| 1������
�ӱ�ƪ���¿�ʼ���ǽ���һ����ƪ������߽���mysql�ĸ��ַ���Ⱥ�Ĵ��ʽ�����µ�����˼·�Ǵ�����MySQL���ӷ�����ʼ���ܣ�ͨ�����ַ����IJ�������������ӵļ�Ⱥ�����������ܺ�������������Щ������иĽ��ġ�MySQL�ļ�Ⱥ���������ر�࣬�⼸ƪ���»�ѡ��һЩ���͵ļ�Ⱥ��������߽��н��ܡ�
2��MySQL������ӷ���������ԭ��
���ǽ���İ汾��������Ŀǰ������������ʹ������version 5.6���У�����һЩ������Version
5.7�����µ�Version 8.0�������Ľ������ⲻӰ�����ͨ������ȥ�����MySQL��Ⱥ�ļ���˼·���������Խ����ֻ���������MariaDB����������Ҫ�ᵽ��MySQL�Դ�����־���ƻ��ƣ�Replicaion���ƣ���
MySQL�Դ�����־���ƻ��Ƴ�ΪMySQL-Replicaion����MySQL����� Version
5.1�汾����Replicaion��������չ�����а汾�ü����Ѿ��dz����죬ͨ������֧�ּ�����Ա������������MySQL��Ⱥ�ṹ����Ȼ���������ǻ������һЩ�ɵ���������/���֧�ֵ�MySQL��Ⱥ������
2-1��MySQL-Replicaion��������ԭ��
Replicaion���ƴӼ������潲���������ֻ�����ɫ��Master��Salve��Master�ڵ㸺����Replicaion�����У���һ�����߶��Ŀ��������ݣ���Salve�ڵ㸺����Replicaion�����н���Master�ڵ㴫�������ݡ���ʵ��ҵ���£�Master�ڵ��Salve�ڵ㻹�ֱ�������һ�����֣�Write�ڵ��Read�ڵ㡪���ǵģ�����Replicaion�������ǿ��Դ�Զ�д����ΪĿ���MySQL��Ⱥ������Ϊ�˱�֤�������Ķ���������ʱ����������壬�ڱ��ģ��ͺ������£������Ƕ���ʹ��Master�ڵ��Salve�ڵ������ijƺ���Replicaion��������MySQL����Ķ�������־ͬ�����ݣ�
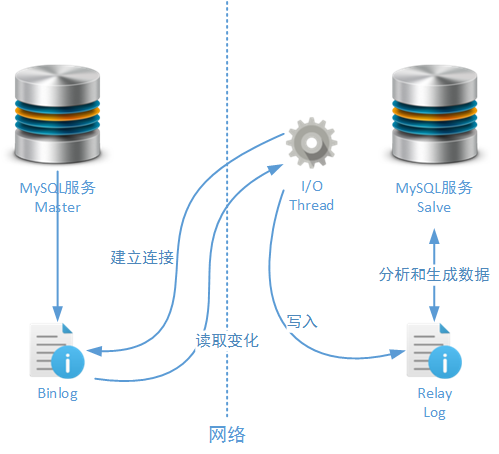
����ͼ��ʾ��Salve��������Ὠ��һ����Master�ڵ���������ӣ���Master�ڵ�Ķ�������־�����仯��һ�����߶��MySQL
Salve����ڵ�ͻ�ͨ������Ӽ�������Щ�仯��־������Salve�ڵ�������ڱ��ؽ���Щ�仯д���м���־�ļ���Relay
Log������������Ϊ�˾�������MySQL�����ڳ����쳣ʱͬ������ʧ�ܣ���ԭ����֮ǰ���ܹ���InnoDB
Log�Ĺ���ԭ�����ơ����м���־�ļ�������ɼ�¼��MySQL Salve����Ὣ��Щ�仯��ӳ����Ӧ�����ݱ��У����һ������ͬ�����̡����Salve�����������־�ļ��еĸ��µ㣨Position����������һ��Replicaion������
����������ж��Ҫ�ض����Խ������ã��������ͨ��sync_binlog��������Master�ڵ������ݲ�����������־д�������ȹ�ϵ������ͨ��binlog_format����������־���ݵ���Ϣ�ṹ������ͨ��sync_relay_log��������Salve�ڵ���ϵͳ������־������д���м���־�ļ���������ȹ�ϵ����Щ����������һЩ��ʾ����ʹ�õIJ������ڱ��ĺ���С�ڽ��н��ܡ�
2-2��MySQLһ����Ӵ��ʽ
������MySQL Replicaion���ƵĻ���������ʽ�����ǽ����ž������ٴ��һ��Master�ڵ��һ��Salve�ڵ㹹�ɵ�MySQL��Ⱥ�����߿��Դ����һ��һ�ӵ�MySQL��Ⱥ������չ���κ�һ����ӵļ�Ⱥ������
���ʵ������ʹ��Version 5.6�汾�������ã���Ȼversion 5.7�汾�İ�װҲ�����Ƶġ����⣬��linux
����ϵͳ�ϣ�Centos 5.6/5.7/6.X����װMySQL����ͽ��л������õĹ��̣�����ƪ�������¶�λԭ������Ͳ��ٽ����������ǽ��ֱ�������ip��Linux������װ��Ⱥ��Master�ڵ��Salve�ڵ㣺
MySQL Master����192.168.61.140
MySQL Salve����192.168.61.141
2-2-1������Master������
������Ҫ����MySQL Master����my.cnf�������ļ�����Ϣ����ҪĿ���ǿ���Master�ڵ��ϵĶ�������־���ܣ�ע������˵����־������InnoDB������־����
# my.cnf�ļ���û���漰Replicaion���Ƶ�������Ϣ��
�Ͳ��������г���
......
# ������־
log_bin
# ������Щ�������ں��Ľ���˵��
sync_binlog=1
binlog_format=mixed
binlog-do-db=qiang
binlog_checksum=CRC32
binlog_cache_size=2M
max_binlog_cache_size=1G
max_binlog_size=100M
# ����Ϊ���MySQL����ڵ�����һ����Ⱥ��Ψһ�� server id��Ϣ
server_id=140
...... |
��Master�ڵ�������У��кܶ�������Զ���־�����ɡ��洢��������̽��п��ơ�������Բμ�MySQL�����еĽ��ܣ�http://dev.mysql.com/doc/refman/5.7/en/replication-options-binary-log.html������������Ҫ����������ʾ���г��ֵIJ������и�Ҫ���ܣ�
sync_binlog���ò�����������Ϊ1��N���κ�ֵ���ò�����ʾMySQL�����ڳɹ���ɶ��ٴβ��ɷָ�����ݲ���������InnoDB�����µ�������������Ž���һ�ζ�������־�ļ���д����������ó�1ʱ��д����־�ļ��Ĵ�������Ƶ���ģ�Ҳ�����һ����I/O�������ģ���ͬʱ����������ֵҲ���ȫ�ġ�
binlog_format���ò�����������������ֵ��row��statement��mixed��row������������־�м�¼���ݱ�ÿһ�о���д�������ĵ�����ֵ����������ͬ����Salve�ڵ㣬Ҳ������������ֵ�����Լ����ݱ��ϵ����ݽ����ģ�statement��ʽ������־�м�¼���ݲ������̣��������յ�ִ�н������������ͬ����Salve�ڵ�����������̣����γ����ռ�¼��mixed����ֵ�����������ּ�¼��ʽ�Ļ���壬MySQL������Զ�ѡ��ǰ����״̬�����ʺϵ���־��¼��ʽ��
binlog-do-db���ò�����������MySQL Master�ڵ�����Ҫ����Replicaion���������ݿ����ơ�
binlog_checksum���ò�����������Master�ڵ��Salve�ڵ��ڽ�����־�ļ�����ͬ��ʱ����ʹ�õ���־����У�鷽ʽ�������������version
5.6�汾��ʼ��֧�ֵ������ù��ܣ�Ĭ��ֵ����CRC32�����MySQL��Ⱥ����MySQL �ڵ�ʹ�õ���version
5.5�����İ汾�������øò�����ֵΪnone��
binlog_cache_size���ò�������Master�ڵ���Ϊÿ���ͻ������ӻỰ��session����ʹ�õģ��������������ʱ�洢��־���ݵĻ����С�����û��ʹ��֧����������棬���Ժ������ֵ�����á�����һ����˵���Ƕ���ʹ��InnoDB���棬���Ը�ֵ������ó�1M����2M�����������ִ�нϸ��ӵ�����������ʵ��Ӵ�Ϊ3M����4M��
max_binlog_cache_size����ֵ��ʾ����MySQL�����У��ܹ�ʹ�õ�binlog_cache��������ֵ����ֵ����sessionΪ��λ�����Ƕ�ȫ�ֽ������á�
max_binlog_size �� �ò������õ���binlog�ļ�������С��MySQL����Ϊ�˱���binlog��־��������Salveͬ��ʧ�ܣ�������������´����µ�binlog�ļ���һ�������MySQL������������һ�������binlog�ļ��Ĵ�С�ﵽһ���趨�ķ�ֵ��Ĭ��Ϊ1GB����max_binlog_size�����������������ֵ�ġ�
���my.cnf�ļ��ĸ��ĺ�����Linux MySql�����µ����þ���Ч�ˡ���������Ҫ��Master�ڵ������ÿɹ����ӵ�Salve�ڵ���Ϣ����������Replicaionͬ�����û���������Ϣ��
# ֻ��MySQL�ͻ��ˣ������Խ������ã�
# ��������ֱ��ʹ��root�˺Ž���ͬ����
�������������²���������ʹ��
> grant replication slave on *.* to root@192.168.61.141 identified by '123456'
# ͨ������������Բ鿴������ɺ��Master�ڵ㹤��״̬
> show master status;
+----------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB
| Executed_Gtid_Set |
+----------------+----------+--------------+------------------+-------------------+
| kp2-bin.000002 | 404 | qiang | | |
+----------------+----------+--------------+------------------+-------------------+ |
����master�ڵ�״̬�������У�File����˵���˵�ǰ��������־�ļ������ƣ�����Ĭ��λ����Linux����ϵͳ�µ�var/lib/mysqlĿ¼�¡�Position����˵���˵�ǰ�������־ͬ�������ݵ�����־�ļ��е�λ�á�Binlog_Do_DB����������֮ǰ���õģ���Ҫ����Replicaion���������ݿ����ƣ�Binlog_Ignore_DB���Ծ�����ȷ���Եģ�����Ҫ����Replicaion���������ݿ����ơ�
2-2-2������Salve������
���MySQL Master��������ú�����������Salve�ڵ����ν������á���������ֻ��ʾһ��Salve�ڵ�����ã��������Ҫ�ڼ�Ⱥ�������µ�Salve�ڵ㣬��ô���ù��̶������Ƶġ�����Ҫע����Master�ڵ��������µ�Salve�ڵ�������Ϣ��
�������ǻ�����Ҫ����Salve�ڵ��my.cnf�ļ���
# my.cnf�ļ���û���漰Replicaion���Ƶ�������Ϣ���Ͳ��������г���
......
# ������־
log-bin
sync_relay_log=1
# ����Ϊ���MySQL����ڵ�����һ����Ⱥ��Ψһ��server id��Ϣ
server_id=140
...... |
��MySQL�ٷ��ĵ���Ҳ��ϸ�������м���־�ĸ��ֿ��Ʋ�������������ֻʹ����sync_relay_log�������������˵����Salve�ڵ��ڳɹ����ܵ����ٴ�Masterͬ����־��Ϣ��ˢ���м���־�ļ������������������Ϊ1��N������һ��ֵ����Ȼ����Ϊ1���������Ȼ������һЩ���ܣ���������־������˵ȴ���ȫ�ġ�
Salve��������Լ�������������Ҫ��Salve�˿�����Ӧ��ͬ�����ܡ���Ҫ��ָ������ͬ����Master�����ַ���û���������Ϣ��
# ��ע���������õ��û�����������ϢҪ��Master�ϵ�����һ��
# ����master log file��ָ�����ļ�
��Ҳ�����Master��ʹ�õ���־�ļ���һ��
> change master to master_host='192.168.61.140',
master_user='root',master_password='123456',
master_log_file='kp2-bin.000002',master_log_pos=120;
# ����Savleͬ��
> start slave;
# Ȼ�����ǾͿ���ʹ����������鿴salve�ڵ��ͬ��״̬
> show slave status;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.61.140
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: kp2-bin.000002
Read_Master_Log_Pos: 404
Relay_Log_File: vm2-relay-bin.000002
Relay_Log_Pos: 565
Relay_Master_Log_File: kp2-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Master_Server_Id: 140
Master_UUID: 19632f72-9a90-11e6-82bd-000c290973df
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay
log;
waiting for the slave I/O thread to update
it
Master_Retry_Count: 86400
......
Auto_Position: 0 |
������Ϲ��̣�һ��һ�ӵ�MySQL��Ⱥ����������ˡ�
2-3��һ����ӷ�����ʹ�ý���
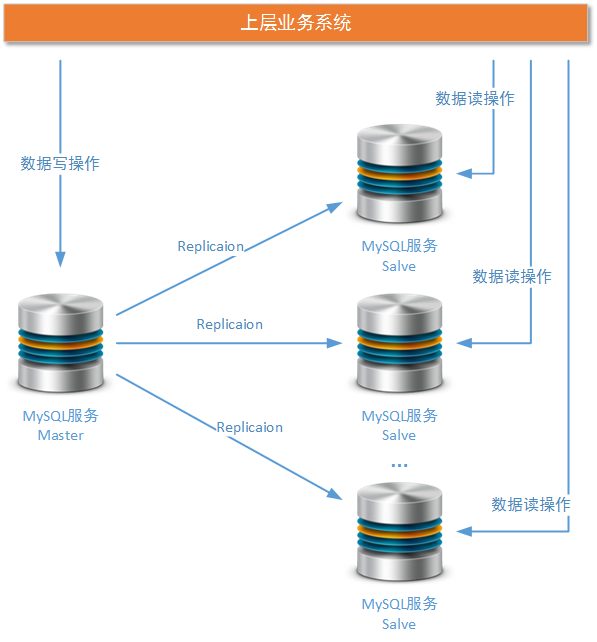
һ����ӵ�MySQL��Ⱥ�������Ѿ����Խ����ϵͳ�ṹ�����ݴ洢������Ҫ���ر����������ݲ�ѯƵ��/����ԶԶ��������д��Ƶ��/������ҵ�����������ϵͳ����Ʒģ�顢����ϵͳ�ij���/˾����Ϣģ�顢����CRMϵͳ�Ŀͻ���Ϣģ�顢���ϵͳ�б���Ļ�����־���ݡ��������ּܹ����������ܽ�����е����⣬���ҷ���������һЩ���Ե����⣨������ϸ���ۣ������������ﱾ����ҪΪ��λ��Ҫʹ������MySQL��Ⱥ�����Ķ����ṩһЩʹ�ý��顣
Master���ڵ�����Ӧ���㹻ǿ����ֻ��������д�������һ����ӵ�MySQL��Ⱥ��ʽ��Ҫ��Զ��ܼ���ҵ��ϵͳ������ҪĿ���ǽ�MySQL����Ķ�дѹ�����з��롣����Master�ڵ���Ҫ���о�������ҵ���д����������Ҳ����ζ��ҵ��ϵͳ���е�д����ѹ�������е�����һ���ڵ��ϣ�writeҵ����������������Ҳ�ȥ�������������ܵ��µ����⣨�������ݻ��ᵽ�������������⣩����������Ҫ��Master�ڵ�������㹻ǿ����������ܲ�����ָͨ��MySQL
InnoDB�����ṩ�ĸ������ã�һ������ʹ��InnoDB���棩�������ҵ���ص���������եȡ�����ܣ�������Ļ���Ҫ����Master�ڵ��Ӳ�����ܡ�
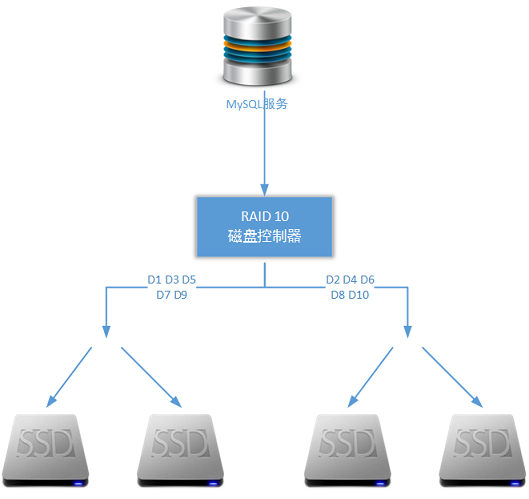
ʹ�ù�̬Ӳ����ΪMySQL����Ŀ�洢��������ʹ��RAID 10����������ΪӲ���㹹�����������������������µ���MySQL����ڵ�Ļ������������Ȼ���߿������Լ����������µĵ�ʵ������������Ҫ����б�Ҫ�ĵ�����
Ӧʹ��һ��������Salve�ڵ���Ϊ���õ�Master�ڵ㣬��Ȼ���ַ�ʽ������Ϊ��ض����Ļ���������Ϊ���ظ߿��÷�����ʵ�ֻ�������Ȼ��Ϊ�˷�ֹ������־�����µı���ʧ�ܣ�������ݵ�Salve�ڵ�Ҳ���Բ���MySQL
Replicaion��������ĵ�����ͬ�����ƣ����磺Rsync��DRBD��Rsync�DZ����ڹ���ʵ���о���ʹ�õģ�����MySQL��������ͬ���ķ�ʽ����DRBD�IJ����ͬ����ʽ�ǻ��������ܹ��ҵ�������ϵķ�ʽ��
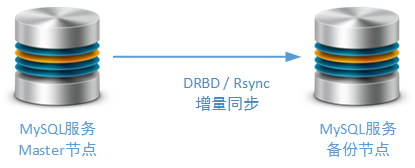
�ں����������У����ǻ���ר���������Master�ڵ�ļ�Ⱥ�������������ҽ���������ʹ���ʺ�ϵͳ����ҵ��ĸ߿��÷���������ʹ��Keepalived
/ Heartbeat��������Master�ڵ���л���
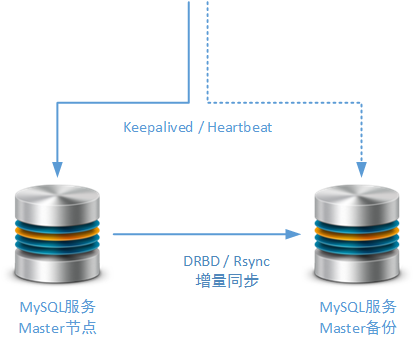
���ӵ�ͳ�Ʋ�ѯ��Ҫר�ŵ�Salve�ڵ����֧�֡�������������ʵʱҵ�������κ�MySQL����ڵ㣬����Щ����ڵ��������е�SQL��ѯӦ�þ����ܼ�������Ҫʹ�������Լ�������֧�֡��ر����������dz�������ݱ������뱣֤���еļ����������������ṩ֧�֣�����Table
Full Scan�ļ������˷�ʽ�����������������������������ܻ������������������������ͨ��MySQL�ṩ��ִ�мƻ����ܣ�������Ա�ܹ��ܷ���ʵ�����ϵ�Ҫ���������ҵ��ϵͳ���ڸ��ӵ�ҵ���ѯҪ�����������ԵIJ�����ˮ�����������Ե�ҵ�����ͳ�Ʊ����ȣ���ô�����ר����һ��������������ʵʱҵ���Salve�ڵ㣬������������
3��������¶������
��������MySQL��Ⱥ����Ҳ���ںܶ�������Ҫ��һ���Ľ����ں����������У����ǻ���������MySQL��Ⱥ�л����ڵ��������⣺
�����ϲ�ϵͳ�����⣺��MySQLһ����Ӽ�Ⱥ�У����ڹ�������ڵ㡣��ô���ϲ�ҵ��ϵͳ�������ݿ����ʱ��������д�������Ƕ����������Ƿ���Ҫ��ȷ֪����Щ����ķ���ڵ㣬�����������أ�Ҫ֪�������ϲ�ҵ��ϵͳ��Ҫ���Ƶ�Ҫ�ر��ԭ��Խ��ʱ����Ҫҵ��ϵͳ������ԱͶ���ά�������ͻ�ʼ��μ�������
�߿��ò�������⣺��MySQLһ����Ӽ�Ⱥ�У���Ȼ���ڶ��Salve�ڵ㣨readҵ�����ʽڵ㣩������һ��ֻ����һ��Master�ڵ㣨writeҵ�����ʽڵ㣩��ijһ����������Salve�ڵ�����ˣ������������Ⱥ���̫��Ӱ�죨������Ӱ���ϲ�ҵ��ϵͳ��ijһ����ϵͳ������ôMySQL��Ⱥ�Ķ̰�����ֻ��һ��Master�ڵ㡪��һ���������ˣ�������Ⱥ�ͻ������������������������DZ�����һЩ�취�ı����DZ�ڷ��ա�
|






