶ࣬����ͼ��ʾ��
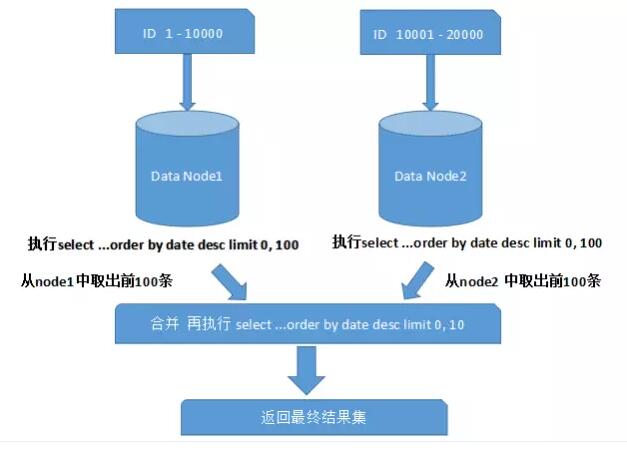
��Щ���߿��ܲ���̫���⣬Ϊʲô�������ȡ��һҳ������������������ȡ��ǰ10���ٺϲ���������ʵ���������⣬��Ϊ����Ƭ�ڵ��е����ݿ���������ģ�Ϊ�������ȷ�ԣ���������з�Ƭ�ڵ��ǰNҳ���ݶ�����ú����ϲ�������ٽ��������������Ȼ�������IJ����DZȽ�������Դ�ģ��û�Խ����ҳ��ϵͳ���ܽ���Խ�
���Ƭ�ĺ�������
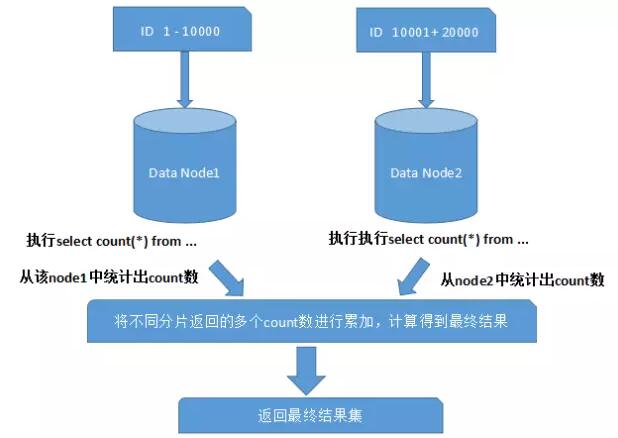
��ʹ��Max��Min��Sum��Count֮��ĺ�������ͳ�ƺͼ����ʱ����Ҫ����ÿ����Ƭ����Դ��ִ����Ӧ�ĺ���������Ȼ���ٽ�������������ж��δ����������ٽ�����������ء�����ͼ��ʾ��
���Ƭjoin
Join�ǹ�ϵ�����ݿ�����õ����ԣ������ڷ�Ƭ��Ⱥ�У�joinҲ��÷dz����ӡ�Ӧ�þ���������Ƭ��join��ѯ�����ֳ�����������Ŀ��Ƭ��ҳ���Ӹ��ӣ����Ҷ����ܵ�Ӱ��ܴ�ͨ�������¼��ַ�ʽ�����⣺
ȫ�ֱ�
ȫ�ֱ��ĸ���֮ǰ�ڡ���ֱ�ֿ⡱ʱ���������˼��һ�£����ǰ�һЩ���������ֵ��ֿ��ܻ����join��ѯ�ı���Ϣ�ŵ�����Ƭ�У��Ӷ�������Ƭ��join��
ER��Ƭ
�ڹ�ϵ�����ݿ��У���֮����������һЩ�����Ĺ�ϵ��������ǿ�����ȷ���ù�����ϵ��������Щ���ڹ�����ϵ�ı���¼�����ͬһ����Ƭ�ϣ���ô���ܺܺõı�����Ƭjoin���⡣��һ�Զ��ϵ������£�����ͨ����ѡ�������ݽ϶����һ�����в�֡�����ͼ��ʾ��
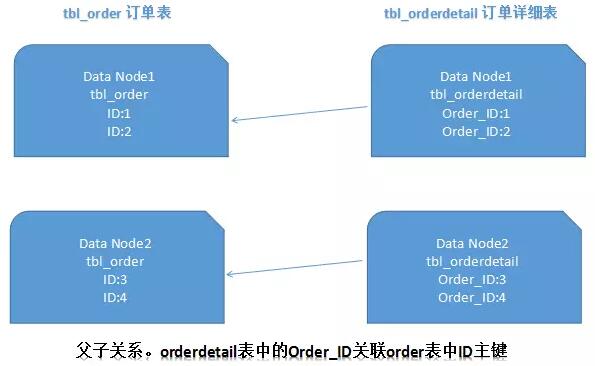
����һ����Data Node1����Ķ������붩����ϸ���Ϳ���ֱ�ӹ��������оֲ���join��ѯ�ˣ�Data
Node2��Ҳһ��������ER��Ƭ�����ַ�ʽ���ܹ���Ч��������ҵ���еĿ��Ƭjoin���⡣
�ڴ����
����spark�ڴ����������������������ܶ������Դ�IJ������⿴�����ƺ����ܹ��õ���������Խ����ݶ���spark��Ⱥ�����ڴ���㣬����������ء�
���Ƭ��������
���Ƭ����Ҳ�ֲ�ʽ������Ҫ�˽�ֲ�ʽ������Ҫ�˽⡰XA�ӿڡ��͡������ύ����ֵ���ᵽ���ǣ�MySQL5.5x��5.6x�е�xa֧���Ǵ�������ģ��ᵼ���������ݲ�һ�¡�ֱ��5.7x�汾�вŵõ�����JavaӦ�ó�����Բ���Atomikos�����ʵ��XA����J2EE��JTA��������Ȥ�Ķ��߿������вο����ֲ�ʽ����һ���Խ�������������ӵ�ַ��
http://www.infoq.com/cn/articles/solution-of-distributed-system-transaction-consistency
���ǵ�ϵͳ�����Ҫ�ֿ�ֱ���
�����������ݣ�����������Щ���ߵ�˼�������ǵ�ϵͳ�Ƿ���Ҫ�ֿ�ֱ���
��ʵ���û����ȷ���жϱ����Ƚ�����ʵ��ҵ������;����жϡ����ձ��߸��˵ľ��飬һ��MySQL����1000W���ҵ�������û������ģ�ǰ����Ӧ��ϵͳ�����ݿ�Ȳ�����ƺ��Ż��ıȽϺã�����Ȼ�����˿��ǵ�ǰ�����������������ʱ����Ϊ�ܹ�ʦ��������Ҫ��ǰ����ϵͳ���굽һ�����ҵ�ҵ����������������ݿ��������QPS���������������������������滮������ǰ������Ӧ����������������������㣬�Һ����ٴ����������Ż�����ô˵������Ҫ���Ƿ�Ƭ�ġ��������������ȥ�����ݿ�������ID��Ϊ��Ƭ�ͺ��������Ǩ�ƹ�����ǰ������
�ܶ��˾��á��ֿ�ֱ��������粻�˳٣�Ӧ�þ�����У���Ϊ����Խ����˾ҵ��չԽ�졢ϵͳԽ��Խ���ӡ�ϵͳ�ع�����չԽ���ѡ����ֻ�������������ôһ����������ҵĹ۵�ǡ���෴�����ڹ�ϵ�����ݿ�����������Ϊ���ܲ���Ƭ�ͱ��Ƭ����������ϵͳ������Ҫ����Ϊ���ݿ��Ƭ���ǵͳɱ�������ѵġ�
��������Ƽ�һ���ȽϿ��Ĺ��ɼ����C�����������������Ĺ�ϵ�����ݿ��л�����֧�֡���ͬ�ķ�������������һ�ű�������������ȴ�Ƿֿ��ģ�����һ���̶�����߲�ѯ���ܣ����Ҷ�Ӧ�ó��������������κδ��롣�������������Ż���һ��ϵͳ����ҵ����д�Լ8000W���ҵ����ݣ����ǵ��ɱ����⣬��ʱ���Dz��á��������������ģ�Ч���Ƚ����ԣ���ϵͳ���еĺ��ȶ���
��
����кܶ���߶����˽ǰ��������û�п�Դ��ѵķֿ�ֱ�����������Ͼ�վ�ھ��˵ļ������ʡ���ܶࡣ��ǰ��Ҫ��������������
����Ӧ�ó�������DDAL���ֲ�ʽ���ݿ���ʲ㣩
�Ƚϵ��͵ľ����Ա��뿪Դ��TDDL����������Դ��Sharding-JDBC�ȡ��ֲ�ʽ���ݷ��ʲ�����Ӳ��Ͷ�룬����������ǿ�Ĵ�˾ͨ����ѡ�����л���տ�Դ��ܽ��ж��ο����Ͷ��ơ���Ӧ�ó����������һ��ϴ����Ӽ����ɱ����Ӷȡ�ͨ����֧���ض��������ƽ̨��Javaƽ̨�ľӶࣩ�����߽�֧���ض������ݿ���ض����ݷ��ʿ�ܼ�����һ��֧��MySQL���ݿ⣬JDBC��MyBatis��Hibernate�ȿ�ܼ�������
���ݿ��м�����Ƚϵ��͵���mycat���ڰ��↑Դ��cobar���������˺ܶ��Ż��Ľ������ں���֮�㣬Ҳ֧�ֺܶ������ԣ�������Go����ʵ��kingSharding���Ƚ����Ƶ�Atlas����360��Դ���ȡ���Щ�м���ڻ�������ҵ�д�����ʹ�á����⣬MySQL
5.x��ҵ���йٷ��ṩ��Fabric���Ҳ�ų�֧�ַ�Ƭ��������������ʹ�õ���ҵ���١�
�м��Ҳ���Գ�Ϊ�������ء�������������mysql_proxy����Ǹ�����ı��棨��MySQL�ٷ��ṩ��������ʵ�֡���д���롱�����м��һ��ʵ�����ض����ݿ������ͨ��Э�飬ģ��һ����ʵ�����ݿ���������˺����ʵ��Server��Ӧ�ó���ͨ��ֱ�������м�����ɡ�����ִ��SQL����ʱ���м���ᰴ��Ԥ�ȶ����Ƭ����SQL�����н�����·�ɣ����Խ���������μ��������շ��ء��������ݿ��м���ļ����ɱ����ͣ���Ӧ�ó������������Լ���û�У���������ֵ�ҵ�������˶����Ӳ��Ͷ�����ά�ɱ���ͬʱ���м������Ҳ��������ƿ���͵���������⣬��Ҫ�ܹ���֤�м�������ĸ߿��á�����չ��
��֮��������ʹ�÷ֲ�ʽ���ݷ��ʲ㻹�����ݿ��м�����������һ���ijɱ����Ӷȣ�Ҳ����һ��������Ӱ�졣���ԣ�������߸���ʵ�������ҵ��չ��Ҫ���ؿ��Ǻ�ѡ��
|






